1. Introduction
Scientists and engineers have traditionally separated the analysis of a multisensory scene into its constituent sensory domains. In this approach, for example, all auditory events are processed separately and independently of visual and/or somatosensory streams, even though the same multisensory event might have created those constituent streams. It was previously necessary to compartmentalize the analysis because of the sheer enormity of information as well as the limitations of experimental techniques and computational resources. With recent advances, it is now possible to perform integrated analysis of sensory systems including interactions within and across sensory modalities. Such efforts are becoming increasingly common in cellular neurophysiology, imaging and psychophysics studies [
1,
2,
3,
4,
5].
Recent evidence from neuroscience [
1,
6] suggests that the traditional view that the low level areas of cortex are strictly unisensory, processing sensory information independently, which is later on merged in higher level associative areas is increasingly becoming obsolete. This has been proved by many fMRI [
7,
8], EEG [
9] and neuro-physiological experiments [
10,
11] at various neural population scales. There is now enough evidence to suggest an interplay of connections among thalamus, primary sensory and higher level association areas which are responsible for audiovisual integration. The broader implications of these biological findings may be that learning, memory and intelligence are tightly associated with the multi-sensory nature of the world.
Hence, incorporating this knowledge in computational algorithms can lead to better scene understanding and object recognition for which there is a great need. Moreover, combining visual and auditory information to associate visual objects with their sounds can lead to better understanding of events. For example, discerning whether the bat hit the baseball during a swing of the bat, tracking objects under severe occlusions or poor lighting conditions, etc. can be more accurately performed only when we take audio and visual counterparts together. The applications of such technologies are numerous and in varied fields.
Kimchi et al. [
12] showed that objects attract human attention in a bottom-up manner. In addition, Nuthmann and Henderson [
13] found that eye fixations of human observers tend to coincide with object centers. Simple pixel based saliency models determine salient locations based on dissimilarities in low-level features such as color, orientation, etc, which do not always coincide with object centers. In a proto-object-based saliency model, the grouping mechanism integrates border ownership (
Section 3.3) information in an annular fashion to create selectivity for objects. This is based on Gestalt properties of convexity, surroundedness and parallelism. Hence, the predicted salient locations in our model generally coincide with object centers, which cannot be achieved with simple feature-based saliency models.
Even though processing of sensory information in the brain involves a combination of feed-forward, feedback and recurrent connections in the neural circuitry, the advantage of a feed-forward model is that information is processed in a single pass, hence making it fast and suitable for real-world applications. Motivated by these factors, we develop a purely bottom-up, proto-object-based audiovisual saliency map (AVSM) for the analysis of dynamic natural scenes.
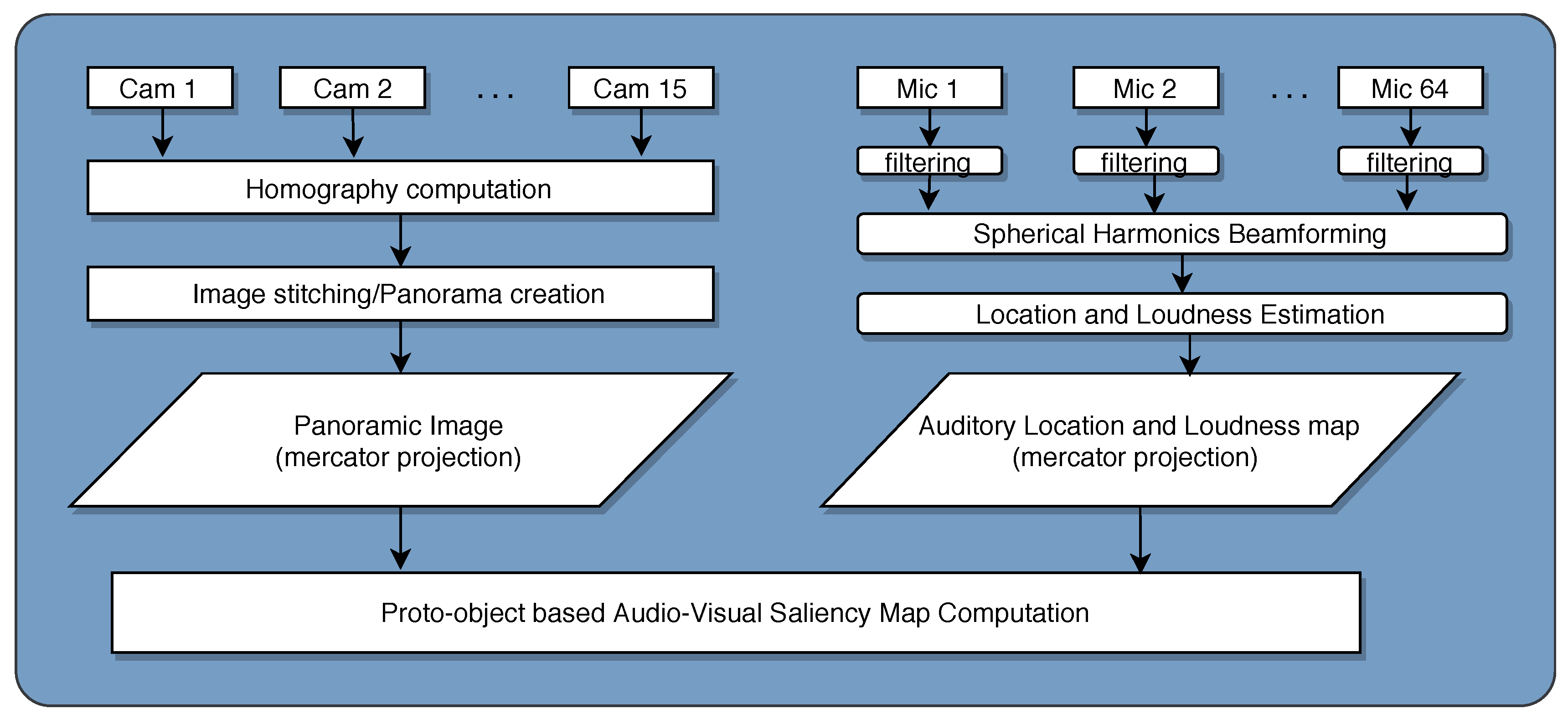
For the computation of AVSM, we need both audio and video data in the same co-ordinate system. Thus, as shown in
Figure 1, we stitch together images from different views to get a 360
panoramic view of the scene. Similarly, direction and loudness of sound sources in the scene are estimated from multi-channel audio sampled on the surface of a sphere. Both video and audio are registered such that they are in the same reference frame. Such spatiotemporally registered audiovisual data are used for saliency map computation, as described in
Section 3. We add visual motion (
Section 3.1.1) as another independent feature type along with color, intensity and orientation [
14], all of which undergo a grouping process (
Section 3.4) to form proto-objects of each feature type. In the auditory domain, we consider the location and intensity of sound as the only proto-objects as these are found to be most influential in drawing the spatial attention of an observer in many psycho-physics studies. Various methods of combination of the auditory and visual proto-object features are considered (
Section 3.6). We demonstrate the efficacy of the AVSM in predicting salient locations in the audiovisual environments by testing it on real world AV data collected from specialized hardware (
Section 4) that can collect 360
audio and video that are temporally synchronized and spatially co-registered. The AVSM captures nearly all visual, auditory and audio-visually salient events, just as any human observer would notice in that environment.
In summary, a better understanding of interaction, information integration and complementarity of information across senses may help us build many intelligent algorithms for scene analysis, object detection and recognition, human activity and gait detection, elder/child care and monitoring, surveillance, robotic navigation, biometrics, etc. with better performance, stability and robustness to noise. In one application, for example, fusing auditory (voice) and visual (face) features improved the performance of speaker identification and face recognition systems [
15,
16]. Hence, our objective in this study is to develop a scene analysis algorithm using multisensory information, specifically vision and audio.
2. Related Work
The study of multi-sensory integration [
3,
6,
17], specifically audiovisual integration [
4,
18], has been an active area of research in neuroscience, psychology and cognitive science. In the computer science and engineering fields, there is an increased interest in the recent times [
19,
20,
21]. For a detailed review of neuroscience and psychophysics research related to audiovisual interaction, please refer to [
3,
17]. Here, we restrict our review to models of perception in audiovisual environments and some application oriented research using audio and video information.
In one of the earliest works [
22], a one-dimensional computational neural model of saccadic eye movement control by Superior Colliculus (SC) is investigated. The model can generate three different types of saccades: visual, multimodal and planned. It takes into account different coordinate transformations between retinotopic and head-centered coordinate systems, and the model is able to elicit multimodal enhancement and depression that is typically observed in SC neurons [
23,
24]. However, the main focus is on Superior Colliculus function rather than studying audiovisual interaction from a salience perspective. A detailed model of the SC is presented in [
25] with the aim of localizing audiovisual stimuli in real time. The model consists of 12,240 topographically organized neurons, which are hierarchically arranged into nine feature maps. The receptive field of these neurons, which are fully connected to their input, are obtained through competitive learning. Intra-aural level differences are used to model auditory localization, while simple spatial and temporal differencing is used to model visual activity. A spiking neuron model [
26] of audiovisual integration in barn owl uses Spike Timing Dependent Plasticity (STDP) to modulate activity dependent axon development, which is responsible for aligning visual and auditory localization maps. A neuromorphic implementation of the same using digital and analog mixed Very Large Scale Integration (mixed VLSI) can be found in [
27].
In another neural model [
28,
29], the visual and auditory neural inputs to the deep SC neuron are modeled as Poisson random variables. Their hypothesis is that the response of SC neurons is proportional to the presence of an audiovisual object/event in that spatial location which is conveyed to topographically arranged deep SC neurons via auditory and visual modalities. The model is able to elicit all properties of the SC neurons. An information theoretic explanation of super-additivity and other phenomena is given in a [
29]. The authors also showed that addition of a cue from another sensory modality increases the certainty of a target’s location only if the input from initial modality/modalities cannot reduce the uncertainty about target. Similar models are proposed in [
30,
31], where the problem is formulated based on Bayes likelihood ratio. An important work [
32] based on Bayesian inference explains a variety of cue combination phenomena including audiovisual spatial location estimation. According to the model, neuronal populations encode stimulus information using probabilistic population codes (PPCs) which represent probability distributions of stimulus properties of any arbitrary distribution and shape. The authors argued that neural populations approximate the Bayes rule using simple linear combination of neuronal population activities.
In [
33], audiovisual arrays for untethered spoken interfaces are developed. The arrays localize the direction and distance of an auditory source from the microphone array, visually localize the auditory source, and then direct the microphone beamformer to track the speaker audio-visually. The method is robust to varying illumination and reverberation, and the authors reported increased speech recognition accuracy using the AV array compared to non-array based processing.
In [
34], the authors found that emotional saliency conveyed through audio, drags an observer’s attention to the corresponding visual object, hence people often fail to notice any visual artifacts present in the video, suggest to exploit this property in intelligent video compression. For the same goal, the authors of [
35] implemented an efficient video coding algorithm based on the audiovisual focus of attention where sound source is identified from the correlation between audio and visual motion information. The same premise that audiovisual events draw an observer’s attention is the basis for their formulation. A similar approach is applied to high definition video compression in [
36]. In these studies, spatial direction of sound was not considered; instead, stereo or mono audio track accompanying the video was used in all computational and experimental work.
In [
37], a multimodal bottom-up attentional system consisting of a combined audiovisual salience map and selective attention mechanism is implemented for the humanoid robot iCub. The visual salience map is computed from color, intensity, orientation and motion maps. The auditory salience map consists of the location of the sound source. Both are registered in ego-centric coordinates. The audiovisual salience map is constructed by performing a pointwise
operation on visual and auditory maps. In an extension to multi-camera setting [
38], the 2D saliency maps are projected into a 3D space using ray tracing and combined as a fuzzy aggregations of salience spaces. In [
39,
40], after computing the audio and visual saliency maps, each salient event/proto-object is parameterized by salience value, cluster center (mean location) and covariance matrix (uncertainty in estimating location). The maps are linearly combined based on [
41]. Extensions of this approach can be found in [
42]. A work related to the one in [
42] is presented in [
43], where a weighted linear combination of proto-object representations obtained using mean-shift clustering is detailed. Even though the method uses linear combination, the authors did not use motion information in computing the visual saliency map. A Self Organizing Map (SOM)-based model of audiovisual integration is presented in [
44], in which the transformations between sensory modalities and the respective sensory reliabilities are learned in an unsupervised manner. A system to detect and track a speaker using a multi-modal, audiovisual sensor set that fuses visual and auditory evidence about the presence of a speaker using Bayes network is presented in [
45]. In a series of papers [
19,
46,
47], audiovisual saliency is computed as a linear mixture of visual and auditory saliency maps for the purpose of movie summarization and key frame detection. No spatial information about audio is considered. The algorithm performs well in summarizing the videos for informativeness and enjoyability for movie clips of various genres. An extension of these models incorporating text saliency can be found in [
48]. By assuming a single moving sound source in the scene, audio was incorporated into the visual saliency map in [
49], where sound location was associated with the visual object by correlating sound properties with the motion signal. By computing Bayesian surprise as in [
50], the authors of [
51] presented a visual attention model driven by auditory cues, where surprising auditory events are used to select synchronized visual features and emphasize them in an audiovisual surprise map. A real-time multi-modal home entertainment system [
52] performing a just-in-time association of features related to a person from audio and video are fused based on the shortest distance between each of the faces (in video) and the audio direction vector. In an intuitive study [
53], speaker localization by measuring the audiovisual synchrony in terms of mutual information between auditory features and pixel intensity change is considered. In a single active speaker scenario, the authors obtained good preliminary results. No microphone arrays are used for the localization task. In [
54], visually detected face location is used to improve the speaker localization using a microphone array. A fast audiovisual attention model for human detection and localization is proposed in [
55].
The effect of sound on gaze behavior in videos is studied in [
20,
56], where a preliminary computational model to predict eye movements is proposed. The authors used motion information to detect sound source. High level features such as face are hand labeled. A comparison of eye movements during visual only and audiovisual conditions with their model shows that adding sound information improves the predictive power of their model. The role of salience, faces and sound in directing the attention of human observers (measured by gaze tracking) is studied with psychophysics experiments and computational modeling in [
57], and an audiovisual attention model for natural conversation scenes is proposed in [
58], where the authors used a speaker diarization algorithm to compute saliency. Even though their study is restricted to conversation of humans and not applicable any generic audiovisual scene, hence cannot be regarded as a generalized model of audiovisual saliency, some interesting results are shown. Using EM algorithm to determine the individual contributions of bottom-up salience, faces and sound in gaze prediction, the authors showed that adding original speech to video improves gaze predictability, whereas adding irrelevant speech or unrelated natural sounds has no effect. By using speaker diarization algorithm [
58], when the weight for active speakers is increased, their audiovisual attention model significantly outperforms the visual saliency model with equal weights for all faces. An audiovisual saliency map is developed in [
59] where features such as color, intensity, orientation, faces and speech are linearly combined with unequal weights to give different types of saliency maps depending on the presence/absence of faces and/or speech. It is not clear as to whether location of the sound is used in this approach. In addition, the authors did not factor in motion, which is an important feature, while designing a saliency map for moving pictures.
More recently, there have been some efforts related to audiovisual saliency [
60,
61,
62,
63], but very few explicitly incorporate spatial (two-dimensional) audio [
62]. However, some of the drawbacks of those models are that they are not based on the neural principles and do not use spatial audio which is an important feature in the auditory domain. Even more importantly, traditional saliency models do no have a notion of proto-objects. In our work, saliency is computed based on proto-objects which helps to localize salient object centers, rather than sharp discontinuities.
3. Model Description
The computation of audiovisual saliency map is similar to the computation of proto-object-based visual saliency map for static images explained in [
14], except for: (i) the addition of two new feature channels, the visual motion channel and the auditory loudness and location channel; and (ii) different ways of combining the conspicuity maps to get the final saliency maps. Hence, whenever the computation is identical to the one in [
14], we only give a gist of that computation to avoid repetition and detailed explanation otherwise.
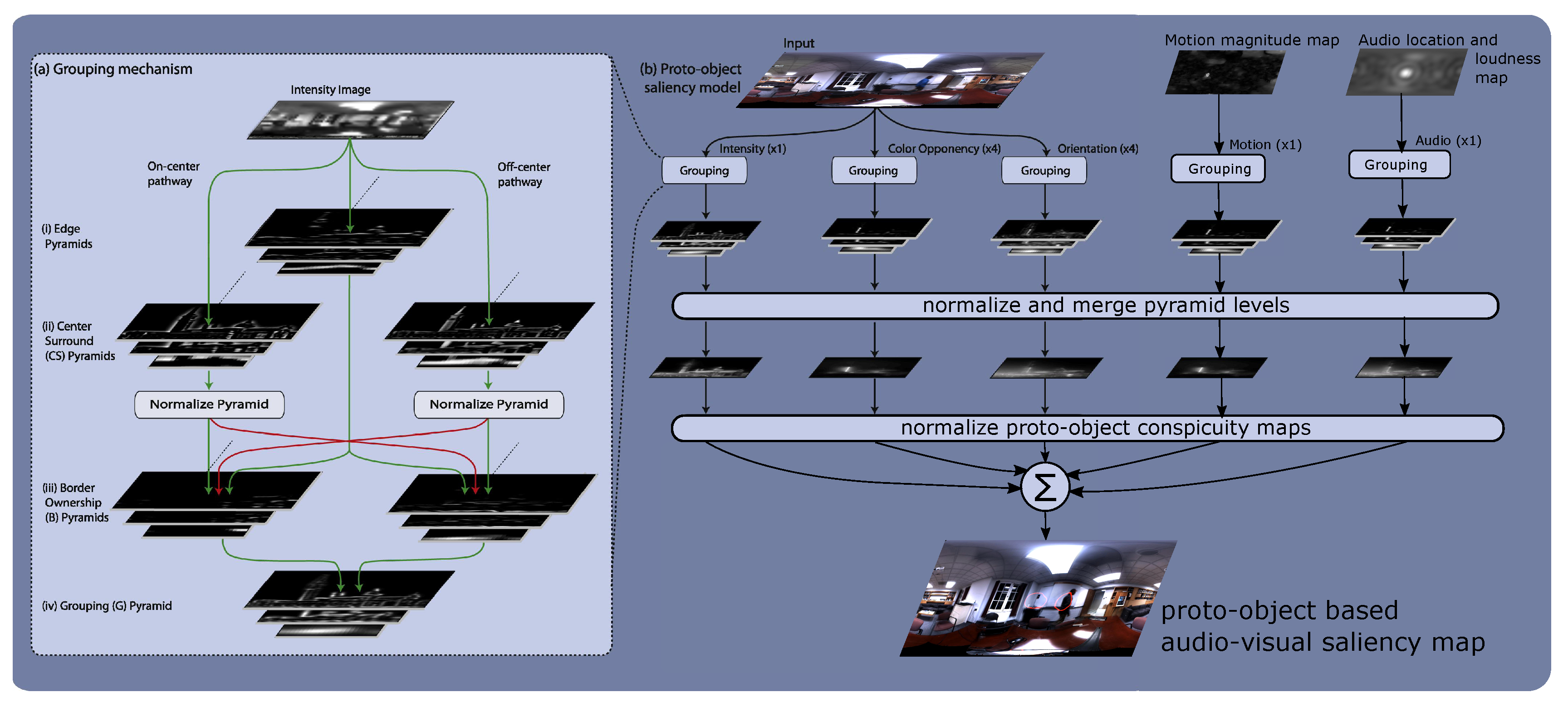
The AVSM is computed by grouping auditory and visual bottom-up features at various scales, then normalizing the grouped features within and across scales, followed by merging features across scales and linear combination of the resulting feature conspicuity maps (
Figure 2). The features are derived from the color video and multi-channel audio input (
Section 4) without any top-down attentional biases, hence the computation is purely bottom-up. The mechanism of grouping “binds” features within a channel into candidate objects or “proto-objects”. Approximate size and location are the only properties of objects that the grouping mechanism estimates, hence they are termed “proto-objects”. Many such proto-objects form simultaneously and dissolve rapidly [
64] in a purely bottom-up manner. Top-down attention is required to hold them together into coherent objects.
In addition, computation of AVSM is completely feed-forward. Many spatial scales are used to achieve scale invariance. First, the independent feature maps are computed; features within each channel are grouped into proto-objects. Such proto-object feature pyramids at various scales are normalized within and across scales. Such feature pyramids are merged across scales followed by normalization across feature channels to give rise to conspicuity maps. The conspicuity maps are linearly combined to get the final AVSM. Each of these steps is explained in more detail below.
3.1. Computation of Feature Channels
We consider color, intensity, orientation and motion as separate, independent feature channels in the visual domain and loudness and spatial location as features in the auditory space. The audiovisual camera equipment used for data gathering (see
Section 4) guarantees spatial and temporal concurrency of audio and video.
A single intensity channel, where intensity is computed as the average of red, green and blue color channels, is used. Four feature sub-channels for angle,
are used for orientation channel. Four color opponency feature sub-channels—red–green (
), green–red (
), blue–yellow (
) and yellow–blue (
)—are used for color channel. The computation of color, orientation and intensity feature channels is identical to Russell et al. [
14].
Visual motion, auditory loudness and location estimate are the newly added features, the computation of which is explained below.
3.1.1. Visual Motion Channel
Motion is computed using the optical flow algorithm described in [
65] and the corresponding code available at [
66]. Consider two successive video frames,
and
. If the underlying object has moved between
t and
, then the intensity at pixel location
at time
t should be the same as in a nearby pixel location at
in the successive frame at
. Using this as one of the constraints, the flow is estimated which gives the horizontal and vertical velocity components,
and
, respectively, at each pixel location
at time
t. For a more detailed explanation, see [
65]. Since we are interested in detecting salient events only, we do not take into account the exact motion at each location as given by
and
; instead, we look at how big the motion is at each location in the image. The magnitude of motion at each location is computed as,
The motion map
gives the magnitude of motion at each location in the visual scene at different time instances
t.
Figure 3A,B shows two successive frames of the video. The computed magnitude of motion using the optic flow method in [
65] is shown in
Figure 3C. The person in the video is the only moving source.
3.1.2. Auditory Loudness and Location Channel
The auditory input consists of a recording of the 3D sound field using 64 microphones arranged on a sphere (see
Section 4 for details). We compute a single map for both loudness and location of sound sources
. The value at a location in the map
gives an estimate of loudness at that location at time
t; hence, we simultaneously get the presence and loudness of sound sources at every location in the entire environment. These two features are computed using the beamforming technique, as described in [
67,
68,
69]. A more detailed account is given in
Section 4. Two different frames of video and the corresponding auditory loudness and location maps superimposed on the visual images are shown in
Figure 4B,F respectively. Warm colors indicate higher intensity of sound from that location in the video.
3.2. Feature Pyramid Decomposition
Feature pyramids are computed for each type. As the scale increases, the resolution of the feature map decreases. The feature maps of successively higher scales are computed by downsampling the feature map from the previous scale. The downsampling factor can be either (half-octave) or 2 (full octave). The feature pyramids thus obtained are used to compute proto-objects by border ownership and grouping computation process explained the next two sections.
3.3. Border Ownership Pyramid Computation
Computation of proto-objects by grouping mechanism can be divided into two sub-steps: (i) border ownership pyramid computation; and (ii) grouping pyramid computation.
The operations performed on any of the features, auditory or visual, is the same. Edges of four orientations,
are computed using the Gabor filter bank. The V1 complex cell responses [
14] thus obtained are used to construct the edge pyramids. Border ownership response is computed by modulating the edge pyramid by the activity of center-surround feature differences on either side of the border. The rationale behind this was the observation made by Zhang and von der Heydt [
70], who reported that the activity border ownership cells was enhanced when image fragments were placed on their preferred side, but suppressed for the non-preferred side.
Two types of center-surround (CS) feature pyramids are used. The center-surround light pyramid detects strong features surrounded by weak ones. Similarly, to detect weak features surrounded by a strong background, a center-surround dark pyramid is used. The rationale behind light and dark CS pyramids is that there can be bright objects on a dark background and vice versa. The center-surround pyramids are constructed by convolving feature maps with Difference of Gaussian (DoG) filters.
The CS pyramid computation is performed in this manner for all feature types including motion and audio, except for the orientation channel. For the orientation feature channel, the DoG filters are replaced by the even symmetric Gabor filters which detect edges. This is because, for the orientation channel, feature contrasts are not typically symmetric as in the case of other channels, but oriented at a specific angle.
An important step in the border ownership computation is normalization of the center-surround feature pyramids. We follow the normalization method used in [
71], which enhances isolated high activities and suppresses many closely clustered similar activities.
This normalization step enables comparison of light and dark CS pyramids. Because of the normalization, border ownership activity and grouping activity are proportionately modulated, deciding relative salience of proto-objects from the grouping activity.
The border ownership (BO) pyramids corresponding to light and dark CS pyramids are constructed by modulating the edge activity by the normalized CS pyramid activity. The light and dark BO pyramids are merged across scales and summed to get contrast polarity invariant BO pyramids. For each orientation, two BO pyramids with opposite BO preferences are be computed. From this, the winning BO pyramids are computed by a winner-take-all mechanism.
3.4. Grouping Pyramid Computation
The grouping computation shifts the BO activity from edge pixels to object centers. Grouping pyramids are computed by integrating the winning BO pyramid activity such that selectivity for Gestalt properties of convexity, proximity and surroundedness is enhanced. This is done by using grouping (G) cells in this computation, which have an annular receptive field. The shape of G cells gives rise to selectivity for convex, surrounded objects. At this stage, we have the grouping or proto-object pyramids which are normalized and combined across scales to compute feature conspicuity maps, and then the saliency map.
3.5. Normalization and Across-Scale Combination of Grouping Pyramids
The computation of grouping pyramids as explained in
Section 3.4 is performed for each feature type. Let us represent the grouping pyramid for intensity feature channel by
, where
k denotes the scale of the proto-object map in the grouping pyramid. The color feature sub-channel grouping pyramids are represented as
for red–green,
for green–red,
for blue–yellow and
for yellow–blue color opponencies. The orientation grouping pyramids are denoted by
where
denotes orientation, motion feature channel by
and auditory location and intensity feature channel by
. The corresponding conspicuity maps for, intensity
, color
, orientation
, motion,
and auditory location and loudness estimate,
are, respectively, obtained as,
where
is a normalization step as explained by Itti et al. [
71], which accentuates strong isolated activity and suppresses many weak activities, the symbol ⨁ denotes “across-scale” addition of the proto-object maps, which is done by resampling (up- or down-sampling depending on the scale,
k) maps at each level to a common scale (in this case, the common scale is
) and then doing pixel-by-pixel addition. We use the same set of parameters as in Table 1 of Russell et al. [
14] for our computation as well.
The conspicuity maps, due to varied number of feature sub-channels, have different ranges of activity; hence, if we linearly combine without any rescaling to a common scale, those features with higher number of sub-channels may dominate. Hence, each feature conspicuity map is rescaled to the same range,
. The conspicuity maps are combined in different ways to get different types of saliency maps, as explained in
Section 3.6.
3.6. Combination of Conspicuity Maps
The visual saliency map is computed as,
where
is the visual saliency map,
is the rescaling operator that rescales each map to the same range,
, and
and
are the individual weights for intensity, color, orientation and motion conspicuity maps, respectively. In our implementation, all weights are equal and each is set to 0.25, i.e.,
.
Since audio is a single feature channel, the conspicuity map for auditory location and loudness is also the auditory saliency map, .
We compute the audiovisual saliency map in three different ways to compare the most effective method to identify salient events (see
Section 5 for related discussion).
In the first method, a weighted combination of all feature maps is done to get the audiovisual saliency map as,
where different weights can be set for
such that the sum of all weights equals 1. In our implementation, all weights are set equal, i.e.,
.
In the second method, the visual saliency map is computed as in Equation (
7) and then a simple average of the visual saliency map and the auditory conspicuity map (also auditory saliency map,
) is computed to get the audiovisual saliency map as,
The distribution of weights in Equation (
9) is different from that in Equation (
8). In Method 2, a “late combination” of the visual and auditory saliency maps is performed, which results in an increase in the weight of the auditory saliency map and a reduction in weights for the individual feature conspicuity maps of the visual domain.
In the last method, in addition to a linear combination of the visual and auditory saliency maps, a product term is added as,
where the symbol ⊗ denotes a point-by-point multiplication of pixel values of the corresponding saliency maps. The effect of the product term is to increase the saliency of those events that are salient in both visual and auditory domains, thereby to enhance the saliency of spatiotemporally concurrent audiovisual events. A comparison of the different saliency maps in detecting salient events is in
Section 5.
5. Results and Discussion
First, we examine which of the three audiovisual saliency computation methods described in
Section 3.6, Equations (
8)–(
10), performs well for different stimulus conditions. Then, we compare results from the best AVSM with the unisensory saliency maps followed by discussion of the results.
All saliency maps computed as explained in
Section 3.6 have salience values in
range. On such a saliency map, unisensory or audiovisual, anything above a threshold of 0.75 is determined as highly salient. This threshold is the same for all saliency maps, visual saliency map (
, variables
dropped as unnecessary here), auditory saliency map (
) and the three different audiovisual saliency maps (
). Hence, this provides a common baseline to compare the workings of unisensory SMs with AVSM, and among different AVSMs.
To visualize the results, we did the following: On the saliency map (can be
,
or
), saliency value-based isocontours for the threshold of 0.75 are drawn and superimposed on each of the input video frame. For example, in
Figure 7,
for Frame #77 of Dataset 2 is shown. Any thing that is inside the closed red contour of
Figure 7B is highly salient and has a saliency value greater than 0.75. Outside the isocontour, the salience value is less than 0.75. Exactly along the isocontour, the salience value is 0.75 (precisely,
).
The results can be best interpreted by watching the input and different saliency map videos. However, since it is not possible to show all the frames and for the lack of a better way of presenting the results, we display the saliency maps for a few key frames only. The videos and individual frames of the saliency maps are available at the url:
https://preview.tinyurl.com/ybg4fch4.
Figure 8 shows
,
and
for input image Frame #393 of Dataset 1. At that moment in the scene, the loudspeaker (at the center of the image frame) was playing a documentary and the person was moving forward. Thus, there is a salient stationary auditory event and a salient visual motion. From visual inspection of
Figure 8, it is clear that
,
and
give roughly the same results and are able to detect salient events in both modalities. This is the behavior we see in all AVSMs (
) for a majority of frames. However, in some cases, when the scene reduces to a static image, the behavior exhibited by each of the methods will be somewhat different.
Consider, for example, Frame #173 of Dataset 3, where the visual scene is equivalent to a static image with a weak auditory stimulus, which is the air conditioning vent noise (
Figure 9). Here, according to
(
Figure 9B), the most salient location coincides with the strongest intensity-based salient location at the bottom part of the image. This is because in
we averaged the conspicuity maps with equal weights. Thus, when salient audio or motion is not present, the AVSM automatically switches to being a static saliency map with color, intensity and orientation as dominant features. However, in
, it is computed as the average of visual and auditory saliency maps, hence it leads to redistribution of weights in such a way that each of the visual features contributes only one-eighth to the final saliency map and audio channel contributes one half. As a result, auditory reflections could be accentuated and show up as salient, which may not match with our judgment, as seen in
Figure 9C. In reality, such auditory reflections are imperceptible, hence may not draw our attention, as indicated by
.
, where a multiplicative term, , is added, accentuates the conjunction of visual and auditory salient events if they are spatiotemporally coincident. However, since auditory and visual saliencies already contribute equally instead of the five independent features making equal contributions, the effect of the multiplicative term is small, thus we see that has similar behavior as . We did not investigate whether the conjunction of individual feature conspicuity maps, e.g. , , etc. can result in a better saliency map. However, based on visual comparison, we can conclude that , where each feature channel contributes equally, irrespective of whether it is visual or auditory, is a better AVSM computation method compared to and .
Thus, an important observation we can make at this point is that, even though vision and audition are two separate sensory modalities and we expect them to equally influence the bottom-up, stimulus driven attention, this may not be the case. Instead, we can conclude that each feature irrespective of the sensory modality makes the same contribution to the final saliency map from a bottom-up perspective.
Next, we compare how performs in comparison to unisensory saliency maps, namely and . Since was found to be better, the other two AVSMs are not discussed.
Figure 10 shows
,
and
for Frame #50 of Dataset 4, where the person moving is the most salient event, which is correctly detected in
and
, but not in
. This is expected.
Next, in
Figure 11, saliency maps for Frame #346 of Dataset 2 are shown, where audio from the loudspeaker is the most salient event, which is correctly detected as salient in
and
but missed in
, which agrees with our judgment.
In Frame #393 of Dataset 1, there is strong motion of the person as well as sound from the loudspeaker. The unisensory and audiovisual saliency maps are shown in
Figure 12. Again, the salients events detected by the respective saliency maps agree with our judgment.
From these results, we can conclude that the unisensory saliency maps detect valid unisensory events which agree with human judgment. At the same time, the audiovisual saliency map detects salient events from both sensory modalities, which again agree with our judgment. Thus, we can say, the AVSM detects more number of valid salient events compared to unisensory saliency maps. The unisensory saliency maps miss the salient events from the other sensory modality. Hence, AVSMs in general, and
in particular, perform better than unisensory saliency maps in detecting valid salient events. As a result, AVSMs can be more useful in a variety of applications such as surveillance, robotic navigation, etc. Overall, the proto-object-based audiovisual saliency map reliably detects valid salient events for all combinations of auditory, visual and audiovisual events in a majority of the frames. The readers can verify themselves additionally by watching the videos or looking at individual video frames at:
https://preview.tinyurl.com/ybg4fch4.
An important distinguishing factor of our AVSM computation comes from the use of proto-objects. With proto-object-based computation, we see that salient locations roughly coincide with object centers giving an estimate of audiovisual “objectness” [
72]. Thus, this enables selection of image regions with possible objects based on saliency values. Moreover, since saliency gives a natural mechanism for ranking scene locations based on salience value, combined with “objectness" that comes from proto-objects, this can serve to select image regions for object recognition, activity recognition, etc. with other methods, such as deep convolutional neural networks [
73,
74].
Second, due to linear combination of feature conspicuity maps, the model adapts itself to any scene type, static or dynamic scenes, with or without audio. Because of this, we get a robust estimate of bottom-up saliency in a majority of cases. In addition, the method works well for a variety of environments, indoor and outdoor.
Finally, the AVSM computed in this manner enables us to represent and compare saliencies of events from two different sensory modalities on a common scale. Other sensory modalities or feature channels can be similarly incorporated into the model.
One of the factors that we have not considered in our model is the temporal modulation of audiovisual saliency. We treat each 100-ms interval as a snapshot, independent of previous frames and compute unisensory and audiovisual saliencies for each 100-ms frame. Even though this “memoryless” computation detects valid salient events well, temporal aspects are found to strongly influence saliency, especially from the auditory domain [
75]. Hence, factoring in the temporal dependence of saliency can further improve the model. For example, in the few cases where saliency maps appears to be noisy, we can improve the results with temporal smoothing of the saliency maps. However, the proportion of such noisy frames is very small compared to valid detections.
Temporal dependence of attention is important from the perspective of perception as well. For example, a continuous motion or an auditory alarm can be salient at the beginning of the event due to abrupt onset, but, if it continues to persist, we may switch our attention to some other event, even though it is prominent in the scene. The mechanism and time course of multisensory attentional modulation needs to be further investigated and incorporated into the model.
Another aspect, related to temporal modulation of audiovisual saliency that we have not considered, is the inhibition of return (IOR) [
71,
76]. IOR refers to increased reaction time to attend to a previously cued spatial location compared to an uncued location. The exact nature of IOR in the case of audiovisual attention is an active topic of research [
77,
78]. More recent experimental evidence [
77] suggests that IOR is not observed in audiovisual attention conditions. If this is the case, not having audiovisual IOR may not be a significantly limiting factor, but certainly worth investigating.
One drawback of our work is that the results are not validated with human psychophysics experiments. Since saliency models aim to predict human attention based on bottom-up features, validating the results with human psychophysics experiments is necessary. Such validation would strengthen the findings of our study even more. Collecting psychophysics data for model validation is challenging because: (i) our data are 360 in both visual and auditory domains, whereas human vision is limited to only 220 (including peripheral vision), hence it necessitates collecting data in a coordinated fashion about other orienting behaviors such as torso movement, head movement, etc.; and (ii) re-creating spatial audio for human rendering comes with its own challenges since the pinna of human ear is uniquely shaped for each individual. Hence, doing a scientifically accurate validation of this perceptual model is beyond the scope of this paper. One might argue that we can draw bounding boxes around salient events and use that as ground-truth for validation. Given that perceptual processes are fast (on the order of milliseconds) and that the translation of what is perceived by the motor system takes considerably higher amount of time, such an experimental design would not be scientifically accurate because it introduces additional influencing variables. Even though we initially considered such a method for validation, we later we dropped the idea and instead focused on a more scientifically accurate method of validation. As we continue to collect experimental data, we would like to present psychophysics validation of the model as soon as possible. However, from visual judgment of the results presented in this work, the readers can verify that the model is capable of selecting valid, perceptually salient audiovisual events for further processing. Moreover, our goal is to build a useful computational tool for automated scene analysis and the results show that the model is capable of doing so.
Lastly, we could not compare the performance of the model with other methods. This is because most audiovisual saliency models do not incorporate spatial aspects of audio such as loudness and location. Moreover, comparing with other models requires psychophysics experimental data, which are not available now. In the future, we would like to compare the performance of our model against other spatiotemporal AV saliency models.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











