1. Introduction
Medical images such as X-ray images and MRIs have been accumulated in the medical field for many years. Meanwhile, data digitalization has rapidly progressed recently, and high volumes of medical data, including images, can now be efficiently stored and used [
1]. Medical images are crucial in diagnosis and treatment decision-making [
2], and they are vital data sources for education and research. Furthermore, advances in machine learning and artificial intelligence in recent years have resulted in rapid advances in using medical data [
3,
4,
5,
6]. This is expected to reduce physician burden and improve diagnostic accuracy.
Medical data provides various aspects of information for each modality. Image data contains anatomical information and details of lesions, whereas text data includes records of physicians’ judgments and patient conditions [
7,
8]. Therefore, integrating images and text is crucial for effectively extracting the complementary information possessed by each, and this is expected to improve diagnostic accuracy and make report generation more efficient. Examples in previous research include a proposed method of simultaneously using images and corresponding diagnostic reports to improve the classification accuracy of lesions and a proposed technology for automatically generating diagnostic reports from images [
9,
10]. Such research has garnered attention as technologies that support decision-making in the medical field by using the interaction between images and text.
In this context, medical image retrieval is a prevailing method for the effective utilization of large volumes of medical data [
11,
12]. Medical image retrieval is a technology that efficiently retrieves similar cases and related information based on images and text that are given as queries. For example, suppose that a user provides a chest X-ray image related to a specific disease as an input. Then, case images with similar characteristics and related diagnostic reports can be obtained. This technology is crucial for diagnostic support and educational purposes. Diagnostic accuracy is expected to be improved by providing related similar cases. Additionally, providing visually similar cases can improve the quality of education for medical students and residents. Furthermore, in research, an efficient collection of similar images is expected to lead to discoveries and the identification of interesting patterns. Therefore, medical image retrieval is expected to have diverse applications in the medical and research fields, and it is an essential means for the practical and effective utilization of large volumes of medical data.
In recent years, attention has been paid to methods that treat images and text in the same embedding space in medical image retrieval [
13,
14,
15,
16]. A representative example is BioMedCLIP [
16], which is a method that learns medical image and text embeddings in a unified manner to enable cross-modal search (image-text and text-image). This approach has considerably improved retrieval performance by modeling the interrelationships between image and text modalities. Additionally, Simon et al. [
17] conducted a comprehensive review of multimodal AI in radiology, discussing how advanced architectures such as transformers and graph neural networks (GNNs) enable the integration of imaging data with various clinical metadata. They highlight both the potential benefits of these methods and critical challenges, including data scarcity, bias, and the lack of standardized taxonomy in multimodal research.
More recently, Ou et al. [
18] proposed a method that integrates medical images and textual reports using a Report Entity Graph and Dual Attention mechanisms. Their approach enhances fine-grained semantic alignment between images and text by structuring radiology reports into entity graphs. This method focuses on cross-modal retrieval tasks, specifically retrieving text from images (image-text) and retrieving images from text (text-image). In addition, Jeong et al. [
19] introduced a retrieval-based chest X-ray report generation module that computes an image–text matching score using a multimodal encoder, improving the selection of the most clinically relevant report. While Jeong et al.’s method effectively refines the image-text retrieval process for report generation, our work targets a different scenario: retrieving image–text pairs from a combined image and text query (image & text-image & text). Hence, rather than focusing on text generation or single-modality retrieval, we aim to jointly model the interaction between images and textual descriptions to facilitate richer multimodal queries. However, these methods treat images and text as separate embeddings and compare them in the same space. Therefore, these methods do not consider learning or integrated representations that combine images and text. This is a major limitation in maximizing the information obtained from both images and text. Therefore, existing research provides a foundation for cross-modal approaches in medical image retrieval. Nonetheless, the above findings suggest a need for new methodologies that integrate information between modalities. Unlike previous studies, which primarily focus on cross-modal retrieval tasks (image-text, text-image), our study tackles a distinct challenge: retrieving image-text pairs using a multimodal query (image & text → image & text). Instead of retrieving a single modality, our method models the interaction between image and text modalities jointly. This approach facilitates more robust multimodal fusion and enhances retrieval performance in clinical applications.
In this study, we tackle the challenge of medical image retrieval by proposing an innovative method that integrates image and text embeddings. Our contributions are as follows:
- 1.
Introduction of a novel image-text fusion strategy;
Conventional medical image retrieval methods treat images and text separately, which limits retrieval effectiveness. The proposed method introduces a cross-attention-based fusion strategy that facilitates more effective multimodal integration by directly modeling the relevance between images and text.
- 2.
Empirical demonstration of the effectiveness of integrated embeddings in medical image retrieval;
This study empirically demonstrates how a unified image-text representation enhances retrieval accuracy, underscoring the importance of multimodal fusion in medical image retrieval. This insight paves the way for leveraging cross-modal relationships in clinical applications.
- 3.
Enhancement of retrieval performance through targeted training of additional layers;
By keeping the original BioMedCLIP model and training only the additional cross-attention layers, we demonstrated that retrieval performance can be significantly improved. This finding highlights that even minimal architectural modifications to pre-trained models can yield substantial improvements, making the approach both computationally efficient and practically valuable.
2. Methods
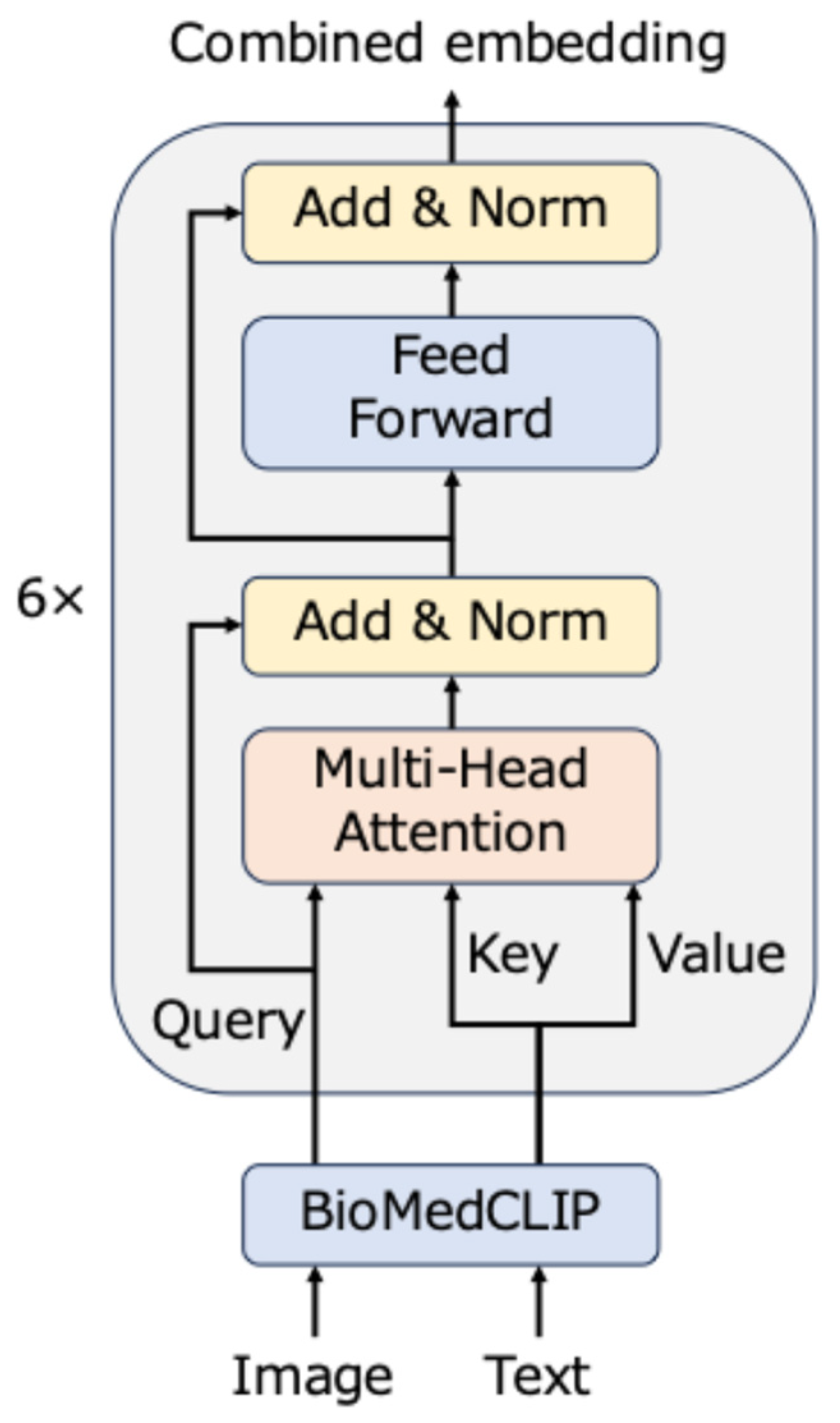
Figure 1 illustrates the proposed model. This model consists of an embedding layer, which comprises a pre-trained BioMedCLIP, and a cross-attention layer that uses a transformer encoder [
20]. First, an image-text pair is input, and two embeddings are obtained by the embedding layer. Subsequently, both embeddings are sent to the cross-attention layer. The cross-attention layer emphasizes the important parts using an attention mechanism and outputs a final embedding that reflects the interaction between modalities. Details of each part of the proposed model are described in the following subsections.
2.1. Embedding Layer
When an image-text pair is provided, each part is input to the image encoder and text encoder of the pre-trained BioMedCLIP.
2.1.1. Image Encoder
BioMedCLIP uses the Vision Transformer (ViT) [
21] as the image encoder. The final ViT layer outputs 768-dimensional embedding. However, in this study, we sought to utilize local information within an image by extracting embeddings for each region from the intermediate ViT layer. Specifically, the input image is divided into 14 × 14 patches (regions), with each patch converted into a 768-dimensional embedding. ViT adds the input patch and a special token for class classification (CLS token) to summarize the overall information. This process results in the entire image being represented as 197 embeddings, including the CLS token (14 × 14 = 196 patches + 1 CLS token), ultimately yielding a (197,768)-dimensional tensor. This embedding in the intermediate layer can be used to model the information of the entire image while preserving its local features.
2.1.2. Text Encoder
The text encoder used by BioMedCLIP is PubMedBERT [
22], which is a domain-specific language model that is pre-trained on medical and biomedical text data. PubMedBERT tokenizes the input text and converts each token into a 768-dimensional embedding. Extremely long input texts are truncated, and those that are too short undergo a padding process such that the final text length has a fixed length of 256 tokens. This results in the entire text being represented as a (256,768)-dimensional tensor. In this study, as with the image encoder, the text encoder effectively used local information in the text by extracting per-token embeddings from the intermediate layer of PubMedBERT. Specifically, the encoder tokenized the input text and obtained the 768-dimensional embeddings of each token from the intermediate layer to obtain embeddings that reflect contextual information while preserving the local features of each token. This process provides a foundation for cross-attention integration with image embeddings without losing per-token information.
2.2. Cross-Attention Layer
The cross-attention layer is crucial in integrating image and text embeddings and learning their interrelationship. In this study, we adopted cross-attention, which uses image embeddings as queries and text embeddings as keys and values. This design is based on the characteristics of text and images and the cross-attention mechanism. Specifically, text data has linear and information-dense characteristics, such as physicians’ diagnostic results and symptom descriptions, and attention mechanisms are effective in highlighting important information. Meanwhile, image data often has structures and lesions that are distributed in a multidimensional manner and are ambiguous. When considering this difference, the design with images as queries and text as keys and values is thought to be optimal for effectively referencing and integrating contextual information in text based on local information in images. Furthermore, the cross-attention output is calculated as a weighted sum of values; therefore, the quality of information contained in the values directly affects the results. This characteristic results in a design where using text with high information density as a value contributes to generating optimal embedding representations. Given the above reasons, this study adopts a cross-attention design with images as queries and text as keys and values.
The calculation of cross-attention is conducted as follows.
- 1.
Create queries, keys, and values;
Convert image embedding
into query
, and text embedding
into key
and value
:
where
are learnable weight matrices.
- 2.
Calculate attention score;
Calculate the inner product of queries and keys and perform scaling and normalization:
where
represents the attention score, indicating which text token each image token should direct its attention towards.
- 3.
Generate output;
Apply the attention score to the value to obtain an output that integrates image and text embeddings:
where
is the combined embedding.
- 4.
Feedforward network (FFN);
Apply a feedforward network to the output of cross-attention and conduct a nonlinear transformation. This further strengthens the feature representation.
- 5.
Layer normalization and residual connection;
Layer normalization and residual connections [
23] are applied to each layer to ensure learning stability and prevent the gradient vanishing problem.
In this study, we adopted a configuration that does not apply positional embeddings. This decision was made based on the characteristics of medical reports and the relationship between medical images and reports. Medical reports vary in writing style depending on the physician, and different expressions may be used for the same condition. Therefore, word-level information tends to be more important for diagnosis than sentence structure or word order. Additionally, in the medical domain, the presence or absence of specific terms, such as disease names and symptoms, often directly influences the diagnosis more than the overall meaning of the text.
On the other hand, medical images contain localized abnormalities (lesions), but they lack sufficient diagnostic information on their own. To address this, we adopted a design in which local information in images is used to reference medical reports (with images as queries and text as keys and values). To learn which information in the report corresponds to the lesion in an image, word-level relevance is more important than absolute positional information in the text. Consequently, applying positional embeddings may impose constraints on the flexible association of words within the text, potentially making information integration less efficient. A detailed comparative experiment and analysis of this effect are presented in
Section 4.
2.3. Loss Function
In this study, we adopted supervised contrastive loss (SupConLoss) [
24] to improve the discriminability between classes in the image and text embedding space. This loss function brings embeddings within the same class closer and moves embeddings of different classes further apart, thereby effectively promoting clustering in the embedding space.
SupConLoss brings all positive examples belonging to the same class closer to the anchor and moves negative examples of different classes further apart. The specific form of the loss function is as follows:
where
are embedding vectors corresponding to positive examples and all examples (including positive and negative examples), respectively;
is the index set of positive examples of the same class as anchor
in the batch;
is the index set of all examples in the batch except anchor
; and
is the temperature scale parameter that controls the scaling of the loss function;
is the total number of samples in the batch;
is the index set of all samples in the batch. When SupConLoss is adopted, embeddings of the same class are brought closer together, and those of different classes are pushed further apart. This design has the following features compared to the conventional triplet loss [
25] and N-pair loss [
26]. First, the loss is calculated using all samples in a batch, allowing for more stable learning. In addition, hard mining does not need to be explicitly conducted, which reduces the uncertainty associated with negative example selection. Furthermore, simultaneously considering many positive and negative examples results in the separability between classes in the embedding space being effectively learned. In this study, we adopted a temperature parameter τ = 0.07 and applied SupConLoss to model the embedding space of images and text in an integrated manner. This is expected to improve performance in retrieval and similarity calculation tasks.
2.4. Evaluation Metrics
The performance of the proposed method and the comparison methods in the retrieval task was evaluated using the following metrics. These metrics were selected due to their widespread use in prior research and their ability to comprehensively assess different aspects of retrieval performance.
This is an index that measures the accuracy rate in the top K retrieval results and is crucial for evaluating retrieval performance when the user only checks the top
K results:
where “Relevant results” refers to images and text in the same class as the query.
This is an index that calculates the mean of the average precision (
AP) for each query and is used to comprehensively evaluate the performance of the entire retrieval results. Here,
mAP evaluates the quality of the ranking of retrieval results by considering where related documents appear in the retrieval results:
where
R is the total number of candidates in the retrieval results that belong to the same class as the query,
P(
k) is the precision of the top k results,
rel(
k) is 1 if the candidate at position k of the retrieval result belongs to the same class and 0 otherwise, and
Q is the total number of all queries.
3. Experiments
3.1. Datasets
The experiments in this study used the MIMIC-CXR [
27,
28,
29,
30,
31], which is a publicly available medical dataset consisting of chest radiographs in DICOM format with free-text radiology reports. The dataset contains 377,110 images corresponding to 227,835 radiographic studies performed at the Beth Israel Deaconess Medical Center in Boston, MA. The data collection and sharing process were approved by the Institutional Review Board (IRB) at the Beth Israel Deaconess Medical Center, and a waiver of informed consent was granted. All data in the dataset are fully de-identified to comply with the Health Insurance Portability and Accountability Act (HIPAA) Safe Harbor requirements. Protected Health Information (PHI) has been removed using both automated and manual de-identification techniques.
Following the methods of MedCLIP [
15] and ConVIRT [
13], we extracted exclusively positive data for the five classes: atelectasis, cardiomegaly, consolidation, edema, and pleural effusion. Here, “exclusively positive” implies that each datum is positive only for a specific class and negative for the rest. We extracted and used the FINDINGS and IMPRESSION sections in the report for text data. Suppose that these sections did not exist; in that case, we used the last paragraph of the report. In the dataset, 20,713 samples contain both FINDINGS and IMPRESSION sections, while 1285 samples lack both sections. Additionally, 5141 samples contain only the FINDINGS section, whereas 11,102 samples contain only the IMPRESSION section.
The dataset was constructed as follows.
- 1.
Test data (mimic-5x200)
Here, mimic-5x200 includes 10 images of each class as query data and 200 images of each class as retrieval candidate data for each of the five classes (atelectasis, cardiomegaly, consolidation, edema, and pleural effusion). The dataset consists of 1050 images, and it was used to evaluate the retrieval task.
- 2.
Training and validation data
The remaining data not included in mimic-5x200 were split at 9:1 and used as training and validation data.
Image and text embeddings were pre-extracted using a pre-trained encoder. Image embeddings were represented as (197,768) dimensions (196 image patches + CLS token), and text embeddings were represented as (256,768) dimensions (256 tokens).
Figure 2 presents examples from the dataset used in this study. As shown in the figure, each report may contain either or both of the FINDINGS and IMPRESSION sections. The FINDINGS section outlines detailed radiological observations, while the IMPRESSION section offers a diagnostic summary based on these observations. If both sections are absent, the final paragraph of the report is used instead, as it may still contain diagnostic information. Additionally, the corresponding chest X-ray images are shown with the reports to illustrate their alignment.
3.2. Baselines
The following comparison methods were used to evaluate the performance of the proposed method.
BioMedCLIP: This is a vision-text integrated model that is specialized for the medical field, where 15 million image-text pairs— PMC-15M—were used for pre-training. The joint embedding of medical images and text achieved high performance in various medical tasks. Reproductions were based on the official code and provided a pre-trained model. A fair comparison was made with the proposed method in this study by adding the self-attention layer to the output embedding of BioMedCLIP and performing additional training by combining images and text. This allowed for a more equitable and more appropriate evaluation of the performance comparison with the proposed method. In addition, we designate BioMedCLIP as our primary baseline for state-of-the-art (SOTA) comparison for the following reasons:
Many existing studies on multimodal retrieval in the medical domain do not release their code or pre-trained models, making direct replication under the same experimental conditions difficult.
BioMedCLIP provides an officially released pre-trained model and code, ensuring reproducibility.
It has demonstrated high performance in various public medical image-text tasks and is currently recognized as one of the most effective open-source models.
Therefore, we treat BioMedCLIP as a practical SOTA benchmark to highlight the effectiveness of our proposed method, given the challenges in directly comparing with other methods under identical settings.
Simple combination method: In this method, image and text embeddings were integrated using straightforward techniques such as Concat (concatenation), Sum(α) (weighted sum), and Mul (element-wise multiplication). These combination methods were applied to embeddings extracted from the final layer of BioMedCLIP + Self-Attention to enable fair comparison under additional training conditions. The Concat method performs concatenation of the image and text embeddings along the feature dimension:
where
and
represent the image and text embeddings, respectively. This method allows the model to learn a fused representation from both modalities. In the Sum(α) method, the integrated embedding is computed as follows:
where
is a weight parameter that controls the balance between the two modalities. In the Mul method, the element-wise multiplication of image and text embeddings is performed:
where
represents element-wise multiplication. This operation captures the interactions between image and text features and emphasizes overlapping information. By applying these methods, we created three different baseline models to compare with our proposed method. These methods facilitate the analysis of the impact of different fusion strategies on retrieval performance.
3.3. Experiment Details
In this study, BioMedCLIP remained unchanged, and only the newly added Self-Attention and Cross-Attention layers were fine-tuned. The rationale behind this design choice is as follows: BioMedCLIP is a large-scale pre-trained model designed for medical image and text understanding. Since its feature extraction capability is already optimized for a wide range of medical datasets, re-training or fine-tuning the entire model from scratch would be computationally expensive and unnecessary for our specific retrieval task. Instead, we focused on optimizing the newly introduced layers to improve the alignment between image and text embeddings.
For training, we used the mimic-5x200 dataset described in
Section 3.1. Specifically, we used 33,471 image-text pairs for training and 3,720 pairs for validation. The training process was conducted using a learning rate of 1 × 10
−4, a batch size of 32, and a total of 30 epochs. The Adam optimizer was used with a dropout rate of 0.1. The Cross-Attention layer consisted of 8 attention heads.
We applied Supervised Contrastive Loss (SupConLoss) as described in
Section 2.3. During training, image-text pairs from the same disease category were encouraged to have similar embeddings, while pairs from different categories were pushed apart. This contrastive learning approach ensured that the model effectively captured the semantic relationships between medical images and their corresponding reports.
The training convergence was monitored using the loss function, and we observed that the model stabilized around epoch 10 to 12, indicating that additional training beyond this point provided negligible improvements. All experiments were run on an NVIDIA Tesla V100 GPU.
To ensure fair comparisons, we also trained a model where a Self-Attention layer was added instead of a Cross-Attention layer. By doing so, we aimed to verify whether the improvement in performance was specifically due to the interaction modeling capability of Cross-Attention. As discussed in
Section 4, our results confirm that fine-tuning the added layers alone is sufficient to achieve superior retrieval accuracy without requiring the full re-training of BioMedCLIP.
3.4. Results
The retrieval performance was evaluated using mAP and Precision@K. As described in
Section 2.4, these metrics measure the relevance of retrieved cases.
Table 1 presents the results of the retrieval tasks (Image-Image, Text-Text, Image-Text, and Text-Image) using the proposed and comparison (BioMedCLIP) methods. The proposed method outperformed the comparison method in all tasks. Notably, the proposed method achieved an mAP of 0.999, outperforming BioMedCLIP-based methods, which achieved a maximum mAP of 0.977 in the Text-Text setting. This indicates that integrating image and text embeddings with cross-attention enables more accurate retrieval results. Furthermore, we compared the proposed method both with and without positional embeddings, as shown in
Table 1. This comparison is analyzed in
Section 4.
Table 2 lists the results of comparing the performance of the proposed method with that of a simple combination method. The results indicate that the proposed cross-attention method outperforms simple fusion techniques such as Concat, Sum(α), and Mul. Specifically, even the best-performing weighted addition (Sum(0.1)) achieved an mAP of 0.980, which is lower than the proposed method’s 0.999. These results suggest that straightforward embedding fusion does not effectively capture the interactions between image and text modalities, whereas cross-attention enables a deeper and more meaningful integration.
We also evaluated the performance of the proposed method when the query and key/value settings were switched. Specifically, when the query was set to text embedding and the key/value was set to image embedding, the mAP dropped to 0.787, indicating a decreased performance. This suggests that using images as queries and text as keys/values represents a more effective configuration for retrieval, which is likely attributable to the higher information density of text data.
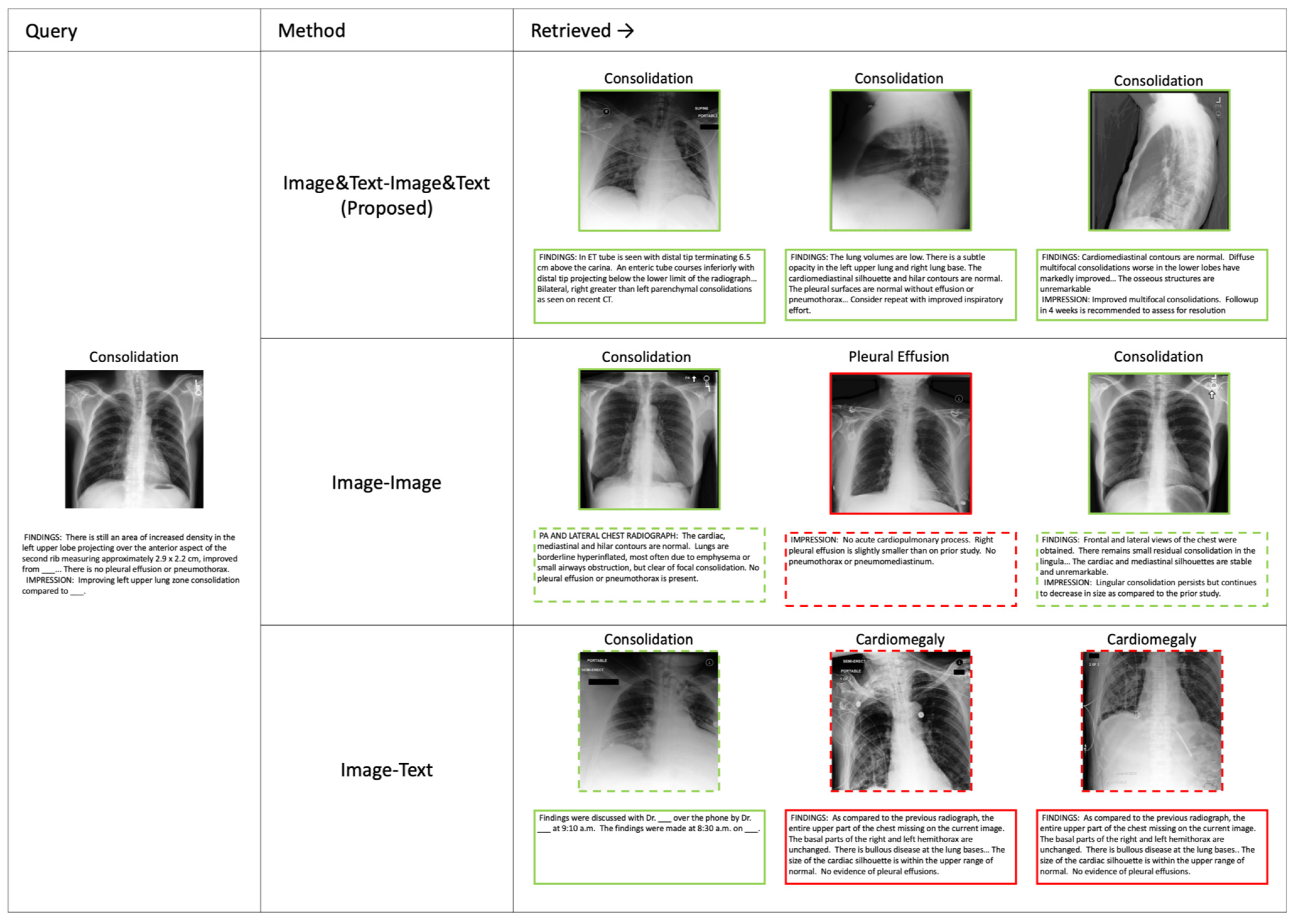
Figure 3 presents retrieval results for three different methods: Image&Text-Image&Text (Proposed), Image-Image, and Image-Text. The retrieved results are ranked, with green-bordered elements representing successful retrievals and red-bordered elements indicating errors. Additionally, the dotted-line elements represent information not used in the retrieval process but included for reference. The proposed method utilizes both image and text inputs for retrieval, while the comparison methods rely on either image or text alone. These retrieval results highlight the advantages of the proposed method in multimodal retrieval tasks, demonstrating its ability to leverage both visual and textual information effectively. A detailed analysis of these qualitative results is provided in
Section 4.
4. Discussion
In this study, we proposed an integrated representation of images and text and evaluated it in a retrieval task to demonstrate its effectiveness. The proposed method achieved higher performance than conventional methods, with an overwhelming accuracy of 1.00 for P@1, signifying that the appropriate retrieval results could be presented as the first result for all queries. This result suggests that the proposed method could effectively utilize the complementary information of both modalities by treating image and text information in an integrated manner. Conventional methods treated images and text as independent embeddings and retrieved them separately. However, cross-attention enabled the direct modeling of the relevance between images and text in our study. This characteristic allows for retrieval that considers complex information interactions, which produce highly accurate results.
In addition, we investigated the effect of using positional embeddings in the proposed method.
Table 1 shows that the proposed method without positional embeddings consistently outperformed the version with positional embeddings. This suggests that incorporating positional embeddings may introduce unnecessary constraints, limiting the flexibility of the attention mechanism. In medical text, keywords such as disease names and symptoms are more critical than sentence structure, making positional information less relevant. Furthermore, since our method aligns image and text embeddings based on semantic relationships rather than strict positional order, removing positional embeddings enhances the model’s ability to extract key information from medical reports effectively. These findings indicate that positional embeddings are not necessarily beneficial when integrating medical images and text in a retrieval system.
Additionally, the proposed method performed exceedingly well compared to the simple combination method, supporting the effectiveness of advanced information fusion using cross-attention. The simple combination method only mechanically combines image and text embeddings and does not sufficiently consider the relevance and interaction between them. We speculated that this limits the expressive power of the integrated embedding and decreases retrieval accuracy.
We also evaluated changes to the query and key/value settings in the proposed method and uncovered that it performed highest when images were used as queries and text as keys/values. Meanwhile, using text as the query and images as the keys/values resulted in an mAP of 0.787, confirming a decrease in performance. This result is possibly due to the fact that text has a high information density and can obtain highly accurate embedding representations when used as values. Specifically, in cross-attention, values are the basis for the final output; therefore, the information density of the data used as values directly influences the results. Using text as a value effectively utilizes its characteristics; however, performance improvement is assumed to be limited for images due to their ambiguity.
Furthermore,
Figure 3 presents qualitative retrieval results that complement the quantitative findings. The proposed Image&Text-Image&Text method consistently retrieves correct results, highlighting the advantage of leveraging multimodal information. In contrast, the Image-Image method frequently retrieves visually similar but incorrect images, as it relies solely on image features without textual context. This suggests that the lack of text-based information limits its ability to retrieve relevant cases accurately. Meanwhile, the Image-Text method struggles to align image and text embeddings effectively, leading to incorrect retrievals. These qualitative results support the superiority of the proposed cross-attention-based method in medical image retrieval, demonstrating its ability to integrate both modalities to improve search accuracy.
The retrieval method proposed in this study, which handles images and text in an integrated manner, is useful in education for residents and case collection due to its characteristics. The proposed method requires images and text as queries and has limitations in diagnostic support; however, the following application scenarios reveal its high practicality.
- 1.
Application in medical education
Using similar previous cases is effective when medical students and residents conduct case studies [
11]. The proposed method provides an opportunity to specifically learn about the diagnostic process and characteristics of cases by inputting images and corresponding diagnostic reports as queries and retrieving similar cases with high accuracy.
- 2.
Application in case collection
Regarding medical research, a retrieval method that considers the interaction between images and text can increase the selection of cases as research and survey subjects. The proposed method can efficiently and accurately collect highly relevant cases using images and text. This is expected to improve the quality of research by enabling the identification of cases that existing methods may overlook.
- 3.
Limitations in diagnostic support
Only images are assumed to be used as queries for diagnostic support; therefore, the direct application of the proposed method is limited. Particularly, text information is often unavailable before the physician writes the diagnosis, and using the characteristics of the proposed method would be challenging in this case. However, the applicable scenario can be expanded using this method in a complementary manner to existing diagnostic support systems.
Thus, we proposed a new retrieval method that handles images and text in an integrated manner and demonstrated its effectiveness; nevertheless, limitations and challenges remain.
- 1.
Applicability and limitations of the proposed method
The proposed method requires images and text as queries; therefore, its application may be limited as diagnostic support. Only images are assumed to be prepared as queries when a physician makes a diagnosis, making the direct use of the proposed method challenging. This aspect needs to be resolved by complementary use with a diagnostic support system or the development of technology to complement text information in the future.
- 2.
Bias due to characteristics of the experimental dataset
In this study, we conducted experiments using the mimic-5x200 dataset that was extracted from the MIMIC-CXR dataset. However, only five specific classes (atelectasis, cardiomegaly, consolidation, edema, and pleural effusion) were targeted; thus, its applicability to other diseases and more diverse classes needs to be evaluated. In addition, the MIMIC-CXR dataset is collected from a single hospital system in the United States and may reflect specific demographic characteristics and clinical practices. This can lead to biases in disease prevalence, imaging protocols, and patient demographics, making the model less generalizable to other regions or healthcare settings. Furthermore, MIMIC-CXR contains English text data, so its versatility is limited regarding non-English-language data. Consequently, models trained on this dataset may exhibit performance degradation when applied to medical data in other languages or when the clinical documentation style differs significantly. These forms of dataset bias potentially impact real-world applications. For instance, if the model is deployed in a region with different patient populations or languages, diagnostic performance and retrieval accuracy could decrease. Similarly, focusing on five classes in the present experiments may not cover complexities such as comorbidities or rarer diseases that appear in real-world clinical settings. Simon et al. [
17] also highlighted such issues in their review of multimodal AI, noting that data scarcity and potential biases in publicly available datasets (e.g., MIMIC) remain critical challenges. In agreement with their observations, our study underscores how limited disease categories and single-institution data can constrain the generalizability of retrieval performance. Although this study focused on a limited number of conditions, our approach is not fundamentally limited to these specific classes. Since the method learns the relationships between image and text representations, it has the potential to generalize to other diseases by incorporating additional and diverse training data. Future work will include experiments on a broader set of conditions to validate its generalizability and address the need for multi-language, multi-regional datasets to reduce biases.
The following research is necessary for overcoming these limitations:
Design of a flexible model that can handle cases where images and text are partially missing.
Additional experiments using medical datasets in other languages.
Extension and evaluation of the model to handle more diverse diseases and classes.
Resolving these challenges would enable the proposed method to evolve into a technology with wider applicability and promote its use in medical settings and research fields.





{kind=link}
{kind=link}
{kind=link}