

Performance Analysis of Statistical, Machine Learning and Deep Learning Models in Long-Term Forecasting of Solar Power Production

 ,
, 

Abstract
1. Introduction
- Temporal aspect: A time series model considers the temporal aspect of the data, specifically the order in which the data points occur, while functional forecasting modeling is more suited to modeling physical systems, which do not have a specific temporal aspect.
- Complexity: Time series models can be more complex than functional models because they need to consider patterns and trends in the data, which may not be captured by a simpler functional model.
- Feature Engineering: Time series ML models often rely on feature engineering, which is the process of creating new features from the raw data, to improve the prediction performance. Functional forecasting modeling does not require feature engineering.
- Data Assumptions: Time series models assume that the data are generated by a stationary process and make assumptions about the underlying distribution of the data, while Bayesian learning models use Bayes’ theorem to update the probability of a hypothesis as more evidence becomes available.
- Predictive model: Time series models are specifically designed to predict future values of a time series based on historical data, whereas Bayesian learning models can be used for a wide range of applications, including time series forecasting, but they may not be as well-suited to the task as a dedicated time series forecasting model.
- Modeling techniques: Time series machine learning models use techniques such as ARIMA, LSTM, and Prophet to improve the prediction performance, whereas Bayesian learning models use techniques such as Markov Chain Monte Carlo (MCMC) and variational inference to estimate the parameters of the model.
- This study aims to provide a comprehensive comparison of popular forecasting models for long-term solar power generation forecasting, an area where there has been limited research.
- The study seeks to understand the relationship between the forecasting model’s input variables and forecasting accuracy.
- The study investigates how the performance of different models changes as the prediction horizon changes.
- The study compares the performance of hybrid and ensemble models to that of single models.
- The study assesses the performance of statistical, ML, DL, and ensemble forecasting models when limited input variables and datasets are available.
2. Limitation of the Existing Empirical-Based Forecasting Model
2.1. The Sunshine-Based Model
2.2. The Cloud-Based Model
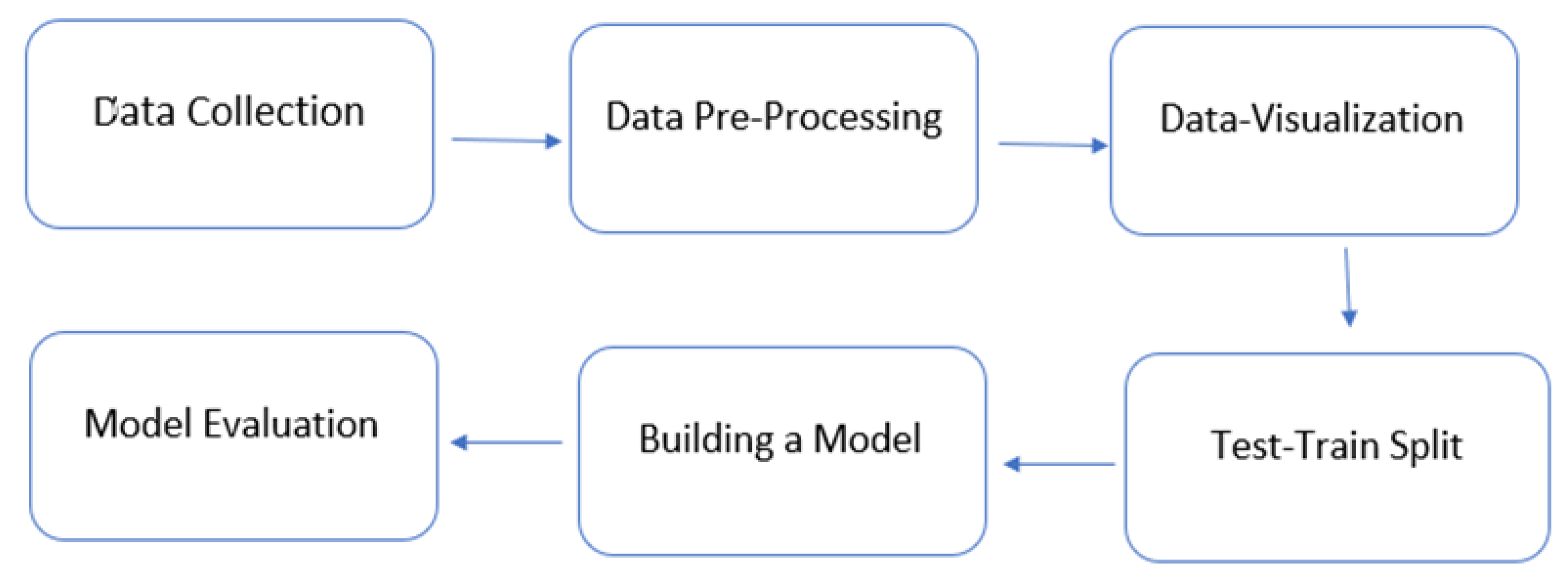
3. Materials and Methods
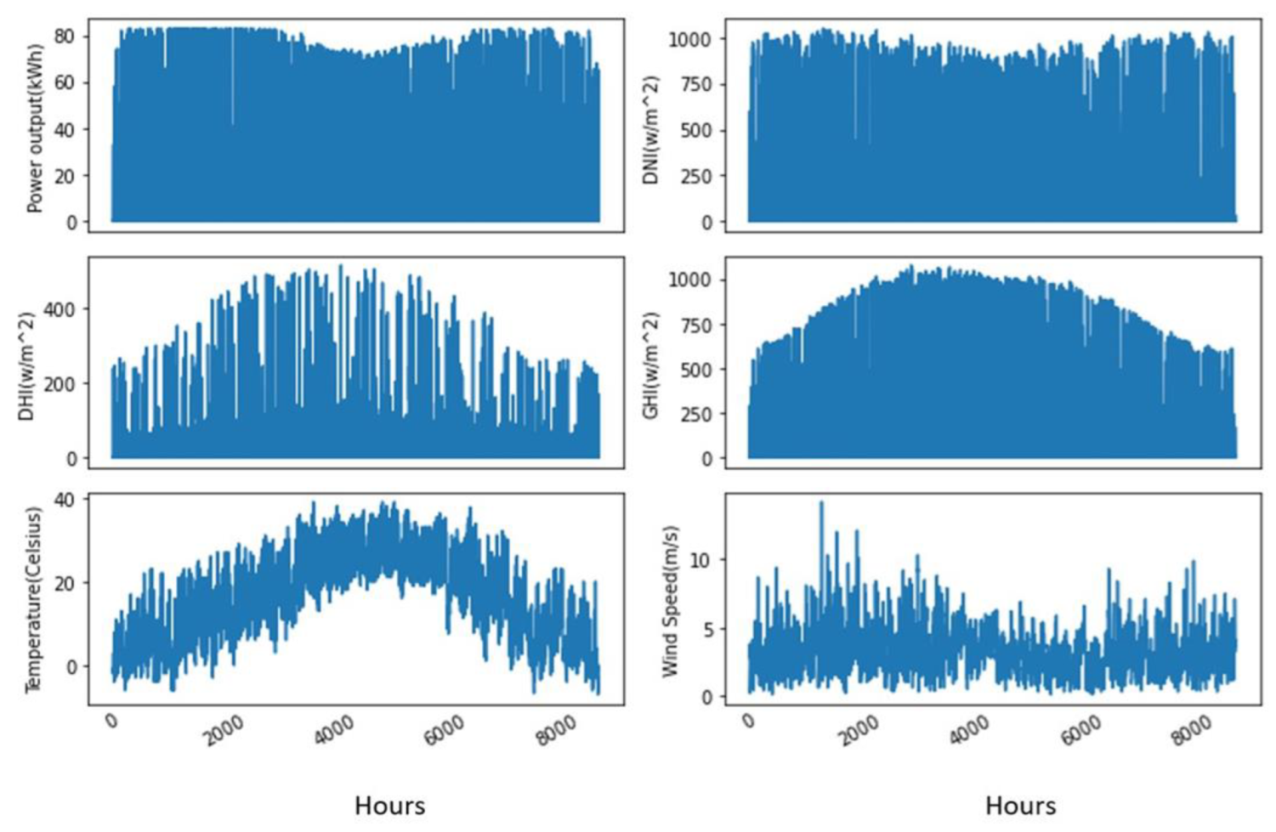
3.1. Data Collection
3.2. Data Pre-Processing
3.3. Data Visualization
3.4. Test-Train Split
3.5. Building a Model
3.6. Model Evaluation
4. Building a Model
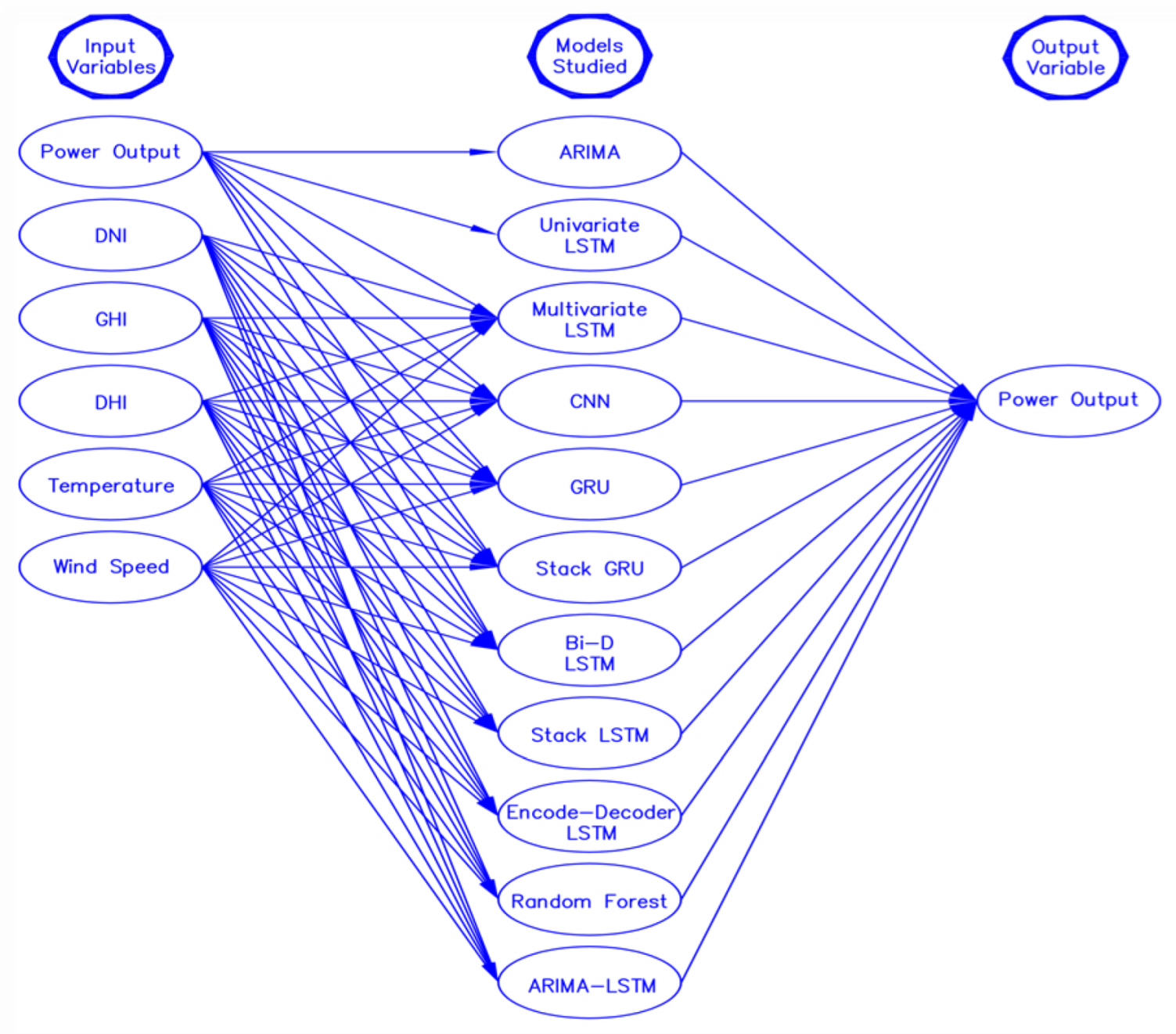
4.1. Univariate Models
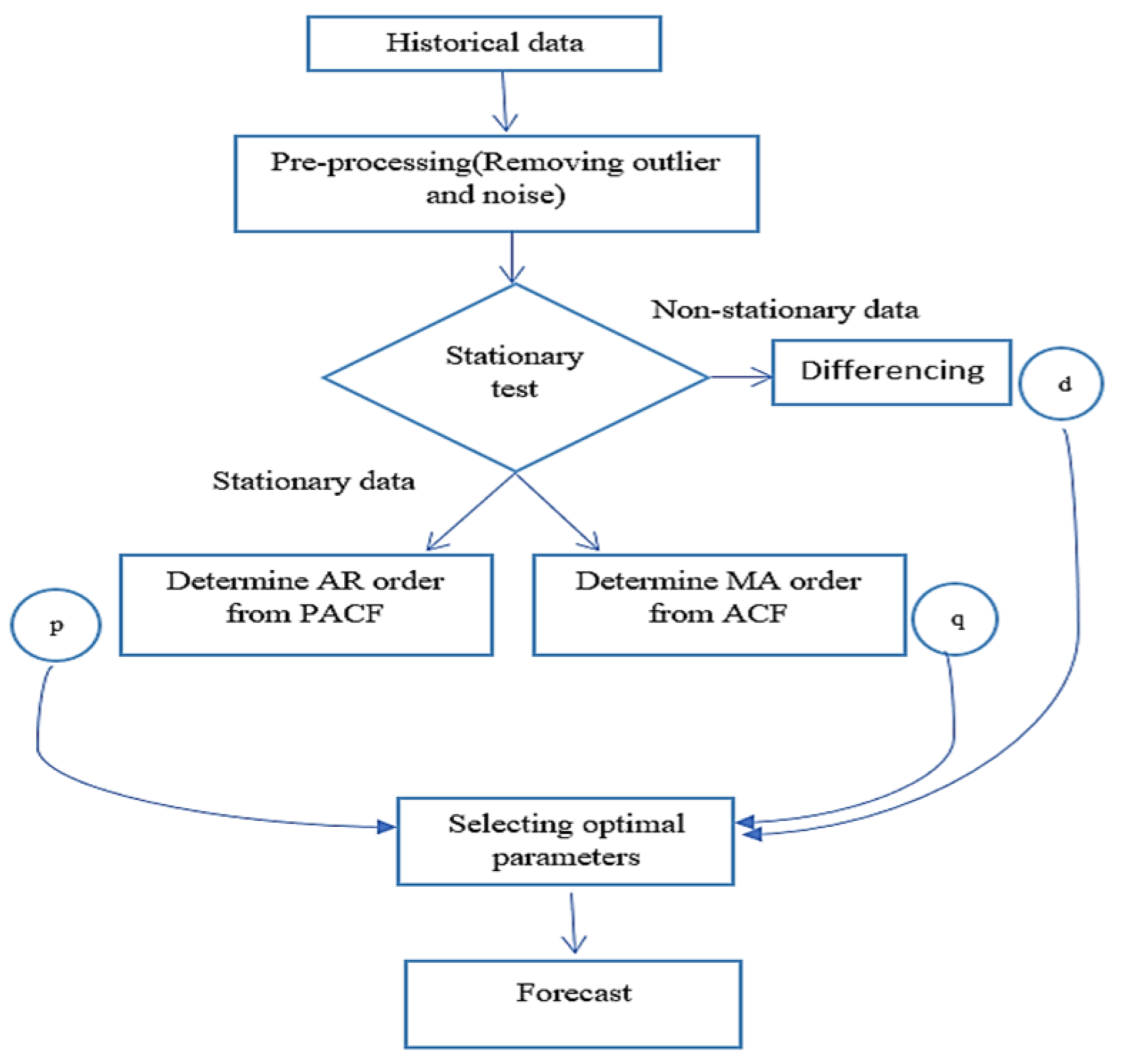
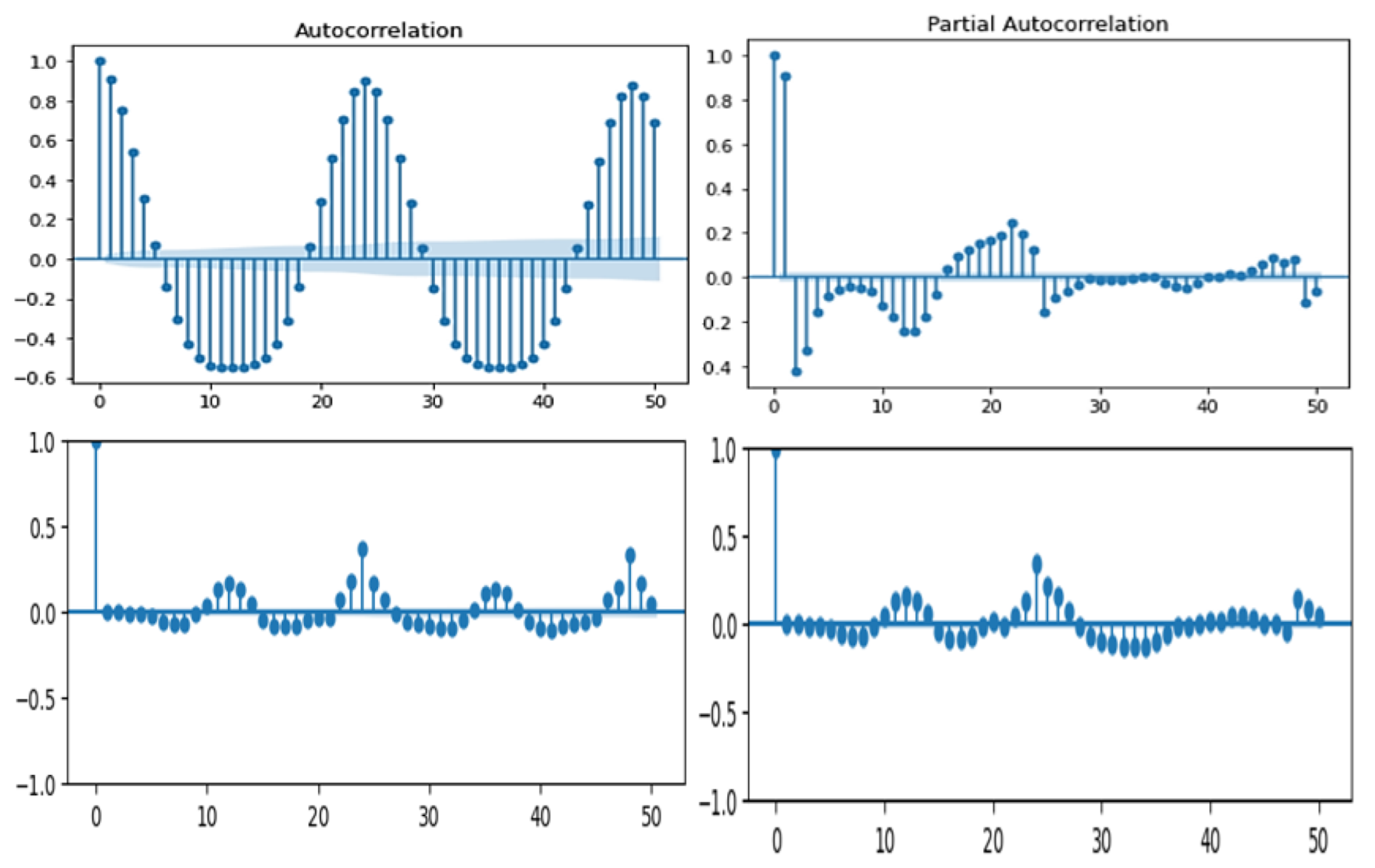
4.1.1. Statistical Model (ARIMA)
- p: corresponds to the quantity of lag observation in a model.
- d: corresponds to the number of times the observed value is different from its lagged value.
- q: corresponds to the order of lagged prediction error.
- Seasonality versus non-seasonality
- Stationarity of the data
- Determining p, d, and q parameters
4.1.2. The Machine Learning Model (SVR)
- Terminologies
- 1.
- Hyperplane
- 2.
- Kernel
- 3.
- Support Vectors
- 4.
- Boundary lines
- Importing libraries and training dataset
- Selection of Kernel
- Determining the SVR parameters
- Correlation matrix and predictions
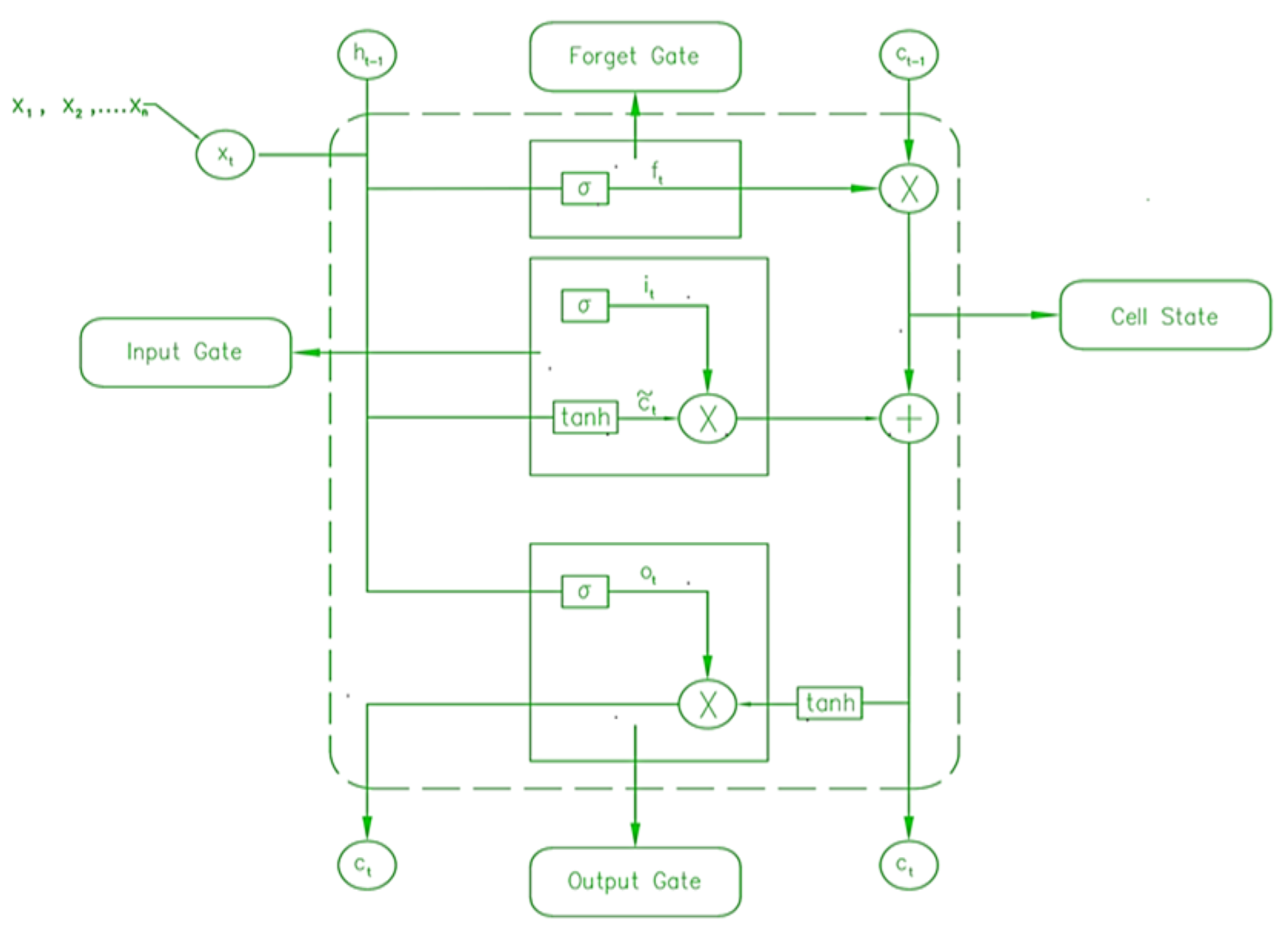
4.1.3. Deep Learning Model (LSTM)
- Gates
- 1.
- Forget gate
- 2.
- Input gate
- 3.
- Output gate
- Execution steps
- Network Architecture
4.2. Multivariate Models
4.2.1. Multivariate-LSTM
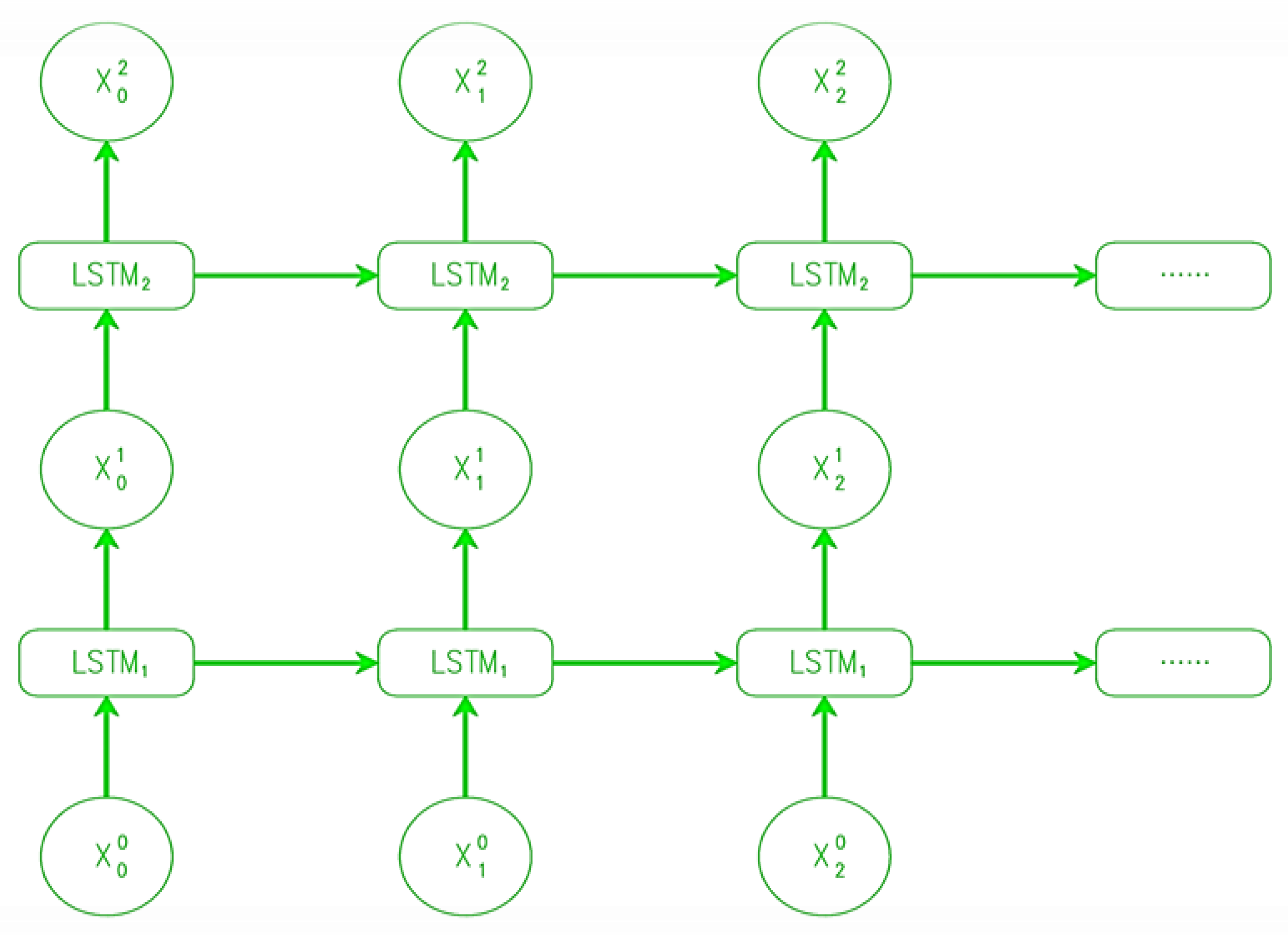
4.2.2. Stacked LSTMs
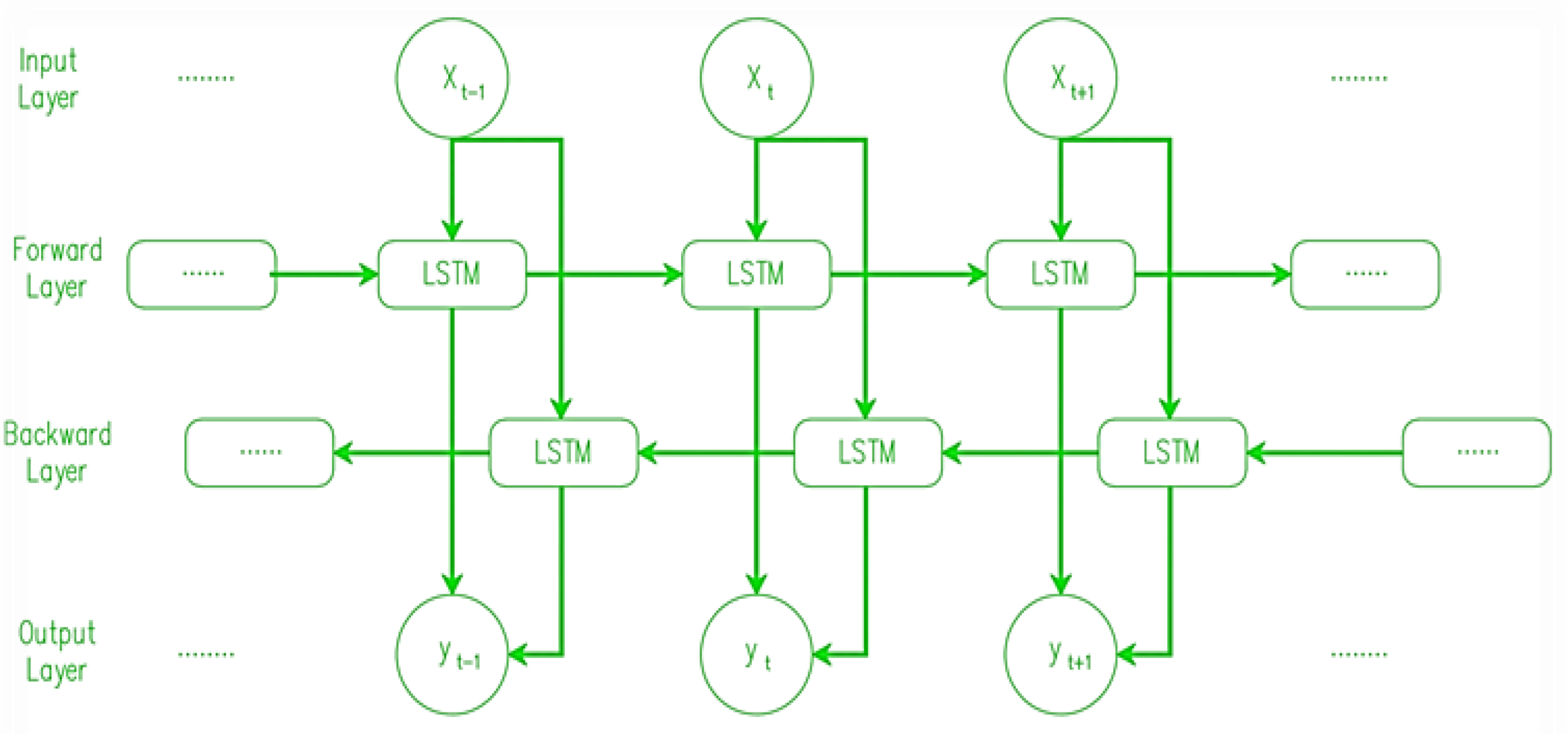
4.2.3. Bi-Directional LSTM
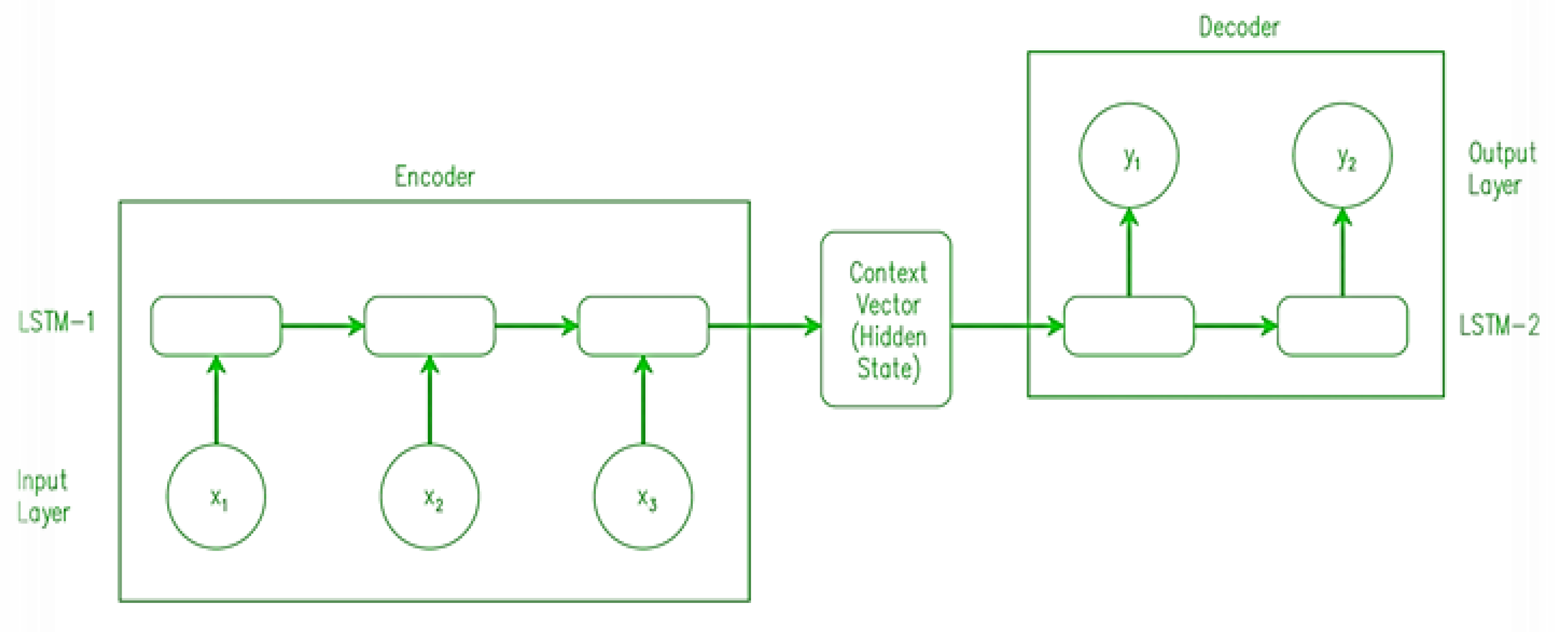
4.2.4. Encoder-Decoder LSTM
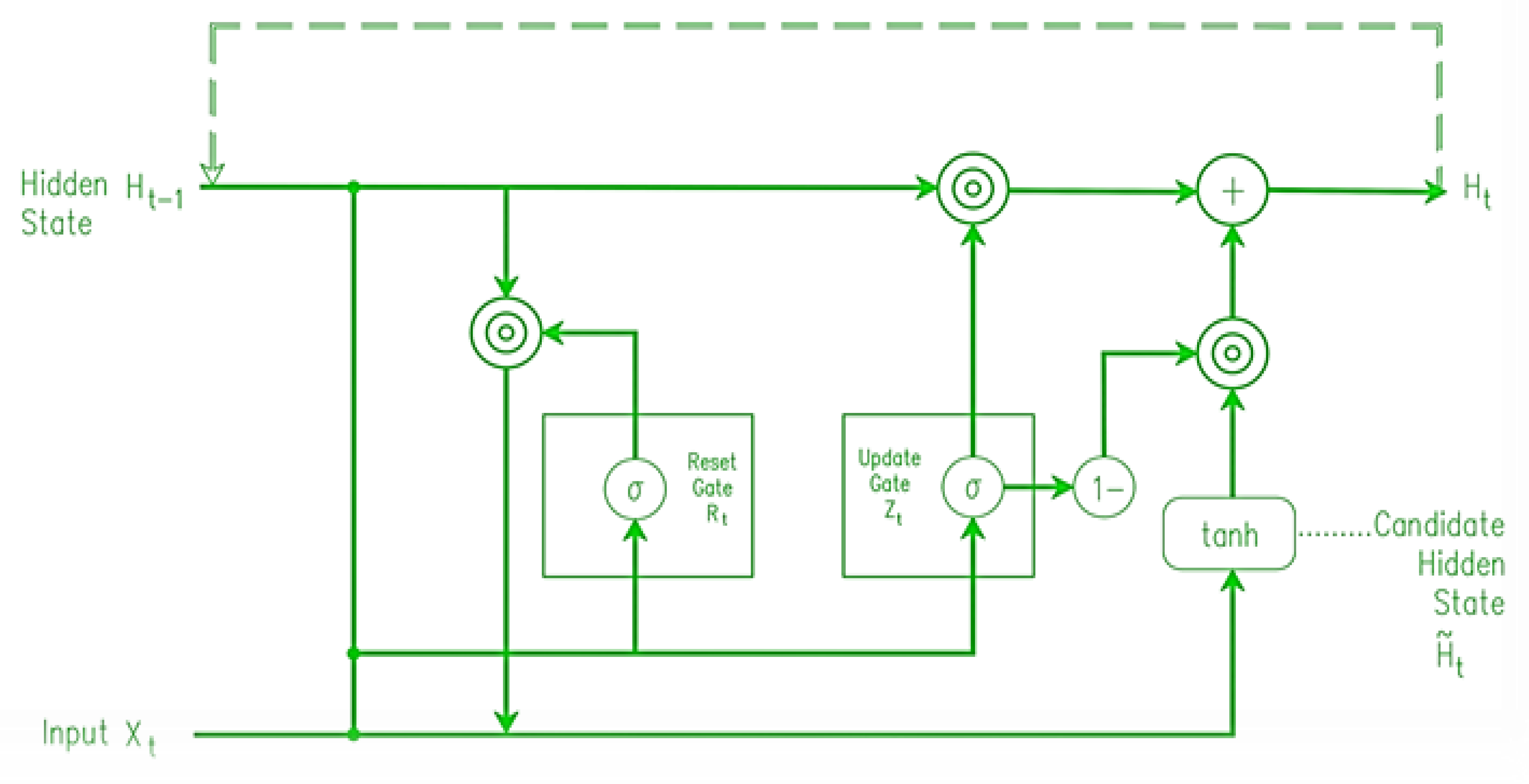
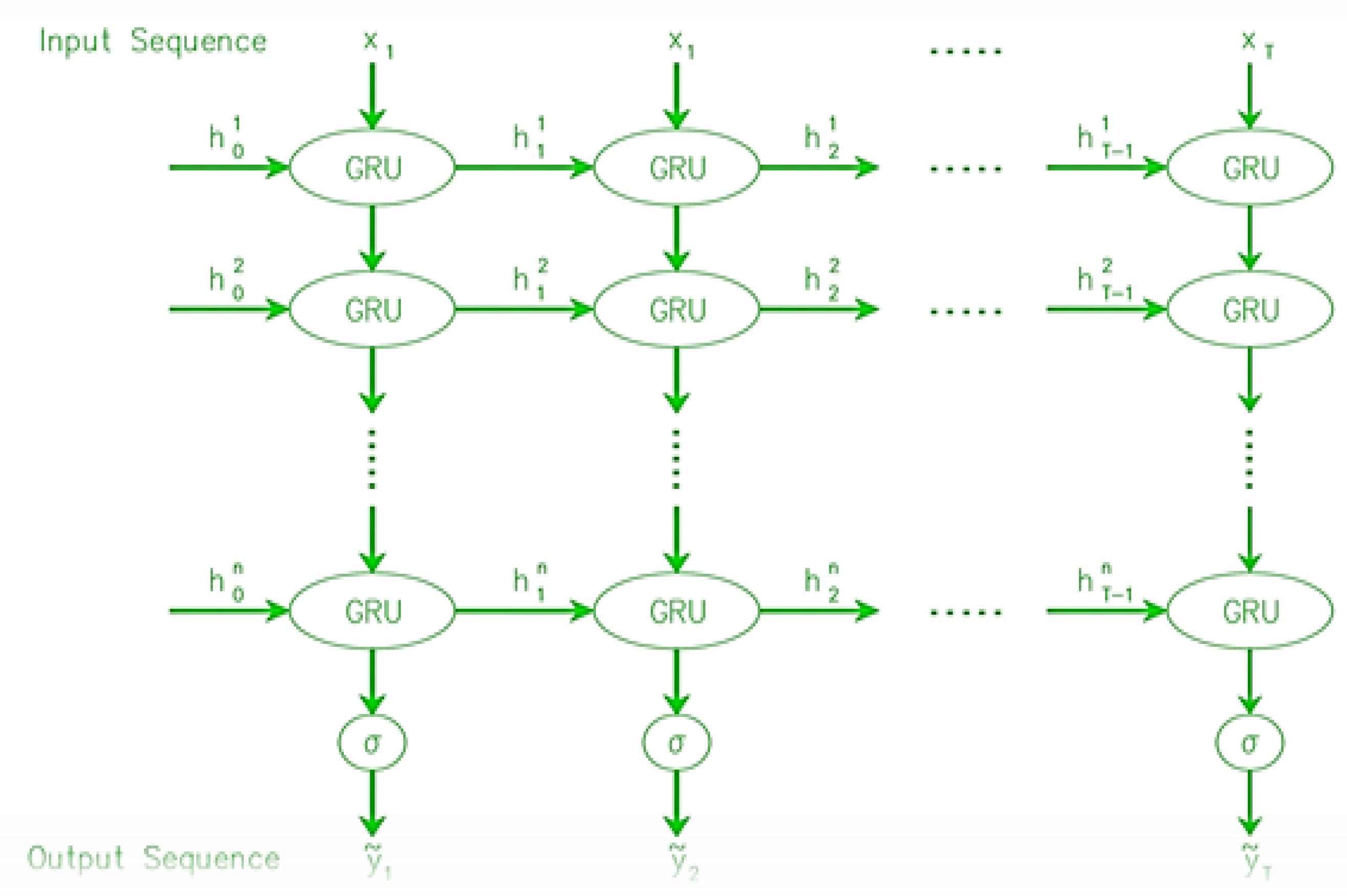
4.2.5. Stacked GRU
4.3. Ensemble Model
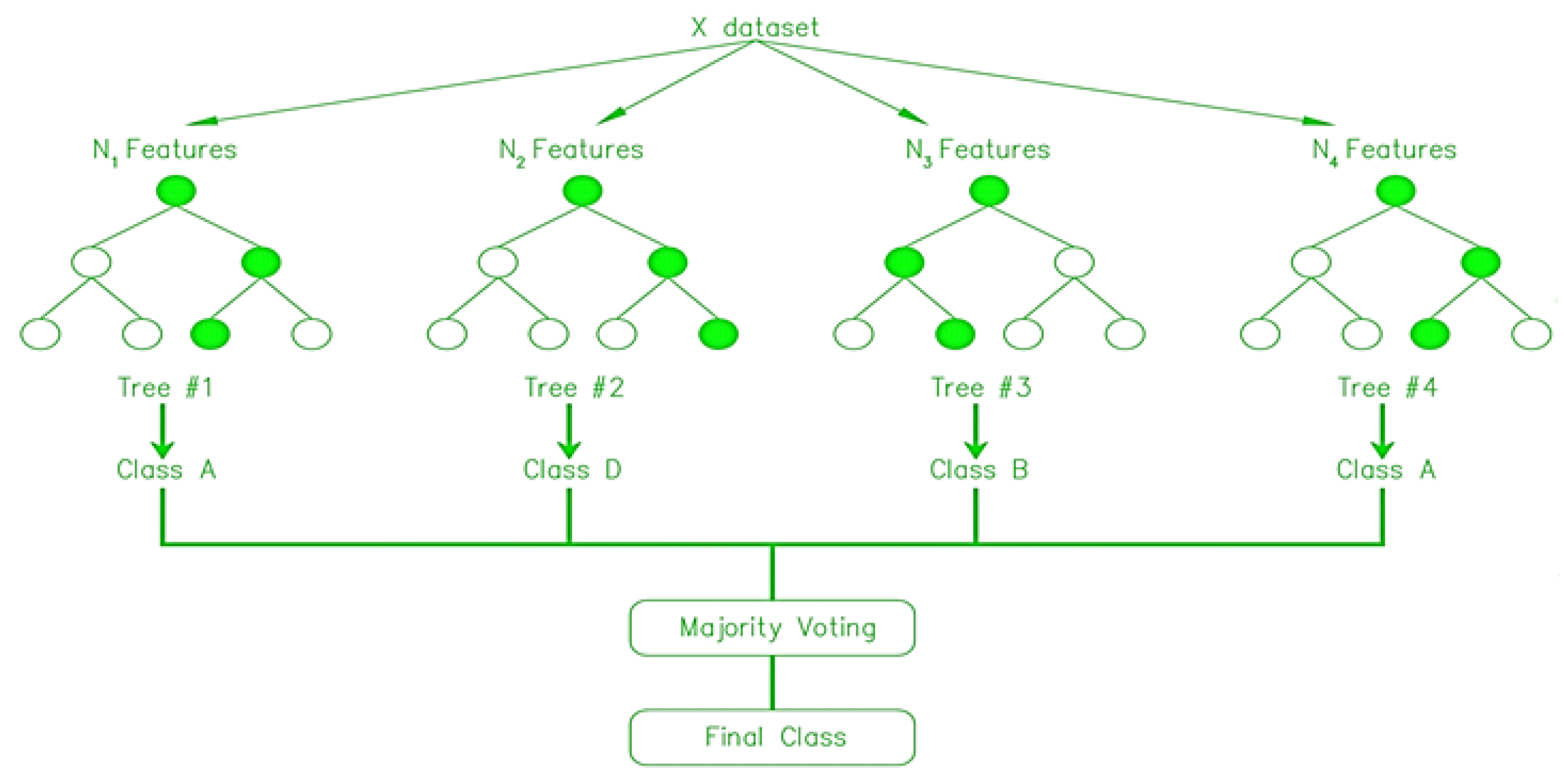
4.3.1. Random Forrest (RF)
4.3.2. ARIMA-LSTM
5. Models’ Performance Comparison and Evaluation
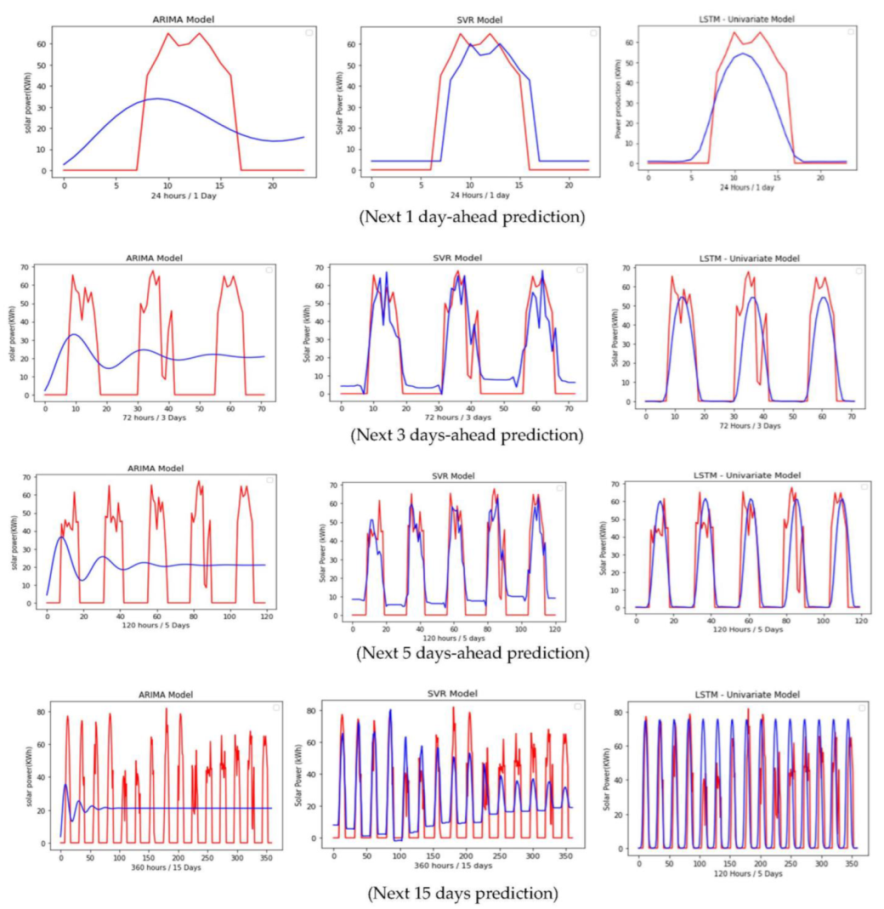
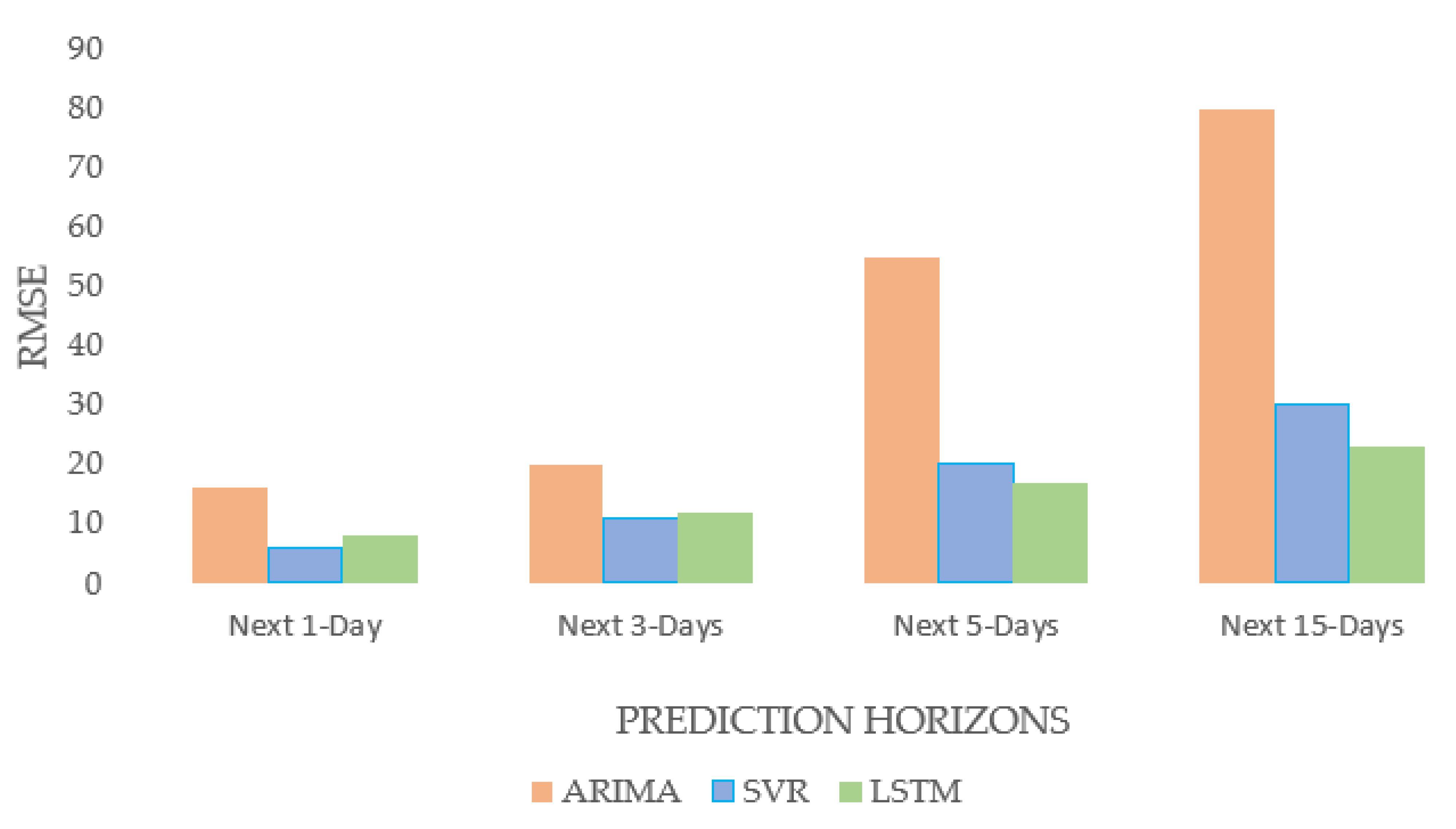
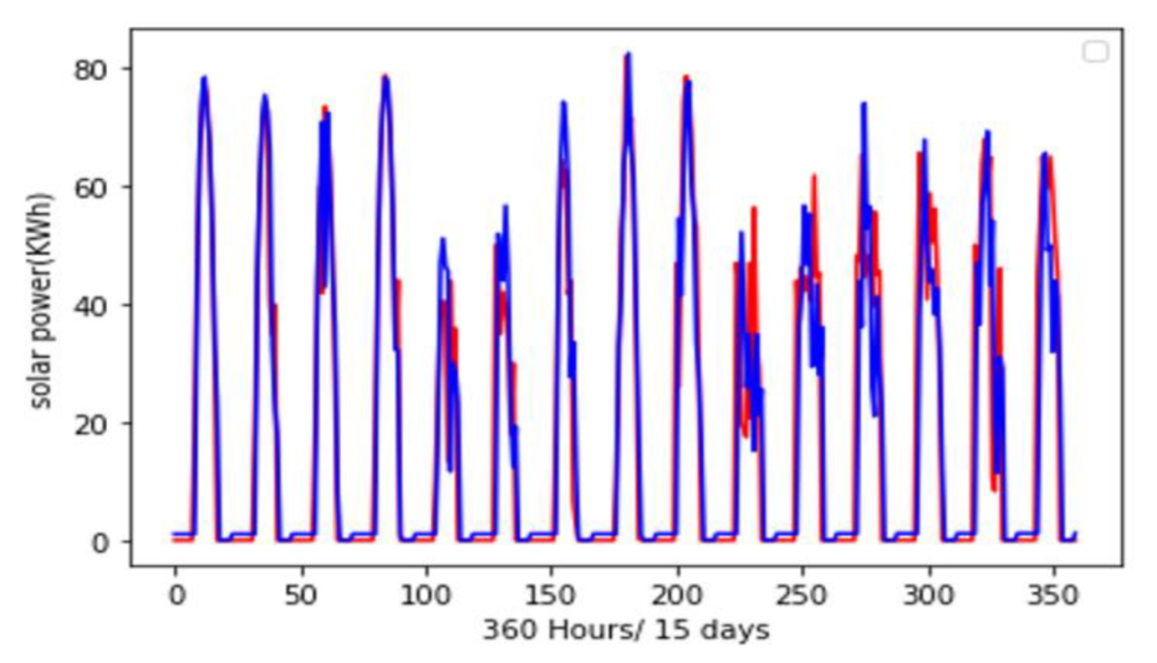
5.1. Comparison between Univariate Models (ARIMA, SVR, LSTM)
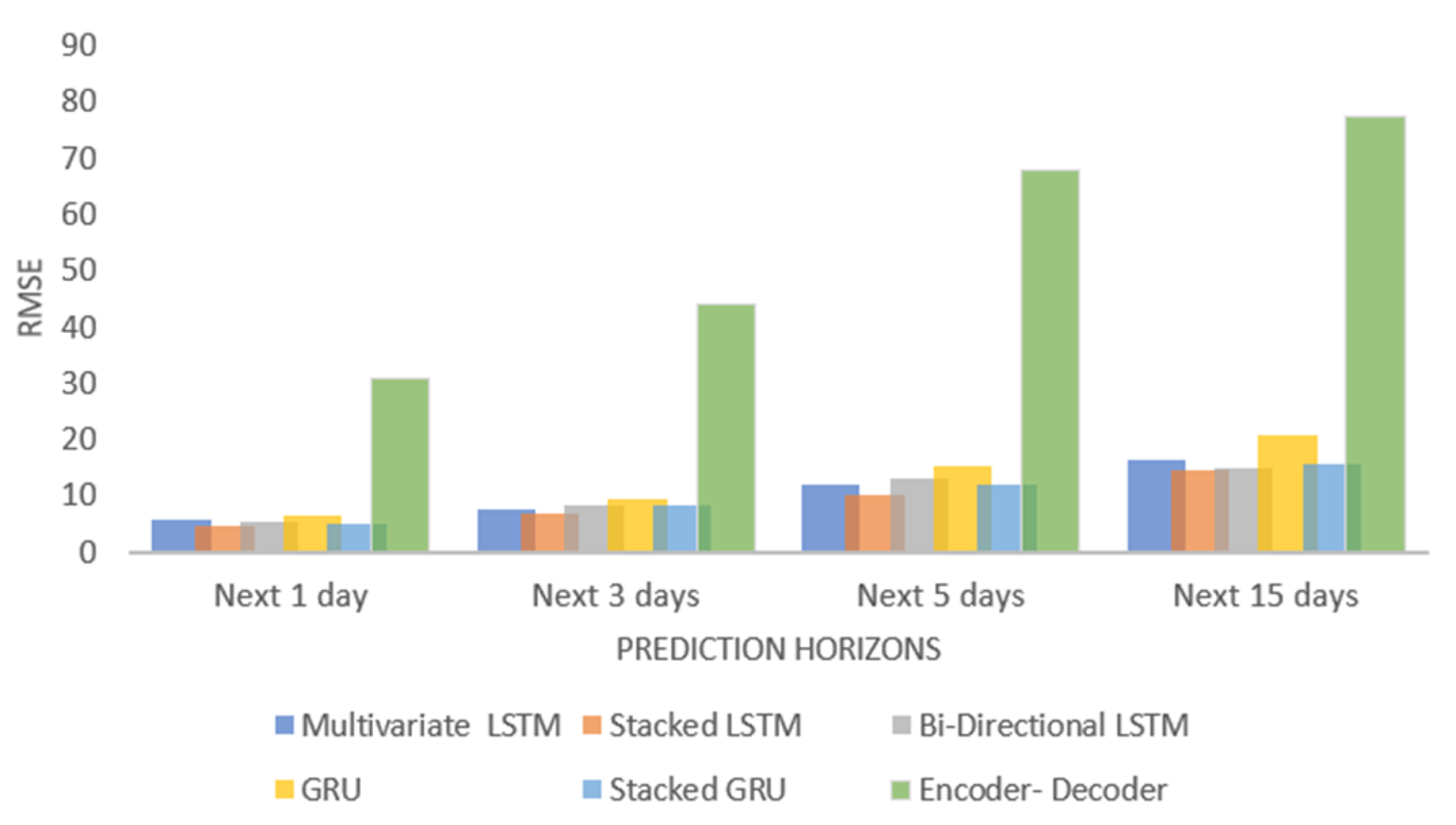
5.2. Comparison between Different Multivariate Models
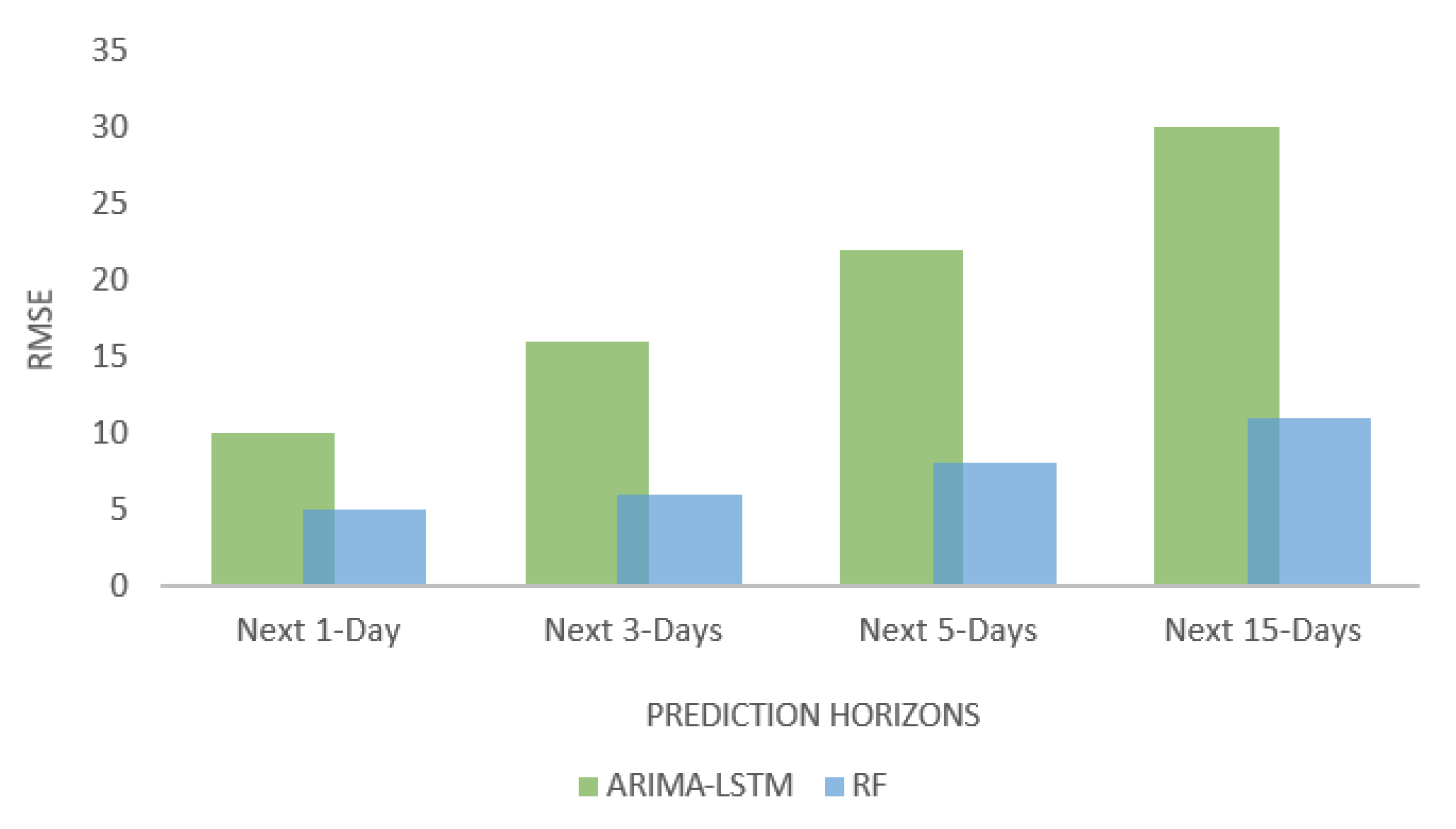
5.3. Comparison of Different Ensemble Models
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dhakal, R.; Sedai, A.; Pol, S.; Parameswaran, S.; Nejat, A.; Moussa, H. A Novel Hybrid Method for Short-Term Wind Speed Prediction Based on Wind Probability Distribution Function and Machine Learning Models. Appl. Sci. 2022, 12, 9038. [Google Scholar] [CrossRef]
- Pol, S.; Houchens, B.; Marian, D.; Westergaard, C. Performance of AeroMINEs for Distributed Wind Energy. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 1241. [Google Scholar]
- Dhakal, R.; Yosfovand, M.; Prasai, S.; Sedai, A.; Pol, S.; Parameswaran, S.; Moussa, H. Deep Learning Model with Probability Density Function and Feature Engineering for Short Term Wind Speed Prediction. In Proceedings of the 2022 North American Power Symposium (NAPS), Salt Lake City, UT, USA, 9–11 October 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Natarajan, V.; Karatampati, P. Survey on renewable energy forecasting using different techniques. In Proceedings of the 2019 2nd International Conference on Power and Embedded Drive Control (ICPEDC), Chennai, India, 21–23 August 2019; IEEE: New York, NY, USA, 2019; pp. 349–354. [Google Scholar]
- Zaouali, K.; Rekik, R.; Bouallegue, R. Deep learning forecasting based on auto-lstm model for home solar power systems. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (Hpcc/Smartcity/Dss), Exeter, UK, 28–30 June 2018; IEEE: New York, NY, USA, 2018; pp. 235–242. [Google Scholar]
- Samanta, M.; Srikanth, B.; Yerrapragada, J.B. Short-Term Power Forecasting of Solar PV Systems Using Machine Learning Techniques. Environ. Sci. Comput. Sci. 2014, 2014, 18566286. [Google Scholar]
- Ahn, H.K.; Park, N. Deep RNN-based photovoltaic power short-term forecast using power IoT sensors. Energies 2021, 14, 436. [Google Scholar] [CrossRef]
- Harrou, F.; Kadri, F.; Sun, Y. Forecasting of photovoltaic solar power production using LSTM approach. Adv. Stat. Model. Forecast. Fault Detect. Renew. Energy Syst. 2020, 3. [Google Scholar]
- Gao, M.; Li, J.; Hong, F.; Long, D. Day-ahead power forecasting in a large-scale photovoltaic plant based on weather classification using LSTM. Energy 2019, 187, 115838. [Google Scholar] [CrossRef]
- Sharma, J.; Soni, S.; Paliwal, P.; Saboor, S.; Chaurasiya, P.K.; Sharifpur, M. A novel long term solar photovoltaic power forecasting approach using LSTM with Nadam optimizer: A case study of India. Energy Sci. Eng. 2022, 10, 2909–2929. [Google Scholar] [CrossRef]
- Fara, L.; Diaconu, A.; Craciunescu, D.; Fara, S. Forecasting of Energy Production for Photovoltaic Systems Based on ARIMA and ANN Advanced Models. Int. J. Photoenergy 2021, 2021, 6777488. [Google Scholar] [CrossRef]
- Sengupta, M.; Habte, A.; Wilbert, S.; Gueymard, C.; Remund, J. Best Practices Handbook for the Collection and Use of Solar Resource Data for Solar Energy Applications; National Renewable Energy Lab.(NREL): Golden, CO, USA, 2021. [Google Scholar]
- Sobri, S.; Koohi-Kamali, S.; Rahim, N.A. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Morf, H. Sunshine and cloud cover prediction based on Markov processes. Sol. Energy 2014, 110, 615–626. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zhang, F.; Cai, H.; Zeng, W.; Wang, X.; Zou, H. Empirical and machine learning models for predicting daily global solar radiation from sunshine duration: A review and case study in China. Renew. Sustain. Energy Rev. 2019, 100, 186–212. [Google Scholar] [CrossRef]
- Wahab, M.A. New approach to estimate Ångström coefficients. Sol. Energy 1993, 51, 241–245. [Google Scholar] [CrossRef]
- Kumler, A.; Xie, Y.; Zhang, Y. A New Approach for Short-Term Solar Radiation Forecasting Using the Estimation of Cloud Fraction and Cloud Albedo; National Renewable Energy Lab.(NREL): Golden, CO, USA, 2018. [Google Scholar]
- Akinoǧlu, B. A review of sunshine-based models used to estimate monthly average global solar radiation. Renew. Energy 1991, 1, 479–497. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Zhang, F.; Ma, X.; Wu, L. Predicting daily diffuse horizontal solar radiation in various climatic regions of China using support vector machine and tree-based soft computing models with local and extrinsic climatic data. J. Clean. Prod. 2020, 248, 119264. [Google Scholar] [CrossRef]
- Tuohy, A.; Zack, J.; Haupt, S.E.; Sharp, J.; Ahlstrom, M.; Dise, S. Solar forecasting: Methods, challenges, and performance. IEEE Power Energy Mag. 2015, 13, 50–59. [Google Scholar] [CrossRef]
- Choudhary, A.; Pandey, D.; Kumar, A. A review of various techniques for solar radiation estimation, In Proceedings of the 2019 3rd International Conference on Recent Developments in Control, Automation & Power Engineering (RDCAPE), Noida, India, 10–11 October 2019; IEEE: New York, NY, USA, 2019; pp. 169–174. [Google Scholar]
- Dazhi, Y.; Walsh, W.; Zibo, D.; Jirutitijaroen, P.; Reindl, T.G. Block matching algorithms: Their applications and limitations in solar irradiance forecasting. Energy Procedia 2013, 33, 335–342. [Google Scholar] [CrossRef]
- Gürel, A.E.; Ağbulut, Ü.; Biçen, Y. Assessment of machine learning, time series, response surface methodology and empirical models in prediction of global solar radiation. J. Clean. Prod. 2020, 277, 122353. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H. A comparison of day-ahead photovoltaic power forecasting models based on deep learning neural network. Appl. Energy 2019, 251, 113315. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Li, P.; Zhou, K.; Lu, X.; Yang, S. A hybrid deep learning model for short-term PV power forecasting. Appl. Energy 2020, 259, 114216. [Google Scholar] [CrossRef]
- Habte, A.; Sengupta, M.; Lopez, A. Evaluation of the National Solar Radiation Database (NSRDB): 1998–2015; National Renewable Energy Lab.(NREL): Golden, CO, USA, 2017. [Google Scholar]
- Freeman, J.M.; DiOrio, N.A.; Blair, N.J.; Neises, T.W.; Wagner, M.J.; Gilman, P.; Janzou, S. System Advisor Model (SAM) General Description (Version 2017.9. 5); National Renewable Energy Lab.(NREL): Golden, CO, USA, 2018. [Google Scholar]
- Bisong, E. Matplotlib and seaborn. In Building Machine Learning and Deep Learning Models on Google Cloud platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 151–165. [Google Scholar]
- Faber, N.K.M. Estimating the uncertainty in estimates of root mean square error of prediction: Application to determining the size of an adequate test set in multivariate calibration. Chemom. Intell. Lab. Syst. 1999, 49, 79–89. [Google Scholar] [CrossRef]
- Hillmer, S.C.; Tiao, G.C. An ARIMA-model-based approach to seasonal adjustment. J. Am. Stat. Assoc. 1982, 77, 63–70. [Google Scholar] [CrossRef]
- Newbold, P. ARIMA model building and the time series analysis approach to forecasting. J. Forecast. 1983, 2, 23–35. [Google Scholar] [CrossRef]
- Noureen, S.; Atique, S.; Roy, V.; Bayne, S. Analysis and application of seasonal ARIMA model in Energy Demand Forecasting: A case study of small scale agricultural load. In Proceedings of the 2019 IEEE 62nd International Midwest Symposium on Circuits and Systems (MWSCAS), Dallas, TX, USA, 4–7 August 2019; IEEE: New York, NY, USA, 2019; pp. 521–524. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in model selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Ibrahim, I.; Abdulazeez, A. The role of machine learning algorithms for diagnosing diseases. J. Appl. Sci. Technol. Trends 2021, 2, 10–19. [Google Scholar] [CrossRef]
- Behravan, I.; Razavi, S.M. A novel machine learning method for estimating football players’ value in the transfer market. Soft Comput. 2021, 25, 2499–2511. [Google Scholar] [CrossRef]
- Zhou, D.-X.; Jetter, K. Approximation with polynomial kernels and SVM classifiers. Adv. Comput. Math. 2006, 25, 323–344. [Google Scholar] [CrossRef]
- Gopi, A.P.; Jyothi, R.; Narayana, V.; Sandeep, K.S. Classification of tweets data based on polarity using improved RBF kernel of SVM. Int. J. Inf. Technol. 2020, 1–16. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Q.; Chen, Y. RBF kernel based support vector machine with universal approximation and its application. In International Symposium on Neural Networks; Springer: Berlin/Heidelberg, Germany, 2004; pp. 512–517. [Google Scholar]
- Huang, Q.; Mao, J.; Liu, Y. An improved grid search algorithm of SVR parameters optimization. In Proceedings of the 2012 IEEE 14th International Conference on Communication Technology, Chengdu, China, 9–11 November 2012; IEEE: New York, NY, USA, 2012; pp. 1022–1026. [Google Scholar]
- Xue, H.; Huynh, D.; Reynolds, M. SS-LSTM: A hierarchical LSTM model for pedestrian trajectory prediction. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1186–1194. [Google Scholar]
- Liu, Y.; Sun, C.; Lin, L.; Wang, X. Learning natural language inference using bidirectional LSTM model and inner-attention. arXiv Prepr. 2016, arXiv:1605.09090. [Google Scholar]
- Khatiwada, A.; Kadariya, P.; Agrahari, S.; Dhakal, R. Big Data Analytics and Deep Learning Based Sentiment Analysis System for Sales Prediction. In Proceedings of the 2019 IEEE Pune Section International Conference (PuneCon), Pune, India, 18–20 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Yao, K.; Cohn, T.; Vylomova, K.; Duh, K.; Dyer, C. Depth-gated LSTM. arXiv 2015, arXiv:1508.03790. [Google Scholar]
- Randles, B.M.; Pasquetto, I.; Golshan, M.; Borgman, C.L. Using the Jupyter notebook as a tool for open science: An empirical study. In Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Toronto, ON, Canada, 19–23 June 2017; IEEE: New York, NY, USA, 2017; pp. 1–2. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Chandriah, K.K.; Naraganahalli, R.V. RNN/LSTM with modified Adam optimizer in deep learning approach for automobile spare parts demand forecasting. Multimed. Tools Appl. 2021, 80, 26145–26159. [Google Scholar] [CrossRef]
- Yu, L.; Qu, J.; Gao, F.; Tian, Y. A novel hierarchical algorithm for bearing fault diagnosis based on stacked LSTM. Shock. Vib. 2019, 2019, 2756284. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Pavithra, M.; Saruladha, K.; Sathyabama, K. GRU based deep learning model for prognosis prediction of disease progression. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Tamil Nadu, India, 27–29 March 2019; IEEE: New York, NY, USA, 2019; pp. 840–844. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; IEEE: New York, NY, USA, 2017; pp. 1597–1600. [Google Scholar]
- Sun, P.; Boukerche, A.; Tao, Y. SSGRU: A novel hybrid stacked GRU-based traffic volume prediction approach in a road network. Comput. Commun. 2020, 160, 502–511. [Google Scholar] [CrossRef]
- Leutbecher, M.; Palmer, T.N. Ensemble forecasting. J. Comput. Phys. 2008, 227, 3515–3539. [Google Scholar] [CrossRef]
- Moon, J.; Kim, Y.; Son, M.; Hwang, E. Hybrid short-term load forecasting scheme using random forest and multilayer perceptron. Energies 2018, 11, 3283. [Google Scholar] [CrossRef]
- Bordarie, J. Predicting intentions to comply with speed limits using a ‘decision tree’ applied to an extended version of the theory of planned behaviour. Transp. Res. Part F Traffic Psychol. Behav. 2019, 63, 174–185. [Google Scholar] [CrossRef]
- Kumar, M.; Thenmozhi, M. Forecasting stock index movement: A comparison of support vector machines and random forest. In Indian Institute of Capital Markets 9th Capital Markets Conference Paper; Indian Institute of Capital Markets: Navi Mumbai, India, 2006. [Google Scholar]
- Andrews, B.H.; Dean, M.; Swain, R.; Cole, C. Building ARIMA and ARIMAX models for predicting long-term disability benefit application rates in the public/private sectors. Soc. Actuar. 2013, 1–54. [Google Scholar]
- Hashemi, R.; Brigode, P.; Garambois, P.-A.; Javelle, P. How can we benefit from regime information to make more effective use of long short-term memory (LSTM) runoff models? Hydrol. Earth Syst. Sci. 2022, 26, 5793–5816. [Google Scholar] [CrossRef]
- Choi, H.K. Stock price correlation coefficient prediction with ARIMA-LSTM hybrid model. ArXiv 2018, arXiv:1808.01560. [Google Scholar]
- Fathi, O. Time series forecasting using a hybrid ARIMA and LSTM model. Velv. Consult. 2019, 1–7. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | t = 1 Day | t = 3 Days | t = 5 Days | t = 15 Days |
|---|---|---|---|---|
| ARIMA | 0.42 | 0.8 | 1.36 | 2.24 |
| SVR | 0.07 | 0.11 | 0.16 | 0.34 |
| u-LSTM | 0.08 | 0.12 | 0.19 | 0.28 |
| m-LSTM | 0.06 | 0.10 | 0.12 | 0.18 |
| s-LSTM | 0.05 | 0.08 | 0.11 | 0.16 |
| GRU | 0.07 | 0.10 | 0.13 | 0.20 |
| s-GRU | 0.06 | 0.10 | 0.12 | 0.17 |
| ED-LSTM | 1.97 | 2.01 | 2.12 | 2.13 |
| b-LSTM | 0.09 | 0.13 | 0.15 | 0.19 |
| ARIMA-LSTM | 0.12 | 0.17 | 0.20 | 0.25 |
| RF | 0.03 | 0.07 | 0.10 | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sedai, A.; Dhakal, R.; Gautam, S.; Dhamala, A.; Bilbao, A.; Wang, Q.; Wigington, A.; Pol, S. Performance Analysis of Statistical, Machine Learning and Deep Learning Models in Long-Term Forecasting of Solar Power Production. Forecasting 2023, 5, 256-284. https://doi.org/10.3390/forecast5010014
Sedai A, Dhakal R, Gautam S, Dhamala A, Bilbao A, Wang Q, Wigington A, Pol S. Performance Analysis of Statistical, Machine Learning and Deep Learning Models in Long-Term Forecasting of Solar Power Production. Forecasting. 2023; 5(1):256-284. https://doi.org/10.3390/forecast5010014
Chicago/Turabian StyleSedai, Ashish, Rabin Dhakal, Shishir Gautam, Anibesh Dhamala, Argenis Bilbao, Qin Wang, Adam Wigington, and Suhas Pol. 2023. "Performance Analysis of Statistical, Machine Learning and Deep Learning Models in Long-Term Forecasting of Solar Power Production" Forecasting 5, no. 1: 256-284. https://doi.org/10.3390/forecast5010014
APA StyleSedai, A., Dhakal, R., Gautam, S., Dhamala, A., Bilbao, A., Wang, Q., Wigington, A., & Pol, S. (2023). Performance Analysis of Statistical, Machine Learning and Deep Learning Models in Long-Term Forecasting of Solar Power Production. Forecasting, 5(1), 256-284. https://doi.org/10.3390/forecast5010014