1. Introduction
With the aging of the human population and its strain on medical resources, modern medicine needs to accurately identify diseases within a short time in order to provide timely and effective treatment options for patients while reducing stress on the healthcare system [
1]. In this context, the rapid development of artificial intelligence and deep learning technologies has provided new possibilities for precision medicine and early disease warning [
2]. At the same time, in the face of a variety of complex and diverse disease types, Artificial Intelligence (AI) uses its efficient and objective calculations along with reasoning to help us accurately identify and judge diseases [
3]. AI not only affects the way patients diagnose diseases, it also affects the entire medical field. The question of how to better combine AI and health care has become a research hotspot for the future [
4]. Traditional diagnostic methods, such as imaging tests (including X-rays, Computed Tomography (CT), Magnetic Resonance Imaging (MRI)) and blood tests, have made significant progress in many areas, but still face several limitations. Firstly, these methods tend to be costly and require long inspection and processing times. Secondly, many diagnostic technologies rely on specialized medical equipment and high-level medical personnel to operate them, resulting in limited popularity. These problems are crying out for more efficient and convenient alternatives.
Against this background, voice detection provides a non-invasive and effective method for identifying and diagnosing various diseases. The human voice is formed by complex physiological structures, neural processes, and respiratory processes, and it carries rich information about an individual’s voice, such as the pitch, timbre, and volume [
5]. Voices contain a time-series feature, which has wide application in many fields, such as human activity recognition [
6], emotion detection [
7], and emotional style transfer [
8]. In the area of healthcare, voice information can provide valuable judgments about an individual’s health status and can reflect the presence of multiple diseases. Parkinson’s disease (PD) is a neurodegenerative movement disorder [
9] and its core symptoms include tremor, stiffness, and bradykinesia [
10]. Dysarthria (such as dysphonia and hoarseness) is often associated with Parkinson’s disease (PD), and these speech problems may appear early in PD or even in the prodromal phase [
11]. Liver complaint can induce neurological complications, which leads to language impairments, including speech fluency and phrase construction impairments [
12,
13]. Lung disease may disrupt the function of the anatomy associated with vocalization, resulting in abnormal or distorted sound quality [
14,
15,
16]. Sinus arrhythmia is related to respiratory patterns [
17,
18], and it can impact the neural regulation of auditory pathways related to speech, vital for both perceiving and producing speech [
19]. Thyroid disease affects the growth and development of sound structures and thus influences pitch, voice, and vocal range [
20,
21]. These medical studies prove that these diseases are directly or indirectly related to voice, and provide a theoretical basis for voice analysis to detect these diseases.
Although sound-based disease diagnosis research has made some progress, it still faces many challenges in multi-disease classification. The first is the complexity of the sound feature extraction. The sound manifestations of different diseases may overlap. The question of how to accurately extract and distinguish these subtle differences is a difficult problem. The second is insufficient data samples. Effective sound classification models rely on a large number of high-quality labeled data. However, in practical applications, especially for some rare diseases, the sound data may be relatively small, resulting in the risk of overfitting (the trained model).
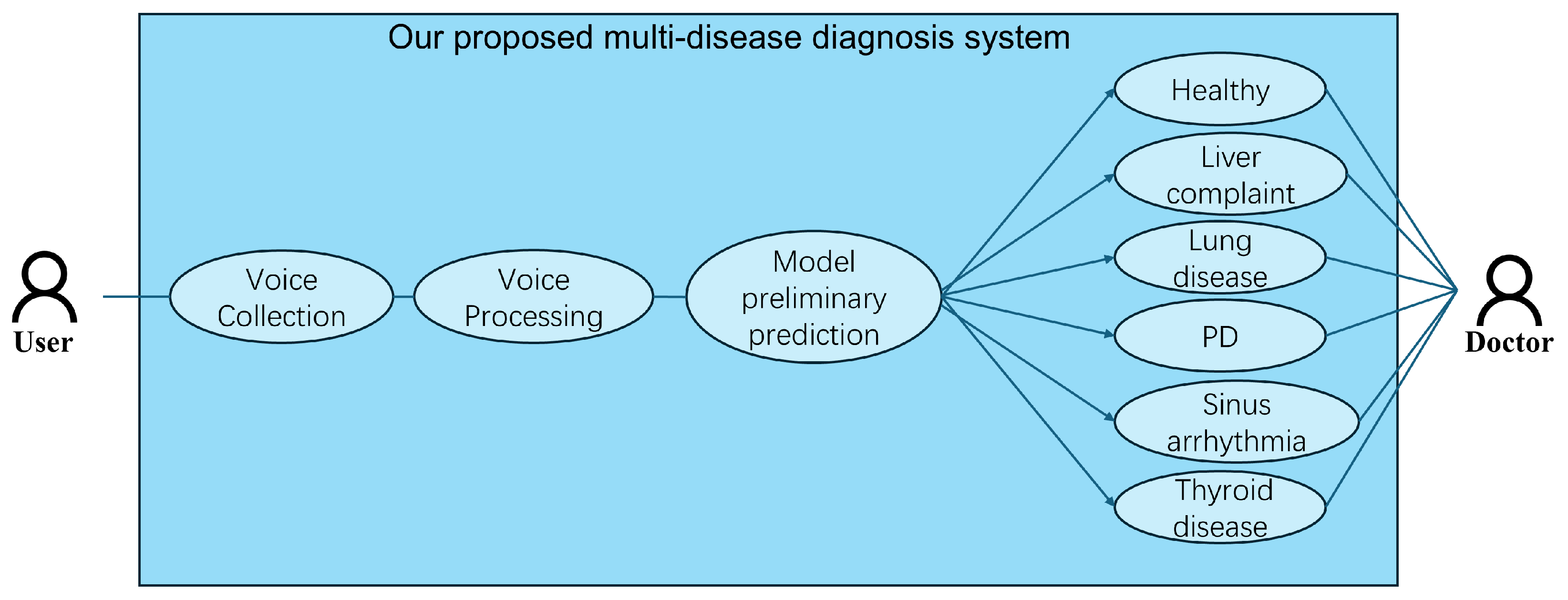
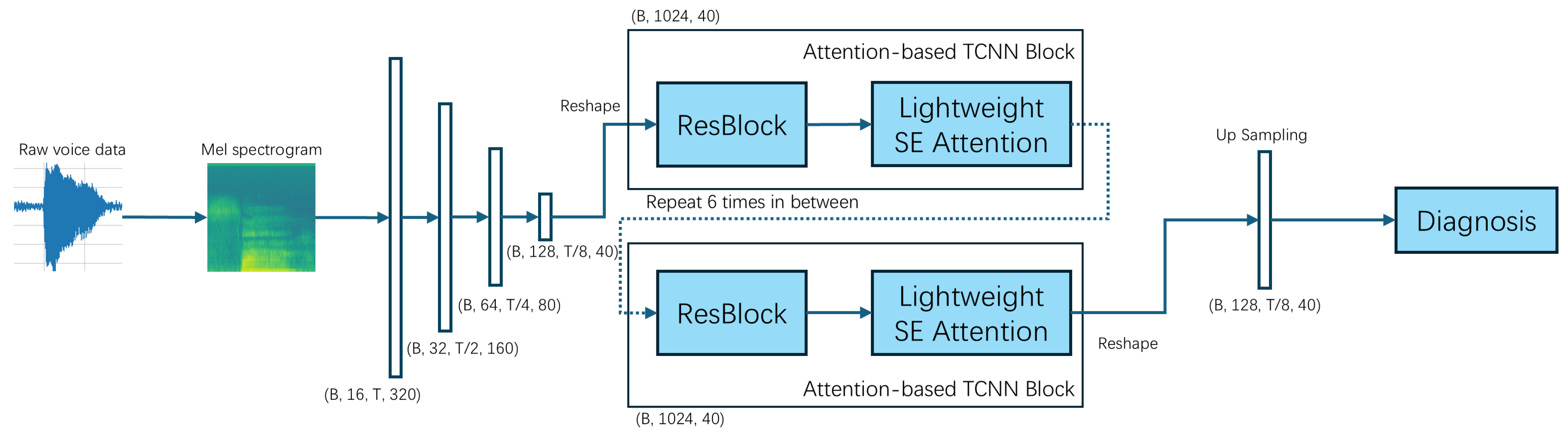
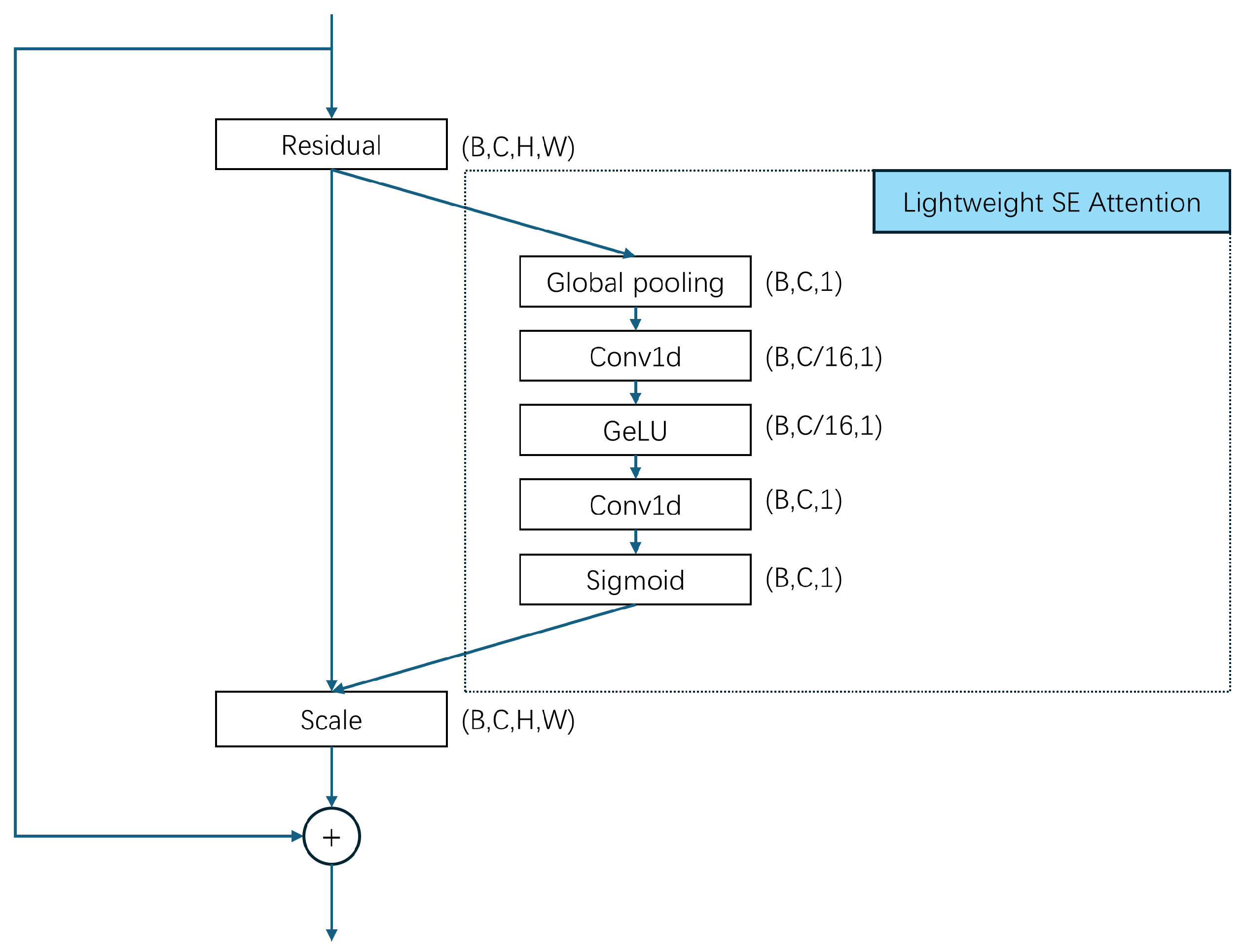
To resolve these issues, in this paper, we hope to realize an efficient and accurate multi-disease classification system and promote the application of sound detection technology in clinical practice. We propose a Lightweight Attention-Based Temporal-CNN model (Voice-AttentionNet) for multi-disease classification. Through deep learning techniques, more representative sound features are extracted to better capture subtle differences in different diseases. Compared with traditional CNNs and Recurrent Neural Networks (RNNs), Temporal-CNN can efficiently capture local patterns in time series data, reduce recursive dependencies in sequence processing, and significantly improve the computation speed. Furthermore, as the traditional CNN usually captures only local patterns, with the attention mechanism (in the proposed method), the model can dynamically adjust the attention degree of the framework to different time step features, so as to improve the modeling ability of key time points, improving the recognition ability of pathological features in voice. To sum up, the main contributions of our work are shown as follows:
We proposed a Lightweight Attention-Based Temporal-CNN model (Voice-AttentionNet), which combines the ability of time series local feature extraction and global dependent modeling to improve the recognition ability of pathological features in speech. The results show our proposed method has promising performance in voice-based multi-disease classification.
We introduced a novel voice-based loss specifically for supervising our proposed Voice-AttentionNet in multi-disease detection with voice data. In the voice-based loss, superiorities from multiple losses were fully considered to optimize the model from different perspectives (overall performance, hard-to-detect voice samples, and regularization effect). The voice-based loss improves the generalization ability of the model and performs well in the case of class imbalance in the dataset.
We performed extensive experiments with comprehensive metrics to evaluate the effectiveness of the proposed Voice-AttentionNet for multi-disease detection with voice data.
4. Experiments and Results
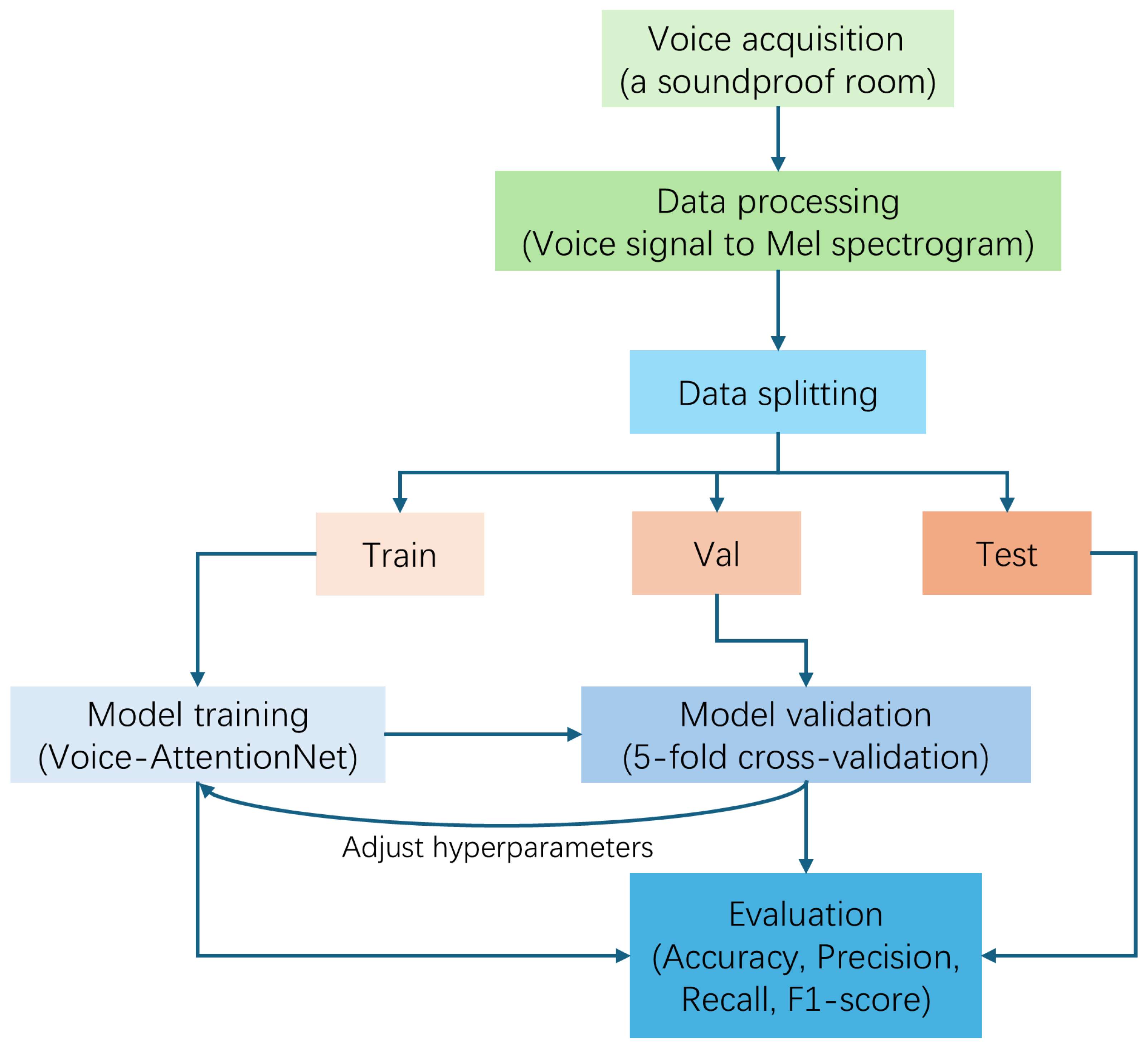
In this section, we describe extensive experiments we conducted to evaluate our proposed method and compare it with common methods. In order to ensure the representativeness and persuasiveness of the experimental comparisons, a large number of subjective and objective analyses were conducted—showing the performance and effect of the model through diagrams and charts, and evaluating the performance of the model through quantitative indicators. In addition, we also conducted an extended test to evaluate the efficiency of the model.
4.1. Datasets
In this study, we used 6 different datasets, with 5 disease datasets (liver complaint, lung disease, PD, sinus arrhythmia, and thyroid disease) and a dataset with healthy individuals. All voice signals in the datasets were captured using the acquisition system [
47] (refer to
Figure 6) from the Guangdong Provincial Hospital of Traditional Chinese Medicine, Guangzhou, China.
Altogether, there are a total of 892 cases (in the datasets). Specific to each category, we have 446 healthy cases, 253 liver complaint cases, 42 lung disease cases, 29 PD, 49 sinus arrhythmia cases, and 73 thyroid disease cases. Each case has about 40 voice samples, and each voice sample is about two seconds long.
Table 1 shows the label distribution for cases and samples. Audio files were recorded at a 192 kHz sampling frequency and 32-bit depth. In the real world, due to the cost of equipment and time, for the diagnosis of diseases, we can only collect a small snippet of the patient’s voice. Therefore, we decided to use each voice sample as the input for training, and predict each sample’s category instead of the case’s category. Since the data distribution is uneven, in order to have a more comprehensive and stable evaluation of the model’s performance, we adopted 5-fold cross-validation, which can reduce the chance of error by averaging multiple validation results and make the performance evaluation more representative. We assigned 20% of the total dataset to the test set, and 20% of the remaining dataset to the validation set (see
Table 2). Because the category data are unbalanced, a few diseases were placed together in broad categories (for more details, please refer to
Appendix A.1).
4.2. Evaluation Protocols
Accuracy is defined as the proportion of samples that are correctly predicted by the model of the total samples. Precision is defined as the proportion of actual positive samples among all samples predicted by the model to be positive. Recall is defined as the proportion of samples that are correctly predicted as positive among all samples that are actually positive. The definition of F1-score is the harmonic average of precision and recall, which comprehensively balances the two, and TP, FP, TN, and FN correspond to true positive, false positive, true negative, and false negative, respectively.
4.3. Implementation Details
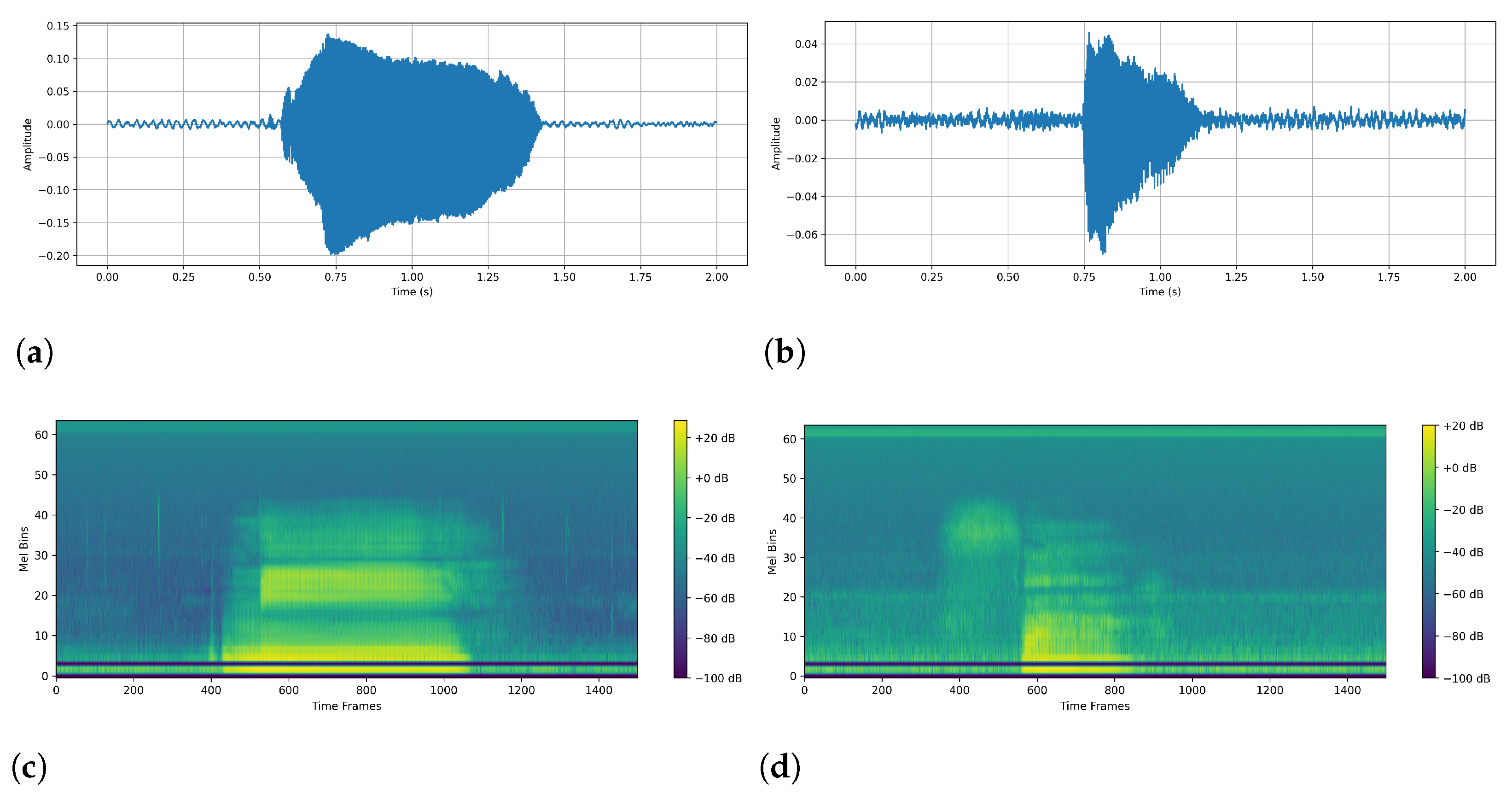
Data Preprocessing: The original data were in .wav format, and we used torchaudio to load each audio file. Then, to ensure the same sampling rate, we unified all audio to a 192 kHz sampling rate. The next step was to ensure that the audio length was uniform. Here, we set the uniform audio length to 2 s (384,000 sampling points). If it was too long, it was cut from the middle, and if it was too short, we applied zeros on both sides. To ensure a fair comparison in the following experiments, we set the same parameters to generate a Mayer spectrogram chart: FFT window size: 1024; steps: 256; Mehr filter banks: 64; min frequency: 20 Hz; max frequency: 96 kHz. The number of time frames in our unified spectrogram was 1500. The final Mayer spectrogram data format is: as follows (1, 64, 1500)—(number of channels, number of Mayer filters, number of time frames).
As for the setup before training, the framework we employed was PyTorch version 2.1.0. All the models were trained for 50 epochs with a batch size of 64 and a learning rate of 0.001 on one NVIDIA 4090 GPU with Intel(R) Core(TM) i7-14700K, 64 GB RAM.
4.4. Validation Performances
In this subsection, we chose some classical models for comparison. VGG was proposed by Simonyan et al. [
49], which provided inspiration for later deep learning models. ResNet was proposed by He et al. [
50], and its idea of Residual Learning was widely used by later deep learning models. TCNN was proposed by Pandey et al. [
48] and it was widely applied to deal with time-series-related tasks. MobileViT was proposed by Mehta [
51], which was a lightweight transformer-based model. RNN was proposed by MI Jordan [
52] and it has had a wide range of applications in processing data sequences. CNN-RNN was proposed by J Wang [
53], which showed excellent performance in multi-label classification tasks. We employed relatively light models, VGG16 and Resnet18, in comparison.
By comparing the results of the validation sets, it is possible to judge the performance of the model on previously unseen data. In order to not make the results seem redundant, we compared the best outputs for all models according to the 5-fold cross-validation. As shown in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8, Voice-AttentionNet+
is stable across a range of diseases, often achieving the best or second-best scores on multiple indicators. Especially in terms of F1-score, the Voice-AttentionNet+
model shows good performance, mainly due to its attention mechanism and the introduction of multi-loss combination. The performance of traditional basic models such as CNN is relatively weak; however, models with mixed architectures and attention mechanisms generally outperform simple architectures. In terms of difficulty of disease recognition, lung disease and Parkinson’s disease are easy to recognize due to obvious voice features (F1-score is generally above 0.93), while thyroid disease and sinus arrhythmia (F1-score is generally below 0.85) are difficult to recognize due to inapparent voice features.
4.5. Test Performances
For the comparison performance on the test set, we used the metrics of average accuracy and best accuracy. The test set was a dataset that was completely independent of the training and validation process—thus, the models had never seen it, allowing it to provide a more impartial evaluation of the performance. In this experiment (as shown in
Table 2), we constructed a dataset consisting of samples from each of the six datasets. The purpose here was to determine the classification accuracy of each sample in this mixed dataset. As shown in
Table 9, our model with
obtained the best performance under these two metrics, while our model without
attained the second-best average accuracy. This shows that our proposed models can adapt to the overall distribution of the data, rather than just performing well in some specific data partitions. In addition, it also illustrates the good generalization ability of our models.
4.6. Visualization
In this subsection, we analyze the classification accuracy of each category in the dataset.
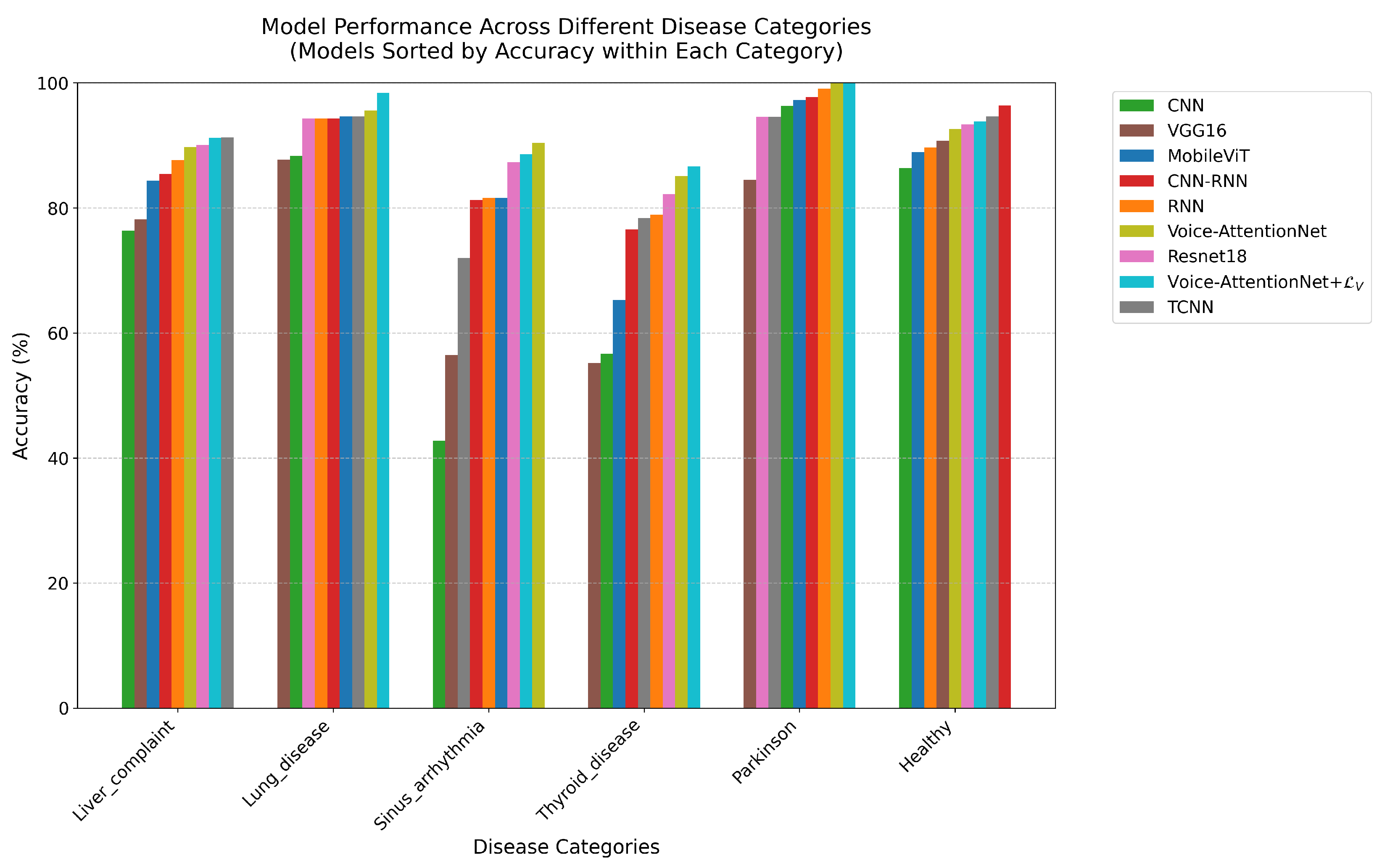
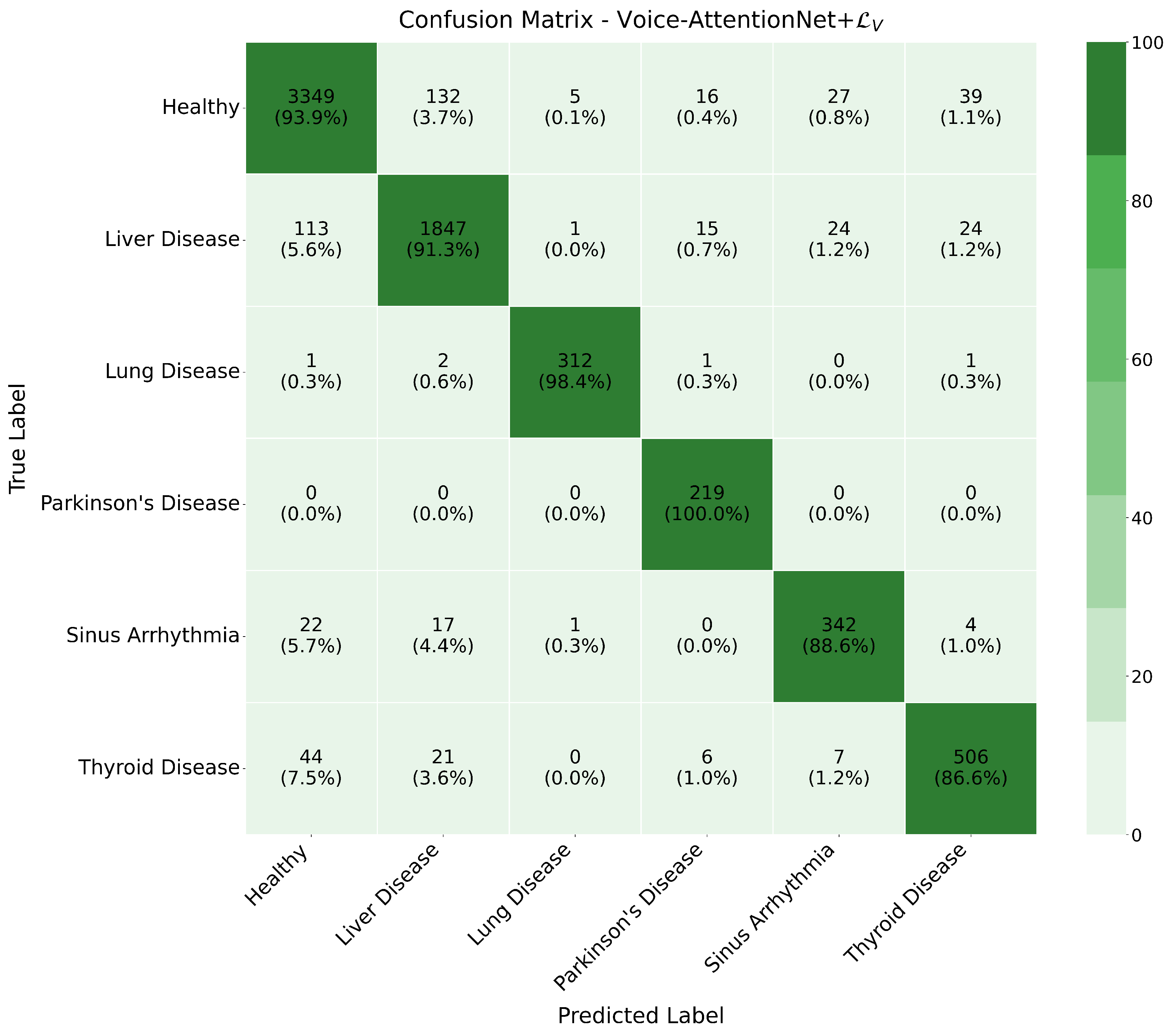
Combined with the comparison graph (
Figure 7) and confusion matrix (since it would be redundant to place them all in the article, we only show the confusion matrix of Voice-AttentionNet+
(
Figure 8) here as an example, with the remaining figure given in the
Supplementary File S1) for the models, for the Healthy category, all models showed stable performance. The CNN-RNN model achieved the best accuracy (96.44%), followed by TCNN (94.65%) and Voice-AttentionNet+
(93.86%). Even the worst-performing VGG16 reached 90.72%, indicating that healthy voice features are relatively easy to identify.
For liver complaint category, TCNN demonstrated the best performance (91.30%), closely followed by Voice-AttentionNet+ (91.25%). The simple RNN achieved 87.65%, while the complex VGG16 only reached 78.16%. These results suggest that liver disease’s effects on speech may be more prominently manifested in temporal features.
Thyroid disease proved to be the most challenging category to identify. The best-performing model, Voice-AttentionNet+, achieved only 86.64% accuracy, while the basic CNN’s accuracy was as low as 56.68%. The notably lower performance across all models suggests that thyroid disease’s effects on speech are more subtle and require sophisticated feature extraction capabilities.
In the sinus arrhythmia category, Voice-AttentionNet showed superior performance (90.41%), while basic CNN performed poorly (42.75%). The wide performance gap between models indicates the complexity of voice features associated with this condition. The attention mechanism demonstrated particular advantages in this task.
For the lung disease category, Voice-AttentionNet+ achieved remarkable accuracy at 98.42%, with other models generally exceeding 85%. These results indicate that lung diseases have significant and detectable effects on voice, even with limited sample sizes.
The Parkinson’s category, despite having the smallest sample size, showed exceptional classification results. Both Voice-AttentionNet+ and Voice-AttentionNet achieved perfect accuracy (100%), while CNN-RNN reached 97.73%, and the base CNN achieved 96.35%. These high accuracy rates suggest that Parkinson’s disease has distinct and easily recognizable effects on speech patterns, even in small samples.
Overall, the effectiveness of speech features in the diagnosis of different diseases varies. Some diseases, such as Parkinson’s disease and lung disease, are so pronounced that they can be accurately identified even in small samples; others, such as thyroid disease, have more subtle voice features that require more advanced models and possibly more training data.
4.7. Test Accuracy for Different Weight Combinations
In this subsection, we describe experiments we conducted to explore how different combinations affect the performance of the model. We explored a single weight, as well as a combination of two weights and a combination of three weights (
Figure 9). We found that the CE and Focal Loss had the greatest impact on model performance, where three weight combinations can further improve performance. Here, the average of each weight can even achieve the best average accuracy on the test set among nine models, and we conducted more experiments of different combinations of the three weights. In this paper, we used CE = 0.4, Focal = 0.4, and Smooth = 0.2 as the default values.
4.8. GPU Training Time Comparison
In this subsection, we compare the GPU training time (refer to
Table 10) among the nine models. Although we added more loss functions, the running time is drastically reduced. We figured out different loss terms may provide complementary gradient information, improving the optimization efficiency of the model, and enabling the optimizer to converge more effectively. This also indirectly shows the effectiveness and feasibility of our designed
.
5. Discussion
To sum up, Voice-AttentionNet shows good performance compared with other classical models on both our validation and test sets; at the same time, the we designed also further improves its performance. This demonstrates that our model is really learning more subtle differences between various diseases, while maintaining good results as demonstrated by precision, recall, F1-score, and accuracy. In addition, Voice-AttentionNet still achieved the second-fastest GPU training time among the comparison models, illustrating the efficiency of our proposed model and designed loss function.
However, the results on the validation set show that Voice-AttentionNet and Voice-AttentionNet+ do not perform best in every case of disease classification. Even though they do perform well in most disease classifications, they are not particularly advantageous compared to other approaches. Hence, there is still room for improvement and progress on Voice-AttentionNet and Voice-AttentionNet+.
For future work, we will explore a more efficient network structure, and further reduce the training time while ensuring training accuracy. At the same time, we will enhance the data preprocessing to make the models better learn tiny features that distinguish the different diseases.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}