
Bayesian Regularized SEM: Current Capabilities and Constraints


Abstract
1. Introduction
“All models are wrong, but some are useful.”George Box
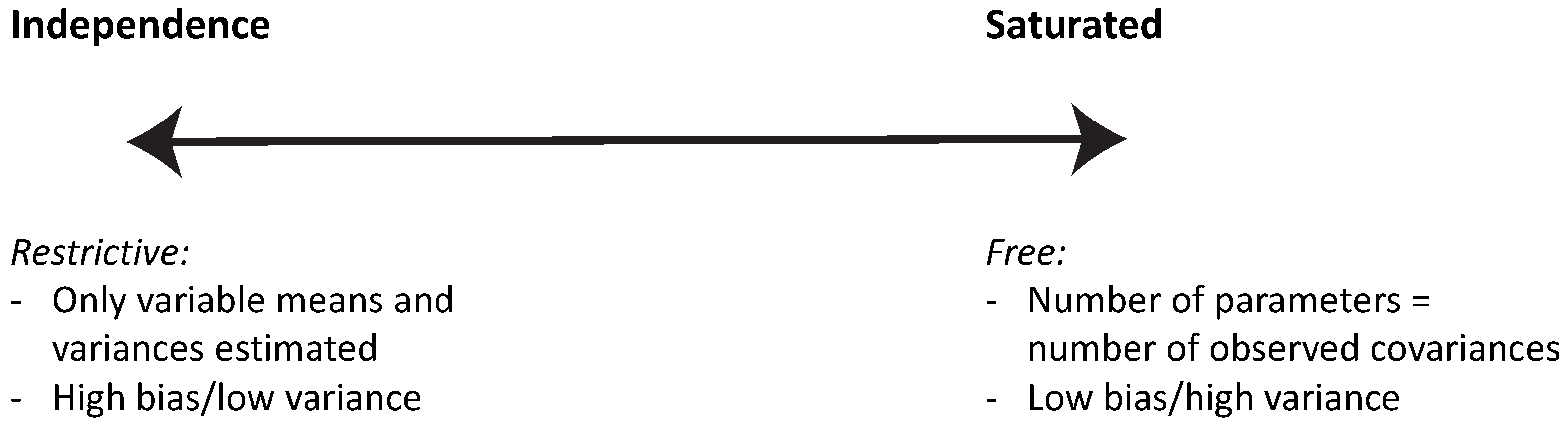
2. Regularized SEM
3. Bayesian Regularized SEM
3.1. Differences between Classical and Bayesian Regularized SEM
3.2. Review of Developments in Bayesian Regularized SEM
3.2.1. Exploratory Factor Analysis
3.2.2. Confirmatory Factor Analysis
3.2.3. Non-Linear SEMs
3.2.4. Other Models
4. An Overview of Software Packages for Regularized SEM
4.1. General Purpose Software That Is Able to Perform Bayesian Regularized SEM
4.2. Software Packages for Classical Regularized SEM
4.3. User-Friendly Software Packages for Bayesian Regularized SEM
5. Empirical Illustration: Regularizing Cross-Loadings in Factor Analysis
5.1. Before the Analysis
5.2. During the Analysis
- Run multiple chains starting from different starting values. Traceplots can be used to visually assess whether the different chains coincide at some point and mix well (i.e., the traceplots should resemble “fat caterpillars”).
- Remove a specified number of initial iterations (“burn-in”) to avoid the final results depending on the starting values. Traceplots based on the iterations without burn-in should immediately indicate nice mixing.
- Consider numerical convergence diagnostics such as the potential scale reduction factor [88], which should be close to 1 (EPSR in LAWBL and Rhat in blavaan).
- Make sure you have a sufficient number of effective samples (Neff in blavaan). Although there are no theoretically derived guidelines, a useful heuristic that has been proposed would be to worry whenever the ratio of effective sample size to full sample size drops below 0.1 [89].
- When in doubt, or when not all diagnostics are (easily) available, you can rerun the analysis with double the number of iterations to ensure stability of the results.
5.3. After the Analysis
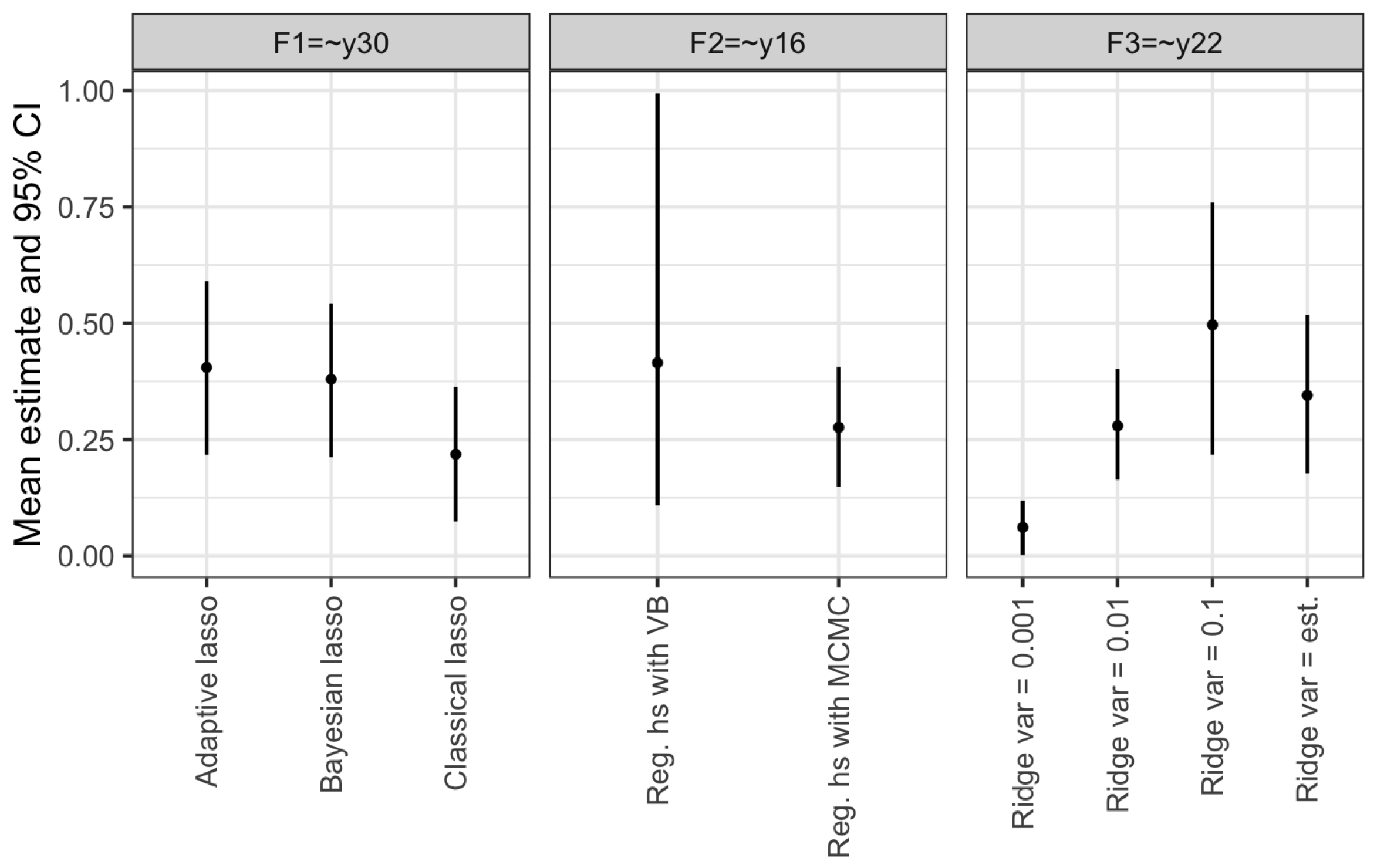
5.3.1. Comparison Variational Bayes and MCMC
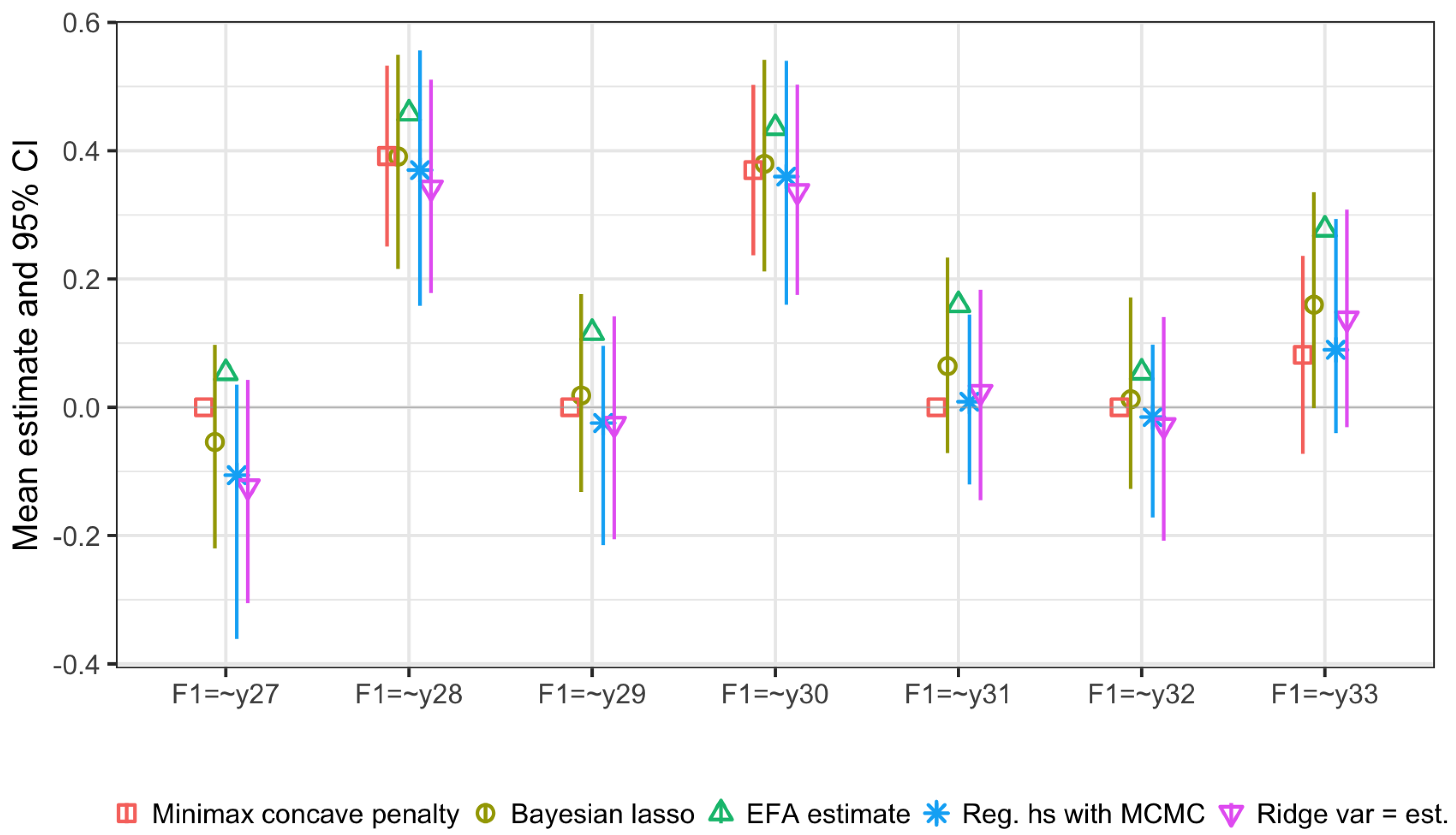
5.3.2. Posterior Estimates Cross-Loadings
5.3.3. Nuisance Parameters
6. Discussion
Future Directions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sörbom, D. Model modification. Psychometrika 1989, 54, 371–384. [Google Scholar] [CrossRef]
- MacCallum, R.C.; Roznowski, M.; Necowitz, L.B. Model modifications in covariance structure analysis: The problem of capitalization on chance. Psychol. Bull. 1992, 111, 490–504. [Google Scholar] [CrossRef]
- Jacobucci, R.; Grimm, K.J.; McArdle, J.J. Regularized Structural Equation Modeling. Struct. Equ. Model. Multidiscip. J. 2016, 23, 555–566. [Google Scholar] [CrossRef] [PubMed]
- Huang, P.H.; Chen, H.; Weng, L.J. A Penalized Likelihood Method for Structural Equation Modeling. Psychometrika 2017, 82, 329–354. [Google Scholar] [CrossRef] [PubMed]
- Jacobucci, R.; Grimm, K.J.; Brandmaier, A.M.; Serang, S.; Kievit, R.A.; Scharf, F.; Li, X.; Ye, A. Regsem: Regularized Structural Equation Modeling, R package version 1.6.2; 2020. Available online: https://cran.r-project.org/web/packages/regsem/regsem.pdf (accessed on 1 July 2023).
- Huang, P.H. lslx: Semi-Confirmatory Structural Equation Modeling via Penalized Likelihood. J. Stat. Softw. 2020, 93, 1–37. [Google Scholar] [CrossRef]
- Arruda, E.H.; Bentler, P.M. A Regularized GLS for Structural Equation Modeling. Struct. Equ. Model. Multidiscip. J. 2017, 24, 657–665. [Google Scholar] [CrossRef]
- Jung, S. Structural equation modeling with small sample sizes using two-stage ridge least-squares estimation. Behav. Res. Methods 2013, 45, 75–81. [Google Scholar] [CrossRef]
- Yuan, K.H.; Chan, W. Structural equation modeling with near singular covariance matrices. Comput. Stat. Data Anal. 2008, 52, 4842–4858. [Google Scholar] [CrossRef]
- Yuan, K.H.; Wu, R.; Bentler, P.M. Ridge structural equation modelling with correlation matrices for ordinal and continuous data. Br. J. Math. Stat. Psychol. 2011, 64, 107–133. [Google Scholar] [CrossRef]
- Choi, J.; Oehlert, G.; Zou, H. A penalized maximum likelihood approach to sparse factor analysis. Stat. Its Interface 2010, 3, 429–436. [Google Scholar] [CrossRef]
- Hirose, K.; Yamamoto, M. Sparse estimation via nonconcave penalized likelihood in factor analysis model. Stat. Comput. 2014, 25, 863–875. [Google Scholar] [CrossRef]
- Jin, S.; Moustaki, I.; Yang-Wallentin, F. Approximated Penalized Maximum Likelihood for Exploratory Factor Analysis: An Orthogonal Case. Psychometrika 2018, 83, 628–649. [Google Scholar] [CrossRef] [PubMed]
- Trendafilov, N.T.; Fontanella, S.; Adachi, K. Sparse Exploratory Factor Analysis. Psychometrika 2017, 82, 778–794. [Google Scholar] [CrossRef] [PubMed]
- Jacobucci, R.; Brandmaier, A.M.; Kievit, R.A. A Practical Guide to Variable Selection in Structural Equation Modeling by Using Regularized Multiple-Indicators, Multiple-Causes Models. Adv. Methods Pract. Psychol. Sci. 2019, 2, 55–76. [Google Scholar] [CrossRef] [PubMed]
- Serang, S.; Jacobucci, R.; Brimhall, K.C.; Grimm, K.J. Exploratory Mediation Analysis via Regularization. Struct. Equ. Model. Multidiscip. J. 2017, 24, 733–744. [Google Scholar] [CrossRef]
- van Kesteren, E.J.; Oberski, D.L. Exploratory Mediation Analysis with Many Potential Mediators. Struct. Equ. Model. Multidiscip. J. 2019, 26, 710–723. [Google Scholar] [CrossRef]
- Zhao, Y.; Luo, X. Pathway lasso: Estimate and select sparse mediation pathways with high dimensional mediators. arXiv 2016, arXiv:1603.07749. [Google Scholar]
- Chen, Y.; Li, X.; Liu, J.; Ying, Z. Regularized Latent Class Analysis with Application in Cognitive Diagnosis. Psychometrika 2017, 82, 660–692. [Google Scholar] [CrossRef]
- Robitzsch, A. Regularized Latent Class Analysis for Polytomous Item Responses: An Application to SPM-LS Data. J. Intell. 2020, 8, 30. [Google Scholar] [CrossRef]
- Liang, X.; Jacobucci, R. Regularized Structural Equation Modeling to Detect Measurement Bias: Evaluation of Lasso, Adaptive Lasso, and Elastic Net. Struct. Equ. Model. Multidiscip. J. 2019, 27, 722–734. [Google Scholar] [CrossRef]
- Magis, D.; Tuerlinckx, F.; Boeck, P.D. Detection of Differential Item Functioning Using the Lasso Approach. J. Educ. Behav. Stat. 2015, 40, 111–135. [Google Scholar] [CrossRef]
- Tutz, G.; Schauberger, G. A Penalty Approach to Differential Item Functioning in Rasch Models. Psychometrika 2013, 80, 21–43. [Google Scholar] [CrossRef] [PubMed]
- Ye, A.; Gates, K.; Henry, T.R.; Luo, L. Path and Directionality Discovery in Individual Dynamic Models: A Regularized Unified Structural Equation Modeling Approach for Hybrid Vector Autoregression. Psychometrika 2020, 86, 404–441. [Google Scholar] [CrossRef]
- Finch, W.H.; Miller, J.E. A Comparison of Regularized Maximum-Likelihood, Regularized 2-Stage Least Squares, and Maximum-Likelihood Estimation with Misspecified Models, Small Samples, and Weak Factor Structure. Multivar. Behav. Res. 2020, 56, 608–626. [Google Scholar] [CrossRef]
- Jacobucci, R.; Grimm, K.J. Comparison of Frequentist and Bayesian Regularization in Structural Equation Modeling. Struct. Equ. Model. Multidiscip. J. 2018, 25, 639–649. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. (Stat. Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; Chapman and Hall/CRC: London, UK, 2019. [Google Scholar]
- Gelman, A.; Carlin, J.; Stern, H.; Dunson, D.; Vehtari, A.; Rubin, B. Bayesian Data Analysis, 3rd ed.; Chapman and Hall/CRC: London, UK, 2013. [Google Scholar] [CrossRef]
- van Erp, S.; Oberski, D.L.; Mulder, J. Shrinkage priors for Bayesian penalized regression. J. Math. Psychol. 2019, 89, 31–50. [Google Scholar] [CrossRef]
- Geminiani, E.; Marra, G.; Moustaki, I. Single- and Multiple-Group Penalized Factor Analysis: A Trust-Region Algorithm Approach with Integrated Automatic Multiple Tuning Parameter Selection. Psychometrika 2021, 86, 65–95. [Google Scholar] [CrossRef] [PubMed]
- Wiel, M.A.; Beest, D.E.T.; Münch, M.M. Learning from a lot: Empirical Bayes for high-dimensional model-based prediction. Scand. J. Stat. 2018, 46, 2–25. [Google Scholar] [CrossRef] [PubMed]
- van Erp, S. A tutorial on Bayesian penalized regression with shrinkage priors for small sample sizes. Small Sample Size Solut. 2020, 71–84. [Google Scholar]
- Carvalho, C.M.; Chang, J.; Lucas, J.E.; Nevins, J.R.; Wang, Q.; West, M. High-Dimensional Sparse Factor Modeling: Applications in Gene Expression Genomics. J. Am. Stat. Assoc. 2008, 103, 1438–1456. [Google Scholar] [CrossRef]
- Chen, J. A Bayesian Regularized Approach to Exploratory Factor Analysis in One Step. Struct. Equ. Model. Multidiscip. J. 2021, 28, 518–528. [Google Scholar] [CrossRef]
- West, M. Bayesian factor regression models in the “large p, small n” paradigm. Bayesian Stat. 2003, 7, 733–742. [Google Scholar]
- Bhattacharya, A.; Dunson, D.B. Sparse Bayesian infinite factor models. Biometrika 2011, 98, 291–306. [Google Scholar] [CrossRef]
- Conti, G.; Fruhwirth-Schnatter, S.; Heckman, J.J.; Piatek, R. Bayesian Exploratory Factor Analysis. J. Econom. 2014, 183, 31–57. [Google Scholar] [CrossRef]
- Legramanti, S.; Durante, D.; Dunson, D.B. Bayesian cumulative shrinkage for infinite factorizations. Biometrika 2020, 107, 745–752. [Google Scholar] [CrossRef]
- Liang, X. Prior Sensitivity in Bayesian Structural Equation Modeling for Sparse Factor Loading Structures. Educ. Psychol. Meas. 2020, 80, 1025–1058. [Google Scholar] [CrossRef]
- Lu, Z.H.; Chow, S.M.; Loken, E. Bayesian Factor Analysis as a Variable-Selection Problem: Alternative Priors and Consequences. Multivar. Behav. Res. 2016, 51, 519–539. [Google Scholar] [CrossRef]
- Muthén, B.O.; Asparouhov, T. Bayesian structural equation modeling: A more flexible representation of substantive theory. Psychol. Methods 2012, 17, 313–335. [Google Scholar] [CrossRef] [PubMed]
- Vamvourellis, K.; Kalogeropoulos, K.; Moustaki, I. Generalised bayesian structural equation modelling. arXiv 2021, arXiv:2104.01603. [Google Scholar]
- Chen, J.; Guo, Z.; Zhang, L.; Pan, J. A partially confirmatory approach to scale development with the Bayesian Lasso. Psychol. Methods 2021, 26, 210–235. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Ip, E.H.; Dubé, L. An alternative to post hoc model modification in confirmatory factor analysis: The Bayesian lasso. Psychol. Methods 2017, 22, 687–704. [Google Scholar] [CrossRef]
- Kang, I.; Yi, W.; Turner, B.M. A regularization method for linking brain and behavior. Psychol. Methods 2022, 27, 400–425. [Google Scholar] [CrossRef] [PubMed]
- Chen, J. A Partially Confirmatory Approach to the Multidimensional Item Response Theory with the Bayesian Lasso. Psychometrika 2020, 85, 738–774. [Google Scholar] [CrossRef]
- Shi, D.; Song, H.; Liao, X.; Terry, R.; Snyder, L.A. Bayesian SEM for Specification Search Problems in Testing Factorial Invariance. Multivar. Behav. Res. 2017, 52, 430–444. [Google Scholar] [CrossRef]
- Chen, S.M.; Bauer, D.J.; Belzak, W.M.; Brandt, H. Advantages of Spike and Slab Priors for Detecting Differential Item Functioning Relative to Other Bayesian Regularizing Priors and Frequentist Lasso. Struct. Equ. Model. Multidiscip. J. 2021, 29, 122–139. [Google Scholar] [CrossRef]
- Guo, R.; Zhu, H.; Chow, S.M.; Ibrahim, J.G. Bayesian Lasso for Semiparametric Structural Equation Models. Biometrics 2012, 68, 567–577. [Google Scholar] [CrossRef]
- Brandt, H.; Cambria, J.; Kelava, A. An Adaptive Bayesian Lasso Approach with Spike-and-Slab Priors to Identify Multiple Linear and Nonlinear Effects in Structural Equation Models. Struct. Equ. Model. Multidiscip. J. 2018, 25, 946–960. [Google Scholar] [CrossRef]
- Feng, X.N.; Wang, G.C.; Wang, Y.F.; Song, X.Y. Structure detection of semiparametric structural equation models with Bayesian adaptive group lasso. Stat. Med. 2015, 34, 1527–1547. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.N.; Wu, H.T.; Song, X.Y. Bayesian Adaptive Lasso for Ordinal Regression With Latent Variables. Sociol. Methods Res. 2015, 46, 926–953. [Google Scholar] [CrossRef]
- Feng, X.N.; Wu, H.T.; Song, X.Y. Bayesian Regularized Multivariate Generalized Latent Variable Models. Struct. Equ. Model. Multidiscip. J. 2017, 24, 341–358. [Google Scholar] [CrossRef]
- Feng, X.N.; Wang, Y.; Lu, B.; Song, X.Y. Bayesian regularized quantile structural equation models. J. Multivar. Anal. 2017, 154, 234–248. [Google Scholar] [CrossRef]
- Chen, J. A Generalized Partially Confirmatory Factor Analysis Framework with Mixed Bayesian Lasso Methods. Multivar. Behav. Res. 2021, 57, 879–894. [Google Scholar] [CrossRef]
- Muthén, L.K.; Muthén, B.O. Mplus User’s Guide, 18th ed.; Muthén and Muthén: Los Angeles, CA, USA, 1998–2017. [Google Scholar]
- Gilks, W.R.; Thomas, A.; Spiegelhalter, D.J. A Language and Program for Complex Bayesian Modelling. Statistician 1994, 43, 169. [Google Scholar] [CrossRef]
- Lunn, D.J.; Thomas, A.; Best, N.; Spiegelhalter, D. WinBUGS-a Bayesian modelling framework: Concepts, structure, and extensibility. Stat. Comput. 2000, 10, 325–337. [Google Scholar] [CrossRef]
- Spiegelhalter, D.; Thomas, A.; Best, N.; Lunn, D.J. OpenBUGS User Manual; Version 3.2.3.; 2014. Available online: https://www.mrc-bsu.cam.ac.uk/wp-content/uploads/2021/06/OpenBUGS_Manual.pdf (accessed on 1 July 2023).
- Plummer, M. JAGS User Manual, version 4.3.0.; 2017. Available online: https://people.stat.sc.edu/hansont/stat740/jags_user_manual.pdf (accessed on 1 July 2023).
- Geman, S.; Geman, D. Stochastic Relaxation, Gibbs Distributions, and the Bayesian Restoration of Images. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 564–584. [Google Scholar] [CrossRef]
- Stan Development Team. Stan Modeling Language Users Guide and Reference Manual; Version 2.32; 2022. Available online: https://hero.epa.gov/hero/index.cfm/reference/details/reference_id/4235802 (accessed on 1 July 2023).
- Hoffman, M.D.; Gelman, A. The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Neal, R.M. MCMC using Hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo; CRC: Boca Raton, FL, USA, 2011; Volume 2, p. 2. [Google Scholar]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2, e55. [Google Scholar] [CrossRef]
- Golding, N. greta: Simple and scalable statistical modelling in R. J. Open Source Softw. 2019, 4, 1601. [Google Scholar] [CrossRef]
- van Kesteren, E.; Oberski, D.L. Flexible Extensions to Structural Equation Models Using Computation Graphs. Struct. Equ. Model. Multidiscip. J. 2021, 29, 233–247. [Google Scholar] [CrossRef]
- Rosseel, Y. lavaan: An R Package for Structural Equation Modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef]
- Zou, H. The Adaptive Lasso and Its Oracle Properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Friemelt, B.; Bloszies, C.; Ernst, M.S.; Peikert, A.; Brandmaier, A.M.; Koch, T. On the Performance of Different Regularization Methods in Bifactor-(S-1) Models with Explanatory Variables: Caveats, Recommendations, and Future Directions. Struct. Equ. Model. Multidiscip. J. 2023, 30, 560–573. [Google Scholar] [CrossRef]
- Orzek, J.H.; Arnold, M.; Voelkle, M.C. Striving for Sparsity: On Exact and Approximate Solutions in Regularized Structural Equation Models. Struct. Equ. Model. Multidiscip. J. 2023, 1–18. [Google Scholar] [CrossRef]
- Merkle, E.C.; Fitzsimmons, E.; Uanhoro, J.; Goodrich, B. Efficient Bayesian Structural Equation Modeling in Stan. J. Stat. Softw. 2021, 100, 1–22. [Google Scholar] [CrossRef]
- Khondker, Z.; Zhu, H.; Chu, H.; Lin, W.; Ibrahim, J. The Bayesian covariance lasso. Stat. Its Interface 2013, 6, 243–259. [Google Scholar] [CrossRef]
- Wang, H. Bayesian Graphical Lasso Models and Efficient Posterior Computation. Bayesian Anal. 2012, 7, 867–886. [Google Scholar] [CrossRef]
- Chen, J. LAWBL: Latent (Variable) Analysis with Bayesian Learning; R Package Version 1.5.0; 2022. Available online: https://cran.r-project.org/web/packages/LAWBL/LAWBL.pdf (accessed on 1 July 2023).
- Zhang, L.; Pan, J.; Dubé, L.; Ip, E.H. blcfa: An R Package for Bayesian Model Modification in Confirmatory Factor Analysis. Struct. Equ. Model. Multidiscip. J. 2021, 28, 649–658. [Google Scholar] [CrossRef]
- Poworoznek, E. Infinitefactor: Bayesian Infinite Factor Models; R Package Version 1.0; 2020. Available online: https://cran.r-project.org/web/packages/infinitefactor/infinitefactor.pdf (accessed on 1 July 2023).
- Bhattacharya, A.; Pati, D.; Pillai, N.S.; Dunson, D.B. Dirichlet-Laplace Priors for Optimal Shrinkage. J. Am. Stat. Assoc. 2015, 110, 1479–1490. [Google Scholar] [CrossRef] [PubMed]
- Jonker, F.; de Looff, P.; van Erp, S.; Nijman, H.; Didden, R. The adaptive ability performance test (ADAPT): A factor analytic study in clients with intellectual disabilities. J. Appl. Res. Intellect. Disabil. 2022, 36, 3–12. [Google Scholar] [CrossRef]
- van Erp, S.; Mulder, J.; Oberski, D.L. Prior sensitivity analysis in default Bayesian structural equation modeling. Psychol. Methods 2018, 23, 363–388. [Google Scholar] [CrossRef]
- van de Schoot, R.; Veen, D.; Smeets, L.; Winter, S.D.; Depaoli, S. A Tutorial on Using The Wambs Checklist to Avoid The Misuse of Bayesian Statistics. In Small Sample Size Solututions; Routledge: Abingdon, UK, 2020; pp. 30–49. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Gabry, J.; Modrak, M. Visual MCMC Diagnostics Using the Bayesplot Package. 2022. Available online: https://mc-stan.org/bayesplot/articles/visual-mcmc-diagnostics.html (accessed on 12 July 2023).
- Kucukelbir, A.; Ranganath, R.; Gelman, A.; Blei, D. Automatic variational inference in Stan. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Zhang, L.; Pan, J.; Ip, E.H. Criteria for Parameter Identification in Bayesian Lasso Methods for Covariance Analysis: Comparing Rules for Thresholding, p-value, and Credible Interval. Struct. Equ. Model. Multidiscip. J. 2021, 28, 941–950. [Google Scholar] [CrossRef]
- Lu, S.; Liu, Y.; Yin, L.; Zhang, K. Confidence Intervals and Regions for the Lasso by Using Stochastic Variational Inequality Techniques in Optimization. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2016, 79, 589–611. [Google Scholar] [CrossRef]
- Huang, P.H. Postselection Inference in Structural Equation Modeling. Multivar. Behav. Res. 2019, 55, 344–360. [Google Scholar] [CrossRef]
- Park, T.; Casella, G. The Bayesian Lasso. J. Am. Stat. Assoc. 2008, 103, 681–686. [Google Scholar] [CrossRef]
- Guo, J.; Marsh, H.W.; Parker, P.D.; Dicke, T.; Lüdtke, O.; Diallo, T.M.O. A Systematic Evaluation and Comparison Between Exploratory Structural Equation Modeling and Bayesian Structural Equation Modeling. Struct. Equ. Model. Multidiscip. J. 2019, 26, 529–556. [Google Scholar] [CrossRef]
- Liang, X.; Yang, Y.; Cao, C. The Performance of ESEM and BSEM in Structural Equation Models with Ordinal Indicators. Struct. Equ. Model. Multidiscip. J. 2020, 27, 874–887. [Google Scholar] [CrossRef]
- Hoijtink, H.; van de Schoot, R. Testing small variance priors using prior-posterior predictive p values. Psychol. Methods 2018, 23, 561–569. [Google Scholar] [CrossRef] [PubMed]
- Garnier-Villarreal, M.; Jorgensen, T.D. Adapting fit indices for Bayesian structural equation modeling: Comparison to maximum likelihood. Psychol. Methods 2020, 25, 46–70. [Google Scholar] [CrossRef]
- Piironen, J.; Vehtari, A. Comparison of Bayesian predictive methods for model selection. Stat. Comput. 2016, 27, 711–735. [Google Scholar] [CrossRef]
- Hahn, P.R.; Carvalho, C.M. Decoupling Shrinkage and Selection in Bayesian Linear Models: A Posterior Summary Perspective. J. Am. Stat. Assoc. 2015, 110, 435–448. [Google Scholar] [CrossRef]
- Biswas, N.; Mackey, L.; Meng, X.L. Scalable Spike-and-Slab. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 2021–2040. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ridge | Lasso | Lasso Extensions | Spike-and-Slab | Other | |
|---|---|---|---|---|---|
| Exploratory factor model | Carvalhoet al. (2008) [37]; Chen (2021) [38]; West (2003) [39] | Bhattacharya & Dunson (2011) [40]; Conti et al. (2014) [41]; Legramanti et al. (2020) [42] | |||
| Confirmatory factor model | Liang (2020) [43] *; Lu et al. (2016) [44]; Muthén and Asparouhov (2012) [45] *; Vamvourellis et al. (2021) [46] | Chen, Guo et al. (2021) [47]; Pan et al. (2017) [48] | Chen, Guo et al. (2021) [47] | Lu et al. (2016) [44] | |
| Neural drift diffusion model | Kang et al. (2022) [49] | ||||
| Item response model | Vamvourellis et al. (2021) [46] | Chen (2020) [50] | |||
| Multiple-group factor model | Shi et al. (2017) [51] * | Chen, Bauer et al. (2021) [52] | Chen, Bauer et al. (2021) [52] | ||
| Non-linear SEM | Guo et al. (2012) [53] | Brandt et al. (2018) [54]; Feng, Wang et al. (2015) [55] | Brandt et al. (2018) [54] | ||
| General SEM | Feng, Wu et al. (2015) [56]; Feng, Wu et al. (2017) [57] | Feng, Wu et al. (2015) [56]; Feng, Wu et al. (2017) [57] | |||
| Quantile SEM | Feng, Wang et al. (2017) [58] | Feng, Wang et al. (2017) [58] | |||
| Latent growth curve model | Jacobucci and Grimm (2018) [26] |
| Package | Open-Source | Free | User-Friendly | Model Flexibility | Penalty/Prior Flexibility |
|---|---|---|---|---|---|
| Classical regularized SEM | |||||
| regsem | + | + | + | + | + |
| lslx | + | + | + | + | + |
| penfa | + | + | + | − | + |
| lessSEM | + | + | + | + | |
| Bayesian regularized SEM | |||||
| Mplus | − | − | − | + | − |
| OpenBUGS/JAGS | + | + | − | + | + |
| Stan | + | + | − | + | + |
| PyMC3 | + | + | − | + | + |
| Greta | + | + | −/+ | + | + |
| TensorSEM | + | + | − | + | + |
| blavaan | + | + | + | + | − |
| LAWBL | + | + | + | − | − |
| blcfa 2 | − | − | |||
| infinitefactor | + | + | + | − | + |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van Erp, S. Bayesian Regularized SEM: Current Capabilities and Constraints. Psych 2023, 5, 814-835. https://doi.org/10.3390/psych5030054
van Erp S. Bayesian Regularized SEM: Current Capabilities and Constraints. Psych. 2023; 5(3):814-835. https://doi.org/10.3390/psych5030054
Chicago/Turabian Stylevan Erp, Sara. 2023. "Bayesian Regularized SEM: Current Capabilities and Constraints" Psych 5, no. 3: 814-835. https://doi.org/10.3390/psych5030054
APA Stylevan Erp, S. (2023). Bayesian Regularized SEM: Current Capabilities and Constraints. Psych, 5(3), 814-835. https://doi.org/10.3390/psych5030054