
ECARRNet: An Efficient LSTM-Based Ensembled Deep Neural Network Architecture for Railway Fault Detection

 ,
, 
 ,
, 
 and
and 
Abstract
1. Introduction
- The dataset which we have collected consists of a total of 428 images from both faulty and non-faulty railway tracks from two different parts of the track, i.e., from rails and fasteners. Since it is hard to find faulty images, we have augmented our dataset to increase in size before training, and class imbalance problems were also fixed using oversampling techniques like SMOTE.
- Three SOTA CNN-based transfer learning models (InceptionV3, InceptionResnetV2, and Xception) have been used to classify and detect the faults on railway tracks, and their respective performances are presented using several metrics such as accuracy curves, confusion matrices, and classification reports.
- An ensembled DL architecture, ECARRNet has been proposed, to predict defective (faulty) and non-defective (non-faulty) railway tracks with greater predictive performance than existing SOTA.
- Explainable AI tools in the form of Grad-CAM and LIME are used to explore the black-box nature of the models and further validate our results to prove the efficacy of our proposed model.
2. Related Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Task | Datasets | Classifiers | Accuracy |
|---|---|---|---|---|
| [13] | Proposed models to detect faults in Loose Ballast, SunKink, Track Switch, and Signals. | Datasets are made from the 100 GB of video data | Inception V3, ResNet50, and Faster R-CNN | 100% |
| [14] | GPS determines the fault’s location and use a GO pro camera to take photographs. | Datasets are made from the images extracted from video data | Yolo v3 | 95% |
| [15] | Proposed a multiphase DL technique to perform segmentation of images. | Datasets are made from the actual rail tracks that are collected by a COTS VTIS. | Visual-based track inspection systems(VTIS), TrackNet | 90% |
| [16] | To detect high-speed railway rail damage, a combination of the U-net graph segmentation network and the saliency cues approach of damage localization was presented. | Type-I RSDDs dataset | SCueU-Net | 99.76% |
| [18] | They proposed defect detection and identification methods using Dense-SIFT features. | Dataset is made up of images that are taken from Beijing Metro Line 6. | RCNN, VGG16 | 97.14% |
| [19] | Proposes a damage detection model where the Image is collected at first using a plane array camera along with LED light to increase the brightness of the picture. | Datasets are made from the images of plane array camera | Directional chain code tracking | .... |
| [20] | A computer-based visual rail condition monitoring is proposed. | Data acquired from a camera placed on top of the train | Image processing | .... |
| [21] | An automated video analysis based rail-track inspection approach. | Data acquired from a video camera placed in front of the train | Image processing | 95.3% |
| [22] | Automated track inspection using computer vision and pattern recognition methods. | Data acquired from a camera placed in front of the moving train | Deep CNN | 95.02% |
| [23] | Using computer vision and pattern recognition, perform risk management in railway systems. | Manually collected images from different rail tracks | Keras, ReLU, CNN | 81.90% |
| [24] | Eexamines the research questions related to agriculture, the models used, the data sources used, and the overall precision attained based on the authors’ performance indicators. | PlantVillage, LifeCLEF, MalayaKew and UC Merced | AlexNet, VGG, and Inception-ResNet | .... |
| [25] | Proposed machine learning-based railway inspection approaches, including a feature-based method and a deep neural network-based method based on acceleration data. | The acceleration dataset was obtained from the sensors mounted to the rail inspection car. | ResNet, FCN | 100% |
| [27] | Provide a more comprehensive survey of the most important aspects of DL and, including those enhancements recently added to the feld. | ImageNet, CIFAR-10, CIFAR-100, MNIST | Xillinx, Voxnet, ResNet | 80% |
| [28] | Shows the use of DL approaches for the analysis of remote sensing (RS) data is rapidly increasing. | Datasets are built from remote sensing (RS) data and satellite data | Sentinel-2, 2-BiLSTM, CamposTaberner | 91.4% |
| [29] | Provide an acoustic analysis-based autonomous railway track defect detection system. | Datasets are built from the data collected on Pakistani railway lines using acoustic signals | Vector machines, LR, RF, and DT | 97% |
| [30] | A DL-based fault diagnosis network for RVSFD was built. | Datasets are built from the data collected from accelerometer sensors. | GONEST-1D CNN | 100% |
3. Methodology
3.1. Overview of the Proposed Architecture
3.1.1. Convolutional Autoencoder
3.1.2. Resnet Based Transfer Learning
3.1.3. Recurrent Neural Network
3.1.4. Fully Connected Layers
3.2. Comparison Models Overview
3.2.1. InceptionV3
3.2.2. Xception
3.2.3. InceptionResNetV2
4. Performance Evaluation Parameters
- TP = True Positive
- FP = False Positive
- FN = False Negative
- TN = True Negative
- = feature map activation
- = neuron significance weight
5. Experimental Results
5.1. Data Collection
5.2. Data Pre-Processing
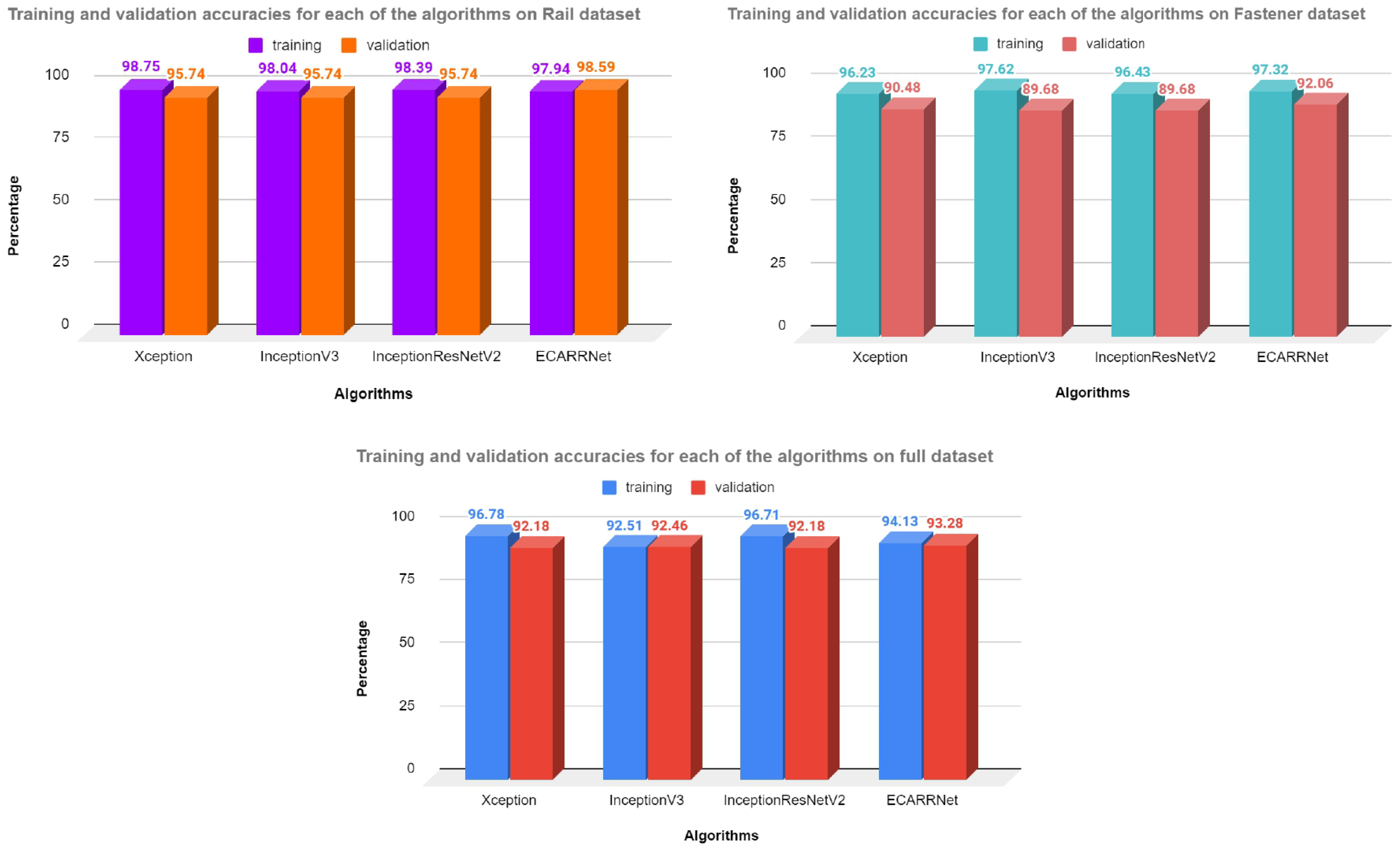
5.3. Results Generated on Rail Dataset
5.4. Results Generated on Fastener Dataset
5.5. Results Generated on Full Dataset
5.6. LIME Visualizations to Explain the Output Predictions of ECARRNet
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singhal, V.; Jain, S.S.; Anand, D.; Singh, A.; Verma, S.; Kavita; Rodrigues, J.J.P.C.; Jhanjhi, N.Z.; Ghosh, U.; Jo, O.; et al. Artificial Intelligence Enabled Road Vehicle-Train Collision Risk Assessment Framework for Unmanned Railway Level Crossings. IEEE Access 2020, 8, 113790–113806. [Google Scholar] [CrossRef]
- Probha, N.A.; Hoque, M.S. A Study on transport safety perspectives in Bangladesh through comparative analysis of roadway, railway and waterway accidents. In Proceedings of the APCIM & ICTTE 2018: 2018 International Conference on Intelligent Medical & International Conference on Transportation and Traffic Engineering, Beijing, China, 21–23 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 81–85. [Google Scholar] [CrossRef]
- Islam, M.M.; Ridwan, A.E.M.; Mary, M.M.; Siam, M.F.; Mumu, S.A.; Rana, S. Design and implementation of a smart bike accident detection system. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 386–389. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; NIPS’12. Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, H.; Zhang, Y.; Kalra, M.K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-Dose CT With a Residual Encoder-Decoder Convolutional Neural Network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef] [PubMed]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung Pattern Classification for Interstitial Lung Diseases Using a Deep Convolutional Neural Network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef] [PubMed]
- Rahman, R.; Rahman, M.A.; Hossain, S.; Hossain, S.; Akhond, M.R.; Hossain, M.I. RansomListener: Ransom Call Sound Investigation Using LSTM and CNN Architectures. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 509–516. [Google Scholar] [CrossRef]
- Ding, C.; Tao, D. Robust Face Recognition via Multimodal Deep Face Representation. IEEE Trans. Multimed. 2015, 17, 2049–2058. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Proceedings of the Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Chamoso, P.; Raveane, W.; Parra, V.; González, A. UAVs Applied to the Counting and Monitoring of Animals. In Ambient Intelligence—Software and Applications; Ramos, C., Novais, P., Nihan, C.E., Corchado Rodríguez, J.M., Eds.; Springer: Cham, Switzerland, 2014; pp. 71–80. [Google Scholar]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. Car detection from low-altitude UAV imagery with the faster R-CNN. J. Adv. Transp. 2017, 2017, 2823617. [Google Scholar] [CrossRef]
- Mittal, S.; Rao, D. Vision Based Railway Track Monitoring using Deep Learning. arXiv 2017, arXiv:1711.06423. [Google Scholar]
- Lin, Y.W.; Hsieh, C.C.; Huang, W.H.; Hsieh, S.L.; Hung, W.H. Railway track fasteners fault detection using deep learning. In Proceedings of the 2019 IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 3–6 October 2019; pp. 187–190. [Google Scholar] [CrossRef]
- James, A.; Jie, W.; Xulei, Y.; Chenghao, Y.; Ngan, N.B.; Yuxin, L.; Yi, S.; Chandrasekhar, V.; Zeng, Z. TrackNet—A deep learning based fault detection for railway track inspection. In Proceedings of the 2018 International Conference on Intelligent Rail Transportation (ICIRT), Singapore, 12–14 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Lu, J.; Liang, B.; Lei, Q.; Li, X.; Liu, J.; Liu, J.; Xu, J.; Wang, W. SCueU-Net: Efficient Damage Detection Method for Railway Rail. IEEE Access 2020, 8, 125109–125120. [Google Scholar] [CrossRef]
- Welankiwar, A.; Sherekar, S.; Bhagat, A.P.; Khodke, P.A. Fault detection in railway tracks using artificial neural networks. In Proceedings of the 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE), San Salvador, El Salvador, 22–24 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Wei, X.; Yang, Z.; Liu, Y.; Wei, D.; Jia, L.; Li, Y. Railway track fastener defect detection based on image processing and deep learning techniques: A comparative study. Eng. Appl. Artif. Intell. 2019, 80, 66–81. [Google Scholar] [CrossRef]
- Min, Y.; Xiao, B.; Dang, J.; Yue, B.; Cheng, T. Real time detection system for rail surface defects based on machine vision. EURASIP J. Image Video Process. 2018, 3, 3. [Google Scholar] [CrossRef]
- Karakose, M.; Yaman, O.; Baygin, M.; Murat, K.; Akin, E. A New Computer Vision Based Method for Rail Track Detection and Fault Diagnosis in Railways. Int. J. Mech. Eng. Robot. Res. 2017, 6, 22–27. [Google Scholar] [CrossRef]
- Singh, M.; Singh, S.; Jaiswal, J.; Hempshall, J. Autonomous rail track inspection using vision based system. In Proceedings of the 2006 IEEE International Conference on Computational Intelligence for Homeland Security and Personal Safety, Alexandria, VA, USA, 16–17 October 2006; pp. 56–59. [Google Scholar] [CrossRef]
- Gibert, X.; Patel, V.M.; Chellappa, R. Deep Multitask Learning for Railway Track Inspection. IEEE Trans. Intell. Transp. Syst. 2017, 18, 153–164. [Google Scholar] [CrossRef]
- Alawad, H.; Kaewunruen, S.; An, M. A Deep Learning Approach Towards Railway Safety Risk Assessment. IEEE Access 2020, 8, 102811–102832. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Yang, C.; Sun, Y.; Ladubec, C.; Liu, Y. Developing Machine Learning-Based Models for Railway Inspection. Appl. Sci. 2021, 11, 13. [Google Scholar] [CrossRef]
- Yao, H.; Zhang, X.; Zhou, X.; Liu, S. Parallel Structure Deep Neural Network Using CNN and RNN with an Attention Mechanism for Breast Cancer Histology Image Classification. Cancers 2019, 11, 1901. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Izquierdo-Verdiguier, E.; Atzberger, C.; Camps-Valls, G.; Gilabert, M.A. Understanding deep learning in land use classifcation based on Sentinel-2 time series. Sci. Rep. 2020, 10, 17188. [Google Scholar] [CrossRef]
- Shafique, R.; Siddiqui, H.U.R.; Rustam, F.; Ullah, S.; Siddique, M.A.; Lee, E.; Ashraf, I.; Dudley, S. A Novel Approach to Railway Track Faults Detection Using Acoustic Analysis. Sensors 2021, 21, 6221. [Google Scholar] [CrossRef]
- Ye, Y.; Huang, P.; Zhang, Y. Deep learning-based fault diagnostic network of high-speed train secondary suspension systems for immunity to track irregularities and wheel wear. Eng. Sci. 2021, 30, 96–116. [Google Scholar] [CrossRef]
- Chen, M.; Shi, X.; Zhang, Y.; Wu, D.; Guizani, M. Deep Feature Learning for Medical Image Analysis with Convolutional Autoencoder Neural Network. IEEE Trans. Big Data 2021, 7, 750–758. [Google Scholar] [CrossRef]
- Zhang, Y. A Better Autoencoder for Image: Convolutional Autoencoder. 2018. Available online: https://users.cecs.anu.edu.au/~Tom.Gedeon/conf/ABCs2018/paper/ABCs2018_paper_58.pdf (accessed on 25 March 2024).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. CoRR 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. CoRR 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Bakker, E.; Guo, Y.; Lew, M. CNN-RNN: A large-scale hierarchical image classification framework. Multimed. Tools Appl. 2018, 77, 10251–10271. [Google Scholar] [CrossRef]
- Yin, Q.; Zhang, R.; Shao, X. CNN and RNN mixed model for image classification. MATEC Web Conf. 2019, 277, 02001. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you?: Explaining the predictions of any classifier. In Proceedings of theKDD ’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Adnan, A.; Hossain, S.; Shihab, R.; Ibne Eunus, S. Railway Track Fault Detection. 2021. Available online: https://www.kaggle.com/datasets/salmaneunus/railway-track-fault-detection (accessed on 25 March 2024).
- Adnan, A.; Hossain, S.; Shihab, R.; Ibne Eunus, S. Railway Track Fault Detection|Dataset 2 (Fastener) 2021. Available online: https://www.kaggle.com/datasets/ashikadnan/railway-track-fault-detection-dataset2fastener (accessed on 25 March 2024).
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]












| Layer Type | Number of Units/Neurons |
|---|---|
| Input | - |
| Conv2D | 128 |
| MaxPooling2D | - |
| Conv2D | 64 |
| MaxPooling2D | - |
| Conv2D | 64 |
| MaxPooling2D | - |
| Conv2D | 64 |
| UpSampling2D | - |
| Conv2D | 128 |
| UpSampling2D | - |
| Conv2D | 1 |
| InceptionResNetV2 | - |
| GlobalAveragePooling2D | - |
| Reshape | - |
| Bidirectional LSTM | 2900 |
| GaussianNoise | - |
| Dense | 100 |
| Dense | 100 |
| Dense | 1 |
| Models | Metrics | Defective | Non Defective | Accuracy | Macro Average | Weighted Average |
|---|---|---|---|---|---|---|
| InceptionV3 | Precision | 0.89 | 0.94 | - | 0.92 | 0.92 |
| Recall | 0.94 | 0.89 | - | 0.92 | 0.91 | |
| F1 Score | 0.91 | 0.92 | 0.91 | 0.91 | 0.91 | |
| Support | 67 | 74 | 141 | 141 | 141 | |
| Inception- ResnetV2 | Precision | 0.94 | 0.96 | - | 0.95 | 0.95 |
| Recall | 0.96 | 0.94 | - | 0.95 | 0.95 | |
| F1 Score | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | |
| Support | 70 | 71 | 141 | 141 | 141 | |
| Xception | Precision | 0.96 | 0.96 | - | 0.96 | 0.96 |
| Recall | 0.96 | 0.96 | - | 0.96 | 0.96 | |
| F1 Score | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | |
| Support | 71 | 70 | 141 | 141 | 141 | |
| ECARRNet | Precision | 0.94 | 0.96 | - | 0.95 | 0.95 |
| Recall | 0.96 | 0.94 | - | 0.95 | 0.95 | |
| F1 Score | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | |
| Support | 70 | 71 | 141 | 141 | 141 |
| Models | Metrics | Defective | Non Defective | Accuracy | Macro Average | Weighted Average |
|---|---|---|---|---|---|---|
| InceptionV3 | Precision | 0.84 | 0.91 | - | 0.88 | 0.88 |
| Recall | 0.91 | 0.85 | - | 0.88 | 0.88 | |
| F1 Score | 0.87 | 0.88 | 0.88 | 0.88 | 0.88 | |
| Support | 117 | 135 | 252 | 252 | 252 | |
| Inception- ResnetV2 | Precision | 0.88 | 0.87 | - | 0.87 | 0.87 |
| Recall | 0.87 | 0.88 | - | 0.87 | 0.87 | |
| F1 Score | 0.87 | 0.87 | 0.87 | 0.87 | 0.87 | |
| Support | 128 | 124 | 252 | 252 | 252 | |
| Xception | Precision | 0.87 | 0.92 | - | 0.89 | 0.89 |
| Recall | 0.92 | 0.87 | - | 0.89 | 0.89 | |
| F1 Score | 0.89 | 0.90 | 0.89 | 0.89 | 0.89 | |
| Support | 119 | 133 | 252 | 252 | 252 | |
| ECARRNet | Precision | 0.87 | 0.87 | - | 0.87 | 0.87 |
| Recall | 0.87 | 0.87 | - | 0.87 | 0.87 | |
| F1 Score | 0.87 | 0.87 | 0.87 | 0.87 | 0.87 | |
| Support | 126 | 126 | 252 | 252 | 252 |
| Models | Metrics | Defective | Non Defective | Accuracy | Macro Average | Weighted Average |
|---|---|---|---|---|---|---|
| InceptionV3 | Precision | 0.89 | 0.91 | - | 0.90 | 0.90 |
| Recall | 0.90 | 0.89 | - | 0.90 | 0.90 | |
| F1 Score | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | |
| Support | 176 | 182 | 358 | 358 | 358 | |
| Inception- ResnetV2 | Precision | 0.88 | 0.84 | - | 0.86 | 0.86 |
| Recall | 0.84 | 0.88 | - | 0.86 | 0.86 | |
| F1 Score | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 | |
| Support | 187 | 171 | 358 | 358 | 358 | |
| Xception | Precision | 0.93 | 0.90 | - | 0.91 | 0.91 |
| Recall | 0.90 | 0.93 | - | 0.91 | 0.91 | |
| F1 Score | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 | |
| Support | 184 | 174 | 358 | 358 | 358 | |
| ECARRNet | Precision | 0.95 | 0.89 | - | 0.92 | 0.92 |
| Recall | 0.89 | 0.95 | - | 0.92 | 0.92 | |
| F1 Score | 0.92 | 0.92 | 0.92 | 0.92 | 0.92 | |
| Support | 189 | 168 | 357 | 357 | 357 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eunus, S.I.; Hossain, S.; Ridwan, A.E.M.; Adnan, A.; Islam, M.S.; Karim, D.Z.; Alam, G.R.; Uddin, J. ECARRNet: An Efficient LSTM-Based Ensembled Deep Neural Network Architecture for Railway Fault Detection. AI 2024, 5, 482-503. https://doi.org/10.3390/ai5020024
Eunus SI, Hossain S, Ridwan AEM, Adnan A, Islam MS, Karim DZ, Alam GR, Uddin J. ECARRNet: An Efficient LSTM-Based Ensembled Deep Neural Network Architecture for Railway Fault Detection. AI. 2024; 5(2):482-503. https://doi.org/10.3390/ai5020024
Chicago/Turabian StyleEunus, Salman Ibne, Shahriar Hossain, A. E. M. Ridwan, Ashik Adnan, Md. Saiful Islam, Dewan Ziaul Karim, Golam Rabiul Alam, and Jia Uddin. 2024. "ECARRNet: An Efficient LSTM-Based Ensembled Deep Neural Network Architecture for Railway Fault Detection" AI 5, no. 2: 482-503. https://doi.org/10.3390/ai5020024
APA StyleEunus, S. I., Hossain, S., Ridwan, A. E. M., Adnan, A., Islam, M. S., Karim, D. Z., Alam, G. R., & Uddin, J. (2024). ECARRNet: An Efficient LSTM-Based Ensembled Deep Neural Network Architecture for Railway Fault Detection. AI, 5(2), 482-503. https://doi.org/10.3390/ai5020024