
A Review of Deep Reinforcement Learning Algorithms for Mobile Robot Path Planning



Abstract
:1. Introduction
2. Obstacle Detection and Its Role in Path Planning
2.1. Vision Sensor
2.2. LiDAR
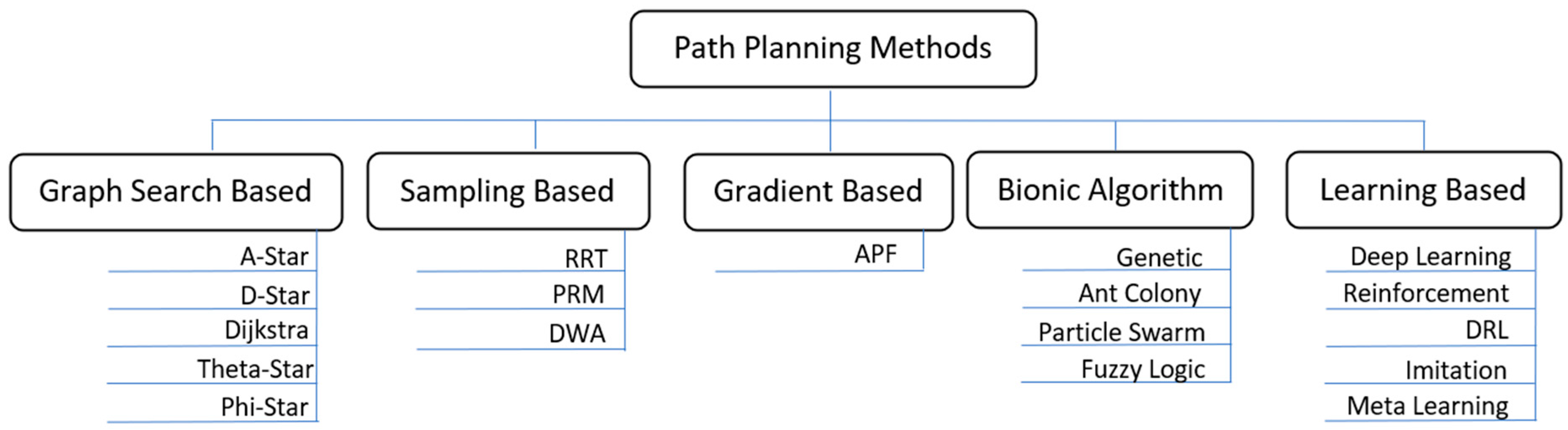
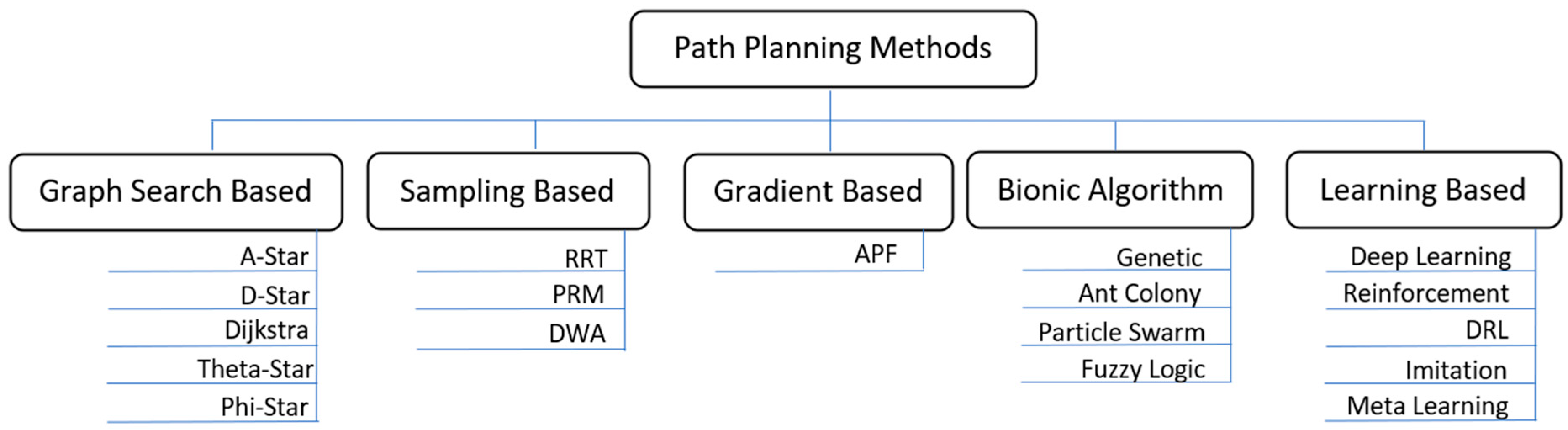
3. Path Planning Methods
3.1. Deep Learning
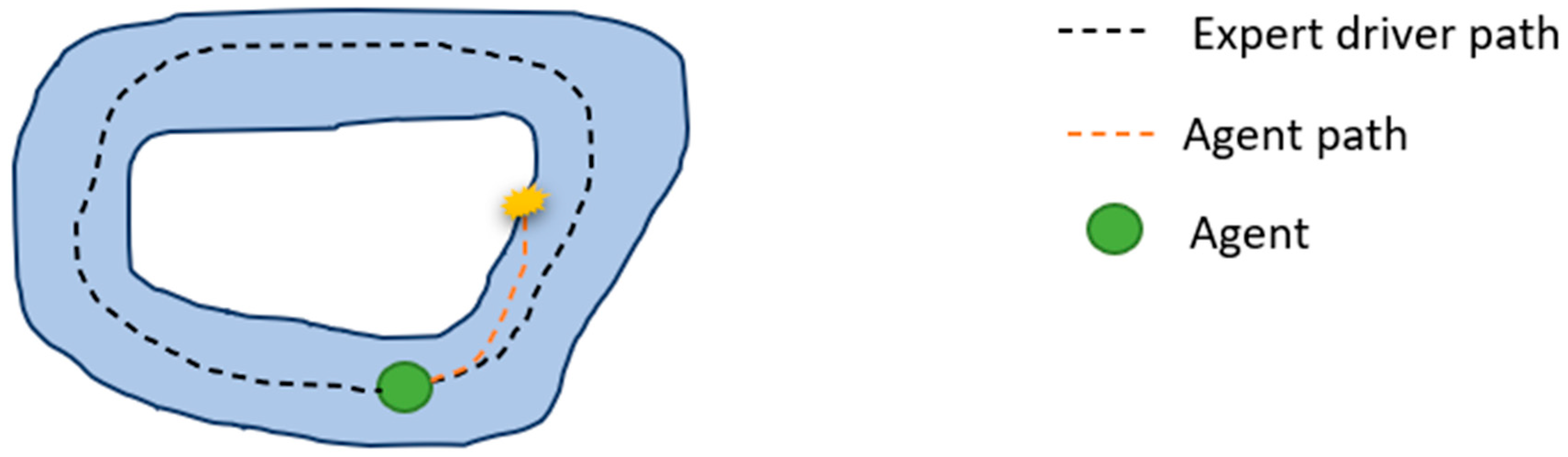
3.2. Imitation Learning
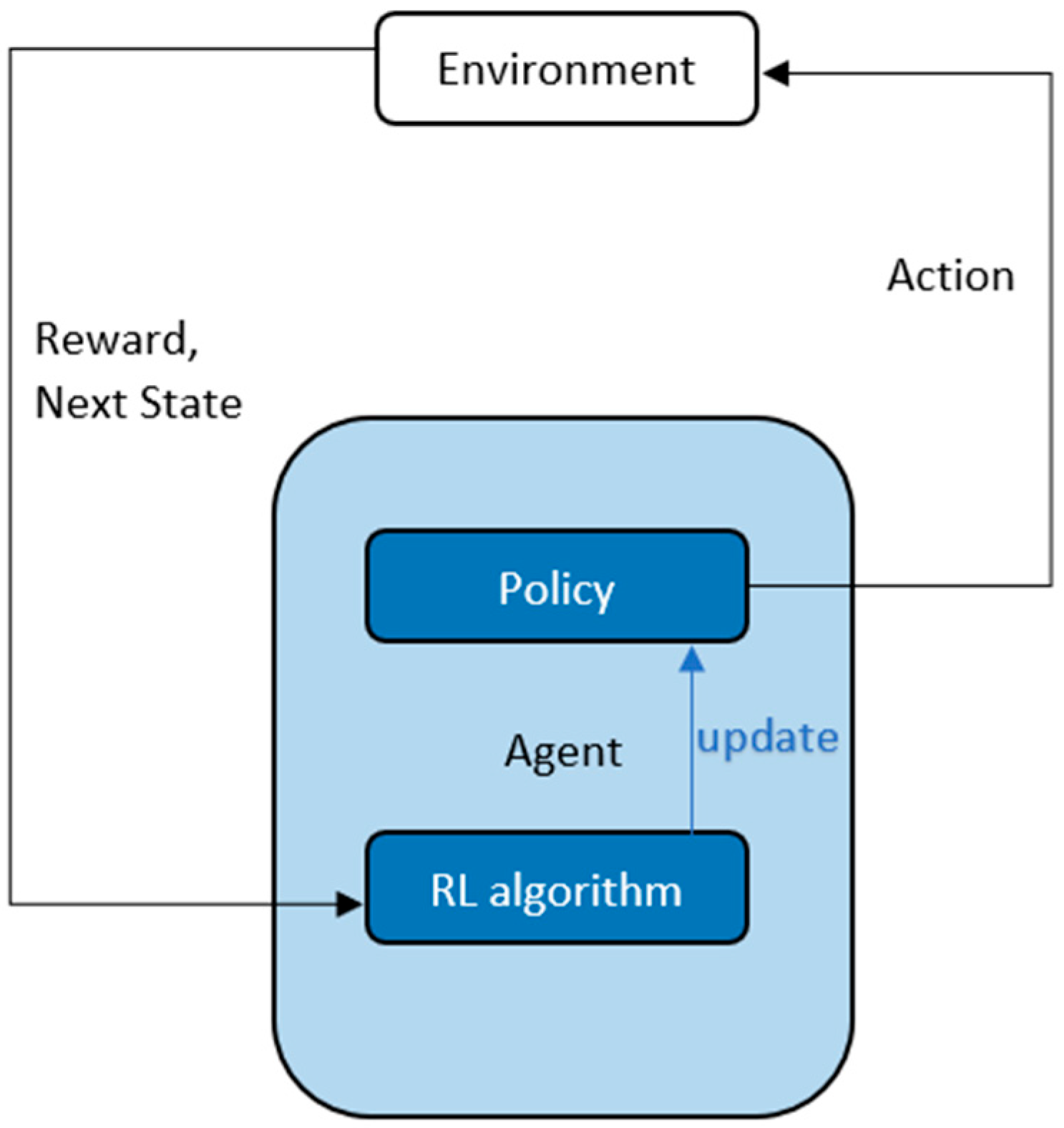
3.3. Reinforcement Learning
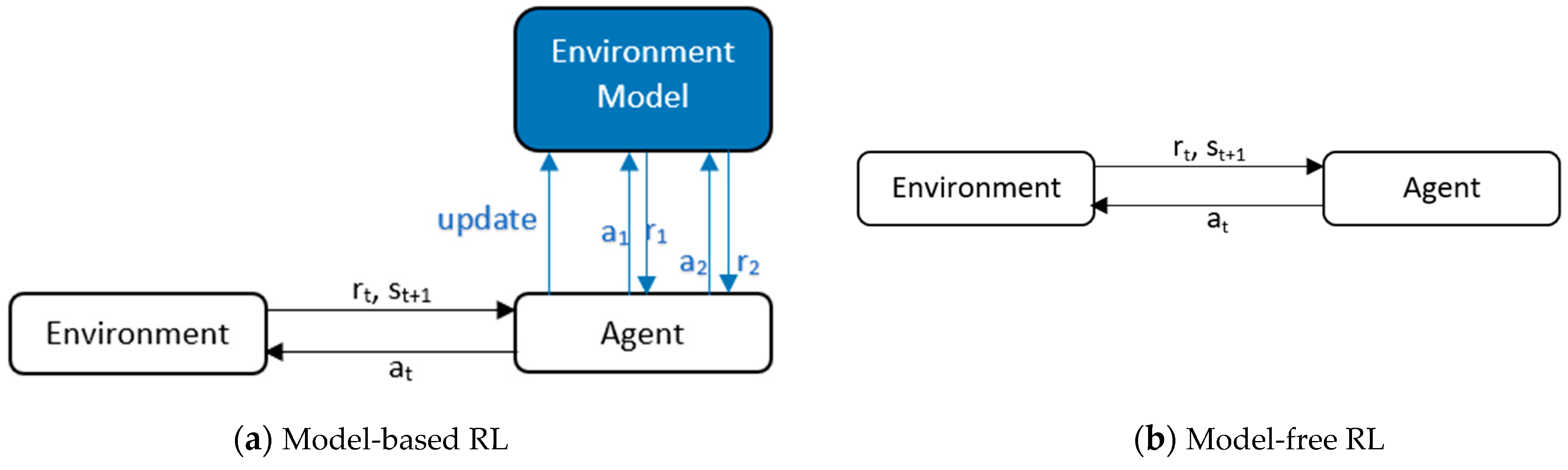
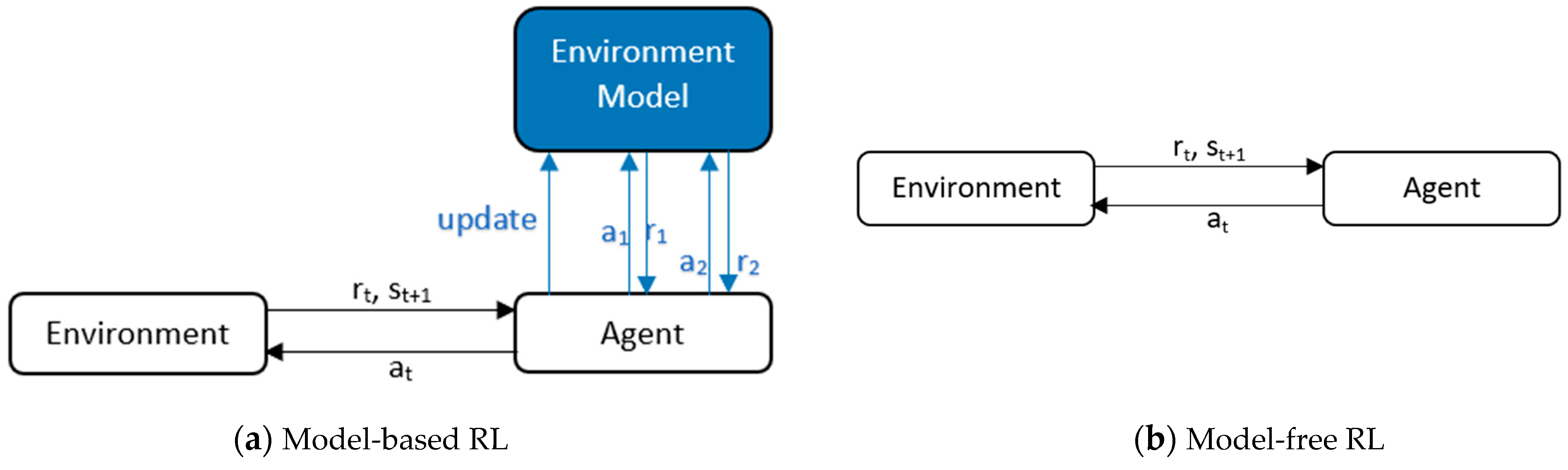
Model-Based vs. Model-Free RL
3.4. Deep Reinforcement Learning
3.4.1. Value-Based Methods
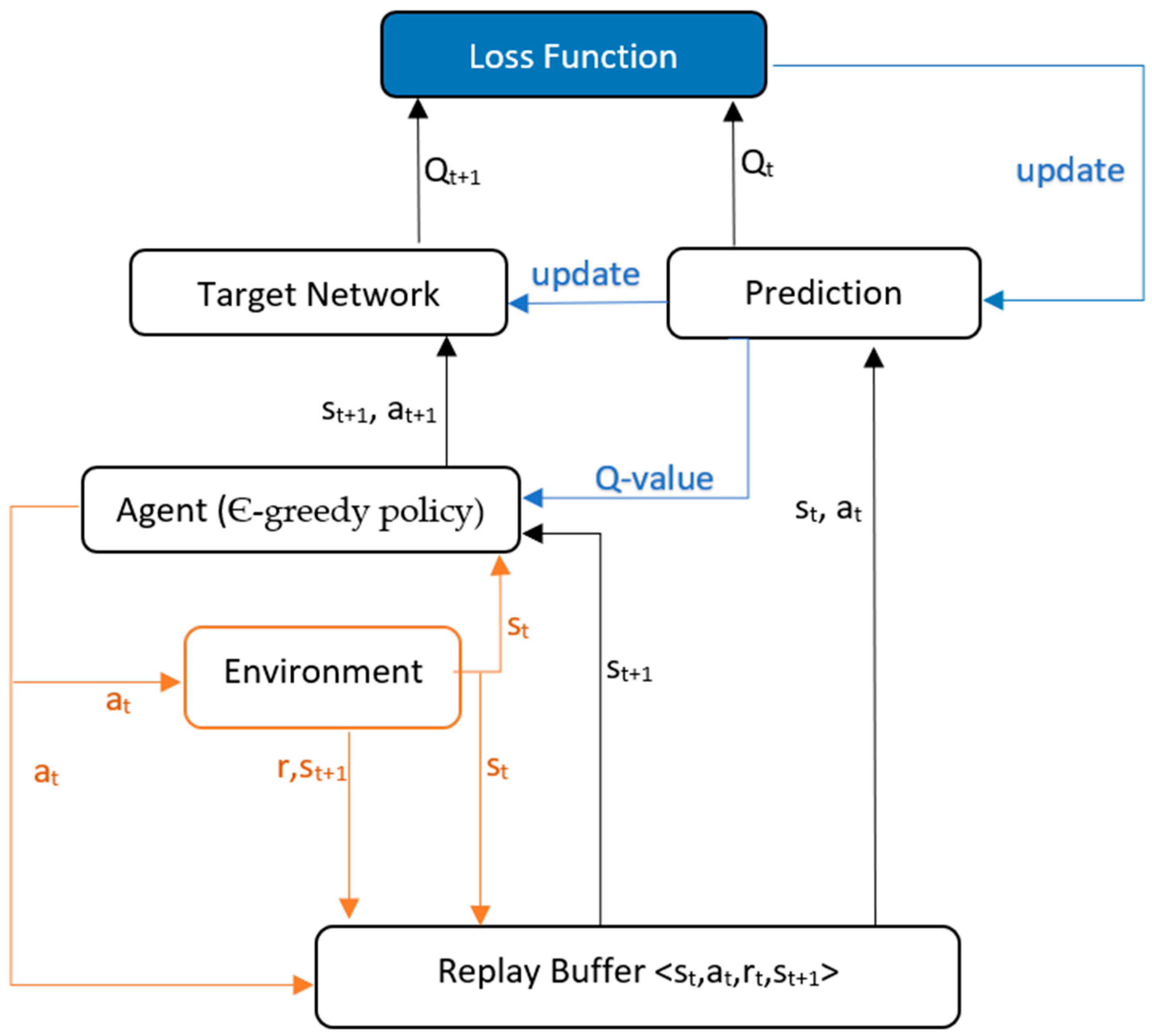
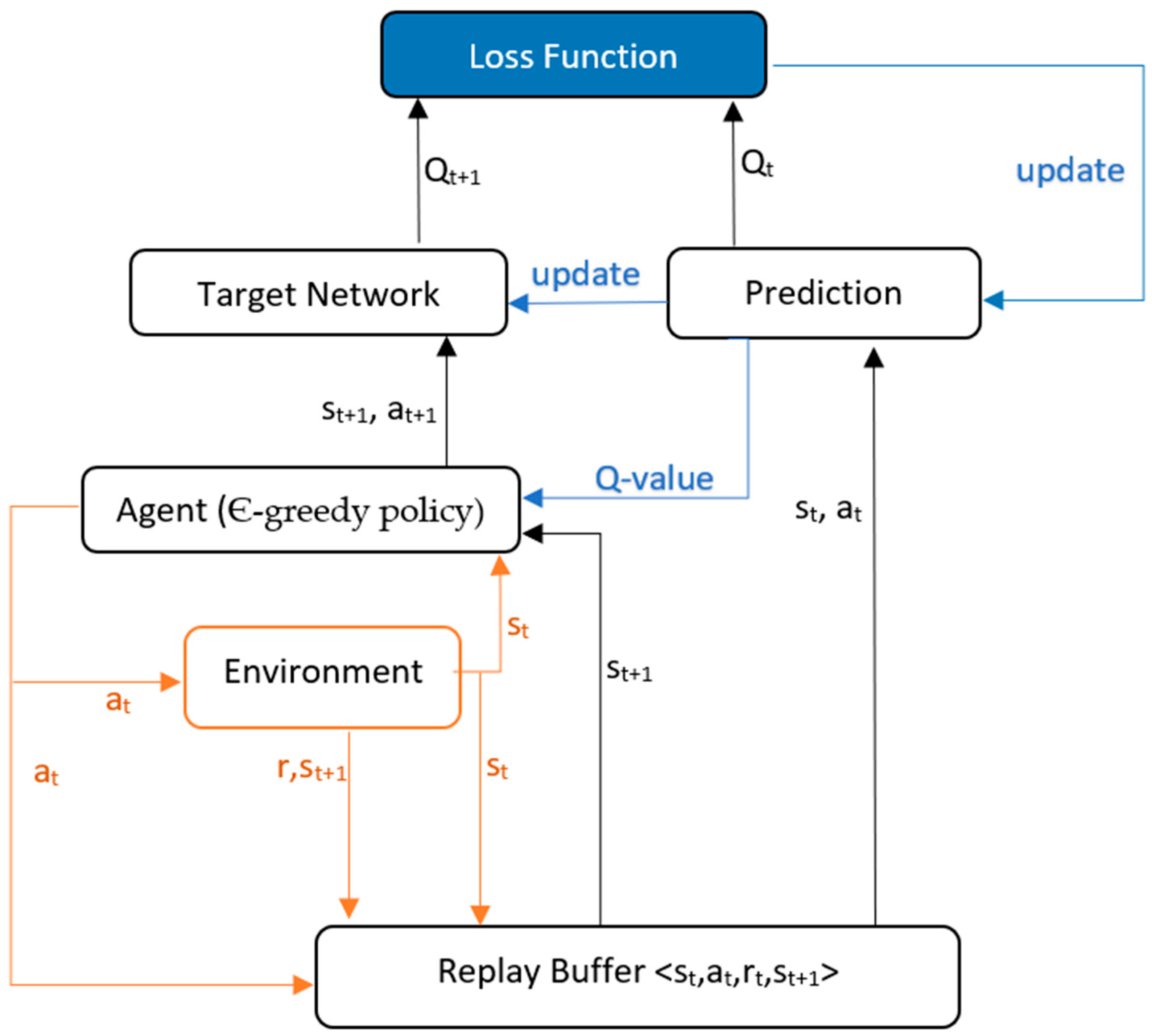
DQN
DDQN
D3QN
3.4.2. Policy-Based
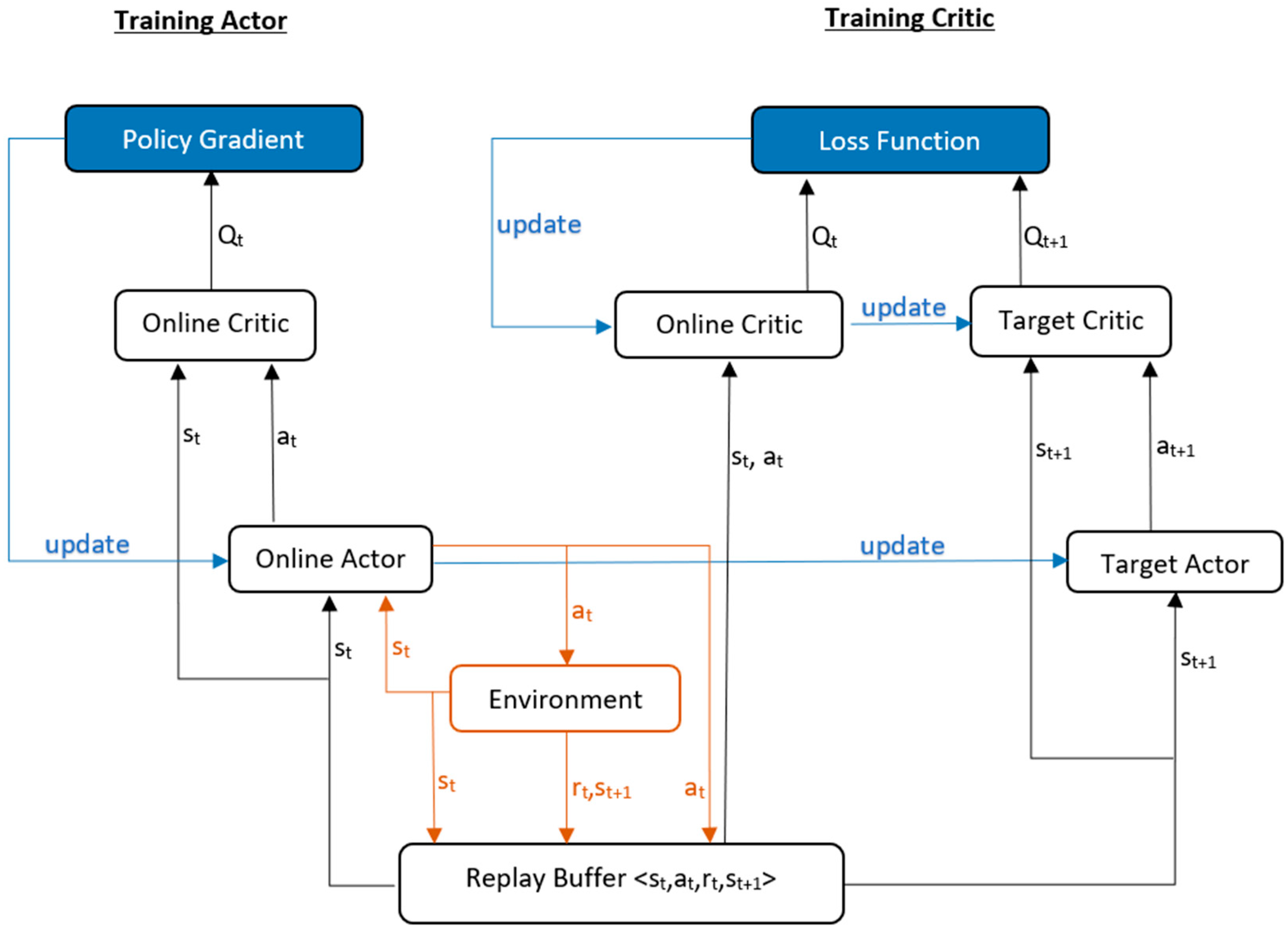
3.4.3. Actor-Critic
DDPG
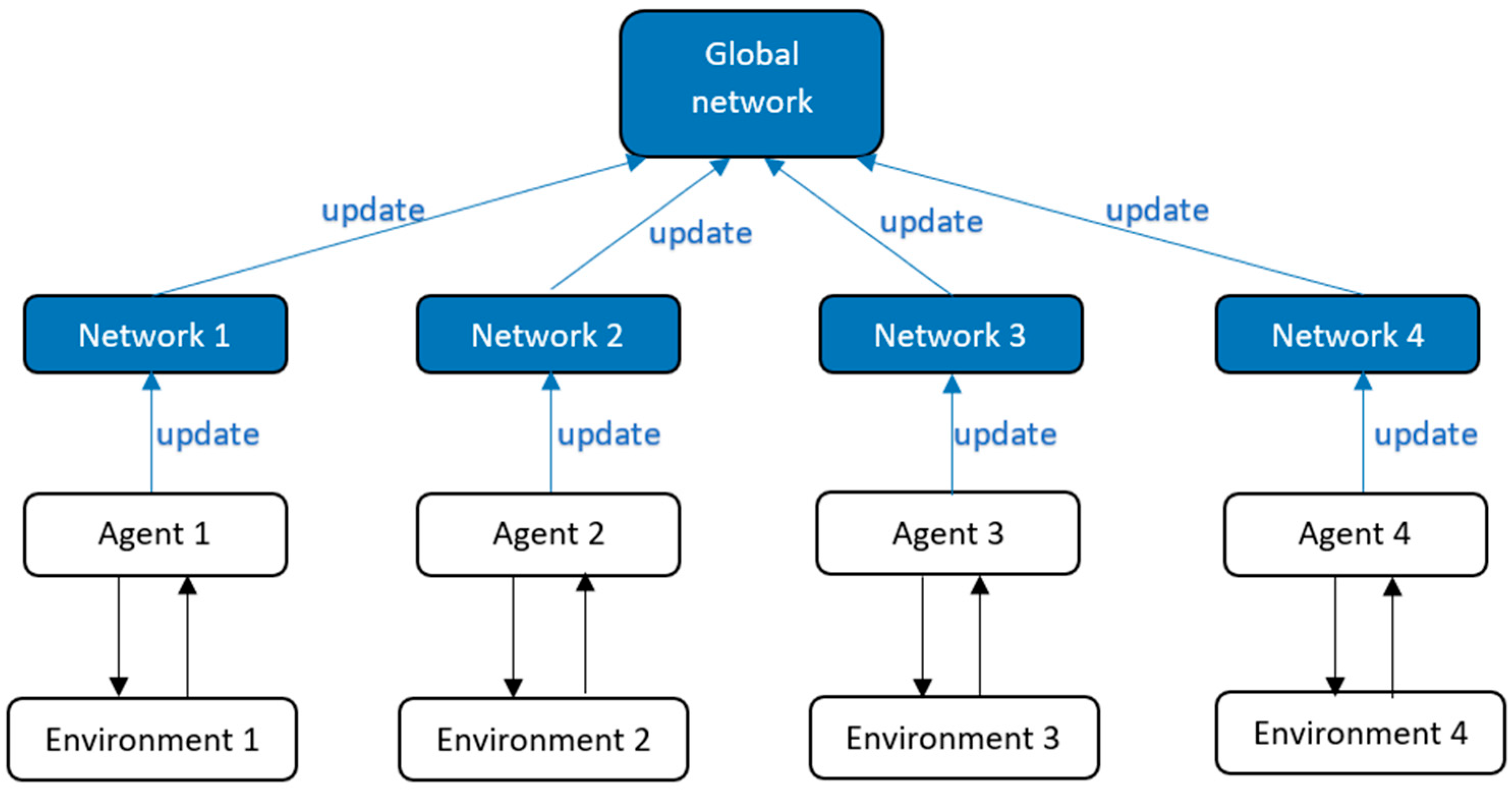
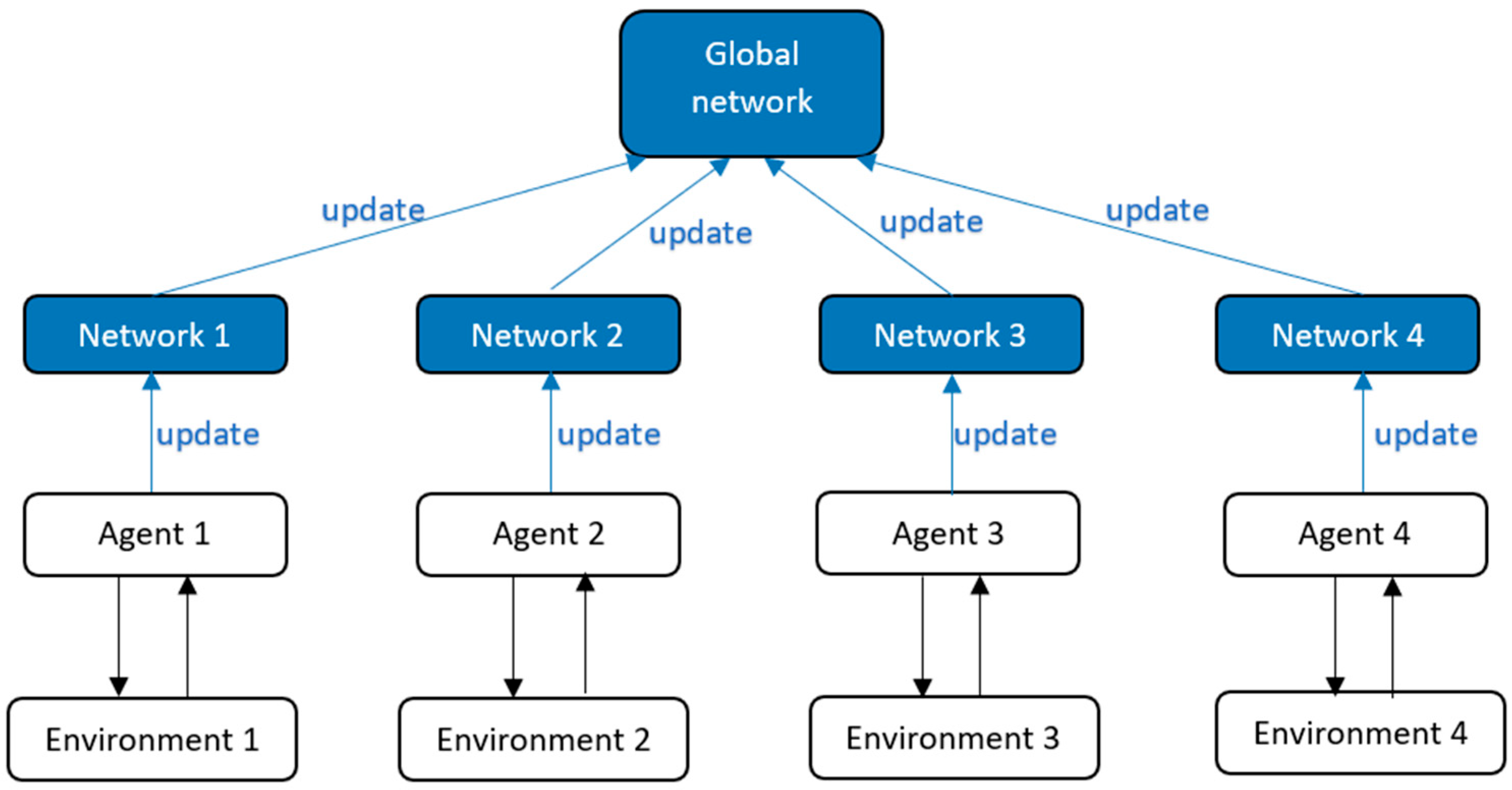
A3C
PPO
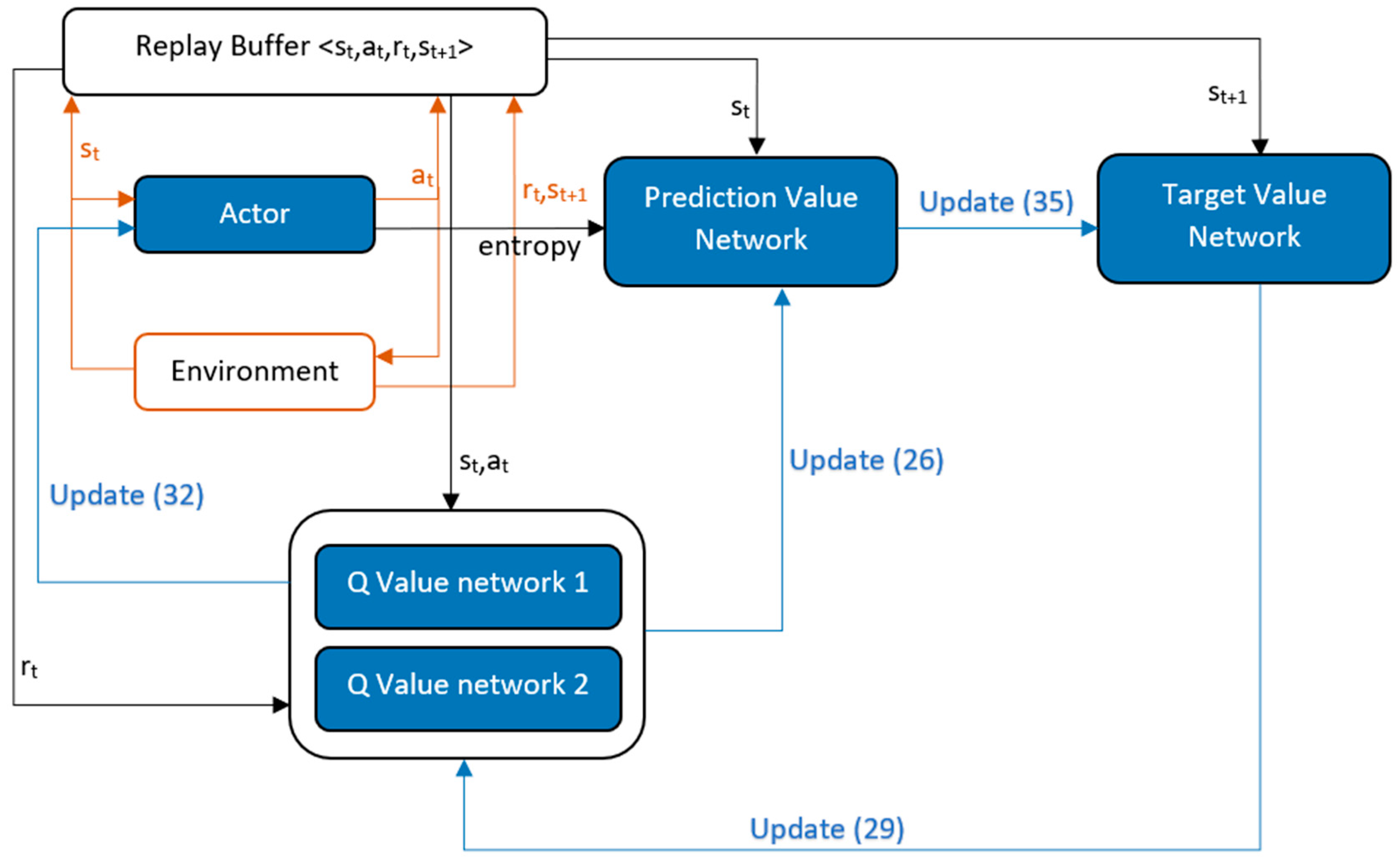
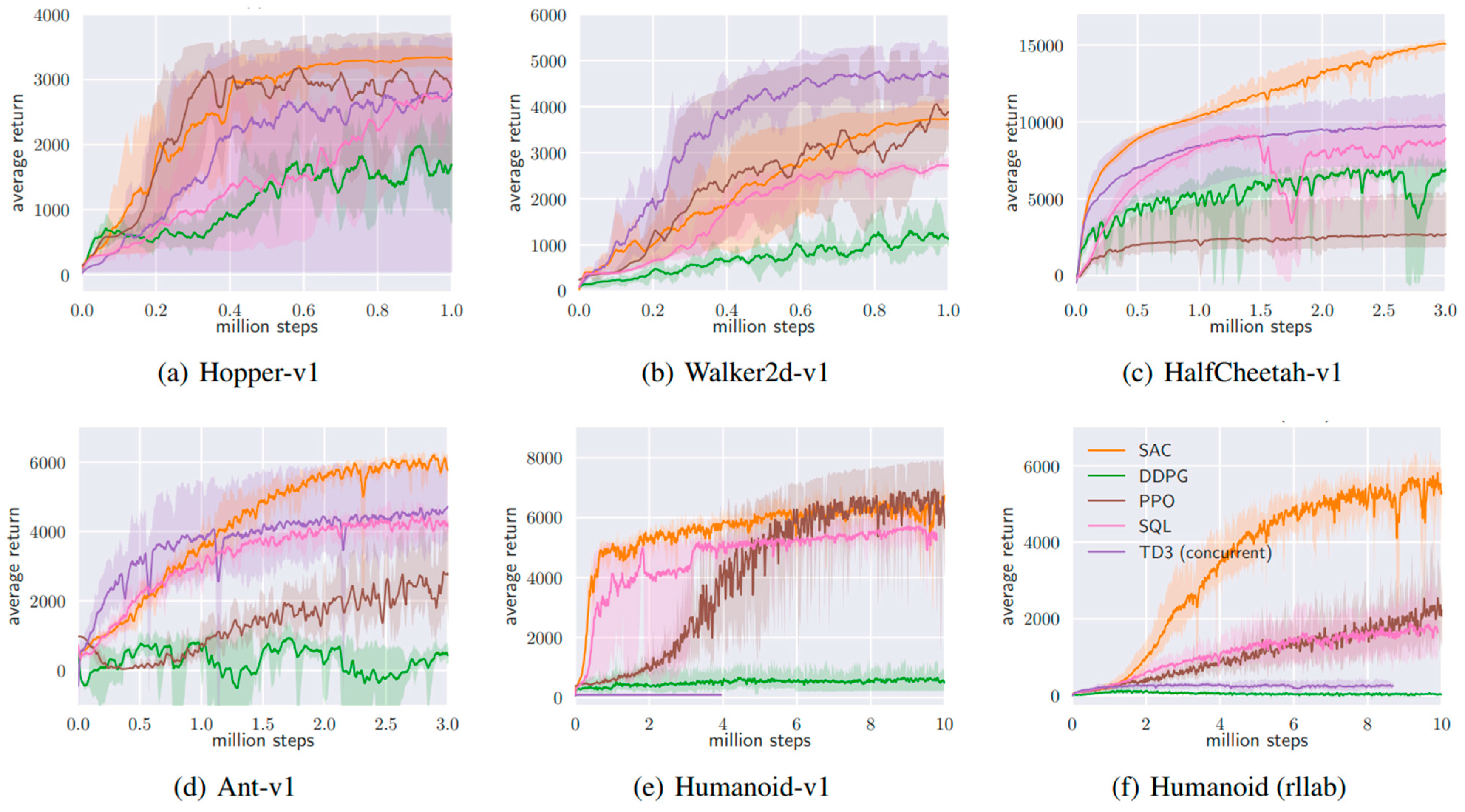
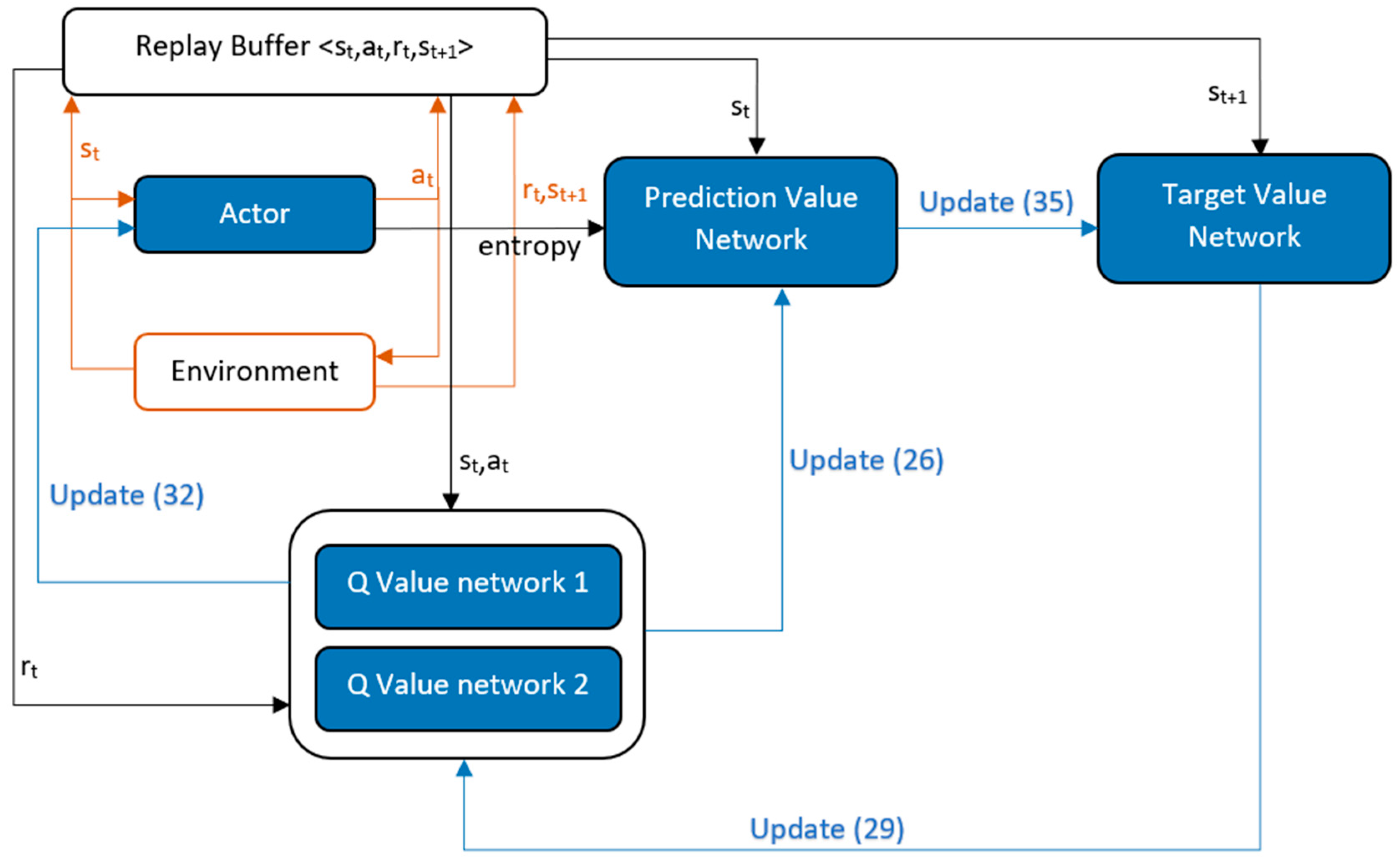
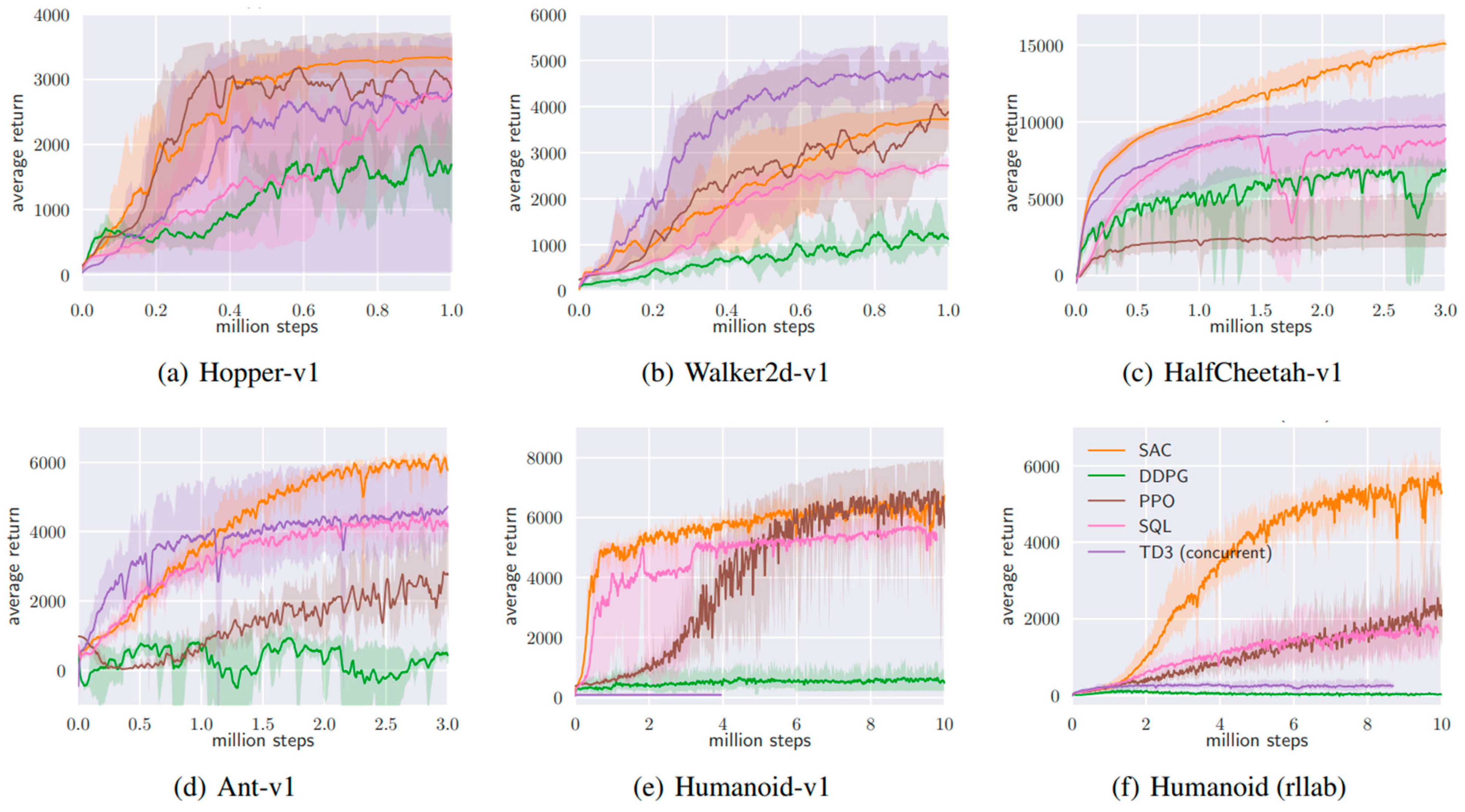
SAC
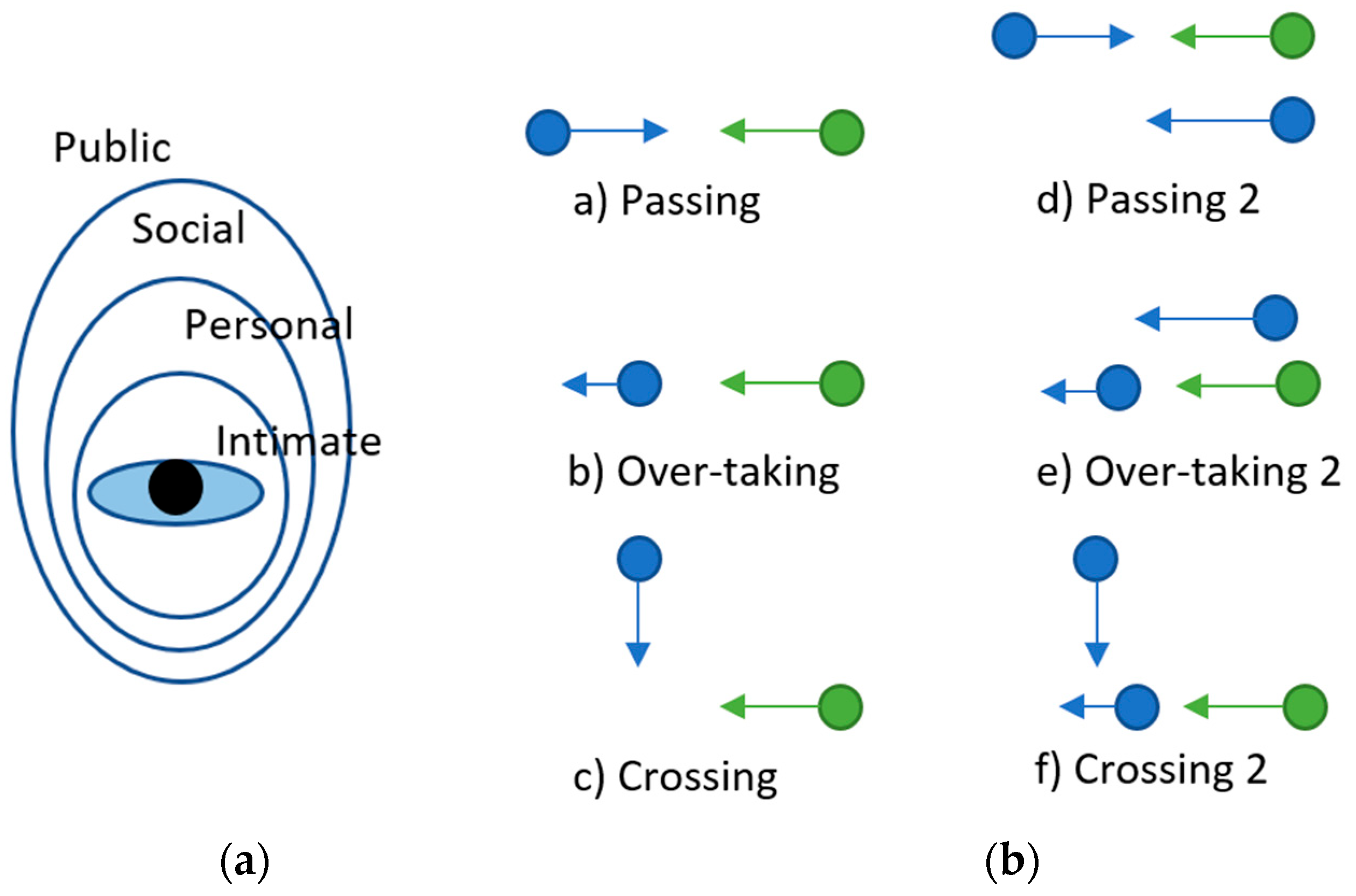
4. Integrating Social Interaction Awareness in Robot Navigation
5. Discussion
5.1. Challenges with DRL
- The reward function defined during initial implementations of DRL methods only included a positive reward for reaching the target and a negative reward for collision. Due to this, there were long intervals where the agent took actions but could not determine how well they were taken. The robot might only get a negative reward due to the collisions, as the probability of reaching a goal with random actions is very low, which can develop timid behavior in the agent. To solve this problem, different techniques such as reward shaping, where the additional reward for moving close to the goal or timestep penalty is added, the intrinsic curiosity module, where the additional reward for exploring a new area is given, the intrinsic reward, where an additional reward is given if the agent is incrementally collecting the reward, the reward for reaching waypoints given by the global planner, etc., are used. Hierarchical RL, where the original task is decomposed into simple tasks, has also been incorporated.
- Almost all DRL agents are first trained in virtual environments before being fine-tuned in real environments. But the virtual environments cannot exactly replicate the real environment, be it the lighting conditions, 3D models, human models, robot dynamics, sensor performance, and other intricacies. This can cause the agent to perform poorly in real environments, but techniques such as adding noise to the input data, using less-dimensional laser data, domain randomization, transfer learning, etc., can be used to improve the performance. Virtual training environments that take robot dynamics into account are also preferred.
- A big problem with deep learning methods is catastrophic forgetting, which means when the network is trained on newer data, the weights are updated and the knowledge learned from previous interactions is overwritten and forgotten. This problem can be solved using episodic memory systems that store past data and replay them with new examples, but it takes a large amount of working memory to store and replay past inputs. Elastic weight consolidation solves the forgetting problem by calculating the Fisher information matrix to quantify the importance of the network parameter weights to the previous task. Deep generative models, such as deep Boltzmann machines or variational autoencoders can be used to generate states that closely match the observed input. Generative adversarial networks can be used to mimic past data that are generated from learned past input distributions [93].
5.2. Future Research Directions
- Currently, each study is focused on a specific setting; a solution that works in every environment, such as a maze, a dynamic environment with human obstacles, sidewalks, or a simple empty environment, is yet to be developed. Training an agent in different environments using transfer learning might solve this problem, but due to catastrophic forgetting, the solution might not be stable. Techniques such as continual learning without catastrophic forgetting and the use of the LSTM network, along with human intent detection and the use of services such as Google Maps for global path planning, need to be exploited and explored further to develop mobile robots that can be seamlessly deployed in environments of varied complexity. Not only different types of spaces but also different lighting and environmental conditions such as weather and natural light need to be considered.
- Pre-processing of LiDAR or camera data is extremely limited in ongoing research. End-to-end path planning algorithms allow the neural networks to judge the input data for themselves to find valid relations, but the decision-making performance can be further improved by augmenting the input data. Techniques such as ego-motion disentanglement, using the difference of two consecutive LiDAR data samples instead of those two samples, have been proven to perform better. More methods for both LiDAR and camera data need to be developed to improve the efficiency of the networks.
- The research on path planning for mobile robots using a combination of model-free and model-based deep reinforcement learning methods is very limited. This method provides the benefit of both a lower computation requirement due to the model-based part and the ability to learn good policies even in the absence of a good model of environmental dynamics. Model-free methods can be used to improve the performance of model-based methods by fine-tuning the model and providing better estimates of the value function.
- Currently, robots observe the environment at a very low level; everything is divided only as available paths or obstacles. A few solutions that use both cameras and LiDAR can differentiate between humans and other obstacles and can use different avoidance modules to plan paths. Robots might need to use object detection modules to differentiate between different types of obstacles, including whether they can be interacted with or not, such as doors, stairs, push buttons, etc. Interacting with objects opens up new avenues of research possibilities. For robots to be deployed as aid bots, they should be able to learn the position of objects and quickly fetch them or place scattered objects at their designated locations. New ways of fusing sensor data or different modules using different sensor data need to be developed.
- The cognitive and understanding abilities of the DRL need to be further enhanced using the experience of human experts. Along with visual information as observation, the integration of human language instructions can also be used to improve the planning performance of the robots for real deployment applications. In some cases, agents can also be provided with non-scale or hand-drawn maps with only landmarks to help them plan a path through unknown environments more efficiently.
- Meta-learning is a relatively new field being implemented for path-planning solutions for mobile robots. It is a type of machine learning in which a model learns how to learn from new tasks or environments. The goal of meta-learning is to enable a model to quickly adapt to new tasks or environments, rather than requiring it to be retrained from scratch for each new task. One common approach is to use a “meta-learner” or “meta-controller” that can learn how to adjust the parameters of other “base-learners” or “base-controllers” based on their performance on different tasks. It can be used to tune the hyperparameters, which are currently selected at random. More research is needed in this field to provide feasible solutions.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Iqbal, J.; Islam, R.U.; Abbas, S.Z.; Khan, A.A.; Ajwad, S.A. Automating industrial tasks through mechatronic systems—A review of robotics in industrial perspective. Tech. Gaz. 2016, 23, 917–924. [Google Scholar] [CrossRef]
- Du, Y.; Hetherington, N.J.; Oon, C.L.; Chan, W.P.; Quintero, C.P.; Croft, E.; Van der Loos, H.M. Group Surfing: A Pedestrian-Based Approach to Sidewalk Robot Navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6518–6524. [Google Scholar] [CrossRef]
- Hurtado, J.V.; Londoño, L.; Valada, A. From Learning to Relearning: A Framework for Diminishing Bias in Social Robot Navigation. Front. Robot. AI 2021, 8, 650325. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Mao, S.; Wu, Z.; Kong, P.; Qiang, H. Improved Path Planning for Indoor Patrol Robot Based on Deep Reinforcement Learning. Symmetry 2022, 14, 132. [Google Scholar] [CrossRef]
- Ko, B.; Choi, H.; Hong, C.; Kim, J.; Kwon, O.; Yoo, C. Neural network-based autonomous navigation for a homecare mobile robot. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2017; pp. 403–406. [Google Scholar] [CrossRef]
- Doroodgar, B.; Nejat, G. A hierarchical reinforcement learning based control architecture for semi-autonomous rescue robots in cluttered environments. In Proceedings of the 2010 IEEE International Conference on Automation Science and Engineering, Toronto, ON, Canada, 21–24 August 2010; pp. 948–953. [Google Scholar] [CrossRef]
- Zhang, K.; Niroui, F.; Ficocelli, M.; Nejat, G. Robot Navigation of Environments with Unknown Rough Terrain Using deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Jin, X.; Wang, Z. Proximal policy optimization based dynamic path planning algorithm for mobile robots. Electron. Lett. 2021, 58, 13–15. [Google Scholar] [CrossRef]
- Marin, P.; Hussein, A.; Gomez, D.; Escalera, A. Global and Local Path Planning Study in a ROS-Based Research Platform for Autonomous Vehicles. J. Adv. Transp. 2018, 2018, 6392697. [Google Scholar] [CrossRef]
- Feng, S.; Sebastian, B.; Ben-Tzvi, P. A Collision Avoidance Method Based on Deep Reinforcement Learning. Robotics 2021, 10, 73. [Google Scholar] [CrossRef]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar] [CrossRef]
- Le Mero, L.; Yi, D.; Dianati, M.; Mouzakitis, A. A Survey on Imitation Learning Techniques for End-to-End Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14128–14147. [Google Scholar] [CrossRef]
- Macek, K.; Petrovic, I.; Peric, N. A reinforcement learning approach to obstacle avoidance of mobile robots. In Proceedings of the 7th International Workshop on Advanced Motion Control—Proceedings (Cat. No.02TH8623), Maribor, Slovenia, 3–5 July 2002; pp. 462–466. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, Y.; Wang, S. A Review of Mobile Robot Path Planning Based on Deep Reinforcement Learning Algorithm. J. Phys. Conf. Ser. 2021, 2138, 012011. [Google Scholar] [CrossRef]
- Wang, P. Research on Comparison of LiDAR and Camera in Autonomous Driving. J. Phys. Conf. Ser. 2021, 2093, 012032. [Google Scholar] [CrossRef]
- Xie, L.; Wang, S.; Markham, A.; Trigoni, N. Towards monocular vision based obstacle avoidance through deep reinforcement learning. arXiv 2017, arXiv:1706.09829. [Google Scholar] [CrossRef]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar] [CrossRef]
- Liang, J.; Patel, U.; Sathyamoorthy, A.J.; Manocha, D. Realtime Collision Avoidance for Mobile Robots in Dense Crowds using Implicit Multi-sensor Fusion and Deep Reinforcement Learning. arXiv 2020, arXiv:2004.03089. [Google Scholar] [CrossRef]
- Li, N.; Ho, C.; Xue, J.; Lim, L.; Chen, G.; Fu, Y.; Lee, L. A Progress Review on Solid-State LiDAR and Nanophotonics-Based LiDAR Sensors. Laser Photonics Rev. 2022, 16, 2100511. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Yu, J.; Su, Y.; Liao, Y. The Path Planning of Mobile Robot by Neural Networks and Hierarchical Reinforcement Learning. Front. Neurorobot. 2020, 14, 63. [Google Scholar] [CrossRef] [PubMed]
- Tao, T.; Liu, K.; Wang, L.; Wu, H. Image Recognition and Analysis of Intrauterine Residues Based on Deep Learning and Semi-Supervised Learning. IEEE Access 2020, 8, 162785–162799. [Google Scholar] [CrossRef]
- Coşkun, M.; Uçar, A.; Yildirim, O.; Demir, Y. Face recognition based on convolutional neural network. In Proceedings of the 2017 International Conference on Modern Electrical and Energy Systems (MEES), Kremenchuk, Ukraine, 15–17 November 2017; pp. 376–379. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Nikitin, Y.; Božek, P.; Peterka, J. Logical–Linguistic Model of Diagnostics of Electric Drives with Sensors Support. Sensors 2020, 20, 4429. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Basu, J.; Bhattacharyya, D.; Kim, T. Use of artificial neural network in pattern recognition. Int. J. Softw. Eng. Its Appl. 2010, 4, 23–34. Available online: https://www.earticle.net/Article/A118913 (accessed on 20 May 2023).
- Zhang, L.; Zhang, Y.; Li, Y. Path planning for indoor Mobile robot based on deep learning. Optik 2020, 219, 165096. [Google Scholar] [CrossRef]
- Jung, S.; Hwang, S.; Shin, H.; Shim, D.H. Perception, Guidance, and Navigation for Indoor Autonomous Drone Racing Using Deep Learning. IEEE Robot. Autom. Lett. 2018, 3, 2539–2544. [Google Scholar] [CrossRef]
- Wu, P.; Cao, Y.; He, Y.; Li, D. Vision-Based Robot Path Planning with Deep Learning. In Computer Vision Systems; Liu, M., Chen, H., Vincze, M., Eds.; ICVS 2017. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10528. [Google Scholar] [CrossRef]
- Osa, T.; Pajarinen, J.; Neumann, G.; Bagnell, J.A.; Abbeel, P.; Peters, J. An Algorithmic Perspective on Imitation Learning. Found. Trends® Robot. 2018, 7, 1–179. [Google Scholar] [CrossRef]
- Tai, L.; Zhang, J.; Liu, M.; Burgard, W. Socially Compliant Navigation through Raw Depth Inputs with Generative Adversarial Imitation Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1111–1117. [Google Scholar] [CrossRef]
- Kim, D.K.; Chen, T. Deep Neural Network for Real-Time Autonomous Indoor Navigation. arXiv 2015, arXiv:1511.04668. [Google Scholar] [CrossRef]
- Wu, K.; Wang, H.; Esfahani, M.A.; Yuan, S. Achieving Real-Time Path Planning in Unknown Environments through Deep Neural Networks. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2093–2102. [Google Scholar] [CrossRef]
- Tai, L.; Li, S.; Liu, M. A deep-network solution towards model-less obstacle avoidance. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 2759–2764. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Lin, C.; Liu, D.; Yu, D. A Novel GRU-RNN Network Model for Dynamic Path Planning of Mobile Robot. IEEE Access 2019, 7, 15140–15151. [Google Scholar] [CrossRef]
- Chehelgami, S.; Ashtari, E.; Basiri, M.A.; Masouleh, M.T.; Kalhor, A. Safe deep learning-based global path planning using a fast collision-free path generator. Robot. Auton. Syst. 2023, 163, 104384. [Google Scholar] [CrossRef]
- Wang, D.; Chen, S.; Zhang, Y.; Liu, L. Path planning of mobile robot in dynamic environment: Fuzzy artificial potential field and extensible neural network. Artif. Life Robot. 2020, 26, 129–139. [Google Scholar] [CrossRef]
- Lu, Y.; Yi, S.; Liu, Y.; Ji, Y. A novel path planning method for biomimetic robot based on deep learning. Assem. Autom. 2016, 36, 186–191. [Google Scholar] [CrossRef]
- Giusti, A.; Guzzi, J.; Ciresan, D.C.; He, F.-L.; Rodriguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.; Brundage, M.; Bharath, A. A Brief Survey of Deep Reinforcement Learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Huang, Q. Model-Based or Model-Free, a Review of Approaches in Reinforcement Learning. In Proceedings of the 2020 International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; pp. 219–221. [Google Scholar] [CrossRef]
- Kahn, G.; Villaflor, A.; Ding, B.; Abbeel, P.; Levine, S. Self-Supervised Deep Reinforcement Learning with Generalized Computation Graphs for Robot Navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Cui, Y.; Zhang, H.; Wang, Y.; Xiong, R. Learning World Transition Model for Socially Aware Robot Navigation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9262–9268. [Google Scholar] [CrossRef]
- Lei, X.; Zhang, Z.; Dong, P. Dynamic Path Planning of Unknown Environment Based on Deep Reinforcement Learning. J. Robot. 2018, 2018, 5781591. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.; Shao, K.; Zhao, D.; Zhu, Y. Recent progress of deep reinforcement learning: From AlphaGo to AlphaGo Zero. Control. Theory Appl. 2018, 34, 1529–1546. [Google Scholar]
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. Proc. Conf. AAAI Artif. Intell. 2017, 31. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, W.; Yu, R.; Zhang, Y. Motion Planning for Mobile Robots—Focusing on Deep Reinforcement Learning: A Systematic Review. IEEE Access 2021, 9, 69061–69081. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. A robot exploration strategy based on Q-learning network. In Proceedings of the 2016 IEEE International Conference on Real-time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 57–62. [Google Scholar] [CrossRef]
- Xin, J.; Zhao, H.; Liu, D.; Li, M. Application of deep reinforcement learning in mobile robot path planning. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 7112–7116. [Google Scholar] [CrossRef]
- Chen, D.; Wei, Y.; Wang, L.; Hong, C.S.; Wang, L.-C.; Han, Z. Deep Reinforcement Learning Based Strategy for Quadrotor UAV Pursuer and Evader Problem. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. Proc. Conf. AAAI Artif. Intell. 2016, 30. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar] [CrossRef]
- Wang, Y.; He, H.; Sun, C. Learning to Navigate Through Complex Dynamic Environment with Modular Deep Reinforcement Learning. IEEE Trans. Games 2018, 10, 400–412. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; De-Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning—Volume 48 (ICML’16), JMLR, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar] [CrossRef]
- Huang, Y.; Wei, G.; Wang, Y. V-D D3QN: The Variant of Double Deep Q-Learning Network with Dueling Architecture. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9130–9135. [Google Scholar] [CrossRef]
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Zhang, D.; Manfredi, L. Path planning for active SLAM based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, 13, 263–272. [Google Scholar] [CrossRef]
- Yin, Y.; Chen, Z.; Liu, G.; Guo, J. A Mapless Local Path Planning Approach Using Deep Reinforcement Learning Framework. Sensors 2023, 23, 2036. [Google Scholar] [CrossRef] [PubMed]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar] [CrossRef]
- Xie, L.; Wang, S.; Rosa, S.; Markham, A.; Trigoni, N. Learning with Training Wheels: Speeding up Training with a Simple Controller for Deep Reinforcement Learning. arXiv 2018, arXiv:1812.05027. [Google Scholar] [CrossRef]
- Li, P.; Ding, X.; Sun, H.; Zhao, S.; Cajo, R. Research on Dynamic Path Planning of Mobile Robot Based on Improved DDPG Algorithm. Mob. Inf. Syst. 2021, 2021, 5169460. [Google Scholar] [CrossRef]
- Cimurs, R.; Lee, J.H.; Suh, I.H. Goal-Oriented Obstacle Avoidance with Deep Reinforcement Learning in Continuous Action Space. Electronics 2020, 9, 411. [Google Scholar] [CrossRef]
- Gao, J.; Ye, W.; Guo, J.; Li, Z. Deep Reinforcement Learning for Indoor Mobile Robot Path Planning. Sensors 2020, 20, 5493. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar] [CrossRef]
- Mirowski, P.; Pascanu, R.; Viola, F.; Soyer, H.; Ballard, A.J.; Banino, A.; Denil, M.; Goroshin, R.; Sifre, L.; Kavukcuoglu, K.; et al. Learning to Navigate in Complex Environments. arXiv 2016, arXiv:1611.03673. [Google Scholar] [CrossRef]
- Brunner, G.; Richter, O.; Wang, Y.; Wattenhofer, R. Teaching a Machine to Read Maps with Deep Reinforcement Learning. Proc. Conf. AAAI Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar] [CrossRef]
- Everett, M.; Chen, Y.F.; How, J.P. Motion Planning Among Dynamic, Decision-Making Agents with Deep Reinforcement Learning. arXiv 2018, arXiv:1805.01956. [Google Scholar] [CrossRef]
- Shi, H.; Shi, L.; Xu, M.; Hwang, K.-S. End-to-End Navigation Strategy with Deep Reinforcement Learning for Mobile Robots. IEEE Trans. Ind. Inform. 2019, 16, 2393–2402. [Google Scholar] [CrossRef]
- Wang, X.; Sun, Y.; Xie, Y.; Bin, J.; Xiao, J. Deep reinforcement learning-aided autonomous navigation with landmark generators. Front. Neurorobot. 2023, 17, 1662–5218. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Chen, X.; Ghadirzadeh, A.; Folkesson, J.; Jensfelt, P. Deep Reinforcement Learning to Acquire Navigation Skills for Wheel-Legged Robots in Complex Environments. arXiv 2018, arXiv:1804.10500. [Google Scholar] [CrossRef]
- Moon, W.; Park, B.; Nengroo, S.H.; Kim, T.; Har, D. Path Planning of Cleaning Robot with Reinforcement Learning. arXiv 2022, arXiv:2208.08211. [Google Scholar] [CrossRef]
- Yu, X.; Wang, P.; Zhang, Z. Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors 2021, 21, 796. [Google Scholar] [CrossRef]
- Long, P.; Fanl, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning. arXiv 2017, arXiv:1709.10082. [Google Scholar] [CrossRef]
- Taschin, F.; Canal, O. Self-Learned Vehicle Control Using PPO. CampusAI. 2020. Available online: https://campusai.github.io/pdf/autonomous_driving.pdf (accessed on 20 May 2023).
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar] [CrossRef]
- Yang, L.; Bi, J.; Yuan, H. Dynamic Path Planning for Mobile Robots with Deep Reinforcement Learning. IFAC-PapersOnLine 2022, 55, 19–24. [Google Scholar] [CrossRef]
- Chaffre, T.; Moras, J.; Chan-Hon-Tong, A.; Marzat, J. Sim-to-Real Transfer with Incremental Environment Complexity for Reinforcement Learning of Depth-Based Robot Navigation. In Proceedings of the 16th International Conference on Informatics in Control, Automation and Robotics 2020, Paris, France, 5–7 July 2021; pp. 314–323. [Google Scholar] [CrossRef]
- Choi, J.; Lee, G.; Lee, C. Reinforcement learning-based dynamic obstacle avoidance and integration of path planning. Intell. Serv. Robot. 2021, 14, 663–677. [Google Scholar] [CrossRef] [PubMed]
- Perez-D’Arpino, C.; Liu, C.; Goebel, P.; Martin-Martin, R.; Savarese, S. Robot Navigation in Constrained Pedestrian Environments using Reinforcement Learning. arXiv 2021, arXiv:2010.08600. [Google Scholar] [CrossRef]
- Lee HyeokSoo, Jeong Jongpil, Velocity range-based reward shaping technique for effective map-less navigation with LiDAR sensor and deep reinforcement learning. Front. Neurorobot. 2023, 17, 1662–5218. [CrossRef]
- Chen, Y.F.; Everett, M.; Liu, M.; How, J.P. Socially aware motion planning with deep reinforcement learning. arXiv 2017, arXiv:1703.08862. [Google Scholar] [CrossRef]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multi-agent collision avoidance with deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar] [CrossRef]
- Semnani, S.H.; Liu, H.; Everett, M.; de Ruiter, A.; How, J.P. Multi-Agent Motion Planning for Dense and Dynamic Environments via Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 3221–3226. [Google Scholar] [CrossRef]
- Lutjens, B.; Everett, M.; How, J.P. Safe Reinforcement Learning with Model Uncertainty Estimates. arXiv 2019, arXiv:1810.08700. [Google Scholar] [CrossRef]
- Chand, A.; Yuta, S. Navigation strategy and path planning for autonomous road crossing by outdoor mobile robots. In Proceedings of the 2011 15th International Conference on Advanced Robotics (ICAR), Tallinn, Estonia, 20–23 June 2011; pp. 161–167. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Intent Prediction of Pedestrians via Motion Trajectories Using Stacked Recurrent Neural Networks. IEEE Trans. Intell. Veh. 2018, 3, 414–424. [Google Scholar] [CrossRef]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual Learning with Deep Generative Replay. arXiv 2017, arXiv:1705.08690. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Network Input | Network Output | Training | Reward Function | Optimization | Testing | Remarks |
|---|---|---|---|---|---|---|---|
| [64] | Last 3 laser scans, Velocity, Target position | Not mentioned | Stage, Gazebo | Collision penalty, Goal reward, Change in goal relative distance reward | Proportional controller assist | Real environment with static obstacles | Trains faster, less sensitive to network structure, better than DDPG |
| [65] | 20D laser data | Angular and linear velocity | Gazebo | Collision penalty, Goal reward, change in goal relative distance reward | Curiosity module, RAdam optimizer, priority experience, transfer learning | Gazebo with dynamic obstacles | Convergence speed + 21%, success rate increased to 90% from 50% |
| [11] | 10D laser data, target position, velocity, | Angular and linear velocity | V-Rep | Collision penalty, goal reward, change in goal relative distance reward | Asynchronous training | Real environment with static obstacles | Mapless navigation capability |
| [66] | Last 10 depth images, target position | Angular and linear velocity | Gazebo | Collision penalty, goal reward, turning penalty | Real environment with dynamic obstacles | Successful navigation with dynamic obstacles | |
| [67] | 10D laser data, velocity, target position | Angular and linear velocity | Gym, Gazebo | Collision penalty, goal reward, change in goal relative distance reward | Transfer learning | Gazebo with dynamic obstacles | Performs comparable to traditional methods |
| [45] | Last 10 laser scans, velocity, target position | Angular and linear velocity | Gazebo | Collision penalty, goal reward, change in goal relative distance reward, close to static and dynamic obstacles penalty | Disentangle ego motion, Conv. LSTM layer | Real environment with dynamic obstacles | Performs better than FDMCA and MNDS [45] |
| Ref. | Network Input | Network Output | Training | Reward Function | Optimization | Testing | Remarks |
|---|---|---|---|---|---|---|---|
| [69] | Last 3 RGB images, previous action, previous reward, agent velocity, | Rotation in small increments, accelerate forward, backward, and sideways, rotational acceleration. | Deepmind lab | Goal reward, reward in the maze to encourage exploration | Loop closure on position, RGB to depth conversion as loss function, stacked LSTM layer | Deepmind lab with static obstacles | Auxiliary tasks improve algorithm’s performance |
| [7] | Elevation map, depth image, Agent orientation, relative goal position | Forward, backward, turn left and right | Gazebo | Goal reward, change in goal relative distance reward, undesirable terminal position penalty | LSTM layer | Gazebo with static obstacles | Navigation capability in unknown environment, 80% success rate |
| [70] | Last ego-motion estimation, goal orientation, last action, last reward, Maze Map, RGB image | Forward, backward, left, right, turn left and right. | DeepMind lab | Collision penalty, goal reward, relative distance to the goal Entropy of location probability distribution | Prioritized experience replay, modular Tasks | DeepMind lab with static obstacles | Agent learns to localize on map |
| [71] | Last 4 RGB images, target image | Forward step, 90-degree turn | AI2-THOR | Goal reward, time penalty | Real environment with static obstacles | AI2-THOR renders virtual environment close to real world thus algorithm performs better in real world. | |
| [17] | Last 4 laser scans, target position | 7 discrete actions | Custom for fast parallel training | Goal reward, Collision penalty, change in goal relative distance reward, undesirable terminal position penalty | Add noise to the input | Real environment with static obstacles | Simulations run 1000 times faster than conventional methods |
| [72] | Goal distance, obstacle position and velocity, distance to obstacle | 11 discrete actions | Collision penalty, Goal reward, close to obstacle penalty | LSTM layer | Real environment with dynamic obstacles | Introduction of LSTM Layer improves performance | |
| [73] | Current state, last action, last reward | 8 discrete actions | DeepMind lab, Gazebo | Goal reward, collision penalty, change in goal relative distance reward, intrinsic reward | Intrinsic reward for exploration, stacked LSTM | Real environment with dynamic obstacles | Incorporating intrinsic Rewards doubled the extrinsic rewards collected |
| Ref. | Network Input | Network Output | Training | Reward Function | Optimization | Testing | Remarks |
|---|---|---|---|---|---|---|---|
| [76] | Greyscale height map, target position, robot pose | Move in the x- and y-axis, Rotate, change height, change width | V-Rep | Collision penalty, time penalty, change in goal relative distance reward | Domain randomization | V-Rep with static obstacles | Use of domain randomized trajectory improves the output. |
| [77] | Surrounding 8 tiles, nearest uncleaned tile | Move forward, Turn 45 degree | Python GUI Tkinter | Cleaned tile penalty, wall collision penalty, rotation penalty, intrinsic reward | Intrinsic reward Transfer learning Elite set | Python GUI Tkinter | Navigation performed on a grid-based environment |
| [78] | Last 4 depth images, Last 3 laser scans, target position, velocity | 10 discrete actions | Gazebo | Collision penalty, goal reward, change in goal relative distance reward, slip rate/angle penalty | Gazebo with static obstacles | Cannot reach target when target is very far or there are very large craters. | |
| [80] | 4 checkpoints, velocity, 12D laser data, | Linear and angular velocity | Unity | Checkpoint reward, time penalty, collision penalty, | Unity with static obstacles, maze-like maps | Algorithm sometimes jump checkpoints to give efficient paths. | |
| [18] | Last 3 depth images, Last 3 laser scans, target position, velocity | Linear and angular velocity | Gazebo | Collision penalty, goal reward, change in goal relative distance reward, Close to obstacle penalty, angular velocity penalty, waypoint reward | Transfer learning | Real-world with dynamic obstacles | Susceptible to robot freezing in very dense environment, works well in complex, occluded scenarios and results in smoother trajectories |
| [8] | Laser scans | 8 discrete actions | Custom | Collision penalty, goal reward, timestep penalty | Real-world with static obstacles. | Number of training epochs is much less compared to other methods |
| Ref. | Network Input | Network Output | Training | Reward Function | Optimization | Testing | Remarks |
|---|---|---|---|---|---|---|---|
| [82] | Location and velocity of agent and obstacles, target location | Linear and angular velocity | Pygame | Face toward the target, move toward the target, close to obstacle penalty, terminal state reward | Prioritized experience replay, state action normalization | Pygame with dynamic obstacles | Performs better than PPO, tested in only 1 2D environment |
| [83] | Last 2 horizontal depth image planes and their difference, target position, last action | Linear and angular velocity | Gazebo | Goal reward, collision penalty, going toward goal reward, going away from goal penalty | Transfer learning | Real environment with dynamic obstacles | Maximum success rate is 47% |
| [84] | Last 3 laser scans, velocity, target position | Linear and angular velocity | Gazebo | Goal reward, collision penalty, going toward goal reward, rotation velocity penalty | Real environment with dynamic obstacles | Performed well in dynamic environment, unable to efficiently move in straight line. Might solve with more training in that environment. | |
| [85] | LiDAR data, 6 waypoints, target position | Linear and angular velocity | Gibson | Goal reward, collision penalty, going toward waypoint reward, reaching waypoint reward, timestep penalty | Transfer learning | Gibson with dynamic obstacles | The learned policy demonstrates behaviors such as slowing down, navigating around pedestrians, and reversing to manage various interactions. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, R.; Ren, J.; Lin, X. A Review of Deep Reinforcement Learning Algorithms for Mobile Robot Path Planning. Vehicles 2023, 5, 1423-1451. https://doi.org/10.3390/vehicles5040078
Singh R, Ren J, Lin X. A Review of Deep Reinforcement Learning Algorithms for Mobile Robot Path Planning. Vehicles. 2023; 5(4):1423-1451. https://doi.org/10.3390/vehicles5040078
Chicago/Turabian StyleSingh, Ramanjeet, Jing Ren, and Xianke Lin. 2023. "A Review of Deep Reinforcement Learning Algorithms for Mobile Robot Path Planning" Vehicles 5, no. 4: 1423-1451. https://doi.org/10.3390/vehicles5040078
APA StyleSingh, R., Ren, J., & Lin, X. (2023). A Review of Deep Reinforcement Learning Algorithms for Mobile Robot Path Planning. Vehicles, 5(4), 1423-1451. https://doi.org/10.3390/vehicles5040078