
A Comprehensive Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques



Abstract
:1. Introduction
- Healthcare: In healthcare, Edge ML enables real-time patient monitoring and personalized treatment strategies. Wearable sensors and smart implants equipped with Edge ML can process data locally, providing immediate health feedback [13]. This advancement permits the early detection of health irregularities and swift responses to potential emergencies, while also maintaining patient data privacy by avoiding the need for data transmission for analysis. Furthermore, in telemedicine, Edge ML could be used to interpret diagnostic imaging locally and provide immediate feedback to remote healthcare professionals, improving patient care efficiency and outcomes.
- Autonomous Vehicles: Edge ML is a key enabler for the advancements in the field of autonomous vehicles, which includes both Unmanned Aerial Vehicles (UAVs) and self-driving cars. These vehicles are packed with a myriad of sensors and cameras that generate enormous amounts of data per second [14]. Processing this data in real-time is crucial for safe and efficient operation, and sending all the data to a cloud server is impractical due to latency and bandwidth constraints. Edge ML, with its capability to process data at the edge, can help in reducing the latency, and enhancing real-time responses.
- Smart City: Edge ML plays a crucial role in the realization of smart cities [15], where real-time data processing is paramount. Applications such as intelligent traffic light control, waste management, and urban planning greatly benefit from ML models that can analyze sensor data on-site and respond promptly to changes in the urban environment. Moreover, Edge ML can power public safety applications such as real-time surveillance systems for crime detection and prevention. Here, edge devices like surveillance cameras equipped with ML algorithms can detect unusual activities or behaviours and alert relevant authorities in real time, potentially preventing incidents and enhancing overall city safety.
- Industrial IoT (IIoT): In the realm of Industrial IoT [16], Edge ML is instrumental in predictive maintenance and resource management. With ML models running at the edge, real-time anomaly detection can be carried out to anticipate equipment failures and proactively schedule maintenance. Additionally, Edge ML can optimize operational efficiency by monitoring production line performance, tracking resource usage, and automating quality control processes.
- What are the computational and environmental constraints and requirements for ML on the edge?
- What are the Edge ML techniques to train intelligent models or enable model inference while meeting Edge ML requirements?
- How can existing ML techniques fit into an edge environment regarding these requirements?
2. Edge Machine Learning: Requirements
2.1. ML Requirements
- Low Task Latency: Task latency refers to the end-to-end processing time for one ML task, in seconds (s), and is determined by both ML models and the supporting computation infrastructure. Low task latency is important to achieve fast or real-time ML capabilities, especially for time-critical use-cases such as autonomous driving. We use the term task latency instead of latency to differentiate this concept from communication latency, which describes the time for sending a request and receiving an answer.
- High Performance: The performance of an ML task is represented by its results and measured by general performance metrics such as top-n accuracy, and f1-score in percentage points (pp), as well as use-case-dependent benchmarks such as General Language Understanding Evaluation (GLUE) benchmark for NLP [27] or Behavior Suite for reinforcement learning [28].
- Generalization and Adaptation: The models are expected to learn the generalized representation of data instead of the task labels, so as to be easily generalized to a domain instead of specific tasks. This brings the models’ capability to solve new and unseen tasks and realize a general ML directly or with a brief adaptation process. Furthermore, facing the disparity between learning and prediction environments, ML models can be quickly adapted to specific environments to solve the environmental specific problems.
- Enhanced Privacy and Security: The data acquired from edge carry much private information, such as personal identity, health status, and messages, preventing these data from being shared in a large extent. In the meantime, frequent data transmission over a network threatens data security as well. The enhanced privacy and security requires the corresponding solution to process data locally and minimize the shared information.
- Labelled Data Independence: The widely applied supervised learning in modern machine learning paradigms requires large amounts of data to train models and generalize knowledge for later inference. However, in practical scenarios, we cannot assume that all data in the edge are correctly labeled. The independence of labelled data indicates the capability of an Edge ML solution to solve one ML task without labelled data or with few labelled data.
2.2. EC Requirements
- Computational Efficiency: Refers to the efficient usage of computational resources to complete an ML task. This includes both processing resources measured by the number of arithmetic operations (OPs), and the required memory measured in MB.
- Optimized Bandwidth: Refers to the optimization of the amount of data transferred over network per task, measured by MB/Task. Frequent and large data exchanges over a network can raise communication and task latency. An optimized bandwidth usage expects Edge ML solutions to balance the data transfer over the network and local data processing.
- Offline Capability: The edge connectivity of edge devices is often weak and/or unstable, requiring operations to be performed on the edge directly. The offline capability refers to the ability to solve an ML task when network connections are lost or without a network connection.
2.3. Overall Requirements
- Availability: Refers to the percentage of time (in percentage points (pp)) that an Edge ML solution is operational and available for processing tasks without failure. For edge ML applications, availability is paramount because these applications often operate in real-time or near-real-time environments, and downtime can result in severe operational and productivity loss.
- Reliability: Refers to the ability of a system or component to perform its required functions under stated conditions for a specified period of time. Reliability can be measured using various metrics such as Mean Time Between Failures (MTBF) and Failure Rate.
- Energy Efficiency: Energy efficiency refers to the number of ML tasks obtained per power unit, in Task/J. The energy efficiency is determined by both the computation and communication design of Edge ML solutions and their supporting hardware.
- Cost optimization: Similar to energy consumption, edge devices are generally low-cost compared to cloud servers. The cost here refers to the total cost of realizing one ML task in an edge environment. This is again determined by both the Edge ML software implementation and its supporting infrastructure usage.
3. Techniques Overview
3.1. Supervised Learning
3.2. Unsupervised Learning
3.3. Reinforcement Learning
4. Edge Inference
4.1. Model Compression and Approximation
4.1.1. Quantization
- Low-Precision Floating-Point Representation: A floating-point parameter describes binary numbers in the exponential form with an arbitrary binary point position such as 32-bit floating point (FP32), 16-bit floating point (FP16), 16-bit Brain Floating Point (BFP16) [34].
- Fixed-Point Representation: A fixed-point parameter [35] uses predetermined precision and binary point locations. Compared to a high-precision floating-point representation, the fixed-point parameter representation can offer faster, cheaper, and more power-efficient arithmetic operations.
- Logarithmic Quantization: In a logarithmic quantization [38], parameters are quantized into powers of two with a scaling factor. Work in [39] shows that a weight’s representation range is more important than its precision in preserving network accuracy. Thus, logarithmic representations can cover wide ranges using fewer bits, compared to the other above-mentioned linear quantization formats.
4.1.2. Weight Reduction
- Pruning. The process of removing redundant or non-critical weights and/or nodes from models [17]: weight-based pruning removes connections between nodes (e.g., neurons in neural network) by setting relevant weights to zero to make the ML models sparse, while node-based pruning removes all target nodes from the ML model to make the model smaller.
- Weight Sharing. The process of grouping similar model parameters into buckets and reuse shared weights in different parts of the model to reduce model size or among models [62] to facilitate the model structure design.
- Low-rank Factorization. The process of decomposing the weight matrix into several low-rank matrices by uncovering explicit latent structures [63].
4.1.3. Knowledge Distillation
4.1.4. Activation Approximation
4.2. Distributed Inference
4.3. Other Inference Acceleration Techniques
4.3.1. Early Exit of Inference (EEoI)
4.3.2. Inference Cache
4.3.3. Model-Specific Inference Acceleration
5. Edge Learning
5.1. Distributed Learning
- Enhanced privacy and security: Edge data often contain sensitive information related to personal or organizational matters that the data owners are reluctant to share. By transmitting only updated model parameters instead of the data, the distributed learning on the edge trains ML models in a privacy-preserving manner. Moreover, the reduced frequency of data transmission enhances the data security by restraining sensitive data only to the edge environment.
- Communication and bandwidth optimization: Uploading data to the cloud leads to a large transmission overhead and is the bottleneck of current learning paradigm [129]. A significant amount of communication is reduced by processing data in the edge nodes, and bandwidth usage optimized via edge distributed learning.
- Cloud-enabled DL. Given a number of distributed and interconnected edge nodes, cloud-enabled DL (see Figure 3a) constructs the global model by aggregating in the cloud the local models’ parameters. These parameters are computed directly in each edge device. Periodically, the cloud server shares the global model parameters to all edge nodes so that the upcoming local model updates are made on the latest global model.
- Edge-enabled DL. In contrast to cloud-enabled DL, Edge-enabled DL (see Figure 3b) uses a local and edge server to aggregate model updates from its managed edge devices. Edge devices, with the management range of an edge server, contribute to the global model training on the edge aggregation server. Since the edge aggregation server is located near the edge devices, edge-enabled DL does not necessitate communications between the edge and the cloud, which thus reduces the communication latency and brings task offline capability. On the other hand, edge-enabled DL is often resource-constrained and can only support a limited number of clients. This usually results in a degradation in task performance over time.
- Hierarchical DL. Hierarchical DL employs both cloud and edge aggregation servers to build the global model. Generally, edge devices within the range of a same-edge server transmit local data to the corresponding edge aggregation server to individually train local models, and then local models’ parameters are shared with the cloud aggregation server to construct the global model. Periodically, the cloud server shares the global model parameters to all edge nodes (i.e., servers and devices), so that the upcoming local model updates are made on the latest global model. By this means, several challenges of distributed learning, such as Non-Identically Distributed Data (Non-IID) [130], imbalanced class [131], and the heterogeneity of edge devices [132] with diverse computation capabilities and network environments, can be targeted in the learning design. In fact, as each edge aggregation server is only responsible for training the local model with the collected data, the cloud aggregation server does not need to deal with data diversity and device heterogeneity across the edge nodes.
5.1.1. Federated Learning
5.1.2. Split Learning
5.2. Transfer Learning
- Data Distribution. The training data obtained in a specific spatial or temporal point can have different distribution to the testing data in an edge environment. The different data distribution, due to different facts such as co-variate shift [160], selection bias [161], and context feature bias [162], could lead to the degradation of model performance in a testing environment. The knowledge transfer between two different data distributions is a subtopic of transfer learning, known as Domain Adaptation (DA) [163].
- Feature Space. Contrary to the homogeneous transfer learning [18] which assumes that the source domain and the target domain consist of the same feature spaces, heterogeneous transfer learning tackles the (TL) case where the source and target domains have different feature spaces [164]. The heterogeneous transfer learning applies a feature space adaptation process to ease the difficulty to collect data within a target domain and expands the transfer learning to broader applications.
- Learning Task Space. Transfer learning also transfers knowledge between two specific learning tasks by use of the inductive biases of the source task to help perform the target task [165]. In this level, the data of the source and target task can have a same or different distribution and feature space. However, the specific source and target tasks are supposed to be similarly correlated either in a parallel manner, e.g., in the tasks of objects identification and person identification, or in a downstream manner, e.g., from a pretext learning task of image representation to a downstream task of an object detection task. It is worth mentioning that the knowledge generalization in an upstream manner from downstream tasks to out-of-distribution data is Domain Generalization (DG) [166].
- Model Collection: An existing trained model on the source domain is acquired.
- Layer Freezing: The first several layers from a source model are frozen to keep the previously learned representation, and the exact layers to freeze are determined by the source model layers which have learned the source data representation [167], i.e., usually the data-encoding part of a model.
- Model Adjustment: The last few layers of the source model are deleted, and again the exact layers to delete are determined by the source model structure [168]. New trainable layers are added after the last layer of the modified source model to learn to turn the previous learned representation into outputs on the target domain.
- Model Training: The updated model is trained with new data from the target domain.
- Model Tuning: At last, an optional step is the tuning process usually based on model fine-tuning [169]. During this step, the entire newly trained model from the previous step is unfrozen and re-trained on the new data from the target domain with a low learning rate. The tuning process potentially further improves the model performance by adapting the newly trained representation to the new data.
- Model Pre-training: A model is pre-trained on the source domain to learn representations from source domain data.
- Model Adjustment: As an optional step in tuning process, the last few layers of the source model are deleted, and new trainable layers are added after the last layer of the modified source model.
- Model Tuning: The entire pre-trained model is trained on the new data from the target domain to map the learned representation to the target output.
- Training Efficiency. The speed of training new models is largely accelerated and uses much less computational resources compared to model training from scratch.
- Less Training Data. The model training or tuning process on the target model requires less training data, and this is especially useful in the case where there is a lot of data available from the source domain and relatively less data for target domain.
- Model Personalization. Transfer learning can quickly specialize pre-trained models to a specific environment and improve accuracy when the original pre-trained model cannot generalize well.
5.3. Meta-Learning
- Metric-based meta-learning learns the meta-knowledge in the form of feature space from previous tasks by associating the feature space with model parameters. New tasks are achieved by comparing new inputs, usually with unseen labels (also known as the query set), to example inputs (a.k.a. the support set) in the learned feature space. The new input will be associated to the label of the example input with which it shares the highest similarity. The idea behind metric-based meta-learning is similar to distance-based clustering algorithms, e.g., K-Nearest Neighbors (KNN) [188] or K-means [189], but with a learned model containing the meta-knowledge. Being simple in computation and fast at test-time with small tasks, metric-based meta-learning is inefficient when the tasks contain a large number of labels to compare, while the fact of relying on labelled examples makes the metric-based meta-learning both specialized at and limited by the supervised learning paradigm.
- Model-based meta-learning relies on an internal or external memory component (i.e., a model) to save previous inputs and to empower the models to maintain a stateful representation of a task as the meta-knowledge. Specifically designed for fast training, the memory component can update its parameters in a few training steps with new data, either by the designed internal architecture or controlled by another meta-learner model [190]. When given new data on a specific task, the model-based meta-learning firstly processes the new data to train and alter the internal state of the model. Since the internal state captures relevant task-specific information, outputs can be generated for unseen labels of the same task or new tasks. Compared to the metric-based meta-learning, model-based meta-learning has a broader applicability to the three basic machine learning paradigms and brings flexibility and dynamics to the meta-learning technique via quick and dynamic model adjustment to new tasks and data.
- Optimization-based meta-learning revises the gradient-based learning optimization algorithm so that the model is specialized at fast learning with a few examples, as the gradient-based optimization is considered to be slow to converge and inefficient with few learning data. Optimization-based meta-learning is generally achieved by a two-level optimization process [187]: base-learners are trained in a task-specific manner, while the meta-learner performs cross-task optimization in such a way that all base learners can quickly learn individual model parameters set for different tasks. Optimization-based meta-learning works better on wider task distributions and enables faster learning compared to the two previous meta-learning techniques. On the other hand, the global optimization procedure leads to an expensive computation workload, as each task’s base-learner is considered [191].
5.4. Self-Supervised Learning
- Generative Learning: Generative learning trains an encoder to encode the input into an explicit vector and a decoder to reconstruct the input from the explicit vector. The training simulates pseudo labels for unlabeled data and is guided by the reconstruction loss between the real input and the reconstructed input.
- Contrastive learning: Contrastive learning trains an encoder to respectively encode inputs into explicit vectors and measure similarity among inputs. The contrastive similarity metric is employed as the contrastive loss for model training. During the training, the contrastive learning calibrates label-free data against themselves to learn high-level generalizable representations.
- Adversarial Learning: Adversarial learning trains an encoder–decoder to generate fake samples and a discriminator to distinguish them from real samples in an adversarial manner. In other words, it learns to reconstruct the original data distribution rather than the samples themselves, and the distributional divergence between original and reconstructed divergence is the loss function to minimize during the training phase. The point-wise (e.g., word in texts) objective of the generative SSL is sensitive to rare examples and contrary to the high-level objective (e.g., texts) in classification tasks, which may result in inherent results without distribution data. Adversarial SSL abandons the point-wise objective and uses the distributional matching objectives for high-level abstraction learning. In the meantime, adversarial learning preserves the decoder component abandoned by the contrastive SSL to stabilize the convergence with more expressiveness.
5.5. Other Learning Paradigms
5.5.1. Multi-Task Learning
5.5.2. Instance-Based Learning
5.5.3. Weakly Supervised Learning
- Incomplete supervision refers to the problem that a predictive model needs to be trained from the ensemble of labelled and unlabeled data, where only a small amount of data is labelled, while other available data remain unlabeled.
- Inexact supervision refers to the problem that a predictive model needs to be trained from data with only coarse-grained label information. The multi-instance learning [248] is a typical learning problem of incomplete supervision where training data are arranged in sets, and a label is provided for the entire set instead of the data themselves.
- Inaccurate supervision concerns the problem that a predictive model needs to be trained from data that are not always labelled with ground-truth. A typical problem of inaccurate supervision is label noise [249], where mislabeled data are expected to be corrected or removed before model training.
5.5.4. Incremental Learning
6. Technique Review Summary
- “+”: The reviewed technique improves the corresponding Edge ML solution regarding the specific Edge ML requirement. For instance, quantization techniques reduce the inference task latency by simplifying the computation complexity.
- “−”: The reviewed technique negatively impacts the corresponding Edge ML solution regarding the specific Edge ML requirement. For instance, quantization techniques lead to accuracy loss during inference due to the low precision representation of data.
- “*”: The impact of the reviewed technique on the corresponding Edge ML solution varies according to the specific configurations or setup. For instance, transfer learning techniques improve the target model performance under the conditions that the source task and the target task are correlated, and the data quantity and quality on the target domain are sufficient. The weakness in data quantity or quality on the target domain can result in unsatisfactory model performance.
- “/”: The reviewed technique does not directly impact the corresponding Edge ML solution regarding the specific Edge ML requirement. For instance, federated learning techniques do not directly improve or worsen the labelled data independence for a supervised learning process.
- Appropriate modelling and learning: all models for ML tasks are designed and trained following the state-of-the-art solution. No serious over-fitting or under-fitting has occurred, so that the models’ performance can be compared before and after applying the Edge ML techniques.
- Statistic scenario: When performing a task, statistic scenarios instead of the best or the worst scenario are considered for techniques evaluation, as certain techniques, e.g., Early Exit of Inference, can produce worse results compared to the corresponding conventional technique in extreme cases where all the side branch classifiers in a model do not produce high enough confidence and thus it fails to stop the inference earlier. However, statistically, the EEoI technique is able to improve energy efficiency and optimize cost when performing a number of running tasks.
7. Edge ML Frameworks
8. Open Issues and Future Directions
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.; Maslej, N.; Brynjolfsson, E.; Etchemendy, J.; Lyons, T.; Manyika, J.; Ngo, H.; Niebles, J.C.; Michael, J.; Sellitto, M.; et al. The AI Index Report 2022; AI Index Steering Committee, Stanford Institute for Human-Centered AI, Stanford University: Stanford, CA, USA, 2022; pp. 1–230. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023. [Google Scholar] [CrossRef]
- Liang, F.; Wu, B.; Dai, X.; Li, K.; Zhao, Y.; Zhang, H.; Zhang, P.; Vajda, P.; Marculescu, D. Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP. arXiv 2022. [Google Scholar] [CrossRef]
- Singer, U.; Polyak, A.; Hayes, T.; Yin, X.; An, J.; Zhang, S.; Hu, Q.; Yang, H.; Ashual, O.; Gafni, O.; et al. Make-A-Video: Text-to-Video Generation without Text-Video Data. arXiv 2022. [Google Scholar] [CrossRef]
- GitHub-Stability-AI/Stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models. 2023. Available online: https://github.com/CompVis/latent-diffusion (accessed on 28 July 2023).
- Romero, A. Wu Dao 2.0: A Monster of 1.75 Trillion Parameters|by Alberto Romero|Medium|Towards Data Science. 2021. Available online: https://towardsdatascience.com/gpt-3-scared-you-meet-wu-dao-2-0-a-monster-of-1-75-trillion-parameters-832cd83db484 (accessed on 28 July 2023).
- Dilley, J.; Maggs, B.; Parikh, J.; Prokop, H.; Sitaraman, R.; Weihl, B. Globally distributed content delivery. IEEE Internet Comput. 2002, 6, 50–58. [Google Scholar] [CrossRef]
- Davis, A.; Parikh, J.; Weihl, W.E. EdgeComputing: Extending enterprise applications to the edge of the internet. In Proceedings of the 13th International World Wide Web Conference on Alternate Track, Papers and Posters, WWW Alt 2004, New York, NY, USA, 19–21 May 2004; pp. 180–187. [Google Scholar] [CrossRef]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- Lee, Y.L.; Tsung, P.K.; Wu, M. Techology trend of edge AI. In Proceedings of the 2018 International Symposium on VLSI Design, Automation and Test, VLSI-DAT 2018, Hsinchu, Taiwan, 16–19 April 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Amin, S.U.; Hossain, M.S. Edge Intelligence and Internet of Things in Healthcare: A Survey. IEEE Access 2021, 9, 45–59. [Google Scholar] [CrossRef]
- Yang, B.; Cao, X.; Xiong, K.; Yuen, C.; Guan, Y.L.; Leng, S.; Qian, L.; Han, Z. Edge Intelligence for Autonomous Driving in 6G Wireless System: Design Challenges and Solutions. IEEE Wirel. Commun. 2021, 28, 40–47. [Google Scholar] [CrossRef]
- Lv, Z.; Chen, D.; Lou, R.; Wang, Q. Intelligent edge computing based on machine learning for smart city. Future Gener. Comput. Syst. 2021, 115, 90–99. [Google Scholar] [CrossRef]
- Tang, S.; Chen, L.; He, K.; Xia, J.; Fan, L.; Nallanathan, A. Computational Intelligence and Deep Learning for Next-Generation Edge-Enabled Industrial IoT. IEEE Trans. Netw. Sci. Eng. 2022. early access. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A Survey of Model Compression and Acceleration for Deep Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutorials 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Edge AI; Springer: Singapore, 2020. [Google Scholar] [CrossRef]
- Abbas, G.; Mehmood, A.; Carsten, M.; Epiphaniou, G.; Lloret, J. Safety, Security and Privacy in Machine Learning Based Internet of Things. J. Sens. Actuator Netw. 2022, 11, 38. [Google Scholar] [CrossRef]
- Mustafa, E.; Shuja, J.; uz Zaman, S.K.; Jehangiri, A.I.; Din, S.; Rehman, F.; Mustafa, S.; Maqsood, T.; Khan, A.N. Joint wireless power transfer and task offloading in mobile edge computing: A survey. Clust. Comput. 2022, 25, 2429–2448. [Google Scholar] [CrossRef]
- Sarwar Murshed, M.G.; Murphy, C.; Hou, D.; Khan, N.; Ananthanarayanan, G.; Hussain, F. Machine Learning at the Network Edge: A Survey. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Li, W.; Liewig, M. A survey of AI accelerators for edge environment. In Advances in Intelligent Systems and Computing; Rocha, A., Adeli, H., Reis, L.P., Costanzo, S., Orovic, I., Moreira, F., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 1160, pp. 35–44. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In EMNLP 2018—2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Proceedings of the 1st Workshop, Brussels, Belgium, 1 November 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 353–355. [Google Scholar] [CrossRef]
- Osband, I.; Doron, Y.; Hessel, M.; Aslanides, J.; Sezener, E.; Saraiva, A.; McKinney, K.; Lattimore, T.; Szepesvari, C.; Singh, S.; et al. Behaviour Suite for Reinforcement Learning. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar] [CrossRef]
- Huisman, M.; van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef]
- Golalipour, K.; Akbari, E.; Hamidi, S.S.; Lee, M.; Enayatifar, R. From clustering to clustering ensemble selection: A review. Eng. Appl. Artif. Intell. 2021, 104, 104388. [Google Scholar] [CrossRef]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.; De Freitas, N. Predicting parameters in deep learning. Adv. Neural Inf. Process. Syst. 2013, 2, 2148–2156. [Google Scholar] [CrossRef]
- Wang, E.; Davis, J.J.; Zhao, R.; Ng, H.C.; Niu, X.; Luk, W.; Cheung, P.Y.; Constantinides, G.A. Deep neural network approximation for custom hardware: Where We’ve Been, Where We’re going. ACM Comput. Surv. 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Wang, S.; Kanwar, P. BFloat16: The Secret to High Performance on Cloud TPUs—Google Cloud Blog. 2021. Available online: https://cloud.google.com/blog/products/ai-machine-learning/bfloat16-the-secret-to-high-performance-on-cloud-tpus (accessed on 28 July 2023).
- Goyal, R.; Vanschoren, J.; van Acht, V.; Nijssen, S. Fixed-point Quantization of Convolutional Neural Networks for Quantized Inference on Embedded Platforms. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2021. [Google Scholar] [CrossRef]
- Yuan, C.; Agaian, S.S. A comprehensive review of Binary Neural Network. Artif. Intell. Rev. 2023. [Google Scholar] [CrossRef]
- Liu, B.; Li, F.; Wang, X.; Zhang, B.; Yan, J. Ternary Weight Networks. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Lee, E.H.; Miyashita, D.; Chai, E.; Murmann, B.; Wong, S.S. LogNet: Energy-efficient neural networks using logarithmic computation. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 5900–5904. [Google Scholar] [CrossRef]
- Lai, L.; Suda, N.; Chandra, V. Deep Convolutional Neural Network Inference with Floating-point Weights and Fixed-point Activations. arXiv 2017. [Google Scholar] [CrossRef]
- Gustafson, J.L.; Yonemoto, I.T. Beating Floating Point at its Own Game: Posit Arithmetic. Supercomput. Front. Innov. 2017, 4, 71–86. [Google Scholar] [CrossRef]
- IEEE Std 754-2008; IEEE Standard for Floating-Point Arithmetic. IEEE: Piscataway, NJ, USA, 2008; pp. 1–70. [CrossRef]
- Gohil, V.; Walia, S.; Mekie, J.; Awasthi, M. Fixed-Posit: A Floating-Point Representation for Error-Resilient Applications. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3341–3345. [Google Scholar] [CrossRef]
- NVIDIA Corporation. Tensor Cores: Versatility for HPC & AI|NVIDIA. 2022. Available online: https://www.nvidia.com/en-us/data-center/tensor-cores/ (accessed on 28 July 2023).
- What Is the TensorFloat-32 Precision Format?|NVIDIA Blog. Available online: https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/ (accessed on 28 July 2023).
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef]
- Lee, S.; Sim, H.; Choi, J.; Lee, J. Successive log quantization for cost-efficient neural networks using stochastic computing. In Proceedings of the Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019; pp. 2–7. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016. [Google Scholar] [CrossRef]
- Jin, X.; Du, X.; Sun, H. VGG-S: Improved Small Sample Image Recognition Model Based on VGG16. In Proceedings of the 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture, AIAM 2021, Manchester, UK, 23–25 October 2021; pp. 229–232. [Google Scholar] [CrossRef]
- Oh, S.; Sim, H.; Lee, S.; Lee, J. Automated Log-Scale Quantization for Low-Cost Deep Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 742–751. [Google Scholar] [CrossRef]
- Qin, H.; Ma, X.; Ding, Y.; Li, X.; Zhang, Y.; Tian, Y.; Ma, Z.; Luo, J.; Liu, X. BiFSMN: Binary Neural Network for Keyword Spotting. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 4346–4352. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018. [Google Scholar] [CrossRef]
- Liu, Z.; Oguz, B.; Pappu, A.; Xiao, L.; Yih, S.; Li, M.; Krishnamoorthi, R.; Mehdad, Y. BiT: Robustly Binarized Multi-distilled Transformer. arXiv 2022, arXiv:2205.13016. [Google Scholar]
- Osorio, J.; Armejach, A.; Petit, E.; Henry, G.; Casas, M. A BF16 FMA is All You Need for DNN Training. IEEE Trans. Emerg. Top. Comput. 2022, 10, 1302–1314. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Y.; Saab, R. Post-training Quantization for Neural Networks with Provable Guarantees. SIAM J. Math. Data Sci. 2023, 5, 373–399. [Google Scholar] [CrossRef]
- De Putter, F.; Corporaal, H. Quantization: How far should we go? In Proceedings of the 2022 25th Euromicro Conference on Digital System Design (DSD), Gran Canaria, Spain, 31 August–2 September 2022; pp. 373–382. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, Z.; Savvides, M.; Cheng, K.T. ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 143–159. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016. [Google Scholar] [CrossRef]
- Ruospo, A.; Sanchez, E.; Traiola, M.; O’Connor, I.; Bosio, A. Investigating data representation for efficient and reliable Convolutional Neural Networks. Microprocess. Microsyst. 2021, 86, 104318. [Google Scholar] [CrossRef]
- Chu, X.; Zhang, B.; Xu, R. FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12219–12228. [Google Scholar] [CrossRef]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. In Proceedings of the BMVC 2014—British Machine Vision Conference 2014, Nottingham, UK, 1–5 September 2014. [Google Scholar] [CrossRef]
- Srinivas, S.; Babu, R.V. Data-free Parameter Pruning for Deep Neural Networks. arXiv 2015. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Dai, X.; Yin, H.; Jha, N.K. NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm. IEEE Trans. Comput. 2019, 68, 1487–1497. [Google Scholar] [CrossRef]
- Yu, J.; Lukefahr, A.; Palframan, D.; Dasika, G.; Das, R.; Mahlke, S. Scalpel: Customizing DNN pruning to the underlying hardware parallelism. In Proceedings of the International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; Volume F1286; pp. 548–560. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Gong, E.; Tang, S.; Dally, W.J.; Pool, J.; Tran, J.; Catanzaro, B.; Narang, S.; Elsen, E.; et al. DSD: Dense-sparse-dense training for deep neural networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Frantar, E.; Alistarh, D. SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot. arXiv 2023, arXiv:2301.00774. [Google Scholar]
- Wu, T.; Li, X.; Zhou, D.; Li, N.; Shi, J. Differential Evolution Based Layer-Wise Weight Pruning for Compressing Deep Neural Networks. Sensors 2021, 21, 880. [Google Scholar] [CrossRef]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. DepGraph: Towards Any Structural Pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 16091–16101. [Google Scholar]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- Gao, X.; Zhao, Y.; Dudziak, L.; Mullins, R.; Xu, C. Dynamic channel pruning: Feature boosting and suppression. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Aich, S.; Yamazaki, M.; Taniguchi, Y.; Stavness, I. Multi-Scale Weight Sharing Network for Image Recognition. Pattern Recognit. Lett. 2020, 131, 348–354. [Google Scholar] [CrossRef]
- Chen, W.; Wilson, J.T.; Tyree, S.; Weinberger, K.Q.; Chen, Y. Compressing neural networks with the hashing trick. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 3, pp. 2275–2284. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Li, Z.; Ghodrati, S.; Yazdanbakhsh, A.; Esmaeilzadeh, H.; Kang, M. Accelerating Atention through Gradient-Based Learned Runtime Pruning. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; Volume 14, pp. 902–915. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, J.; Wang, Z. Accelerating Recurrent Neural Networks: A Memory-Efficient Approach. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2763–2775. [Google Scholar] [CrossRef]
- Wang, S.; Li, Z.; Ding, C.; Yuan, B.; Qiu, Q.; Wang, Y.; Liang, Y. C-LSTM: Enabling efficient LSTM using structured compression techniques on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, FPGA 2018, Monterey, CA, USA, 25–27 February 2018; pp. 11–20. [Google Scholar] [CrossRef]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient Neural Architecture Search via parameter Sharing. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 9, pp. 6522–6531. [Google Scholar]
- Liu, Y.; Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Tan, K.C. A Survey on Evolutionary Neural Architecture Search. IEEE Trans. Neural Networks Learn. Syst. 2023, 34, 550–570. [Google Scholar] [CrossRef]
- Denton, E.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv. Neural Inf. Process. Syst. 2014, 2, 1269–1277. [Google Scholar] [CrossRef]
- Chen, P.H.; Hsian-Fu, Y.; Dhillon, I.S.; Cho-Jui, H. DRONE: Data-aware Low-rank Compression for Large NLP Models. Adv. Neural Inf. Process. Syst. 2021, 35, 29321–29334. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Dolan, W.B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), Jeju Island, Republic of Korea, 14 October 2005; pp. 9–16. [Google Scholar]
- Warstadt, A.; Singh, A.; Bowman, S.R. Neural Network Acceptability Judgments. Trans. Assoc. Comput. Linguist. 2019, 7, 625–641. [Google Scholar] [CrossRef]
- STSBenchmark. STSbenchmark-Stswiki. 2019. Available online: https://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark%0Ahttps://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark (accessed on 28 July 2023).
- Borup, K.; Andersen, L.N. Even your Teacher Needs Guidance: Ground-Truth Targets Dampen Regularization Imposed by Self-Distillation. Adv. Neural Inf. Process. Syst. 2021, 7, 5316–5327. [Google Scholar] [CrossRef]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 743–752. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Wen, T.; Lai, S.; Qian, X. Preparing lessons: Improve knowledge distillation with better supervision. Neurocomputing 2021, 454, 25–33. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. Cs.Toronto.Edu 2009, 1–58. [Google Scholar]
- Darlow, L.N.; Crowley, E.J.; Antoniou, A.; Storkey, A.J. CINIC-10 is not ImageNet or CIFAR-10. arXiv 2018. [Google Scholar] [CrossRef]
- Le, Y.; Yang, X. Tiny ImageNet Visual Recognition Challenge; Stanford CS231N; Stanford University: Stanford, CA, USA, 2015. [Google Scholar]
- Zhang, J.; Peng, H.; Wu, K.; Liu, M.; Xiao, B.; Fu, J.; Yuan, L. MiniViT: Compressing Vision Transformers with Weight Multiplexing; Technical Report; Microsoft: Redmond, DC, USA, 2022. [Google Scholar]
- Amin, H.; Curtis, K.M.; Hayes-Gill, B.R. Piecewise linear approximation applied to nonlinear function of a neural network. IEEE Proc. Circuits Devices Syst. 1997, 144, 313–317. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, J.; Ge, Y. Handling Vanishing Gradient Problem Using Artificial Derivative. IEEE Access 2021, 9, 22371–22377. [Google Scholar] [CrossRef]
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. DeepThings: Distributed adaptive deep learning inference on resource-constrained IoT edge clusters. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks, IPSN 2016, Vienna, Austria, 11–14 April 2016. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Du, J.; Zhu, X.; Shen, M.; Du, Y.; Lu, Y.; Xiao, N.; Liao, X. Model Parallelism Optimization for Distributed Inference Via Decoupled CNN Structure. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1665–1676. [Google Scholar] [CrossRef]
- Hemmat, M.; Davoodi, A.; Hu, Y.H. EdgenAI: Distributed Inference with Local Edge Devices and Minimal Latency. In Proceedings of the Asia and South Pacific Design Automation Conference, ASP-DAC, Taipei, Taiwan, 17–20 January 2022; pp. 544–549. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. BranchyNet: Fast inference via early exiting from deep neural networks. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, C.; Ge, T.; McAuley, J.; Xu, K.; Wei, F. BERT loses patience: Fast and robust inference with early exit. In Proceedings of the Advances in Neural Information Processing Systems, Online. 6–12 December 2020. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A Lite Bert for Self-Supervised Learning of Language Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar] [CrossRef]
- Drolia, U.; Guo, K.; Tan, J.; Gandhi, R.; Narasimhan, P. Cachier: Edge-Caching for Recognition Applications. In Proceedings of the International Conference on Distributed Computing Systems, Atlanta, GA, USA, 5–8 June 2017; pp. 276–286. [Google Scholar] [CrossRef]
- Xu, M.; Zhu, M.; Liu, Y.; Lin, F.X.; Liu, X. DeepCache: Principled cache for mobile deep vision. In Proceedings of the Annual International Conference on Mobile Computing and Networking, MOBICOM, New Delhi, India, 29 October–2 November 2018; pp. 129–144. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, C.; Han, S.; Zhang, L.L.; Yin, B.; Liu, Y.; Xu, M. Boosting Mobile CNN Inference through Semantic Memory. In Proceedings of the 29th ACM International Conference on Multimedia, MM 2021, Online. 20–24 October 2021; pp. 2362–2371. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobileNetV3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2021; pp. 1314–1324. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-aware neural network adaptation for mobile applications. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 11214, pp. 289–304. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Dong, P.; Wang, S.; Niu, W.; Zhang, C.; Lin, S.; Li, Z.; Gong, Y.; Ren, B.; Lin, X.; Tao, D. RTMobile: Beyond real-time mobile acceleration of RNNs for speech recognition. In Proceedings of the Design Automation Conference, Online. 20–24 July 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5999–6009. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, T.; Roberts, A.; Hesslow, D.; Le Scao, T.; Chung, H.W.; Beltagy, I.; Launay, J.; Raffel, C. What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? Proc. Mach. Learn. Res. 2022, 162, 22964–22984. [Google Scholar]
- Wang, X.; Zhang, L.L.; Wang, Y.; Yang, M. Towards Efficient Vision Transformer Inference: A First Study of Transformers on Mobile Devices. In Proceedings of the 23rd Annual International Workshop on Mobile Computing Systems and Applications, HotMobile 2022, Orange County, CA, USA, 22–23 February 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12239–12249. [Google Scholar] [CrossRef]
- Roh, B.; Shin, J.; Shin, W.; Kim, S. Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity. arXiv 2021. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, E.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. EfficientFormer: Vision Transformers at MobileNet Speed. arXiv 2022. [Google Scholar] [CrossRef]
- McMahan, B.; Daniel Ramage. Federated Learning: Collaborative Machine Learning without Centralized Training Data—Google Research Blog. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 28 July 2023).
- Wink, T.; Nochta, Z. An Approach for Peer-to-Peer Federated Learning. In Proceedings of the 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops, DSN-W 2021, Taipei, Taiwan, 21–24 June 2021; pp. 150–157. [Google Scholar] [CrossRef]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, Ft. Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar] [CrossRef]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM SIGPLAN Not. 2017, 52, 615–629. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Wang, L.; Xu, S.; Wang, X.; Zhu, Q. Addressing Class Imbalance in Federated Learning. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, AAAI 2021, Online. 2–9 February 2021; Volume 11B, pp. 10165–10173. [Google Scholar] [CrossRef]
- Xu, C.; Qu, Y.; Xiang, Y.; Gao, L. Asynchronous Federated Learning on Heterogeneous Devices: A Survey. ACM Comput. Surv 2021, 37, 27. [Google Scholar] [CrossRef]
- Alistarh, D.; Grubic, D.; Li, J.Z.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1710–1721. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated Learning for Healthcare Informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Mori, J.; Teranishi, I.; Furukawa, R. Continual Horizontal Federated Learning for Heterogeneous Data. In Proceedings of the International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2022. [Google Scholar] [CrossRef]
- Nock, R.; Hardy, S.; Henecka, W.; Ivey-Law, H.; Patrini, G.; Smith, G.; Thorne, B. Entity Resolution and Federated Learning get a Federated Resolution. arXiv 2018. [Google Scholar] [CrossRef]
- Feng, S.; Yu, H. Multi-Participant Multi-Class Vertical Federated Learning. arXiv 2020. [Google Scholar] [CrossRef]
- Li, Y.; Nie, F.; Huang, H.; Huang, J. Large-scale multi-view spectral clustering via bipartite graph. Proc. Natl. Conf. Artif. Intell. 2015, 4, 2750–2756. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef]
- Wang, K.I.; Zhou, X.; Liang, W.; Yan, Z.; She, J. Federated Transfer Learning Based Cross-Domain Prediction for Smart Manufacturing. IEEE Trans. Ind. Inform. 2022, 18, 4088–4096. [Google Scholar] [CrossRef]
- Ferryman, J.; Shahrokni, A. PETS2009: Dataset and challenge. In Proceedings of the 12th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, PETS-Winter 2009, Snowbird, UT, USA, 7–12 December 2009. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Zhao, J.; Yang, Q. Threats to Federated Learning. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12500, pp. 3–16. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, B.; Luo, W.; Chen, F. Autoencoder-based representation learning and its application in intelligent fault diagnosis: A review. Meas. J. Int. Meas. Confed. 2022, 189, 110460. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Vincent Poor, H. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutorials 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Ghimire, B.; Rawat, D.B. Recent Advances on Federated Learning for Cybersecurity and Cybersecurity for Federated Learning for Internet of Things. IEEE Internet Things J. 2022, 9, 8229–8249. [Google Scholar] [CrossRef]
- Sun, T.; Li, D.; Wang, B. Decentralized Federated Averaging. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4289–4301. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Jadbabaie, A.; Mokhtari, A.; Hassani, H.; Pedarsani, R. FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization. Proc. Mach. Learn. Res. 2020, 108, 2021–2031. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Lyu, L.; Huang, Y.; Xie, X. Communication-efficient federated learning via knowledge distillation. Nat. Commun. 2022, 13, 2032. [Google Scholar] [CrossRef]
- DInh, C.T.; Tran, N.H.; Nguyen, M.N.; Hong, C.S.; Bao, W.; Zomaya, A.Y.; Gramoli, V. Federated Learning over Wireless Networks: Convergence Analysis and Resource Allocation. IEEE/ACM Trans. Netw. 2021, 29, 398–409. [Google Scholar] [CrossRef]
- Stiglitz, J.E. Self-selection and Pareto efficient taxation. J. Public Econ. 1982, 17, 213–240. [Google Scholar] [CrossRef]
- Xu, Z.; Yu, F.; Xiong, J.; Chen, X. Helios: Heterogeneity-Aware Federated Learning with Dynamically Balanced Collaboration. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 5–9 December 2021; pp. 997–1002. [Google Scholar] [CrossRef]
- Hahn, S.J.; Jeong, M.; Lee, J. Connecting Low-Loss Subspace for Personalized Federated Learning. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 505–515. [Google Scholar] [CrossRef]
- Gupta, O.; Raskar, R. Distributed learning of deep neural network over multiple agents. J. Netw. Comput. Appl. 2018, 116, 1–8. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Vinyals, O.; Saxe, A.M. Qualitatively characterizing neural network optimization problems. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Vepakomma, P.; Gupta, O.; Swedish, T.; Raskar, R. Split learning for health: Distributed deep learning without sharing raw patient data. arXiv 2018. [Google Scholar] [CrossRef]
- Thapa, C.; Arachchige, P.C.M.; Camtepe, S.; Sun, L. SplitFed: When Federated Learning Meets Split Learning. In Proceedings of the 36th AAAI Conference on Innovative Applications of Artificial Intelligence, AAAI 2022, Arlington, VA, USA, 17–19 November 2022; Volume 36, pp. 8485–8493. [Google Scholar] [CrossRef]
- Panigrahi, S.; Nanda, A.; Swarnkar, T. A Survey on Transfer Learning. Smart Innov. Syst. Technol. 2021, 194, 781–789. [Google Scholar] [CrossRef]
- Sugiyama, M.; Suzuki, T.; Nakajima, S.; Kashima, H.; Von Bünau, P.; Kawanabe, M. Direct importance estimation for covariate shift adaptation. Ann. Inst. Stat. Math. 2008, 60, 699–746. [Google Scholar] [CrossRef]
- Huang, J.; Smola, A.J.; Gretton, A.; Borgwardt, K.M.; Schölkopf, B. Correcting Sample Selection Bias by Unlabeled Data. In Proceedings of the NIPS 2006: 19th International Conference on Neural Information Processing Systems, Whistler, BC, Canada, 8–9 December 2006; pp. 601–608. [Google Scholar] [CrossRef]
- Singh, K.K.; Mahajan, D.; Grauman, K.; Lee, Y.J.; Feiszli, M.; Ghadiyaram, D. Don’t Judge an Object by Its Context: Learning to Overcome Contextual Bias. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11067–11075. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Long, M.; Jordan, M.I. Bridging theory and algorithm for domain adaptation. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 12805–12823. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization: A Survey. arXiv 2021. [Google Scholar] [CrossRef]
- Li, X.; Grandvalet, Y.; Davoine, F. Explicit inductive bias for transfer learning with convolutional networks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 6, pp. 4408–4419. [Google Scholar] [CrossRef]
- Zhi, W.; Chen, Z.; Yueng, H.W.F.; Lu, Z.; Zandavi, S.M.; Chung, Y.Y. Layer Removal for Transfer Learning with Deep Convolutional Neural Networks. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; Volume 10635, pp. 460–469. [Google Scholar] [CrossRef]
- Chu, B.; Madhavan, V.; Beijbom, O.; Hoffman, J.; Darrell, T. Best practices for fine-tuning visual classifiers to new domains. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- You, K.; Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Universal domain adaptation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2715–2724. [Google Scholar] [CrossRef]
- Rios-Urrego, C.D.; Vásquez-Correa, J.C.; Orozco-Arroyave, J.R.; Nöth, E. Transfer learning to detect parkinson’s disease from speech in different languages using convolutional neural networks with layer freezing. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Science and Business Media Deutschland GmbH: Cham, Switzerland, 2020; Volume 12284, pp. 331–339. [Google Scholar] [CrossRef]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.M.; Chen, W.; et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Kara, O.; Sehanobish, A.; Corzo, H.H. Fine-tuning Vision Transformers for the Prediction of State Variables in Ising Models. arXiv 2021. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 328–339. [Google Scholar] [CrossRef]
- Houlsby, N.; Giurgiu, A.; Jastrzçbski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 4944–4953. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the EMNLP 2021—2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 3045–3059. [Google Scholar] [CrossRef]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. arXiv 2022. [Google Scholar] [CrossRef]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling Instruction-Finetuned Language Models. arXiv 2022. [Google Scholar] [CrossRef]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter tuning and performance assessment of statistical and machine-learning algorithms using spatial data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef]
- Wang, Z.; Dai, Z.; Poczos, B.; Carbonell, J. Characterizing and avoiding negative transfer. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11285–11294. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Roy, S.; Roth, D. Solving general arithmetic word problems. In Proceedings of the EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1743–1752. [Google Scholar] [CrossRef]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-Learning: A Survey. arXiv 2018. [Google Scholar] [CrossRef]
- Peng, H. A Brief Summary of Interactions Between Meta-Learning and Self-Supervised Learning. arXiv 2021. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 3, pp. 1856–1868. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for kNN Classification. ACM Trans. Intell. Syst. Technol. 2017, 8, 1–19. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Learning the k in kmeans. In Advances in Neural Information Processing Systems; Thrun, S., Saul, L., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2004; Volume 17, pp. 1–8. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; Volume 4, pp. 2740–2751. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research Progress on Few-Shot Learning for Remote Sensing Image Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Gupta, A.; Mendonca, R.; Liu, Y.X.; Abbeel, P.; Levine, S. Meta-reinforcement learning of structured exploration strategies. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 5302–5311. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Callaway, F.; Chang, M.B.; Grant, E.; Krueger, P.M.; Lieder, F. Doing more with less: Meta-reasoning and meta-learning in humans and machines. Curr. Opin. Behav. Sci. 2019, 29, 24–30. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Chen, W.Y.; Wang, Y.C.F.; Liu, Y.C.; Kira, Z.; Huang, J.B. A closer look at few-shot classification. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Bennequin, E. Meta-learning algorithms for Few-Shot Computer Vision. arXiv 2019. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; pp. 1–11. [Google Scholar]
- Romera-Paredes, B.; Torr, P.H. An embarrassingly simple approach to zero-shot learning. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 3, pp. 2142–2151. [Google Scholar] [CrossRef]
- Verma, V.K.; Rai, P. A Simple Exponential Family Framework for Zero-Shot Learning. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; Volume 10535, pp. 792–808. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. Proc. Mach. Learn. Res. 2021, 139, 8748–8763. [Google Scholar] [CrossRef]
- Belkhale, S.; Li, R.; Kahn, G.; McAllister, R.; Calandra, R.; Levine, S. Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads. IEEE Robot. Autom. Lett. 2021, 6, 1471–1478. [Google Scholar] [CrossRef]
- Rajeswaran, A.; Kakade, S.M.; Finn, C.; Levine, S. Meta-learning with implicit gradients. Adv. Neural Inf. Process. Syst. 2019, 32, 113–124. [Google Scholar] [CrossRef]
- Finn, C.; Rajeswaran, A.; Kakade, S.; Levine, S. Online meta-learning. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 3398–3410. [Google Scholar] [CrossRef]
- Wang, W.; Zheng, V.W.; Yu, H.; Miao, C. A survey of zero-shot learning: Settings, methods, and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–37. [Google Scholar] [CrossRef]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to detect unseen object classes by between-class attribute transfer. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 951–958. [Google Scholar] [CrossRef]
- Patterson, G.; Hays, J. SUN attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar] [CrossRef]
- Farhadi, A.; Endres, I.; Hoiem, D.; Forsyth, D. Describing objects by their attributes. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1778–1785. [Google Scholar] [CrossRef]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. The Omniglot challenge: A 3-year progress report. Curr. Opin. Behav. Sci. 2019, 29, 97–104. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text Data Augmentation for Deep Learning. J. Big Data 2021, 8, 1–34. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised Learning: Generative or Contrastive. arXiv 2021. [Google Scholar] [CrossRef]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-Supervised Representation Learning: Introduction, advances, and challenges. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. AMMUS: A Survey of Transformer-based Pretrained Models in Natural Language Processing. arXiv 2021. [Google Scholar] [CrossRef]
- Xie, Y.; Xu, Z.; Zhang, J.; Wang, Z.; Ji, S. Self-Supervised Learning of Graph Neural Networks: A Unified Review. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2412–2429. [Google Scholar] [CrossRef]
- Baevski, A.; Hsu, W.N.; Xu, Q.; Babu, A.; Gu, J.; Auli, M. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language. arXiv 2022. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1–9. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Chang, K.W.; Sun, Y. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Online. 6–10 July 2020; pp. 1857–1867. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Vienna, Austria, 12–18 July 2020; pp. 1575–1585. [Google Scholar]
- Donahue, J.; Darrell, T.; Krähenbühl, P. Adversarial feature learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Donahue, J.; Simonyan, K. Large scale adversarial representation learning. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar] [CrossRef]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36. [Google Scholar] [CrossRef]
- Tran, M.T.; Kim, S.H.; Yang, H.J.; Lee, G.S. Deep learning-based inpainting for chest X-ray image. In Proceedings of the 9th International Conference on Smart Media and Applications, Jeju, Republic of Korea, 17–19 September 2020; pp. 267–271. [Google Scholar] [CrossRef]
- Zhuang, W.; Wen, Y.; Zhang, S. Divergence-Aware Federated Self-Supervised Learning. In Proceedings of the 10th International Conference on Learning Representations, ICLR 2022, Vienna, Austria, 7–11 May 2022. [Google Scholar] [CrossRef]
- Mao, H.H. A Survey on Self-supervised Pre-training for Sequential Transfer Learning in Neural Networks. arXiv 2020. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the Advances in Neural Information Processing Systems, Online. 6–12 December 2020. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12356, pp. 776–794. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-Training Text Encoders As Discriminators Rather Than Generators. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar] [CrossRef]
- Dai, Q.; Li, Q.; Tang, J.; Wang, D. Adversarial network embedding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 2167–2174. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Li, W.; Zemi, D.H.; Redon, V.; Matthieu, L. Multi-Task Attention Network for Digital Context Classification from Internet Traffic. In Proceedings of the 2022 7th International Conference on Machine Learning Technologies (ICMLT), Rome, Italy, 11–13 March 2022; pp. 1–12. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Yang, Y.; Hospedales, T.M. Trace norm regularised deep multi-task learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Rago, A.; Piro, G.; Boggia, G.; Dini, P. Multi-Task Learning at the Mobile Edge: An Effective Way to Combine Traffic Classification and Prediction. IEEE Trans. Veh. Technol. 2020, 69, 10362–10374. [Google Scholar] [CrossRef]
- Chen, Q.; Zheng, Z.; Hu, C.; Wang, D.; Liu, F. On-Edge Multi-Task Transfer Learning: Model and Practice with Data-Driven Task Allocation. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1357–1371. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Ghosh, J.; Nag, A. An Overview of Radial Basis Function Networks. Stud. Fuzziness Soft Comput. 2001, 67, 1–36. [Google Scholar] [CrossRef]
- Watson, I.; Marir, F. Case-Based Reasoning: A Review. Knowl. Eng. Rev. 2009, 9, 327–354. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, X.; Liu, Y.; Xi, Q. A Distributed Storage and Computation k-Nearest Neighbor Algorithm Based Cloud-Edge Computing for Cyber-Physical-Social Systems. IEEE Access 2020, 8, 50118–50130. [Google Scholar] [CrossRef]
- González-Briones, A.; Prieto, J.; De La Prieta, F.; Herrera-Viedma, E.; Corchado, J.M. Energy optimization using a case-based reasoning strategy. Sensors 2018, 18, 865. [Google Scholar] [CrossRef]
- Ratner, A.; Varma, P.; Hancock, B.; Ré, C. Weak Supervision: A New Programming Paradigm for Machine Learning|SAIL Blog. 2019. Available online: http://ai.stanford.edu/blog/weak-supervision (accessed on 28 July 2023).
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Wei, X.S.; Wu, J.; Zhou, Z.H. Scalable algorithms for multi-instance learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 975–987. [Google Scholar] [CrossRef]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef]
- Nodet, P.; Lemaire, V.; Bondu, A.; Cornuejols, A.; Ouorou, A. From Weakly Supervised Learning to Biquality Learning: An Introduction. In Proceedings of the International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning, 2nd ed.; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Rahman, S.; Khan, S.; Barnes, N. Transductive learning for zero-shot object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6081–6090. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey. Mach. Learn. 2010, 15, 201–221. [Google Scholar]
- Sharma, Y.; Shrivastava, A.; Ehsan, L.; Moskaluk, C.A.; Syed, S.; Brown, D.E. Cluster-to-Conquer: A Framework for End-to-End Multi-Instance Learning for Whole Slide Image Classification. Proc. Mach. Learn. Res. 2021, 143, 682–698. [Google Scholar]
- Eberts, M.; Ulges, A. An end-to-end model for entity-level relation extraction using multi-instance learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2021, Online. 19–23 April 2021; pp. 3650–3660. [Google Scholar] [CrossRef]
- Luo, Z.; Guillory, D.; Shi, B.; Ke, W.; Wan, F.; Darrell, T.; Xu, H. Weakly-Supervised Action Localization with Expectation-Maximization Multi-Instance Learning. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12374, pp. 729–745. [Google Scholar] [CrossRef]
- Raju, A.; Yao, J.; Haq, M.M.H.; Jonnagaddala, J.; Huang, J. Graph Attention Multi-instance Learning for Accurate Colorectal Cancer Staging. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12265, pp. 529–539. [Google Scholar] [CrossRef]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? In Proceedings of the NIPS’19: 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 4694–4703. [Google Scholar]
- Gao, W.; Wang, L.; Li, Y.F.; Zhou, Z.H. Risk minimization in the presence of label noise. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 1575–1581. [Google Scholar]
- Lukasik, M.; Bhojanapalli, S.; Menon, A.; Kumar, S. Does label smoothing mitigate label noise? In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; Volume 119, pp. 6448–6458. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; Mcguinness, K. Unsupervised Label Noise Modeling and Loss Correction. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 312–321. [Google Scholar]
- Losing, V.; Hammer, B.; Wersing, H. Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing 2018, 275, 1261–1274. [Google Scholar] [CrossRef]
- He, J.; Mao, R.; Shao, Z.; Zhu, F. Incremental learning in online scenario. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13923–13932. [Google Scholar] [CrossRef]
- Lin, J.; Kolcz, A. Large-scale machine learning at Twitter. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 793–804. [Google Scholar] [CrossRef]
- Ling, C.X.; Bohn, T. A Deep Learning Framework for Lifelong Machine Learning. arXiv 2021. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under Concept Drift: A Review. IEEE Trans. Knowl. Data Eng. 2019, 31, 2346–2363. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Maloof, M.A.; Michalski, R.S. Incremental learning with partial instance memory. Artif. Intell. 2004, 154, 95–126. [Google Scholar] [CrossRef]
- Piyasena, D.; Thathsara, M.; Kanagarajah, S.; Lam, S.K.; Wu, M. Dynamically Growing Neural Network Architecture for Lifelong Deep Learning on the Edge. In Proceedings of the 30th International Conference on Field-Programmable Logic and Applications, FPL 2020, Gothenburg, Sweden, 31 August–4 September 2020; pp. 262–268. [Google Scholar] [CrossRef]
- Marsland, S.; Shapiro, J.; Nehmzow, U. A self-organising network that grows when required. Neural Netw. 2002, 15, 1041–1058. [Google Scholar] [CrossRef]
- Singh, A.; Bhadani, R. Mobile Deep Learning with TensorFlow Lite, ML Kit and Flutter; Packt Publisher: Birmingham, UK, 2020; 380p. [Google Scholar]
- Pang, B.; Nijkamp, E.; Wu, Y.N. Deep Learning With TensorFlow: A Review. J. Educ. Behav. Stat. 2020, 45, 227–248. [Google Scholar] [CrossRef]
- PyTorch. Home|PyTorch. 2022. Available online: https://pytorch.org/mobile/home/ (accessed on 28 July 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the NIPS’19: 33rd International Conference on Neural Information Processing Systems, hlVancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8026–8037. [Google Scholar]
- Marques, O. Machine Learning with Core ML. In Springer Briefs in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 29–40. [Google Scholar] [CrossRef]
- Cass, S. Taking AI to the edge: Google’s TPU now comes in a maker-friendly package. IEEE Spectr. 2019, 56, 16–17. [Google Scholar] [CrossRef]
- Ionice, M.H.; Gregg, D. The Movidius Myriad architecture’s potential for scientific computing. IEEE Micro 2015, 35, 6–14. [Google Scholar] [CrossRef]
- STMicroelectronics. STM32 32-bit ARM Cortex MCUs-STMicroelectronics. 2014. Available online: http://www.st.com/web/catalog/mmc/FM141/SC1169 (accessed on 28 July 2023).
- Sun, D.; Liu, S.; Gaudiot, J.L. Enabling Embedded Inference Engine with ARM Compute Library: A Case Study. arXiv 2017, arXiv:1704.03751. [Google Scholar]
- Jeong, E.J.; Kim, J.; Tan, S.; Lee, J.; Ha, S. Deep Learning Inference Parallelization on Heterogeneous Processors with TensorRT. IEEE Embed. Syst. Lett. 2022, 14, 15–18. [Google Scholar] [CrossRef]
- NVIDIA. EGX Platform for Accelerated Computing|NVIDIA. 2023. Available online: https://www.nvidia.com/en-us/data-center/products/egx/ (accessed on 28 July 2023).
- Qualcomm Technologies, I. Qualcomm Neural Processing SDK for AI—Qualcomm Developer Network. 2021. Available online: https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk (accessed on 28 July 2023).
- GitHub—Majianjia/Nnom: A Higher-Level Neural Network Library for Microcontrollers. 2021. Available online: https://github.com/majianjia/nnom (accessed on 28 July 2023).
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 22–25 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- STMicroelectronics. X-CUBE-AI—AI Expansion Pack for STM32CubeMX—STMicroelectronics. 2022. Available online: https://www.st.com/en/embedded-software/x-cube-ai.html (accessed on 28 July 2023).
- Narayanan, D.; Shoeybi, M.; Casper, J.; LeGresley, P.; Patwary, M.; Korthikanti, V.; Vainbrand, D.; Kashinkunti, P.; Bernauer, J.; Catanzaro, B.; et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, MI, USA, 14–19 November 2021. [Google Scholar] [CrossRef]
- Rasley, J.; Rajbhandari, S.; Ruwase, O.; He, Y. DeepSpeed: System Optimizations Enable Training Deep Learning Models with over 100 Billion Parameters. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Online. 6–10 July 2020; pp. 3505–3506. [Google Scholar] [CrossRef]
- GitHub—Tensorflow/Mesh: Mesh TensorFlow: Model Parallelism Made Easier. Available online: https://github.com/tensorflow/mesh (accessed on 28 July 2023).
- Chen, L. Deep Learning and Practice with MindSpore; Cognitive Intelligence and Robotics; Springer: Singapore, 2021; pp. 1–531. [Google Scholar] [CrossRef]
- Google Inc. TensorFlow Federated. 2022. Available online: https://www.tensorflow.org/federated (accessed on 28 July 2023).
- Intel. Intel/Openfl: An Open Framework for Federated Learning. Available online: https://github.com/intel/openfl (accessed on 28 July 2023).
- Nvidia Clara. NVIDIA Clara|NVIDIA Developer. 2020. Available online: https://developer.nvidia.com/blog/federated-learning-clara/ (accessed on 28 July 2023).
- Standards by ISO/IEC JTC. ISO—ISO/IEC JTC 1/SC 42—Artificial Intelligence. 2022. Available online: https://www.iso.org/committee/6794475/x/catalogue/ (accessed on 28 July 2023).
- International Telecommunication Union (ITU). Focus Group on AI for Autonomous and Assisted Driving (FG-AI4AD). 2021. Available online: https://www.itu.int/en/ITU-T/focusgroups/ai4ad/Pages/default.aspx (accessed on 28 July 2023).
- ITU-T FG-ML5G. Focus Group on Machine Learning for Future Networks Including 5G. 2018. Available online: https://www.itu.int/en/ITU-T/focusgroups/ml5g/Pages/default.aspx (accessed on 28 July 2023).
- Dahmen-Lhuissier, S. ETSI—Multi-Access Edge Computing—Standards for MEC. 2020. Available online: https://www.etsi.org/technologies/multi-access-edge-computing (accessed on 28 July 2023).
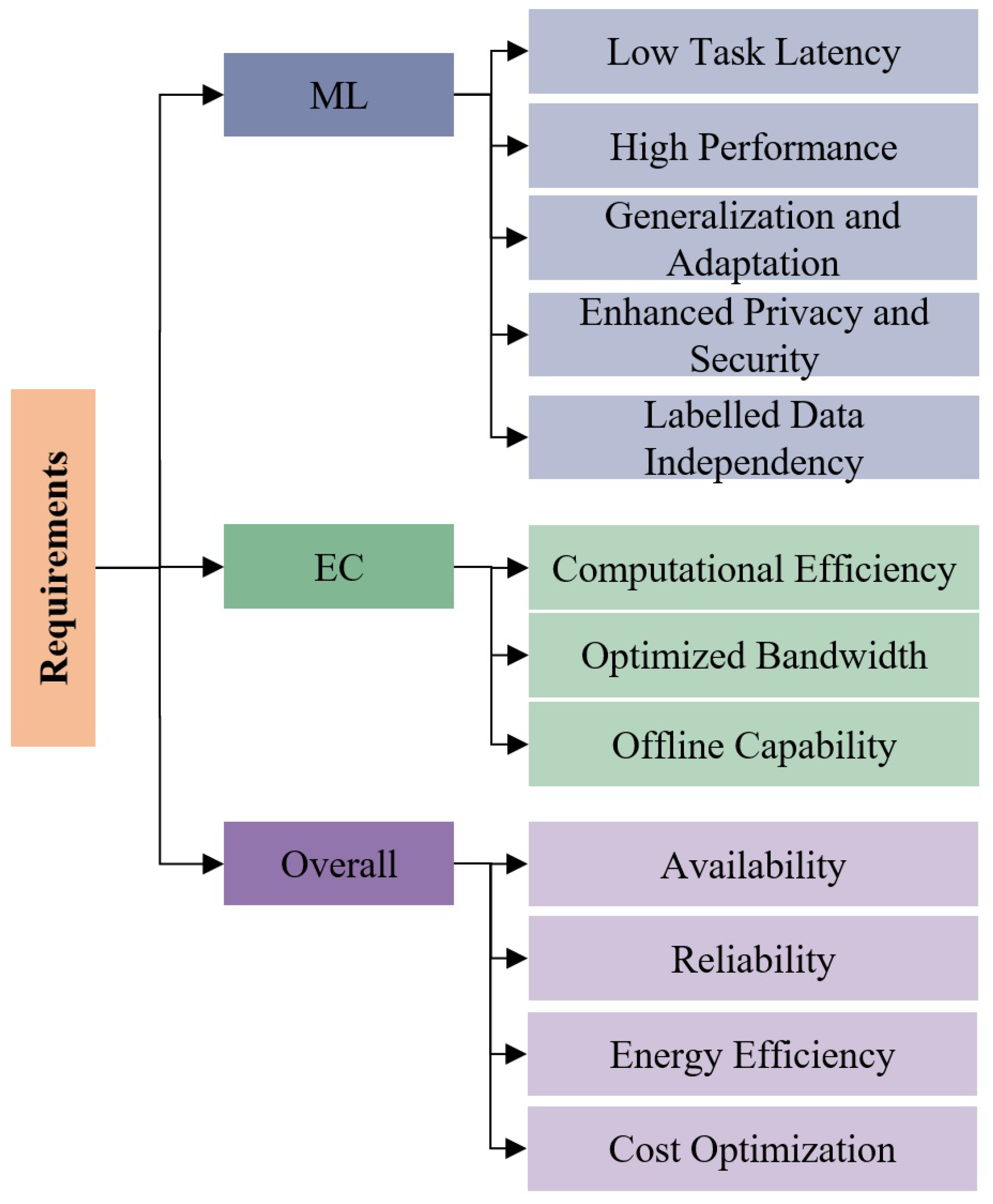

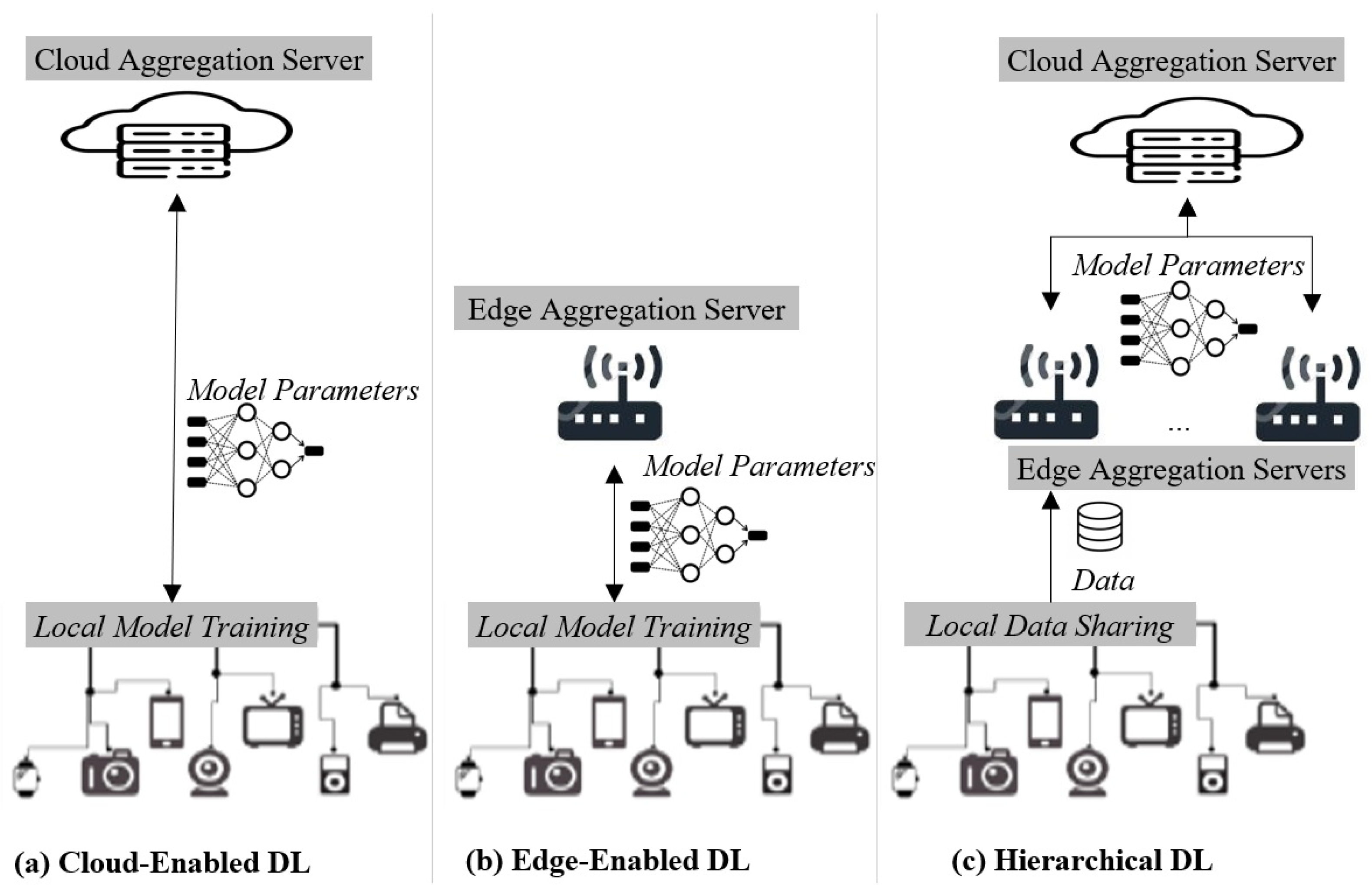
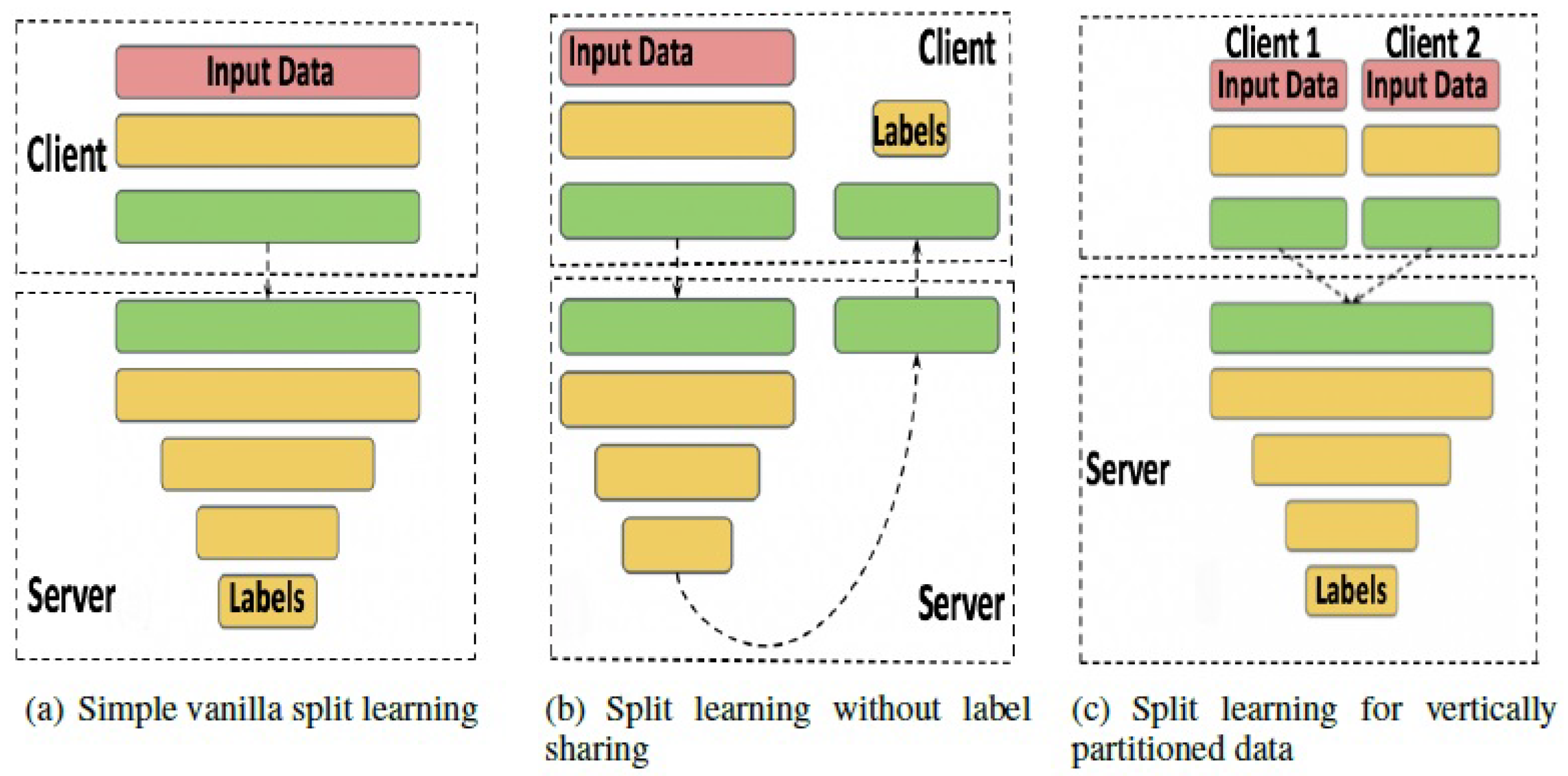
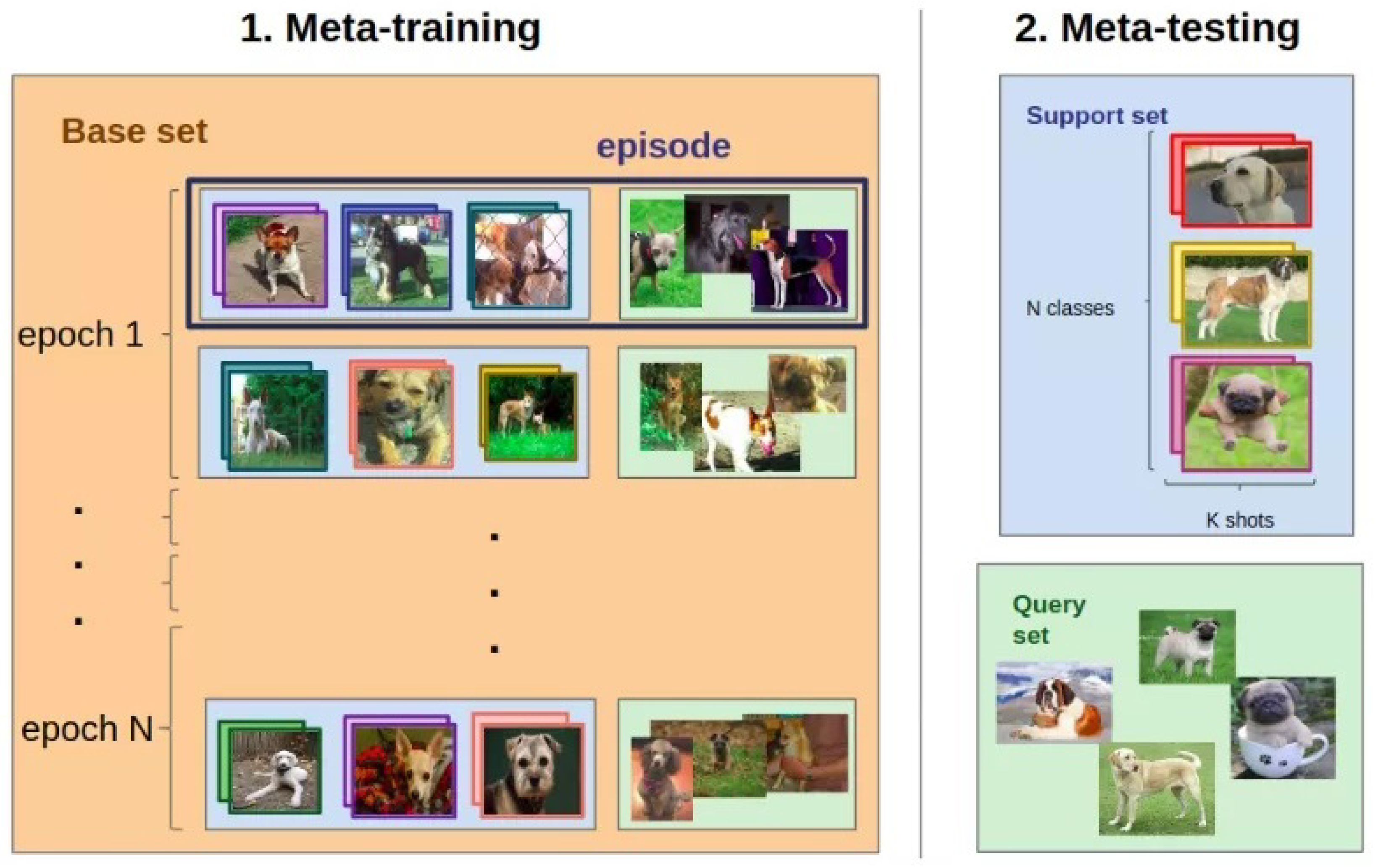
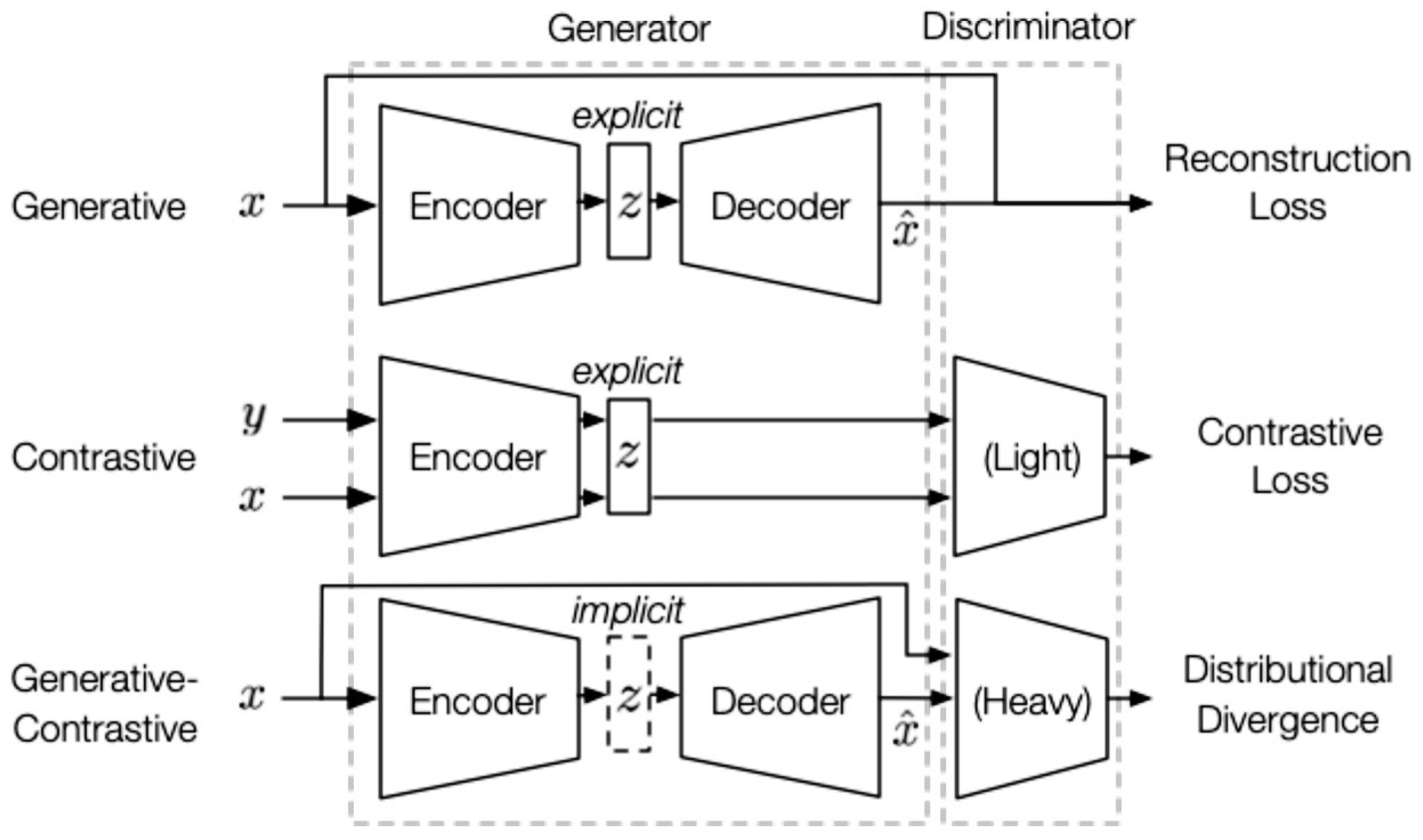


{kind=link}
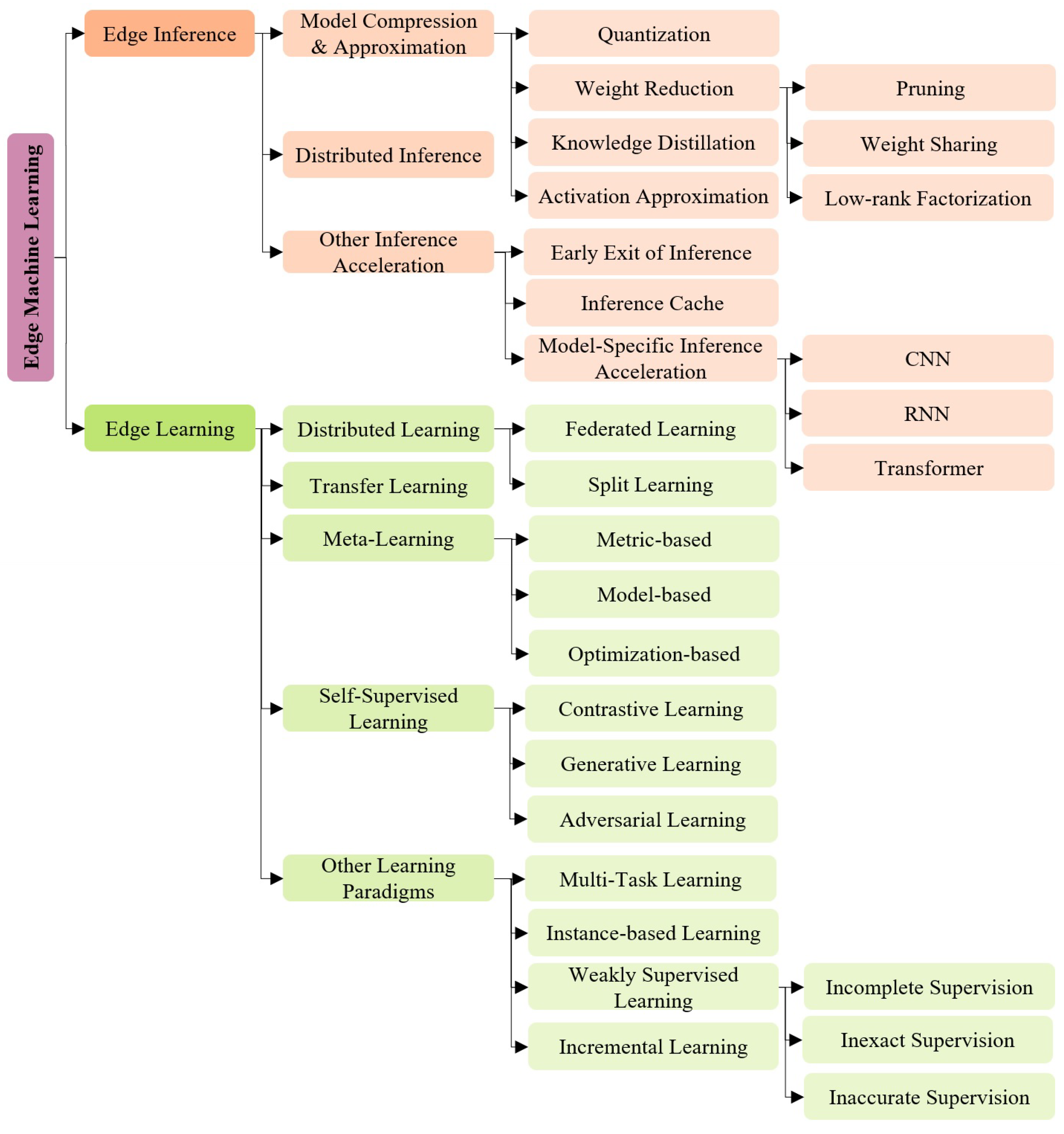{kind=link}
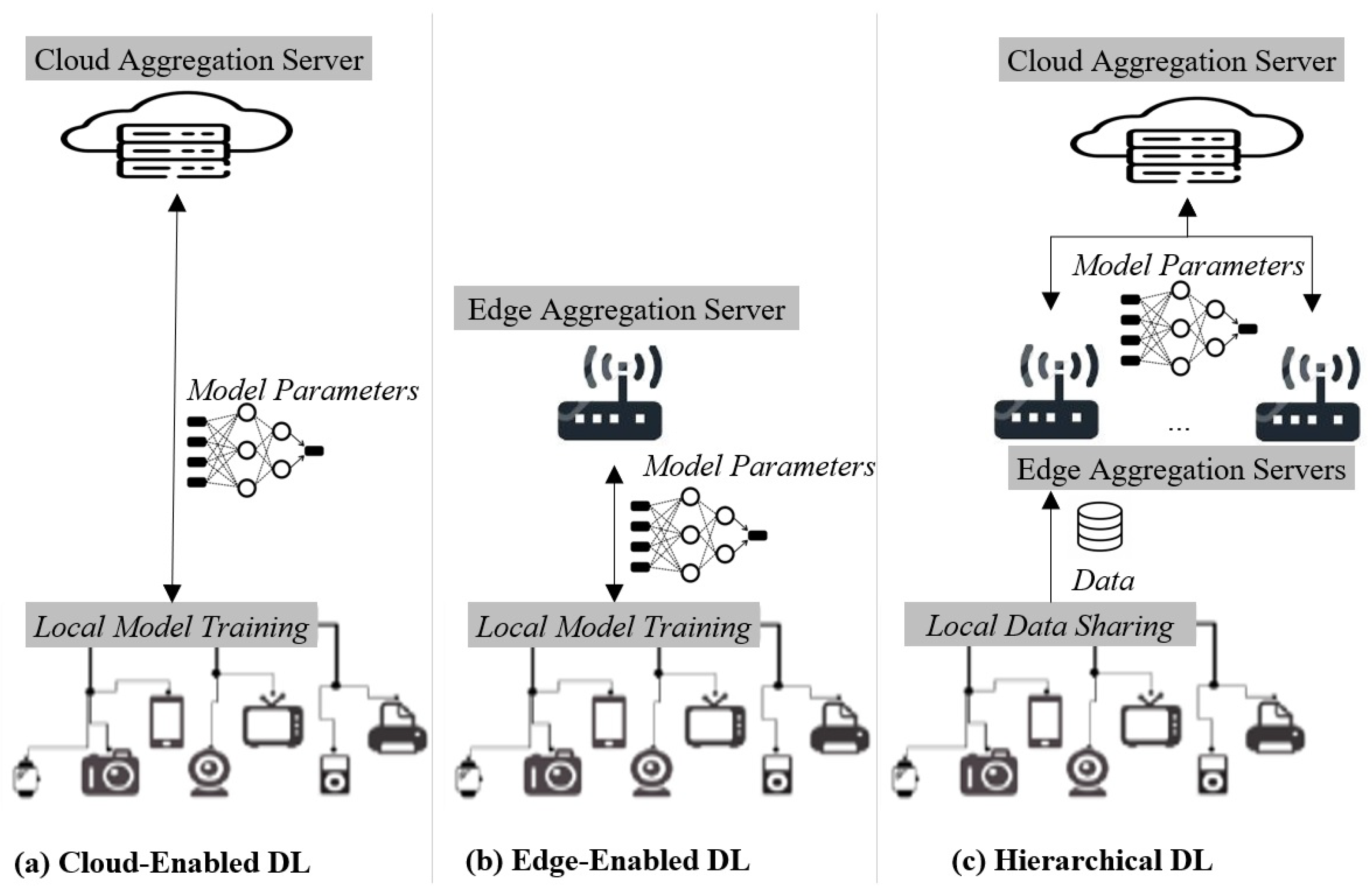{kind=link}
{kind=link}
{kind=link}
{kind=link}
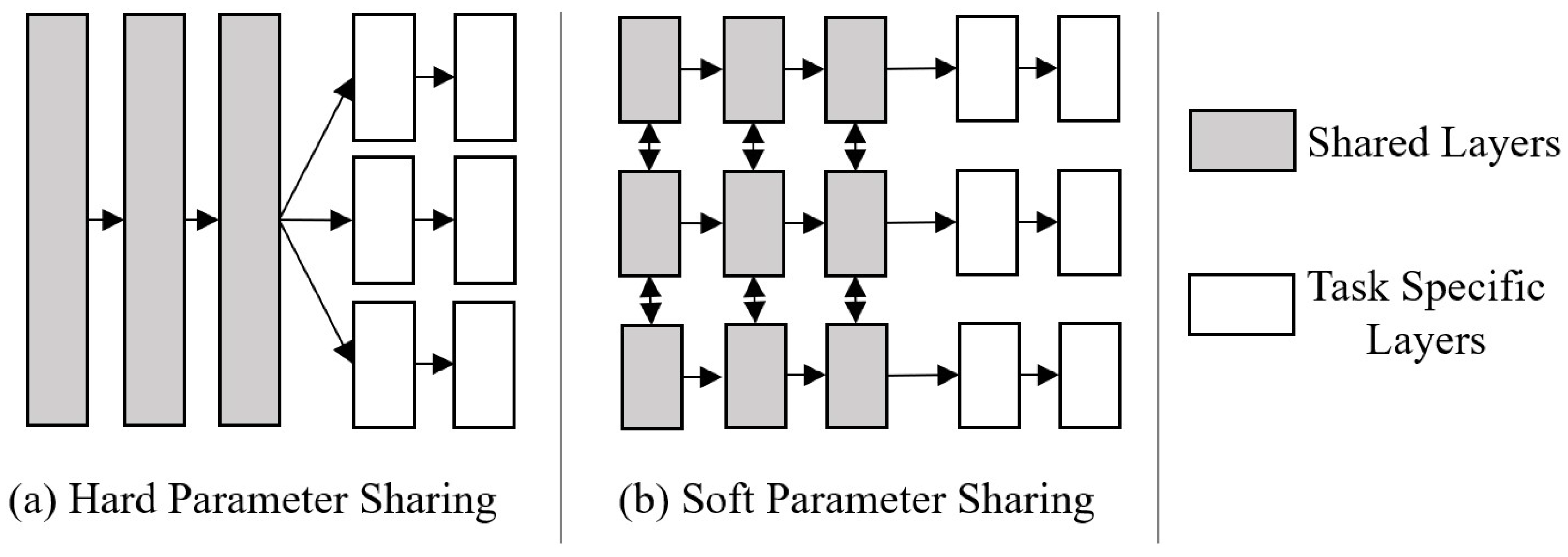{kind=link}
{kind=link}
| Work | Contribution | Results and Insights |
|---|---|---|
| Posit Representation [40] | The Posit is a data type designed to supersede IEEE Standard 754 floating-point numbers [41]. | Provides larger dynamic range and higher accuracy than traditional floats, along with simpler hardware implementation and exception handling. |
| Fixed-Posit Representation [42] | Extended the Posit data type by maintaining a fixed count of the bits, unlike conventional posits that have a configurable number of regime and exponent bits. | Enhances the power and area efficiency compared to both Posit and 32-bit IEEE-754 floating-point representations. Improvements of up to 70% in power, 66% in area, and 26% in delay. |
| Tensor Cores [43] | NVIDIA’s Tensor Cores is specialized hardware designed for performing the tensor/matrix computations with mixed-precision computations, enabling FP8 in the Transformer Engine, Tensor Float 32 (TF32) [44], and FP16. | Provide an order-of-magnitude higher performance with reduced precisions |
| 8-bit Quantization [45] | An 8-bit quantization schema for MobileNet [46] on the ARM NEON-based implementation. | Model size reduction: 4×. Inference task latency reduction: up to 50%. Accuracy drop: 1.8% for COCO datasett [47]. |
| SLQ [48] | A successive logarithmic quantization (SLQ) scheme to quantize the training error again when the quantization error is higher than a certain threshold. | Accuracy drop: less than 1.5% for AlexNet [49], SqueezeNet [50], and VGG-S [51] at 4 to 5-bit weight representation. |
| SLQ Training [52] | A specific training method for the Successive Logarithmic Quantization (SLQ) scheme. | Performance degradation of around 1% at 3-bit weight quantization. |
| Binary Network [53] | An accurate and efficient binary neural network for keyword-spotting applications, along with a binarization-aware training method for optimization. | Impressive 22.3 times speedup of task latency and 15.5 times storage-saving with only less than 3% accuracy drop on Google Speech Commands V1-12 task [54]. |
| Binary Distilled Transformer [55] | A binarized multi-distilled transformer including a two-set binarization scheme, an elastic binary activation function with learned parameters, and a method for successively distilling models. | Accuracy of fully binarized transformer models approaches a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%. |
| FMA [56] | A new class of Fused Multiply–Add (FMA) operators built on BFP16 arithmetic while maintaining accuracy comparable to that of the standard FP32. | Improved performance by 1.28–1.35× on ResNet compared to FP32. |
| Methods | Target Models | Main Results |
|---|---|---|
| Node-based Pruning [64] | CNNs | 35% pruning, 2.2% accuracy loss |
| Grow-and-Prune [66] | DNNs | 15.7×, 30.2× compression |
| Dense-Sparse-Dense [68] | ResNet, VGG-16 | 1.1% to 4.3% accuracy increase |
| SparseGPT [71] | GPT models | 50% sparsity |
| Differential Layer-Wise Pruning [72] | LeNet, AlexNet, VGG16 | 10× to 29× compression |
| DepGraph Structural Pruning [73] | Any Model Structure | 8–16× speedup, −6% to +0.3% accuracy change |
| Dynamic Channel Pruning [75] | ResNet-18 | 2× acceleration, 2.54% top-1, 1.46% top-5 accuracy loss |
| Multi-Scale Weight Sharing [76] | ResNets | 25% fewer parameters |
| HashedNets [77] | 5-layer CNN | 64% compression, 0.7% accuracy improvement |
| Gradient-Based Pruning [79] | Transformers | 1.9× speed, 3.9× energy efficiency, <0.2% accuracy loss |
| Data and Features for FL | ||
|---|---|---|
| HFL | VFL | FTL |
| [126,128,135,136] | [137,138] | [140,141] |
| Challenges | ||
| Enhanced Security | Efficient Communication | Optimized Resources |
| [144,147,148] | [145,148,149,150] | [146,151,153] |
| Works | Methods | Insights |
|---|---|---|
| [172] | Layer Freezing | Frozen of consecutive layers to identify characterizing topology. |
| [173] | Parameter-Efficient Fine-tuning | Optimization of a small portion of parameters. |
| [174,175] | Large Model Tuning | Fine-tuning large pre-trained models. |
| [176] | Adapter Module Based Tuning | Few trainable parameters added per task. |
| [177] | Prompt Tuning | Competitive with scale, outperforms GPT-3’s few-shots learning. |
| [178] | Prompt Tuning | Increased zero-shot accuracy with “Let’s think step by step”. |
| [179] | Instruction Fine-tuning | Large margin outperformance with FLan-PaLM 540B. |
| [180] | Hyper-parameter Tuning | Finding optimal model hyper-parameters. |
| [181] | Negative Transfer | Adversarial network to filter unrelated source data. |
| Works | Methods | Results and Insights |
|---|---|---|
| Metric-based: Few-shot learning [196,197] | N-way K-shot learning. | Efficient for small tasks, but inefficient for large label sets. |
| Metric-based: LSTM-based meta-learner [198] | Captures both short-term and long-term knowledge. | Rapidly converges a base learner to a locally optimal solution and in the meantime learns a task-common initialization as the base learner. |
| Metric-based: Zero-shot learning [199] | Two linear layers network modeling relationships among features, attributes, and classes. | Outperforms state-of-the-art approaches on several datasets by up to 17%. |
| Metric-based: Class distribution learning [200] | Represents each class as a probability distribution, defined as functions of the respective observed class attributes. | Leverages additional unlabeled data from unseen classes and improves estimates of their class-conditional distributions; Superior results in the same datasets compared to [199]. |
| Metric-based: CLIP [201] | Pre-training of vision models from raw-text-describing images. | Benchmarks on over 30 CV datasets produce competitive results with fully supervised baselines |
| Model-based: MANN [190] | Model-based controller with an external memory component and Least Recently Used Access (LRUA) method. | Superior to LSTM in two meta-learning tasks. |
| Model-based: Drone adaptation [202] | Dynamics model with shared dynamics parameters and adaptation parameters. | Drone control with unknown payloads; autonomous determination of payload parameters and adjustment of flight control; performance improvement over non-adaptive methods on several suspended payload transportation tasks. |
| Optimization-based: MAML [187] | Gradient descent with model-specific updates. | General optimization tasks; simple and general, but higher-order derivatives potentially decrease performance. |
| Optimization-based: iMAML [203] | Approximation of higher-order derivatives. | General optimization tasks; more robust for larger optimization paths with same computational costs. |
| Optimization-based: online MAML [204] | Extension of MAML for online learning scenarios. | Continuous learning from newly generated data; strong in model specialization, but computation cost grows over time. |
| Works | Methods | Results and Insights |
|---|---|---|
| Masked Prediction Method [182,217,218,219] | Generative SSL model that trains by filling in intentionally removed and missing data. | Effective to build pre-trained models in different areas like language, speech recognition, image regions, and graph edges. |
| Dat2Vec [217] | A general framework for SSL in speech, NLP and CV data. Predicts latent representations of the full input data based on a masked view of the input. | Performs competitively on major benchmarks in speech recognition, image classification, and natural language understanding. |
| MoCo [220] | Contrastive SSL with two encoders. Encodes two augmented versions of the same input images into queries and keys. | Outperforms its supervised pre-training counterpart in several CV tasks. |
| SimCLR [221] | A framework for contrastive learning of visual representations. Employs various image augmentation operations and contrastive cross-entropy loss. | Achieves a relative improvement of 7% over previous state-of-the-art, matching the performance of a supervised ResNet-50. |
| BiGANs [222] | Projects data back into the latent space to boost auxiliary supervised discrimination tasks. | Captures the difference at the semantic level without making any assumptions about the data. |
| BigBiGAN [223] | Extends the BiGAN model on representation learning by adding an encoder and correspondingly updating the discriminator. | Achieves the state-of-the-art in both unsupervised representation learning on ImageNet, and unconditional image generation. |
| Image Completion [224] | Uses adversarial SSL for image completion by training a global and local context discriminator networks. | Can complete images of arbitrary resolutions by filling in missing regions of any shape. |
| Image Inpainting [225] | Uses adversarial SSL for image completion in masked chest X-ray images. | Facilitates abnormality detection in the healthcare domain. |
| SSL with Federated Learning [226] | Empirical study of federated SSL for privacy preserving and representation learning with unlabeled data. | Tackles the non-IID data challenge of FL. |
| SSL with Meta Learning [186] | Reviews the intersection between SSL and meta-learning. | Shows how SSL can improve the generalization capability of models. |
| SSL with Transfer Learning [227] | The SSL applications within the transfer learning framework | Introduces methods for designing pre-training tasks across different domains. |
| Edge ML Techniques | Edge ML Requirements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Machine Learning | Edge Computing | |||||||||
| Low Task Latency | High Performance | Generalization and Adaptation | Enhanced Privacy and Security | Labelled Data Independency | Computational Efficiency | Optimized Bandwidth | Offline Capability | |||
| Edge Inference | Model Compression and Approximation | Quantization | + | * | / | / | / | + | / | / |
| Weight Reduction | + | * | / | / | / | + | / | / | ||
| Knowledge Distillation | + | − | / | / | / | + | / | / | ||
| Activation Function Approximation | + | − | / | / | / | + | / | / | ||
| Distributed Inference | + | / | / | / | / | − | − | − | ||
| Other Inference Acceleration | Early Exit | + | - | / | / | / | + | / | / | |
| Inference Cache | + | − | / | / | / | + | / | / | ||
| Model-Specific Inference Acceleration | + | − | / | / | / | + | / | / | ||
| Edge Learning | Distributed Learning | Federated Learning | + | − | / | + | / | − | + | − |
| Split Learning | + | / | / | + | / | − | + | − | ||
| Transfer Learning | + | * | / | / | + | + | / | / | ||
| Meta-Learning | + | / | + | / | + | * | / | / | ||
| Self-Supervised Learning | + | + | + | / | + | + | / | / | ||
| Other Learning Paradigms | Multi-Task Learning | + | + | / | / | / | + | / | / | |
| Instance-based Learning | * | * | / | / | + | * | / | / | ||
| Weakly Supervised Learning | + | / | / | / | + | / | / | / | ||
| Incremental Learning | − | + | + | / | / | − | − | / | ||
| Edge ML Techniques | Edge ML Requirements | |||||
|---|---|---|---|---|---|---|
| Overall | ||||||
| Availability | Reliability | Energy Efficiency | Cost Optimization | |||
| Edge Inference | Model Compression and Approximation | Quantization | + | * | + | + |
| Weight Reduction | + | * | + | + | ||
| Knowledge Distillation | + | * | + | + | ||
| Activation Function Approximation | + | * | + | + | ||
| Distributed Inference | + | + | − | − | ||
| Other Inference Acceleration | Early Exit | + | − | + | + | |
| Inference Cache | + | + | + | + | ||
| Model-Specific Inference Acceleration | + | * | + | + | ||
| Edge Learning | Distributed Learning | Federated Learning | + | * | + | + |
| Split Learning | + | * | + | + | ||
| Transfer Learning | + | * | + | + | ||
| Meta-Learning | * | + | * | * | ||
| Self-Supervised Learning | * | + | + | + | ||
| Other Learning Paradigms | Multi-Task Learning | + | + | + | + | |
| Instance-based Learning | * | * | * | * | ||
| Weakly Supervised Learning | + | − | + | + | ||
| Incremental Learning | + | + | + | + | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Hacid, H.; Almazrouei, E.; Debbah, M. A Comprehensive Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques. AI 2023, 4, 729-786. https://doi.org/10.3390/ai4030039
Li W, Hacid H, Almazrouei E, Debbah M. A Comprehensive Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques. AI. 2023; 4(3):729-786. https://doi.org/10.3390/ai4030039
Chicago/Turabian StyleLi, Wenbin, Hakim Hacid, Ebtesam Almazrouei, and Merouane Debbah. 2023. "A Comprehensive Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques" AI 4, no. 3: 729-786. https://doi.org/10.3390/ai4030039
APA StyleLi, W., Hacid, H., Almazrouei, E., & Debbah, M. (2023). A Comprehensive Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques. AI, 4(3), 729-786. https://doi.org/10.3390/ai4030039