
Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures



Abstract
1. Introduction
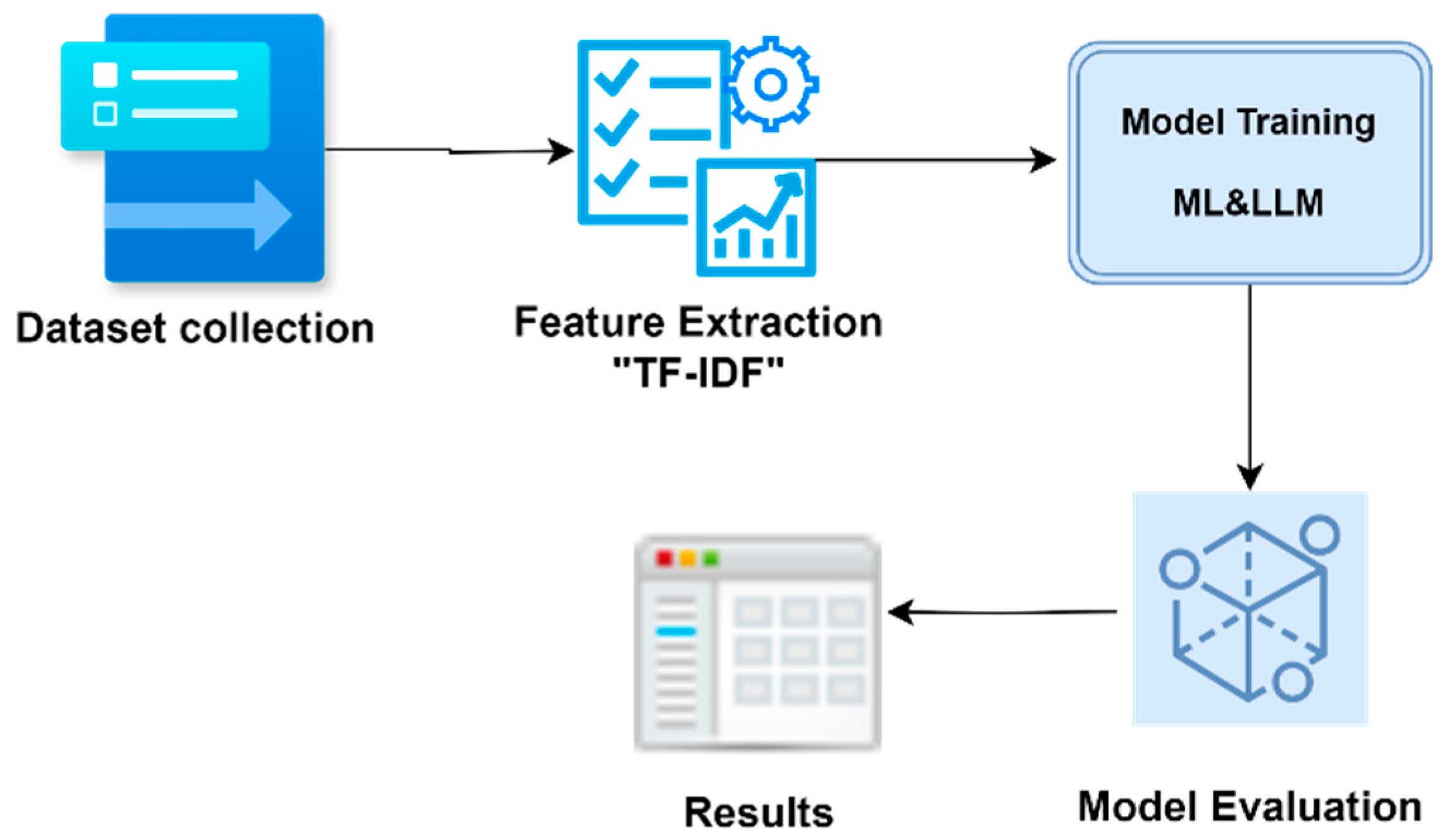
2. Materials and Methods
2.1. Enhancements in Online Recruitment Systems through AI and ML
2.2. Enhancements in Online Recruitment Systems through LLMs
- Dataset Description:
- TF-IDF Vectorization:
- Machine Learning Models:
- Multinomial Naïve Bayes:
- Support Vector Machine (SVM):
- Logistic Regression:
- Decision Trees:
- XGBoost:
- Large Language Models:
- ChatGPT:
- Meta’s LLaMA:
- Evaluation Metrics:
3. Results
3.1. Category Mapping
3.2. API Integration
3.3. Comparative Analysis
- GPT-3: The accuracy of GPT-3 dropped from 0.906 to 0.849, illustrating its susceptibility to changes in a dataset. This suggested that while GPT-3 was highly accurate with the original data, its performance significantly declined with the new data, emphasizing the need for regular retraining or fine-tuning.
- LLAMA: In contrast, LLAMA’s accuracy increased substantially from 0.725 to 0.813 with the updated dataset. This improvement indicated that LLAMA can adapt well to new features and distinctions present in updated data, making it a suitable choice for dynamic environments where data frequently change.
- SVM: Support Vector Machine (SVM) achieved perfect accuracy (100%) on both datasets, demonstrating exceptional robustness. This consistency suggested that SVM is highly reliable and less sensitive to variations in data, making it an excellent choice due to its stable and consistent performance.
- Multinomial Naive Bayes: The accuracy of Multinomial Naive Bayes decreased from 0.917 to 0.834, likely due to the changes in the word distributions. This model’s performance indicated that it may be more sensitive to variations in text data, necessitating careful monitoring and possible adjustments when data characteristics change.
- Logistic Regression: Logistic Regression maintained a high accuracy of 0.979 across both datasets, demonstrating stability. This model’s consistent performance suggested that it can reliably handle data variations without significant losses in accuracy, making it a strong candidate for applications requiring steady performance.
- Decision Trees: The accuracy of Decision Trees was reduced from 0.989 to 0.917, indicating possible overfitting on the original dataset. This drop highlighted the model’s potential vulnerability to overfitting and suggested that it may require pruning or other regularization techniques to improve generalization to new data.
- XGBoost: XGBoost’s accuracy dropped slightly from 0.99 to 0.968, showing some sensitivity to data changes but still performing well overall. This model’s high performance, despite the slight decline, underscored its resilience and adaptability, making it a reliable choice for varied data circumstances.
4. Discussion
4.1. Future Direction in Online Recruitment Systems
4.2. The Role of Virtual Reality in Candidate Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arman, M. The Advantages of Online Recruitment and Selection: A Systematic Review of Cost and Time Efficiency. Bus. Manag. Strategy 2023, 14, 220–240. [Google Scholar] [CrossRef]
- Tian, X.; Pavur, R.; Han, H.; Zhang, L. A machine learning-based human resources recruitment system for business process management: Using LSA, BERT and SVM. Bus. Process Manag. J. 2023, 29, 202–222. [Google Scholar] [CrossRef]
- Wu, L.; Qiu, Z.; Zheng, Z.; Zhu, H.; Chen, E. Exploring large language model for graph data understanding in online job recommendations. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024; Volume 38, pp. 9178–9186. [Google Scholar]
- Josu, A.; Brinner, J.; Athira, B. Improving job recruitment with an interview bot: A study on NLP techniques and AI technologies. In Advances in Networks, Intelligence and Computing; CRC Press: Boca Raton, FL, USA, 2024; pp. 579–586. [Google Scholar]
- Ponnaboyina, R.; Makala, R.; Venkateswara Reddy, E. Smart recruitment system using deep learning with natural language processing. In Intelligent Systems and Sustainable Computing: Proceedings of ICISSC 2021; Springer Nature: Singapore, 2022; pp. 647–655. [Google Scholar]
- Ele, B.I.; Ele, A.A.; Agaba, F. Intelligent-based job applicants’assessment and recruitment system. Technology 2024, 6, 25–46. [Google Scholar]
- Ujlayan, A.; Bhattacharya, S.; Sonakshi, A. Machine Learning-Based AI Framework to Optimize the Recruitment Screening Process. JGBC 2023, 18 (Suppl. S1), 38–53. [Google Scholar] [CrossRef]
- Maree, M.; Kmail, A.B.; Belkhatir, M. Analysis and shortcomings of e-recruitment systems: Towards a semantics-based approach addressing knowledge incompleteness and limited domain coverage. J. Inf. Sci. 2019, 45, 713–735. [Google Scholar] [CrossRef]
- Kmail, A.B.; Maree, M.; Belkhatir, M.; Alhashmi, S.M. An Automatic Online Recruitment System based on Multiple Semantic Resources and Concept-relatedness measures. In Proceedings of the 23rd IEEE International Conference on Tools with Artificial Intelligence (ICTAI’15), Vietri sul Mare, Italy, 9–11 November 2015. [Google Scholar]
- Lee, B.C.; Kim, B.Y. A decision-making model for adopting an ai-generated recruitment interview system. Management (IJM) 2021, 12, 548–560. [Google Scholar]
- Appadoo, K.; Soonnoo, M.B.; Mungloo-Dilmohamud, Z. Job recommendation system, machine learning, regression, classification, natural language processing. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; pp. 1–6. [Google Scholar]
- Du, Y.; Luo, D.; Yan, R.; Wang, X.; Liu, H.; Zhu, H.; Song, Y.; Zhang, J. Enhancing job recommendation through llm-based generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024; Volume 38, pp. 8363–8371. [Google Scholar]
- Zheng, Z.; Qiu, Z.; Hu, X.; Wu, L.; Zhu, H.; Xiong, H. Generative job recommendations with large language model. arXiv 2023, arXiv:2307.02157. [Google Scholar]
- Available online: https://www.kaggle.com/datasets/jillanisofttech/updated-resume-dataset (accessed on 15 June 2024).
- Wendland, A.; Zenere, M.; Niemann, J. Introduction to text classification: Impact of stemming and comparing TF-IDF and count vectorization as feature extraction technique. In Systems, Software and Services Process Improvement: 28th European Conference, EuroSPI 2021, Krems, Austria, 1–3 September 2021, Proceedings 28; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 289–300. [Google Scholar]
- Xu, S.; Li, Y.; Wang, Z. Bayesian multinomial Naïve Bayes classifier to text classification. In Advanced Multimedia and Ubiquitous Engineering: MUE/FutureTech 2017; Springer: Singapore, 2017; pp. 347–352. [Google Scholar]
- Pisner, D.A.; Schnyer, D.M. Support vector machine. In Machine Learning; Academic Press: Cambridge, MA, USA, 2020; pp. 101–121. [Google Scholar]
- Qi, Z. The text classification of theft crime based on TF-IDF and XGBoost model. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 1241–1246. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Kmail, A.B.; Maree, M.; Belkhatir, M. MatchingSem: Online Recruitment System based on Multiple Semantic Resources. In Proceedings of the 12th IEEE International Conference on Fuzzy Systems and Knowledge Discovery (FSKD’15), Zhangjiajie, China, 15–17 August 2015. [Google Scholar]
- Available online: https://www.mckinsey.com/capabilities/risk-and-resilience/our-insights (accessed on 15 June 2024).
- Available online: https://www.emptor.io/blog/data-security-in-hiring-best-practices-for-protecting-sensitive-information/ (accessed on 15 June 2024).
- GDPR. General Data Protection Regulation. 2018. Available online: https://gdpr-info.eu/ (accessed on 21 November 2020).
- Dhanala, N.S.; Radha, D. Implementation and Testing of a Blockchain based Recruitment Management System. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 583–588. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Methodology | Summary |
|---|---|---|
| [2] | Latent Semantic Analysis (LSA) and BERT with Support Vector Machines (SVM) | Improves resume screening by detecting patterns in textual data and enhancing model efficiency through cross-validation |
| [4] | Natural Language Processing (NLP) and AI | Development of an interview bot that evaluates candidate responses to improve recruitment efficiency and reduce bias |
| [5] | Deep Learning and NLP (SRS) | Smart Recruitment Systems (SRS) classify and rank resumes by standardizing and parsing information, improving candidate selection |
| [11] | (JobFit) Recommender Systems, Machine Learning, and Historical Data | JobFit predicts the best candidates for a job by generating a compatibility score, aiding HR professionals in candidate selection |
| [6] | Waterfall Model, PHP, and MySQL | An automated recruitment system that uses AI to improve efficiency and accuracy in matching candidates to jobs |
| [7] | Analytics-Based Recruitment | An analytics-based method to match job postings with resumes, significantly reducing manual screening efforts |
| [10] | Analytic Hierarchy Process (AHP) | A decision-making model for AI recruitment systems focusing on criteria like ease of use, job fit, and perceived utility |
| [3] | Behavioral Graph Analysis (BGA) with LLMs | Enhances job recommendations by understanding and utilizing behavioral graphs to improve recruitment outcomes |
| [12] | LLM-Based GANs Interactive Recommendation (LGIR) | Improves resume completeness by extracting user features and using GANs to align low-quality resumes with high-quality generated equivalents |
| [13] | GIRL Generative Job Recommendation with LLMs and Reinforced Learning | Generates job descriptions based on CVs, providing personalized job suggestions and enhancing the job-seeking experience |
| [8] | Semantic Resources (WordNet and YAGO3) and NLP | An e-recruitment system that match resumes with job postings by extracting features and using skill-relatedness algorithms to improve candidate relevance |
| Job Category | Number of Resumes |
|---|---|
| Data Science | 40 |
| HR | 43 |
| Advocate | 19 |
| Arts | 35 |
| Web Designing | 44 |
| Mechanical Engineer | 39 |
| Sales | 39 |
| Health and Fitness | 29 |
| Civil Engineer | 23 |
| Java Developer | 83 |
| Business Analyst | 27 |
| SAP Developer | 23 |
| Automation Testing | 25 |
| Electrical Engineering | 53 |
| Operation Manager | 39 |
| Python Developer | 47 |
| DevOps Engineer | 54 |
| Network Security Engineer | 24 |
| PMO | 29 |
| Database | 32 |
| Hadoop | 41 |
| ETL Developer | 39 |
| DotNet Developer | 27 |
| Blockchain | 39 |
| Testing | 69 |
| Model | Original Dataset | Updated Dataset |
|---|---|---|
| GPT | 90.6% | 84.9% |
| LLAMA | 72.5% | 81.3% |
| SVM | 100% | 100% |
| Multinomial Naive Bayes | 91.7% | 83.4% |
| Logistic Regression | 97.9% | 97.9% |
| Decision Trees | 98.9% | 91.7% |
| XGBoost | 99.0% | 96.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maree, M.; Shehada, W. Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures. AI 2024, 5, 1377-1390. https://doi.org/10.3390/ai5030066
Maree M, Shehada W. Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures. AI. 2024; 5(3):1377-1390. https://doi.org/10.3390/ai5030066
Chicago/Turabian StyleMaree, Mohammed, and Wala’a Shehada. 2024. "Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures" AI 5, no. 3: 1377-1390. https://doi.org/10.3390/ai5030066
APA StyleMaree, M., & Shehada, W. (2024). Optimizing Curriculum Vitae Concordance: A Comparative Examination of Classical Machine Learning Algorithms and Large Language Model Architectures. AI, 5(3), 1377-1390. https://doi.org/10.3390/ai5030066