

A Practice-Oriented Computational Thinking Framework for Teaching Neural Networks to Working Professionals

Abstract
1. Introduction
- Research Question 1: How can a computational thinking framework be tailored for working professionals, and how should it align with both the standard data science pipeline and artificial intelligence instructional taxonomy? To address this question, this study proposes a computational thinking framework specifically designed for working professionals who apply neural networks in real-world data science contexts.
- Research Question 2: How can the proposed computational thinking framework be implemented to improve participants’ computational thinking skills and neural network competence? Leveraging the proposed tailored computational thinking framework, this study develops a detailed instructional framework with various learning activities. They were implemented across 28 course runs (2019–2024).
2. Background and Related Works
2.1. Computational Thinking
2.2. Instructional Taxonomy
2.3. Machine Learning Education
2.4. Analysis of Related Works
3. Methodology
3.1. Course Context
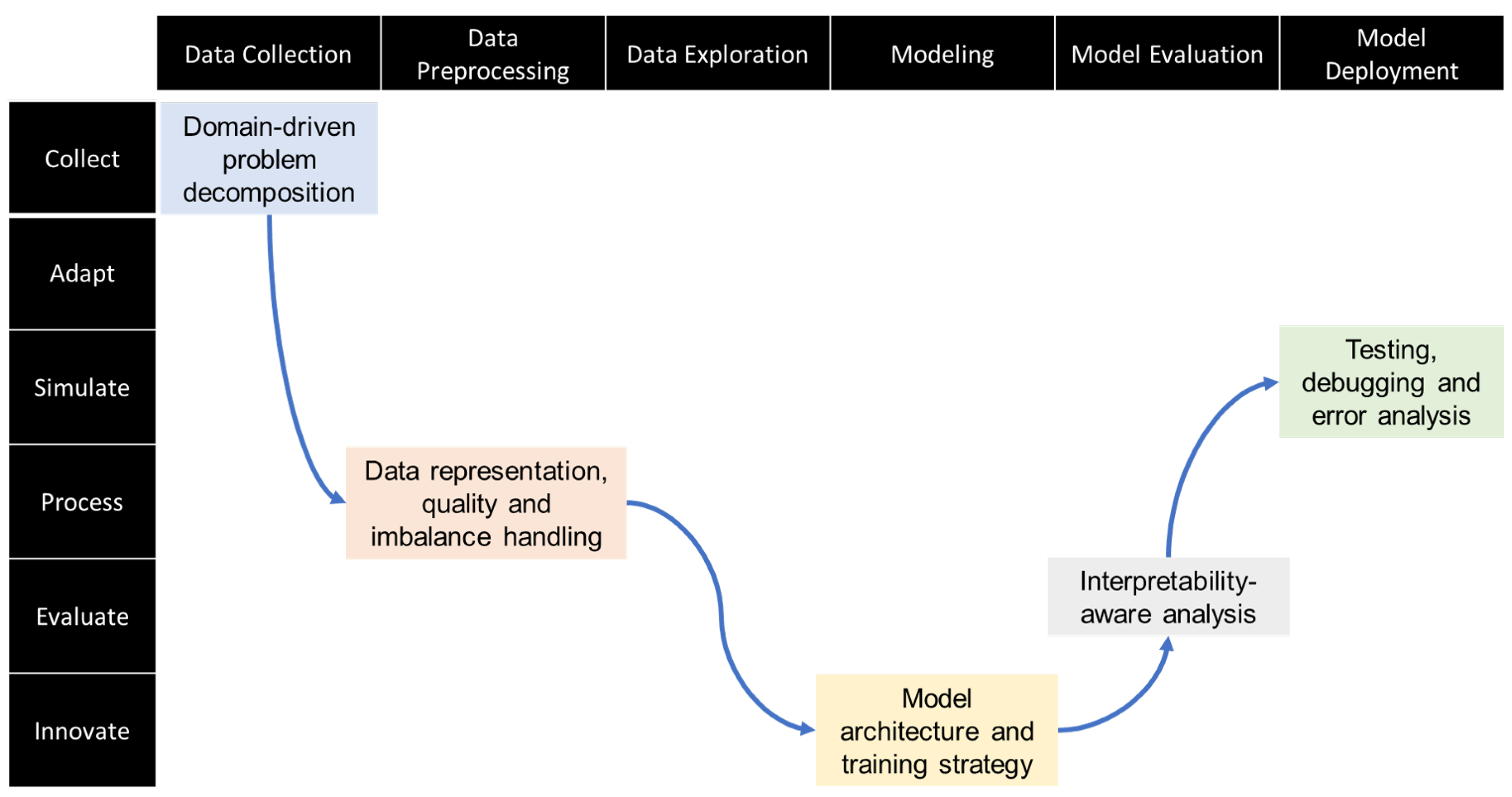
3.2. Proposed Framework
- The first part is problem decomposition, which means turning a big business question into smaller tasks, like gathering the right data, defining what needs to be predicted, and deciding how to measure success.
- Next is data representation, quality, and imbalance handling. This involves turning raw data into useful features, fixing missing or incorrect values, and making sure rare cases are not ignored.
- The third part is model architecture and training strategy. This means choosing the right type of neural network and setting up how it will learn, including selecting loss functions, handling class imbalance, and tuning settings for the best results.
- The fourth component is interpretability-aware analysis, which helps explain why the model makes certain predictions. Tools like feature importance are used to check if the model focuses on the right things and to build trust in its output.
- Finally, testing, debugging, and error analysis ensure that everything works correctly. This includes checking the data pipeline, monitoring training results, and studying errors to improve the model.
3.3. Course Implementation
3.3.1. Lecture
3.3.2. Programming Workshop
3.3.3. Case Study
3.3.4. Group Discussion
3.3.5. Assessment
4. Implementations and Reflections
4.1. Implementations
- Skill-related (Q1–Q2). These items assess whether the course materials and activities enabled participants to acquire practical skills and knowledge they can apply to neural network tasks.
- Delivery-related (Q3–Q4). These items capture participants’ reflections on (i) their confidence in applying what they learned and (ii) the instructor’s effectiveness in explaining concepts and facilitating class interaction.
- Overall satisfaction (Q5). This item measures whether the course met its stated objectives and provides an overall indicator of participant satisfaction.
4.2. Instructor Reflection
4.3. Limitations
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, J.C.; Pratt, T.L. Navigating AI Integration in Career and Technical Education: Diffusion Challenges, Opportunities, and Decisions. Educ. Sci. 2024, 14, 1285. [Google Scholar] [CrossRef]
- Babashahi, L.; Barbosa, C.E.; Lima, Y.; Lyra, A.; Salazar, H.; Argolo, M.; Almeida, M.A.d.; Souza, J.M.d. AI in the Workplace: A Systematic Review of Skill Transformation in the Industry. Adm. Sci. 2024, 14, 127. [Google Scholar] [CrossRef]
- Sidhu, G.S.; Sayem, M.A.; Taslima, N.; Anwar, A.S.; Chowdhury, F.; Rowshon, M. AI and Workforce Development: A Comparative Analysis of Skill Gaps and Training Needs in Emerging Economies. Int. J. Bus. Manag. Sci. 2024, 4, 12–28. [Google Scholar] [CrossRef]
- Xu, J.J.; Babaian, T. Artificial intelligence in business curriculum: The pedagogy and learning outcomes. Int. J. Manag. Educ. 2021, 19, 100550. [Google Scholar] [CrossRef]
- Memarian, B.; Doleck, T. Teaching and learning artificial intelligence: Insights from the literature. Educ. Inf. Technol. 2024, 29, 21523–21546. [Google Scholar] [CrossRef]
- Geron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Salazar-Gomez, A.F.; Bagiati, A.; Minicucci, N.; Kennedy, K.D.; Du, X.; Breazeal, C. Designing and implementing an AI education program for learners with diverse background at scale. In Proceedings of the IEEE Frontiers in Education Conference, Uppsala, Sweden, 8–11 October 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Schleiss, J.; Laupichler, M.C.; Raupach, T.; Stober, S. AI Course Design Planning Framework: Developing Domain-Specific AI Education Courses. Educ. Sci. 2023, 13, 954. [Google Scholar] [CrossRef]
- Juca-Aulestia, M.; Cabrera-Paucar, E.; Sánchez-Burneo, V. Education and Characteristics of Computational Thinking: A Systematic Literature Review. In Proceedings of the World Conference on Information Systems and Technologies, Pisa, Italy, 4–6 April 2023; Volume 800, pp. 156–171. [Google Scholar] [CrossRef]
- Dohn, N.B.; Kafai, Y.; Mørch, A.; Ragni, M. Survey: Artificial Intelligence, Computational Thinking and Learning. KI Kunstl. Intell. 2022, 36, 5–16. [Google Scholar] [CrossRef]
- Wing, J.M. Computational thinking. Commun. ACM 2006, 49, 33–35. [Google Scholar] [CrossRef]
- Tedre, M. Computational Thinking 2.0. In Proceedings of the Proceedings of the 17th Workshop in Primary and Secondary Computing Education, Morschach, Switzerland, 31 October–2 November 2022. [CrossRef]
- Denning, P.J.; Tedre, M. Computational thinking for professionals. Commun. ACM 2021, 64, 30–33. [Google Scholar] [CrossRef]
- Lyon, J.A.; Magana, A.J. Computational thinking in higher education: A review of the literature. Comput. Appl. Eng. Educ. 2020, 28, 1174–1189. [Google Scholar] [CrossRef]
- Tsai, M.J.; Liang, J.C.; Hsu, C.Y. The Computational Thinking Scale for Computer Literacy Education. J. Educ. Comput. Res. 2021, 59, 579–602. [Google Scholar] [CrossRef]
- Agbo, F.J.; Everetts, C. Towards Computing Education for Lifelong Learners: Exploring Computational Thinking Unplugged Approaches. In Proceedings of the ACM Virtual Global Computing Education Conference, Virtual, 5–8 December 2024; pp. 295–296. [Google Scholar] [CrossRef]
- Angeli, C.; Giannakos, M. Computational thinking education: Issues and challenges. Comput. Hum. Behav. 2020, 105, 106185. [Google Scholar] [CrossRef]
- de Jong, I.; Jeuring, J. Computational Thinking Interventions in Higher Education: A Scoping Literature Review of Interventions Used to Teach Computational Thinking. In Proceedings of the International Conference on Computing Education Research, Virtual, 10–12 August 2020. [Google Scholar] [CrossRef]
- Liu, T. Relationships Between Executive Functions and Computational Thinking. J. Educ. Comput. Res. 2024, 62, 1267–1301. [Google Scholar] [CrossRef]
- Ezeamuzie, N.O.; Leung, J.S.C. Computational Thinking Through an Empirical Lens: A Systematic Review of Literature. J. Educ. Comput. Res. 2022, 60, 481–511. [Google Scholar] [CrossRef]
- Parsazadeh, N.; Cheng, P.Y.; Wu, T.T.; Huang, Y.M. Integrating Computational Thinking Concept Into Digital Storytelling to Improve Learners’ Motivation and Performance. J. Educ. Comput. Res. 2021, 59, 470–495. [Google Scholar] [CrossRef]
- Zhou, C.; Zhang, W. Computational Thinking (CT) towards Creative Action: Developing a Project-Based Instructional Taxonomy (PBIT) in AI Education. Educ. Sci. 2024, 14, 134. [Google Scholar] [CrossRef]
- Bloom, B. Taxonomy of Educational Objectives: The Classification of Educational Goals; Number 1 in Taxonomy of Educational Objectives; The Classification of Educational Goals: Longmans, Green, 1956. [Google Scholar]
- Anderson, L.W.; Krathwohl, D.R. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives; Longman: London, UK, 2001. [Google Scholar]
- Churches, A. Bloom’s Digital Taxonomy. 2008. Available online: http://burtonslifelearning.pbworks.com/f/BloomDigitalTaxonomy2001.pdf (accessed on 25 May 2025).
- Hmoud, M.; Shaqour, A. AIEd Bloom’s Taxonomy: A Proposed Model for Enhancing Educational Efficiency and Effectiveness in the Artificial Intelligence Era. Int. J. Technol. Learn. 2024, 31, 111–128. [Google Scholar] [CrossRef]
- Ng, D.T.K.; Lee, M.; Tan, R.J.Y.; Hu, X.; Downie, J.S.; Chu, S.K.W. A review of AI teaching and learning from 2000 to 2020. Educ. Inf. Technol. 2023, 28, 8445–8501. [Google Scholar] [CrossRef]
- Hazzan, O.; Mike, K. Guide to Teaching Data Science: An Interdisciplinary Approach; Springer: Cham, Switzerland, 2023; pp. 1–321. [Google Scholar] [CrossRef]
- Camerlingo, G.; Fantozzi, P.; Laura, L.; Parrillo, M. Teaching Neural Networks Using Comic Strips. In Proceedings of the International Conference in Methodologies and Intelligent Systems for Technology Enhanced Learning, Salamanca, Spain, 26–28 June 2024; pp. 1–10. [Google Scholar] [CrossRef]
- Xiao, T.; Gao, D.; Chen, S.; Mei, X.; Yang, Y.; Lu, X. Artificial Neural Network Course Designing Based on Large-Unit Teaching Mode. In Proceedings of the International Conference on Computer Science and Technologies in Education, Xi’an, China, 19–21 April 2024; pp. 342–346. [Google Scholar] [CrossRef]
- Nadzinski, G.; Gerazov, B.; Zlatinov, S.; Kartalov, T.; Dimitrovska, M.M.; Gjoreski, H.; Chavdarov, R.; Kokolanski, Z.; Atanasov, I.; Horstmann, J.; et al. Data Science and Machine Learning Teaching Practices with Focus on Vocational Education and Training. Inform. Educ. 2023, 22, 671–690. [Google Scholar] [CrossRef]
- Dogan, G. Teaching Machine Learning with Applied Interdisciplinary Real World Projects. In Proceedings of the Machine Learning Research; ML Research Press: Norfolk, MA, USA, 2022; Volume 207, pp. 12–15. [Google Scholar]
- Brungel, R.; Bracke, B.; Ruckert, J.; Friedrich, C.M. Teaching Machine Learning with Industrial Projects in a Joint Computer Science Master Course: Experiences, Challenges, Perspectives. In Proceedings of the IEEE German Education Conference, Berlin, Germany, 2–4 August 2023. [Google Scholar] [CrossRef]
- Stoyanovich, J. Teaching Responsible Data Science. In Proceedings of the International Workshop on Data Systems Education, Philadelphia, PA, USA, 12–17 June 2022; pp. 4–9. [Google Scholar] [CrossRef]
- Lewis, A.; Stoyanovich, J. Teaching Responsible Data Science: Charting New Pedagogical Territory. Int. J. Artif. Intell. Educ. 2022, 32, 783–807. [Google Scholar] [CrossRef]
- Mersha, M.; Lam, K.; Wood, J.; AlShami, A.K.; Kalita, J. Explainable artificial intelligence: A survey of needs, techniques, applications, and future direction. Neurocomputing 2024, 599, 128111. [Google Scholar] [CrossRef]
- Sheridan, H.; Murphy, E.; O’Sullivan, D. Human Centered Approaches and Taxonomies for Explainable Artificial Intelligence. In Proceedings of the International Conference on Human-Computer Interaction, Washington, DC, USA, 29 June–4 July 2024; pp. 144–163. [Google Scholar] [CrossRef]
- Williams, G.J. Data Mining with Rattle and R: The Art of Excavating Data for Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Demšar, J.; Curk, T.; Erjavec, A.; Črt Gorup; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml (accessed on 25 May 2025).
- Google. Google Colaboratory. 2025. Available online: https://colab.research.google.com/ (accessed on 25 May 2025).
- UCI Machine Learning Repository. APS Failure at Scania Trucks. 2016. Available online: https://archive.ics.uci.edu/dataset/421/aps+failure+at+scania+trucks (accessed on 25 May 2025). [CrossRef]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Comput. Surv. 2022, 55, 114. [Google Scholar] [CrossRef]
- Instructure. Canvas LMS. 2025. Available online: https://www.instructure.com/canvas (accessed on 25 May 2025).

{kind=link}
| Lecture | Hands-on Programming | Discussion | |
|---|---|---|---|
| Domain-driven problem decomposition | Formulate a business analytics question and decompose it into machine learning tasks. Start with a use case (like predictive maintenance) and show step-by-step how to turn the business goal into sub-tasks, such as data collection, annotation, and success metrics. | Provide a small CSV file of machine operation records. Students write a short script that lists the subtasks as to-do comments and then programmatically checks whether each required column and label exists in the file. | Split into groups; let them outline which subtasks they would create and why. Groups share their formulations. |
| Data representation, quality, and imbalance handling | Cover data preprocessing, encoding (one-hot, embeddings), handling missing values, detecting data drift, and techniques such as weighting for rare classes. | Use the public dataset; students clean nulls, scale numerical data, and print before/after class counts. | Ask learners to reflect on which preprocessing step changed performance most and debate whether synthetic examples could create hidden bias. |
| Model architecture and training strategy | Define the neural network architecture, such as multiple layer perceptron, and define the training strategy, such as the choice of loss, data augmentation (if necessary), optimizer, hyperparameters such as learning rate, epoch, etc. | Students build a neural network with a programming tool, perform model training with different architectures and configurations, and plot the model performance curve for the training and validation dataset. | Learners debate trade-offs and the choice of the best model based on speed, accuracy, and model complexity. |
| Interpretability-aware analysis | Explain the black-box neural network model, such as global and local feature importance and inner calculations. | Load the trained neural network model and apply the explainer tool to plot the feature importance curve; students write two sentences interpreting the top few features. | Discuss and share the identified important features; debate them with the business domain understanding of the dataset. |
| Testing, debugging, and error analysis | Cover the model maintenance, updating, and tuning instead of retraining from the scratch. | Students write a test that fails if any feature contains nulls at prediction time and implement a confusion-matrix heatmap across customer data subsets. | Simulate the model failure scenarios, such as the model precision suddenly falling for the new data; teams inspect provided logs and propose root causes and fix solutions. |
| Year | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 |
|---|---|---|---|---|---|---|
| Number of runs | 9 | 9 | 4 | 2 | 2 | 2 |
| Number of Participants Per Class | ≤20 | 21–40 | 41–60 | ≥61 |
|---|---|---|---|---|
| Number of runs | 15 | 9 | 2 | 2 |
| Skill-related | Q1 | The training resources provided were useful for my learning. |
| Q2 | I have acquired new skills and/or knowledge from the training. | |
| Delivery-related | Q3 | I am confident that I am able to apply what I learnt in the course. |
| Q4 | The instructor was able to communicate ideas effectively, link concepts to practices with examples, and has good class interaction and facilitation/coaching. | |
| Overall | Q5 | The course met its intended objective (s). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, J. A Practice-Oriented Computational Thinking Framework for Teaching Neural Networks to Working Professionals. AI 2025, 6, 140. https://doi.org/10.3390/ai6070140
Tian J. A Practice-Oriented Computational Thinking Framework for Teaching Neural Networks to Working Professionals. AI. 2025; 6(7):140. https://doi.org/10.3390/ai6070140
Chicago/Turabian StyleTian, Jing. 2025. "A Practice-Oriented Computational Thinking Framework for Teaching Neural Networks to Working Professionals" AI 6, no. 7: 140. https://doi.org/10.3390/ai6070140
APA StyleTian, J. (2025). A Practice-Oriented Computational Thinking Framework for Teaching Neural Networks to Working Professionals. AI, 6(7), 140. https://doi.org/10.3390/ai6070140