
DNA Data Storage


Abstract
1. Introduction
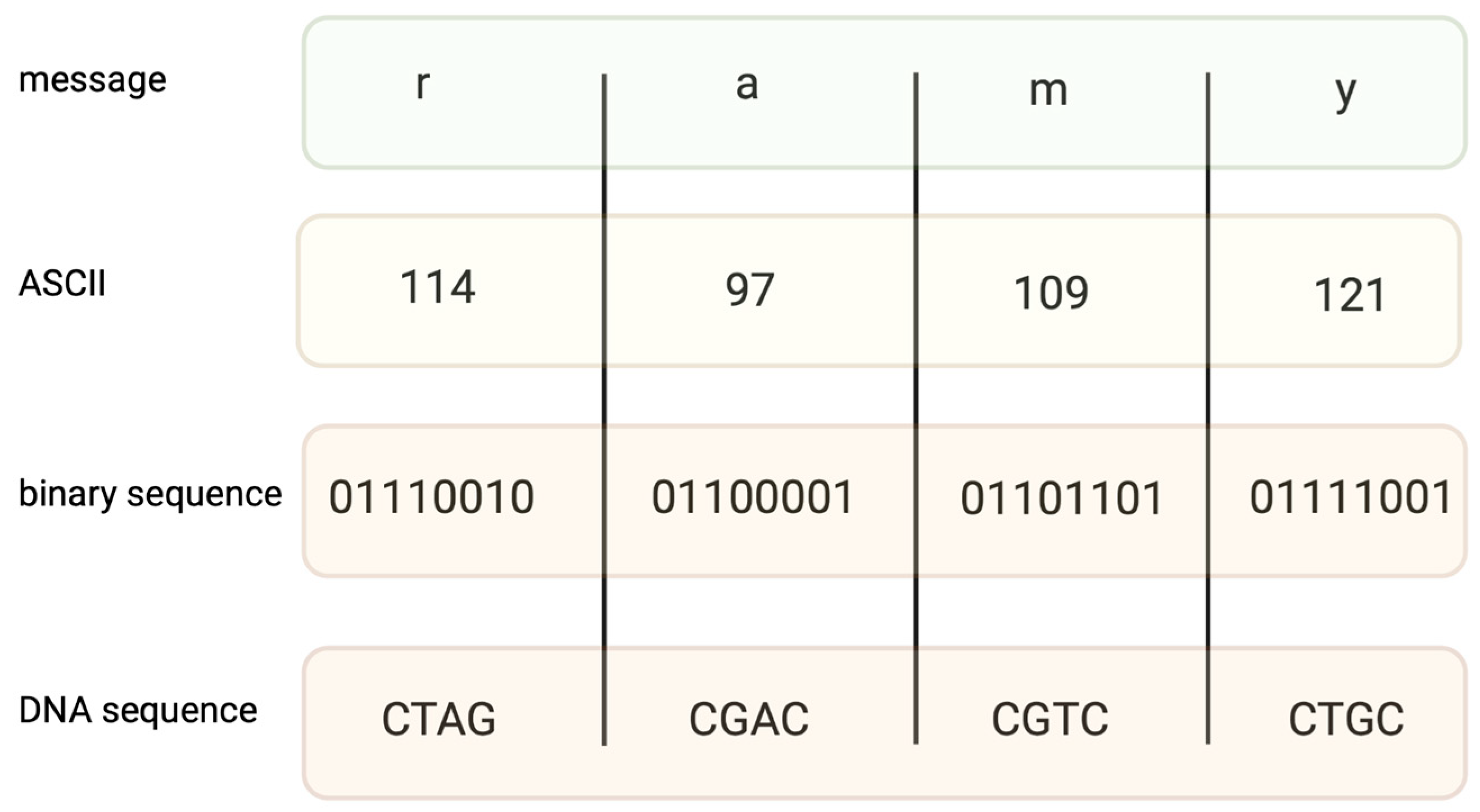
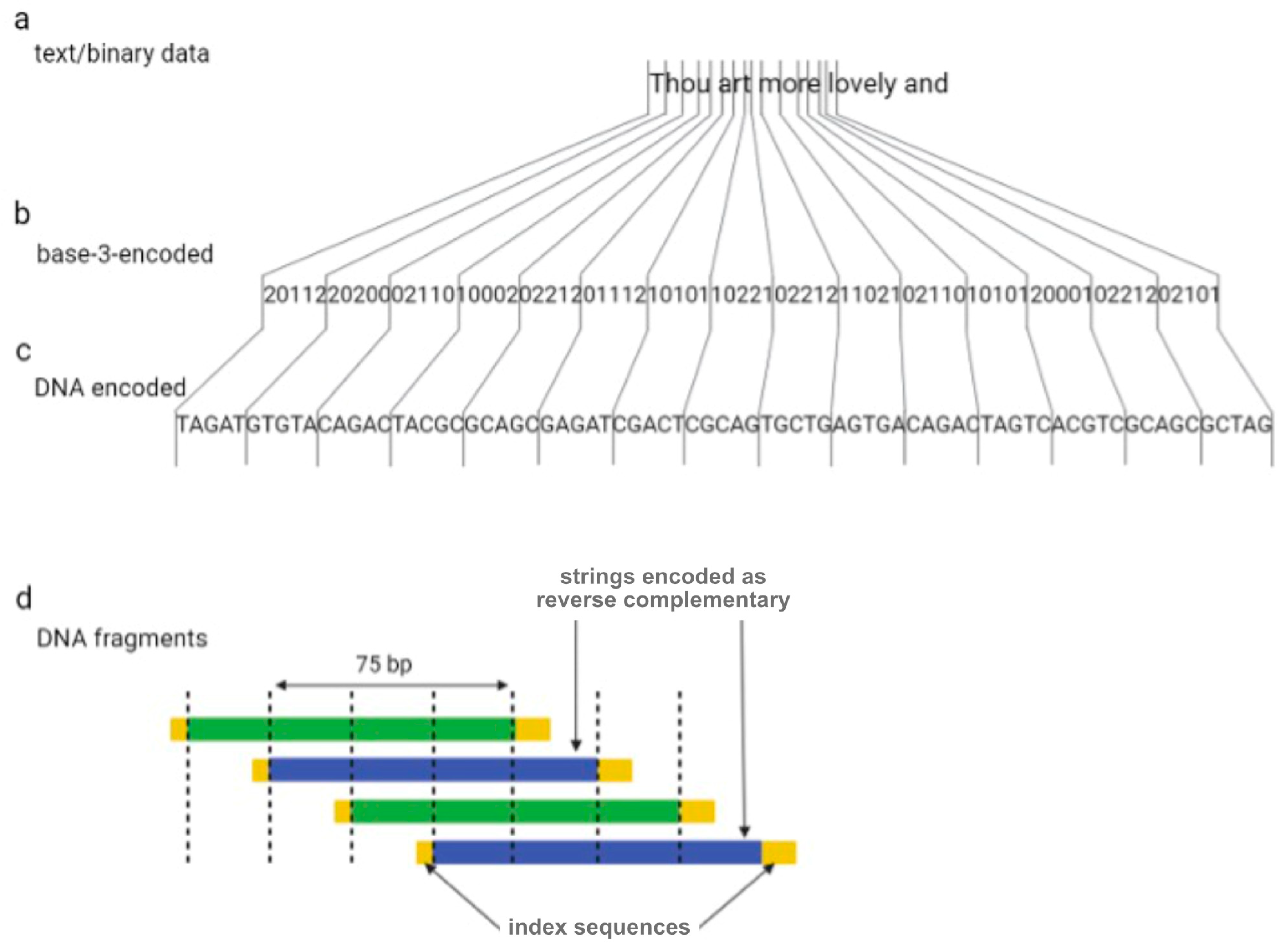
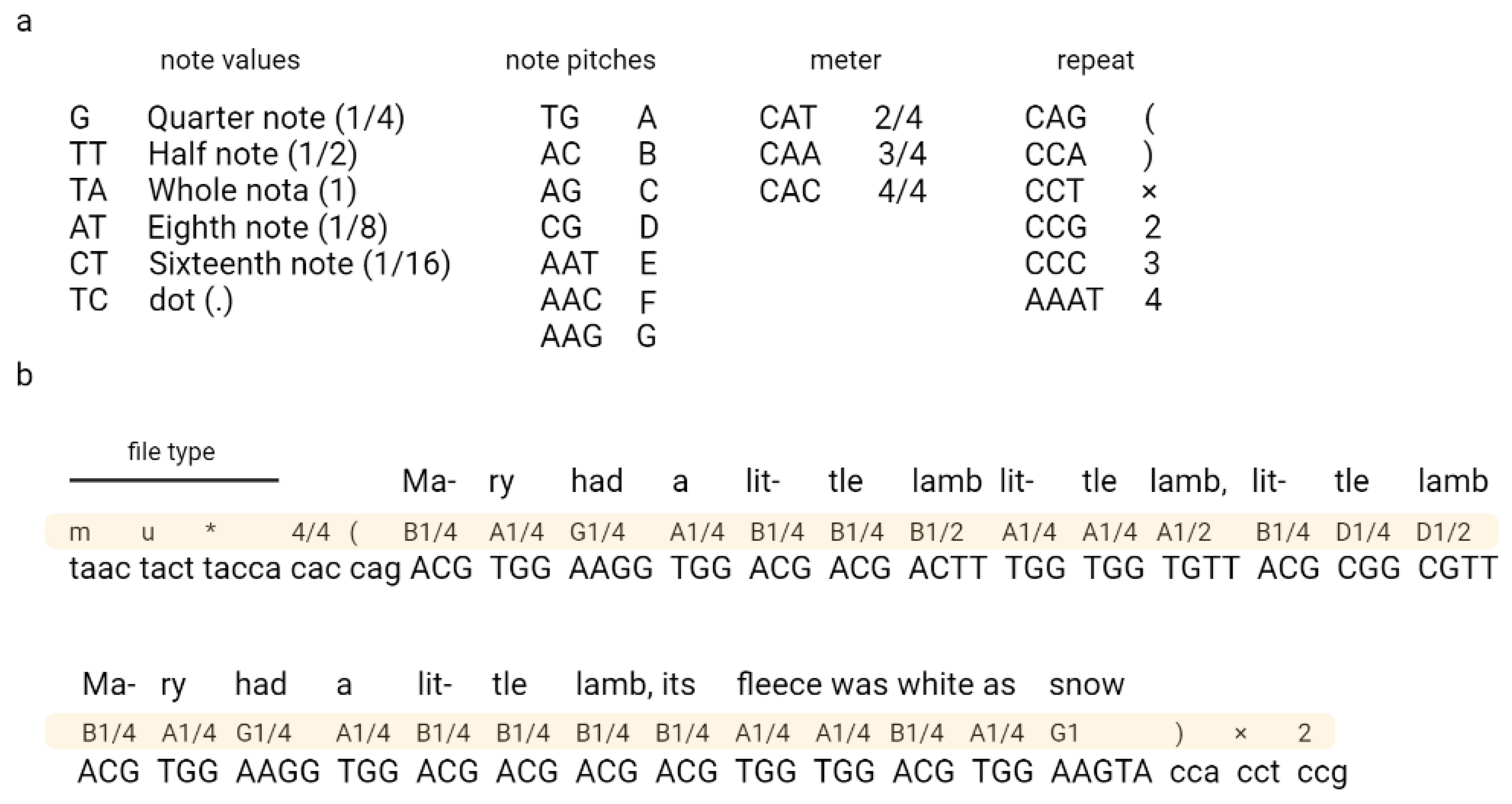
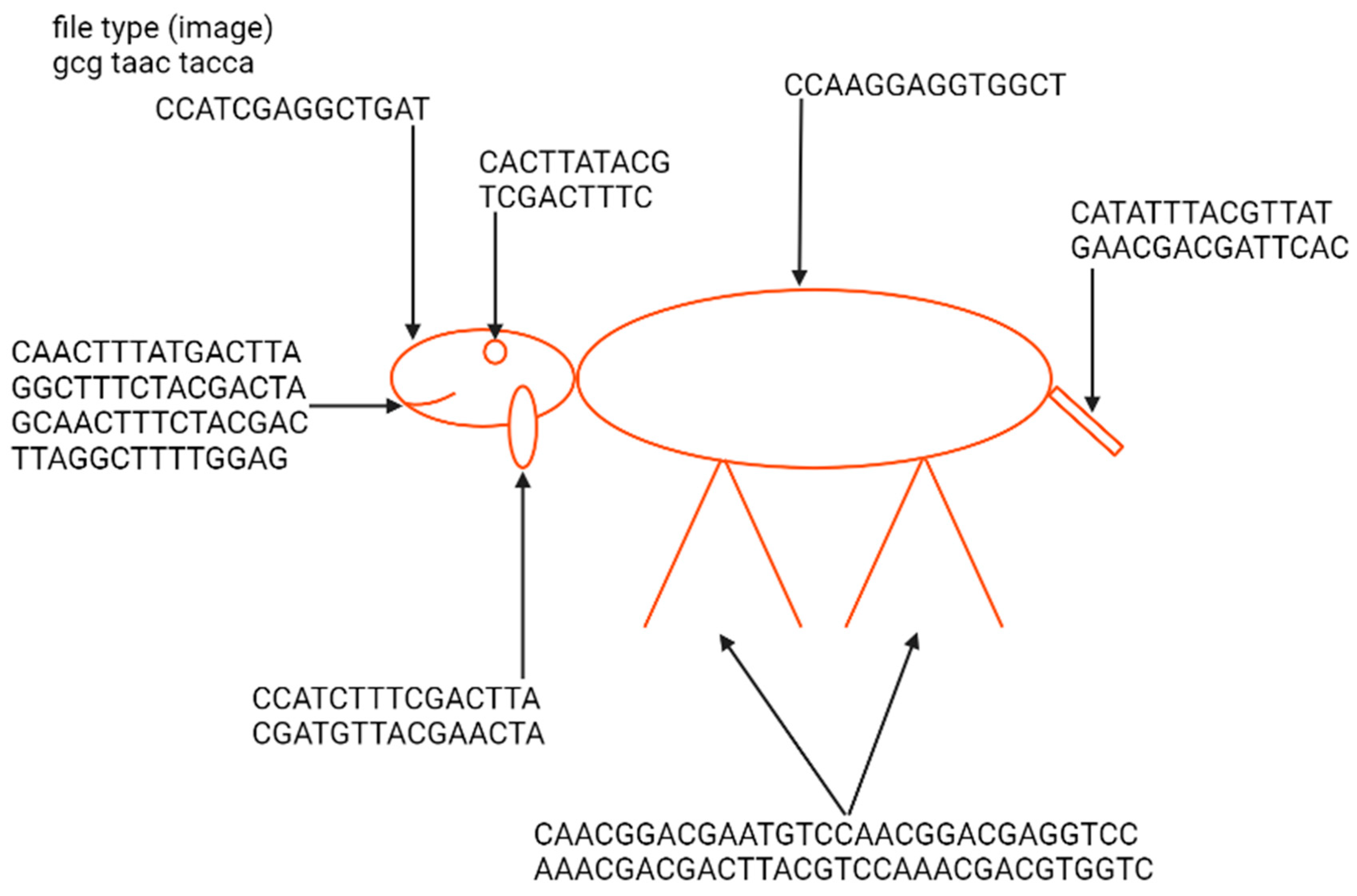
2. Coding Files in DNA
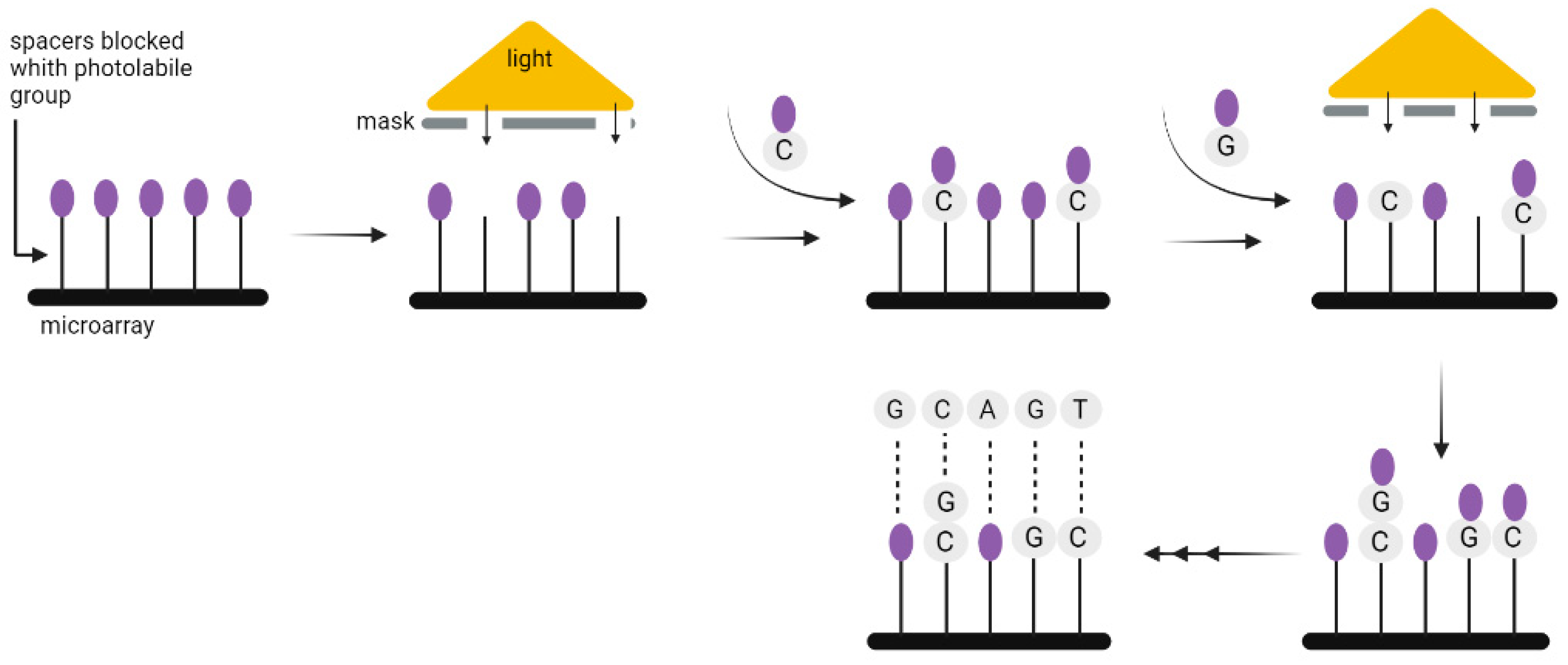
3. Synthesis of DNA Strings
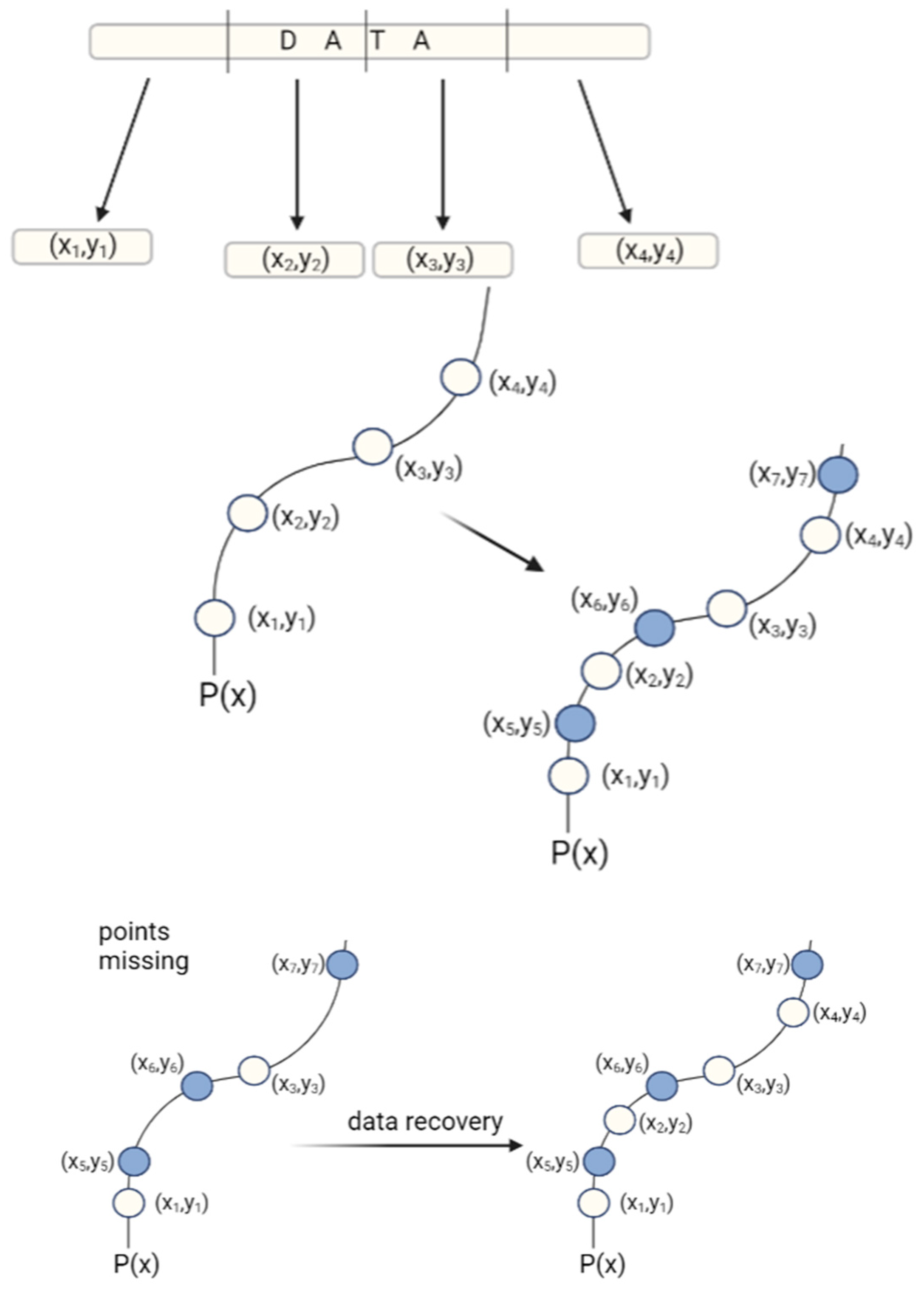
4. New Storage Medium, Old Problems, and Solutions
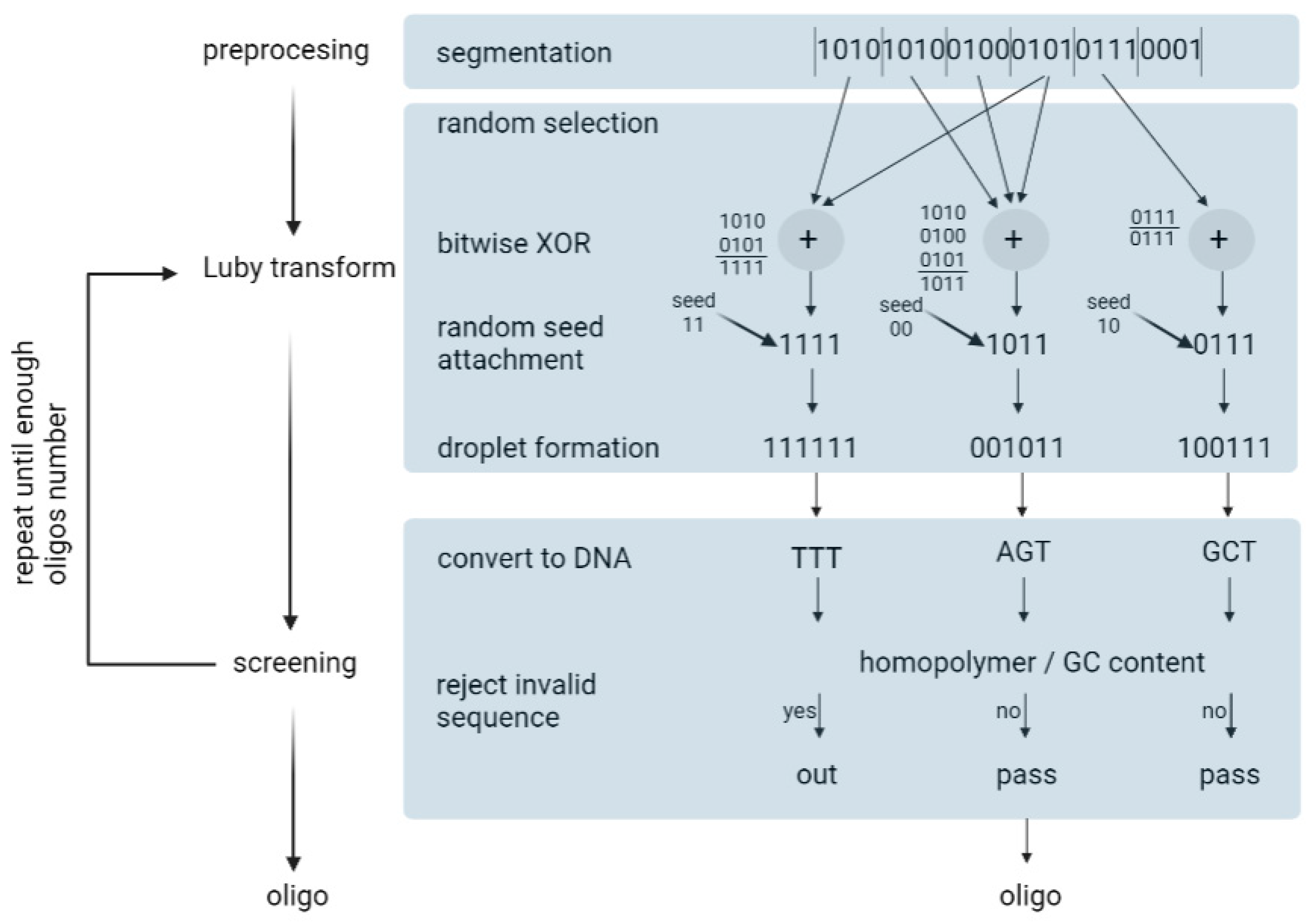
- Preprocessing—In this step, the input file is compressed using a lossless algorithm. Then, the algorithm partitions the file into non-overlapping K segments, in which each segment is L bits long. L is defined by the user.
- Luby transformation—This step consists of many substeps. Briefly, a pseudo-random number generator determines the number of segments that will be packed into a single packet. Encoded segments become packets known as droplets. For this, the algorithm uses a robust solution probability distribution, which assumes that most of the droplets will be created with a small number of input segments. On the segments of one droplet, the algorithm performs a bitwise exclusive or XOR operation. For example, consider that the algorithm randomly selected three input fragments: 0100, 1100, 1001. In this case, the droplet is 0100 ⊕1100 ⊕1001 = 0001. In the end, the algorithm adds an index that specifies the binary representation of the seed, which, in turn, corresponds to the state of the random number generator of the transform during the generation of the droplet. Finally, it enables the decoder algorithm to infer the identities of the segments in the droplet.
- Screening—In the last step, the algorithm excludes those strings that do not pass the biochemical constraints. Firstly, binary data are translated into a nucleotide sequence: {00, 01, 10, 11} to {A, C, G, T}. Then, DNA strings are screened for GC content and homopolymers. The sequences that do not pass the screen are removed and the formation and screening of the oligonucleotides are repeated until the desired conditions are obtained. In practice, the authors recommend synthesizing 5–10% more oligonucleotides than the input segments.
5. DNA Preservation
5.1. In Vitro Preservation
5.2. In Vivo Preservation
6. DNA Sequencing
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- De Silva, P.Y.; Ganegoda, G.U. New Trends of Digital Data Storage in DNA. BioMed Res. Int. 2016, 2016, 8072463. [Google Scholar] [CrossRef] [PubMed]
- Rydning, J.; Reinsel, D.; Gantz, J. The Digitization of the World from Edge to Core; IDC: Framingham, MA, USA, 2018. [Google Scholar]
- Ceze, L.; Nivala, J.; Strauss, K. Molecular Digital Data Storage Using DNA. Nat. Rev. Genet. 2019, 20, 456–466. [Google Scholar] [CrossRef] [PubMed]
- Grass, R.N.; Heckel, R.; Puddu, M.; Paunescu, D.; Stark, W.J. Robust Chemical Preservation of Digital Information on DNA in Silica with Error-Correcting Codes. Angew. Chem. Int. Ed. Engl. 2015, 54, 2552–2555. [Google Scholar] [CrossRef] [PubMed]
- Zhirnov, V.; Zadegan, R.M.; Sandhu, G.S.; Church, G.M.; Hughes, W.L. Nucleic Acid Memory. Nat. Mater. 2016, 15, 366–370. [Google Scholar] [CrossRef] [PubMed]
- Van der Valk, T.; Pečnerová, P.; Díez-Del-Molino, D.; Bergström, A.; Oppenheimer, J.; Hartmann, S.; Xenikoudakis, G.; Thomas, J.A.; Dehasque, M.; Sağlıcan, E.; et al. Million-Year-Old DNA Sheds Light on the Genomic History of Mammoths. Nature 2021, 591, 265–269. [Google Scholar] [CrossRef]
- Horneck, G.; Klaus, D.M.; Mancinelli, R.L. Space Microbiology. Microbiol. Mol. Biol. Rev. 2010, 74, 121–156. [Google Scholar] [CrossRef]
- Horneck, G.; Bücker, H.; Reitz, G. Long-Term Survival of Bacterial Spores in Space. Adv. Space Res. 1994, 14, 41–45. [Google Scholar] [CrossRef]
- Cadet, J.; Sage, E.; Douki, T. Ultraviolet Radiation-Mediated Damage to Cellular DNA. Mutat. Res. 2005, 571, 3–17. [Google Scholar] [CrossRef]
- Xue, Y.; Nicholson, W.L. The Two Major Spore DNA Repair Pathways, Nucleotide Excision Repair and Spore Photoproduct Lyase, Are Sufficient for the Resistance of Bacillus Subtilis Spores to Artificial UV-C and UV-B but Not to Solar Radiation. Appl. Environ. Microbiol. 1996, 62, 2221–2227. [Google Scholar] [CrossRef]
- Sancho, L.G.; de la Torre, R.; Horneck, G.; Ascaso, C.; de Los Rios, A.; Pintado, A.; Wierzchos, J.; Schuster, M. Lichens Survive in Space: Results from the 2005 LICHENS Experiment. Astrobiology 2007, 7, 443–454. [Google Scholar] [CrossRef]
- Gauslaa, Y.; Solhaug, K.A. Photoinhibition in Lichens Depends on Cortical Characteristics and Hydration. Lichenologist 2004, 36, 133–143. [Google Scholar] [CrossRef]
- Ahmed, R.K.; Mohammed, I.J. Developing a New Hybrid Cipher Algorithm Using DNA and RC4. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 71. [Google Scholar]
- Zhang, Y.; Kong, L.; Wang, F.; Li, B.; Ma, C.; Chen, D.; Liu, K.; Fan, C.; Zhang, H. Information Stored in Nanoscale: Encoding Data in a Single DNA Strand with Base64. Nano Today 2020, 33, 100871. [Google Scholar] [CrossRef]
- Church, G.M.; Gao, Y.; Kosuri, S. Next-Generation Digital Information Storage in DNA. Science 2012, 337, 1628. [Google Scholar] [CrossRef]
- Goldman, N.; Bertone, P.; Chen, S.; Dessimoz, C.; LeProust, E.M.; Sipos, B.; Birney, E. Towards Practical, High-Capacity, Low-Maintenance Information Storage in Synthesized DNA. Nature 2013, 494, 77–80. [Google Scholar] [CrossRef]
- Ailenberg, M.; Rotstein, O.D. An Improved Huffman Coding Method for Archiving Text, Images, and Music Characters in DNA. BioTechniques 2009, 47, 747–754. [Google Scholar] [CrossRef]
- Yazdi, S.M.H.T.; Gabrys, R.; Milenkovic, O. Portable and Error-Free DNA-Based Data Storage. Sci. Rep. 2017, 7, 5011. [Google Scholar] [CrossRef]
- Shipman, S.L.; Nivala, J.; Macklis, J.D.; Church, G.M. CRISPR-Cas Encoding of a Digital Movie into the Genomes of a Population of Living Bacteria. Nature 2017, 547, 345–349. [Google Scholar] [CrossRef]
- Bornholt, J.; Lopez, R.; Carmean, D.M.; Ceze, L.; Seelig, G.; Strauss, K. A DNA-Based Archival Storage System. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems, Atlanta, GA, USA, 2–6 April 2016; ACM: Atlanta, GA, USA, 2016; pp. 637–649. [Google Scholar]
- Blawat, M.; Gaedke, K.; Hütter, I.; Chen, X.-M.; Turczyk, B.; Inverso, S.; Pruitt, B.W.; Church, G.M. Forward Error Correction for DNA Data Storage. Procedia Comput. Sci. 2016, 80, 1011–1022. [Google Scholar] [CrossRef]
- Organick, L.; Ang, S.D.; Chen, Y.-J.; Lopez, R.; Yekhanin, S.; Makarychev, K.; Racz, M.Z.; Kamath, G.; Gopalan, P.; Nguyen, B.; et al. Random Access in Large-Scale DNA Data Storage. Nat. Biotechnol. 2018, 36, 242–248. [Google Scholar] [CrossRef]
- Choi, Y.; Ryu, T.; Lee, A.C.; Choi, H.; Lee, H.; Park, J.; Song, S.-H.; Kim, S.; Kim, H.; Park, W.; et al. High Information Capacity DNA-based Data Storage with Augmented Encoding Characters Using Degenerate Bases. Sci. Rep. 2019, 9, 6582. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.H.; Kalhor, R.; Goela, N.; Bolot, J.; Church, G.M. Terminator-Free Template-Independent Enzymatic DNA Synthesis for Digital Information Storage. Nat. Commun. 2019, 10, 2383. [Google Scholar] [CrossRef] [PubMed]
- Tabatabaei, S.K.; Wang, B.; Athreya, N.B.M.; Enghiad, B.; Hernandez, A.G.; Fields, C.J.; Leburton, J.-P.; Soloveichik, D.; Zhao, H.; Milenkovic, O. DNA Punch Cards for Storing Data on Native DNA Sequences via Enzymatic Nicking. Nat. Commun. 2020, 11, 1742. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; McCloskey, C.M.; Chaput, J.C. Reading and Writing Digital Information in TNA. ACS Synth. Biol. 2020, 9, 2936–2942. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Zhang, Y.; Liu, Y.; Wu, Q.; Su, J.; Wang, F.; Chen, D.; Fan, C.; Liu, K.; Zhang, H. DNA-Based Concatenated Encoding System for High-Reliability and High-Density Data Storage. Small Methods 2022, 6, e2101335. [Google Scholar] [CrossRef]
- Mayer, C.; McInroy, G.R.; Murat, P.; Van Delft, P.; Balasubramanian, S. An Epigenetics-Inspired DNA-Based Data Storage System. Angew. Chem. Int. Ed. 2016, 55, 11144–11148. [Google Scholar] [CrossRef]
- Sinyakov, A.N.; Ryabinin, V.A.; Kostina, E.V. Application of Array-Based Oligonucleotides for Synthesis of Genetic Designs. Mol. Biol. 2021, 55, 487–500. [Google Scholar] [CrossRef]
- Song, L.-F.; Deng, Z.-H.; Gong, Z.-Y.; Li, L.-L.; Li, B.-Z. Large-Scale de Novo Oligonucleotide Synthesis for Whole-Genome Synthesis and Data Storage: Challenges and Opportunities. Front. Bioeng. Biotechnol. 2021, 9, 689797. [Google Scholar] [CrossRef]
- Heckel, R.; Shomorony, I.; Ramchandran, K.; Tse, D.N.C. Fundamental Limits of DNA Storage Systems. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 3130–3134. [Google Scholar]
- Zhang, Y.; Ren, Y.; Liu, Y.; Wang, F.; Zhang, H.; Liu, K. Preservation and Encryption in DNA Digital Data Storage. Chempluschem 2022, 87, e202200183. [Google Scholar] [CrossRef]
- Meiser, L.C.; Antkowiak, P.L.; Koch, J.; Chen, W.D.; Kohll, A.X.; Stark, W.J.; Heckel, R.; Grass, R.N. Reading and Writing Digital Data in DNA. Nat. Protoc. 2020, 15, 86–101. [Google Scholar] [CrossRef]
- Xie, R.; Zan, X.; Chu, L.; Su, Y.; Xu, P.; Liu, W. Study of the Error Correction Capability of Multiple Sequence Alignment Algorithm(MAFFT) in DNA Storage. BMC Bioinform. 2023, 24, 111. [Google Scholar] [CrossRef]
- Erlich, Y.; Zielinski, D. DNA Fountain Enables a Robust and Efficient Storage Architecture. Science 2017, 355, 950–954. [Google Scholar] [CrossRef]
- Tan, X.; Ge, L.; Zhang, T.; Lu, Z. Preservation of DNA for Data Storage. Russ. Chem. Rev. 2021, 90, 280–291. [Google Scholar] [CrossRef]
- Doricchi, A.; Platnich, C.M.; Gimpel, A.; Horn, F.; Earle, M.; Lanzavecchia, G.; Cortajarena, A.L.; Liz-Marzán, L.M.; Liu, N.; Heckel, R.; et al. Emerging Approaches to DNA Data Storage: Challenges and Prospects. ACS Nano 2022, 16, 17552–17571. [Google Scholar] [CrossRef]
- Paunescu, D.; Puddu, M.; Soellner, J.O.B.; Stoessel, P.R.; Grass, R.N. Reversible DNA Encapsulation in Silica to Produce ROS-Resistant and Heat-Resistant Synthetic DNA “Fossils”. Nat. Protoc. 2013, 8, 2440–2448. [Google Scholar] [CrossRef]
- Newman, S.; Stephenson, A.P.; Willsey, M.; Nguyen, B.H.; Takahashi, C.N.; Strauss, K.; Ceze, L. High Density DNA Data Storage Library via Dehydration with Digital Microfluidic Retrieval. Nat. Commun. 2019, 10, 1706. [Google Scholar] [CrossRef]
- Choi, Y.; Bae, H.J.; Lee, A.C.; Choi, H.; Lee, D.; Ryu, T.; Hyun, J.; Kim, S.; Kim, H.; Song, S.-H.; et al. DNA Micro-Disks for the Management of DNA-Based Data Storage with Index and Write-Once-Read-Many(WORM) Memory Features. Adv. Mater. 2020, 32, e2001249. [Google Scholar] [CrossRef]
- Anchordoquy, T.J.; Molina, M.C. Preservation of DNA. Cell Preserv. Technol. 2007, 5, 180–188. [Google Scholar] [CrossRef]
- Ivanova, N.V.; Kuzmina, M.L. Protocols for Dry DNA Storage and Shipment at Room Temperature. Mol. Ecol. Resour. 2013, 13, 890–898. [Google Scholar] [CrossRef]
- Chen, W.D.; Kohll, A.X.; Nguyen, B.H.; Koch, J.; Heckel, R.; Stark, W.J.; Ceze, L.; Strauss, K.; Grass, R.N. Combining Data Longevity with High Storage Capacity—Layer-by-Layer DNA Encapsulated in Magnetic Nanoparticles. Adv. Funct. Mater. 2019, 29, 1901672. [Google Scholar] [CrossRef]
- Kim, T.W.; Kim, I.Y.; Park, D.-H.; Choy, J.-H.; Hwang, S.-J. Highly Stable Nanocontainer of APTES-Anchored Layered Titanate Nanosheet for Reliable Protection/Recovery of Nucleic Acid. Sci. Rep. 2016, 6, 21993. [Google Scholar] [CrossRef] [PubMed]
- Frantzen, M.a.J.; Silk, J.B.; Ferguson, J.W.H.; Wayne, R.K.; Kohn, M.H. Empirical Evaluation of Preservation Methods for Faecal DNA. Mol. Ecol. 1998, 7, 1423–1428. [Google Scholar] [CrossRef] [PubMed]
- Kilpatrick, C.W. Noncryogenic Preservation of Mammalian Tissues for DNA Extraction: An Assessment of Storage Methods. Biochem. Genet. 2002, 40, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Murphy, M.A.; Waits, L.P.; Kendall, K.C.; Wasser, S.K.; Higbee, J.A.; Bogden, R. An Evaluation of Long-Term Preservation Methods for Brown Bear(Ursus Arctos) Faecal DNA Samples. Conserv. Genet. 2002, 3, 435–440. [Google Scholar] [CrossRef]
- Vitošević, K.; Todorović, M.; Slović, Ž.; Varljen, T.; Matić, S.; Todorović, D. DNA Isolated from Formalin-Fixed Paraffin-Embedded Healthy Tissue after 30 Years of Storage Can Be Used for Forensic Studies. Forensic. Sci. Med. Pathol. 2021, 17, 47–57. [Google Scholar] [CrossRef]
- Ferrer, I.; Armstrong, J.; Capellari, S.; Parchi, P.; Arzberger, T.; Bell, J.; Budka, H.; Ströbel, T.; Giaccone, G.; Rossi, G.; et al. Effects of Formalin Fixation, Paraffin Embedding, and Time of Storage on DNA Preservation in Brain Tissue: A BrainNet Europe Study. Brain Pathol. 2007, 17, 297–303. [Google Scholar] [CrossRef]
- Smith, S.; Morin, P.A. Optimal Storage Conditions for Highly Dilute DNA Samples: A Role for Trehalose as a Preserving Agent. J. Forensic. Sci. 2005, 50, 1101–1108. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Park, J.; Park, S.J.; Lee, C.-S.; Hwang, S.; Shin, Y.-B.; Ha, T.H.; Kim, M. Long-Term Stability and Integrity of Plasmid-Based DNA Data Storage. Polymers 2018, 10, 28. [Google Scholar] [CrossRef]
- Allentoft, M.E.; Collins, M.; Harker, D.; Haile, J.; Oskam, C.L.; Hale, M.L.; Campos, P.F.; Samaniego, J.A.; Gilbert, M.T.P.; Willerslev, E.; et al. The Half-Life of DNA in Bone: Measuring Decay Kinetics in 158 Dated Fossils. Proc. Biol. Sci. 2012, 279, 4724–4733. [Google Scholar] [CrossRef]
- Chaorattanakawee, S.; Natalang, O.; Hananantachai, H.; Nacher, M.; Brockman, A.; Krudsood, S.; Looareesuwan, S.; Patarapotikul, J. Storage Duration and Polymerase Chain Reaction Detection of Plasmodium Falciparum from Blood Spots on Filter Paper. Am. J. Trop. Med. Hyg. 2003, 69, 42–44. [Google Scholar] [CrossRef]
- Saieg, M.A.; Geddie, W.R.; Boerner, S.L.; Liu, N.; Tsao, M.; Zhang, T.; Kamel-Reid, S.; da Cunha Santos, G. The Use of FTA Cards for Preserving Unfixed Cytological Material for High-Throughput Molecular Analysis. Cancer Cytopathol. 2012, 120, 206–214. [Google Scholar] [CrossRef]
- Koch, J.; Gantenbein, S.; Masania, K.; Stark, W.J.; Erlich, Y.; Grass, R.N. A DNA-of-Things Storage Architecture to Create Materials with Embedded Memory. Nat. Biotechnol. 2020, 38, 39–43. [Google Scholar] [CrossRef]
- Antkowiak, P.L.; Koch, J.; Rzepka, P.; Nguyen, B.H.; Strauss, K.; Stark, W.J.; Grass, R.N. Anhydrous Calcium Phosphate Crystals Stabilize DNA for Dry Storage. Chem. Commun. 2022, 58, 3174–3177. [Google Scholar] [CrossRef]
- Coudy, D.; Colotte, M.; Luis, A.; Tuffet, S.; Bonnet, J. Long Term Conservation of DNA at Ambient Temperature. Implications for DNA Data Storage. PLoS ONE 2021, 16, e0259868. [Google Scholar] [CrossRef]
- Clermont, D.; Santoni, S.; Saker, S.; Gomard, M.; Gardais, E.; Bizet, C. Assessment of DNA Encapsulation, a New Room-Temperature DNA Storage Method. Biopreserv. Biobank. 2014, 12, 176–183. [Google Scholar] [CrossRef]
- Organick, L.; Nguyen, B.H.; McAmis, R.; Chen, W.D.; Kohll, A.X.; Ang, S.D.; Grass, R.N.; Ceze, L.; Strauss, K. An Empirical Comparison of Preservation Methods for Synthetic DNA Data Storage. Small Methods 2021, 5, 2001094. [Google Scholar] [CrossRef]
- Evans, R.K.; Xu, Z.; Bohannon, K.E.; Wang, B.; Bruner, M.W.; Volkin, D.B. Evaluation of Degradation Pathways for Plasmid Dna in Pharmaceutical Formulations via Accelerated Stability Studies. J. Pharm. Sci. 2000, 89, 76–87. [Google Scholar] [CrossRef]
- Puddu, M.; Paunescu, D.; Stark, W.J.; Grass, R.N. Magnetically Recoverable, Thermostable, Hydrophobic DNA/Silica Encapsulates and Their Application as Invisible Oil Tags. ACS Nano 2014, 8, 2677–2685. [Google Scholar] [CrossRef]
- Kohll, A.X.; Antkowiak, P.L.; Chen, W.D.; Nguyen, B.H.; Stark, W.J.; Ceze, L.; Strauss, K.; Grass, R.N. Stabilizing Synthetic DNA for Long-Term Data Storage with Earth Alkaline Salts. Chem. Commun. 2020, 56, 3613–3616. [Google Scholar] [CrossRef]
- Bonnet, J.; Colotte, M.; Coudy, D.; Couallier, V.; Portier, J.; Morin, B.; Tuffet, S. Chain and Conformation Stability of Solid-State DNA: Implications for Room Temperature Storage. Nucleic Acids Res. 2010, 38, 1531–1546. [Google Scholar] [CrossRef]
- Cherng, J.-Y.; Talsma, H.; Crommelin, D.J.A.; Hennink, W.E. Long Term Stability of Poly((2-Dimethylamino)Ethyl Methacrylate)-Based Gene Delivery Systems. Pharm. Res. 1999, 16, 1417–1423. [Google Scholar] [CrossRef] [PubMed]
- Molina, M.D.C.; Anchordoquy, T.J. Degradation of Lyophilized Lipid/DNA Complexes during Storage: The Role of Lipid and Reactive Oxygen Species. Biochim. Biophys. Acta Biomembr. 2008, 1778, 2119–2126. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Lei, Q.; Guo, J.; Gao, Y.; Shi, J.; Yu, H.; Yin, W.; Cao, J.; Xiao, B.; Andreo, J.; et al. Long-Term Whole Blood DNA Preservation by Cost-Efficient Cryosilicification. Nat. Commun. 2022, 13, 6265. [Google Scholar] [CrossRef] [PubMed]
- Hao, M.; Qiao, H.; Gao, Y.; Wang, Z.; Qiao, X.; Chen, X.; Qi, H. A Mixed Culture of Bacterial Cells Enables an Economic DNA Storage on a Large Scale. Commun. Biol. 2020, 3, 416. [Google Scholar] [CrossRef]
- Lee, H.; Popodi, E.; Tang, H.; Foster, P.L. Rate and Molecular Spectrum of Spontaneous Mutations in the Bacterium Escherichia Coli as Determined by Whole-Genome Sequencing. Proc. Natl. Acad. Sci. USA 2012, 109, E2774–E2783. [Google Scholar] [CrossRef]
- Chen, W.; Han, M.; Zhou, J.; Ge, Q.; Wang, P.; Zhang, X.; Zhu, S.; Song, L.; Yuan, Y. An Artificial Chromosome for Data Storage. Natl. Sci. Rev. 2021, 8, nwab028. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, C.; Wei, R.; Han, M.; Wang, S.; Yang, K.; Zhang, L.; Chen, W.; Wen, M.; Li, C.; et al. Exogenous artificial DNA forms chromatin structure with active transcription in yeast. Sci. China Life Sci. 2021, 65, 851–860. [Google Scholar] [CrossRef]
- Meas, R.; Wyrick, J.J.; Smerdon, M.J. Nucleosomes regulate base excision repair in chromatin. Mutat. Res.-Rev. Mutat. Res. 2019, 780, 29–36. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, Y.; Jia, J.; Fang, Y.; Tang, Y.; Wu, H.; Fang, D. H3K36me3, message from chromatin to DNA damage repair. Cell Biosci. 2020, 10, 9. [Google Scholar] [CrossRef]
- Hao, Y.; Li, Q.; Fan, C.; Wang, F. Data Storage Based on DNA. Small Struct. 2021, 2, 2000046. [Google Scholar] [CrossRef]
- Liu, Y.; Ren, Y.; Li, J.; Wang, F.; Wang, F.; Ma, C.; Chen, D.; Jiang, X.; Fan, C.; Zhang, H.; et al. In Vivo Processing of Digital Information Molecularly with Targeted Specificity and Robust Reliability. Sci. Adv. 2022, 8, eabo7415. [Google Scholar] [CrossRef]
- Al Mamun, A.A.M.; Lombardo, M.-J.; Shee, C.; Lisewski, A.M.; Gonzalez, C.; Lin, D.; Nehring, R.B.; Saint-Ruf, C.; Gibson, J.L.; Frisch, R.L.; et al. Identity and function of a large gene network underlying mutagenic repair of DNA breaks. Science 2012, 338, 1344–1348. [Google Scholar] [CrossRef]
- Oller, A.R.; Schaaper, R.M. Spontaneous mutation in Escherichia coli containing the dnaE911 DNA polymerase antimutator allele. Genetics 1994, 138, 263–270. [Google Scholar] [CrossRef]
- Schaaper, R.M. Suppressors of Escherichia coli mutT: Anitimutators for DNA replication errors. Mutat. Res. 1996, 350, 17–23. [Google Scholar] [CrossRef]
- Woo, A.C.; Faure, L.; Dapa, T.; Matic, I. Heterogeneity of spontaneous DNA replication errors in single isogenic Escherichia coli cells. Sci. Adv. 2018, 4, eaat1608. [Google Scholar] [CrossRef]
- Tabatabaei, S.K.; Pham, B.; Pan, C.; Liu, J.; Chandak, S.; Shorkey, S.A.; Hernandez, A.G.; Aksimentiev, A.; Chen, M.; Schroeder, C.M.; et al. Expanding the Molecular Alphabet of DNA-Based Data Storage Systems with Neural Network Nanopore Readout Processing. Nano Lett. 2022, 22, 1905–1914. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Data Size | Length of Strings | Encoding Method | Redundancy or Error Correction | Modification | Reference |
|---|---|---|---|---|---|---|
| Bornholt et al. | 51 KB | 120 | Huffman code | DNA string exclusive-or | – | [20] |
| Blawat et al. | 22 MB | 230 | Own bit mapping | BCH code | – | [21] |
| Organick et al. | 200 MB | ~150 | Base-4 | Reed–Solomon | – | [22] |
| Choi et al. | 854 B | 85 | Own bit mapping | Reed–Solomon | Degenerate bases | [23] |
| Lee et al. | 96 B | ~50 | ASCII | codec | Enzymatic DNA synthesis | [24] |
| Tabatabaei et al. | 2 KB; 392 KB | 450 | Own bit mapping | Not needed | Enzymatic nicking (Pf Ago) | [25] |
| Yang et al. | 23 KB | 83 | A, C = 0; G, T = 1 | n.d. | TNA | [26] |
| Ren et al. | 682 B; 39 KB; 28 MB | ~100 | RABR; RALR | Reed–Solomon | Artificial nucleotides | [27] |
| Mayer et al. | 24,5–33,6 KB | ~40 | ASCII; Elias gamma | n.d. | Epigenetic encoding | [28] |
| Storage Method | Time | Temperature | PCR Success | Reference |
|---|---|---|---|---|
| Chemical encapsulation | ||||
| Silica nanoparticles | 9 months | RT | x | [43] |
| DNA-layered titanate nanohybrid | 1 month | x | x | [44] |
| Solution Preservation | ||||
| ”DNA stable” | 4 years | RT | 98% | [42] |
| DMSO salt solution | 4 months | RT | 42% | [45] |
| DMSO salt solution | 2 years | RT | x | [46] |
| 70% ethanol | 4 months | RT | 27% | [45] |
| 70% ethanol | 2 years | RT | x | [46] |
| 90% ethanol | 6 months | RT | 96% | [47] |
| Formalin-fixed | 30 years | RT | 30% | [48] |
| Formalin-fixed | 2–6 years | RT | x | [49] |
| Paraffin-embedded tissues | 2–6 years | RT | x | [49] |
| DETs buffer | 6 months | RT | 92% | [47] |
| TE buffer | 1 night | −20 °C | 100% | [50] |
| TE buffer | 3 years | −20 °C | x | [51] |
| Dehydratation | ||||
| Ancient bone | 521 years | 13 °C | x | [52] |
| Filter Paper | 4 years | RT | 82.5% | [53] |
| Dried DNA | 4 months | RT | 35% | [45] |
| FTA cards | up to 128 days | RT | 95% | [54] |
| Silica Gel | 6 months | RT | 50% | [47] |
| Oven-dried | 6 months | RT | 72% | [47] |
| Oven-dried | 6 months | −20 °C | 86% | [47] |
| Freeze drying | ||||
| DNA | 4 years | 4 °C | 49% | [42] |
| Storage Method | Time | Temperature | Relative Humidity | Half-Life | Temperature | C/C0 | Reference |
|---|---|---|---|---|---|---|---|
| Experimental Conditions | Parameters in Non-Experimental Conditions | ||||||
| Chemical encapsulation | |||||||
| Silica nanoparticles | 2 weeks | 70 °C | 50% | 20–90 years | 20 °C | 90% | [43] |
| Silica nanoparticles | 10 days | 60 °C | 50% | 5 months | RT | 65% | [55] |
| Calcium phosphate crystals | 6 days | 70 °C | 50% | 1 year | 10 °C | 0.1% | [56] |
| ”DNAshell” | 2 days | 100 °C | 50% | 1 million years | 25 °C | x | [57] |
| ”DNAshell” | 30 h | 76 °C | 50% | 100 years | 25 °C | x | [58] |
| ”DNAshell” + trehalose | 1 month | 76 °C | 50% | 2000 years | 25 °C | x | [58] |
| In silica | 1 week | 70 °C | 50% | 200 years | 10 °C | 10% | [4] |
| Solution Preservation | |||||||
| ”DNA stable” | 1 week | 65 °C | 50% | 4 years | 25 °C | 10% | [4] |
| ”GenTra” | 1 week | 65 °C | 50% | 2 years | 25 °C | 50% | [59] |
| TE buffer | 20 days | 65 °C | 50% | 20 years | −20 °C | x | [51] |
| Dehydratation | |||||||
| DNA | 6 weeks | 50 °C | 50% | x | x | 10% | [60] |
| DNA silica fossilization | 35 days | 65 °C | 50% | 2 years | RT | 15% | [61] |
| Dehydration with earth alkaline salts | 6 days | 70 °C | 50% | 750 years | 10 °C | 10% | [62] |
| DNA micro-disc | 2 weeks | 70 °C | 50% | >700 years | 0 °C | x | [40] |
| DNA with trehalose | 10 days | 70 °C | 75% | 17 years | 10 °C | x | [63] |
| Filter card | 1 week | 70 °C | 50% | 3.7 years | 25 °C | 1% | [4] |
| Freeze drying | |||||||
| Polymer-plasmid complexes | 10 months | 40 °C | 50% | 3 years | RT | x | [64] |
| Trehalose | 2 months | 60 °C | 50% | 2 years | RT | x | [65] |
| Cryosilicified samples | 4 weeks | 70 °C | 60% | 1200 years | 20 °C | 31% | [66] |
| Additives | |||||||
| Trehalose | 2 years | 56 °C | 50% | 20 years | RT | 50% | [42] |
| Trehalose | 1 week | 65 °C | 50% | 160 years | 10 °C | 20% | [59] |
| PVA | 2 years | 56 °C | 50% | 20 years | RT | 15% | [42] |
| ”Sugar mix” | 1 week | 65 °C | 50% | 1 year | 20 °C | 30% | [59] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buko, T.; Tuczko, N.; Ishikawa, T. DNA Data Storage. BioTech 2023, 12, 44. https://doi.org/10.3390/biotech12020044
Buko T, Tuczko N, Ishikawa T. DNA Data Storage. BioTech. 2023; 12(2):44. https://doi.org/10.3390/biotech12020044
Chicago/Turabian StyleBuko, Tomasz, Nella Tuczko, and Takao Ishikawa. 2023. "DNA Data Storage" BioTech 12, no. 2: 44. https://doi.org/10.3390/biotech12020044
APA StyleBuko, T., Tuczko, N., & Ishikawa, T. (2023). DNA Data Storage. BioTech, 12(2), 44. https://doi.org/10.3390/biotech12020044