1. Introduction
The Internet of Things (IoT) aims to embody into the internet a large number of heterogeneous and pervasive objects that, through standard communication protocols and unique addressing schemes, provide services to the final users [
1]. The number and types of applications that can be realized using these technologies is ever increasing with the most powerful ones requiring things to collaborate by exchanging information and services, e.g., cars that exchange information about the traffic status and the sprinkler that obtains triggering events from distributed smoke detectors.
Such future IoT applications will likely be developed, making use of a service-oriented architecture, where each device can play the role of a service provider, a service requester, or both. IoT is moving towards a model where things look for other things to provide composite services for the benefit of human beings (object-object interaction) [
2]. With such an interaction model, it is essential to understand how the information provided by each object can be processed automatically by any other peer in the system. This cannot clearly disregard the level of trustworthiness of the object providing information and services, which should take into account its profile and history. Trust and Reputation Models (TRMs) have the goal to guarantee that actions taken by entities in a system reflect their trustworthiness values, and to prevent these values from being manipulated by malicious entities.
The cornerstone to any TRMs is their ability to generate a coherent evaluation of the information received. From the analysis of the past works, an element that is frequently missing and only sometimes superficially treated is the generation of feedback. Indeed, when an object receives the requested service, it needs to evaluate whether the service is consistent with its query and so rates it [
3]. The feedback has the fundamental role of being the source of every trust model, which processes the ones received in the past to drive the computation of the trust level. Until now, the proposed algorithms have assumed that a node is able to perfectly rate the received service and only focus on the trust computation techniques.
Feedback generation is strictly tied to how well the information received matches the request. To this end, the requester has to compute a reference value, which is usually not available since an object does not have any knowledge regarding the ground-truth value of the requested information. Our paper works in this direction with the goal to estimate a reference value and to use it in order to assign feedback to the providers, and thus provides the following contributions:
First, we define the problem of feedback evaluation in the IoT. We also propose different metrics to evaluate a reference value and how this value should be used to rate services.
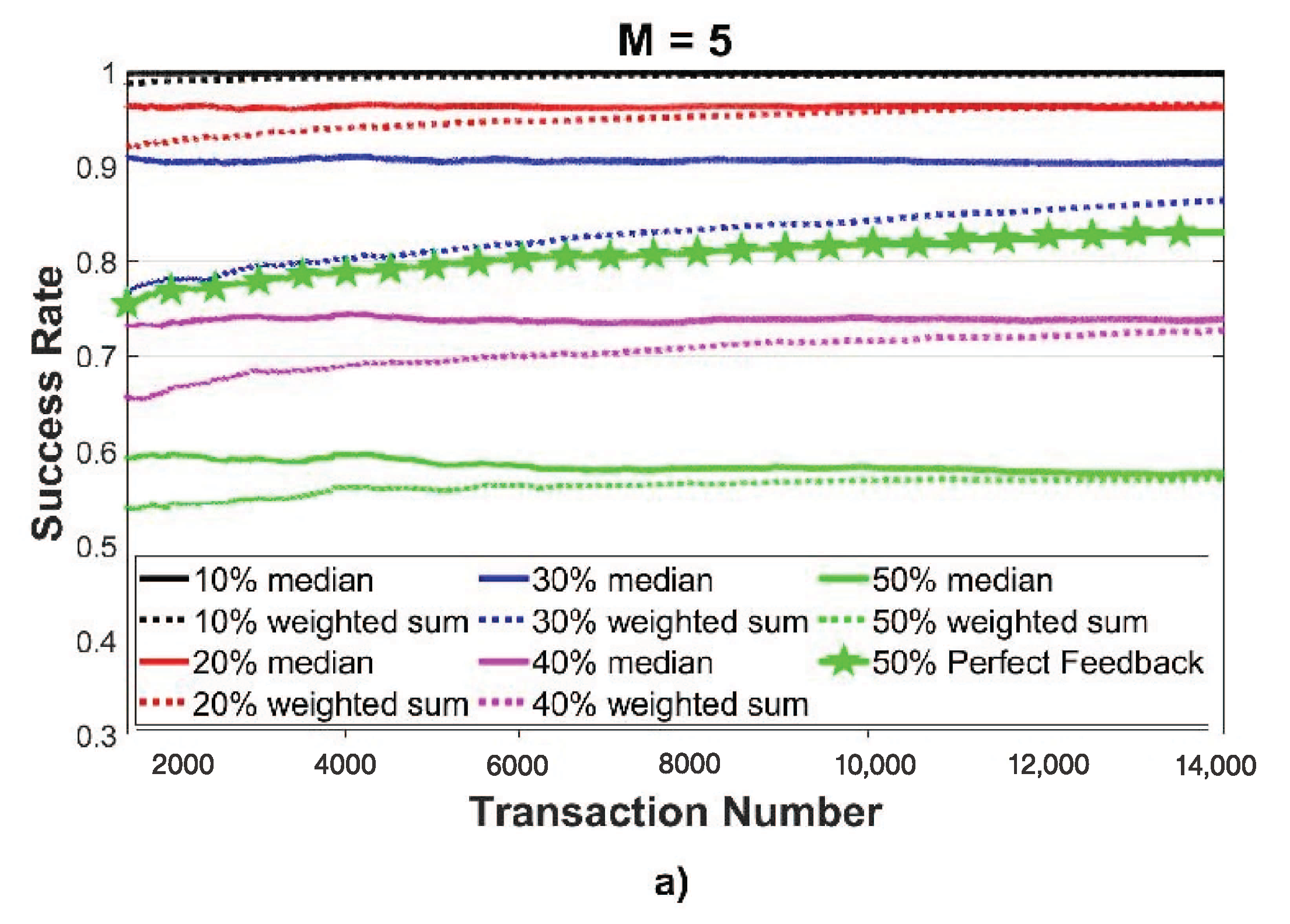
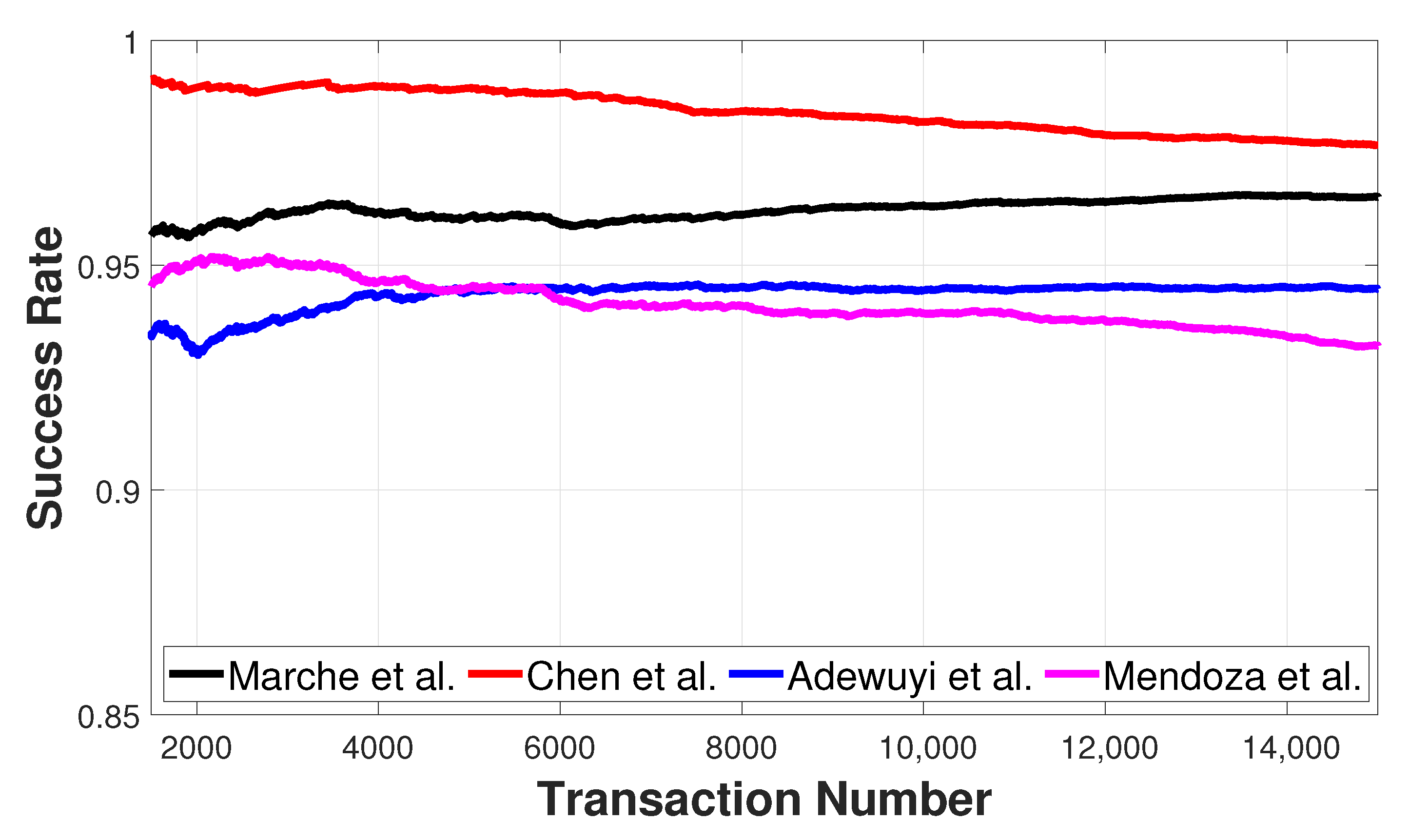
Second, we propose a new collusive attack on trust that aims to influence the evaluation of the reference value and thus to confuse the IoT network. Moreover, we test the resiliency of existing models against it and show how the proposed TRMs are not able to efficiently identify such an attack.
Third, by using a dataset of real IoT objects, we conduct extensive experiments to analyze the impact of the proposed metrics and the eventual errors in the feedback assignment. Furthermore, we compare different TRMs in order to study the impact of the service and feedback evaluation.
The rest of the paper is organized as follows:
Section 2 presents a brief survey on trust management models and, in particular, their approach to the problem of feedback evaluation. In
Section 3, we define the problem, introduce the used notations and illustrate the proposed service and feedback evaluation model.
Section 4 presents the model performance under different conditions, while
Section 5 draws final remarks.
2. State of the Art
Trustworthiness is recognized as a critical factor for the Internet of Things, and the different algorithms used to implement it play an essential role [
4]. Generally, trust among devices allows to share opinions between them and can be used by a requester to decide whether to require information from the provider [
5]. In recent years, many researchers have examined the problem of trust, so the literature is now quite abundant. This section provides a brief overview regarding the background of trustworthiness management in the IoT. In particular, we focus on the use of feedback and its importance for trust algorithms, taking into consideration the main characteristics discussed in the following, and we do not intend to cover all of the published papers.
Dimension: The feedback is expressed by a value that may be continuous or discrete. The feedback values are generated on the basis of the considered model, and they are used to compose the trust values.
Sharing: The feedback could be available for all the nodes in the network or only for the releasing node. Generally, it is shared in order to improve a recommendation mechanism. Otherwise, it is not shared and is used only by the agent responsible for the trust values.
Metrics: The feedback consists of the evaluation of the interaction, and it is based on defined metrics. Usually, the models make use of QoS metrics, such as memory consumption or energy cost. However, often the authors do not depict how the feedback is generated and assume that an agent is able to perfectly evaluate a service without providing any explanation.
Source: The feedback could be released by different sources—an IoT node, an agent, or an end-user. For the decentralized mechanism, generally, the source might be the requester node. Otherwise, usually in centralized models, an agent is responsible for feedback generation.
Among the analyzed works considering the concept of trust in the IoT, in [
6] the authors propose a centralized trust management architecture based on IoT clusters for countering bad-mouthing attacks. The architecture allows IoT devices and applications to contact each other, making use of trust manager nodes responsible for the communication and data transporting. The trust manager generates the feedback and evaluates the interactions, thanks to QoS parameters, such as memory efficiency. In addition, it takes care of all the trust values and all clusters’ management.
Another model against bad-mouthing attacks is described in [
7]. The authors illustrate a decentralized trust management model, using direct and indirect observations. Each requester node evaluates the received service according to their resource-consuming capabilities and other QoS parameters (each service has different energy requirements, memory, and processing in a node). The produced feedback consists of a continuous value, where high values require more processing capacity, while differently low values do not require many resources. Nodes share feedback with each other, and thus, it is used to calculate trust values.
Among the approaches, those developed to oppose other types of attacks are described [
8,
9]. In the first work, the authors propose a hybrid trust protocol to allow users to query services toward IoT providers. Each user can evaluate a provider in a trusted environment, where the trust is composed of recommendations from neighbors and direct experience. The feedback reports are shared to a cloud server that takes care of all the trust values. Unfortunately, the authors do not provide any information about the feedback evaluation. In the second one, the authors take into account machine-learning principles to classify the trust features and combine them to produce a final trust value in a decentralized architecture. Each requester node selects a provider based on a machine-learning algorithm and considers feedback values in
, where 0 represents a scarce service and 1 a good one.
Furthermore, relevant approaches developed for attacks in a specific scenario are presented in [
10,
11]. In the first paper, the authors illustrate a trusted approach for vehicle-to-vehicle communications, combining vehicle certificates and trust management. Vehicles communicate with each other in a peer-to-peer distribution model and can take decisions based on the reputation of all nodes. Each object evaluates by itself the feedback and shares it with all the other nodes in the network. Additionally, in [
11], the authors depict a decentralized technique to improve performance in a vehicular network. An intelligent protocol is developed in order to achieve a good decision with inaccurate and erroneous information and adapt to a dynamic communication environment. Each node evaluates the feedback with QoS metrics, such as the data traffic or the link quality, and expresses it with a continuous variable. Any feedback is shared.
Moreover, two recent works, refs [
12,
13] illustrate a trust model for a general scenario. The authors in [
12] propose a trust management framework for collaborative IoT applications. The trust of each node is based on past interactions, recommendations and QoS parameters. Moreover, the requester node evaluates the feedback and depicts it in a continuous range based on the specific scenario. The sharing through the neighbour nodes allows improving collaboration and resistance against collusive attacks. Furthermore, in [
14], the authors develop a trust architecture that integrates software-defined networks to improve organization and reputation management. A reputation node in charge takes care of the nodes’ trust, according to their operations. The node evaluates the interaction measuring node operations and considers the feedback into three layers: normal, fault and malicious.
In recent years, many researchers have tried to improve the reliability of trust models in terms of the ability to detect malicious behaviors, e.g., by making use of machine learning [
15], or employing Markov matrices [
16]. In the first work, the authors propose a decentralized trust management model for social IoT. With the benefit of social networks, such as improved searching mechanisms and resources discovery, the approach attempts to detect the most trust attacks in the state of the art. Each requester node evaluates the interaction by itself in a continuous range
and shares the feedback with its neighbor and pre-trusted nodes. Any information about the metrics used for the evaluation is illustrated. In the second one, discrete feedback is used to evaluate the nodes’ interactions in a scenario with various types of attacks. Each node evaluates the feedback and shares it with its neighbor nodes; this value and the recommendations are employed to model the individual trust value.
Table 1 shows a classification of the trust models based on the use of feedback values and takes into consideration the characteristics mentioned above.
3. Feedback Evaluation
3.1. Reference Scenario
The focus of this paper is to propose a feedback evaluation mechanism that is able to rate the service received by the requester.
In our model, the set of nodes in the network is represented by with cardinality I, where is the generic node. Every node in our network can provide one or more services, so is the set of services that can be provided by . The reference scenario is then represented by an application installed in a node , or in the connected cloud space, requesting a particular service : a service discovery component in the network is able to return to a list of potential providers . At this point, TRMs usually assume that the requester is able to perfectly evaluate the service, and then it has to select only one of the providers in based on their level of trust. However, the requester does not know the ground-truth value of the service and has, then, no means to evaluate whether the received service is good or not and its level of accuracy. In order to assess a value for the service to be used by the application, the requester has to contact more than one provider in : from every provider , the requester receives a value for the service and then has to aggregate all the received values into a reference value . Moreover, to compute the trust level of every provider, a TRM has to rely on the previous interactions among the nodes in the form of feedback, which represents how a requester is satisfied with the received service. After every transaction, the requester has to assign a feedback to all the providers to evaluate the service, based on the provided values and on their “distance” from the computed reference value . Each feedback can be expressed using values in the continuous range , where 1 is used when the requester is fully satisfied by the service and 0 otherwise.
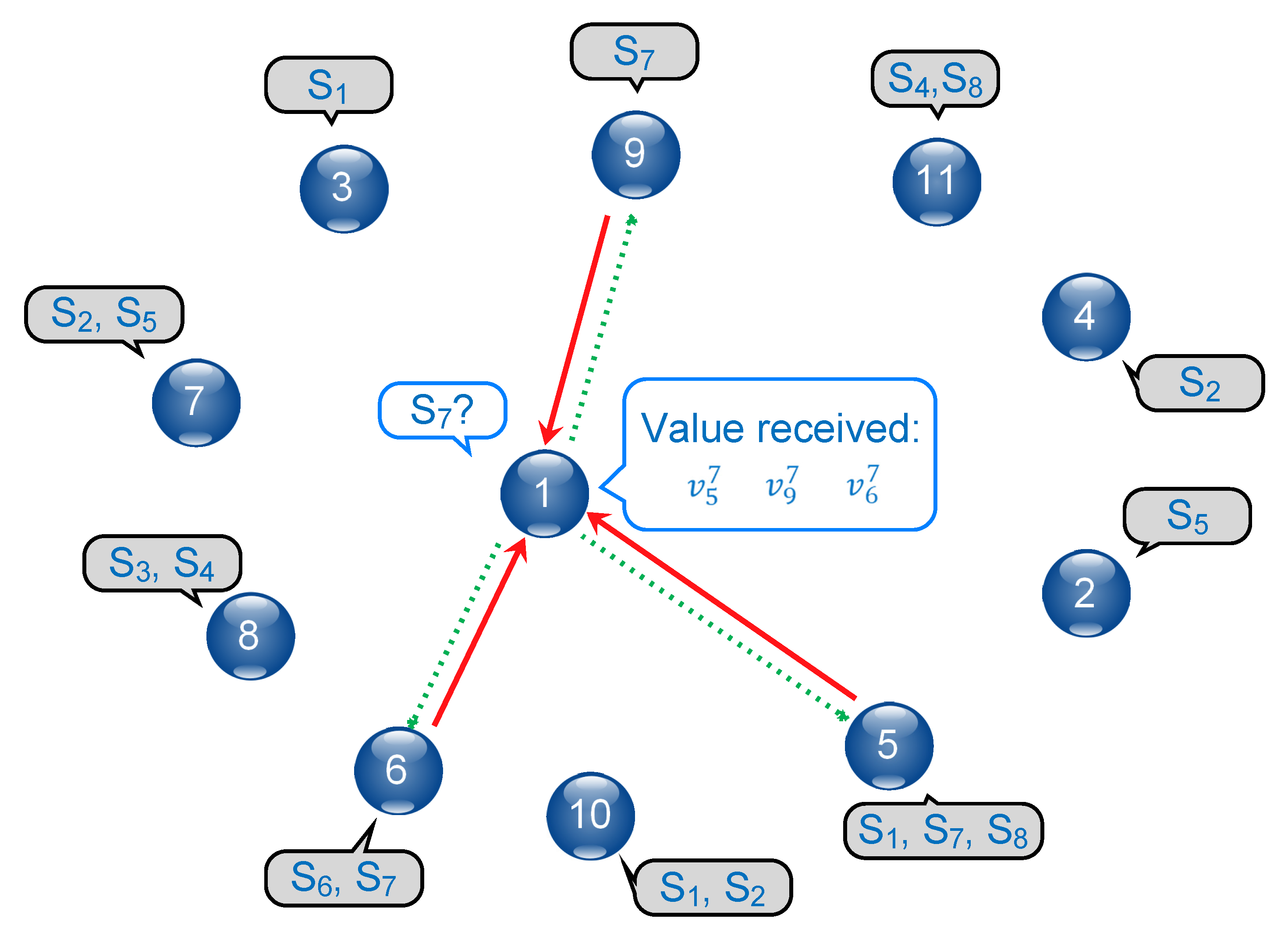
Figure 1 provides a simple example of a generic graph
, with each node capable of providing one or more services, as highlighted in the grey clouds;
is the node that is requesting the service
, as highlighted in the white cloud;
is the set of nodes that can provide the requested service. For each of the providers in
, the requester
receives a value for the service
(red lines in the Figure), then aggregates them to compute the reference value
. Based on this value,
can rate the providers individually and assign to each of them feedback (dotted green lines in the Figure) that can be used to update their trustworthiness levels.
The goal of the feedback evaluation algorithm is two-fold: compute the reference value that will be used by the application and estimate the reliability of the providers. This step is fundamental to help the requester to assess a solid value for the requested service and to reward/penalize the providers so as to avoid any malicious node in future transactions.
3.2. Service and Feedback Evaluation Model
According to the presented scenario, we propose a service and feedback evaluation model, where each node, during a transaction, calculates the reference value to be passed to the application. This value is then used as a reference to compute the feedback that will be assigned to the different providers. In this way, every TRM can have information regarding the past interactions available to be used for the trust computation value.
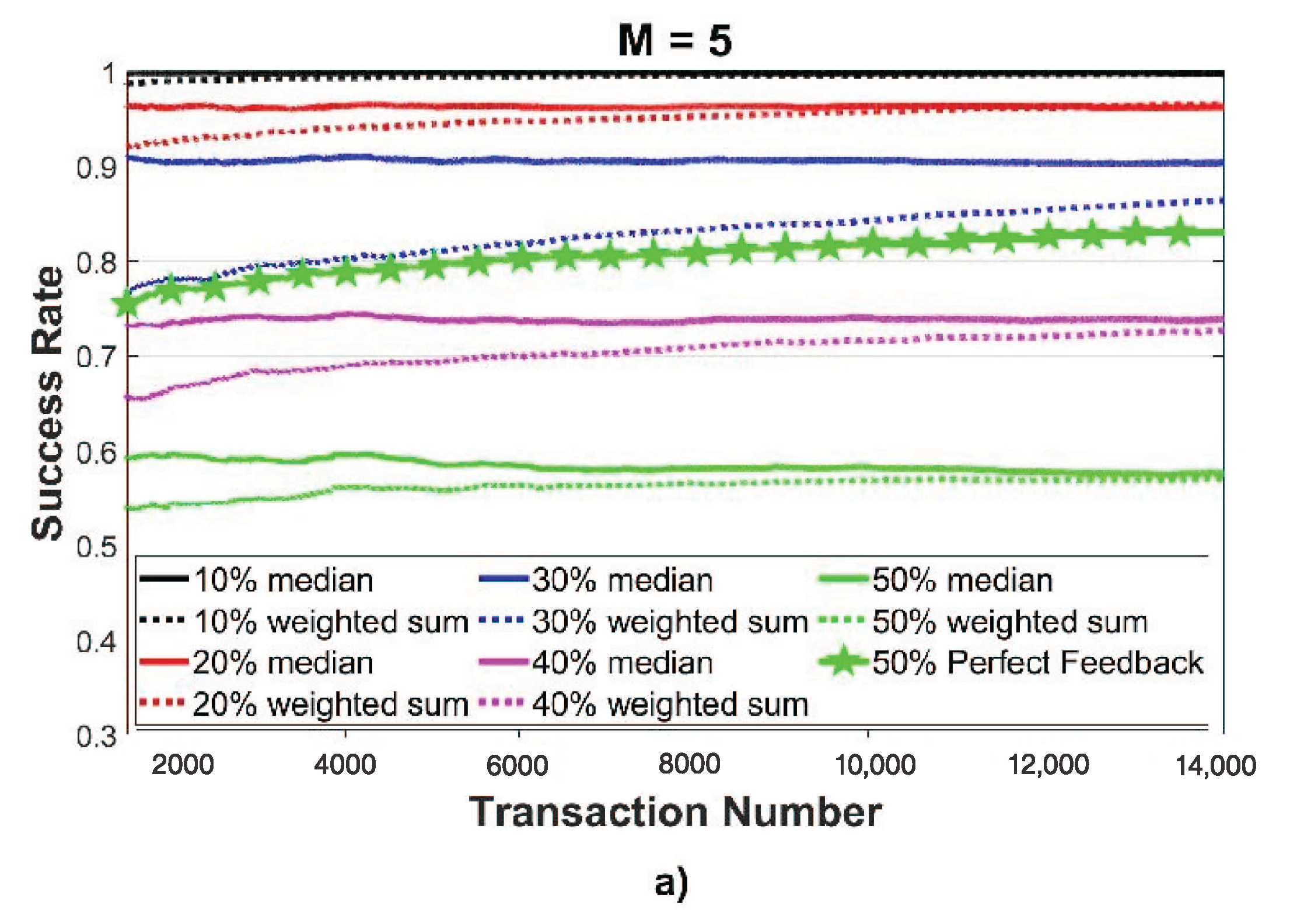
Whenever a node has the need to retrieve a service, it has to select a subset of providers from the list of potential providers . To this end, the requester immediately discards any provider with a trust value lower than a given threshold , so that the reliable providers are included in the set , where is the trust of node toward node . The value of the threshold has to be decided based on the TRM implemented in the system since different models have different dynamics to label a node as malicious. From this set, the requester contacts the most trustworthy providers of M in order to actually require a service’s value.
When the requester receives all the service’s values from the providers, it has to implement some mechanism in order to infer the reference value to be passed to the application. Several strategies can be used:
Mean of all the values obtained by the M providers;
Sum of all the values obtained by the M providers weighted by their trustworthiness;
Median of all the values obtained by the M providers.
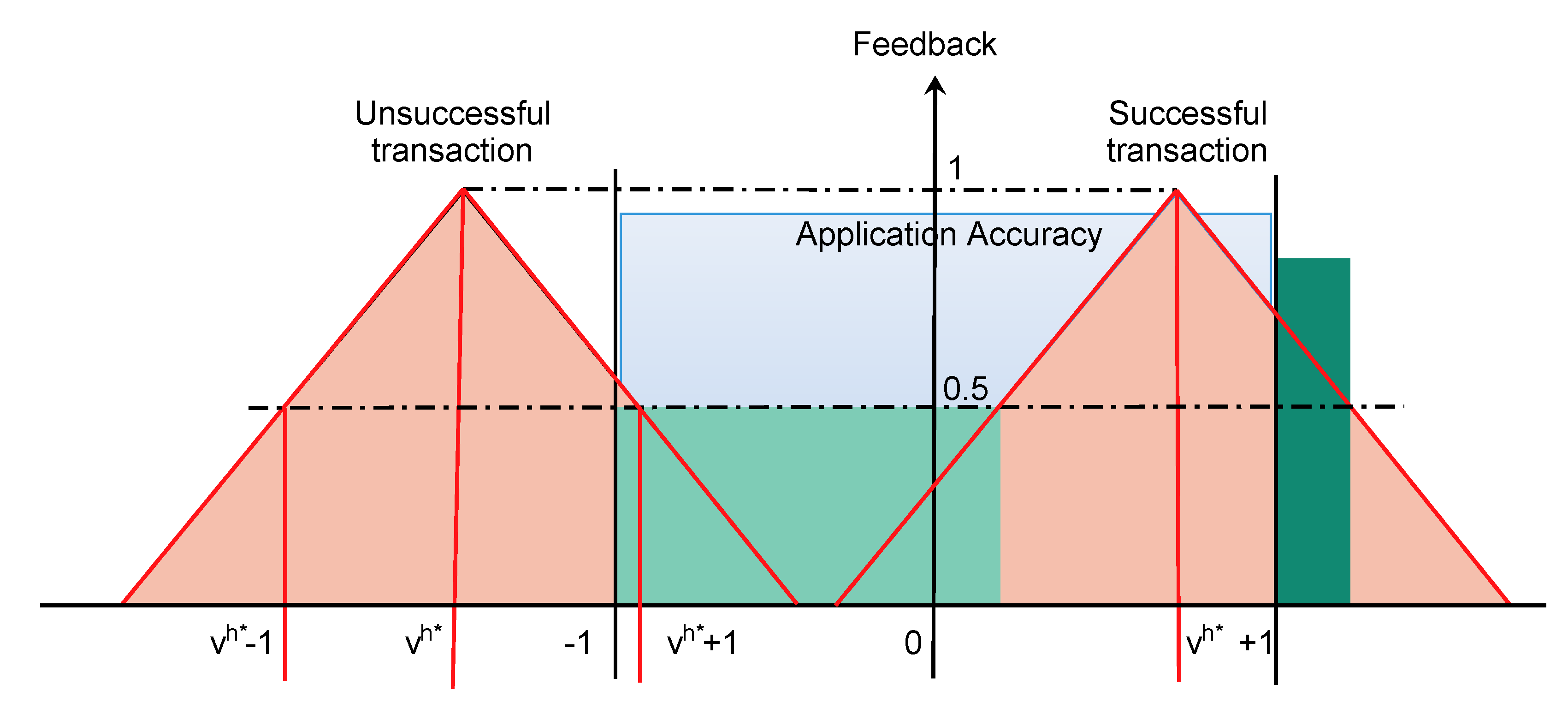
Since every application requires a certain accuracy, it is possible to assign feedback to the different providers. For simplicity, we consider the ground-truth value to be 0, and we always normalize the application accuracy so that values in the interval
are acceptable by the application (blue area in
Figure 2). The reference value
, calculated with one of the metrics proposed above, can deviate from the ground-truth value; in this case, if
is still within the application accuracy, i.e.,
, the transaction is labeled as successful. Otherwise, it means the malicious attack was able to confuse the network and the transaction was unsuccessful.
The requester is unable to assess the outcome of the transaction, so despite its result, it has to assign feedback to each of the providers. The maximum feedback is assigned to those providers that sent exactly the reference value
, while the other providers receive lower feedback based on how much the provided value is distant from
, as shown by the orange areas in
Figure 2. Nodes that have provided values with a distance equal to the accuracy of the application, i.e.,
and
, which represent the points of greatest uncertainty, are assigned feedback equal to 0.5. For intermediate values, the feedback follows a linear behavior, but other approaches are feasible and could also depend on the application at hand.
Due to the difference between the pseudo and the ground-truth value, feedback assignment leads to error in the evaluation of the providers: benevolent nodes that provided values in the light green area are given feedback lower than
and, in some cases, even 0, while malicious nodes that provided values unacceptable by the application, i.e., outside of the blue area of application accuracy, are given positive feedback, as it is the case of the dark green area in
Figure 2.
The introduction of a feedback evaluation system leads to a new malicious behavior that would not be possible if the requester is able to perfectly rate the received service. Generally, malicious behavior is a strategic behavior corresponding to an opportunistic participant who cheats whenever it is advantageous for it to do so. The goal of a node performing maliciously is usually to provide low quality or false services in order to save its own resources; at the same time, it aims to maintain a high value of trust toward the rest of the network so that other nodes will be agreeable in providing their services when requested. A group of nodes (collusive attack) can work together to provide the same malicious value so as to influence the reference value , let the requester believe that it is the correct value to be passed to the application, and assign to them a positive feedback. To the best of our knowledge, this is the first time this attack is presented; therefore, TRMs were never tested against it and we do not know their ability to detect and react to such an attack.
5. Conclusions
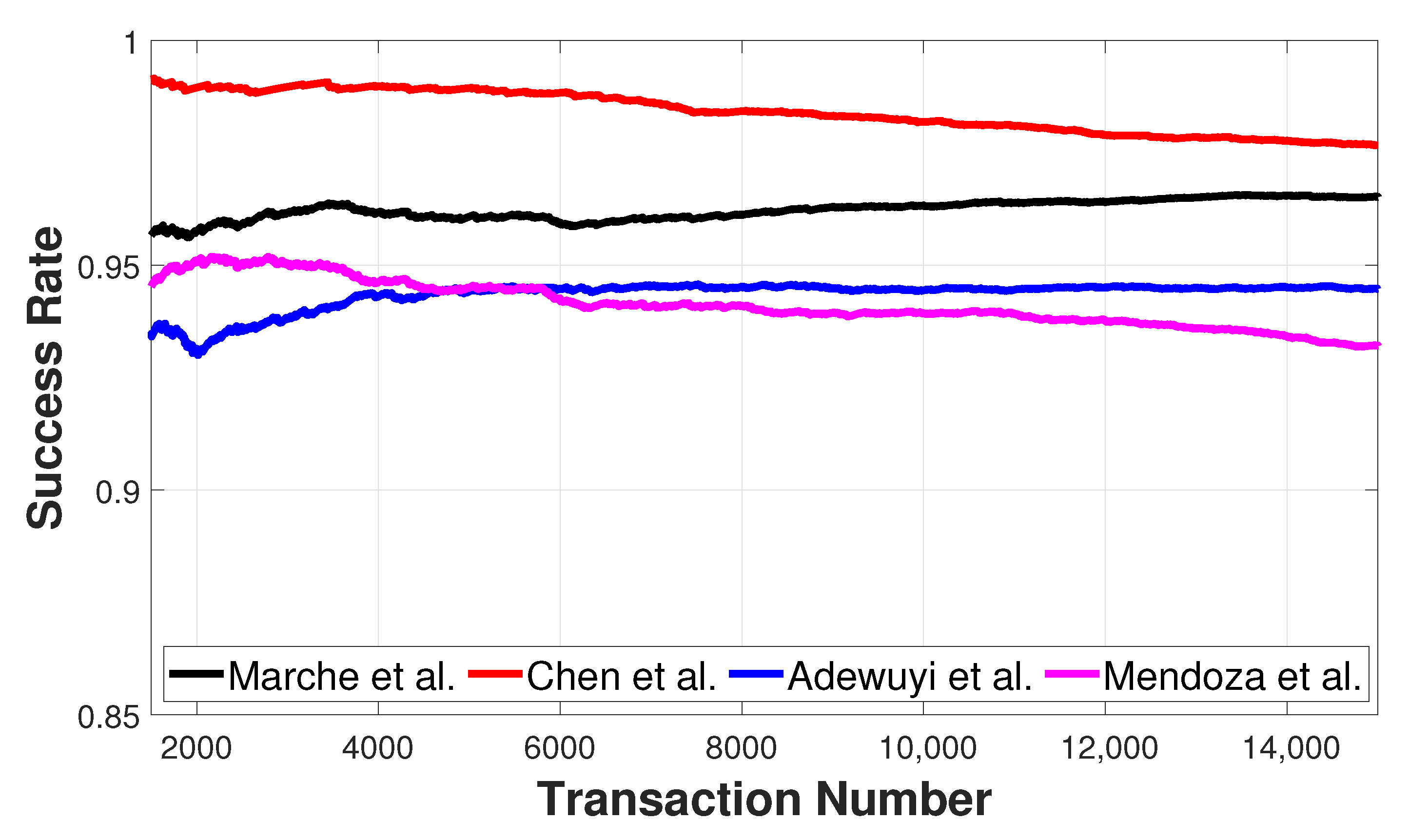
In this paper, we have defined the problem of feedback evaluation in the IoT and proposed different metrics to evaluate a reference value that should be used to rate the service received by the providers. The introduction of a mechanism to assign feedback to the services providers leads to error in the evaluation of the providers, due to the difference between the pseudo and the ground-truth value. This means that, even without any malicious nodes, benevolent devices could be assigned with negative feedback. Furthermore, we have observed that, regardless of the ability to provide perfect feedback, choosing more providers enables trust management systems to converge faster. Among the different approaches proposed, the median one is the most reliable since there must be malicious nodes in order for the transaction to be labeled as unsuccessful. However, by choosing more providers, a new malicious attack can be proposed: it is a collusive attack on trust, where a group of nodes works together to provide the same malicious value. The attack aims to influence the evaluation of the reference value and, thus, to confuse the IoT network. The proposed service and feedback evaluation methods were applied to well-known trust algorithms; the experiments have shown their importance and the challenges of generating consistent feedback for the trust evaluation in the exchange of services in IoT.
We plan to extend our methods by considering a more realistic scenario. In particular, we want to differentiate the accuracy of each application and consider that each node has different accuracies based on the service provided. This way, also benevolent nodes with low accuracy can provide values outside the range accepted by the application and, therefore, receive low ratings. We then expect that the goal of TRMs will shift: they will not only have to prevent malicious entities from hampering the services, but they will have to select the best provider based on the application at hand.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}