A New Inference Approach for Type-II Generalized Birnbaum-Saunders Distribution


Abstract
:1. Introduction
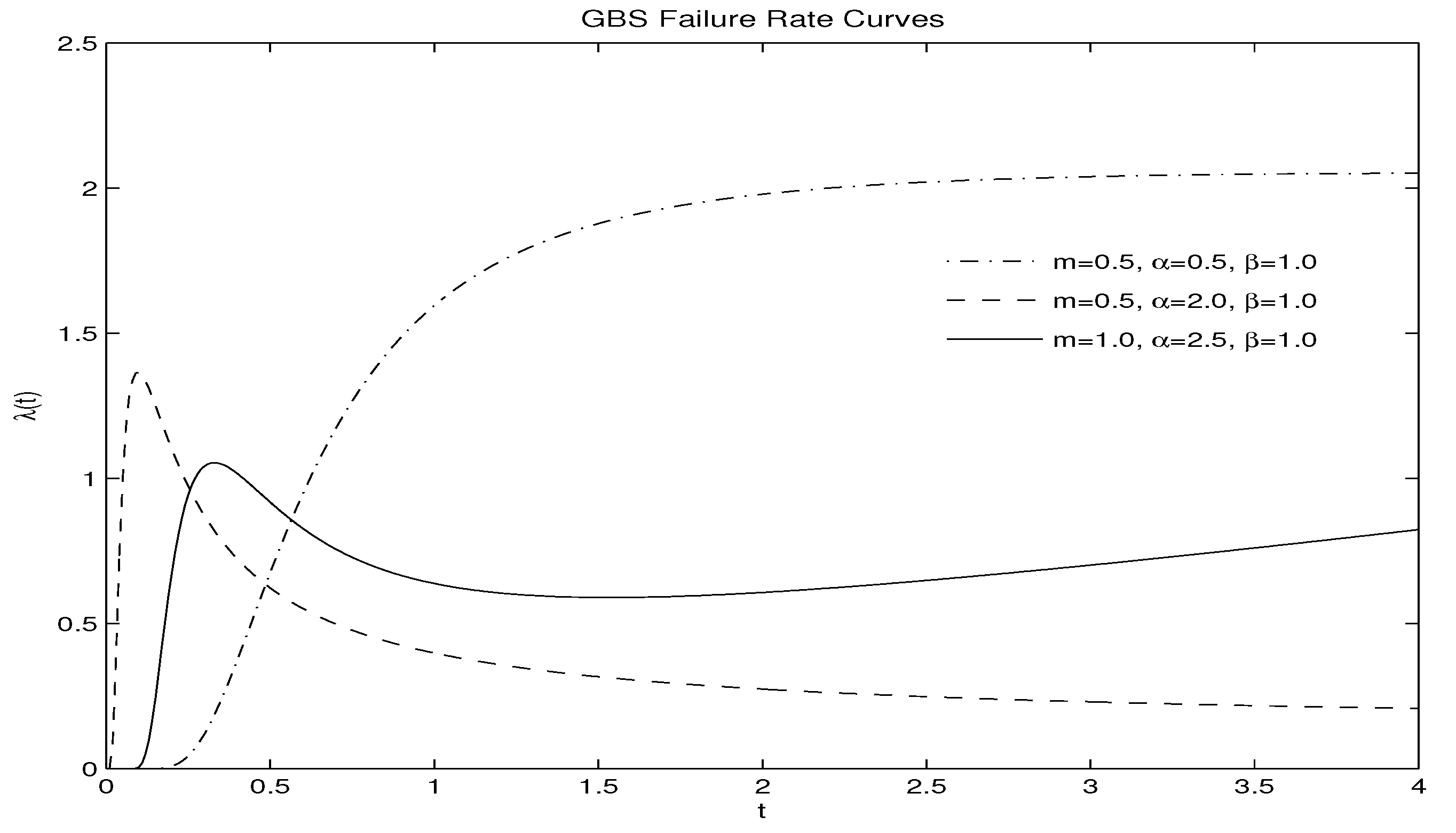
2. Properties of GBS-II
3. Inference Approach
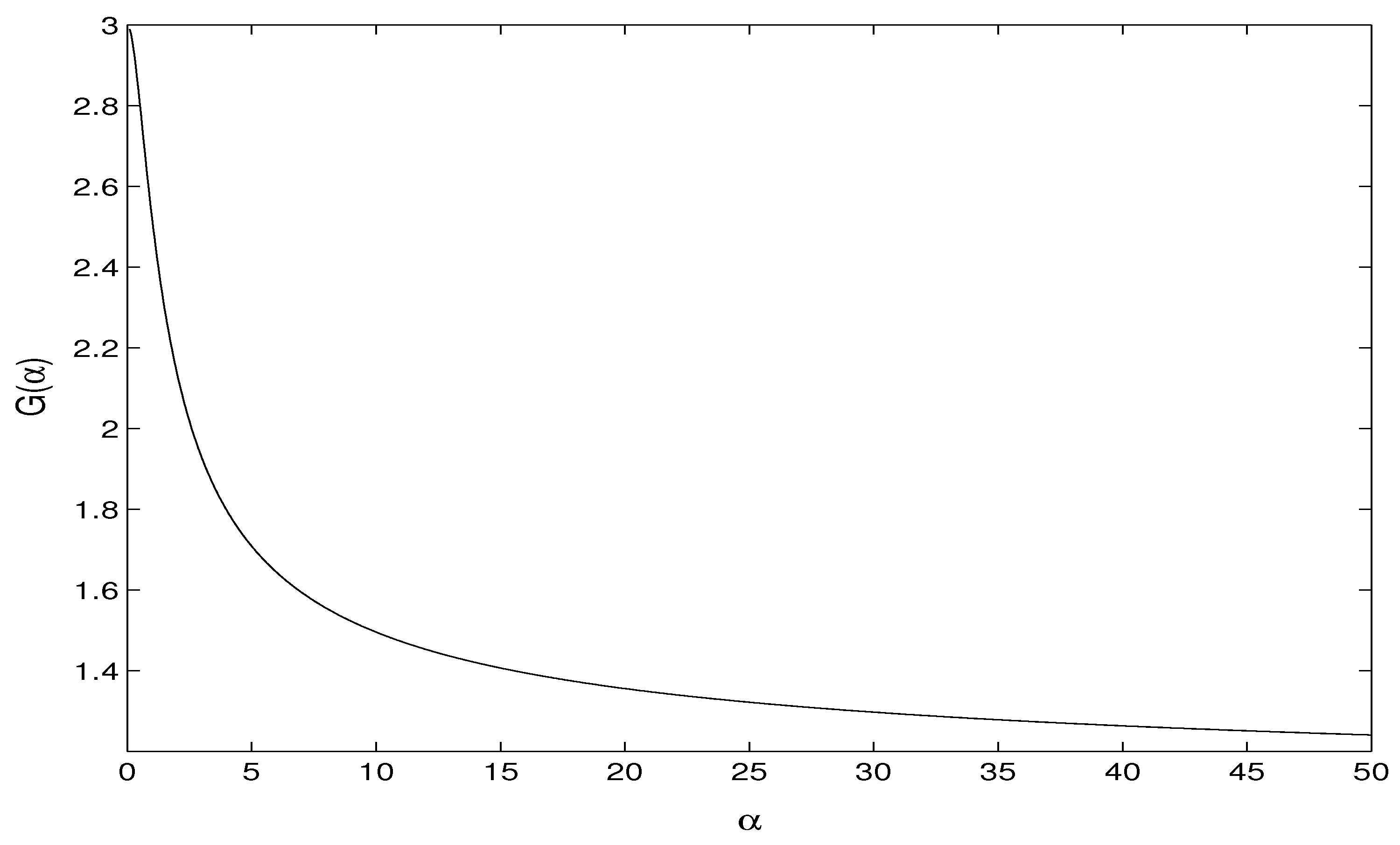
3.1. New Estimation Method
3.2. Hypothesis Tests
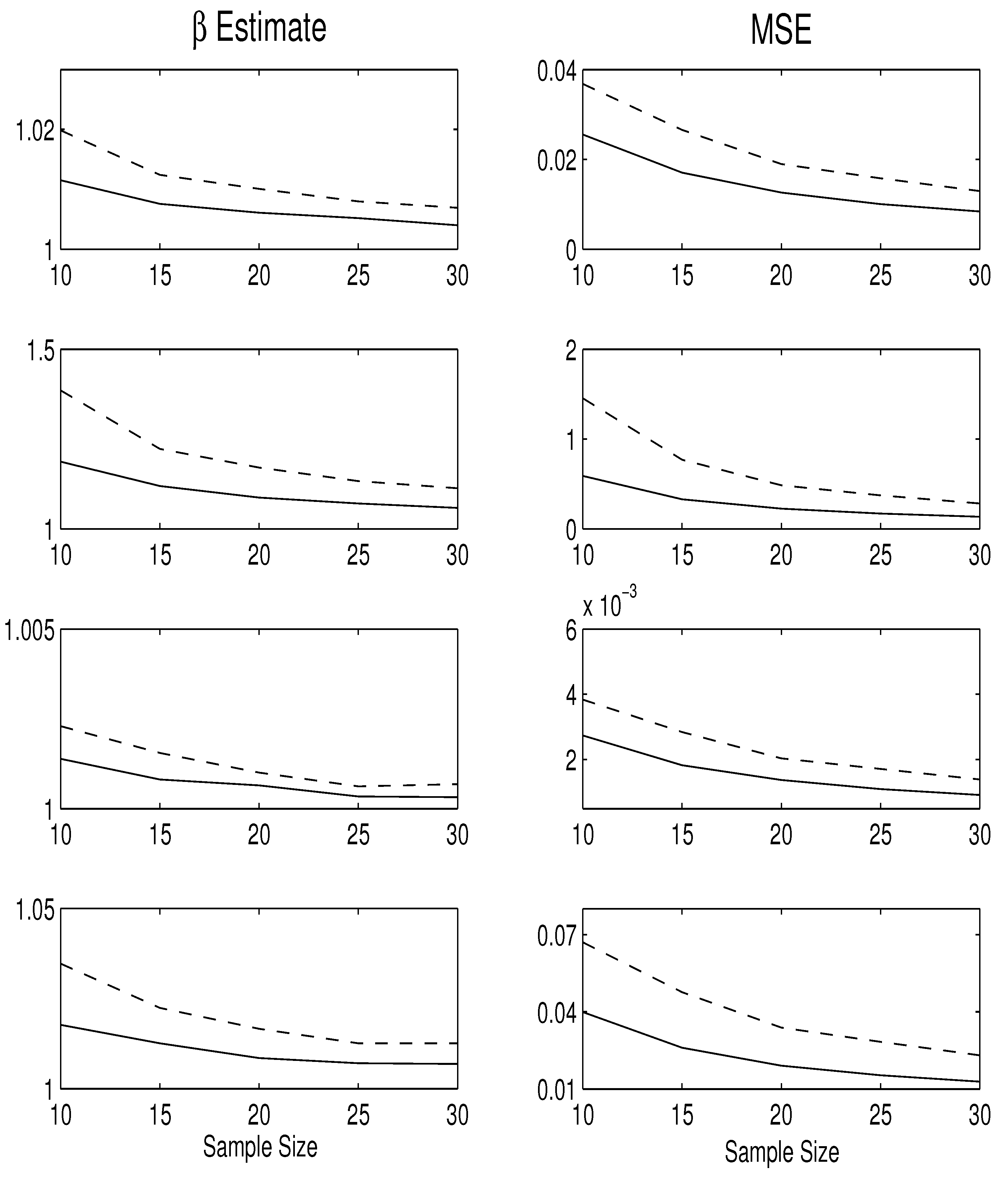
4. Simulation Study
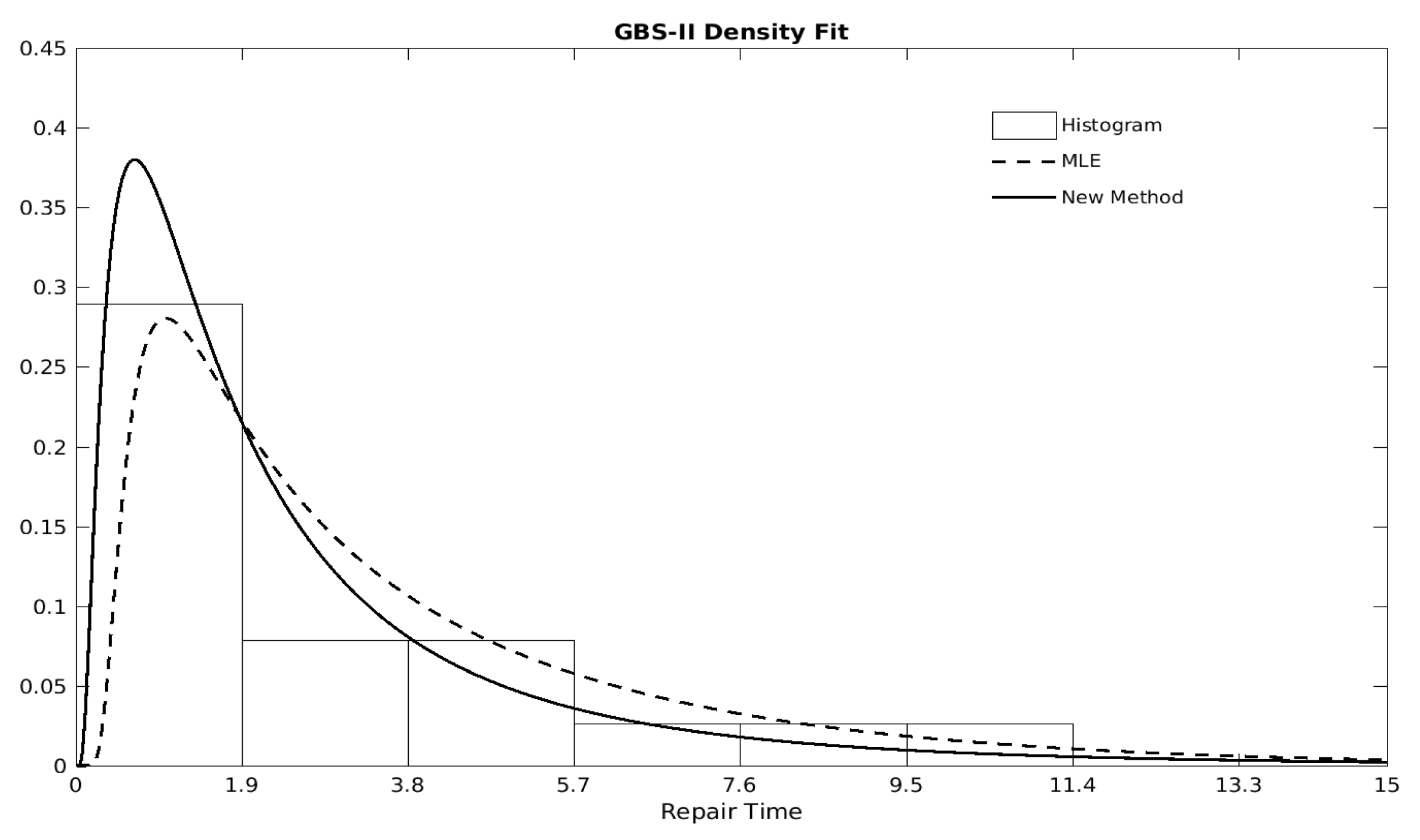
5. Real Data Analysis
6. Conclusions Remarks
Funding
Conflicts of Interest
Appendix A
- (1)
- .In this case, for . (i) if , then . With , we know that in . Thus, there exists a root of to have , and when ; when . Therefore is a unimodal. (ii) if , then . Thus there is a unique root of the quadratic function with , and when , ; when . Therefore there is one root of such that , and when ; when . It results in is unimodal.
- (2)
- and .(i) if , then . Also , and so in . Hence there is a root of with , and when ; when . It indicates that is unimodal. (ii) if , then . Hence there is a unique root of with , and when ; when . Thus there exists a root of with , and when ; when . Therefore is unimodal.
- (3)
- and .Thus , and so there is a unique root of satisfying that: when and when . In addition, , and so two cases need to be discussed. (i) if there is only one root for , then for . Hence there is a unique root of the cubic function . Thus , and when , when . So is unimodal. (ii) if there are two distinct roots for , then we know that: when , when , and when . There could be two cases: (a) If the cubic function has one or two distinct roots, then one root, say , leads to , and in ; in . Hence is unimodal; (b) If has three distinct real roots , then we have that , and that: when , when , when , when . It indicates is bimodal.
References
- Stacy, E.W. A Generalization of the Gamma Distribution. Ann. Math. Stat. 1962, 33, 1187–1192. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K. Exponentiated Weibull family for analyzing bathtub failure-ratedata. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Marshall, A.W.; Olkin, I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Rubio, F.J.; Hong, Y. Survival and lifetime data analysis with a flexible class of distributions. J. Appl. Stat. 2016, 43, 1794–1813. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundub, D.; Balakrishnan, N. Modified moment estimation for the two-parameter Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 2003, 43, 283–298. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cribari-Neto, F.; Vasconcellos, K.L.P. Improved statistical inference for the two-parameter Birnbaum-Saunders distribution. Comput. Stat. Data Anal. 2007, 51, 4656–4681. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Zhu, X. An improved method of estimation for the parameters of the Birnbaum-Saunders distribution. J. Stat. Comput. Simul. 2014, 84, 2285–2294. [Google Scholar] [CrossRef]
- Leiva, V. The Birnbaum-Saunders Distribution; Academic Press: New York, NY, USA, 2016. [Google Scholar]
- Díaz-García, J.A.; Leiva, V. A new family of life distributions based on elliptically contoured distributions. J. Stat. Plan. Inference 2005, 128, 445–457, Erratum in 2007, 137, 1512–1513. [Google Scholar] [CrossRef]
- Leiva, V.; Riquelme, M.; Balakrishnan, N.; Sanhueza, A. Lifetime analysis based on the generalized Birnbaum-Saunders distribution. Comput. Stat. Data Anal. 2008, 52, 2079–2097. [Google Scholar] [CrossRef]
- Leiva, V.; Vilca-Labra, F.; Balakrishnan, N.; Sanhueza, A. A skewed sinh-normal distribution and its properties and application to air pollution. Commun. Stat. Theory Methods 2010, 39, 426–443. [Google Scholar] [CrossRef]
- Sanhueza, A.; Leiva, V.; Balakrishnan, N. The generalized Birnbaum-Saunders and its theory, methodology, and application. Commun. Stat. Theory Methods 2008, 37, 645–670. [Google Scholar] [CrossRef]
- Kundu, D.; Balakrishnan, N.; Jamalizadeh, A. Generalized multivariate Birnbaum-Saunders distributions and related inferential issues. J. Multivar. Anal. 2013, 116, 230–244. [Google Scholar] [CrossRef]
- Saulo, H.; Balakrishnan, N.; Zhu, X.; Gonzales, J.F.B.; Leao, J. Estimation in generalized bivariate Birnbaum-Saunders models. Metrika 2017, 80, 427–453. [Google Scholar] [CrossRef]
- Díaz-García, J.A.; Domínguez-Molina, J.R. Some generalizations of Birnbaum-Saunders and sinh-normal distributions. Int. Math. Forum 2006, 1, 1709–1727. [Google Scholar] [CrossRef]
- Fierro, R.; Leiva, V.; Ruggeri, F.; Sanhuezad, A. On a Birnbaum–Saunders distribution arising from a non-homogeneous Poisson process. Stat. Probab. Lett. 2013, 83, 1233–1239. [Google Scholar] [CrossRef]
- Owen, W.J. A new three-parameter extension to the Birnbaum-Saunders distribution. IEEE Trans. Reliab. 2006, 55, 475–479. [Google Scholar] [CrossRef]
- Owen, W.J.; Ng, H.K.T. Revisit of relationships and models for the Birnbaum-Saunders and inverse-Gaussian distribution. J. Stat. Distrib. Appl. 2015, 2. [Google Scholar] [CrossRef]
- Desmond, A.F. On the relationship between two fatigue-life models. IEEE Trans. Reliab. 1986, 35, 167–169. [Google Scholar] [CrossRef]
- Rieck, J.R. A moment-generating function with application to the Birnbaum-Saunders distribution. Commun. Stat. Theory Methods 1999, 28, 2213–2222. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons: New York, NY, USA, 1995. [Google Scholar]
- Greene, W.H. Econometric Analysis, 5th ed.; Prentice Hall: New York, NY, USA, 2003. [Google Scholar]
- Bebu, I.; Mathew, T. Confidence intervals for limited moments and truncated moments in normal and lognormal models. Stat. Probab. Lett. 2009, 79, 375–380. [Google Scholar] [CrossRef]
- Terrell, G.R. The gradient statistic. Comput. Sci. Stat. 2002, 34, 206–215. [Google Scholar]
- Sen, P.; Singer, J. Large Sample Methods in Statistics: An Introduction with Applications; Chapman & Hall: New York, NY, USA, 1993. [Google Scholar]
- Balakrishnan, N.; Leiva, V.; Sanhueza, A.; Cabrera, E. Mixture inverse Gaussian distribution and its transformations, moments and applications. Statistics 2009, 43, 91–104. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | ML Method | New Method | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | MSE | AL | CP (%) | Bias | MSE | AL | CP (%) | ||
| 20 | m | 0.1237 | 0.2901 | 1.2266 | 92.39 | 0.1190 | 0.1882 | 0.7592 | 92.88 |
| 0.1405 | 0.1582 | 0.4803 | 92.15 | 0.1354 | 0.1445 | 0.4618 | 92.75 | ||
| 0.0318 | 0.0729 | 0.2894 | 93.79 | 0.0227 | 0.0638 | 0.2336 | 94.26 | ||
| 30 | 0.1103 | 0.2370 | 1.1059 | 93.14 | 0.1112 | 0.1684 | 0.5340 | 94.01 | |
| 0.1302 | 0.1366 | 0.4579 | 93.25 | 0.1161 | 0.1101 | 0.4089 | 94.57 | ||
| 0.0251 | 0.0680 | 0.2169 | 94.24 | 0.0216 | 0.0512 | 0.1213 | 94.85 | ||
| 50 | 0.1050 | 0.1335 | 0.9773 | 94.43 | 0.0933 | 0.1120 | 0.2252 | 94.90 | |
| 0.1128 | 0.1160 | 0.4039 | 94.70 | 0.1116 | 0.0974 | 0.3330 | 95.10 | ||
| 0.0120 | 0.0246 | 0.1358 | 95.12 | 0.0036 | 0.0116 | 0.1054 | 95.19 | ||
| 20 | m | 0.1103 | 0.1310 | 1.0148 | 93.29 | 0.1081 | 0.1187 | 0.7357 | 93.71 |
| 0.1232 | 0.1077 | 0.3602 | 93.33 | 0.1128 | 0.1029 | 0.3552 | 93.44 | ||
| 0.0320 | 0.0948 | 0.3190 | 93.79 | 0.0228 | 0.0727 | 0.2311 | 94.55 | ||
| 30 | 0.1058 | 0.1240 | 0.9389 | 94.55 | 0.1023 | 0.1130 | 0.5694 | 94.80 | |
| 0.1190 | 0.1068 | 0.3466 | 94.43 | 0.1053 | 0.0910 | 0.3191 | 94.75 | ||
| 0.0160 | 0.0679 | 0.2432 | 94.82 | 0.0103 | 0.0620 | 0.1650 | 95.10 | ||
| 50 | 0.0812 | 0.1161 | 0.5510 | 94.44 | 0.0211 | 0.0832 | 0.3794 | 95.20 | |
| 0.0505 | 0.0743 | 0.2130 | 94.50 | 0.0334 | 0.0586 | 0.1842 | 95.19 | ||
| 0.0083 | 0.0350 | 0.1961 | 95.16 | 0.0035 | 0.0212 | 0.0823 | 95.23 | ||
| 20 | m | 0.1801 | 0.1352 | 0.9770 | 91.90 | 0.1631 | 0.1227 | 0.7119 | 92.97 |
| 0.2250 | 0.2437 | 0.6224 | 92.17 | 0.2041 | 0.1498 | 0.4870 | 92.80 | ||
| 0.0374 | 0.1072 | 0.4733 | 93.48 | 0.0280 | 0.0840 | 0.2202 | 93.96 | ||
| 30 | 0.1625 | 0.1232 | 0.9025 | 93.54 | 0.1480 | 0.1112 | 0.6117 | 94.25 | |
| 0.1858 | 0.2043 | 0.5804 | 93.79 | 0.1503 | 0.1255 | 0.4040 | 94.31 | ||
| 0.0229 | 0.0733 | 0.3484 | 94.25 | 0.0117 | 0.0629 | 0.1130 | 94.81 | ||
| 50 | 0.1151 | 0.1110 | 0.5139 | 93.42 | 0.0980 | 0.1051 | 0.4287 | 94.53 | |
| 0.1353 | 0.1670 | 0.4080 | 94.29 | 0.1143 | 0.1058 | 0.3090 | 94.74 | ||
| 0.0137 | 0.0420 | 0.2602 | 95.02 | 0.0102 | 0.0319 | 0.0852 | 95.18 | ||
| 20 | m | 0.2778 | 0.1342 | 0.9744 | 92.32 | 0.2180 | 0.1171 | 0.7069 | 93.35 |
| 0.3490 | 0.2783 | 0.8688 | 93.17 | 0.2896 | 0.2225 | 0.7213 | 93.07 | ||
| 0.0533 | 0.1440 | 0.5220 | 93.87 | 0.0432 | 0.0941 | 0.2860 | 94.10 | ||
| 30 | 0.2591 | 0.1301 | 0.8974 | 93.28 | 0.1744 | 0.1104 | 0.6785 | 94.03 | |
| 0.3016 | 0.2353 | 0.7740 | 93.77 | 0.1948 | 0.2056 | 0.6442 | 94.60 | ||
| 0.0430 | 0.1075 | 0.4249 | 94.29 | 0.0337 | 0.0735 | 0.1670 | 94.77 | ||
| 50 | 0.1607 | 0.1095 | 0.7050 | 94.25 | 0.1157 | 0.0933 | 0.5690 | 95.01 | |
| 0.2060 | 0.1845 | 0.5217 | 94.66 | 0.1312 | 0.1560 | 0.4117 | 95.08 | ||
| 0.0207 | 0.0681 | 0.2683 | 94.90 | 0.0111 | 0.0420 | 0.0790 | 95.24 | ||
| 20 | m | 0.3756 | 0.2143 | 1.1208 | 90.67 | 0.2962 | 0.1745 | 1.1081 | 92.41 |
| 0.4231 | 0.3277 | 1.1310 | 91.83 | 0.3480 | 0.2749 | 1.1109 | 92.20 | ||
| 0.0811 | 0.1730 | 0.6542 | 92.71 | 0.0503 | 0.1121 | 0.3259 | 93.35 | ||
| 30 | 0.3184 | 0.1806 | 1.0915 | 91.88 | 0.2361 | 0.1487 | 1.0672 | 93.36 | |
| 0.3523 | 0.2751 | 1.1064 | 92.13 | 0.2782 | 0.2260 | 1.0798 | 93.22 | ||
| 0.0729 | 0.1493 | 0.4849 | 93.18 | 0.0425 | 0.0986 | 0.2264 | 94.27 | ||
| 50 | 0.2597 | 0.1564 | 0.9188 | 93.84 | 0.1986 | 0.1204 | 0.8974 | 94.58 | |
| 0.2873 | 0.2109 | 0.9167 | 93.47 | 0.2319 | 0.1708 | 0.8887 | 94.13 | ||
| 0.0519 | 0.0933 | 0.3225 | 94.29 | 0.0296 | 0.0507 | 0.1137 | 94.73 | ||
| n | with | |||||||||||
| 10 | 12.78 | 6.74 | 9.38 | 5.75 | 12.69 | 6.70 | 11.09 | 5.68 | 12.73 | 6.80 | 11.50 | 5.89 |
| 20 | 12.40 | 6.52 | 9.41 | 5.49 | 12.36 | 6.54 | 10.73 | 5.45 | 12.61 | 6.70 | 11.34 | 5.48 |
| 30 | 11.82 | 6.30 | 9.64 | 5.42 | 11.56 | 6.28 | 10.54 | 5.39 | 12.38 | 6.54 | 11.19 | 5.39 |
| 40 | 11.46 | 6.25 | 9.76 | 5.37 | 11.20 | 6.15 | 10.37 | 5.26 | 12.30 | 6.40 | 10.78 | 5.28 |
| 50 | 11.12 | 6.05 | 9.88 | 5.23 | 10.98 | 5.90 | 10.23 | 5.14 | 11.86 | 6.22 | 10.55 | 5.19 |
| with | ||||||||||||
| 10 | 11.38 | 6.10 | 10.50 | 5.81 | 11.41 | 6.11 | 11.40 | 4.15 | 12.60 | 6.11 | 9.02 | 4.09 |
| 20 | 11.15 | 6.04 | 10.32 | 5.62 | 11.27 | 6.03 | 11.22 | 4.38 | 12.36 | 6.03 | 9.10 | 4.24 |
| 30 | 10.88 | 5.60 | 10.17 | 5.37 | 11.15 | 5.57 | 11.04 | 4.60 | 12.13 | 5.44 | 9.40 | 4.40 |
| 40 | 10.74 | 5.49 | 10.52 | 5.29 | 10.84 | 5.40 | 10.80 | 4.80 | 11.82 | 5.32 | 9.55 | 4.62 |
| 50 | 10.39 | 5.26 | 10.25 | 5.19 | 10.53 | 5.33 | 10.43 | 4.86 | 11.62 | 5.23 | 9.74 | 4.80 |
| with | ||||||||||||
| 10 | 11.45 | 6.87 | 11.42 | 5.74 | 12.48 | 6.63 | 11.51 | 4.59 | 12.56 | 6.38 | 12.37 | 4.55 |
| 20 | 11.32 | 6.68 | 11.30 | 5.56 | 12.34 | 6.55 | 11.30 | 4.75 | 12.40 | 6.25 | 12.19 | 4.66 |
| 30 | 10.89 | 6.50 | 10.79 | 5.39 | 12.25 | 6.38 | 11.19 | 4.83 | 12.20 | 6.21 | 11.68 | 4.75 |
| 40 | 10.71 | 6.38 | 10.67 | 5.26 | 11.94 | 6.31 | 10.88 | 4.90 | 11.85 | 6.05 | 11.42 | 4.84 |
| 50 | 10.37 | 6.15 | 10.25 | 5.13 | 11.30 | 6.10 | 10.48 | 4.94 | 11.51 | 5.89 | 10.91 | 4.90 |
| n | |||||||||
| 20 | 1.00 | 5.43 | 5.28 | 0.50 | 5.41 | 5.30 | 1.00 | 5.34 | 5.22 |
| 1.05 | 20.88 | 22.42 | 0.55 | 24.13 | 26.48 | 1.05 | 25.33 | 26.26 | |
| 1.10 | 31.30 | 32.58 | 0.60 | 34.37 | 38.72 | 1.10 | 40.54 | 41.64 | |
| 1.15 | 46.91 | 48.41 | 0.65 | 50.05 | 53.27 | 1.15 | 56.36 | 58.26 | |
| 50 | 1.00 | 5.21 | 5.18 | 0.50 | 5.25 | 5.23 | 1.00 | 5.28 | 5.15 |
| 1.05 | 28.87 | 29.78 | 0.55 | 28.81 | 30.13 | 1.05 | 33.07 | 36.10 | |
| 1.10 | 45.45 | 48.57 | 0.60 | 49.30 | 50.78 | 1.10 | 54.44 | 55.85 | |
| 1.15 | 60.82 | 63.45 | 0.65 | 64.01 | 65.39 | 1.15 | 67.13 | 69.07 | |
| 100 | 1.00 | 5.08 | 5.05 | 0.50 | 5.11 | 5.04 | 1.00 | 5.06 | 5.03 |
| 1.05 | 32.12 | 38.36 | 0.55 | 40.04 | 42.77 | 1.05 | 43.07 | 46.08 | |
| 1.10 | 71.28 | 77.23 | 0.60 | 76.24 | 79.62 | 1.10 | 79.77 | 83.45 | |
| 1.15 | 86.78 | 89.14 | 0.65 | 89.00 | 91.31 | 1.15 | 90.51 | 93.05 | |
| 20 | 1.50 | 5.48 | 5.31 | 1.00 | 5.50 | 5.33 | 2.00 | 5.49 | 5.30 |
| 1.55 | 22.80 | 25.67 | 1.05 | 25.36 | 27.08 | 2.05 | 25.05 | 27.37 | |
| 1.60 | 34.62 | 35.10 | 1.10 | 37.11 | 39.12 | 2.10 | 38.25 | 40.18 | |
| 1.65 | 47.31 | 49.00 | 1.15 | 48.50 | 50.85 | 2.15 | 50.08 | 51.72 | |
| 50 | 1.50 | 5.37 | 5.24 | 1.00 | 5.35 | 5.29 | 2.00 | 5.34 | 5.22 |
| 1.55 | 29.20 | 30.50 | 1.05 | 28.15 | 30.74 | 2.05 | 30.18 | 32.85 | |
| 1.60 | 46.20 | 48.09 | 1.10 | 46.38 | 48.25 | 2.10 | 49.28 | 52.10 | |
| 1.65 | 60.72 | 63.74 | 1.15 | 61.76 | 64.16 | 2.15 | 65.50 | 68.07 | |
| 100 | 1.50 | 5.12 | 5.07 | 1.00 | 5.14 | 5.09 | 2.00 | 5.11 | 5.04 |
| 1.55 | 33.03 | 36.15 | 1.05 | 38.05 | 38.20 | 2.05 | 40.17 | 42.20 | |
| 1.60 | 69.85 | 72.10 | 1.10 | 74.18 | 78.09 | 2.10 | 78.15 | 82.12 | |
| 1.65 | 85.86 | 88.85 | 1.15 | 87.15 | 91.24 | 2.15 | 88.27 | 91.11 | |
| Method | m (SE) | (SE) | (SE) | , BIC |
|---|---|---|---|---|
| MLE | 0.8326 (0.5792) | 1.6820 (1.2643) | 2.6093 (0.1828) | 97.27, 103.40 |
| 95% CI | (0.2170, 1.8444) | (0.3743, 8.5531) | (1.3854, 3.2163) | |
| New | 0.4657 (0.2478) | 1.0322 (0.5366) | 1.7727 (0.1439) | 19.82, 93.71 |
| 95% CI | (0.3229, 0.6436) | (0.7634, 1.6216) | (1.0545, 2.9831) |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sha, N. A New Inference Approach for Type-II Generalized Birnbaum-Saunders Distribution. Stats 2019, 2, 148-163. https://doi.org/10.3390/stats2010011
Sha N. A New Inference Approach for Type-II Generalized Birnbaum-Saunders Distribution. Stats. 2019; 2(1):148-163. https://doi.org/10.3390/stats2010011
Chicago/Turabian StyleSha, Naijun. 2019. "A New Inference Approach for Type-II Generalized Birnbaum-Saunders Distribution" Stats 2, no. 1: 148-163. https://doi.org/10.3390/stats2010011
APA StyleSha, N. (2019). A New Inference Approach for Type-II Generalized Birnbaum-Saunders Distribution. Stats, 2(1), 148-163. https://doi.org/10.3390/stats2010011