Abstract
Traditional regression estimators like Ordinary Least Squares (OLS) and classical ridge regression often fail under multicollinearity and outlier contamination respectively. Although recently developed two-parameter ridge regression (TPRR) estimators improve efficiency by introducing dual shrinkage parameters, they remain sensitive to extreme observations. This study develops a new class of Two-Parameter Robust Ridge M-Estimators (TPRRM) that integrate dual shrinkage with robust M-estimation to simultaneously address multicollinearity and outliers. A Monte Carlo simulation study, conducted under varying sample sizes, predictor dimensions, correlation levels, and contamination structures, compares the proposed estimators with OLS, ridge, and the most recent TPRR estimators. The results demonstrate that TPRRM consistently achieves the lowest Mean Squared Error (MSE), particularly in heavy-tailed and outlier-prone scenarios. Application to the Tobacco and Gasoline Consumption datasets further validates the superiority of the proposed methods in real-world conditions. The findings confirm that the proposed TPRRM fills a critical methodological gap by offering estimators that are not only efficient under multicollinearity, but also robust against departures from normality.
1. Introduction
Linear regression (LR) is a foundational statistical technique that models the relationship between a dependent variable and one or more independent variables. It can range from simple linear regression, which uses a single predictor, to multiple linear regression (MLR) that incorporates numerous predictors, thus allowing for a more comprehensive understanding of how various factors influence the dependent variable. The mathematical form of MLRM [1] is
where y denotes an n × 1 vector of response variables, and X represents a known n × p matrix of predictor variables. The vector β is a p × 1 vector of unknown regression parameters, while ε is an n × 1 vector of error terms, satisfying E(ε) = 0 and V(ε) = σ2 In, where In is the n × n identity matrix. Typically, the Ordinary Least Squares (OLS) method is used to estimate the model parameters; it is a widely adopted approach due to its efficiency and ease of interpretation [2]. OLS estimation calculates the regression coefficients by minimizing the sum of squared residuals, thereby fitting the best linear line to the data. The simplicity of this method has made it a cornerstone in statistical analysis, but it requires various assumptions to ensure the validity and reliability of its predictions. The OLS of β is defined as
where V = . OLS is the best linear unbiased estimator under some classical assumptions, like no correlation among predictors, i.e., no multicollinearity, no outliers, finite error variance, and correct model specification. Studies have shown that the above OLS estimator can yield inaccurate results when these model assumptions are violated [3]. However, even in the presence of multicollinearity, the OLS estimator retains optimal prediction properties under the classical assumptions of no outliers and finite error variance. However, in finite samples or when variance inflation becomes severe, the OLS estimates may become unstable, leading to poor practical performance [4]. In such cases, ridge regression [5] introduces a small bias that reduces variance, yielding more stable coefficient estimates and, in practice, improved predictive performance, particularly in finite samples or in data prone to noise and outliers. This adjustment helps to improve the model’s accuracy and prevents the coefficient estimates from becoming excessively large in the presence of highly correlated predictors. Ridge regression is therefore valuable in refining the predictive capacity of MLR models, especially when multicollinearity is unavoidable due to the nature of the data. From 1970 until now, almost 400 estimators have been suggested in the literature to combat the problem of MC [6]. The ridge regression estimator of β is defined as
where k > 0 is the ridge or shrinkage parameter. To enhance the efficiency of the ridge estimator, ref. [7] introduced an additional parameter, termed ‘q’, alongside k, resulting in the two-parameter ridge regression (TPRR) estimator, which is defined as
where
The value of ‘q’ in the above equation is derived by maximizing the coefficient of determination, while the value of ‘k’ is chosen to minimize the Mean Squared Error (MSE). It is important to note that k and q are shrinkage parameters, whereas the ridge regression and its two-parameter extensions are the corresponding estimators that utilize these parameters. This distinction is crucial, as the efficiency of an estimator depends on how appropriately its shrinkage parameters are chosen.
Notable work in the area of two-parameter estimators has been conducted in [8,9,10,11,12]. To simultaneously address multicollinearity and outliers, robust ridge M-estimators were introduced in [13] based on the work of [14,15]. The objective function for the robust M ridge regression used in [13] was based on Huber’s loss function [16].
These M-based ridge regression estimators demonstrate a smaller Mean Squared Error (MSE) compared to traditional ridge regression estimators. Recent advancements in this area have been made in [17,18,19]. The same concept of using M estimators to derive a robust version of a ridge estimator was extended to the two-parameter ridge regression approach by Ertaş et al. in 2015, by combining the benefits of robust M-estimation and the most efficient two-parameter ridge regression in order to handle both MC and outliers effectively [20]. Recent work in this area was conducted in [21].
Now, motivated by the idea of Ertas et al., the purpose of this study is to refine existing techniques and develop more adaptive and resilient estimation frameworks. This study proposes and evaluates a new TPRRM approach to tackle the combined challenges of MC and outliers. Through simulation studies and numerical examples, the research aims to demonstrate that these new estimators outperform existing methods. The goal of this paper is to improve the reliability and accuracy of regression models in datasets that are rich in outliers, contributing to more informed and effective decision-making in statistical modeling.
The organization of the paper is as follows: Section 2 presents the methodology, along with an introduction to the proposed estimator. A simulation study is conducted in Section 3. Section 4 illustrates the advantages of the proposed estimator using the Tobacco and Gasoline Consumption datasets. Some concluding remarks are presented in Section 5.
2. Materials and Method
For mathematical convenience, regression is expressed in canonical form. Equation (1), in orthogonal form, is
Here, , and , C is an orthogonal matrix containing eigen vectors of X′X such that and = , where are the ordered eigen values of matrix X′X. is the identity matrix of order p. Now the canonical form of Equations (2) and (3) is
The canonical form of the M estimator of the above equation is
The canonical form of Equation (4) is
The canonical form of the M estimator of the above equation is
Here, is an M estimator such that and . The canonical forms of the OLS, ridge, robust ridge, and two-parameter ridge estimators are presented in Equations (8)–(12). The Mean Squared Errors (MSEs) of these estimators are given in (13)–(18), with robust versions based on [22].
Here, , is replaced by , where is a robust estimator based on the M-estimator proposed by [23].
2.1. Existing Estimators
- The groundbreaking ridge estimator introduced by Hoerl & Kennard (1970a) is as follows [5]:where
- The second ridge estimator introduced by Hoerl & Kennard (1970b) is as follows [24]:
- 3.
- Ref. [14] generalized the idea of Hoerl & Kennard (1970a) and suggested a new estimator, denoted as HKB:
- 4.
- Kibria (2003) suggested three new ridge regression estimators by taking the AM, GM, and Median of Hoerl & Kennard (1970a, ref. [5]) [25]:
- 5.
- Similarly, Khalaf et al. (2013) proposed an estimator by combining the idea of Hoerl & Kennard (1970b, ref. [24]) with the concept of weight, as follows [26]:
These estimators reduce instability in coefficient estimates caused by multicollinearity, yet they remain sensitive to outliers. Their performance deteriorates under contamination, which limits their applicability in real-world data, where assumptions of normality and clean samples rarely hold.
2.2. Two-Parameter Ridge Regression Estimator
- To improve the fit quality of the one-parameter ridge regression, ref. [7] recommended using the k value defined in Equation (20) along with the parameter ‘q’ from Equation (5), thus introducing the concept of the two-parameter robust ridge regression estimator (TPRRE) [7].
- Inspired by [7], Toker & Kaçiranlar (2013) introduced a new TPRRE based on optimal selection of the k and q values [8].
- 3.
- The latest advancements in the field of TPRRE were introduced by Khan et al. (2024) [11], who proposed six new estimators with the goal of enhancing the accuracy of ridge estimation.
Recent contributions by [11] propose six new TPRR estimators, further improving estimation under MC. However, their framework does not account for robustness against non-normal errors and outliers. As such, while TPRR improves efficiency through two shrinkage parameters, it still inherits the vulnerability of ridge-type estimators to contaminated data.
2.3. Proposed Estimator
Now, motivated by the idea of [12,20,21], we propose Two-Parameter Robust Ridge M-Estimators (TPRRM). The novelty lies in embedding dual shrinkage parameters within a robust M-estimation framework, thereby achieving efficiency under multicollinearity while ensuring resilience to outliers. Unlike existing two-parameter estimators, the proposed TPRRM preserves the strengths of dual shrinkage while mitigating contamination effects. Through both simulation and application to the Tobacco dataset, we empirically demonstrate that TPRRM consistently outperforms classical ridge, robust ridge, and the most recent TPRR estimators.
The proposed estimators are as follows.
Ref. [26] suggested a weight for ridge estimators as follows:
Following [19], we modified Equation (34) and used its M-version, as follows:
We multiplied Equations (28)–(33) by Equation (35) and obtained our six new proposed estimators, BAD1, BAD2, BAD3, BAD4, BAD5, and BAD6, which are given below:
The above value of k will be used in Equation (5) to calculate the value of . Then both and value will be put into Equation (4) to estimate
A simulation study is performed in the section below to compare the performance of the suggested estimator with that of existing estimators.
3. Simulation Study
3.1. Simulation Design
To examine the performance of the proposed and existing estimators under diverse conditions, a Monte Carlo simulation experiment incorporating varying levels of multicollinearity, error variance, sample sizes, and numbers of predictors has been used. The data-generating process was adapted from the work of [11,18,27,28].
The predictor variables were generated as follows:
where zij ∼ N(0,1) and ρ denotes the correlation between regressors. This design ensures that the predictors exhibit the desired degree of multicollinearity.
To capture a wide range of conditions, we consider pairwise correlations as ρ = {0.85, 0.90, 0.95, 0.99, 0.999}, ranging from moderate to near-perfect multicollinearity. The number of predictors is p = {4, 10} and the sample size is n = {20, 50, 100}.
The regression coefficients β were generated using the Most Favorable (MF) direction approach, which ensures comparability across estimators [12]. Without loss of generality, the intercept term was set to zero. The error term εi was generated from two distributions: normal distribution, εi ∼ N(0,σ2), and heavy-tailed distribution, εi ∼ Cauchy (0,1). The variance parameter was varied across four levels, σ2 = {0.5, 1, 5, 10}, allowing us to assess estimator performance under both low- and high-noise conditions.
To assess robustness, contamination was introduced by replacing randomly selected response values (yj) with values shifted in the y-direction. Two contamination levels were considered, 10% and 20%, generated by taking the error variance as ‘σ2 + 10’ and ‘σ2 + 20’ respectively. For robust ridge M-type estimators, the Huber objective function is used in conjunction with the ‘rlm()’ function to calculate the M-estimator.
The response variable was then computed as follows:
3.2. Performance Evaluation Criteria
Unlike OLS, ridge estimators introduce a certain degree of bias. The MSE criterion provides a more appropriate basis for evaluating and comparing such biased estimators, as mentioned by [10,12]. Furthermore, the existing literature consistently emphasizes the use of the minimum MSE criterion as the standard for identifying the most efficient estimator [12,19,27]. The MSE is defined as
Each scenario was replicated 5000 times to ensure stable results. The estimated MSE (EMSE) was computed as follows:
All simulations and calculation were performed using R version 4.5.1 programing language, and the results are summarized in both tabular and graphical form.
3.3. Simulation Results Discussion
Table 1, Table 2, Table 3 and Table 4 (and Supplementary Tables S1–S8) illustrate the estimated Mean Squared Error (MSE) of estimators for normally distributed errors with 10% and 20% outliers in the response variable. Table 5 contains comprehensive data for the Cauchy distribution. Table 6 provides a bird’s-eye view of all the situations considered in the simulation study of the proposed and existing estimators, and thoroughly reviews the top-performing estimators for all situations studied. Figure 1 is the diagnostic plot confirms the presence of three outliers (green dots), which are clearly separated from the fitted model (red dots and line), supporting the use of a BAD4. This plot visually demonstrates how the estimator is not influenced by these extreme data points, thereby producing a more reliable regression fit.

Table 1.
Estimated MSE values with ,
, and 10% outliers in the y-direction.
Table 2.
Estimated MSE values with ,
, and 20% outliers in the y-direction.
Table 3.
Estimated MSE values with ,
, and 10% outliers in the y-direction.
Table 4.
Estimated MSE values with ,
, and 20% outliers in the y-direction.
Table 5.
Estimated MSE values from heavy-tailed distribution, i.e., standardized Cauchy distribution.
Table 6.
Summary table of recommended estimators in terms of minimum MSE values.
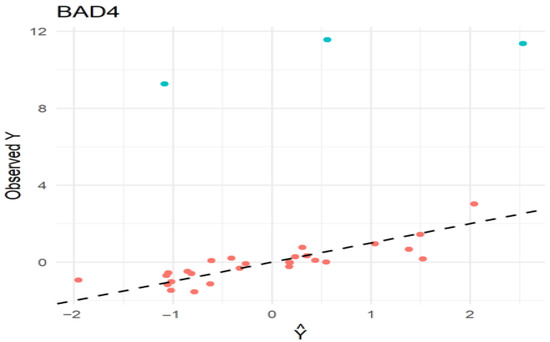
Figure 1.
Diagnostic plot of BAD4 estimator (observed vs. predicted values).
The bold value represents the smaller MSE. The simulation results in Table 1, Table 2, Table 3, Table 4 and Table 5 reveal that the BAD estimators (BAD1 to BAD6) demonstrate exceptional robustness against outliers across the varying scenarios presented in the tables. Overall, the BAD estimators maintain low Mean Squared Error (MSE) values, demonstrating superior performance compared to other methods such as OLS, HK, and HKB. Among them, BAD1 and BAD4 consistently yield the lowest MSEs, making them reliable choices—particularly in scenarios with lower confidence levels (0.85 and 0.95) and 10% outliers. As the confidence level increases (up to 0.999) or the percentage of outliers rises to 20%, BAD4 remains especially effective, highlighting its versatility and robustness under extreme conditions. BAD2, BAD3, and BAD5 also perform well, with minimal MSE variation, particularly at higher confidence levels. Although BAD6 shows slightly higher MSE under less extreme conditions, it proves advantageous in cases involving severe outliers and high confidence levels, indicating its suitability for more challenging datasets. In summary, BAD4 emerges as the most robust and versatile estimator overall, while BAD1 is optimal for scenarios with moderate outlier influence. For conditions involving a higher proportion of outliers and stringent confidence requirements, BAD2, BAD5, and BAD6 also deliver strong, reliable performance, making them valuable options for practical applications with noisy data.
The results from Table 5 reveal that, in the case of the heavy-tailed standardized Cauchy distribution, where outliers strongly affect the performance of traditional methods, the BAD estimators consistently demonstrate superior performance by maintaining low Mean Squared Error (MSE) values. Unlike traditional estimators such as OLS, HK, and HKB, which exhibit significantly higher MSE values, especially under high multicollinearity (0.99 and 0.999), the BAD estimators prove to be much more robust. The BAD4 estimator, in particular, achieves remarkably low MSE values even under extreme multicollinearity conditions. These findings highlight the robustness and accuracy of the BAD series in such challenging scenarios, making them a preferable choice when working with heavy-tailed data.
Table 6 provides a bird’s-eye view of all the scenarios explored in the simulation study.
4. Real Life Application
4.1. Tobacco Data
This section includes an empirical case that demonstrates the performance of the novel estimators. We followed [29,30,31] in analyzing tobacco data. The data includes thirty (30) observations of different tobacco mixes. The percentage concentrations of four essential components are employed as predictor variables, with the quantity of heat created by the tobacco during smoking serving as a response variable. The regression model for the tobacco data is shown below.
Figure 2 illustrating the relationships between variables , , , , and . The lower triangular matrix displays scatterplots, visualizing the linear relationships between pairs of variables. The upper triangular matrix shows the Pearson correlation coefficients (r), with asterisks (∗∗∗) indicating the strong positive correlation > 0.9. The diagonal panels show the kernel density distribution for each variable. The condition number of this data is obtained as 1855.526, which indicates severe multicollinearity among the predictors. Based on the covariance matrix, observations 4, 18, and 29 are identified as outliers.
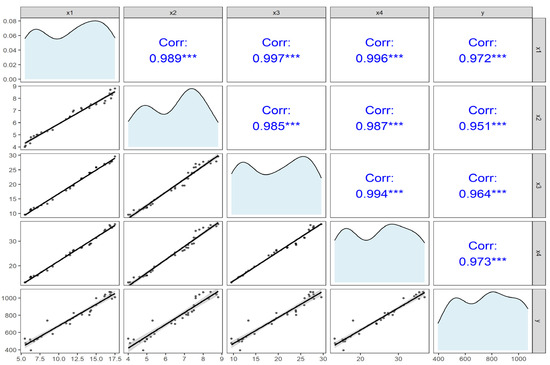
Figure 2.
Pairwise correlation between variables of tobacco data of ref. [32].
Table 7 provides a comparative analysis of various regression estimators, including traditional methods like OLS, HK, and HKB, as well as robust estimators such as SH, RM, and the novel BAD series (BAD1 to BAD6), applied to the tobacco dataset. The MSE values indicate the error level for each estimator, with a lower MSE representing better performance.
Table 7.
Estimated regression coefficients and MSE values of tobacco data of ref. [32].
The results highlight the limitations of traditional methods like OLS, which has the highest MSE (32.4972), suggesting poor robustness against multicollinearity and outliers. On the other hand, the novel BAD estimators demonstrate significantly lower MSE values. In particular, BAD6 achieves the lowest MSE (1.7834), indicating superior performance and robustness, especially in handling the severe multicollinearity and outliers present in the tobacco data. This is further supported by the regression coefficients, where BAD6 shows consistent and stable values.
BAD1, BAD3, and BAD4 also exhibit strong performance, with MSE values of 2.5162, 2.8647, and 2.9447, respectively, indicating their effectiveness as well. Notably, BAD4 achieves the lowest regression coefficient estimates, suggesting high precision and stability.
The robust performance of BAD6, followed closely by BAD1 and BAD4, suggests that these novel estimators provide a reliable alternative to traditional methods, particularly in datasets affected by multicollinearity and outliers. The bolded values indicate the estimators with the minimum MSE, further emphasizing the effectiveness of BAD estimators in this empirical case study.
To compare the statistical properties of estimators, the 95% CI was computed for each regression coefficient under OLS, ridge regression, robust ridge, and two-parameter robust ridge regression. The confidence intervals were constructed using asymptotic variance–covariance matrices. The variance–covariance matrix for OLS is given by
and for RR, by
The standard errors (SE) were obtained from the diagonal elements of these matrices, and the 95% CIs were obtained as follows:
where , is the quantile of Student’s t-distribution with n − 1 degrees of freedom.
The 95% CIs for the predictors are presented in Table 8. We denote and as the lower and upper bounds of the confidence interval, respectively [10].
Table 8.
Confidence intervals (95%) for tobacco data.
In Table 8, where the CI values are presented, it is clear that traditional estimators such as OLS, HK, HKB, LC, and RM exhibit wide ranges, reflecting higher variability and lower precision. KAM and KMS provide somewhat narrower bounds, with KMS showing improved stability compared to OLS. The shrinkage-type estimators (ST, SH1–SH6) considerably reduce interval widths, with SH2–SH5 in particular producing highly compact bounds that suggest strong reliability. Most notably, the BAD family (BAD1–BAD6) achieves the narrowest intervals overall, with BAD4 displaying the smallest and most consistent ranges across all coefficients, marking it as the most precise and stable estimator among those compared.
Figure 3 illustrates a response plot using the BAD4 estimator. It shows the relationship between the fitted values (predicted values) and the observed values of a variable Y. The x-axis represents the fitted values () from BAD4, which are the predicted values from a statistical model using a BAD4 estimator. The y-axis represents the observed Y, which are the actual data points. The plot illustrates how well the BAD4 estimator fits the data while highlighting potential outliers. Most points (blue) align with the model’s predictions, indicating a good overall fit. One point’s X-outlier (orange) stands out with unusually high leverage. This diagnostic tool helps to visually identify influential observations that may affect model performance.
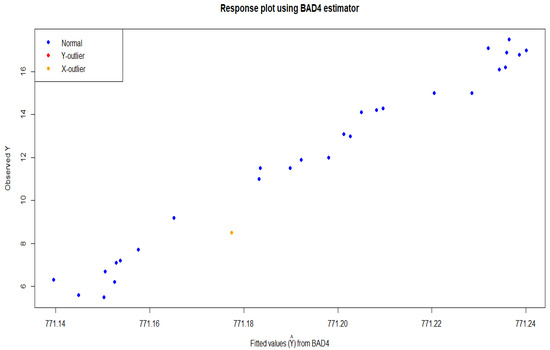
Figure 3.
Diagnosis of influential observation and BAD4 estimator.
4.2. Gasoline Consumption Data
To further evaluate the performance of the proposed estimators under severe multicollinearity with y-direction outliers, the Gasoline Consumption dataset was analyzed [33]. This dataset comprises 30 automobile models, with fuel consumption (miles per gallon, y) as the response variable and four predictors: displacement (X1), horsepower (X2), torque (X3), and width (X4). The linear regression model is expressed as follows:
The eigen values (λ1 = 3.606, λ2 = 0.335, λ3 = 0.052, λ4 = 0.007) yield a condition number of 531.128 and a condition index of 23.046, confirming severe multicollinearity. Outlier detection using Cook’s distance identified observations 8 and 24 (values 0.01 and 0.00, respectively) as having negligible influence on regression estimates. Correlation analysis (Figure 4) revealed strong positive associations among predictors, while gasoline consumption showed a moderate negative relationship with all explanatory variables.
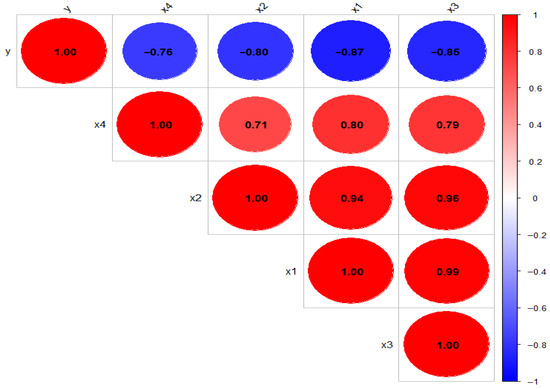
Figure 4.
Pairwise correlation between variables of gasoline consumption data.
The results in Table 8 demonstrate that the proposed estimators significantly outperform OLS and RM, which yield very high MSE values (41.67 and 43.39, respectively), indicating poor predictive accuracy under multicollinearity and outliers. In contrast, estimators such as BAD2 (MSE = 1.9266), BAD3 (MSE = 1.9338), and BAD5 (MSE = 1.9339) achieve the lowest MSE values, demonstrating superior efficiency.
Table 9 below demonstrates that in the case of severe multicollinearity along with outliers, as in the gasoline consumption data, all the BAD estimators perform well compared to other traditional and newly developed TPREs, among which the BAD2 estimator outperforms all the others with a lower MSE; the same results are presented in a bar chart (Figure 5).
Table 9.
Estimated regression coefficients and MSE of gasoline consumption data.
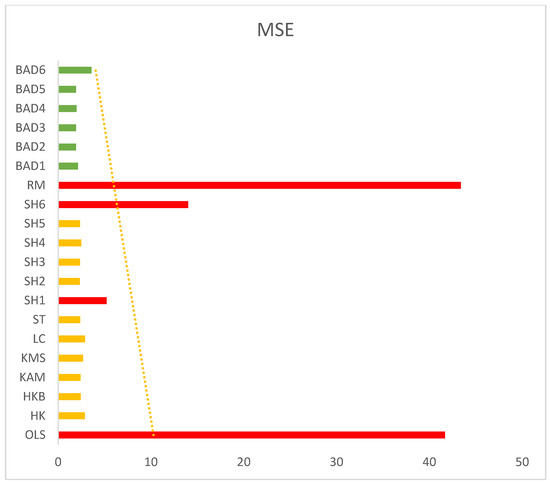
Figure 5.
Estimated MSE of OLS, RR, TPRR, and TPRRE on gasoline consumption data.
Table 10 present the 95% CI results for the proposed estimator, and demonstrate that the most striking results come from the BAD estimators (BAD1–BAD6), which consistently generate extremely narrow and stable confidence intervals. Among them, BAD4 demonstrates the smallest and most uniform ranges for all coefficients, establishing it as the most precise and reliable estimator for the gasoline consumption data.
Table 10.
Confidence intervals (95%) for gasoline consumption data.
5. Some Concluding Remarks
This study presented a comparative analysis of traditional regression estimators (OLS), one-parameter ridge estimators and recently proposed two-parameter ridge estimators (SH1–SH6), traditional robust ridge, and a novel class of Two-Parameter Robust Ridge M-Estimators (BAD1–BAD6). Both simulation experiments and real-life datasets (Tobacco and Gasoline Consumption) were used to evaluate performance, with MSE serving as the primary criterion. The findings demonstrate that OLS is highly sensitive to multicollinearity and outliers, producing unstable and inefficient estimates under such conditions. Recently developed two-parameter ridge estimators improved estimation accuracy over classical ridge forms by introducing an additional shrinkage parameter, yet they remain vulnerable to extreme data contamination. Robust ridge estimators demonstrated resilience to outliers, but were less efficient under severe multicollinearity. In contrast, the proposed BAD series of Two-Parameter Robust Ridge M-Estimators successfully integrates the dual benefits of robustness and efficiency. Specifically, BAD2, BAD4, and BAD6 consistently achieved the lowest MSE values across diverse scenarios, showing greater stability compared to both earlier two-parameter ridge estimators and robust single-parameter methods. These results provide justification for the theoretical superiority and practical utility of the proposed class.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/stats8040084/s1: Table S1. Estimated MSE with , , and 10% outliers in the y-direction. Table S2. Estimated MSE with , , and 20% outliers in the y-direction. Table S3. Estimated MSE with , , and 10% outliers in the y-direction. Table S4. Estimated MSE with , , and 20% outliers in the y-direction. Table S5. Estimated MSE with , , and 10% outliers in the y-direction. Table S6. Estimated MSE with , , and 20% outliers in the y-direction. Table S7. Estimated MSE with , , and 10% outliers in the y-direction. Table S8. Estimated MSE with , , and 20% outliers in the y-direction.
Author Contributions
B.H. contributed to the methodology, data analysis, and manuscript writing. S.M.A. supervised the research work. D.W. co-supervised the research and developed the R code. B.M.G.K. provided proofreading of the final manuscript and addressed the reviewers’ comments. All authors have read and agreed to the published version of the manuscript.
Funding
This study receives no external fund.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request. Further, no experiments on humans and/or use of human tissue samples were involved in this study.
Acknowledgments
The authors are thankful to the editors and reviewers for their valuable comments and suggestions, which have certainly helped to improve the quality and presentation of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mao, S. Statistical Derivation of Linear Regression. In International Conference on Statistics, Applied Mathematics, and Computing Science (CSAMCS 2021); SPIE: Bellingham, WA, USA, 2022; Volume 12163, pp. 893–901. [Google Scholar]
- Maulud, D.; Abdulazeez, A.M. A Review on Linear Regression Comprehensive in Machine Learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Lukman, A.F.; Mohammed, S.; Olaluwoye, O.; Farghali, R.A. Handling Multicollinearity and Outliers in Logistic Regression Using the Robust Kibria–Lukman Estimator. Axioms 2024, 14, 19. [Google Scholar] [CrossRef]
- Lukman, A.F.; Jegede, S.L.; Bellob, A.B.; Binuomote, S.; Haadi, A. Modified Ridge-Type Estimator with Prior Information. Int. J. Eng. Res. Technol. 2019, 12, 1668–1676. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Mermi, S.; Göktaş, A.; Akkuş, Ö. How Well Do Ridge Parameter Estimators Proposed so Far Perform in Terms of Normality, Outlier Detection, and MSE Criteria? Commun. Stat. Comput. 2024. [Google Scholar] [CrossRef]
- Lipovetsky, S.; Conklin, W.M. Ridge Regression in Two-Parameter Solution. Appl. Stoch. Model. Bus. Ind. 2005, 21, 525–540. [Google Scholar] [CrossRef]
- Toker, S.; Kaçiranlar, S. On the Performance of Two Parameter Ridge Estimator under the Mean Square Error Criterion. Appl. Math. Comput. 2013, 219, 4718–4728. [Google Scholar] [CrossRef]
- Abdelwahab, M.M.; Abonazel, M.R.; Hammad, A.T.; El-Masry, A.M. Modified Two-Parameter Liu Estimator for Addressing Multicollinearity in the Poisson Regression Model. Axioms 2024, 13, 46. [Google Scholar] [CrossRef]
- Alharthi, M.F.; Akhtar, N. Modified Two-Parameter Ridge Estimators for Enhanced Regression Performance in the Presence of Multicollinearity: Simulations and Medical Data Applications. Axioms 2025, 14, 527. [Google Scholar] [CrossRef]
- Shakir, M.; Ali, A.; Suhail, M.; Sadun, E. On the Estimation of Ridge Penalty in Linear Regression: Simulation and Application. Kuwait J. Sci. 2024, 51, 100273. [Google Scholar] [CrossRef]
- Khan, M.S. Adaptive Penalized Regression for High-Efficiency Estimation in Correlated Predictor Settings: A Data-Driven Shrinkage Approach. Mathematics 2025, 13, 2884. [Google Scholar] [CrossRef]
- Silvapulle, M.J. Robust Ridge Regression Based On An M-Estimator. Austral. J. Stat. 1991, 33, 319–333. [Google Scholar]
- Hoerl, A.E.; Kannard, R.W.; Baldwin, K.F. Ridge Regression: Some Simulations. Commun. Stat. Methods 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Lawless, J.F.; Wang, P. A Simulation Study Of Ridge And Other Regression Estimators. Commun. Stat.—Theory Methods 1976, 5, 307–323. [Google Scholar] [CrossRef]
- Begashaw, G.B.; Yohannes, Y.B. Review of Outlier Detection and Identifying Using Robust Regression Model. Int. J. Syst. Sci. Appl. Math. 2020, 5, 4–11. [Google Scholar] [CrossRef]
- Majid, A.; Ahmad, S.; Aslam, M.; Kashif, M. A Robust Kibria–Lukman Estimator for Linear Regression Model to Combat Multicollinearity and Outliers. Concurr. Comput. Pract. Exp. 2023, 35, e7533. [Google Scholar] [CrossRef]
- Suhail, M.; Chand, S.; Aslam, M. New Quantile Based Ridge M-Estimator for Linear Regression Models with Multicollinearity and Outliers. Commun. Stat. Simul. Comput. 2023, 52, 1418–1435. [Google Scholar] [CrossRef]
- Wasim, D.; Suhail, M.; Albalawi, O.; Shabbir, M. Weighted Penalized M-Estimators in Robust Ridge Regression: An Application to Gasoline Consumption Data. J. Stat. Comput. Simul. 2024, 94, 3427–3456. [Google Scholar] [CrossRef]
- Ertaş, H.; Toker, S.; Kaçıranlar, S. Robust Two Parameter Ridge M-Estimator for Linear Regression. J. Appl. Stat. 2015, 42, 1490–1502. [Google Scholar] [CrossRef]
- Yasin, S.; Salem, S.; Ayed, H.; Kamal, S.; Suhail, M.; Khan, Y.A. Modified Robust Ridge M-Estimators in Two-Parameter Ridge Regression Model. Math. Probl. Eng. 2021, 2021, 1845914. [Google Scholar] [CrossRef]
- Wasim, D.; Khan, S.A.; Suhail, M. Modified Robust Ridge M-Estimators for Linear Regression Models: An Application to Tobacco Data. J. Stat. Comput. Simul. 2023, 93, 2703–2724. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistical Procedures; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Applications to Nonorthogonal Problems. Technometrics 1970, 12, 69–82. [Google Scholar] [CrossRef]
- Kibria, B.M.G. Performance of Some New Ridge Regression Estimators. Commun. Stat. Part B Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Khalaf, G.; Mansson, K.; Shukur, G. Modified Ridge Regression Estimators. Commun. Stat.—Theory Methods 2013, 42, 1476–1487. [Google Scholar] [CrossRef]
- Dar, I.S.; Chand, S.; Shabbir, M.; Kibria, B.M.G. Condition-Index Based New Ridge Regression Estimator for Linear Regression Model with Multicollinearity. Kuwait J. Sci. 2023, 50, 91–96. [Google Scholar] [CrossRef]
- Ali, A.; Suhail, M.; Awwad, F.A. On the Performance of Two-Parameter Ridge Estimators for Handling Multicollinearity Problem in Linear Regression: Simulation and Application. AIP Adv. 2023, 13, 115208. [Google Scholar] [CrossRef]
- Ertaş, H. A Modified Ridge M-Estimator for Linear Regression Model with Multicollinearity and Outliers. Commun. Stat. Simul. Comput. 2018, 47, 1240–1250. [Google Scholar] [CrossRef]
- Suhail, M.; Chand, S.; Kibria, B.M.G. Quantile-Based Robust Ridge m-Estimator for Linear Regression Model in Presence of Multicollinearity and Outliers. Commun. Stat. Simul. Comput. 2021, 50, 3194–3206. [Google Scholar] [CrossRef]
- Wasim, D.; Khan, S.A.; Suhail, M.; Shabbir, M. New Penalized M-Estimators in Robust Ridge Regression: Real Life Applications Using Sports and Tobacco Data. Commun. Stat. Simul. Comput. 2025, 54, 1746–1765. [Google Scholar] [CrossRef]
- Myers, R.H.; Sliema, B. Classical and Modern Regression with Applications; Duxbury Thomson Learning: Pacific Grove, CA, USA, 1990. [Google Scholar]
- Babar, I.; Ayed, H.; Chand, S.; Suhail, M.; Khan, Y.A.; Marzouki, R. Modified Liu Estimators in the Linear Regression Model: An Application to Tobacco Data. PLoS ONE 2021, 16, e0259991. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).