
Modeling and Optimization of Concrete Mixtures Using Machine Learning Estimators and Genetic Algorithms

 ,
,  , ,
, ,
Abstract
1. Introduction
1.1. Related Works
1.2. Research Significance
2. Materials and Methods
2.1. Problem Statement
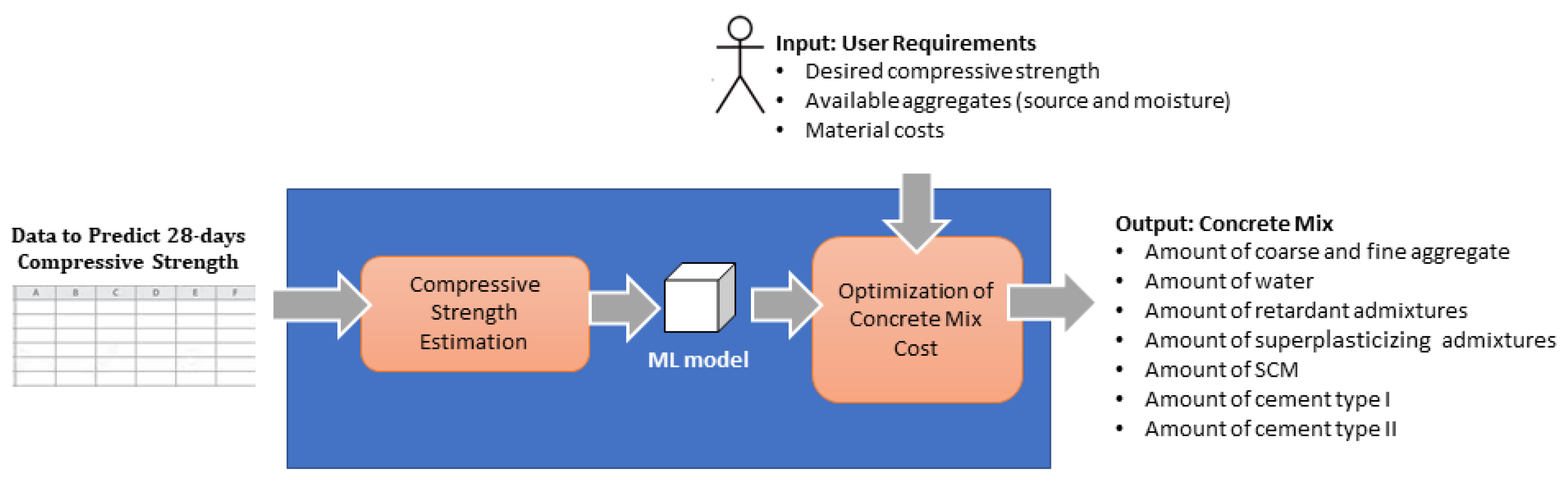
2.2. Design and Implementation of the Framework
2.2.1. Framework Architecture
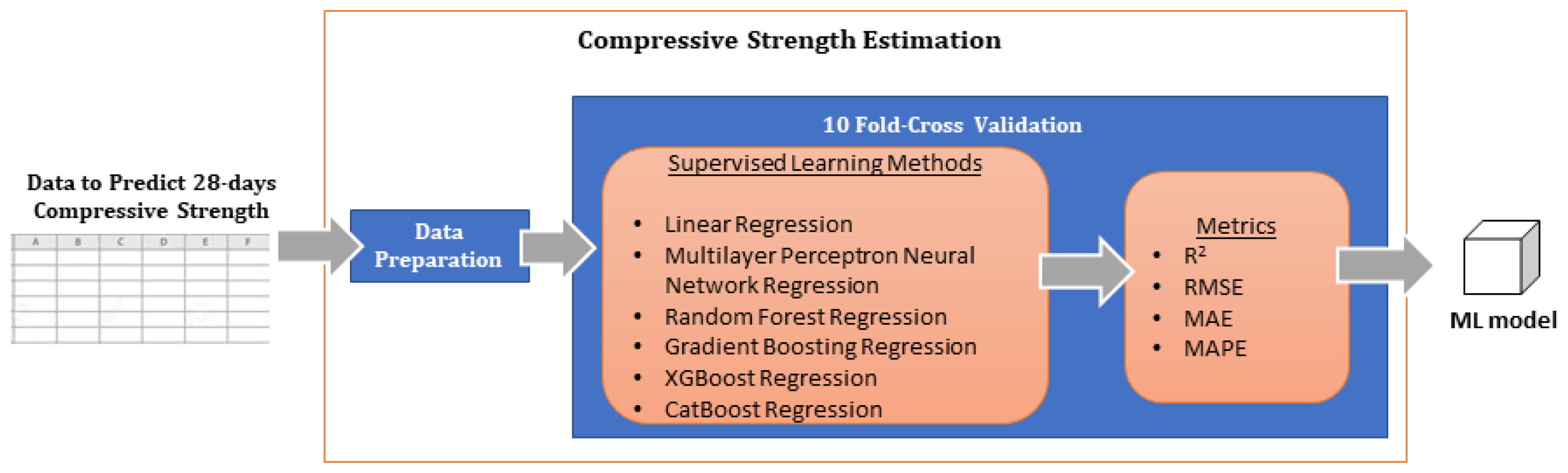
2.2.2. Compressive Strength Estimation
- The removal of samples not meeting the volumetric restriction of 1 m3, thus resulting in the elimination of 4055 samples and leaving 15,239 samples in the dataset.
- The detection and removal of outliers using various outlier detection algorithms, including isolation forest trees, local outlier factor, and elliptic envelope. These are standard outlier detection algorithms included in thescikit-learn package [19]. After the outlier elimination step, 13,195 samples remained in the dataset.
- The verification of various restrictions on the remaining samples, such as water-to-cement ratio ranges and the ratios of fine aggregates to total aggregates. Samples failing to meet the restrictions were discarded, thus resulting in 11,428 definitive samples used for training and evaluating the optimization framework.
- The creation of dummy variables for nominal columns and the z normalization of numerical columns. The aggregate moisture and quantity variables were treated as different attributes for each of the sources. A correlation analysis was used to select the relevant variables.
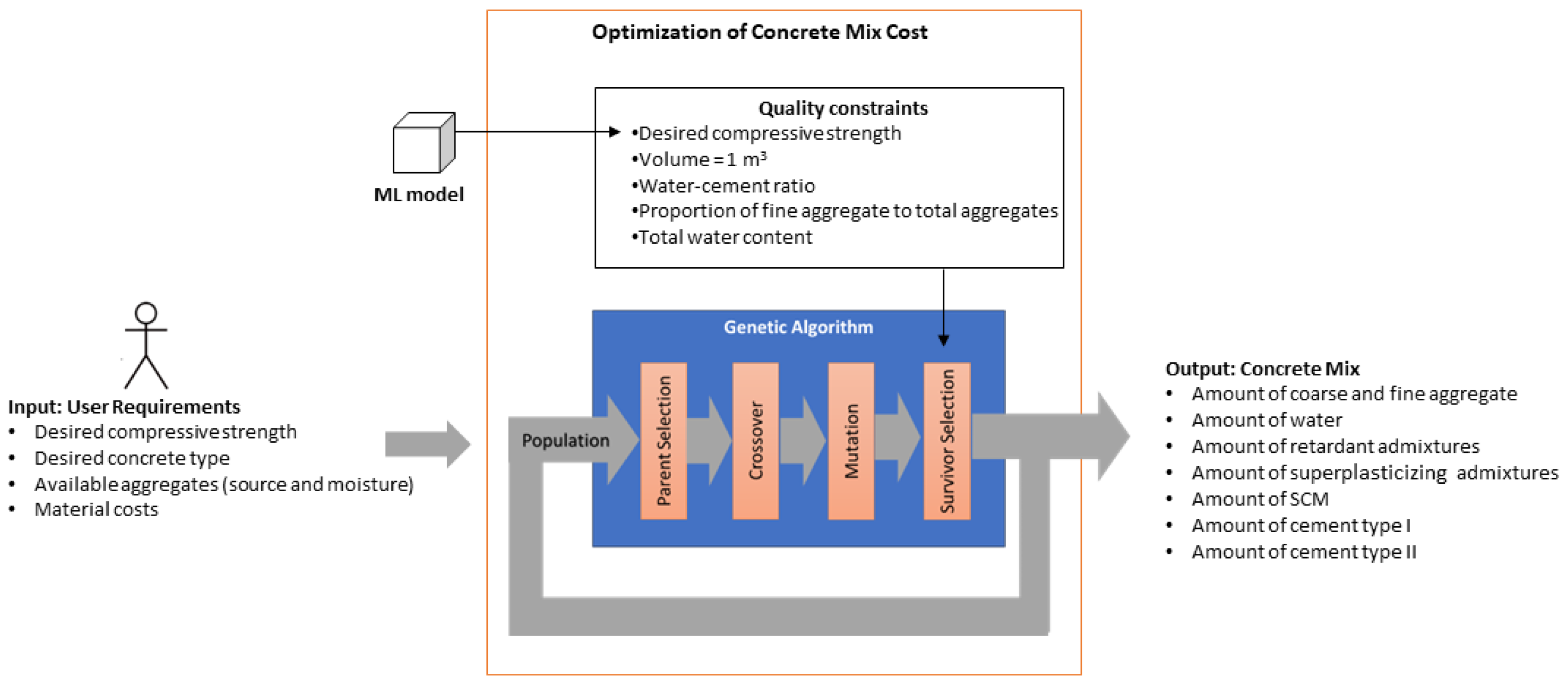
2.2.3. Optimization of the Concrete Mixture
- Parent selection: During the selection process, each individual undergoes an evaluation of its fitness function , and individuals with higher fitness have a higher probability of being selected for reproduction, while those with lower fitness have a lower probability.
- Crossover: This operation yields a new set of individuals by pairing parents and merging their genetic material—for instance, through a linear combination of the two vectors—to result in a new individual .
- Mutation: This step introduces random alterations to some genes (vector components), thus aiming to enable mutated individuals to explore different regions of the solution space.
- Survivor selection: This step determines which individuals from the current population will pass on to the next generation. This process is based on the fitness of each individual, which is defined as a measure of its ability to solve the problem. The top-performing individuals are retained in the population (elitism).
- The cost function (1) yields values within the range in currency units, where cost minimization is the objective.
- The fractions within the quality constraints specified by (2) are dimensionless fractions within the range , with 0 indicating perfect adherence to the constraint. These constraints include the target , the water–cement ratio, and the proportion of fine aggregates to the total aggregates.
- The volumetric constraint (3) represents the deviation from 1 m3. To penalize negative and positive deviations, the penalty is defined as the squared difference, which ensures that the error is in the range .
2.2.4. Implementation and Deployment
3. Results and Discussion
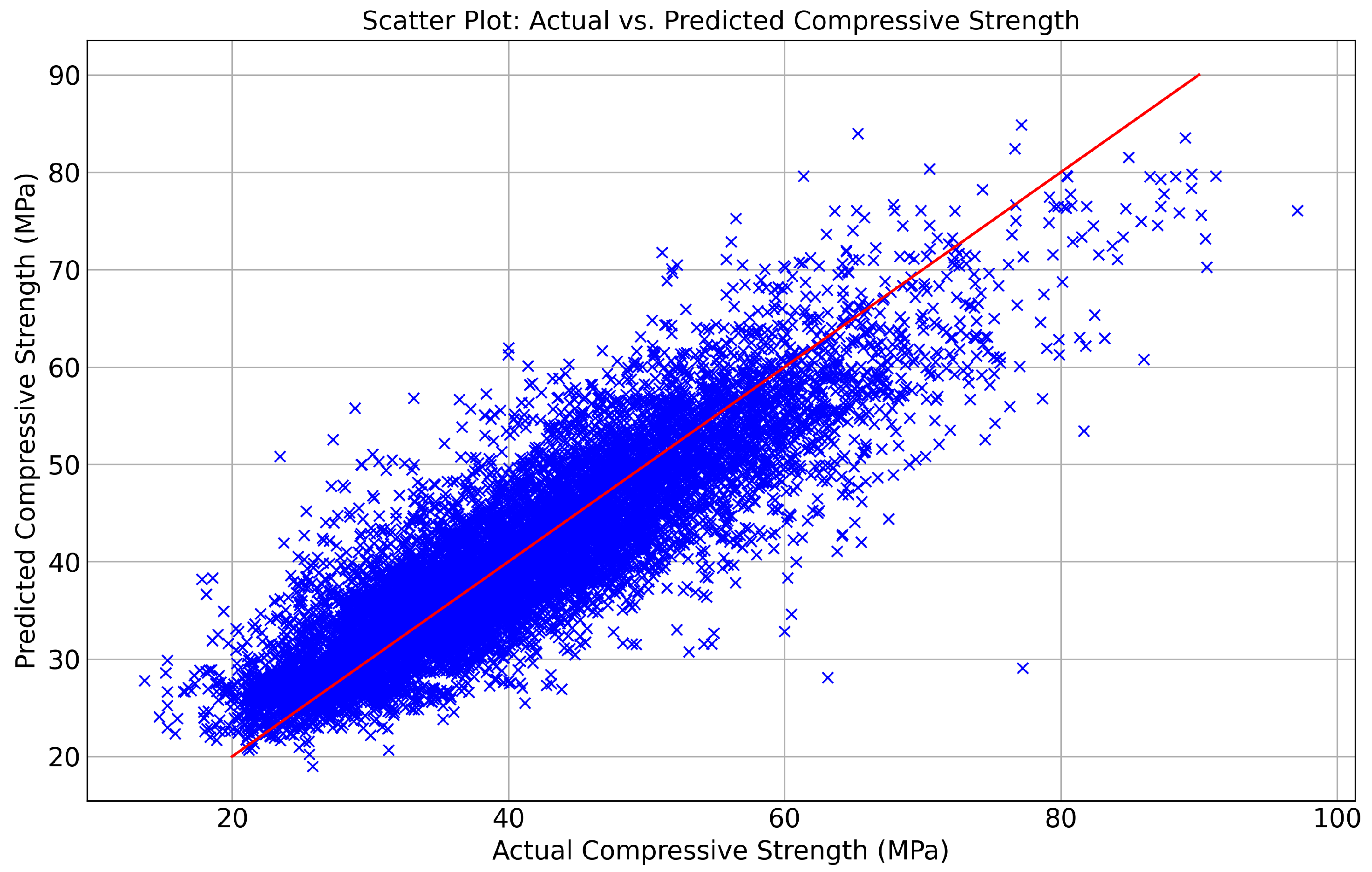
3.1. Compressive Strength Estimation
3.2. Optimization of Concrete Mixture Cost
- To construct a test case, a pair of coarse and fine aggregate sources was selected, and the dataset was filtered for these sources. Based on the resulting samples, a histogram of was generated, and the interval with the highest sample count was identified. If the sample count fell below 10, the interval was discarded. This selection formed a set of samples, denoted as K, thus offering a representative sample size within a narrow range for comparison against the solution of the optimization algorithm.
- The selected interval from step 1 represented the mode of samples for the chosen aggregate pair. The midpoint of this interval was designated as the target for the optimization problem.
- The optimization algorithm was then executed to identify an optimal solution utilizing the same aggregates and the determined in step 2. The optimization algorithm produced the optimized mixture, thus referred to as .
- It is noteworthy that may not fully comply with all restrictions, as these are treated as penalties within the fitness function. Therefore, it was verified that the solution satisfied the restrictions.
- The cost of was ranked along all samples in K in descending order of cost. A ranking of indicates that has the lowest cost among all samples in K, while a ranking of signifies that has the highest cost among the samples in K. This ranking served as an indicator of the optimality of solutions obtained by the optimization algorithm.
- The aforementioned procedure was repeated for N test cases utilizing different aggregate source combinations.
3.3. Ethical Considerations
4. Conclusions
- The framework effectively integrates machine learning and genetic algorithms to optimize concrete mixtures. It allows for cost optimization while maintaining specified compressive strength requirements and other mix design restrictions. The process ensures that the generated solutions are practical and meet user-defined constraints.
- Various machine learning models were evaluated to estimate compressive strength. The best prediction performance was obtained by the CatBoost regression algorithm, which achieved superior performance for all error metrics and consistency in its predictions. The model demonstrated strong generalization capabilities, with minimal disparities between the training and test set errors, thus indicating that it was not overfitted.
- The optimization algorithm was assessed by comparing its solutions against a representative set of samples. The optimization process was evaluated across 188 test cases considering different combinations of aggregates and the target compressive strength. The cost of the optimized mixture was compared with the real data points of similar characteristics. The comparison showed that approximately of the cases yielded the lowest cost solutions among the similar samples. The median of the optimized cost cases was more cost-effective than of the comparable samples.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mehta, P.K.; Monteiro, P.J.M. Concrete: Microstructure, Properties, and Materials, 4th ed.; McGraw Hill: New York, NY, USA, 2014. [Google Scholar]
- Hover, K.C. The influence of water on the performance of concrete. Constr. Build. Mater. 2011, 25, 3003–3013. [Google Scholar] [CrossRef]
- Kosmatka, S.H.; Panarese, W.C.; Kerkhoff, B. Design and Control of Concrete Mixtures; Portland Cement Association: Washington, DC, USA, 2005. [Google Scholar]
- Mehta, P.K. Advancements in Concrete Technology. Concr. Int. 1999, 21, 69–76. [Google Scholar]
- Crompton, S. Advances in Concrete Technology. Concr. Int. 2010, 21, 69–76. [Google Scholar]
- DeRousseau, M.A.; Kasprzyk, J.R.; Srubar, W.V. Multi-objective optimization methods for designing low-carbon concrete mixtures. Front. Mater. 2021, 8, 680895. [Google Scholar] [CrossRef]
- Park, W.; Noguchi, T.; Lee, H. Genetic algorithm in mix proportion design of recycled aggregate concrete. Comput. Concr. 2013, 11, 183–199. [Google Scholar] [CrossRef]
- Nunez, I.; Marani, A.; Flah, M.; Nehdi, M.L. Estimating compressive strength of modern concrete mixtures using computational intelligence: A systematic review. Constr. Build. Mater. 2021, 310, 125279. [Google Scholar] [CrossRef]
- Abbas, Y.M.; Khan, M.I. Robust machine learning framework for modeling the compressive strength of SFRC: Database Compilation, Predictive Analysis, and Empirical Verification. Materials 2023, 16, 7178. [Google Scholar] [CrossRef]
- Ahmad, S.; Alghamdi, S.A. A statistical approach to optimizing concrete mixture design. Sci. World J. 2014, 2014, 561539. [Google Scholar] [CrossRef]
- Kharazi, M. Designing and Optimizing of Concrete Mix Proportion Using Statistical Mixture Design Methodology. Master’s Thesis, Memorial University of Newfoundland, St. John’s, NL, Canada, 2013. [Google Scholar]
- Parichatprecha, R.; Nimityongskul, P.; Parichatprecha, R.; Nimityongskul, P. An integrated approach for optimum design of HPC mix proportion using genetic algorithm and artificial neural networks. Comput. Concr. 2009, 6, 253. [Google Scholar] [CrossRef]
- Amirjanov, A.; Sobol, K. Optimal proportioning of concrete aggregates using a self-adaptive genetic algorithm. Comput. Concr. 2005, 2, 411–421. [Google Scholar] [CrossRef]
- DeRousseau, M.A.; Kasprzyk, J.R.; Srubar, W.V., III. Computational design optimization of concrete mixtures: A review. Cem. Concr. Res. 2018, 109, 42–53. [Google Scholar] [CrossRef]
- Reed, P.M.; Hadka, D.; Herman, J.D.; Kasprzyk, J.R.; Kollat, J.B. Evolutionary multiobjective optimization in water resources: The past, present, and future. Adv. Water Resour. 2013, 51, 438–456. [Google Scholar] [CrossRef]
- Zheng, W.; Shui, Z.; Xu, Z.; Gao, X.; Zhang, S. Multi-objective optimization of concrete mix design based on machine learning. J. Build. Eng. 2023, 76, 107396. [Google Scholar] [CrossRef]
- Yang, S.; Chen, H.; Feng, Z.; Qin, Y.; Zhang, J.; Cao, Y.; Liu, Y. Intelligent multiobjective optimization for high-performance concrete mix proportion design: A hybrid machine learning approach. Eng. Appl. Artif. Intell. 2023, 126, 106868. [Google Scholar] [CrossRef]
- Chen, F.; Xu, W.; Wen, Q.; Zhang, G.; Xu, L.; Fan, D.; Yu, R. Advancing concrete mix proportion through hybrid intelligence: A multi-objective optimization approach. Material 2023, 16, 6448. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Van Mulbregt, P. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Huang, Y.; Wang, Y.; Ma, G. Multi-objective optimization of concrete mixture proportions using machine learning and metaheuristic algorithms. Constr. Build. Mater. 2020, 253, 119208. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Li, H.; He, Y.; Zhang, Z.; Huang, J. Mixture Optimization of Cementitious Materials Using Machine Learning and Metaheuristic Algorithms: State of the Art and Future Prospects. Material 2022, 15, 7830. [Google Scholar] [CrossRef]
- Charhate, S.; Subhedar, M.; Adsul, N. Prediction of Concrete Properties Using Multiple Linear Regression and Artificial Neural Network. J. Soft Comput. Civ. Eng. 2018, 2, 27–38. [Google Scholar] [CrossRef]
- Grajski, K.A.; Breiman, L.; Prisco, G.V.D.; Freeman, W.J. Classification of EEG Spatial Patterns with a Tree-Structured Methodology: CART. IEEE Trans. Biomed. Eng. 1986, BME-33, 1076–1086. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Support Vector Machine: Principles, Parameters, and Applications; Academic Press: Cambridge, MA, USA, 2017; pp. 515–535. [Google Scholar] [CrossRef]
- Li, H.; Lin, J.; Lei, X.; Wei, T. Compressive strength prediction of basalt fiber reinforced concrete via random forest algorithm. Mater. Today Commun. 2022, 30, 103117. [Google Scholar] [CrossRef]
- Alhakeem, Z.M.; Jebur, Y.M.; Henedy, S.N.; Imran, H.; Bernardo, L.F.; Hussein, H.M. Prediction of Ecofriendly Concrete Compressive Strength Using Gradient Boosting Regression Tree Combined with GridSearchCV Hyperparameter-Optimization Techniques. Material 2022, 15, 7432. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Huang, H. Predicting compressive and flexural strength of high-performance concrete using a dynamic Catboost Regression model combined with individual and ensemble optimization techniques. Mater. Today Commun. 2024, 38, 108174. [Google Scholar] [CrossRef]
- Vargas, J.F.; Oviedo, A.I.; Ortega, N.A.; Orozco, E.; Gómez, A.; Londoño, J.M. Machine-Learning-Based Predictive Models for Compressive Strength, Flexural Strength, and Slump of Concrete. Appl. Sci. 2024, 14, 4426. [Google Scholar] [CrossRef]
- Li, D.; Tang, Z.; Kang, Q.; Zhang, X.; Li, Y. Machine Learning-Based Method for Predicting Compressive Strength of Concrete. Processes 2023, 11, 390. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Suleiman, A.; Abdullahi, U.; Ahmad, U.A. An Analysis of Residuals in Multiple Regressions. Int. J. Adv. Sci. Eng. 2015, 3, 2348–7550. [Google Scholar]
- C39/C39M; Standard Test Method for Compressive Strength of Cylindrical Concrete Specimens. American Society for Testing and Materials (ASTM): West Conshohocken, PA, USA, 2017.
- ACI CODE-318-19(22); Building Code Requirements for Structural Concrete and Commentary (Reapproved 2022). American Concrete Institute (ACI): Columbia, MD, USA, 2014.
- BS 8500-1:2023; BSI Knowledge. British Standards Institution (BSI): London, UK, 2023.
- Marco ético Para la Inteligencia Artificial en Colombia; Technical Report; Gobierno de Colombia: Bogotá, Colombia, 2021.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | ML Technique | Description |
|---|---|---|
| [22] | Linear Regression (LR) | Linear regression works by fitting a linear model to the input data to predict continuous target variables based on one or more predictor variables. |
| [23] | Decision Tree Regression (RT) | Regression trees are predictive models that recursively partition the feature space into regions, where each region is associated with a constant value prediction for the target variable. |
| [12,18,22] | Multilayer Perceptron Neural Network Regression (MLP) | Neural networks process information by simulating the interconnected structure of neurons in the brain to learn and make predictions. |
| [24] | Support Vector Machine Regression (SVM) | Support vector machine regression finds the optimal hyperplane in a high-dimensional space to predict continuous outcomes by maximizing the margin between the observed data points and the decision boundary. |
| [25] | Random Forest Regression (RF) | The random forest regressor is an ensemble learning method that builds multiple decision trees and averages their predictions to improve accuracy. |
| [26] | Gradient Boosting Regression (GBoost) | Gradient boosting regression builds a predictive model by combining multiple weak learners sequentially, with each subsequent model focusing on the errors of its predecessors. |
| [9] | XGBoost Regression (XGBoost) | XGBoost regression, short for extreme gradient boosting regression, constructs an ensemble of weak learners, typically decision trees, sequentially as [x]. XGBoost and Gboost share some concepts. While gradient boosting regression is a sequential learning technique, XGBoost incorporates enhancements such as parallelization and tree pruning. |
| [27] | CatBoost Regression (CatBoost) | CatBoost regression is an algorithm that utilizes gradient boosting to build predictive models, specifically designed to handle categorical features efficiently, while also implementing various optimizations to improve performance and accuracy. |
| Component | Units |
|---|---|
| Coarse aggregate quantity | kg/m3 |
| Fine aggregate quantity | kg/m3 |
| Water | L/m3 |
| Retarding admixture | g/m3 |
| Superplasticizing addmixture | g/m3 |
| SCM | kg/m3 |
| Cement type I | kg/m3 |
| Cement type II | kg/m3 |
| Component | Units | Min | Max |
|---|---|---|---|
| Water | L/m3 | 40 | 200 |
| Cement type I | kg/m3 | 200 | 1000 |
| Cement type II | kg/m3 | 0 | 1000 |
| Retarding admixture | g/m3 | 0 | 5000 |
| Superplasticizing addmixture | g/m3 | 0 | 5000 |
| SCM | kg/m3 | 0 | 100 |
| Fine aggregate source | nominal | ||
| Fine aggregate quantity | kg/m3 | 0 | 2000 |
| Fine aggregate moisture | % | 0 | 15 |
| Coarse aggregate source | nominal | ||
| Coarse aggregate quantity | kg/m3 | 0 | 2500 |
| Coarse aggregate moisture | % | 0 | 6 |
| 28th-day compressive strength (target variable) | MPa | 10 | 100 |
| Regression Method | RMSE (MPa) | MAE (MPa) | MAPE (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Test | Train | Test | Train | Test | Train | Test | Train | |
| CatBoost | 0.76 | 0.88 | 5.32 | 3.90 | 4.10 | 3.00 | 10.52 | 7.79 |
| RF | 0.72 | 0.85 | 5.61 | 4.62 | 4.32 | 3.55 | 11.06 | 7.62 |
| XGBoost | 0.72 | 0.84 | 5.63 | 4.52 | 4.36 | 3.37 | 11.15 | 7.23 |
| GBoost | 0.71 | 0.81 | 5.64 | 4.85 | 4.38 | 3.73 | 11.35 | 9.74 |
| MLP | 0.71 | 0.82 | 5.71 | 4.36 | 4.34 | 3.29 | 11.32 | 8.51 |
| Linear | 0.68 | 0.89 | 6.12 | 5.16 | 5.12 | 3.93 | 12.32 | 10.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oviedo, A.I.; Londoño, J.M.; Vargas, J.F.; Zuluaga, C.; Gómez, A. Modeling and Optimization of Concrete Mixtures Using Machine Learning Estimators and Genetic Algorithms. Modelling 2024, 5, 642-658. https://doi.org/10.3390/modelling5030034
Oviedo AI, Londoño JM, Vargas JF, Zuluaga C, Gómez A. Modeling and Optimization of Concrete Mixtures Using Machine Learning Estimators and Genetic Algorithms. Modelling. 2024; 5(3):642-658. https://doi.org/10.3390/modelling5030034
Chicago/Turabian StyleOviedo, Ana I., Jorge M. Londoño, John F. Vargas, Carolina Zuluaga, and Ana Gómez. 2024. "Modeling and Optimization of Concrete Mixtures Using Machine Learning Estimators and Genetic Algorithms" Modelling 5, no. 3: 642-658. https://doi.org/10.3390/modelling5030034
APA StyleOviedo, A. I., Londoño, J. M., Vargas, J. F., Zuluaga, C., & Gómez, A. (2024). Modeling and Optimization of Concrete Mixtures Using Machine Learning Estimators and Genetic Algorithms. Modelling, 5(3), 642-658. https://doi.org/10.3390/modelling5030034