
From Machine Learning-Based to LLM-Enhanced: An Application-Focused Analysis of How Social IoT Benefits from LLMs


Abstract
1. Introduction
2. Background and Motivation
2.1. Large Language Model (LLM)
- Fine-tuning tailors LLMs to specific domains by adjusting their weights on compact, task-focused datasets, boosting both relevance and accuracy without full model retraining [8]. Techniques such as adapter tuning and low-rank adaptation (LoRA) embed lightweight trainable layers into the existing network, preserving the original model’s strengths while refining it for new applications [15,16].
- Prompt engineering serves as the cornerstone for optimizing LLM performance, particularly when tasks require intricate, multi-step reasoning. Techniques such as the chain of thought (CoT) prompting guide models through sequential logical steps, substantially enhancing their capacity for human-like reasoning [17]. Building on this foundation, frameworks like the tree of thought (ToT) [18] and graph of thought (GoT) [19] further structure problem-solving by organizing potential solution paths into hierarchical trees or interconnected graphs.
- Initially, Retrieval-augmented generation (RAG) was designed to fill gaps in a model’s pretrained knowledge base, enabling the generation of up-to-date and deeply relevant responses [20]. In SIoT applications, RAG-based solutions fuse real-world social data into the inference process, significantly boosting the LLMs’ accuracy and responsiveness [21].
- Large multimodal models (LMMs) extend LLMs by incorporating additional modalities such as images, audio, and video, enabling richer understanding and reasoning across multiple types of input [22]. In terms of processing data from socialized devices, LMMs can significantly enhance system intelligence by allowing devices to perceive and interpret multimodal data from their environment, e.g., recognizing visual cues, processing voice commands, or analyzing sensor patterns [23]. Thus, such capability supports more human-like interaction and contextual awareness in SIoT.
2.2. ML and LLMs
2.3. LLM-Enhanced SIoT Applications
2.4. Related Work
2.5. Scope and Methodology
3. Recommendation
3.1. ML- and DL-Based Recommendation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Cost | Efficiency | QoS | Accuracy |
|---|---|---|---|---|
| [32] | Moderate (SVM training and feature engineering) | Good (optimized kernel and margin selection) | Moderate (sensitive to feature noise) | Competitive (effective for simple queries) |
| [33] | Moderate (manual feature curation costs) | Good (efficient hand-crafted ranking pipelines) | Moderate (depends on feature quality) | Higher (with well-tuned features) |
| [34] | Moderate (ranking optimization overhead) | Good (fast scoring methods for retrieval) | Moderate (balanced for ad-hoc queries) | Competitive (optimized listwise training) |
| [35] | Moderate (lightweight compression improves cost) | Good (sparse attention helps efficiency) | Good (consistent performance under load) | Good (tuned through lightweight retraining) |
| [36] | High (large CNN with dense parameters) | Low (sequential bottlenecks in CNN layers) | High (excellent matching quality) | Good (effective at local matching) |
| [37] | Moderate (offloading strategies help balance cost) | Good (dynamic task scheduling) | Good (stable across varying loads) | Good (maintained under dynamic load) |
| [38] | High (full model inference on edge devices) | Good (token filtering reduces computation) | High (designed for scalable inference) | Maintained (even with early exit methods) |
| [39] | Moderate (memory-intensive processing) | Moderate (model pruning needed for speed) | Moderate (query complexity affects output) | Moderate (affected by over-pruning) |
| [40] | Moderate (attention-based retrieval modules) | Good (attention mechanisms tuned for speed) | Good (balanced generalization and specificity) | Good (balances general and specific queries) |
| [41] | Moderate (structured interaction models) | Good (stable in controlled environments) | Moderate (effective for narrow tasks) | Good (semantic match at structure level) |
| [42] | High (large-scale multi-pass ranking) | Moderate (bottlenecked by query expansion) | Moderate (fragile under noisy queries) | Moderate (good for shallow retrieval) |
| [43] | High (complex neural model with fine-tuning) | Moderate (trade-off between precision and latency) | High (high relevance in dense retrieval) | High (top-tier retrieval scores) |
| [44] | Moderate (efficient CNN designs) | Good (streamlined convolution operations) | Moderate (solid for local matching tasks) | Moderate (effective in local semantic capture) |
| [45] | Moderate (cost due to feature generation) | Moderate (relies on external pre-processing) | Moderate (less robust to domain shift) | Moderate (moderate semantic fidelity) |
| [46] | Moderate (modular lightweight components) | Good (task modularization improves execution) | Good (adapts across multiple scenarios) | Good (high precision with multi-tasking) |
| [47] | High (deep retrieval and re-ranking cost) | Moderate (depth increases retrieval latency) | Moderate (overfitting risk on small datasets) | High (deep architectures improve precision) |
3.2. LLM-Enhanced Recommendation
3.3. Observation
3.4. Challenges and Future Directions
4. Search
4.1. ML- and DL-Based Search
| Ref. | Cost | Efficiency | QoS | Accuracy |
|---|---|---|---|---|
| [54] | Moderate (multi-view embeddings increase compute slightly) | Good (sparse retrieval efficient) | Good (multi-view robust search) | High (boosts dense retrieval models) |
| [55] | Moderate (knowledge distillation needed) | Good (multi-teacher setup enhances retrieval) | Good (knowledge transfer helps robustness) | Good (higher MRR scores) |
| [56] | High (generative ranking model training) | Moderate (two-phase training slows process) | High (direct ranking objective alignment) | High (outperforms dense retrievers) |
| [57] | High (multimodal input handling) | Moderate (multimodal fusion overhead) | Good (robust web navigation) | Good (strong benchmark results) |
| [58] | High (curriculum + reinforcement learning) | Moderate (open-domain variability affects speed) | Good (adaptive policy for different tasks) | High (state-of-the-art web benchmarks) |
| [59] | Moderate (collaborative retrieval adds complexity) | Moderate (multi-agent message passing) | Good (team-based query refinement) | Good (robust collective retrieval) |
| [60] | High (search across 100 s of pages needs scaling) | Moderate (long-context needs tuning) | Good (parallel searching improves planning) | High (cognitive simulation enhances results) |
| [61] | Moderate (noise-tolerant agent navigation) | Good (aligned demonstrations boost stability) | Good (decision-making under noise) | Good (benchmark improvements) |
| [62] | High (open-ended multi-agent Internet search) | Moderate (complex messaging system) | Good (scalable teaming architecture) | Good (prototype shows promise) |
| [63] | Moderate (Slack platform dependency) | Good (lightweight agent for collaboration) | Good (real-time collaborative QA) | Moderate (depends on platform reliability) |
| [64] | Moderate (large web screenshot processing) | Moderate (HTML + image multimodal fusion) | Good (real-world task completion) | Good (benchmarks on real websites) |
| [63] | Moderate (suboptimal page navigation overhead) | Moderate (curriculum policy needed) | Moderate (versatility struggles) | Good (good closed benchmark results) |
| [66] | Moderate (lightweight retrieval agents) | Good (flexible multi-agent collaboration) | Good (dynamic agent teaming) | Moderate (prototype-level so far) |
| [67] | Moderate (scalable messaging) | Good (low-overhead team communication) | Good (prototype shows scalability) | Moderate (real-world implementation pending) |
| [68] | Moderate (batch processing efficiencies) | Good (processing optimization effective) | Good (batch search scalability) | Good (strong page-level recall) |
4.2. LLM-Enhanced Search
4.3. Observation
4.4. Challenges and Future Directions
5. Data Management
5.1. ML- and DL-Based Data Management
| Ref. | Cost | Efficiency | QoS | Accuracy |
|---|---|---|---|---|
| [72] | Moderate (manual modeling effort) | Good (structured forecasting) | Good (structured, time-series focused) | Moderate (manual tuning needed) |
| [73] | Moderate (automated data cleaning) | Good (automated statistical inference) | Good (relational inference) | Good (belief propagation aids correction) |
| [74] | Moderate (early feature engineering models) | Good (feature-based scalability) | Moderate (general prediction tasks) | Good (feature-rich models) |
| [75] | High (training Transformer models) | Moderate (task-specific finetuning needed) | Good (table-semantics parsing) | High (transformer-based learning) |
| [76] | High (pretraining and tuning requirements) | Moderate (large models slow reasoning) | Good (query optimization and rewriting) | High (full LLM with database tuning) |
| [77] | Moderate (program synthesis overhead) | Good (example-driven automation) | Good (multi-step transformations) | Good (program synthesis achieves generalization) |
| [78] | Moderate (complex operator sets) | Good (auto-synthesis, minimal human intervention) | Good (handling non-relational tables) | Good (no example dependency boosts transferability) |
| [79] | High (joint modeling text and tables) | Moderate (scale limitations on large tables) | Good (semantic understanding boost) | Good (contextual retrieval precision) |
| [80] | Moderate (tuple-to-X task finetuning) | Good (pretrained generalizability) | Good (tuple matching and error resilience) | High (structured task performance) |
| [81] | Moderate (SQL-query based LLM interaction) | Moderate (complexity of SQL query generation) | Good (structured querying support) | Moderate (dependent on SQL formulation quality) |
| [82] | High (database-optimized LLM system) | Good (adaptability across tasks) | Good (adaptive database operations) | High (optimized for data management tasks) |
| [18] | Moderate (error diagnosis processing) | Moderate (reasoning efficiency based on task complexity) | Moderate (diagnosis system robustness) | Good (error localization accurate) |
| [83] | Moderate (deliberate search overhead) | Good (tree-search reduces random exploration) | Good (structured and open text reasoning) | Good (planning improves context coherence) |
| [84] | Moderate (integration with structured data) | Moderate (schema mapping overhead) | Moderate (inconsistent schema adaptation) | Good (provenance tracking helps reliability) |
| [85] | High (multi-modal cross-domain reasoning) | Moderate (scalability needs optimization) | Good (dynamic multimodal integration) | Moderate (cross-modal noise handling challenges) |
5.2. LLM-Enhanced Data Management
5.3. Observation
5.4. Challenges and Future Directions
6. Discussion
6.1. Timeline View of Collected Papers
6.2. Overall Challenges and Future Directions
6.2.1. Security and Privacy
6.2.2. Computational Costs and Real-Time Constraints
6.2.3. Energy Inefficiency and Sustainability
6.2.4. Ethical and Societal Concerns
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| SIoT | Social Internet of Things |
| ML | Machine Learning |
| DL | Deep Learning |
| RAG | Retrieval-Augmented Generation |
| LMM | Large Multimodal Model |
| CoT | Chain of Thought |
| ToT | Tree of Thought |
| GoT | Graph of Thought |
| T2T | Thing-to-Thing |
| H2H | Human-to-Human |
References
- Kranz, M.; Roalter, L.; Michahelles, F. Things that twitter: Social networks and the internet of things. In Proceedings of the What Can the Internet of Things do for the Citizen (CIoT) Workshop at the Eighth International Conference on Pervasive Computing (Pervasive 2010), Helsinki, Finland, 17 May 2010; pp. 1–10. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. Siot: Giving a social structure to the internet of things. IEEE Commun. Lett. 2011, 15, 1193–1195. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G.; Nitti, M. The social internet of things (siot)–when social networks meet the internet of things: Concept, architecture and network characterization. Comput. Netw. 2012, 56, 3594–3608. [Google Scholar] [CrossRef]
- Ortiz, A.M.; Hussein, D.; Park, S.; Han, S.N.; Crespi, N. The cluster between internet of things and social networks: Review and research challenges. IEEE Internet Things J. 2014, 1, 206–215. [Google Scholar] [CrossRef]
- Shahab, S.; Agarwal, P.; Mufti, T.; Obaid, A.J. SIoT (social internet of things): A review. In ICT Analysis and Applications; Springer: Singapore, 2022; pp. 289–297. [Google Scholar]
- Malekshahi Rad, M.; Rahmani, A.M.; Sahafi, A.; Nasih Qader, N. Social Internet of Things: Vision, challenges, and trends. Hum.-Centric Comput. Inf. Sci. 2020, 10, 52. [Google Scholar] [CrossRef]
- Dhelim, S.; Ning, H.; Farha, F.; Chen, L.; Atzori, L.; Daneshmand, M. IoT-enabled social relationships meet artificial social intelligence. IEEE Internet Things J. 2021, 8, 17817–17828. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K.N. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- OpenAI. Introducing GPT-4o: Our Fastest and Most Affordable Flagship Model. 2024. Available online: https://platform.openai.com/docs/models (accessed on 26 February 2025).
- Meta-AI. Llama 3.1: Advanced Open-Source Language Model. 2024. Available online: https://ai.meta.com/blog/meta-llama-3-1/ (accessed on 26 February 2025).
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Matwin, S.; Milios, A.; Prałat, P.; Soares, A.; Théberge, F. Survey of generative methods for social media analysis. arXiv 2021, arXiv:2112.07041. [Google Scholar]
- Sarhaddi, F.; Nguyen, N.T.; Zuniga, A.; Hui, P.; Tarkoma, S.; Flores, H.; Nurmi, P. LLMs and IoT: A Comprehensive Survey on Large Language Models and the Internet of Things. TechRxiv 2025. [Google Scholar] [CrossRef]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: Cambridge, MA, USA, 2019; pp. 2790–2799. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. ICLR 2022, 1, 3. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.; Cao, Y.; Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 11809–11822. [Google Scholar]
- Besta, M.; Blach, N.; Kubicek, A.; Gerstenberger, R.; Podstawski, M.; Gianinazzi, L.; Gajda, J.; Lehmann, T.; Niewiadomski, H.; Nyczyk, P.; et al. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. Proc. AAAI Conf. Artif. Intell. 2024, 38, 17682–17690. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Zeng, J.; Huang, R.; Malik, W.; Yin, L.; Babic, B.; Shacham, D.; Yan, X.; Yang, J.; He, Q. Large language models for social networks: Applications, challenges, and solutions. arXiv 2024, arXiv:2401.02575. [Google Scholar]
- Huang, D.; Yan, C.; Li, Q.; Peng, X. From large language models to large multimodal models: A literature review. Appl. Sci. 2024, 14, 5068. [Google Scholar] [CrossRef]
- Du, N.; Wang, H.; Faloutsos, C. Analysis of large multi-modal social networks: Patterns and a generator. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; Proceedings, Part I 21. Springer: Berlin/Heidelberg, Germany, 2010; pp. 393–408. [Google Scholar]
- Farhadi, B.; Asghari, P.; Mahdipour, E.; Javadi, H.H.S. A novel recommendation-based framework for reconnecting and selecting the efficient friendship path in the heterogeneous social IoT network. Comput. Netw. 2025, 258, 111016. [Google Scholar] [CrossRef]
- Becherer, M.; Hussain, O.K.; Zhang, Y.; den Hartog, F.; Chang, E. On trust recommendations in the social internet of things—A survey. ACM Comput. Surv. 2024, 56, 1–35. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Qian, C.; Liang, F.; Liao, W.; Blasch, E.P.; Yu, W. Secure IoT search engine: Survey, challenges issues, case study, and future research direction. IEEE Internet Things J. 2022, 9, 16807–16823. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Qian, C.; Gao, W.; Liang, F.; Hua, K.; Yu, W. Towards efficient and intelligent internet of things search engine. IEEE Access 2021, 9, 15778–15795. [Google Scholar] [CrossRef]
- Amin, F.; Majeed, A.; Mateen, A.; Abbasi, R.; Hwang, S.O. A systematic survey on the recent advancements in the Social Internet of Things. IEEE Access 2022, 10, 63867–63884. [Google Scholar] [CrossRef]
- Gharaibeh, A.; Salahuddin, M.A.; Hussini, S.J.; Khreishah, A.; Khalil, I.; Guizani, M.; Al-Fuqaha, A. Smart cities: A survey on data management, security, and enabling technologies. IEEE Commun. Surv. Tutor. 2017, 19, 2456–2501. [Google Scholar] [CrossRef]
- Ferrara, E. Large language models for wearable sensor-based human activity recognition, health monitoring, and behavioral modeling: A survey of early trends, datasets, and challenges. Sensors 2024, 24, 5045. [Google Scholar] [CrossRef]
- Kök, İ.; Demirci, O.; Özdemir, S. When IoT Meet LLMs: Applications and Challenges. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; IEEE: New York, NY, USA, 2024; pp. 7075–7084. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 565–573. [Google Scholar]
- Chen, X.; Zhang, Y.; Qin, Z. Dynamic explainable recommendation based on neural attentive models. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 53–60. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; IEEE: New York, NY, USA, 2018; pp. 197–206. [Google Scholar]
- Zhang, A.; Chen, Y.; Sheng, L.; Wang, X.; Chua, T.S. On generative agents in recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 1807–1817. [Google Scholar]
- Feng, Y.; Liu, S.; Xue, Z.; Cai, Q.; Hu, L.; Jiang, P.; Gai, K.; Sun, F. A large language model enhanced conversational recommender system. arXiv 2023, arXiv:2308.06212. [Google Scholar]
- Ji, J.; Li, Z.; Xu, S.; Hua, W.; Ge, Y.; Tan, J.; Zhang, Y. Genrec: Large language model for generative recommendation. In Proceedings of the European Conference on Information Retrieval, Glasgow, UK, 24–28 March 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 494–502. [Google Scholar]
- Zhang, J.; Xie, R.; Hou, Y.; Zhao, X.; Lin, L.; Wen, J.R. Recommendation as instruction following: A large language model empowered recommendation approach. In ACM Transactions on Information Systems; Association for Computing Machinery: New York, NY, USA, 2023. [Google Scholar]
- Liu, Y.; Wang, Y.; Sun, L.; Yu, P.S. Rec-gpt4v: Multimodal recommendation with large vision-language models. arXiv 2024, arXiv:2402.08670. [Google Scholar]
- He, Z.; Xie, Z.; Jha, R.; Steck, H.; Liang, D.; Feng, Y.; Majumder, B.P.; Kallus, N.; McAuley, J. Large language models as zero-shot conversational recommenders. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 720–730. [Google Scholar]
- Wang, Y.; Chu, Z.; Ouyang, X.; Wang, S.; Hao, H.; Shen, Y.; Gu, J.; Xue, S.; Zhang, J.Y.; Cui, Q.; et al. Enhancing recommender systems with large language model reasoning graphs. arXiv 2023, arXiv:2308.10835. [Google Scholar]
- Huang, X.; Lian, J.; Lei, Y.; Yao, J.; Lian, D.; Xie, X. Recommender ai agent: Integrating large language models for interactive recommendations. arXiv 2023, arXiv:2308.16505. [Google Scholar] [CrossRef]
- Luo, S.; Yao, Y.; He, B.; Huang, Y.; Zhou, A.; Zhang, X.; Xiao, Y.; Zhan, M.; Song, L. Integrating large language models into recommendation via mutual augmentation and adaptive aggregation. arXiv 2024, arXiv:2401.13870. [Google Scholar]
- Li, Y.; Lin, X.; Wang, W.; Feng, F.; Pang, L.; Li, W.; Nie, L.; He, X.; Chua, T.S. A survey of generative search and recommendation in the era of large language models. arXiv 2024, arXiv:2404.16924. [Google Scholar]
- Xue, Y.; Greenewald, K.; Mroueh, Y.; Mirzasoleiman, B. Verify when Uncertain: Beyond Self-Consistency in Black Box Hallucination Detection. arXiv 2025, arXiv:2502.15845. [Google Scholar]
- McKenna, N.; Li, T.; Cheng, L.; Hosseini, M.J.; Johnson, M.; Steedman, M. Sources of hallucination by large language models on inference tasks. arXiv 2023, arXiv:2305.14552. [Google Scholar]
- Liu, H.; Wang, Y.; Fan, W.; Liu, X.; Li, Y.; Jain, S.; Liu, Y.; Jain, A.; Tang, J. Trustworthy ai: A computational perspective. ACM Trans. Intell. Syst. Technol. 2022, 14, 1–59. [Google Scholar] [CrossRef]
- Li, Y.; Tan, Z.; Liu, Y. Privacy-preserving prompt tuning for large language model services. arXiv 2023, arXiv:2305.06212. [Google Scholar]
- Zhou, H.; Lee, K.H.; Zhan, Z.; Chen, Y.; Li, Z.; Wang, Z.; Haddadi, H.; Yilmaz, E. Trustrag: Enhancing robustness and trustworthiness in rag. arXiv 2025, arXiv:2501.00879. [Google Scholar]
- Nallapati, R. Discriminative models for information retrieval. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 64–71. [Google Scholar]
- Liu, T.Y. Learning to rank for information retrieval. Found. Trends® Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Palangi, H.; Deng, L.; Shen, Y.; Gao, J.; He, X.; Chen, J.; Song, X.; Ward, R. Deep sentence embedding using long short-term memory networks: Analysis and application to information retrieval. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 694–707. [Google Scholar] [CrossRef]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. Adv. Neural Inf. Process. Syst. 2014, 27, 2042–2050. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. A latent semantic model with convolutional-pooling structure for information retrieval. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 101–110. [Google Scholar]
- Lai, H.; Liu, X.; Iong, I.L.; Yao, S.; Chen, Y.; Shen, P.; Yu, H.; Zhang, H.; Zhang, X.; Dong, Y.; et al. AutoWebGLM: A Large Language Model-based Web Navigating Agent. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 5295–5306. [Google Scholar]
- He, H.; Yao, W.; Ma, K.; Yu, W.; Dai, Y.; Zhang, H.; Lan, Z.; Yu, D. WebVoyager: Building an end-to-end web agent with large multimodal models. arXiv 2024, arXiv:2401.13919. [Google Scholar]
- Chen, W.; You, Z.; Li, R.; Guan, Y.; Qian, C.; Zhao, C.; Yang, C.; Xie, R.; Liu, Z.; Sun, M. Internet of agents: Weaving a web of heterogeneous agents for collaborative intelligence. arXiv 2024, arXiv:2407.07061. [Google Scholar]
- Chen, Z.; Liu, K.; Wang, Q.; Liu, J.; Zhang, W.; Chen, K.; Zhao, F. Mindsearch: Mimicking human minds elicits deep ai searcher. arXiv 2024, arXiv:2407.20183. [Google Scholar]
- Li, Y.; Yang, N.; Wang, L.; Wei, F.; Li, W. Learning to rank in generative retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, USA, 20–27 February 2024; Volume 38, pp. 8716–8723. [Google Scholar]
- Li, Y.; Yang, N.; Wang, L.; Wei, F.; Li, W. Multiview identifiers enhanced generative retrieval. arXiv 2023, arXiv:2305.16675. [Google Scholar]
- Li, Y.; Zhang, Z.; Wang, W.; Nie, L.; Li, W.; Chua, T.S. Distillation enhanced generative retrieval. arXiv 2024, arXiv:2402.10769. [Google Scholar]
- Gong, P.; Li, J.; Mao, J. Cosearchagent: A lightweight collaborative search agent with large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 2729–2733. [Google Scholar]
- Qin, Y.; Cai, Z.; Jin, D.; Yan, L.; Liang, S.; Zhu, K.; Lin, Y.; Han, X.; Ding, N.; Wang, H.; et al. Webcpm: Interactive web search for chinese long-form question answering. arXiv 2023, arXiv:2305.06849. [Google Scholar]
- Zhou, R.; Yang, Y.; Wen, M.; Wen, Y.; Wang, W.; Xi, C.; Xu, G.; Yu, Y.; Zhang, W. TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 3–13. [Google Scholar]
- Li, Y.; Wang, W.; Qu, L.; Nie, L.; Li, W.; Chua, T.S. Generative cross-modal retrieval: Memorizing images in multimodal language models for retrieval and beyond. arXiv 2024, arXiv:2402.10805. [Google Scholar]
- Long, X.; Ma, Z.; Hua, E.; Zhang, K.; Qi, B.; Zhou, B. Retrieval-Augmented Visual Question Answering via Built-in Autoregressive Search Engines. arXiv 2025, arXiv:2502.16641. [Google Scholar] [CrossRef]
- Rashid, M.S.; Meem, J.A.; Dong, Y.; Hristidis, V. EcoRank: Budget-Constrained Text Re-ranking Using Large Language Models. arXiv 2024, arXiv:2402.10866. [Google Scholar]
- Duan, S.; Babu, S. Processing forecasting queries. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 711–722. [Google Scholar]
- Mayfield, C.; Neville, J.; Prabhakar, S. ERACER: A database approach for statistical inference and data cleaning. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 75–86. [Google Scholar]
- Rendle, S. Scaling factorization machines to relational data. Proc. VLDB Endow. 2013, 6, 337–348. [Google Scholar] [CrossRef]
- Miao, H.; Li, A.; Davis, L.S.; Deshpande, A. Modelhub: Towards unified data and lifecycle management for deep learning. arXiv 2016, arXiv:1611.06224. [Google Scholar]
- Wang, W.; Zhang, M.; Chen, G.; Jagadish, H.; Ooi, B.C.; Tan, K.L. Database meets deep learning: Challenges and opportunities. ACM Sigmod Rec. 2016, 45, 17–22. [Google Scholar] [CrossRef]
- Jin, Z.; Anderson, M.R.; Cafarella, M.; Jagadish, H. Foofah: Transforming data by example. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 683–698. [Google Scholar]
- Yin, P.; Neubig, G.; Yih, W.t.; Riedel, S. TaBERT: Pretraining for joint understanding of textual and tabular data. arXiv 2020, arXiv:2005.08314. [Google Scholar]
- Tang, N.; Fan, J.; Li, F.; Tu, J.; Du, X.; Li, G.; Madden, S.; Ouzzani, M. RPT: Relational pre-trained transformer is almost all you need towards democratizing data preparation. arXiv 2020, arXiv:2012.02469. [Google Scholar] [CrossRef]
- Li, P.; He, Y.; Yan, C.; Wang, Y.; Chaudhuri, S. Auto-tables: Synthesizing multi-step transformations to relationalize tables without using examples. arXiv 2023, arXiv:2307.14565. [Google Scholar] [CrossRef]
- Chen, Z.; Gu, Z.; Cao, L.; Fan, J.; Madden, S.; Tang, N. Symphony: Towards Natural Language Query Answering over Multi-modal Data Lakes. In Proceedings of the CIDR, Amsterdam, The Netherlands, 8–11 January 2023; pp. 1–7. [Google Scholar]
- Saeed, M.; De Cao, N.; Papotti, P. Querying large language models with SQL. arXiv 2023, arXiv:2304.00472. [Google Scholar]
- Halevy, A.; Dwivedi-Yu, J. Learnings from data integration for augmented language models. arXiv 2023, arXiv:2304.04576. [Google Scholar]
- Zhou, X.; Sun, Z.; Li, G. Db-gpt: Large language model meets database. Data Sci. Eng. 2024, 9, 102–111. [Google Scholar] [CrossRef]
- Zhou, X.; Li, G.; Sun, Z.; Liu, Z.; Chen, W.; Wu, J.; Liu, J.; Feng, R.; Zeng, G. D-bot: Database diagnosis system using large language models. arXiv 2023, arXiv:2312.01454. [Google Scholar] [CrossRef]
- Yang, H.; Wu, R.; Xu, W. TransCompressor: LLM-Powered Multimodal Data Compression for Smart Transportation. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, Washington, DC, USA, 18–22 November 2024; pp. 2335–2340. [Google Scholar]
- Xu, R.; Qi, Z.; Guo, Z.; Wang, C.; Wang, H.; Zhang, Y.; Xu, W. Knowledge conflicts for llms: A survey. arXiv 2024, arXiv:2403.08319. [Google Scholar]
- Ling, L.; Rabbi, F.; Wang, S.; Yang, J. Bias Unveiled: Investigating Social Bias in LLM-Generated Code. arXiv 2024, arXiv:2411.10351. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Z.; Ji, S.; Wang, T. Trojaning language models for fun and profit. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 6–10 September 2021; IEEE: New York, NY, USA, 2021; pp. 179–197. [Google Scholar]
- Wan, A.; Wallace, E.; Shen, S.; Klein, D. Poisoning language models during instruction tuning. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: Cambridge, MA, USA, 2023; pp. 35413–35425. [Google Scholar]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Harang, R. Securing Llm Systems Against Prompt Injection. Available online: https://developer.nvidia.com/blog/securing-llm-systems-against-prompt-injection/ (accessed on 15 October 2024).
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, USA, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Zhang, K.; Liu, J. Review on the application of knowledge graph in cyber security assessment. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 768, p. 052103. [Google Scholar]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, Y.; Qian, B.; Shi, X.; Shu, Y.; Chen, J. A review on edge large language models: Design, execution, and applications. ACM Comput. Surv. 2025, 57, 1–35. [Google Scholar] [CrossRef]
- Ji, Y.; Xiang, Y.; Li, J.; Chen, W.; Liu, Z.; Chen, K.; Zhang, M. Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization. arXiv 2024, arXiv:2405.10616. [Google Scholar]
- Zadeh, A.H.; Mahmoud, M.; Abdelhadi, A.; Moshovos, A. Mokey: Enabling narrow fixed-point inference for out-of-the-box floating-point transformer models. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–12 June 2022; pp. 888–901. [Google Scholar]
- He, Y.; Fang, J.; Yu, F.R.; Leung, V.C. Large language models (LLMs) inference offloading and resource allocation in cloud-edge computing: An active inference approach. IEEE Trans. Mob. Comput. 2024, 23, 11253–11264. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhou, B.; Ding, Y.; Liu, S. Towards sustainable large language model serving. ACM SIGENERGY Energy Inform. Rev. 2024, 4, 134–140. [Google Scholar] [CrossRef]
- Argerich, M.F.; Patiño-Martínez, M. Measuring and improving the energy efficiency of large language models inference. IEEE Access 2024, 12, 80194–80207. [Google Scholar] [CrossRef]
- Hazra, S. Review on Social and Ethical Concerns of Generative AI and IoT. In Generative AI: Current Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2024; pp. 257–285. [Google Scholar]




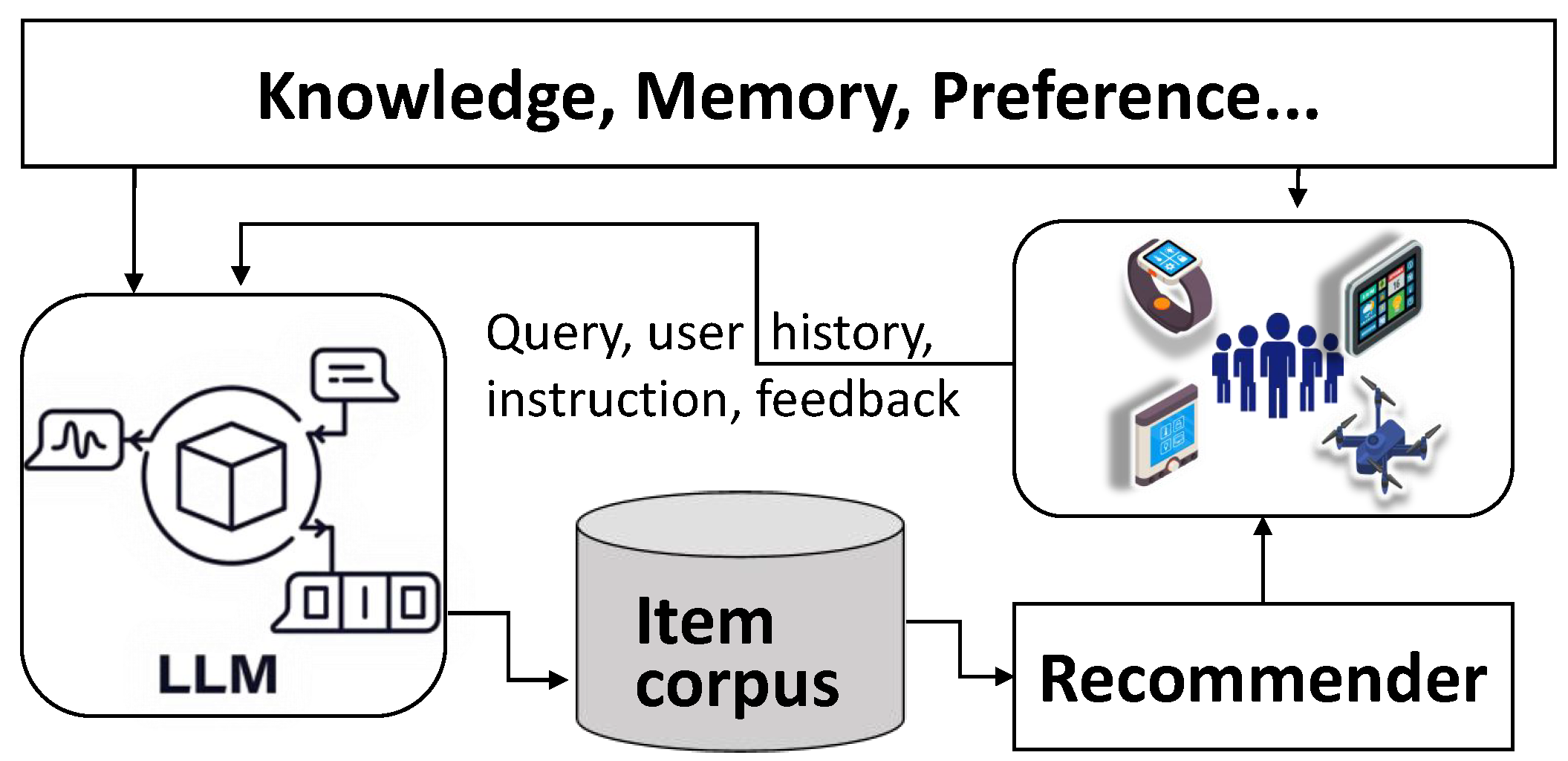


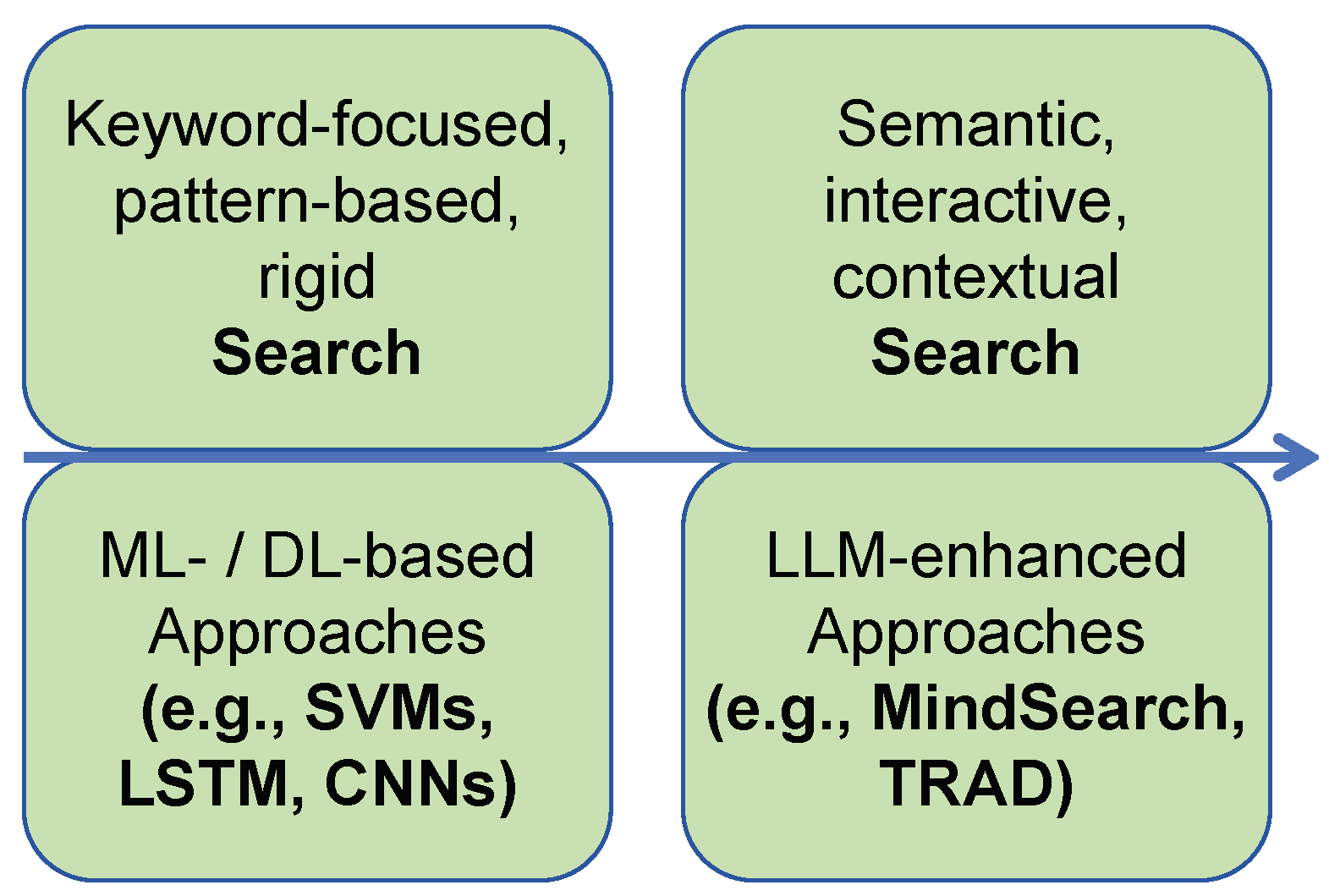
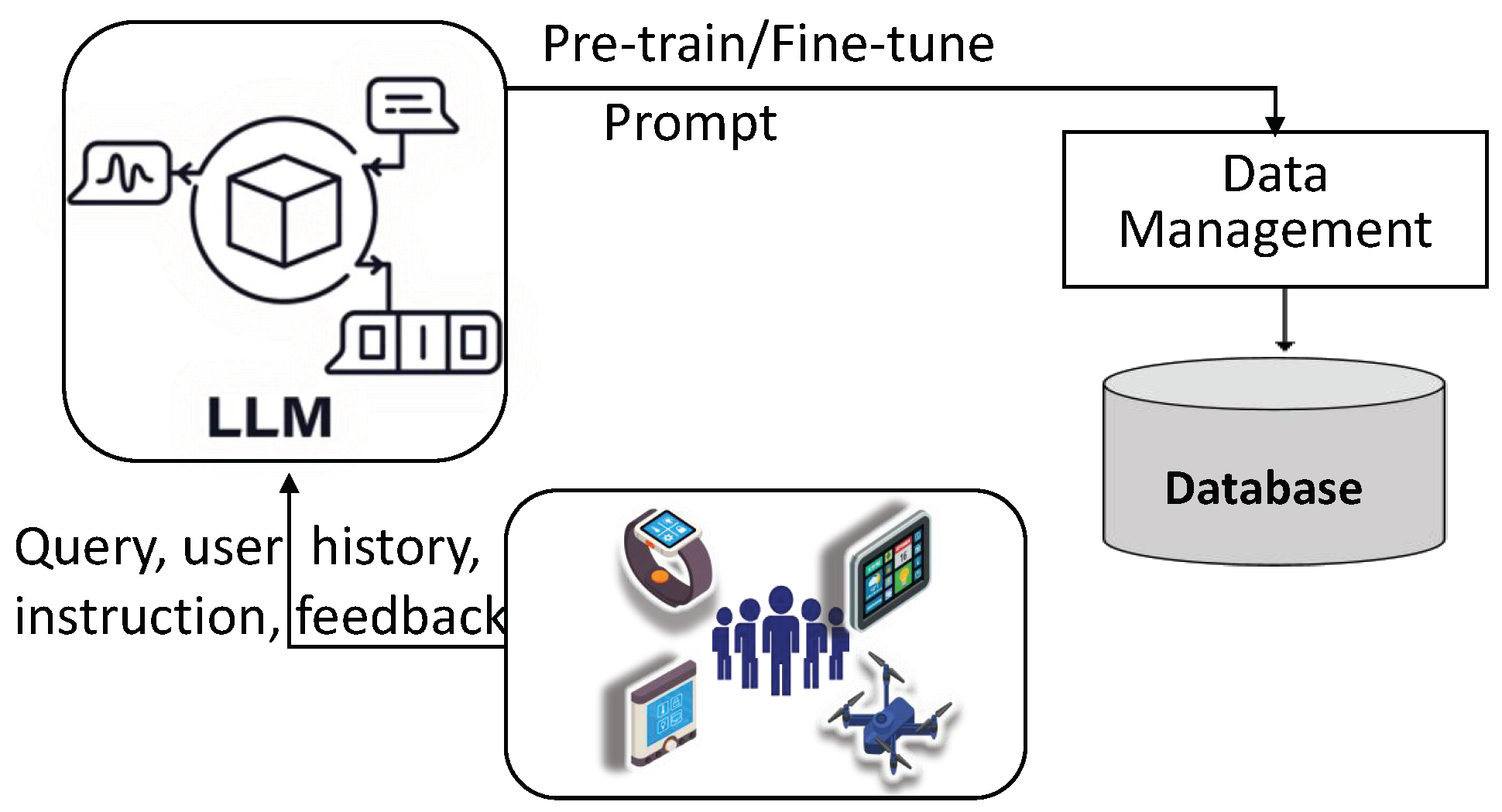
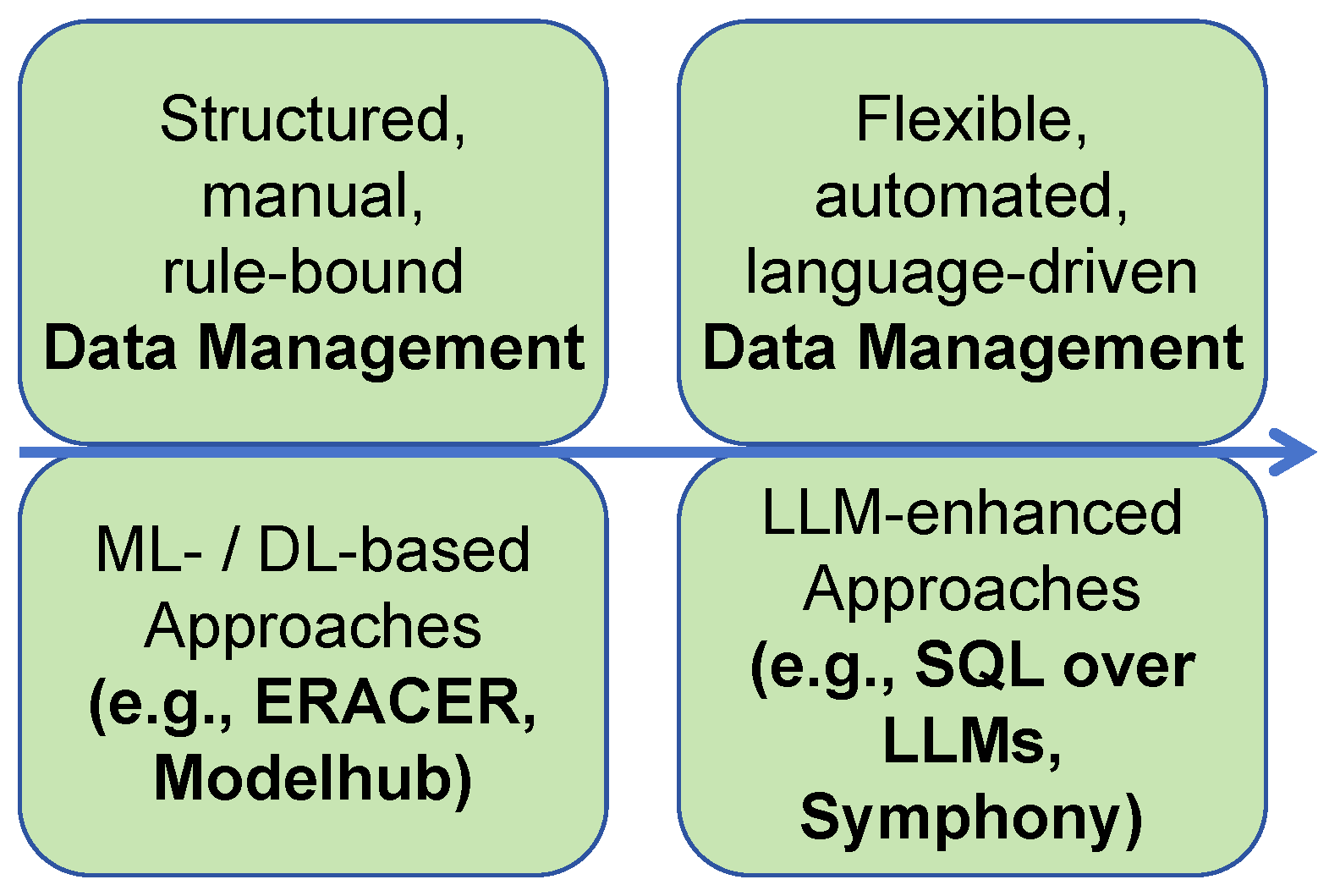

| Ref. | Focus Area | LLM Integration | Application | Vulnerability |
|---|---|---|---|---|
| [30] | Wearable Sensor-based | ✓ | Wearable healthcare use cases | ∼ |
| [31] | General IoT | ✓ | Industrial and edge IoT examples | ∼ |
| [6] | SIoT | - | SIoT architecture, relationships | ✓ |
| [5] | SIoT | - | General SIoT features and models | - |
| Our work | SIoT | ✓ | Recommendation, search, data management | ✓ |
| No. | Group | Keywords and Phrases |
|---|---|---|
| 1 | SIoT Core | “Social IoT” OR “SIoT” OR “Social Internet of Things” |
| 2 | LLM | “Large Language Models” OR “LLMs” OR “Large Models” |
| 3 | ML/DL | “Machine Learning” OR “Deep Learning” OR “Neural Networks” |
| 4 | Recommendation | “Recommendation system” OR “Recommender system” |
| 5 | Search | “Semantic search” OR “Information retrieval” OR “Natural language search” OR “question answering” |
| 6 | Data | “Data processing” OR “Data management” OR “Database” |
| 7 | Related Domains | “Social networks” OR “Social Media” OR “Social computing” |
| Year | Ref. | Method/Model | Feature |
|---|---|---|---|
| 2009 | [32] | Matrix Factorization | Latent factor models for rating prediction and recommendation |
| 2003 | [33] | Collaborative Filtering | Scalable real-time recommendation system at Amazon |
| 2001 | [34] | Collaborative Filtering | Item similarity-based recommendation for scalability and quality |
| 2019 | [35] | BERT | Sequential recommendation using bidirectional transformer representations |
| 2018 | [36] | CNN | Top-N sequential recommendation via convolutional sequence embedding |
| 2019 | [37] | GRU+CNN+Attention | Explainable recommendations via user modeling and attentive review integration |
| 2018 | [38] | Transformer-based | SASRec: Self-attentive sequential recommendation with adaptive focus |
| 2024 | [39] | ChatGPT | Agent4Rec simulates user behavior using generative agents for recommendation testing |
| 2024 | [40] | LLaMA | LLMCRS coordinates sub-task resolution and dialogue generation in CRS |
| 2023 | [41] | LLaMA | GenRec uses LLMs to directly generate item recommendations from user context |
| 2024 | [42] | Flan-T5-XL | InstructRec frames recommendation as instruction following with instruction tuning |
| 2024 | [43] | GPT-4V, LLaVA-7B/13B | Rec-GPT4V employs large vision–language models for multimodal recommendation |
| 2023 | [44] | GPT-4/ChatGPT | LLMs evaluated as conversational recommenders on real Reddit data |
| 2024 | [45] | GPT-4/ChatGPT | LLMRG generates reasoning graphs to enhance interpretability in recommendations |
| 2024 | [46] | GPT-4 | InteRecAgent integrates LLMs with traditional tools for interactive recommendation |
| 2024 | [47] | LLaMA | Llama4Rec integrates conventional models via mutual augmentation |
| Year | Ref. | Method/Model | Feature |
|---|---|---|---|
| 2004 | [54] | SVM, MaxEnt | Discriminative models for relevance classification in information retrieval |
| 2009 | [55] | Point/Pair/Listwise | Categorization of learning to rank methods in information retrieval |
| 2016 | [56] | LSTM-RNN | Deep sentence embedding for semantic similarity and document retrieval |
| 2015 | [57] | CNN | CNN architectures for sentence-level semantic matching |
| 2014 | [58] | CNN | Convolutional Latent Semantic Model for contextual web document ranking |
| 2024 | [59] | ChatGLM | Web navigation agent that surpasses GPT-4 using curriculum training and RLHF |
| 2024 | [60] | GPT-4V | Multimodal web agent executing end-to-end tasks via visual and text input |
| 2024 | [61] | GPT-4, GPT-3.5 | Internet of Agents framework for collaborative multi-agent systems |
| 2024 | [62] | GPT-4o | MindSearch mimics human web search for multi-agent information integration |
| 2024 | [63] | BART-type | LTRGR enables generative retrieval to directly learn to rank |
| 2024 | [64] | BART-large | DGR enhances generative retrieval via knowledge distillation |
| 2023 | [65] | BART-large | Multi-view identifiers boost retrieval performance in generative systems |
| 2024 | [66] | ChatGPT | CoSearchAgent supports collaborative searching in messaging platforms |
| 2023 | [67] | Chinese PLMs | Interactive LFQA for Chinese using web search and synthesis models |
| 2024 | [68] | GPT-4 | TRAD improves decision-making via step-wise thought retrieval |
| Year | Ref. | Method/Model | Feature |
|---|---|---|---|
| 2007 | [72] | MLR + Bayesian Networks | Forecasting queries over time-series data |
| 2010 | [73] | Belief Propagation | Statistical data cleaning in relational databases |
| 2013 | [74] | Factorization Machines | Relational predictive modeling with high-cardinality data |
| 2016 | [75] | Delta Encoding | Lifecycle management for deep learning models |
| 2016 | [76] | DL System Optimization | System-level optimization for deep learning training |
| 2017 | [77] | A* Algorithm | Programming-by-example for data transformation (Foofah) |
| 2020 | [78] | BERT+table pretraining | Pretrained model for joint understanding of text and tabular data |
| 2021 | [79] | BERT+GPT hybrid | Relational pre-trained Transformer for data preparation automation |
| 2023 | [80] | No specified | Multi-step transformation synthesis to relationalize tables (Auto-Tables) |
| 2023 | [81] | GPT-3 | Hybrid SQL querying over LLMs and databases |
| 2023 | [82] | GPT-3/3.5+FlanT5 | Vision for hybrid LLM-DBMS systems for data access and integration |
| 2023 | [18] | GPT-4, PaLM | Tree of Thoughts: deliberate planning framework for reasoning with LLMs |
| 2023 | [83] | No specified | Lessons from data integration systems to inform augmented LLM research |
| 2024 | [84] | GPT-3.5 | LLM framework for query rewrite, index tuning, and database optimization |
| 2024 | [85] | GPT-4 | Automated database diagnosis for root cause analysis and optimization |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Su, R. From Machine Learning-Based to LLM-Enhanced: An Application-Focused Analysis of How Social IoT Benefits from LLMs. IoT 2025, 6, 26. https://doi.org/10.3390/iot6020026
Yang L, Su R. From Machine Learning-Based to LLM-Enhanced: An Application-Focused Analysis of How Social IoT Benefits from LLMs. IoT. 2025; 6(2):26. https://doi.org/10.3390/iot6020026
Chicago/Turabian StyleYang, Lijie, and Runbo Su. 2025. "From Machine Learning-Based to LLM-Enhanced: An Application-Focused Analysis of How Social IoT Benefits from LLMs" IoT 6, no. 2: 26. https://doi.org/10.3390/iot6020026
APA StyleYang, L., & Su, R. (2025). From Machine Learning-Based to LLM-Enhanced: An Application-Focused Analysis of How Social IoT Benefits from LLMs. IoT, 6(2), 26. https://doi.org/10.3390/iot6020026