
Intelligent Energy Management across Smart Grids Deploying 6G IoT, AI, and Blockchain in Sustainable Smart Cities

 , ,
, ,  , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Background
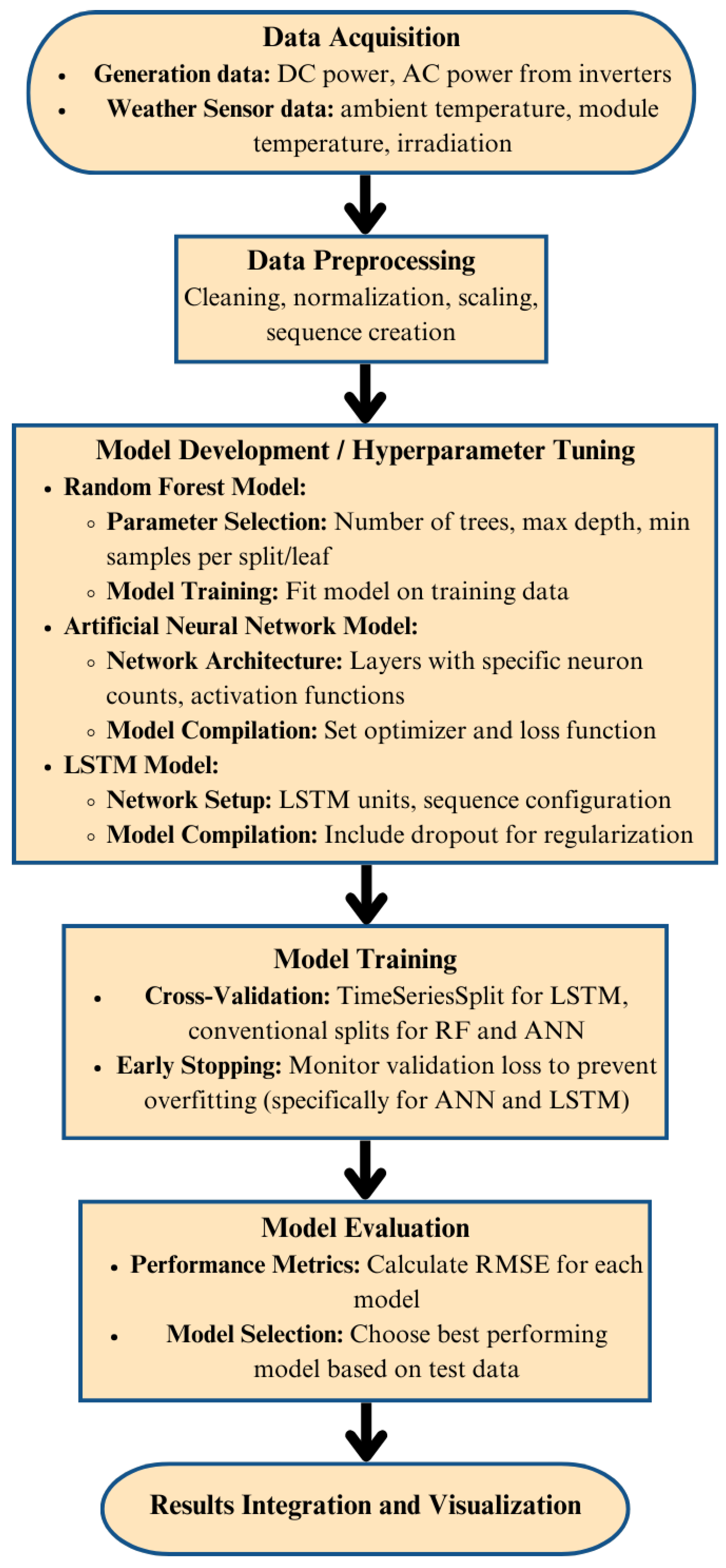
3. Materials and Methods
3.1. Grid-Level Stability Management
3.1.1. Methodology
3.1.2. Datasets
3.1.3. Algorithms
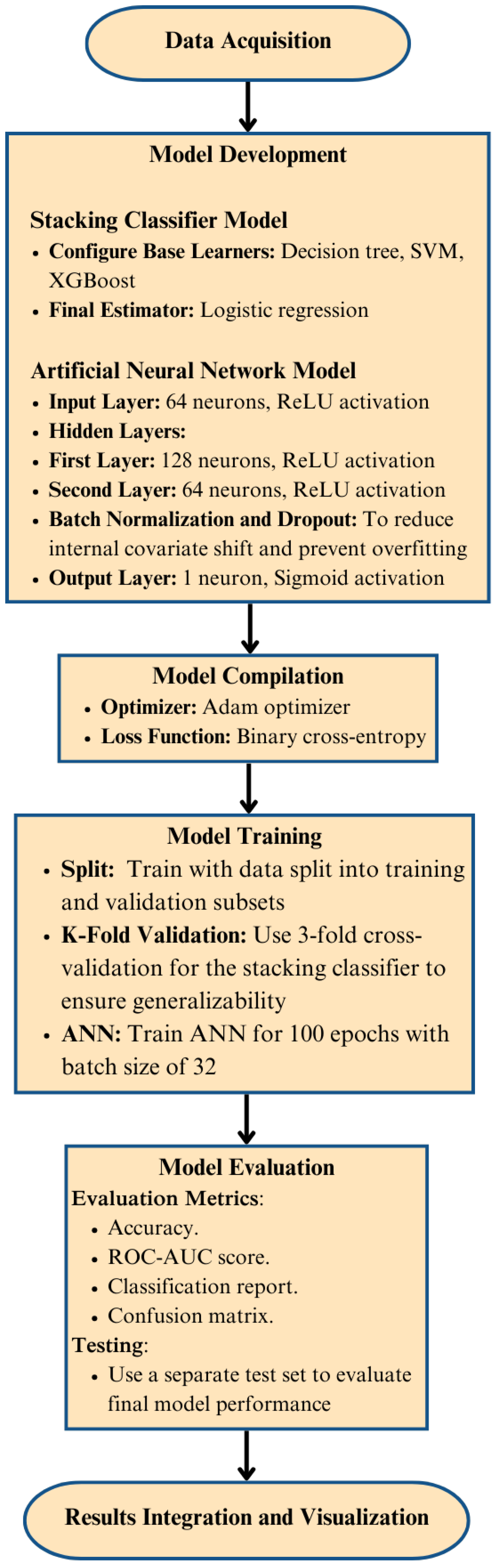
3.1.4. Model Development
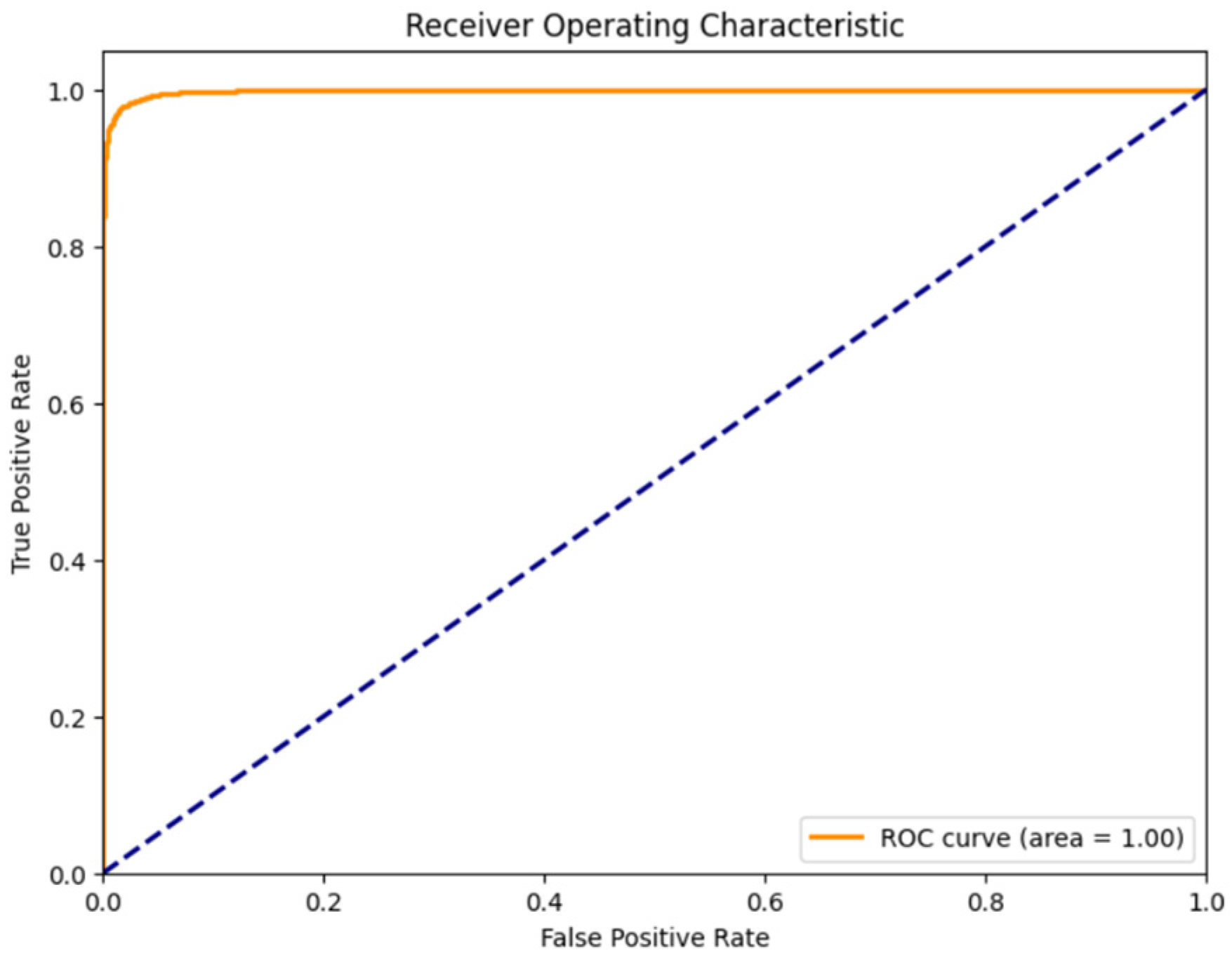
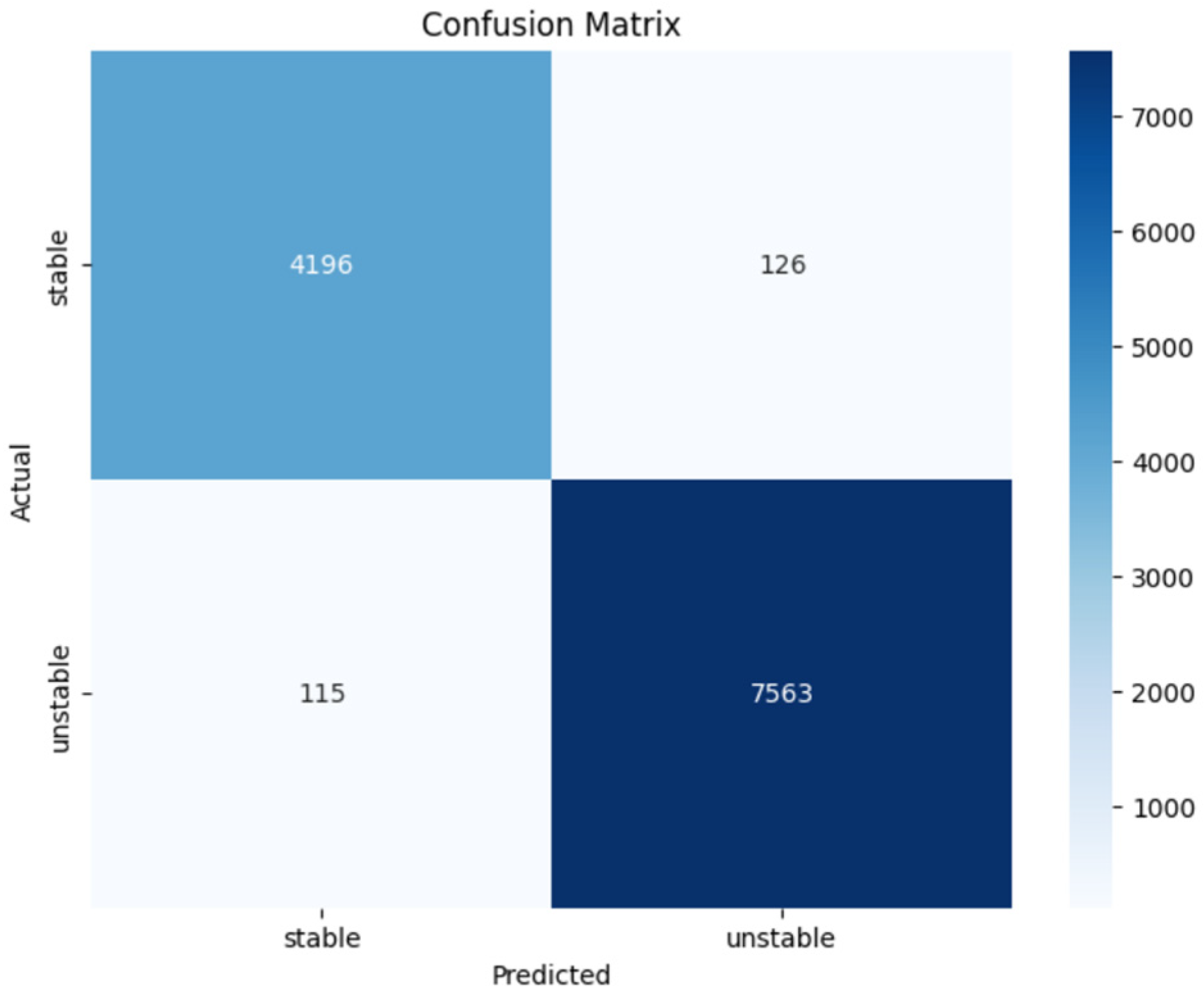
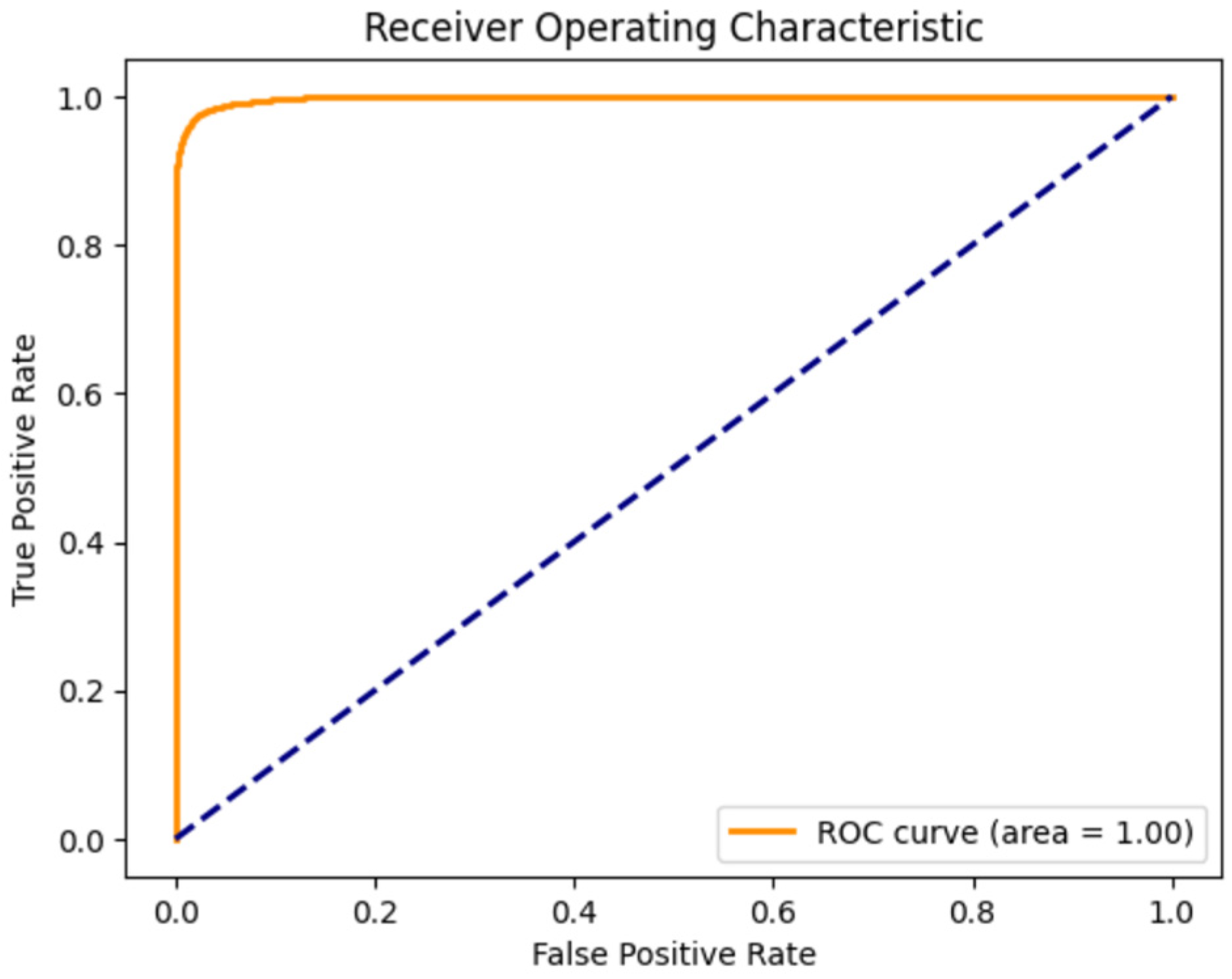
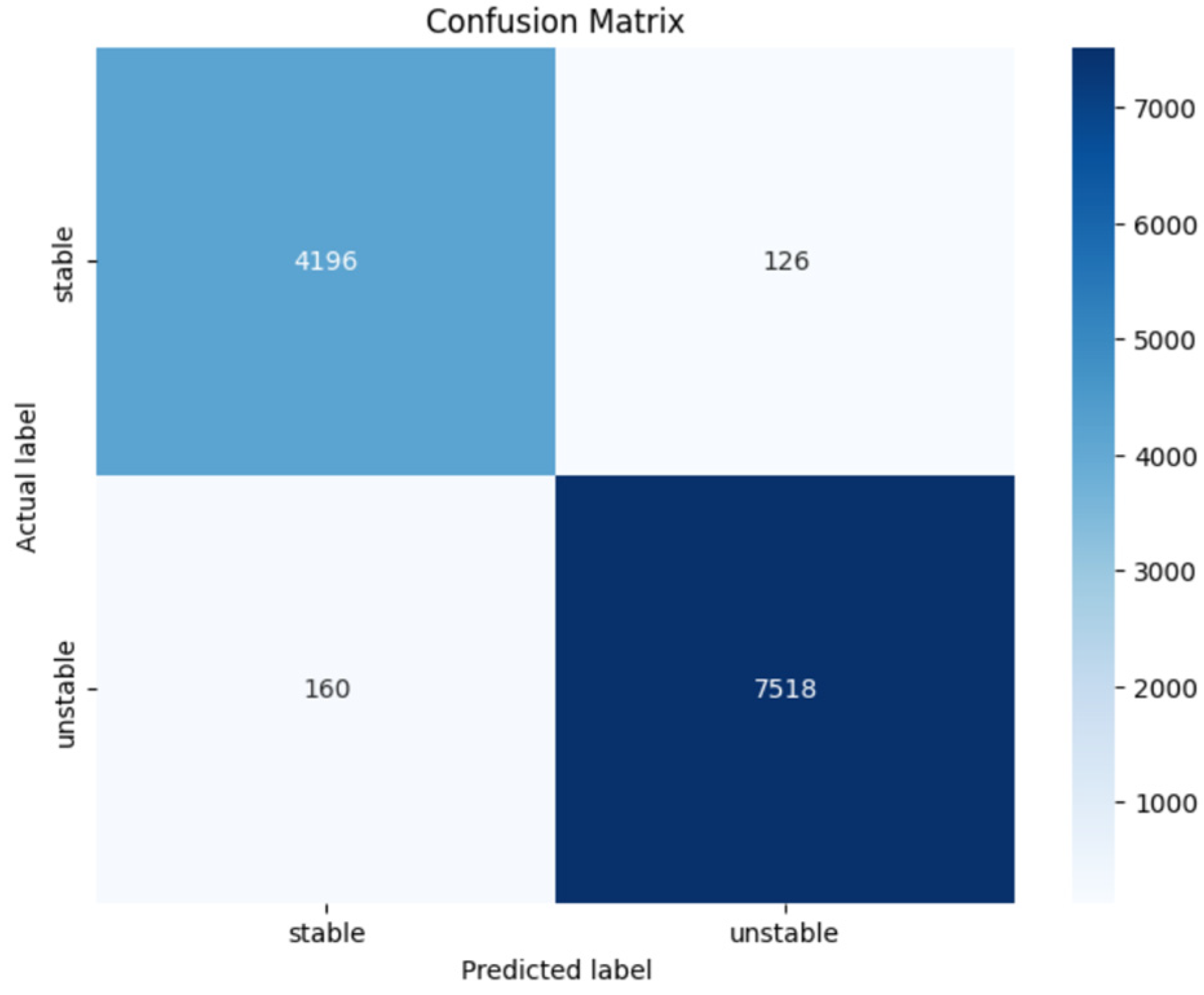
3.1.5. Results and Discussion
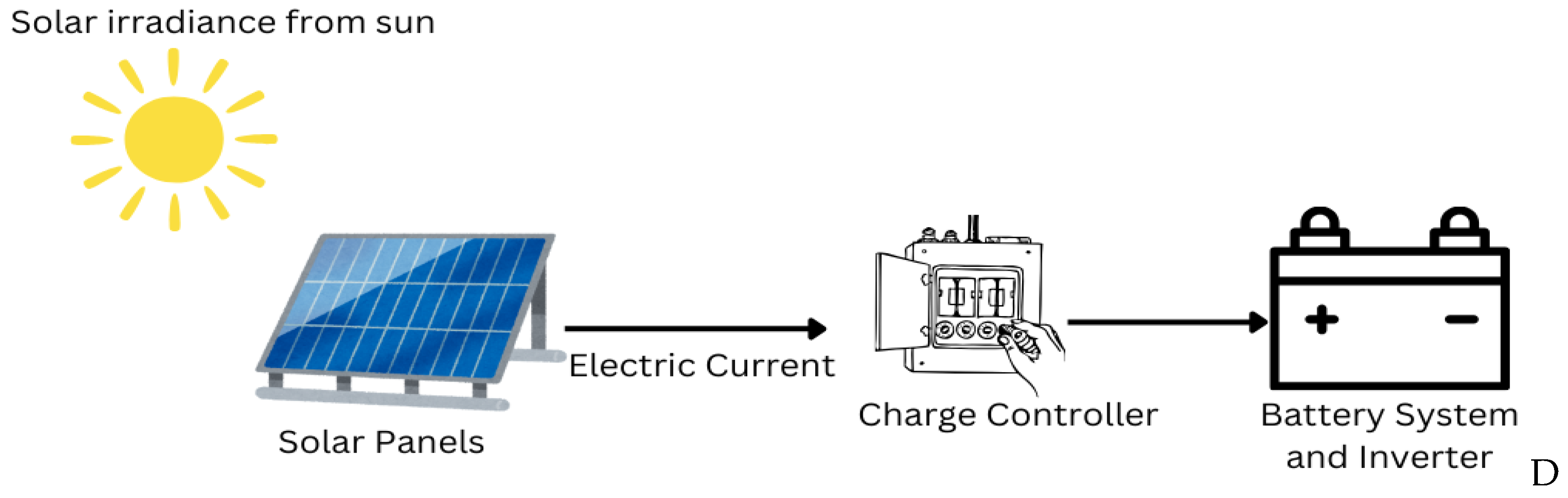
3.2. Solar Energy Forecasting
3.2.1. Methodology
3.2.2. Dataset
3.2.3. Algorithms
- Input Layer: The input layer consists of neurons equal to the number of features used, which, in this case, are the ambient temperature, module temperature, and irradiation. This layer serves as the entry point for data to be processed by subsequent layers.
- First Hidden Layer: This layer has 256 neurons and uses the ReLU (rectified linear unit) activation function. ReLU is chosen for its ability to introduce nonlinearity into the model, helping to capture complex patterns in the data.
- Dropout: A dropout rate of 30% is used after the first and subsequent batch normalization layers to prevent overfitting.
- Second Hidden Layer: This contains 128 neurons, also with ReLU activation, further processing the inputs received from the first hidden layer.
- Further layers follow a similar structure but gradually reduce the number of neurons (64 and 32 neurons, respectively), applying batch normalization and dropout after each layer to enhance model generalization.
- Output Layer: The final layer is a single neuron with a linear activation function, which outputs the continuous value predicting the solar power output.
- Input Layer: This is configured to accept sequences of a specified number of past observations (n_steps), which include the same features as the ANN model. The shape of the input layer is, therefore, n_steps—the number of past observations).
- LSTM Layer: The core of this model is an LSTM layer with 50 units. LSTM units are well-suited for time-series data because they can maintain long-term dependencies, thus remembering important information for long periods and forgetting unnecessary information.
- Output Layer: Similar to the ANN model, the LSTM has an output layer with one neuron with a linear activation function to predict the solar power output. This setup directly maps the processed features to a predicted value.
3.2.4. Model Development
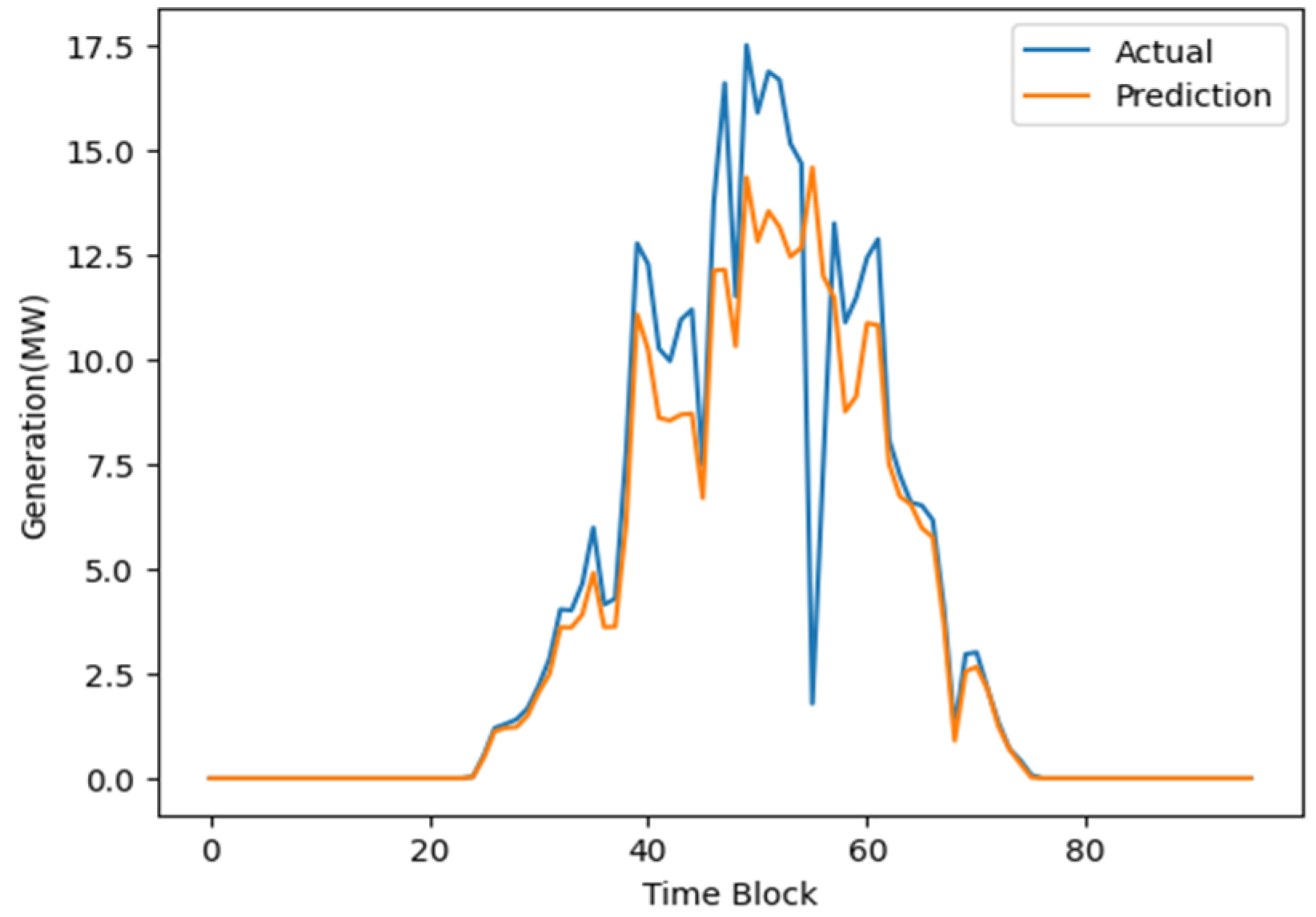
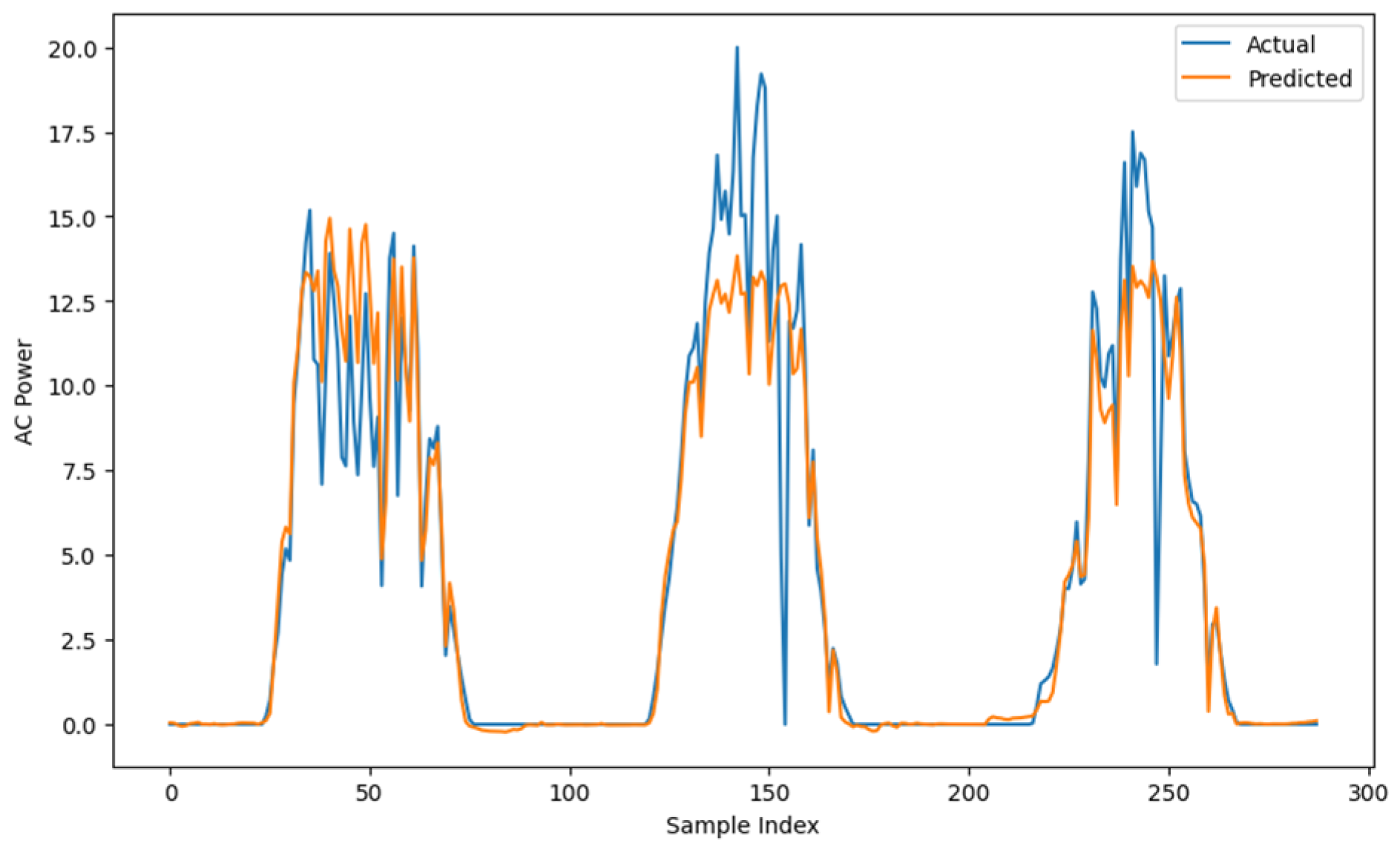
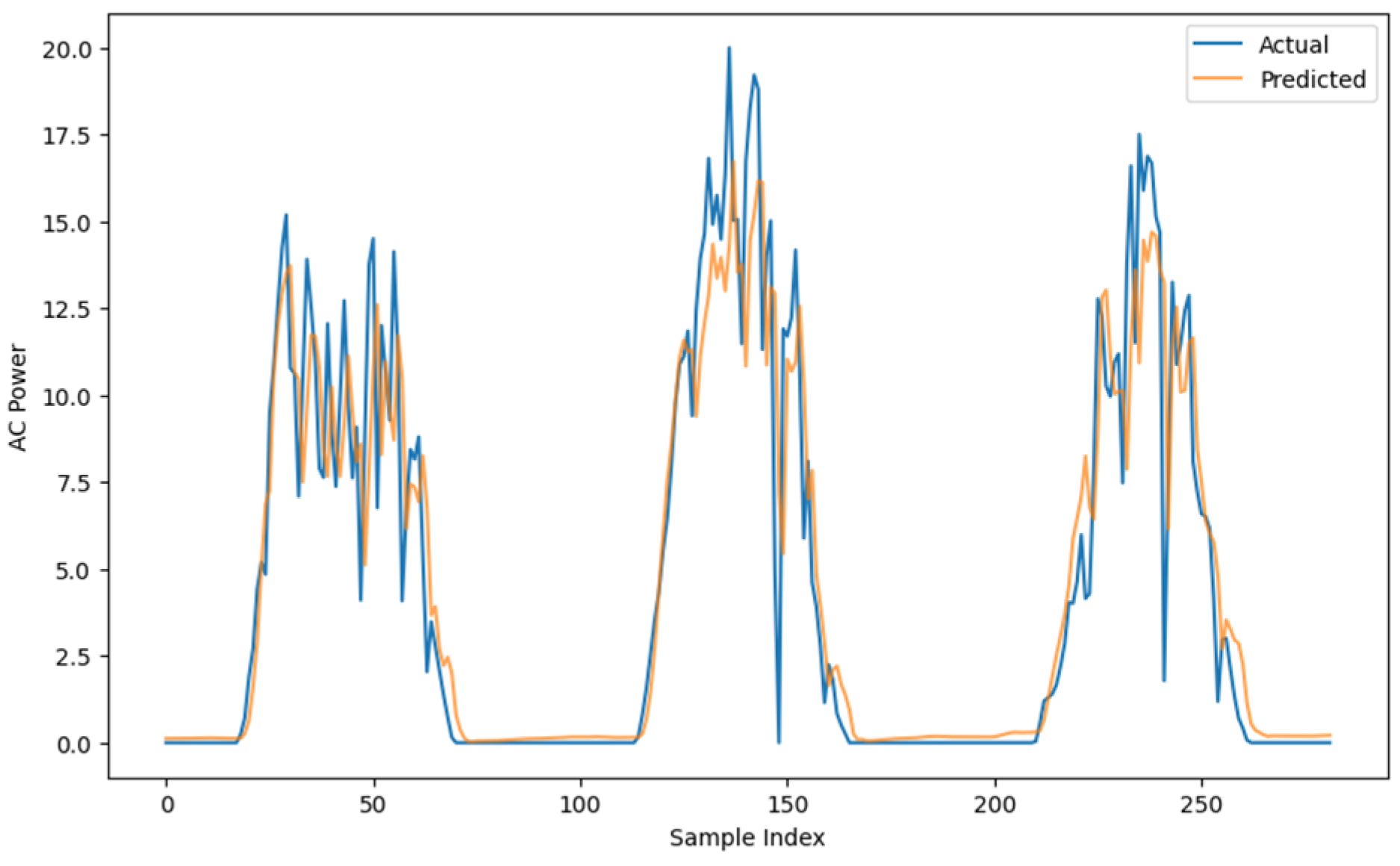
3.2.5. Results and Discussion
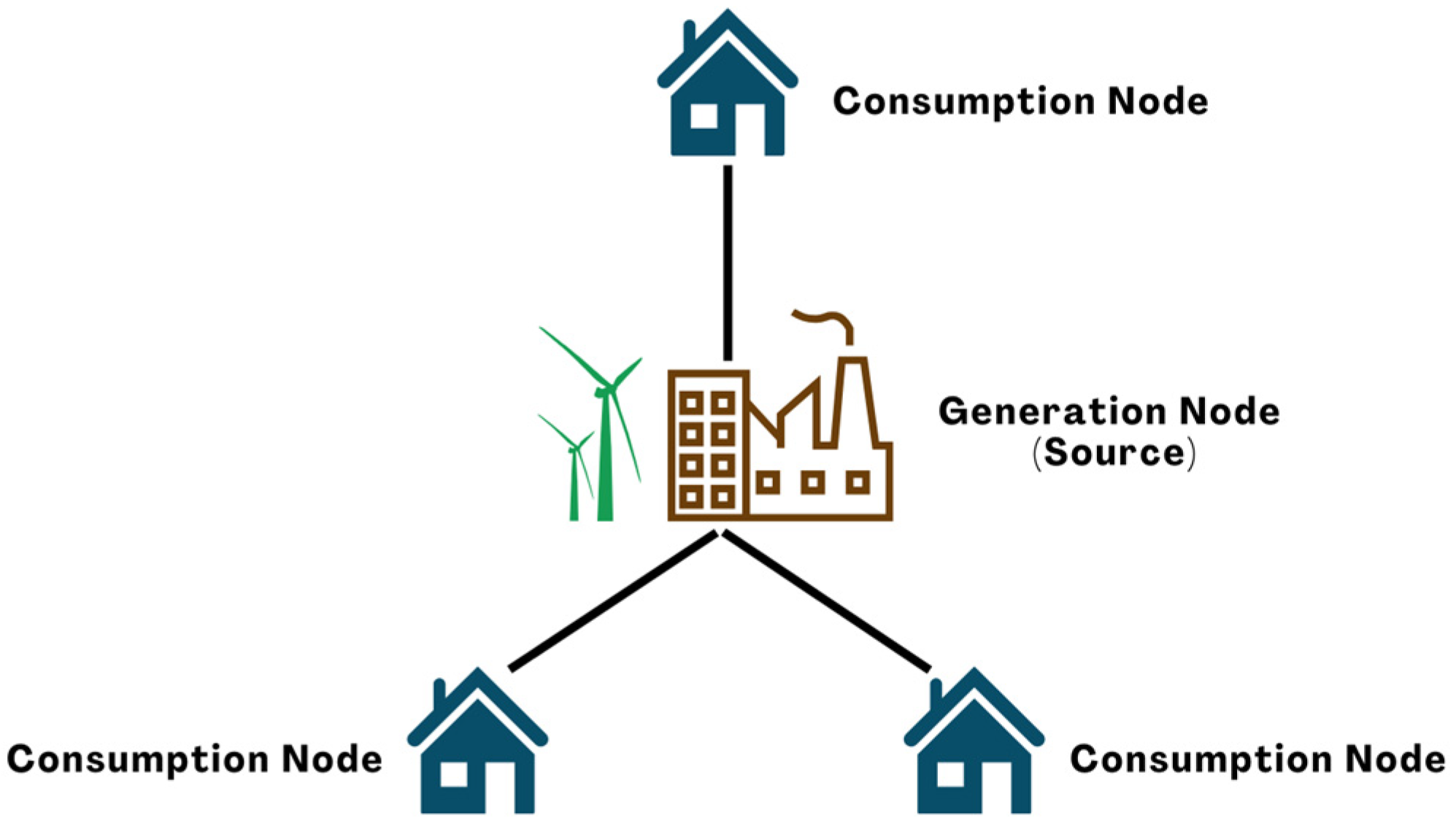
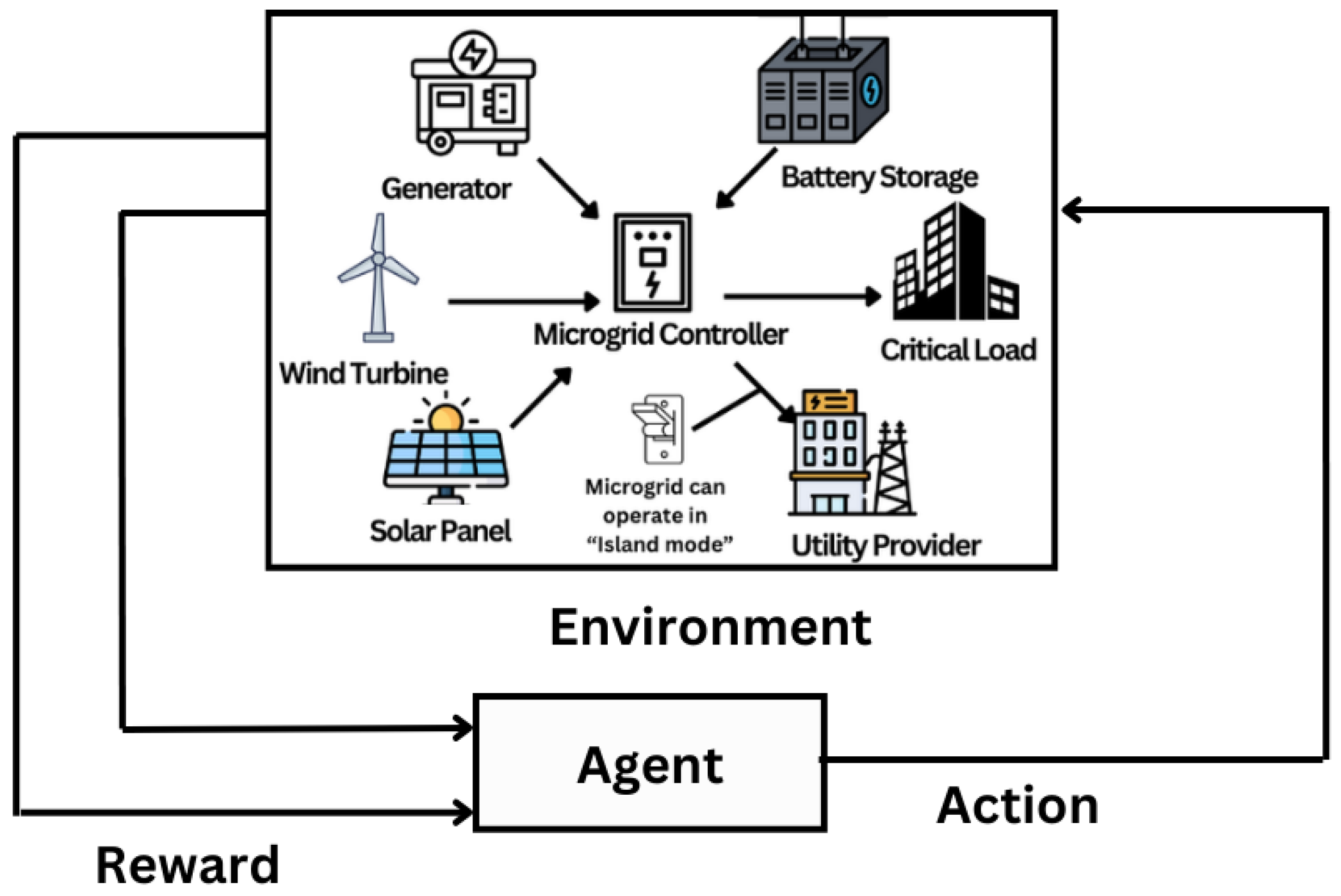
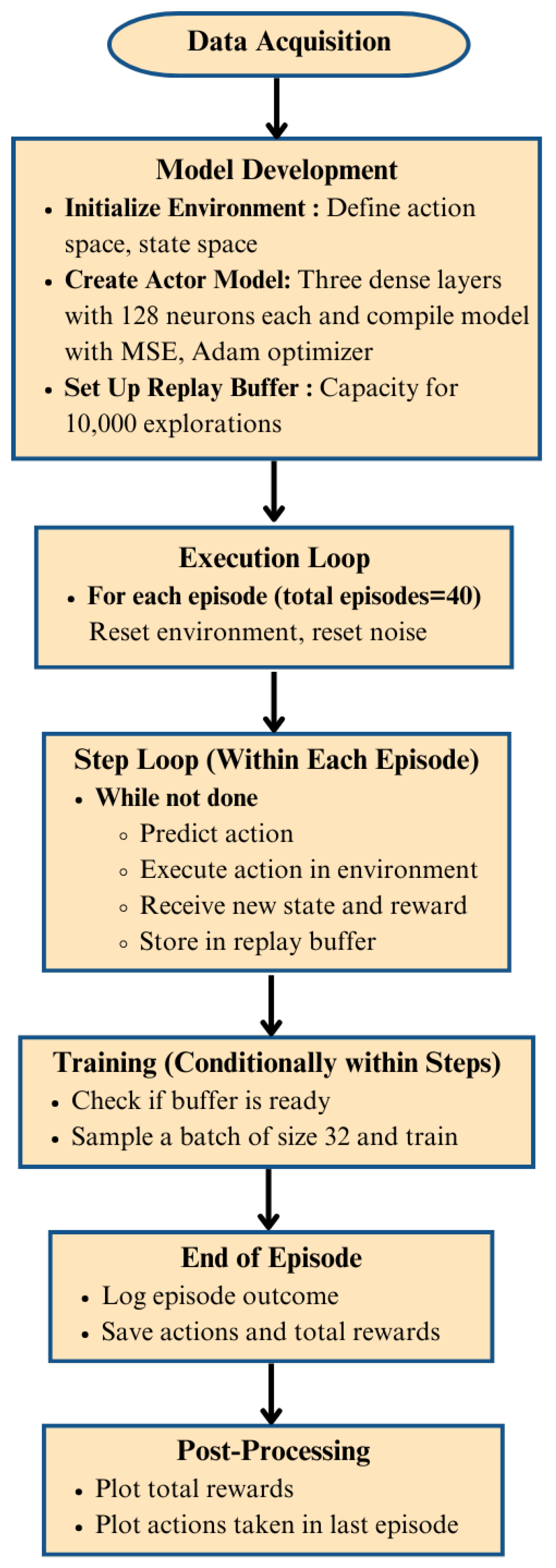
3.3. Microgrid Energy Management
3.3.1. Methodology
3.3.2. Dataset
3.3.3. Algorithms
- Input Layer: Adjusted to receive the four features of the environment’s state.
- Hidden Layers: Two hidden layers, each with 24 neurons, employ rectified linear unit (ReLU) activation functions. ReLU is chosen for its nonlinear properties and efficiency, allowing the model to learn complex patterns and interactions between the input features without falling into the pitfalls of gradient-vanishing problems, common with the sigmoid or tanh functions.
- Output Layer: The final layer of the network consists of two neurons corresponding to the two possible actions: the battery discharge rate and the PV utilization rate. This layer uses a linear activation function, which directly outputs the Q-values for each possible action given the current state.
3.3.4. Model Development
- Q(s,a) is the Q-value for a given state s and action a;
- α is the learning rate;
- rt+1 is the reward received after taking action at in state st;
- γ is the discount factor, which weighs the importance of future rewards;
- maxaQ(st+1,a) represents the maximum predicted Q-value in the next state across all possible actions.
- PV Utilization Reward: 0.1 × PV × pv_utilizationThis term rewards the utilization of photovoltaic energy, which encourages the model to maximize the use of solar energy. The coefficient 0.1 scales the reward to ensure balance with other terms in the equation.
- Grid Import Penalty: −0.1 × grid_importThis term penalizes the import of energy from the grid, promoting energy independence and incentivizing the model to use locally generated solar power and stored energy. The negative sign ensures it acts as a penalty, reducing the total reward.
- Battery Discharge Management: −0.1 × |storage_charge − discharge|This term penalizes excessive discharge from the battery, ensuring that the battery usage is managed efficiently and sustainability. The absolute difference between the storage charge and the discharge rate is taken to make the penalty symmetric, whether the action results in overcharging or over-discharging.
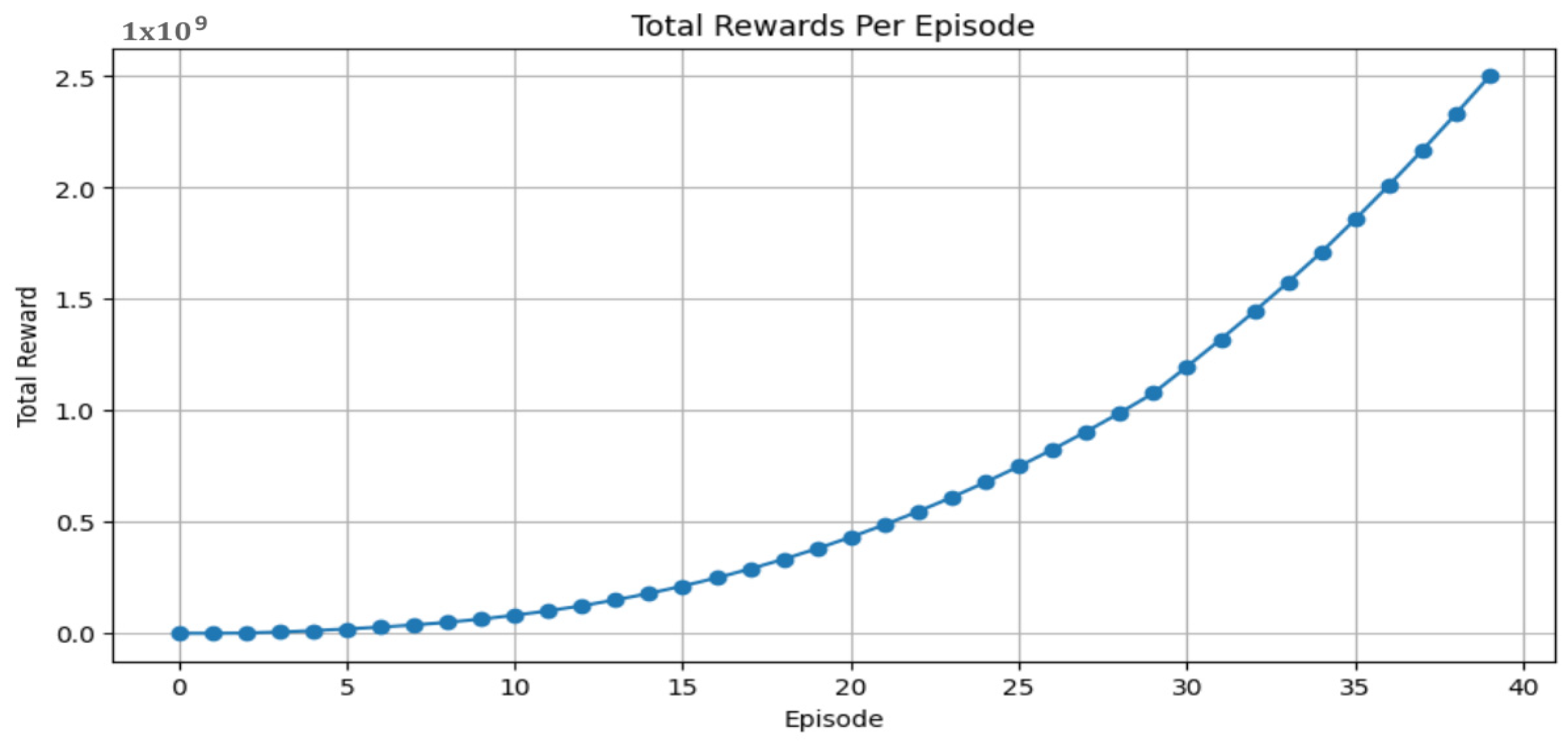
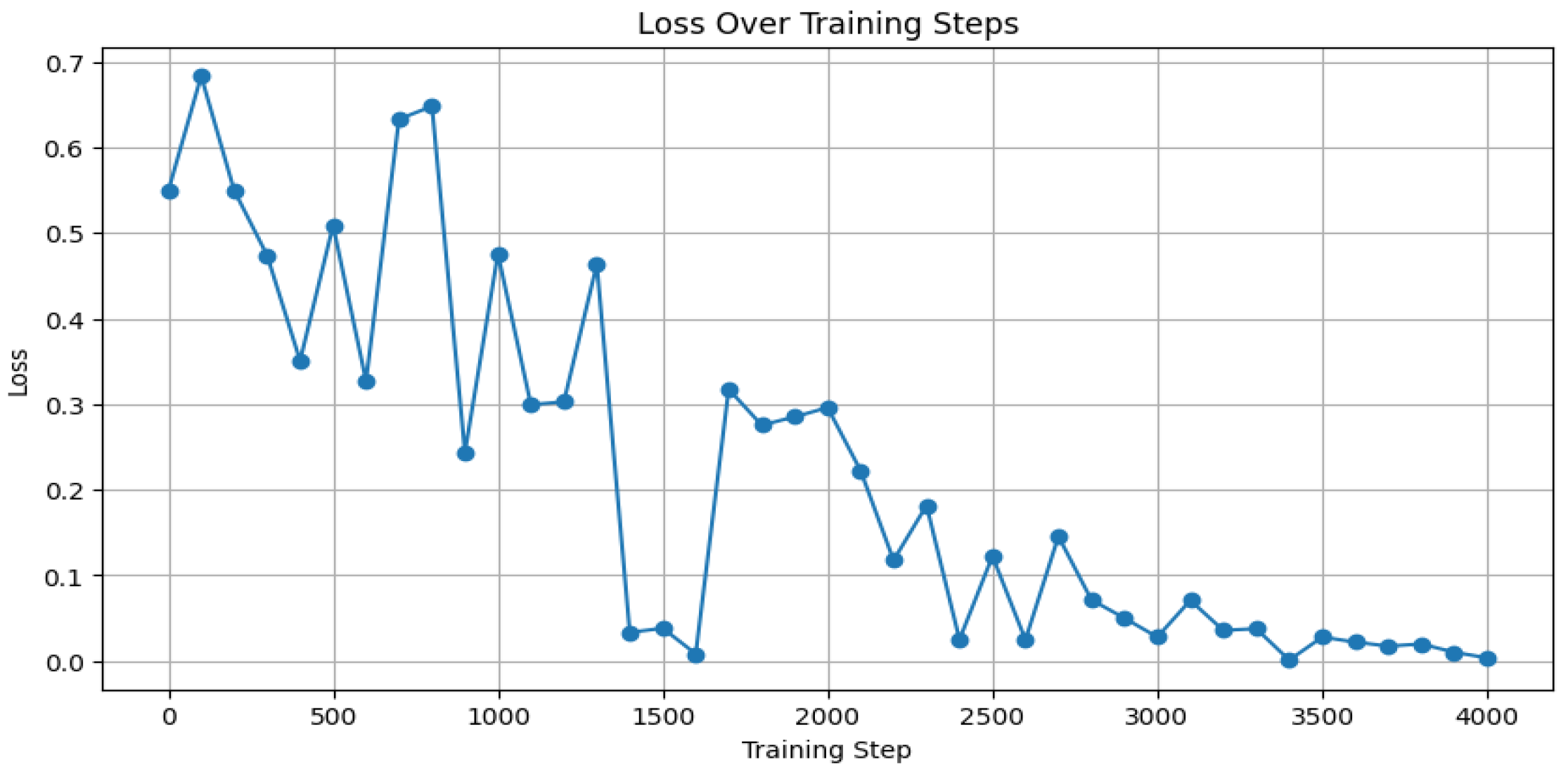
3.3.5. Results and Discussion
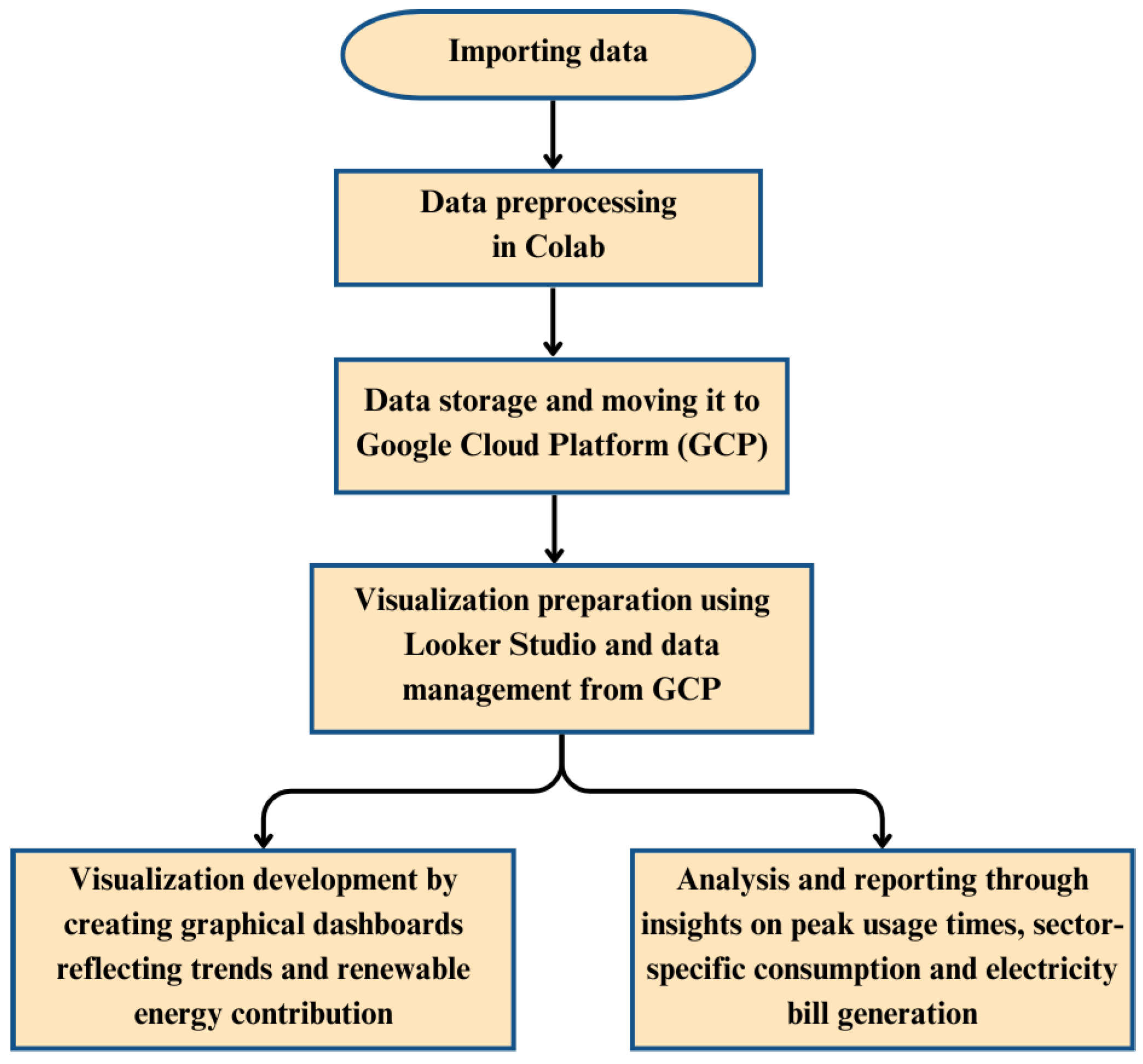
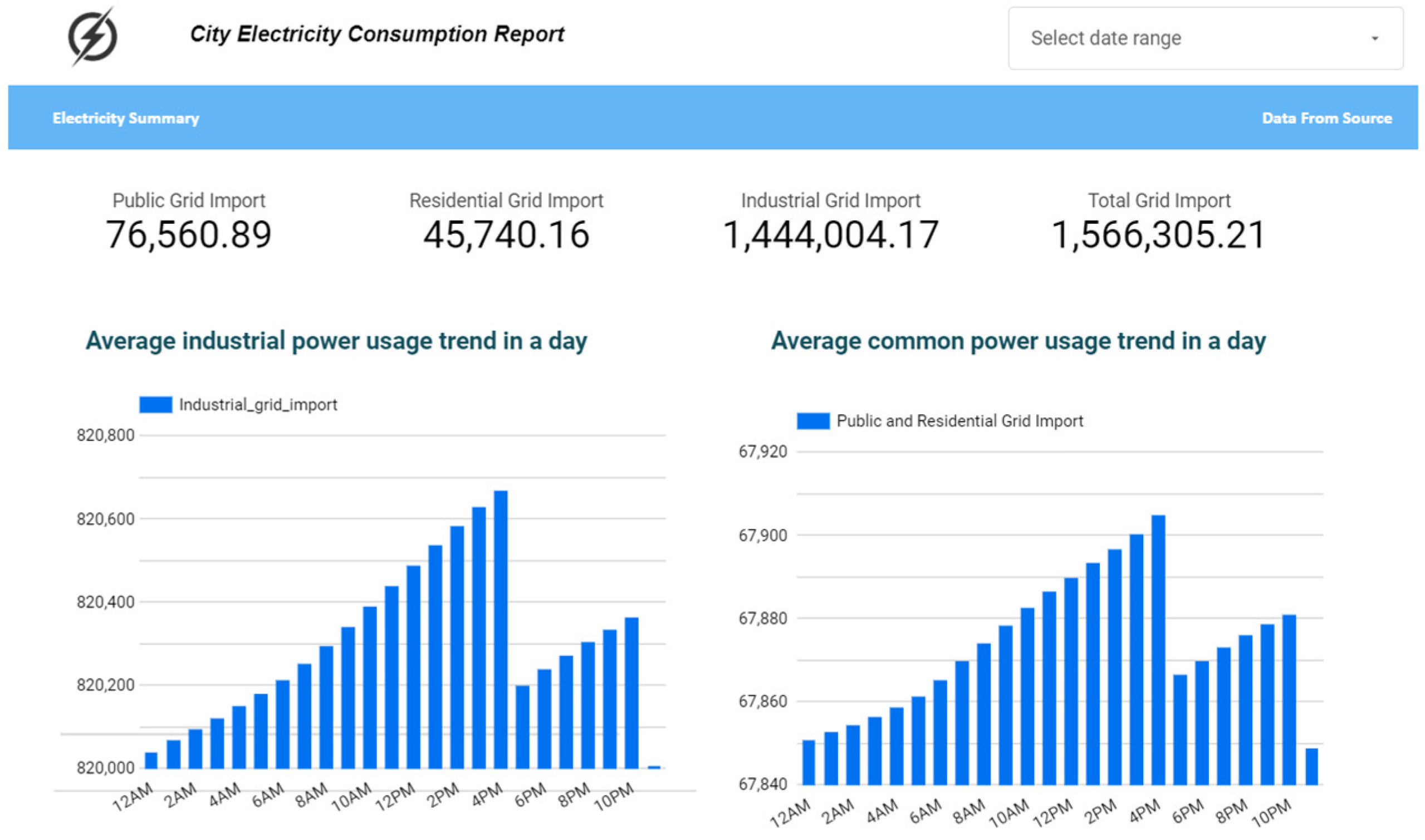
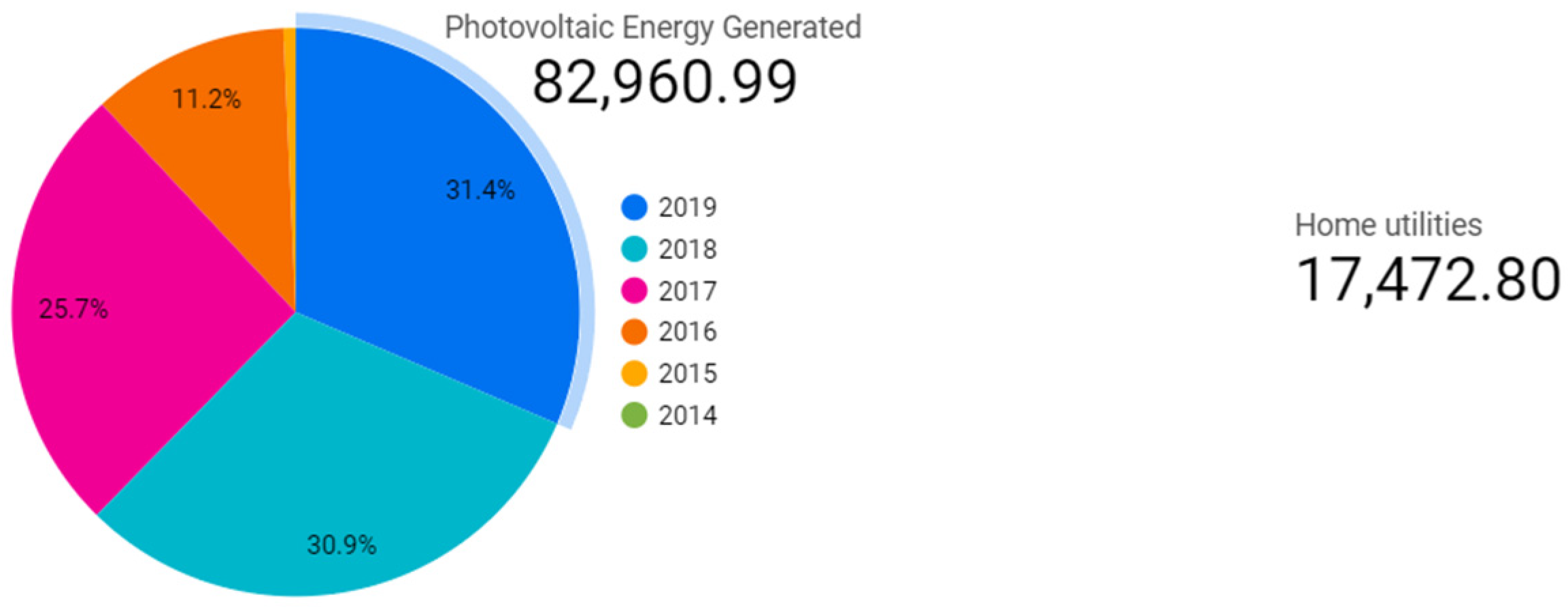
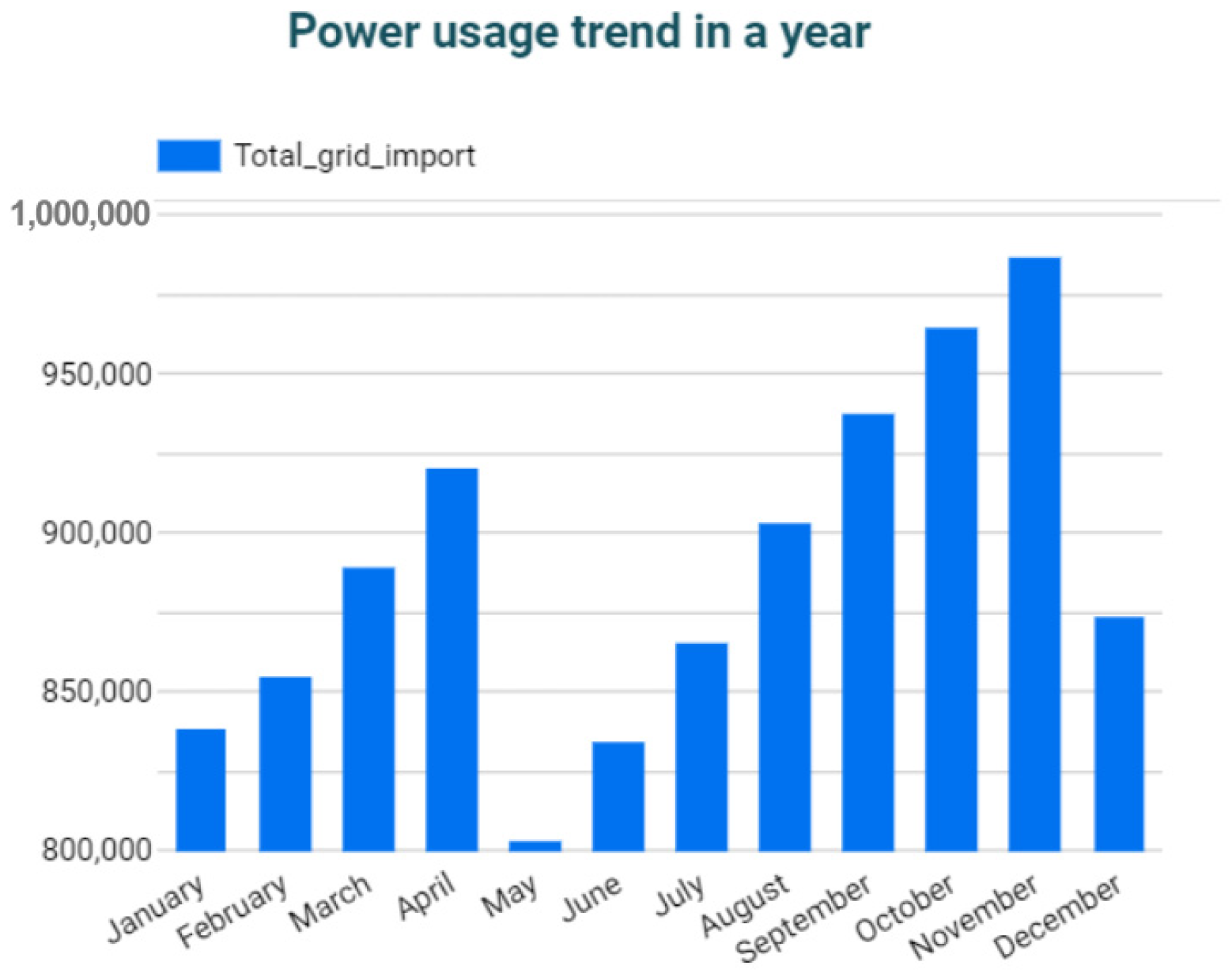
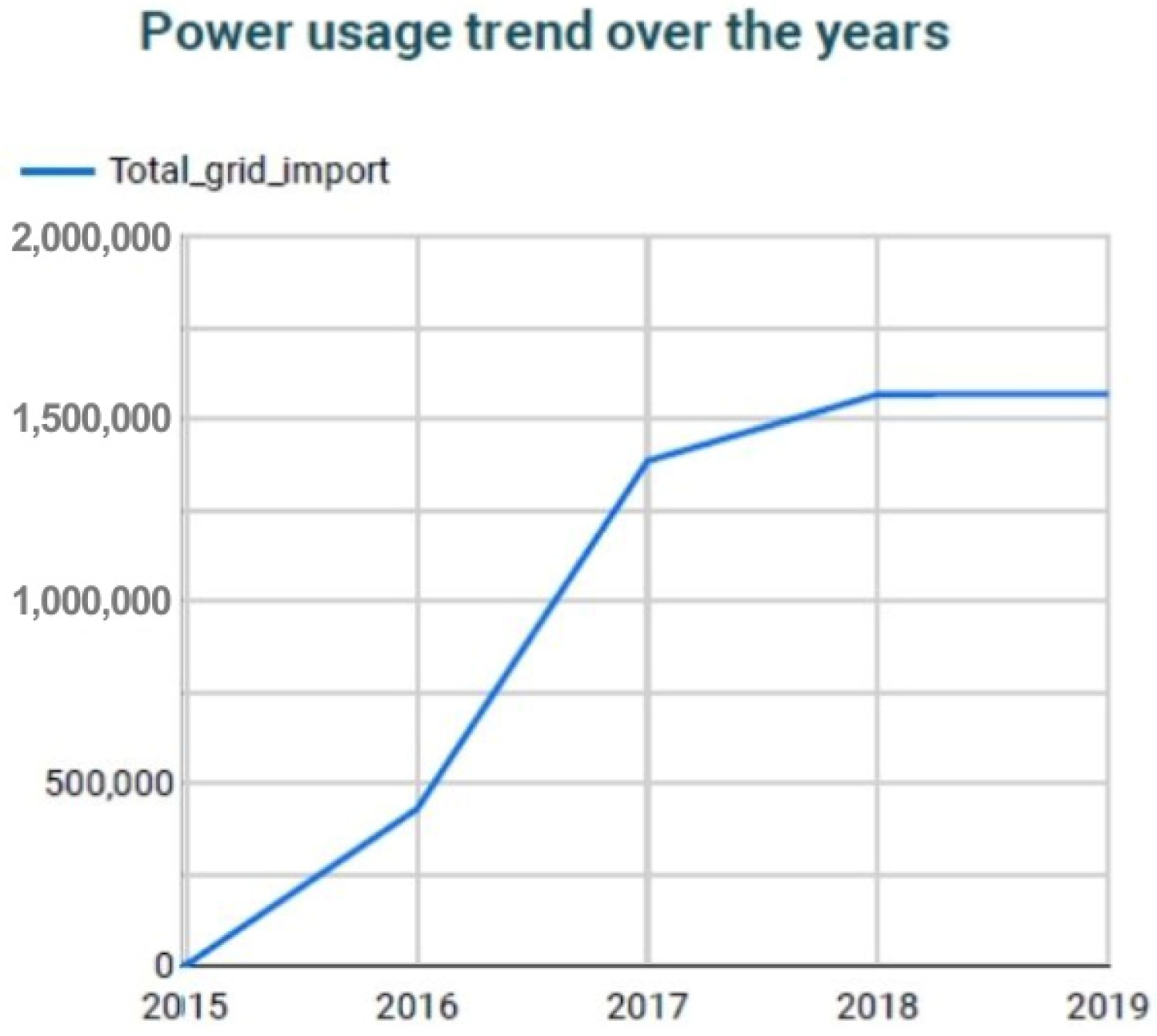
3.4. Interactive Data Visualization and Analytics
3.4.1. Software Used
3.4.2. Methodology
3.4.3. Results and Discussions
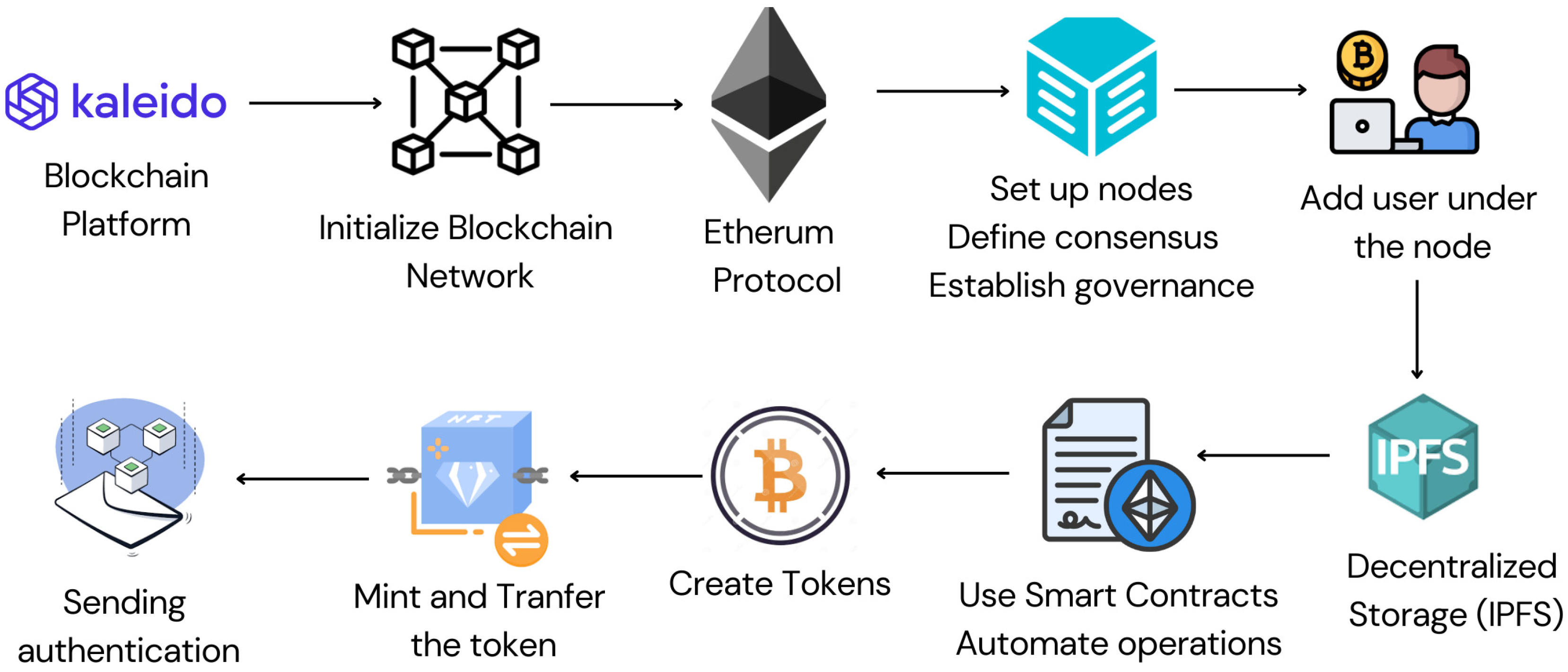
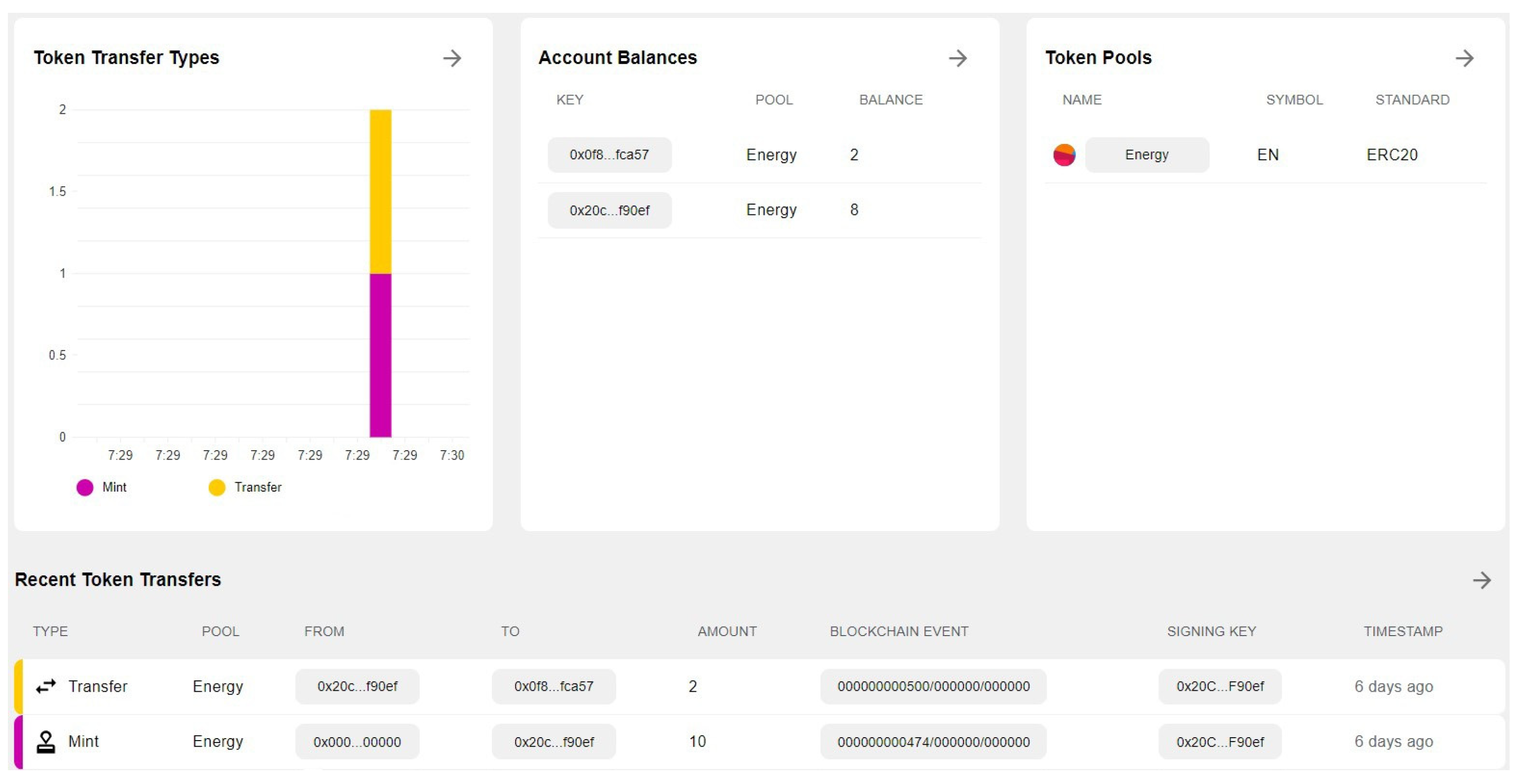
3.5. Blockchain Integration
3.5.1. Software Used
3.5.2. Methodology
- 1.
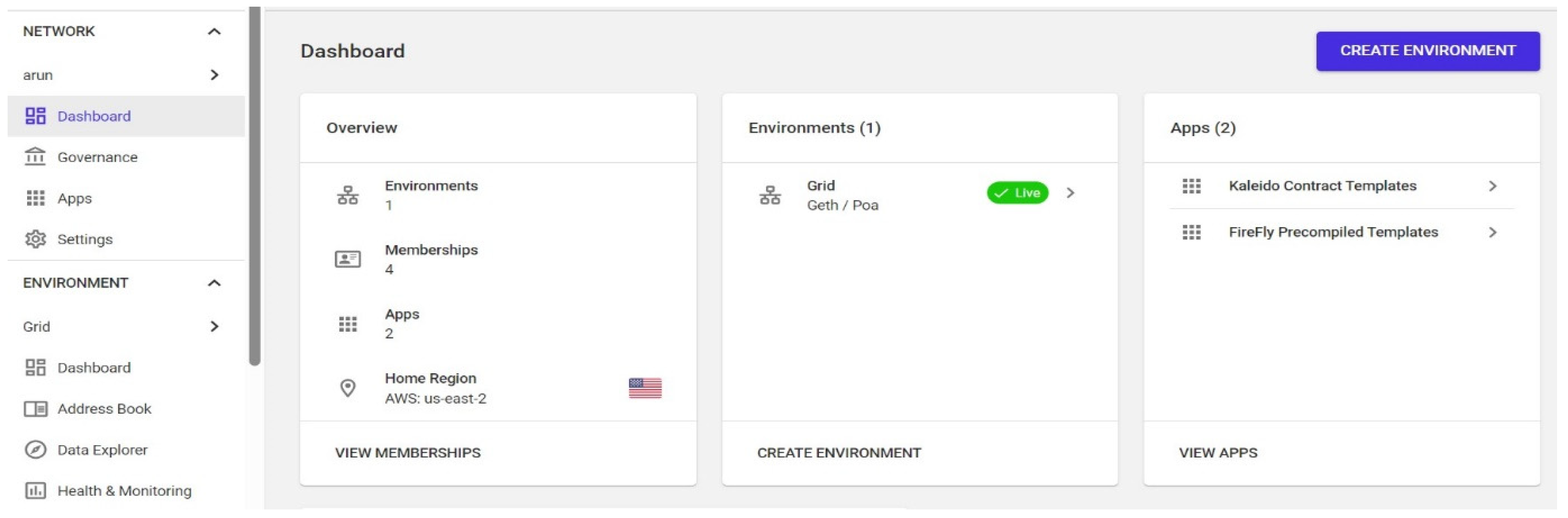
- Start by creating an account on Kaleido’s platform. The full flowchart is explained in Figure 21.
- 2.
- Set Up the blockchain network.
- 3.
- Create Memberships
- 4.
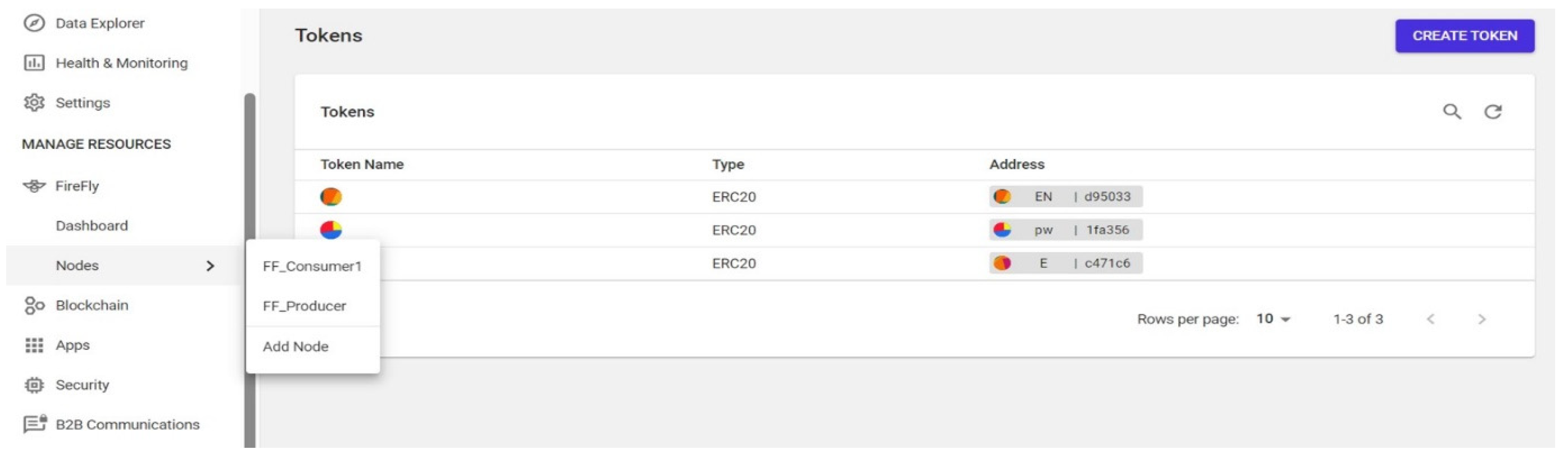
- Create Firefly Node
- 5.
- Deploy ERC720 Contract
- 6.
- Teach Firefly About the NFT
- 7.
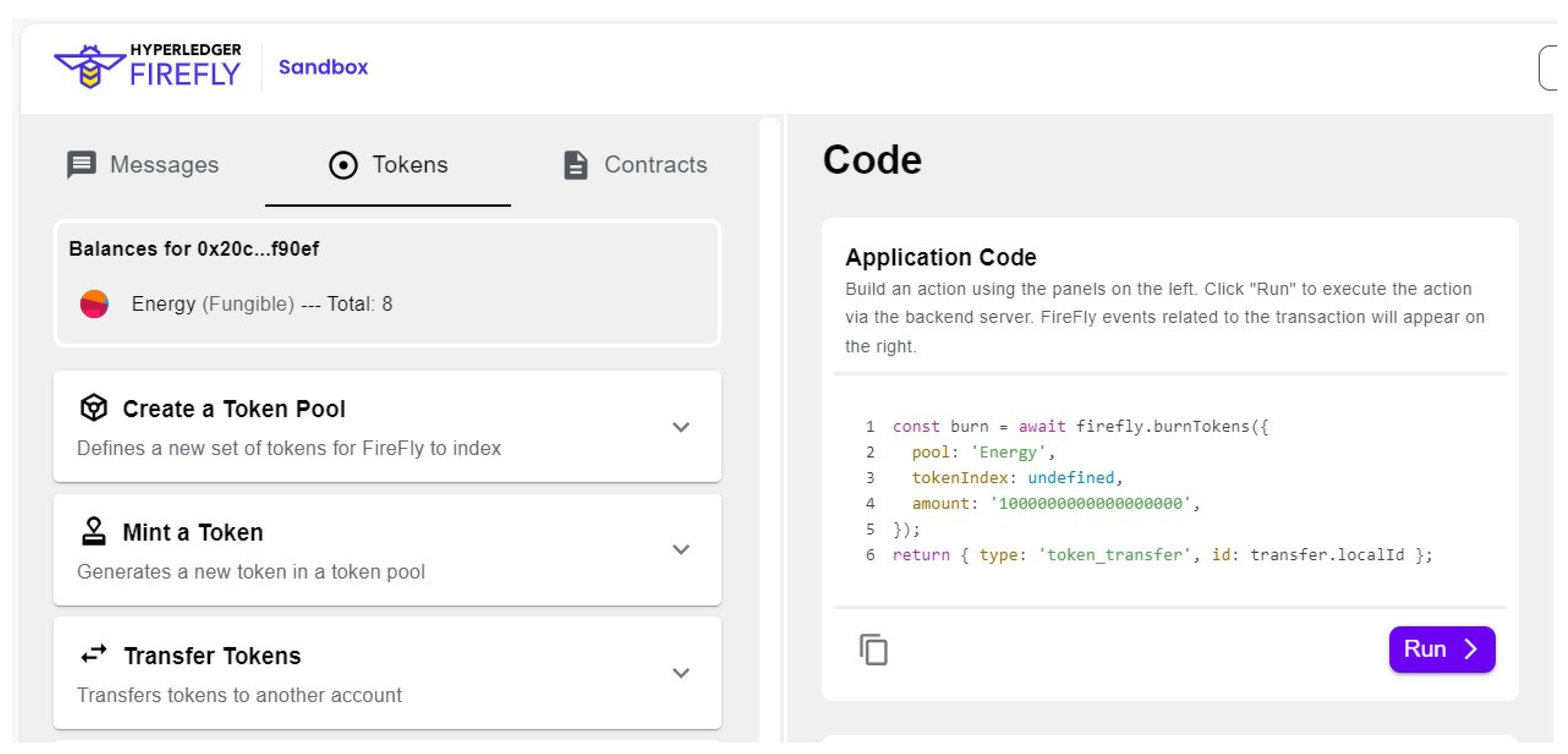
- Mint the NFT
- 8.
- Transfer the NFT and Broadcast a Message
- 9.
- Verify That the Producer Has Received the Token
3.5.3. Results and Discussions
4. Conclusions
5. Additional Explorations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Salam, S.S.A.; Petra, M.I.; Azad, A.K.; Sulthan, S.M.; Raj, V. A Comparative Study on Forecasting Solar Photovoltaic Power Generation Using Artificial Neural Networks. In Proceedings of the 2023 Innovations in Power and Advanced Computing Technologies (i-PACT), Kuala Lumpur, Malaysia, 8–10 December 2023; pp. 1–6. [Google Scholar]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Accurate Smart-Grid Stability Forecasting Based on Deep Learning: Point and Interval Estimation Method. In Proceedings of the 2021 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 19–20 April 2021; pp. 1–6. [Google Scholar]
- Salam, A.; El Hibaoui, A. Applying Deep Learning Model to Predict Smart Grid Stability. In Proceedings of the 2021 9th International Renewable and Sustainable Energy Conference (IRSEC), Tetouan, Morocco, 23–27 November 2021; pp. 1–9. [Google Scholar]
- Abbass, M.J.; Lis, R.; Mushtaq, Z. Artificial Neural Network (ANN)-Based Voltage Stability Prediction of Test Microgrid Grid. IEEE Access 2023, 11, 58994–59001. [Google Scholar] [CrossRef]
- Boucetta, L.N.; Amrane, Y.; Arezki, S. Comparative Analysis of LSTM, GRU, and MLP Neural Networks for Short-Term Solar Power Forecasting. In Proceedings of the 2023 (ICEEAT), Batna, Algeria, 19–20 December 2023; pp. 1–6. [Google Scholar]
- Singh, A.; Singh, P.; Agrawal, N.; Gupta, P. Estimating the Stability of Smart Grids Using Optimised Artificial Neural Network. In Proceedings of the 2023 International Conference on (REEDCON), New Delhi, India, 1–3 May 2023; pp. 380–384. [Google Scholar]
- Redan, R.N.; Othman, M.M.; Hasan, K.; Ahmadipour, M. Random Forest with Daubechies Wavelet and Multiple Time Lags for Solar Irradiance Forecasting. In Proceedings of the 2023 IEEE 3rd (ICPEA), Putrajaya, Malaysia, 6–7 March 2023; pp. 374–378. [Google Scholar]
- Foruzan, E.; Soh, L.-K.; Asgarpoor, S. Reinforcement Learning Approach for Optimal Distributed Energy Management in a Microgrid. IEEE Trans. Power Syst. 2018, 33, 5749–5758. [Google Scholar] [CrossRef]
- Zhong, Y.-J.; Wu, Y.-K. Short-Term Solar Power Forecasts Considering Various Weather Variables. In Proceedings of the 2020 International Symposium on Computer, Consumer and Control (IS3C), Taichung City, Taiwan, 13–16 November 2020; pp. 432–435. [Google Scholar]
- Siriwardana, S.; Nishshanka, T.; Peiris, A.; Boralessa, M.A.K.S.; Hemapala, K.T.M.U.; Saravanan, V. Solar Photovoltaic Energy Forecasting Using Improved Ensemble Method For Micro-grid Energy Management. In Proceedings of the 2022 IEEE 2nd International Symposium on Sustainable Energy, Signal Processing and Cyber Security (iSSSC), Gunupur, Odisha, India, 15–17 December 2022; pp. 1–6. [Google Scholar]
- Boumaiza, A.; Sanfilippo, A. AI for Energy: A Blockchain-based Trading market. In Proceedings of the IECON 2022—48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 18–21 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Sang, Y.; Cali, U.; Kuzlu, M.; Pipattanasomporn, M.; Lima, C.; Chen, S. IEEE SA Blockchain in Energy Standardization Framework: Grid and Prosumer Use Cases. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting (PESGM), Montreal, QC, Canada, 2–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Plaza, C.; Gil, J.; de Chezelles, F.; Strang, K.A. Distributed Solar Self-Consumption and Blockchain Solar Energy Exchanges on the Public Grid Within an Energy Community. In Proceedings of the 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Palermo, Italy, 12–15 June 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Dimobi, I.; Pipattanasomporn, M.; Rahman, S. A Transactive Grid with Microgrids Using Blockchain for the Energy Internet. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Tiwari, H.; Raj, A.; Singh, U.K.; Fatima, H. Generative AI for NFTs using GANs. In Proceedings of the 2024 11th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 28 February–1 March 2024; pp. 488–492. [Google Scholar] [CrossRef]
- Hopfield, J.J. Artificial neural networks. IEEE Circuits Devices Mag. 1998, 4, 3–10. [Google Scholar] [CrossRef]
- Schäfer, B.; Grabow, C.; Auer, S.; Kurths, J.; Witthaut, D.; Timme, M. Taming instabilities in power grid networks by decentralized control. Eur. Phys. J. Spec. Top. 2016, 225, 569–582. [Google Scholar] [CrossRef]
- Arzamasov, V.; Böhm, K.; Jochem, P. Towards Concise Models of Grid Stability. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘16), San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity Analysis of k-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://github.com/ColasGael/Machine-Learning-for-Solar-Energy-Prediction/tree/master/Datasets/ (accessed on 28 January 2024).
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–15 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G.; Learning, R. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Microgrid Controllers: Functions and Benefits. Available online: https://247mesa.com/microgrid-controllers-functions-and-benefits/ (accessed on 12 December 2023).
- Open Power System Data. 2020. Data Package Household Data. Version 15 April 2020. Available online: https://data.open-power-system-data.org/household_data/2020-04-15/ (accessed on 10 January 2024).
- Gupta; Goswami, P.; Chaudhary, N.; Bansal, R. Deploying an Application using Google Cloud Platform. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; pp. 236–239. [Google Scholar] [CrossRef]
- Pulipati, S. Data Storytelling with Google Looker Studio: A Hands-on Guide to Using Looker Studio for Building Compelling and Effective Dashboards; Packt Publishing: Birmingham, UK, 2022. [Google Scholar]
- Samaniego, M.; Jamsrandorj, U.; Deters, R. Blockchain as a Service for IoT. In Proceedings of the 2016 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Chengdu, China, 15–18 December 2016; pp. 433–436. [Google Scholar] [CrossRef]
- Christidis, K.; Devetsikiotis, M. Blockchains and Smart Contracts for the Internet of Things. IEEE Access 2016, 4, 2292–2303. [Google Scholar] [CrossRef]
- Thakkar, P.; Nathan, S.; Viswanathan, B. Performance Benchmarking and Optimizing Hyperledger Fabric Blockchain Platform. In Proceedings of the 2018 IEEE 26th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Milwaukee, WI, USA, 25–28 September 2018; pp. 264–276. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Stable | 0.97 | 0.97 | 0.97 | 4322 |
| Unstable | 0.98 | 0.99 | 0.98 | 7678 |
| Accuracy | 0.98 | 12,000 | ||
| Macro Avg | 0.98 | 0.98 | 0.98 | 12,000 |
| Weighted Avg | 0.98 | 0.98 | 0.98 | 12,000 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Stable | 0.96 | 0.97 | 0.97 | 4322 |
| Unstable | 0.98 | 0.98 | 0.98 | 7678 |
| Accuracy | 0.98 | 12,000 | ||
| Macro Avg | 0.97 | 0.98 | 0.97 | 12,000 |
| Weighted Avg | 0.98 | 0.98 | 0.98 | 12,000 |
| Column | Description |
|---|---|
| DATE_TIME | 15 min timestamp |
| PLANT_ID | Constant value throughout |
| SOURCE_KEY | Unique inverter ID |
| DC_POWER | DC power generated by that inverter |
| AC_POWER | AC power after conversion |
| DAILY_YIELD | Total power generated that day |
| TOTAL_YIELD | Total inverter yield |
| Column | Description |
|---|---|
| DATE_TIME | 15 min timestamp |
| PLANT_ID | Constant value throughout |
| SOURCE_KEY | Unique inverter ID |
| AMBIENT_TEMPERATURE | Ambient temperature at the plant |
| MODULE_TEMPERATURE | AC power after conversion |
| IRRADIATION | Amount of irradiation |
| S. No. | Model Used | RMSE Error |
|---|---|---|
| 1 | Random forest | 1.908 |
| 2 | Artificial neural network | 1.805 |
| 3 | Bidirectional LSTM | 2.055 |
| Date | Hour | Actual Gen (MW) | Predicted Gen (MW) | Deviation % |
|---|---|---|---|---|
| 15-06-2020 | 8 | 13.229 | 12.257 | −7.349 |
| 9 | 9.745 | 10.586 | 8.635 | |
| 10 | 11.348 | 10.965 | −3.376 | |
| 11 | 8.998 | 8.732 | −2.953 | |
| 12 | 9.977 | 9.366 | −6.121 | |
| 13 | 8.952 | 7.413 | −17.198 | |
| 14 | 10.980 | 10.634 | −3.150 | |
| 15 | 9.643 | 10.119 | 4.930 | |
| 16 | 8.017 | 6.966 | −13.115 | |
| 17 | 3.406 | 5.645 | 65.754 | |
| 18 | 2.054 | 2.688 | 30.837 | |
| 16-06-2020 | 8 | 9.927 | 10.284 | 3.601 |
| 9 | 11.906 | 10.767 | −9.564 | |
| 10 | 15.527 | 13.166 | −15.205 | |
| 11 | 16.456 | 14.503 | −11.869 | |
| 12 | 15.378 | 13.143 | −14.532 | |
| 13 | 15.831 | 14.591 | −7.834 | |
| 14 | 7.970 | 9.662 | 21.224 | |
| 15 | 12.195 | 11.304 | −7.306 | |
| 16 | 5.629 | 7.497 | 33.170 | |
| 17 | 1.994 | 2.630 | 31.898 | |
| 18 | 0.835 | 2.203 | 163.803 | |
| 17-06-2020 | 8 | 4.665 | 5.985 | 28.285 |
| 9 | 7.247 | 7.608 | 4.980 | |
| 10 | 10.858 | 11.742 | 8.141 | |
| 11 | 12.249 | 9.925 | −18.971 | |
| 12 | 15.441 | 13.208 | −14.460 | |
| 13 | 12.071 | 14.022 | 16.161 | |
| 14 | 10.768 | 10.040 | −6.759 | |
| 15 | 10.154 | 10.423 | 2.645 | |
| 16 | 5.840 | 6.417 | 9.888 | |
| 17 | 2.321 | 3.567 | 53.689 | |
| 18 | 1.326 | 2.951 | 122.454 |
| Column | Description |
|---|---|
| utc_timestamp | 15 min timestamp |
| grid_import | Units used from grid |
| pv | Solar energy produced |
| storage_charge | Units charged |
| storage_decharge | Units discharged |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
A T, M.R.; B, B.; R R, S.A.P.; Naidu, R.C.; M, R.K.; Ramachandran, P.; Rajkumar, S.; Kumar, V.N.; Aggarwal, G.; Siddiqui, A.M. Intelligent Energy Management across Smart Grids Deploying 6G IoT, AI, and Blockchain in Sustainable Smart Cities. IoT 2024, 5, 560-591. https://doi.org/10.3390/iot5030025
A T MR, B B, R R SAP, Naidu RC, M RK, Ramachandran P, Rajkumar S, Kumar VN, Aggarwal G, Siddiqui AM. Intelligent Energy Management across Smart Grids Deploying 6G IoT, AI, and Blockchain in Sustainable Smart Cities. IoT. 2024; 5(3):560-591. https://doi.org/10.3390/iot5030025
Chicago/Turabian StyleA T, Mithul Raaj, Balaji B, Sai Arun Pravin R R, Rani Chinnappa Naidu, Rajesh Kumar M, Prakash Ramachandran, Sujatha Rajkumar, Vaegae Naveen Kumar, Geetika Aggarwal, and Arooj Mubashara Siddiqui. 2024. "Intelligent Energy Management across Smart Grids Deploying 6G IoT, AI, and Blockchain in Sustainable Smart Cities" IoT 5, no. 3: 560-591. https://doi.org/10.3390/iot5030025
APA StyleA T, M. R., B, B., R R, S. A. P., Naidu, R. C., M, R. K., Ramachandran, P., Rajkumar, S., Kumar, V. N., Aggarwal, G., & Siddiqui, A. M. (2024). Intelligent Energy Management across Smart Grids Deploying 6G IoT, AI, and Blockchain in Sustainable Smart Cities. IoT, 5(3), 560-591. https://doi.org/10.3390/iot5030025