4.2. Biased-BN Strategies
In our first experiment, we investigate the impacts of using diverse BN initialization strategies on the training process of a plain neural network with a depth of 90 intermediate blocks, as defined in
Figure 6. According to our introductory examination of the degradation problem in
Figure 1, a plain network with a depth of 90 blocks noticeably suffers from degenerative effects for the standard BN
initialization with conventional activation functions. Specifically, we want to address in our experiment the following Research Questions (RQ)s:
- RQ 1:
Can BN layers act as ANGs for subsequent activation functions to enable the training of deeper neural networks?
- RQ 1a:
What are preferable BN initializations?
- RQ 1b:
What is the appearance of BN’s parameters after successful model training?
To be consistent with the analysis setup in
Figure 1, all configurations are applied on the MNIST classification dataset for five runs with 180 epochs each. For the default BN
initialization, we re-use the previous analysis results which are emphasized with an asterisk appended to the configuration name. The analysis results of testing varying BN initialization strategies are illustrated in
Figure 7. In addition,
Table 2 and
Table 3 summarize the final accuracies reached after the application of all training epochs.
RQ 1a: The development of the training losses in
Figure 7 reveal the importance of an appropriate harmonization between the initialization of BN’s parameters and the utilized activation function. In accordance with our former thoughts, shifting the input distribution to rectified activation functions into one of their linear regions drastically improves the performance for the best model and all models on average without additional costs. In particular, the analysis results in
Figure 7 and
Table 2 support our hypothesis that a small overlap between the input distribution and nonlinear regions of an activation function may be helpful for steering network optimization. In that sense, ReLU and ELU effectively mitigate the degradation problem with BN
but become stepwise inferior when further increasing the bias parameter
. However, Leaky ReLU counterintuitively works best for BN
on average, indicating a latent interdependence between the type of nonlinearity and the degree of its usage through the input distribution.
The training progressions for the sigmoid and the hyperbolic tangent illustrate that point-symmetric activation functions to the origin potentially profit from input distribution scaling, which also controls the usage of nonlinear regions. Although sigmoid and tanh can effectively prevent network degeneration for single runs with a parameter initialization of
, their performance on average remains unstable, as displayed in
Table 3. This circumstance can be explained with Equation (
16) that emphasizes the impact of the scaling factor
on the variance in feature values. Thus,
is a more critical parameter to adjust than
because of its direct influence on the severity of layer-wise feature discrimination.
The analysis results imply that biasing the initialization of BN
towards linear processing regions of the activation function is crucial if the
nonlinear capacity of a neural network exceeds the required representational expressiveness determined by the application task complexity. Since the degradation problem occurs in very deep networks with linear activation function (cf.
Figure 1), we recommend selecting the parameter
to locate the normalized input distribution in linear progress with small overlaps of nonlinear behavior. We assume that a limited degree of nonlinear behavior allows a neural network to transfer only a relevant subset of output signals per layer which prevents information diffusion.
RQ 1b: The last two rows in
Figure 7 display the mean parameter deviations per BN layer from their initial values. For obtaining meaningful results, the parameter constellation of the resulting models from the superior BN initialization scheme is considered for each activation function. Parameter deviations are visualized for the best run and as average over all runs per subplot. The computation rule for the mean deviation of the bias parameter
is stated as
where
l specifies the index of the considered BN layer,
n equals the number of features in this BN layer and
corresponds to the initial parameter value. Since we apply the same initialization scheme to all BN layers and each intermediate block in our network architecture contains an equal number of neurons,
n and
stay identical for all BN layers. The computation rule in Equation (
21) analogously holds for the scaling parameter
.
Regarding the mean deviations for the parameter , we observe a similar pattern of parameter usage independent from the concrete activation function. In more detail, the neural networks tend to increase their parameter adjustments beginning from the centered layers, at half of the network depth, into the direction of the first and the last network layers. These parameter adjustments form a valley-like structure with, typically, a higher mountain arising in the lower network area. A straightforward explanation for the strong bias parameter modifications in the lower network layers constitutes the process of representation learning, in which the selective power of nonlinearities is accessed to differentiate between sample features in order to establish higher-order object classes. We assume that this process continues until a suitable granularity level of object classes is reached for achieving the training objective. In the case of the MNIST dataset, the highest-order entities probably correspond to the ten digit classes. The continual decrease in parameter adjustments from the lower network layers to the centered layers visualizes the diminishing of feature/concept diversity with increasing abstraction level, i.e., few higher-order concepts are composed of many lower-order concepts.
Since the network potential exceeds the needed representational capacity for solving the MNIST classification task, the final entity encodings are passed via almost linear processing through the centered network layers. The absence of degradation effects despite the long sequence of nearly linear processing layers around half of the network depth supports our former assumption of preventing information diffusion by eliminating individual neuron outputs per layer. We hypothesize that the increasing parameter modifications after the centered layers serve the task-specific interpretation of the learned representations with a rising degree of detail. Possibly, this circumstance also holds for shallower neural networks but is usually not observable because of an almost full exploitation of nonlinear capacities.
The last row in
Figure 7 highlights the sparse usage of the scaling parameter
in contrast to the bias parameter
. The main purpose of optimizing the parameter
appears to control the feature variances according to Equation (
16). This explanation is supported by the slight parameter deviations in the lower layers which we assign to the process of representation learning, and the strong parameter adaption in the last layer for increasing the sensitivity to feature discrimination with the aim to solve the classification task.
RQ 1: The analysis results point out that BN layers can indeed act as ANGs for subsequent activation functions to enable the training of deeper neural networks. A necessary requirement, for example, is a BN initialization scheme that biases the network mechanics towards linear processing at the start of the training procedure. On the one hand, adjusting the bias parameter is a cost-free option to effectively mitigate the degradation problem with relatively stable performance over several runs. On the other hand, the scaling parameter has a limited ability to restrict the usage of nonlinear behavior and significantly influences the severity of feature discrimination, leading to a fragile performance over multiple runs. The experiment results indicate that the centric linear regions in the point-symmetric activation functions of sigmoid and tanh may be insufficiently large to establish ANGs through BN layers. Interestingly, ReLU achieves superior performance with the desirable properties of fast convergence and high accuracy with small variance over several runs, but only for the BN initialization scheme.
Despite the stabilizing effects of a proper BN initialization on the resulting performance of deeper neural networks, the training progress in
Figure 7 rarely constitutes monotonically decreasing functions. Specifically, we assume that the heavy peaks in the training losses occur as a consequence of parameter adjustments in the lower layers that cause accumulated modifications in the neural activity of the following layers, leading to strong gradient changes. This situation is probably even amplified by the disruptive nature of nonlinearities. Consistent with these observations, the training process takes a long duration on average to consolidate an adequate direction of optimization. Nevertheless, the results suggest that network depth remains an important factor for the required number of training epochs due to the needed time for learning the passing of the relevant output signals per layer. In the subsequent experiment, we will investigate how the training process of very deep neural networks can be further stabilized.
4.3. Handling Salient Gradients with AMSGrad
AMSGrad [
46] extends gradient descent optimizers which are based on moving averages, such as Adam, to normalize their gradient updates by means of the maximum gradient change observed in the training course. This proceeding especially prevents temporary increases in the effective learning rate for rare but salient gradients [
46]. Our motivation behind the equipment of the Adam optimizer with AMSGrad is summarized in the following research question:
- RQ 2:
Does AMSGrad improve training loss convergence for deeper neural networks through sober handling of salient gradients?
To answer this question, we investigate the smoothness of the training loss progress when Adam is enhanced with AMSGrad. For this purpose, we run the same setup as in our previous experiment with 90 intermediate blocks but apply solely the superior BN
initialization strategy per activation function. The analysis results are visualized in
Figure 8 and
Table 4.
RQ 2: According to
Figure 8, the slight modification of AMSGrad in the Adam optimizer substantially smooths the training loss progress and promotes fast convergence in the early training stages for all considered activation functions.
Table 4 exhibits that AMSGrad leads to higher final accuracies with significantly smaller variance over multiple runs for the rectified functions. In fact, AMSGrad improves the best-reached accuracies for ReLU, Leaky ReLU and ELU with superior BN initialization by
percentage points, respectively. The corresponding mean accuracies are even more convincing with an improvement of
percentage points and a vanishing small variance each time below a quarter of a percentage point. These results indicate that AMSGrad’s handling of salient gradients allows properly initialized deeper neural networks to make use of their extended network depth in fulfilling the defined training objective. Specifically, AMSGrad prevents network degeneration by obviating the falling into a network configuration with an exceeded integration of nonlinear behavior. It is noteworthy that the high accuracies in
Table 4 result from a network with a bandwidth of solely 32 neurons in each fully connected hidden layer. This observation supports the well-known intuition of the representational power induced by the vertical depth of a neural network. The symmetric activation functions tanh and sigmoid still suffer from their insufficiently large linear interval around the origin, which is observable through their fragile performance over multiple runs. The exceptionally high accuracy in the best run for tanh may be explainable as a lucky beneficial network parameter constellation which was mainly reached by chance. Nevertheless, AMSGrad entails the tendency to reduce the occurrence of disruptive parameter changes during network optimization. We assume that this tendency accounts for the degraded performance of the sigmoid activation function in the current experiment.
All experiments conducted so far imply that adding nonlinear behavior works similarly to a trapdoor function, where introducing further nonlinearities in a neural network is controllable by the learning procedure but the intentional reverse operation appears as an over-proportional more severe or even impossible task. In general, our empirical results suggest that a biased network initialization towards linearity and the smoothing of salient gradients with AMSGrad, not only retains performance but enables deeper neural networks to translate auxiliary nonlinear capacities into performance improvements. Since the optimization of deeper neural networks provokes strong gradient changes initiated by the accumulated effects of parameter adjustments over the vertical network size, we identify the appropriate handling of salient gradients, e.g., with AMSGrad, as an essential requirement for training success.
Motivated by the positive results with AMSGrad, we investigate in our next experiment how the training convergence is affected by further increasing the network depth. Again, we formulate the analysis reason as a research question:
- RQ 3:
What are the limitations of initially biased scalar-neuron networks towards linear processing regarding an increase in network depth?
In this experiment, we plan to aggressively increase the network depth with
intermediate blocks to reveal if performance degeneration still occurs and how it precisely appears. As the rectified functions performed similarly well for a depth of 90 blocks, the analysis is restricted to the use of ReLU with BN
. Our previous experiment emphasized the fast convergence of the training loss if AMSGrad is applied. To save valuable computational resources, we first determine the required number of epochs until convergence. The accuracy gain
at epoch
t for all remaining epochs
can be defined as
where
means the expected accuracy after epoch
t and
equals the expected accuracy value of convergence. For the sake of simplicity, we assume that all training courses produce only monotonically increasing accuracy functions. The gain in accuracy is approximated based on the mean training loss development from the preceding experiment. The left subfigure (a) of
Figure 9 presents the percentage gain in accuracy for the activation functions ReLU, Leaky ReLU and ELU. In each case,
is chosen as the final accuracy value after the termination of the 180 training epochs. ReLU and ELU achieve after circa 70 epochs
of the final accuracy value, whereas ELU takes about additional 30 epochs. Since we expect a network with a further increased depth and an initialization biased towards linear processing to converge within a similar time window as the identical network with fewer layers, we restrict the training process for all network depths to 80 epochs. The experiment results are summarized in subfigure (b) of
Figure 9 and in the first section of
Table 5.
RQ 3: In subfigure (b) of
Figure 9, we still encounter the degradation problem where network performance gradually degenerates with an increase in network depth. In accordance with our expectations, all losses seem to converge at an early stage of the training process. Moreover, AMSGrad effectively smooths the training loss curves, even for the deepest network with 500 intermediate blocks. Interestingly, the use of biased batch normalization towards linear processing and AMSGrad enables a network with 300 fully-connected layers in the best run to retain an accuracy over
for the MNIST classification task after solely 80 training epochs, as reported in
Table 5. Performance degeneration probably still happens, despite initially biased linear processing capabilities, because of the conceptual deficiency in single-path plain networks to establish direct identity mappings.
4.4. Linear-Initialized Parametric Activation Functions
Now we want to examine if parametric activation functions can create ANGs in a similar manner to BN, and if both strategies can cooperate to enhance the resulting network performance. For this purpose, we formulate the following research questions:
- RQ 4:
Constitute parametric activation functions a valid alternative for realizing ANGs?
- RQ 4a:
Can BN and parametric activation functions operate complementary?
- RQ 4b:
What is the parameter appearance of BN and the parametric activation function after successful model training?
To answer these questions, we sequentially investigate the effects of the parametric activation functions PReLU, SReLU/D-PReLU and APLU on the resulting model performance. All configurations train a neural network with a depth of 90 intermediate blocks on the MNIST classification dataset over five runs with 180 epochs each. The Adam optimizer is equipped with AMSGrad for smoothing salient gradients. To explore the influence of PReLU and APLU on network stability isolated from BN (apart from BN’s distribution normalization property), we test both activation functions with BN
and BN
. According to the empirical results in [
31], we choose for APLU the numbers of piecewise-linear components of
. In the case of D-PReLU, the biased BN initialization uses a random choice between the values
with equal probability per neuron to ensure a balanced usage of nonlinear regions. For a fair comparison between SReLU and D-PReLU, SReLU’s adaptive thresholds follow the initialization
and
. In contrast to the use of solely biased BN, initializing parametric activation functions towards linear processing creates network symmetry without overlaps of nonlinear regions. To counteract this condition, we additionally try for PReLU’s learnable parameter, an initialization with slight variation, i.e.,
. The experimental results are reported in the first four columns of
Figure 10 and in
Table 6,
Table 7 and
Table 8.
RQ 4: The first two columns of
Figure 10 visualize the mean and best training loss developments for the parametric activation functions. First of all, involving a small variation in the initial parameter values of PReLU slightly accelerates training convergence independent from the concrete BN initialization. For that reason, the parameters of SReLU (thresholds excluded), D-PReLU and APLU were also initialized with the same degree of variation for all configurations. At this point, we see a differentiated picture insofar PReLU suffers from slightly degraded accuracy with higher result variance if BN is initially biased, but APLU significantly benefits from biased BN. D-PReLU with its biased BN strategy actually achieves the highest accuracy on average with marginal variance. Surprisingly, although SReLU possesses auxiliary threshold parameters that are jointly learned during training, performance still degenerates at certain points that cannot be fully recovered. Despite APLU’s expressive power for function approximation, increasing its number of piecewise-linear components drastically reduces the training convergence and resulting performance when unbiased BN is used. Thus, parametric activation functions can potentially constitute a valid alternative for realizing ANGs, but they assemble less smooth transitions for integrating nonlinear behavior than biased BN.
RQ 4a: According to
Table 7 and
Table 8, the combined use of D-PReLU and APLU with biased BN indeed operate complementarily. Result variance is kept minimal and final accuracies are at least slightly enhanced. Especially, APLU can only benefit from a raised amount of components if BN is initially biased. PReLU shows the inverse relationship in
Table 6. However, its training loss also converges faster and smoother with biased BN.
RQ 4b: The third and fourth columns of
Figure 10 display the final parameter deviations of BN and the parametric activation functions from their initial values, indicating the usage level of nonlinear behavior per network layer. For each activation function, the superior model configuration by means of the highest-reached accuracy on average is used. Except for APLU, the single-component variant is preferred for better visualization. The parameter modifications agree with the results from our previous experiments where mostly linear processing occurs around the centered layers at half of the network depth. Again, these results imply that initially biasing a neural network towards mostly linear processing serves a network to restrict nonlinear behavior before degradation effects arise.
Finally, we elaborate on the robustness of parametric activation functions against the degradation problem by gradually increasing the network depth:
- RQ 5:
To which extent alleviate parametric activation functions the degradation problem regarding an increase in network depth?
Per parametric activation function, the superior configuration from the preceded experiment is utilized. The analysis results are summarized in the last column of
Figure 10 and in the corresponding sections of
Table 5.
RQ 5: The mean training loss progress in the last column of
Figure 10 reveals a special resilience of parametric activation functions against the degradation problem; preconditioned, the number of adjustable parameters per activation function is moderate. In that sense, PReLU and D-PReLU outperform APLU with its five piecewise-linear components resulting in ten learnable parameters per neuron. It is remarkable that PReLU and D-PReLU keep performance degeneration relatively small in vast networks with five hundred stacked fully connected layers. This observation leads to the insight that parametric activation functions could constitute a crucial factor in facilitating the training of enormously deep neural networks. This insight is also supported by the permanent high accuracies achieved in the best run per network depth, as stated in
Table 5. In fact, the minor performance reductions in PReLU and D-PReLU in the best runs can probably be attributed to the constant number of 80 training epochs for all network depths. However, the degradation problem still arises as an average performance deficit with a significant gain in result variability. One possible explanation to harmonize both contradictory observations is the disruptive nature of activation function modifications, which might be helpful for faster exploration of the available solution space.
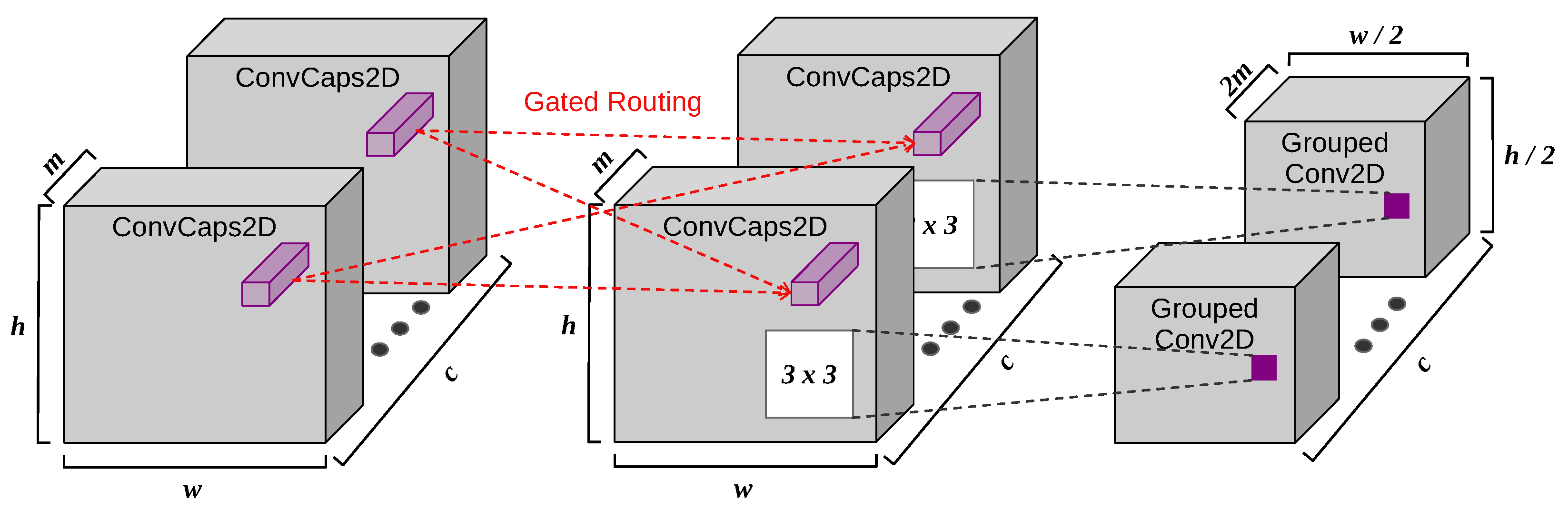
4.6. Convolutional Capsule Network
In our final experiment, we investigate the potential of a pure capsule-driven network with GR on the task of image classification. For this purpose, we apply a convolutional CapsNet on the datasets Fashion-MNIST and SVHN. In short, the network is composed of capsule-based feature maps with GR between feature maps of the same dimensionality,
grouped convolutions [
27] for downsampling feature dimensions, and 30 dense capsule blocks. Network scaling is modest in order to keep computation time feasible. A detailed architecture description can be found in
Appendix C. To the best of our knowledge, this is the first pure capsule-driven architecture. Usually, capsules merely take place in the final two network layers of an extended net structure. We formulate the following research question:
- RQ 7:
Provide capsules the potential to embody arbitrary-level entities?
As a strategy against overfitting, dataset-specific data augmentation is used. The data augmentation for Fashion-MNIST includes horizontal flip (
), random zoom and translation with factors of
. The data augmentation for SVHN imitates the natural variances in the data using random zoom, translation and shear with factors of
. In addition, random rotation with a maximal magnitude of
from
is employed. For each dataset, five randomly initialized CapsNets are trained over 100 epochs. The experimental results are illustrated in
Figure 12 and
Table 10.
RQ 7: The training and validation loss developments in
Figure 12 point out that entirely capsule-oriented networks can operate on low-level and high-level entities. This is also supported by the adaptation of GR’s bias parameter similar to our previous results. However, our pure CapsNet does not achieve state-of-the-art test accuracy, as stated in
Table 10. We attribute this deficit to CapsNets’ major limitation of intense computational complexity, resulting in long training sessions even for small architectures. We have the hope that future research into efficient routing algorithms and their low-level implementations will make CapsNets applicable to a broader range of machine-learning tasks.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}