
Classification of Nuclear Reactor Operations Using Spatial Importance and Multisensor Networks



Abstract
1. Introduction
2. Previous Power Prediction Analyses at the High Flux Isotope Reactor
3. Dataset and Models
3.1. High Flux Isotope Reactor
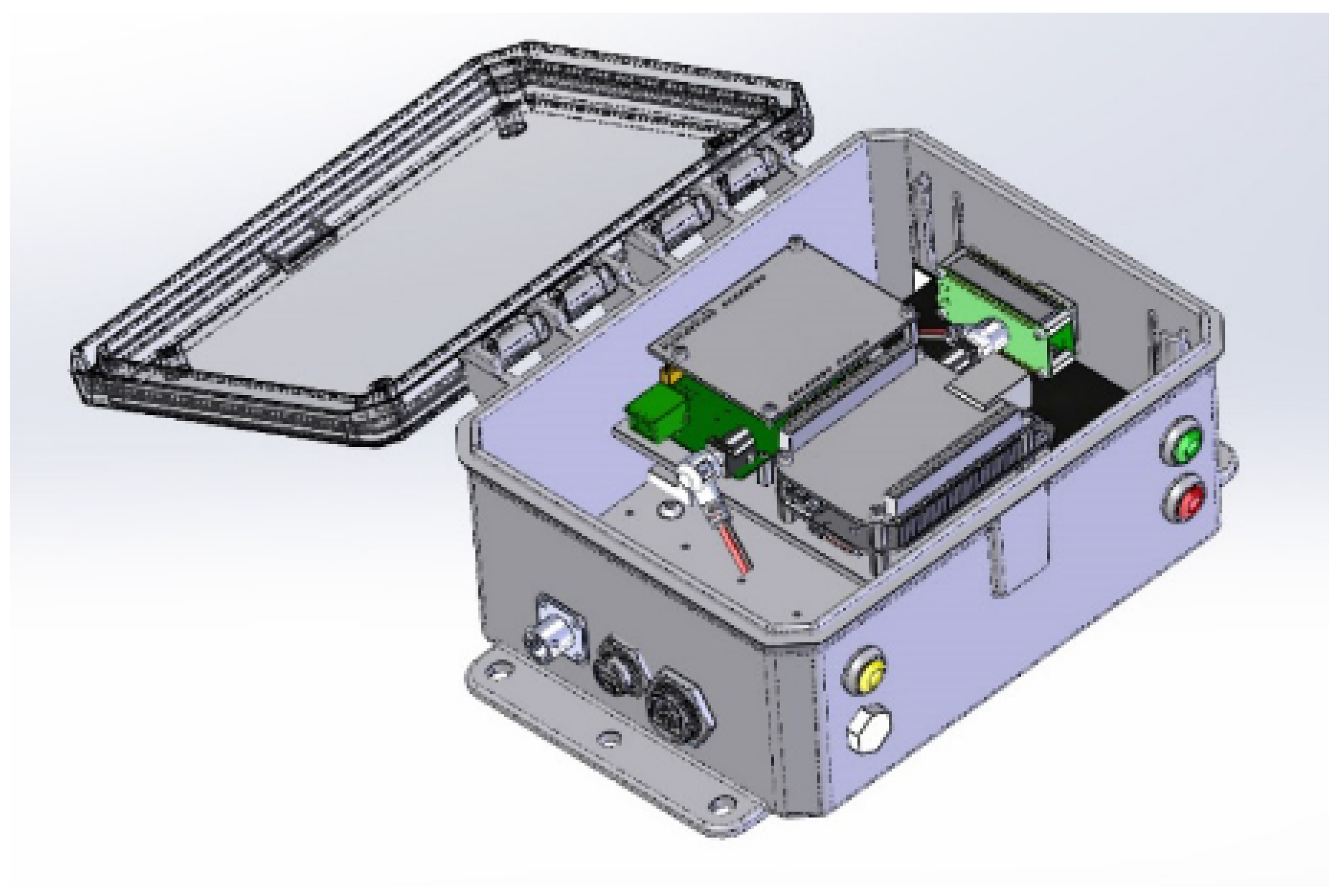
3.2. Merlyn Multisensor Platform
3.3. Data Products
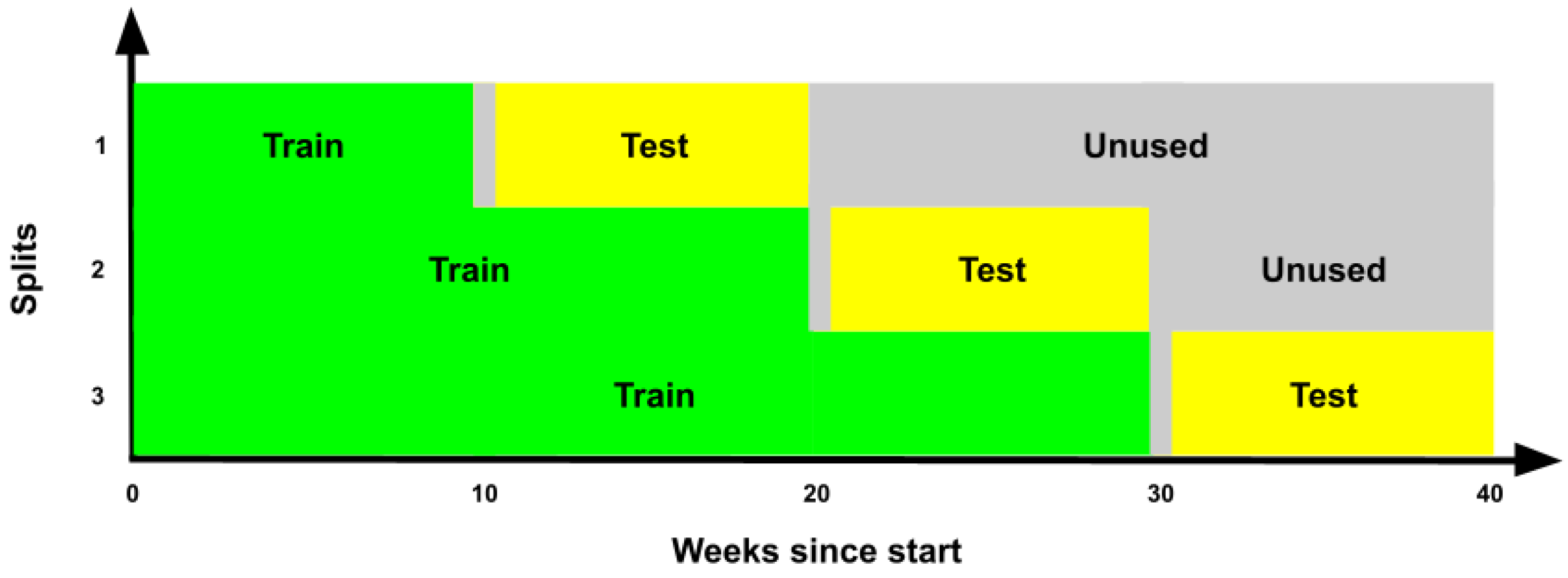
3.4. Data Partitioning
3.5. Baseline Modeling Efforts
4. Feature Importance and Wrapper Methods
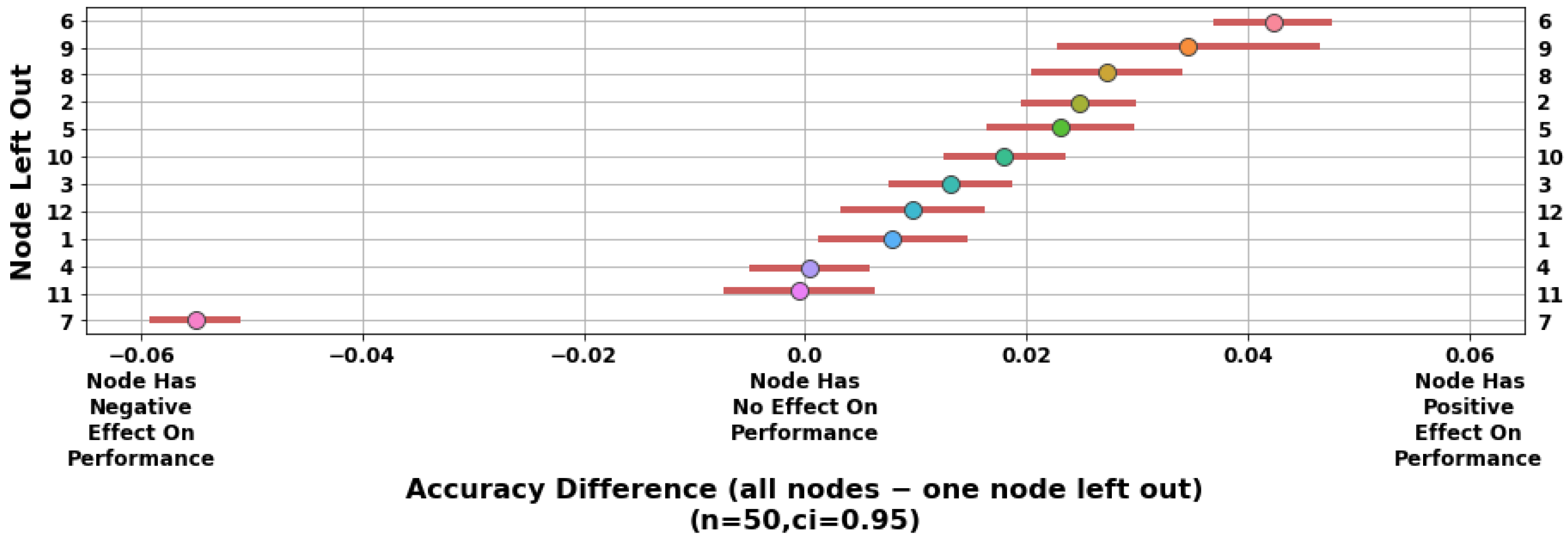
4.1. Feature Importance
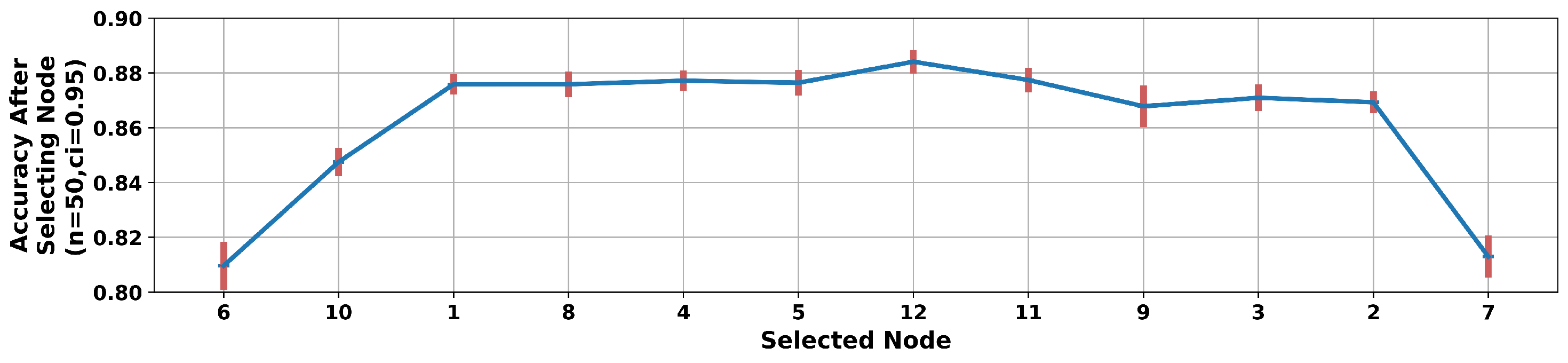
4.2. Wrapper Methods
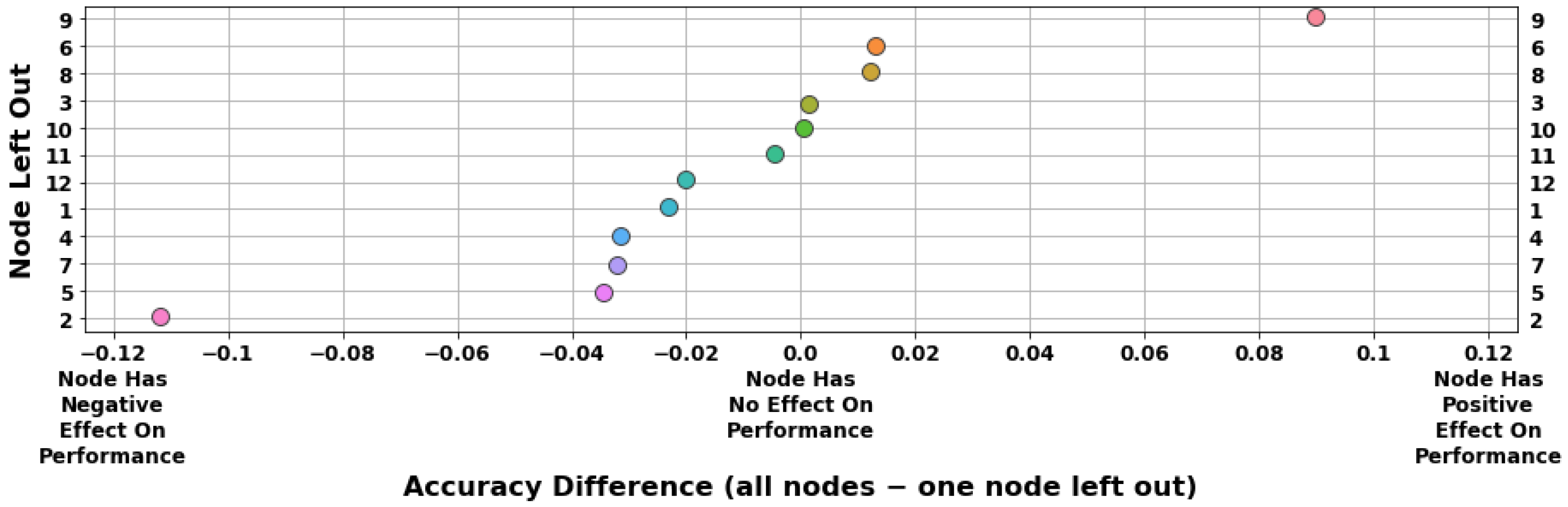
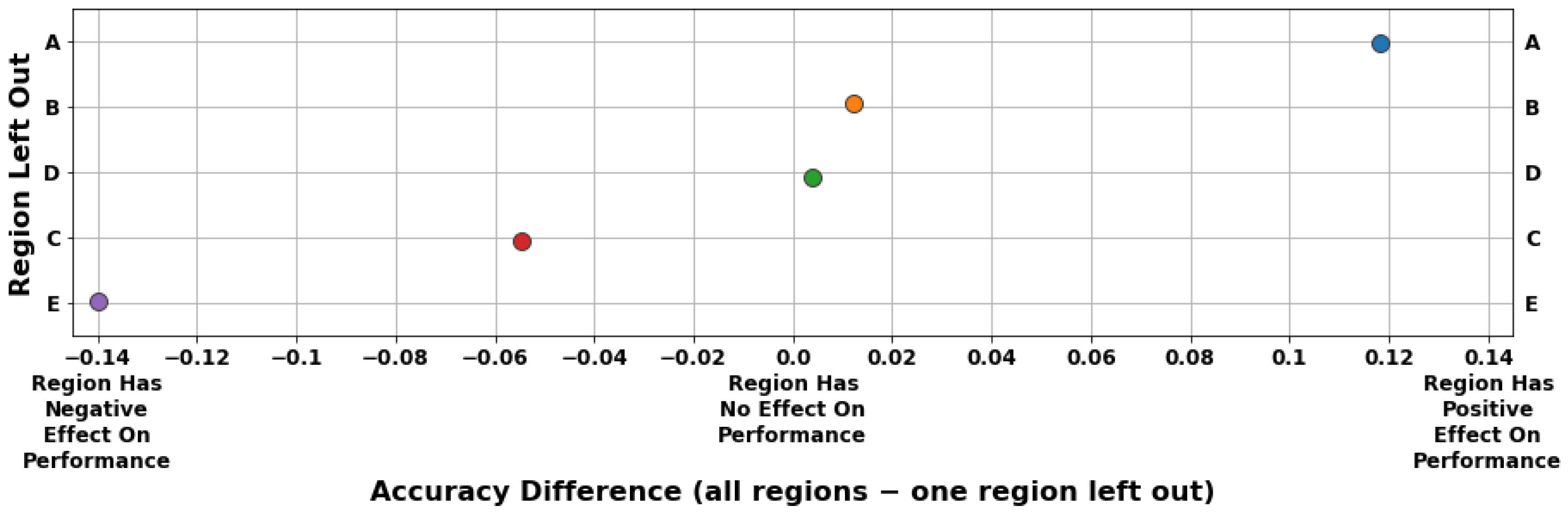
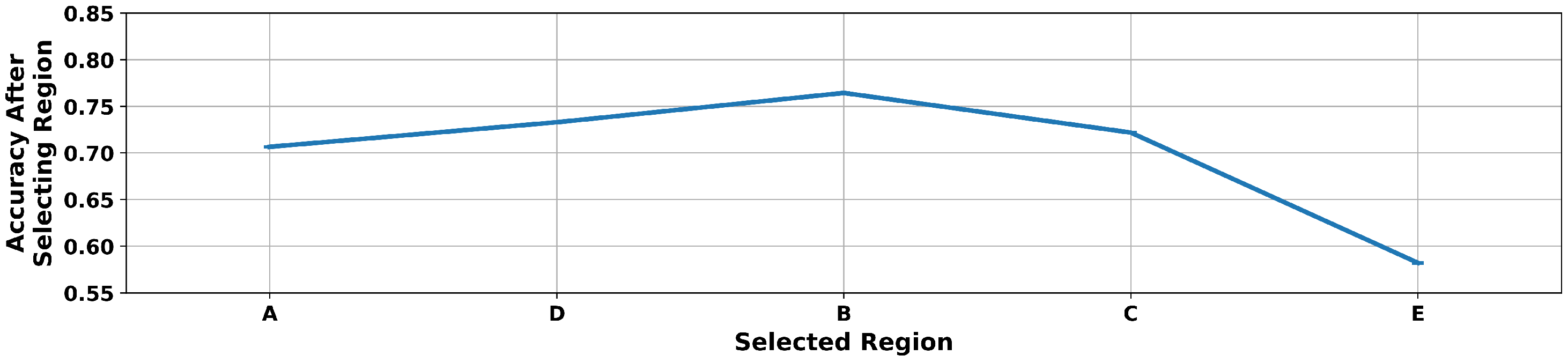
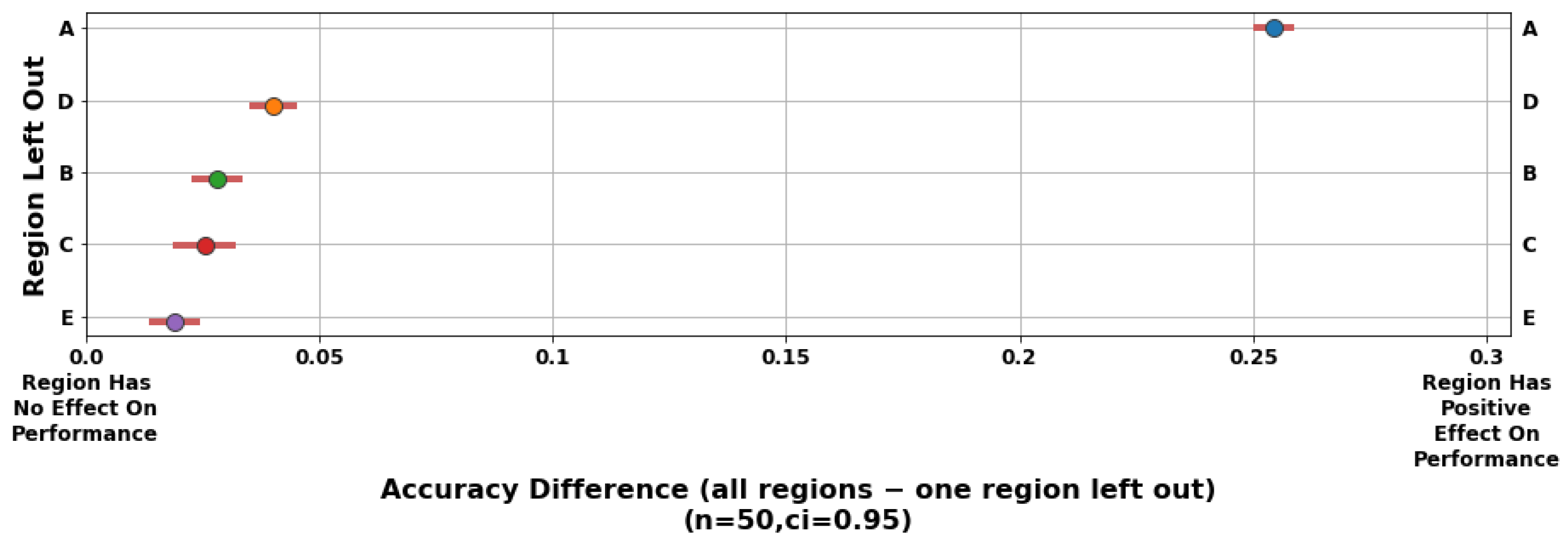
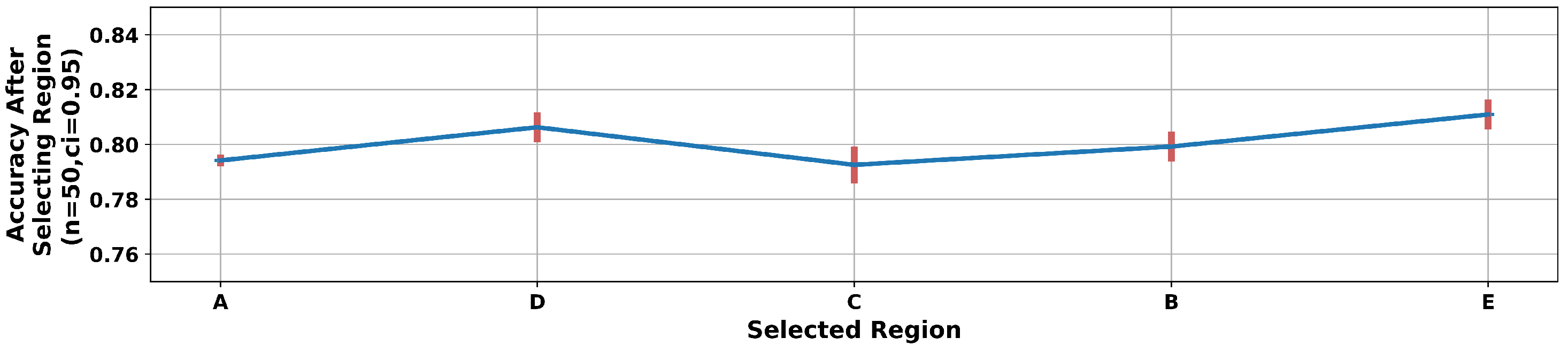
4.3. Node and Region Importance
5. Analysis and Results
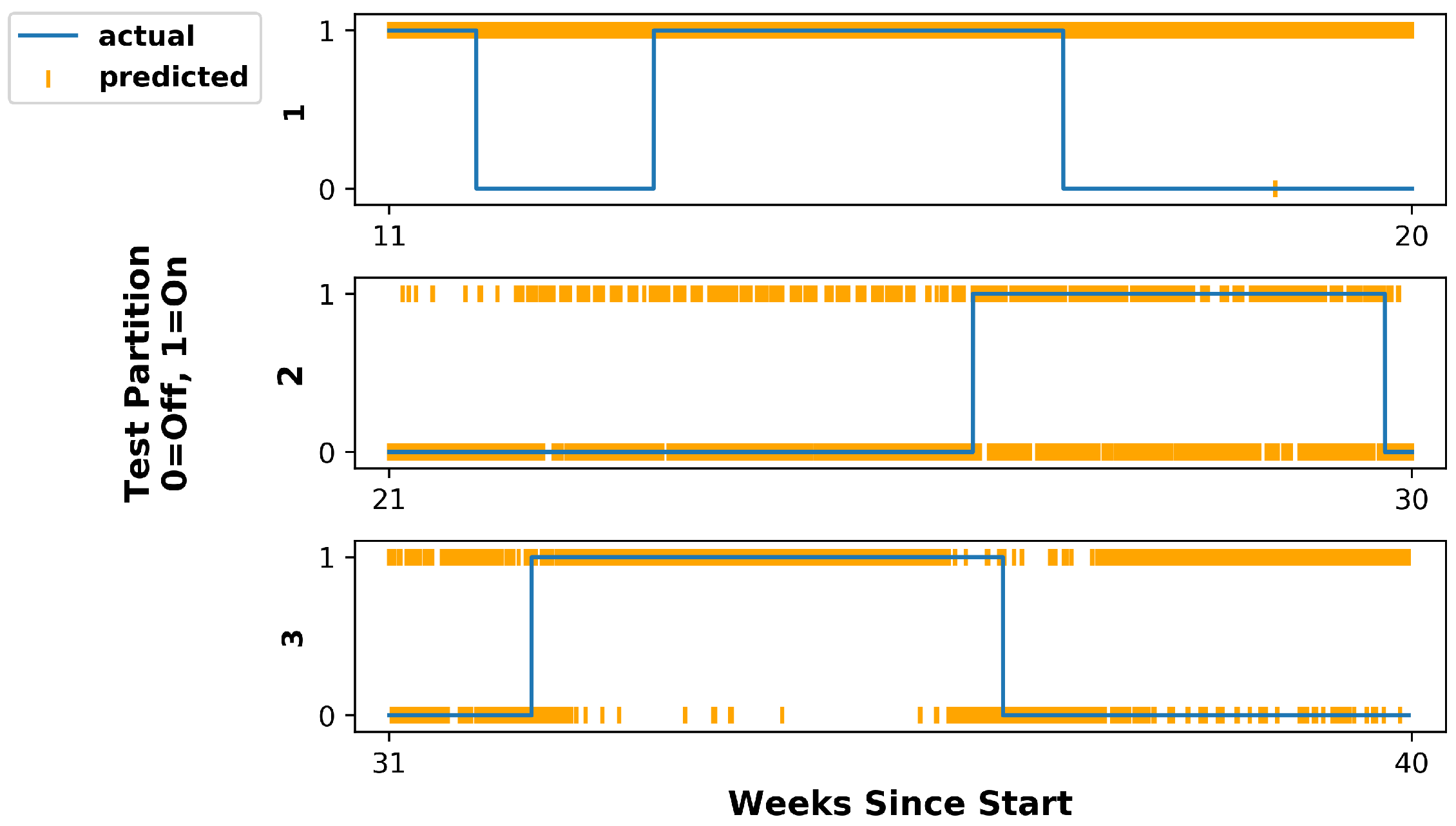
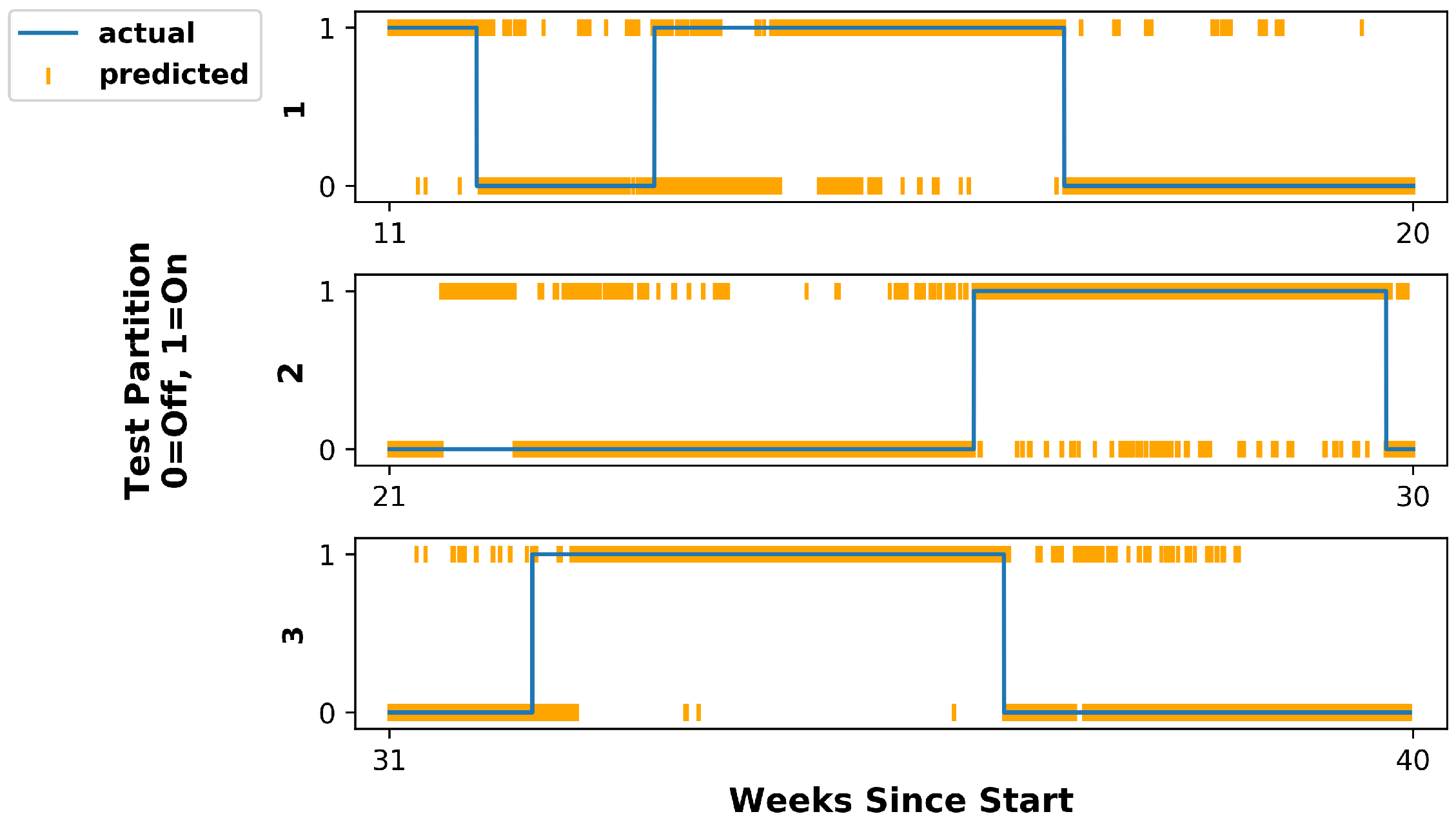
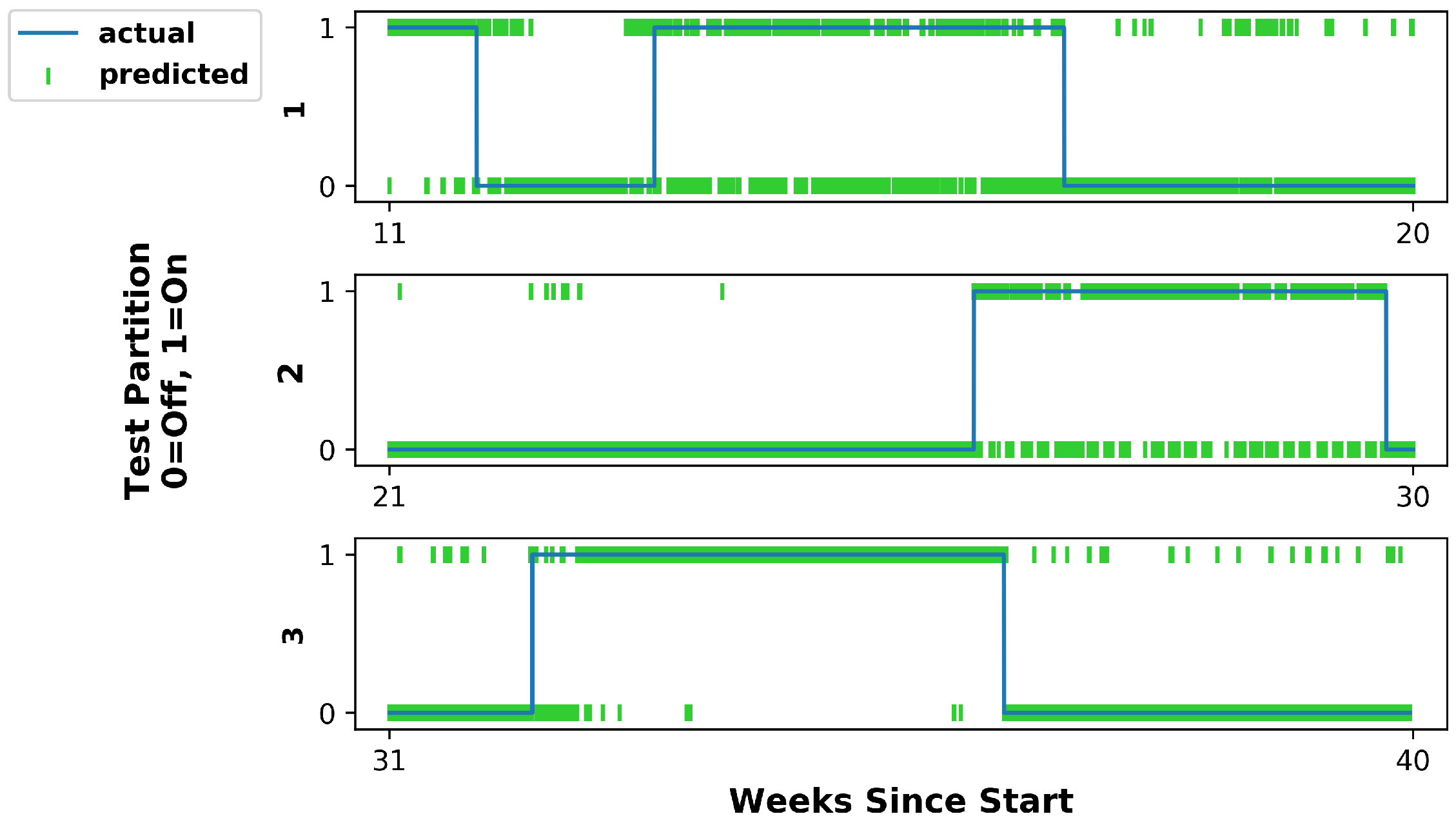
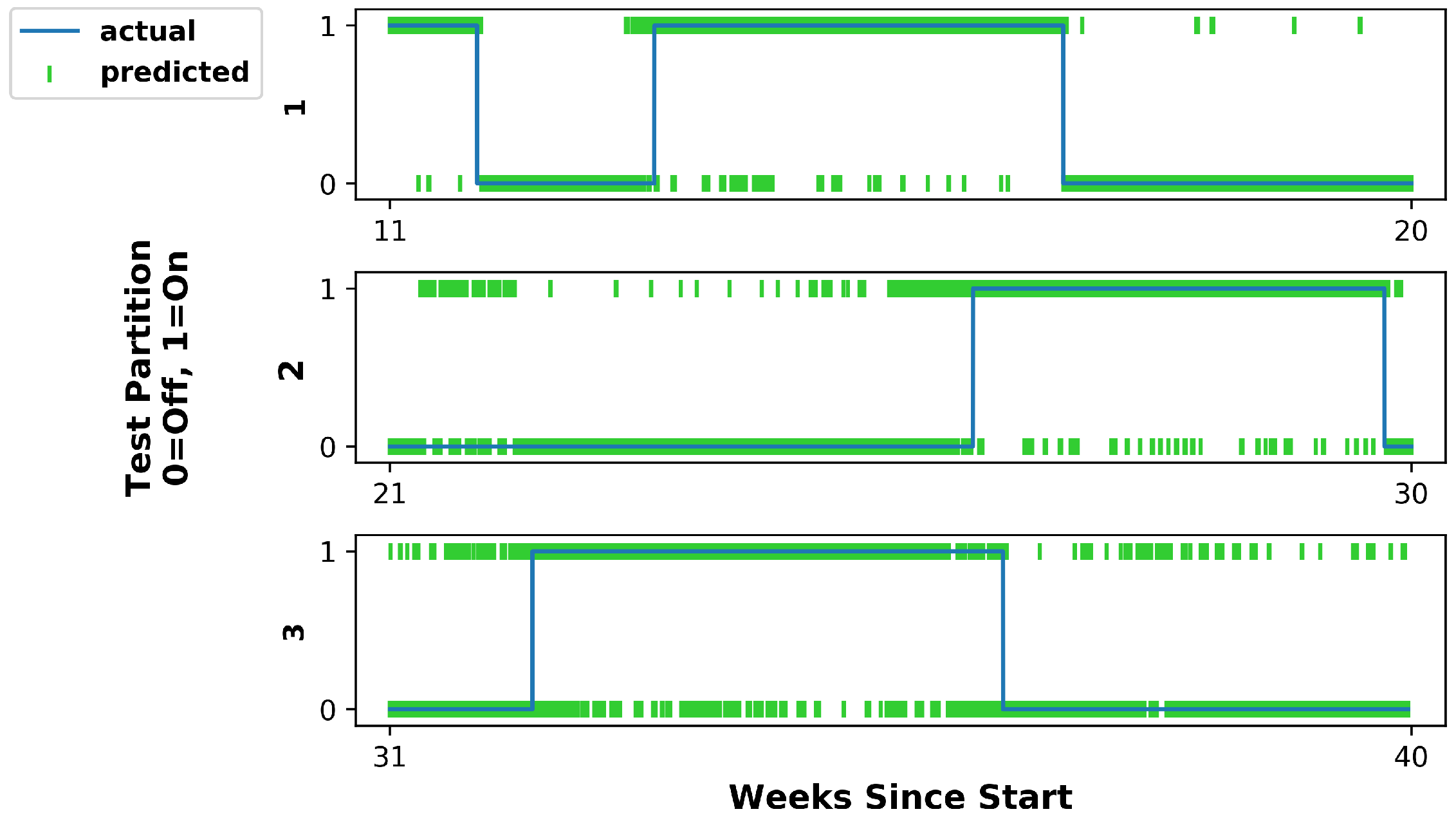
5.1. Hidden Markov Model
5.2. Feed-Forward Neural Network
5.3. Discussion
6. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FFS | Forward Feature Selection |
| FNS | Forward Node Selection |
| FRS | Forward Region Selection |
| HMM | Hidden Markov Model |
| HFIR | High Flux Isotope Reactor |
| LOCO | Leave One Covariate Out |
| LONO | Leave One Node Out |
| LORO | Leave One Region Out |
| NOAA | National Oceanic and Atmospheric Administration |
References
- Abe, N. The NPT at Fifty: Successes and Failures. J. Peace Nucl. Disarm. 2020, 3, 224–233. [Google Scholar] [CrossRef]
- Gastelum, Z.; Goldblum, B.; Shead, T.; Stewart, C.; Miller, K.; Luttman, A. Integrating Physical and Informational Sensing to Support Nonproliferation Assessments of Nuclear-Related Facilities. In Proceedings of the Institute of Nuclear Materials Management (INMM) 60th Annual Meeting, Palm Springs, CA, USA, 14–18 July 2019; pp. 1–10. [Google Scholar]
- Stewart, C.L.; Goldblum, B.L.; Tsai, Y.A.; Chockkalingam, S.; Padhy, S.; Wright, A. Multimodal Data Analytics for Nuclear Facility Monitoring. In Proceedings of the Institute of Nuclear Materials Management (INMM) 60th Annual Meeting, Palm Springs, CA, USA, 14–18 July 2019; pp. 1–10. [Google Scholar]
- Ramirez, C.; Rao, N.S.V. Reactor Facility Operational State Classification Using Gas Effluents and Radiation Measurements. In Proceedings of the 2018 IEEE Nuclear Science Symposium and Medical Imaging Conference Proceedings (NSS/MIC), Sydney, NSW, Australia, 10–17 November 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Ramirez, C.; Rao, N.S.V. Facility On/Off Inference by Fusing Multiple Effluence Measurements. In Proceedings of the 2017 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), Atlanta, GA, USA, 21–28 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Flynn, G.; Parikh, N.K.; Egid, A.; Casleton, E. Predicting the Power Level of a Nuclear Reactor by Combining Multiple Modalities. In Proceedings of the Institute of Nuclear Materials Management (INMM) 60th Annual Meeting, Palm Springs, CA, USA, 14–18 July 2019; pp. 1–10. [Google Scholar]
- Parikh, N.; Flynn, G.; Casleton, E.; Archer, D.; Karnowski, T.; Nicholson, A.; Maceira, M.; Marcillo, O.; Ray, W.; Wetherington, R. Predicting the Power Level of a Nuclear Reactor using a Time Series-based Approach. In Proceedings of the Institute of Nuclear Materials Management (INMM) 61st Annual Meeting, Online, 12–16 July 2020. [Google Scholar]
- Parikh, N.; Flynn, G.; Archer, D.; Karnowski, T.; Maceira, M.; Marcillo, O.; Ray, W.; Wetherington, R.; Willis, M.; Nicholson, A. Data and Model Selection to Detect Sparse Events from Multiple Sensor Modalities. In Proceedings of the 2021 INMM and ESARDA Joint Annual Meeting, Online, 23–26, 30 August–1 September 2021. [Google Scholar]
- Rao, N.S.V.; Greulich, C.; Sen, S.; Dayman, K.J.; Hite, J.; Ray, W.; Hale, R.; Nicholson, A.D.; Johnson, J.; Hunley, R.D.; et al. Reactor Power Level Estimation by Fusing Multi-Modal Sensor Measurements. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Chai, C.; Ramirez, C.; Maceira, M.; Marcillo, O. Monitoring Operational States of a Nuclear Reactor Using Seismoacoustic Signatures and Machine Learning. Seismol. Res. Lett. 2022, 93, 1660–1672. [Google Scholar] [CrossRef]
- Schmidt, E.; Work, R.; Catz, S.; Horvitz, E.; Chien, S.; Jassy, A.; Clyburn, M.; Louie, G.; Darby, C.; Mark, W.; et al. Final Report; National Security Commission on Artificial Intelligence: Washington, DC, USA, 2021. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability: In Machine Learning, the Concept of Interpretability is Both Important and Slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Chandler, D.; Betzler, B.R.; Davidson, E.; Ilas, G. Modeling and simulation of a High Flux Isotope Reactor representative core model for updated performance and safety basis assessments. Nucl. Eng. Des. 2020, 366, 110752. [Google Scholar] [CrossRef]
- Robinson, S.M.; Benker, D.E.; Collins, E.D.; Ezold, J.G.; Garrison, J.R.; Hogle, S.L. Production of Cf-252 and other transplutonium isotopes at Oak Ridge National Laboratory. Radiochim. Acta 2020, 108, 737–746. [Google Scholar] [CrossRef]
- Coley, G. BeagleBone Black System Reference Manual. Beagleboard. Rev. C.1. 2014. Available online: https://cdn.sparkfun.com/datasheets/Dev/Beagle/BBB_SRM_C.pdf (accessed on 15 April 2019).
- Atmel Corporation. 8-bit AVR Microcontroller with 32K Bytes In-System Programmable Flash. Rev. 7810D-AVR-01/15. 2015. Available online: https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-7810-Automotive-Microcontrollers-ATmega328P_Datasheet.pdf (accessed on 15 April 2019).
- ROHM Semiconductor. SensorShield-EVK-003 Manual. Rev.001. 2018. Available online: http://rohmfs.rohm.com/en/products/databook/applinote/ic/sensor/sensorshield-evk-003_ug-e.pdf (accessed on 15 April 2019).
- Kionix. 8g/16g/32g Tri-axis Digital Accelerometer Specifications. Rev. 2.0. 2017. Available online: https://d10bqar0tuhard.cloudfront.net/en/datasheet/KX224-1053-Specifications-Rev-2.0.pdf (accessed on 15 April 2019).
- ROHM Semiconductor. Optical Proximity Sensor and Ambient Light Sensor with IrLED. Rev.001. 2016. Available online: https://fscdn.rohm.com/en/products/databook/datasheet/opto/optical_sensor/opto_module/rpr-0521rs-e.pdf (accessed on 15 April 2019).
- ROHM Semiconductor. Magnetic Sensor Series: 3-Axis Digital Magnetometer IC. Rev.001. 2016. Available online: https://fscdn.rohm.com/en/products/databook/datasheet/ic/sensor/geomagnetic/bm1422agmv-e.pdf (accessed on 15 April 2019).
- ROHM Semiconductor. Pressure Sensor Series: Pressure Sensor IC. Rev.003. 2016. Available online: https://fscdn.rohm.com/en/products/databook/datasheet/ic/sensor/pressure/bm1383aglv-e.pdf (accessed on 15 April 2019).
- ROHM Semiconductor. Temperature Sensor IC. Rev.001. 2015. Available online: https://fscdn.rohm.com/en/products/databook/datasheet/ic/sensor/temperature/bd1020hfv-e.pdf (accessed on 15 April 2019).
- NOAA. Climate Data Online. 2021. Available online: https://www.ncdc.noaa.gov/cdo-web/ (accessed on 19 April 2020).
- Rubin, D. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Varma, S.; Simon, R. Bias in error estimation when using cross-validation for model selection. BMC Bioinform. 2006, 7, 91. [Google Scholar] [CrossRef] [PubMed]
- Roberts, D.; Bahn, V.; Ciuti, S.; Boyce, M.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Software. 2015. Available online: tensorflow.org (accessed on 15 April 2019).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- HMMLearn. Available online: http://hmmlearn.readthedocs.org/ (accessed on 19 April 2021).
- Seymore, K.; McCallum, A.; Rosenfeld, R. Learning Hidden Markov Model Structure for Information Extraction. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI) ’99 Workshop on Machine Learning for Information Extraction, Orlando, FL, USA, 18–19 July 1999; pp. 37–42. [Google Scholar]
- Forney, G. The Viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Sazli, M. A brief review of feed-forward neural networks. Commun. Fac. Sci. Univ. Ank. Ser. A2–A3 2006, 50, 11–17. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; Conference Track Proceedings: Ithaca, NY, USA, 2015; pp. 1–10. [Google Scholar]
- Bach, F.; Jenatton, R.; Mairal, J.; Obozinski, G. Convex Optimization with Sparsity-Inducing Norms. In Optimization for Machine Learning; The MIT Press: Cambridge, MA, USA, 2011; Volume 5, pp. 19–53. [Google Scholar]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Washington, DC, USA, 18–22 June 1989; IEEE: Piscataway, NJ, USA, 1989; Volume 1, pp. 593–605. [Google Scholar] [CrossRef]
- Wang, X.; Cao, W. Non-iterative approaches in training feed-forward neural networks and their applications. Soft Comput. 2018, 22, 3473–3476. [Google Scholar] [CrossRef]
- Cao, W.; Wang, X.; Ming, Z.; Gao, J. A review on neural networks with random weights. Neurocomputing 2018, 275, 278–287. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Gevrey, M.; Dimopoulos, I.; Lek, S. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol. Model. 2003, 160, 249–264. [Google Scholar] [CrossRef]
- Zemp, R.; Tanadini, M.; Plüss, S.; Schnüriger, K.; Singh, N.; Taylor, W.; Lorenzetti, S. Application of Machine Learning Approaches for Classifying Sitting Posture Based on Force and Acceleration Sensors. BioMed Res. Int. 2016, 2016, 5978489. [Google Scholar] [CrossRef]
- Knaak, C.; Thombansen, U.; Abels, P.; Kröger, M. Machine learning as a comparative tool to determine the relevance of signal features in laser welding. Procedia CIRP 2018, 74, 623–627. [Google Scholar] [CrossRef]
- Semaan, R. Optimal sensor placement using machine learning. Comput. Fluids 2017, 159, 167–176. [Google Scholar] [CrossRef]
- Han, H.; Gu, B.; Wang, T.; Li, Z. Important sensors for chiller fault detection and diagnosis (FDD) from the perspective of feature selection and machine learning. Int. J. Refrig. 2011, 34, 586–599. [Google Scholar] [CrossRef]
- Chen, Q.; Pan, G.; Chena, W.; Wu, P. A Novel Explainable Deep Belief Network Framework and Its Application for Feature Importance Analysis. IEEE Sens. J. 2021, 21, 25001–25009. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Kohavi, R.; John, G. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Lei, J.; G’Sell, M.; Rinaldo, A.; Tibshirani, R.; Wasserman, L. Distribution-Free Predictive Inference for Regression. J. Am. Stat. Assoc. 2018, 113, 1094–1111. [Google Scholar] [CrossRef]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Grouped variable importance with random forests and application to multiple functional data analysis. Comput. Stat. Data Anal. 2015, 90, 15–35. [Google Scholar] [CrossRef]
- Chakraborty, D.; Pal, N. Selecting Useful Groups of Features in a Connectionist Framework. IEEE Trans. Neural Networks 2008, 19, 381–396. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Y.; Wu, Y.; Zhu, J. Variable selection for the multicategory SVM via adaptive sup-norm regularization. Electron. J. Stat. 2008, 2, 149–167. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B Statist. Methodol. 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Covert, I.; Lundberg, S.; Lee, S. Understanding Global Feature Contributions With Additive Importance Measures. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 17212–17223. [Google Scholar]
- Hensley, J. Cooling Tower Fundamentals, 2nd ed.; SPX Cooling Technologies, Inc.: Overland Park, KS, USA, 2009. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification Furthermore, Regression Trees, 1st ed.; Routledge: New York, NY, USA, 1984. [Google Scholar]
- Bennett, P. Assessing the Calibration of Naive Bayes Posterior Estimates; Technical Report CMU-CS-00-155; Computer Science Department, School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 2000. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Beretta, L.; Santaniello, A. Nearest neighbor imputation algorithms: A critical evaluation. BMC Med. Inform. Decis. Mak. 2016, 16, 74. [Google Scholar] [CrossRef]
- Webster, R.; Oliver, M. Geostatistics for Environmental Scientists; John Wiley & Sons: Chichester, UK, 2007. [Google Scholar]
- Hamed, T. Recursive Feature Addition: A Novel Feature Selection Technique, Including a Proof of Concept in Network Security. Doctoral Dissertation, The University of Guelph, Guelph, ON, Canada, 2017. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
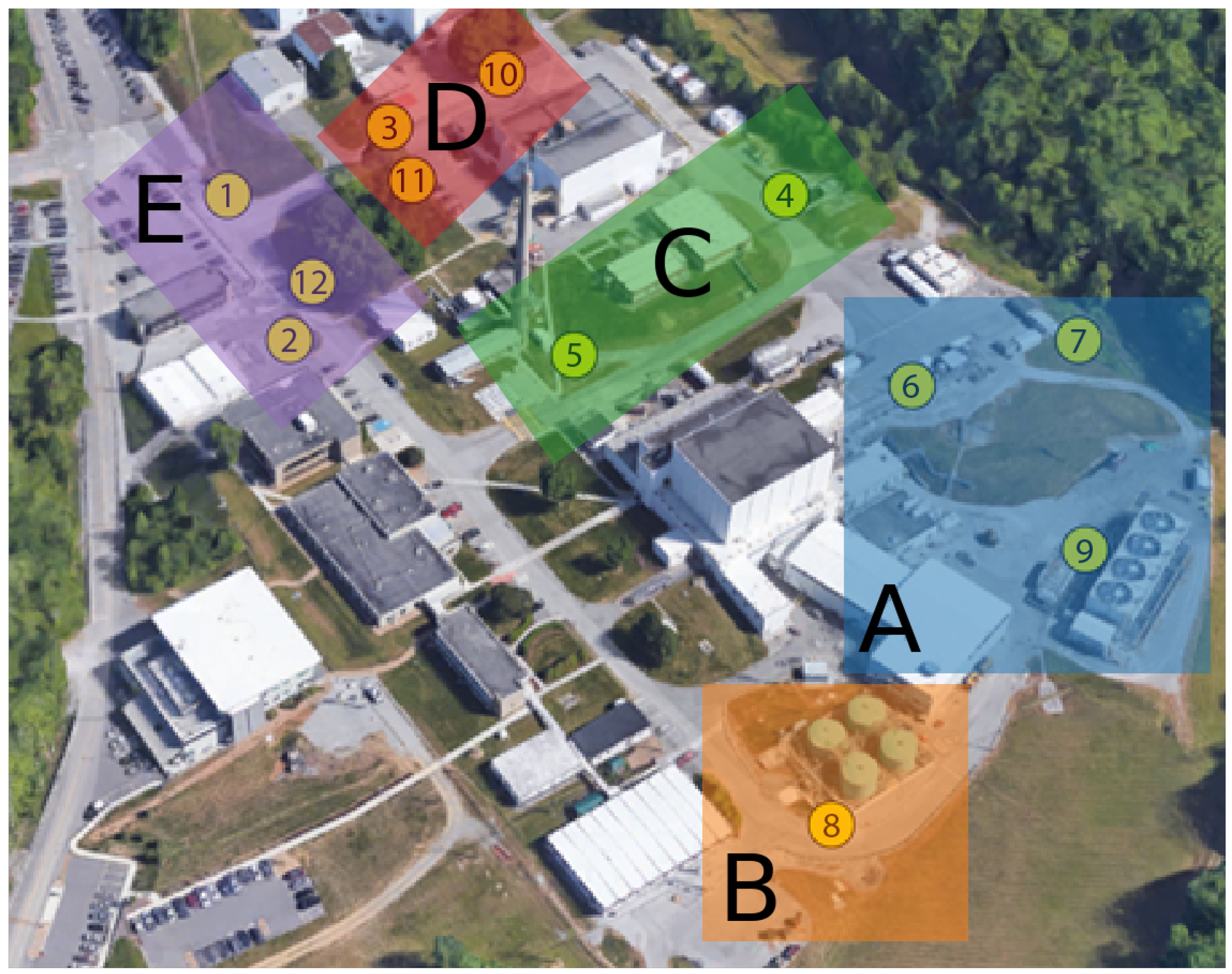
| Region | Nodes | Description |
|---|---|---|
| A | 6, 7, 9 | Reactor Building and Cooling Tower |
| B | 8 | Liquid Storage Tanks |
| C | 4, 5 | Offices near the REDC Facility |
| D | 3, 10, 11 | Target Processing Facility |
| E | 1, 2, 12 | Main Entrance to Complex |
| Modality | Sensor |
|---|---|
| Acceleration (3-axis) | Kionix KX-224-1053 [20] |
| Ambient Light | ROHM RPR-0521RS [21] |
| Magnetic Field (3-axis) | ROHM 1422AGMV [22] |
| Pressure (Barometric) | ROHM BM1383AGLV [23] |
| Temperature | ROHM BD1020HFV [24] |
| Region | Accuracy |
|---|---|
| A | |
| B | |
| C | |
| D | |
| E |
| Node 9 Feature | Average Gini Importance |
|---|---|
| Magnetic Field Variance | 0.639 |
| Acceleration Mean | 0.145 |
| Pressure Mean | 0.107 |
| Acceleration Variance | 0.052 |
| Magnetic Field Mean | 0.020 |
| Pressure Variance | 0.012 |
| Ambient Light Mean | 0.005 |
| Ambient Light Variance | 0.005 |
| Temperature Mean | 0.005 |
| Temperature Variance | 0.003 |
| Missing Flag | 0.002 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tibbetts, J.; Goldblum, B.L.; Stewart, C.; Hashemizadeh, A. Classification of Nuclear Reactor Operations Using Spatial Importance and Multisensor Networks. J. Nucl. Eng. 2022, 3, 243-262. https://doi.org/10.3390/jne3040014
Tibbetts J, Goldblum BL, Stewart C, Hashemizadeh A. Classification of Nuclear Reactor Operations Using Spatial Importance and Multisensor Networks. Journal of Nuclear Engineering. 2022; 3(4):243-262. https://doi.org/10.3390/jne3040014
Chicago/Turabian StyleTibbetts, Jake, Bethany L. Goldblum, Christopher Stewart, and Arman Hashemizadeh. 2022. "Classification of Nuclear Reactor Operations Using Spatial Importance and Multisensor Networks" Journal of Nuclear Engineering 3, no. 4: 243-262. https://doi.org/10.3390/jne3040014
APA StyleTibbetts, J., Goldblum, B. L., Stewart, C., & Hashemizadeh, A. (2022). Classification of Nuclear Reactor Operations Using Spatial Importance and Multisensor Networks. Journal of Nuclear Engineering, 3(4), 243-262. https://doi.org/10.3390/jne3040014