1. Introduction
Generative AI, exemplified by large language models (LLMs) like ChatGPT, is transforming the way of information acquisition, significantly altering work practices and business operations [
1,
2]. Nevertheless, these models frequently yield outputs that are ambiguous or otherwise misaligned with users’ expectations [
3,
4]. Moreover, the sequential decision-making processes by which ChatGPT generates its responses are not yet fully transparent, even to its developers at OpenAI [
5], and can be elucidated only partially by specialists in natural language processing (NLP) [
6]. On the other hand, users frequently rely on ChatGPT for information beyond their expertise; however, the inability to evaluate output reliability could lead to serious operational failures in high-risk settings [
7]. This reflects a growing disconnect between users and AI systems, diminishing trust and introducing emergent risks.
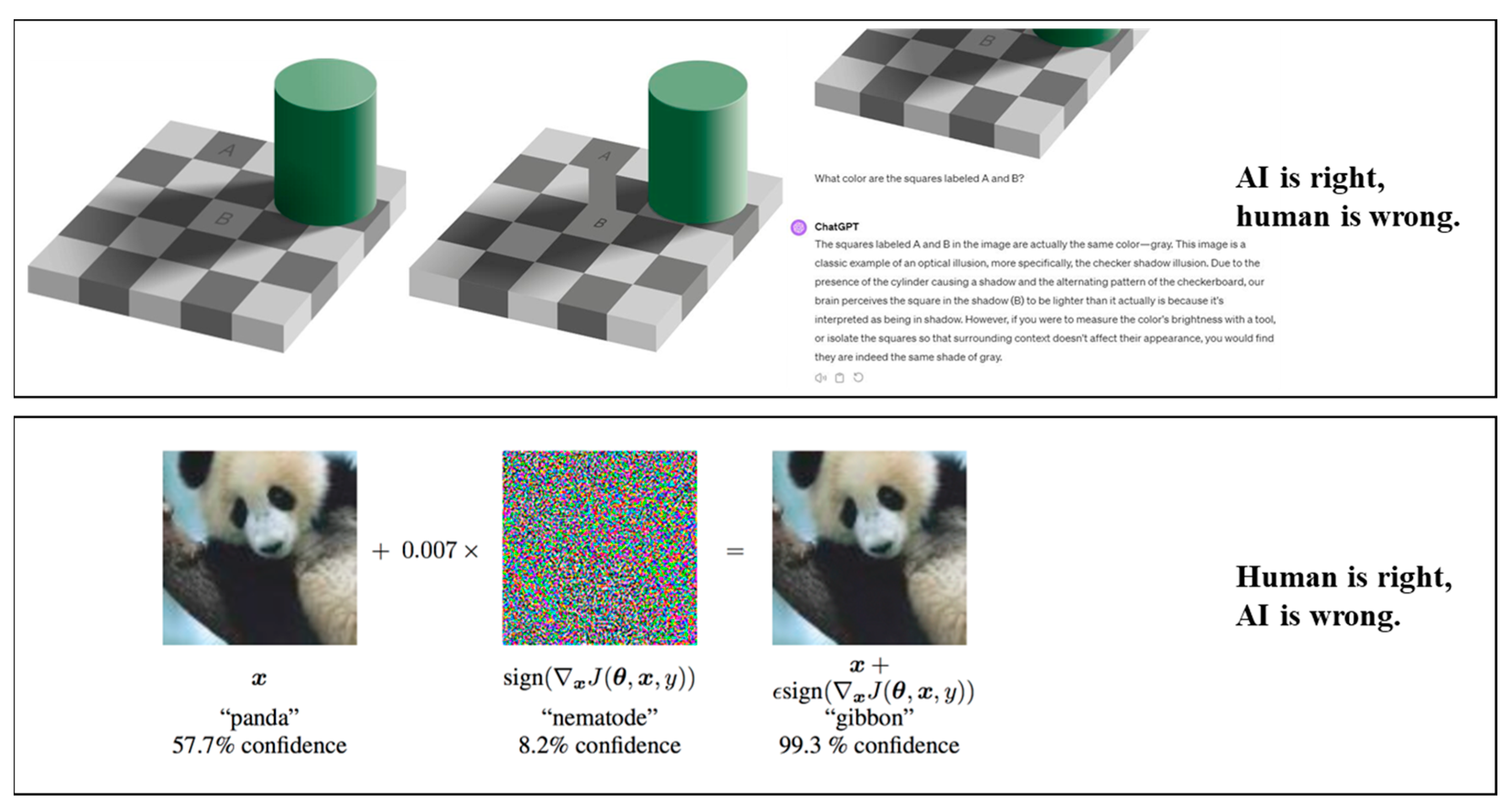
Conversely, from a human cognitive standpoint, outputs from ChatGPT that deviate from human expectations are often perceived as incorrect; however, this assumption does not always align with the actual operational logic or intent of the model. For instance, in the well-known case of an optical illusion (
Figure 1), humans are unable to accurately perceive the color equivalence between squares A and B due to perceptual biases [
8]; however, AI systems, unconstrained by such cognitive limitations, can correctly identify the color consistency. Similarly, in image recognition tasks, when presented with an adversarial example, humans can readily identify a noise-perturbed image of a panda as still being a panda [
9]. In contrast, AI models are susceptible to such perturbations and may misclassify the image, for example, labeling the panda as a gibbon, despite the apparent visual consistency to human observers.
These two examples highlight a critical issue: neither humans nor AI systems can consistently achieve correct judgments, as each is subject to distinct limitations, such as cognitive biases in humans and vulnerability to adversarial manipulation or distribution shifts in AI. From a cognitive-science perspective, humans rely on embodied perception [
10], causal reasoning [
11], and situation awareness [
12] when interpreting uncertain environments. By contrast, AI models derive “meaning” from high-dimensional statistical regularities, which can diverge sharply from human mental models [
13,
14]. Similarly, a parallel strand of work in human–AI interaction in industrial scenarios documents cognitive conflict between operators and automated systems [
15,
16]. Notably, the growing disparity in capabilities between human cognition and AI has become a subject of increasing concern.
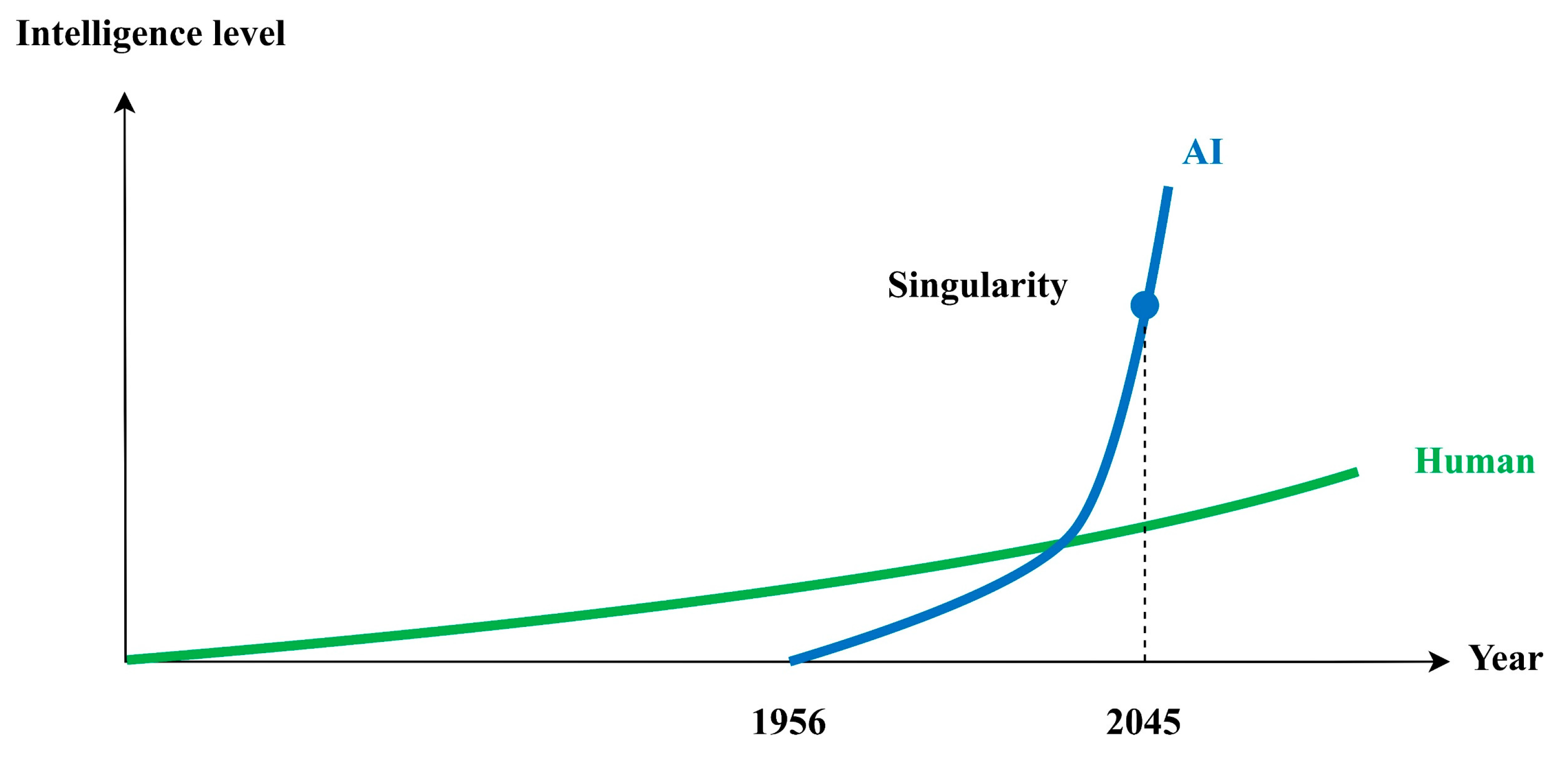
For instance,
Figure 2 illustrates the trajectories of intelligence growth for both humans and AI. Evidently, ChatGPT demonstrates that the capabilities of a single AI system can, in certain domains, exceed those of individual human users. This widening gap between artificial and human intelligence may constitute an emerging source of risk. Given that generative AI is designed to emulate human cognition, a critical question arises: has this imitation process already introduced fundamental divergences, particularly in algorithmic and architectural design? This study seeks to explore that question through a set of targeted hypotheses.
Using LLMs as representative examples of AI systems, early safety critiques have primarily focused on output-level failures, including hallucinations, toxicity, and biased responses. For example, researchers characterized LLMs as “stochastic parrots”, warning that fluent text can mask severe factual errors and ethical hazards [
19]. Such hallucinations may demonstrate unreliability with fake information impact and may translate into misleading advice in safety-critical contexts [
20]. However, these investigations frame risk as a downstream behavioral phenomenon: the model’s internal operations remain opaque, and any misalignment is inferred only from problematic answers. In recent technical surveys on embedding bias [
21], positional encoding design [
22], attention reliability [
23], and optimization drift [
24], each isolates one component with descriptive or statistical presentation, yet they do not integrate these pieces into a unified, risk-oriented framework.
Thus, no prior study has quantitatively traced the divergence between human reasoning and AI output back to the Transformer’s core building blocks—vectorization, positional encoding, attention scoring, and optimization loops. Addressing this gap, the present work operationalizes the notion of architectural distance: measurable discrepancies (e.g., cosine similarity or cross-entropy) between human-aligned semantic space and the internal representations produced at each layer. By linking those distances to concrete safety-relevant behaviors, we provide the first end-to-end account of how internal design choices propagate to external risk. Therefore, this study aims to address the following research questions:
Is it the architecture design of AI that ultimately leads to the difference between humans and AI?
What algorithms themselves contribute to this gap in the structure?
What distance formula can be used to measure these gaps?
A reminder to readers of the structure of this paper:
Section 2 is the methodology to identify risk in the Transformer model (the foundation of ChatGPT), mostly based on expert heuristic evaluation and structural analysis;
Section 3 is the results and detailed presentation of the risks;
Section 4 is a case study with experiments to demonstrate the findings;
Section 5 is the detailed discussion on notable problems and questions;
Section 6 are remarkable conclusions.
2. Methodology
This study selects the Transformer model as the research object [
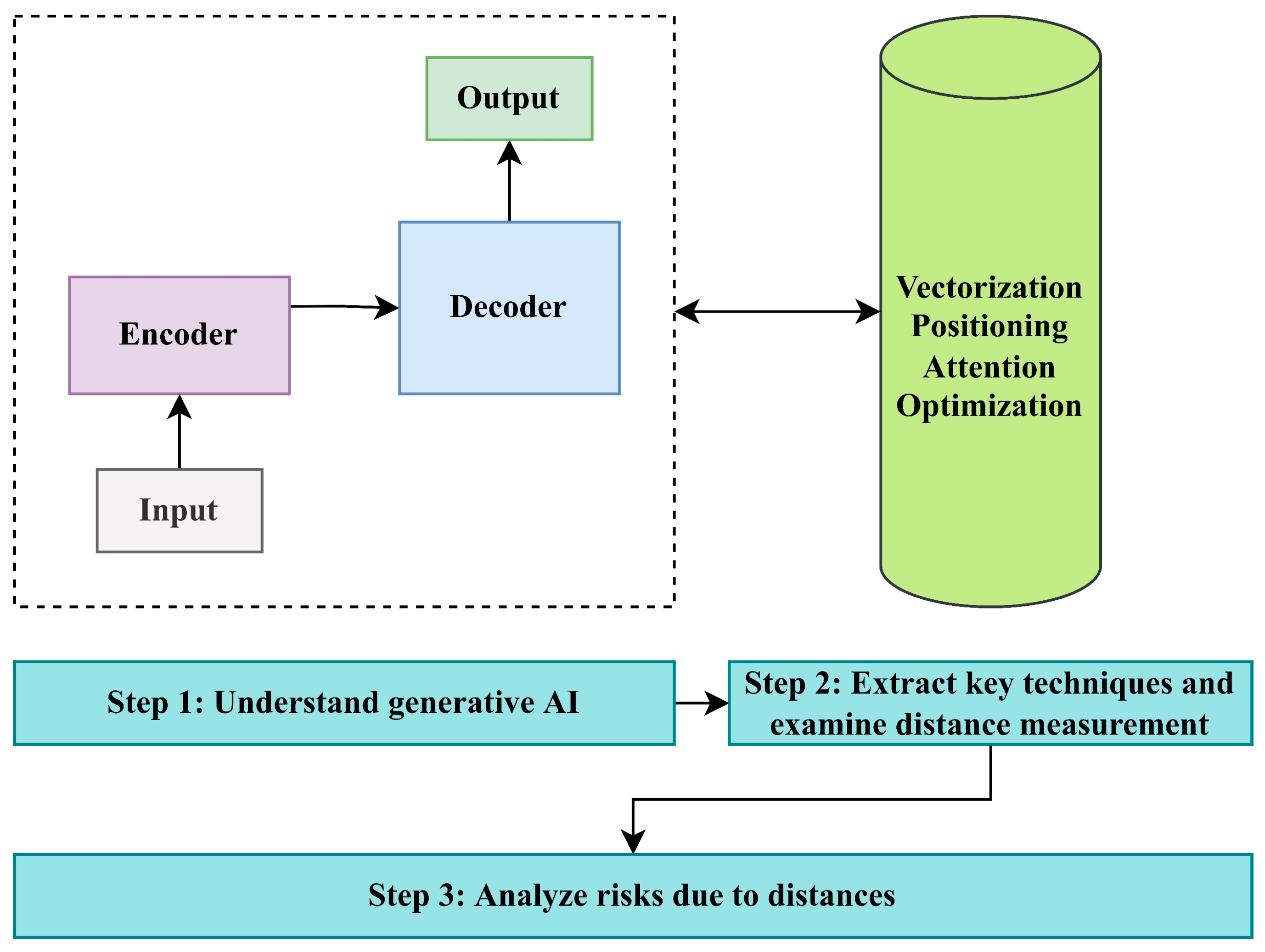
25], which is the fundamental architecture of ChatGPT and most other generative AI, aiming to understand its operating logic, extract key techniques and algorithms, and then use distance measurement methods to verify whether there is a distance between humans and AI. Finally, expert-based heuristic evaluations, guided by technical analysis of the Transformer architecture and informed by prior literature in cognitive modeling and AI interpretability, are employed to examine and analyze the associated risks. The overall methodological framework is presented in
Figure 3.
The detailed steps are introduced as follows:
Step 1: Understand generative AI and how it approaches or surpasses human cognition.
Through a systematic review of NLP tasks and model evolution, this study traces how generative AI progressively approximates human natural language capabilities. This process is critically examined to assess whether such approximation introduces inherent risks arising from architectural or cognitive misalignments.
Step 2: Extract key techniques and examine the distance measurement.
Among the various technologies and algorithms employed in the Transformer model, this study focuses on four core components: vectorization, positional encoding, attention mechanisms, and optimization. Each is examined in depth to assess whether its design introduces measurable divergences, referred to as architectural distances, from human semantic reasoning, and whether such distances may constitute a source of risk.
Simultaneously, we evaluate commonly used distance metrics, including cosine similarity, cross-entropy, and vector norms. These metrics are applied to the selected architectural components to determine whether quantifiable distance measures are embedded within these mechanisms and to explore the extent to which such computational distances contribute to cognitive or operational risks.
Step 3: Analyze risks due to distances.
To assess potential risks introduced by architectural components, we conducted an expert-informed heuristic evaluation. Both authors possess domain expertise in AI architecture and risk analysis. Each independently analyzed how vectorization, positioning, attention, and optimization could introduce divergence from human cognition. This evaluation was structured around a comparative review of each architectural component and its functional implications. Findings were then synthesized through multiple rounds of collaborative discussion until consensus was reached. While not a formal Delphi study, this approach incorporates elements of structured expert judgment and qualitative consensus-building.
It is noted that, due to ethical considerations regarding the use of human subjects in safety and risk evaluations, both the AI response and the simulated human response were generated using ChatGPT. The “human response” was approximated through a prompt designed to elicit a more conversational, human-like answer. No actual human participants were involved in this study, which we acknowledge as a methodological limitation. While this approach enables controlled comparisons, future work may incorporate real human expert input to validate and refine these distance measures.
3. Results
3.1. Understand the Transformer and Its Techniques
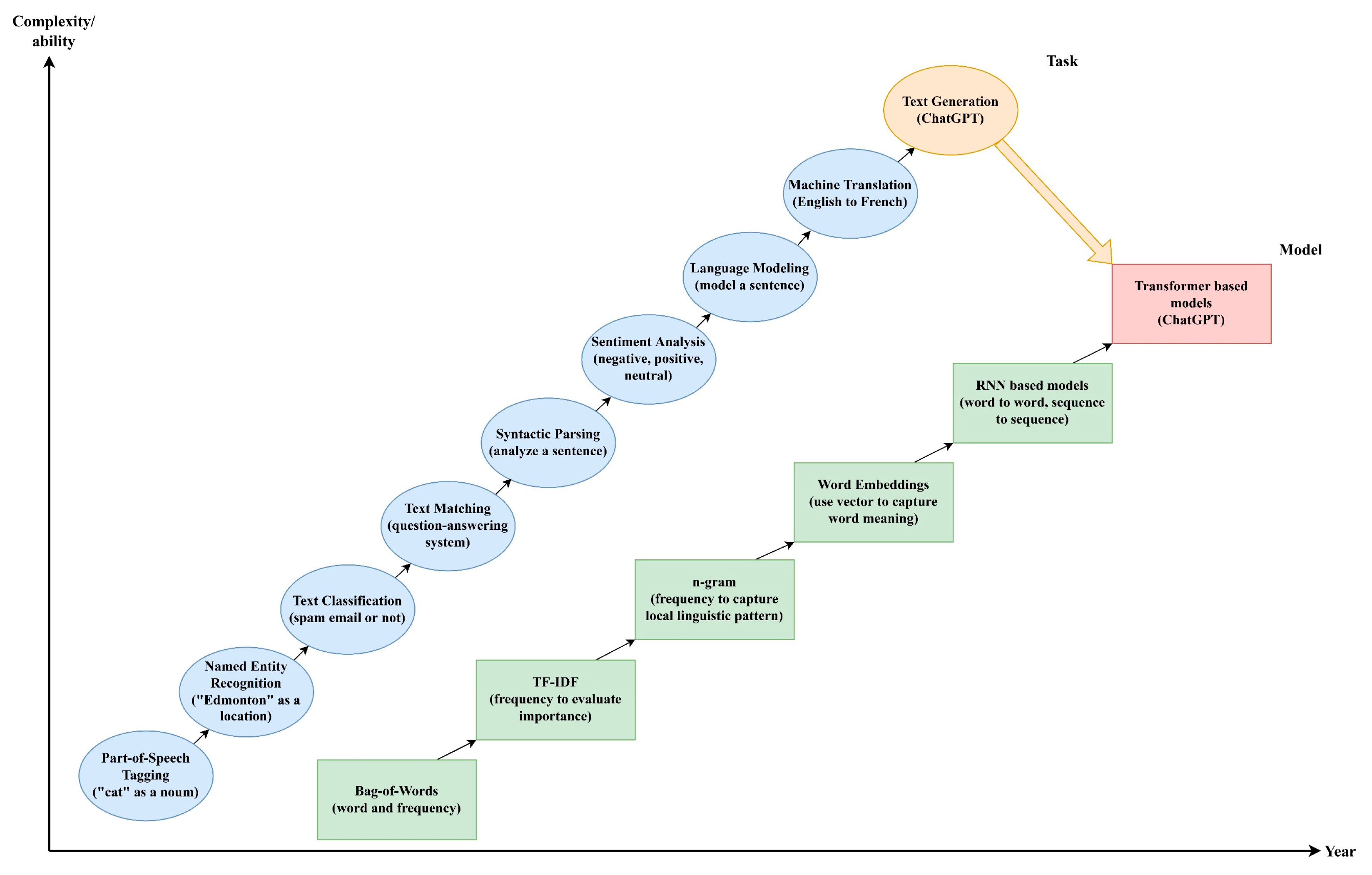
Initially, NLP tasks focused on part-of-speech tagging and named entity recognition [
26], which involved basic categorization of text elements, such as identifying “cat” as a noun and recognizing “Edmonton” as a location. As the field progressed, more sophisticated tasks such as text matching, syntactic parsing, sentiment analysis, and language modeling became central to NLP, supporting complex applications like spam detection, question-answering systems, machine translation, and automated text generation (ChatGPT) [
27]. This trajectory mirrors the human language acquisition process—from understanding simple words to mastering complex communication.
Figure 4 describes the roadmap of NLP from the perspectives of task and model.
On the modeling front, the initial bag-of-words (BOW) model quantified textual data by simply counting the frequency of word occurrences. This model evolved into the Term Frequency-Inverse Document Frequency (TF-IDF) approach, which enhances word importance measurement by accounting for the frequency of words across different documents [
28]. Progressing further, the n-gram models were developed to capture local linguistic patterns by considering sequences of “n” words. The field then advanced to the development of word embeddings, a sophisticated method that uses multidimensional vectors to represent words, capturing not only the semantic meanings but also the contextual relationships between them. Then the introduction of neural networks, especially Recurrent Neural Networks (RNNs) and their enhancements, brought profound improvements in processing sequences and capturing long-range dependencies within texts [
29,
30]. The development of Transformer architecture represented a breakthrough, utilizing self-attention mechanisms to manage global dependencies within text more effectively.
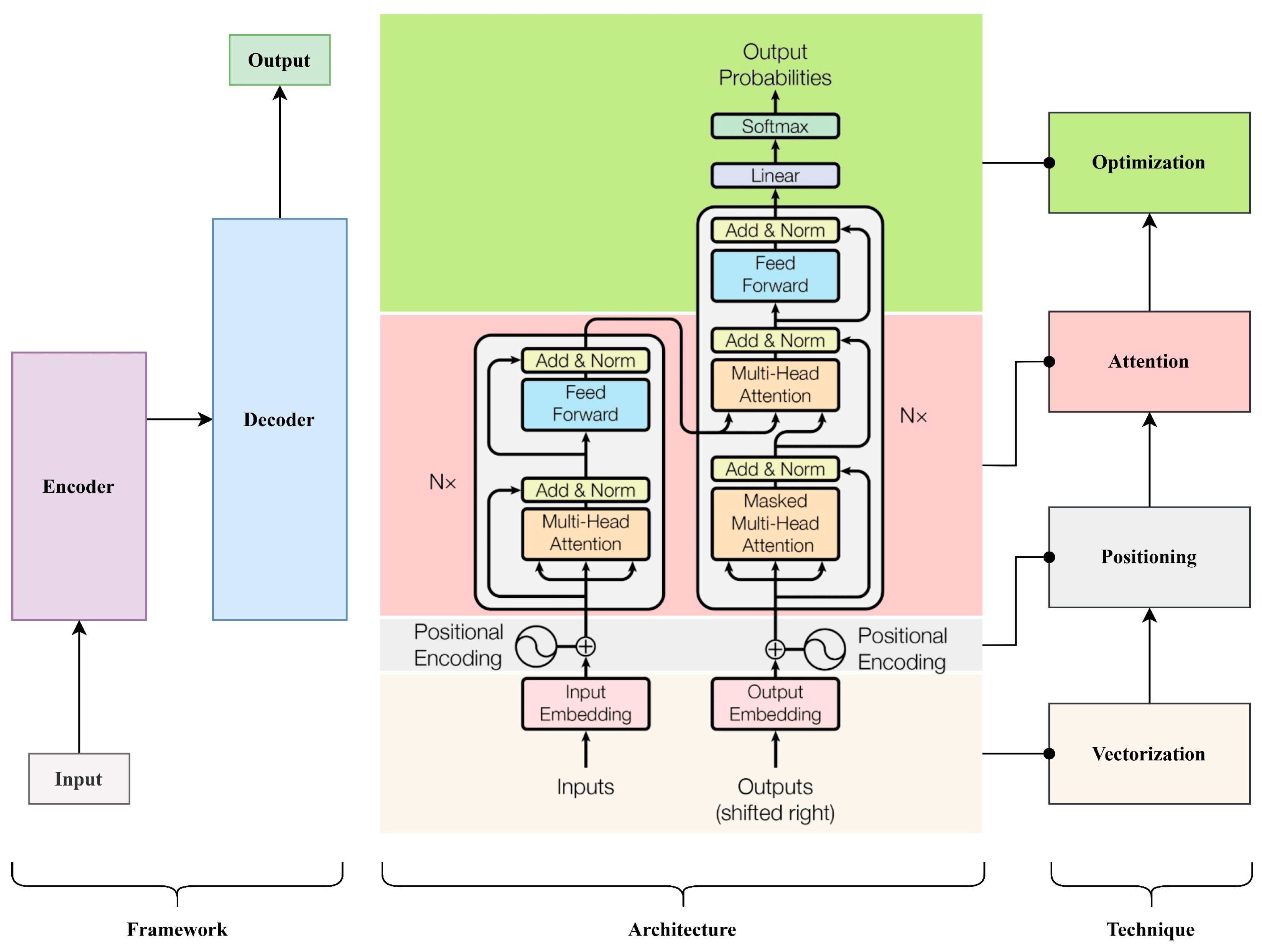
As for the architecture of the Transformer model (
Figure 5), briefly, it comprises an encoder, a decoder, and an output layer (
Table 1). The encoder encodes input sequences into contextual representations through multiple layers, each containing self-attention mechanisms, position-wise feedforward networks, and residual connections [
31]. Similarly, the decoder is responsible for generating target sequences. The output layer utilizes a SoftMax function to compute probability distributions for tokens. This comprehensive architecture utilizes four key techniques: vectorization, positioning, attention, and activation.
The architecture of the Transformer appears to mimic the human brain’s thinking and speaking process, initially acquiring information before producing it—essentially encoding followed by decoding. While this aligns broadly, there remains a clear disparity in practical application.
3.2. Distances and Risks in Vectorization
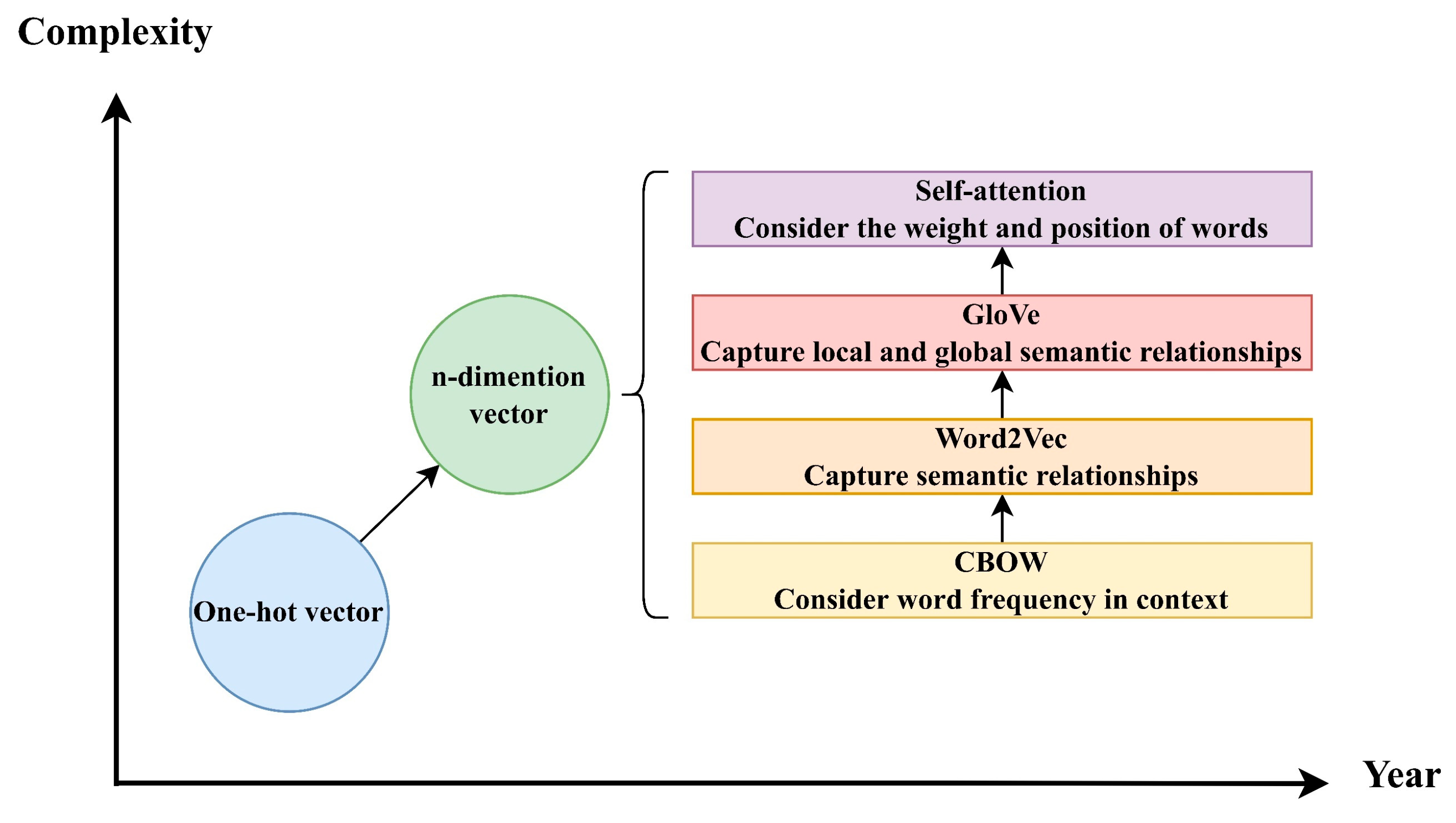
Vectorization, or word embedding, refers to the process of converting textual elements into numerical vector representations, enabling computational models to process and interpret language in a machine-readable format (
Figure 6). Initial methods, such as one-hot encoding, assigned each word a unique vector in a high-dimensional space; however, these representations were sparse and failed to capture semantic relationships between tokens. The introduction of the distributional hypothesis in the 1990s—asserting that words occurring in similar contexts tend to have similar meanings—led to the development of predictive embedding models such as continuous bag-of-words (CBOW) and skip-gram. These models, particularly Word2Vec, produced dense, low-dimensional vectors that encoded contextual meaning based on local co-occurrence patterns. Subsequent models like GloVe extended this approach by incorporating global co-occurrence statistics, enhancing the ability to capture broader semantic regularities.
Despite their utility, such static embeddings assign a single representation to each word, thereby failing to account for context-dependent meanings or polysemy. This limitation has been addressed by the emergence of contextual embeddings, driven by Transformer-based architectures such as BERT and GPT. These models generate dynamic representations of words conditioned on their surrounding context, enabling more accurate semantic interpretation. By leveraging mechanisms such as self-attention and subword tokenization, contextual models offer greater flexibility, robustness to rare or unseen words, and improved performance across a wide range of natural language processing tasks. The evolution from sparse, context-independent representations to rich, context-sensitive embeddings reflects a significant advancement in computational linguistics, underpinning the capabilities of modern generative AI systems.
In the Transformer, each word is allocated a unique token ID within a vast vocabulary, ensuring a comprehensive representation of linguistic elements. Consequently, when a sequence is fed into the Transformer model, it undergoes tokenization, assigning each token an ID, followed by embedding to transform it into a 512-dimensional vector. In the idealized and conceptual design, each vector element symbolizes a specific attribute, with numbers ranging from [−1, 1] to indicate a word’s association with a certain trait loosely. For example, if “cat” had a dimension for “living being,” a value of 0.6 suggested a slight relevance (
Figure 7).
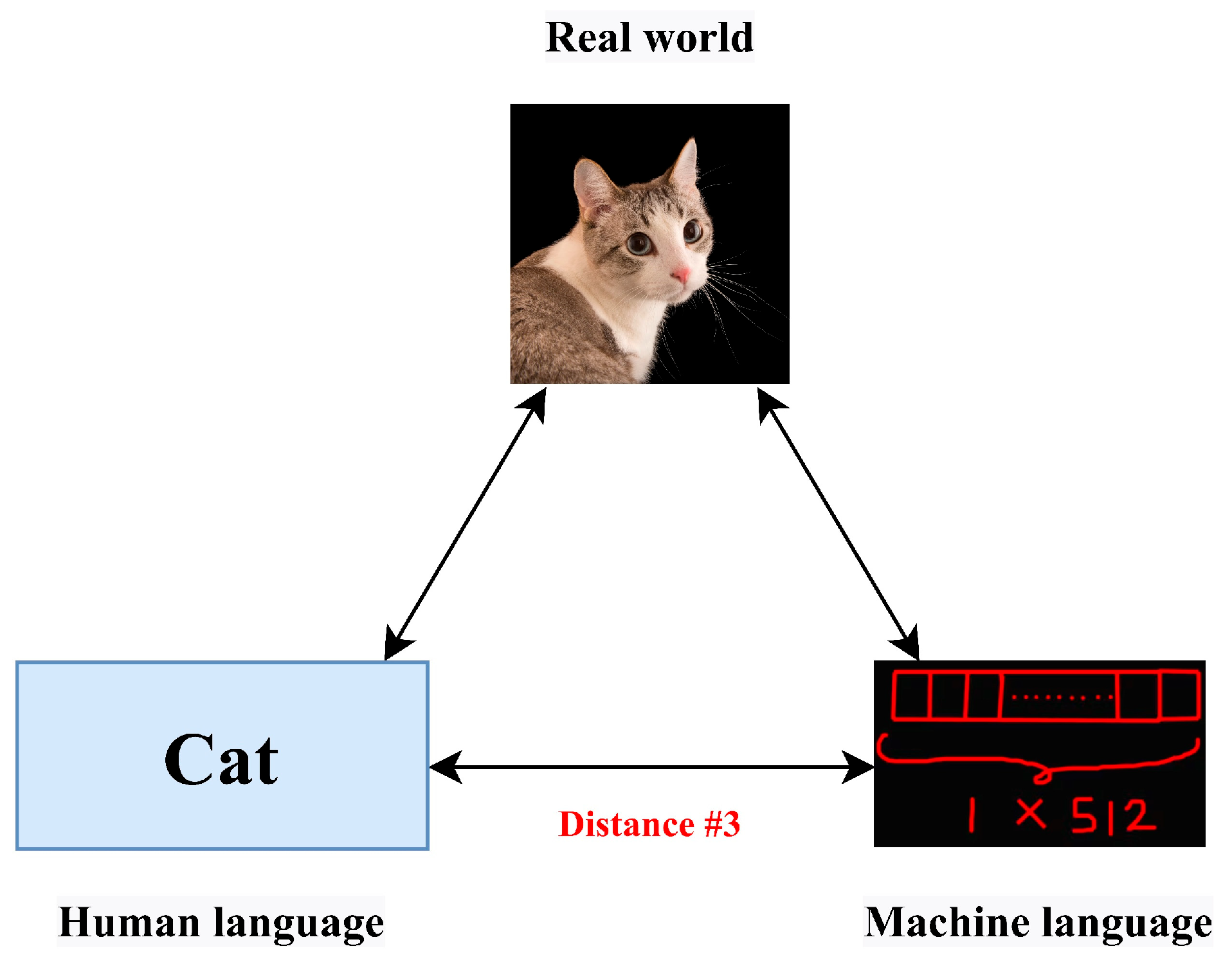
Thus, there are two distances involved here. First, when considering the linguistic feature of living beings, we assign a value of 0.6 to measure the distance to 1, which is completely consistent with semantics, or −1, which is completely inconsistent with the feature’s meaning. The other is that during the training process, the Transformer learns the characteristics of words from a large amount of text and generates a vector corresponding to “cat”. Each element of this vector has been completely matched with the linguistic feature assignment of each element in the original design. Irrelevant, this constitutes the distance between the interpretable original meaning of “cat” and the cat vector of the Transformer. Even if we can manually define an interpretable cat vector, it is completely different from the cat vector in Transformer, and there is a distance between the two vectors. In addition, there is a significant distance from the human language “cat” to the 512-dimensional vector in Transformer (
Figure 8).
Therefore, we use cosine similarity to measure the similarity between two vectors, and then define the distance between the two vectors as
Cosine similarity captures the angular relationship between high-dimensional vectors representing semantic meaning. It thus serves as a proxy for semantic alignment between AI-generated and human-intended responses, closely approximating how humans judge similarity in meaning or topic and measuring the distance between them.
Such representational distances may introduce potential risks. First, they entail a loss of interpretability. Algebraic forms, such as vectors and matrices, abstract real-world entities into high-dimensional spaces, often obscuring their intuitive meaning. In particular, the specific significance of individual dimensions or elements within these representations is difficult to discern. Furthermore, in machine learning, model performance heavily depends on appropriate feature selection. Relying solely on raw vectorized features may be suboptimal, necessitating additional feature engineering to extract more informative representations.
In addition, such representations may introduce numeric bias. Vector- and matrix-based encodings can distort relational meaning by imposing artificial numerical structures, potentially causing the model to become overly sensitive or insensitive to certain features. For instance, encoding categorical items as 0, 1, and 2 implies equal spacing between them, although no such ordinal relationship may exist. Similarly, labeling Boolean values as 0 and 1 may suggest a minimal distance, while the semantic gap could be substantial. As a result, while word vectors can capture certain semantic patterns, they often fail to align with human intuition, leading to a loss of interpretive clarity.
3.3. Distances and Risks in Positioning
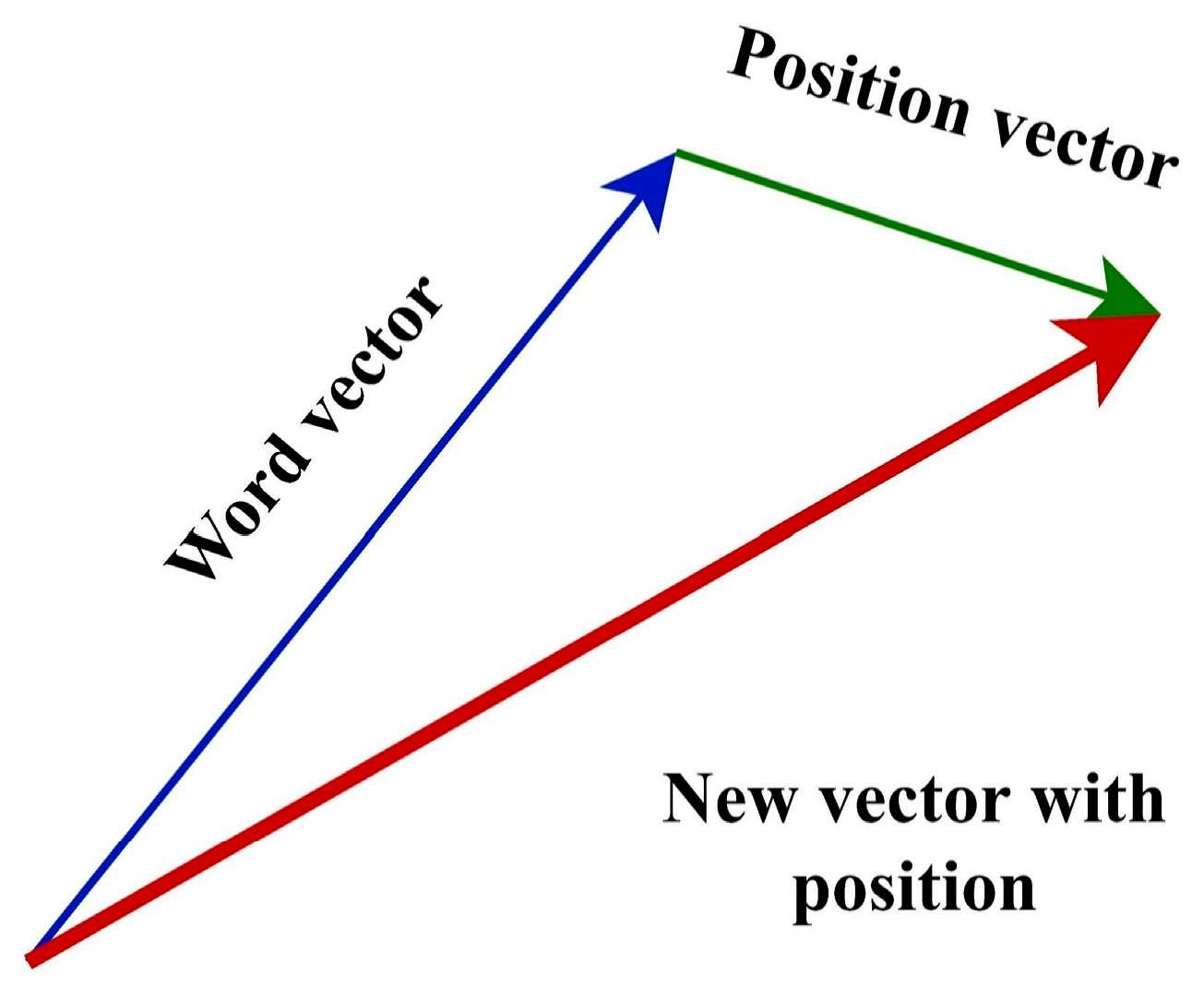
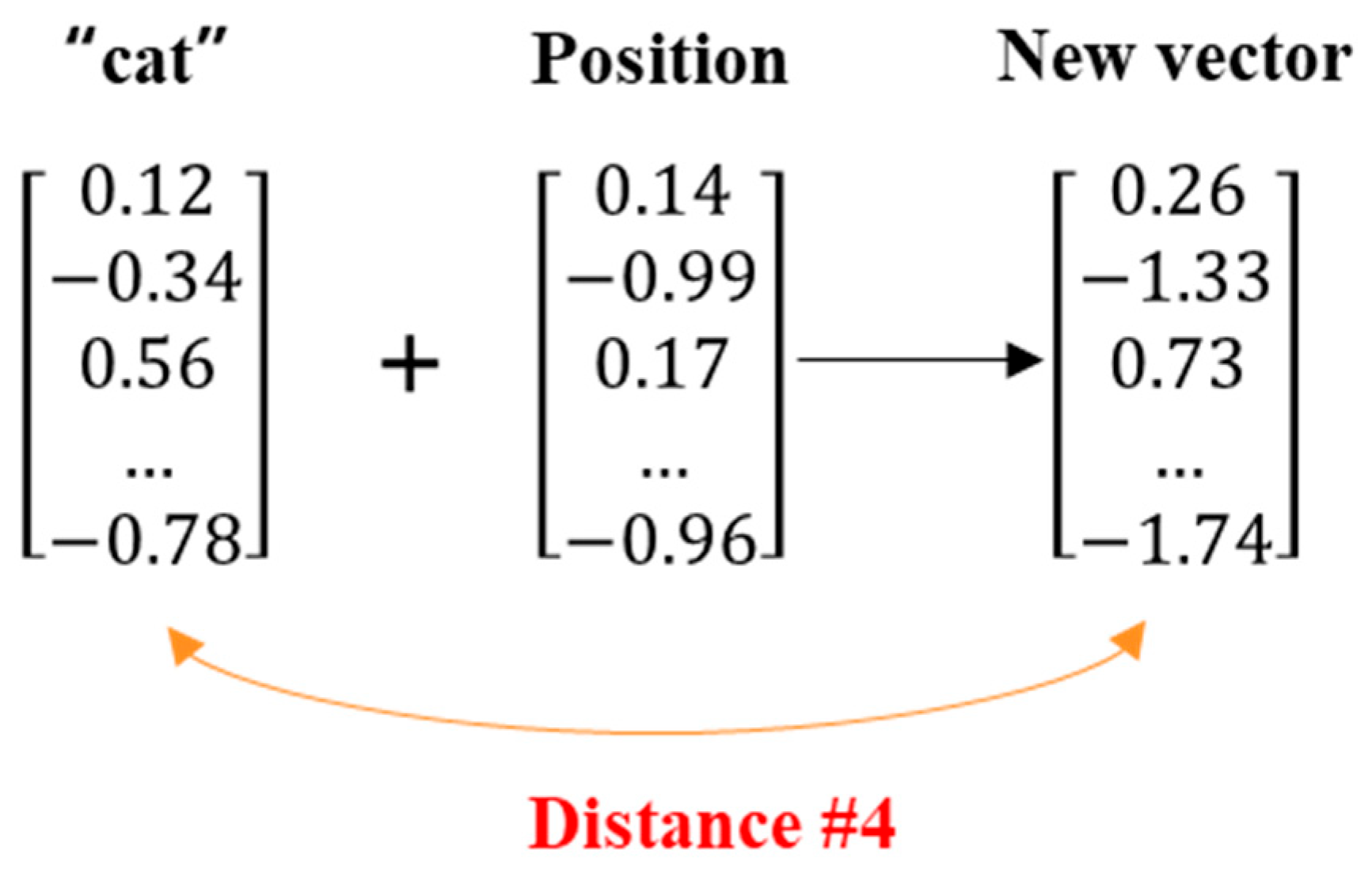
As described above, each input word is represented by a vector that captures the semantic meaning of the word based on its context in the training data. However, since the Transformer processes all input tokens in parallel, it cannot inherently understand the sequential order of these tokens. To address this, the Transformer adds a position vector to each word vector. The word vector and the position vector are combined (typically by element-wise addition) to produce a new vector that represents the semantic meaning of the word and its position in the sentence (
Figure 9).
According to the principles of vector addition, the resulting vector differs notably from the original position vector (
Figure 10), indicating a semantic shift. Given the absence of significant numerical similarity, the new vector likely corresponds to a different word. Distance metrics such as Euclidean distance, Manhattan distance, and cosine similarity further quantify this divergence, highlighting the presence of a measurable gap between the two vectors.
This gap between true and processed information underscores the nuanced balance required in data preprocessing, where decisions must be made judiciously to optimize model performance while mitigating the risk of information loss. Thus, most transformations, such as positioning, are a kind of manipulation. Therefore, it is crucial to carefully consider the trade-offs and potential implications of each transformation step.
3.4. Distances and Risks in Attention
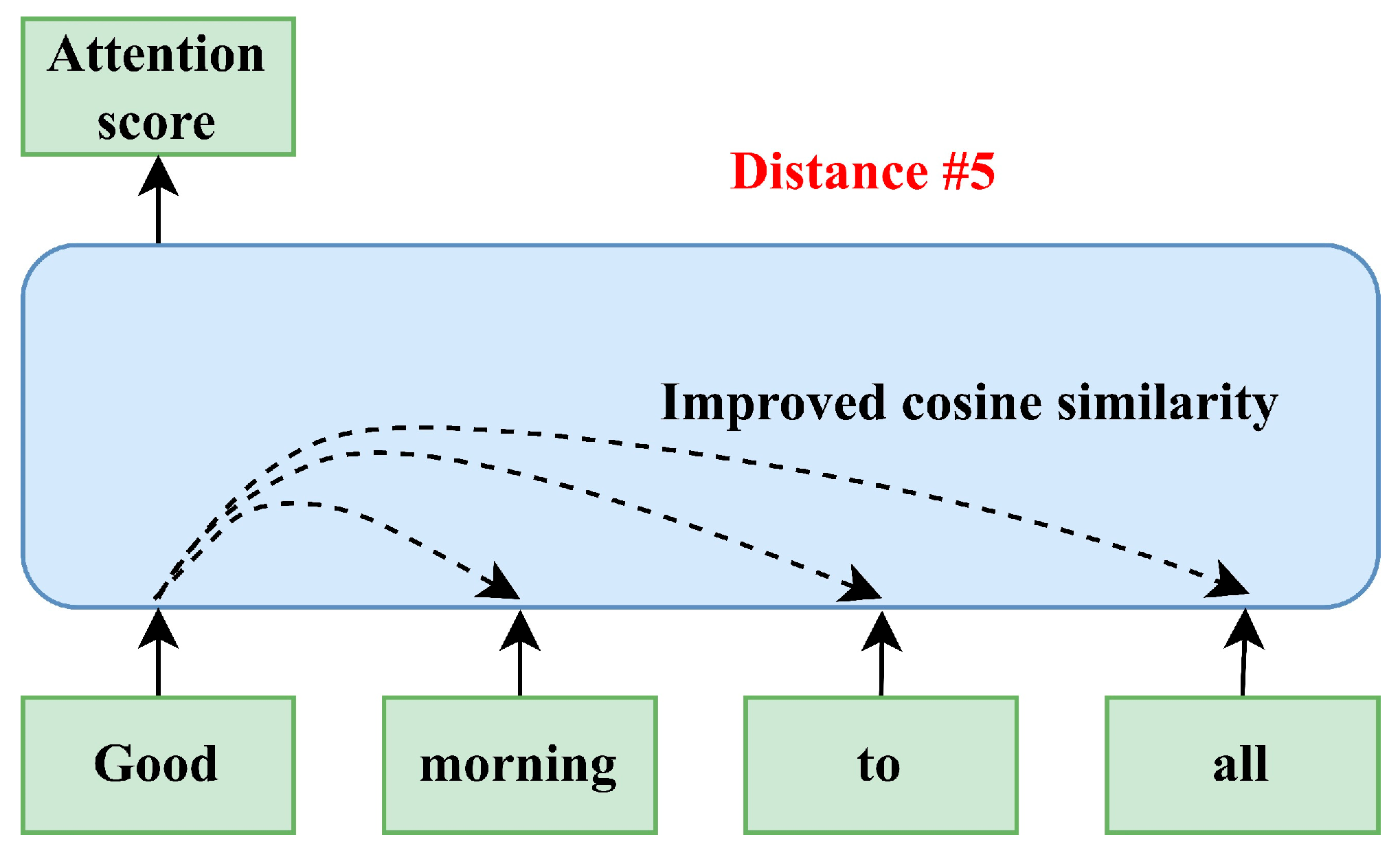
Beyond the incorporation of positional information, the distribution of attention across words in a sequence plays a critical role in capturing contextual dependencies. The self-attention mechanism addresses this requirement by computing attention scores that quantify the relational importance between each word and all others in the sequence. These scores are used to generate context-aware representations, enabling the model to dynamically weigh the influence of different tokens based on their relevance to a given word. As illustrated in
Figure 11, the attention score functions as a similarity measure, allowing the model to align and integrate semantic information across the input sequence.
Initially, each word or token is mapped into three distinct vectors—query (
), key (
), and value (
)—through learned linear transformations of the input embeddings. These vectors are then used within the self-attention mechanism to compute attention scores that govern how much focus the model allocates to each token in the sequence. As shown in
Figure 12, the formulation of the attention score can be interpreted as a modified version of cosine similarity, capturing the angular relationship between query and key vectors. This score serves as a proxy for semantic relatedness: smaller distances (i.e., higher similarity) indicate stronger contextual relevance between tokens, while larger distances reflect weaker associations.
However, cosine similarity may not be the true measurement of human attention. The attention mechanism represents a significant simplification when compared to the multifaceted nature of human attention processes. Typically implemented through methods such as dot-product attention in Transformer models, fundamentally relies on static, predefined mathematical rules that govern the interaction between elements of input data. This process, while efficient, cannot inherently incorporate the nuanced, context-dependent variability that characterizes human attention. The foundational differences in how attention is modeled create a discernible gap between artificial and human cognitive processes. Such a representation should be approached with heightened scrutiny and methodological caution.
3.5. Distances and Risks in Optimization
Optimization in the Transformer involves adjusting the model’s parameters to minimize the loss function, typically cross-entropy, during pre-training and fine-tuning phases. Cross-entropy quantifies the difference between predicted and target probability distributions. In cognitive terms, this reflects the expectation gap between what a human anticipates and what the AI system produces. This measure translates abstract computational operations into approximations of cognitive mismatch or divergence. This process is critical for enhancing the model’s ability to generate coherent and contextually appropriate text. Cross-entropy specifically measures the discrepancy between the predicted probability distribution of the potential answers and the human-expected answer (
Figure 13). However, this mathematical approach to modeling loss introduces a conceptual gap between the model’s simplifications and the complex reality of human language understanding. This loss is also a distance.
Moreover, the use of common loss functions such as Mean Absolute Error (MAE), Mean Squared Error (MSE), and cross-entropy in optimization represents various methods of calculating distance. These metrics quantify the divergence between the model’s predictions and the manually labeled real-world data, essentially measuring the gap between the constructed model and reality. It is critical to recognize that there will always be some level of discrepancy between any model and the intricate dynamics of real-world phenomena.
Minimizing this gap through optimization poses its own set of challenges and risks. The relentless pursuit of minimizing these loss metrics can sometimes lead to unintended consequences. For instance, overfitting a model to reduce loss on training data can degrade its ability to generalize to new, unseen data. Such a focus might achieve lower numerical values in loss functions yet fail to capture the true essence and variability of human language. In addition, this is also similar to the adversarial attack on image recognition. This difference underscores the limitations of current AI systems, which rely on numerical assessments that may not fully capture the nuanced ways humans process and respond to information.
4. Case Study
To contextualize the theoretical findings and demonstrate their practical implications, this section presents a case study involving fall-prevention guidance in the construction domain. Before detailing the specific experimental procedures and outcomes, we first summarize the key results from
Section 3 in a comparative format.
Table 2 links each Transformer architectural component to its corresponding distance metric, describes the nature of divergence it introduces, and identifies the associated cognitive or operational risk. Six types of distance were discussed previously. For clarity and ease of presentation, four of these were selected and simulated during the case study. This consolidated view helps illustrate how internal model mechanisms can propagate measurable semantic shifts that may compromise human–AI collaboration in safety-critical applications. Therefore, the substantial divergence observed in the final outputs perceived by humans is the cumulative effect of underlying architectural distances within the model.
This table serves as a bridge between internal computational abstractions and external safety concerns, reinforcing our central argument: architectural design choices within generative AI systems can introduce quantifiable semantic distances that manifest as real-world cognitive and operational risks. The following case study applies this framework to a real-world scenario, empirically examining each architectural distance using comparative outputs from ChatGPT.
4.1. Experiment
As is known, falls from heights are one of the major hazards in construction [
32,
33]. Therefore, this experiment focuses on the responses on how to prevent falls. The initial intent of this study was to pose the question, “
How do you prevent falls when working at heights?” to both a human and ChatGPT, subsequently calculating the distances between their responses to elucidate the potential risks associated with such distances.
The experiment was conducted on 19 April 2025, in the ChatGPT 4o. First, we asked ChatGPT the question, and it answered as shown in
Figure 14.
On the other hand, in light of ethical considerations concerning the involvement of construction workers, the research instead opted to employ ChatGPT for simulating dialogues between humans. The outcomes of these simulated conversations are depicted in
Figure 15.
The two answers are defined as “text 1” and “text 2”. We code the programs in Python 3-based Jupyter Notebook 7 to examine the distances introduced by vectorization, positioning, attention, and optimization.
4.2. Vectorization Distance
We coded the program as shown in
Figure 16. The test steps are: Use the TF-IDF vectorization method to convert the texts into vectors; calculate the cosine similarity between the vectors of text 1 and text 2.
In the responses provided, they both mention personal protective equipment (PPE), training, planning, and inspection, primarily focusing on the preparatory work required before working at heights. However, there is still a significant distance between the two answers (0.57).
4.3. Positioning Distance
We continue to use TF-IDF to generate the vector of text 1 without positioning encoding. Subsequently, we use a Transformer-based BERT model to generate the vector of text 1 with positioning information. Then we calculate the cosine similarity of the two vectors and the distance as
Notably, this comparison highlights the impact of positional encoding. TF-IDF is a frequency-based, position-independent method, while BERT generates contextualized embeddings that incorporate both semantics and token position. By comparing their outputs for the same text, we quantify the “positioning distance” introduced by Transformer-based positional encoding. The substantial distance between the two vectors indicates that when a piece of text is transformed into a vector, and a new vector is subsequently created by incorporating positional information, the resulting vectors are significantly different. This suggests that the new vector may encapsulate entirely new textual information.
4.4. Attention Distance
We coded a program to calculate the attention score of each word in text 1 and ranked the top 20 as shown in
Table 3.
The attention score analysis indicates that the model disproportionately highlights non-salient tokens—chiefly the term “workers” and assorted punctuation—rather than the conceptually critical phrases. Even when the scope is broadened to the 20 highest-scoring tokens, words such as “supervision”, “fall”, “work”, and “heights” still fail to capture the passage’s central safety themes of personal protective equipment, training, and inspection. This pattern suggests that ChatGPT produces verbose output with diluted topical focus, making it difficult for users to identify essential information and potentially undermining safety-critical comprehension.
4.5. Optimization Distance
Upon querying ChatGPT an additional five times, it produced five distinct responses. We computed the cosine similarity and distance between the initial response and these subsequent answers, as shown in
Table 4.
The results reveal a progressively decreasing similarity and an increasing distance. This phenomenon elucidates why, upon not receiving a satisfactory answer initially and reposting the question to ChatGPT, the model continues to fail to provide a satisfactory response, with the quality of answers deteriorating further with each attempt.
The reason for querying ChatGPT multiple times using the same question was to assess semantic consistency and output stability—two critical aspects in safety-critical applications. Despite identical prompts, each response diverged significantly, with cosine similarity dropping from 0.40 to 0.10 across iterations. This drift illustrates what we term “optimization distance”, reflecting how internal probabilistic sampling and training dynamics can lead to response inconsistency. Such variability poses a real-world risk when users depend on AI-generated advice that may shift unpredictably with each interaction.
5. Discussion
5.1. Significance by Extending Prior Work
The results of this study emphasize the nuanced risks that arise from human-generative AI interactions. The research has identified specific gaps where AI’s processing diverges significantly from human cognitive and perceptual processes, measured by distances, leading to potential risks that could impact both the effectiveness and trustworthiness of AI systems.
Our “distance” diagnostics complement—rather than replicate—earlier, mainly qualitative, observations. Studies on embedding bias reveal that word vectors can entrench stereotypes, while we extend that line by showing how vectorization distance (0.57 in our case study) directly erodes interpretability in fall-prevention advice, a link previously unquantified. Work on positional encodings reports accuracy drops when encodings are poorly initialized; our positioning distance metric (0.86) translates that abstract degradation into a tangible shift in semantic focus, demonstrating how the same advisory sentence is re-interpreted once positional vectors are injected. Attention-centric papers treat attention maps as explanatory artefacts; we show that attention misalignment manifests numerically (top 20 tokens dominated by punctuation), and it fails to accurately identify or prioritize the specific words that humans consider most important for understanding, confirming that dot-product similarity is a poor proxy for human salience in safety narratives. Finally, optimization-drift research has uncovered response variability across prompts. By measuring a monotonic decline in cosine similarity—from 0.40 to 0.10 across six queries—we quantify that drift as an “optimization distance” and tie it to a practical usability risk: declining answer quality under repeated questioning.
Thus, these comparisons illustrate that previous studies describe what can go wrong (biased embeddings, unstable attention, prompt drift) in isolation, whereas our framework pinpoints where the misalignment originates inside the Transformer stack and how large each gap is. This layered, numerical perspective can guide targeted mitigations, e.g., embedding-space regularization, learnable relative position encodings, or drift-aware optimization schedules, thereby advancing the safety discourse from symptom reporting to architectural remedy.
5.2. Broader Risk Dimensions
Beyond the architectural distances quantified in this study, several broader dimensions of risk deserve attention for a more comprehensive understanding of human–AI misalignment. These dimensions, though not measured directly, represent critical factors that influence the safe and effective deployment of generative AI systems in real-world environments.
First, the contextual sensitivity of AI systems plays a pivotal role in shaping risk outcomes. The nature and magnitude of risk vary considerably across application domains. For instance, AI deployed in construction, healthcare, process industries, or autonomous vehicles operates under high safety and reliability demands, where even minor misinterpretations can lead to serious consequences. In contrast, applications in customer service or entertainment contexts may tolerate greater variability. These differences highlight the importance of tailoring AI outputs to scenario-specific expectations, ensuring that model behavior aligns with both domain knowledge and user mental models.
Another concern lies in the misuse and misinterpretation of AI-generated outputs. When responses lack clear contextual grounding or indicators of reliability, users may over-trust or misapply the information provided. This risk is especially acute in high-stakes environments where AI outputs might influence critical decision-making. Incorporating mechanisms such as confidence scores, disclaimers, or usage context annotations could help users better understand the intended scope and limitations of the responses, thereby reducing the likelihood of misapplication.
The distinction between human and AI error handling further complicates these interactions. While human errors often stem from cognitive limitations such as fatigue or distraction, AI errors typically arise from architectural factors, training biases, or probabilistic response generation. Generative models like GPT may produce responses that are syntactically and semantically plausible yet contextually inappropriate. To mitigate these risks, future systems should incorporate dynamic feedback loops, error detection protocols, and human-in-the-loop oversight to adaptively correct or flag questionable outputs in real time.
Finally, it is important to consider how users perceive reliability in AI-generated outputs. Generative models tend to produce clustered responses that are semantically similar across repeated prompts. This consistency may give the illusion of reliability, leading users to underestimate the risk of divergence from human reasoning. However, as shown in our analysis, even these clustered outputs can harbor meaningful semantic gaps. Recognizing and communicating this phenomenon is essential for appropriate trust calibration and for preventing overreliance on superficially stable but architecturally misaligned responses.
5.3. Risk Mitigation and Design Recommendations
To effectively mitigate the architectural risks identified in this study, both technical refinements within AI models and broader design strategies are necessary. These efforts aim to reduce semantic divergence, improve interpretability, and ensure safer deployment of generative AI in high-stakes contexts.
At the architectural level, several model enhancements show promise. Embedding-space regularization can help maintain semantic consistency by constraining vector representations to align more closely with human conceptual structures. This can reduce unintended drift and improve output coherence. Similarly, implementing learnable relative positional encodings allows the model to dynamically adjust how it encodes token order and contextual relationships, offering a more flexible and linguistically grounded alternative to static position vectors. Additionally, drift-aware optimization schedules—which incorporate task-specific consistency metrics or user feedback—can help stabilize AI responses across repeated queries, an important factor in safety-critical applications where output variability may erode user trust.
In industrial applications, where operational safety is paramount, technical improvements alone are insufficient. It is essential to embed generative AI systems within existing fail-safe mechanisms. These include physical safeguards such as safety interlocks, intrinsic safety systems, and hardware-based fail-safes. While the adoption of AI in process industries, construction, and manufacturing continues to grow, these traditional safety barriers must remain in place to prevent AI-driven errors from escalating into real-world hazards. They serve as a final line of defense and should be viewed as complementary, rather than redundant, to AI design improvements.
Furthermore, the identification of architectural distances points to several human-centered design strategies essential for improving the usability and safety of generative AI systems in high-stakes environments. A key priority is trust calibration [
34,
35], ensuring that users neither over-trust nor under-trust AI outputs by embedding interface cues that communicate uncertainty and output variability. Closely related is the need for greater explainability: making internal processes more transparent through visual or textual indicators such as attention heatmaps, semantic similarity scores, or drift alerts can help users assess whether the AI’s reasoning aligns with human expectations [
36,
37]. These cues support human-in-the-loop design [
38,
39], where operators are empowered to intervene when misalignment occurs [
40]. In addition, incorporating adaptive feedback loops, enabling users to clarify intent, provide corrections, or reprioritize focus, can further reduce cognitive risks and enhance system reliability.
6. Conclusions
This study introduced the concept of architectural distance to describe and quantify semantic and interpretive divergences between human reasoning and generative AI outputs. By tracing these divergences to the fundamental components of the Transformer architecture—vectorization, positional encoding, attention mechanisms, and optimization—we proposed a systematic framework to identify where and how misalignment arises within LLMs. Using distance metrics such as cosine similarity and cross-entropy, we moved beyond anecdotal descriptions toward empirical quantification of these cognitive and operational gaps. As a result, six types of architectural distances are identified and evaluated for cognitive and operational risks.
Our case study demonstrated that even in routine, safety-relevant tasks—such as generating fall-prevention guidance—substantial architectural distances can emerge, degrading interpretability, semantic focus, and response consistency. Unlike prior research that addresses AI failures in isolation (e.g., biased embeddings, prompt drift, or attention instability), this work offers a layered, integrated perspective that links specific architectural features to real-world risks.
However, several limitations must be acknowledged. First, the study used a single LLM (ChatGPT) to simulate both AI and human responses, which may limit ecological validity. Due to the ethical concerns in safety scenarios, no actual human participant data were used, and thus the architectural distances reflect divergence from human-like expectations rather than empirically validated human cognition. Second, our distance metrics, while useful for quantifying divergence, may not fully capture the nuances of meaning, context, or user perception. Third, the experimental scope was limited to one case study scenario in the domain of occupational safety. Generalizability to other high-risk domains (e.g., medicine, finance, autonomous systems) requires further investigation.
Future research can address these limitations in several ways. Comparative studies across multiple LLMs and model families platforms (e.g., Claude, Gemini, Llama) would help validate whether architectural distances are model-specific or systemic. Incorporating human-in-the-loop evaluations and cognitive benchmarking can provide richer insight into how these distances affect user comprehension, trust, and decision-making. Additionally, longitudinal testing, examining how architectural distances evolve across model updates, may uncover stability trends and risks associated with continual optimization. Finally, further development of adaptive safety architectures that fuse generative AI with symbolic reasoning, sensor feedback, or embedded fail-safes may offer a more robust solution to the risks posed by architectural misalignment.
Author Contributions
Conceptualization, H.W. and P.H.; methodology, H.W.; software, H.W.; validation, H.W. and P.H.; formal analysis, H.W.; investigation, H.W.; resources, H.W. and P.H.; data curation, H.W.; writing—original draft preparation, H.W.; writing—review and editing, P.H.; visualization, H.W.; supervision, H.W.; project administration, H.W.; funding acquisition, H.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Sciences and Engineering Research Council of Canada (NSERC) of the Alliance Grant- Federated Platform for Construction Simulation (572086-22) during the first author’s postdoctoral employment at the University of Alberta.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Some or all data, models, or code that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The first author gratefully acknowledges the guidance of Simaan AbouRizk at the University of Alberta during his postdoctoral research and the initial stage of this work. The authors sincerely thank technical writer Kohlbey Ozipko for her support in preparing this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nazir, A.; Wang, Z. A comprehensive survey of ChatGPT: Advancements, applications, prospects, and challenges. Meta-Radiology 2023, 1, 100022. [Google Scholar] [CrossRef] [PubMed]
- Brynjolfsson, E.; Li, D.; Raymond, L. Generative AI at Work. Q. J. Econ. 2025, 140, 889–942. [Google Scholar] [CrossRef]
- Zuccon, G.; Koopman, B.; Shaik, R. ChatGPT Hallucinates when Attributing Answer. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, Beijing, China, 26–28 November 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 46–51. [Google Scholar] [CrossRef]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Oviedo-Trespalacios, O.; Peden, A.E.; Cole-Hunter, T.; Costantini, A.; Haghani, M.; Rod, J.E.; Kelly, S.; Torkamaan, H.; Tariq, A.; Newton, J.D.A.; et al. The risks of using ChatGPT to obtain common safety-related information and advice. Saf. Sci. 2023, 167, 106244. [Google Scholar] [CrossRef]
- Adelson, E.H. Lightness Perception and Lightness Illusions. In The New Cognitive Neurosciences, 2nd ed.; Gazzaniga, M.S., Ed.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples, CoRR abs/1412.6572. 2014. Available online: https://api.semanticscholar.org/CorpusID:6706414 (accessed on 4 May 2025).
- Adams, F. Aizawa. The bounds of cognition. Philos. Psychol. 2001, 14, 43–64. [Google Scholar] [CrossRef]
- Pearl, J. Causality, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for explainable AI: Challenges and prospects. arXiv 2018, arXiv:1812.04608. [Google Scholar]
- Wen, H.; Amin, M.T.; Khan, F.; Ahmed, S.; Imtiaz, S.; Pistikopoulos, S. A methodology to assess human-automated system conflict from safety perspective. Comput. Chem. Eng. 2022, 165, 107939. [Google Scholar] [CrossRef]
- Arunthavanathan, R.; Sajid, Z.; Khan, F.; Pistikopoulos, E. Artificial intelligence—Human intelligence conflict and its impact on process system safety. Digit. Chem. Eng. 2024, 11, 100151. [Google Scholar] [CrossRef]
- Wen, H.; Amin, M.D.T.; Khan, F.; Ahmed, S.; Imtiaz, S.; Pistikopoulos, E. Assessment of Situation Awareness Conflict Risk between Human and AI in Process System Operation. Ind. Eng. Chem. Res. 2023, 62, 4028–4038. [Google Scholar] [CrossRef] [PubMed]
- Grossman, L. 2045: The year man becomes immortal. Time 2011, 177, 1. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big. In FAccT 2021, Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; USA Association for Computing Machinery, Inc.: New York, NY, USA, 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Amaro, I.; Barra, P.; Greca, A.D.; Francese, R.; Tucci, C. Believe in Artificial Intelligence? A User Study on the ChatGPT’s Fake Information Impact. IEEE Trans. Comput. Soc. Syst. 2024, 11, 5168–5177. [Google Scholar] [CrossRef]
- Guo, Y.; Guo, M.; Su, J.; Yang, Z.; Zhu, M.; Li, H.; Qiu, M.; Liu, S.S. Bias in large language models: Origin, evaluation, and mitigation. arXiv 2024, arXiv:2411.10915. [Google Scholar]
- Irani, H.; Metsis, V. Positional encoding in transformer-based time series models: A survey. arXiv 2025, arXiv:2502.12370. [Google Scholar]
- Wu, C.; Wu, F.; Huang, Y. DA-Transformer: Distance-aware Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Online, 6–11 June 2021; pp. 2059–2068. [Google Scholar] [CrossRef]
- Abdelnabi, S.; Fay, A.; Cherubin, G.; Salem, A.; Fritz, M.; Paverd, A. Are you still on track!? Catching LLM Task Drift with Activations. arXiv 2024, arXiv:2406.00799. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Jones, K.S. Natural Language Processing: A Historical Review. In Current Issues in Computational Linguistics: In Honour of Don Walker; Zampolli, A., Calzolari, N., Palmer, M., Eds.; Springer: Dordrecht, The Netherlands, 1994; pp. 3–16. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khan, S.K.; Prasad, M. A Comprehensive Survey on Word Representation Models: From Classical to State-of-the-Art Word Representation Language Models. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–35. [Google Scholar] [CrossRef]
- Patil, R.; Boit, S.; Gudivada, V.; Nandigam, J. A Survey of Text Representation and Embedding Techniques in NLP. IEEE Access 2023, 11, 36120–36146. [Google Scholar] [CrossRef]
- Dhar, A.; Mukherjee, H.; Dash, N.S.; Roy, K. Text categorization: Past and present. Artif. Intell. Rev. 2021, 54, 3007–3054. [Google Scholar] [CrossRef]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.-L.; Tang, Y. A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Nguyen, L.D.; Tran, D.Q.; Chandrawinata, M.P. Predicting Safety Risk of Working at Heights Using Bayesian Networks. J. Constr. Eng. Manag. 2016, 142, 04016041. [Google Scholar] [CrossRef]
- Nadhim, E.A.; Hon, C.; Xia, B.; Stewart, I.; Fang, D. Falls from Height in the Construction Industry: A Critical Review of the Scientific Literature. Int. J. Environ. Res. Public Health 2016, 13, 638. [Google Scholar] [CrossRef]
- Gebru, B.; Zeleke, L.; Blankson, D.; Nabil, M.; Nateghi, S.; Homaifar, A.; Tunstel, E. A Review on Human–Machine Trust Evaluation: Human-Centric and Machine-Centric Perspectives. IEEE Trans. Hum. Mach. Syst. 2022, 52, 952–962. [Google Scholar] [CrossRef]
- Wischnewski, M.; Krämer, N.; Müller, E. Measuring and Understanding Trust Calibrations for Automated Systems: A Survey of the State-Of-The-Art and Future Directions. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023. [Google Scholar] [CrossRef]
- Lopez-Gazpio, I.; Maritxalar, M.; Gonzalez-Agirre, A.; Rigau, G.; Uria, L.; Agirre, E. Interpretable semantic textual similarity: Finding and explaining differences between sentences. Knowl. Based Syst. 2017, 119, 186–199. [Google Scholar] [CrossRef]
- Vig, J. A multiscale visualization of attention in the transformer model. arXiv 2019, arXiv:1906.05714. [Google Scholar]
- Mosqueira-Rey, E.; Hernández-Pereira, E.; Alonso-Ríos, D.; Bobes-Bascarán, J.; Fernández-Leal, Á. Human-in-the-loop machine learning: A state of the art. Artif. Intell. Rev. 2023, 56, 3005–3054. [Google Scholar] [CrossRef]
- Drori, I.; Te’eni, D. Human-in-the-Loop AI Reviewing: Feasibility, Opportunities, and Risks. J. Assoc. Inf. Syst. 2024, 25, 98–109. [Google Scholar] [CrossRef]
- Wen, H. Chapter Two—Human-AI collaboration for enhanced safety. In Method of Process Systems in Energy Systems: Current System Part 1; Khan, F.I., Pistikopoulos, E.N., Sajid, Z., Eds.; Elsevier: Amsterdam, The Netherlands, 2024; pp. 51–80. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}