
High-Performance and Lightweight AI Model with Integrated Self-Attention Layers for Soybean Pod Number Estimation


Abstract
1. Introduction
- (1)
- Development of a set of lightweight AI models for soybean pod estimation: This research introduces a set of AI models that combines CNNs and transformer mechanisms. CNNs effectively capture spatial features such as texture and structure from soybean field images, while self-attention mechanisms capture long-range dependencies and global context. This hybrid feature is good at accurate estimation of soybean pod density in complex backgrounds with varying lighting conditions and nearby environments with fallen leaves, soil clumps, and withered weeds.
- (2)
- Weight quantization of our lightweight AI models: In order to make AI models accessible to farmers in rural areas with limited computational resources, this research demonstrates the use of weight quantization techniques to reduce the memory footprint and computational overhead. The quantized models retain high accuracy while being optimized to run efficiently on edge devices.
- (3)
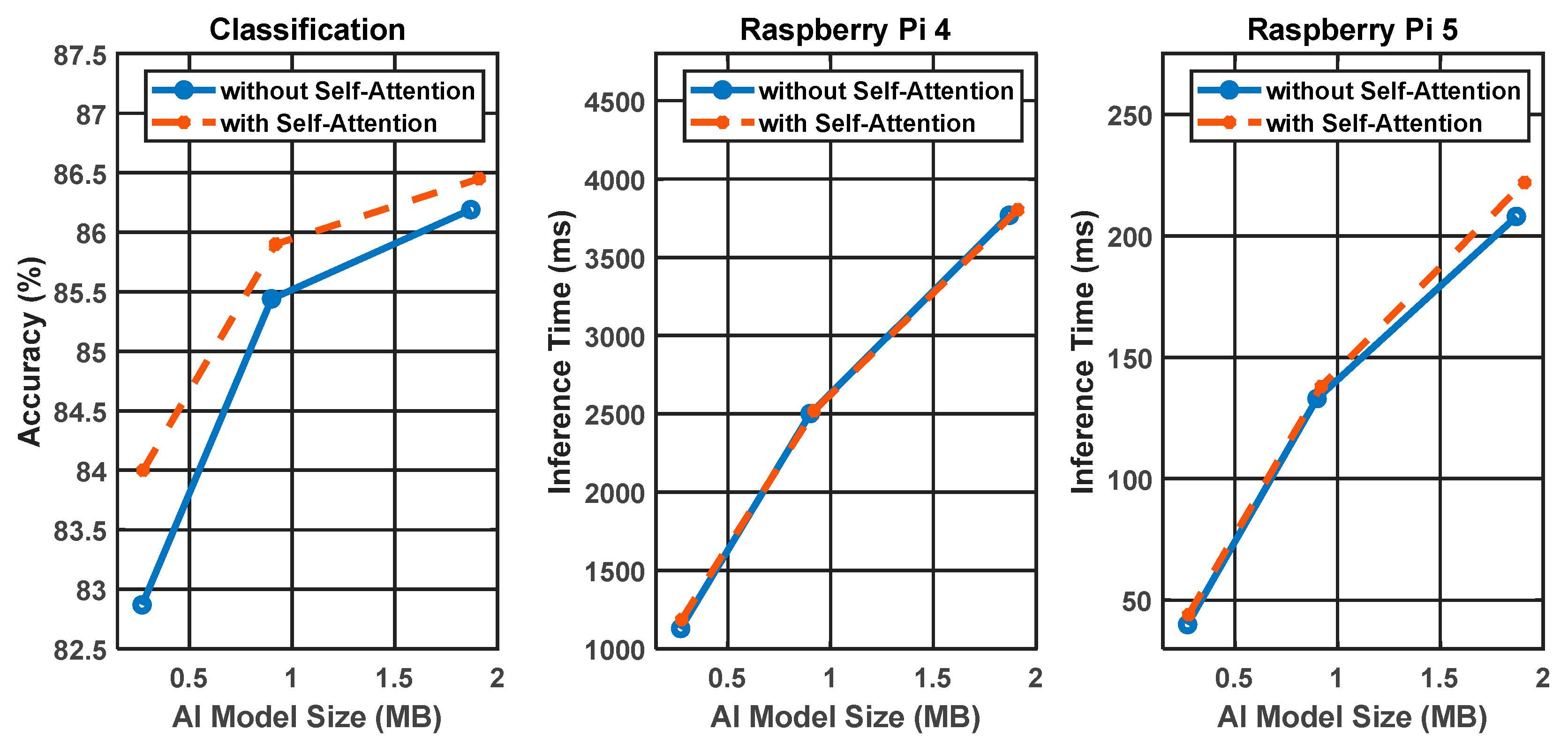
- Evaluation of the proposed model performance on Raspberry Pi 4 and 5: The research also evaluates our model performance on edge devices with the Edge Impulse platform, which is a leading online platform for edge AI evaluation [16]. The evaluation results show that the inference speed is only 0.26–0.89 frames per second in Raspberry Pi 4 and 4.5–25 frames per second in Raspberry Pi 5, which depends on the variant of our proposed models. In addition, their memory footprints range from 0.27 MB to 1.91 MB, leaving ample space within each Raspberry Pi’s memory for the operating system, camera services, and image preprocessing.
2. Related Work
3. Proposed AI Design and Evaluation
3.1. Design Considerations
3.2. Dataset Construction and Preprocessing
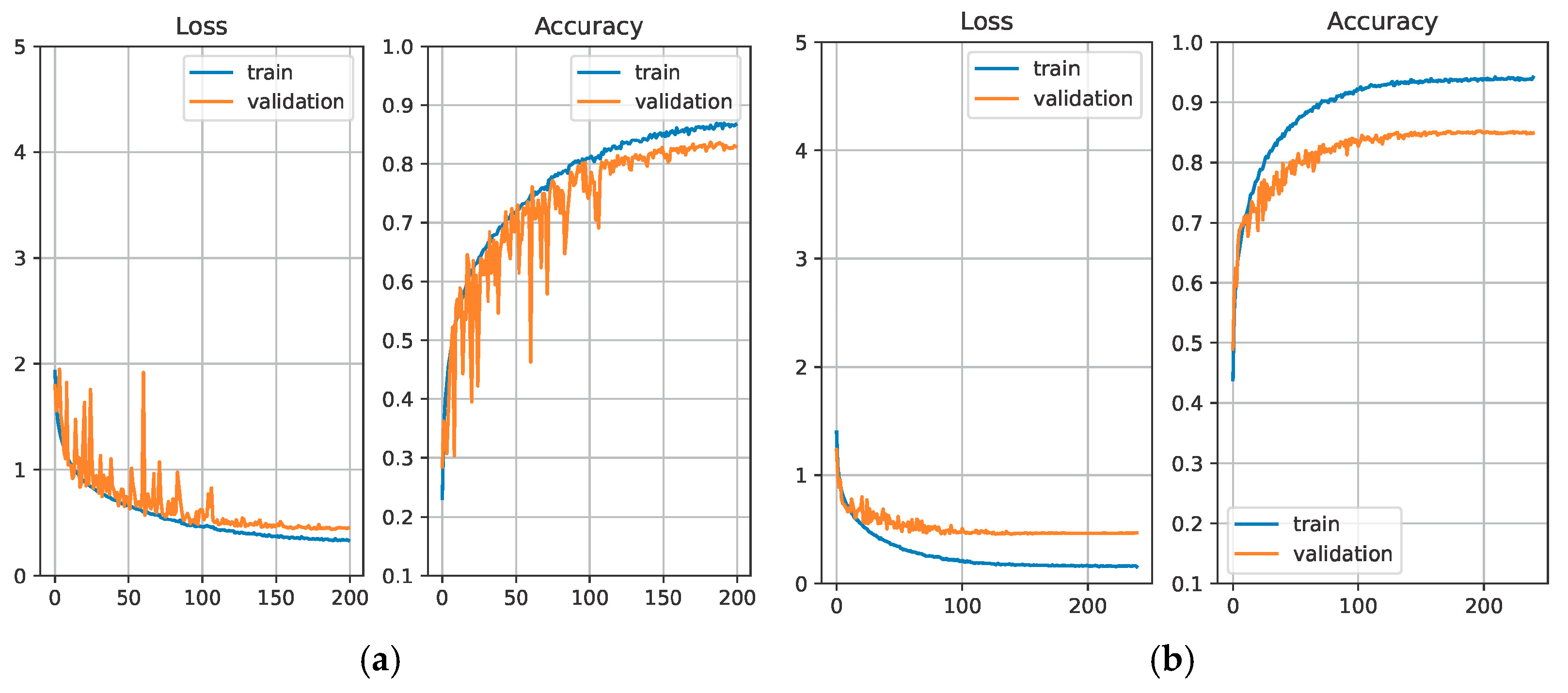
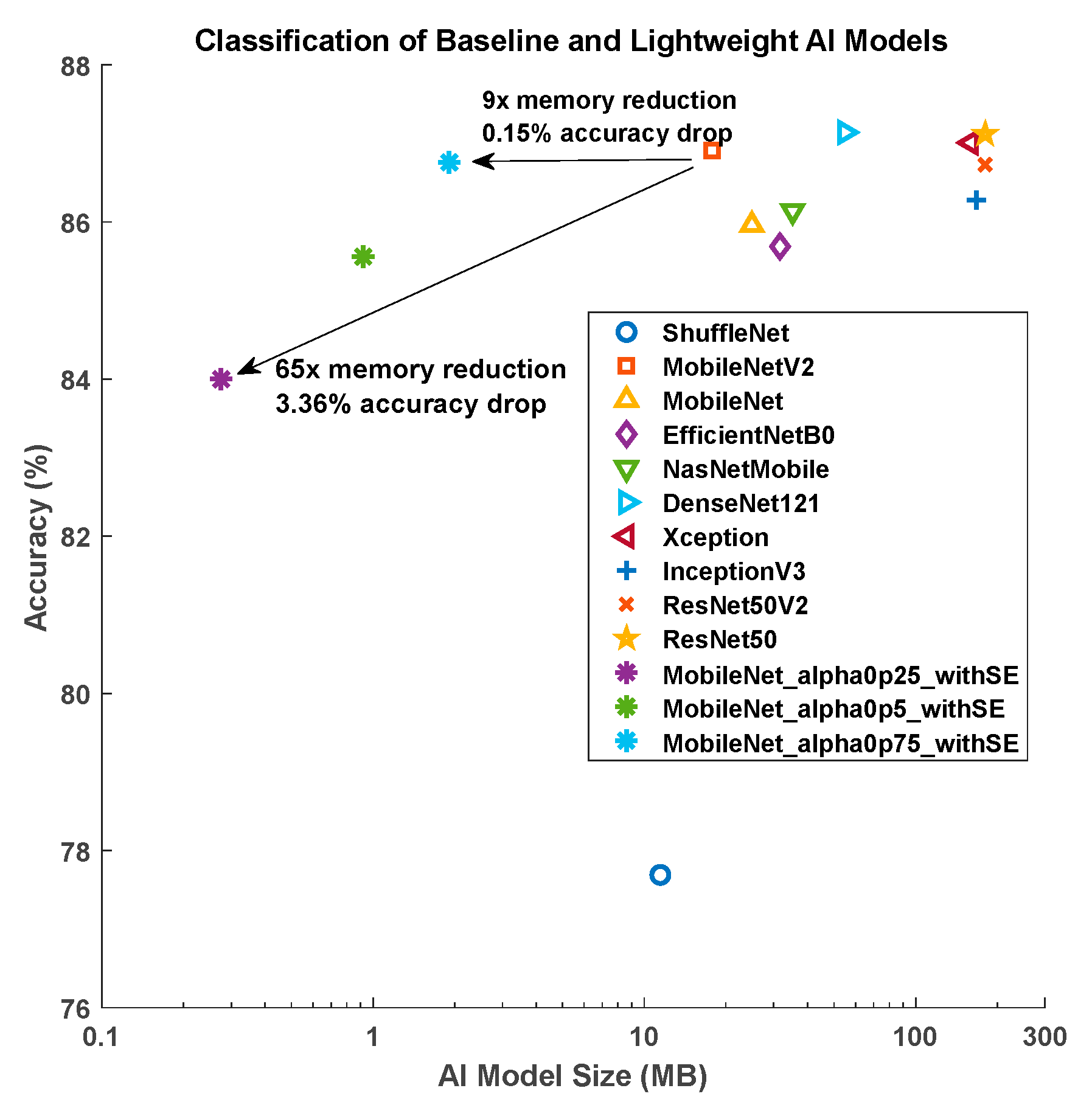
3.3. Baseline AI Model Performance
3.4. Baseline AI Models with Simplification
3.5. AI Models with Integrated Self-Attention Layers
3.6. Simplified Baseline AI Models with Weight Quantization
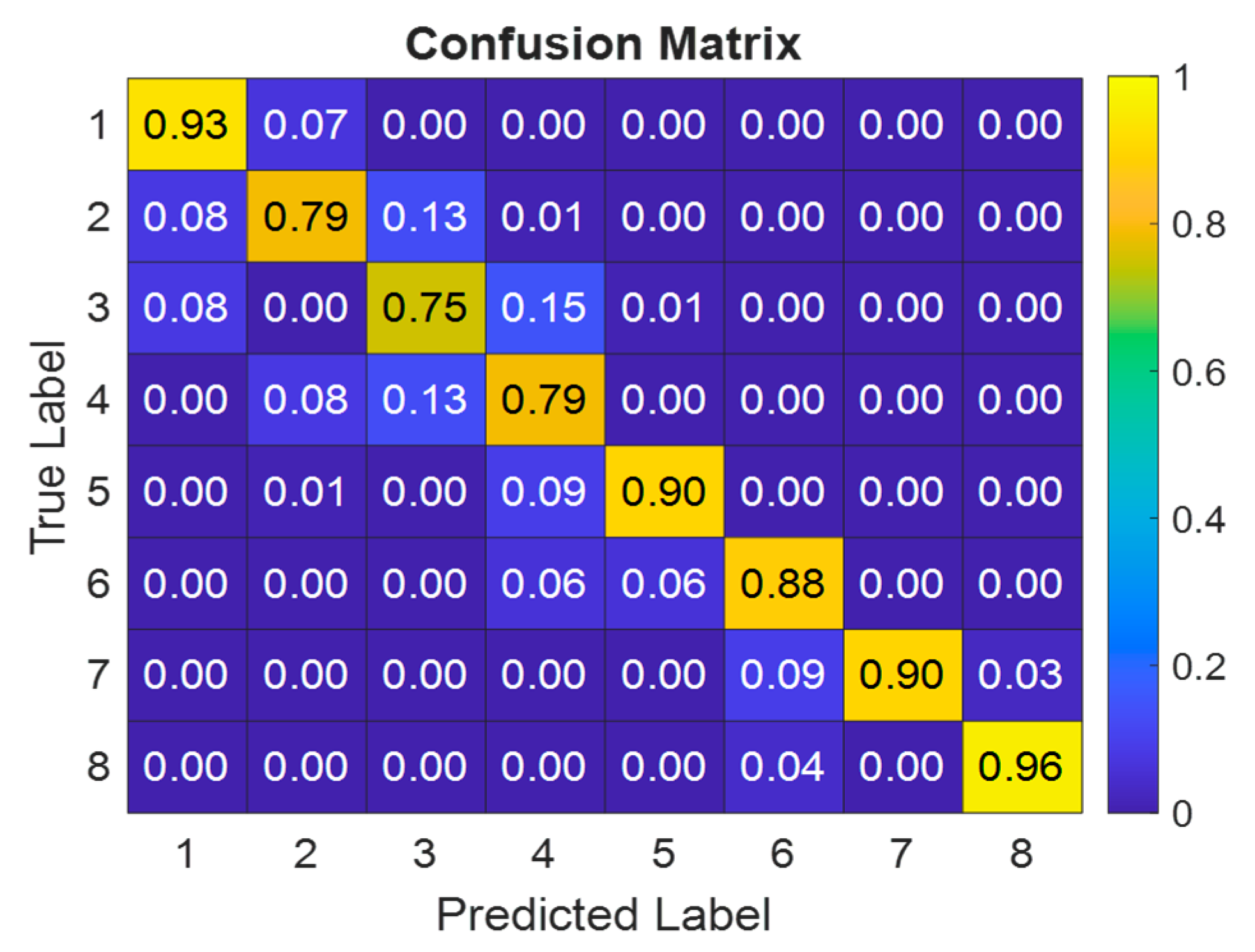
4. Results and Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Medic, J.; Atkinson, C.; Hurburgh, C.R. Current knowledge in soybean composition. J. Am. Oil Chem. Soc. 2014, 91, 363–384. [Google Scholar] [CrossRef]
- He, H.; Ma, X.; Guan, H.; Wang, F.; Shen, P. Recognition of soybean pods and yield prediction based on improved deep learning model. Front. Plant Sci. 2023, 13, 1096619. [Google Scholar] [CrossRef]
- Zhang, C.; Kovacs, J.M. The application of small unmanned aerial systems for precision agriculture: A review. Precis. Agric. 2012, 13, 693–712. [Google Scholar] [CrossRef]
- Hu, C.; Sapkota, B.B.; Thomasson, J.A.; Bagavathiannan, M.V. Influence of image quality and light consistency on the performance of convolutional neural networks for weed mapping. Remote Sens. 2021, 13, 2140. [Google Scholar] [CrossRef]
- Gao, J.; French, A.P.; Pound, M.P.; He, Y.; Pridmore, T.P.; Pieters, J.G. Deep convolutional neural networks for image-based Convolvulus sepium detection in sugar beet fields. Plant Methods 2020, 16, 29. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, J.; Magar, R.T.; Chen, D.; Lin, F.; Wang, D.; Yin, X.; Zhuang, W.; Li, Z. SoybeanNet: Transformer-based convolutional neural network for soybean pod counting from Unmanned Aerial Vehicle (UAV) images. Comput. Electron. Agric. 2024, 220, 108861. [Google Scholar] [CrossRef]
- Sarkar, S.; Zhou, J.; Scaboo, A.; Zhou, J.; Aloysius, N.; Lim, T.T. Assessment of soybean lodging using UAV imagery and machine learning. Plants 2023, 12, 2893. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, Y.; Chen, H.; Sun, G.; Wang, L.; Li, M.; Sun, X.; Feng, P.; Yan, L.; Qiu, L.; et al. Soybean yield estimation and lodging classification based on UAV multi-source data and self-supervised contrastive learning. Comput. Electron. Agric. 2025, 230, 109822. [Google Scholar] [CrossRef]
- Zhao, J.; Kaga, A.; Yamada, T.; Komatsu, K.; Hirata, K.; Kikuchi, A.; Hirafuji, M.; Ninomiya, S.; Guo, W. Improved field-based soybean seed counting and localization with feature level considered. Plant Phenomics 2023, 5, 0026. [Google Scholar] [CrossRef]
- Adedeji, O.; Abdalla, A.; Ghimire, B.; Ritchie, G.; Guo, W. Flight Altitude and Sensor Angle Affect Unmanned Aerial System Cotton Plant Height Assessments. Drones 2024, 8, 746. [Google Scholar] [CrossRef]
- Sonmez, D.; Cetin, A. An End-to-End Deployment Workflow for AI Enabled Agriculture Applications at the Edge. In Proceedings of the 2024 6th International Conference on Computing and Informatics (ICCI), New Cairo, Cairo, Egypt, 6–7 March 2024; pp. 506–511. [Google Scholar]
- Zhang, X.; Cao, Z.; Dong, W. Overview of edge computing in the agricultural internet of things: Key technologies, applications, challenges. IEEE Access 2020, 8, 141748–141761. [Google Scholar] [CrossRef]
- Joshi, H. Edge-AI for Agriculture: Lightweight Vision Models for Disease Detection in Resource-Limited Settings. arXiv 2024, arXiv:2412.18635. [Google Scholar]
- Lv, Z.; Yang, S.; Ma, S.; Wang, Q.; Sun, J.; Du, L.; Han, J.; Guo, Y.; Zhang, H. Efficient Deployment of Peanut Leaf Disease Detection Models on Edge AI Devices. Agriculture 2025, 15, 332. [Google Scholar] [CrossRef]
- Edge Impulse. Available online: https://edgeimpulse.com/ (accessed on 1 May 2025).
- Li, Y.; Jia, J.; Zhang, L.; Khattak, A.M.; Sun, S.; Gao, W.; Wang, M. Soybean seed counting based on pod image using two-column convolution neural network. IEEE Access 2019, 7, 64177–64185. [Google Scholar] [CrossRef]
- Xiang, S.; Wang, S.; Xu, M.; Wang, W.; Liu, W. YOLO POD: A fast and accurate multi-task model for dense Soybean Pod counting. Plant Methods 2023, 19, 8. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Zhuang, Y.; Li, J.; Zhang, Y.; Wang, Z.; Zhao, J.; Li, D.; Gao, Y. SPCN: An Innovative Soybean Pod Counting Network Based on HDC Strategy and Attention Mechanism. Agriculture 2024, 14, 1347. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yu, Z.; Wang, Y.; Ye, J.; Liufu, S.; Lu, D.; Zhu, X.; Yang, Z.; Tan, Q. Accurate and fast implementation of soybean pod counting and localization from high-resolution image. Front. Plant Sci. 2024, 15, 1320109. [Google Scholar] [CrossRef] [PubMed]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. Podnet: Pooled outputs distillation for small-tasks incremental learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XX 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 86–102. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Wu, K.; Wang, T.; Rao, Y.; Jin, X.; Wang, X.; Li, J.; Zhang, Z.; Jiang, Z.; Shao, X.; Zhang, W. Practical framework for generative on-branch soybean pod detection in occlusion and class imbalance scenes. Eng. Appl. Artif. Intell. 2025, 139, 109613. [Google Scholar] [CrossRef]
- Combine Harvester. Available online: https://www.deere.com/assets/pdfs/common/qrg/x9-rth-soybeans.pdf (accessed on 1 May 2025).
- Huang, Q. Towards indoor suctionable object classification and recycling: Developing a lightweight AI model for robot vacuum cleaners. Appl. Sci. 2023, 13, 10031. [Google Scholar] [CrossRef]
- Tang, Z.; Luo, L.; Xie, B.; Zhu, Y.; Zhao, R.; Bi, L.; Lu, C. Automatic sparse connectivity learning for neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7350–7364. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Han, K.; Xu, C.; Xu, C.; Tao, D.; Xu, C. Searching for low-bit weights in quantized neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 4091–4102. [Google Scholar]
- Chenna, D. Edge AI: Quantization as the key to on-device smartness. J. ID 2023, 4867, 9994. [Google Scholar]
- Kulkarni, U.; Meena, S.M.; Gurlahosur, S.V.; Benagi, P.; Kashyap, A.; Ansari, A.; Karnam, V. AI model compression for edge devices using optimization techniques. In Modern Approaches in Machine Learning and Cognitive Science: A Walkthrough: Latest Trends in AI, Volume 2; Springer International Publishing: Cham, Switzerland, 2021; pp. 227–240. [Google Scholar]
- Soybean Pod Images from UAVs. Available online: https://www.kaggle.com/datasets/jiajiali/uav-based-soybean-pod-images (accessed on 1 May 2025).
- Xie, W.; Zhao, M.; Liu, Y.; Yang, D.; Huang, K.; Fan, C.; Wang, Z. Recent advances in Transformer technology for agriculture: A comprehensive survey. Eng. Appl. Artif. Intell. 2024, 138, 109412. [Google Scholar] [CrossRef]
- Huang, Q.; Tang, Z. High-performance and lightweight ai model for robot vacuum cleaners with low bitwidth strong non-uniform quantization. AI 2023, 4, 531–550. [Google Scholar] [CrossRef]
- TensorFlow Lite. Available online: https://ai.google.dev/edge/litert (accessed on 1 May 2025).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AI Model Architecture | Number of Parameters (Unit: Million) | Accuracy (Unit: %) | Dataset | Inference Speed (Unit: Frame per Second) |
|---|---|---|---|---|
| Two-column CNN [17] | N/A | N/A | With a black cloth background | N/A |
| YOLO POD [18] | 78.6 | 83.9 | 2.16 on GeForce 2080 Ti GPU | |
| SPCN [21] | >144 | N/A | N/A | |
| PodNet [23] | 2.48 | 82.8 | 43.48 on GTX1080Ti GPU | |
| GenPoD [26] | >6.2 | 81.1 | N/A | |
| P2PNet-Soy [10] | >138 | N/A | With in-field background | N/A |
| SoybeanNet [7] | 29–88 | 84.51 | N/A |
| Dataset | Category | Soybean Pod Numbers of Different Category Pods | |||||||
|---|---|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | ||
| Number of Soybean Pods in an Image | (<40) | (41, 80) | (81, 120) | (121, 160) | (161, 200) | (201, 240) | (241, 280) | (>281) | |
| Training | 23,662 | 3027 | 2928 | 2972 | 2984 | 2958 | 2916 | 2937 | 2940 |
| Validation | 5068 | 648 | 627 | 636 | 639 | 634 | 625 | 629 | 630 |
| Testing | 5079 | 650 | 629 | 638 | 641 | 635 | 626 | 630 | 630 |
| AI Model Architecture | Number of Trainable Parameters | Memory Footprint (Unit: MB) | Accuracy (Unit: %) |
|---|---|---|---|
| ShuffleNet | 1,482,368 | 11.45 | 77.69 |
| MobileNetV2 | 2,268,232 | 17.80 | 86.91 |
| MobileNet | 3,237,064 | 24.95 | 85.96 |
| EfficientNetB0 | 4,059,819 | 31.65 | 85.69 |
| NasNetMobile | 4,278,172 | 35.26 | 86.14 |
| DenseNet121 | 7,045,704 | 54.95 | 87.14 |
| Xception | 20,877,872 | 159.61 | 87.01 |
| InceptionV3 | 21,819,176 | 167.44 | 86.28 |
| ResNet50V2 | 23,581,192 | 180.41 | 86.73 |
| ResNet50 | 23,604,104 | 180.58 | 87.1 |
| AI Model Architecture | Alpha | Number of Trainable Parameters | Memory Footprint (Unit: MB) | Accuracy (Unit: %) |
|---|---|---|---|---|
| MobileNet | 0.25 | 220,600 | 2.00 | 82.97 |
| 0.5 | 833,640 | 6.66 | 85.67 | |
| 0.75 | 1,839,128 | 14.31 | 86.83 | |
| 1 | 3,237,064 | 24.95 | 85.96 | |
| MobileNetV2 | 0.25 | 259,016 | 2.56 | 79.27 |
| 0.5 | 716,472 | 6.02 | 85.00 | |
| 0.75 | 1,292,312 | 11.15 | 86.02 | |
| 1 | 2,268,232 | 17.80 | 86.91 |
| AI Model Architecture | Alpha | Number of Trainable Parameters | Memory Footprint (Unit: MB) | Additional Memory Due to SE Blocks (Unit: %) |
|---|---|---|---|---|
| MobileNet | 0.25 | 228,792 | 2.07 | 3.5 |
| 0.5 | 866,408 | 6.91 | 3.8 | |
| 0.75 | 1,912,856 | 14.88 | 4.0 |
| AI Model Architecture | SE Blocks | Memory Footprint (Unit: MB) | Classification Accuracy (Unit: %) | Inference Speed on Raspberry Pi 4 (Unit: Frame per Second) | Inference Speed on Raspberry Pi 5 (Unit: Frame per Second) |
|---|---|---|---|---|---|
| MobileNet_alpha0p25 | No | 0.27 | 82.87 | 0.89 | 25 |
| Yes | 0.275 | 84.0 | 0.84 | 22.73 | |
| MobileNet_alpha0p5 | No | 0.9 | 85.44 | 0.40 | 7.52 |
| Yes | 0.92 | 85.56 | 0.40 | 7.25 | |
| MobileNet_alpha0p75 | No | 1.87 | 86.04 | 0.27 | 4.81 |
| Yes | 1.91 | 86.76 | 0.26 | 4.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q. High-Performance and Lightweight AI Model with Integrated Self-Attention Layers for Soybean Pod Number Estimation. AI 2025, 6, 135. https://doi.org/10.3390/ai6070135
Huang Q. High-Performance and Lightweight AI Model with Integrated Self-Attention Layers for Soybean Pod Number Estimation. AI. 2025; 6(7):135. https://doi.org/10.3390/ai6070135
Chicago/Turabian StyleHuang, Qian. 2025. "High-Performance and Lightweight AI Model with Integrated Self-Attention Layers for Soybean Pod Number Estimation" AI 6, no. 7: 135. https://doi.org/10.3390/ai6070135
APA StyleHuang, Q. (2025). High-Performance and Lightweight AI Model with Integrated Self-Attention Layers for Soybean Pod Number Estimation. AI, 6(7), 135. https://doi.org/10.3390/ai6070135