1. Introduction
Complex systems can be modeled as networks that are composed of subnets called communities, which are denser and more connected than the other parts of the network.
The structures of communities are directly related to the functions of a network. Identifying these structures is expected to yield helpful intuitions about the functional organization of the specific network. Community detection has been the most important topic in complex networks in recent decades, and one that has attracted many researchers, aiming to discover groups of nodes based on modular tendencies. The ability to detect communities provides deeper insight into the functionality of groups and how the networks are formed.
Different studies have various perspectives on detecting network communities, such as partitioning methods, modularity-based methods, factorization-based methods, etc. [
1,
2]. Some methods consider the global structure and the whole network’s perspective, such as Infomap [
3], Louvain [
4], Fastgreedy [
5], etc. while in many cases, they suffer from high cost and complexity.
On the other hand, some methods consider the local structure and extract the local information of the nodes [
1,
2,
3,
4]. These methods conquer the limitations of global structure-based methods. However, due to the significant development and growth of social networks, and the lack of access to global structure information, these types of algorithms may fall into a local minimum and may not have the desired accuracy, despite their low time complexity.
Therefore, creating a balance between global and local information, accuracy and time complexity is one of the crucial issues in community detection. Another important point is to achieve established and assured communities. In general, the environment of complex networks in terms of the relationships and interactions between their members can be considered as a game in which nodes as players or agents try to join or leave a community based on similar characteristics. On one hand, we can consider a cooperative environment as one where individuals with similar features interact with each other, they constitute the communities and attempt to promote the community’s utility. On the other hand, it can also be considered a competitive space in which agents try to join or leave their communities and enhance their profits. A logical approach is necessary to interpret these relations. By borrowing game theoretical concepts from economics, this issue can easily be analyzed.
Game theory is a very useful mathematical means for studying strategic conditions and modeling the competition and cooperation between decision-makers to provide rational and optimal solutions in complicated situations. Generally, game theory is divided into two categories: cooperative and non-cooperative. A game that focuses on the member’s cooperation is classified as a cooperative game [
6], where every individual tries to improve the coalition’s utility. Conversely, in non-cooperative games, individuals attempt to increase their own utilities and ignore the group’s profits.
Hence, we came up with the idea to take into account both global and local information structures and cooperative and non-cooperative games to extract more satisfactory and assured communities. The proposed algorithm includes four stages: finding the important and central vertices, propagating the labels and identifying initial communities, merging these communities, and finally stabilizing them and assuring the nodes’ allocation.
Taking this algorithm into account, the overall efficiency of the proposed algorithm increased, and the computational cost diminished remarkably. The subsequent parts of this paper are organized as follows: In
Section 2, the literature about various approaches to community detection problems is reviewed. The basic concepts are mentioned in
Section 3. The proposed model is brought up in
Section 4. Analysis of the experimental results is discussed in
Section 5, and finally concluding remarks and future works are presented in
Section 6.
2. Related Work
A community is a subset of elements close to each other within their group rather than to the rest of the network. According to [
1], approximately, the nodes of the same community exhibit similar characteristics, functions, and/or roles.
Community detection is one of the most fascinating research topics which has attracted the attention of many scientists in several fields, such as biology, statistics, economics, and computer science [
1]. In general, community detection is an NP-Complete problem [
2,
3]. Various studies in the literature have tried extracting communities according to the global structure and whole network’s perspectives, like Infomap [
3], Louvain [
4], Fastgreedy [
5], etc., while in many cases, they suffer high cost and complexity.
Conversely, some methods consider the local structure and extract the local information of the nodes, and do not focus on the global knowledge of the network. Therefore, they are not as robust as the global algorithms. In addition, these types of methods may be caught into a local optimum. In contrast, they demonstrate less time complexity than global methods and are applicable to large-scale networks.
Some of the local algorithms are based on clustering, [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]. However, these approaches have some limitations, such as poor cluster descriptors and their high sensitivity to initial phase settings.
So, considering both global and local structures in community detection can be useful in eliminating the limitations of each method [
19].
It is also noticeable that the communities detected based on the above-mentioned approaches may not be sufficiently qualified, to the extent that some nodes may be assigned to unreliable groups.
To circumvent this problem, game theoretical approaches to identifying communities have been proposed.
They have imagined the community detection issue as a game, in which each member rationally chooses a community and maximizes its score. Members of a community also attempt to enhance the group’s utility.
Many approaches address the problem of community detection by using the non-cooperative game theory, and some others employ the cooperative one. Along the cooperative line, where individuals form a group based on the similarity of their communal interests, Mcsweeney et al. [
20] considered each node as a player in a hedonic game, which tries to form fair and stable community structures. Zhou et al. [
21], suggested the Shapley value to detect communities of a given social network. Additionally, they proposed a coalitional game for investigating communities based on the topological structure of nodes [
16]. Hajibagheri and his colleagues [
22] imagined each node as a rational individual trying to maximize the Shapley value. They considered community structure as Nash equilibrium. Two approaches from cooperative game theory based on the Myerson value and hedonic games were recommended in [
23]. Both of them detected communities with different resolutions. Xu Zhou et al. [
24] considered nodes as players who try to enhance the utility of their coalition by participating in a cooperative game. They proposed an edge weight computation for calculating the Shapley value of nodes and coalitions.
Regarding the non-cooperative aspect, according to Chen et al. [
25], the utility of an agent is determined as gain and loss functions based on the modularity and community membership fee, respectively. Finally, the community structure was revealed by the local equilibrium of the game. Additionally, the authors in [
26] regarded each vertex as an agent trying to join a community and assumed its utility as a linear function. Nash’s stability guarantees the stability of communities. A framework based on the iterative game has been proposed in [
27] for detecting communities in social networks. They considered nodes as rational agents who play the game to enhance their utilities. To reveal community structure, a weighted potential game was defined in [
23]. Communities become stable as they reach the Nash equilibrium point. Zhao et al. [
28] suggested Co-game, a game-theoretic approach for extracting community in real networks. This method produces finer-grained partitions in the detection process by combining individual games and equilibrium.
An algorithm, based on game theory for detecting communities in online social networks, was also proposed by Vincezo Moscato et al. [
29]. They modeled the process of community formation as a game, in which each node as a player aims to maximize its goal. A new approach based on both cooperative and non-cooperative games for detecting communities was suggested by [
30], which considered nodes as players in cooperative games who attempt to enhance the group’s utility while engaging in a non-cooperative game to improve their utility.
In the first phase, this method, similarly to a hierarchical agglomerative method, considers a cooperative game in which individuals in a social network are modeled as rational players and aims to improve the utility of the group by cooperating with other players to form coalitions. In large datasets, this method, like other local and agglomerating approaches, typically suffers from high computational complexity.
The main problem with the existing approaches to game-theory-based community detection is that the game is initially started with single nodes. The main problem with the existing approaches to game-theory-based community detection is that the game is initially started with single nodes, with a large amount of comparisons between them, which in turn increases the computational cost, while in our approach the game is just considered for some extracted initial communities, thus leading to fewer comparisons between the nodes.
3. Basic Concepts
3.1. The Necessity of Representing the Network
Given a network is a set of nodes, where N is the number of nodes. consists of the set of edges, where encodes the edge between and .
3.2. Community Detection
The community detection is to extract K communities, i.e., , such that K ≪ N and . If these communities are non-empty, mutually exclusive subsets of V, i.e., , this is non-overlapping community detection, and nodes only can join one community. Conversely, this is entitled as overlapping communities, where nodes can join more than one community.
3.3. Sorensen Index
Sorensen–Dice coefficient, in short, the “Sorensen Index” [
26], is a statistic that measures the similarity between two nodes by dividing the size of the intersection of their neighbor’s sets by the total number of their members (Equation (1)). The Sorensen index considers the degree of the two nodes and the number of their common neighbors.
The Sorensen index output is between 0 and 1:
where
, and
are the neighbor sets and the degree of node i, respectively.
3.4. Game Theory Background
Game theory is a very useful mathematical means for studying strategic conditions between decision-makers to provide rational solutions in complicated situations. The environment of the relationships and interactions between the members of complex networks can be considered as a game in which nodes as players try to join or leave a community based on similar characteristics, where the decisions of one player influence the other player’s payoffs [
25].
Let be the utility function of node. For each community, demonstrates the utility of node i by being in the community. Each node (player) tries to join a community and enhance its utility. It should be noted that the utility of any node depends on the community to which it belongs.
4. The Proposed Model
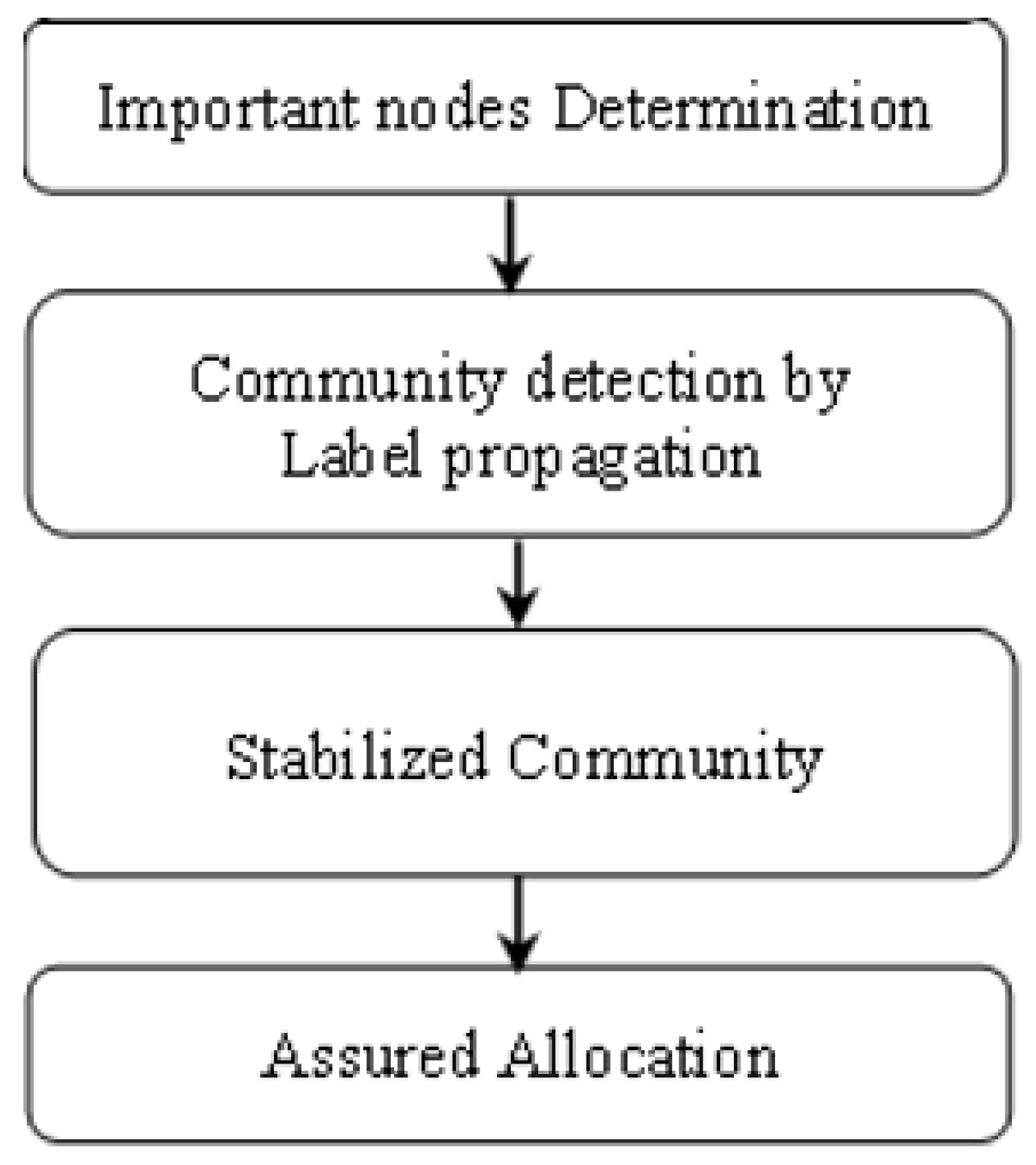
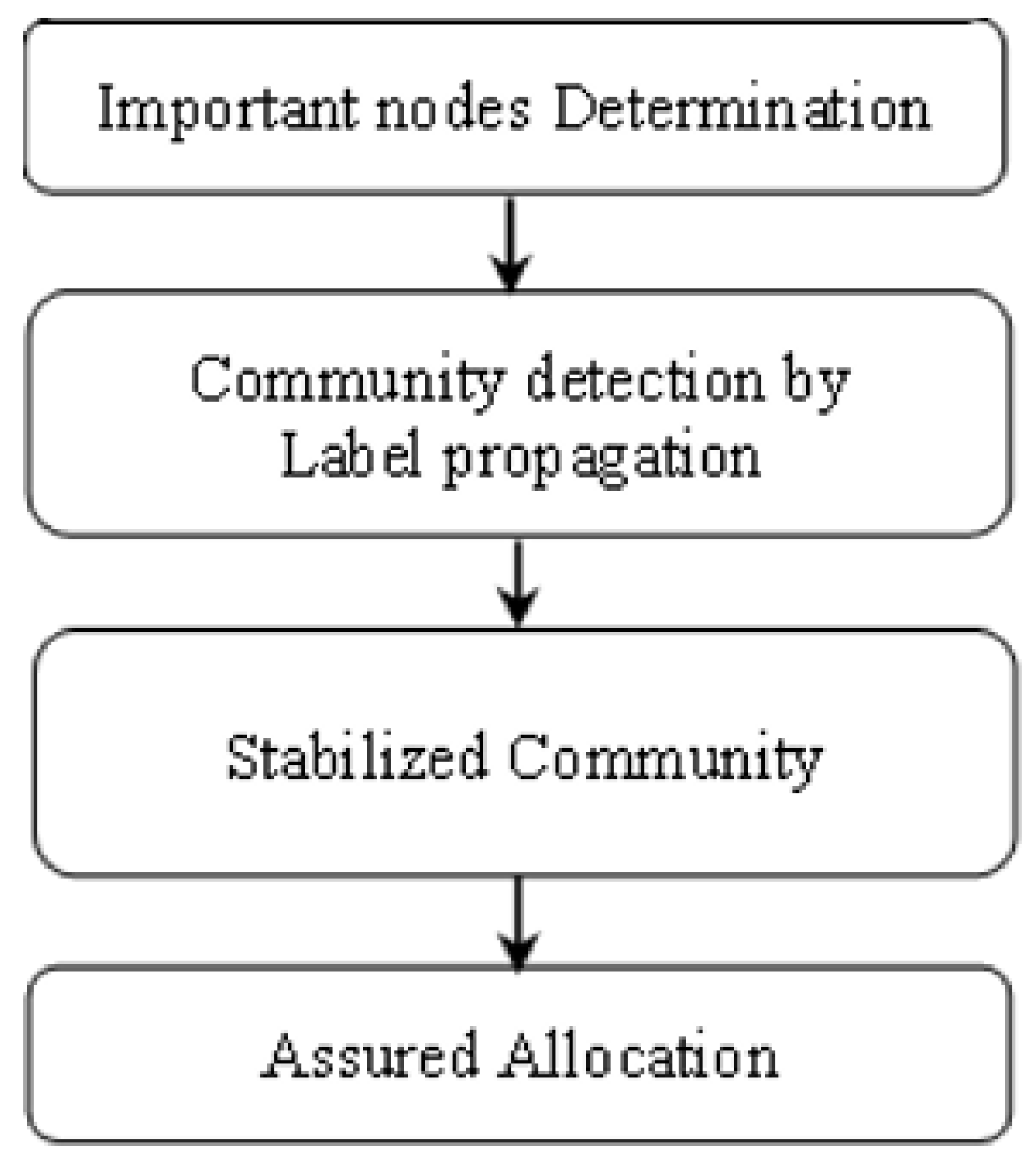
As mentioned before, the four-stage algorithm (FSA) has considered both global and local information structures with regard to the network. An overview of the proposed method can be seen in
Figure 1.
Let us say, in the first step of the proposed algorithm, important nodes are determined according to their degree and relative distance. In the second step, the initial communities are detected based on the label propagation method. Next, the extracted communities are stabilized by the cooperative game, and finally, the non-cooperative game is applied to these clusters to ensure a rational allocation of nodes to the established communities.
So, identifying central nodes, label propagation, stabilizing the extracted communities, and ensuring the rational allocation of nodes to the established communities, can be considered the main characteristics of our approach.
Out of the above stages, the first two stages have been observed in previous works [
25,
27].
However, to be assured that the extracted communities would be stable, the third stage has been added based on the idea of a cooperative game. However, there are cases where a limited number of nodes may exist that could affiliate with a variety of different communities. In these cases, the fourth stage, which is based on the idea of a non-cooperative game, would help us to ensure the rational allocation of these nodes to the deserving/properly established communities.
One of the main problems of community detection is to discover communities which are sufficiently qualified. Therefore, inventing an algorithm that can assign nodes to reliable groups is one of the most important topics in complex networks, such as social networks. Therefore, the proposed algorithm attempts to obtain high-quality and reliable communities by relying on cooperative and non-cooperative games.
4.1. Important Nodes Determination
Important nodes in a community have a high degree of surrounding neighbors. Approximately, the nodes with this characteristic are more likely to be the communities’ centers. Speaking intuitively, the distances between important nodes are often far apart. Therefore, it can be assumed that the distance between two important nodes is not less than the average network distance. The average distance of graph G is [
25]:
where
d(
u,
v) is the shortest distance between
u and
v.
Then, rank all nodes by their degrees; B = .
Then, let
be the set of important nodes. Initially, the highest-ranking node is settled in
:
Repeat this until the distance between two nodes is not greater than the average distance of the graph (Equation (2)).
4.2. Community Detection by Label Propagation
Nodes in a community have similar characteristics and common interests and are more connected to each other than the rest of the network.
Having identified the important nodes in the network, the remaining nodes join the communities according to the Sorensen index, which is a useful index for comparing similarities between the samples [
26].
Now, if we assume that every important node in C corresponds to an identified community, then we label every node
as the node
if
are neighbors:
So, label u according to v. Repeat this process until all nodes have been labeled and assigned to the initial communities.
4.3. Stabilized Community
After the initial communities were formed by Label propagation, it is worth observing that some communities have only one member—in other words, they are sparse and do not have suitable quality—and these single nodes should join other communities with more nodes. For the sake of improving the quality, it is necessary to merge and reduce the initial communities. In this regard, we utilized the advantages of cooperative (coalitional form) games with a transferable utility, which is assumed that the earnings of a coalition (utility) can be distributed among the individuals in any conceivable way [
28].
The reason for using cooperative game theory is that members of a community, based on their commitment towards the entire community, try to obtain a higher utility through cooperation. In other words, nodes in a network are modeled as logical agents (players), which try to form coalitions (communities) and cooperate to improve the group’s utility.
Coalitions with single or fewer nodes join larger groups according to the utility measurement. The community, which gains the highest utility, is selected as the final community, and the single node, or the group with fewer members, joins it. Merging operations will continue until the utility no longer improved the utility of the merged coalitions. In this situation, the game has reached an equilibrium, and accordingly no coalition is willing to merge with the others. In this way, the number of communities will reduce, and high-quality coalitions will be obtained. In other words, the communities are stabilized.
Given
be a coalition of G = <V, E>. The utility function
of
S is:
where |
E| is the total number of edges in G,
is the number of edges that connect nodes within
, and
is the sum of the degrees of the nodes within
.
is based on Newman’s modularity metric (Q) [
25]. The modularity metric is one of the famous metrics that has been used in many kinds of research to measure the quality of the community structure in networks. The main idea of this index is based on comparing edge density within communities with the expected number in a random network. Thus, the value of 1 means that a network community structure has the highest possible strength [
29].
Stable coalitions: A community is a stable coalition which is not eager to participate in the merged operation to improve its utility. In other words, tries to join if then it prefers to stay in the previous situation and with no further will to join .
Utility increment: In the merge operation of , let be a super-coalition of obtained by the merged operation, so the utility increment of is defined by . It means that the utility of should increase within the merging coalition.
Generally, if and and then two communities are joined, the newly joined communities are added to a new list which includes stable coalitions.
Stable coalitions are products of an equilibrium state for coalitions in which no group of agents has an interest in further merging operations.
It should be noted that coalitions with at least one edge in between are merged.
4.4. Assured Allocation
Having attained the set of stabilized communities, the non-cooperative game then takes place. The nodes may not be in their exact coalition. In this game, each node is considered a selfish agent, which attempts to join or leave a coalition from γ (stabilized communities’ structure) based on its utility measurement. If by joining a coalition its utility increases, then it will leave the current coalition and join the new one.
Utility function of an agent: Let
,
the utility function is as [
25]:
is the number of edges between x and coalition . is the degree of x. measures the closeness between x and the targeted community . The higher value of, the more similarity that exists between x and.
Join and Leave: node x joins the community
Node
x leaves its community
and joins community
:
α and β are the lower and upper bounds of the utility value of x, respectively.
The Four-Stage Algorithm (FSA) is described in
Table 1.
As mentioned before, after identifying the important nodes in the network, the remaining nodes join the initial communities according to the Sorensen similarity index.
The cooperative game initiates between these communities. Given , two communities in S, if the utility of joining these two communities () is greater than the utility of each of them, then the joining operation occurs and is added to a new list Υ, and the two communities are merged. Once equilibrium has been achieved, the utility of each group cannot be demonstrated. The stable communities are then identified; however, some nodes may not satisfy their utilities, and they begin to play the non-cooperative game to improve their utilities.
Each node evaluates the other communities and calculates its utility if it joins them. If the value is more than ω and lower than ε, the node leaves its current position and joins the new community. The algorithm ends when the agents are not interested in joining other communities to improve their utility values and are interested in staying in their current situation.
Since the cooperative game runs on the results of the initial clustering rather than singleton nodes, the complexity is reduced. In addition, because the non-cooperative game applied on the stabilized clusters has been achieved by the cooperative game, the nodes are most likely to be in their exact coalitions and therefore there would have been no intention to change membership in their community due to improving their utilities.
5. Analysis of the Experimental Results
To evaluate the capabilities and effectiveness of the proposed approach, the experiments are conducted on real networks with/without the ground truth and the benchmark network of Lancichinetti and Fortunato [
9]. The outcomes of the four-stage algorithm are compared by seven other community detection methods: Three-stage algorithm (TS) [
25], Louvain [
4], Infomap [
3], Fastgreedy [
5], Walktrap [
30], Eigenvector [
31], and Label propagation (LPA) [
32].
Before debating on the experimental results, two famous functions for evaluating the proposed algorithm are introduced as follows:
Normalized Mutual Information (NMI): This is a well-known approach for evaluating the performance of community detection algorithms, which determines the amount of similarity between the partition proposed by the algorithm and the desired partition [
5]. The NMI between two identical partitions is 1 [
33].
The standard normalized mutual information (NMI) metric defined in [
33], is determined as follows:
where
I(
X,
Y) is the mutual information between X and Y.
H(
X) and
H(
Y) are the entropy of
X,
Y. If the communities of
X and
Y are independent, then knowing X does not provide information about
Y, therefore NMI(
X,
Y) = 0.
Modularity: This is a famous evaluation index, proposed by Newman and Girvan [
34], for measuring the quality of the community structure in networks. The main idea of this index is based on comparing edge density within communities with the expected number in a random network.
The definition of modularity is:
where
m is the total number of edges,
is the adjacency matrix,
is the degree of the
, and
δ is an indicator function which is 1 if
i and
j are in the same community (
=
Cj) and output 0 if they are in different communities.
The modularity value ranges between 0 and 1. If the whole graph is assumed as a community, the modularity value would be zero. A higher value of Q indicates a better community structure.
5.1. Real Networks with Ground Truth
In this research, the following four real networks with ground truth are used to test the efficiency and accuracy of the proposed algorithm.
Dolphin Network [
34]: This network includes 62 nodes and 159 edges, which represent the relationships between two groups of dolphins.
Zachary Karate Club Network [
4]: It consists of 34 nodes and 79 edges that were set between the individuals who intend to join one of the two clubs.
American College Football Network [
35]: This network originates from the United States college football. It consists of 115 nodes and 616 edges. The team represented as nodes and edges have defined the regular season games between two related teams.
Polbooks network [
5]: It includes 105 nodes and 882 links. The network consists of the US political books’ data which were recorded in 2005 by Adamic and Glance.
Table 2 shows the NMI and the modularity values of only Label propagation, after applying the cooperative game and finally after running the non-cooperative game in the four real networks with ground truth.
Table 2 indicates that the Label propagation method does not work properly in this situation. Because some obtained communities have low quality and are sparse, they need to merge with the other strong ones to qualify for the final communities. After applying the cooperative game to the Label propagation results, the NMI value and the modularity were improved due to the cluster merging process and stabilization point achievement.
As we may see, after running the non-cooperative game on the results of the cooperative approach, promising results were obtained. Once the equilibrium point is achieved, the condition of all nodes and communities stabilizes.
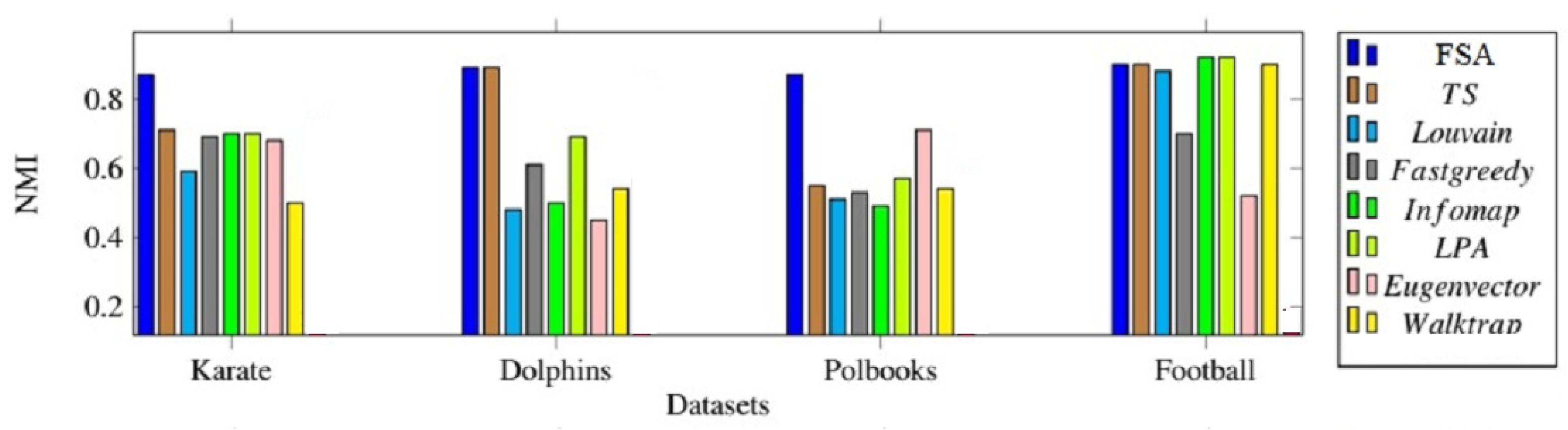
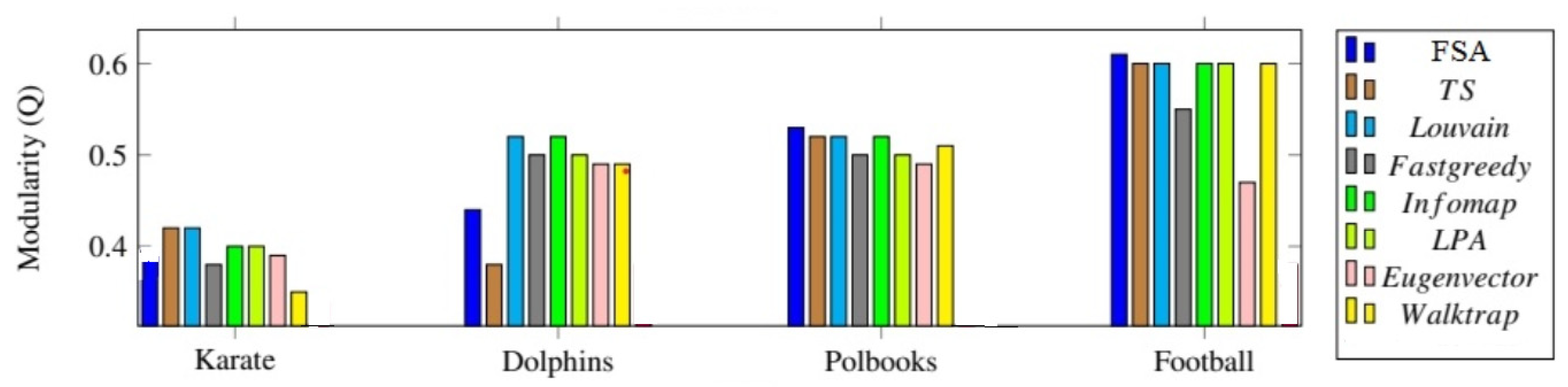
Figure 2 and
Figure 3 show the modularity and NMI values for the applied algorithms in the four real networks, respectively.
As can be seen, the Four-Stage Algorithm (FSA) yielded better results in terms of NMI, particularly for the karate and polbooks networks. In addition, for the other datasets, the four-stage algorithm remains competitive.
In terms of modularity, the Four-Stage Algorithm (FSA) is better than other methods in dolphin, Football, and polbooks networks.
According to the results in
Table 3, in most cases, the FSA method works much better than other clustering methods in the NMI and modularity. TS algorithm is in second place in this list, which has extracted four communities for the polbooks dataset, while the number of communities is two in the ground truth.
5.2. Real Networks without Ground Truth
Additionally, to evaluate the efficiency and accuracy of the four-stage and seven other algorithms, three real networks without ground truth are investigated as follows:
Lesmis network [
36]: This undirected network contains co-occurrences of characters in Victor Hugo’s novel “Les Misérables”, as compiled by Donald Ervin Knuth. Nodes represent characters and the edge between two nodes shows that these two characters appeared in the same chapter of the book.
Adjnoun network [
31]: A network of common adjective and noun adjacencies for the novel “David Copperfield” by Charles Dickens, as described by M. Newman. Nodes represent the most common adjectives and nouns in the novel. Edges connect each pair of words that are in adjacent positions in the text of the book.
Jazz network [
37]: is the collaboration network between jazz musicians. The nodes are jazz musicians and the edges indicate the cooperation of two musicians in a band.
Table 4 represents the results of the modularity (Q) [
38] and the number of detected communities (C) in real datasets without ground truth. In the Lesmis dataset, the maximum modularity, Q = 0.56, belongs to the Louvain algorithm, while in the Adjnoun and Jazz datasets, the proposed method has a more promising result.
The number of extracted communities in
Table 4 reveals that in the Lesmis dataset, FSA, TS, Louvain, and eigenvector achieve good results. FSA, TS, Louvain, and Fastgreedy detected an identical number of communities in the Adjnoun network, and in the Jazz network, the FSA algorithm detected three communities that are close to TS, Louvain, and Fastgreedy, However, its larity has been slightly improved in two recent datasets. Walktrap has performed very differently in these networks than the other algorithms.
5.3. Time Analysis of the Proposed Algorithm
The calculated running time (in seconds) for the FSA algorithm and other algorithms in real-world datasets is shown in
Table 5. All of the experiments are implemented on a desktop PC with an Intel Core i7 CPU (3.4 GHz) and 8 GB RAM.
5.4. Benchmark Networks
In this section, a series of benchmark networks are applied according to the method of Lancichinetti, Fortunato, and Raddichi (LFR) [
9]. These networks have power law distributions and to some extent are suitable for evaluating the performance of community detection algorithms [
39,
40,
41,
42,
43,
44,
45].
The parameters used in this research are the same as [
9] except the number of nodes in the network (n) which is considered as n = 50, 100, 150, 200.
The power law exponent for the size of communities: β = 1.
As seen in
Table 6, the NMI value for the label propagation method is lower than the other steps.
In the cooperative game deployment step, the NMI value and the modularity were improved due to the merging process and reaching the stabilizing communities. Finally, using the non-cooperative game step, promising values of NMI and modularity were obtained, as each node tries to improve its utility and stabilize its position in the communities.
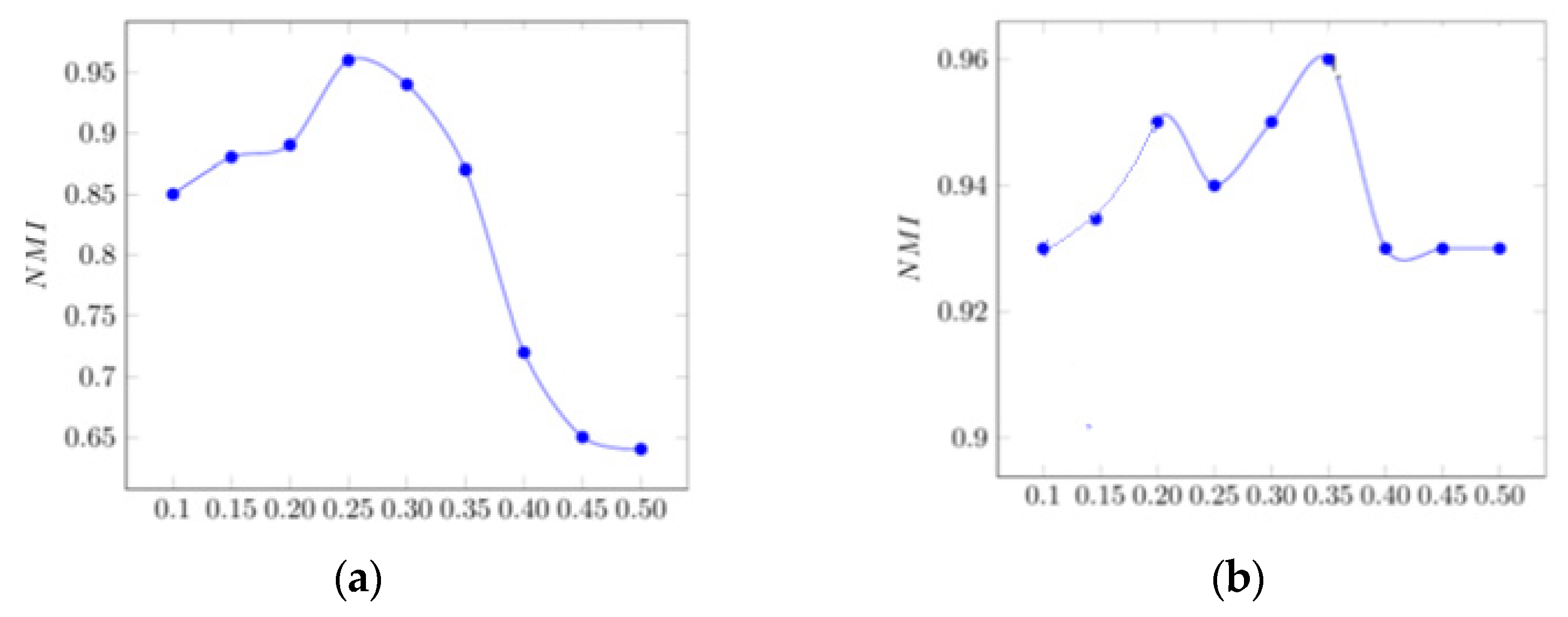
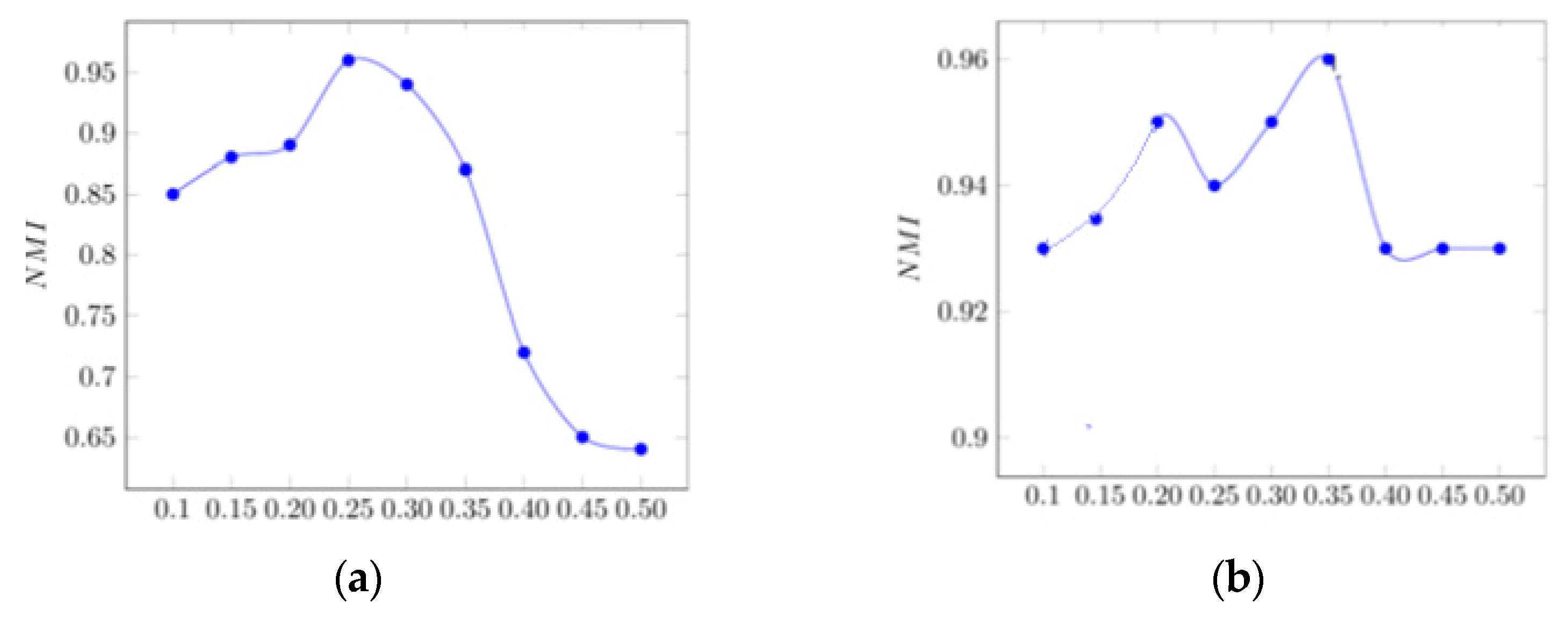
According to
Figure 4a, initially, with the increase in ε, the probability of removing nodes from the clusters increases, and those nodes which have fewer connections with each cluster are removed. As a result, the NMI value will increase.
However, after a while, when the ε value exceeds the threshold (approximately 0.24), nodes that have more intra-cluster communications will also be removed from that cluster and the NMI value will subsequently decrease sharply.
In
Figure 4b, the optimal value of ω is approximately 0.35, and for the higher values, the NMI value will practically not change, and nodes will rarely join the clusters.
6. Concluding Remarks and Future Works
In this paper, we suggested a powerful and effective community detection approach that incorporates global and local information into community detection. First, important nodes in the networks are determined and then label propagation is applied to find the initial clusters. However, some sparse clusters require merging with other strong types and their situation stabilizes; therefore, a cooperative game is used Ultimately, this guarantees a rational allocation of nodes to established communities, where a non-cooperative game is performed on each node.
The experimental results confirm the performance of our approach and demonstrate that cooperative and non-cooperative game approaches boost each other to detect more stables and assured communities.
We evaluated the proposed method on several standard real networks and benchmark datasets and compared the performance of the FSA method with other algorithms. There are several advantages of the proposed method, including the formation of high-quality communities, solving the problem of community quality dependency on the inappropriately selected node, and allocate nodes to their stable communities.
The proposed method can respond successfully to a wide range of real-world issues like real business recommendations, precision marketing, etc. The application of the FSA algorithm in healthcare is settled by its fundamental idea; it can be applied to the diagnosis and treatment of diseases in general, and mental diseases in particular. It can be used to identify the patients, enhance their conditions, and detect the contagion of the disease. By using this method, it is possible to easily solve the challenges of the supply and demand side, which improves the condition of patients.
Additionally, it is also suitable for recommending and finding friends on social networks.
The proposed algorithm has high performance in small- and medium-size data sets. Although it has limitations in large datasets, where the number of extracted communities is large, it takes time to detect suitable communities once we use game theory, especially when it comes to considering non-cooperative games.
Furthermore, it can only detect non-overlapping communities from unweighted and undirected networks.
For future work, some solutions, such as deep learning methods, can be used to extract features that are more beneficial to large networks, especially those with semantic content. Furthermore, overlapping communities and weighted networks would be considered.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}