


SMART Restaurant ReCommender: A Context-Aware Restaurant Recommendation Engine


Abstract
1. Introduction
- Integration of LLMs with real-time data APIs: This research proposes a novel approach that combines the sophisticated natural language understanding capabilities of LLMs, such as ChatGPT, with the dynamic data access provided by Google Places API to deliver personalized and context-aware restaurant recommendations.
- Experimental evaluation: A thorough experimental analysis to evaluate the performance of the proposed system, demonstrating its superiority in accuracy and user satisfaction compared to traditional recommendation systems.
- Scalable architecture proposal: This research designs a scalable framework that enhances restaurant recommendation processes and is adaptable to various other domains, such as travel, entertainment, and healthcare.
2. Related Work
2.1. LLM Effectiveness in API Interactions
2.2. Fine-Tuning for Enhanced Performance
2.3. LLMs in Recommendation Systems
2.4. Challenges in LLM Applications
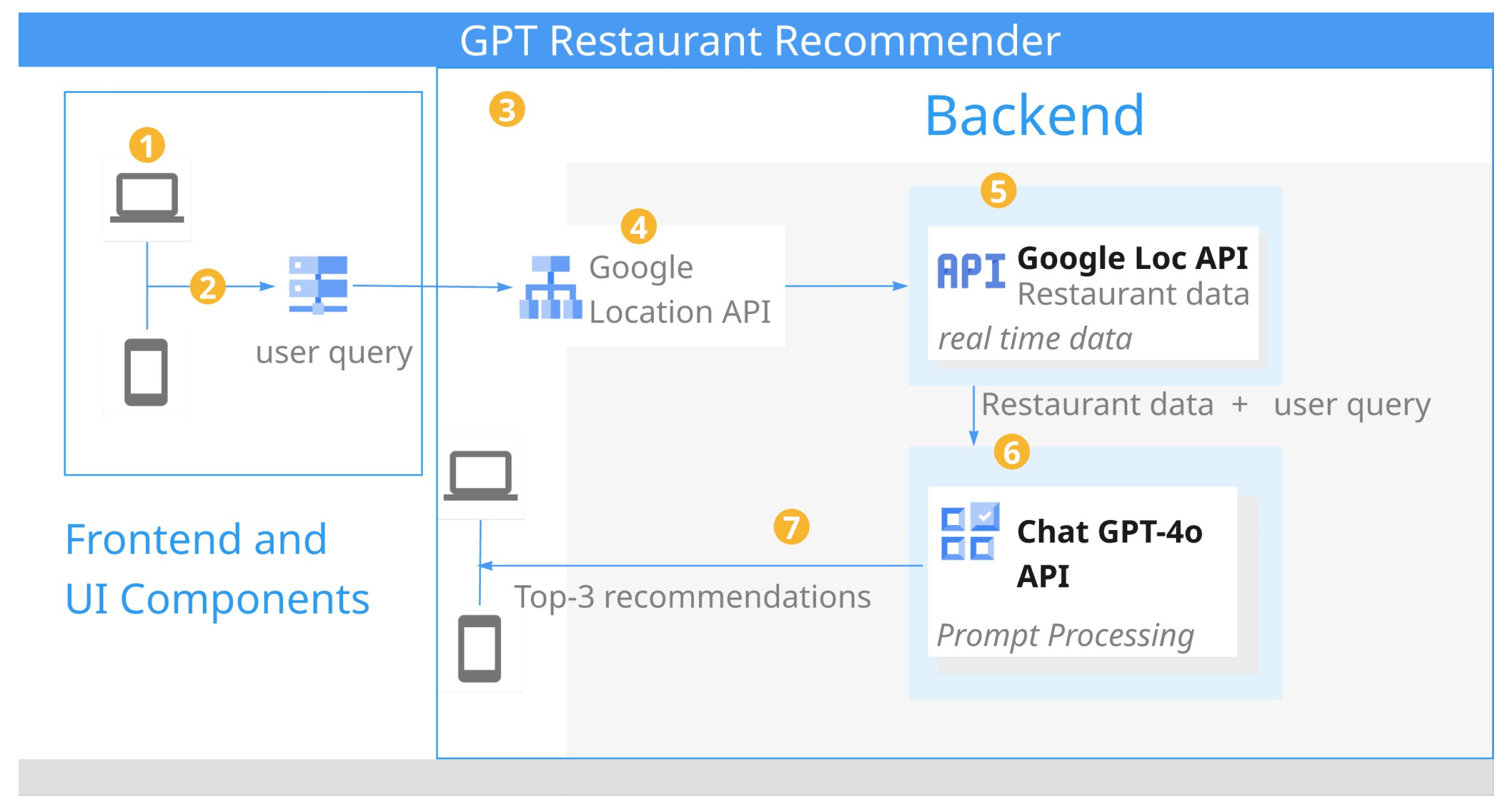
3. Proposed System: GPT Restaurant Recommender
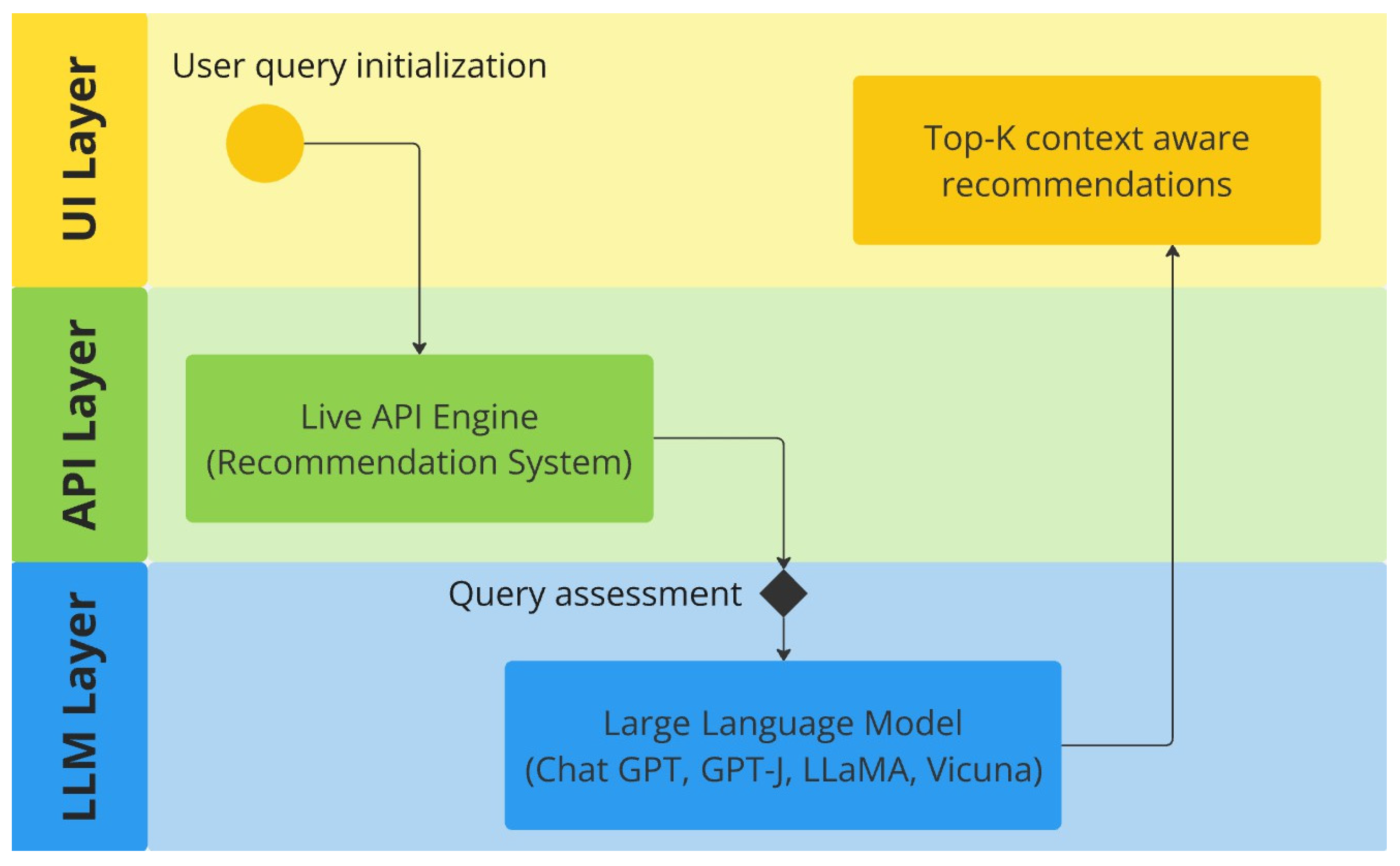
3.1. Framework Design
3.2. Architecture Design
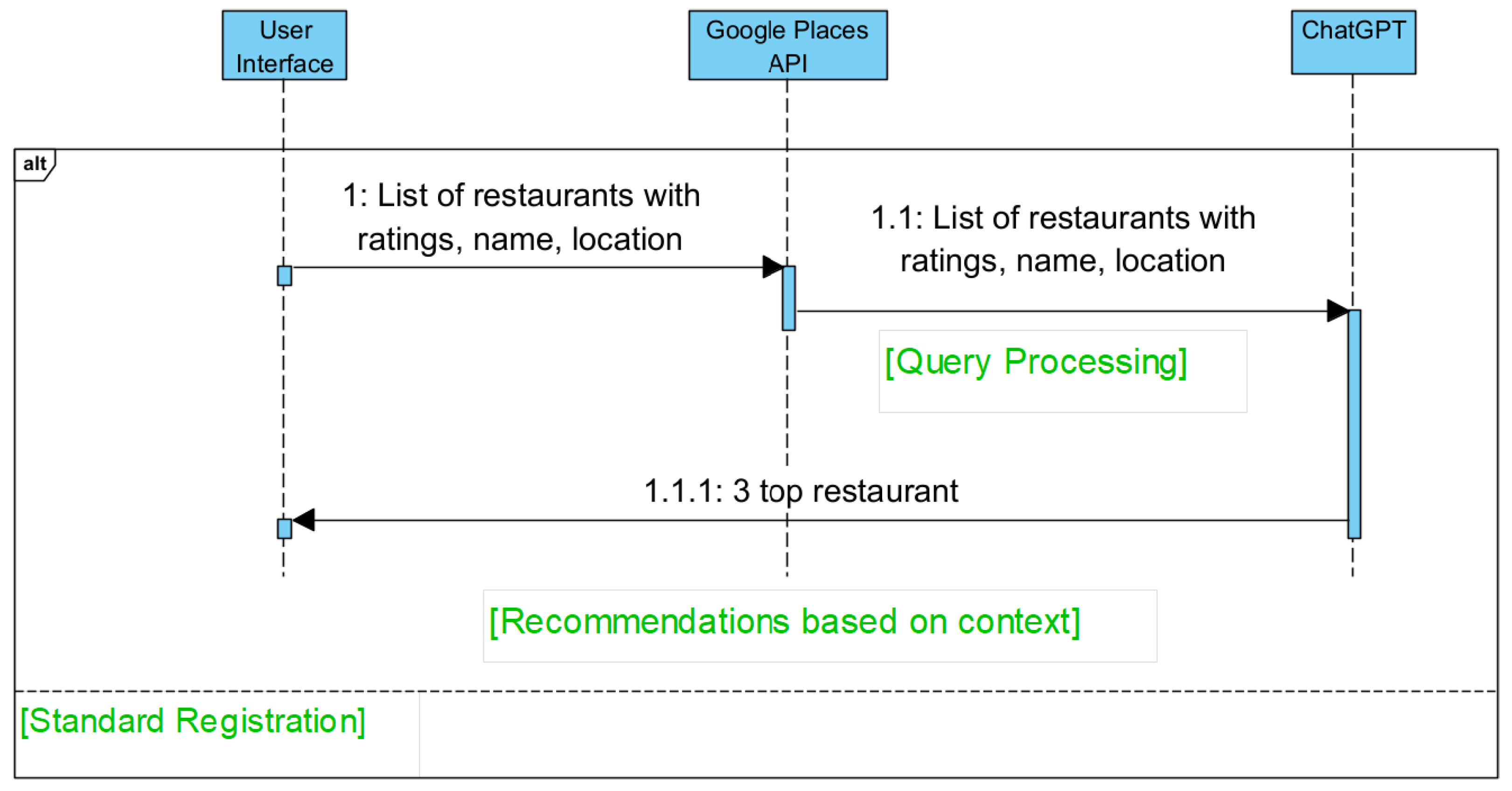
3.3. Process Flow
3.4. System User Interface
3.5. Technical Features and System Architecture
3.5.1. Technology Stack
3.5.2. Data Flow and Processing
3.5.3. Scalability and Performance
3.5.4. Security and Privacy Measures
3.6. Detailed Description of Personalized Recommendations
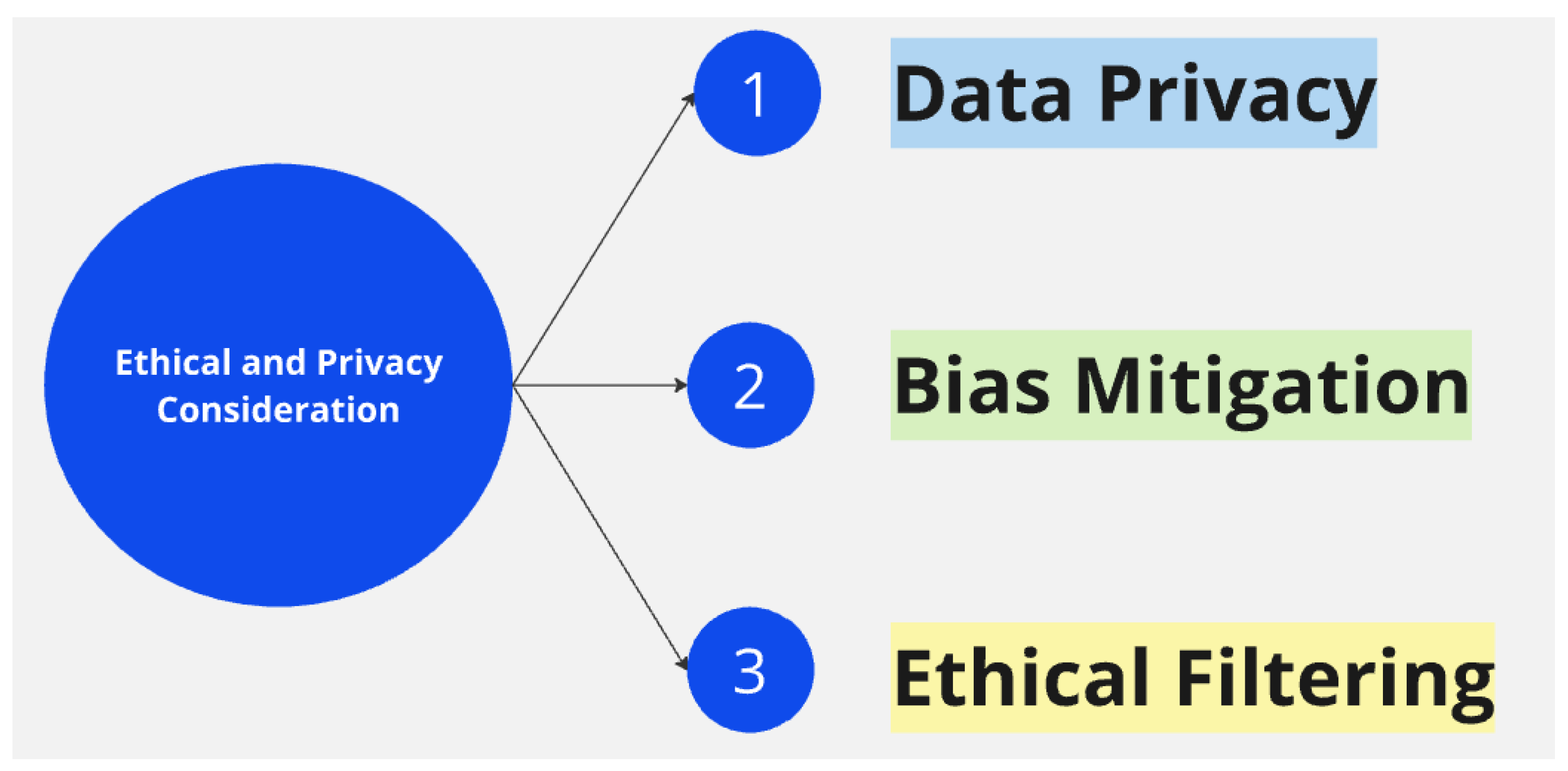
3.7. Ethical and Privacy Consideration
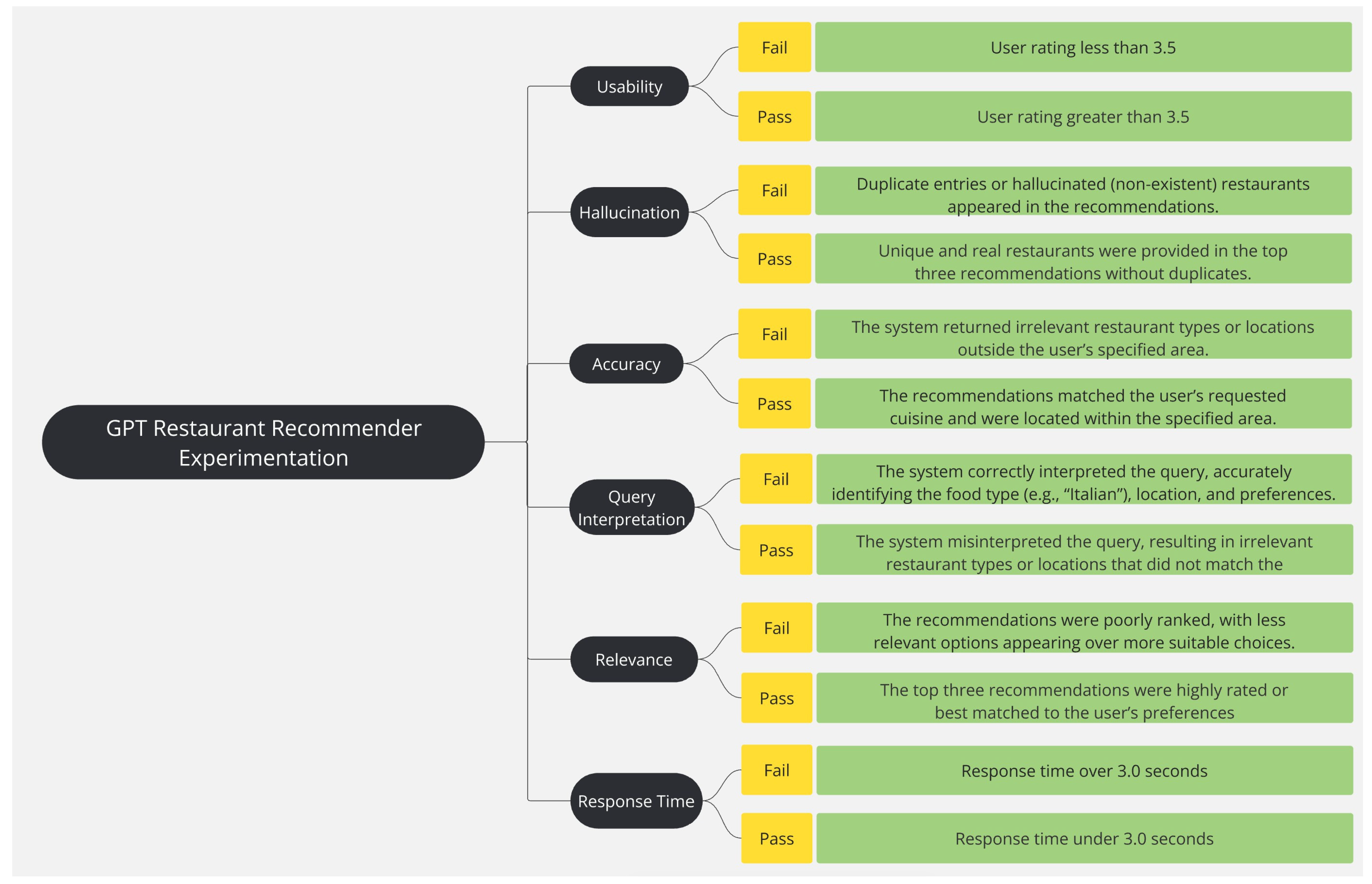
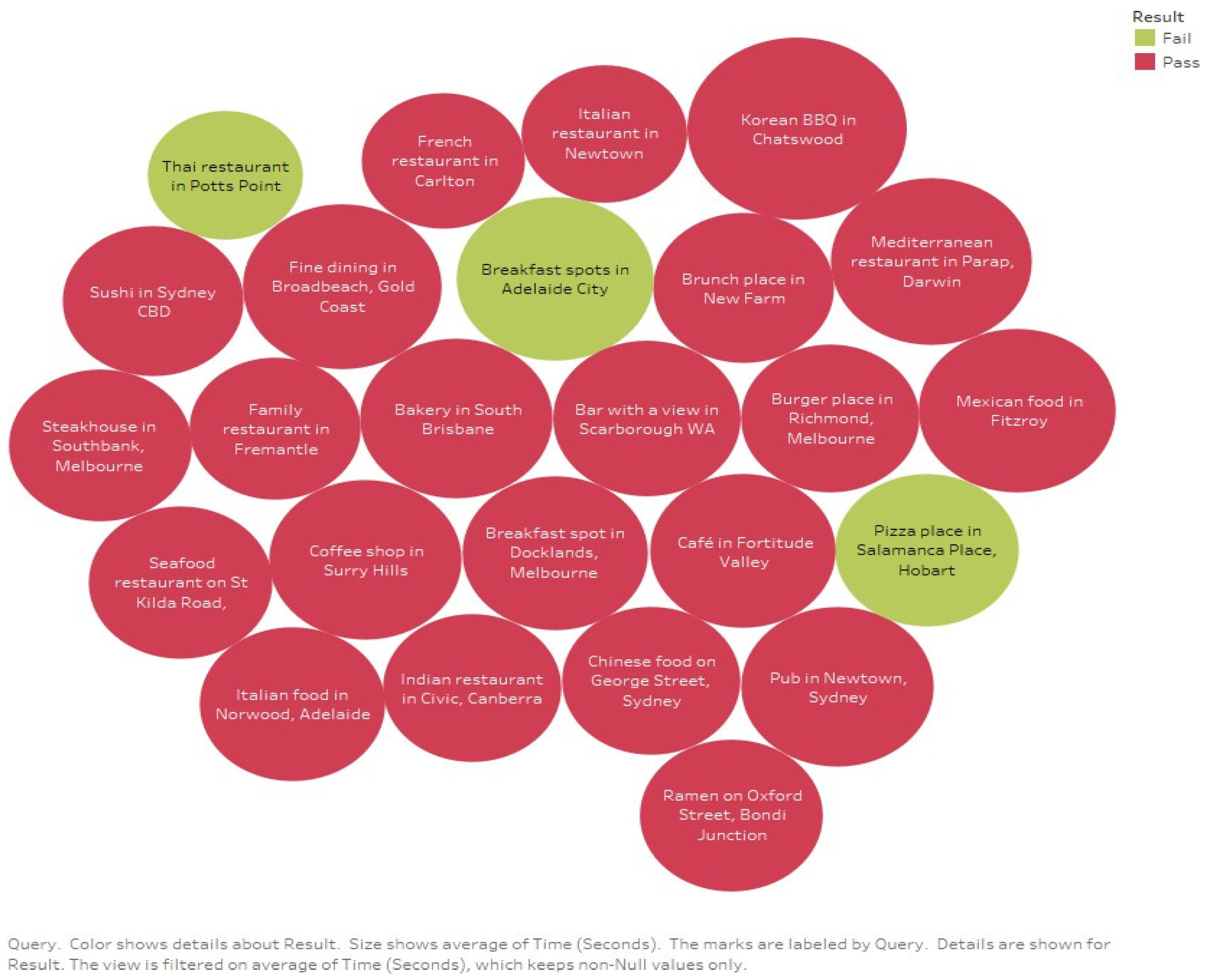
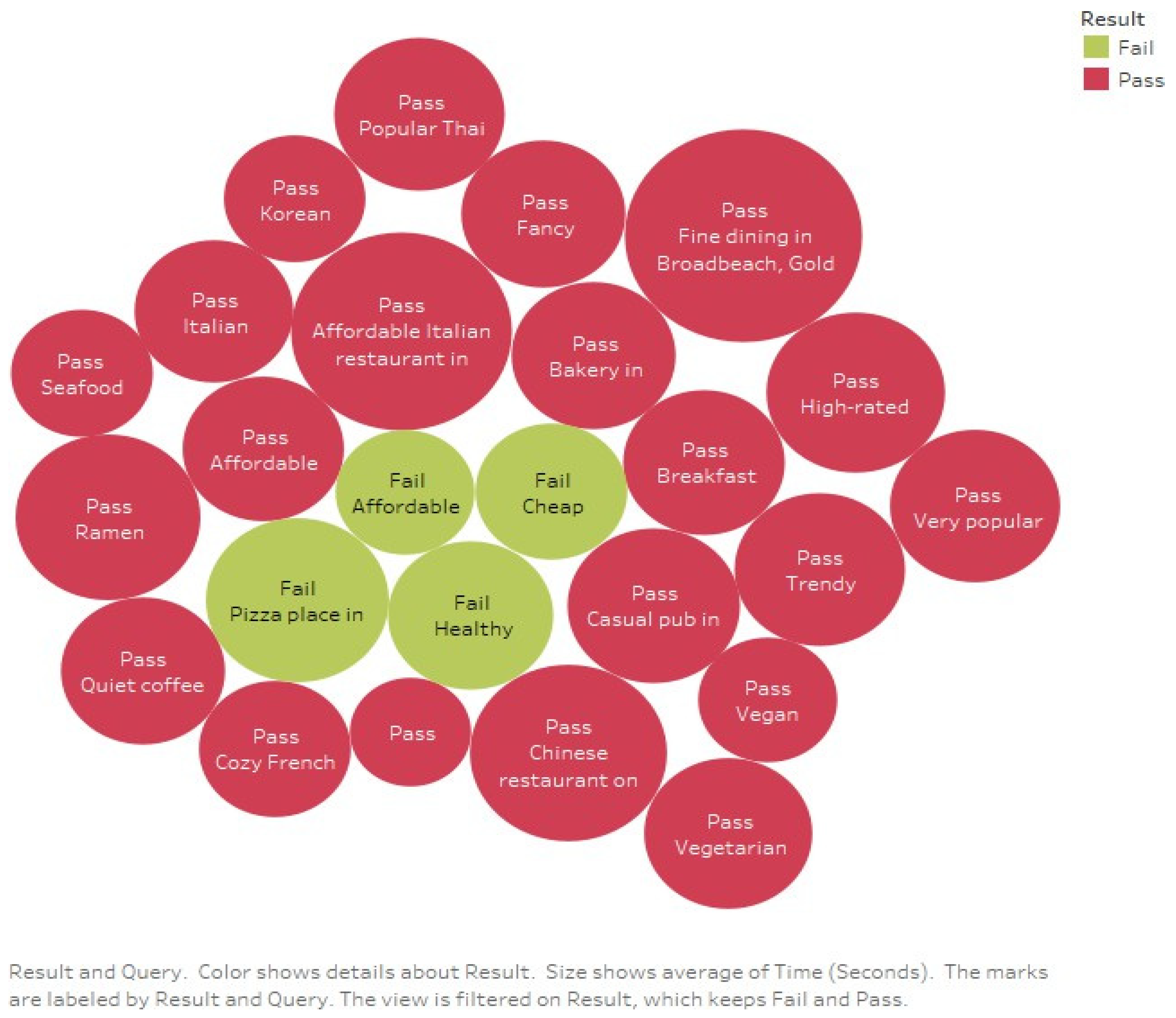
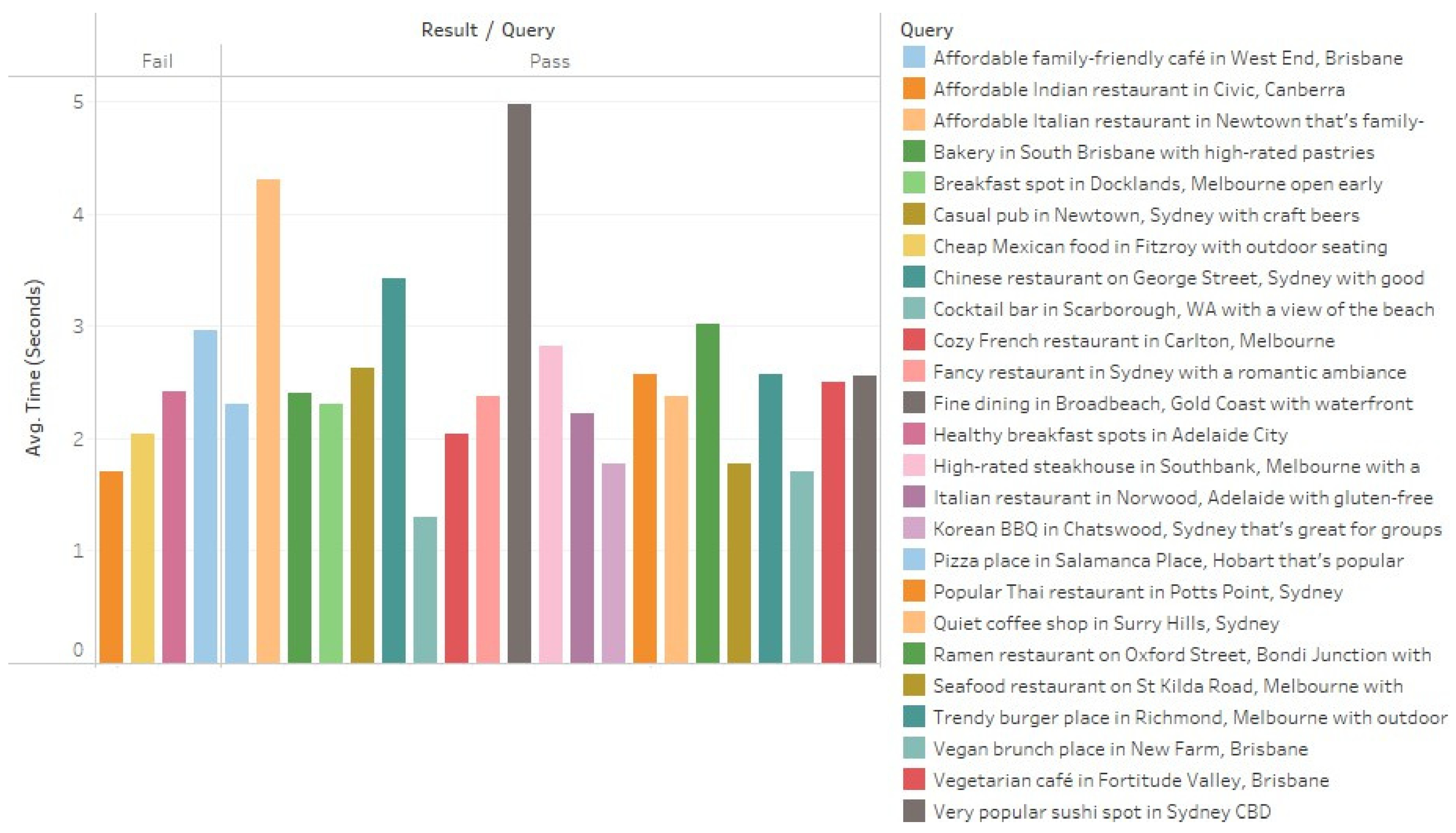
4. Experimentation and Evaluation
4.1. Evaluation Criteria
4.2. Comparative Discussion
4.3. Comparative Analysis with Major AI Services
5. Results Evaluation and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Johnsen, M. (Ed.) Developing AI Applications with Large Language Models. 2025. Available online: https://www.maria-johnsen.com/ai-applications-with-large-language-models/ (accessed on 21 February 2025).
- Zhao, Z.; Fan, W.; Li, J.; Liu, Y.; Mei, X.; Wang, Y.; Wen, Z.; Wang, F.; Zhao, X.; Tang, J.; et al. Recommender systems in the era of large language models (llms). IEEE Trans. Knowl. Data Eng. 2024, 1–20. [Google Scholar]
- Li, J.; Xu, J.; Huang, S.; Chen, Y.; Li, W.; Liu, J.; Lian, Y.; Pan, J.; Ding, L.; Zhou, H.; et al. Large language model inference acceleration: A comprehensive hardware perspective. arXiv 2024, arXiv:2410.04466. [Google Scholar]
- Gokul, A. LLMs and AI: Understanding Its Reach and Impact. Preprints 2023. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Y.; Liu, D.; Chen, L. Large Language Models for Generative Recommendation: A Survey and Visionary Discussions. arXiv 2024, arXiv:cs.IR/2309.01157. [Google Scholar]
- Silva, B.; Tesfagiorgis, Y.G. Large Language Models as an Interface to Interact with API Tools in Natural Language. 2023. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1801354&dswid=5686 (accessed on 21 February 2025).
- Spinellis, D. Pair Programming with Generative AI. 2024. Available online: https://research.tudelft.nl/en/publications/pair-programming-with-generative-ai (accessed on 21 February 2025).
- Patil, S.G.; Zhang, T.; Wang, X.; Gonzalez, J.E. Gorilla: Large language model connected with massive APIs. arXiv 2023, arXiv:2305.15334. [Google Scholar]
- Luo, D.; Zhang, C.; Zhang, Y.; Li, H. CrossTune: Black-box few-shot classification with label enhancement. arXiv 2024, arXiv:2403.12468. [Google Scholar]
- Fan, W.; Zhao, Z.; Li, J.; Liu, Y.; Mei, X.; Wang, Y.; Tang, J.; Li, Q. Recommender Systems in the Era of Large Language Models (LLMs). IEEE Trans. Knowl. Data Eng. 2023, 36, 6889–6907. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. Precision-Driven Product Recommendation Software: Unsupervised Models, Evaluated by GPT-4 LLM for Enhanced Recommender Systems. Software 2024, 3, 62–80. [Google Scholar] [CrossRef]
- Mao, J.; Zou, D.; Sheng, L.; Liu, S.; Gao, C.; Wang, Y. Identify critical nodes in complex networks with large language models. arXiv 2024, arXiv:2403.03962. [Google Scholar]
- Lin, J.; Dai, X.; Xi, Y.; Liu, W.; Chen, B.; Zhang, H.; Liu, Y.; Wu, C.; Li, X.; Zhu, C.; et al. How can recommender systems benefit from large language models: A survey. ACM Trans. Inf. Syst. 2023, 43, 1–47. [Google Scholar]
- Hu, S.; Tu, Y.; Han, X.; He, C.; Cui, G.; Long, X. MiniCPM: Unveiling the potential of small language models with scalable training strategies. arXiv 2024, arXiv:2404.06395. [Google Scholar]
- Corecco, N.; Piatti, G.; Lanzendörfer, L.A.; Fan, F.X.; Wattenhofer, R. An LLM-based Recommender System Environment. arXiv 2024, arXiv:2406.01631. [Google Scholar]
- shadcn. shadcn/ui: Modern UI Components for React. shadcn/ui Official Documentation. 2025. Available online: https://ui.shadcn.com/ (accessed on 17 January 2025).
- Optimizing: Third Party Libraries|Next.js—Nextjs.org. Available online: https://nextjs.org/docs/app/building-your-application/optimizing/third-party-libraries (accessed on 17 January 2025).
- Vercel AI SDK. OpenAI—SDK Documentation. Vercel AI SDK. 2025. Available online: https://sdk.vercel.ai/providers/ai-sdk-providers/openai (accessed on 17 January 2025).
- Next.js by Vercel—The React Framework—Nextjs.org. Available online: https://nextjs.org (accessed on 15 January 2025).
- Vercel: Build and Deploy the Best Web Experiences with the Frontend Cloud—Vercel—Vercel.com. Available online: https://vercel.com/ (accessed on 15 January 2025).
- Raza, S.; Rahman, M.; Kamawal, S.; Toroghi, A.; Raval, A.; Navah, F.; Kazemeini, A. A comprehensive review of recommender systems: Transitioning from theory to practice. arXiv 2024, arXiv:2407.13699. [Google Scholar]
- Roy, D.; Dutta, M. A systematic review and research perspective on recommender systems. J. Big Data 2022, 9, 59. [Google Scholar]
- Gope, J.; Jain, S.K. A survey on solving cold start problem in recommender systems. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 133–138. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Key Findings |
|---|---|
| Silva & Tesfagiorgis (2023) [6] | Effective prompt designs & fine-tuning methods. |
| Patil et al. (2023) [8] | Fine-tuned LLMs outperform GPT-4 in API interactions. |
| Luo et al. (2024) [9] | Fine-tuning improves LLM performance w.r.t. response times. |
| Roumeliotis et al. (2024) [11] | LLM-based unsupervised clustering enhances recommendation precision. |
| Spinellis (2024) [7] | Linguistic structures are crucial for precise API calls. |
| Mao et al. (2024) [12] | LLMs handle diverse inputs efficiently but risk stability. |
| Lin et al. (2023) [13] | Examined LLMs in recommendation pipelines, focusing on efficiency and ethical considerations. |
| Hu et al. (2024) [14] | Scalable training strategies might compromise LLM efficiency. |
| Nathan et al. & Giorgio et al. (2024) [15] | Integrated LLMs to improve RL-based recommendations. |
| Fan et al. (2023) [10] | Emphasized the fine-tuning of prompt design to leverage the effectiveness of the LLMs for context-aware recommendations. |
| Metrics(s) | Criteria |
|---|---|
| Handling of Complex Queries | Recommendations on varied choice in a single query, such as “affordable” or “family friendly”. |
| Location-Based Results | Recommendations based on the user’s specified location, i.e., suburb, city, or street. |
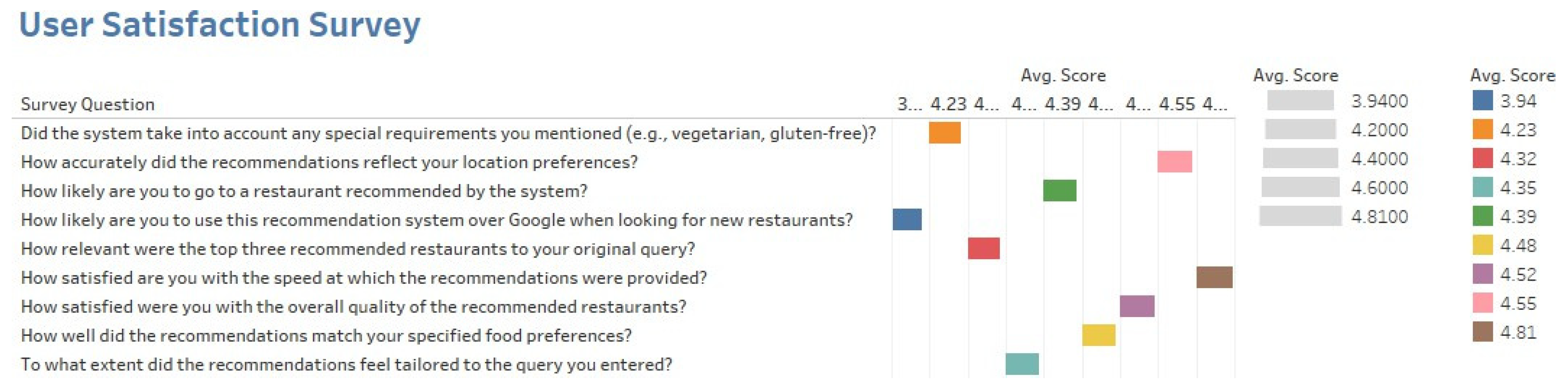
| User Satisfaction | User satisfaction should be between the scale of 4.0–5.0. |
| System Response Time | Response time of under 3.0 s. |
| Query Type | Outcome | Success Rate (%) |
|---|---|---|
| Simple Query | Pass | 88.0 |
| Fail | 12.0 | |
| Complex Query | Pass | 84.0 |
| Fail | 16.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ubaid, A.; Lie, A.; Lin, X. SMART Restaurant ReCommender: A Context-Aware Restaurant Recommendation Engine. AI 2025, 6, 64. https://doi.org/10.3390/ai6040064
Ubaid A, Lie A, Lin X. SMART Restaurant ReCommender: A Context-Aware Restaurant Recommendation Engine. AI. 2025; 6(4):64. https://doi.org/10.3390/ai6040064
Chicago/Turabian StyleUbaid, Ayesha, Adrian Lie, and Xiaojie Lin. 2025. "SMART Restaurant ReCommender: A Context-Aware Restaurant Recommendation Engine" AI 6, no. 4: 64. https://doi.org/10.3390/ai6040064
APA StyleUbaid, A., Lie, A., & Lin, X. (2025). SMART Restaurant ReCommender: A Context-Aware Restaurant Recommendation Engine. AI, 6(4), 64. https://doi.org/10.3390/ai6040064