Our two-stage method begins by estimating multivariate SRM parameters to obtain point estimates of covariance matrices at each level of interest (group, case, dyad), as well as estimates of their sampling (co)variances (i.e., ACOV). Stage 1 point estimates are then treated as input data to estimate SR-SEM parameters in Stage 2.
2.2.1. Stage 1: Estimate Multivariate SRM Parameters
Whereas Nestler [
30] proposed a Fisher-scoring algorithm to obtain ML estimates of multivariate SRM parameters (see Equations (
6)–(
8)), Stage 1 of our two-stage method utilizes MCMC estimation [
15,
31,
33] by employing a modified Hamiltonian Monte Carlo algorithm known as the No-U-Turn Sampler (NUTS) [
73], available in the general Bayesian modeling R package
rstan [
74,
75]. Unlike other MCMC methods such as Gibbs sampling, the NUTS simultaneously samples the entire vector of all unknown parameters from a multidimensional parameter space. A practical advantage over Gibbs sampling is that priors do not need to be conjugate, so researchers can specify prior distributions that are intuitive to interpret.
The unknown parameters in Stage 1 included the round-robin variable means, the level-specific random effects, and the
SDs of—and correlations among—the random effects. We used weakly informative priors to estimate the SRM distributional parameters (i.e., the mean vector and level-specific covariance matrices). Given the scale of the observed data (1–6 Likert scale, median of possible values = 3.5), we specified priors for the round-robin variable means as normal with unit variance, centered at
:
This prior reflects the belief that the mean is most likely to be in the range of 2.5–4.5 (68% of probability mass) and is relatively unlikely (though not impossible) to be near the endpoints of the scale. Viewing histograms of the round-robin variables easily confirms this is not unreasonable for these data.
As advised by Gelman [
76] and recommended by the Stan developers (who maintain a web page with recommendations and further reading about specifying priors:
https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations#prior-for-scale-parameters-in-hierarchical-models, accessed on 27 January 2024), the
SDs of level-specific random effects were specified with Student’s
distributions, truncated below at zero (so
SDs could not be negative). The kurtosis (
) is undefined due to division by 0 (thus approaches infinity in the limit), making it less restrictive than a truncated normal distribution about values being much larger than the mean. Simulation research has shown that this prior works well in variance-decomposition models [
77], and it is the default prior for scale parameters in the R package
brms [
78]. Stan provides location (
) and scale (
) parameters, to center the
t distribution at a different mean or to have greater variance. We selected scaling parameters for each variance component to reflect our prior belief (based on most empirical SRM research) that the majority of variance would be relationship-specific (i.e., at the dyad level). Given that the total variance of each round-robin variable was slightly greater than 1 (min = 1.05, max = 1.144), a
t distribution centered at 0.5 places a mode at nearly 50% of the total variance, but a scaling parameter of 0.5 still allows for a high prior probability that the relationship variance is as little as 0 or as large as 1 (which would be nearly 100% of the observed variance):
Given that the groups were formed by random assignment, we expected very little group-level variance, and so the prior mean of
was specified as quite small:
whereas we expected the person-level effects to have larger variance components (thus, higher prior means):
Priors for all
SDs were specified with scaling factors of
, making them only weakly informative because no variance component was precluded from being as small as 0 or as large as 1.
Priors for the group- and case-level correlation matrices (
, i.e., standardized covariance matrices
) were specified to follow an LKJ distribution [
79]:
A shape parameter
would imply a uniform distribution (i.e., all correlation matrices are equally likely, with values spanning
), whereas higher values of
correspond to distributions with a mode at the identity matrix (i.e., correlations of zero) and correlations distributed symmetrically around zero. Thus, a value of
is close to a uniform distribution but with a slightly higher probability of correlations being smaller than larger in absolute value. This expectation conforms to most published SRM results, where large correlations (
) are much rarer than small-to-moderate correlations. However, the “low” mode at the identity matrix is only weakly informative, so the posterior is overwhelmingly influenced by the data.
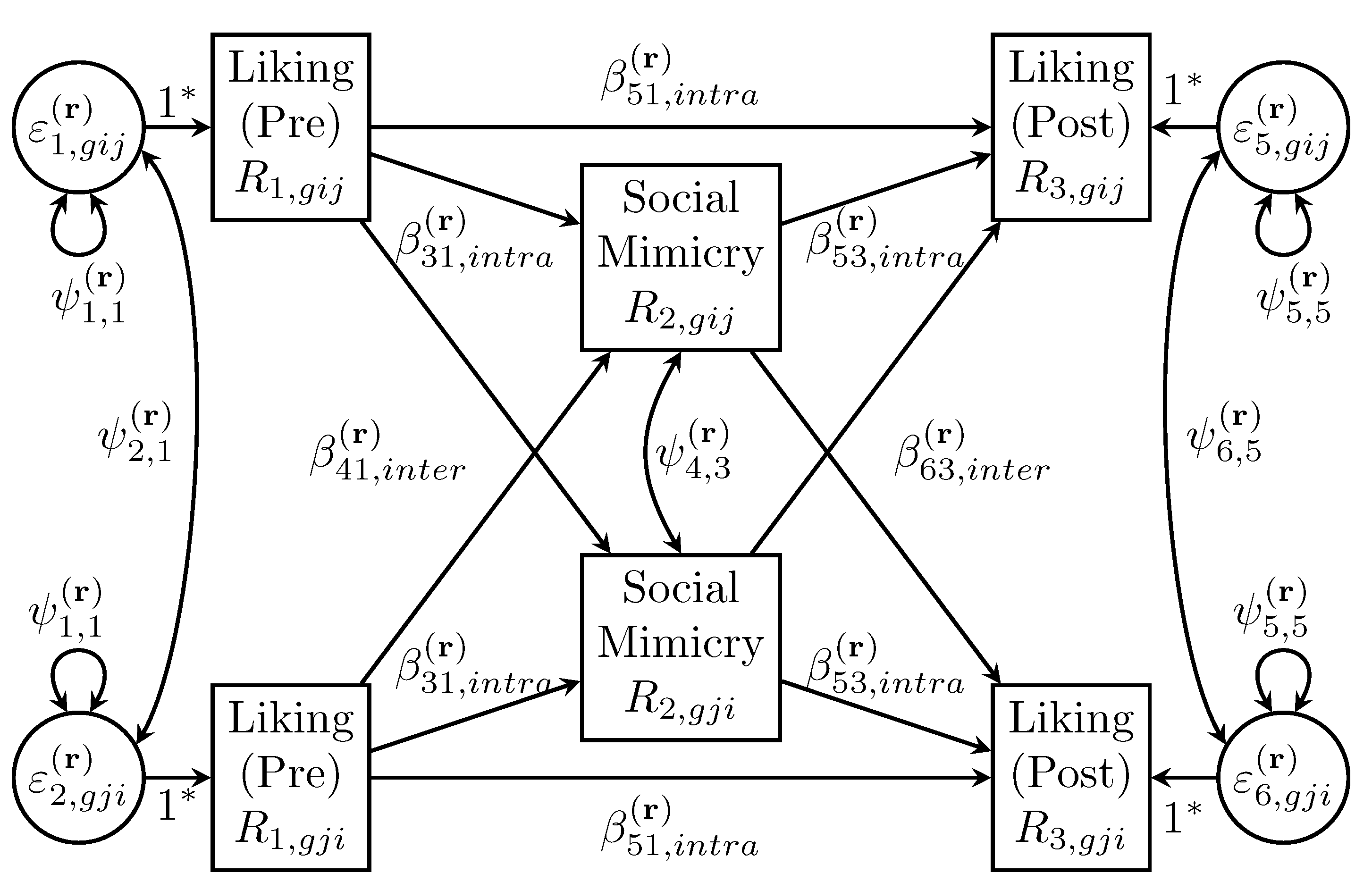
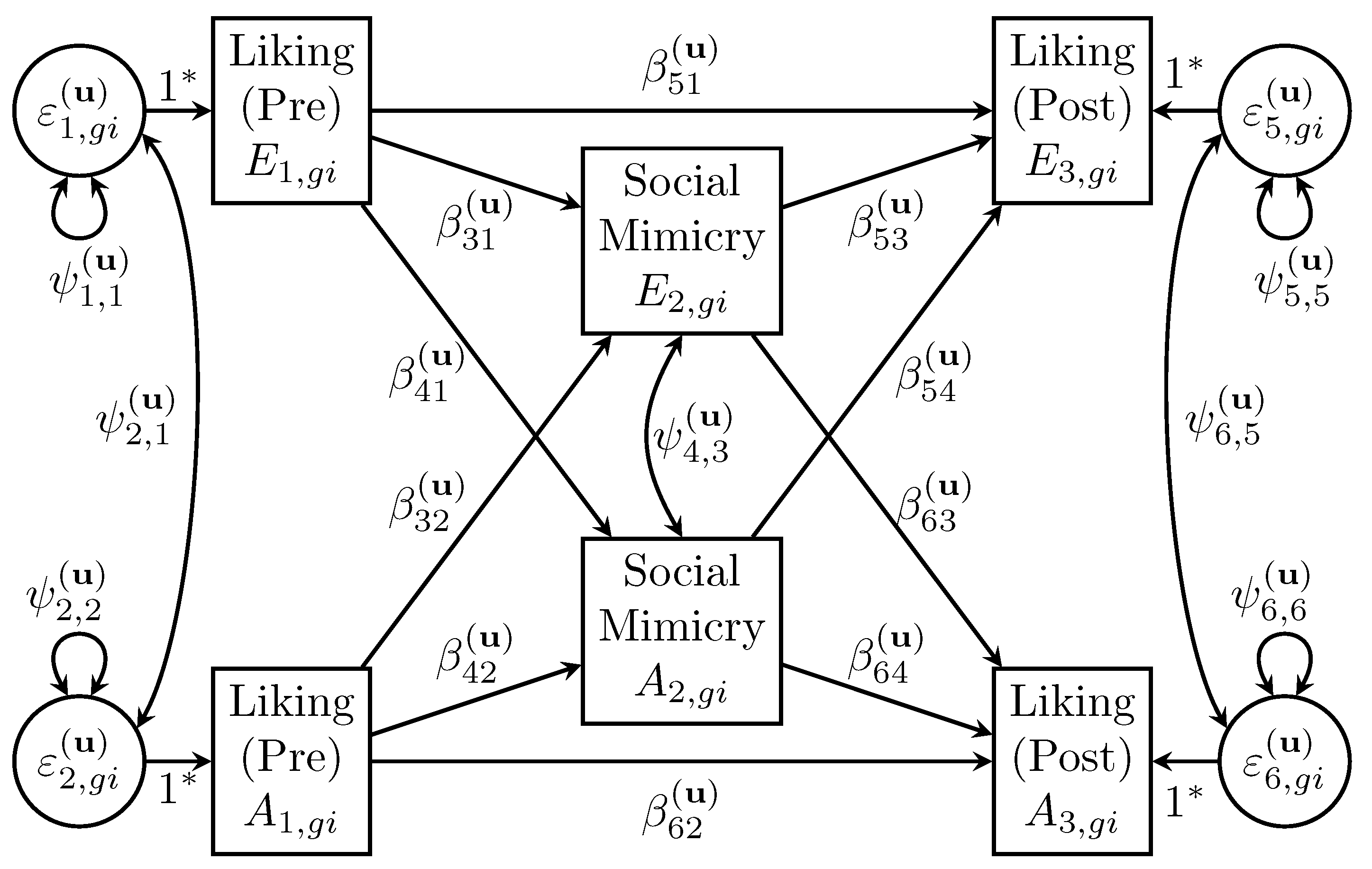
The dyad-level correlation matrix has several equality constraints reflecting indistinguishable dyads, whereas an LKJ prior’s only restriction is that the correlation matrix is positive definite. Given
V round-robin variables, the number of unique covariances
(=correlations in
) would be
and the number of unique covariances in
would be
. However, the number of unique covariances in
would be
, consisting of
V dyadic reciprocities (one per variable),
intrapersonal correlations between variables, and
interpersonal correlations between variables (e.g., Equation (
8)). An LKJ prior would not allow for these equality constraints, so a prior must be specified to sample each correlation separately, which are then scaled to covariances and placed into their appropriate positions in
. To maintain the requirement that
is positive definite, Lüdtke et al. [
7] proposed placing constraints on the determinants of its principle minors, as described by [
80]. Although this was shown to be feasible for bivariate models when using Gibbs sampling via WinBUGS [
7,
80], specifying such constraints for multivariate SRMs with arbitrary
becomes infeasibly tedious. Luckily, the
blavaan package [
81] has already demonstrated that the adaptive nature of Stan’s NUTS algorithm tends to “learn” quickly during the warm-up samples to avoid non-positive-definite (NPD) corners of the parameter space that lead to rejecting the sample.
Inspired by the priors used for correlations in the
blavaan package [
81], rescaled Beta distributions were specified as priors for all correlations at the dyad level:
A
distribution provides support on the
scale (rather than the usual
scale) by multiplying a sampled value by 2 then subtracting 1. A Beta prior with
corresponds to a perfectly uniform distribution, where larger shape parameters imply sharper peaks, remaining symmetric as long as
(implying the highest prior density at a correlation of 0). Our chosen shape parameters in Equation (
42) were 1.5, yielding very little density for extremely large absolute values of correlations. Specifically, the central 60% of probability density for a
distribution captures correlations of
, and the central 90% captures correlations of
. One can visualize this distribution with the R syntax:
curve(dbeta((x+1)/2, 1.5, 1.5), from = −1, to = 1). Thus, similar to the LKJ priors, the parameters of these Beta priors were specified such that there was a “low” mode at correlations of zero but were similar enough to a uniform distribution spanning
that posterior distributions were overwhelmingly influenced by the data.
Although it is possible to sample combinations of correlations that yield NPD correlation matrices, such samples are less likely given the slight prior restrictions on very large correlation values. Nonetheless, NPD matrices were frequent enough during the adaptation phase that the algorithm would fail before sampling. To avoid this, we chose to randomly sample starting values from a smaller range—drawn from a
distribution—rather than from Stan’s default
distribution, using the argument
init_r = 0.5 (see
Appendix B).
Hyperpriors for random effects parameters at the group and case levels were effectively the covariance matrices implied by the estimated correlations and
SDs (see Equations (
6) and (
7), respectively). However, as the Stan syntax in
Appendix A reveals, we achieved greater stability and computational efficiency in two ways. First, we used Stan’s Cholesky parameterization of the multinormal sampling function, which uses a Cholesky decomposition of the correlation matrix that we calculated in our Stan syntax. Second, we sampled random effects from multivariate standard-normal distributions (i.e., with unit variance). The sampled random effects were then multiplied by their respective
SDs when calculating expected values
for each dyadic observation:
Finally, each dyadic observation’s likelihood was specified as a multivariate normal distribution with mean vector equal to the expected values in Equation (
43):
where
is the dyad-level covariance matrix. As with the random effect hyperpriors, our Stan syntax in
Appendix A uses the Cholesky parameterization for computational efficiency. Note that when the vector of observations
is incomplete, the likelihood in Equation (
44) is also the prior for missing data that are sampled from the posterior (i.e., data augmentation; [
31,
33]).
Four chains of 5000 iterations—2500 burn-in and 2500 posterior samples—each were used to estimate the joint posterior distribution of model parameters, yielding 10,000 posterior samples for inference. Initial values for each Markov chain in Stage 1 were randomly sampled from a uniform distribution. Convergence was diagnosed by inspecting traceplots to verify adequate mixing. Effective posterior sample sizes were sufficiently large for all parameters (range: 282–10,100), and all parameters had a sufficiently small potential scale-reduction factor (PSRF [
82] or
). The multivariate PSRF [
83] was 1.03, which we deemed sufficiently small for the purposes of this demonstration. See
Appendix B for R syntax to fit the Stan model in
Appendix A.
2.2.2. Prepare Stage 1 Results for Stage 2 Input
Following MCMC estimation in
rstan, we calculated the covariance matrix implied by the estimated correlations and
SDs in each posterior sample (see
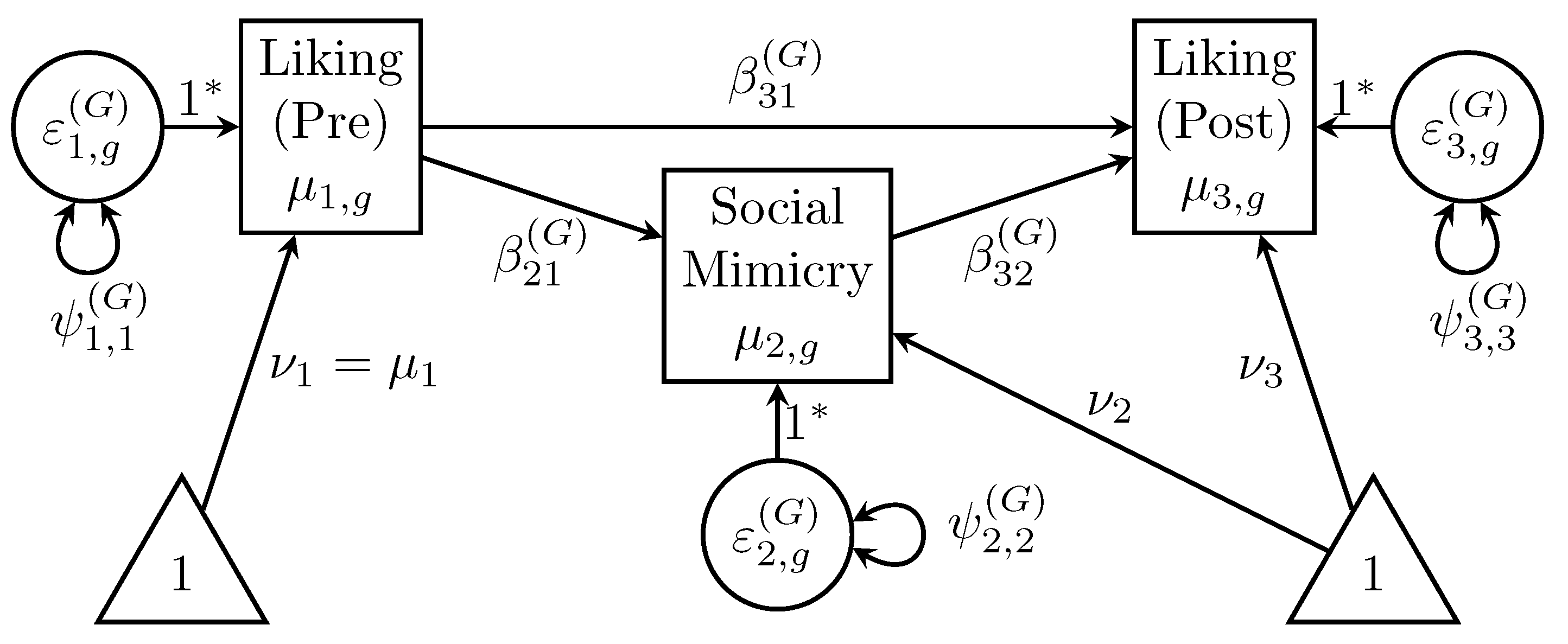
Appendix B.1). Point estimates were computed as the average of the estimated (co)variances across posterior samples—i.e., expected a posteriori (EAP) estimates. This is analogous to Rubin’s rules for pooled estimates across multiple imputations of missing data. The missing values in our example are latent variables (i.e., random effects, which are missing for all sampling units), and every posterior sample imputes (or “augments”) those missing values by sampling them from the posterior. However, our interest is not in those plausible-value estimates but in the summary statistics used as their hyperparameters. Thus, the Stage 1 output of interest includes three level-specific covariance matrices between the SRM components (and group-level means). Interpreting these multivariate SRM parameters might also be of substantive interest, in which case uncertainty about estimates can be quantified by computing credible intervals from the empirical posterior distribution.
Next, we prepare Stage 1 results for ML estimation of SR-SEM parameters in Stage 2 by adapting methods described in
Section 1.2.1 for efficient SEM estimation with multiple imputations. We must prepare point estimates (EAPs, as described above) of level-specific summary statistics to use as input data. To obtain
SEs and test statistics that account for the uncertainty of the estimated summary statistics, we must calculate
× ACOV, as we describe next.
When using multiple imputations of missing data,
Section 1.1.3 explained that two sources of uncertainty (complete- and missing-data sampling variance) must be pooled. This is because imputed data sets are analyzed using complete-data statistical methods after the incomplete data are imputed using a separate statistical model. The missing-data component (
B) then needs to be added to the complete-data component (
W) of overall sampling variance. Using MCMC makes this unnecessary because the missing data (random effects) are augmented during estimation of the parameters of interest, so the imputation and analysis models are concurrent.
Therefore, an estimate of the ACOV matrix is obtained simply by computing the posterior sampling (co)variances between the SRM mean and (co)variance parameters estimated in Stage 1. The calculation is conducted by arranging a data matrix with SRM parameters of interest in columns, and each row contains a sample from the posterior distribution. We then use scalar multiplication to obtain
by multiplying the level-specific ACOV by that level’s number of observations.
Appendix B.1 shows how the computation can be conducted in R for the dyad-level SRM parameters, which in our example had a dyad-level sample size of
observed interactions. Our OSF project (
https://osf.io/2qs5w/) provides R syntax for these calculations at the dyad, case, and group levels.
2.2.3. Stage 2: Estimate SR-SEM Parameters
Estimation of the SR-SEM parameters described in
Section 1.2.3 can proceed by passing Stage 1 estimated summary statistics as input data to standard SEM software. We used the R package
lavaan [
57] to separately specify and estimate a SEM for each level of analysis. It is also possible to specify a multilevel SR-SEM for multiple levels simultaneously by treating each level as an independent group in a multigroup SEM. We provide
lavaan syntax to specify a multilevel SR-SEM as a multigroup SEM in our OSF project (
https://osf.io/2qs5w/). Obtaining the true likelihood of the data would require constraints based on (average) network size, as suggested for ML-SEM estimation using “MuML” [
63]. Determining the weights needed to apply such constraints lies beyond the scope of the current work and is unnecessary given the use of a residual-based rather than likelihood-ratio test statistic [
10,
11]) by minimizing the usual ML discrepancy function:
where
p is the number of (components of) variables being modeled;
is the saturated-model Stage 1 estimate of a level-specific covariance matrix in Equations (
6), (
7), or (
8) (analogous to a sample covariance matrix
of observed variables in standard SEM); and
is a nested covariance matrix constrained as a function of estimated level-specific model parameters
(see Equations (
28), (
32), and (
36) for population formulae). Analogous mean-structure parameters
and
in the last added term of Equation (
45) are only an option in the group-level model (Equation (
28)). Note that the discrepancy function in Equation (
45) is applied to any level-specific summary statistics, so it is not equivalent to the likelihood function in Ref. [
8] (p. 877, Equation (
19)), which is defined for observed round-robin variables rather than for their latent components.
The
lavaan syntax to specify the structural model for the relations between the SRM components at the dyad level is presented in
Appendix C. Syntax to specify SR-SEMs at the group and case levels can be found in our OSF project (
https://osf.io/2qs5w/). In traditional SEM, there is no matrix of regression slopes among observed variables, only among latent variables (i.e.,
in Equation (
17)). However, when an observed variable
y is regressed on another in
lavaan model syntax,
lavaan implicitly “promotes” the observed variable to the latent space by treating it as a single-indicator factor (i.e.,
, so each
) without measurement error (i.e.,
, so each
). In
srm syntax for FIML (also provided in our OSF project:
https://osf.io/2qs5w/), the single-indicator factors must be specified explicitly to conduct a path analysis. In both
lavaan and
srm syntax, equality constraints representing indistinguishability can be specified by using the same label for multiple parameters (see
Appendix C).
The
matrix can be passed to the
lavaan() argument
NACOV= in order to obtain corrected
s for Stage 2 point estimates [
10,
11]; see Savalei [
60] for more details. The same
matrix is also used to calculate a residual-based test statistic [
59] to test the null hypothesis of equal
and saturated-model
matrices. The end of
Appendix C shows how to request
-based fit indices using the residual-based statistic, but we do not report fit indices here. Further research is warranted to investigate the sampling behavior of fit indices using this method. Other standard outputs are also available from
lavaan, such as standardized solutions to report effect sizes and correlation residuals to assist diagnosing model misspecification.













{kind=link}
{kind=link}
{kind=link}