1. Introduction
Finding ways of predicting the outcome in different sport games from past and current data is an attractive problem for different people, ranging from the sports teams’ coaches to gambling agencies to fans of that sport. There is no doubt that statistical tools are needed to construct an effective and accurate model to predict the outcome of sporting events. In the last decades, predicting match results has attracted much attention from researchers using new methods of statistics, data mining and machine learning, especially in popular sports such as football, basketball, baseball and soccer.
Ice hockey is a popular sport especially in the US and Canada for which there exists a rich dataset available at
www.nhl.com. Several publications have appeared in recent years documenting different statistical analysis of the hockey data. Gramacy et al. [
1] studied individual contributions of team members using regularized logistic regression. Sadeghkhani and Ahmed [
2] estimated the density of scoring time in a hockey game using prior information such as a team’s ranking in the previous season and experts’ opinions. Suzuki et al. [
3] proposed a Bayesian approach in predicting the match outcomes in the 2006 World Cup.
However, to the authors’ best knowledge, very few publications currently available in the literature address the issue of Bayesian density estimation of number of the goals. This paper proposes a unique method to estimate the density of number of the goals. We also consider the points in the previous games, away and home factors, and specialists’ opinions to improve our predictions.
The remainder of the paper is organized as follows: In
Section 2, we provide definitions and preliminary remarks about two assumptions to model the number of goals in a hockey game.
Section 3 discusses how to find Bayesian predictive density estimators for each model.
Section 4 addresses how one can enter other factors such as home bonus, away malus, experts’ opinions in detail. In
Section 5, we study an application of the proposed methods in predicting the number of goals as well as the result of the game. Finally, we make some concluding remarks in
Section 6.
2. Problem Set-Up and Different Models
Poisson distribution has been used in the context of count data, but the fact that the dispersion index (the ratio of variance to mean) equals one is a big concern in practice. Conway and Maxwell [
4] introduced the Conway–Maxwell–Poisson (COM-P) distribution, which, similar to the Poisson distribution, belongs to the exponential family of distributions and, therefore, the Bayesian analysis (because of the conjugate prior) of number of events becomes more computationally tractable.
Kadane et al. [
5] studied a necessary and sufficient condition on the hyperparameters of the conjugate family for the prior to be proper and discussed methods of sampling from the conjugate distribution.
The COM-P distribution processes an extra parameter and was originally developed as a solution of handling a queuing system with state-dependant arrivals. It has has been used widely in the models that that have over-dispersion or under-dispersion, i.e., the mean is smaller or larger than variance, respectively. For more information, see Shmueli et al. [
6].
A random variable (rv for short) has the
distribution if it has the probability mass function (pmf) in the form of
where
is the normalizing constant. It is easy to see the Poisson distribution,
, obtained when
. Furthermore, the density in (
1) belongs to exponential family and values of
and
are equivalent to under- and over- dispersion each. When
, tending
gives Bernoulli with parameter
while the geometric distribution corresponds to limiting
with pmf of
, for
.
Imoto [
7] generalized the COM-P to a distribution which has a larger tail and embraces the negative binomial distribution and applicable to the excess zeros model as well.
An rv
X is said to have a generalized COM-P (GCOM-P) with three parameters
,
and
, if
where
is the normalizing constant. When
,
and
or
,
and
,
converge. This distribution reduces to a COM-P distribution with parameter
and
when
and to a negative binomial when
.
3. Bayesian Prior and Posterior Predictive Density Estimations
As can be seen in the literature, gamma distribution is being used as conjugate prior for a Poisson distribution. Suppose ), choosing with the pdf results in the posterior density . The marginal distribution of X, known as a prior predictive density estimator, and posterior predictive density estimator are negative binomial distribution. Rv has the pmf , .
Lemma 1. If and , the prior predictive density is given bywhile the posterior predictive density of future rv. Y, is given by Proof. The prior predictive in (
3) is the marginal distribution of
X and can be found as follows:
Equation (
4) can be obtained similarly from
and the posterior density of
based on
, is
. □
In the COM-P model, Equation (
1), Kadane et al. [
5] used the extended bivariate gamma distribution denoted by
, and given by
where the normalization constant in (
5), is given by
and
,
and
needs to satisfy the following condition so that
becomes finite:
Next lemma, similarly to Lemma 1, provides the predictive distributions.
Lemma 2. If , as in (1), for , and presented in (5), then: the posterior has the same distribution to (5) with , , and . the prior predictive density (marginal density of X) is given by the posterior predictive density of future rv Y, for is given by
Proof. The proof is straightforward and analogous to the proof of Lemma 1 and has therefore been omitted. □
4. Modelling Number of Goals Using Prior Elicitation Method
In this section, we make two different assumptions: (I) let us assume the number of goals scored by each team is a Poisson rv and (II) it has COM-P. In addition, suppose that A is a team playing home and B is a team playing away and hence, is the number of goals scored by team A to team B and , vice-versa.
4.1. Assumption I: Distribution for Modelling Number of Goals
Assume that
and
, are independently distributed as follows:
where
can be interpreted as the mean number of goals team
A scores against team
B and
is the number of goals team
B scores against team
A in a future game. As discussed earlier, one can use conjugate prior
(for home) as a
, where the jeffreys non–informative prior
is its special case. Here, we are interested in employing experts’ opinions about the upcoming match’s score. This is called prior elicitation and can be determined by
:
where
,
, is the
i-th expert’s opinion about number of goals that home team
A will score against away team
B in the future game. Choosing
returns the
as a prior and ignores the specialists’ opinion factor. Analogously, we can set prior of
in the same manner.
We have used the specialists to improve our beliefs about
(or
), but we can also benefit from other sources of information, such as previous data. Since usually (not necessarily) the number of goals is larger when team plays home and smaller when team plays away, we can use the model home-bonus factor
h, and away or visiting-malus factor
v.
Alternatively, one can consider the teams’ points as well. The mean of number of goals
A scores versus team
B is directly related to
h and points obtained by team
A, namely
(in the previous games or last season), and has an indirect relationship with
a and points obtained by team
B,
. Consequently, we can update prior density in (9) (for both
and
) as follows:
Making use of Equations (
10) and (
11), along with Lemma 1, gives the prior and posterior predictive density estimators for the number of goals team
A scores to team
B, which are, respectively, given by
and
where
is the number of goals team
A has scored in the previous season (or prior to the upcoming game) when played at home versus opponents and
and
’s are (all) opponents’ points in previous season (or prior to the upcoming game) who faces team
A and
is the number of games team
A host team
B. Similarly, for the number of goals, team
B scores in the home of team
A, we have
where
is the number of goals team
B has scored in the previous season (or up to upcoming game) when played on the way versus opponents and
and
’s are (all) opponents’ points in previous season (or prior to the upcoming match) who hosted team
B.
4.2. Assumption II: Model of Number of Goals
A question that may arise is, “What if the distributions of the number of goals do not obey a Poisson distribution?” In this assumption we contemplate the
distribution given in (
1) as a distribution of the number of goals. Therefore,
and
are independently distributed as follows:
We use
in (
5) as a conjugate prior. Note that for instance, the conditional distribution
is
and
is
, where Bet is a beta distribution. Similar to assumption (I), the corresponding prior elicitation can be defined as follows:
which is the
, with
where
is number of goals scored in a game where team
A is at home, hosting teams similar to team
B when they were on the road.
,
,
,
are as defined in assumption (I). This can be done similarly to obtain
,
,
, and
, correspondingly.
Finally, we can pose the other additional information home–bonus factor
h, away–malus factor
v, points
and,
into our prior yielding the joint distribution
and
obtained from
Using (18) and (19), along with Lemma 2, result in obtaining the prior predictive density estimation of the number of goals team
A scores against team
B as follows:
Furthermore, the posterior predictive density of the number of goals team
A scores against team
B is as follows:
Equations (20) and (21) hold for number of goals teams B scores versus team A by replacing , , with , , respectively.
5. Example of Predicting the Scores and Results
This section addresses prediction results based on our models, as attained in the previous section. For a given match team where A hosts team B, outcomes of that match under the format win, draw and loss can be predicted via the number of goals scored by the two teams, A and B. Let the probabilities associated with win, draw and loss of team A from the predictive distributions versus team B, denoted by , and . So we can write , , and .
Let us suppose that we are interested in predicting the match outcome of
A: Edmonton Oilers (home) vs
B: Arizona Coyotes (away). Data for the season 2017/18 plus current season 2018/19 until the date of writing this manuscript on 29 January 2019 available at
nhl.com has been used. In order to use experts’ opinions, we have asked 5 specialists to give their opinion about the upcoming match result,
and
as follows:
| 5 | 1 | 6 | 1 | 4 |
| 2 | 3 | 3 | 2 | 1 |
Moreover, the number of goals the Edmonton Oilers scored versus teams which had similar performance to the Arizona Coyotes when playing as a visitor, points per game, and the number of goals Arizona scored versus the teams had similar performance to Edmonton when playing at home (we asked specialists about those teams) are given in
Table 1.
Assumption I:
is considered for the prior distribution (since in practice the mean of scores by each team is about 4 goals) along with as in (9).
(a) Prior predictive density estimator corresponds to no matches having been played and we do not have any source of information but experts’ opinions about the upcoming game, Edmonton Oilers vs Arizona Coyotes. Making use of Equations (12) and (14) yield
which correspond to the probabilities below in
Table 2.
(b) We consider the posterior predictive densities using Equations (
13) and (
15) respectively. Therefore, we have
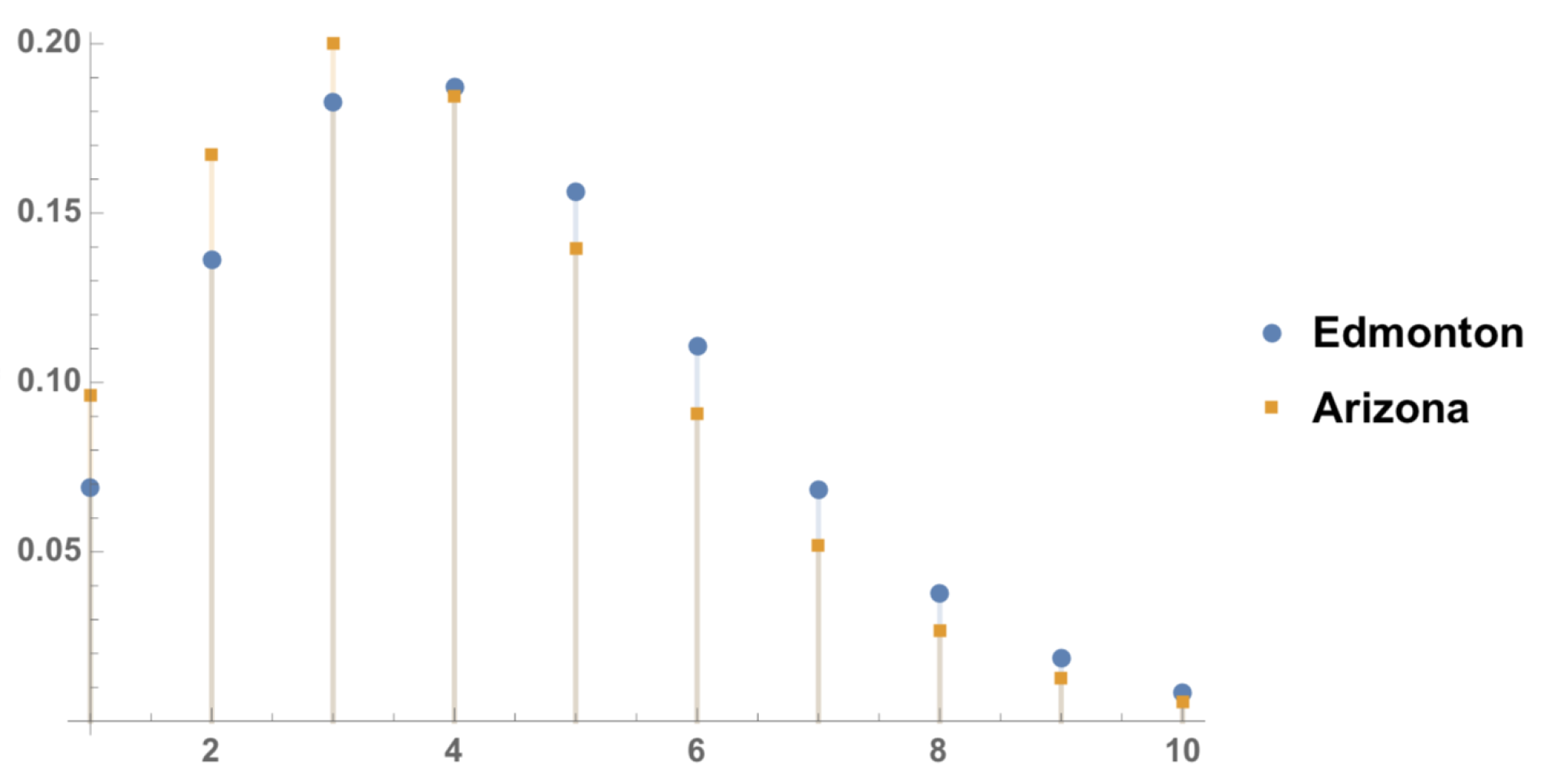
In other words, making use of data from season
up to current date and specialists’ opinions, we are expecting Edmonton Oilers will score
, while Arizona Coyotes scores
.
Table 3 and
Figure 1 illustrate the result.
The most probable result is 4–3, in favor of Edmonton. Without using experts’ opinions, i.e., , we have and , which corresponds to = 0.37, and , respectively.
Assumption II:
Let us take
,
and
. These choices result in having the expectation of
equals
based on the prior distribution in (
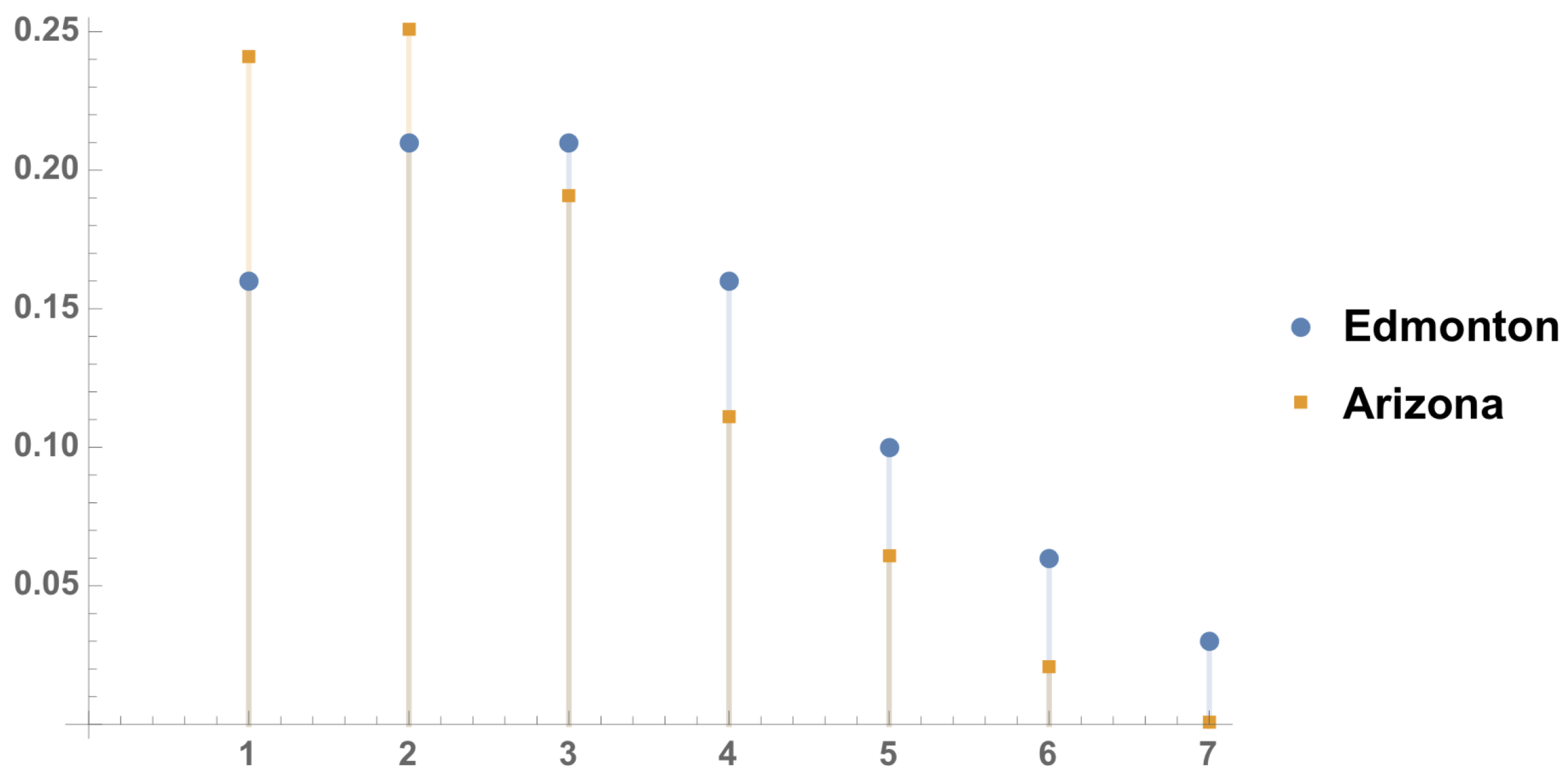
5). By applying (21), the posterior predictive densities of the number of the goals in the upcoming match Edmonton versus Arizona, along with corresponding plot, are given in
Table 4 and
Figure 2.
Also from
Table 4, we are expecting to see
for Edmonton and
goals for Arizona.
Table 5 shows the winning probabilities and one can predict that in the upcoming match, based on assumption II, Arizona will win the match in the Edmonton’s home, and most probable result is 3–2.
5.1. Prediction Errors
Prediction errors (pe’s) of our posterior predictive distributions in the two assumptions, when the specialists’ opinions matter, (namely
and
respectively) are evaluated by measuring the Kullback–Leibler distance as below.
where
is the Poisson distribution in (8) and
for
are given in (
13) and (21), respectively. This can be repeated for
and
as well.
According to
Table 1, one needs to calculate the distance between
and
regarding number of goals team
A scores against team
B and the distance between
and
regarding number of goals team
B scores
A in Assumption I. There we have
and
. In contrast, if we follow Assumption II based on
Table 4, the prediction errors become
and
, respectively.
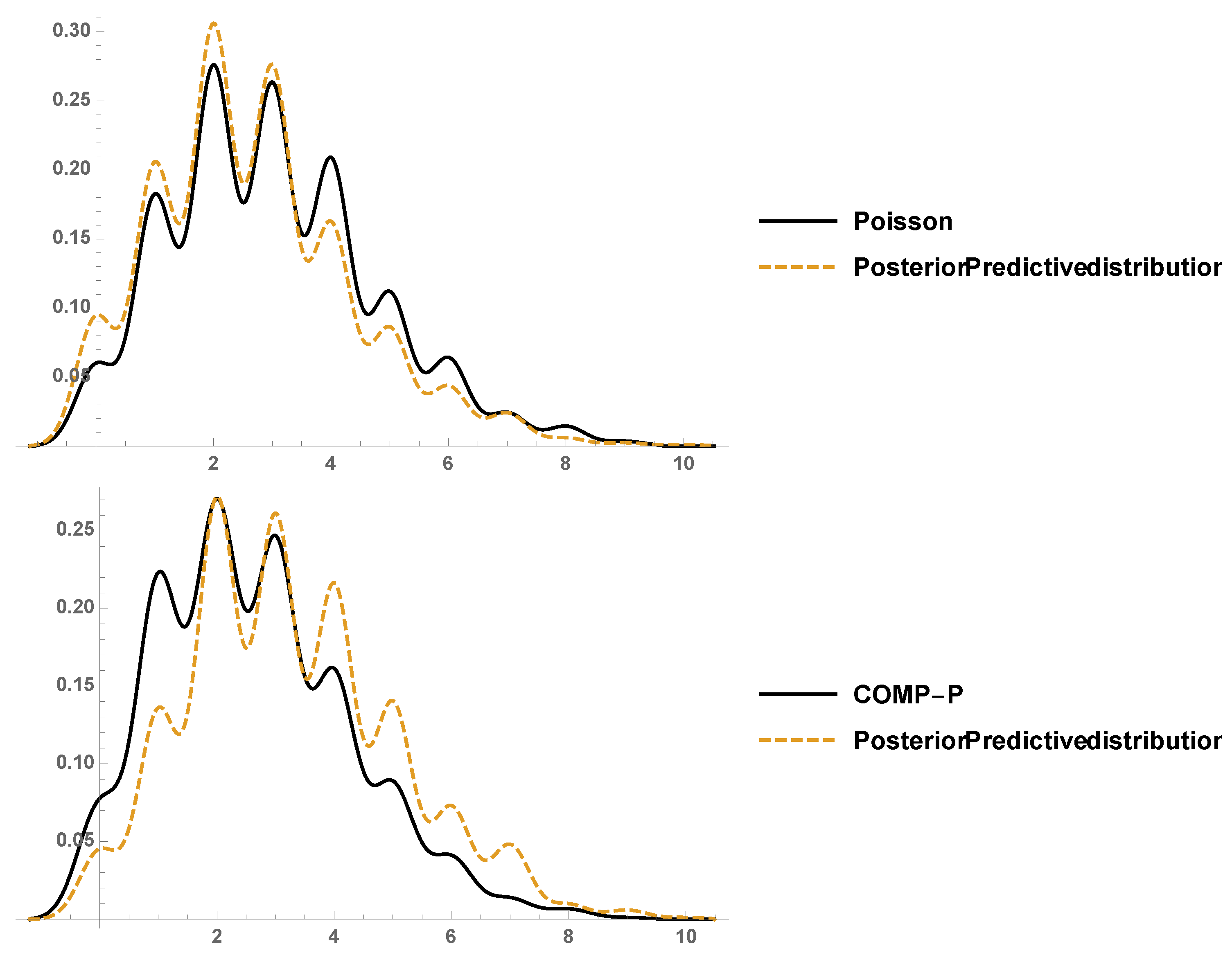
5.2. Simulation Study
We consider a small simulation study based on a sample of size of 1000, in order to investigate the proposed posterior density estimators regarding number of goals team
B scores against team
A in
Section 5.
Figure 3 depicts the assumed underlying model Po (Assumption I) and COM-P (Assumption II) along with their corresponding posterior predictive densities. It can be seen that model assumption I and its posterior predictive density estimator performs better for the number of goals.
6. Conclusions
In summation, we have proposed Bayesian predictive density estimators for the number of goals in a hockey match and consequently predicting the winner of the game. We considered two different assumptions and furthermore we considered points in previous games, away and home factors, and specialists’ opinions to improve our predictions. Assumption I, is based on that the underlying model, i.e., the number of goals in hockey, follows the Poisson distributions, and Assumption II considers the COM-P. However, based on prediction errors, it is easier to assume Assumption I. Eventually, the predictors based on either Assumption I or II, confirm that Edmonton (home team) will win game the next match versus Arizona (away team) by a difference of one goal with 48 and 55 percent, respectively.




{kind=link}
{kind=link}
{kind=link}