
SemConvTree: Semantic Convolutional Quadtrees for Multi-Scale Event Detection in Smart City
 , , , ,
, , , ,
Abstract
Highlights
- Enhanced Event Detection Accuracy: The introduction of the SemConvTree model, which integrates improved versions of BERTopic, TSB-ARTM, and SBert-Zero-Shot, enables a significant enhancement in the detection accuracy of urban events. The model’s ability to incorporate semantic analysis along with statistical evaluations allows for discerning and categorizing events from social media data more precisely. This results in approximately a 40% increase in the F1-score for event detection compared to previous methods.
- Semantic Analysis for Event Identification: The SemConvTree model leverages semi-supervised learning techniques to analyze the semantic content of social media posts. This approach helps in understanding the nuanced contexts of urban events, improving the identification process. The model not only recognizes the occurrence of events but also categorizes them into meaningful groups based on their semantic characteristics, which is crucial for effective urban management and planning.
- The increased accuracy in event detection ensures that urban planners and emergency services can respond more effectively to both planned and unplanned urban events. More accurate data leads to better resource allocation, ensuring that services are deployed where they are most needed. This could lead to enhanced safety, improved traffic management, and better crowd control during events, ultimately enhancing urban living conditions.
- By effectively categorizing urban events based on their semantic characteristics, city administrators can gain insights into the types of events that are prevalent in different areas of the city. This can inform more targeted community engagement strategies, help in the planning of public services and facilities, and ensure that urban policies are closely aligned with the actual dynamics of the city. Additionally, this can aid in long-term urban development strategies by identifying evolving trends and shifts in urban activity patterns.
Abstract
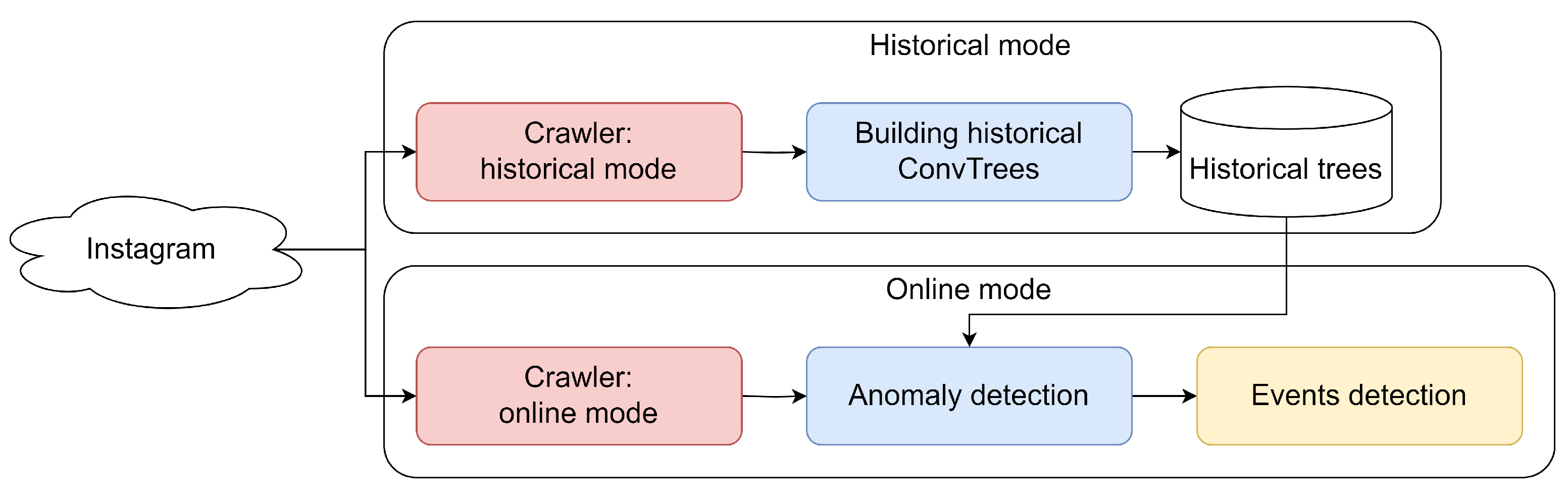
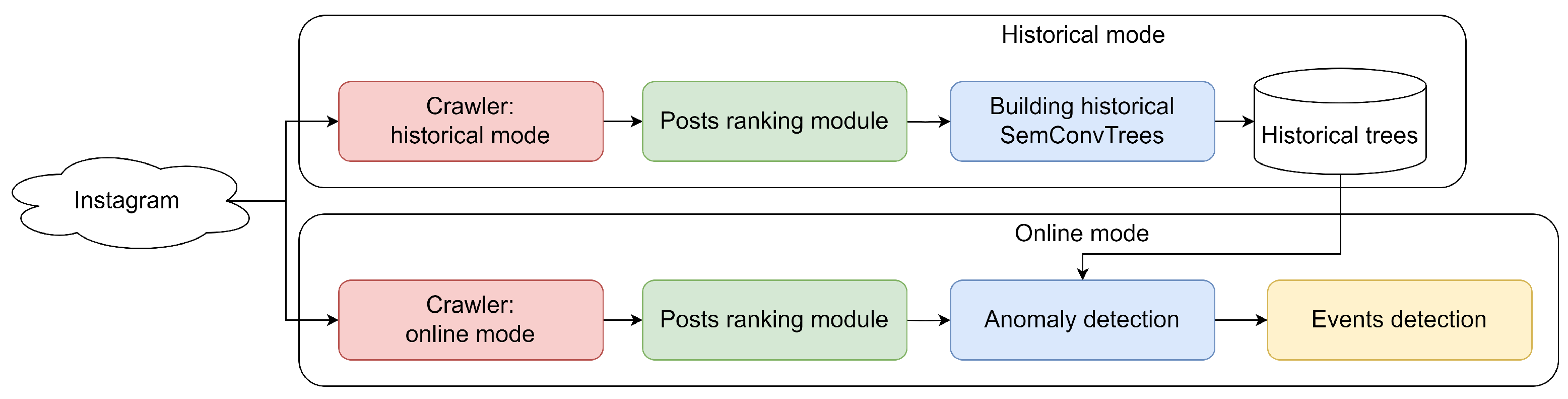
1. Introduction
- Data collectors;
- The semantics extraction and ranking module;
- The adaptive mesh generation module;
- The anomaly detection module;
- The anomaly filtering and event linking module.
2. Related Works
2.1. Frequency-Based Methods
2.2. Modern Techniques
2.2.1. Modern NLP
2.2.2. Multimodal Approaches
2.2.3. Filtering Noise
2.3. Low-Scale Events
3. Semantic Convolutional Quadtree
3.1. ConvTree
3.2. Semantic-Based Model for Anomaly Detection
3.3. Construction Algorithm
4. Semantic Filtering
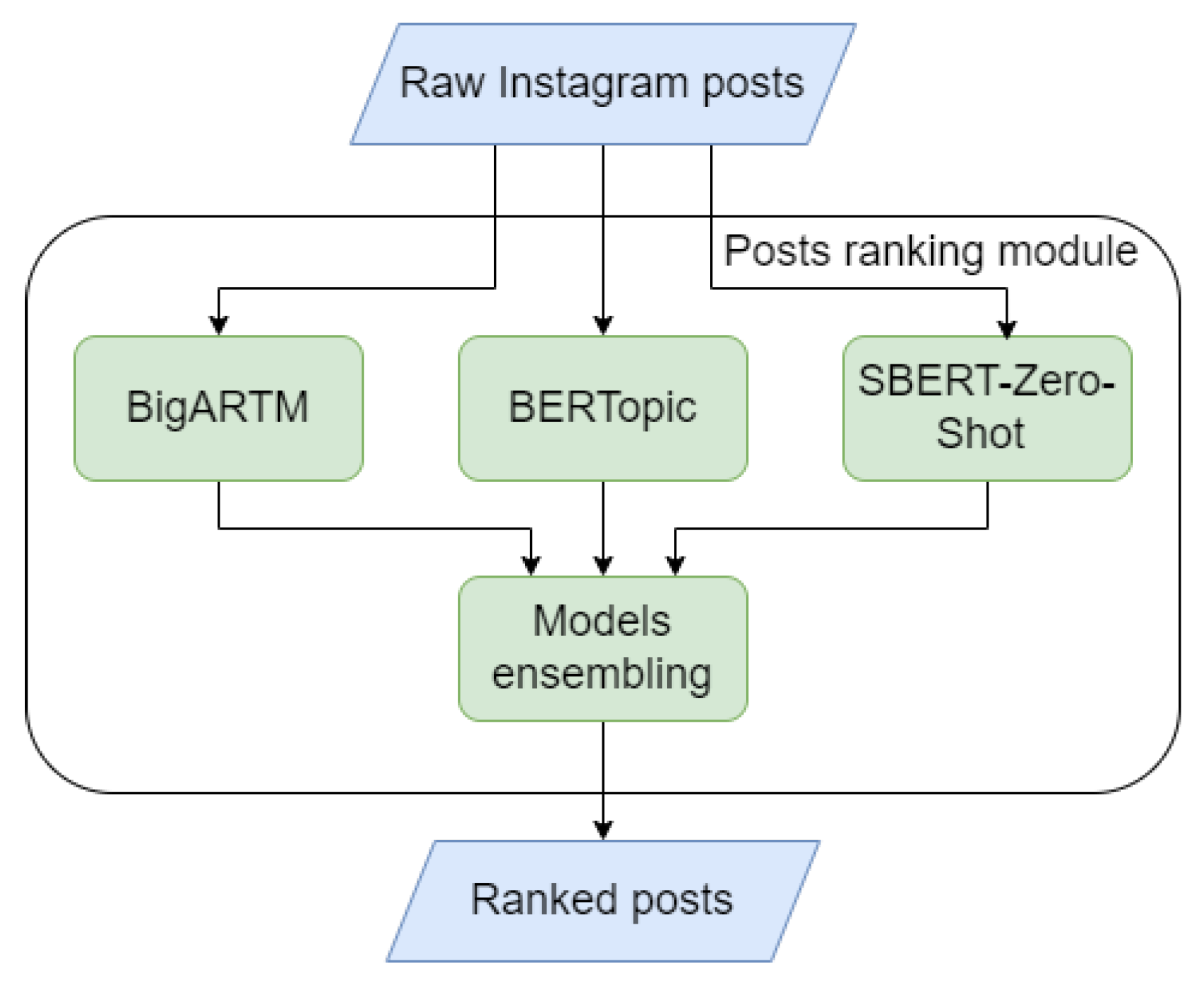
4.1. BERTopic
4.2. TSB-ARTM
4.3. SBert-Zero-Shot
4.4. Models Comparison
5. Experimental Evaluation
5.1. DataSet
5.2. Experimental Studies
6. Conclusions and Future Works
7. Compliance with Ethical Standards
8. Research Data Policy and Data Availability Statement
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dixon, S.J. Number of Social Media Users Worldwide from 2017 to 2028 (in Billions). May 2024. Available online: https://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/ (accessed on 5 June 2024).
- Wolniak, R.; Stecuła, K. Artificial Intelligence in Smart Cities—Applications, Barriers, and Future Directions: A Review. Smart Cities 2024, 7, 1346–1389. [Google Scholar] [CrossRef]
- Earle, P.S.; Bowden, D.C.; Guy, M. Twitter earthquake detection: Earthquake monitoring in a social world. Ann. Geophys. 2012, 54. [Google Scholar] [CrossRef]
- Osborne, M.; Moran, S.; McCreadie, R.; Lunen, A.V.; Sykora, M.; Cano, E.; Ireson, N.; Macdonald, C.; Ounis, I.; He, Y.; et al. Real-Time Detection, Tracking, and Monitoring of Automatically Discovered Events in Social Media. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014. [Google Scholar] [CrossRef]
- Lim, B.H.; Lu, D.; Chen, T.; Kan, M.Y. #mytweet via Instagram. In Proceedings of the Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, Paris, France, 25–28 August 2015; ACM: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Giridhar, P.; Wang, S.; Abdelzaher, T.; Amin, T.A.; Kaplan, L. Social Fusion: Integrating Twitter and Instagram for Event Monitoring. In Proceedings of the 2017 IEEE International Conference on Autonomic Computing (ICAC), Columbus, OH, USA, 17–21 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, G.; Yuan, Q.; Zhuang, H.; Zheng, Y.; Kaplan, L.; Wang, S.; Han, J. GeoBurst: Real-Time Local Event Detection in Geo-Tagged Tweet Streams. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ′16, New York, NY, USA, 17–21 July 2016; pp. 513–522. [Google Scholar] [CrossRef]
- McMinn, A.; Moshfeghi, Y.; Jose, J. Building a large-scale corpus for evaluating event detection on twitter. In Proceedings of the International Conference on Information and Knowledge Management, Proceedings, San Francisco, CA, USA, 27 October–1 November 2013; pp. 409–418. [Google Scholar] [CrossRef]
- Zhang, C.; Lei, D.; Yuan, Q.; Zhuang, H.; Kaplan, L.; Wang, S.; Han, J. GeoBurst+: Effective and Real-Time Local Event Detection in Geo-Tagged Tweet Streams. ACM Trans. Intell. Syst. Technol. 2018, 9, 34. [Google Scholar] [CrossRef]
- Krumm, J.; Horvitz, E. Eyewitness. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Bellevue, WA, USA, 3–6 November 2015; ACM: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Visheratin, A.A.; Mukhina, K.D.; Visheratina, A.K.; Nasonov, D.; Boukhanovsky, A.V. Multiscale event detection using convolutional quadtrees and adaptive geogrids. In Proceedings of the 2nd ACM SIGSPATIAL Workshop on Analytics for Local Events and News, Seattle, WA, USA, 6 November 2018; ACM: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Saha, K.; Seybolt, J.; Mattingly, S.M.; Aledavood, T.; Konjeti, C.; Martinez, G.J.; Grover, T.; Mark, G.; De Choudhury, M. What Life Events Are Disclosed on Social Media, How, When, and By Whom? In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, CHI ′21, New York, NY, USA, 8–13 May 2021. [Google Scholar] [CrossRef]
- DiCarlo, M.F.; Berglund, E.Z. Use of social media to seek and provide help in Hurricanes Florence and Michael. Smart Cities 2020, 3, 1187–1218. [Google Scholar] [CrossRef]
- Becker, H.; Naaman, M.; Gravano, L. Beyond Trending Topics: Real-World Event Identification on Twitter. Proc. Int. AAAI Conf. Web Soc. Media 2021, 5, 438–441. [Google Scholar] [CrossRef]
- Khodabakhsh, M.; Kahani, M.; Bagheri, E.; Noorian, Z. Detecting life events from Twitter based on temporal semantic features. Knowl.-Based Syst. 2018, 148, 1–16. [Google Scholar] [CrossRef]
- Sufi, F.K. AI-SocialDisaster: An AI-based software for identifying and analyzing natural disasters from social media. Softw. Impacts 2022, 13, 100319. [Google Scholar] [CrossRef]
- Cresci, S.; Tesconi, M.; Cimino, A.; Dell’Orletta, F. A Linguistically-Driven Approach to Cross-Event Damage Assessment of Natural Disasters from Social Media Messages. In Proceedings of the 24th International Conference on World Wide Web, WWW ′15 Companion, New York, NY, USA, 18–22 May 2015; pp. 1195–1200. [Google Scholar] [CrossRef]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. EvenTweet: Online localized event detection from twitter. Proc. VLDB Endow. 2013, 6, 1326–1329. [Google Scholar] [CrossRef]
- Neruda, G.A.; Winarko, E. Traffic Event Detection from Twitter Using a Combination of CNN and BERT. In Proceedings of the 2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Virtual, 23–26 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Timokhin, S.; Sadrani, M.; Antoniou, C. Predicting venue popularity using crowd-sourced and passive sensor data. Smart Cities 2020, 3, 42. [Google Scholar] [CrossRef]
- Afyouni, I.; Aghbari, Z.A.; Razack, R.A. Multi-feature, multi-modal, and multi-source social event detection: A comprehensive survey. Inf. Fusion 2022, 79, 279–308. [Google Scholar] [CrossRef]
- Said, N.; Ahmad, K.; Regular, M.; Pogorelov, K.; Hassan, L.; Ahmad, N.; Conci, N. Natural Disasters Detection in Social Media and Satellite imagery: A survey. arXiv 2019, arXiv:1901.04277. [Google Scholar]
- Atefeh, F.; Khreich, W. A Survey of Techniques for Event Detection in Twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Saeed, Z.; Abbasi, R.; Maqbool, O.; Sadaf, A.; Razzak, I.; Daud, A.; Aljohani, N.; Xu, G. Twitter: A Survey and Framework on Event Detection Techniques. J. Grid Comput. 2019. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Ada, I.; Berthold, M.R. Unifying Change—Towards a Framework for Detecting the Unexpected. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 555–559. [Google Scholar] [CrossRef]
- Dries, A.; Rückert, U. Adaptive concept drift detection. Stat. Anal. Data Min. ASA Data Sci. J. 2009, 2, 311–327. [Google Scholar] [CrossRef]
- Liu, N. Topic Detection and Tracking. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer US: Boston, MA, USA, 2009; pp. 3121–3124. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Chen, Y.; Wang, S.; Li, Z.; Xia, J. Event detection and popularity prediction in microblogging. Neurocomputing 2015, 149, 1469–1480. [Google Scholar] [CrossRef]
- Brants, T.; Chen, F.; Farahat, A. A System for New Event Detection. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, SIGIR ′03, New York, NY, USA, 28 July–1 August 2003; pp. 330–337. [Google Scholar] [CrossRef]
- Kaleel, S.B.; Abhari, A. Cluster-discovery of Twitter messages for event detection and trending. J. Comput. Sci. 2015, 6, 47–57. [Google Scholar] [CrossRef]
- Aiello, L.M.; Petkos, G.; Martin, C.; Corney, D.; Papadopoulos, S.; Skraba, R.; Göker, A.; Kompatsiaris, I.; Jaimes, A. Sensing Trending Topics in Twitter. IEEE Trans. Multimed. 2013, 15, 1268–1282. [Google Scholar] [CrossRef]
- Lampos, V.; Cristianini, N. Nowcasting Events from the Social Web with Statistical Learning. ACM Trans. Intell. Syst. Technol. 2012, 3, 72. [Google Scholar] [CrossRef]
- Weng, J.; Yao, Y.; Leonardi, E.; Lee, B.S. Event Detection in Twitter. Proc. Int. AAAI Conf. Web Soc. Media 2011, 5, 401–408. [Google Scholar] [CrossRef]
- Cheng, T.; Wicks, T. Event Detection using Twitter: A Spatio-Temporal Approach. PLoS ONE 2014, 9, e97807. [Google Scholar] [CrossRef] [PubMed]
- Weiler, A.; Grossniklaus, M.; Scholl, M. Event Identification and Tracking in Social Media Streaming Data. In Proceedings of the CEUR Workshop Proceedings, Athens, Greece, 28 March 2014; Volume 1133. [Google Scholar]
- He, Q.; Chang, K.; Lim, E.P. Analyzing Feature Trajectories for Event Detection. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ′07, New York, NY, USA, 23–27 July 2007; pp. 207–214. [Google Scholar] [CrossRef]
- Kleinberg, J. Bursty and Hierarchical Structure in Streams. Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. 2002, 7, 91–101. [Google Scholar] [CrossRef]
- Fung, G.P.C.; Yu, J.X.; Yu, P.S.; Lu, H. Parameter Free Bursty Events Detection in Text Streams. In Proceedings of the 31st International Conference on Very Large Data Bases, VLDB Endowment, VLDB ’05, Trondheim, Norway, 30 August–2 September 2005; pp. 181–192. [Google Scholar]
- He, Q.; Chang, K.; Lim, E.P.; Zhang, J. Bursty Feature Representation for Clustering Text Streams. In Proceedings of the SDM, Minneapolis, MN, USA, 26–28 April 2007. [Google Scholar]
- Kumar, R.; Novak, J.; Raghavan, P.; Tomkins, A. On the Bursty Evolution of Blogspace. In Proceedings of the 12th International Conference on World Wide Web, WWW ′03, New York, NY, USA, 20–24 May 2003; pp. 568–576. [Google Scholar] [CrossRef]
- Mei, Q.; Zhai, C. Discovering Evolutionary Theme Patterns from Text: An Exploration of Temporal Text Mining. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, KDD ′05, New York, NY, USA, 21–24 August 2005; pp. 198–207. [Google Scholar] [CrossRef]
- Zhou, D.; Chen, L.; He, Y. An Unsupervised Framework of Exploring Events on Twitter: Filtering, Extraction and Categorization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI ′15, Austin, TX, USA, 25–30 January 2015; AAAI Press: Washington, DC, USA, 2015; pp. 2468–2474. [Google Scholar]
- Lee, R.; Wakamiya, S.; Sumiya, K. Discovery of unusual regional social activities using geo-tagged microblogs. World Wide Web 2011, 14, 321–349. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, C.; Zhang, W.; Han, J.; Wang, J.; Aggarwal, C.; Huang, J. STREAMCUBE: Hierarchical spatio-temporal hashtag clustering for event exploration over the Twitter stream. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; IEEE: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Rehman, F.U.; Afyouni, I.; Lbath, A.; Basalamah, S. Understanding the Spatio-Temporal Scope of Multi-scale Social Events. In Proceedings of the 1st ACM SIGSPATIAL Workshop on Analytics for Local Events and News, Redondo Beach, CA, USA, 7–10 November 2017; ACM: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. EMNLP 2014, 14, 1532–1543. [Google Scholar] [CrossRef]
- Zhang, Y.; Shirakawa, M.; Hara, T. A General Method for Event Detection on Social Media. In Proceedings of the Symposium on Advances in Databases and Information Systems, Tartu, Estonia, 24–26 August 2021. [Google Scholar]
- Hettiarachchi, H.; Adedoyin-Olowe, M.; Bhogal, J.; Gaber, M.M. Embed2Detect: Temporally clustered embedded words for event detection in social media. Mach. Learn. 2021, 111, 49–87. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Hong Kong, 3–7 November 2019. [Google Scholar]
- Wei, Z.; Yongli, W. Chinese Event Detection Combining BERT Model with Recurrent Neural Networks. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 1625–1629. [Google Scholar] [CrossRef]
- Huang, L.; Shi, P.; Zhu, H.; Chen, T. Early detection of emergency events from social media: A new text clustering approach. Nat. Hazards 2022, 111, 851–875. [Google Scholar] [CrossRef] [PubMed]
- McDonald, R.; Nivre, J. Analyzing and Integrating Dependency Parsers. Comput. Linguist. 2011, 37, 197–230. [Google Scholar] [CrossRef]
- Nguyen, T.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 5 January 2016; pp. 300–309. [Google Scholar] [CrossRef]
- Liu, X.; Luo, Z.; Huang, H. Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event Detection with Multi-Order Graph Convolution and Aggregated Attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5766–5770. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903. [Google Scholar]
- Dutta, S.; Ma, L.; Saha, T.K.; Lu, D.; Tetreault, J.; Jaimes, A. GTN-ED: Event Detection Using Graph Transformer Networks. arXiv 2021, arXiv:2104.15104. [Google Scholar]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large Language Models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Snoek, C.G.M.; Worring, M.; Smeulders, A.W.M. Early versus late fusion in semantic video analysis. In Proceedings of the MULTIMEDIA ′05, Besancon, France, 6–9 February 2005. [Google Scholar]
- Sukel, M.; Rudinac, S.; Worring, M. Multimodal Classification of Urban Micro-Events. arXiv 2019, arXiv:1904.13349. [Google Scholar]
- Cui, W.; Du, J.; Wang, D.; Kou, F.; Xue, Z. MVGAN: Multi-View Graph Attention Network for Social Event Detection. ACM Trans. Intell. Syst. Technol. 2021, 12, 27. [Google Scholar] [CrossRef]
- Jony, R.I.; Woodley, A.; Perrin, D. Fusing Visual Features and Metadata to Detect Flooding in Flickr Images. In Proceedings of the 2020 Digital Image Computing: Techniques and Applications (DICTA), Melbourne, Australia, 29 November–2 December 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Petkos, G.; Papadopoulos, S.; Kompatsiaris, I. Social event detection using multimodal clustering and integrating supervisory signals. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, ICMR 2012, Hong Kong, 5–8 June 2012. [Google Scholar] [CrossRef]
- Schinas, M.; Papadopoulos, S.; Petkos, G.; Kompatsiaris, I.; Mitkas, P. Multimodal Graph-based Event Detection and Summarization in Social Media Streams. Int. J. Multimed. Inf. Retr. 2015, 189–192. [Google Scholar] [CrossRef]
- Tong, M.; Wang, S.; Cao, Y.; Xu, B.; Li, J.; Hou, L.; Chua, T.S. Image Enhanced Event Detection in News Articles. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9040–9047. [Google Scholar] [CrossRef]
- Guo, C.; Tian, X. Event recognition in personal photo collections using hierarchical model and multiple features. In Proceedings of the 2015 IEEE 17th International Workshop on Multimedia Signal Processing (MMSP), Xiamen, China, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Kaneko, T.; Yanai, K. Event photo mining from Twitter using keyword bursts and image clustering. Neurocomputing 2016, 172, 143–158. [Google Scholar] [CrossRef]
- Zaharieva, M.; Zeppelzauer, M.; Breiteneder, C. Automated Social Event Detection in Large Photo Collections. In Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, ICMR ′13, New York, NY, USA, 16–29 April 2013; pp. 167–174. [Google Scholar] [CrossRef]
- Ali, F.; Ali, A.; Imran, M.; Naqvi, R.A.; Siddiqi, M.H.; Kwak, K.S. Traffic accident detection and condition analysis based on social networking data. Accid. Anal. Prev. 2021, 151, 105973. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Sokolova, M.; Huang, K.; Matwin, S.; Ramisch, J.J.; Sazonova, V.; Black, R.; Orwa, C.; Ochieng, S.; Sambuli, N. Topic Modelling and Event Identification from Twitter Textual Data. arXiv 2016, arXiv:1608.02519. [Google Scholar]
- Zhang, C.; Wang, H.; Cao, L.; Wang, W.; Xu, F. A Hybrid Term-Term Relations Analysis Approach for Topic Detection. Knowl.-Based Syst. 2016, 93, 109–120. [Google Scholar] [CrossRef]
- Choi, D.; Park, S.; Ham, D.; Lim, H.; Bok, K.; Yoo, J. Local Event Detection Scheme by Analyzing Relevant Documents in Social Networks. Appl. Sci. 2021, 11, 577. [Google Scholar] [CrossRef]
- Vorontsov, K.; Frei, O.; Apishev, M.; Romov, P.; Dudarenko, M. BigARTM: Open Source Library for Regularized Multimodal Topic Modeling of Large Collections. In Communications in Computer and Information Science; Springer International Publishing: Berlin, Germany, 2015; pp. 370–381. [Google Scholar] [CrossRef]
- Vorontsov, K.V. Additive regularization for topic models of text collections. Doklady Math. 2014, 89, 301–304. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, L.; Lei, D.; Yuan, Q.; Zhuang, H.; Hanratty, T.; Han, J. TrioVecEvent. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Wei, H.; Zhou, H.; Sankaranarayanan, J.; Sengupta, S.; Samet, H. DeLLe. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Analytics for Local Events and News, Chicago, IL, USA, 5 November 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Chaffey, D. Global Social Media Statistics Research Summary 2022; Smart Insights: Leeds, UK, 2022. [Google Scholar]
- Korneev, A.; Kovalchuk, M.; Filatova, A.; Tereshkin, S. Towards comparable event detection approaches development in social media. Procedia Comput. Sci. 2022, 212, 312–321. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Model | Recall of the Non-Events Posts Detection | ||||||
|---|---|---|---|---|---|---|---|
| All | M | A | E | Feb | Jun | Oct | |
| BERTopic | 0.42 | 0.43 | 0.39 | 0.41 | 0.42 | 0.43 | 0.39 |
| TSB-ARTM | 0.51 | 0.48 | 0.5 | 0.49 | 0.48 | 0.52 | 0.51 |
| SBert-Zero-Shot | 0.46 | 0.44 | 0.47 | 0.46 | 0.45 | 0.47 | 0.48 |
| Models ensemble | 0.61 | 0.59 | 0.6 | 0.62 | 0.59 | 0.6 | 0.61 |
| Category | Posts Number | Category | Posts Number |
|---|---|---|---|
| Festival | 64 | Concert | 115 |
| Sport event | 317 | National holiday | 214 |
| Show/ Flashmob/ Pride | 55 | Exhibition | 46 |
| Stroll/ Camping | 120 | Accident | 2 |
| Lectures/Conferences | 3 | Other | 2289 |
| Other private event | 135 | Private celebration | 157 |
| Food | 594 | Other public event | 164 |
| Event advertisement | 80 | Other advertisement | 205 |
| Future event | 17 | Retrospective event | 36 |
| Unsure | 2031 |
| Method | Precision | Recall | Avg. Events per Day |
|---|---|---|---|
| Eyewitness [10] | 70% | - | - |
| GeoBurst+ [9] | 35% | 48% | - |
| TrioVecEvent [83] | 78% | 60% | - |
| ConvTree [11] | 77% | 18% | 22.2 |
| SemConvTree | 86% | 64% | 365.6 |
| Method | Count of Events | Count of Event Posts |
|---|---|---|
| ConvTree | 10,757 | 151,084 |
| ConvTree with high sensitive and noise events | 263,533 | 803,454 |
| SemConvTree | 177,315 | 538,628 |
| Model | All | Feb | Jun | Oct | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | P | R | P | R | P | R | |
| ConvTree [11] | 0.77 | 0.18 | 0.78 | 0.21 | 0.77 | 0.17 | 0.77 | 0.17 |
| SemConvTree | 0.86 | 0.64 | 0.87 | 0.58 | 0.85 | 0.63 | 0.86 | 0.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovalchuk, M.A.; Filatova, A.; Korneev, A.; Koreneva, M.; Nasonov, D.; Voskresenskii, A.; Boukhanovsky, A. SemConvTree: Semantic Convolutional Quadtrees for Multi-Scale Event Detection in Smart City. Smart Cities 2024, 7, 2763-2780. https://doi.org/10.3390/smartcities7050107
Kovalchuk MA, Filatova A, Korneev A, Koreneva M, Nasonov D, Voskresenskii A, Boukhanovsky A. SemConvTree: Semantic Convolutional Quadtrees for Multi-Scale Event Detection in Smart City. Smart Cities. 2024; 7(5):2763-2780. https://doi.org/10.3390/smartcities7050107
Chicago/Turabian StyleKovalchuk, Mikhail Andeevich, Anastasiia Filatova, Aleksei Korneev, Mariia Koreneva, Denis Nasonov, Aleksandr Voskresenskii, and Alexander Boukhanovsky. 2024. "SemConvTree: Semantic Convolutional Quadtrees for Multi-Scale Event Detection in Smart City" Smart Cities 7, no. 5: 2763-2780. https://doi.org/10.3390/smartcities7050107
APA StyleKovalchuk, M. A., Filatova, A., Korneev, A., Koreneva, M., Nasonov, D., Voskresenskii, A., & Boukhanovsky, A. (2024). SemConvTree: Semantic Convolutional Quadtrees for Multi-Scale Event Detection in Smart City. Smart Cities, 7(5), 2763-2780. https://doi.org/10.3390/smartcities7050107