1. Introduction
Large-scale assessments (LSA), such as the U.S. National Assessment of Educational Progress (NAEP) and the Trends in International Mathematics and Science Study (TIMSS), use plausible values to accurately estimate population estimates of respondent performance [
1]. Plausible values are used in LSA because traditional item response theory models result in biased estimates of population parameters (Note that an LSA with a high-reliability assessment would not need to use plausible values). Plausible values are routinely generated by the statistical agency responsible for the data collection, and can be used to generate unbiased population estimates (Conditional on the validity of the survey sampling strategy and psychometric instrument. These are not minor issues, but they are not the focus of this paper). These plausible values come from a conditioning model that includes information from all background variables, generally through a dimension reduction (i.e., principal component analysis) on the full set of covariates. However, when the analyst brings in data not available to the statistical agency, or they incorporate data on the file but not yet synthesized on the file—such as many results derived from process data—they will need to generate new plausible values with a new conditioning model to obtain unbiased regression parameters. (PISA includes some process data variables [
2]. Though any such attempt only scratches the surface of process data variables [
3].) In addition, if the question of interest can be stated as a regression,
direct estimation, where the coefficients from the conditioning model itself are used, is an unbiased estimator of the regression coefficients [
4].
This paper describes the methods of the
Dire package for direct estimation and generation of new plausible values (Dire 2.1.1 CRAN:
https://cran.r-project.org/web/packages/Dire/index.html, GitHub:
https://github.com/American-Institutes-for-Research/Dire, Vignette:
https://cran.r-project.org/web/packages/Dire/vignettes/MML.pdf (accessed on 16 August 2023)). The existing
TAM software performs all of the necessary steps to go from item responses to estimate item parameters and produce new plausible values [
5].
Dire, especially when paired with
EdSurvey [
6], instead focuses on estimating new latent regression models and plausible values for LSA where the user wants to use the existing item parameters published by the statistical agency sharing the results. In addition,
Dire is intended to be able to estimate high-dimensional models used in NAEP where the mathematics scale is a composite of five correlated subscales, as well as TIMSS where four- (grade 4) or five- (grade 8) constructs are estimated in a multi-dimensional model to estimate subscales [
7].
We show the model used by Dire to estimate a conditioning model. We then show the estimation strategy used by Dire to estimate high-dimensional models without suffering from exponential-time costs, and how plausible values are generated. We provide a simple example of using Dire to estimate a new conditioning model with EdSurvey; for completeness we also show how to estimate a toy example (that is not an existing LSA) in Dire without using EdSurvey.
2. Background
Typically, student ability is estimated by a factor score (e.g., EAP, WLE, or MLE) of a corresponding IRT model. Those student abilities can then be used in subsequent analysis. With a high-reliability test, this is a valid method of analysis because the measurement error represents a small portion of the total test variance. As such, many existing methods for IRT available in R [
8] focus on estimation of a
for each student, which can then be used in subsequent analysis.
LSA are designed to estimate population characteristics directly and do not provide estimates of individual scores. They instead provide random draws from distributions for individual proficiencies in the form of plausible values.
It is possible to estimate plausible values using proprietary software such as Mplus [
9]. For users who are interested in open source software, R [
8] has become popular as a way to share software and methods.
In the R psychometrics view [
10], a few packages have capabilities for drawing plausible values (the focus of the
Dire package):
TAM [
5],
mirt [
11], and
Dire. Additionally, the
NEPSscaling package may be used to draw plausible values focusing on data from the German National Educational Panel Study (NEPS) [
12]. The models shown in this paper may be fit with
TAM,
mirt, or
Dire. In contrast to
mirt and
TAM,
Dire uses a different method of calculating the multi-dimensional integral. Where
TAM and
mirt calculate a multi-dimensional integral by calculating all of the dimensions at once,
Dire does so one- or two-dimensions at a time. When
Dire estimates the conditioning model, it uses the existing item parameters. The
EdSurvey package will download and format them for NAEP and TIMSS data for the user so that the process is seamless.
The methods in
Dire, similar to other plausible value approaches, mirror those used in the statistical package AM [
13] and result in unbiased estimates of parameters included in the conditioning model [
1,
4].
The
Dire package is integrated into the
EdSurvey package, which allows users to download, read in, manipulate, and analyze U.S. NCES, IEA, and OECD LSA data. For a detailed overview of the functionality of the
EdSurvey package, see [
6]. This paper synthesizes portions of the methodology covered in the
Dire vignette with worked examples to provide an overview of the methods and application of
Dire in analyzing LSA data.
3. Methodology in Dire
Generating plausible values requires first estimating a marginal maximum likelihood (MML) model, (Note that we refer to the model as using a
log-likelihood throughout this paper, but the model is weighted by survey sample weights for each student and so it is correctly a
pseudo log-likelihood. One important implication of this is that likelihood ratio tests are not valid, so the absolute values of the modeled likelihoods are not relevant) and then estimating a posterior distribution for each test taker, conditional on the model and the test taker’s responses [
14]. The regression coefficients in the marginal maximum likelihood model can be used directly in a process known as
direct estimation [
4]. The methodology described in the following sections allows for efficient and accurate recovery of model parameters [
4].
3.1. Marginal Maximum Likelihood
3.1.1. Likelihood
MML estimation extends the methodology of standard maximum likelihood (ML) estimation to situations where variables of interest are latent (not directly observable), such as student math ability. The principal difference is that the latent variable is not assumed to be known and is thus integrated out over a distribution of possible values—that this step is analogous to multiple imputation is one of the key insights of [
1].
In MML estimation, an individual student’s likelihood has two components: (1) the probability of observing the student’s item responses, given their latent ability, and (2) the probability that a student with a given set of covariate levels would have this student ability, conditional on the regression coefficients and the residual variance. The product of these two terms is then integrated out over all possible student ability levels—this is the marginalization in MML.
The first component, the probability of observing the student’s item responses, is captured by an item response theory (IRT) model dependent upon the item parameters, and the student’s score on the item. The latter component is the latent regression model and is modeled as a normal distribution with
, where
is student
i’s (
) covariates in an
row vector, and
are the
m regression parameters associated with that vector. In the uni-dimensional case, we define the latent regression model as
where
is a normal distribution with mean zero and standard deviation
. The assumption follows that the conditional distribution of
is
, where
f represents the normal density function. The full likelihood function for a single construct for student
i is then represented as
where
represents student
i’s response to item
h,
is student
i’s latent ability,
is the sampling weight for student
i,
is the vector of item parameters for item
h, and the student sees
H items [An added complication is that students do not take the same assessment. TIMSS takes the full assessment pool and generates 14 different student achievement booklets through matrix sampling, such that each item will appear in two booklets. Students complete only one of these booklets and hence see only a fraction of the total items [
15]; NAEP similarly uses rotated forms [
16]. However, this issue is not discussed further because it represents only minor technical problems for MML that are ignored because it primarily adds notational complexity—for example, the items become student-specific, which would need to be indicated in the product over
h]. Looking at the left hand side of the equation,
is the vector of student
i’s responses across the
H items, and
is a matrix whose rows are the vectors
,
.
Here,
is a random variable, while
,
, and
are fixed [In the context of LSA, the IRT parameters are generally estimated first and then treated as fixed when estimating the latent regression model [
17,
18]. These item parameter estimates are included on the data file, so
Dire treats them as fixed]. The parameters to estimate are
and
.
In the composite scoring framework, where overall ability is measured as a weighted sum of multiple potentially correlated subdimensions, things are considerably more complicated [Given the focus on LSA, similar to NAEP and TIMSS,
Dire fits a between-item multidimensional model]. Now
is a vector, with an element for each construct, and dependence between the constructs is allowed by modeling the residual as a multivariate normal with residual
. We assume here that each item is associated with only one construct. The target integral to evaluate is then:
where
J is the number of constructs, and
are the residuals
for student
i. The terms here are analogous to those in Equation (
2) but are now also indexed by the construct, i.e.,
is student
i’s response to item
h within construct
j,
is student
i’s latent ability in construct
j, and
is the vector of item parameters for item
h (
) in construct
j. For compactness, we have dropped the
term here and in the next section, but the weighting is still implied. The integral in Equation (
2) (and consequently in Equation (
3), which generalizes Equation (
2)) is intractable and thus requires numeric approximation.
3.1.2. Integral Approximation
Several methods have been proposed in the literature for high-dimensional integral approximation, including stochastic expectation maximization (EM), Metropolis–Hastings Robbins–Monro (MH-RM), and both fixed and adaptive quadrature [
19]. Stochastic methods are considered more computationally efficient than numeric quadrature when the number of latent dimensions (i.e., number of constructs) exceeds three, as the requisite number of evaluations only increases linearly [
20]. Adaptive quadrature tries to overcome this limitation by decreasing the number of points needed for accurate approximation, but is still subject to computational complexity that grows exponentially with the number of dimensions [
21,
22]. For a recent review of related methods, see [
19].
With a large number of test items, the dispersion of the likelihood given the response patterns is small, and fixed point quadrature would inadequately approximate the likelihood [
21,
22]. However, in the context of LSA, relatively few items are administered to each student in a given subject. This results in a more dispersed likelihood that fixed point quadrature is suited to approximate. Additionally, in the uni-dimensional case, fixed quadrature has been shown to be more efficient than, e.g., MH-RM, with comparable accuracy [
22].
Dire, following the methodology of [
4], transforms the problem of approximating a multi-dimensional integral into one of estimating a uni-dimensional integral per subscale. To do this, we make the observation that the multi-dimensional case is analogous to a seemingly unrelated regression (SUR) model with identical regressors and normally distributed errors that are correlated across equations. It is shown in [
23] that for this special case of a SUR model, estimates are no more efficient when regressors are estimated simultaneously vs. separately. We begin by writing the joint density as a product of a marginal and a conditional, as in Equation (
4).
By partitioning the likelihood this way, we obtain an additively separable likelihood once logs are taken, allowing for maximization of each part of the likelihood independently.
In the context of SUR, one possible approach to estimation is the two-step procedure of iterated feasible generalized least squares (FGLS) [
23]. In the first step, weighted least squares (WLS) is used to estimate regression coefficients. Residuals from these estimates are then used to estimate the covariance matrix. In the second step, the estimated covariance matrix is used to update the estimated coefficient matrix. While the first step is able to be decomposed for each latent variable, the second step cannot be when the latent variables are correlated [
24]. As an alternative, we can estimate the parameters through direct maximization. To do so, we must approximate the uni-dimensional integral for each of
j subscales. In this new context of a uni-dimensional integral (with theoretically high dispersion), fixed point quadrature is expected to perform well.
Dire creates a fixed grid of integration points that the integral is then evaluated over. Because latent ability is assumed to follow a standard normal distribution when calibrating item difficulty, the default range for this grid is chosen to be
. Within this range, 30 equidistant quadrature points are chosen by default. The user may specify an alternative range and number of quadrature points.
This quadrature representation is shown in Equation (
5). Here, the integration nodes
stand in for student latent ability, and
is the distance between any two subsequent nodes. The term
c is a constant that depends on the other dimensions (or constructs) that are now not a function of
nor the residual variance
term.
Instead of needing to optimize a multi-dimensional integral over all subscales simultaneously, the process is simplified considerably to:
The second step takes advantage of the fact that a multivariate normal is conditionally a multivariate normal distribution, after conditioning on a subset of the variables. The likelihood of the covariance between two subscales is defined as:
where the left-hand side has been simplified to indicate the only parameter being estimated is
, the covariance between subscales one and two. Here,
is the bivariate normal distribution, evaluated at a mean of
, with covariance matrix having diagonal elements
and off-diagonal elements both
. The second integral is the multivariate normal distribution of all other variables, conditional on the first two values. Because this second term is a constant, it can be replaced with the term
and ignored when maximizing the integral.
3.2. Parameter Estimation
3.2.1. Estimating and
To estimate the
and
terms, we plug in the normal distribution for
f and use the univariate objective function in Equation (
5) which can be maximized accordingly by dropping the trailing
c term (because it is irrelevant for maximization). We once again make the survey sample weighting explicit and define the log-likelihood:
where as before the integration nodes
stand in for the latent ability, previously labeled
,
is the distance between any subsequent node pair, and
is the sampling weight for student
i. As we are now summing across all students, we let
denote the vector of student sample weights, while
is an
matrix of student item responses, and
is the
design matrix. The first component of this likelihood is the univariate normal of the residuals,
. The second component is the probability of student
i’s responses, given the item parameters and the node. Item scoring may be 3-PL, graded response, or partial credit (see the
Dire documentation for how to specify the parameters).
The full likelihood for a given student is comprised of the density of their latent ability and the product of their response probabilities across all items, each respective to the appropriate IRT model. To make this computation more efficient, Dire calculates the item response likelihoods outside of the optimized function, since these do not depend on and . The optimization then only takes place over the univariate normal portion of the likelihood. Dire takes a robust approach to optimization that begins with using the memory-efficient L-BFGS-B algorithm to identify a maximum. Because the L-BFGS-B implementation programmed in R does not have a convergence criterion based on the gradient, Dire further refines these estimates with a series of Newton steps, using the gradient as a convergence criterion—since a maximum has zero gradient, by definition. Because the integration nodes and item parameters are fixed during optimization, the term will not change over the surface of or , so it is only necessary to evaluate it once per student over the grid.
To demonstrate this, we consider an example using the TIMSS 2019 8th-grade math results for Singapore.
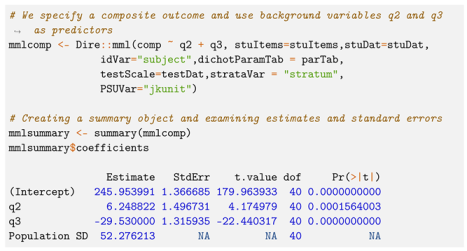
Figure 1 shows a single student’s item responses for the items in the
Algebra construct. While the International Association for the Evaluation of Educational Achievement (IEA) typically estimates TIMSS math and science scores as if it had an overall score (where all items are in the math construct), for illustrative purposes we estimate it as a composite score instead where the constructs are distinct and correlated. (IEA does fit the subscales as correlated constructs, but we are focusing on the subjects [
25]. Nevertheless, a
Dire user could fit the model we fit for NAEP for TIMSS data and recover the subscales (throwing out the implied but never used composite score that would also have to be calculated)).
We aggregate their likelihood across all items in the construct through a summation of their item-level likelihoods. We are then able to observe how a student’s likelihood surface changes as we change the conditioning model by varying
and
.
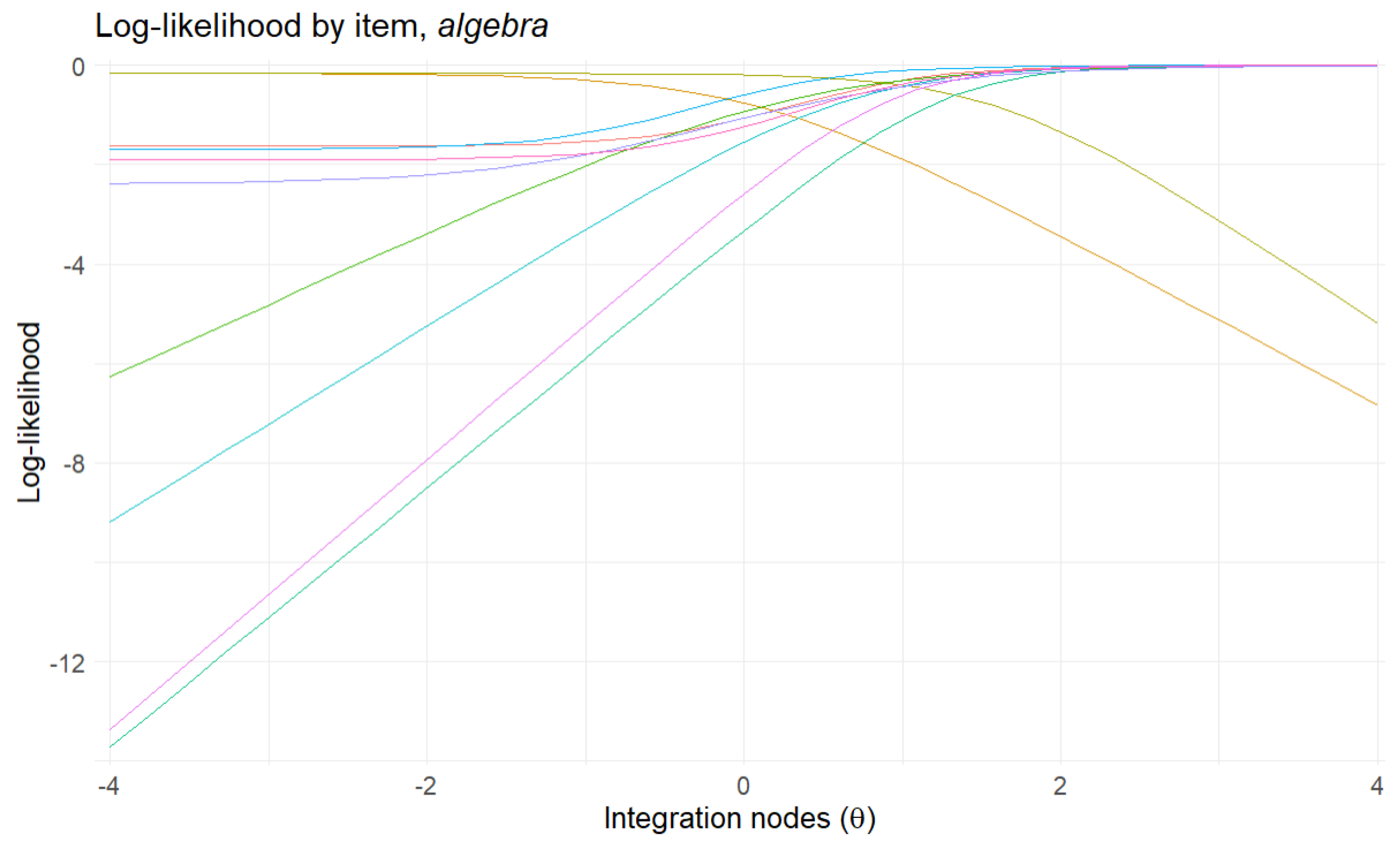
Figure 2 shows that as we increase
, the surface becomes wider, and as we increase
, the distribution’s peak moves to the right. The black line represents the base likelihood of the student’s item responses without a conditioning model.
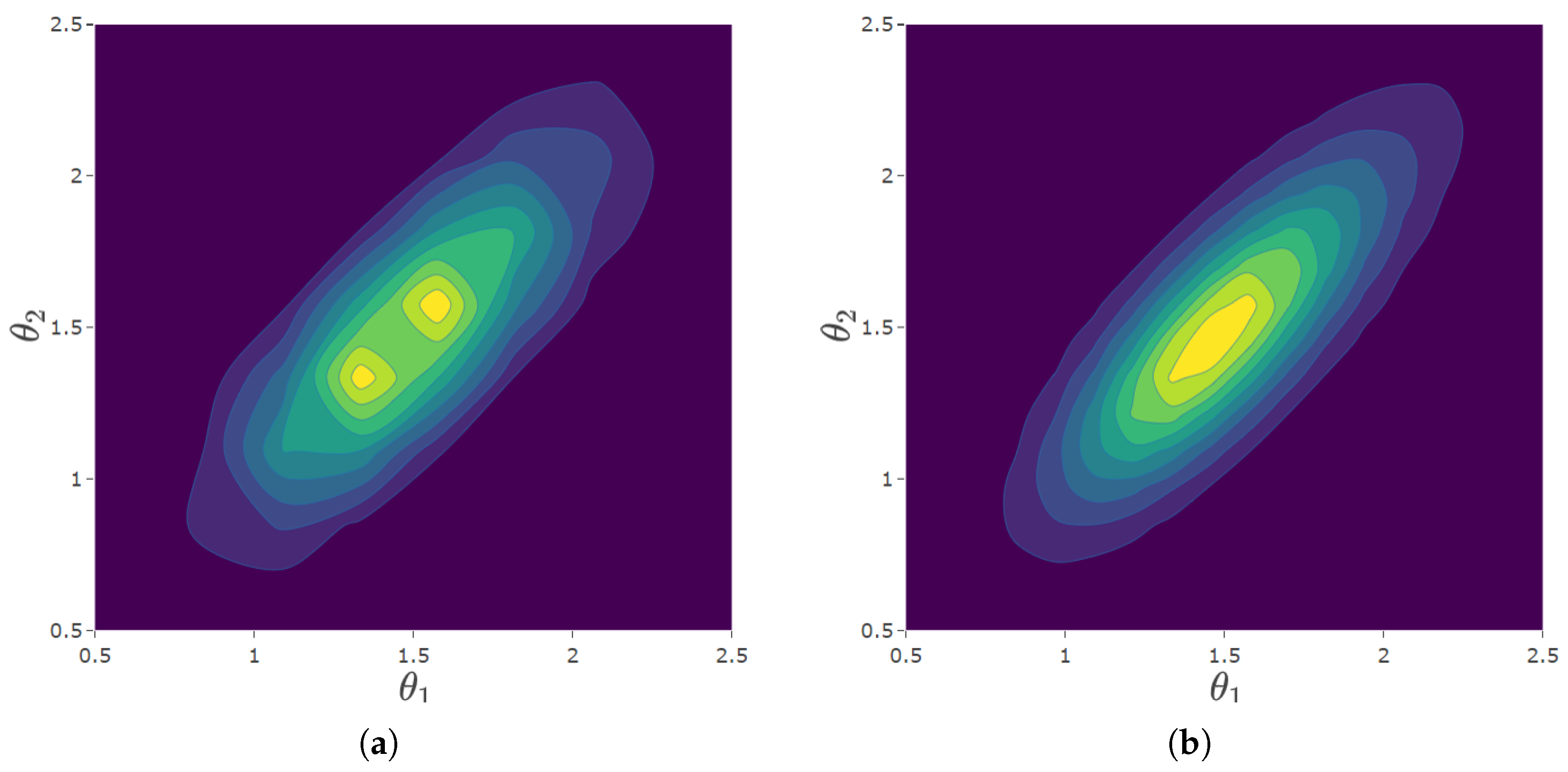
3.2.2. Estimating covariance terms,
Once the convergence criteria have been met, the second step is to estimate the correlations between each pair of constructs. Each construct’s likelihood is evaluated at the same fixed nodes, thus for each node pair we evaluate the bivariate normal likelihood for the current value of
. The summation of these evaluations shown in Equation (
9) becomes the objective function for the Newton optimization routine.
For any fixed
n, this corresponds to a single student’s likelihood. We take the same student whose likelihood surface we examined previously on the
Algebra subscale and now consider their composite likelihood, comprised of the
Algebra and
Geometry subscales.
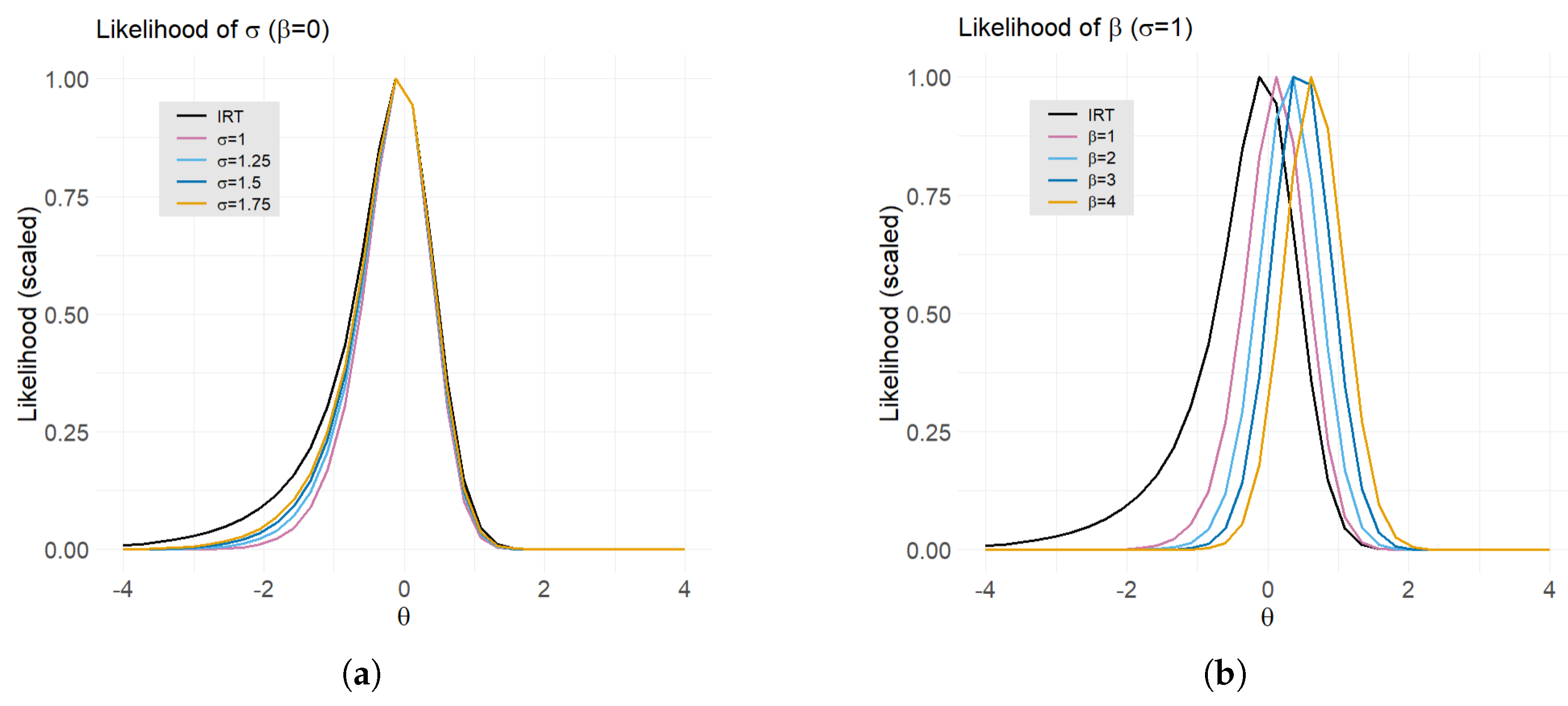
Figure 3 shows (a) the item response likelihood across the two constructs, (b) the likelihood of the student’s latent trait, and (c) the product of (a) and (b), where (c) is the function we seek to maximize, as a function of
, holding
,
,
,
all fixed. The figure shows that the student’s total likelihood, being the product of a normal distribution and an IRT model, also appears approximately normal. This is the
posterior distribution of the latent trait,
, and will be relevant later for estimating group statistics.
Contrary to the procedure of the AM software [
13],
Dire optimizes
by optimizing the correlation,
r, in the Fisher Z space [Since variance terms have already been estimated at this stage, the covariance can be obtained by optimizing the correlation and calculating
]. This is a transformation defined by
where
r is the current value of the correlation. The benefit of optimizing in this space is that it maps the (−1,1) interval of a correlation to the real number line and consequently does not have to deal with proposed Newton steps outside of the allowable bounds. This allows for better handling and estimation of correlations between highly correlated constructs.
Though this procedure circumvents scenarios that would impede the optimization routine, it does not address the challenge of accurately estimating high correlations. When constructs are highly correlated, we observe that evaluation at subsequent node pairs may produce drastically different likelihoods. The true parameter value can “fall through the cracks”, and we are left with a biased estimate of the correlation.
One solution would be to evaluate the likelihood surface over a finer grid (i.e., significantly increase the number of nodes), but this quickly becomes computationally burdensome as the size of the data increases.
Dire introduces a novel solution for accurately estimating correlations that relies on spline interpolation of the likelihood surfaces. Consider the Gaussian densities in
Figure 3—the narrow, elongated shape suggests that the algebra and geometry constructs are highly correlated for this student. In
Figure 4, we compare a student’s likelihood using the standard grid and the grid produced with a cubic spline interpolation of the likelihood surface. The approximation of the likelihood surface using the standard grid is subject to discontinuities that are not real but the result of discretization.
Table 1 shows the estimated correlation, log-likelihood, and computing time for a variety of methods. The inefficacy of the standard grid becomes apparent, as we see the extent to which the estimated likelihood differs depending on the number of nodes. The spline interpolated grid requires greater computation time than the standard grid for a set value of
q, but the relative improvement in estimation justifies its use. Spline interpolation results in nearly the same estimated correlation as if we had used 4x the number of nodes, at roughly a quarter of the computing time.
3.3. Variance Estimation
Dire estimates the variances of
, as well as the residual variances (diagonal of the covariance matrix), using the cluster-robust (CR-0) method in Binder [
26]. This method is also known as the Taylor Series Method, e.g., in Wolter’s survey sampling text [
27]. These methods account for the weights and are cluster-robust in the sense of estimating arbitrary covariances between units within strata.
The Taylor series method involves estimating the variance for the set of parameters
using
where
is the vector of first derivatives of the score function with respect to the elements of
(and so has the same dimensions as
), and
is the estimated covariance term for
.
is obtained using survey sample methods for a two-stage sample, i.e.,:
where
s indexes the strata, and
p indexes the PSUs in the strata, of which there are
in the
sth stratum. Here, the
g terms are defined by
where
is the log-likelihood function for only those units in stratum
s in PSU
p, evaluated at the estimated value for
(based on the full data).
The derivative vector (
) can be calculated as the inverse Hessian of the likelihood function, or (assuming information equality [
23]), as the sum of the stratum-level Jacobians of
. The latter option is provided because it allows for replication of results from the AM software [
13], but the former is recommended and is the default.
3.4. Plausible Values
Having estimated the model through MML as described in the preceding sections, we are able to draw plausible values for each student’s latent ability in these constructs through the following procedure:
Holding fixed, draw from a normal approximation to the posterior of
Using the same
and
, compute the posterior distribution of
for each student using the same quadrature nodes as in the initial optimization routine. Compute the mean and variance of each student’s posterior distribution as:
where
is the product of item response probabilities for individual
i evaluated at node
.
Using the mean and standard deviation from Step 2, randomly draw from a normal approximation to the posterior distribution.
This is straightforward in the case of a single construct. When there are multiple constructs, in addition to the posterior mean and variance for each individual construct, we compute posterior correlations between each pair of constructs in order to form the posterior covariance matrix, . Plausible values are then drawn from a multivariate normal approximation to the posterior with mean and covariance matrix .
The normal approximation to the posterior distribution seems reasonable given
Figure 3c,f and
Figure 4b, each of which show approximately normally distributed looking surfaces, and both of which are based on published student data. More importantly, given
Dire’s focus on LSA, this follows the methodology of NAEP and TIMSS [
16,
17].
Contrary to a standard Empirical Bayes (EB) approach, step (1) treats the population regression coefficients as random variables. EB does not fully account for the uncertainty in the modeled component and may result in biased statistics. By having a stochastic
we can integrate out this source of uncertainty. Once plausible values have been drawn, group level statistics may be calculated by first calculating the statistic for each of
m plausible values. The average of these
m estimates becomes the final estimate [
28].
Plausible values are included in the data files provided by NCES, IEA, and OECD. As such, it only becomes necessary to draw new plausible values when there is a desire to estimate regression coefficients for variables that were not part of the conditioning model fit by these agencies. For a detailed discussion on the motivation and use of plausible values, see [
1].
Having drawn plausible values, the user should use them according to Rubin’s rule [
28], as explained in [
29].
4. Examples
To analyze assessment data using the Dire package, the minimum necessary components are:
These components are readily accessible and appropriately formatted for
Dire out of the box when reading in data using the
EdSurvey package. For users wishing to simulate some or all of this information, the
lsasim R package provides a set of functions for simulating LSA data [
30].
The following examples show (1) a general workflow of using Dire to estimate regression parameters and draw new plausible values using simulated data, and (2) how to use Dire with existing LSA data to address a particular research question.
4.1. Simulated Data
Using
lsasim, we simulated background variables for 2000 students divided into 40 strata and 2 sampling units, as well as their responses to 20 dichotomous items divided into two subscales and the parameters for those items (see
Appendix A).
To fit a latent regression model by marginal maximum likelihood, we call the function ‘Dire::mml’. The parameters to be specified are:
formula: the model to be fit, expressed as Y X1 + …+ XK
stuItems: student item responses
stuDat: student background variables, weights, and other sampling information
idVar: student identifier variable in stuDat
dichotParamTab: item parameters for dichotomous items
polyParamTab: item parameters for polytomous items
testScale: location, scale, and weights for each (sub)test
strataVar: a variable in stuDat, indicating the stratum for each row
PSUVar: a variable in stuDat, the primary sampling unit (PSU)
The general workflow is then straightforward. Once all necessary components are defined, the user need only determine the model they wish to fit. The outcome can be a single subscale (e.g., if one wished to estimate population parameters for Algebra proficiency), or it can be a composite of multiple subscales, such as in NAEP. Our simulated data contain two subscales, A and B, which we may fit a composite of.
If one wished to make their simulated data available for secondary analyses, they may also wish to provide plausible values. This can be achieved using the ‘Dire::drawPVs’ function, which requires only a MML model object and a desired number of PVs to generate.
Consistent with IEA’s procedures in 2019 TIMSS, we draw five plausible values in this example [
7]. Drawing more plausible values slows computation but always increases the accuracy of the estimates and variance estimates (Lou and Dimitrov [
31] conclude, “The results indicate that 20 is the minimum number of plausible values required to obtain point estimates of the IRT ability parameter that are comparable to marginal maximum likelihood estimation(MMLE)/expected a posteriori (EAP) estimates”).
4.2. TIMSS Data
We first calculate each student’s total time (screen time, summed across all items) on math and science in minutes. Then we Z-scored these values. For TIMSS 2019 Grade 8 USA, with math achievement as our outcome, we consider a conditioning model with predictors of total time on the math blocks, total time on the science blocks, and which block students were exposed to first (math or science). Students are randomly assigned to one of 14 booklets, half of which present the science blocks first, and half of which present math first. Using this information, we created a binary variable equal to “M” if a student sees math first and “S” if they see science first, with “M” serving as the reference level. We additionally consider the two-way interactions of these predictors.
![Psych 05 00058 i003]()
Notice that this is not intended to be a sophisticated look at mathematics screen time. A few issues arise, one being that students who see harder items may take longer to complete the items. For a more sophisticated approach to analyzing process data in this context, see [
32,
33]. However, the same criticism is not true of the time spent on science, since these items have no loading onto the mathematics test scores.
Having created the Z-scored time on assessment and first assessment (math or science) variables, we fit a new conditioning model using only the variables in our regression. We then drew plausible values from this conditioning model and fit a linear regression with these covariates to both the original and new plausible values. These plausible values could be used to fit models nested inside of the conditioning model, so if there are multiple regressions, the conditioning model could incorporate every covariate in them and then the plausible values could be used many times—as is typical of the plausible values that are provided on the original data [
1].
We note that these models use “treatment coding”, so first_subject is 1 when the student takes science first and zero otherwise.
5. Results
Table 2 shows the summary results from fitting the MML model described above, i.e., with regression parameters obtained through direct estimation and standard errors obtained via the CR-0 method described in
Section 3.3.
The estimated coefficient of 13.95 is the simple slope for time spent on math; that is, for a one standard deviation increase in time spent on math, the predicted scale score will increase by 13.95, assuming the student sees the math block first (i.e., ) and spends an average amount of time on the science block (i.e., , since the times are standardized). These assumptions (, ) are necessary because of the interaction terms—described below.
The estimated coefficient of −2.84 is the simple slope for time spent on science, implying that for a one standard deviation increase in time spent on science, the predicted scale score will decrease by −2.84. Here again, because of the interactions, we assume the math block is seen first, and that the student spends an average amount of time on the math block (i.e., = 0).
The estimated coefficient of 16.73 for the first block seen implies that if a student spends an average amount of time on both the math and science blocks, seeing the science block first is associated with a predicted scale score increase of 16.73 points.
The estimated coefficient of 41.83 for the interaction of first block seen and time spent on math represents the change in slope of when students see the science block first; that is, when a student sees science first, each one standard deviation increase in is associated with an increase in predicted scale score of 13.95 + 41.83.
Similarly, the estimated coefficient of −38.31 for the interaction of first block seen and time spent on science represents the change in slope of when students see the science block first. When a student sees science first, each one standard deviation increase in is associated with a decrease in predicted scale score of −2.84–38.31.
Lastly, the estimated coefficient of −13.3 for the interaction of time spent on math and time spent on science represents the change in slope of for a one standard deviation increase in time spent on science, and vice versa.
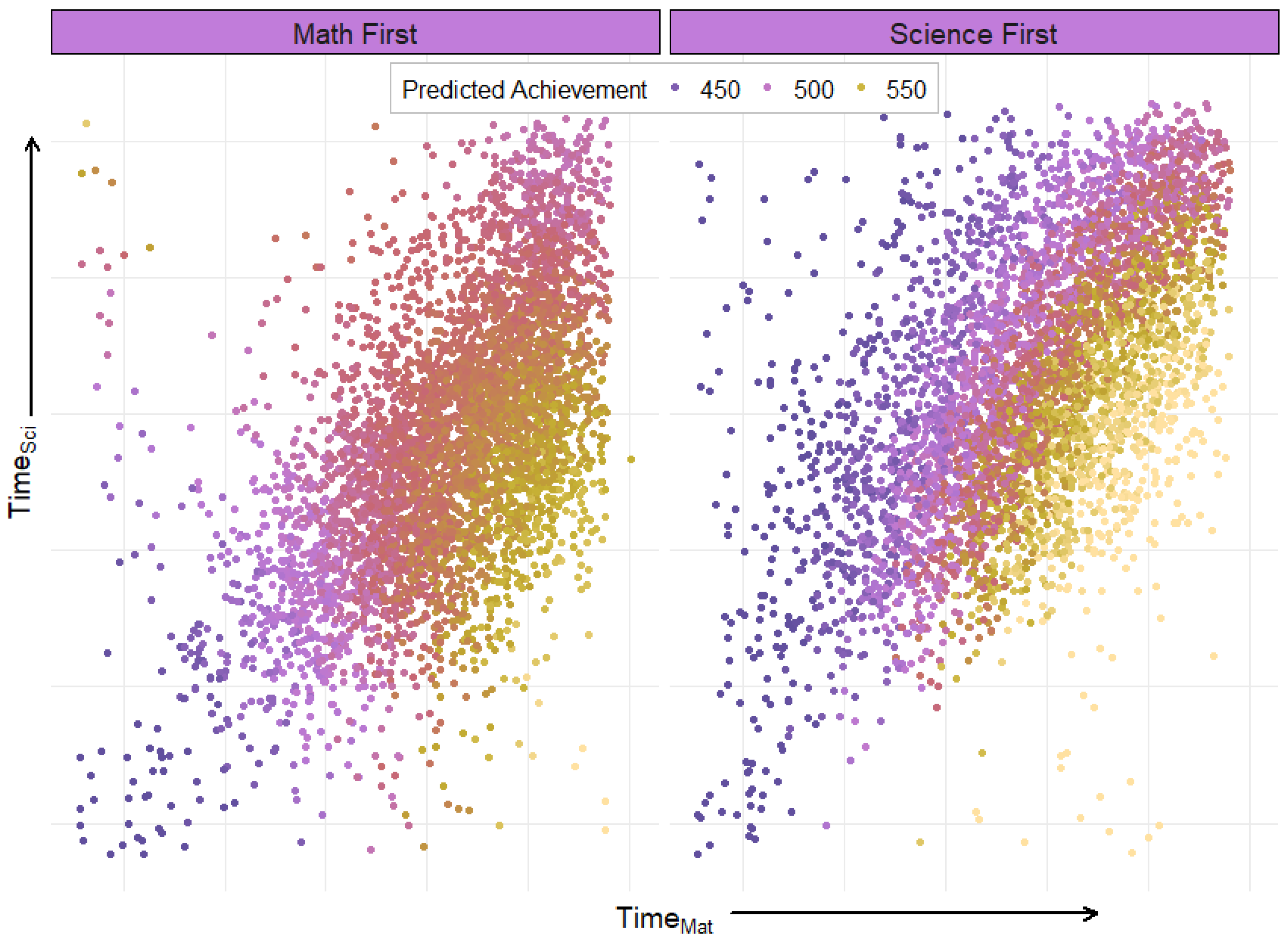
To aid the reader in understanding the net result of these interactions,
Figure 5 shows predicted score as a function of time spent on math vs. time spent on science for students who saw math vs. science items first. Results are color-coded by predicted math achievement to demonstrate the association between time spent on the test and modeled score.
Taking all of the above into consideration, we expect the highest math achievement from a student who sees science first, spends a below average amount of time on science, and spends an above average amount of time on math. Likewise, we expect the lowest math achievement from a student who either sees math first and spends a below average amount of time on math and science items, or sees science first and spends an above average amount of time on science and a below average amount of time on math. A possible explanation could be that students seeing science first were better primed for the math items.
We draw five plausible values with this conditioning model, and then fit two linear regressions with the same variables used in the conditioning model: one using the original plausible values, and one using the newly generated ones.
Table 3 shows the results of these two models, and
Figure 6 compares the estimates and standard errors.
6. Discussion and Conclusions
Understanding the population characteristics of student achievement is a complex task—especially when trying to augment existing surveys with additional data. Because the tests are designed to minimize response burden, they can only be used with a conditioning model (e.g., plausible values) to achieve an unbiased estimate. Further, a conditioning model must be fit that includes all variables of interest for the study. In our case, that is a new conditioning model because the process data variables are not included in the conditioning model.
NAEP and TIMSS each have plausible values made available to researchers for their analyses, but this places limitations on including external data or process data in the conditioning model. Dire enables users to use direct estimation, or simply fit a large conditioning model that includes external or process data variables. Once the conditioning model is fit, the user can draw new plausible values in order to have unbiased estimators of conditional statistics. Dire estimates the conditioning model efficiently by maximizing one subtest at a time (in the case of composite scores such as in NAEP or for TIMSS subtests). In addition, when the correlations are high it is often neceessary to use a higher density grid. To quickly calculate that, spline interpolation is applied, for accurate and fast estimation of correlations between subscales—this is novel in Dire and was used because the approximation was observed to be fast and accurate.
In our example, we fit a conditioning model with process data variables. We used direct estimation to estimate regression coefficients from an unbiased estimator. We then generated plausible values from that conditioning model and compared the results of a linear regression on the new plausible values that do include these variables to the original plausible values that do not. Setting aside the intercept, the estimated coefficients were further from zero (four of six cases), had smaller standard errors (five of six cases), larger degrees of freedom (five of six cases), and smaller p-values (four of six cases).
The model showed a surprisingly intricate association between time on tests and which test was first, with all interactions showing statistical significance and
Figure 5 showing increases in total time (movement along the 45-degree line) being either non-linear (left plot: math first) or nearly unassociated with math score (right plot: science first).
We do not intend for these results on time spent on the exam to be a final word on the topic—they are merely presented as an example. In addition, screen time is not very informative, and does not add insight into what the student was doing. For example, a student who spends more time checking previous items is undertaking a very different activity than one who has the screen on one item with no clicks for an extended period. One hint is that there could be a “warm-up” effect, but this does not clarify why students who take more time on science after completing their math assessment have lower scores.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}