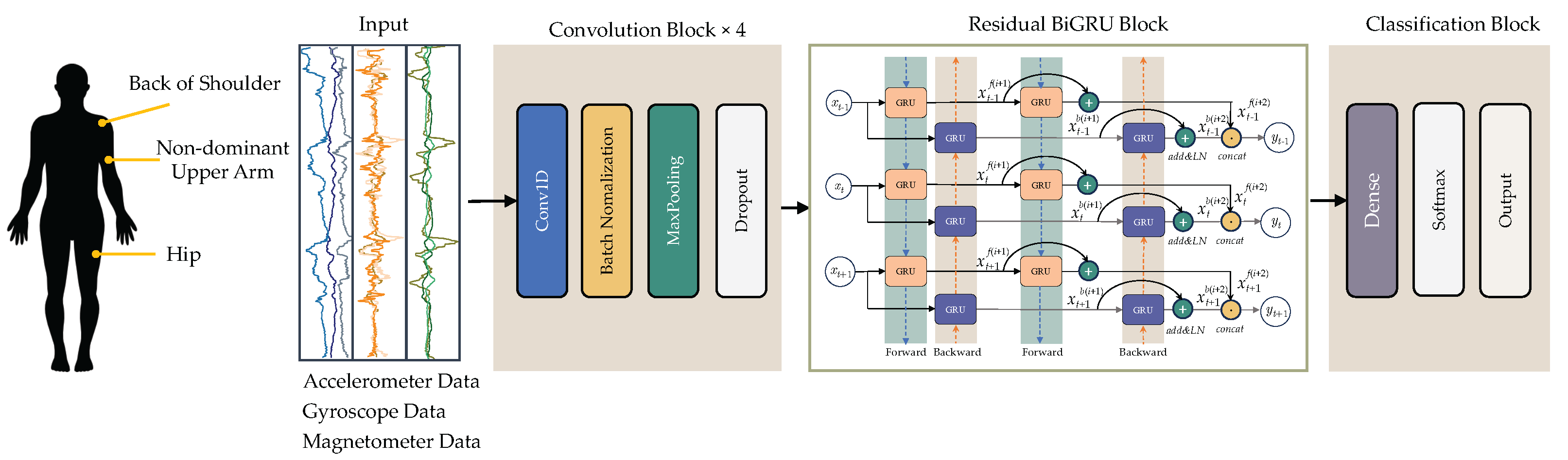
4.1. Experiment Settings
This study employed the Google Colab Pro+ platform, leveraging a Tesla L4 GPU to expedite the training processes of deep learning models. The architecture of the proposed CNN-ResBiGRU model, along with various baseline deep learning models, was implemented in Python (version 3.11.13) using TensorFlow (version 2.17.1) and CUDA (version 12.4) as computational backends.
Several essential Python libraries supported the development and experimentation process:
NumPy (version 1.26.4) and Pandas (version 2.2.2) were utilized for efficient data manipulation, including data acquisition, processing, and sensor-based analysis.
Matplotlib (version 3.10.0) and Seaborn (version 0.13.2) served as visualization tools to graphically present the results of exploratory data analysis and model performance.
Scikit-learn (Sklearn 1.5.2) was employed for data sampling and pre-processing during various phases of experimentation.
TensorFlow in combination with Keras (version 2.5.0) was used to construct and train the deep learning models.
To assess the effectiveness of the proposed methodology, comprehensive experimental analyses were carried out using the VTT-ConIoT dataset. A 5-fold cross-validation strategy was adopted to ensure the consistency and generalizability of the results.
Three separate experimental setups were designed to evaluate the model’s performance across different activity classification challenges:
Scenario I addressed a binary classification task by differentiating between recommended and non-recommended construction activities. This setup emphasized safety and ergonomic considerations by organizing the 16 activities into two overarching categories.
Scenario II focused on a task-oriented classification framework, wherein the 16 activities were grouped into six general functional clusters: painting, cleaning, climbing, hands-up work, floor-related tasks, and walking movements. This scenario aimed to assess the model’s capability to detect broader construction task types.
Scenario III evaluated the model’s proficiency in identifying all 16 distinct activity classes individually. This configuration represented the most detailed and complex classification challenge, intended to test the comprehensive discriminative ability of the proposed CNN-ResBiGRU approach.
4.1.1. Cross-Validation Strategy
To assess the robustness and adaptability of our proposed method, we employed a participant-independent 5-fold cross-validation technique. The dataset, comprising sensor data from 13 distinct individuals, was partitioned in such a way that no participant’s data appeared simultaneously in both the training and testing subsets within any given fold.
In each fold, approximately 80% of the participants—equivalent to 10 individuals—were randomly selected for the training set, while the remaining 3 participants (around 20%) formed the testing set. This design ensured that the model was evaluated on data from participants it had not encountered during training, thereby offering a more realistic estimation of its generalization capabilities in real-world scenarios.
Moreover, within each fold’s training set, we allocated 20% of the samples, chosen at random, to serve as a validation set. This subset was used for tasks such as tuning model hyperparameters and implementing early stopping criteria. Consequently, each fold utilized roughly 64% of the entire dataset for model training, 16% for validation, and 20% for final testing.
This cross-validation methodology was uniformly adopted across all experimental configurations, including variations in sensor placement and time window size, to ensure a consistent and unbiased comparison of results.
4.1.2. Baseline Performance
To accurately interpret our experimental outcomes, we first established baseline performance thresholds for each classification task. In Scenario I, which involves binary classification, we derived a baseline based on the distribution of activity classes. Specifically, within the VTT-ConIoT dataset, 11 out of 16 activities (equivalent to 62.5%) are categorized as recommended. As a result, a naive classifier that always predicts the majority class would achieve a baseline accuracy of 68.75.
In Scenario II, corresponding to the six-class classification, the task categories are more evenly distributed across the six classes. Therefore, the expected accuracy of a simple model predicting the most frequent class would be around 16.7%.
For Scenario III, which involves classifying 16 distinct activities, assuming a uniform distribution across all classes, a random guess would yield an accuracy of approximately 6.25%.
These baseline values represent the minimal performance thresholds against which the efficacy of our CNN-ResBiGRU model is assessed. They provide essential reference points for evaluating how well the proposed approach performs across varying sensor placements and segmentation window lengths.
4.2. Experimental Results
This section presents the experimental assessments carried out to evaluate the effectiveness of the proposed CNN-ResBiGRU model. The recognition performance was examined across three distinct activity classification tasks.
The experimental findings from Scenario I, as detailed in
Table 4, highlight the impact of sensor placement and window length on the binary classification of construction activities into recommended and non-recommended categories. The classification outcomes varied depending on the location of the sensors, with each position presenting unique strengths.
Among the configurations, the sensor positioned on the back displayed consistently strong performance across various window durations. Accuracy values ranged from 92.75% to 93.91%, with the highest accuracy of 93.85% recorded when a 6 s window was used. This configuration also yielded balanced precision and recall scores of 92.16% and 91.53%, respectively. These results indicate that back-mounted sensors can capture key distinguishing features of physical activity in construction environments.
The hand sensor configuration emerged as the most effective single-sensor setup. It reached the highest observed accuracy of 95.03% when a 4 s window size was applied. This superior performance can be attributed to the hand’s sensitivity to motion, which enables it to register nuanced activity patterns typical in construction tasks. In addition, this sensor maintained high levels of both precision and recall across all window lengths, suggesting reliable classification capability.
Although the hip-mounted sensor exhibited slightly reduced performance relative to the back and hand placements, it still delivered satisfactory results. The best accuracy for this position was 93.22% using a 4 s window. The comparatively lower performance is likely due to the hip region displaying less differentiated motion patterns between recommended and non-recommended behaviors.
The most notable outcome was observed in the multi-sensor configuration labeled “All,” which combined data from multiple sensor locations. This fusion-based approach significantly outperformed the individual sensor configurations across all evaluation metrics. It achieved the highest accuracy of 97.32% using a 4 s window, alongside excellent precision (96.45%) and recall (96.43%) values. These results affirm the advantages of integrating multiple sensor inputs to capture more comprehensive information about worker activities.
Regarding the analysis of window durations, the 4 s window generally offered the most favorable balance across different sensor setups. This duration appears well-suited to capture the temporal characteristics of construction activities while maintaining computational efficiency. The reliability of the results is further supported by the low standard deviations observed across evaluation metrics, indicating the consistent and stable performance of the CNN-ResBiGRU model.
The results from Scenario II (
Table 5), which focused on classifying construction activities into six functional groups, confirm the effectiveness of the CNN-ResBiGRU model across various sensor placements and window durations. The back sensor showed strong and consistent performance, with accuracy ranging from 91.01% to 92.27%. Its best results were with 8 s windows, achieving 92.27% accuracy, 92.83% precision, and 92.17% recall, indicating its suitability for capturing full-body movements.
The hand sensor, while slightly less accurate than in binary classification (Scenario I), still performed well, particularly with 4 s windows—yielding 91.87% accuracy, 91.90% precision, and 92.01% recall. The minor decline may be due to the increased difficulty of distinguishing six classes rather than two.
The hip sensor showed a distinct pattern. Although generally lower in performance than the back and hand placements, it achieved its highest accuracy (91.90%) with 8 s windows. This suggests it benefits from longer temporal contexts to recognize complex activities.
The multi-sensor setup (“All”) delivered the highest performance overall. With just a 2 s window, it reached 97.14% accuracy, along with precision and recall values of 97.22% and 97.20%, respectively. Notably, its accuracy remained above 95% across all window sizes, demonstrating the robustness of sensor fusion and its potential for fast and reliable classification.
Although standard deviations were slightly higher than in Scenario I, they remained low overall, indicating stable model behavior despite the increased task complexity. These findings highlight the model’s effectiveness in multi-class recognition tasks. They also suggest that while individual sensors are adequate, combining multiple sensors greatly enhances recognition performance—particularly for real-time applications requiring rapid activity classification.
Table 6 reports the findings from Scenario III, which involves the most complex task—classifying all 16 individual construction activities. The results highlight noticeable variations in model performance across different sensor types and window durations, illustrating the challenges of fine-grained activity recognition.
The back sensor exhibited moderate effectiveness, with accuracy ranging from 80.48% to 83.40%. Its highest performance occurred with a 4 s window, achieving 83.40% accuracy, 84.01% precision, and 83.38% recall. Compared to previous scenarios, this decrease in accuracy is expected due to the increased classification complexity. Moreover, performance declined as the window lengthened, indicating that shorter windows more effectively capture distinct movement patterns.
The hand sensor slightly outperformed the back sensor, with accuracy ranging from 78.36% to 83.09%. Its optimal result, also at 4 s, yielded 83.09% accuracy, 83.81% precision, and 83.08% recall. However, performance dropped when using windows longer than 6 s, suggesting that brief time frames are more suitable for recognizing hand-based activities.
The hip sensor showed the lowest accuracy among all single-sensor setups, ranging from 76.96% to 82.61%. Still, its best performance also occurred at the 4 s window. This consistent trend across all placements reinforces the conclusion that a 4 s window offers a balanced duration for capturing relevant features while preserving temporal specificity.
The multi-sensor configuration (“All”) significantly outperformed individual sensors. It reached its highest performance with a 4 s window, recording 98.68% accuracy, 98.73% precision, and 98.69% recall. The pronounced performance gap between this setup and single-sensor configurations was more significant than in earlier scenarios, emphasizing the growing importance of sensor fusion as classification complexity increases. Notably, even with extended windows, the multi-sensor approach maintained high reliability, though peak accuracy was still achieved with shorter durations.
Standard deviations were slightly higher than in Scenarios I and II, which aligns with the increased difficulty of differentiating between 16 distinct classes. The multi-sensor model exhibited greater consistency, showing less variability than single-sensor alternatives.
Therefore, these results confirm that fine-grained recognition tasks challenge single-sensor systems, but the CNN-ResBiGRU model with multi-sensor fusion provides a highly accurate and stable solution. The 4 s window consistently delivers optimal performance, and combining data from multiple sensors proves essential for high-precision, detailed activity classification in construction environments.
4.3. Comparison Results with State-of-the-Art Models
To validate the performance and advantages of the proposed CNN-ResBiGRU architecture in the context of CWAR, we conducted an extensive comparative evaluation against state-of-the-art methods using the publicly available VTT-ConIoT benchmark dataset. By employing identical experimental setups and standardized evaluation protocols, we ensured a fair and consistent comparison across all models.
To maintain methodological integrity and avoid bias, we reproduced the experimental procedures established in the baseline study [
19]. The evaluation process involved segmenting each pre-processed one-minute signal using fixed-duration sliding windows of 2, 5, and 10 s, each advanced by a one-second overlap. For model validation, we adopted a strict leave-one-subject-out (LOSO) cross-validation framework. In this scheme, for a dataset comprising
N participants,
N separate models were independently trained and assessed. Each iteration excluded one subject from the training set, using their data solely for testing, while the remaining participants contributed to the training set.
This validation strategy provides a robust measure of the model’s ability to generalize across unseen individuals, effectively addressing the challenge of inter-subject variability that commonly affects human activity recognition systems. Through the LOSO process, a total of thirteen models per classification algorithm and data modality were generated and evaluated.
Although this approach captures the nuanced behavioral patterns of individual construction workers, the aggregate performance metrics offer a clear representation of the model’s overall generalization strength. To further examine model reliability, we calculated and reported classification accuracy across all test subjects. These results reveal both the variability and consistency of the model when applied to participants whose data were not included in the training set.
Table 7 provides a detailed comparative analysis between the proposed CNN-ResBiGRU framework and the traditional SVM baseline under varying segmentation window lengths and classification complexities. The experimental findings indicate that our deep learning model consistently delivers superior performance across all tested configurations.
In the six-class classification scenario, the CNN-ResBiGRU model achieved recognition accuracies of 90.24%, 93.46%, and 95.79% for window lengths of 2, 5, and 10 s, respectively. In contrast, the corresponding SVM baseline produced accuracies of 86%, 89%, and 94% under the same conditions. This translates to improvements of 4.24%, 4.46%, and 1.79% across the respective window sizes, underscoring the effectiveness of our architecture in moderately complex classification tasks.
More notably, the advantages of our model become even more pronounced in the more complex 16-class classification task. The CNN-ResBiGRU achieved accuracies of 76.10%, 81.60%, and 91.20% for window sizes of 2 s, 5 s, and 10 s, respectively. In comparison, the baseline SVM model reached only 72%, 78%, and 84%. These results reflect performance gains of 4.10%, 3.60%, and 7.20%, thereby demonstrating the model’s robustness and scalability in addressing high-dimensional, multi-class activity recognition challenges.





{kind=link}
{kind=link}