


Distributed Interference-Aware Power Optimization for Multi-Task Over-the-Air Federated Learning


Abstract
1. Introduction
1.1. Related Work
1.2. Contributions
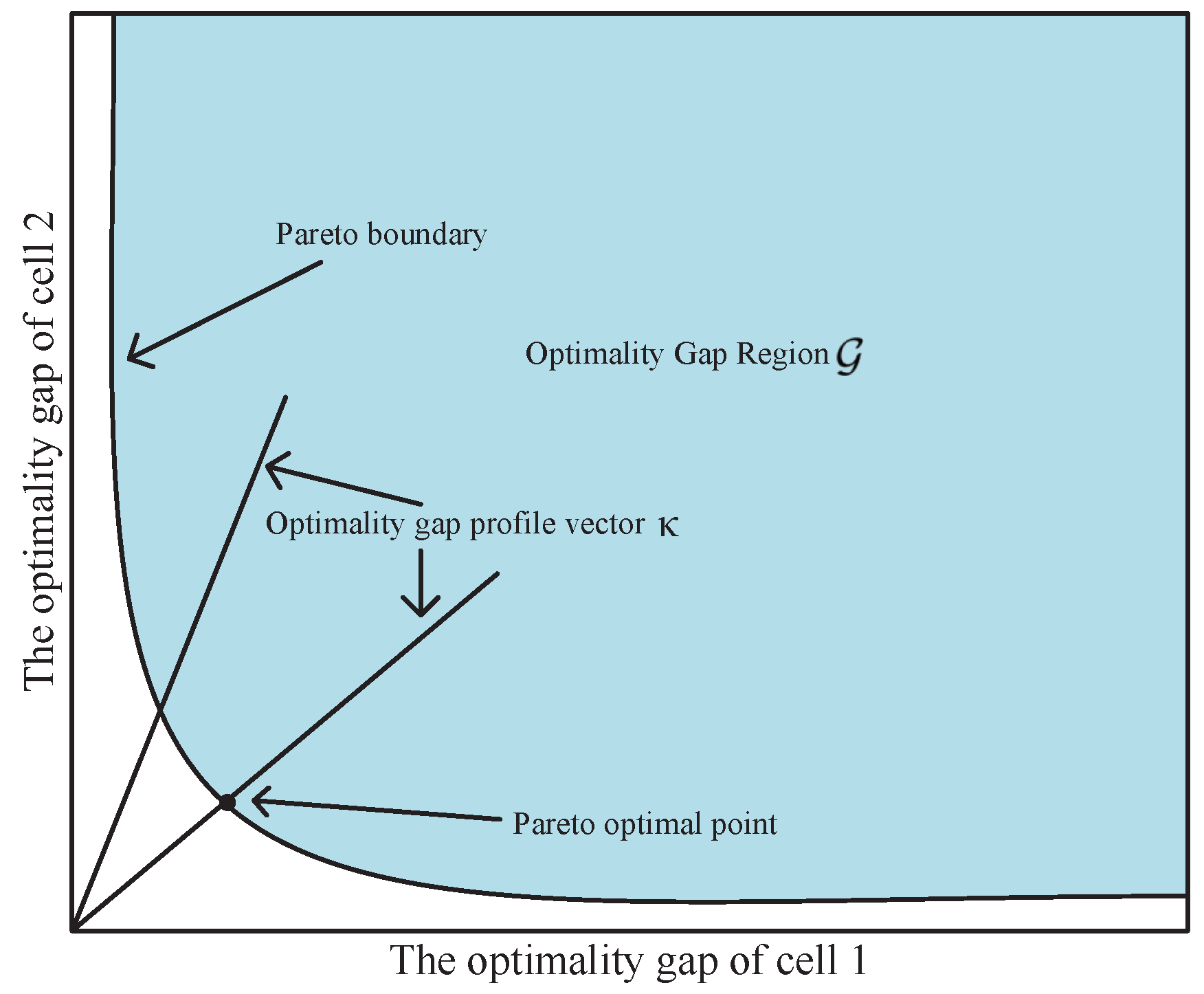
- System modeling and centralized optimization: We construct a multi-cell parallel Air-FL system model, detail the AirComp architecture between devices and APs, and establish the interference mechanisms under shared spectrum conditions. We analyze the impact of aggregation errors on the convergence of the optimality gap and formulate a power control optimization problem aimed at minimizing the total optimality gap across all cells. To characterize performance trade-offs, we employ the Pareto boundary theory and design a centralized power control algorithm to delineate the Pareto boundary.
- Distributed optimization via IT: We propose a distributed optimization scheme based on IT, which decouples the globally coupled problem into locally solvable subproblems. Each cell independently adjusts its transmit power using local CSI. To address the non-convexity of the subproblems, we first transform them into convex problems and then develop an analytical solution framework grounded in Lagrangian duality theory and implement a dynamic IT update mechanism to iteratively approach the Pareto boundary.
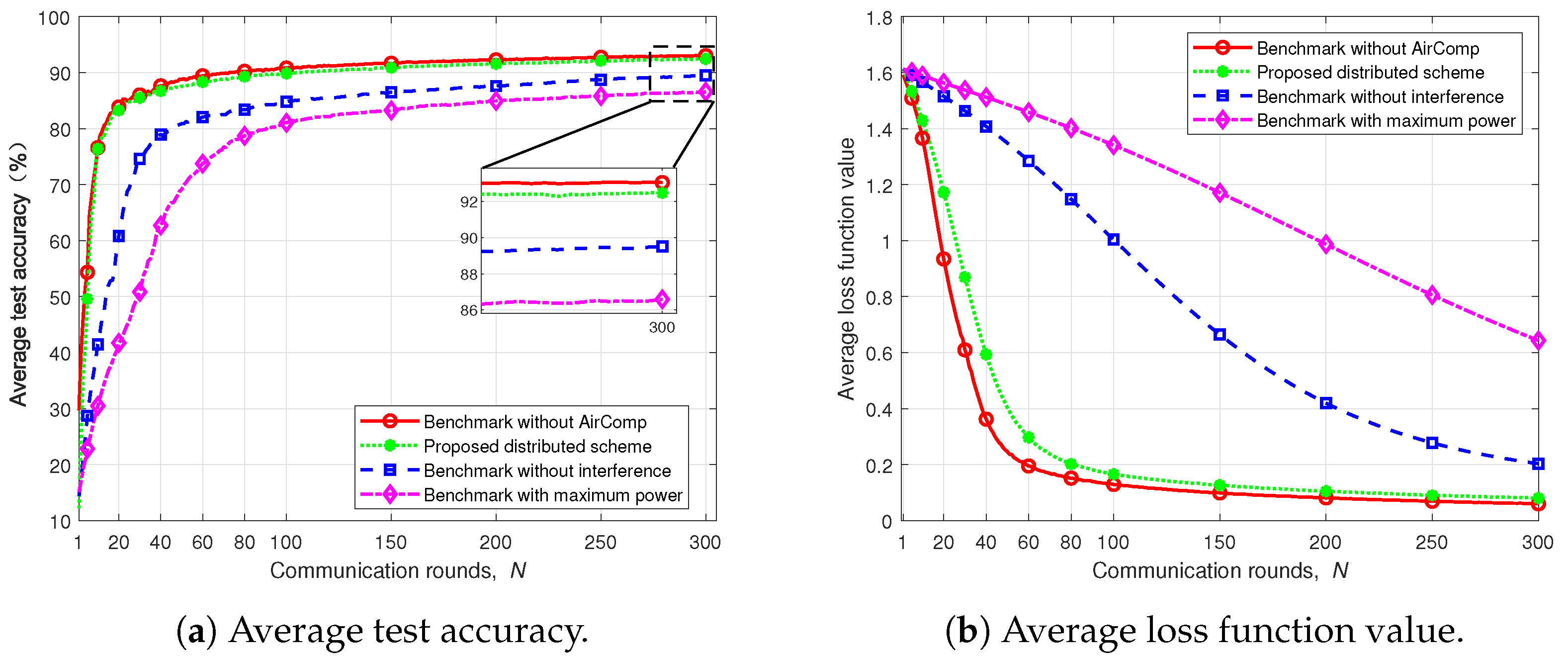
- Simulation validation: Through numerical simulations, we validate the efficacy of our proposed scheme. The results demonstrate that our approach surpasses baseline methods in terms of training convergence speed, cross-cell performance balance, and test accuracy. Moreover, it achieves stable convergence within a limited number of iterations, underscoring its practicality and effectiveness in complex multi-task edge intelligence scenarios.
2. System Model
2.1. Federated Learning Model
2.2. Communication Model
3. Convergence Analysis and Problem Formulation
3.1. Assumptions
3.2. Optimality Gap vs. Aggregation Error
3.3. Problem Formulation
3.4. Pareto Boundary Definition and Characterization
4. Proposed Method
4.1. Centralized Scheme
4.1.1. Denoising Factor Optimization
4.1.2. Device Transmit Power Optimization
| Algorithm 1: Centralized scheme for solving problem . |
|
4.2. Distributed Scheme
| Algorithm 2: IT-based decentralized scheme for solving problem . |
|
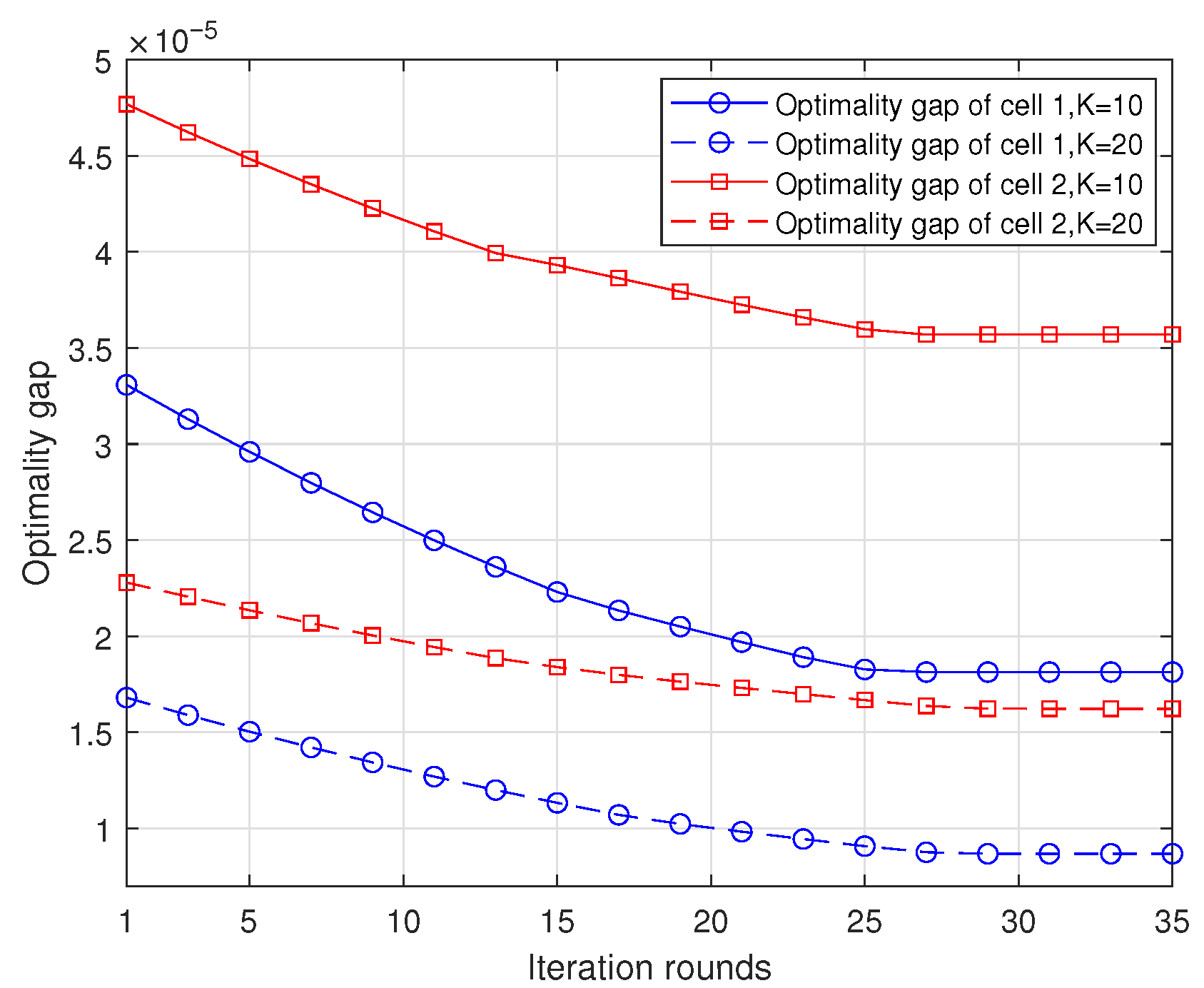
5. Numerical Results
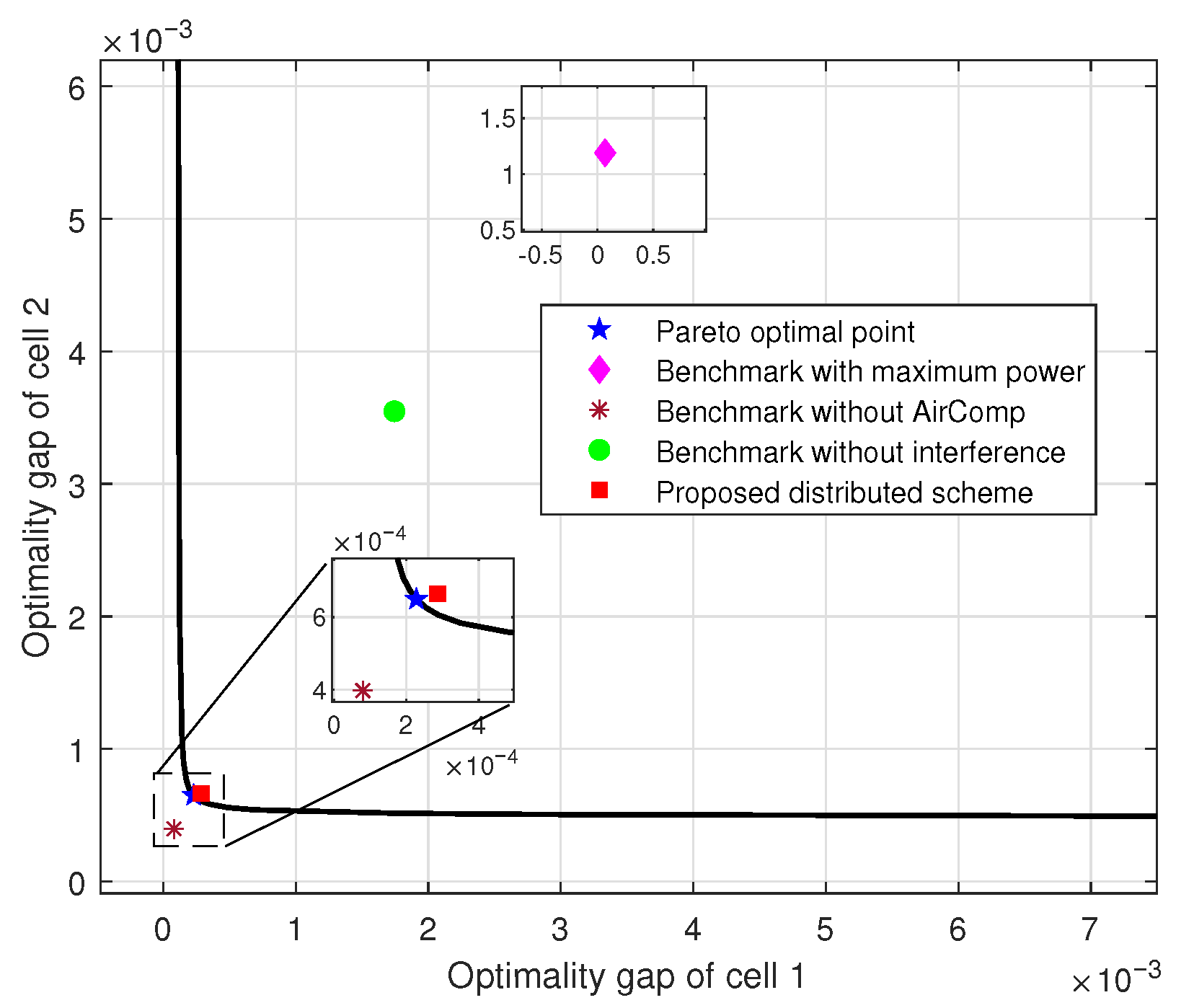
5.1. Simulation Setup and Benchmark Schemes
- Benchmark with maximum power: In this scheme, all devices transmit at their maximum power levels, i.e., . This scheme requires no CSI collection and represents the simplest power control strategy.
- Benchmark without AirComp: In this scheme, all devices transmit their local model updates to their respective APs, which perform aggregation without any interference. This scenario assumes an ideal communication environment, serving as an upper performance bound.
- Benchmark without interference: In this scheme, each AP optimizes the device transmit power and denoising factor based solely on intra-cell CSI, without coordinating with other APs. The optimization problem for AP m is formulated as
5.2. Multi-Task Ridge Regression Performance
5.3. Performance on Multi-Task MNIST Dataset
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | Federated learning |
| AirComp | Over-the-air computation |
| Air-FL | Over-the-air federated learning |
| IT | Interference temperature |
| CSI | Channel state information |
| STAR-RIS | simultaneously transmitting and reflecting reconfigurable intelligent surface |
| MSE | mean squared error |
| AO | Alternating optimization |
| AP | Access point |
| FedSGD | Federated stochastic gradient descent |
| AWGN | Additive white Gaussian noise |
| SOCP | Second-order cone program |
| KKT | Karush–Kuhn–Tucker |
| non-IID | non-identically distributed |
| MNIST | Modified national institute of standard and technology |
| LoS | line-of-sight |
| NLoS | non-line-of-sight |
| CNN | Convolutional neural network |
| ReLU | Rectified linear unit |
References
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed machine learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When edge meets learning: Adaptive control for resource-constrained distributed machine learning. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Honolulu, HI, USA, 16–19 April 2018; pp. 63–71. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2017, arXiv:1602.05629v4. [Google Scholar]
- Imteaj, A.; Thakker, U.; Wang, S.; Li, J.; Amini, M.H. A survey on federated learning for resource-constrained IoT devices. IEEE Internet Things J. 2022, 9, 1–24. [Google Scholar] [CrossRef]
- Zhou, C.; Liu, J.; Jia, J.; Zhou, J.; Zhou, Y.; Dai, H.; Dou, D. Efficient device scheduling with multi-job federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 9971–9979. [Google Scholar] [CrossRef]
- Ma, H.; Guo, H.; Lau, V.K.N. Communication-efficient federated multitask learning over wireless networks. IEEE Internet Things J. 2023, 10, 609–624. [Google Scholar] [CrossRef]
- Sami, H.U.; Güler, B. Over-the-air clustered federated learning. IEEE Trans. Wirel. Commun. 2023, 23, 7877–7893. [Google Scholar] [CrossRef]
- Cao, X.; Başar, T.; Diggavi, S.; Eldar, Y.C.; Letaief, K.B.; Poor, H.V.; Zhang, J. Communication-efficient distributed learning: An overview. IEEE J. Sel. Areas Commun. 2023, 41, 851–873. [Google Scholar] [CrossRef]
- Cao, X.; Lyu, Z.; Zhu, G.; Xu, J.; Xu, L.; Cui, S. An overview on over-the-air federated edge learning. IEEE Wirel. Commun. 2024, 31, 202–210. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y.; Zhou, Y.; Shi, Y.; Jiang, C.; Letaief, K.B. Over-the-air computation for 6G: Foundations, technologies, and applications. IEEE Internet Things J. 2024, 11, 24634–24658. [Google Scholar] [CrossRef]
- Şahin, A.; Yang, R. A survey on over-the-air computation. IEEE Commun. Surv. Tuts. 2023, 25, 1877–1908. [Google Scholar] [CrossRef]
- Zhu, J.; Shi, Y.; Zhou, Y.; Jiang, C.; Chen, W.; Letaief, K.B. Over-the-air federated learning and optimization. IEEE Internet Things J. 2024, 11, 16996–17020. [Google Scholar] [CrossRef]
- Azimi-Abarghouyi, S.M.; Fodor, V. Scalable hierarchical over-the-air federated learning. IEEE Trans. Wirel. Commun. 2024, 23, 8480–8496. [Google Scholar] [CrossRef]
- Aygün, O.; Kazemi, M.; Gündüz, D.; Duman, T.M. Over-the-air federated edge learning with hierarchical clustering. IEEE Trans. Wirel. Commun. 2024, 23, 17856–17871. [Google Scholar] [CrossRef]
- Asaad, S.; Wang, P.; Tabassum, H. Over-the-air FEEL with integrated sensing: Joint scheduling and beamforming design. IEEE Trans. Wirel. Commun. 2025, 24, 3273–3288. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, Q.; Zhu, G.; Jiang, H.; Eldar, Y.C.; Cui, S. Communication-and-energy efficient over-the-air federated learning. IEEE Trans. Wirel. Commun. 2025, 24, 767–782. [Google Scholar] [CrossRef]
- Zhong, C.; Yang, H.; Yuan, X. Over-the-air federated multi-task learning over MIMO multiple access channels. IEEE Trans. Wirel. Commun. 2023, 22, 3853–3868. [Google Scholar] [CrossRef]
- Li, F.; Ye, Q.; Fapi, E.T.; Sun, W.; Jiang, Y. Multi-cell over-the-air computation systems with spectrum sharing: A perspective from α-fairness. IEEE Trans. Veh. Technol. 2023, 72, 16249–16265. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, Y.; Shi, Y.; Zhuang, W. Interference management for over-the-air federated learning in multi-cell wireless networks. IEEE J. Sel. Areas Commun. 2022, 40, 2361–2377. [Google Scholar] [CrossRef]
- Zeng, X.; Mao, Y.; Shi, Y. STAR-RIS assisted over-the-air vertical federated learning in multi-cell wireless networks. In Proceedings of the IEEE International Conference on Communications Workshops (ICC Wkshps), Rome, Italy, 28 May–1 June 2023; pp. 361–366. [Google Scholar] [CrossRef]
- Zhou, F.; Wang, Z.; Shan, H.; Wu, L.; Tian, X.; Shi, Y.; Zhou, Y. Over-the-air hierarchical personalized federated learning. IEEE Trans. Veh. Technol. 2025, 74, 5006–5021. [Google Scholar] [CrossRef]
- Guo, W.; Huang, C.; Qin, X.; Yang, L.; Zhang, W. Dynamic clustering and power control for two-tier wireless federated learning. IEEE Trans. Wirel. Commun. 2024, 23, 1356–1371. [Google Scholar] [CrossRef]
- Li, W.; Chen, G.; Zhang, X.; Wang, N.; Ouyang, D.; Chen, C. Efficient and secure aggregation framework for federated-learning-based spectrum sharing. IEEE Internet Things J. 2024, 11, 17223–17236. [Google Scholar] [CrossRef]
- Wu, T.; Qu, Y.; Liu, C.; Dai, H.; Dong, C.; Cao, J. Cost-efficient federated learning for edge intelligence in multi-cell networks. IEEE/ACM Trans. Netw. 2024, 32, 4472–4487. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of Fedavg on Non-Iid Data. arXiv 2019, arXiv:1907.02189v4. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Feng, C.; Yang, H.H.; Hu, D.; Zhao, Z.; Quek, T.Q.S.; Min, G. Mobility-aware cluster federated learning in hierarchical wireless networks. IEEE Trans. Wirel. Commun. 2022, 21, 8441–8458. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Cao, X.; Zhu, G.; Xu, J.; Wang, Z.; Cui, S. Optimized power control design for over-the-air federated edge learning. IEEE J. Sel. Areas Commun. 2022, 40, 342–358. [Google Scholar] [CrossRef]
- Lan, Q.; Kang, H.S.; Huang, K. Simultaneous signal-and-interference alignment for two-cell over-the-air computation. IEEE Wirel. Commun. Lett. 2020, 9, 1342–1345. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: MATLAB Software for Disciplined Convex Programming. 2016. Available online: http://cvxr.com/cvx (accessed on 3 July 2025).
- Boyd, S.P.; Vandenberghe, L. Convex Optimization. 2004. Available online: https://web.stanford.edu/~boyd/cvxbook/ (accessed on 3 July 2025).
- Xu, J.; Yao, J. Exploiting physical-layer security for multiuser multicarrier computation offloading. IEEE Wirel. Commun. Lett. 2019, 8, 9–12. [Google Scholar] [CrossRef]
- Cao, X.; Zhu, G.; Xu, J.; Huang, K. Cooperative interference management for over-the-air computation networks. IEEE Trans. Wirel. Commun. 2021, 20, 2634–2651. [Google Scholar] [CrossRef]
- Jiao, L.; Ge, Y.; Zeng, K.; Hilburn, B. Location privacy and spectrum efficiency enhancement in spectrum sharing systems. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 1472–1488. [Google Scholar] [CrossRef]
- Liu, D.; Simeone, O. Privacy for free: Wireless federated learning via uncoded transmission with adaptive power control. IEEE J. Sel. Areas Commun. 2021, 39, 170–185. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Focuses | Contributions | Limitations |
|---|---|---|---|
| [19] | Achieved efficient downlink and uplink model aggregation in multi-cell Air-FL. | Constructed the Pareto boundary to characterize performance trade-offs among multiple tasks. | Do not fully consider the long-term effect of cumulative aggregation errors on convergence. |
| [20] | Addressed inter-cell interference in multi-cell using simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted Air-FL. | Characterized Pareto-optimal gaps for inter-cell trade-offs and demonstrated mean squared error (MSE) reduction in uplink/downlink via experiments. | Assumed low noise, neglected higher-order errors, and experimented only cover two-cell networks. |
| [21] | Addressed data heterogeneity in hierarchical FL. | Derived the convergence bound under inter-cluster interference and data heterogeneity. | AF with lower communication overhead was not considered. |
| [22] | Optimized the learning performance of two-tier Air-FL. | Derived the impact of aggregation errors on convergence performance. | The impact of inter-cluster interference was not considered. |
| [23] | Addressed the issues of low communication efficiency and weak privacy protection in Air-FL spectrum sharing. | Proposed a compressed sensing-based Air-FL framework to achieve efficient and secure aggregation that is noise-free/encryption-free. | Intra-group nodes require strict synchronization; pseudo-transmitters add redundancy. |
| [24] | Optimized the joint edge aggregation and association decision-making for Air-FL. | Proposed a theoretically guaranteed two-stage search algorithm, reconstructed the supermodular function, and extended a flexible bandwidth allocation scheme. | The algorithm complexity increases significantly with network scale. |
| Parameter | Value |
|---|---|
| K | 10 |
| 20 | |
| dB | |
| 3 | |
| W | |
| 1 W | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, C.; He, D.; Yao, J. Distributed Interference-Aware Power Optimization for Multi-Task Over-the-Air Federated Learning. Telecom 2025, 6, 51. https://doi.org/10.3390/telecom6030051
Tang C, He D, Yao J. Distributed Interference-Aware Power Optimization for Multi-Task Over-the-Air Federated Learning. Telecom. 2025; 6(3):51. https://doi.org/10.3390/telecom6030051
Chicago/Turabian StyleTang, Chao, Dashun He, and Jianping Yao. 2025. "Distributed Interference-Aware Power Optimization for Multi-Task Over-the-Air Federated Learning" Telecom 6, no. 3: 51. https://doi.org/10.3390/telecom6030051
APA StyleTang, C., He, D., & Yao, J. (2025). Distributed Interference-Aware Power Optimization for Multi-Task Over-the-Air Federated Learning. Telecom, 6(3), 51. https://doi.org/10.3390/telecom6030051