
Fire and Smoke Detection in Complex Environments


Abstract
1. Introduction
- We introduce a novel approach for fire and smoke detection by integrating a ViT with YOLOv5s, combining the strengths of attention-based feature extraction and real-time object detection.
- We provide a detailed analysis of the performance of the modified model in comparison to baseline YOLOv5 variants, highlighting improvements in precision, recall, and mAP.
- We demonstrate the effectiveness of our approach in real-world fire and smoke detection scenarios using a comprehensive dataset, emphasizing the model’s robustness under varying environmental conditions.
2. Related Work
2.1. Traditional Vision-Based Fire Detection Methods
2.2. Deep Learning-Based Object Detection for Fire and Smoke
2.3. Attention Mechanisms and Vision Transformers in Object Detection
3. Methodology
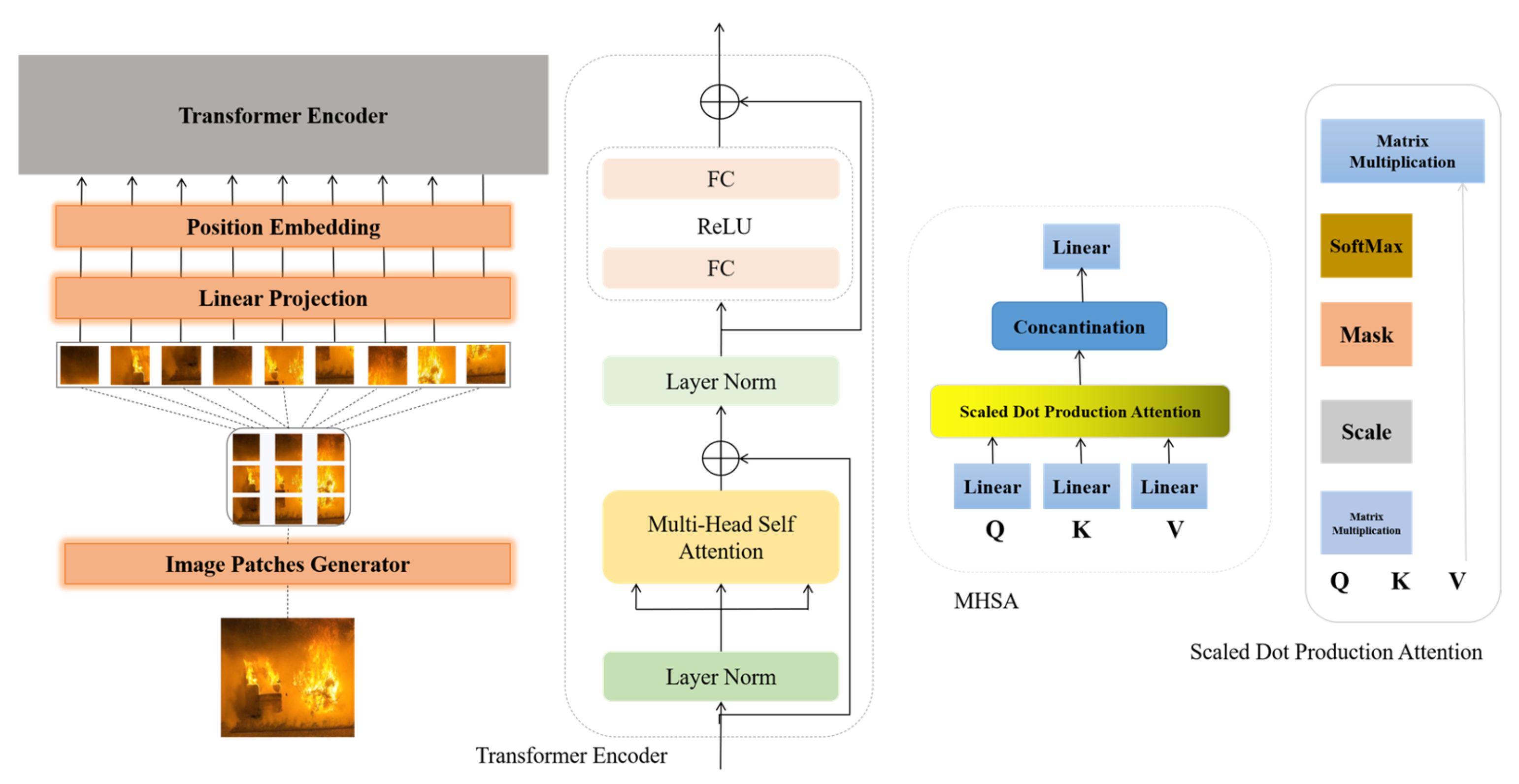
3.1. Vision Transformer
3.2. YOLOv5s
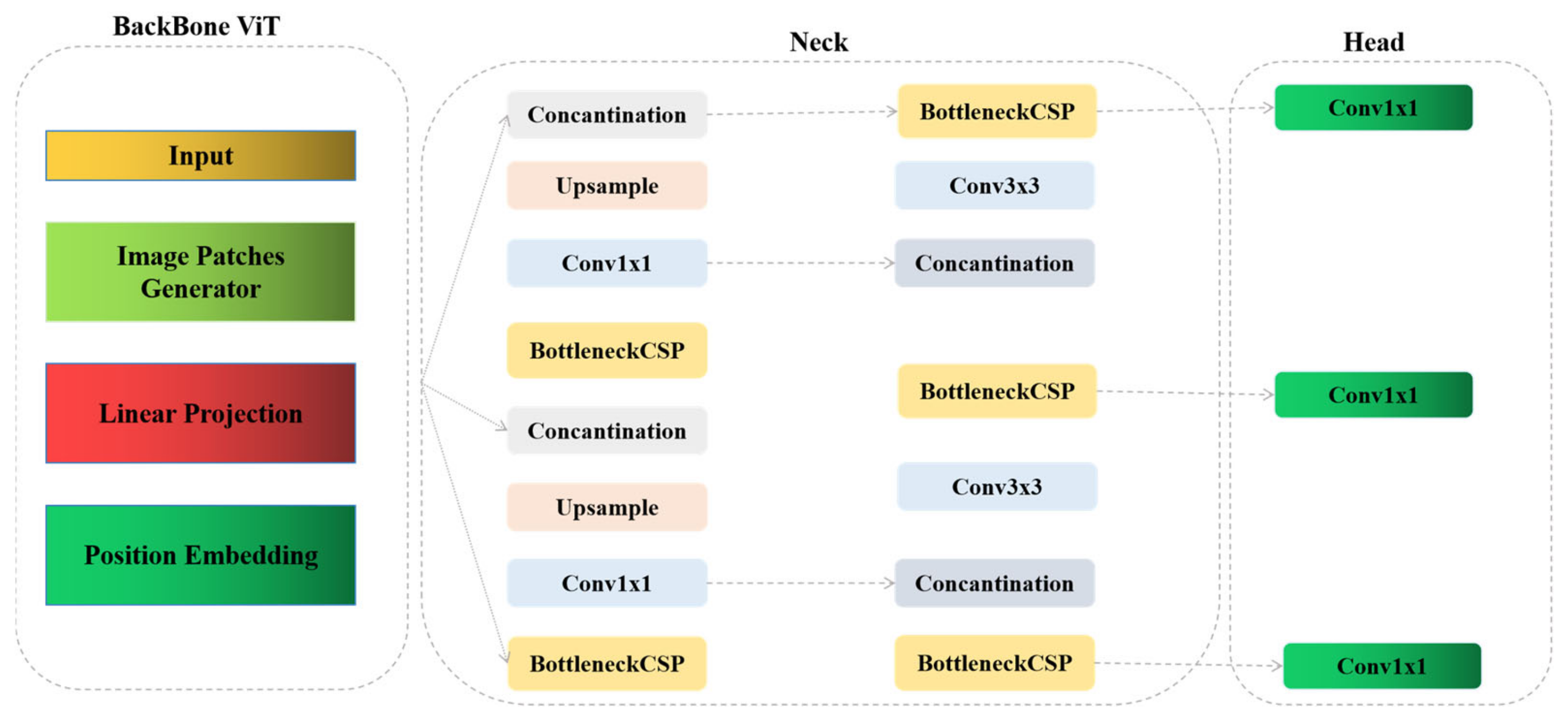
3.3. The Modified YOLOv5s
4. Experiment and Results
4.1. Dataset
4.2. Data Preprocessing
4.3. Metrics
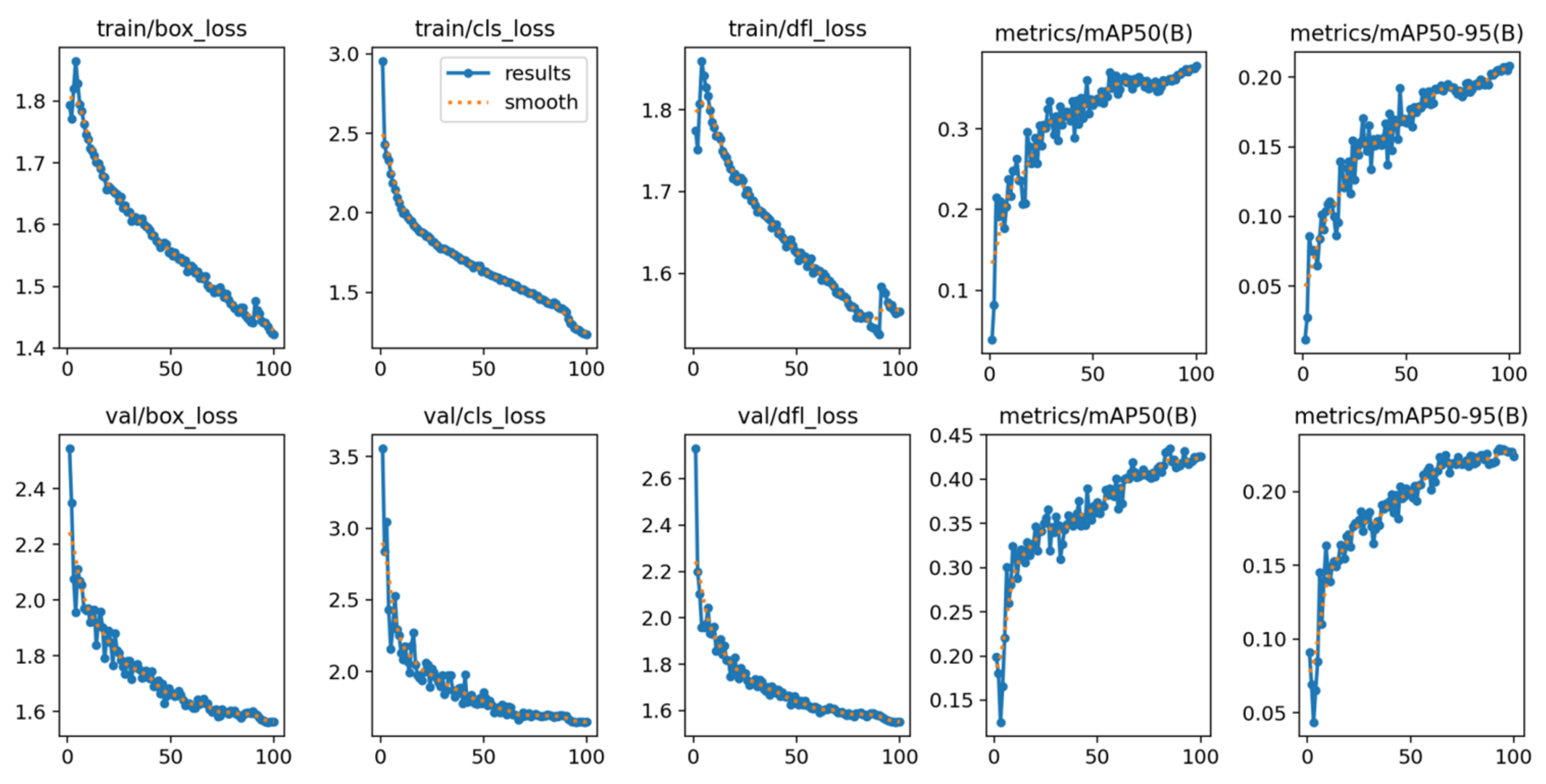
4.4. The Experiment Results
4.5. Comparison with State-of-the-Art Models
4.6. Dataset and Environmental Impact Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, Z.; Hamdan, E.; Zhao, Y.; Ye, T.; Pan, H.; Cetin, A.E. Wildfire detection via transfer learning: A survey. Signal Image Video Process. 2024, 18, 207–214. [Google Scholar] [CrossRef]
- Akyol, K. A comprehensive comparison study of traditional classifiers and deep neural networks for forest fire detection. Clust. Comput. 2024, 27, 1201–1215. [Google Scholar] [CrossRef]
- Jin, L.; Yu, Y.; Zhou, J.; Bai, D.; Lin, H.; Zhou, H. SWVR: A lightweight deep learning algorithm for forest fire detection and recognition. Forests 2024, 15, 204. [Google Scholar] [CrossRef]
- Shakhnoza, M.; Sabina, U.; Sevara, M.; Cho, Y.I. Novel video surveillance-based fire and smoke classification using attentional feature map in capsule networks. Sensors 2021, 22, 98. [Google Scholar] [CrossRef] [PubMed]
- Paidipati, K.K.; Kurangi, C.; Reddy, A.S.K.; Kadiravan, G.; Shah, N.H. Wireless sensor network assisted automated forest fire detection using deep learning and computer vision model. Multimed. Tools Appl. 2024, 83, 26733–26750. [Google Scholar] [CrossRef]
- Akhmedov, F.; Nasimov, R.; Abdusalomov, A. Dehazing Algorithm Integration with YOLO-v10 for Ship Fire Detection. Fire 2024, 7, 332. [Google Scholar] [CrossRef]
- Cao, L.; Shen, Z.; Xu, S. Efficient forest fire detection based on an improved YOLO model. Vis. Intell. 2024, 2, 20. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Wang, C.; Li, X.; Xian, B.; Yu, H. Visual fire detection using deep learning: A survey. Neurocomputing 2024, 127975. [Google Scholar] [CrossRef]
- Safarov, F.; Akhmedov, F.; Abdusalomov, A.B.; Nasimov, R.; Cho, Y.I. Real-time deep learning-based drowsiness detection: Leveraging computer-vision and eye-blink analyses for enhanced road safety. Sensors 2023, 23, 6459. [Google Scholar] [CrossRef] [PubMed]
- Xiang, S.; Yin, S.; Yu, G.; Xu, X.; Yu, L. Factory Fire Detection using TRA-YOLO Network. In Proceedings of the 2024 36th Chinese Control and Decision Conference (CCDC), Xi’an, China, 25–27 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 3777–3782. [Google Scholar]
- Yandouzi, M.; Berrahal, M.; Grari, M.; Boukabous, M.; Moussaoui, O.; Azizi, M.; Ghoumid, K.; Elmiad, A.K. Semantic segmentation and thermal imaging for forest fires detection and monitoring by drones. Bull. Electr. Eng. Inform. 2024, 13, 2784–2796. [Google Scholar] [CrossRef]
- Titu, M.F.S.; Pavel, M.A.; Michael, G.K.O.; Babar, H.; Aman, U.; Khan, R. Real-Time Fire Detection: Integrating Lightweight Deep Learning Models on Drones with Edge Computing. Drones 2024, 8, 483. [Google Scholar] [CrossRef]
- Bu, F.; Gharajeh, M.S. Intelligent and vision-based fire detection systems: A survey. Image Vis. Comput. 2019, 91, 103803. [Google Scholar] [CrossRef]
- Thanga Manickam, M.; Yogesh, M.; Sridhar, P.; Thangavel, S.K.; Parameswaran, L. Video-based fire detection by transforming to optimal color space. In Proceedings of the International Conference On Computational Vision and Bio Inspired Computing, Coimbatore, India, 25–26 September 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 1256–1264. [Google Scholar]
- Khondaker, A.; Khandaker, A.; Uddin, J. Computer vision-based early fire detection using enhanced chromatic segmentation and optical flow analysis technique. Int. Arab J. Inf. Technol. 2020, 17, 947–953. [Google Scholar] [CrossRef]
- Rahman, M.A.; Hasan, S.T.; Kader, M.A. Computer vision based industrial and forest fire detection using support vector machine (SVM). In Proceedings of the 2022 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 25–28 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 233–238. [Google Scholar]
- Sharma, J.; Granmo, O.C.; Goodwin, M.; Fidje, J.T. Deep convolutional neural networks for fire detection in images. In Engineering Applications of Neural Networks: 18th International Conference, EANN 2017, Athens, Greece, 25–27 August 2017, Proceedings; Springer International Publishing: Cham, Switzerland, 2017; pp. 183–193. [Google Scholar]
- Kim, Y.J.; Kim, E.G. Fire detection system using faster R-CNN. In Proceedings of the International Conference on Future Information & Communication Engineering, Kunming, China, 8–10 December 2017; Volume 9, pp. 261–264. [Google Scholar]
- Nguyen, A.Q.; Nguyen, H.T.; Tran, V.C.; Pham, H.X.; Pestana, J. A visual real-time fire detection using single shot multibox detector for uav-based fire surveillance. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc Island, Vietnam, 13–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 338–343. [Google Scholar]
- Zhou, M.; Wu, L.; Liu, S.; Li, J. UAV forest fire detection based on lightweight YOLOv5 model. Multimed. Tools Appl. 2024, 83, 61777–61788. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, Y. Lightweight Fire Detection Algorithm Based on Improved YOLOv5. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 809. [Google Scholar] [CrossRef]
- Xu, H.; Li, B.; Zhong, F. Light-YOLOv5: A lightweight algorithm for improved YOLOv5 in complex fire scenarios. Appl. Sci. 2022, 12, 12312. [Google Scholar] [CrossRef]
- Shahid, M.; Hua, K.L. Fire detection using transformer network. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21 August 2021; pp. 627–630. [Google Scholar]
- Lv, C.; Zhou, H.; Chen, Y.; Fan, D.; Di, F. A lightweight fire detection algorithm for small targets based on YOLOv5s. Sci. Rep. 2024, 14, 14104. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Lu, Z.; Zhang, R.; Li, J.; Wang, S.; Fan, J. An effective graph embedded YOLOv5 model for forest fire detection. Comput. Intell. 2024, 40, e12640. [Google Scholar] [CrossRef]
- Kim, S.; Jang, I.S.; Ko, B.C. Domain-free fire detection using the spatial-temporal attention transform of the YOLO backbone. Pattern Anal. Appl. 2024, 27, 45. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.; Ding, W.; Li, C. YOlOv5s-ACE: Forest Fire Object Detection Algorithm Based on Improved YOLOv5s. In Fire Technology; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Yang, W.; Yang, Z.; Wu, M.; Zhang, G.; Zhu, Y.; Sun, Y. SIMCB-Yolo: An Efficient Multi-Scale Network for Detecting Forest Fire Smoke. Forests 2024, 15, 1137. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Precision | Recall | mAP@0.5 | Params | Flops (G) | Epochs |
|---|---|---|---|---|---|---|
| Yolov5n (nano) | 0.357 | 0.487 | 0.419 | 11 | 4.1 | 100 |
| Yolov5s (small) | 0.484 | 0.641 | 0.617 | 12 | 8.1 | 100 |
| Yolov5m (medium) | 0.576 | 0.628 | 0.635 | 14 | 10.2 | 100 |
| Ours | 0.583 | 0.657 | 0.664 | 12 | 10 | 100 |
| Models | Train Box Loss | Train Object Loss | Train Class Loss | Val Box Loss | Val Object Loss | Val Class Loss |
|---|---|---|---|---|---|---|
| Yolov5n (nano) | 0.0712 | 0.0092 | 1.2021 | 0.0802 | 0.0075 | 1.1245 |
| Yolov5s (small) | 0.0642 | 0.0102 | 1.0102 | 0.0719 | 0.0078 | 0.9433 |
| Yolov5m (medium) | 0.0622 | 0.0080 | 0.9832 | 0.0785 | 0.0064 | 0.9013 |
| Ours | 0.0602 | 0.0076 | 0.9707 | 0.0717 | 0.0051 | 0.9008 |
| Model | mAP (%) | FPS (Frames Per Second) | Precision (%) | Recall (%) |
|---|---|---|---|---|
| TRA-YOLO [10] | 78.5 | 50 | 78.7 | 80.9 |
| SIMCB-Yolo [28] | 85.6 | 65 | 80.5 | 82.3 |
| Improved YOLOv5s [9] | 82.1 | 55 | 82.1 | 83.2 |
| Lightweight Fire Detection [20] | 98.3 | 85 | 94.8 | 94.3 |
| Domain-Free Fire Detection [26] | 94.5 | 75 | 93.5 | 92.8 |
| YOLOv5s-ACE [27] | 84.1 | 70 | 86.3 | 84.5 |
| Proposed Model (ours) | 96.0 | 85 | 96.8 | 97.0 |
| Lighting Condition | Precision | Recall | mAP@0.5 |
|---|---|---|---|
| Daylight | 0.72 | 0.68 | 0.70 |
| Low-Light | 0.63 | 0.57 | 0.60 |
| Nighttime | 0.55 | 0.50 | 0.52 |
| Weather Condition | Precision | Recall | mAP@0.5 | False Positives (%) |
|---|---|---|---|---|
| Clear Skies | 0.68 | 0.65 | 0.67 | 5% |
| Fog | 0.52 | 0.49 | 0.51 | 20% |
| Rain | 0.60 | 0.58 | 0.59 | 10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safarov, F.; Muksimova, S.; Kamoliddin, M.; Cho, Y.I. Fire and Smoke Detection in Complex Environments. Fire 2024, 7, 389. https://doi.org/10.3390/fire7110389
Safarov F, Muksimova S, Kamoliddin M, Cho YI. Fire and Smoke Detection in Complex Environments. Fire. 2024; 7(11):389. https://doi.org/10.3390/fire7110389
Chicago/Turabian StyleSafarov, Furkat, Shakhnoza Muksimova, Misirov Kamoliddin, and Young Im Cho. 2024. "Fire and Smoke Detection in Complex Environments" Fire 7, no. 11: 389. https://doi.org/10.3390/fire7110389
APA StyleSafarov, F., Muksimova, S., Kamoliddin, M., & Cho, Y. I. (2024). Fire and Smoke Detection in Complex Environments. Fire, 7(11), 389. https://doi.org/10.3390/fire7110389