
Optimal Estimators of Cross-Partial Derivatives and Surrogates of Functions

Abstract
1. Introduction
- Are simple to use and generic by making use of d independent variables that are symmetrically distributed about zero and a set of constraints;
- Lead to dimension-free upper bounds of the biases related to the approximations of cross-partial derivatives for a wide class of functions;
- Provide estimators of cross-partial derivatives that reach the optimal and parametric rates of convergence;
- Can be used for computing all the cross-partial derivatives and emulators of functions at given points using a small number of model runs.
2. Preliminary
3. Surrogates of Cross-Partial Derivatives and New Emulators of Functions
3.1. New Expressions of Cross-Partial Derivatives
- Denote . The reals s are used for controlling the order of derivatives (i.e., ) we are interested in, while s help in selecting one particular derivative of order . Finally, s aim at defining a neighborhood of a sample point of that will be used. Thus, using and keeping in mind the variance of , we assume that
3.2. Upper Bounds of Biases
3.3. Convergence Analysis
3.4. Derivative-Based Emulators of Smooth Functions
4. Applications: Computing Sensitivity Indices
5. Illustrations: Screening and Emulators of Models
5.1. Test Functions
5.1.1. Ishigami’s Function ()
5.1.2. Sobol’s g-Function ()
- If , the values of sensitivity indices are , , , , and , . Thus, this function has a low effective dimension (function of type A), and it belongs to with (see Section 3.4).
- If , the first and total indices are given as follows: , . Thus, all inputs are important, but there is no interaction among these inputs. This function has a high effective dimension (function of type B). Note that it belongs to .
- If , the function belongs to the class of functions with important interactions among inputs. Indeed, we have and , . All the inputs are relevant due to important interactions (function of type C). Then, this function belongs to with .
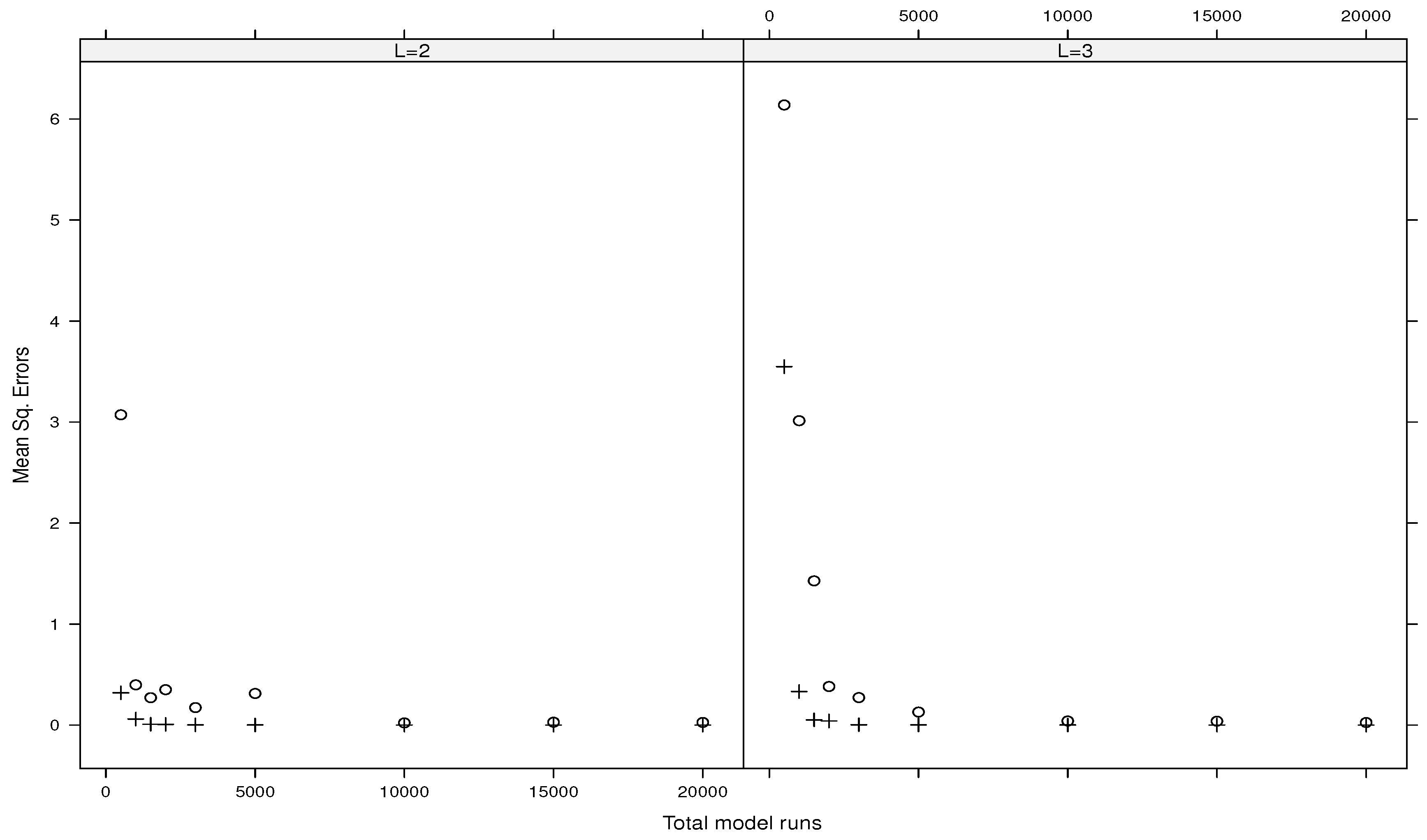
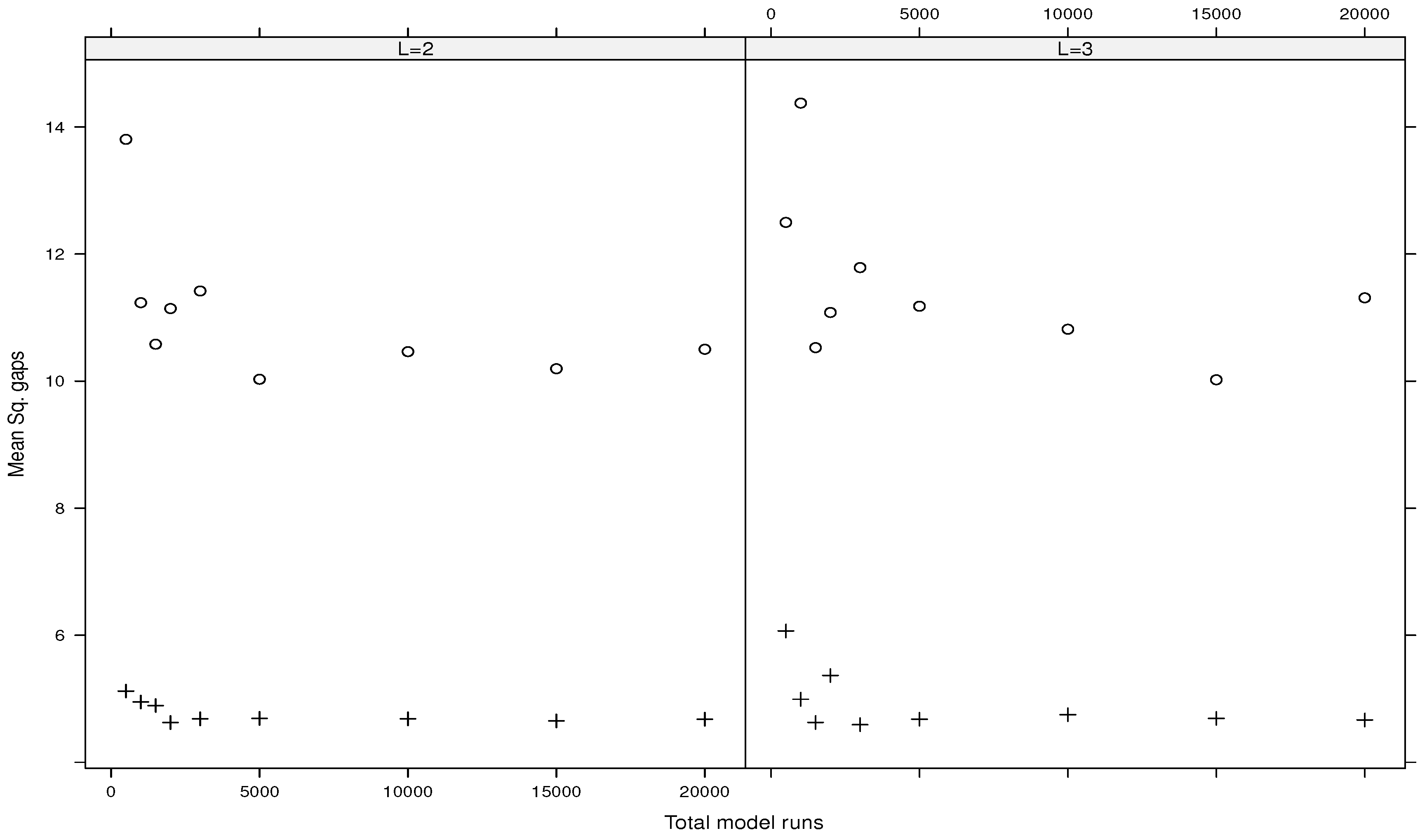
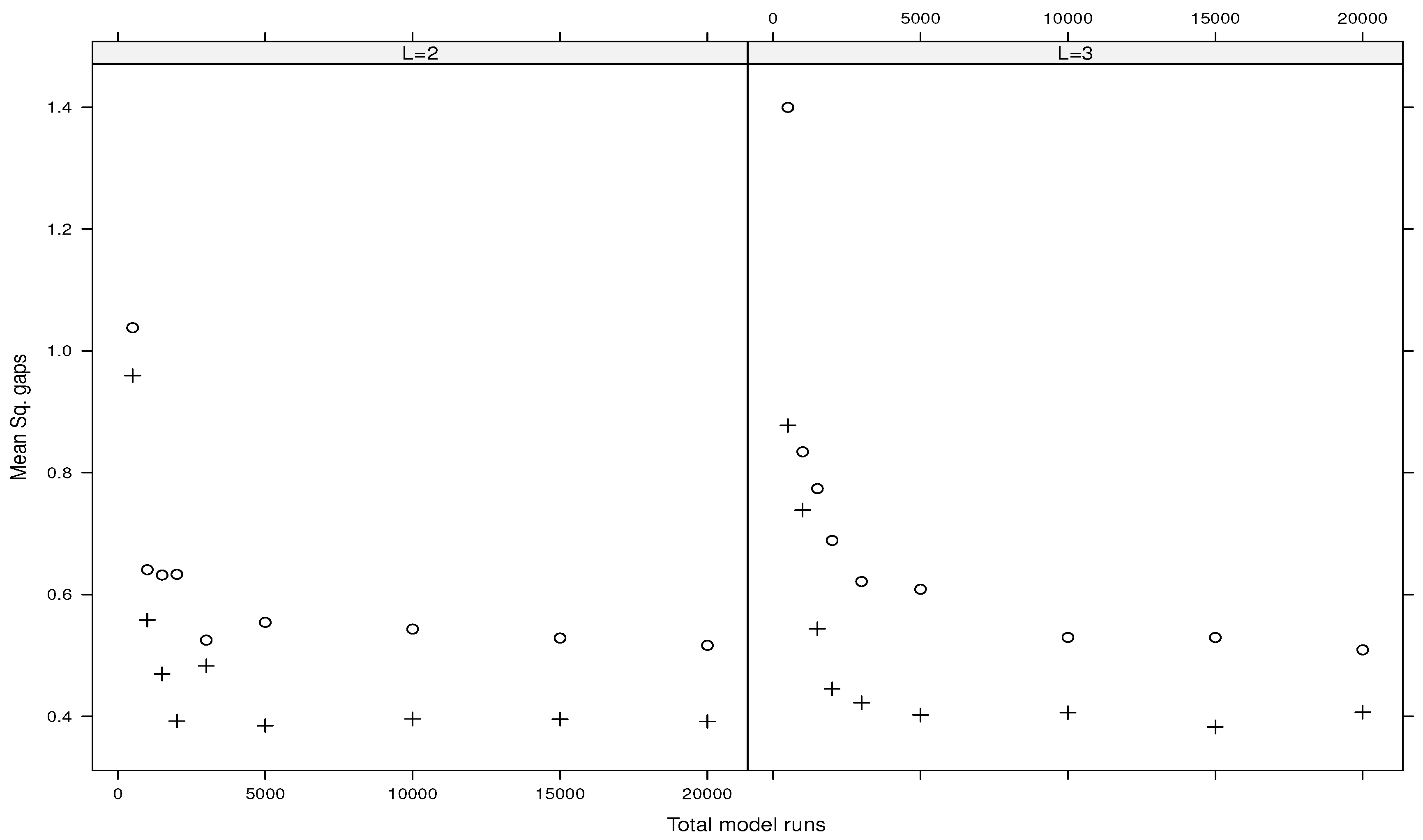
5.2. Numerical Comparisons of Estimators
5.3. Emulations of the g-Function of Type B
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Corollary 1
- Let , , and consider the set . As , the expansion of giveswith the remainder term . Thus, and
Appendix C. Proof of Corollary 2
- Let . As , we can writewith the remainder term . Using and Theorem 1, the results hold by analogy to the proof of Corollary 1. Indeed, if , then
Appendix D. Proof of Theorem 2
Appendix E. Proof of Corollary 3
Appendix F. Proof of Theorem 3
Appendix G. On Remark 6
References
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Fabian, V. Stochastic approximation. In Optimizing Methods in Statistics; Elsevier: Amsterdam, The Netherlands, 1971; pp. 439–470. [Google Scholar]
- Nemirovsky, A.; Yudin, D. Problem Complexity and Method Efficiency in Optimization; Wiley & Sons: New York, NY, USA, 1983. [Google Scholar]
- Polyak, B.; Tsybakov, A. Optimal accuracy orders of stochastic approximation algorithms. Probl. Peredachi Inf. 1990, 2, 45–53. [Google Scholar]
- Cristea, M. On global implicit function theorem. J. Math. Anal. Appl. 2017, 456, 1290–1302. [Google Scholar] [CrossRef]
- Lamboni, M. Derivative formulas and gradient of functions with non-independent variables. Axioms 2023, 12, 845. [Google Scholar] [CrossRef]
- Morris, M.D.; Mitchell, T.J.; Ylvisaker, D. Bayesian design and analysis of computer experiments: Use of derivatives in surface prediction. Technometrics 1993, 35, 243–255. [Google Scholar] [CrossRef]
- Solak, E.; Murray-Smith, R.; Leithead, W.; Leith, D.; Rasmussen, C. Derivative observations in Gaussian process models of dynamic systems. In Advances in Neural Information Processing Systems 15; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Hoeffding, W. A class of statistics with asymptotically normal distribution. Ann. Math. Stat. 1948, 19, 293–325. [Google Scholar] [CrossRef]
- Efron, B.; Stein, C. The jacknife estimate of variance. Ann. Stat. 1981, 9, 586–596. [Google Scholar] [CrossRef]
- Sobol, I.M. Sensitivity analysis for non-linear mathematical models. Math. Model. Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- Rabitz, H. General foundations of high dimensional model representations. J. Math. Chem. 1999, 25, 197–233. [Google Scholar] [CrossRef]
- Saltelli, A.; Chan, K.; Scott, E. Variance-Based Methods, Probability and Statistics; John Wiley and Sons: Hoboken, NJ, USA, 2000. [Google Scholar]
- Lamboni, M. Weak derivative-based expansion of functions: ANOVA and some inequalities. Math. Comput. Simul. 2022, 194, 691–718. [Google Scholar] [CrossRef]
- Currin, C.; Mitchell, T.; Morris, M.; Ylvisaker, D. Bayesian prediction of deterministic functions, with applications to the design and analysis of computer experiments. J. Am. Stat. Assoc. 1991, 86, 953–963. [Google Scholar] [CrossRef]
- Oakley, J.E.; O’Hagan, A. Probabilistic sensitivity analysis of complex models: A bayesian approach. J. R. Stat. Soc. Ser. B Stat. Methodol. 2004, 66, 751–769. [Google Scholar] [CrossRef]
- Conti, S.; O’Hagan, A. Bayesian emulation of complex multi-output and dynamic computer models. J. Stat. Plan. Inference 2010, 140, 640–651. [Google Scholar] [CrossRef]
- Haylock, R.G.; O’Hagan, A.; Bernardo, J.M. On inference for outputs of computationally expensive algorithms with uncertainty on the inputs. In Bayesian Statistics 5: Proceedings of the Fifth Valencia International Meeting; Oxford Academic: Oxford, UK, 1996; Volume 5, pp. 629–638. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Bayesian calibration of computer models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 425–464. [Google Scholar] [CrossRef]
- Sudret, B. Global sensitivity analysis using polynomial chaos expansions. Reliab. Eng. Syst. Saf. 2008, 93, 964–979. [Google Scholar] [CrossRef]
- Wahba, G. An introduction to (smoothing spline) anova models in rkhs with examples in geographical data, medicine, atmospheric science and machine learning. arXiv 2004, arXiv:math/0410419. [Google Scholar] [CrossRef]
- Sobol, I.M.; Kucherenko, S. Derivative based global sensitivity measures and the link with global sensitivity indices. Math. Comput. Simul. 2009, 79, 3009–3017. [Google Scholar] [CrossRef]
- Kucherenko, S.; Rodriguez-Fernandez, M.; Pantelides, C.; Shah, N. Monte Carlo evaluation of derivative-based global sensitivity measures. Reliab. Eng. Syst. Saf. 2009, 94, 1135–1148. [Google Scholar] [CrossRef]
- Lamboni, M.; Iooss, B.; Popelin, A.-L.; Gamboa, F. Derivative-based global sensitivity measures: General links with Sobol’ indices and numerical tests. Math. Comput. Simul. 2013, 87, 45–54. [Google Scholar] [CrossRef]
- Roustant, O.; Fruth, J.; Iooss, B.; Kuhnt, S. Crossed-derivative based sensitivity measures for interaction screening. Math. Comput. Simul. 2014, 105, 105–118. [Google Scholar] [CrossRef]
- Lamboni, M. Derivative-based generalized sensitivity indices and Sobol’ indices. Math. Comput. Simul. 2020, 170, 236–256. [Google Scholar] [CrossRef]
- Lamboni, M.; Kucherenko, S. Multivariate sensitivity analysis and derivative-based global sensitivity measures with dependent variables. Reliab. Eng. Syst. Saf. 2021, 212, 107519. [Google Scholar] [CrossRef]
- Lamboni, M. Measuring inputs-outputs association for time-dependent hazard models under safety objectives using kernels. Int. J. Uncertain. Quantif. 2024, 1–17. [Google Scholar] [CrossRef]
- Lamboni, M. Kernel-based measures of association between inputs and outputs using ANOVA. Sankhya A 2024. [CrossRef]
- Russi, T.M. Uncertainty Quantification with Experimental Data and Complex System Models; Spring: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Constantine, P.; Dow, E.; Wang, S. Active subspace methods in theory and practice: Applications to kriging surfaces. SIAM J. Sci. Comput. 2014, 36, 1500–1524. [Google Scholar] [CrossRef]
- Zahm, O.; Constantine, P.G.; Prieur, C.; Marzouk, Y.M. Gradient-based dimension reduction of multivariate vector-valued functions. SIAM J. Sci. Comput. 2020, 42, A534–A558. [Google Scholar] [CrossRef]
- Kucherenko, S.; Shah, N.; Zaccheus, O. Application of Active Subspaces for Model Reduction and Identification of Design Space; Springer: Berlin/Heidelberg, Germany, 2024; pp. 412–418. [Google Scholar]
- Kubicek, M.; Minisci, E.; Cisternino, M. High dimensional sensitivity analysis using surrogate modeling and high dimensional model representation. Int. J. Uncertain. Quantif. 2015, 5, 393–414. [Google Scholar] [CrossRef]
- Kuo, F.; Sloan, I.; Wasilkowski, G.; Woźniakowski, H. On decompositions of multivariate functions. Math. Comput. 2010, 79, 953–966. [Google Scholar] [CrossRef]
- Bates, D.; Watts, D. Relative curvature measures of nonlinearity. J. Royal Stat. Soc. Ser. B 1980, 42, 1–25. [Google Scholar] [CrossRef]
- Guidotti, E. calculus: High-dimensional numerical and symbolic calculus in R. J. Stat. Softw. 2022, 104, 1–37. [Google Scholar] [CrossRef]
- Le Dimet, F.-X.; Talagrand, O. Variational algorithms for analysis and assimilation of meteorological observations: Theoretical aspects. Tellus A Dyn. Meteorol. Oceanogr. 1986, 38, 97–110. [Google Scholar] [CrossRef]
- Le Dimet, F.X.; Ngodock, H.E.; Luong, B.; Verron, J. Sensitivity analysis in variational data assimilation. J. Meteorol. Soc. Jpn. 1997, 75, 245–255. [Google Scholar] [CrossRef]
- Cacuci, D.G. Sensitivity and Uncertainty Analysis—Theory, Chapman & Hall; CRC: Boca Raton, FL, USA, 2005. [Google Scholar]
- Gunzburger, M.D. Perspectives in Flow Control and Optimization; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Borzi, A.; Schulz, V. Computational Optimization of Systems Governed by Partial Differential Equations; SIAM: Philadelphia, PA, USA, 2012. [Google Scholar]
- Ghanem, R.; Higdon, D.; Owhadi, H. Handbook of Uncertainty Quantification; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Wang, Z.; Navon, I.M.; Le Dimet, F.-X.; Zou, X. The second order adjoint analysis: Theory and applications. Meteorol. Atmos. Phys. 1992, 50, 3–20. [Google Scholar] [CrossRef]
- Agarwal, A.; Dekel, O.; Xiao, L. Optimal algorithms for online convex optimization with multi-point bandit feedback. In Proceedings of the 23rd Conference on Learning Theory, Haifa, Israel, 27–29 June 2010; pp. 28–40. [Google Scholar]
- Bach, F.; Perchet, V. Highly-smooth zero-th order online optimization. In Proceedings of the 29th Annual Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; Feldman, V., Rakhlin, A., Shamir, O., Eds.; Volume 49, pp. 257–283. [Google Scholar]
- Akhavan, A.; Pontil, M.; Tsybakov, A.B. Exploiting Higher Order Smoothness in Derivative-Free Optimization and Continuous Bandits, NIPS’20; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Lamboni, M. Optimal and efficient approximations of gradients of functions with nonindependent variables. Axioms 2024, 13, 426. [Google Scholar] [CrossRef]
- Patelli, E.; Pradlwarter, H. Monte Carlo gradient estimation in high dimensions. Int. J. Numer. Methods Eng. 2010, 81, 172–188. [Google Scholar] [CrossRef]
- Prashanth, L.; Bhatnagar, S.; Fu, M.; Marcus, S. Adaptive system optimization using random directions stochastic approximation. IEEE Trans. Autom. Control. 2016, 62, 2223–2238. [Google Scholar]
- Agarwal, N.; Bullins, B.; Hazan, E. Second-order stochastic optimization for machine learning in linear time. J. Mach. Learn. Res. 2017, 18, 4148–4187. [Google Scholar]
- Zhu, J.; Wang, L.; Spall, J.C. Efficient implementation of second-order stochastic approximation algorithms in high-dimensional problems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3087–3099. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J. Hessian estimation via stein’s identity in black-box problems. In Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference, Online, 15–17 August 2022; Bruna, J., Hesthaven, J., Zdeborova, L., Eds.; Volume 145 of Proceedings of Machine Learning Research, PMLR. pp. 1161–1178. [Google Scholar]
- Erdogdu, M.A. Newton-stein method: A second order method for glms via stein’ s lemma. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Stein, C.; Diaconis, P.; Holmes, S.; Reinert, G. Use of exchangeable pairs in the analysis of simulations. Lect.-Notes-Monogr. Ser. 2004, 46, 1–26. [Google Scholar]
- Zemanian, A. Distribution Theory and Transform Analysis: An Introduction to Generalized Functions, with Applications, Dover Books on Advanced Mathematics; Dover Publications: Mineola, NY, USA, 1987. [Google Scholar]
- Strichartz, R. A Guide to Distribution Theory and Fourier Transforms, Studies in Advanced Mathematics; CRC Press: Boca, FL, USA, 1994. [Google Scholar]
- Rawashdeh, E. A simple method for finding the inverse matrix of Vandermonde matrix. Math. Vesn. 2019, 71, 207–213. [Google Scholar]
- Arafat, A.; El-Mikkawy, M. A fast novel recursive algorithm for computing the inverse of a generalized Vandermonde matrix. Axioms 2023, 12, 27. [Google Scholar] [CrossRef]
- Morris, M. Factorial sampling plans for preliminary computational experiments. Technometrics 1991, 33, 161–174. [Google Scholar] [CrossRef]
- Roustant, O.; Barthe, F.; Iooss, B. Poincaré inequalities on intervals-application to sensitivity analysis. Electron. J. Stat. 2017, 11, 3081–3119. [Google Scholar] [CrossRef]
- Lamboni, M. Multivariate sensitivity analysis: Minimum variance unbiased estimators of the first-order and total-effect covariance matrices. Reliab. Eng. Syst. Saf. 2019, 187, 67–92. [Google Scholar] [CrossRef]
- Homma, T.; Saltelli, A. Importance measures in global sensitivity analysis of nonlinear models. Reliab. Eng. Syst. Saf. 1996, 52, 1–17. [Google Scholar] [CrossRef]
- Dutang, C.; Savicky, P. R Package, version 1.13. Randtoolbox: Generating and Testing Random Numbers. The R Foundation: Vienna, Austria, 2013. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X1 | X2 | X3 | |
|---|---|---|---|
| 0.249 | 0.318 | −0.006 | |
| 1.420 | 4.872 | 0.711 |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Type A | ||||||||||
| 0.330 | 0.324 | 0.006 | 0.005 | 0.006 | 0.006 | 0.005 | 0.005 | 0.006 | 0.005 | |
| 2.022 | 2.005 | 0.045 | 0.046 | 0.047 | 0.047 | 0.046 | 0.046 | 0.046 | 0.047 | |
| Type B | ||||||||||
| 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 | |
| 0.362 | 0.363 | 0.363 | 0.362 | 0.363 | 0.362 | 0.363 | 0.362 | 0.363 | 0.363 | |
| Type C | ||||||||||
| 0.028 | 0.028 | 0.032 | 0.032 | 0.035 | 0.041 | 0.031 | 0.030 | 0.036 | 0.034 | |
| 2.033 | 1.301 | 1.825 | 1.605 | 1.634 | 1.641 | 2.216 | 1.526 | 1.793 | 1.503 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lamboni, M. Optimal Estimators of Cross-Partial Derivatives and Surrogates of Functions. Stats 2024, 7, 697-718. https://doi.org/10.3390/stats7030042
Lamboni M. Optimal Estimators of Cross-Partial Derivatives and Surrogates of Functions. Stats. 2024; 7(3):697-718. https://doi.org/10.3390/stats7030042
Chicago/Turabian StyleLamboni, Matieyendou. 2024. "Optimal Estimators of Cross-Partial Derivatives and Surrogates of Functions" Stats 7, no. 3: 697-718. https://doi.org/10.3390/stats7030042
APA StyleLamboni, M. (2024). Optimal Estimators of Cross-Partial Derivatives and Surrogates of Functions. Stats, 7(3), 697-718. https://doi.org/10.3390/stats7030042