1. Introduction
Structural equation models (SEMs) and confirmatory factor analysis (CFA) are important statistical methods for analyzing multivariate data in the social sciences [
1,
2,
3,
4,
5]. In these models, a multivariate vector
of
I continuous observed variables (also referred to as items or indicators) is modeled as a function of a vector of latent variables (i.e., factors or traits)
. SEMs represent the mean vector
and the covariance matrix
of the random variable
as a function of an unknown parameter vector
. In SEMs, constrained estimation of the moment structure of the multivariate normal distribution is applied [
6].
The measurement model in an SEM is given as
We denote the covariance matrix
. The vectors
and
are multivariate normally distributed. In addition,
and
are uncorrelated random vectors. In CFA, the multivariate normal (MVN) distribution is represented as
and
. Hence, one can represent the mean and the covariance matrix in CFA as
In SEM, a matrix
of regression coefficients can additionally be specified such that
Hence, the mean vector and the covariance matrix are represented in SEM as
where
is the identity matrix.
Researchers often parsimoniously parameterize the mean vector and the covariance matrix using a parameter
as a summary in an SEM. The model assumptions in SEMs are, at best, merely an approximation of a true data-generating model. In SEMs, model deviations (i.e., model errors) in covariances emerge as a difference between a population covariance matrix
and a model-implied covariance matrix
(see [
7,
8,
9]). Simultaneously, model errors in the mean vector cause a difference between the population mean vector
and the model-implied mean vector
. As a result, the SEM is misspecified at the population level. It should be noted that the model errors are defined at the population level in infinite sample sizes. In real-data applications with limited sample sizes, the empirical covariance matrix
estimates the population covariance matrix
, while the mean vector
estimates the population mean vector
.
In this work, estimators with some resistance to model deviations are investigated. In more depth, the presence of some amount of model errors should have no impact on the parameter estimate
. This robustness property is denoted as model robustness, and it adheres to robust statistics principles [
10,
11,
12]. Model errors in SEMs appear as residuals in the modeled mean vector and the modeled covariance matrix, whereas in traditional robust statistics, observations (i.e., cases or subjects) do not obey an imposed statistical model and should be considered as outliers. That is, an estimator in an SEM should automatically recognize large deviations in
and
as outliers that should not significantly damage the estimated parameter
.
In previous research, the
loss function has been used for model-robust estimation based on moments [
13,
14]. Non-robust estimators such as maximum likelihood or unweighted and weighted least square estimates will typically result in biased estimates in the presence of model error [
14]. In this article, we more thoroughly discuss the choice of the tuning parameter
in differentiable approximations of the nondifferentiable
loss functions. Furthermore, we compare the
loss function with a recently proposed differentiable approximation of the
loss function and a direct minimization of a smoothed version of the Bayesian information criterion [
15] in regularized estimation. Notable, the
loss function minimizes the number of model deviations in a fitted model. If only a few entries in the modeled mean vector (or mean vectors) or covariance matrix (or covariance matrices) deviate from zero at the population level, while all other entries equal zero, the
loss function would be the most appropriate fit function. In contrast, if all model deviations differ from zero and unsystematically fluctuate around zero, the
or
loss functions with
would be less appropriate. Finally, standard errors for the proposed model-robust estimators based on the delta method are derived in this article. Their performance is assessed by evaluating coverage rates.
To sum up, this article focuses on implementation details of SEM estimation based on the
(
) and the newly proposed
loss functions, while [
16] was devoted to regularized SEM estimation, which can also be utilized for model-robust estimation. A comparison of regularized estimation and robust loss functions can be found in [
14].
The remainder of the article is organized as follows. Model-robust SEM estimation based on the robust
and
loss functions is treated in
Section 2.
Section 3 introduces direct BIC minimization as a special approach to regularized maximum likelihood estimation.
Section 4 is devoted to details of standard error computation. In
Section 5, research questions are formulated that are addressed in two subsequent simulation studies. In
Section 6, bias and root mean square error of model-robust SEM estimators are of interest.
Section 7 reports findings regarding the standard error estimation regarding coverage rates. Finally, the article closes with a discussion in
Section 8.
2. and Loss Functions in SEM Estimation
We now describe model-robust moment estimation of multiple-group SEMs. The treatment closely follows previous work in Refs. [
14,
16].
The empirical mean vector and the empirical covariance matrix are sufficient statistics for estimating and when modeling multivariate normally distributed data with no missing values. In particular, they are also sufficient statistics of and that are constrained functions of a parameter vector . Hence, and are also sufficient statistics for the parameter vector that contains K elements.
Now, assume that there are G groups with sample sizes , mean vectors , and covariance matrices (). Let be the vector of sufficient statistics in group g, where denotes the operator that stacks all nonredundant matrix entries on top of one another. Furthermore, the vector contains the sufficient statistics of all G groups.
The population mean vectors and covariance matrices are denoted by
and
, respectively. The model-implied mean vectors and covariance matrices are denoted by
and
, respectively. It is worth noting that the parameter vector
lacks an index
g, indicating that there can be common and unique parameters across groups. Equal factor loadings and item intercepts across groups are frequently imposed in a multiple-group CFA (i.e., measurement invariance is specified [
17,
18]).
In model-robust SEM estimation discussed in this article, discrepancies
and
are minimized according to a loss function
. There are two kinds of errors that are only, for simplicity, discussed for the mean structure. We can express the discrepancy in the mean structure as
The first term describes a discrepancy due to sampling variation (i.e., with respect to the sampling of subjects). This term can typically be reduced when larger samples are drawn. The second term indicates a model error. This term exists at the population level and, therefore, does not vanish with increasing sample sizes. In model-robust estimation, a few entries in the model error are allowed to differ from zero (i.e., a sparsity assumption), corresponding to model misspecification. Note that the sparsity assumption is vital for the performance of model-robust estimators.
In robust moment estimation, the following fit function
is minimized:
In the first term at the right side of the equation in (
6), discrepancies in the sample means
from the model-implied mean
for item
i in group
g are considered. In the second term at the right side of the equation in (
6), discrepancies in the sample covariances
from the model-implied covariance
for items
i and
j in group
g are considered. The weights
(
) and
(
) are known but can be set to one if all variables have (approximately) the same standard deviation in the sample comprising all groups or the original scaling of the variables reflects the intended weighing of sampling and model errors. The loss function
in (
6) should be chosen such that it is resistant to outlying effects in the mean and the covariance structure.
The robust mean absolute deviation (MAD) loss function
was examined in [
19,
20]. When compared to usually employed SEM estimation approaches, this fit function is more robust to a few model violations, such as unmodeled item intercepts or unmodeled residual correlations of residuals (see [
7]).
In this article, we investigate the
loss function
It has been shown that
provides more efficient model-robust estimates than
(see [
7,
13]). The
loss function with
is the square loss function
and corresponds to unweighted least squares (ULSs) estimation. However, this loss function does not possess the model robustness property [
7]. The
loss function
(i.e.,
) is implemented in invariance alignment [
21,
22,
23] and penalized structural equation modeling [
24] in the popular Mplus software (Version 8.10.,
https://www.statmodel.com/support/index.shtml (accessed on 25 September 2023)). The critical aspect of the
loss function
defined in (
7) is that it is a nondifferentiable function. Consequently, the fit function
in (
6) is also nondifferentiable, which does not allow the application of general-purpose optimizers that rely on the differentiable optimization functions. As a remedy, the nondifferentiable
loss function
can be replaced by a differentiable approximation
, which is close to
, but differentiable on the entire real line. The approximating function
is defined as
where
is a tuning parameter that should be small enough such that
is close to
but large enough to ensure estimation stability. Replacing the nondifferentiable
by the differentiable approximation
has been previously recommended by [
13,
21,
25,
26].
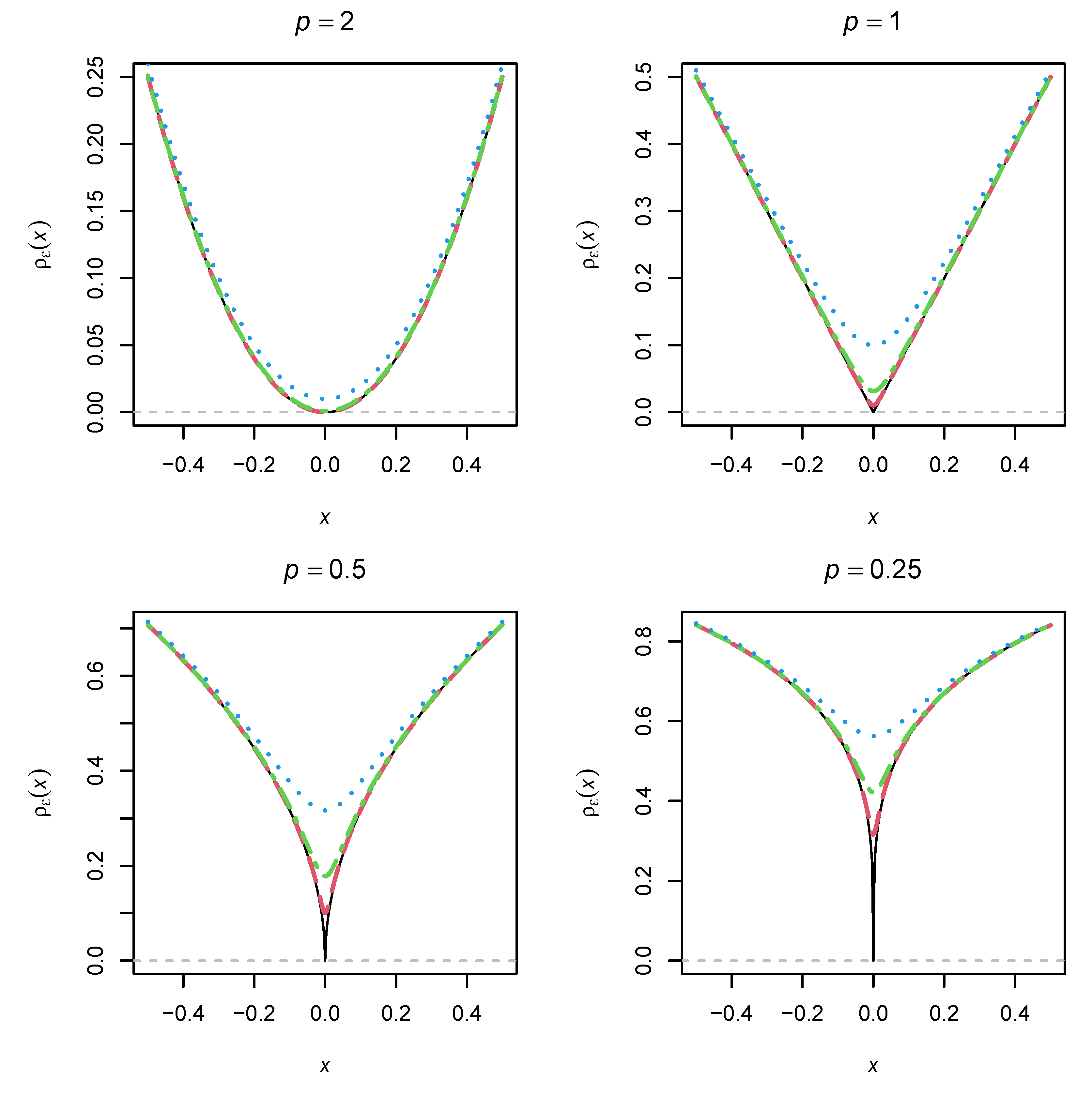
The loss function
and its differentiable approximation
are displayed for six different values of
p in
Figure 1. It can be seen (and shown) that
for all
and
. Furthermore, the loss function
is much steeper at
for a smaller
p. With a larger
, the approximation
becomes smoother. Choosing an appropriate tuning parameter
is therefore important when applying model-robust moment estimation based on the
loss function.
It might be tempting to use a very small
p close to zero. Such a loss function is close to the
loss function, which takes the value of 1 for all arguments differently from
and 0 for
. If the sparsity assumption of model errors holds, the
would theoretically be the most desirable loss function [
27,
28]. However, as shown in
Figure 1,
for
does not have a clear minimum zero, making this differentiable loss function difficult to apply in practical optimization.
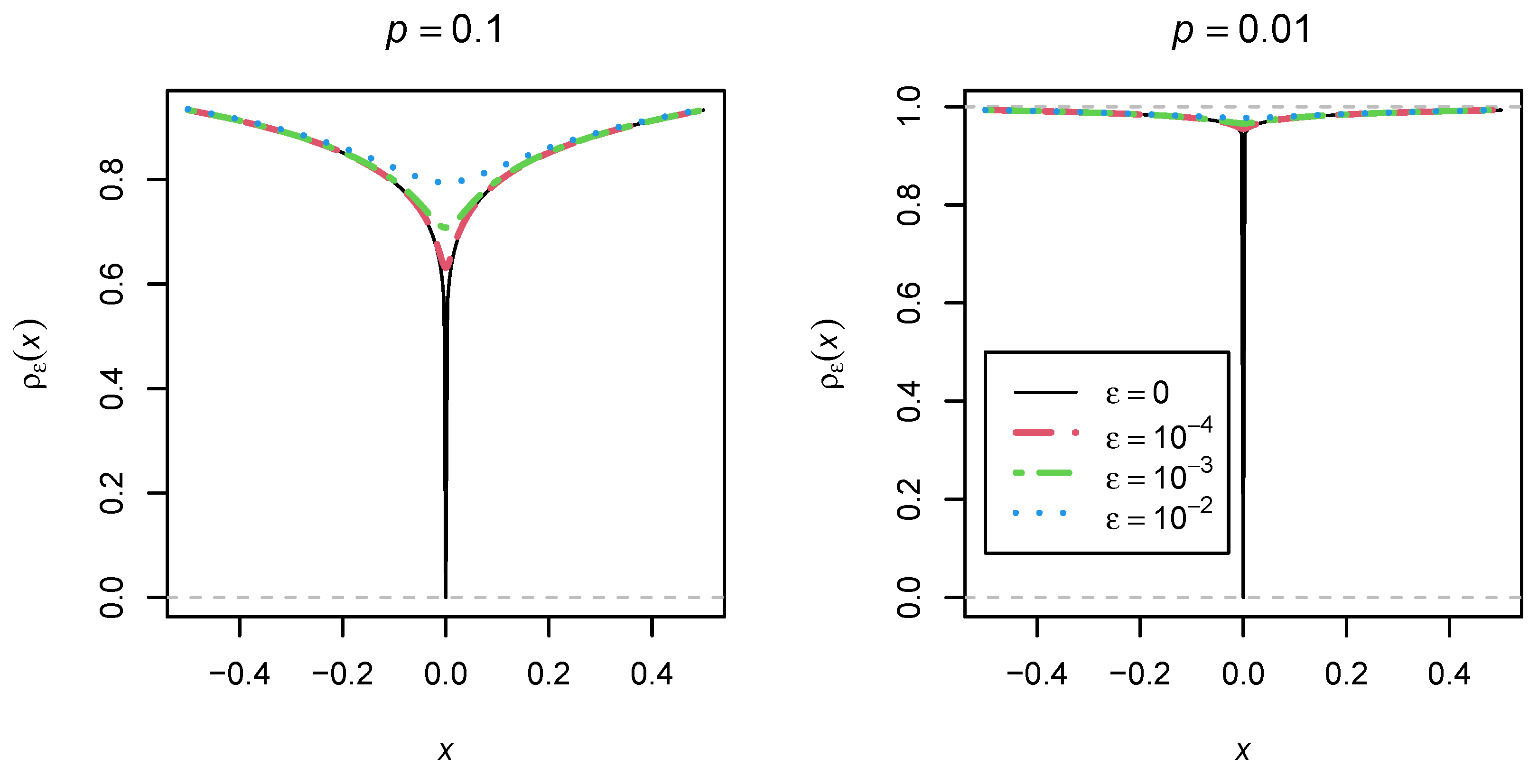
O’Neill and Burke [
15,
29] proposed the following differentiable approximation
of the
loss function in a recent work related to regularized estimation:
where
is again a tuning parameter. The differentiable approximation
is displayed for different
values in
Figure 2. It can be seen that the functional form of
seems much nicer to use in optimization than
with a
p close to 0. Hence,
might be a useful alternative robust loss function whose performance in the presence of model errors has to be evaluated.
In practical minimization of
in (
6), when
is replaced with
(using an appropriate
p) or
, it is advisable to use reasonable starting values and to minimize
using a sequence of differentiable approximations
with decreasing
values (i.e., subsequently fitting
with
, while using the previously obtained parameter estimate as the initial value for the subsequent minimization problem).
3. A Direct BIC Minimization in Regularized Maximum Likelihood Estimation
Most frequently, SEMs are estimated with maximum likelihood (ML) estimation. This estimation method provides the most efficient estimates for correctly specified models. However, the efficiency properties are lost in the case of misspecified SEMs.
As an alternative, regularized ML estimation can be used that introduces an overidentified SEM by allowing free group-specific item intercepts and residual covariances. To identify the model, a penalty function on the overidentified parameters is imposed that is targeted at the sparsity structure of model errors. The methodological literature has extensively documented the regularized estimation of single-group and multiple-group SEMs [
30,
31,
32,
33]. Cross-loadings, residual covariances, or item intercepts are regularized in these applications. Regularized SEM estimation enables flexible yet parsimonious model specifications.
In ML estimation, the fit function
is the negative log-likelihood function based on the multivariate normal distribution that is defined as [
2,
4]
In empirical applications, the model-implied mean vectors
and covariance matrices
will often be misspecified [
34,
35,
36], and
can be understood as a pseudo-true parameter that is defined as the minimizer of
in (
10).
In regularized SEM estimation, a penalty function
is added to the log-likelihood fit function
that imposes some sparsity assumption on a subset of model parameters [
31,
33]. In order to enforce sparsity, the penalty function
is often chosen to be nondifferentiable. Define a known parameter
for all parameters
, where
indicates that for the
kth entry
in
a penalty function is applied. The penalized log-likelihood function is defined as
where
is a regularization parameter, and
is a scaling factor that frequently equals the total sample size
. The regularized (or penalized) ML estimate is defined as the minimizer of
.
The least absolute shrinkage and selection operator (LASSO; ref. [
37]) or the smoothly clipped absolute deviation (SCAD; ref. [
38]) penalty functions have been frequently used in regularized SEM estimation. For a fixed value of
, a subset of
parameters for which the penalty function is applied (i.e.,
) will result in estimates of zero. That is, a sparse
vector is obtained as the result of regularized estimation. However, the estimate of
depends on the fixed regularization parameter
; that is,
As a result, the parameter estimate
of
depends on the unknown parameter
. To avoid this problem, the regularized SEM can be repeatedly estimated on a finite grid of regularization parameters
(e.g., on an equidistant grid between 0.01 and 1.00 with increments of 0.01). The Bayesian information criterion (BIC), defined by
may be used to choose an optimal regularization parameter
, where
H denotes the number of parameters. Because the minimization of BIC is equivalent to the minimization of BIC/2, the final parameter estimate
is determined as
where the function
is an indicator whether
is different from 0:
In particular, the quantity
in (
13) counts the number of parameter estimates
for
for which the penalty function is applied (i.e.,
) and differs from 0.
As becomes clear, regularization SEM estimation necessitates fitting an SEM on a grid of the regularization parameter
. This approach is computationally intensive, especially for SEMs with a large number of parameters. The final parameter estimate is obtained by minimizing the BIC across all estimated regularized SEMs. A naïve idea might be directly minimizing the BIC to avoid repeated estimation that involves regularization parameter selection. It should be noted that only a subset of parameters for which sparsity should be imposed is relevant in the BIC computation. Hence, a parameter estimate
by minimizing the BIC is provided by
The optimization function in (
15) employs an
penalty function [
39,
40] with a fixed regularization parameter
. This optimization function contains the nondifferentiable indicator function
that counts the number of regularized parameters that differ from 0. The ingenious idea of O’Neill and Burke [
15] was to replace the nondifferentiable
loss function
with its differentiable approximation
(see (
8) and Ref. [
16] for a more comprehensive treatment). Therefore, the parameter
can be estimated as
The estimation approach from (
16) is referred to as the smoothed direct BIC minimization (DBIC) approach. This method has been used to estimate regularized distributional regression models [
15].
It has been shown in SEMs that the DBIC approach performs similarly to regularized estimation based on the indirect approach by minimizing the BIC on a finite grid of regularization parameters [
16]. Hence, we confine ourselves in this article to compare the model-robust moment estimation methods with different values of the power
p with the DBIC estimator.
4. Computation of Standard Errors
In this section, the computation of the variance matrix of parameter estimates
from model-robust moment estimation and DBIC estimation using the fit functions in (
6) and (
16), respectively, is described (see also [
14,
16] for a similar treatment). Both methods minimize a differentiable (approximation) function
with respect to
as a function of sufficient statistics
(see also [
41]). The vector of estimated sufficient statistics
is approximately normally distributed (see [
3]); that is,
for a true population parameter
of sufficient statistics. Let
be the vector of partial derivatives with respect to
. The parameter estimate
fulfills the nonlinear equation
. The delta method [
34] can be employed to derive the variance matrix of
. Assume that there exists a (pseudo-)true parameter
such that
.
Now, we conduct a Taylor expansion of
(see [
3,
5,
42]). Denote by
and
the matrices of second-order partial derivatives of
with respect to
and
, respectively. The Taylor expansion can be written as
By solving (
18) for
, we get the approximation
By defining
when substituting
and
with
and
, respectively, we get by using the multivariate delta method [
34]
The square root of diagonal elements of
computed from (
20) may be used to calculate standard errors for elements in
.
Statistical Inference for Parameter Differences of Different
Models Based on the Same Dataset
In this section, statistical inference for differences in parameters from different models based on the same dataset is discussed. For example, researchers could use the
loss function with
,
, and
. It should be evaluated whether the estimated factor means from different models that employ the different loss functions are statistically significant. Importantly, the different models rely on the same dataset and its vector of sufficient statistics
. Hence, the standard error of a parameter difference from parameters of different models can be smaller than the standard error of a single model because the data are used twice. The M-estimation framework can also be utilized to derive the variance estimate of a parameter difference [
43,
44]. The different loss functions provide different estimates
for models
. At the population level, the parameters are denoted as
. Note that the population parameters differ in the case of misspecified SEMs. In the following, we discuss the case
to reduce notation.
Following the lines of the variance derivation in the previous section, we can approximate the estimate of model
m by using (
19)
where
is defined as in (
19). Note that
due to choosing different loss functions. Researchers can now ask whether the parameter difference
(or some entries of it) significantly differs from
. From (
21), we obtain
where
. We then obtain the variance estimate of
as
The unknown matrix can be estimated by its sample analog .
6. Simulation Study 1: Bias and RMSE
This Simulation Study 1 examined the impact of group-specific item intercepts in a multiple-group one-dimensional factor model on bias and RMSE of factor means and factor variances. In the data-generating model (DGM), measurement invariance was violated. That is, differential item functioning (DIF; refs. [
45,
46]) occurred, and hence, DIF effects in item intercepts were simulated.
6.1. Method
The DGM in the simulation study was identical to Simulation Study 2 in [
14] and mimicked [
21]. The data were simulated from a one-dimensional factor model involving five items and three groups. The factor variable
was normally distributed with group means
,
, and
and group variances
,
, and
, respectively. All five factor loadings were set to 1, and all measurement error variances were set to 1 in all groups and uncorrelated with each other. The factor variable and residual variables were normally distributed.
Only a subset of group-specific item intercepts was simulated differently from zero. These nonzero item intercepts indicated measurement noninvariance (i.e., the presence of DIF effects). One of the five items in each group had a DIF effect. However, different items across the three groups were affected by the DIF. In the first group, the fourth item intercepts had a DIF effect . In the second group, the first item had a DIF effect , while the second item had a DIF effect in the third group. The DIF effect was chosen as 0, 0.3, or 0.6. The value of represented the situation of measurement invariance. The sample size per group was chosen as , , , or .
All analysis models were a multiple-group one-factor model. For identification reasons, the mean of the factor variable in the first group was fixed at 0, and the standard deviation in the first group was fixed at 1. Invariant factor loadings and residual variances were specified across groups. In model-robust moment estimation (ME), we also assumed invariant item intercepts. We utilized the powers
,
, and
for the loss function
defined in (
8) combined with values of the tuning parameter
chosen as
(=0.01),
(=0.001), and
(=0.0001). The resulting estimators will be denoted by ME0.5, ME0.25, and ME0.1, in the following Results sections, respectively. Moreover, we used the loss function
defined in (
9) with the same
tuning parameter values as for
to approximate the
loss function (denoted by ME0 in the following
Section 6.2). Furthermore, we used DBIC estimation in which all group-specific item intercepts were allowed to differ across groups. The indicator variables
involved in the DBIC approach (see (
16)) of the model parameter vector
take only the value 1 for item intercepts. For all other elements of
, they are set to 0. Therefore, the DBIC approach effectively minimizes the number of estimated item intercepts in its penalty. We also chose the tuning parameter values as
chosen as
,
, and
.
We did not use the power
in model-robust moment estimation because it resulted in biased estimates in the presence of DIF [
14]. However, we included the non-robust ML estimation method for a more comprehensive comparison of the estimation methods.
In total,
R = 5000 replications were conducted for all 3 (DIF effect size
) × 4 (sample size
N) = 12 conditions of the simulation study. We investigated the estimation quality of factor means (i.e.,
and
) and factor variances (i.e.,
and
) in the second and third groups. Bias, RMSE, and relative RMSE were computed to assess the performance of the different estimators. Let
be a model parameter estimate in replication
. The bias was estimated by
where
denotes the true parameter value. The RMSE was estimated by
Note that holds because the mean square error (i.e., the square of the RMSE) is the sum of the square of the bias and the variance of an estimator. A relative RMSE can be defined by dividing the RMSE of an estimator by the RMSE of a chosen reference model. To ease the reading of the numeric values of the relative RMSE, the values were multiplied by 100. This quantity can then easily be converted as a percentage gain or loss of a particular estimator compared to a reference model.
The entire simulation study was carried out in the R [
47] software (Version 4.3.1). The SEMs were estimated using the
sirt::mgsem() function in the R package sirt (Version 4.0-19; ref. [
48]). Information about model specification can be found in the material located at
https://osf.io/ng6s3 (accessed on 25 September 2023).
Researchers interested in fitting a particular model without interest in studying the entire simulation code are referred to the manual help site of the
mgsem function in the R package sirt [
48]. They can type
?sirt::mgsem in the R console (or look at
https://alexanderrobitzsch.r-universe.dev/sirt/doc/manual.html#mgsem (accessed on 25 September 2023)) and find an example for applying the ME estimator for an existing dataset.
6.2. Results
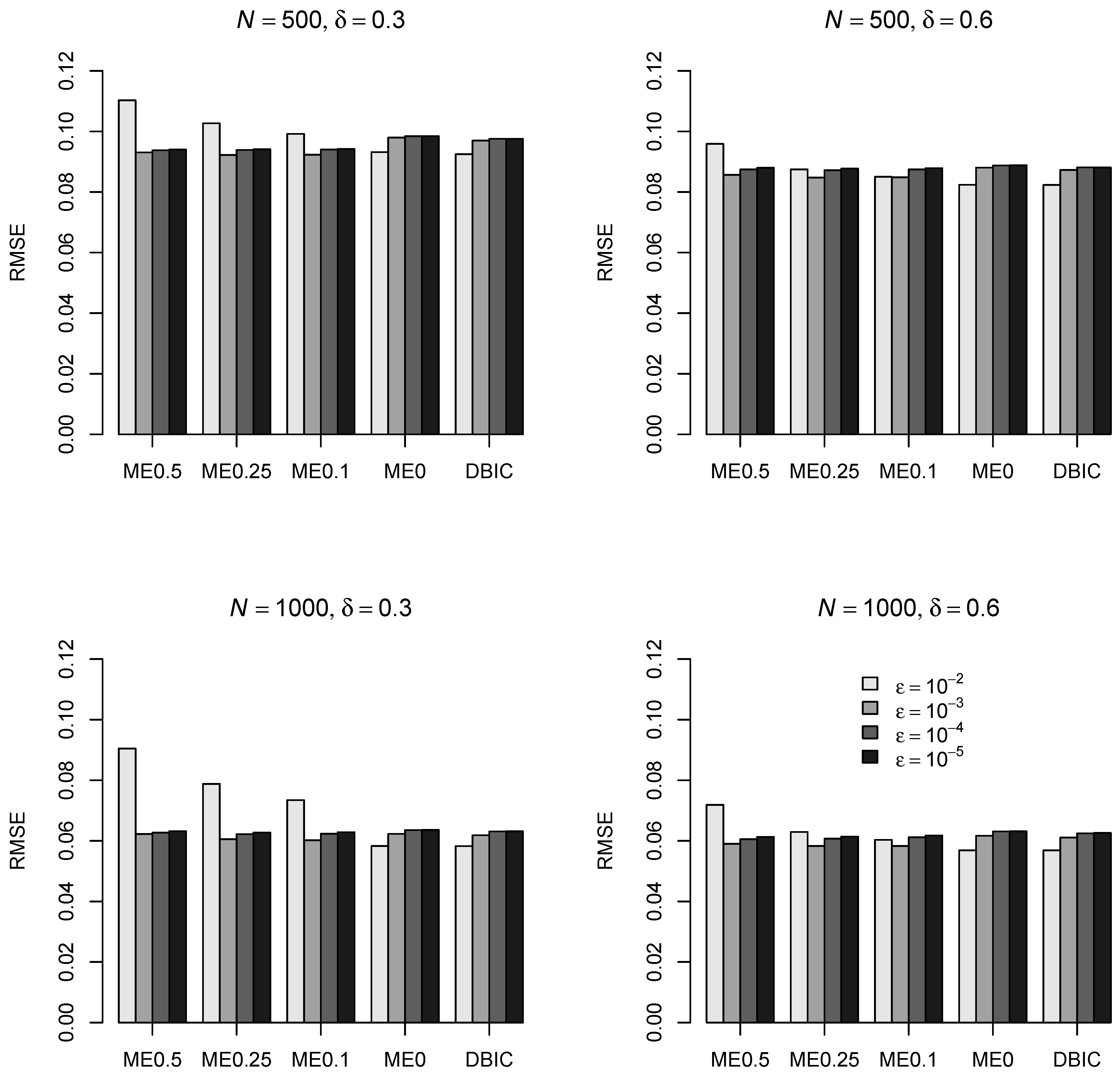
Figure 3 displays the RMSE of factor mean
in the second group for the different estimators for DIF effect sizes
and
and sample sizes
and
as a function of the tuning parameter
. It can be seen that
was optimal with respect to the RMSE for ME0.5, ME0.25, and ME0.1, while
resulted in the smallest RMSE for ME0 and DBIC. The findings were very similar for the factor mean
in the third group and the sample sizes
and
.
Table 1 displays the bias and relative RMSE of factor means and factor variances as a function of the DIF effect size and the sample size for the different estimation methods. We chose the tuning parameter
for the estimators ME0.5, ME0.25, and ME0.1, and
for the estimators ME0 and DBIC because they resulted in the smallest RMSE of factor means according to the findings of
Figure 3.
Overall, all estimators except for ML were approximately unbiased for factor variances in all conditions and for factor means in the absence of DIF effects (i.e., and measurement invariance holds) except for the sample size . Slightly biased estimates were obtained for ME with a larger p, such as in ME0.5. However, the bias decreased with increasing sample size. The ME0 and DBIC were unbiased across all conditions, followed by the estimators ME0.1, ME0.25, and ME0.5, with increasing absolute bias. There was substantial bias for estimated factor means for ML estimation, while the estimates of factor variances were approximately unbiased for ML.
To compare the estimation accuracy in terms of the relative RMSE, we chose ME0.5 (with
) as the reference model. Hence, the relative RMSE was 100 for this method in
Table 1. It turned out that ME0 and DBIC were superior to the other estimators with non-negligible efficiency gains. For example, for the factor mean
in the second group,
, and
, the efficiency gain in terms of the RMSE was 6.4% (=100 − 93.6) for ME0 and 6.5% for DBIC. Across all conditions, no noteworthy differences between ME0 and DBIC estimators were found.
ML estimates were slightly more efficient than ME estimates in the absence of DIF. However, the efficiency gains of ML decrease with increasing sample size.
To conclude, it seems promising to replace the loss function using the power (i.e., ME0.5) with the loss function implemented in ME0 or regularized estimation in DBIC for large sample sizes or . Similar performance of the different estimators was found for , while the power was the frontrunner for .
8. Discussion
In this article, we compared model-robust moment estimation with a recently proposed variant of regularized ML estimation by O’Neill and Burke [
15] that directly maximizes the BIC (i.e., the DBIC estimator). In the DBIC estimation, these authors suggested a differentiable approximation of the
loss function, which was also used in model-robust moment estimation. Interestingly, the
loss function outperformed
loss functions for
regarding bias and RMSE. Furthermore, model-robust moment estimation with the
loss function performed very similarly to the DBIC estimator. Moreover, the estimation of standard errors was successfully implemented for all estimators because coverage rates were acceptable for all parameters in all simulation conditions.
In line with previous studies, we anticipate that sample sizes must be sufficiently large in order to achieve the model-robustness properties of the and loss functions. If the sample size is too small (e.g., subjects in a multiple-group SEM analysis), the sampling error in moments that are used as sufficient statistics in the SEM can exceed model errors (i.e., unmodeled group-specific item intercepts). In this case, model-robust methods are not expected to perform well. In fact, Simulation Study 1 revealed that is preferable to other loss functions with or the loss function for , while the situation changes with larger sample sizes such as .
Simulation Study 1 indicated that the tuning parameter
in the differentiable approximation of the nondifferentiable
loss function should be used for the
loss function for
,
, or
. In contrast,
was found optimal for the
loss function and the direct BIC minimization estimation approach in regularized estimation. We expect that these findings will transfer to other models that involve standardized variables. In our experience from regularized estimation and the invariance alignment approach [
21], using a value of
(such as
and smaller values) tuning parameter that is too small is prohibitive because it more likely results in convergence issues in the local optima of the fit function.
In our simulation studies, we only considered model errors in item intercepts. Future simulation studies could also investigate model errors in the covariance structure (i.e., unmodeled residual correlations). Of course, model errors in the mean and the covariance structure can also be simultaneously examined.
A requirement to achieve model robustness of SEM estimators is that model errors in the mean or covariance structure are sparsely distributed. That is, only a few entries are allowed to differ from zero, while the majority of model errors must be (approximately) zero. If factor loadings were not invariant across groups, more densely distributed model errors would result. As a consequence, model-robust moment estimation will likely not work, and regularized maximum likelihood estimation might be preferred. However, the DBIC minimization method for regularized maximum likelihood estimation can also be utilized in this case if the number of group-specific factor loadings is counted in the BIC penalty term.
In this article, we only applied the
and
loss functions to continuous items. However, the principle directly transfers to SEMs of ordinal data that are based on fitting thresholds and polychoric correlations [
50] instead of means and covariances for continuous data, respectively. Moreover, the model-robust estimators could also be applied to two-step estimation methods of multilevel structural equation models [
51,
52].
To sum up, model-robust SEM estimators based on the (for ) and loss functions are attractive to researchers who do not want model estimates being influenced by the presence of a few model deviations (i.e., model errors). In contrast, usually employed (non-robust) SEM estimators such as maximum likelihood estimation are impacted by model errors. In this sense, misfitting models do not necessarily result in biased estimates when using model-robust estimation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}