


Hierarchical Stratification for Spatial Sampling and Digital Mapping of Soil Attributes


Abstract
1. Introduction
2. Materials and Methods
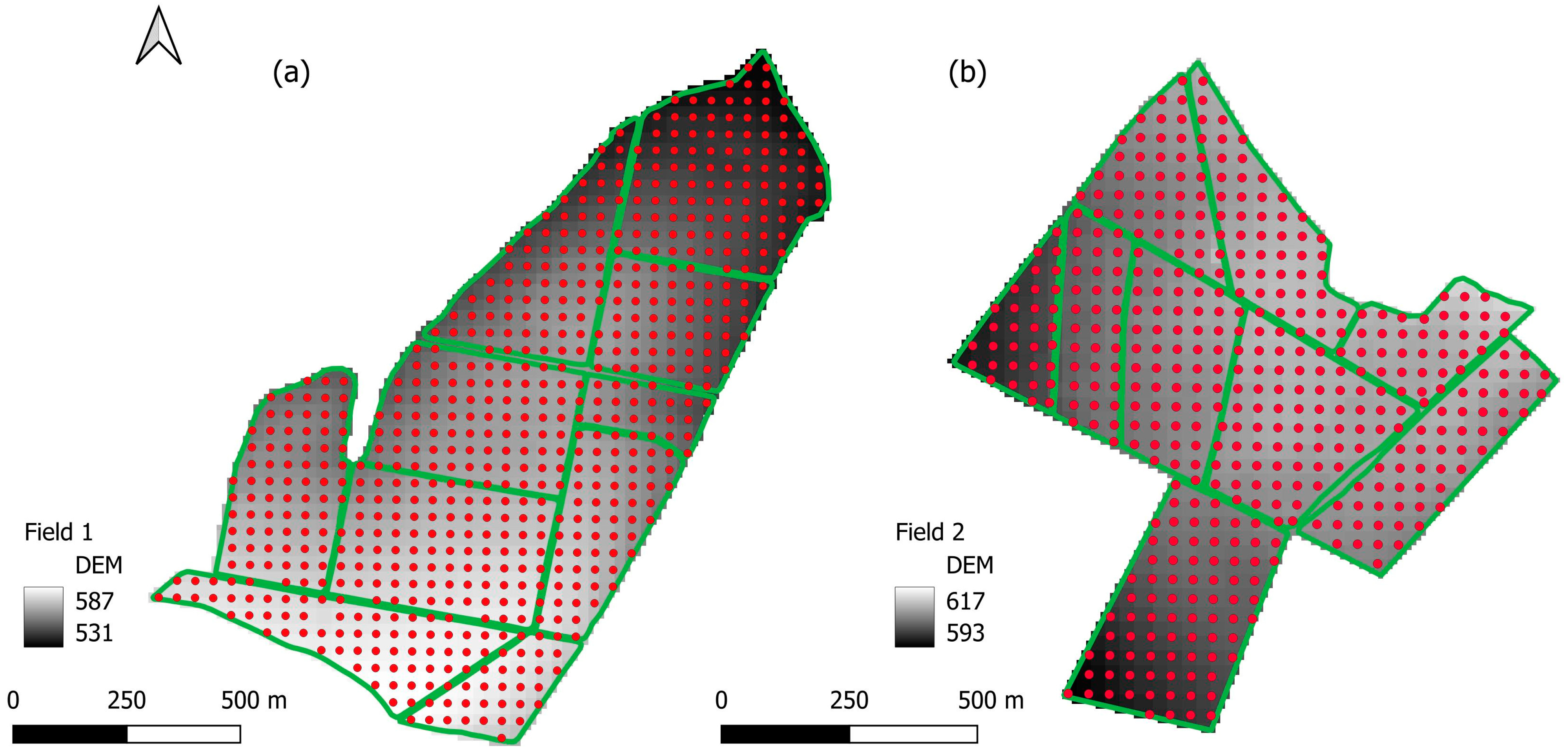
2.1. Study Areas
2.2. Soil Sampling
2.3. Field Covariates
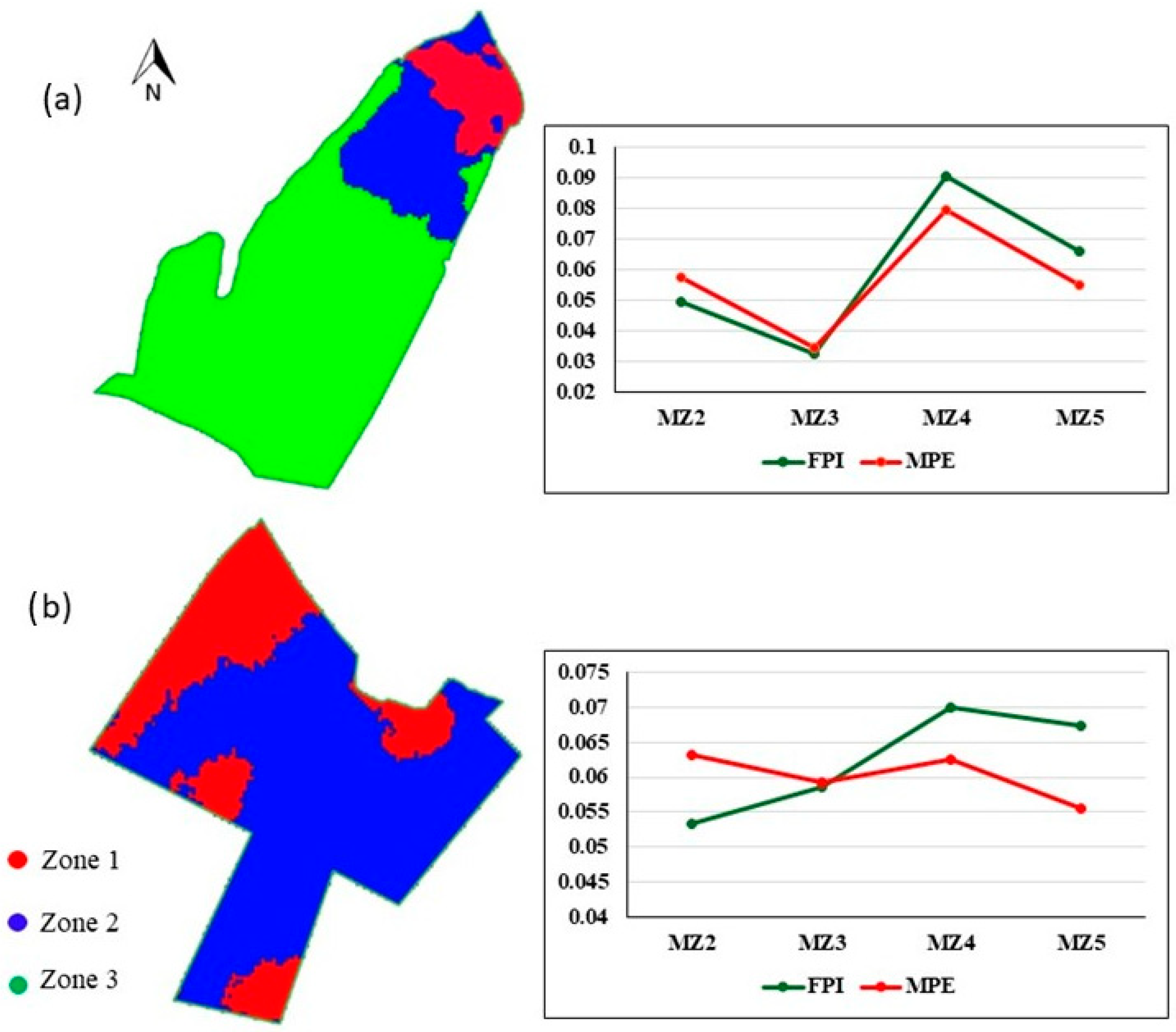
2.4. Inference of Soil Macro-Homogeneity
2.5. Determination of the Ideal Number of Points per Homogeneous Macro-Zone
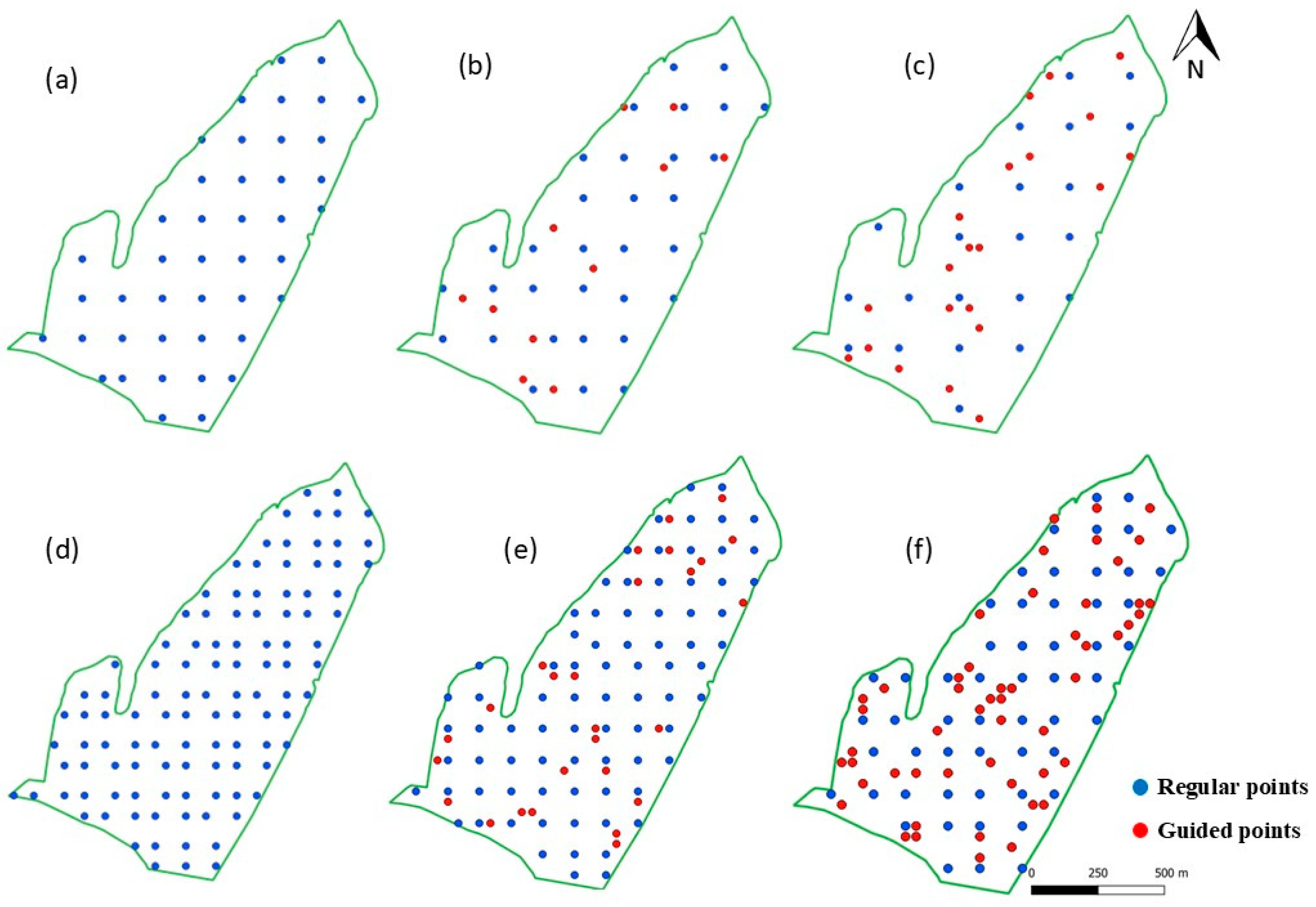
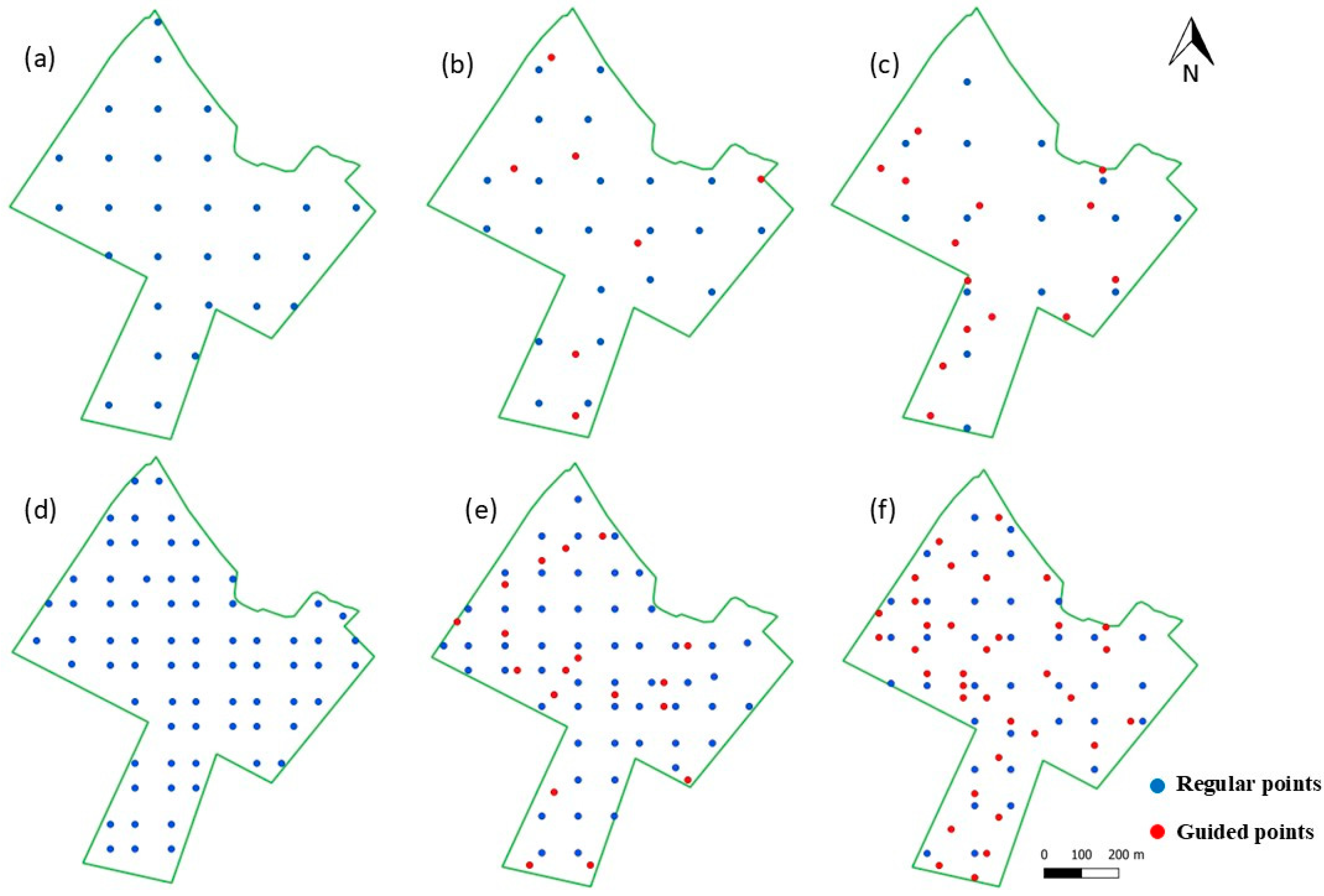
2.6. Inference of Soil Micro-Homogeneity and Location of Targeted Sampling Points
2.7. Interpolation
2.8. Analysis of Results
3. Results and Discussion
3.1. Clay Content Mapping
3.1.1. One Sample per Hectare
3.1.2. One Sample per 2.5 Hectares
3.2. Phosphorus Mapping
3.2.1. One Sample per Hectare
3.2.2. One Sample per 2.5 Hectares
3.3. Potassium Mapping
3.3.1. One Sample per Hectare
3.3.2. One Sample per 2.5 Hectares
3.4. Final Considerations and Opportunities of Hierarchical Stratification
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Molin, J.P.; Amaral, L.R.; Colaço, A. Agricultura de Precisão; Oficina de textos: Sao Paulo, Brazil, 2015. [Google Scholar]
- Brus, D.J. Sampling for digital soil mapping: A tutorial supported by R scripts. Geoderma 2019, 338, 464–480. [Google Scholar] [CrossRef]
- Soares, A. Geostatica para as Ciencias da Terra e do Ambiente, 3rd ed.; IST Press: Sao Paulo, Brazil, 2000. [Google Scholar]
- Marchant, B.P.; Mcbratney, A.B.; Lark, R.M.; Minasny, B. Amostragem multifásica otimizada para levantamentos de remediação de solo. Estat. Espac. 2013, 4, 1–13. [Google Scholar]
- Cherubin, M.R.; Damian, J.M.; Tavares, T.R.; Trevisan, R.G.; Colaço, A.F.; Eitelwein, M.T.; Martello, M.; Inamasu, R.Y.; Pias, O.H.d.C.; Molin, J.P. Precision agriculture in Brazil: The trajectory of 25 years of scientific research. Agriculture 2022, 12, 1882. [Google Scholar] [CrossRef]
- Cherubin, M.R.; Santi, A.L.; Eitelwein, M.T.; Menegol, D.R.; Ros, C.O.D.; Pias, O.H.D.C.; Berghetti, J. Eficiência de malhas amostrais utilizadas na caracterização da variabilidade espacial de fósforo e potássio. Ciênc. Rural 2014, 44, 425–432. [Google Scholar] [CrossRef]
- Nanni, M.R.; Povh, F.P.; Demattê, J.A.M.; Oliveira, R.B.D.; Chicati, M.L.; Cezar, E. Optimum size in grid soil sampling for variable rate application in site-specific management. Sci. Agric. 2011, 68, 386–392. [Google Scholar] [CrossRef]
- Baio, F.H.R.; Alixame, D.; Neves, D.C.; Teodoro, L.P.R.; da Silva Júnior, C.A.; Shiratsuchi, L.S.; de Oliveira, J.T.; Teodoro, P.E. Adding random points to sampling grids to improve the quality of soil fertility maps. Precis. Agric. 2023, 24, 2081–2097. [Google Scholar] [CrossRef]
- Karp, F.H.S.; Adamchuk, V.; Dutilleul, P.; Melnitchouck, A. Comparative study of interpolation methods for low-density sampling. Precis. Agric. 2024, 25, 2776–2800. [Google Scholar] [CrossRef]
- Pusch, M.; Samuel-Rosa, A.; Magalhães, P.S.G.; Amaral, L.R. Covariates in sample planning optimization for digital soil fertility mapping in agricultural areas. Geoderma 2023, 429, 116252. [Google Scholar] [CrossRef]
- De Caires, S.A.; Keshavarzi, A.; Bottega, E.L.; Kaya, F. Towards site-specific management of soil organic carbon: Comparing support vector machine and ordinary kriging approaches based on pedo-geomorphometric factors. Comput. Electron. Agric. 2024, 216, 108545. [Google Scholar] [CrossRef]
- Wang, Y.; Qi, Q.; Bao, Z.; Wu, L.; Geng, Q.; Wang, J. A novel sampling design considering the local heterogeneity of soil for farm field-level mapping with multiple soil properties. Precis. Agric. 2023, 24, 1–22. [Google Scholar] [CrossRef]
- Mello, D.C.; Demattê, J.A.; Silvero, N.E.; Di Raimo, L.A.; Poppiel, R.R.; Mello, F.A.; Rizzo, R. Soil magnetic susceptibility and its relationship with naturally occurring processes and soil attributes in pedosphere, in a tropical environment. Geoderma 2020, 372, 114364. [Google Scholar] [CrossRef]
- De Petris, S.; Boccardo, P.; Borgogno-Mondino, E. Detection and characterization of oil palm plantations through MODIS EVI time series. Int. J. Remote Sens. 2019, 40, 7297–7311. [Google Scholar] [CrossRef]
- Řezník, T.; Pavelka, T.; Herman, L.; Lukas, V.; Širůček, P.; Leitgeb, Š.; Leitner, F. Prediction of yield productivity zones from Landsat 8 and Sentinel-2A/B and their evaluation using farm machinery measurements. Remote Sens. 2020, 1212, 1917. [Google Scholar] [CrossRef]
- Santos, H.G.; Jacomine, P.K.T.; Dos Anjos, L.H.C.; De Oliveira, V.A.; Lumbreras, J.F.; Coelho, M.R.; Cunha, T.J.F. Brazilian System of Soil Classification (Sistema Brasileiro de Classificação de Solos), 5th ed.; EMBRAPA: Brasília, Brazil, 2018. (In Portuguese) [Google Scholar]
- Cantarella, H.; Raij, B.V.; Quaggio, J.A.; Boaretto, R.M.; Mattos, D. Recomendação de Adubação e Calagem para o Estado de São Paulo, 2nd ed.; Boletim Técnico, 100; Instituto Agronômico: Campinas, Brasil, 2023; p. 183. [Google Scholar]
- Amer, F.; Bouldin, D.R.; Black, C.A.; Duke, F.R. Characterization of soil phosphorus by anion exchange resin adsorption and P 32-equilibration. Plant Soil 1955, 6, 391–408. [Google Scholar] [CrossRef]
- Van Raij, B.; Camargo, A.P.D.; Cantarella, H.; Silva, N.M.D. Exchangeable aluminum and base saturation as criteria for lime requirement. Bragantia 1983, 42, 149–156. [Google Scholar] [CrossRef]
- Bouyoucos, G.J. Hydrometer method improved for making particle size analyses of soils 1. Agron. J. 1962, 54, 464–465. [Google Scholar] [CrossRef]
- Maher, B.A. Characterisation of soils by mineral magnetic measurements. Phys. Earth Planet. Inter. 1986, 42, 76–92. [Google Scholar] [CrossRef]
- Matias, S.S.R.; Marques Júnior, J.; Siqueira, D.S.; Pereira, G.T. Modelos de paisagem e susceptibilidade magnética na identificação e caracterização do solo. Pesqui. Agropecu. Trop. 2013, 43, 93–103. [Google Scholar] [CrossRef]
- Matos, A.P.D.; Matias, S.S.R.; Nunes, R.K.L.; Morais, E.M.; Tavares Filho, G.S. Soil management of limed areas cultivated with banana identified by magnetic susceptibility. Rev. Ceres 2023, 70, 17–24. [Google Scholar] [CrossRef]
- Maia, F.C.; Bufon, V.B.; Leão, T.P. Vegetation indices as a tool for mapping sugarcane management zones. Precis. Agric. 2023, 24, 213–234. [Google Scholar] [CrossRef]
- De Almeida, G.S.; Rizzo, R.; Amorim, M.T.A.; Dos Santos, N.V.; Rosas, J.T.F.; Campos, L.R.; Demattê, J.A. Monitoring soil–plant interactions and maize yield by satellite vegetation indexes, soil electrical conductivity and management zones. Precis. Agric. 2023, 24, 1380–1400. [Google Scholar] [CrossRef]
- Justice, C.O.; Vermote, E.; Townshend, J.R.; Defries, R.; Roy, D.P.; Hall, D.K.; Barnsley, M.J. The Moderate Resolution Imaging Spectroradiometer (MODIS): Land remote sensing for global change research. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1228–1249. [Google Scholar] [CrossRef]
- Amaral, L.R.; Oldoni, H.; Baptista, G.M.; Ferreira, G.H.; Freitas, R.G.; Martins, C.L.; Santos, A.F. Remote sensing imagery to predict soybean yield: A case study of vegetation indices contribution. Precis. Agric. 2024, 25, 2375–2393. [Google Scholar] [CrossRef]
- Cunha, I.A.; Baptista, G.M.; Prudente, V.H.R.; Melo, D.D.; Amaral, L.R. Integration of Optical and Synthetic Aperture Radar Data with Different Synthetic Aperture Radar Image Processing Techniques and Development Stages to Improve Soybean Yield Prediction. Agriculture 2024, 14, 2032. [Google Scholar] [CrossRef]
- Oldoni, H.; Terra, V.S.S.; Timm, L.C.; Júnior, C.R.; Monteiro, A.B. Delineation of management zones in a peach orchard using multivariate and geostatistical analyses. Soil Tillage Res. 2019, 191, 1–10. [Google Scholar] [CrossRef]
- Córdoba, M.A.; Bruno, C.I.; Costa, J.L.; Peralta, N.R.; Balzarini, M.G. Protocol for multivariate homogeneous zone delineation in precision agriculture. Biosyst. Eng. 2016, 143, 95–107. [Google Scholar] [CrossRef]
- McBratney, A.B.; Moore, A.W. Application of fuzzy sets to climatic classification. Agric. For. Meteorol. 1985, 35, 165–185. [Google Scholar] [CrossRef]
- Boydell, B.; McBratney, A.B. Identifying potential within-field management zones from cotton-yield estimates. Precis. Agric. 2002, 3, 9–23. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- An, Y.; Yang, L.; Zhu, A.X.; Qin, C.; Shi, J. Identification of representative samples from existing samples for digital soil mapping. Geoderma 2018, 311, 109–119. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. A tutorial guide to geostatistics: Computing and modelling variograms and kriging. Catena 2014, 113, 56–69. [Google Scholar] [CrossRef]
- Bellon-Maurel, V.; Fernandez-Ahumada, E.; Palagos, B.; Roger, J.M.; McBratney, A. Critical review of chemometric indicators commonly used for assessing the quality of the prediction of soil attributes by NIR spectroscopy. TrAC Trends Anal. Chem. 2010, 29, 1073–1081. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A.M. Predictive performance of mobile vis-near infrared spectroscopy for key soil properties at different geographical scales by using spiking and data mining techniques. Catena 2017, 151, 118–129. [Google Scholar] [CrossRef]
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef] [PubMed]
- López-Castañeda, A.; Zavala-Cruz, J.; Palma-López, D.J.; Rincón-Ramírez, J.A.; Bautista, F. Digital mapping of soil profile properties for precision agriculture in developing countries. Agronomy 2022, 12, 353. [Google Scholar] [CrossRef]
- Bottega, E.L.; de Queiroz, D.M.; Pinto, F.D.A.C.; de Souza, C.M. Spatial variability of soil attributes in no a no-tillage system with crop rotation in the Brazilian savannah. Rev. Ciênc. Agron. 2013, 44, 1. [Google Scholar] [CrossRef]
- Silva, P.; Chaves, L.H. Avaliação e variabilidade espacial de fósforo, potássio e matéria orgânica em Alissolos. Rev. Bras. Eng. Agríc. Ambient. 2001, 5, 431–436. [Google Scholar] [CrossRef]
- Amaral, L.R.D.; Justina, D.D.D. Spatial dependence degree and sampling neighborhood influence on interpolation process for fertilizer prescription maps. Eng. Agríc. 2019, 39, 85–95. [Google Scholar] [CrossRef]
- Silva, C.D.O.F.; Grego, C.R.; Manzione, R.L.; Oliveira, S.R.D.M. Improving Coffee Yield Interpolation in the Presence of Outliers Using Multivariate Geostatistics and Satellite Data. AgriEngineering 2024, 6, 81–94. [Google Scholar] [CrossRef]
- Szatmári, G.; László, P.; Takács, K.; Szabó, J.; Bakacsi, Z.; Koós, S.; Pásztor, L. Optimization of second-phase sampling for multivariate soil mapping purposes: Case study from a wine region, Hungary. Geoderma 2019, 352, 373–384. [Google Scholar] [CrossRef]
- Malavolta, E. Elementos de Nutrição Mineral de Plantas; Agronômica Ceres: São Paulo, Brazil, 1980. [Google Scholar]
- Teixeira, D.D.; Marques Jr, J.; Siqueira, D.S.; Vasconcelos, V.; Carvalho Jr, O.A.; Martins, É.S.; Pereira, G.T. Sample planning for quantifying and mapping magnetic susceptibility, clay content, and base saturation using auxiliary information. Geoderma 2017, 305, 208–218. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field 1 | Mean | Median | SD | CV% | Minimum | Maximum |
| Clay | 460.57 | 459.00 | 108.68 | 23.60 | 108.00 | 750.00 |
| K | 6.08 | 5.30 | 3.07 | 50.52 | 0.80 | 19.30 |
| P | 50.60 | 45.00 | 23.56 | 46.56 | 13.00 | 164.00 |
| Field 2 | Mean | Median | SD | CV% | Minimum | Maximum |
| Clay | 530.16 | 531.50 | 36.14 | 6.82 | 426.00 | 626.00 |
| K | 1.42 | 1.30 | 0.37 | 26.07 | 0.80 | 3.30 |
| P | 15.06 | 14.00 | 6.76 | 44.90 | 6.00 | 45.00 |
| Season 1 | Season 2 | Season 3 | Season 4 | Season 5 | |
|---|---|---|---|---|---|
| Field 1 | 20 June 2020 | 23 February 2021 | 21 January 2022 | 30 June | 25 June 2023 |
| Field 2 | 24 February 2019 | 10 March 2020 | 23 February 2021 | 4 April 2022 | 25 March 2023 |
| One Sample/ha | One Sample/2.5 ha | |||||
|---|---|---|---|---|---|---|
| Field 1 | Regular | 25% | 50% | Regular | 25% | 50% |
| Guided pts | 0 | 27 | 53 | 0 | 11 | 21 |
| Regular pts | 107 | 80 | 54 | 43 | 32 | 22 |
| Field 2 | Regular | 25% | 50% | Regular | 25% | 50% |
| Guided pts | 0 | 18 | 36 | 0 | 7 | 14 |
| Regular pts | 72 | 54 | 54 | 29 | 22 | 15 |
| One Sample per 2.5 ha | One Sample per ha | ||||||
|---|---|---|---|---|---|---|---|
| Field 1 | Reference | 25% | 50% | Regular | 25% | 50% | Regular |
| P | 1.30 | 1.10 | 1.14 | 1.17 | 1.13 | 1.24 | 1.19 |
| K | 2.13 | 1.63 | 1.75 | 1.64 | 1.79 | 1.94 | 1.82 |
| Clay | 4.12 | 2.18 | 2.60 | 2.19 | 3.03 | 3.82 | 3.13 |
| Field 2 | Reference | 25% | 50% | Regular | 25% | 50% | Regular |
| P | 2.09 | 1.62 | 1.79 | 1.49 | 1.75 | 1.58 | 1.80 |
| K | 1.37 | 1.05 | 1.11 | 1.08 | 1.17 | 1.17 | 1.21 |
| Clay | 1.78 | 1.41 | 1.28 | 1.31 | 1.37 | 1.49 | 1.49 |
 > 2.5; 2.5 >
> 2.5; 2.5 >  > 2.0; 2.0 >
> 2.0; 2.0 >  > 1.7; 1.7 >
> 1.7; 1.7 >  > 1.4; 1.4 >
> 1.4; 1.4 >  .
.| Field 1 | C0 | C1 | A | RMSE | R | Model | Moran | p-Value |
| P | 0 | 500 | 251 | 22.14 | 0.33 | Exp | 0.2 | 0.001 |
| K | 2.93 | 2.6 | 485 | 1.78 | 0.81 | Gau | 0.66 | 0.001 |
| Clay | 0 | 10,000 | 600 | 28.88 | 0.95 | Exp | 0.85 | 0.001 |
| Field 2 | C0 | C1 | A | RMSE | R | Model | Moran | p-Value |
| P | 12 | 30 | 400 | 4.78 | 0.70 | Exp | 0.46 | 0.001 |
| K | 0.04 | 0.1 | 395 | 0.29 | 0.57 | Exp | 0.29 | 0.001 |
| Clay | 200 | 1000 | 220 | 26.06 | 0.68 | Exp | 0.36 | 0.001 |
| Regular | 25% | 50% | ||||
|---|---|---|---|---|---|---|
| Field 1 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 38.01 | 0.93 | 39.23 | 0.92 | 31.12 | 0.92 |
| One sample per 2.5 ha | 54.33 | 0.86 | 54.41 | 0.86 | 45.63 | 0.88 |
| Field 2 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 31.07 | 0.49 | 33.88 | 0.44 | 31.12 | 0.54 |
| One sample per 2.5 ha | 35.42 | 0.38 | 32.85 | 0.44 | 36.09 | 0.39 |
| Attribute | P | K | Clay | MSa | EVI |
|---|---|---|---|---|---|
| P | 0.170 | −0.003 ns | −0.370 | −0.350 | |
| K | 0.250 | 0.086 | −0.001 ns | −0.059 ns | |
| Clay | 0.015 ns | 0.470 | 0.140 | 0.012 ns | |
| MSa | 0.078 ns | −0.610 | −0.620 | 0.310 | |
| EVI | 0.079 ns | −0.280 | −0.490 | 0.310 |
| Regular | 25% | 50% | ||||
|---|---|---|---|---|---|---|
| Field 1 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 24.93 | 0.22 | 25.44 | 0.12 | 23.32 | 0.30 |
| One sample per 2.5 ha | 24.72 | 0.24 | 26.20 | 0.22 | 25.26 | 0.09 |
| Field 2 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 5.54 | 0.65 | 5.69 | 0.63 | 6.30 | 0.62 |
| One sample per 2.5 ha | 6.69 | 0.54 | 6.14 | 0.52 | 5.57 | 0.66 |
| Regular | 25% | 50% | ||||
|---|---|---|---|---|---|---|
| Field 1 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 2.08 | 0.70 | 2.12 | 0.69 | 1.95 | 0.71 |
| One sample per 2.5 ha | 2.31 | 0.64 | 2.33 | 0.61 | 2.17 | 0.61 |
| Field 2 | RMSE | r | RMSE | r | RMSE | r |
| One sample per ha | 0.33 | 0.49 | 0.34 | 0.49 | 0.34 | 0.42 |
| One sample per 2.5 ha | 0.37 | 0.38 | 0.38 | 0.44 | 0.36 | 0.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melo, D.D.; Cunha, I.A.; Amaral, L.R. Hierarchical Stratification for Spatial Sampling and Digital Mapping of Soil Attributes. AgriEngineering 2025, 7, 10. https://doi.org/10.3390/agriengineering7010010
Melo DD, Cunha IA, Amaral LR. Hierarchical Stratification for Spatial Sampling and Digital Mapping of Soil Attributes. AgriEngineering. 2025; 7(1):10. https://doi.org/10.3390/agriengineering7010010
Chicago/Turabian StyleMelo, Derlei D., Isabella A. Cunha, and Lucas R. Amaral. 2025. "Hierarchical Stratification for Spatial Sampling and Digital Mapping of Soil Attributes" AgriEngineering 7, no. 1: 10. https://doi.org/10.3390/agriengineering7010010
APA StyleMelo, D. D., Cunha, I. A., & Amaral, L. R. (2025). Hierarchical Stratification for Spatial Sampling and Digital Mapping of Soil Attributes. AgriEngineering, 7(1), 10. https://doi.org/10.3390/agriengineering7010010