Abstract
In this paper, we investigate a validation process in order to assess the predictive capabilities of a single degree-of-freedom oscillator. Model validation is understood here as the process of determining the accuracy with which a model can predict observed physical events or important features of the physical system. Therefore, assessment of the model needs to be performed with respect to the conditions under which the model is used in actual simulations of the system and to specific quantities of interest used for decision-making. Model validation also supposes that the model be trained and tested against experimental data. In this work, virtual data are produced from a non-linear single degree-of-freedom oscillator, the so-called oracle model, which is supposed to provide an accurate representation of reality. The mathematical model to be validated is derived from the oracle model by simply neglecting the non-linear term. The model parameters are identified via Bayesian updating. This calibration process also includes a modeling error due to model misspecification and modeled as a normal probability density function with zero mean and standard deviation to be calibrated.
1. Introduction
Quantifying uncertainty is a problem common to scientists dealing with mathematical models of physical processes. There are a wide range of numerical methods to solve systems of ordinary differential equations, such as the Euler method, higher-order Taylor methods, and Runge–Kutta methods. For systems of partial differential equations, we consider several numerical methods, such as finite difference, finite element, finite volume, and spectral methods to produce solutions to physical models based on differential equations. If numeral methods are used, the resulting solution is an approximation to the true underlying solution and usually consists of a single solution set when parameter and starting values are known and specified. However, in many processes there exist various sources of noise to the process. Aleatoric uncertainty is an “external error” which may take the form of measurement error or some other error associated with generating the solution. The key to external (Aleatoric) error is that the error exists on the solution set. Epistemic uncertainty is model uncertainty/misspecification uncertainty which exists in the formulation of the model. This can be a result of not accounting for various components of a model. Epistemic uncertainty can be considered “internal error” as it exists before the solution to the differential equation is generated. For a very good overview of Bayesian model calibration, see [1], as it addresses many of the issues associated when quantifying uncertainty for computer models, while, for quantifying uncertainty for differential equations models, see [2]. For a good reference for techniques dealing with model inadequacy, see [3], and for work on model misspecification and model order see [4].
These two different types of uncertainty are manifested in different ways. For example, external error is manifested by unstructured random noise about the solution set. In contrast, internal error is propagated through the differential equation solver and may manifest itself as structured changes in the solution set which is called uncertainty propagation [5]. To highlight this issue consider the simple differential equation with no uncertainty introduced:
this has the well known solution with initial condition :
To account for external error the solution to Equation (1) would be:
where follows some appropriate probability distribution. However, if we have internal error then Equation (1) would be:
where follows some appropriate probability distribution. Let be the solution to Equation (1), then if an external error is added to the model we have , where follows some appropriate probability distribution. One can see the effects of both types of errors in Figure 1.
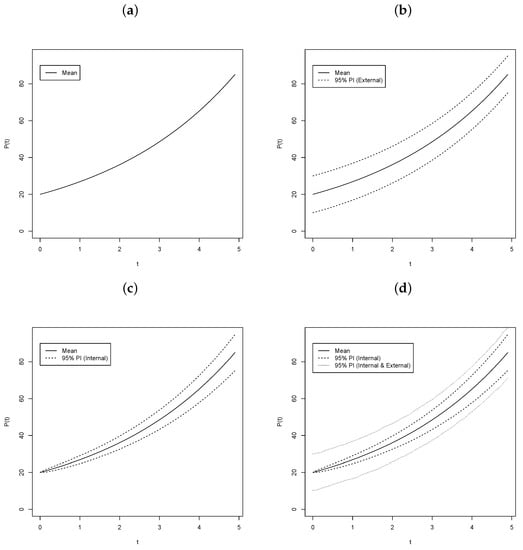
Figure 1.
Trajectoriesfor simple population growth equation with: No Error (a), External Error (b), Internal Error (c), and Internal and External Error (d).
To construct the plots in Figure 1, simulation was used to ensure that the error structure was correctly represented, using 10,000 simulations. In panel (a) of Figure 1, the trajectory for an exponential growth model with and , which contains no error. This subfigure shows exactly what one would expect. For panel (b), the exponential growth model with with external error . Notice that the error bands are virtually equidistant from the mean line. For panel (c), the exponential growth model the with internal error is plotted. In contrast to the external error only model the error bands increase in width as the time increases. Panel (d) shows the internal error with external error added to it. Notice that the internal plus external error is not simply and addition of the two error as might think. This phenomenon is our motivation for this research.
The question we focus on here is can a model be purposely misspecified in order to improve computation time while still accounting for uncertainty induced due to this misspecification? Model misspecification is an important question especially when using deterministic models as they are typically assumed to be correct [6]. To approach this problem the Bayesian framework will be used from a fully Bayesian perspective [7,8] as it allows for a natural method to quantify uncertainty from different sources.
Notation
We have two major steps producing attributes, e.g., forcing, displacement, velocity and acceleration. All attributes in the training step will be denoted by superscript while attributes in the validation step will not have any superscript. In each of the major step we have four different sets of attributes:
- The true unobserved attributes u, v, a produced by the system; i.e., the solution of the non-oracle differential equation using the true parameters , forcing f and no internal or external errors. This is our target.
- The observed attributes , , produced by the system; i.e., the solution of the non-oracle differential equation using the true parameters and the true forcing f with true external and internal errors added. This together with the forcing are our data.
- The fitted/predicted attributes , , , defined as the solution of either the oracle or non-oracle differential equation using estimated parameters , with predicted external and internal errors added.
- Attributes , , that are the solution of the oracle or non-oracle differential equation using estimated parameters with predicted internal and no external error added. These will be used for estimation of maximum.
2. Models
Suppose that the dynamics of a given system be modeled by an abstract initial-value problem:
with appropriate boundary conditions, where denotes the derivative of u with respect to the time variable t. Furthermore, we suppose that the function can be separated into lower- and higher-order dynamics, G and H, respectively, such as:
for some ℓ smaller than or equal to n and assume that the higher-order term H has smaller effects than the lower-order term for some values of the input parameters of the model. Due to the added complexity and computational cost associated with the solution of the higher-order dynamics model, one may want to introduce a misspecified model by retaining the lower-order dynamics in the following manner:
where is a random process governed by some probability distribution with mean 0 and variance . This model ignores the additional complexity of full model but accounts for the associated uncertainty through . In the following, we consider a non-linear single degree-of-freedom oscillator as the full model, which we will hereafter refer to as the oracle model, and a linear single degree-of-freedom oscillator as the misspecified model.
2.1. Non-Linear Single Degree-of-Freedom Oscillator
The displacement around the equilibrium position of a non-linear single degree-of-freedom oscillator is governed by:
where denotes the time-derivative of u, is the linear component of the spring stiffness coefficient, is the higher-order component of spring stiffness, m is the mass of the object attached to the spring, and is the damping coefficient. Moreover, the system is subjected to the external forcing and initial displacement and velocity .
A single degree-of-freedom oscillator is a popular model for modeling spring behavior. In an experimental setting, one can imagine that the spring be subjected to a sinusoidal forcing term by using a cam to apply a periodic and continuous force to the spring. From a mathematical point of view, any sufficiently smooth function can be represented as a Fourier series, in which case, the forcing term is given as a linear combination of trigonometric functions. In this work, the external forcing used in the generation of data for parameter identification will be chosen in the form:
where is the amplitude and is an input parameter to control the angular frequency of the forcing term.
We also suppose that the external forcing is subjected to unforeseen errors. These errors are collectively denoted by such that the system is modeled by:
In the following, we assume that above system is too complex to solve and has to be simplified in order to be tractable. Another point of view is that one does not necessarily know how to model all the physical phenomena occurring in the system.
2.2. Linear Single Degree-of-Freedom Oscillator
The model given in (10) can be decomposed into linear and non-linear components. Using the notation of (6), we have:
with and . Considering a model that retains the linear component, , as defined in (11), and omitting the non-linear component, , we arrive at the misspecified model:
Note that the variable in (13) accounts for both the model misspecification and errors in the forcing. Due to being governed by a probability distribution, then will also be governed by some probability distribution with some mean and variance . In fact, the proposed formulation does not allow one to separate the uncertainty due to the non-linear component from possible errors when observing the forcing term. In other words, can be viewed as a modeling error, “internal” to the system, in contrast to the traditional approach in which one considers an “external” error, to explain the error associated with the system solution. Finally notice, that if we fit Equations (10) and (13) to data, the estimated values of and will be different depending on whether the cubic term is included or not.
In the following, the model defined in (10) will be referred to as the Oracle model and the misspecified model defined in (13) as the non-Oracle model. Figure 2 shows an example of sampled data for f versus u using forcing (9) with and . As expected the data show a cubic relationship between displacement and forcing. The least squares estimated Oracle and non-Oracle models are overlaid on the data and show that the Oracle model fits extremely well the data while the non-Oracle model seems to provide a reasonable approximation. From a computational standpoint, the non-Oracle model is very appealing since its solution is far less computationally demanding than the Oracle model.
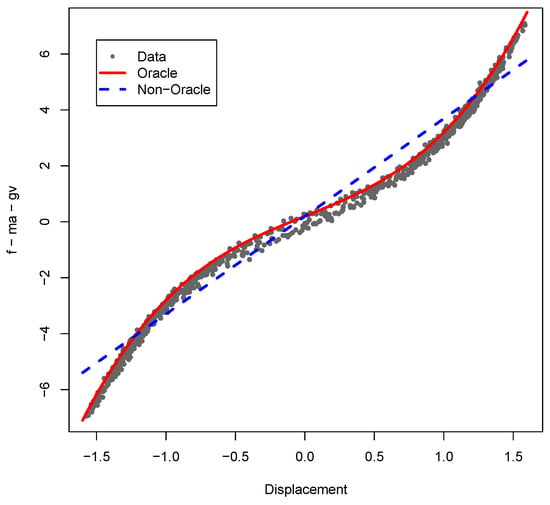
Figure 2.
Force versus displacement with Oracle and non-Oracle models using forcing given by (9) with and centered Gaussian internal error with .
Upon applying a force to the system, we suppose that we can track the state of the system at times , which will result in the forcing vector , internal errors ), as well as the solution vectors for displacement, for velocity, and for acceleration. These unobserved quantities will be considered as a target for our estimation procedure. The solution vectors are actually observed contaminated with external errors and the observed solution vectors will be denoted by for displacement, , for velocity and for acceleration. These quantities will be referred to as data in our estimation procedure.
Figure 3 shows an example forcing (9) with (Panel a) and the resulting solutions of displacement (Panel b), velocity (Panel c), and acceleration (Panel d). Notice that the solutions for displacement are quite close in behavior with the non-Oracle model being somewhat smoother than the Oracle model. For velocity (Panel b), we observe that there is a marked difference between the Oracle and non-Oracle solutions. Specifically, the non-Oracle solutions do not fit well in the extremes and lack some dynamics exhibited by the Oracle model. The acceleration trajectories (Panel d) show that there is also a much stronger difference between the Oracle and non-Oracle models. Again, the non-Oracle model performs poorly at the extremes and lacks much of the dynamic behavior versus the Oracle model. One question of interest is whether the uncertainty associated with the non-Oracle model can be correctly quantified so that the model can be reliably used to create prediction intervals that have well calibrated coverage probabilities.
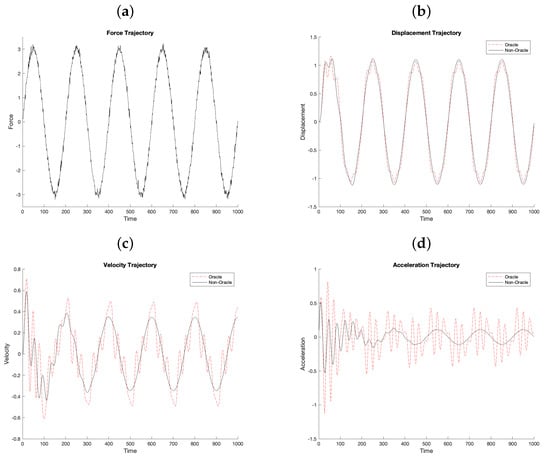
Figure 3.
Force (a) Displacement (b), Velocity (c), and Acceleration (d) trajectories for Oracle and non-Oracle models with .
3. Model Estimation
In an experimental setting, the data that will be observed at regular sampling times and contaminated with errors. For any time t the following likelihood is employed:
where is the solution of the differential equation at time t given the parameter values , forcing and internal errors ; is a matrix with diagonal elements and zeros elsewhere. It is assumed that the given the parameters and the resulting solution to the differential equations the residuals are independent across time. For notation, let be the observed data.
A Bayesian approach is employed for inferences about the parameters and to create posterior predictive intervals. To obtain the posterior distribution of we use Bayes theorem given by (see [9]):
where:
The following vague prior distributions are employed:
Using this prior distribution and likelihood specification the posterior distribution is not analytically tractable, hence sampling is employed. In this work, is set to 10 for , which allows for high values (near 10) without the need to worry about extreme values as other distributions, such as an Inverse-Gamma, might provide. A Metropolis–Hastings embedded in a Gibbs sampler, where each parameter is sampled from its full conditional distribution using the Metropolis–Hastings algorithm, is implemented in MATLAB to obtain samples from the posterior distribution, with details given in Section 4. This algorithm was chosen as it is easy to implement in MATLAB.
3.1. Solving the Differential Equation
At each step of the Metropolis-Hastings sampler the differential equation needs to be solved regardless of whether the model is the Oracle or non-Oracle models. To solve the differential equation, the time interval is partitioned into N subintervals , , with and . For simplicity here, the time step is taken uniform. Given and , the initial acceleration is estimated as:
The acceleration, velocity, and displacement are updated at the subsequent time , , as:
where and are the standard parameters of the Newmark scheme. The parameters are chosen here as , , , and . By choosing and this represents the average constant acceleration scheme for the Newmark solver to ensures unconditional stability is achieved [10]. It should be noted that the settings for and can influence the computational time for the solver. For example, and the solver takes approximately 0.010 s to solve 1000 time steps, compared to when and where the solver takes approximately 0.021 s to complete the computations; and when and , the solver takes approximately 0.018 s to complete the computations. Similarly, when and , the solver takes approximately 0.017 s to complete the same computations.
3.2. Verification Example
As a verification that the approach is viable, a dataset was generated using the sinusoidal forcing given by Equation (9) with forcing parameters , , , and model parameters , , and . A total of 120,000 samples are taken from the posterior distribution using 10 chains of 12,000 with the first 2000 samples discarded as burn-in samples and the remaining 10,000 samples thinned by 10 resulting in 10 sets of 1000 samples resulting in 10,000 samples from which all inferences will be made. For the non-Oracle model the computing time is approximately 73.2 s and for the Oracle model the computing time is approximately 764.4 s. Sampler diagnostics, such as traceplots, as well as autocorrelation within chains, were examined for convergence, mixing, and to determine the thinning rate. Full computation details are presented in Section 4.
Table 1 shows the true values for the Oracle model and the 95% credible intervals based on sample quantiles, , for both the Oracle and non-Oracle models. Notice that the posterior credible intervals correctly capture the true values of the model parameters. This provides evidence that the model parameter estimation approach is valid.

Table 1.
Parameter estimates given by approximately 95% credible intervals, , for both Oracle and non-Oracle models using simulated forcing data with , . Based on 10,000 posterior samples.
4. Simulation Study
Of particular interest is model validation. Specifically, under what training dataset conditions are the models valid? Furthermore, under what conditions is the non-Oracle model competitive with the Oracle model? In this case, model validity is defined to be the predictive performance of the models for predicting both future values and maximum values. As this is a predictive study, a training dataset obtained using a training forcing is used to obtain samples from the posterior distribution of . Additionally, a separate and independent validation forcing is applied to obtain solutions . To validate the models the validation trajectories are compared with their posterior predictive distribution given by
To make the situation more realistic we accommodate possible internal errors in the system by using instead of the true forcing a forcing contaminated by fixed realization of internal errors , where are independent centered Gaussian random variables with standard deviation . The training datasets are generated using Equation (9) with amplitude at the levels of 1 (low), 5 (medium), and 10 (high), and forcing error at (low), (medium), and (high). The model parameters are specified as , , , and for all simulations. Since the interest is in estimating both future values and maximum value, the predictive distribution of the trajectories for all N time steps ahead are considered. Note that this is different from the traditional one, two, ten, etc., step ahead approach.
The validation forcings are generated using two regimes: Sinusoidal and Erratic. The Sinusoidal regime is uses Equation (9) with and centered Gaussian internal errors with . Panel (a) of Figure 4 shows a representative realization of the Sinusoidal regime when the training dataset is generated using the same parameters. Furthermore, Figure 4 show the validation trajectories for displacement (Panels b), velocity (Panel c), and acceleration (panel d) all with their 95% posterior predictive intervals. Notice that the posterior predictive intervals appear to have high coverage probabilities for displacement, velocity, and acceleration. This gives evidence that using sinusoidal training dataset gives a valid model for predicting the same system.
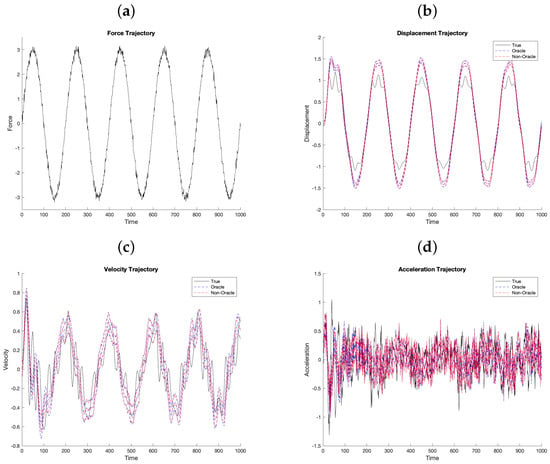
Figure 4.
Training Force Contaminated with internal error (a) Displacement (b), Velocity (c) and Acceleration (d) trajectories. The Displacement, Velocity, and Accelerations have 95% posterior predictive intervals as well.
To understand how the sinusoidal training regime performs on a process that is dramatically different the Erratic regime is employed. The Erratic regime validation data generation processes is a realization of a sum of two stochastic processes. The first is a Gaussian moving average process with a small variance, , serving as a background noise. The second process is a smoothed version of a marked Poisson process and models large shocks. The time of the large shocks is given by Poisson process with the amplitude modelled by a Gaussian random variable with a relatively large variance, . Panel (a) of Figure 5 shows a representative realization. Notice that the process is very different from the sinusoidal process. However, by considering Panels (b, c, and d) one can see that the posterior predictive intervals appear to capture the process quite well.
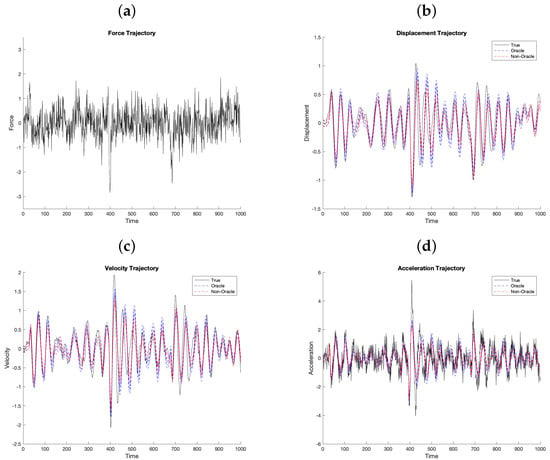
Figure 5.
Validation Force (a) Displacement (b), Velocity (c), and Acceleration (d) trajectories. The Displacement, Velocity, and Accelerations have 95% posterior predictive intervals as well.
A simulation study is conducted by varying the training amplitude and assessing the performance of posterior predictive intervals on capturing the true value. The training datasets were created using the sinusoidal regime with amplitude, at levels 1, 5, and 10. These levels of are chosen so that there is a scenario in which a small, an accurate, and a large training amplitude is considered. The internal error standard deviation is also varied and set to levels , , and which correspond to a small, an accurate, and a large training noise. For each amplitude and noise combination 100 datasets were generated and MCMC samples from the posterior predictive distribution were obtained for each dataset for both the Oracle and non-Oracle models. For each amplitude, noise and Oracle/non-Oracle combination datasets two validation forcing datasets were generated, one using sinusoidal forcing and the other using erratic forcing. The simulation study was replicated 100 times. A Metropolis–Hastings embedded in a Gibbs sampler was implemented in MATLAB to obtain samples from the posterior predictive distribution. A total of 30,000 samples were taken from the posterior distribution with the first 20,000 samples discarded as burn-in samples and the remaining 10,000 samples thinned by 10 resulting in a set of 1000 samples from which all inferences will be made. Sampler diagnostics, such as traceplots, as well as autocorrelation within chains, were examined for convergence, mixing, and to determine the thinning rate. Example traceplots and auto-correlation plots for the Oracle model can be found in Figure A1 and Figure A2, respectively. Notice the chains appear to have converged and a thinning of every 10th sample will keep the auto-correlation between samples below 0.25. As one may be concerned with the choice of on its impact on the posterior distribution of , a small sensitivity study is presented in Figure A3 that shows the kernel density estimates of the posterior distribution of when , and 10. Notice that the posterior distributions in all cases essentially agree with each other, hence choice of should not have any large influence on the inferences.
Using the 2.5% and 97.5% quantiles from the MCMC samples from the posterior predictive distribution a 95% predictive interval is created for each , , and using each contaminated validation forcing . Let be the solution attribute of interest, such as , or and be the true value of the attribute at time t for simulation replicate i and be the 95% posterior predictive interval for the attribute at time t for simulation replicate i. The posterior predictive coverage rates for attribute Z were calculated using:
where is an indicator function taking on the value 1 if and 0 otherwise.
Table 2 shows the results from the simulation study of the average coverage probability of the 95% posterior predictive intervals for , , and for both Oracle and non-Oracle models across both validation regimes. Notice that for scenarios when is 0.5 or higher the coverage probabilities are quite good for all attributes, across all training amplitudes for both the Oracle and non-Oracle models using both Sinusoidal and Erratic validation forcing. Additionally, notice that the Oracle model performs reasonably well when is 0.05 when is 5 or 10. Furthermore, when the training Amplitude is higher the coverage probabilities are improve in all cases. This suggests that provided the typical range of the training forcing amplitude plus the internal error, , is larger than the typical forcing that would be applied in practice the non-Oracle model is valid for predicting the attributes. In cases where the typical forcing that would be applied in practice has low noise the Oracle model should be preferred.
Table 2.
Average coverage probabilities of u, v, and a for both Oracle and non-Oracle models. The models were trained on a sinusoidal training system with amplitudes , force error and validated on both Erratic and Sinusoidal systems with Erratic system with typical validation amplitude of 5, created using Erratic system variances and Sinusoidal parameters . Based on 100 simulations.
Since the coverage probabilities are quite good when the training set exhibits more extreme amplitudes than the validation data one would like to determine the difference in the widths of the prediction intervals. Again, let Z be the solution attribute of interest, such as u, v or a, and be the true value of the attribute at time t for simulation replicate i and be the 95% posterior predictive interval for the attribute at time t for simulation replicate i. The average posterior predictive interval widths, using an norm, for attribute Z were calculated using:
Table 3 shows the average posterior predictive interval widths for u, v, and a for both Oracle and non-Oracle models using a training system with and internal error standard deviation , and validated using both Erratic and Sinusoidal systems. Notice that the average interval widths are systematically higher for the non-Oracle versus the Oracle. This is to be expected since the non-Oracle model will always have a larger estimated internal error which is then propagated through the system. Furthermore, notice that the interval widths for the non-Oracle models are about twice the interval width of the Oracle models. Hence, the trade off of using the non-Oracle model is much wider predictive intervals.
Table 3.
Average posterior predictive interval widths of u, v and a for both Oracle and non-Oracle models. The models were trained on a sinusoidal training system with amplitudes , force error and validated on both Erratic and Sinusoidal systems with Erratic system with typical validation amplitude of 5, created using Erratic system variances and Sinusoidal parameters . Based on 100 simulations.
The results from the simulation study above show that both the Oracle and non-Oracle models perform well when considering estimating the true value of the system. Since mechanical systems often fail at the extremes engineers are quite interested in predicting the extreme values of the system across time. To study this a simulation study was conducted using the same simulation experimental design, MCMC sampling scheme, and replications as above with the maximum values of each of the attributes as the quantity of interest. As above, let Z denote the attribute of interest, typically displacement, velocity, or acceleration. To obtain a posterior predictive interval for the following approach is used. For the draw from the posterior distribution of , the corresponding solution trajectory for Z is created without using external error. The solution is denoted by for times , and the maximum value across t is obtained, . Finally, the external error with variance given by the corresponding mth posterior sample is added to obtain . The 2.5% and 97.5% quantiles for are used to create a 95% posterior predictive interval for M denoted by . Let be the true maximum value of the system under forcing for simulation replicate i and be the corresponding 95% posterior predictive interval of the maximum value. The coverage posterior predictive coverage rates for the maximum were calculated using:
where is an indicator function taking on the value 1 if and 0 otherwise.
Table 4 shows the results of the coverage probabilities when using the posterior predictive distribution to predict the maximum value for each attribute for both Oracle and non-Oracle models across various Sinusoidal training amplitudes and noise for both Sinusoidal and Erratic validation regimes. Notice that the results are much different when attempting to predict the maximum value. Both the Oracle and non-Oracle methods work well when the validation forcing has similar amplitude and error as the training amplitude and errors. Consider when and then coverage probabilities for the maximum value are high across both Sinusoidal and Erratic validation regimes and across all attributes. When and then the Oracle model appears to work well but the non-Oracle model does not. This is consistent across all attributes and both validation regimes. When is large relative to the training error and when the training and validation amplitudes differ both the Oracle and non-Oracle models perform poorly across both validation regimes.
Table 4.
Coverage probabilities of maximum values for u, v, and a for both Oracle and non-Oracle models. The models were trained on a sinusoidal training system with amplitudes , force error and validated on both Erratic and Sinusoidal systems with Erratic system with typical validation amplitude of 5, created using Erratic system variances and Sinusoidal parameters . Based on 100 simulations.
5. Discussion
This work introduced a novel approach to both quantify the uncertainty associate with model misspecification, as well as create predictive distributions that incorporate this uncertainty. By introducing an “inside” error term, into the system captures the model misspecification and forcing noise which is quantified in the parameter. A Bayesian approach allows for the estimation of the model parameters, as well as the posterior predictive distributions. The posterior distribution of allows for the study of the misspecification uncertainty where large values of would indicate a large model misspecification and small values would indicate the model is reasonably specified. Furthermore, by propagating the error associated with model misspecification the misspecified model can be can be made into a valid predictive model for estimating the mean value of the system. In certain conditions, one can also achieve this for estimating the maximum value of the system. However, care should be taken in both of these cases to ensure that the training dataset is representative of conditions that the real system may experience.
The single degree of freedom oscillator is used as a simple example to illustrate the method. Extending this approach into systems such as Elasto-Plastic model, Accelerometer, Seismometer, and Estimates of Peak Roof Displacement [6,11]. Other applications include dynamic behavior of systems with fractional damping and dynamical analysis on single degree of freedom semi-active control systems with a fractional order derivative [12,13]. Another extension of this work could be to model space-time phenomena similar to those studied by [14], as there is inherent error in the model structure, as well as measurement error. One important question that needs consideration is the structure of the internal and external errors and their impact on resulting inferences. In the case that the Gaussian likelihood assumption is not valid, one may need to consider other estimation procedures than Metropolis-Hastings samplers and may wish to consider Approximate Bayesian Computation (ABC). For a good overview of using ABC with dynamical models, see [15].
The approach presented is computationally intensive which may be prohibitive for complex systems that in and of themselves are computationally demanding. Nevertheless, as computation speed and capacity increases this approach may become viable for more and more complex models.
Author Contributions
Conceptualization, S.P.; methodology, E.B., R.G., J.H. and F.R.; software, E.B. and J.H.; validation, R.G. and F.R.; formal analysis, R.G. and S.P.; investigation, S.G.; resources, S.G.; writing—original draft preparation, E.B. and J.H.; writing—review and editing, R.G., S.G. and F.R.; supervision, S.G.; project administration, S.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable. This study did not involve humans or animals.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank the opportunities provided by SAMSI. We would also like to thank Raul Tempone and the King Abdullah University of Science and Technology for hosting a research retreat to work on this project. In addition, the authors would like to thank Qatar Foundation and VCU Qatar for their support through the Mathematical Data Science Lab.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| SAMSI | Statistics and Applied Mathematical Sciences Institute |
| LD | Linear dichroism |
Appendix A
This appendix contains information regarding the MCMC sample evaluation and a sensitivity study on the prior distribution for .
Appendix A.1
This section shows the MCMC diagnostics used for the samples obtained via the Metropolis–Hastings sampler. The Oracle model was considered with , , , , , and . Figure A1 shows the trace plots for the 10,000 MCMC samples for g (panel a), (panel b), (panel c), (panel d), (panel e), and (panel f). Notice that the sampler appears to have converged for each of the parameters as all traceplots are near stationary.

Figure A1.
Exampletraceplots from the MCMC samples g (panel a), (panel b), (panel c), (panel d), (panel e), and (panel f).
Figure A2 shows the auto-correlation plots for the pre-thinned 100,000 MCMC samples for g (panel a), (panel b), (panel c), (panel d), (panel e), and (panel f). Thinning by every 10th sample will keep the auto-correlation between sequential samples below 0.25.

Figure A2.
Example autocorrelation plots from the MCMC samples: g (panel a), (panel b), (panel c), (panel d), (panel e), and (panel f).
Appendix A.2
Figure A3 shows the kernel density estimates for for prior specifications of where , and 10. Notice that the posterior density estimates agree with each other quite well across all values of , suggesting that the influence of is minimal on inferences.

Figure A3.
Kernel density estimates of the posterior distribution for across prior distribution parameter specifications of , and 10.
References
- Kennedy, M.C.; O’Hagan, A. Bayesian Calibration of Computer Models. J. R. Stat. Soc. B 2001, 63, 425–464. [Google Scholar] [CrossRef]
- Chkrebtii, O.A.; Campbell, D.A.; Calderhead, B.; Girolami, M.A. Bayesian Solution Uncertainty Quantification for Differential Equations. Bayesian Anal. 2016, 11, 1239–1267. [Google Scholar] [CrossRef]
- Morrison, R.E.; Oliver, T.A.; Moser, R.D. Representing model inadequacy: A stochastic operator approach. SIAM/ASA J. Uncertain. Quantif. 2018, 6, 457–496. [Google Scholar] [CrossRef]
- Wu, S.; Hannig, J.; Lee, C.M.T. Uncertainty quantification for principal component regression. Electron. J. Stat. 2021, 15, 2157–2178. [Google Scholar] [CrossRef]
- Lee, S.H.; Chen, W. A comparative study of uncertainty propagation methods for black-box-type problems. Struct. Multidiscip. Optim. 2009, 37, 239–253. [Google Scholar] [CrossRef]
- Strong, M.; Oakley, J.E. When Is a Model Good Enough? Deriving the Expected Value of Model Improvement via Specifying Internal Model Discrepancies. J. Uncertain. Quantif. 2014, 2, 106–125. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Liu, F.; Bayarri, M.J.; Berger, J.O. Modularization in Bayesian Analysis, with Emphasis on Analysis of Computer Models. Bayesian Anal. 2009, 4, 119–150. [Google Scholar] [CrossRef]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis, 2nd ed.; Springer: New York, NY, USA, 1985. [Google Scholar]
- Newmark, N.M. A method of computation for structural dynamics. J. Eng. Mech. Div. 1959, 85, 67–94. [Google Scholar] [CrossRef]
- Newman, J.; Makarenkov, P. Resonance oscillations in a mass-spring impact oscillator. Nonlinear Dyn. 2015, 79, 111–118. [Google Scholar] [CrossRef]
- Shen, Y.; Fan, M.; Li, X.; Yang, S.; Xing, H. Dynamical Analysis on Single Degree-of-Freedom Semiactive Control System by Using Fractional-Order Derivative. Math. Probl. Eng. 2015, 2015, 272790. [Google Scholar] [CrossRef]
- Zarraga, O.; Sarría, I.; Garcxixa-Barruetabeña, J.; Cortés, F. An Analysis of the Dynamical Behaviour of Systems with Fractional Damping for Mechanical Engineering Applications. Symmetry 2019, 11, 1499. [Google Scholar] [CrossRef]
- Wikle, C.K.; Berliner, L.M.; Cressie, N. Hierarchical Bayesian space-time models. Environ. Ecological Stat. 1998, 5, 117–154. [Google Scholar] [CrossRef]
- Toni, T.; Welch, D.; Strelkowa, N.; Ipsen, A.; Stumpf, M.P.H. Approximate Bayesian computation scheme for parameter inference and model selection in dynamical systems. J. R. Soc. Interface 2009, 6, 187–202. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).