1. Introduction
Industry 4.0, also known as the Fourth Industrial Revolution, represents a paradigm shift in manufacturing and industrial processes through the integration of the latest digital technologies. This revolution brings together the Internet of Things (IoT), artificial intelligence, machine learning, robotics, cloud computing, edge computing, and big data analytics to create highly automated, intelligent, and interconnected systems [
1,
2]. Industry 4.0 utilizes these technologies to enable real-time monitoring, predictive maintenance, and self-optimization of processes, leading to greater efficiency, flexibility, and cost savings. These innovations enable machines and systems to communicate with one another, collect and analyze vast amounts of real-time data, make autonomous decisions, and adapt dynamically to changing conditions. This convergence of physical and digital technologies transforms traditional industries, reshaping supply chains, enhancing productivity, and fostering innovation across sectors like manufacturing, logistics, healthcare, and energy [
1,
3]. The result is a more efficient, flexible, and adaptive production environment, where downtime is minimized and productivity is maximized.
Artificial intelligence (AI) plays a significant role in Industry 4.0 by driving automation, optimization, and decision-making processes within smart factories and industrial systems [
4,
5]. AI technologies, such as machine learning, neural networks, and computer vision, enable machines to analyze large volumes of data generated by sensors, IoT devices, and other systems. This allows for real-time monitoring, predictive maintenance, and autonomous adjustments to production lines, which significantly improves efficiency and reduces downtime. AI also supports quality control by detecting defects, analyzing patterns, and even suggesting improvements without human intervention. Furthermore, AI-powered systems enhance supply chain management by predicting demand, optimizing inventory levels, and streamlining logistics. Tiny devices (such as IoT devices) are increasingly being utilized to perform machine learning tasks. Even though these devices often have limited computational resources and memory, they are being used in machine learning training through techniques like edge computing, federated learning, and model compression [
6,
7].
Federated learning (FL), which is the most well-known approach for distributed industrial systems, offers significant benefits to enhance data privacy and reduce data transfer [
8]. However, maintaining model consistency across devices with different computational capabilities is a challenge. To address this, asynchronous updates and federated averaging algorithms are used, allowing devices to contribute to the global model at their own pace [
9]. One major challenge is data heterogeneity, where data distributed across different devices and locations may vary in quality, format, and distribution, leading to difficulties in training consistent and accurate models [
9,
10,
11]. Several methods have been proposed to address this challenge, including clustered and personalized federated learning techniques [
12], which train models to specific local environments while still contributing to the global model. Another challenge is model computation and communication overhead, as devices must frequently exchange model updates, which can strain network resources and reduce efficiency. Solutions such as model sparsification and compression techniques can minimize the amount of data exchanged between devices and the central server [
13,
14]. However, implementing compression and sparsification introduces delays and additional overhead, particularly for resource-constrained devices and real-time applications.
In this paper, we proposed a typical clustered federated learning approach that employs representative parameter sharing and utilizes previously recorded aggregated parameters to optimize performance and resources for industrial tiny devices. The server initiates training by distributing an initial model to connected edge devices. After local training, edge devices send updated parameters and computational resources back to the server. Once the server receives updates from all edge devices, it clusters them based on their data distribution and logs the updated parameters for future training rounds. To reduce unnecessary communication costs, only a powerful device from each cluster can send updates to the server as parameter distributions are similar within the cluster. Hence, the server selects two cluster heads per group, one active and one backup, based on computational resource, performance, and communication delay, which are responsible for handling the communication. Furthermore, previously aggregated parameter samples are incorporated into the aggregation process through weighted averaging, with newer parameters given a higher ratio to improve predictive performance. To the best of the authors’ knowledge, representative parameter sharing with one active and one backup cluster head, as well as the utilization of previously aggregated parameter samples, has not been explored in the existing literature for minimizing resource usage and enhancing performance in Industry 4.0 tiny devices.
The rest of this study is presented as follows.
Section 2 describes the related literature in the field, and
Section 3 briefs the proposed approach’s methodology with pseudocode, equations, and figures.
Section 4 presents the experimental evaluation of the proposed methodology with the existing state of the art. The conclusion and future work are presented in
Section 5.
3. Methodology
The Methodology Section outlines the approach adopted in this study, structured into five subsections:
Section 3.1: Overview of the Proposed Framework, describing the system’s design;
Section 3.2: Model Initialization, detailing initial parameter setup;
Section 3.3: Edge Device Training, explaining local training processes;
Section 3.4: Clustering and Cluster Head Selection, outlining the clustering approach and selection criteria; and
Section 3.5: Utilization of Previously Aggregated Parameters, discussing the use of past aggregated data to enhance performance.
3.1. Overview of the Proposed Framework
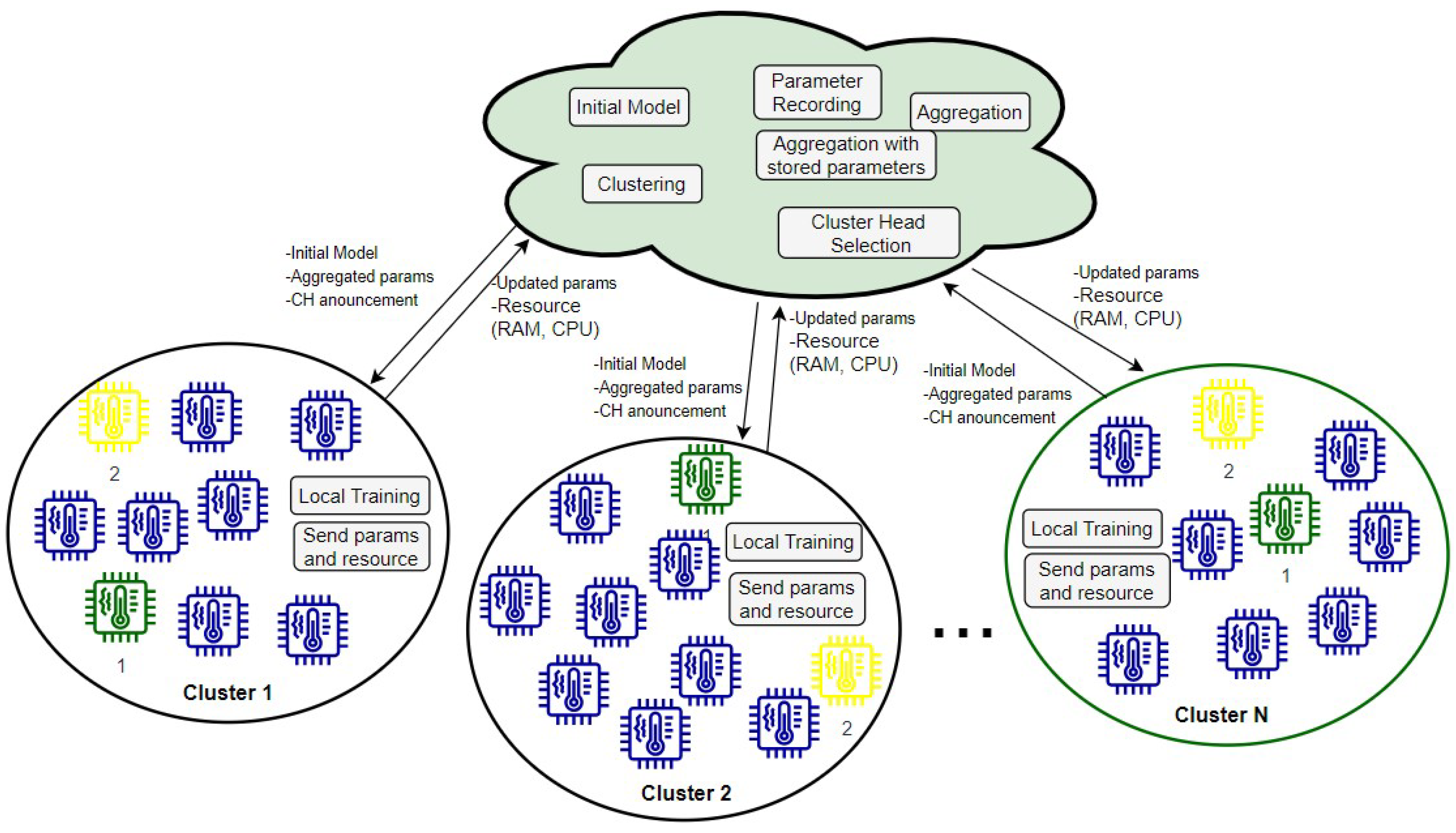
In this study, a representative-based parameter-sharing framework is proposed for clustered federated learning. As shown in
Figure 1, the training process is initiated by the server, which distributes the initial model to all connected edge devices. Upon receiving the initial model in the first round, edge devices begin training using their available collected data. Subsequently, they transmit updated parameters and computational resources back to the server. Upon receiving the updated parameters and computational capabilities of the edge devices, the server is responsible for clustering, selecting cluster heads, aggregating parameters, and finally distributing the aggregated parameters along with the announcement of the cluster heads.
If the parameter distribution of edge devices is similar, it is unnecessary to receive parameters from all of them in every round. Consequently, one of the most powerful edge devices in terms of resources and predictive performance within each group can send parameters to the server. Hence, the server gathers all parameters, performs clustering, and selects two cluster head candidates. The two cluster heads are elected based on their resource, performance, and delay. The top-ranked edge device, labeled green in
Figure 1, sends the parameters to the server, while the second-ranked device, labeled yellow in
Figure 1, serves as the backup cluster head. The clustering algorithm employs edge device parameters and data distribution for grouping. Then, the server sends a message for the elected devices, which announces if they are selected as cluster heads or backup cluster heads. This approach conserves communication costs, computational costs at the server, and parameter transmission at edge devices, and delays while aggregating redundant parameters.
All of the aggregated parameters are stored at the server. To enhance performance, we leverage samples of these stored aggregated parameters in the current aggregation process. The proposed method randomly selects some of the stored aggregated parameters and applies weighted averaging with the current aggregated value. The current aggregated value is assigned a higher ratio, while the remaining parameters receive a lower ratio. The ratio of the stored parameters depends on their age, with newer parameters receiving a higher ratio and older ones receiving a lower ratio.
3.2. Model Initialization
The central server initiates the training process by creating an initial global model, denoted as
. Algorithm 1 depicts the server-side operation, including parameter initialization, clustering, cluster head selection, parameter aggregation, and reuse of previously aggregated parameters. This initial model serves as the starting point for all edge devices participating in the federated learning process. The server distributes
to all connected edge devices simultaneously. These edge devices, which are typically distributed across different geographical locations and possess varying computational resources and local data distributions, receive the initial model parameters. This initial distribution ensures that every edge device starts the training process from the same baseline model, facilitating a more coordinated and synchronized training process across the network. By providing a unified initial model, the server sets a common ground for the subsequent training iterations, allowing the edge devices to begin their local training with consistent parameters. This step is crucial for maintaining uniformity and ensuring that the aggregation of parameters in later stages is meaningful and effective, ultimately contributing to the stability and convergence of the federated learning system.
| Algorithm 1 Server-side training |
- 1:
Input: - 2:
Output: - 3:
Initialize model parameters - 4:
if round then - 5:
Distribute to all edge devices - 6:
- 7:
Receive data distribution of edge devices (), performance, and resources of edge devices - 8:
▹ Server performs clustering - 9:
for each cluster in clusters do - 10:
▹ Select top 2 devices based on resources, performance, and delay - 11:
- 12:
end for - 13:
▹ Aggregation of parameters at the server - 14:
- 15:
▹ Store Aggregated Parameters - 16:
Broadcast aggregated parameters () and Cluster Head Status (CH status) - 17:
else - 18:
▹ Server receives parameters from cluster heads - 19:
- 20:
▹ Randomly choose among the aggregated parameters - 21:
- 22:
▹ Assign weight values to the set of chosen stored parameters - 23:
- 24:
▹ Aggregation of current parameters at the server - 25:
- 26:
▹ Current parameter update with stored parameters - 27:
▹ Store Aggregated Parameters - 28:
- 29:
Broadcast aggregated parameters () - 30:
end if
|
3.3. Edge Device Training
As shown in Algorithm 2, the edge devices start training after receiving the initial global model parameters
from the central server. Using these initial parameters, each device then proceeds to train the model on its own local dataset
. This involves running several iterations of a training algorithm. The process includes calculating the gradient of the loss with respect to the model parameters, updating the parameters accordingly, and repeating this over multiple epochs until convergence. Through this localized training, each edge device refines the model to better fit its specific data, resulting in updated parameters
that capture local data patterns. The local training allows each edge device to contribute unique insights from its own data without sharing the data themselves, thereby preserving privacy. By the end of each round of training, all edge devices have locally optimized versions of the model parameters, ready to be aggregated by the central server. This decentralized approach not only enhances the model’s overall performance and robustness by incorporating diverse data distributions but also maintains data security by keeping the data local to each device.
where edge device
receives
and updates it using its local data
, and Train(
, D) represents a training procedure that updates the model parameters
using the dataset D.
| Algorithm 2 Client-side training |
- 1:
Input: - 2:
Output: - 3:
if round then - 4:
Edge device receives initial model from the server - 5:
▹ Undertake training with the available data - 6:
Send , data distribution , performance, and resources to the server - 7:
else - 8:
receives aggregated parameters and CH status from the server - 9:
- 10:
if CH status = 1 then - 11:
Send parameters to the server - 12:
end if - 13:
end if
|
Once each edge device completes its local training, it transmits its updated model parameters back to the central server. Along with these parameters, the edge devices also send information about their computational resources, data distribution, and performance metrics. This additional information includes details such as processing power, memory availability, network bandwidth, and training efficiency, which are essential for the server to evaluate the capability and reliability of each device. This transmission allows the server to gather a comprehensive dataset comprising the updated parameters from all participating devices, as well as insights into the resources and performance of each device. This information is crucial for the subsequent steps, where the server will perform clustering and select cluster heads based on these metrics to optimize the federated learning process. The aim is to efficiently manage the communication overhead and computational load while ensuring that the model continues to improve in a resource-effective manner.
3.4. Clustering and Cluster Head Selection
Once the central server receives the updated model parameters
and resource metrics from all edge devices, it groups these devices into clusters based on the similarity of their parameter distributions and data characteristics. The goal is to create clusters (C1, C2, …, Ck) such that devices within the same cluster have similar parameter updates, indicating they are learning from similar data patterns. This grouping helps to optimize the federated learning process by reducing similar parameter transmissions and focusing on representative updates. Consequently, communication costs are minimized as the cluster members stopped transmitting updated parameters to the server. By leveraging the natural similarities among the devices, the server can ensure more efficient communication and aggregation, ultimately improving the overall learning efficiency and model performance.
where k is the number of clusters.
Following the clustering step, the server proceeds to select two cluster head candidates from each cluster k. These candidates are chosen based on a combination of factors, including their computational resources, predictive performance, and communication delay. The server evaluates each device within a cluster and ranks them accordingly. The top-ranked device, designated as the primary cluster head
, is responsible for sending its updated parameters
to the server. The second-ranked devices,
, serve as backup cluster heads. These backups ensure robustness in the system; if the primary cluster head fails or encounters issues, the backups can take over the transmission duties. By selecting cluster heads based on resource availability and performance, the server optimizes the parameter aggregation process, minimizes communication overhead, and enhances the reliability and scalability of the federated learning framework. This strategic selection ensures that the most capable and efficient devices are utilized to represent each cluster, thereby contributing to the overall effectiveness of the model training process.
where wC, wM, wP, wD are weights for CPU, memory, performance, and delay, respectively
For electing cluster heads, we utilized a multi-criteria decision-making approach, as presented in Equations (3)–(8) and Algorithm 3. It begins by taking input metrics for each IoT device, including CPU capacity, memory capacity, prediction performance, and communication delay, along with assigned weights for each criterion. It then normalizes these metrics to a common scale, where higher values represent better performance (except for communication delay, where lower values are better). We assign an equal weight for all criteria to avoid bias, as prioritizing each criterion depends on specific application scenarios and expert decisions. Next, it computes an aggregate score for each device by applying the weighted sum of these normalized values. Finally, the device with the highest aggregate score is selected as the cluster head.
| Algorithm 3 Multi-criteria decision-making approach for cluster head selection |
- 1:
Input: Performance (Perf), Communication Delay (Delay), Resources (CPU, MEM) of edge devices - 2:
Output: Selected Cluster Heads (, ) - 3:
Server receives performance (Perf), communication delay (Delay), and resources (CPU, MEM) of edge devices - 4:
Initialize weights uniformly (, , , for CPU, memory, performance, and delay respectively) ▹ Normalize the criteria - 5:
for each edge device do - 6:
- 7:
- 8:
- 9:
- 10:
end for ▹ Calculate score for each edge device - 11:
for each edge device do - 12:
- 13:
end for - 14:
▹ Select the top 2 edge devices with the highest scores - 15:
|
3.5. Utilization of Previously Aggregated Parameters
The server continuously records the output of the aggregated parameters from each round. In this phase, the central server retains a history of past aggregated model parameters to enhance future aggregation processes. By maintaining this repository, the server can leverage the diversity and robustness of these historical parameters. The stored aggregated parameters reflect various stages of model training influenced by different subsets of edge devices and their local data distributions, thus enriching the server’s capability to produce a more generalized and stable model in future rounds. This storage mechanism is a strategic measure to prevent the loss of useful information and to continually improve the model by integrating knowledge from past iterations. These sets of stored parameters can be denoted as
where t is the number of the current round, and S is the set of stored aggregated parameters
The server takes samples of previously aggregated parameters and utilizes weighted averaging to incorporate them into the current aggregation. Once the server receives the current round’s parameters
from the selected cluster heads, it performs a weighted averaging of these parameters with a randomly selected subset of stored parameters
. The recent set of aggregated parameters is assigned a higher weight
to ensure that the latest training updates have a significant impact on the global model. The stored parameters are assigned weights
based on their age, with newer stored parameters receiving higher weights than older ones. The equation for weighted averaging is formulated as
where
is the weight for the current aggregated parameters,
is the weight for the stored aggregated parameters (
),
is the current aggregation output, S’ is the set of selected parameters
, and
is the set of selected stored aggregation.
This method was designed to balance the influence of recent updates with the historical knowledge captured in previous rounds, promoting a more stable and robust model. By integrating past and present parameters, the server enhances the model’s ability to generalize across diverse and potentially non-IID data distributions from different edge devices. This weighted averaging approach helps mitigate the effects of noise and outliers in any single round, leading to a more consistent and reliable federated learning process.
4. Results
In this section, we present and analyze the results obtained from the experimental evaluation to assess the performance of the proposed approach compared with existing methods. The experiment was performed on a machine with 64 GB RAM and an “NVIDIA GeForce RTX 4060 Ti” GPU processor (Santa Clara, CA, USA), operating at a base clock speed of 3.2 GHz. The proposed algorithm was implemented using Python with the TensorFlow framework. We selected Gated Recurrent Units (GRUs) for implementing the proposed approach due to its ability to efficiently handle complex time-series data. GRUs are highly effective at capturing temporal dependencies while being computationally lighter than other recurrent neural networks, which makes them suitable for resource-constrained devices. Their lightweight architecture ensures faster training and inference, which is crucial for applications on devices with limited processing power and memory.
We employ a multi-threading approach to simulate the implementation of the client–server architecture [
36,
37]. The server program operates on the main thread, while separate threads are allocated for each task running on edge nodes. Tasks including model initialization, parameter recording, clustering, cluster head selection, and aggregation are executed on the main thread. In contrast, the tasks in Algorithm 1 for edge devices, which involve local training and resource and parameter sharing, are processed in subthreads.
The remainder of this section is structured as follows:
Section 4.1: Dataset and Evaluation Metrics describes the data used and the metrics for evaluation;
Section 4.2: Baseline Methods outlines the comparison approaches;
Section 4.3: Time Complexity Analysis, analyzes the computational efficiency; and
Section 4.4: Simulation Results, presents and interpreting the outcomes of the experiments.
4.1. Dataset and Evaluation Metrics
The experiment utilized the Ton-IoT testbed dataset sourced from the University of New South Wales, focusing on specific subsets among a total of seven distinct sensor datasets [
38]. In particular, the Weather and Thermostat datasets, which include both attacked and normal categories, were utilized among the seven subsets of the Ton-IoT dataset to assess the effectiveness of the proposed methodology. The rationale for choosing the weather subset is its significant impact on industrial processes, such as cooling and heating systems, while the thermostat subset represents internal control systems critical for maintaining operational efficiency in industrial environments. The weather subset contains 650,242 records, with 14% of them being attacked, while the thermostat subset has 442,228 records, 13% of which are attacked. The entire dataset was evenly split into 40 rounds to simulate federated learning, with 70% of the data used for training the model and 30% reserved for testing.
A comprehensive comparative analysis was conducted between the proposed approach and the selected baseline methods. A variety of metrics were used in this evaluation, including accuracy, precision, recall, first harmonic mean of precision and recall (F1-score), time complexity analysis, and processing time. The processing time and time complexity analysis were utilized to assess the computational cost and complexity associated with both the proposed and the baseline methods. Besides, we computed the standard deviation (
) of the accuracy to measure the variability in the results across rounds. This provides insight into the consistency of the model’s performance, with lower values indicating stable accuracy and higher values reflecting greater fluctuations.
Table 1 presents the parameter settings employed during the experiment.
4.2. Baseline Methods
The proposed methodology was meticulously evaluated against Federated Averaging and Clustered Federated Averaging (Clustered Fed-Avg), which are the most widely adopted frameworks in the realm of federated learning [
33,
36]. This comparative analysis aims to demonstrate the advantages and efficiencies of the proposed approach, particularly in terms of its prediction performance and computational efficiency. By contrasting the proposed method with Federated Averaging and Clustered Fed-Avg, this study aimed to demonstrate how the proposed method addresses some of the limitations associated with traditional federated learning methods. This comparison provides valuable insights into its potential applications and contributions to the advancement of federated learning practices in Industry 4.0.
4.3. Time Complexity Analysis
Both theoretical and runtime evaluations were conducted to assess the effectiveness of the proposed approach. Time complexity analysis was assessed to evaluate the computational overhead. As depicted in Algorithm 1, edge devices should only send the updated parameters in the first round, which saves the additional resources required for sending them back. For the subsequent round, only the cluster heads are required to send updated parameters. Hence, let D be the dimension of the parameter and R be the number of rounds; then, the time complexity for sending parameters is O(1) and receiving parameters is . However, the time complexity of Federated Averaging and Clustered Fed-Avg for both sending and receiving is , since they must send and receive from all member edge devices. The time complexity of parameter aggregation for the proposed method is , as the server receives updated parameters only from each cluster head: where C is the number of clusters. In contrast, for Federated Averaging and Clustered Fed-Avg, the time complexity is , where N is the total number of edge devices. The server should also undertake clustering, cluster head selection, and sampling of the stored aggregated parameters. For the cluster head selection process, lines 5 through 13 of Algorithm 3 include two independent loops, resulting in a time complexity of . The time complexity of clustering and sampling depends on the specific methods utilized.
To sum up, the cluster members can conserve resources required for sending updated parameters compared with Federated Averaging and Clustered Fed-Avg. The cluster heads need to send updated parameters, but they are able to manage this as they are assumed to have better resources than the other cluster members. Although the server incurs some additional overhead for storing aggregated parameters, clustering, cluster head selection, and sampling the aggregated parameters, it only aggregates a smaller number of parameters sent by the cluster heads.
4.4. Simulation Results
Figure 2a,b presents a comparison of the training times for the weather and thermostat datasets, respectively. These figures clearly highlight that the proposed model significantly reduces the training time in comparison with the Federated Averaging and Clustered Fed-Avg. The reduction in training time becomes particularly noticeable starting from the second training round. This notable improvement is primarily due to the proposed model’s ability to cluster the edge devices and focus on training only the cluster heads’ data after the first round. By limiting the training to the most representative data from the cluster heads, the model avoids redundant processing, resulting in a more efficient training process.
Table 2 and
Table 3 depict the experimental outcomes assessing the performance of the proposed approach on weather and thermostat datasets, respectively. The results demonstrate that the proposed method achieves notable improvements over the baseline approaches. Specifically, it enhances the model’s ability to categorize data points with their respective labels. This improvement underscores the efficacy of the systematic strategies employed in the proposed methodology. Specifically, the utilization of previously aggregated parameters in the current round, combined with the grouping of edge devices by similar distributions for aggregation, significantly contributes to the improved results.
5. Conclusions
This study introduces an enhanced clustered federated learning approach by incorporating representative-based parameter sharing and utilizing previously stored aggregated parameters to optimize resources and improve performance. By strategically clustering edge devices based on their parameter and data distributions, the proposed method reduces the parameter transmissions from all member edge devices, thus minimizing communication and computational costs. The use of cluster heads that are selected based on resource availability, performance, and latency further enhances efficiency by allowing only the most capable devices to transmit updated parameters. Additionally, the weighted averaging of stored aggregated parameters with new values improves the model’s performance over time, with a bias towards more recent data. The results of the experimental evaluation are promising in terms of resource optimization and prediction performance.
In the proposed method, equal weights have been applied to the cluster head selection criteria; however, future work could delve into biased weight assignments based on the relative importance of the criteria for specific application scenarios. Due to resource limitations, the experiment was conducted using threading simulation and two subsets of TON-IoT datasets. Hence, future works could focus on securing additional resources to enable practical implementation and testing of the proposed method on more real-time datasets.





{kind=link}
{kind=link}