1. Background
Particle Swarm Optimization (PSO), similar to other non-exhaustive optimization methods such as brute-force search [
1], often performs well in some problems but fails in others due to the common issue of becoming trapped in local optima or suboptimal solutions. Two primary disadvantages of PSO are premature convergence and dependency on parameter settings. Premature convergence occurs when swarm particles converge too quickly towards a point near the best-known positions, which may not necessarily represent the optimal solution [
2]. The rapid information exchange among particles often intensifies this issue, leading to uniformity, reduced diversity, and an increased risk of settling in local optima [
3]. Additionally, PSO’s performance can vary significantly depending on its parameter settings, which are not universally effective across different problems [
4]. The main issue comes from balancing exploration (global search) and exploitation (local search). Multiple methods have been proposed to enhance PSO’s effectiveness and reduce its tendency to become stuck in undesirable solutions. The three primary strategies that have been identified for enhancing Particle Swarm Optimization (PSO) are parameter adjustments, modifications to algorithm components, and hybridization with other algorithms.
Adjusting parameters entails customizing several elements of PSO, including either the topology or the significant parameters, such as the weight of inertia, coefficients of acceleration, and the size of the population [
5]. Modifying components pertains to altering or updating rules for velocity or position (this may also include introducing new components or changing how they are calculated). Hybridizing the algorithm involves combining PSO with different techniques to leverage the strengths of multiple approaches. For instance, integrating PSO with clustering algorithms can enhance the optimization process, enabling more effective search techniques [
6]. Additionally, incorporating crossover operators from genetic algorithms into PSO may further strengthen the optimization framework [
7]. This research specifically examines the integration of machine learning to improve the predictive capabilities of PSO’s search process.
Through hybridization with other machine learning algorithms, this paper proposes a novel way of adjusting key PSO parameters, precisely inertia weight and acceleration coefficients. However, selecting optimal parameters is inherently complex and may vary from one problem to another [
4].
To address this matter, we model the online parameter setting problem of PSO using a partially observed Markov decision process (POMDP). This model reflects dynamic state changes in particles across different phases: exploration, exploitation, convergence, and transitions out of local optima. Furthermore, the behavior of particles across iterations is monitored through partial observations of these states, which guide the model in selecting the most appropriate action for each belief state. The solution to this model involves both a Hidden Markov Model (HMM) and a Deep Q-Network (DQN). The HMM employs a Viterbi classification algorithm to capture the belief states of the particles. Subsequently, based on deep reinforcement learning techniques, the optimal actions for adjusting PSO parameters—namely the inertia weight and acceleration factors—are determined and applied at each iteration.
In our earlier work [
8], we already explored the use of the Hidden Markov Model (a supervised learning technique) for the online estimation and adjustment of parameters in Particle Swarm Optimization (PSO). Building on this, we now advance our approach by integrating a partially observed Markov decision process (POMDP), further enhanced by adding a Deep Q-Network (DQN) specifically to resolve the POMDP. This refined strategy enables dynamic, real-time optimization of PSO parameters with each iteration, offering a more precise and adaptable mechanism for parameter tuning.
The subsequent sections of this research work are arranged as outlined below:
Section 2 reveals a comprehensive review of the literature.
Section 3 elaborates on the POMDP model and details the integration of the DQN model.
Section 4 is entirely devoted to presenting the empirical findings. Finally, the conclusion is provided in
Section 5, which encapsulates our findings and reflections.
2. Related Works
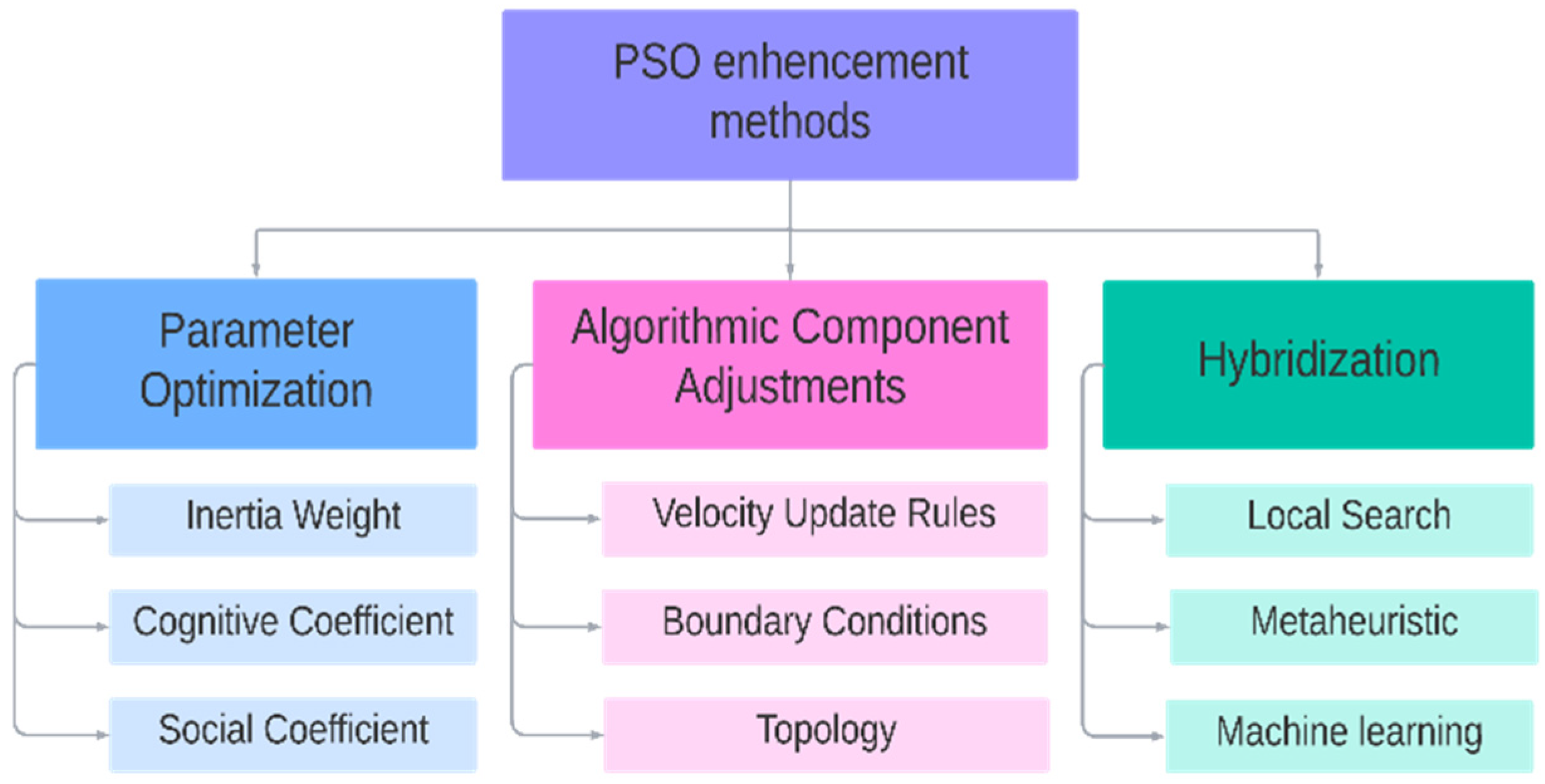
Several strategies have been established to improve Particle Swarm Optimization (PSO) in the past decade. Improvements in PSO have been categorized into three key methodologies, as shown in
Figure 1: parameter optimization [
9], algorithmic component adjustments [
10], and integration with other algorithms (hybridization) [
11]. Parameter optimization entails fine-tuning PSO settings, including topology, coefficients for acceleration and inertia, and population size. Adjustments to algorithmic components involve modifying velocity or position update rules, which may include creating or recalibrating existing elements. Hybridization with other techniques allows PSO to leverage complementary algorithms, enhancing its performance and problem-solving capabilities.
Firstly, parameter setting for PSO algorithm has caused significant difficulty in the area of iterative optimization techniques in recent years [
12]. Recent research [
13,
14] has identified two primary approaches to parameter setting: parameter tuning and parameter control.
Parameter tuning entails establishing the algorithm’s parameters to specific values found via simulations [
15]. This approach has also been applied in airline scheduling problems [
16,
17], where a Hidden Markov Model was investigated for tuning metaheuristics [
18]. In contrast, parameter control refers to the process of dynamically modifying parameter values while the algorithm is running [
19,
20]. This method can be classified into static, adaptive, or self-adaptive approaches.
Static parameter control utilizes some pre-established rules, sometimes referred to as a time-varying rule, to modify parameter values depending on the PSO iteration number [
21]. Adaptive control of parameters employs some function to establish a relationship between the feedback obtained from the current optimization process and the value of the PSO parameter [
22].
In a previous work [
8], a Hidden Markov Model (HMM) was used as an online classification method to estimate PSO states, which are exploration, exploitation, convergence, and jumping out [
23]. The earlier approach adaptively adjusts the acceleration factors c1 and c2. In [
9], an equivalent HMM-based approach was applied to adapt the population size along with the acceleration factors. Another work [
24] leveraged HMM-detected PSO states to control the inertia weight also using HMM classification.
Self-adaptive parameter control embeds the parameters within each particle, enabling these parameters to vary and develop during the algorithm’s execution [
25]. Notably, the use of a classification model has been explored for adapting PSO parameters, providing a probabilistic framework for dynamic adjustments, like in [
26], where the authors proposed a probabilistic finite state machine design for self-parameter adaptations of each particle in PSO, enhancing its adaptability and robustness. Similarly, the authors of [
23] further incorporated a self-dynamic adaptation of population size across iterations.
Additionally, PSO parameter adjustment may be performed in two contexts: homogeneous and heterogeneous swarms [
27]. In a homogeneous swarm, all particles exhibit uniform behavior, but in a heterogeneous swarm, several distinct behaviors coexist concurrently [
28]. Recent studies have introduced cooperative multi-swarm strategies and adaptive cooperation using a Markov Model, enhancing the performance and robustness of PSO in various applications [
29,
30].
Furthermore, the authors of [
20,
31] presented an in-depth investigation of the latest advances in PSO, exploring different parameter control methodologies and real-world applications. The research results jointly give important insights into the techniques and the resulting impacts on the PSO algorithm.
Other recent advancements in Particle Swarm Optimization (PSO) have focused on enhancing key algorithmic components, including velocity update rules, boundary conditions, and topology structures. These components are crucial for the overall performance, stability, and convergence of PSO algorithms. The velocity update calculus in Particle Swarm Optimization (PSO) is essential for managing particle movement and ensuring successful convergence. The authors of [
32] presented adaptive velocity update techniques that dynamically alter parameters depending on the optimization process. Their analysis gives insights into how these updates boost PSO’s convergence and stability. Meanwhile, managing boundary conditions efficiently is essential for maintaining the search space’s integrity and preventing particles from running away. The authors of [
33] addressed unique boundary management approaches that retain particle diversity while preserving search space boundaries. Their thorough review underlines recent measures and their influence on PSO performance.
Additionally, the topology of PSO specifies the structure of communication links within particles, significantly affecting the algorithm’s efficiency. The authors of [
14] examined different topology patterns and their effects on PSO achievement. Their work offers suggestions for choosing suitable structures based on specific optimization problems. Also, the authors of [
29,
30] examined cooperative plans through PSO topologies, emphasizing the advantages of multi-swarm cooperation and adaptive communication frameworks. These studies indicate how cooperative strategies may boost PSO performance by enhancing exploration and exploitation balance and strengthening the robustness of the optimization process.
Hybridization in PSO leverages multiple strategies to increase the algorithm’s effectiveness. The authors of [
34] reported that hybrid approaches have shown success in resolving complex optimization problems and therefore validated the usefulness of combining PSO with local search methods, meta-heuristics, and machine learning. One hybrid strategy involves adding local search methods to refine solutions near potential regions determined by PSO, which aids in attaining quicker convergence and more accurate solutions. For example, the authors of [
35] combined dynamic multi-PSO with gravitational search algorithms to solve complex optimization problems. Another hybrid approach involves combining PSO with other metaheuristics like simulated annealing or a genetic algorithm, balancing their strengths to avoid local optima and the premature convergence phenomenon. The authors of [
36] demonstrated a hybrid PSO–firefly algorithm to enhance cloud performances. The authors of [
37] proved that integrating the global search capacity of genetic algorithms with the convergence speed of PSO will result in a significant improvement compared to other methods.
Integrating machine learning with PSO enables adaptive parameter control and dynamic modification of the algorithm’s behavior. Techniques like supervised learning [
38] and deep learning [
39] have been utilized to inform and optimize PSO’s parameter adjustments effectively. For instance, the authors of [
40] used a multilayer PSO with ANN, adapting network topology and synaptic weights. This adaptive approach allowed for the dynamic control of parameters, boosting optimization efficiency and accuracy. The authors of [
41] proposed one reinforcement learning-based parameter adaptation approach for PSO, showcasing its effective and adaptive capabilities. This approach was further validated in a recent study [
42], emphasizing the usefulness of reinforcement learning hybridized with PSO for suitable adaptation. Such models can predict optimal settings, assess the optimization state, and guide the search process, significantly enhancing PSO’s efficiency [
43,
44]. They also handle complex optimization challenges, solidifying PSO’s role as an effective and versatile hybrid optimization method.
3. Deep Q-Network-Based Adaptive PSO
This section describes the background knowledge, some essential concepts of the literature, and our previous algorithm, HMM-APSO [
8], which provided the foundation for presenting our parameter adaptation control method using a Q-network. The suggested technique is about dynamically balancing the states of PSO to identify optimal parameter values which assure success in different optimization settings. Using a Hidden Markov Model (HMM) helps identify these appropriate states via analyzing the evolution and transitions all over the PSO iterations. Once the most suitable state is determined, establishing a Deep Q-Network (DQN) permits the selection of the optimal action, indicating the best suited parameter values in that state. This combination provides adaptive and strategic adjustments to PSO parameters, boosting performance by dynamically modifying the algorithm. This dynamic adaptation helps strike a balance between PSO states, leading to higher convergence and improvements in accuracy.
3.1. Theoretical Framework
Regarding the new approach proposed this work, we utilize the classical version of Particle Swarm Optimization (PSO) given in [
45], which features a global topology where each particle is connected to every other particle and influenced by the global best (gBest) particle. Each particle
i is described by two vectors: velocity vector
and position vector
. The following equations define how those vectors are updated at each iteration
:
We assume that there are N particles of the swarm in S space. Here, i indicates the particle’s index, and t is the iteration’s index; and are defined in the interval [0,1], representing two independently and uniformly distributed random variables. The inertia weight w is generally adjusted to decrease linearly from 1 to 0 throughout the execution. The constants and are named acceleration factors. indicates the personal best position of particle . refers to the global best position.
In
Figure 2, the diagram shows the iteration steps of PSO. The stopping criteria commonly have a maximum number of loops or some convergence criteria.
3.2. Markov Chain on PSO
PSO can be analyzed by examining its stochastic behavior as a multi-stochastic process. As identified by previous researchers, notable work on PSO is based on empirical studies using simulations, and less work has been conducted to analyze PSO theoretically. In [
46], a few theoretical propositions were utilized to explore the stochastic process of PSO.
According to [
47], the PSO state takes into account as much detail as possible in the process. Previous researchers [
46] have proven that the PSO state is memory-less. The state was defined by
W is called a state at time t. It proved the stationarity of the Markov chain on the PSO. We assume that the information contained in W(t) is enough for future moves, and it depends only on the actual iteration state and not the past iteration state. The effect of the current state on the future states is not dependent on its past states. Thus, PSO’s behavior only depends on the actual state, not on the succession of the past, which rides on previous achievements.
To evaluate the success of the state, ST, in PSO, an index is defined to reflect the current accomplishment based on particle positions and probability concepts due to their stochastic movements. These states are categorized into classes identified as levels. The levels follow a stochastic process described as
Forming a Markov chain [
48,
49,
50] on PSO levels, this approach, detailed in [
46], ensures the achievement is position-dependent, aligning with the probabilistic nature of particle movements.
We define, as shown in [
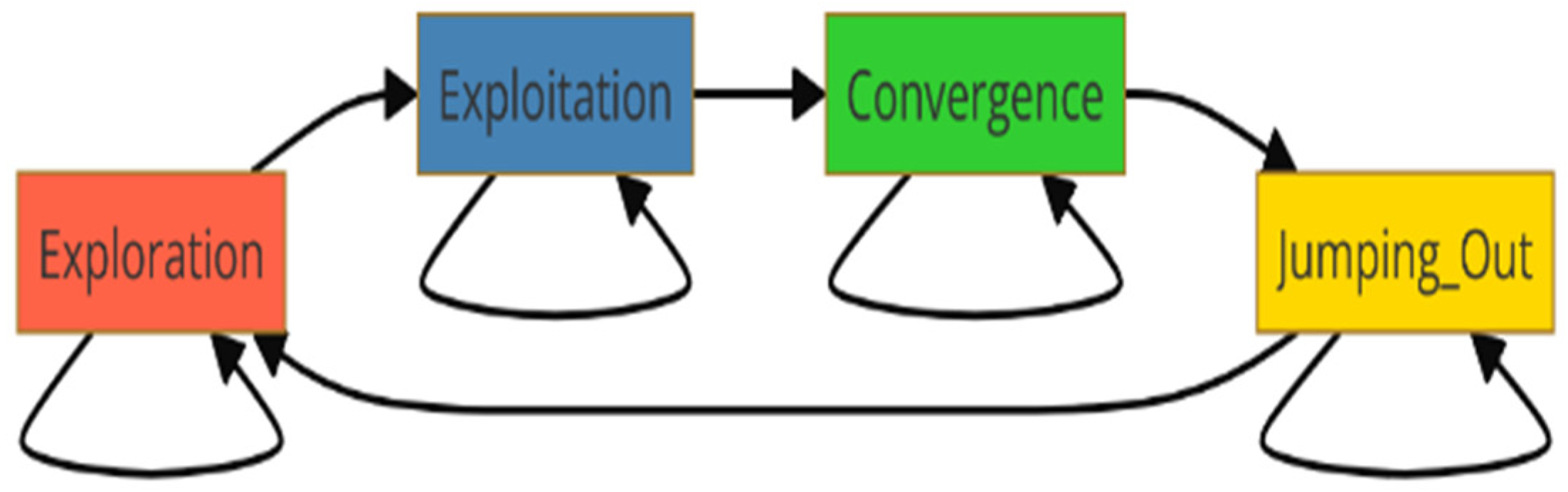
51], four evolutionary levels considered as a global state of the PSO swarm, namely the following:
L = {exploration, exploitation, convergence, jumping out}.
The Markov chain represents the PSO states in
Figure 3. The arrows show the possible transitions between states.
Although the exploration state describes the process of looking at a large area in solution space to avoid local optima, in the exploitation state, the swarm adjusts the solution at the best-known locations to serve the purpose of accuracy. The convergence state involves stable particles, and it is focused on the optimal solution so that the best results may be reached. The jumping-out state adds randomness to escape local optima and continue seeking the global optimum, maintaining variety and avoiding premature convergence. One must balance these states of PSO, giving the appropriate parameter setting for it to be successful when used in optimization situations.
3.3. Partially Observed Markov Decision Process in PSO
Based on the previous paragraph, we define a POMDP [
52] on the PSO to build a model of control and adaptation of PSO parameters according to the swarm state. We can characterize a POMDP over PSO since there are already PSO states in the swarm: L = {exploration, exploitation, convergence, jumping out}. The state of each particle is not directly observable. Still, it is inferred through an evolutionary factor
that reflects the relative positions of particles and is defined by the average distance of each particle to all others, as described in [
51]. The actions are variations in the PSO parameters, and the reward is the measured enhancement of the best solution. This approach gives a perfect way for PSO to dynamically control and optimize its parameters based on the observed swarm behavior.
Formally, the POMDP is defined as a tuple as follows:
is the mean distance of Gbest to all other particles:
where
is the distance between a particle
and the other particles.
We define four parameters setting combinations .
Actions include setting values for inertia weight, cognitive coefficient, social coefficient, and randomness.
is the probability of transitioning from state to state given an action .
Z is the observation probability of
given the next state
and the action
.
This is the reward received after taking action in a state and the measurement enhancement of the best solution.
Initial Belief State : This is the initial probability distribution over states. It will be given as an exploration state with a probability equal to 1 and 0 for other states; this means that we assume an exploration state at iteration one.
The objective is to select the actions a ∈ A that maximize the expected cumulative reward over time, accounting for the partially observable nature of the states through the observed parameter f.
Then, the policy π maps the history of observations and actions to actions such that the expected sum of rewards is maximized.
To solve this model, we conduct an approach integrating the Hidden Markov Model and Q-network [
53]. It is an advantageous solution strategy due to the complementary strengths of these methods.
Using this approach, we can handle partial observability efficiently by using HMMs to maintain and update the belief state of the swarm. A belief state is a probability distribution over possible states that enables the swarm to make effective inferences about the state of its environment, even when the true state is not directly observable. It combines the powerful deep-learning approximation algorithms of complex functions for high-dimensional state spaces into the Q-network [
53] used for action selection. This way, the agent can learn an optimal policy that maximizes the long-term reward while solving this partial observability problem. The state estimate generated by our proposed solution is effectively aggregated by HMMs, leading to scalable Q-networks that can be efficiently used for policy learning in POMDPs.
The following paragraphs will detail the HMM and Q-network models.
3.4. HMM Belief State Classification
The Hidden Markov Model (HMM) is used for PSO state classification due to its advantage in sequence analysis, notably in voice recognition and classification domains. HMMs have proven effectiveness for sequence analysis [
54], especially in representing systems with hidden states and time-dependent interactions. This results from their capacity to manage sequential data with inherent stochastic processes. Algorithms including Baum–Welch and Viterbi allow HMMs to continually estimate model parameters while identifying the most probable sequence of hidden states, thereby enhancing accurate classification and prediction in intricate temporal patterns.
We set the HMM with a triple , and is a probability space where the whole processes are defined:
, the vector representing initial state probabilities. Π = [1 0 0 0]: Initial state probability specifying a first deterministic initialization in the exploration state.
=
, the transition matrix between states,
,
. We supposed a 1/2 value of transition probabilities for all possible transitions in
Figure 3.
, the emission matrix named likewise a confusion matrix, , .
The evolutionary factor
f, representing particle distribution in a search, is used as an observation source in the Hidden Markov Model. Since
f is continuous within
, it is discretized into seven subintervals [
23]:
Each value of f is assigned to an interval, resulting in a discrete state based on the interval number. Then, matrix B has dimensions of .
Probabilities are deduced from an earlier work [
23] as follows:
where once the parameters of the HMM are initialized, the Algorithm 1 Baum–Welch algorithm [
55] is employed to compute and update the emission and transition probabilities iteratively. This process enhances the accuracy and adaptability of the HMM during the classification stage.
| Algorithm 1: Baum–Welch Algorithm [55] |
![Modelling 05 00089 i001]() |
Subsequently, at each iteration, the Viterbi algorithm [
56] is utilized to estimate the belief state of the swarm. Algorithm 2 shows the pseudo-code which describes the state sequence
(where
) assuming a succession of observations O (
. Transitions between the four states are adjusted based on the classifications provided by the HMM.
| Algorithm 2: Viterbi algorithm [56] |
![Modelling 05 00089 i002]() |
Additionally, for each state of the swarm as determined by the HMM classification, the subsequent actions are determined by the Q-network, as detailed in the following paragraph.
3.5. Deep Q-Network-Based Parameter Setting Actions
After determining the belief state of the PSO, the Q-network is used to determine the suitable action that corresponds to the parametric adjustment control of the PSO. The Q-network, specifically the Deep Q-Network (DQN), is a kind of neural network that will be used to approximate the Q-value function in reinforcement learning, giving the optimal action selection strategy.
A formal description of the Q-network’s architecture is provided in
Figure 3:
The input layer of four possible values and four dimensions: state 1 , state 2 , state 3 , and state 4 .
So, we have four neurons, each representing one element of the one-hot encoded state vector. It will receive the state representation of the belief state in the POMDP calculated previously by the HMM classification. Each neuron in this layer corresponds to one element of the state.
Hidden layers include a fully connected layer with h1 = 32 neurons and ReLU activation.
The output layer of dimension 4 that corresponds to the number of possible actions.
Q-values that represent the expected cumulative reward for each action in the provided state are determined as follows:
Fitness is the fitness function used in PSO, and is the iteration number; we are supposed to have a minimization problem.
The pseudo-code of the Algorithm 3 DQN algorithm is as follows:
| Algorithm 3: DQN algorithm [57] |
![Modelling 05 00089 i003]() |
Regarding the action set, each of the four actions defines the parameter setting of acceleration coefficients and inertia weight. The parameter adaptation is carried out according to four actions:
Action 1:
- -
Random values of inertia weight between
and
:
: the function that generates random values in [0,1].
- -
Increase and decrease .
Action 2:
- -
The inertia weight is calculated according to its distance from other particles:
- -
Increase and slightly decrease .
Action 3:
- -
The maximum value of .
- -
Slightly increase and decrease .
Action 4:
- -
The minimum value of the inertia weight: .
- -
Decrease and increase .
These parameter variation actions are deduced from the best-known literature on PSO parameters’ online control, such as [
24,
51].
The complete applied framework for adapting the parameters in PSO is described in the next paragraph.
3.6. The PSO-Based DQN Algorithm
The parameter adaptation of PSO will be carried out according to the POMDP presented earlier. The POMDP framework enables the modeling of uncertain environments, providing a robust mechanism for dynamically adapting the parameters of PSO based on the actual state and observations. In this approach, a Hidden Markov Model (HMM) will be used to identify hidden states that correspond to various ways of adapting the optimization process, including exploration, exploitation, jumping out, and convergence. By recognizing these hidden states, the HMM can adequately track the optimization dynamics and provide information for the following actions. The DQN, with its advanced deep learning capabilities, will subsequently choose the most appropriate strategy for selecting actions in each recognized state. The following Algorithm 4 illustrates the approach steps.
| Algorithm 4: DQNPSO |
![Modelling 05 00089 i004]() |
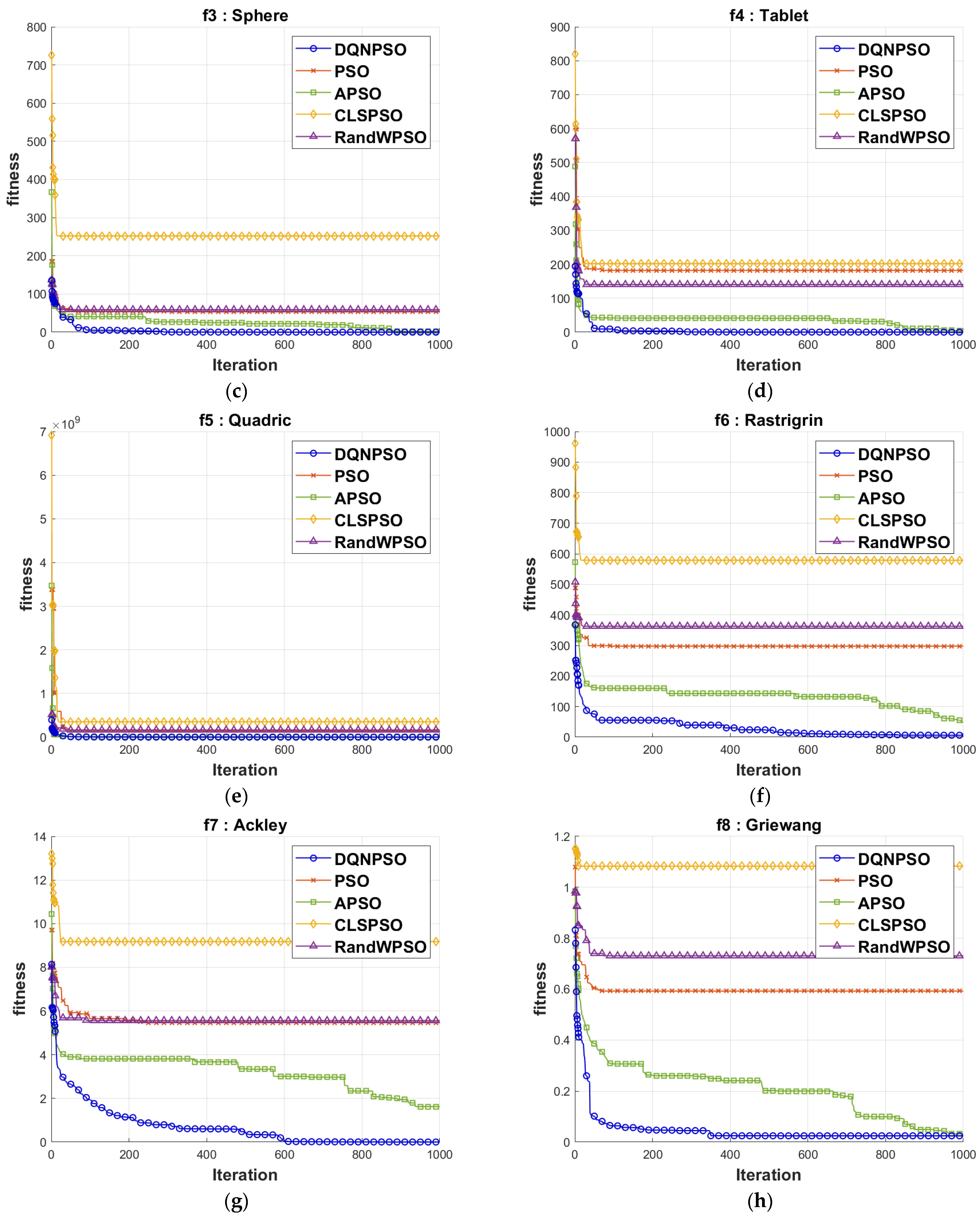
The PSO method is designed to optimize its parameters by maintaining a balance between exploring new solutions and exploiting established, highly effective ones. It is also successful at escaping local optima and rapidly converging to optimum solutions, enhancing overall performance. An experimental study was conducted, and it is described in the following section to display the effectiveness of the newly adopted method.
5. Conclusions
In conclusion, this research proposes significant advances in Particle Swarm Optimization (PSO) by integrating a deep machine learning approach, namely Deep Q-network, for dynamic parameter setting in a homogenous PSO framework. By solving the prevalent issues of slowing down convergence or being stuck in local optima, this suggested approach considerably boosts the entire performance of the PSO. The newly introduced DPQ-PSO framework, which combines a partly observed Markov decision process model with Hidden Markov Model classification and a Deep Q-Network, offers an adaptive method for real-time parameter adaptation. The experimental findings regarding several benchmark unimodal and multimodal functions verify the superior performance of the DPQ-PSO algorithm, providing considerable increases in solution accuracy and convergence speed compared to current techniques. However, this approach suffers from an increased CPU time due to the computational complexity introduced by the integration of deep learning. This novel method not only increases the application capacity of PSO in handling complex optimization issues but also sets a new benchmark in improving metaheuristic algorithms using deep machine learning approaches.
Future research should focus on the augmented computational time resulting from deep learning integration by exploring model optimization strategies, such as pruning the DQN parameters, alongside parallel computing methods for improved scalability. Extending DPQPSO to heterogeneous systems could increase solution variety, while integrating other advanced reinforcement learning techniques like Proximal policy optimization could further develop parameter adaptation. Furthermore, the DPQPSO framework has substantial potential for real-world applications, improving performance in several domains, and implementing this method in complex optimization tasks, such as engineering design and scheduling, will further support its efficacy.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}