Adversarial Learning for Product Recommendation

Abstract
1. Introduction
- Mapping: Direct modeling of the joint distribution between product views and buys for a user segment;
- Data structure & semantics: Inputs to the trained generative model are (1) user segment and (2) noise vectors; the outputs are matrices of coupled (view, buy) predictions;
- Coverage: Complete, large-scale product catalogs are represented in each generated distribution;
- Data compression: Application of a linear encoding algorithm to very high-dimensional data vectors, enabling computation and ultimate decoding to product space;
- Commercial focus on transaction (versus rating) for recommended products by design.
2. Methods
2.1. Background-Generative Adversarial Networks
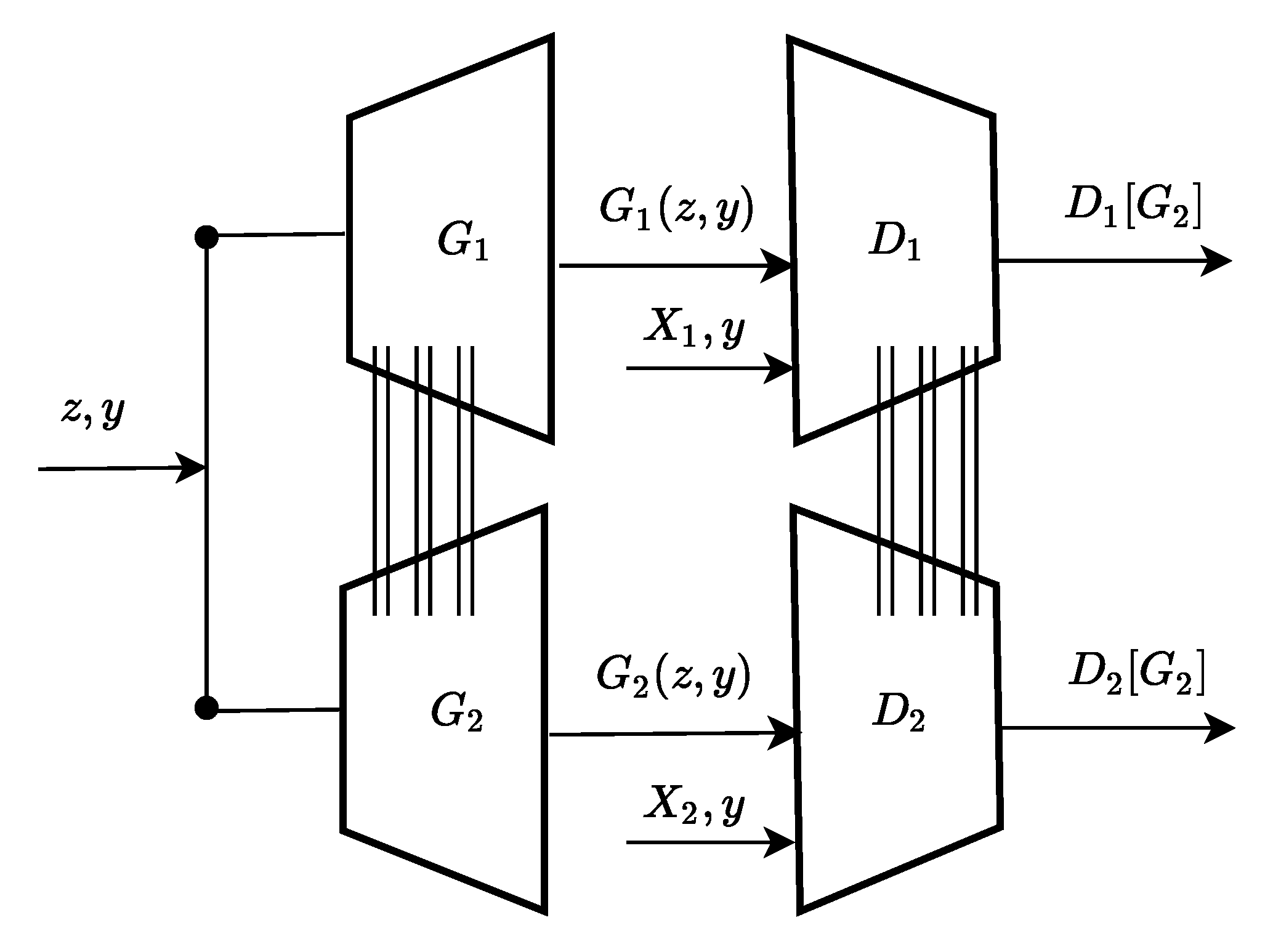
2.2. Model Architecture
2.3. Data Preparation
2.4. Evaluation Metrics
- 1
- Specific items contained within the overlapping category sets that are both viewed and “bought”—a putative conversion rate;
- 2
- Coherence between categories in the paired recommendations.
2.5. Recommendation Experiments
3. Results And Discussion
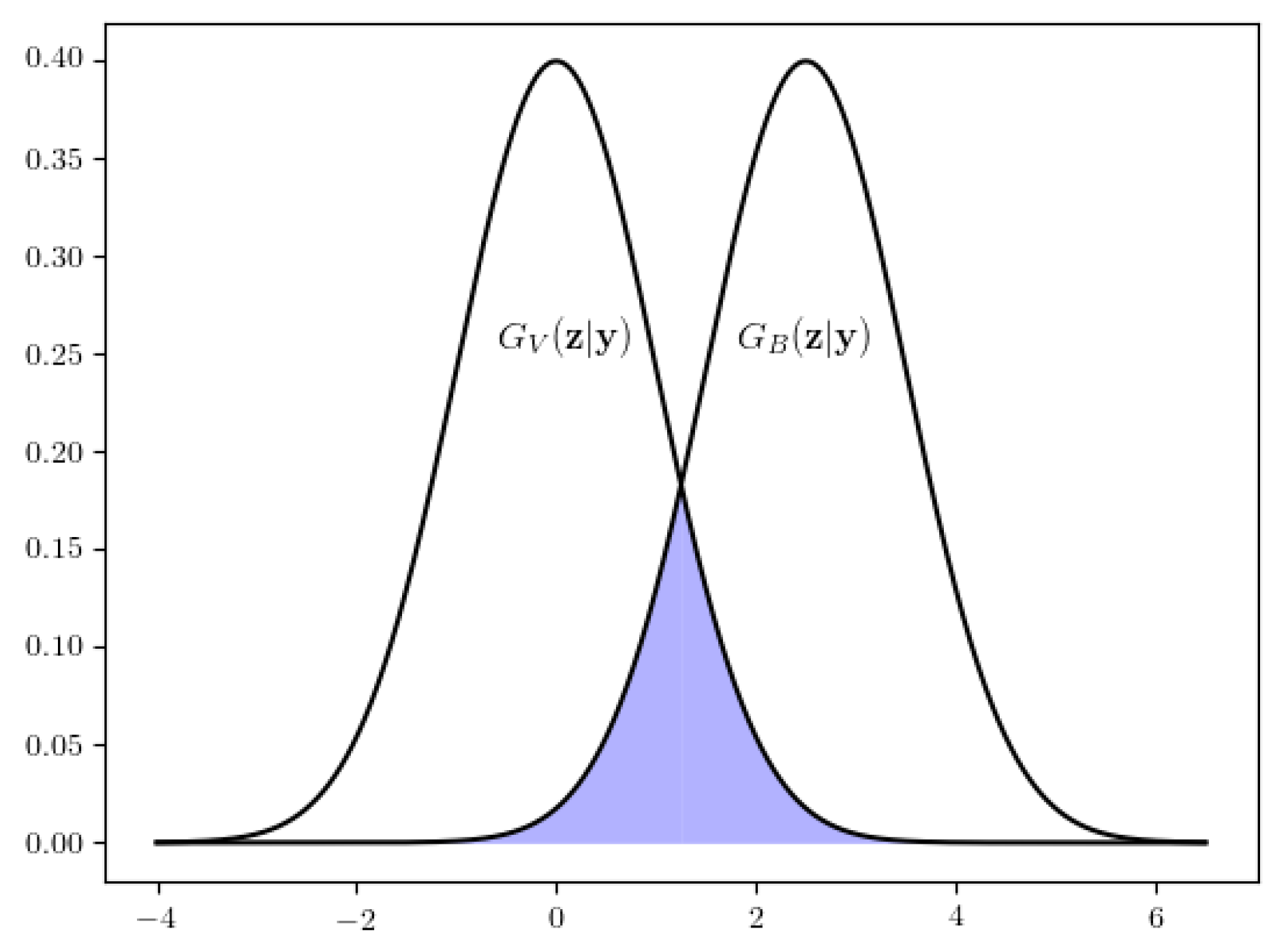
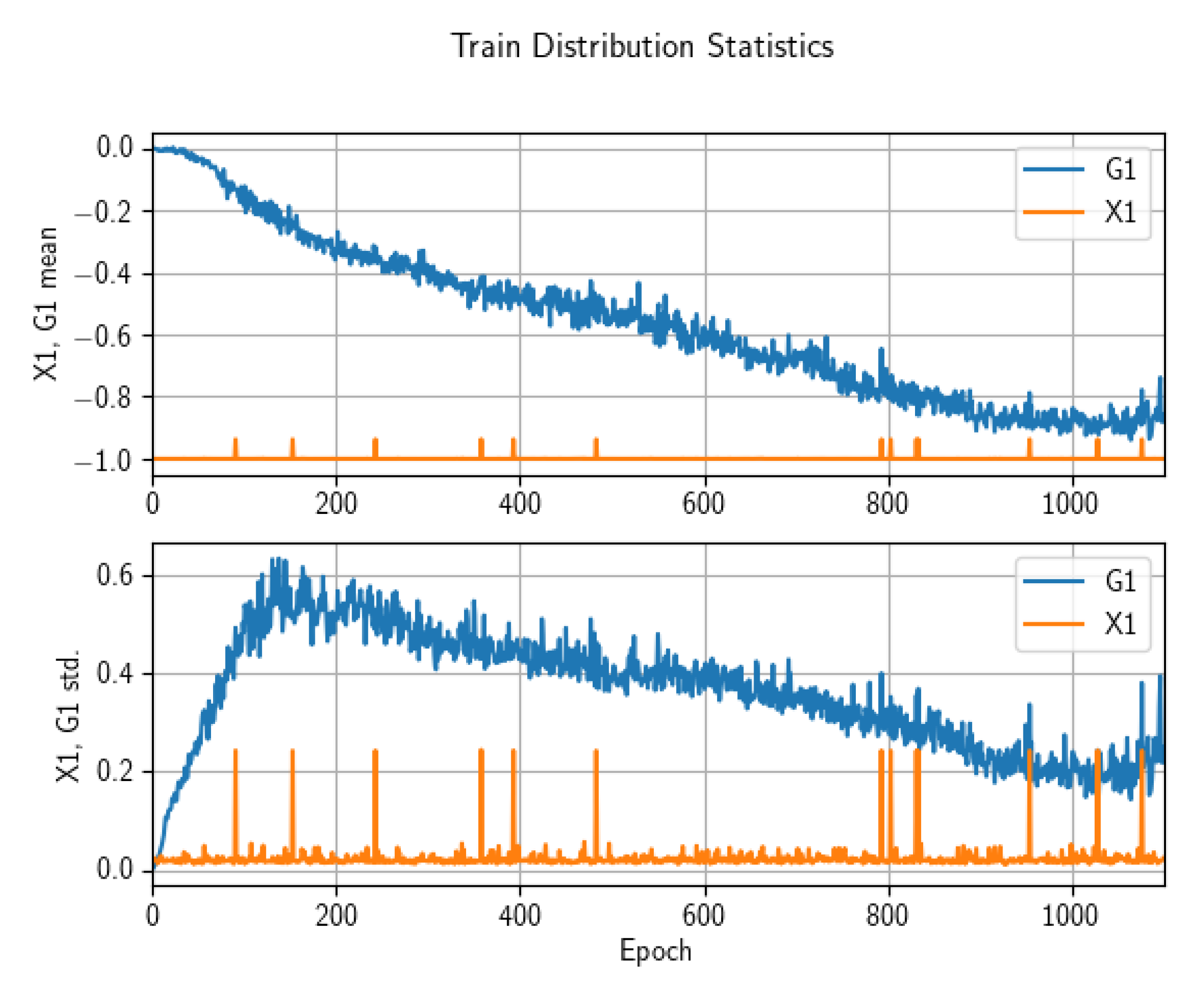
3.1. Main Statistical Results
3.2. Benchmark Comparison Results
3.3. Discussion
3.3.1. Comparison with Other Recommenders
3.3.2. Drawbacks of Current Method
3.3.3. General Discussion Points
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| GAN | Generative adversarial network |
| CVR | Conversion rate |
| NCF | Neural collaborative filtering |
| MLP | Multilayer perceptron |
| RNN | Recurrent neural network |
References
- Gilula, Z.; McCulloch, R.; Ross, P. A direct approach to data fusion. J. Mark. Res. 2006, XLIII, 73–83. [Google Scholar] [CrossRef]
- Anderson, C. The Long Tail: Why the Future of Business Is Selling Less of More; Hyperion Press: New York, NY, USA, 2006. [Google Scholar]
- MacKenzie, I.; Meyer, C.; Noble, S. How Retailers Can Keep Up with Consumers. 2013. Available online: Https://mck.co/2fGI7Vj (accessed on 9 June 2019).
- Gomez-Uribe, C.; Hunt, N. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Trans. Manag. Inf. Syst. 2015, 6, 1–19. [Google Scholar] [CrossRef]
- Iyengar, S.; Lepper, M. When Choice is Demotivating: Can One Desire Too Much of a Good Thing? J. Personal. Soc. Psychol. 2001, 79, 995–1006. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.I.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2018, 52, 1–37. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Brand, M. Fast online SVD revisions for lightweight recommender systems. In Proceedings of the SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. AutoRec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, May 2015. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based Recommendations with Recurrent Neural Networks. arXiv, 2015; arXiv:1511.06939. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar] [CrossRef]
- Yoo, J.; Ha, H.; Yi, J.; Ryu, J.; Kim, C.; Ha, J.; Kim, Y.; Yoon, S. Energy-Based Sequence GANs for Recommendation and Their Connection to Imitation Learning. arXiv, 2017; arXiv:1706.09200. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv, 2014; arXiv:1406.2661. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
- Gauthier, J. Conditional generative adversarial nets for convolutional face generation. Cl. Proj. Stanf. CS231N Convol. Neural Netw. Vis. Recognit. 2014, 2014, 2. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled Generative Adversarial Networks. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 469–477. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 31 August 2020).
- Linder-Norén, E. Keras-GAN: Keras Implementations of Generative Adversarial Networks. 2018. Available online: https://github.com/eriklindernoren/Keras-GAN (accessed on 31 August 2020).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lehmann, J.; Lalmas, M.; Yom-Tov, E.; Dupret, G. Models of User Engagement. In UMAP’12-Proceedings of the 20th International Conference on User Modeling, Adaptation, and Personalization; Springer: Berlin/Heidelberg, Germany, 2012; pp. 164–175. [Google Scholar] [CrossRef]
- MacKay, D. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- McNee, S.M.; Riedl, J.; Konstan, J.A. Being accurate is not enough: How accuracy metrics have hurt recommender systems. In Proceedings of the CHI Extended Abstracts on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006. [Google Scholar]
- Castells, P.; Vargas, S.; Wang, J. Novelty and Diversity Metrics for Recommender Systems: Choice, Discovery and Relevance. In Proceedings of the International Workshop on Diversity in Document Retrieval (DDR-2011), Dublin, Ireland, April 2011. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar] [CrossRef]
- Jannach, D.; Jugovac, M. Measuring the Business Value of Recommender Systems. ACM Trans. Manag. Inf. Syst. 2019, 10, 1–23. [Google Scholar] [CrossRef]
- Wen, H.; Zhang, J.; Wang, Y.; Bao, W.; Lin, Q.; Yang, K. Conversion Rate Prediction via Post-Click Behaviour Modeling. arXiv, 2019; arXiv:cs.LG/1910.07099. [Google Scholar]
- Bermeitinger, B.; Hrycej, T.; Handschuh, S. Representational Capacity of Deep Neural Networks—A Computing Study. arXiv, 2019; arXiv:1907.08475. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 2234–2242. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv, 2017; arXiv:1710.10196. [Google Scholar]
- Ogonowski, P. 15 Ecommerce Conversion Rate Statistics. 2020. Available online: https://www.growcode.com/blog/ecommerce-conversion-rate (accessed on 6 April 2020).
- Gilotte, A.; Calauzènes, C.; Nedelec, T.; Abraham, A.; Dollé, S. Offline A/B Testing for Recommender Systems. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining-WSDM ’18, Marina Del Rey, CA, USA, 5–9 February 2018. [Google Scholar]
- Harper, F.M.; Konstan, J. The MovieLens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the IEEE International Conference on Data Mining (ICDM 2008), Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Yang, L.; Cui, Y.; Xuan, Y.; Wang, C.; Belongie, S.; Estrin, D. Unbiased Offline Recommender Evaluation for Missing-Not-At-Random Implicit Feedback. In Proceedings of the Twelfth ACM Conference on Recommender Systems (RecSys ‘18), Vancouver, BC, Canada, 2–7 October 2018. [Google Scholar]
- Arora, S.; Zhang, Y. Do GANs actually learn the distribution? An empirical study. arXiv, 2017; arXiv:1706.08224. [Google Scholar]
- Dacrema, M.F.; Boglio, S.; Cremonesi, P.; Jannach, D. A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research. arXiv, 2019; arXiv:1911.07698. [Google Scholar]





{kind=link}
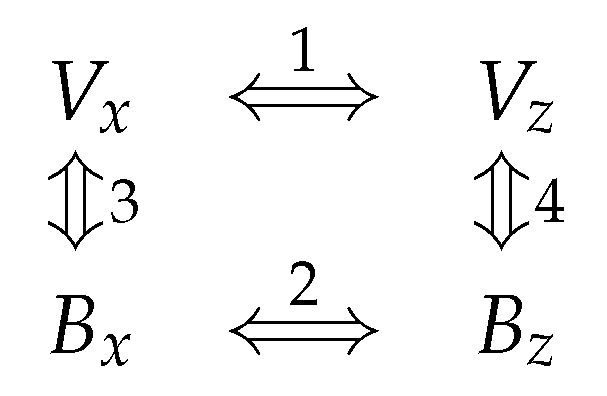{kind=link}
{kind=link}
{kind=link}
| ID | D Layer | Output Size | ID | G Layer | Output Size |
|---|---|---|---|---|---|
| 1 | Input (y) | (?,1) | 1 | Input (y) | (?,1) |
| 2 | Embedding | (?,1,500700) | 2 | Embedding | (?,1,100) |
| 3 | Flatten | (?,500700) | 3 | Flatten | (?,100) |
| 4 | Reshape | (?,1669,300,1) | 4 | Input (z) | (?,100) |
| 5 | Input (X) | (?,1669,300,1) | 5 | Multiply (3,4) | (?,100) |
| 6 | Multiply (4,5) | (?,1669,300,1) | 6,7 | Dense, ReLU | (?,128) |
| 7 | AvgPooling | (?,834,15,1) | 8 | BatchNorm. | (?,128) |
| 8 | Flatten | (?,125100) | 9 | Dropout | (?,128) |
| 9,10 | Dense, ReLU | (?,512) | 10,11 | Dense, ReLU | (?,256) |
| 11,12 | Dense, ReLU | (?,256) | 12 | BatchNorm. | (?,256) |
| 13,14 | Dense, ReLU | (?,64) | 13 | Dropout | (?,256) |
| 15 | Dense | (?,1) | 14 | Dense | (?,500700) |
| 15 | Reshape | (?,1669,300,1) |
| Segment | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| Count | n/a | 309 | 1182 | 1510 | 7590 |
| y | #I | #C | CVR | CVRrn | Jc | |
|---|---|---|---|---|---|---|
| 1 | 1648 | 239 | 1.763 | 0.0005 | 8.19 | 50.66 |
| 2 | 2037 | 213 | 1.414 | 0.0004 | 7.37 | 51.36 |
| 3 | 2522 | 190 | 1.323 | 0.0005 | 6.13 | 50.04 |
| 4 | 1419 | 222 | 1.644 | 0.0004 | 7.57 | 50.81 |
| GAN | Industry | Product |
|---|---|---|
| 1.536 | 2.089 | 1.827 |
| Algorithm | Reference | Recommender Input | Recommender Output |
|---|---|---|---|
| MLP+Matrix factorization | He et al. [9] | User, item vectors | Item ratings |
| Autoencoder | Sedhain et al. [10] | User, item vectors | Item ratings |
| Recurrent neural network | Hidasi et al. [11] | Item sequence | Next item |
| Graph neural network | Ying et al. [12] | Item/feature graph | Top items |
| Sequence GAN | Yoo et al. [13] | Item sequence | Next item |
| RecommenderGAN | This work | Noise, user vectors | View, buy matrices |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bock, J.R.; Maewal, A. Adversarial Learning for Product Recommendation. AI 2020, 1, 376-388. https://doi.org/10.3390/ai1030025
Bock JR, Maewal A. Adversarial Learning for Product Recommendation. AI. 2020; 1(3):376-388. https://doi.org/10.3390/ai1030025
Chicago/Turabian StyleBock, Joel R., and Akhilesh Maewal. 2020. "Adversarial Learning for Product Recommendation" AI 1, no. 3: 376-388. https://doi.org/10.3390/ai1030025
APA StyleBock, J. R., & Maewal, A. (2020). Adversarial Learning for Product Recommendation. AI, 1(3), 376-388. https://doi.org/10.3390/ai1030025