Big data science and analytics is instigating a radical change in the basic concepts, assumptions, and experimental practices of science—thought patterns or ways of reasoning within the ruling theory of science, marking a paradigm shift from the dominant scientific way of looking at the world. The use of big data analytics as a framework has tremendous potential to advance or replace the prevailing scientific method. It has been argued that the unfolding and soaring deluge of data renders the scientific method obsolete, and it heralds the end (or decline) of theory resulting from the generalizations obtained from the experiments conducted by scientists as part of the scientific method. On the whole, the current model of reality, which has dominated a protracted period of puzzle-solving, is undergoing sudden drastic change, with wide ranging societal implications.
4.1. On the Old and New Way of Doing Science
One of the key questions the philosophers of science are concerned with and actively study is: Why do scientists continue to rely on models and theories which they know are partially inaccurate, among others? Indeed, how many of the theoretical models have been modified, overturned, or disregarded in light of new evidence and novel perspectives? How many of the theoretical models that have constantly been corrected or refined are still useful? And how many of the yet useful theoretical models are able to consistently, if imperfectly, explain the world around us? The attempt to answer these questions prompts us to question the accuracy of such models in the first place. The term ‘model’ enjoys a broad range of uses in science. Here, I shall examine one important use of this term: theoretical models that are quite distinct from other conceptions, sometimes called models. The philosophers of science have highlighted the importance of models, and they have claimed that their consideration will illuminate the structure, interpretation, and development of scientific thinking. A theoretical model is a group of related theories that are designed to provide explanations within a scientific domain for a community of practitioners. As a coherent whole, it is characterized by [
17]:
involving a conceptual foundation for a scientific domain;
understanding and describing problems within that domain and specifies solutions;
being grounded in prior empirical findings and scientific literature;
being able to predict outcomes in situations where these outcomes can occur far in the future;
guiding the specification of a priori postulations and hypotheses;
using rigorous methodologies to investigate them; and,
providing a framework for the interpretation and understanding of the unexpected results of scientific investigations.
The history of science is replete with epistemological breaks, what Bachelard (1986) [
29] refers to as unthought/unconscious structures that are immanent within the realm of the sciences. It, as asserted by Bachelard (1986) [
29], consists in the formation and establishment of these epistemological breaks, and then the subsequent tearing down of the obstacles. The latter stage is an epistemological rupture—where an unconscious obstacle to scientific thought is thoroughly ruptured or broken away from. Indeed, as asserted by Foucault (1970 [
30], pp. xxi–xxii), knowledge is a matter of episteme: a pre-cognitive space that determines ‘on what historical
a priori, and in the element of what positivity, ideas could appear, sciences be established, experiences be reflected in philosophies, rationalities be formed, only, perhaps, to dissolve and vanish soon afterwards’. In a nutshell, the history of science has shown that the turbulence that sets in can lead to an epistemological break or paradigm shift that takes place over varied periods of time. This implies that, among others, all of the theoretical models are flawed, if not wrong, and increasingly, we can do better or succeed without them. For example, while quantum mechanics is yet another theoretical model that is flawed, no doubt a caricature of a more complex underlying reality, quantum mechanics based on statistical analysis offers a way better picture of reality. The basic argument is that, the more we learn about natural phenomena, the further we find ourselves from a theoretical model that can explain them. Nevertheless, we do not have to settle for theoretical models, as we grow up in an era of massively abundant data, a deluge or corpus that is indeed being treated as a laboratory of the human condition, thereby providing the raw material for sifting through the most measured and tracked age in history. In the upcoming Exabyte/Zettabyte Age, the analysis of the deluge of data will generate valuable knowledge and deep insights, which will be good enough to enhance human decisions and thus practices, as well as advance and accelerate progress on science. In the data-intensive approach to scientific discovery, no causal analysis and assumptions about any kind of relationships are required; moreover, such an approach applies sophisticated methods (i.e., advanced simulation models informed by the science of complexity in terms of the common dynamical properties, processes, and behaviors that characterize complex systems) for predicting outcomes far in the future with unprecedented accuracy, as well as uses rigorous frameworks (e.g., data mining, statistical analysis, etc.) to answer challenging analytical questions. (See Bibri 2018 [
24] for a detailed account and discussion of complexity science and complex systems in relation to smart sustainable cities of the future). With the deluge of the data that are available thanks to its new and extensive sources, the numbers (overwhelming data quantities) speak for themselves, and many complex phenomena and theories of human behavior can be tracked and measured with unprecedented fidelity in a world where large-scale computation, novel data-intensive techniques and algorithms, and advanced mathematical models—technologies underpinning big data computing/analytics—replace every other tool that might be brought to bear.
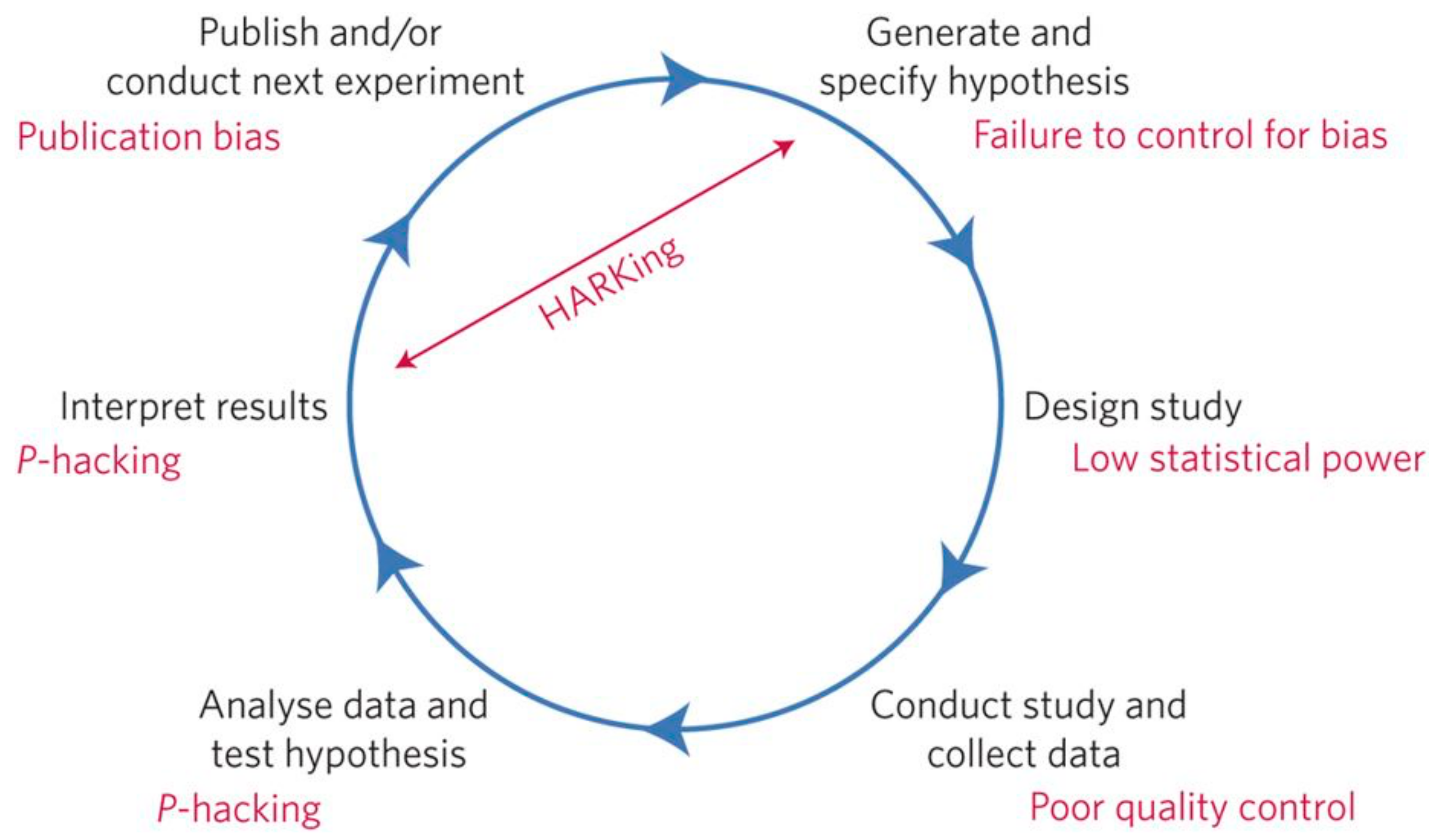
The big target is science where the scientific approach is built around testable hypotheses, a way of doing science that has prevailed for hundreds of years. Hypothesized models, as systems visualized in the minds of scientists, are tested, and subsequently experiments confirm or falsify the models of how the world works. In science, the term ‘model’ can have different meanings, depending on the context of its use (e.g., a physical model of a system that can be used for demonstrative purposes, an idea about how something works, an object or process that is used to describe and explain phenomena that cannot be experienced directly, etc.). Models are central to what scientists do in their research and when communicating their explanations related to new scientific theories. As a research method, scientific modeling means creating a mathematical or logical model—a set of equations that indirectly represents a real-world system or process—as a basis for simulation: an imitation or emulation of the operation of a real-world system. These equations (often characterizing the nature of the reciprocal relationships pertaining to the system) are based on relevant information regarding the system and on sets of hypotheses about how the system works. The act of simulating the system requires that a model be developed, which represents the key characteristics, behaviors, and functions of that system. The model represents the system itself, whereas the simulation represents the operation of the system over time. In this regard, given a set of parameters, a model can generate expectations about how the system will behave in a particular situation. A model and the hypotheses it is based upon are supported when the model generates expectations that match the behavior of its real-world counterpart. For what it entails in terms of oversimplification, modeling often involves idealizing the system in some way—leaving some aspects of the real system out of the model in order to make the model computationally easier to work with in terms of simulation. Regardless, for a scientific hypothesis to be meaningfully tested, it must be falsifiable, which implies that it is possible to identify a possible outcome of an experiment or observation that conflicts with the predictions deduced from the hypothesis. In relation to hypothesis testing, it is important for scientists to understand the underlying mechanisms that connect two variables, since correlation does not imply causation, and hence, no conclusions should be drawn simply on the basis of correlation between two variables. A statistical hypothesis is testable on the basis of observing a process that is modeled via a set of random variables, and statistical hypothesis test is a method of statistical inference. In the statistics literature, statistical hypothesis testing plays a fundamental role [
31] in statistical inference, as well as in the whole of statistics. As concluded by Lehmann (1992) [
32] in a comprehensive review, despite its shortcomings, the new paradigm of statistical hypothesis, and the many developments carried out within its framework continue to play a central role in both the theory and practice of statistics. However, significance testing has particularly been the favored statistical tool in some experimental social sciences [
33], while other fields have favored the estimation of parameters (e.g., effect size). It is used as a substitute for the traditional comparison of the predicted value and experimental result at the core of the scientific method. While hypothesis testing is of continuing interest to philosophers [
34,
35], statisticians, in other contexts, discuss much of their criticism of it; especially correlation does not imply causation. Covering a wide variety of issues, the criticism of statistical hypothesis testing fills volumes (e.g., [
36,
37,
38,
39,
40,
41]). As a bias related to science when performing experiments to test hypotheses, a scientist may have a preference for one outcome over another [
42,
43]. Nonetheless, eliminating this bias can be achieved by careful experimental design and transparency, as well as a thorough peer review [
44,
45]. A normal practice for independent researchers after the publication of the results of an experiment is to double-check how the research was carried out, and to follow up by performing similar experiments to determine how dependable the results might be [
46]. Taken in its entirety, the scientific method allows for highly creative problem solving while minimizing any effects of the confirmation bias and other subjective biases [
47].
The prevailing scientific approach is increasingly becoming obsolete as faced with the unfolding and soaring deluge of data related to a large number and variety of phenomena. Such deluge is available for scientific exploration within many different disciplines and fields. The data that were collected from various sensors, e.g., remote sensing technologies, are analyzed to extract useful knowledge and valuable insights for societal benefits, where a large number of scientists can collaborate in terms of designing, operating, and analyzing the products of sensor devices and networks for scientific studies. The data that were produced from several scientific explorations require advanced tools to facilitate the efficiency of their management, processing, analysis, validation, visualization, and dissemination, while preserving the intrinsic value of the data. Further, data-intensive approach to science is a promising epistemological shift, where colossal amounts of data allow for us to say that correlation is enough using data science systems, processes, and methods, specifically big data computing and the underlying enabling technologies. We can analyze the data regarding hypotheses about what they might show, and accordingly, we can stop looking for models. We can throw the numbers into huge computing clusters (dedicated data processing platforms) and let statistical or data mining algorithms discover patterns and make correlations from these discoveries where science cannot. It comes at no surprise that the application and use of big data analytics is increasingly gaining traction and foothold in many scientific research fields, taking over the prevailing scientific method.
4.2. Data-Intensive Science as an Epistemological Shift and Its Underpinnings
Data-intensive science/scientific development as a new paradigm has emerged as a result of the recent advances in data science systems, processes, and methods, and thus big data computing and the underlying enabling technologies. Turing award winner Jim Gray envisions data science as the new paradigm of science, and asserts that everything about science is changing, because of the impact of advanced ICT and the evolving data deluge [
48]. The Exabyte Age is upon us. Data-intensive scientific discovery is the fourth paradigm of science where science involves the exploration and mining of scientific data and using advanced big data analytics techniques to unify theory, simulation, and experimental verification [
48]. The first paradigm is where science used empirical methods thousands of years ago; the second paradigm is where science became a theoretical field a few hundred years ago, involving the process of generating and testing hypotheses; and, the third paradigm is where science used calculation, conducting simulation and verification by computation in recent decades [
48].
Data-intensive science as an epistemological shift mainly involves two positions. The first position is a form of inductive empiricism in which the data deluge, through analytics, as manifested in the data being wrangled through an array of multitudinous algorithms to discover the most salient factors regarding complex phenomena, can speak for itself free of human framing and subjectivism, and without being guided by theory (as based on conceptual foundations, prior empirical findings, and scientific literature). As argued by Anderson (2008) [
49], ‘the data deluge makes the scientific method obsolete’ and that within big data studies ‘correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all’. This relates to exploratory data analysis, which may not have pre-specified hypotheses; unlike confirmatory data analysis that was used in the traditional way of doing science that does have such hypotheses. The second position is data-driven science, which seeks to generate hypotheses out of the data rather than out of the theory, thereby seeking to hold to the tenets of the scientific method and knowledge-driven science ([
50], p. 613). Here, the conventional deductive approach can still be employed to test the validity of potential hypotheses, but on the basis of guided knowledge discovery techniques that can be used to mine the data to identify such hypotheses. It is argued that data-driven science will become the new dominant mode of scientific method in the upcoming Exabyte/Zettabyte Age, because its epistemology is suited to exploring and extracting useful knowledge and valuable insights from enormous, relational datasets of high potential to generate more holistic and extensive models and theories of entire complex systems rather than parts of them, an aspect that traditional knowledge-driven science has failed to achieve [
5,
50].
The best practical example of inductive empiricism that is associated with the recent epistemological shift in science is the shotgun gene sequencing by John Craig Venter, while using statistical analysis as a big data analytics technique. Venter went from sequencing individual organisms to sequencing entire ecosystems, enabled by high-speed sequencers and supercomputers that statistically analyze the data they produce. As an alternative to the costly option of using supercomputers, advanced data processing platforms are designed for handling the storage, analysis, and management of large datasets directed for scientific and academic explorations. As an example of such platforms, Hadoop MapReduce is widely used in this regard due to the suitability of its functionalities with respect to dealing with colossal amounts of data, as well as to its advantages that are associated with load balancing, cost effectiveness, flexibility, and processing power. Hadoop allows for distributing the processing load among the cluster nodes, which enhances the processing power; to add or remove nodes in the cluster according to the requirements; to make the homogenous cluster with various group of machines; and, to handle unstructured data [
24]. Further to the point, in his endeavor of sequencing the air in 2005, Venter discovered thousands of previously unknown species of bacteria and other life-forms. He can tell you almost nothing about the species he found; does not know what they look like, how they live, or much of anything else about their morphology; and, does not even have their entire genome. A statistical blip—a unique sequence that, being unlike any other sequence in the database, must represent a new species—is all he has, which would be impossible to achieve with the old way of conducting scientific research or doing science. The point is that, Venter has advanced biology more than anyone else of his generation by analyzing data with high-performance computing resources, thanks to big data computing and the underlying enabling technologies. The future potential of data-intensive science is so enormous that this kind of thinking is poised to go mainstream, pervading many different scientific and academic fields. While learning to use and mastering data processing platforms or supercomputers may be challenging, the opportunity is tremendous in the sense that the new availability of huge amounts of data, along with the statistical analysis and data mining tools to crunch these numbers, offers a whole new way of explaining and understanding the world around us.
Following the Kuhnian paradigm shift, data-intensive science is a paradigmatic break with the current paradigm of science. As such, it represents universally recognized scientific achievements that, for the current period of time, provide model problems and solutions for a community of practitioners as associated with both inductive empiricism and data-driven science, that is:
what is to be observed and scrutinized;
the kind of questions that are supposed to be asked and probed for answers;
how these questions are to be structured;
what predictions made by the primary theory within the discipline;
how the results of scientific investigations should be interpreted; and,
how an experiment is to be conducted, and what equipment is available to conduct the investigation.
As to inductive empiricism, the scientific method becomes obsolete due to the massive data available for scientific exploration, correlation supersedes causation, and coherent models and unified are not required for scientific advancement. Concerning data-driven science, hypotheses are generated out of the data rather than out of the theory; the deductive approach is used to test the validity of potential hypotheses on the basis of guided knowledge discovery techniques; useful knowledge is explored and extracted from massive, interconnected datasets; and, holistic and extensive models and theories of entire complex systems can be generated.
In light of the above, data-intensive science represents a fundamental change in thought patterns, including theories, assumptions, and experimental practices. Kuhn (1962) [
16] suggests that the history of science can be divided up into times of normal science and briefer periods of revolutionary science. He characterizes normal science (when scientists add to, elaborate on, and work with a central, accepted scientific theory) as the process of observation and puzzle solving that takes place within a paradigm, whereas revolutionary science occurs when one paradigm overtakes another in a paradigm shift (e.g., [
51]). He asserts that, during times of revolutionary science, anomalies refuting the accepted theory have built up to such a point that the old theory is broken down and a new one is built to take its place in a paradigm shift. Each paradigm has its own distinct questions, aims, procedures, and interpretations. The choice between paradigms involves setting two or more depictions against the world and deciding which likeness is most promising. With the above in mind, it has been argued that scientists are currently encountering inconsistencies and anomalies, which have partly brushed away as acceptable levels of error for quite sometime, and they have partly been ignored and not dealt with, with different levels of significance to the practitioners of science. These inconsistencies and anomalies have been mounting up towards a point when researchers in many scientific fields are increasingly favoring the data-intensive approach to science, thereby no longer working within the existing framework of science. In short, a significant number of inconsistencies and anomalies are arising, and data-intensive science is making sense of them. As repeatedly shown by the history of science, there again is a turbulence setting in that is triggering a paradigm shift in science as being driven and shaped by data science, and hence the emerging advancements and innovations in big data computing and the underlying enabling technologies. Indeed, data-intensive science is taking an identifiable form and increasingly gaining its own new followers, which are currently in the phase of intellectual conflict with the hold-outs of the old paradigm of science. In this regard, this new scientific truth is not only making its opponents see the light, but eventually die, manifested in the new generation of data science advocates growing up that is familiar with this truth.
In addition, the rationale for the choice of the data-intensive approach to science as an exemplar is a specific way of viewing the current reality, where this view and the status of this exemplar are mutually reinforcing. This paradigm shift in science is so convincing that normally renders the possibility of new epistemological alternatives intuitive, thereby not obscuring the possibility of the existence of other imageries that are hidden behind the current paradigm of science. Arguably, the conviction that the current paradigm of science is reality tends to disqualify evidence that might undermine the paradigm of science itself, which leads to a build-up of reconciled inconsistencies and anomalies that are determined to accumulate, and thus cause a paradigm shift in science. This is responsible for the eventual revolutionary overthrow of the incumbent paradigm of science, and its replacement by a new one [
16]. Yet, the acceptance or rejection of a paradigm is a social process as much as a logical process, an argument that relates to relativism: the idea that knowledge and truth exist in relation to culture, society, or historical context, and are not absolute, or that views are relative to differences in perception and consideration. There is no universal, objective truth according to relativism; rather, each point of view has its own truth. Kuhn (1962 [
16], p. 170) denies the accusation of being a relativist later in his postscript: ‘scientific development is … a unidirectional and irreversible process. Later scientific theories are better than earlier ones for solving puzzles… That is not a relativist’s position, and it displays the sense in which I am a convinced believer in scientific progress’.
The popularity of the term ‘data science’ has exploded in the academia where many critical academics see no distinction between data science and statistics. However, many statisticians envision data science as an increasingly inclusive applied field that grows out of traditional statistics and goes beyond traditional analytics. This implies that data science differs from statistics. One key difference is that statisticians are able, by means of data science methods, systems, and processes to develop models for highly complex systems that were unfathomable: incapable of being fully explored or understood, before. In addition, emerging in the wake of big data, data science, as argued by Donoho (2015) [
7], does not equate to big data in that the size of the data set is not a criterion to distinguish data science and statistics. Additionally, data science is a heavily applied field where academic programs currently do not sufficiently prepare data scientists for the jobs in that many graduate programs misleadingly advertise their analytics and statistics training as the essence of a data science program [
6,
7]. From a technical perspective, while statistics emphasizes models grounded in probability theory to deal with data arising from real-world phenomena, and it provides principles and tools for the construction of statistical hypotheses as models that involve, such modeling processes as data generation, evaluation and assessment, prediction, and uncertainty quantification, data science brings to statistics large-scale compute (modern computational infrastructures), data-intensive techniques, algorithmic design and analysis, large datasets, and advanced mathematical models.
Data science, most often linked to the big data explosion, is the amalgamation of numerous parental disciplines, as mentioned above. As an example of capturing this, Blei and Smyth (2017) [
52] describe data science is ‘the child of statistics and computer science’, where the ‘child’ metaphor appropriately depicts that data science inherits from both its parents, but eventually evolves into its own entity. They further elaborate: ‘data science focuses on exploiting the modern deluge of data for prediction, exploration, understanding, and intervention. It emphasizes the value and necessity of approximation and simplification; it values effective communication of the results of a data analysis and of the understanding about the world and data that we glean from it; it prioritizes an understanding of the optimization algorithms and transparently managing the inevitable tradeoff between accuracy and speed; it promotes domain-specific analyses, where data scientists and domain experts work together to balance appropriate assumptions with computationally efficient methods’ [
52].
Data science is largely seen as the umbrella discipline that incorporates a number of other disciplines. As an interdisciplinary field, data science employs methodologies and practices from across several academic disciplines while morphing them into a new discipline. Data science is often said to include particularly the allure of big data, the fascination of unstructured data, the advancement of data-intensive techniques and algorithms, and the precision of mathematics and statistics. One implication of this is that data science is different from the existing practice of data analysis across all disciplines, which only focuses on explaining data sets. The practical engineering goal of data science: actionable knowledge and consistent patterns for generating predictive models takes it beyond traditional approaches to analytics. Currently, the data in those disciplines and applied fields that lacked solid theories, like the social sciences and related disciplines, could be utilized to generate powerful predictive models [
53]. Cleveland (2001) [
54] urges prioritizing extracting applicable predictive tools over explanatory theories from colossal amounts of data. For the future of data science, Donoho (2015) [
7] projects an ever-growing environment for open science where data sets used for academic publications are accessible to all researchers. Open science also involves making scientific research available to all levels of an inquiring society, as well as disseminating, sharing, and developing knowledge through collaborative networks. Several research institutes have already announced plans to enhance the reproducibility and transparency of research data [
55]. Likewise, other big journals are following suit [
56,
57]. The future of data science not only exceeds the boundary of statistical theories in scale and methodology, but data science will revolutionize current academia and research paradigms [
7]. The scope and impact of data science will, as concluded by Donoho (2015) [
7], continue to enormously expand in the upcoming decades as scientific data and data about science itself become overwhelmingly abundant and ubiquitously available. Already, significant progress has been made within data science, information science, computer science, and complexity science with respect to handling and extracting knowledge and insights from big data and these have been utilized within urban science (e.g., [
8,
58,
59]).
Data science, which is the new paradigm of science, employs scientific methods, systems, processes, and algorithms to extract useful knowledge and valuable insights from large masses of data in various forms, both structured and unstructured. It uses theories and techniques that are drawn from many fields within the context of statistics, mathematics, computer science, and information science. Data science (and thus big data analytics) techniques, such as data mining and pattern recognition, statistical analysis, machine learning, data visualization, and visual analytics, and optimization and simulation modeling are largely in the early stages of their development, given that the statistical methods that have prevailed over several decades were originally designed to perform data-scarce science, i.e., to identify significant correlations and relationships from small, clean sample data sizes with known attributes or properties. Nonetheless, recent years have witnessed a remarkable progress within computer science, information science, and data science with regard to handling and extracting knowledge from large masses of data, and these have been utilized in urban science. The evolving big data computing model represents the challenging task of data organization, processing, and analysis associated with the process of knowledge discovery from voluminous, varied, real-time, exhaustive, fine-grained, indexical, dynamic, flexible, and relational data. This approach is at the core of epistemology in terms of the nature of knowledge and how it can be generated, as well as involves the questionability of the existing knowledge claims, the criteria for knowledge and justification, and the sources and scope of knowledge as issues that are at the center of debate in epistemology.
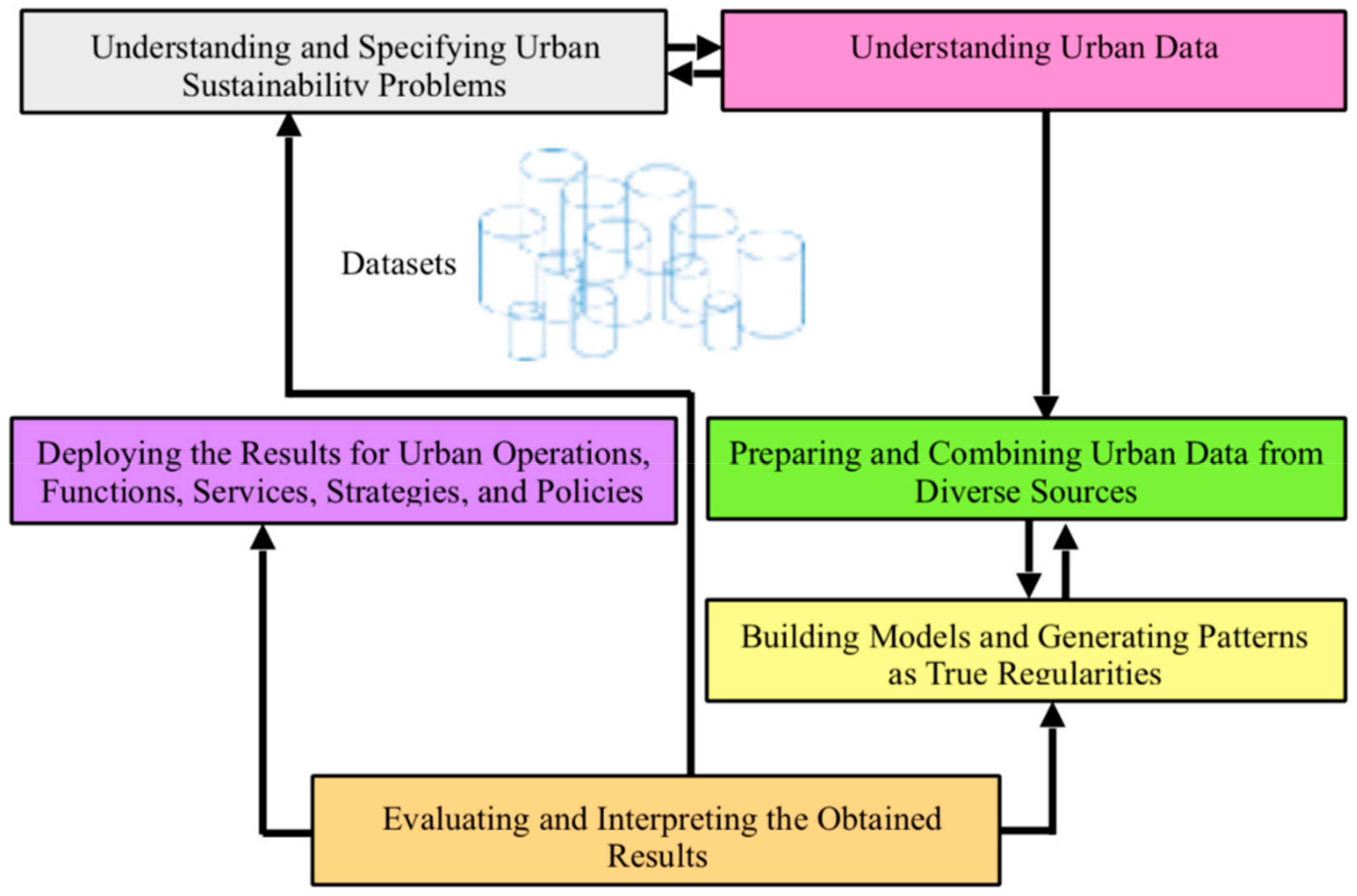
Using the process of data mining/knowledge discovery as a systematic framework with well-defined stages for structuring data-analytic thinking and practice is increasingly pervading scientific disciplines in terms of research and innovation (e.g., [
2]). Worth pointing out in this regard is that the best opportunity for using the data deluge is to harness and analyze data not as an end in itself, but rather to develop big theories, e.g., about how smart sustainable/sustainable smart cities can be operated, managed, planned, designed, developed, and governed in ways that overcome the challenges of sustainability and urbanization. In this context, big data analytics can be exploited to reveal hidden and previously unknown patterns and discover meaningful correlations in large datasets pertaining to natural and social sciences so to develop more effective ways of responding to population growth, environmental pressures, changes in socio-economic needs, global shifts/trends, discontinuities, and societal transitions in the form of new processes, systems, designs, strategies, and policies, as well as products and services. In the meantime, to really get a grip on the use of big data analytics to address the challenges of sustainability in an increasingly urbanized world, new theory about big data analytics theory—meta-theory—is necessary. From a general perspective, West (2013) [
60] vividly argues that big data require big theories. Specific to smart sustainable/sustainable smart urbanism, discovering patterns and making correlations from the deluge of urban data can only ever occur through the lens of a new kind of theory [
3,
24]. Especially, data-intensive science needs to meet three criteria in order to match the Kuhn’s (1962, 1996) [
16] notion of paradigm shift: it must be based on and provide a meta-theory, be acknowledged by a scientific community of practitioners, and possess a number of successful practices. The extant literature shows that data-intensive science as a paradigm shift is still evolving in terms of meta-theory—but has a large number of successful practices and it is acknowledged by the scientific community.
There are varied arguments about whether big data computing will herald the end of theory, and hence the extent to which it has the answers, as manifested in the number of the emerging epistemological positions pertaining to data-intensive science. This particularly pertains to the ways supercomputers: large-scale computation, data-intensive techniques and algorithms, and advanced mathematical models used in building and performing big data analytics, can potentially generate more useful, insightful, or accurate results than domain experts, scientists, specialists, and researchers who traditionally craft targeted hypotheses and devise research strategies. This revolutionary notion is increasingly entering the research practices of institutions, organizations, and governments. The idea being that the data deluge can reveal secrets to us that we now have the power and prowess to uncover. In other words, we no longer need to postulate and hypothesize; we simply need to let machines lead us to the patterns, correlations, trends, and shifts in social, economic, political, and environmental relationships. There is no denial of the significance of the analytical power of big data. The huge resources being invested in both the public and private sectors to further investigate and advance big data computing is a testament to this. Having recently, as a research wave and direction, permeated and dominated academic circles industries, coupled with its research status being consolidated as one of the most fertile areas of investigation, big data analytics has attracted researchers, scholars, scientists, experts, practitioners, policymakers, and decision makers from diverse disciplines and professional fields—given its importance and relevance for generating well-informed decisions and deep insights of highly useful value. Therefore, big data analytics is a rapidly expanding research area and is becoming a ubiquitous term in understanding and solving complex challenges and problems in many different domains. The big data movement has been propelled by the intensive R&D activities taking place in academic and research institutions, as well as in industries and businesses—with huge expectations being placed on the upcoming innovations and advancements in the field. In particular, a large part of ICT investment is being directed by giant technology companies, such as Google, IBM, Oracle, Microsoft, SAP, and CISCO, towards creating novel computing models and enhancing existing practices pertaining to the storage, management, processing, analysis, modelling, simulation, and evaluation of big data, as well as to the visualisation and deployment of the analytical outcome for different purposes [
58]. Big data computing is undoubtedly useful for addressing and overcoming many important issues that are faced by society, including sustainability and urbanization, but it is important to ensure that we are far from being seduced by the promises and claims of big data computing to render theory unnecessary. Especially, there is a risk that big data leads to a shift in focus towards short-term, predictive, non-explanatory models, abandoning theory. Nevertheless, there are some projections, though, that most, if not all, of the social questions that are of most concern to us will be answered based on sifting through and harvesting sufficient quantities of big data. However, several skeptical views challenge the achievability of this vision or the realization of this prospect, being predicated on the assumption that there will always be uneven data shadows and inherent biases in how information is used and technology is produced. Therefore, it is equally important not to overlook the important role of expert domains or specialists to offer insights into what the data deluge can do, but perhaps they do not reveal it.
4.3. The Data–Intensive Scientific Approach to Urban Sustainability Science and Related Wicked Problems
Cities are full of complex issues that are not easily captured or steered. The problems of cities are primarily about people and their environment and life. Physical, infrastructural, environmental, economic, and social issues in contemporary cities define what planners call ‘wicked problems’, a term that has gained currency in urban planning and policy analysis, especially after the adoption of sustainable development within urban planning and development since the early 1990s. Cities are characterized by wicked problems [
61,
62], i.e., difficult to define, unpredictable, and defying standard principles of science and rational decision-making. When tackling wicked problems, they become worse due to the unanticipated effects and unforeseen consequences that were overlooked, because the systems in question were not approached from a holistic perspective, or were treated in too immediate and simplistic terms [
1]. The essential character of wicked problems is that they, according to Rittel and Webber (1973) [
62], cannot be solved in practice by a central planner. Bettencourt (2014) [
21] reformulates some of their arguments in modern form in what is called the ‘planner’s problem,’ which has two distinct facets: (1) the knowledge problem and (2) the calculation problem. The first problem refers to the planning data needed to map and understand the current state of the smart sustainable city in this context. It is conceivable that urban life and physical infrastructure could be adequately sensed in several million places at fine temporal rates, generating huge but manageable rates of information flow by the advanced forms of ICT. It is not impossible, albeit still implausible, to conceive and develop technologies that would enable a planner to have access to detailed information about every aspect of the infrastructure, services, social lives, and environmental states in a smart sustainable city. The second problem refers to the computational complexity to carry out the actual task of planning in terms of the number of steps necessary to identify and assess all possible scenarios and choose the best possible course of action. Unsurprisingly, the exhaustive approach of assessing all possible scenarios in such city is impractical due to the fact that it entails the consideration of impossibly large spaces of possibilities.
As a scientific discipline, urban sustainability science integrates urban sustainability, urban science, and sustainability science. The notion of sustainability has been applied to urban planning and development since the early 1990s. This was marked by the emergence of the notion of urban sustainability. Urban sustainability science has theoretical foundations and assumptions from which it has grown that have solidified into a defined science after the establishment of sustainability science, which emerged in the early 2000s [
1]. Sustainability science focuses specifically on understanding the dynamic interactions of socio-ecological systems, of which cities represent perfect examples. As such, it can serve as a theoretical basis for urban planning and development under what is labeled ‘sustainable urbanism’ that can effectively engage with the wicked problems that are presented by cities and their sustainability. The objective of urban sustainability is to uphold the changing dynamics and hence reciprocal relationships (within and across levels and scales) that maintain the ability of the city to provide not just life-supporting, but also life-enhancing, conditions, as exhibited by its collective behavior. To achieve this, the city should work towards enhancing the underlying environmental, physical, social, and economic systems over the long run by means of sustainable interventions and programs using advanced technologies and their novel applications, with the primary purpose of maintaining predictable patterns of behavior, and hence stable reciprocal relationships that are responsible for generating such patterns. Typically, such relationships cycle to produce the behavioral patterns that the city exhibits as a result of its operational functioning, planning, design, and development in the context of sustainability. In particular, as the positive adaptation of the city depends upon how well it is adjusted with the environment, it needs to make changes to protect itself and grows to accomplish its goals in terms of achieving the ultimate goal of sustainability. One way of doing this is to self-correct itself based on reactions from the natural/environmental system with respect to climate change and related hazards and upheavals. This feature relates to the adaptive nature of complex systems in that they have the capacity to change and learn from experience. To put it differently, the objective of urban sustainability can be accomplished by rendering the city dynamic in its conception, scalable in its design, efficient in its operational functioning, and flexible in its planning, which is of crucial importance in dealing with population growth, environmental pressures, changes in socio-economic needs, global shifts, discontinuities, and societal transitions [
1]. This involves maintaining the critical structures, key dependencies, functional integrity, resource availability, well-being, and capacity for the regeneration and evolution of the city. What is important with respect to ensuring the persistence of structures and conditions necessary for keeping the city system within a preferred stability state is the need for continuous reflection as an effective way to learn from both failures and successes, as well as to achieve a deep understanding of how socio-ecological systems function to be able to work with, anticipate, and harness the dynamics within such systems.
The quest for finding an urban planning and development paradigm that can accommodate the wicked problems of cities and their sustainability and overcome the complexity and unpredictability introduced by social factors is increasingly inspiring scholars to combine urban sustainability and sustainability science under what has recently been termed as ‘urban sustainability science’. This is, in turn, being informed by urban science and thus big data science and analytics. While the introduction of sustainability to the goals of urban planning and development added another layer of complexity brought about by the consideration of environmental externalities and social and economic concerns, the new urban science has opened new windows of opportunity to deal with such issues in cities on the basis of modern computation and data abundance. Indeed, sustainability as entailing complex dynamics of human-natural system interactions requires a decisive, radical change in the way that science is undertaken and developed. This change is what data-intensive scientific development is about—as enabled and driven by big data science and analytics.
The great innovation of big data science and analytics and the underlying technologies is that the urban problems should be approached in full knowledge, which supposes a new approach to scientific development that is based on massive-scale data. As an evolving, systematic enterprise building and organizing knowledge in the form of explanations and predictions about the world, data-intensive scientific development entails using data-driven inductive empiricism and data-driven science. These recent epistemological approaches are at the core of urban science [
8], which informs urban sustainability science. This is due to their critical importance and relevance to urban practices, such as operational functioning, planning, design, and development in the context of sustainability.
There are various reasons that justify the adoption of data-intensive scientific development in urban sustainability science. It is imperative for urban sustainability science, a field that focuses on understanding the dynamic interactions of the social and ecological systems of the city, to develop and apply an advanced approach to scientific inquiry and exploration for dealing with the kind of wicked problems and intractable issues pertaining to urbanism as a set of multifaceted, contingent practices. Additionally, urban sustainability science should embrace data-intensive scientific development in order to be able to transform knowledge regarding how the natural and human systems in cities interact in terms of the underlying (changing) dynamics for the purpose of designing, developing, implementing, evaluating, and enhancing human engineered systems as practical solutions and interventions that support the idea of the socio-ecological system in balance. This embrace is additionally aimed at nurturing and sustaining the linkages between scientific research and technological innovation and policy and public administration processes in relevance to sustainability. To put it differently, the data-intensive approach to urban sustainability science is of high relevance in the cultivation, integration, and application of knowledge about natural systems gained, especially from the historical sciences, and its coordination with knowledge about human interrelationships gained from the social sciences and humanities. This is of crucial importance in evaluating, mitigating, and minimizing the intended and untended consequences of anthropogenic influence on social and ecological systems across the globe and into the future. More to the appropriateness of data-intensive scientific development, urban sustainability science mixes and fuses disciplines across the natural sciences, social sciences, formal sciences, and applied sciences. The philosophical and analytical framework of urban sustainability science draws on and links with numerous disciplines and fields, and it is studied and examined in various contexts of environmental, social, economic, and cultural development and managed over many temporal and spatial scales. The focus ranges from macro levels starting from the (sustainability) of planet Earth to the sustainability of societies, regions, and cities, as well as economies, ecosystems, and communities, and to micro levels that are encompassed in streets, buildings, and individual lifestyles [
24]. In view of that, big data computing can perform more effectively with respect to achieving the desired outcomes that are expected from the application of interdisciplinarity and transdisciplinarity as scholarly enterprises due to the underlying analytical power, coupled with the data deluge available for scientific inquiry and exploration. This is particularly important in the context of urban science for gaining new interactional and unifiable knowledge necessary for exploring and exploiting the opportunity of using advanced technologies to solve real-world problems and challenges, especially those that are associated with sustainability and urbanization.
The solutions to the kind of wicked problems and intractable issues that are associated with urban sustainability are anchored in the recognition that the urban world has become integrated, complex, intricate, contingent, and uncertain. The data-intensive approach to urban sustainability science is primarily meant to facilitate the link of such problems and issues to the type of problems and issues explored and probed by sustainability science, as well as demonstrates how the understanding of cities, as instances of socio-ecological systems, provides a conceptual and analytical framework for addressing and overcoming some of the challenges that are characteristic to such problems and issues. There is a host of new practices that sustainability science could bring to urban sustainability under the umbrella or sphere of data-intensive science, an argument that needs to be further developed and to become part of mainstream debates in urban research and practice. This argument is being stimulated by the ongoing discussion and development of the new ideas regarding the untapped potential of big data computing and the underlying enabling technologies for advancing both sustainability science and urban sustainability as well as merging them into a holistic framework that is informed by the new urban science. This kind of integrated, holistic framework should focus on probing the complex mechanisms that are involved in the profound interactions between environmental, social, economic, and physical systems to understand their behavioral patterns and changing dynamics so as to develop upstream solutions for tackling the complex challenges that are associated with the systematic degradation of the natural and environmental systems and the concomitant perils to the human and social systems. Urban sustainability science as a research field seeks to give the broad-based and crossover approach of urban sustainability a solid scientific foundation. It also provides a critical and analytical framework for urban sustainability and, to draw on Reitan (2005) [
63], it must encompass different magnitudes of scales (of time, space, and function), multiple balances (dynamics), multiple actors (interests), and multiple failures (systemic faults). In addition, it should be viewed as a field that is defined more by the kind of wicked problems and intractable issues it addresses rather than by the scientific and academic disciplines that it employs, thereby being neither basic nor applied research; it serves the need for advancing both knowledge discovery and actionable decisions by creating a dynamic bridge between the two thanks to new big data analytics techniques.
By and large, the link between sustainable urban development and urban data science stems from the idea that the former is an aspiration that should, as realized by many scholars over the past two decade or so, be achieved only on the basis of advanced scientific knowledge, and thus the approach to producing it, thereby the relevance of big data science and analytics. This has justified the establishment of a new branch of science—urban sustainability science—due to the fact that the city is confronted at an ever unprecedented rate and larger scale with the ramifications of its own success as a product of social revolution. The way that things have changed in recent years (and the attempts being undertaken to take this into account) calls for a novel approach to science for explaining, predicting, and understanding the underlying web of the ongoing, reciprocal relationships that are cycling to generate the patterns of behavior that the complex city system is exhibiting, and for figuring out the mechanisms that such a system is using to control itself. The point is that the complexities, uncertainties, and hazards of the human adventure are triggering drastic changes that increasingly require insights from all of the sciences to tackle them if there is a shred of seriousness about the aspiration to improve sustainability, resilience, and the quality of life, i.e., sustainable urban development.
The essential opportunities and challenges of the use of big data computing and the underlying enabling technologies in smart sustainable/sustainable smart urbanism as a practical application of urban sustainability science have, despite their appeal, not been sufficiently systemized and formally structured. In particular, the necessary conditions for the strategic application of big data science and analytics in such urbanism need to be spelled out, and their limitations must also be anticipated and elucidated [
1]. There are different ways of addressing these and other important questions when considering the available interdisciplinary and transdisciplinary knowledge of such urbanism in the big data age (see Bibri 2019a [
58] for an overview). In this line of thinking, Bettencourt (2014) [
21] attempts to answer some of these questions by formalizing the use of big data analytics in urban planning and policy in light of the conceptual frameworks of engineering, and this shows that this formalization enables identifying the necessary conditions for the effective use of big data in urban planning and policy that address a large array of urban issues. This is intended to demonstrate that big data computing and the underlying enabling technologies are providing new opportunities for the application of advanced engineering solutions to smart sustainable/sustainable smart cities. It is conspicuous that big data science and analytics may offer radically novel solutions to the wicked problems of urban sustainability related to planning, design, and development. Big data computing is so fast in comparison to most physical, environmental, social, and economic phenomena that myriads of key urban planning and policy problems are falling within this window of opportunity [
24]. In such circumstances, models of system response enabled by big data analytics can be very simple and crude, and typically be linearized (see [
64]). Thus, the analytical engineering approach conveniently bypasses the complexity that can arise in the nested systems of smart sustainable/sustainable smart cities at longer temporal or larger spatial scales. Bibri (2019) [
1] summarizes some of the key urban sustainability problems with their typical temporal and spatial scales and the nature of their operating outcomes. The unique potential of big data science and analytics in this regard lies in essentially advancing urban sustainability and solving related complex issues without coherent models, unified theories, or any mechanistic explanation at all, thanks to the data deluge that makes the scientific method obsolete, and within big data studies correlation supersedes causation. Many examples of planning, design, management, and policy practices in those cities that use data successfully can have this flavor, irrespective of whether their development and implementation involve organizations or computer algorithms [
1].

{kind=link}
{kind=link}