
An Edge-Based LWM2M Proxy for Device Management to Efficiently Support QoS-Aware IoT Services



Abstract
:1. Introduction
2. Related Work
2.1. Background on OMA LWM2M
2.2. Related Work on IoT Proxies
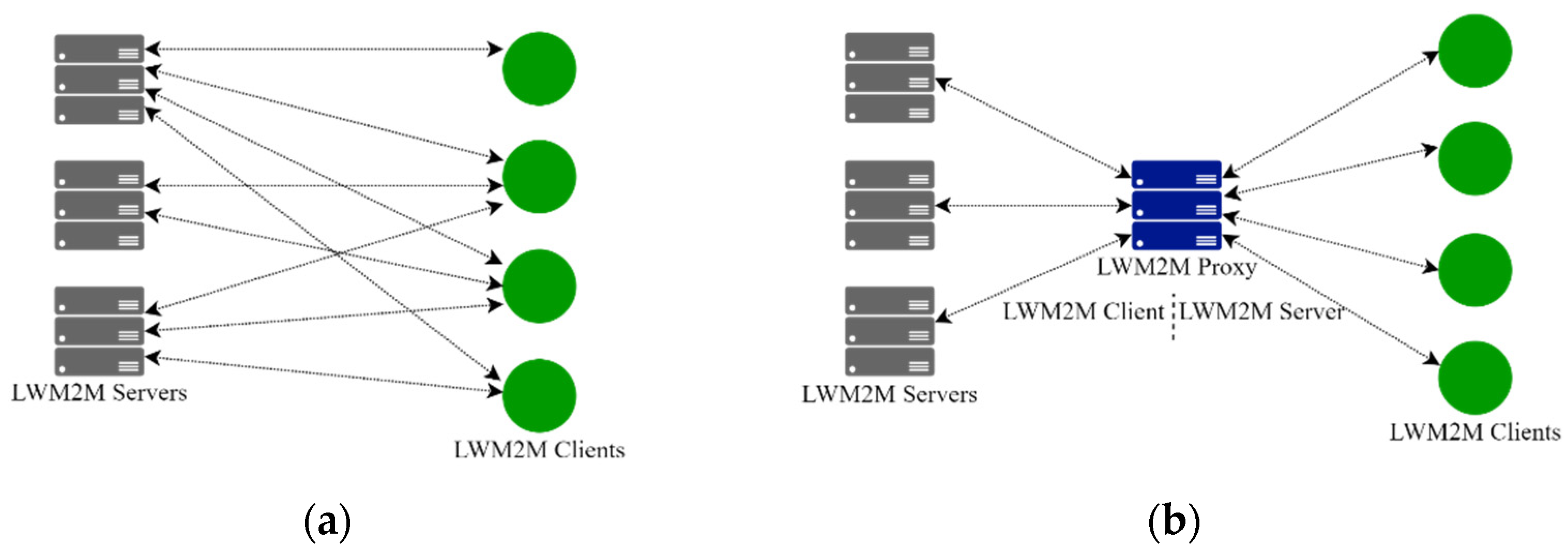
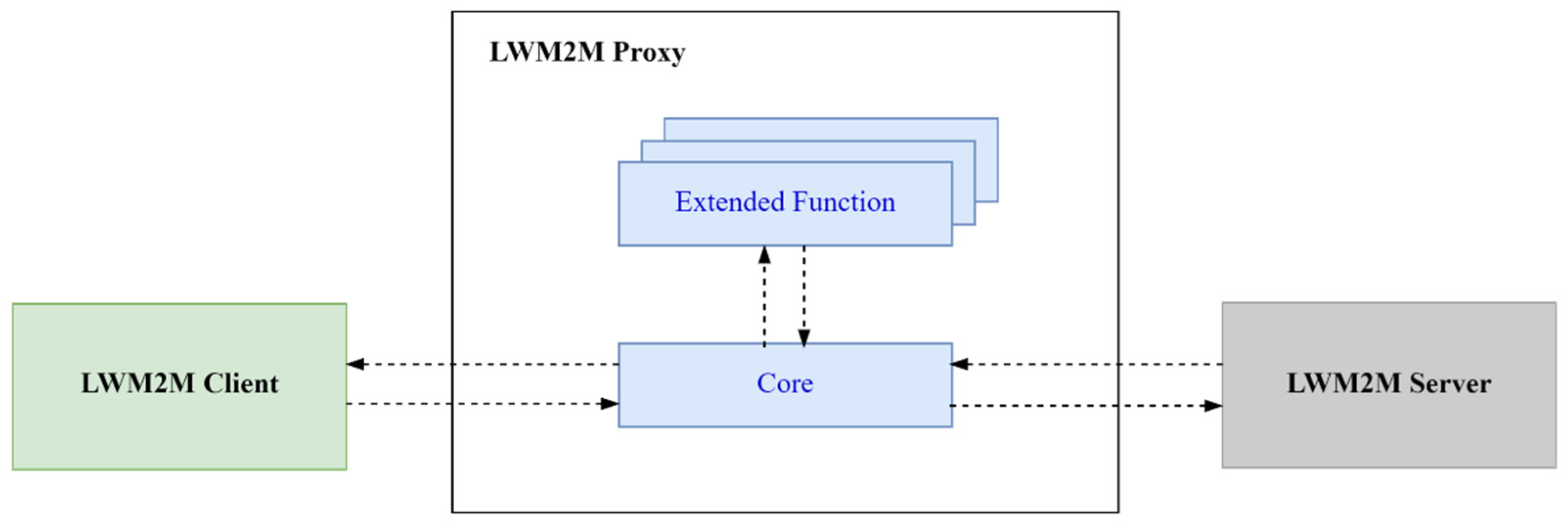
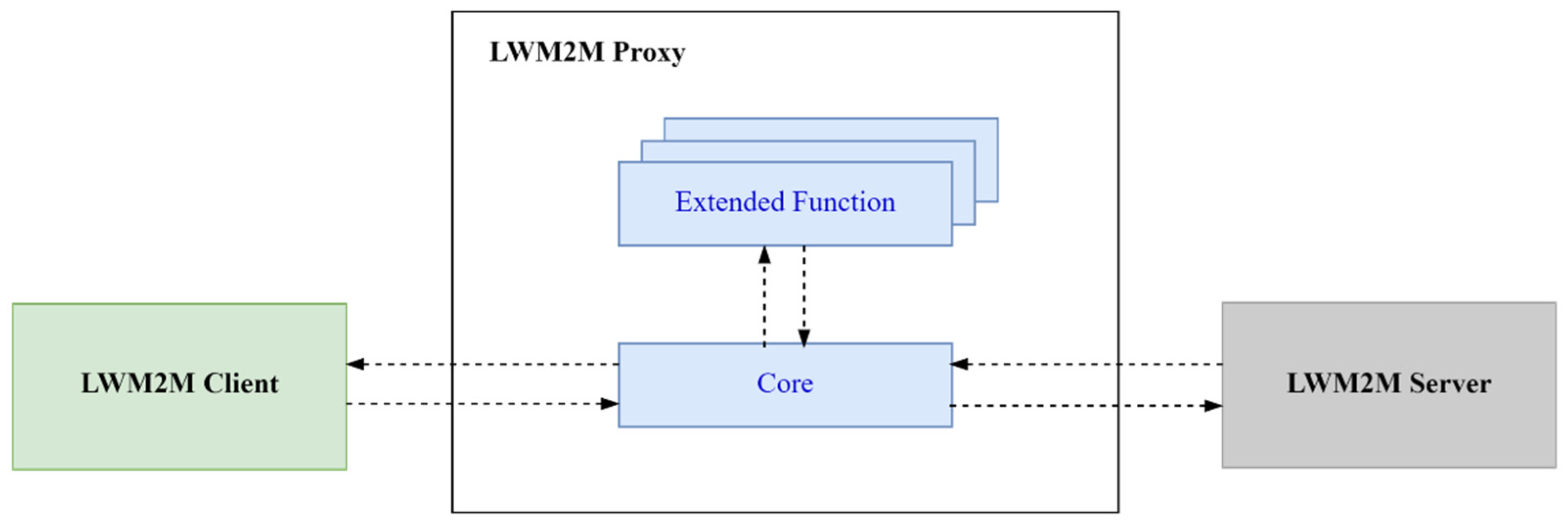
3. LWM2M Proxy
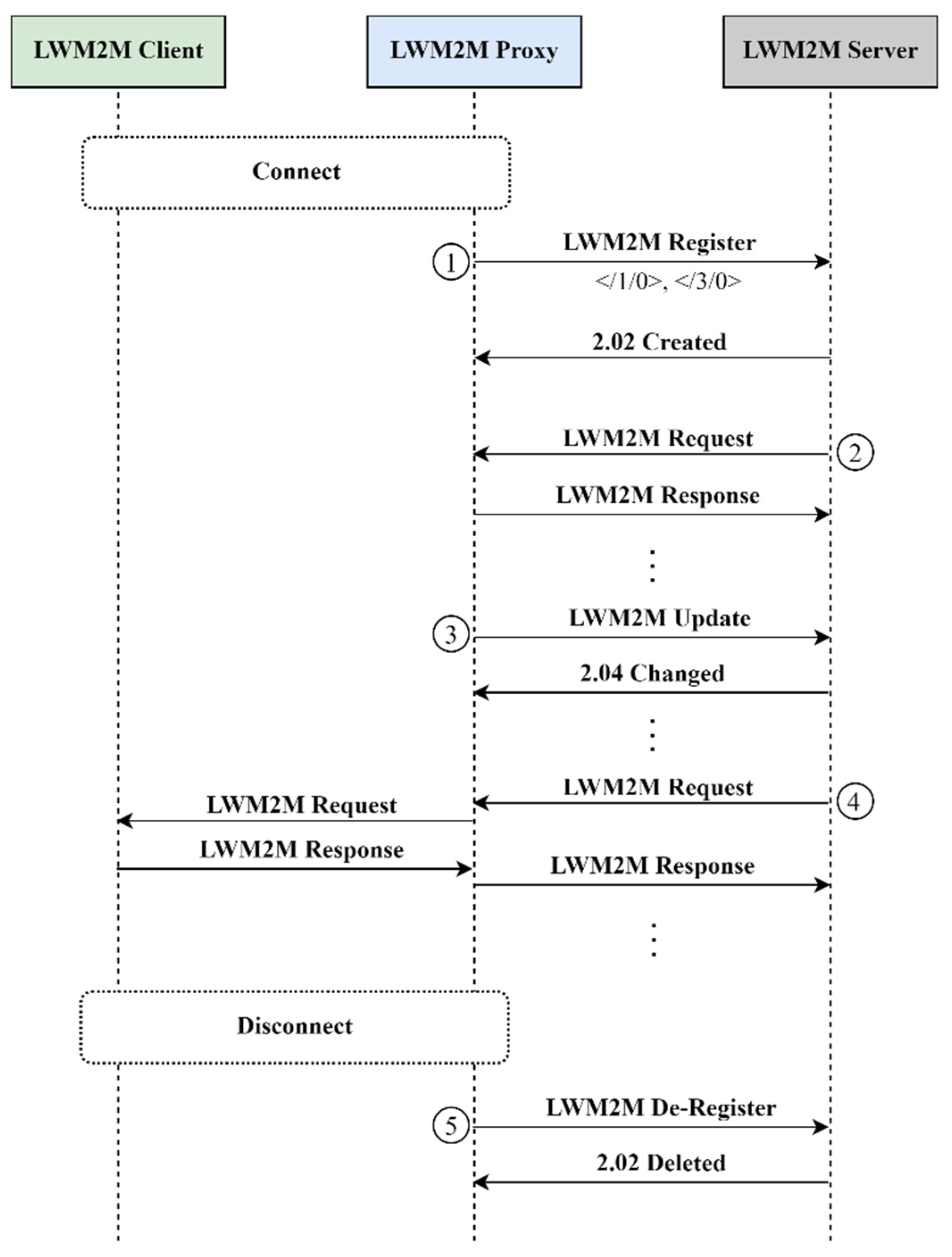
3.1. Register, Update and De-Register
3.2. Write-Attributes
3.3. Discover
3.4. Create
3.5. Write
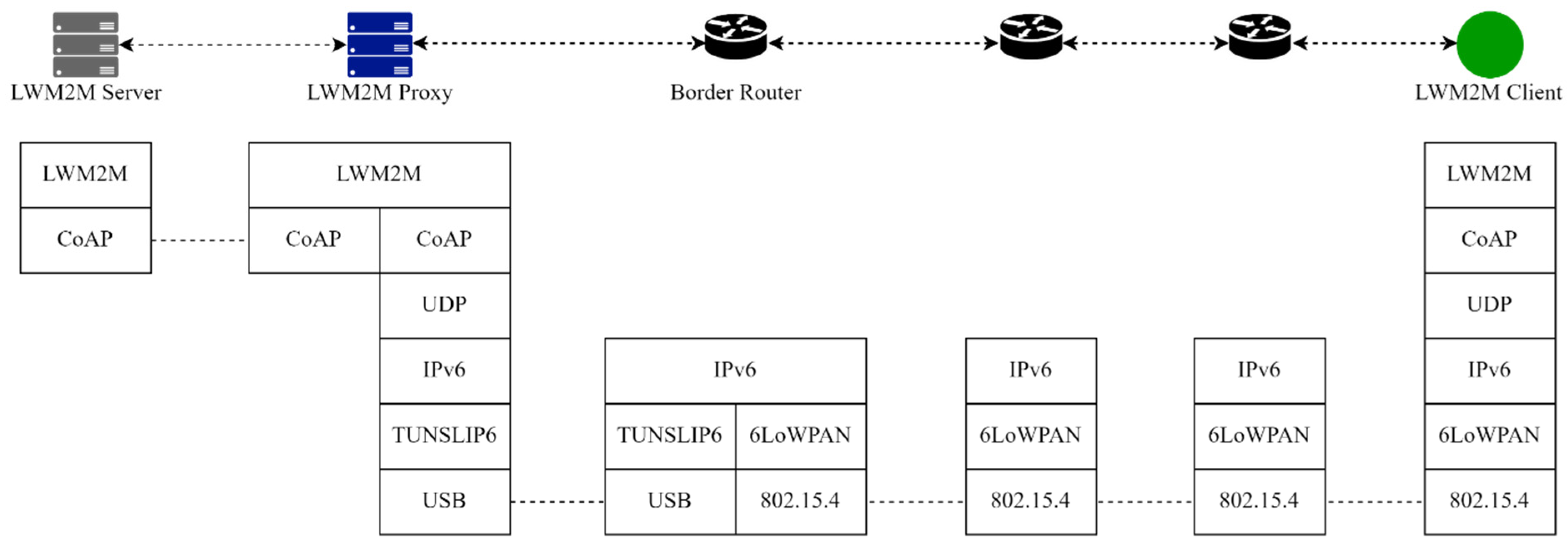
3.6. Proxy Deployment
4. QoS-Oriented Extended Functions
4.1. Requests-Shaping
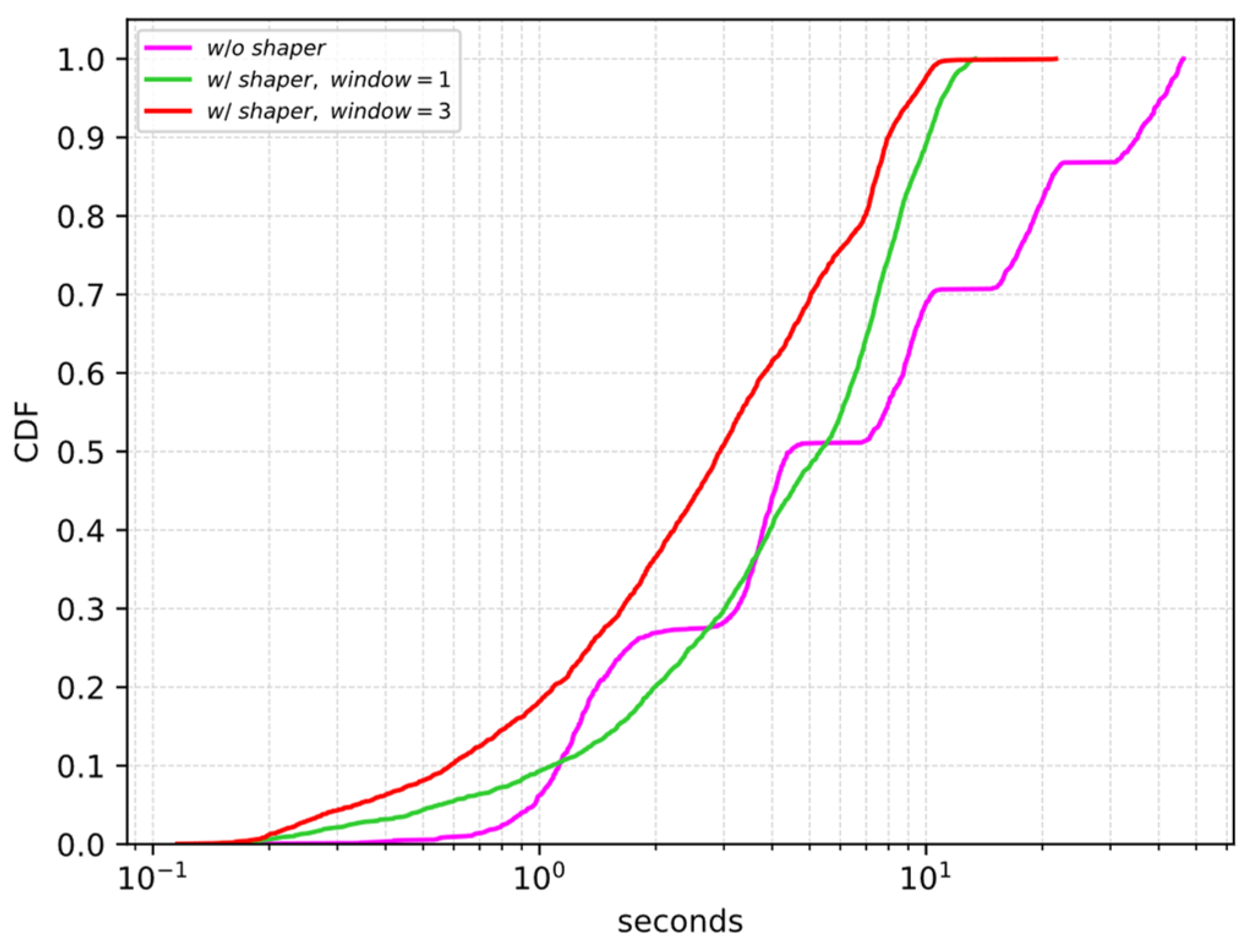
4.1.1. Requests Shaping Algorithm
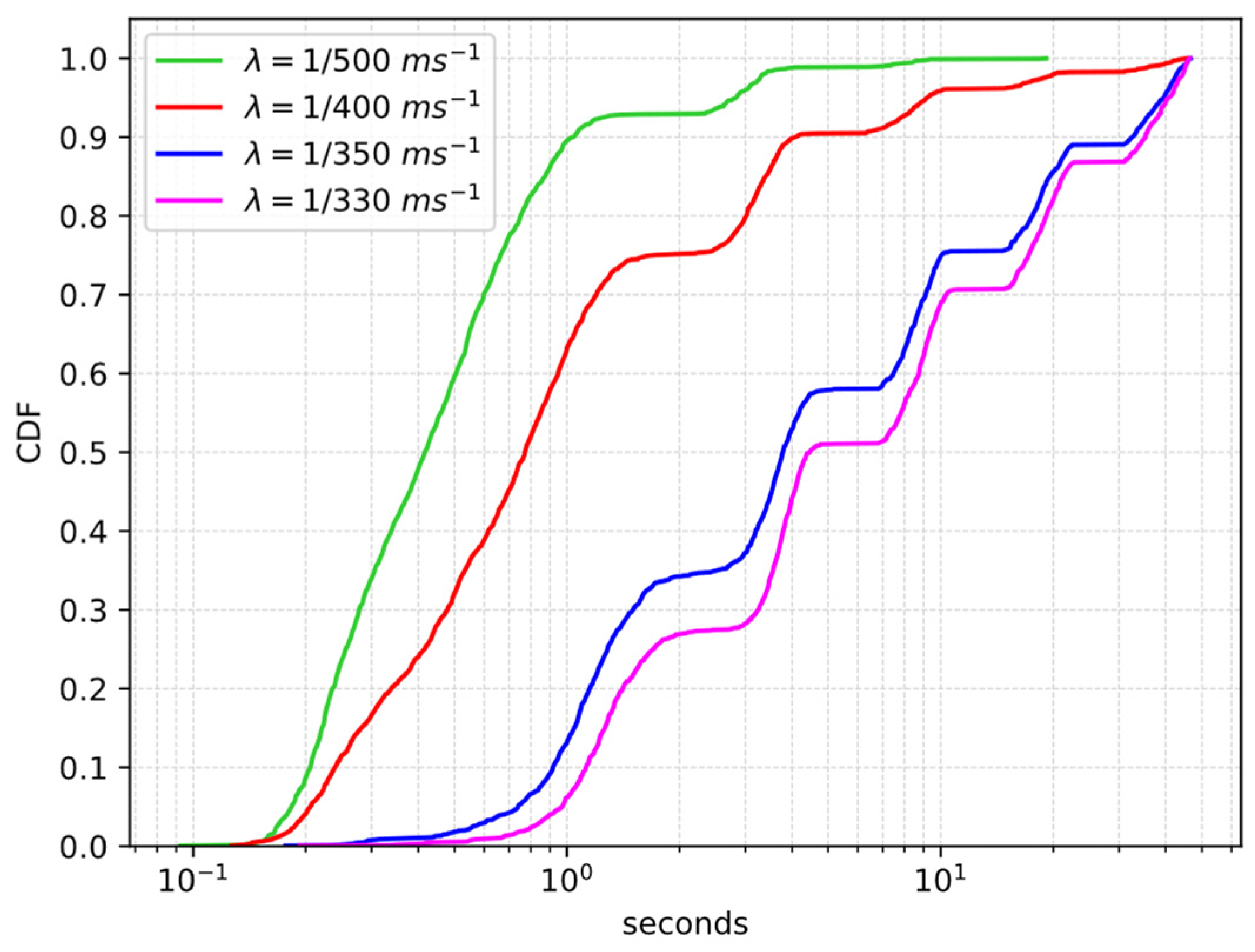
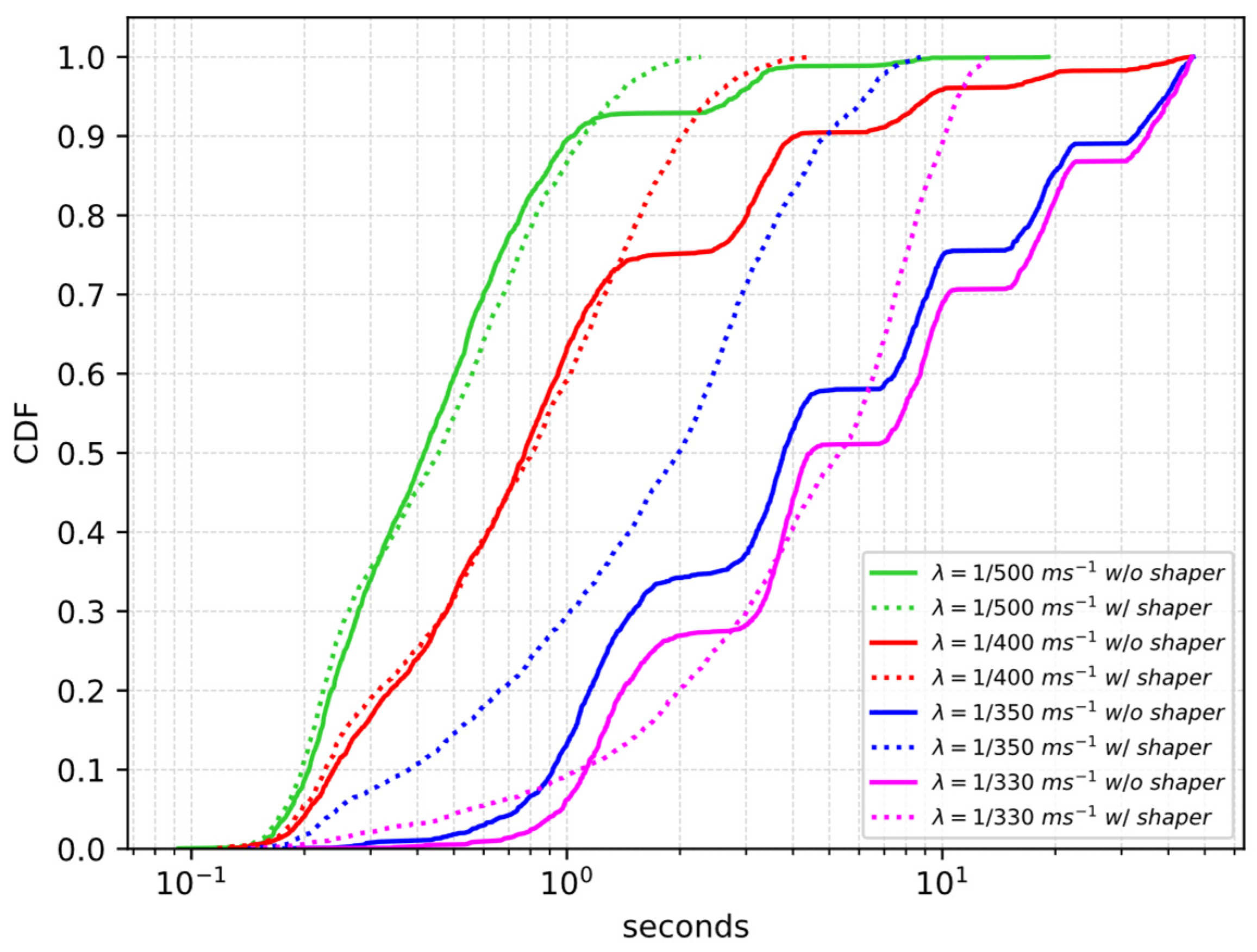
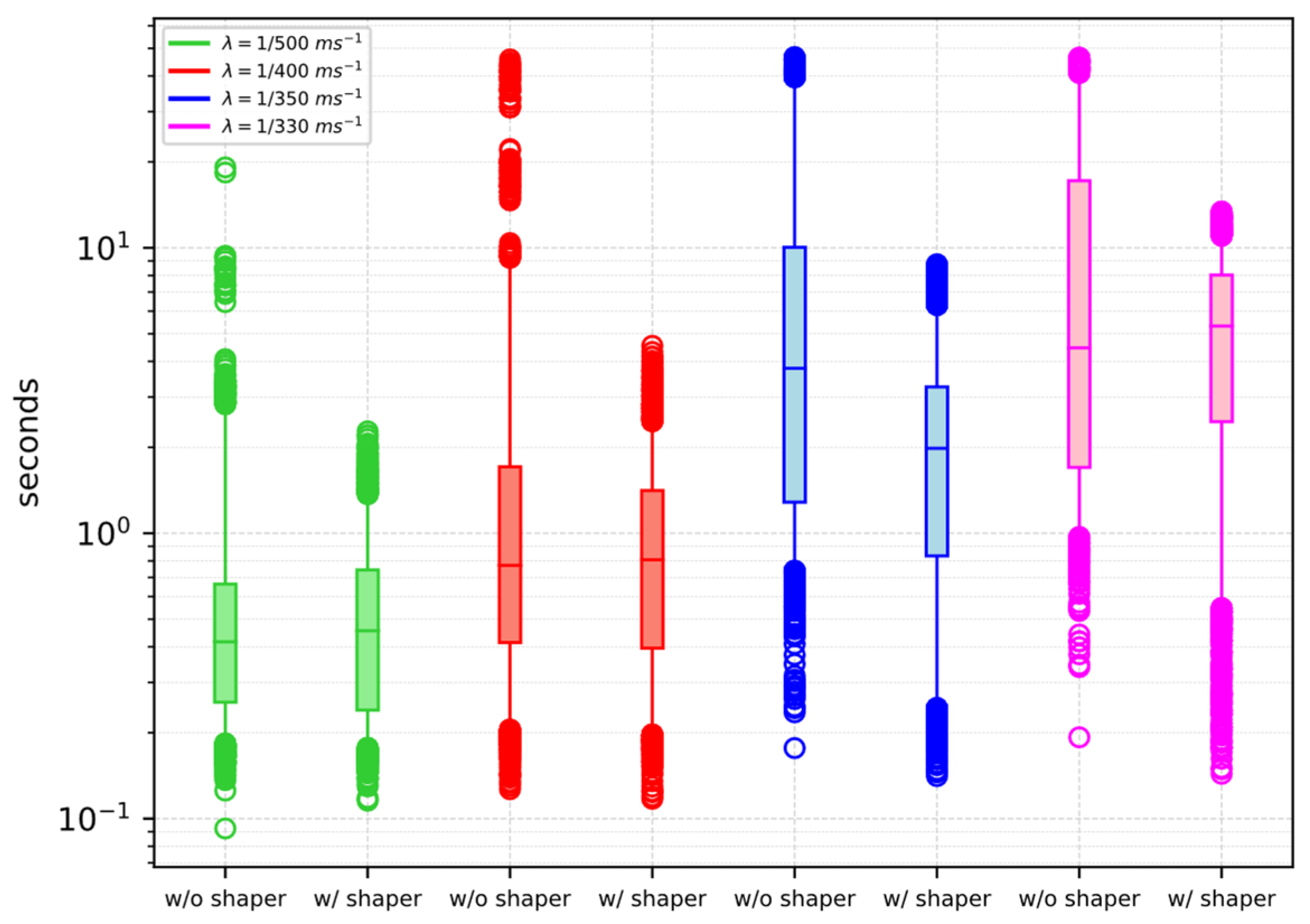
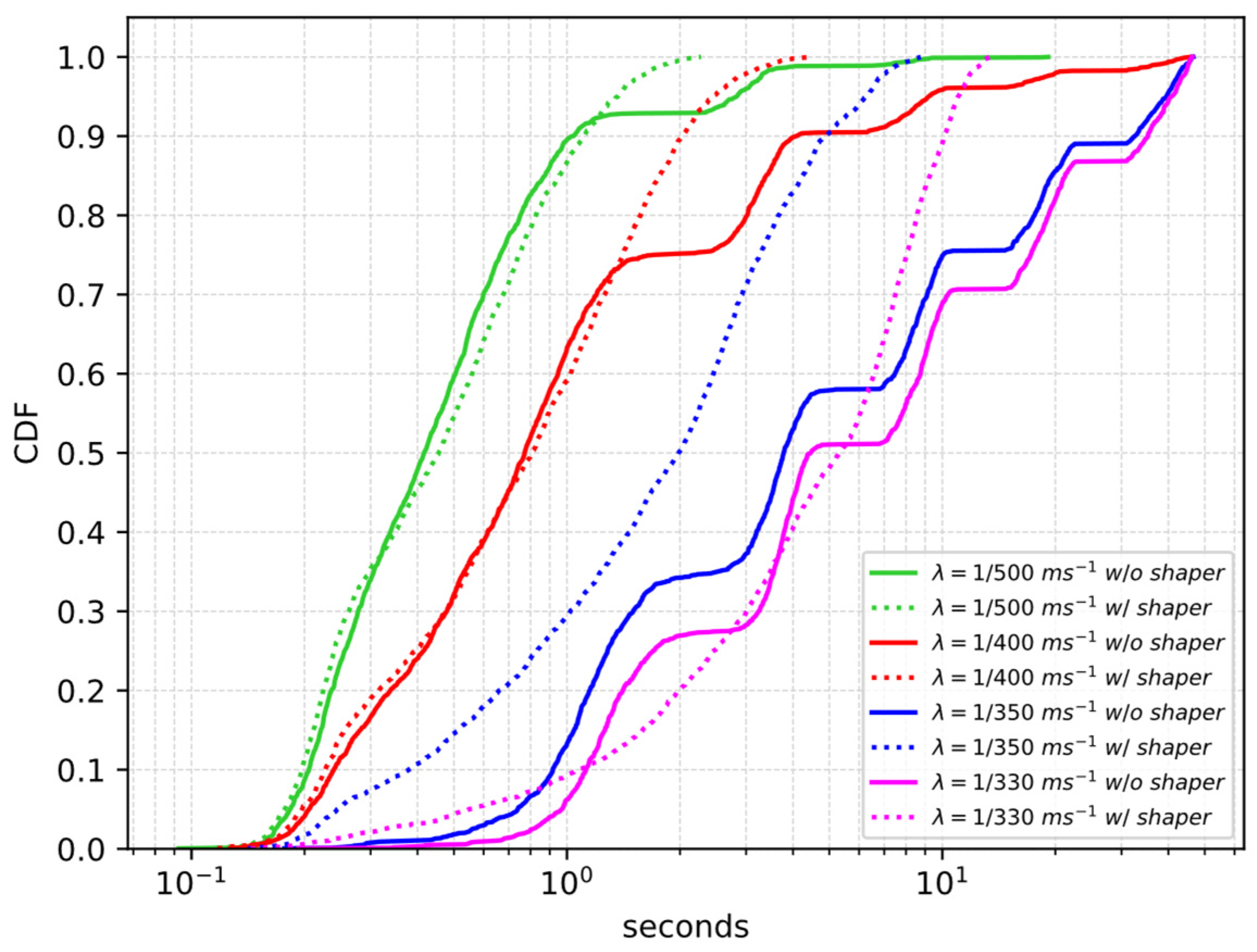
4.1.2. Performance Evaluation
4.2. Caching
4.2.1. Cache-Management Scheme
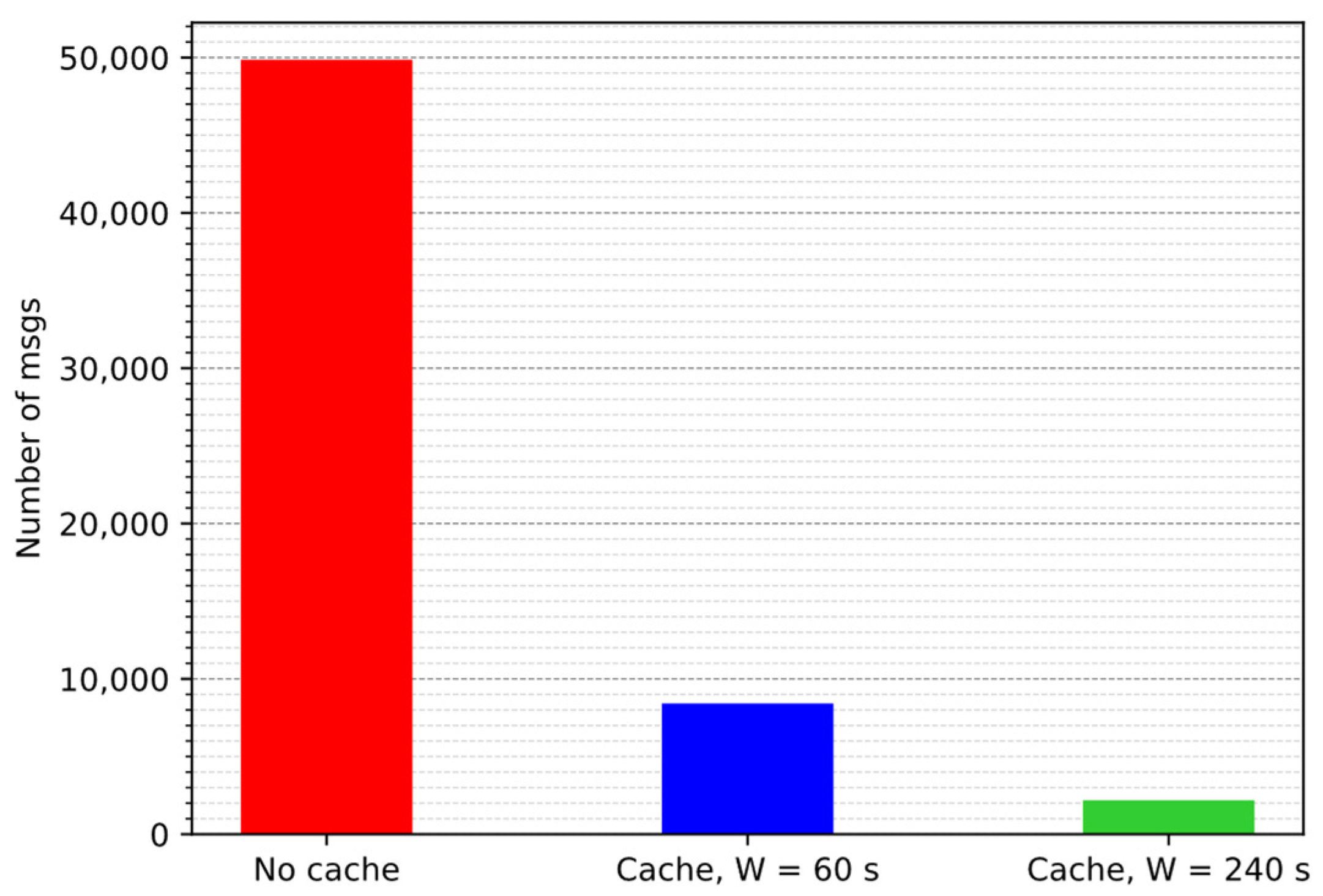
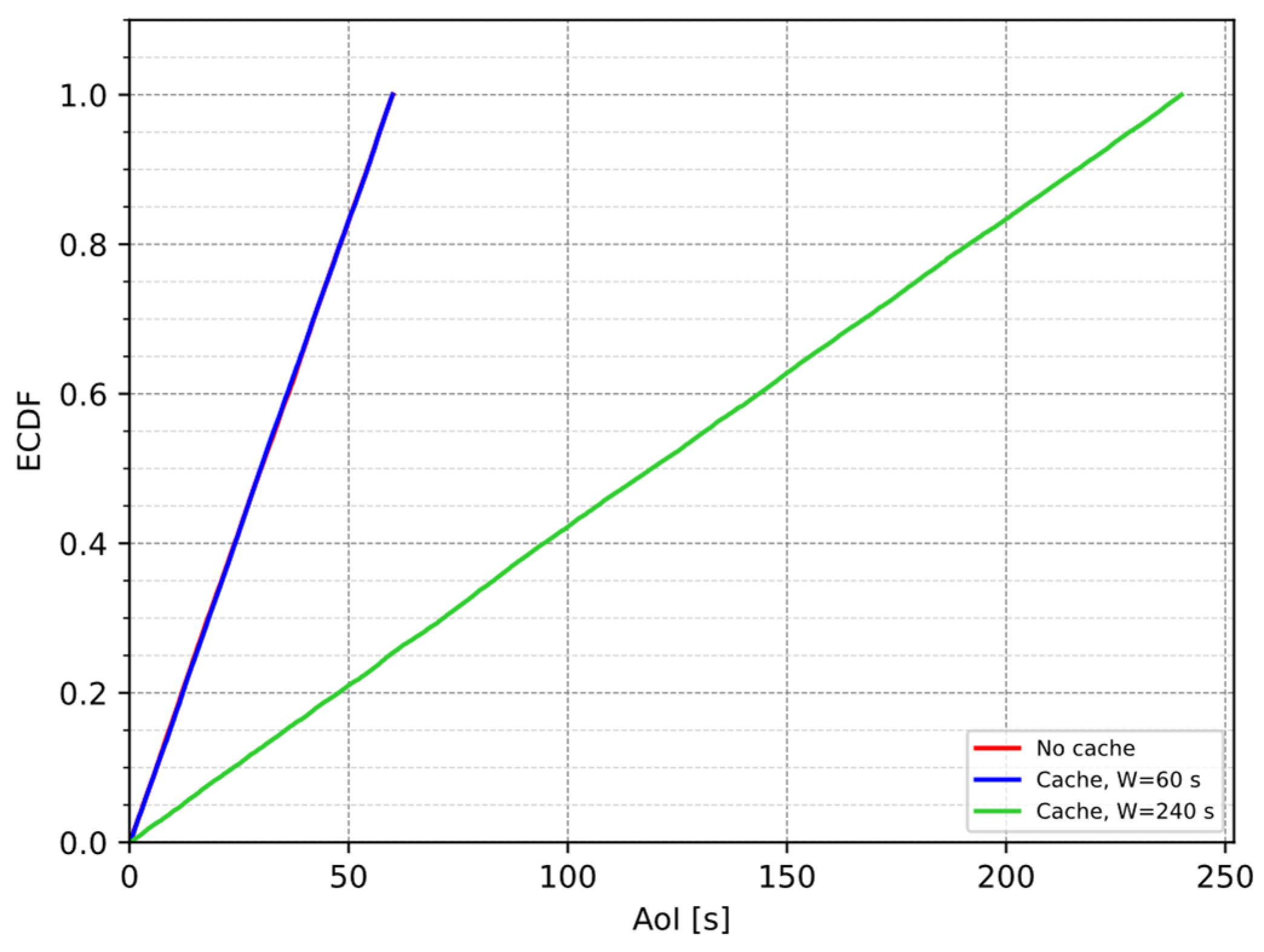
4.2.2. Performance Evaluation
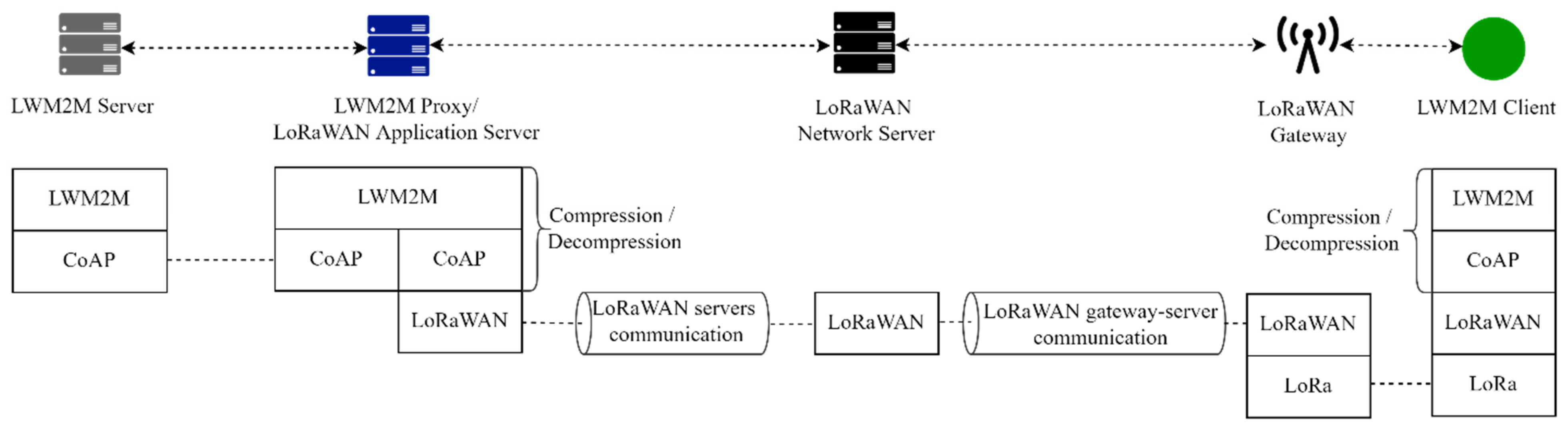
4.3. Compression
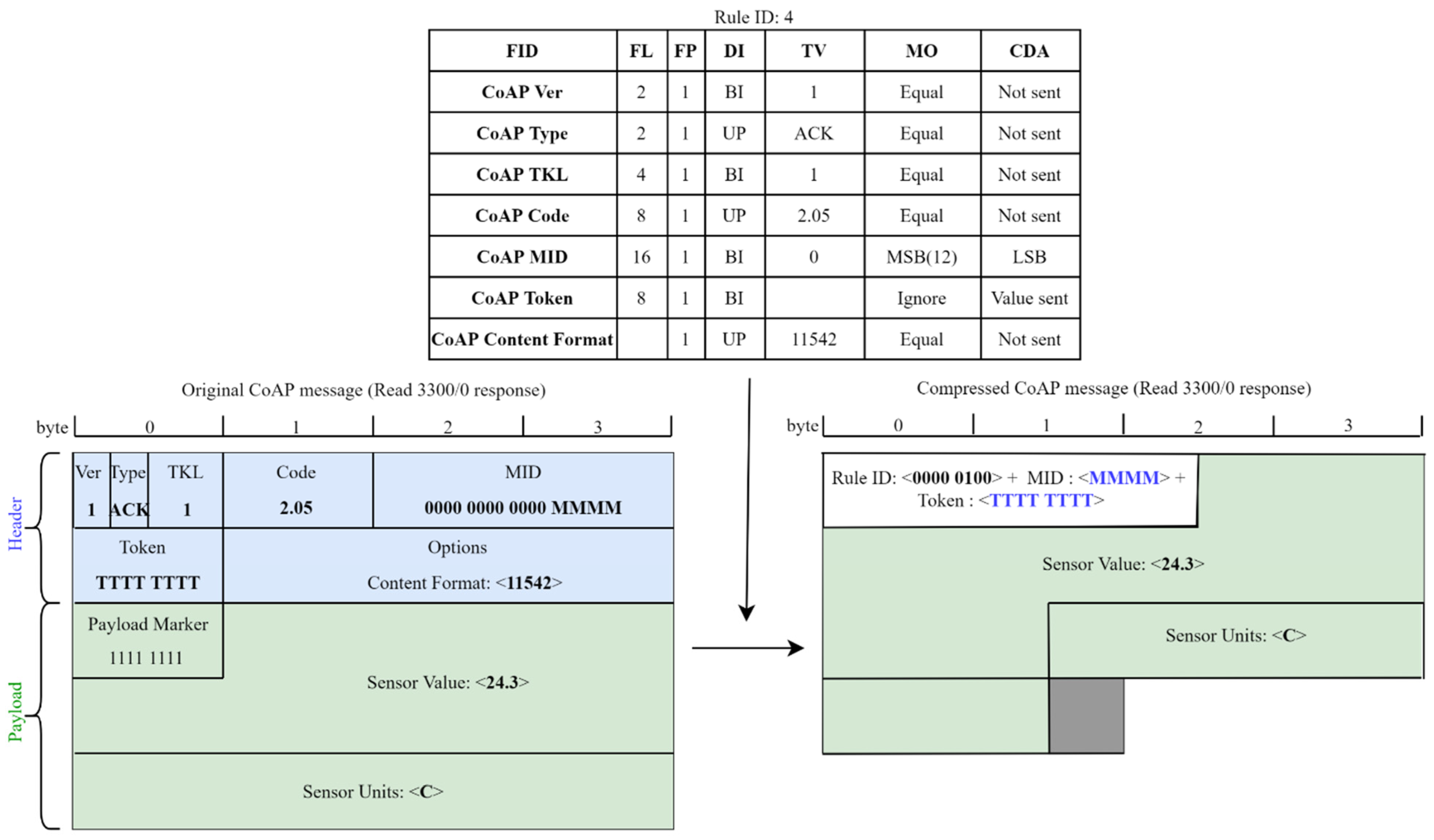
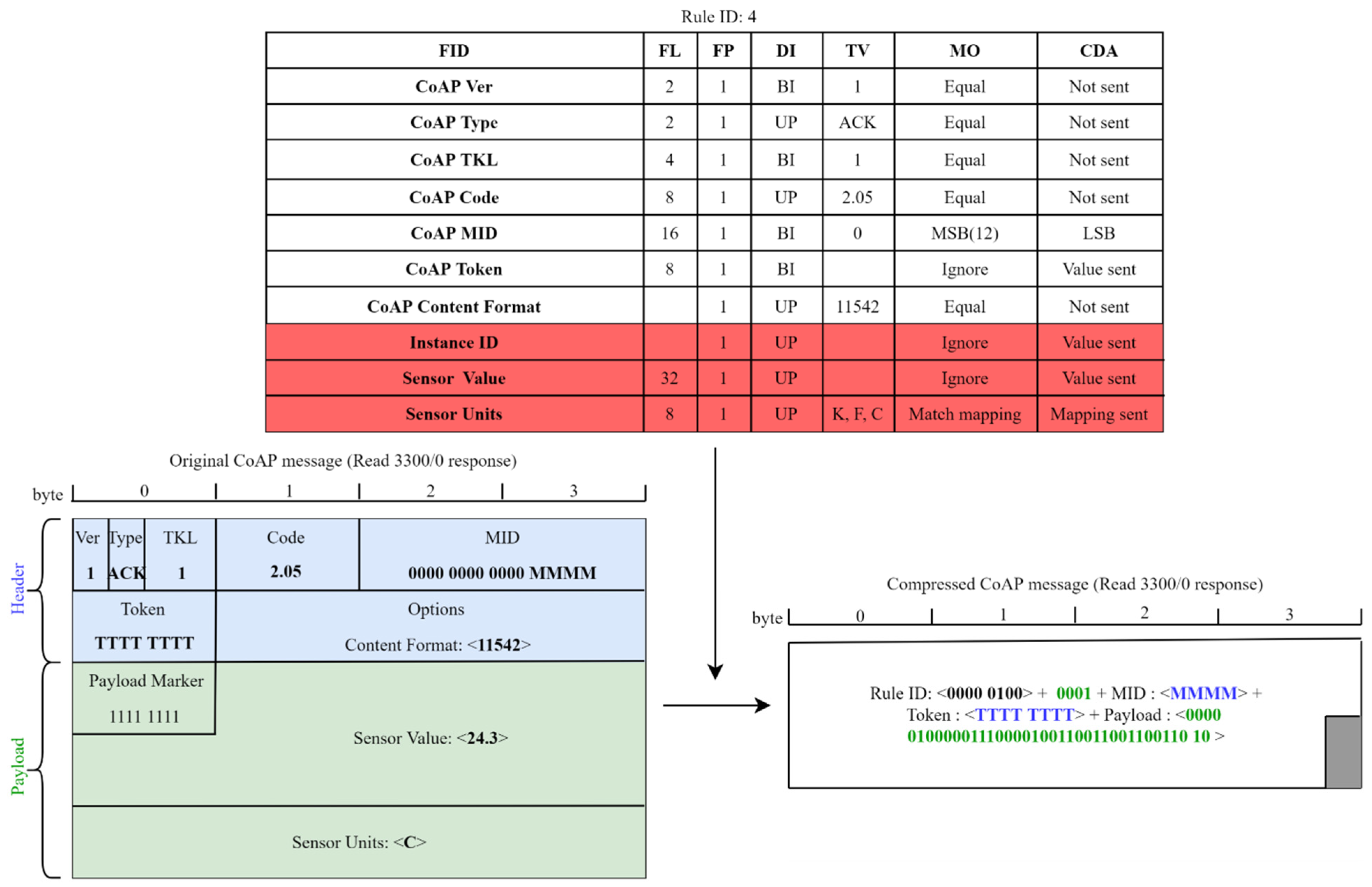
- The CoAP version, type, and token length fields have been elided, since their values are known.
- The CoAP code field has been reduced to the set of the used codes for each operation, defining a mapping list.
- The CoAP message id has been reduced to a four bits value, using the MSB (most significant bits) matching operator.
- The CoAP token field needs to be transmitted, but, since the token length is known, it is not necessary to send the size.
- The CoAP content format and accept fields have been elided when only a single value is possible; otherwise, they have been reduced to the set of used values using a mapping list.
- The CoAP uri path fields have been elided when only a single value is possible; otherwise, they have been reduced to the set of used values using a mapping list. Since the number of uri path elements may vary, it has been decided to define the length to variable and send a compression residue with a length of 0 when the uri path is empty.
- The CoAP uri query fields are used for setting the attributes, so they have been reduced to only their numeric values using the MSB matching operator. Since the number of uri query elements may vary, it has been decided to define the length to variable and send a compression residue with a length of 0 when the uri query is empty.
4.3.1. Extended SCHC for LWM2M
4.3.2. Performance Evaluation
- a Client. The device that runs the Client is an Heltec WIFI LoRa 32 (V2) and implements a Server Object Instance (ObjectID: 1), a Device Object Instance (ObjectID: 3), and a Temperature Object Instance (ObjectID: 3303). Each of these Objects implements the mandatory resources. The Read, Write, and Execute operations are implemented for Server and Device Objects. The Observe, Notify, and Cancel Observation are implemented for Temperature Object.
- a LoRaWAN Gateway. The gateway is a Laird Sentrius RG186. The gateway relays messages between devices and a network server in the backend using the Gateway Message Protocol (GWMP) [29]. Thus, communication between gateways and network server is via JSON/GWMP/UDP/IP.
- a LoRaWAN Network Server. The network server routes the packets to the application server.
- a LWM2M Proxy/LoRaWAN Application Server. The communication between the application server and the network server is via JSON over TCP over IP [30].
- a Server.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Shelby, Z.; Koster, M.; Bormann, C.; van der Stok, P.; Amsüss, C. CoRE Resource Directory, Internet-Draft Draft-Ietf-Core-Resource-Directory-28; IETF: Fremont, CA, USA, 2021. [Google Scholar]
- Broadband Forum TR-069: “CPE WAN Management Protocol v1.4”. Available online: https://www.broadband-forum.org/download/TR-069_Amendment-6.pdf (accessed on 24 January 2022).
- Available online: http://onem2m.org/ (accessed on 24 January 2022).
- Open Mobile Alliance. Lightweight Machine to Machine Technical Specification: Core; Open Mobile Alliance: San Diego, CA, USA, 2020. [Google Scholar]
- Open Mobile Alliance. Lightweight Machine to Machine Technical Specification: Transport Bindings; Open Mobile Alliance: San Diego, CA, USA, 2020. [Google Scholar]
- Beniwal, G.; Singhrova, A. A systematic literature review on IoT gateways. J. King Saud Univ. Comput. Inf. Sci. 2021, in press. [Google Scholar] [CrossRef]
- Pappalardo, M.; Tanganelli, G.; Mingozzi, E. Enhanced Support of LWM2M in Low Power and Lossy Networks. In Proceedings of the IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020. [Google Scholar]
- Available online: https://datatracker.ietf.org/wg/6lowpan/documents/ (accessed on 24 January 2022).
- Yates, R.D.; Sun, Y.; Brown, D.R.; Kaul, S.K.; Modiano, E.; Ulukus, S. Age of information: An introduction and survey. IEEE J. Sel. Areas Commun. 2021, 39, 1183–1210. [Google Scholar] [CrossRef]
- LoRa Alliance. LoRaWAN 1.1 Specification. 2017. Available online: https://resources.lora-alliance.org/technical-specifications/lorawan-specification-v1-1 (accessed on 24 January 2022).
- Filho, F.L.; Rocha, R.L.; Abbas, C.J.B.; Martins, L.M.C.E.; Canedo, E.D.; de Sousa, R.T. QoS Scheduling Algorithm for a Fog IoT Gateway. In Proceedings of the Workshop on Communication Networks and Power Systems (WCNPS), Brasilia, Brazil, 3–4 October 2019. [Google Scholar]
- Mingozzi, E.; Tanganelli, G.; Vallati, C. CoAP Proxy Virtualization for the Web of Things. In Proceedings of the IEEE 6th International Conference on Cloud Computing Technology and Science, Singapore, 15–18 December 2014. [Google Scholar]
- Ludovici, A.; Calveras, A. A proxy design to leverage the interconnection of coap wireless sensor networks with web applications. Sensors 2015, 15, 1217–1244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lai, W.K.; Wang, Y.C.; Lin, S.Y. Efficient Scheduling, Caching, and Merging of Notifications to Save Message Costs in IoT Networks Using CoAP. IEEE Internet Things J. 2020, 8, 1016–1029. [Google Scholar] [CrossRef]
- Robles, M.I.; D’Ambrosio, D.; Bolonio, J.J.; Komu, M. Device Group Management in Constrained Networks. In Proceedings of the IEEE International Conference on Pervasive Computing and Communication Workshops, Sydney, Australia, 14–18 March 2016. [Google Scholar]
- Hoebeke, J.; Haxhibeqiri, J.; Moons, B.; van Eeghem, M.; Rossey, J.; Karagaac, A.; Famaey, J. A Cloud-based Virtual Network Operator for Managing Multimodal LPWA Networks and Devices. In Proceedings of the 2018 3rd Cloudification of the Internet of Things (CIoT), Paris, France, 2–4 July 2018. [Google Scholar]
- Sanchez-Gomez, J.; Gallego-Madrid, J.; Sanchez-Iborra, R.; Santa, J.; Skarmeta, A.F. Impact of SCHC compression and fragmentation in LPWAN: A case study with LoRaWAN. Sensors 2020, 20, 280. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Available online: https://github.com/contiki-ng/cooja (accessed on 24 January 2022).
- IEEE Std 802.15.4-2015; IEEE Standard for Low-Rate Wireless Networks. IEEE: Piscataway Township, NJ, USA, 2016.
- Winter, T.; Thubert, P.; Brandt, A.; Hui, J.; Kelsey, R.; Levis, P.; Pister, K.; Struik, R.; Vasseur, J.P.; Alexander, R. RPL: IPv6 Routing Protocol for Low-Power and Lossy Networks; RFC 6550; IETF: Fremont, CA, USA, 2012. [Google Scholar]
- Farrell, S. Low-Power Wide Area Network (Lpwan) Overview; RFC 8376; IETF: Fremont, CA, USA, 2018. [Google Scholar]
- Available online: https://github.com/eclipse/leshan (accessed on 24 January 2022).
- Zhong, J.; Yates, R.D.; Soljanin, E. Two Freshness Metrics for Local Cache Refresh. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018. [Google Scholar]
- Pappalardo, M.; Mingozzi, E.; Virdis, A. A Model-Driven Approach to AoI-Based Cache Management in IoT. In Proceedings of the IEEE International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Porto, Portugal, 25–27 October 2021. [Google Scholar]
- FUOTA Working Group of the LoRa Alliance Technical Committee. LoRaWAN Fragmented Data Block Transport Specification. 2018. Available online: https://lora-alliance.org/wp-content/uploads/2020/11/fragmented_data_block_transport_v1.0.0.pdf (accessed on 24 January 2022).
- Minaburo, A.; Toutain, L.; Gomez, C.; Barthel, D.; Zúñiga, J.C. SCHC: Generic Framework for Static Context Header Compression and Fragmentation; Technical Report RFC 8724; IETF: Fremont, CA, USA, 2020. [Google Scholar]
- Gomez, C.; Minaburo, A.; Toutain, L.; Barthel, D.; Zuniga, J.C. IPv6 over LPWANs: Connecting Low Power Wide Area Networks to the Internet (of Things). IEEE Wirel. Commun. 2020, 27, 206–213. [Google Scholar] [CrossRef]
- Minaburo, A.; Toutain, L.; Andreasen, R. Static Context Header Compression (SCHC) for the Constrained Application Protocol (CoAP); RFC 8824; IETF: Fremont, CA, USA, 2021. [Google Scholar]
- Semtech Ltd. LoRaWAN Network Server Demonstration: Gateway to Server Interface Definition. 2015. Available online: https://www.thethingsnetwork.org/forum/uploads/default/original/1X/4fbda86583605f4aa24dcedaab874ca5a1572825.pdf (accessed on 24 January 2022).
- Semtech Ltd. LoRaWAN Network Server Demonstration: Inter-Server Interface Definition. 2015. Available online: https://www.thethingsnetwork.org/forum/uploads/default/original/1X/555030509bdcdee51a0d3d87382a17dd6211b11c.pdf (accessed on 24 January 2022).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interface | Operation |
|---|---|
| Client Registration | Register: the Client registers with the Server |
| Update: the Client updates registration information | |
| De-register: the Client de-registers with the Server | |
| Device Management and Service Enablement | Read: the Server accesses the value of a Resource, a Resource Instance, an Object Instance or an Object |
| Discover: the Server learns the attributes of an Object, Object Instances, and Resources, and discovers which Resources are instantiated in a given Object Instance | |
| Write: the Server changes the value of a Resource, a Resource Instance, and multiple Resources from an Object Instance | |
| Write-Attributes: the Server modifies the notification attributes | |
| Execute: the Server performs some action on individual Resources | |
| Create: the Server creates Object Instances within the Client | |
| Delete: the Server deletes an Object Instance or a Resource Instance within the Client | |
| Information Reporting | Observe: the Server initiates an observation request for changes of a specific Resource, Resources within an Object Instance or for all the Object Instances of an Object within the Client |
| Cancel-Observation: the Server ends an observation relationship | |
| Notify: the Client sends the new value of the Object Instance or Resource to the Server |
| [ms−1] | w/o Shaper | w/ Shaper |
|---|---|---|
| 1/500 | 0 | 0 |
| 1/400 | 0.9% | 0 |
| 1/350 | 30.6% | 0 |
| 1/330 | 42.1% | 0 |
| Type of Message | Read Object | Notify Object | Read Resource | Write Object | Write Resources | Write Resource | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3/0 | 1/0 | 3303/0 | 3/0/11 | 3/0/16 | 1/0/0 | 1/0/1 | 1/0/6 | 1/0/7 | 1/0 | 1/0/1 and 1/0/6 | 1/0/1 and 1/0/7 | 1/0/6 and 1/0/7 | 1/0/1 | 1/0/6 | 1/0/7 | |
| Percentage reduction | 58.8% | 75% | 44.4% | 35.7% | 37.5% | 37.5% | 21.4% | 37.5% | 37.5% | 56% | 54.5% | 54.5% | 63.2% | 45% | 64.3% | 64.3% |
| Compression ratio | 2.43 | 6 | 1.8 | 1.56 | 1.6 | 1.6 | 1.27 | 1.6 | 1.6 | 2.27 | 2.2 | 2.2 | 2.71 | 1.81 | 2.8 | 2.8 |
| Fit in a LoRaWAN packet | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pappalardo, M.; Virdis, A.; Mingozzi, E. An Edge-Based LWM2M Proxy for Device Management to Efficiently Support QoS-Aware IoT Services. IoT 2022, 3, 169-190. https://doi.org/10.3390/iot3010011
Pappalardo M, Virdis A, Mingozzi E. An Edge-Based LWM2M Proxy for Device Management to Efficiently Support QoS-Aware IoT Services. IoT. 2022; 3(1):169-190. https://doi.org/10.3390/iot3010011
Chicago/Turabian StylePappalardo, Martina, Antonio Virdis, and Enzo Mingozzi. 2022. "An Edge-Based LWM2M Proxy for Device Management to Efficiently Support QoS-Aware IoT Services" IoT 3, no. 1: 169-190. https://doi.org/10.3390/iot3010011
APA StylePappalardo, M., Virdis, A., & Mingozzi, E. (2022). An Edge-Based LWM2M Proxy for Device Management to Efficiently Support QoS-Aware IoT Services. IoT, 3(1), 169-190. https://doi.org/10.3390/iot3010011