1. Introduction
Obtaining good user data has always been a critical task for Machine Learning (ML) applications. Innovative model architectures like Diffusion models and Transformers are trained on an enormous amount of data to provide satisfying results. Data can be obtained either from well-curated datasets or by crawling the open internet. Furthermore, accessing new end-user data or data collected or generated by Internet of Things (IoT) devices can be beneficial, especially in terms of fine-tuning and personalization. However, there is a vital matter of privacy when handling user data, therefore, Federated Learning (FL) has been proposed as a solution [
1], enabling decentralized training across multiple clients while maintaining data privacy. With the FL approach, clients train a shared global model on their local data, with the coordination of a central server. Clients send only the model weight updates, and their raw data are not shared with other clients or the central server. This method can be beneficial, especially in cases where data privacy and security are prioritized, such as in healthcare, finance, and mobile applications [
2,
3].
FL may offer some important advantages; however, it also presents several distinctive challenges compared to centralized or classic Distributed Machine Learning (DML), particularly in the realm of optimization [
4]. The primary obstacles include handling non-independent and identically distributed (non-IID) data across clients, managing communication overhead, and ensuring model convergence despite intermittent partial client participation [
5,
6,
7,
8,
9]. Classic optimization techniques like Stochastic Gradient Descent (SGD) tend to be more sensitive to hyperparameter selection and tuning; therefore, they often struggle in such environments [
10]. Additionally, client data heterogeneity and the decentralized nature of FL tend to worsen troubling issues such as client drift, where local model updates diverge from the global objective, leading to suboptimal performance and slower convergence [
11,
12].
To overcome these challenges, adaptive optimization methods have gained popularity in FL. These methods dynamically adjust Learning Rates (LRs) based on the historical gradient information, therefore enhancing convergence speed and model generalization [
13,
14,
15]. Adaptive optimizers such as Adam, Yogi, or Adagrad have been proposed as server optimizers in FL settings [
10], showing positive findings by tackling issues related to hyperparameter sensitivity and gradient noise. However, convergence speed and generalization are more challenging issues when dealing with non-IID data in an FL setting. Adabound and AdaDB have been proposed as a way to address these challenges, and they demonstrate promising results in centralized and DML training [
16,
17]. These methods introduced the concept of bound adaptive optimization, an innovative strategy adding an element-wise clipping operation, thus providing faster convergence and better generalization. Traditional adaptive optimizers do not consider the variability in data distribution across clients, which can lead to inefficient updates and slower convergence.
In this research, AdaDB is adapted in the FL setting (FedAdaDB), investigating the power of a data-bound adaptive optimizer in an FL setting. The proposed data-bound adaptive algorithm, FedAdaDB, incorporates data-specific characteristics into the optimization process. By adapting LRs not just based on gradient history but also indirectly based on the nature of the data of each client, this algorithm attempts to achieve faster convergence and more robust performance in the FL context. This paper demonstrates notable advancements in the field of federated optimization through the development and evaluation of FedAdaDB. Some of the paper contributions are as follows: (1) Algorithm Innovation: The introduction of the FedAdaDB algorithm, which leverages data-bound techniques to dynamically adjust optimization strategies based on client-specific data characteristics, improving the efficiency and effectiveness of the learning process. (2) Empirical Validation: Through extensive experiments on diverse FL benchmarks, it is shown that FedAdaDB can improve convergence speed, model accuracy, and robustness to data heterogeneity compared to traditional and existing adaptive federated optimizers. (3) Algorithm comparison: FedAdaDB results are compared with the results of the baseline non-adaptive algorithm FedAvg and the widely used FedAdam adaptive algorithm on three different datasets and learning tasks. The algorithms’ hyperparameters are meticulously fine-tuned via grid search to ensure a balanced comparison of every algorithm’s best performance.
6. Discussion
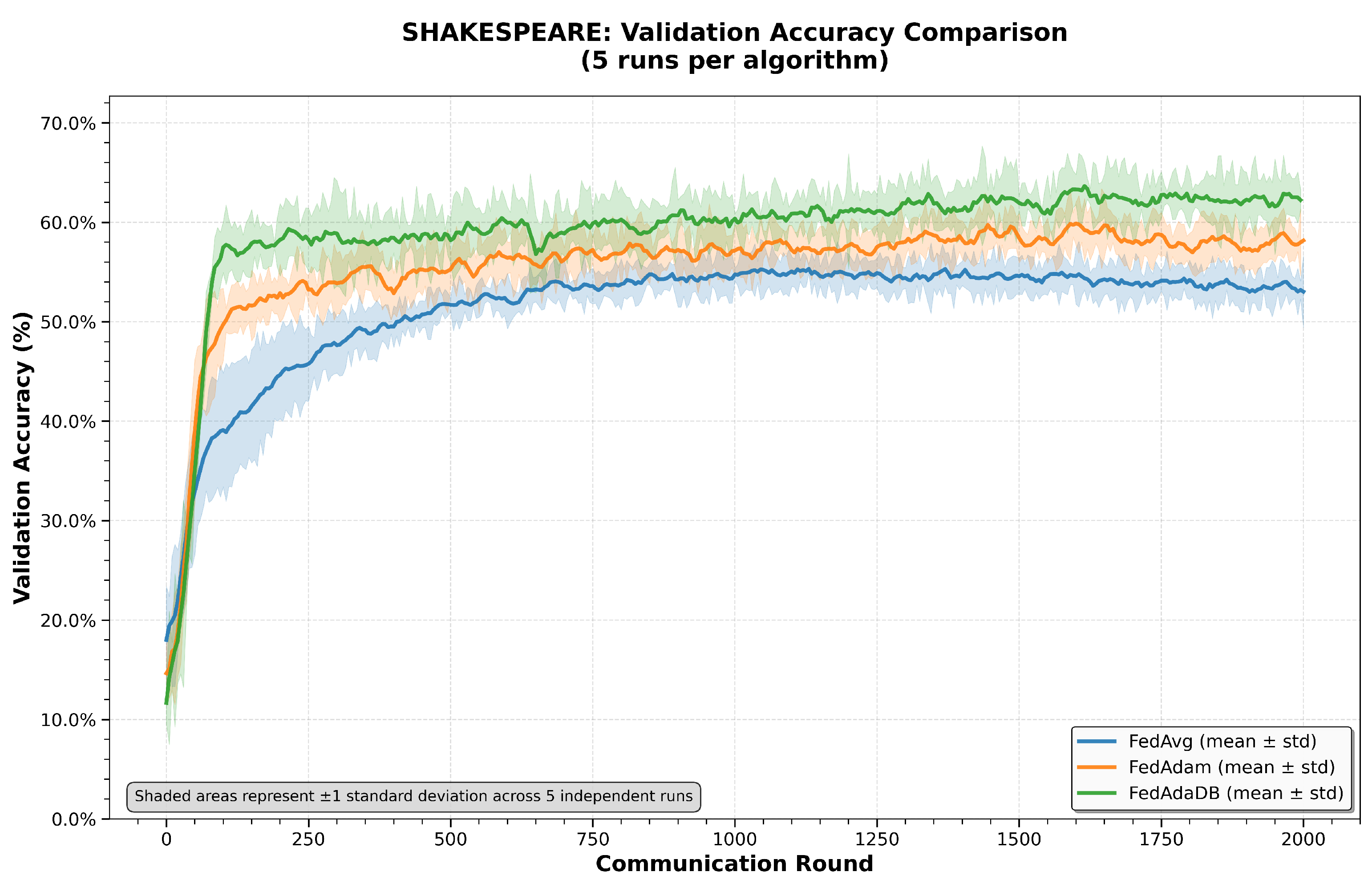
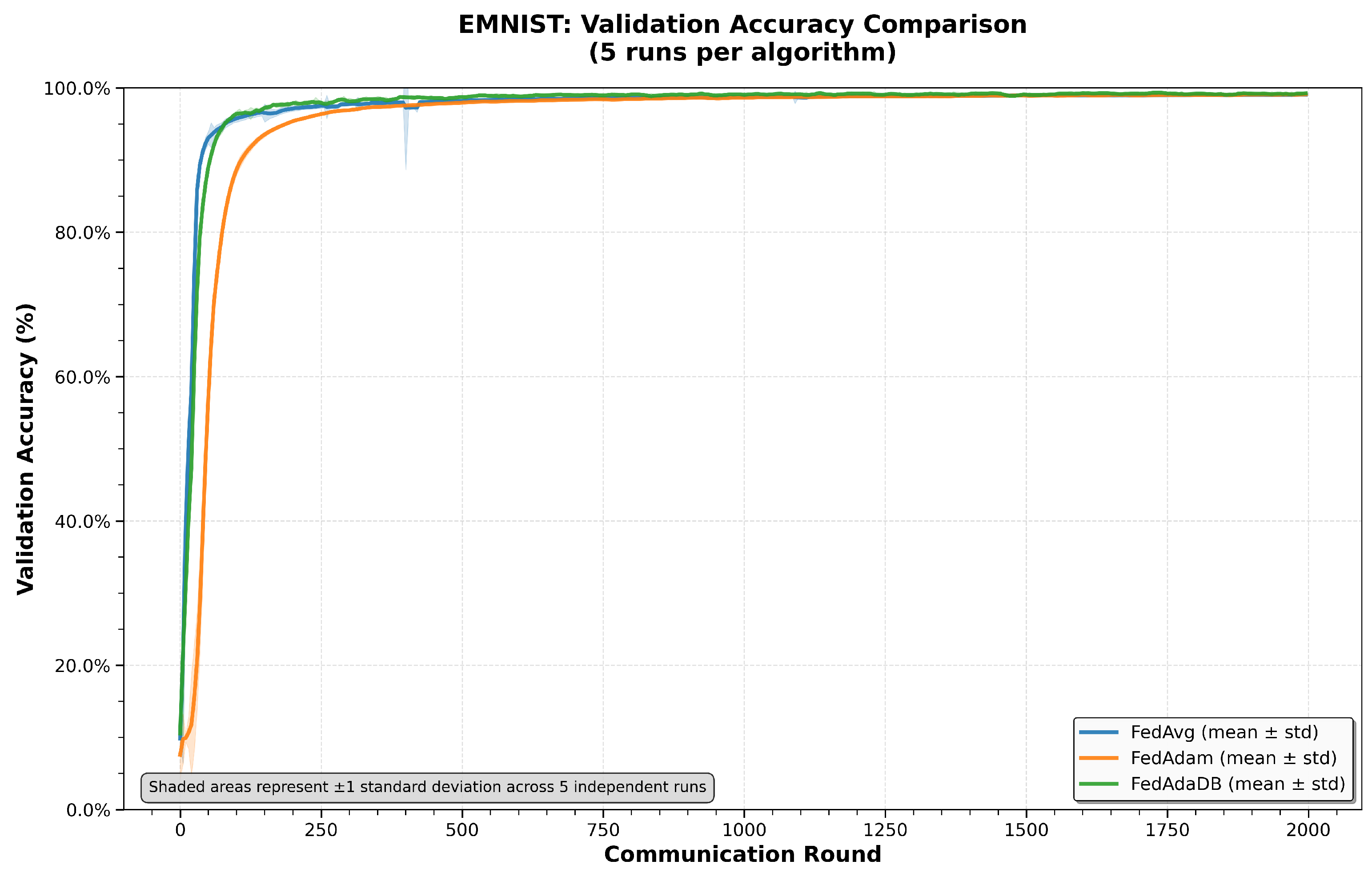
In this section, the results of the executed tests will be discussed and analyzed in depth to investigate the initial hypotheses, stating that the data-bound adaptive optimizer in the FL environment can be proven beneficial, compared to other FL algorithms, like the baseline non-adaptive FedAvg and the widely used adaptive FedAdam. The overall comparison across CIFAR100, Shakespeare, and EMNIST datasets indicates that FedAdaDB’s data-bound learning-rate clipping consistently improves validation accuracy, while also enhancing stability once a satisfactory performance level is reached. There is an apparent trade-off in the early convergence, where FedAdaDB sacrifices some convergence speed due to the clipping mechanism, which will be discussed in more detail later in this section. Moreover, paired t-tests confirm that the results are statistically significant on more challenging, heterogeneous tasks such as NCP using the Shakespeare dataset and image classification with the CIFAR100 dataset. On the other hand, on relatively easier tasks, like handwritten character recognition, using the EMNIST dataset, every algorithm performs fairly well, and FedAdaDB’s improvements are smaller and do not hold a strong statistical significance.
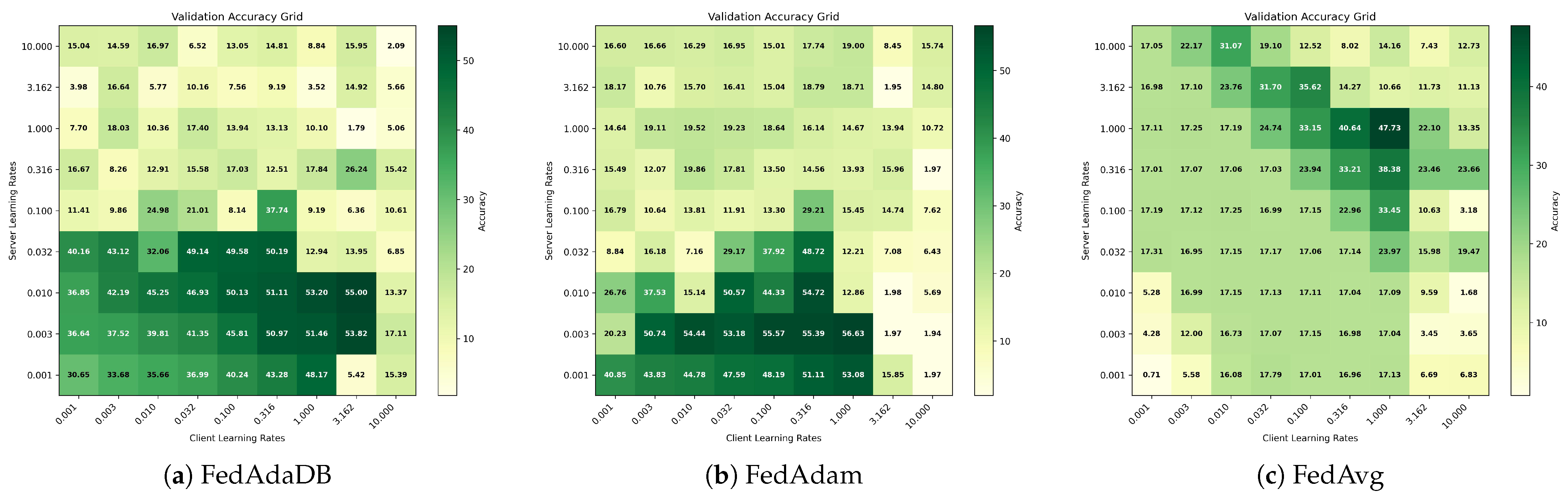
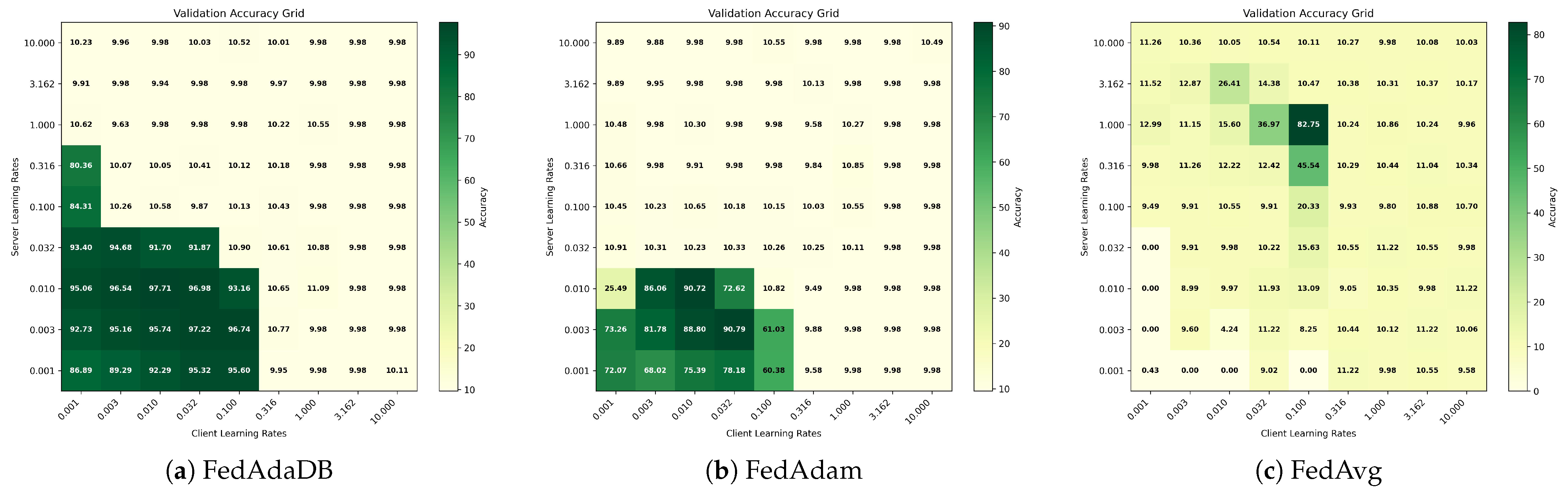
Regarding the final validation accuracy metric, according to
Table 1, FedAdaDB demonstrates the highest average values over the last 100 rounds. These results highlight that, given enough communication rounds, server-side clipping leads to better results on the global model. While the server operates on aggregated updates rather than on raw client data, these aggregates still carry valuable information about the collective gradient landscape. FedAdaDB’s bounding technique likely mitigates the impact of divergent or noisy updates [
49] stemming from client non-IID data and client drift, which can lead optimizers without clipping to converge to suboptimal solutions. The clipping prevents overly aggressive steps in the global model update, offering a more stable trajectory towards better generalizing minima, especially in complex, non-convex landscapes typical of the deep learning models used in FL. Moreover, SGD tends to achieve better generalization than Adam [
50], and FedAdaDB’s data-bound clipping dictates the server optimizer to act more like Adam in the early stages and gradually move to an SGD-like behavior.
The convergence at an early stage indicates the algorithm’s convergence speed, and it is measured by the “Rounds to Threshold” metric. By examining the CIFAR100 dataset results, the FedAdaDB algorithm needs 220 rounds to reach 20% of validation accuracy, which is slower than both FedAdam and FedAvg, which require 135 and 155 rounds, respectively. The results are shifted when examining the 35% threshold where FedAdaDB requires only 565 rounds, which is significantly faster than FedAvg and even FedAdam, with 1465 and 605 rounds, respectively. As expected, FedAdaDB’s clipping mechanism has an impact on the convergence speed [
17]. Clipping can lead to slower but often better convergence [
51], since very large or noisy gradients are getting cut. However, after some training rounds, once past initial noise, the data-bound clipping seems to accelerate the meaningful learning. Similarly, on the EMNIST dataset, FedAdaDB needs 30 rounds to reach the 75% threshold and 45 rounds to achieve 85%, while FedAvg reaches 75% in 20 rounds and 85% in 30%. In this task, FedAdaDB outperformed FedAdam, which required 70 rounds to reach the 75% threshold and 85 rounds for the 85%. On this relatively easier task, FedAvg had an advantage and managed to converge faster since the clipping mechanism delayed FedAdaDB at the early stage. However, it offered an advantage over the FedAdam algorithm at an early stage. Finally, on the Shakespeare dataset the convergence dynamics present a different pattern. For the first threshold of 35% validation accuracy, both FedAdaDB and FedAdam demonstrate fast convergence, reaching the target in 50 rounds, surpassing FedAvg, which required 60 rounds. This suggests that, for the specific challenges of the Shakespeare dataset, characterized by significant data heterogeneity across clients [
43], the stabilizing effect of FedAdaDB’s data-bound clipping might immediately counteract potential instability or excessively large gradients that could impose difficulties on other methods. The adaptive nature of both FedAdaDB and FedAdam provides an early advantage over the simpler FedAvg in the task of NCP. Moving to the higher 45% accuracy threshold, FedAdaDB achieves this in 70 rounds. While FedAdam reaches this slightly faster at 60 rounds, FedAdaDB maintains a substantial lead over FedAvg, which lags significantly, requiring 200 rounds. This indicates that while FedAdam’s adaptive learning rates might provide a slight edge in pure speed during this phase, FedAdaDB’s clipping mechanism continues to ensure robust and efficient progress. The data-bound clipping appears to achieve a good balance, preventing harmful model updates without overly restricting progress, leading to strong performance throughout the training process on this dataset.
The third metric, “Avg Acc Post-Threshold”, is an index of how stable are an algorithm’s results once the model has surpassed a satisfactory performance level. Across all datasets (
Table 1,
Table 2 and
Table 3), FedAdaDB consistently reaches higher average accuracies post-threshold compared to FedAvg and FedAdam. In the CIFAR100 dataset, FedAdaDB attains a post-35% accuracy of 41.91%, outperforming FedAdam (38.11%) and FedAvg (35.37%). The same behavior is more apparent on Shakespeare, with a FedAdaDB average accuracy of 60.65% vs. 57.07% and 52.25% on FedAdam and FedAvg, respectively. Accordingly, on the EMNIST dataset an average of 98.89% vs. 98.82% and 98.52%. These results are strongly linked to FedAdaDB’ s adaptive gradient clipping mechanism, which gradually transitions toward a plain SGD behavior as training progresses. When the LR decays or gradients become sparse, for example, in latter training rounds of an SGD, its generalization performance is closely tied to its stability. SGD tends to maintain or improve stability under the aforementioned conditions, especially when aided by regularization, like clipping or weight decay [
52]. FedAdaDB’ s design allows for aggressive adaptation in early rounds, while converging toward a more stable, SGD-like regime later. This is likely why FedAdaDB performs better in the post-threshold phase. In contrast, FedAdam, though initially fast in convergence, presents less stability in the post-threshold metric, possibly due to the adaptivity of its momentum-based updates, which may introduce some variance. FedAvg, which lacks any adaptive mechanism to regulate instability, results in consistently lower post-threshold accuracy.
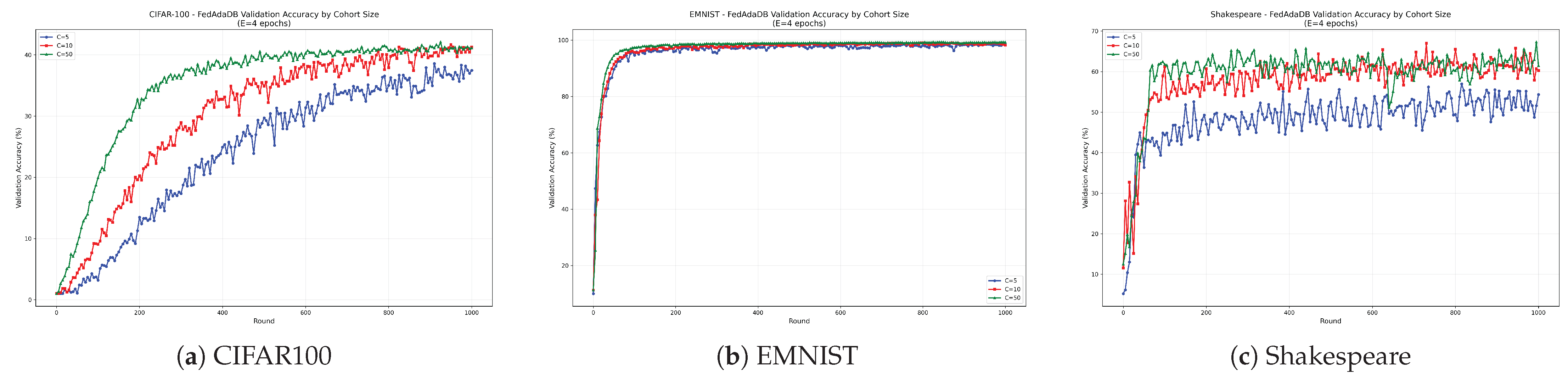
Analyzing FedAdaDB’s behavior under varying client participation levels, as presented in
Figure 11, reveals that the algorithm generally benefits from larger cohort sizes, particularly on more complex datasets like CIFAR100 and Shakespeare. Increasing the number of participating clients per round (from C = 5 to C = 10 and C = 50) typically led to faster convergence and improved validation accuracy. This is aligned with the expectation that aggregating updates from a larger and more diverse set of clients per round can enhance the learning process. These findings suggest that, while FedAdaDB is robust, its convergence speed and the quality of the global model can be further optimized in practice by increasing client participation in each training round, where feasible. On the other hand, it is worth mentioning that, while increasing client participation leads to faster convergence, it has a limited impact on the final validation accuracy. Therefore, this is another trade-off that should be taken into consideration. Increasing the cohort size results in more client power consumption and increased data transfer and communication overhead. Additionally, continuously increasing the cohort size may introduce side effects such as generalization issues, diminishing returns, or catastrophic training [
47].
While the empirical evidence supports the effectiveness and convergence of FedAdaDB, a formal and rigorous theoretical convergence analysis within the FL constraints and characteristics remains an important task for future investigation. Such an analysis would need to explicitly account for factors like data heterogeneity, partial client participation, and the impact of communication rounds on the convergence rate and quality. Proving that AdaDB’s convergence conditions are strictly met by the server-side optimizer using aggregated updates would solidify the theoretical concepts of FedAdaDB.
6.1. Statistical Significance
Analyzing the paired
t-test results on the final validation accuracy, there seems to be a confirmation of the practical relevance of the observed improvements of FedAdaDB over the other two algorithms. Regarding the CIFAR100 dataset in
Table 4, FedAdaDB against FedAdam returns a
p-value of
, and against FedAvg,
. Therefore, the gains of FedAdaDB are considered significant. Similarly, on the Shakespeare dataset in
Table 5, the statistical significance is also strong, with a
p-value of
when comparing FedAdaDB with FedAdam and
when comparing with FedAvg. On the EMNIST dataset in
Table 6, neither comparison crosses the typical
threshold (FedAdaDB vs. FedAdam
; FedAdaDB vs. FedAvg
), which reflects the marginal statistical importance of FedAdaDB’s improvements in a relatively easy learning task.
6.2. Limitations and Future Work
This paper demonstrates that FedAdaDB’s data-bound clipping mechanism can significantly improve the final model’s accuracy and stability when applied on the server-side optimizer. The results underlined that FedAdaDB shows a slower convergence at an early stage due to the clipping mechanism that penalizes aggressive updates. This characteristic of slower initial convergence warrants further discussion, particularly in the context of real-world FL deployments, which often suffer from communication impairments, such as packet losses or variable channel quality [
53,
54]. In such challenging communication environments, the slightly increased number of communication rounds that FedAdaDB might require to reach initial performance thresholds could become a more pronounced limitation. If communication rounds are frequently disrupted, delayed, or costly, an algorithm that takes longer to exhibit substantial gains in its early phases might be less practical, as each successful communication round becomes more critical. Therefore, if an application instructs that the initial convergence speed should be prioritized over the achieved final accuracy, then the selection of the most suitable server-side optimizer should be re-evaluated. Moreover, FedAdaDB architecture introduces an additional hyperparameter, the final LR
. Tuning an extra hyperparameter will increase the time and computational resources needed to achieve the ideal settings of the optimizer. Future researchers and practitioners could expand the application of the data-bound clipping mechanism to other adaptive optimizers like Yogi. Additionally, FedAdaDB could be evaluated in settings with more strict communication constraints, potentially combining it with techniques to reduce communication overhead. Techniques such as gradient sparsification or quantization have been proven to be beneficial [
55]. Jump transmission is another promising approach in this domain, where only the model parameter differences are sent to the server, significantly reducing the volume of transmitted data without impacting model performance [
56]. Furthermore, to more comprehensively investigate FedAdaDB’s universality and superiority, future work should include empirical comparisons against a wider range of recent federated optimization algorithms, such as FedYogi or FedLion. Such comparisons would provide deeper insights into the relative strengths of different adaptive and debiasing strategies in FL.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}