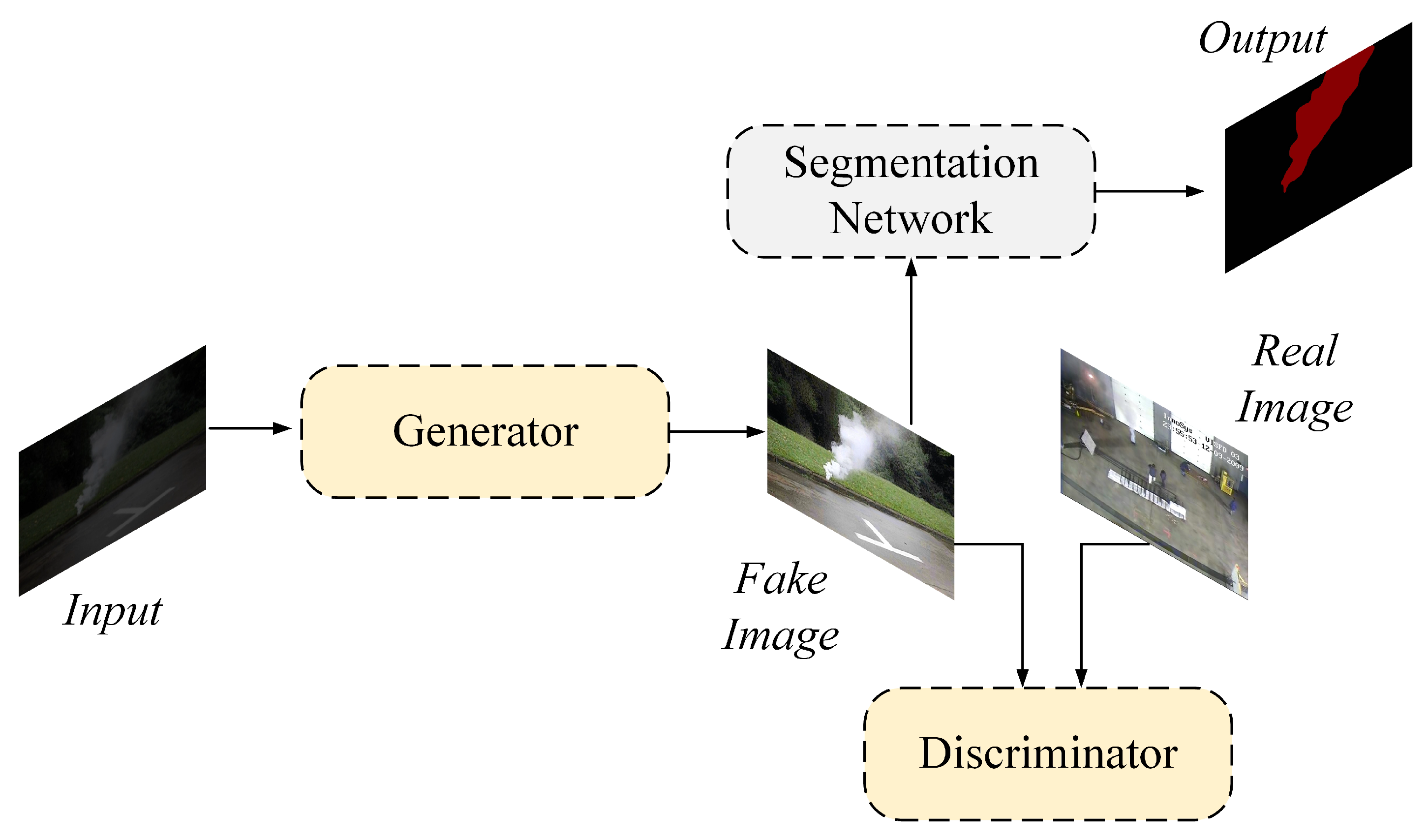
By cascading the two network models, it is possible to avoid the need for complex fusion methods while effectively reducing the model’s complexity and computational scale. Furthermore, our approach allows for the enhancement and segmentation networks to be replaced based on different task scenes and requirements, improving the method’s generalization and flexibility. Our highly efficient and adaptable approach makes it a valuable tool for applications in low-light environments.
3.1. Image Enhancement Network
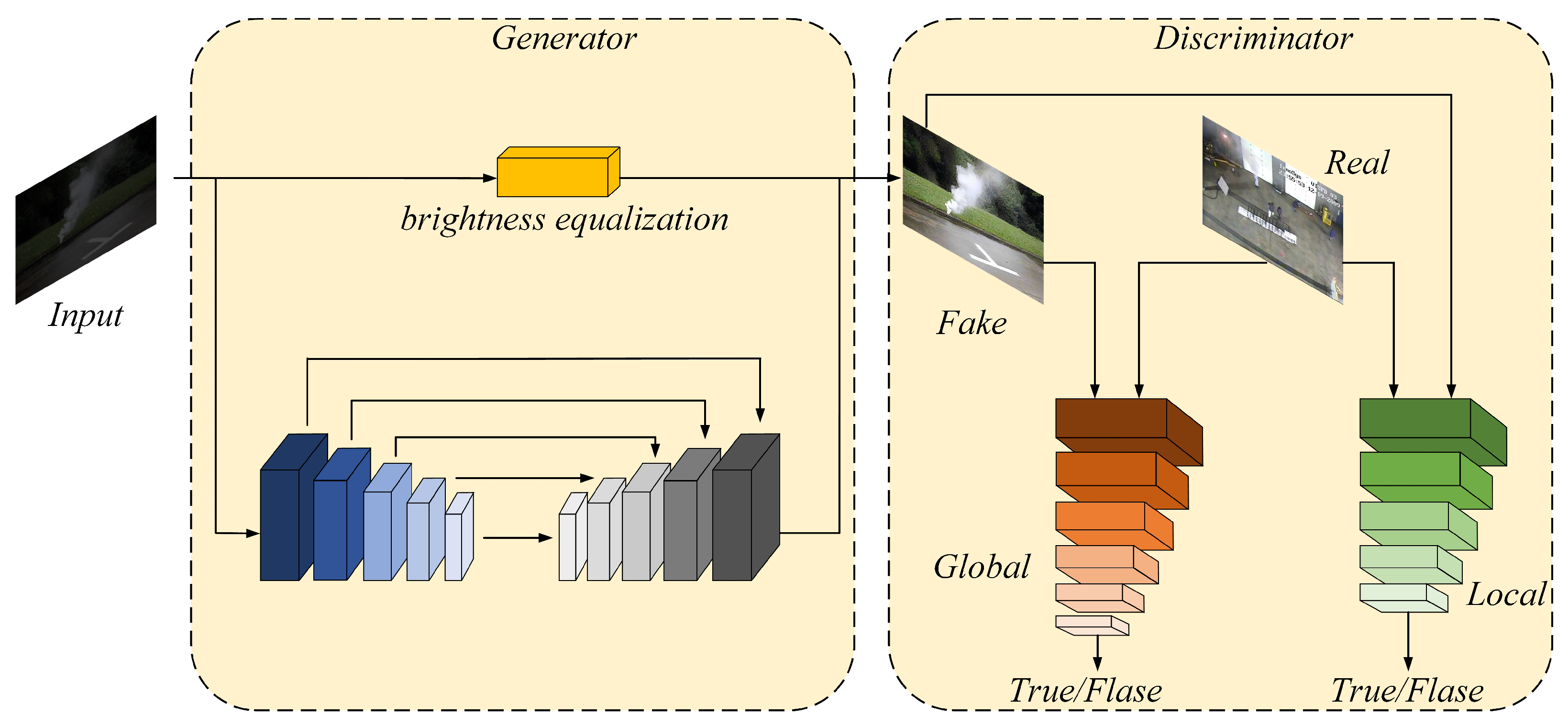
To improve the smoke characteristics in low-light environments, we modify the CycleGAN model as the main component of our image enhancement network. The original CycleGAN has difficulty preserving image details during the enhancement process, which results in artifacts, blur, and noise in enhanced images, making the subsequent segmentation task challenging. Inspired by EnlightenGAN [
14], we modify the generator network with an encoder–decoder structure to restore the smoke details accurately. We also add a brightness equalization branch to balance the brightness of each part of an image. To ensure that the smoke features are preserved during the enhancement process, we attach a similarity discriminant branch to the discriminator network based on a two-branch form.
Figure 2 shows the structure of our low-light smoke image enhancement algorithm.
The encoder follows the same structure as EnlightenGAN, while the decoder part’s upsampling process is completed using PixelShuffle [
15]. Through convolution and multi-channel recombination, the low-resolution feature map transforms into a high-resolution feature map. PixelShuffle is used mainly to handle the loss of details during upsampling based on a single feature map. The skip connection between the encoding and decoding stages ensures that original image features are transmitted, allowing some of the lost details from downsampling to be recovered. The brightness equalization branch applies additional weights to darker areas of the images, which can make them brighter—at the same time, suppressing the enhancement effect of brighter areas to avoid overexposure problems. The structure of the brightness equalization branch is shown in
Figure 3.
To ensure that the brightness equalization branch is sensitive to variable levels of darkness in low-light images, we choose the Parametric Rectified Linear Unit (PReLU) [
16] as the activation function. By adjusting the parameters in PReLU adaptively according to different brightness levels in different areas of the images, the equalization branch’s sensitivity to different brightness levels is significantly improved. Inspired by EnlightenGAN’s dual discriminant branch, our discriminator enhances the global brightness level and corrects image details. However, the generator’s skip connection can only partially counteract the loss or change of image features during enhancement. To further recover detailed features, we design a similarity discrimination branch that works in couple with the subsequent segmentation model in the discriminator network, ensuring that the image enhancement process will not significantly impact the smoke features. The discriminator structure, including the similarity discriminant branch, is illustrated in
Figure 4.
For the local discriminator, we modify the loss function of the original LS-GAN [
17] with the least squares loss:
For the global discriminator, to improve the quality of the generated images and reduce the training time, we refine the original loss function with the standard function of the relativistic adversarial network [
18]. The least square loss of the global discriminator according to the corresponding regression target is
where
D represents the discriminator network.
and
represent the distribution of real and fake images.
With unsupervised training, the transfer effect of domains is controlled by the difference between the quadratically generated and real images. To ensure that the characteristic information of the smoke area remains unchanged, we append the cycle consistency loss based on the LS-GAN loss, which helps to prevent the subsequent segmentation process from being adversely affected. The cyclic consistency loss expression is as follows:
where
G and
F represent the generators in two directions,
x represents the low-light images,
y represents the images in the daytime, and the difference between images is measured by 1-norm.
As shown in
Figure 4, our similarity discrimination branch effectively mitigates the loss and alteration of image specifics caused by downsampling in enhancement networks. Therefore, we increase the object similarity loss using the segmentation model:
where
represents the pixel-by-pixel classification results obtained by the subsequent semantic segmentation algorithm of the fake and real images.
H,
W, and
C are the dimensions of the corresponding feature maps. We use Mean Squared Error (MSE) to represent the absolute difference between two image segmentation results.
improves the recovery of details of the images. However, it also leads to blurry output images since quality evaluation indicators such as MSE only consider the difference between pixels at a single point without considering the correlation between them. They ignore the correlation between pixels. Therefore, we incorporate a loss based on the Structure Similarity Index Measure (SSIM) between the real images and the quadratically generated images:
where
indicates the structural similarity loss added to the cyclic generation discriminant, and
represents the structural similarity difference for
G and
F added in the one-way generation process.
In summary, the loss function of the image enhancement network we proposed is as follows:
where
,
, and
are the balance parameters that control the proportion of different loss functions. Based on the various experiments we conducted, we found that the parameters
,
, and
are the most suitable for our enhancement network. We use two branches to calculate the LS-GAN loss based on the two-branch discriminator, while the remaining three loss functions are calculated solely based on the generator network.
3.2. Semantic Segmentation Network
When it comes to smoke segmentation, it can be quite challenging due to the extensive range of sizes, strong diffusion, and changeable shapes of smoke. Background information can also significantly affect the segmentation results, making it even more difficult to obtain satisfactory results. Therefore, the networks which work well for other targets may not be effective for smoke segmentation tasks. To meet the requirements of video monitoring and analysis systems for detecting and announcing fire accidents, we propose a semantic segmentation network based on HRNet [
19] and HRFormer [
20]. It allows for the extraction of multi-scale features of smoke, making it possible to segment smoke images enhanced by our image enhancement network accurately. The structure of our semantic segmentation algorithm is shown in
Figure 5.
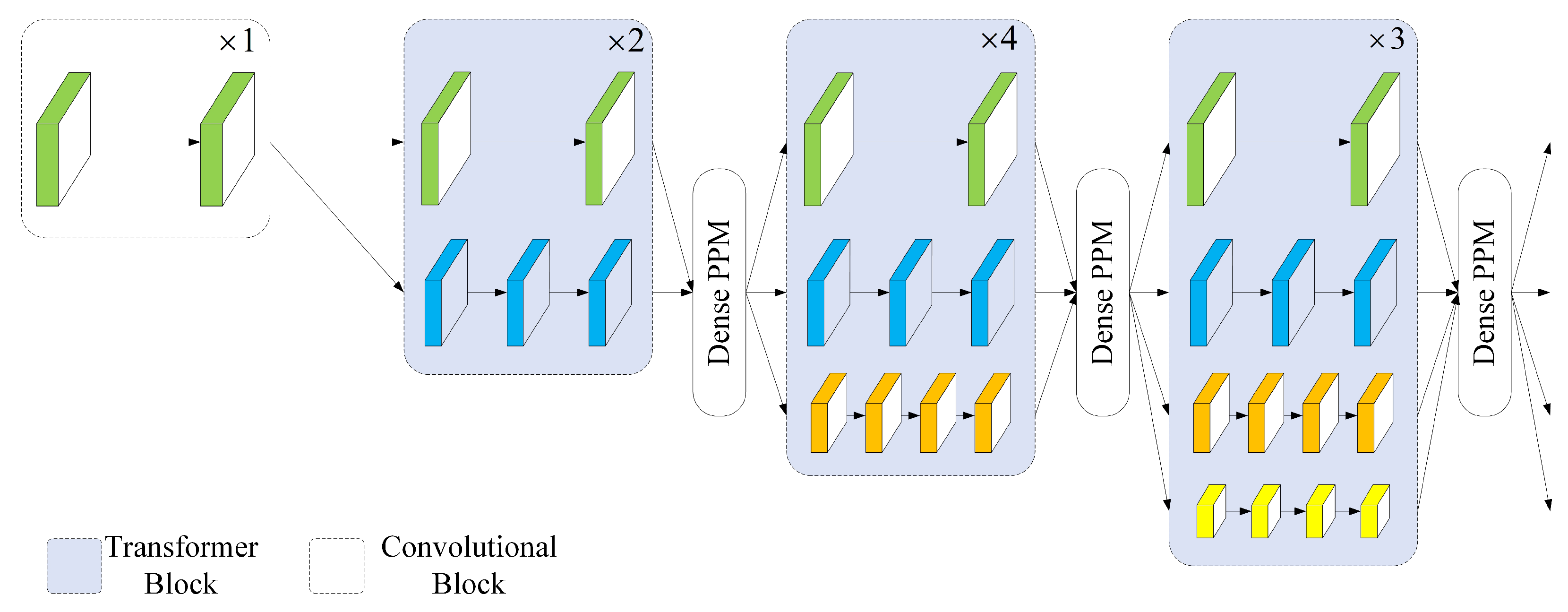
Due to the variable scales and shapes of smoke, feature extraction concentrating on one single scale makes it challenging to obtain accurate segmentation results. We modify HRFormer’s Transformer block to handle multi-scale changes in the targets effectively. Additionally, using 3 × 3 depth-wise convolution for information interaction between windows in HRFormer is not sufficient, as it barely covers the internal features of the windows. Meanwhile, increasing the sizes of convolution kernels will import more background information. Therefore, we use the Shifted Window-based Multi-head Self-Attention (SW-MSA) [
21] of a Swin Transformer (SW-Trans) instead. The entire structure of our feature extraction module is shown in
Figure 6.
Compared with the classical network structure of HRNet, our shallow and deep module parts utilize different numbers of feature extraction units. The high-resolution branches generate larger feature maps with fewer output dimensions, which allow for better preservation of pixel spatial positioning information. On the other hand, the low-resolution branches generate smaller feature maps with a larger number of output dimensions, making them better at extracting abstract semantic features. We gradually increase the number of Transformer blocks in our network from high-resolution to low-resolution branches, which allows us to extract both local details and global semantic information in parallel.
The parameters of our feature extraction modules are shown in
Table 1.
,
,
, and
represent the numbers of modules in different stages, and
,
,
, and
represent the numbers of Transformer blocks in each branch of different modules.
Consistent with
Figure 5,
,
,
, and
are 1, 2, 4, and 3, and
,
,
, and
are 2, 3, 4, and 4. The numbers of Transformer block channels at different resolutions are, respectively, 32, 64, 128, and 256 at 4, 8, 16, and 32 times. The numbers of self-attention heads are, respectively, 1, 2, 4, and 8. The Multi-Layer Perception (MLP) extension ratio in all transformer blocks is 4.
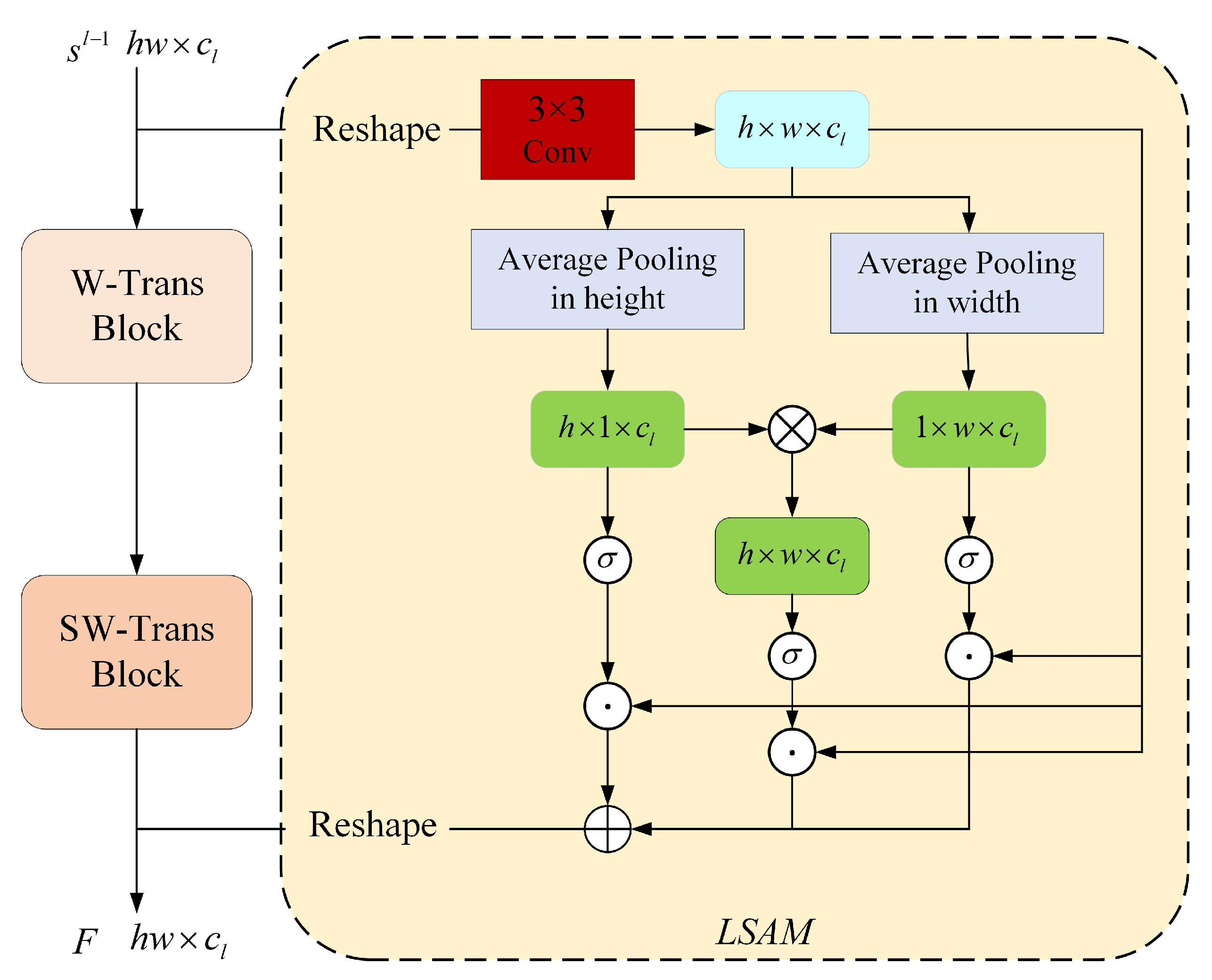
By incorporating the Local Spatial Attention Module (LSAM) and the Global Channel Attention Module (GCAM), we improve our Transformer block’s ability to extract local spatial information and aggregate global context information. The structure of our Transformer block is shown in
Figure 7.
The LSAM structure is shown in
Figure 8, and the GCAM structure is shown in
Figure 9.
LSAM reshapes the tokens into feature maps before extracting structural information through a 3 × 3 convolutional layer. Depending on the stage and branch where the transformer block is located,
H and
W take different values. Once the structural information is extracted, global average pooling is performed in the width and height directions to obtain statistical information:
where
and
are one-dimensional spatial attention vectors in the height and width directions.
is the feature map obtained by the convolutional layer, and the Batch Normalization (BN) and Gaussian Error Linear Unit (GELU) activation functions are used after convolution. The corresponding operating ranges are
,
, and
.
A feature map of
is obtained by matrix multiplication using the tensors in the width and height directions within each channel:
After obtaining two spatial attention vectors in the height and width direction and a two-dimensional spatial attention feature map with information interaction in two directions, the next step is to activate the three attention weight vectors with the sigmoid function. These weight vectors are multiplied point by point to the original feature map. Then the spatial position attention map
of LSAM is obtained. The output feature map of LSAM is calculated by adding
M to the output
of the SW-Trans branch yields:
where ⊕ represents the point-by-point summation, ⊙ represents the point-by-point product, and
represents the reshaping of the feature maps.
The attention feature vectors in different directions can capture long-distance feature dependencies in their respective direction. By integrating the spatial position information of two directions after multiplying, a two-dimensional spatial mapping between the features and the pixels can be established. LSAM can effectively extract the regional features of smoke, which helps suppress background information and noise to a certain extent.
GCAM performs global average pooling and global max pooling of LSAM output features in the spatial dimension. By learning the weight distributions of the obtained max pooling features and average pooling features in the channel dimension through a shared fully connected layer, GCAM can reduce the dimensionality of the channel features and acquire two feature vectors. After applying GELU activation, the fully connected layer upgrades the feature maps and restores the initial number of channels. Finally, the two attention vectors of features are added and activated by the sigmoid function before being applied to the output features of LSAM to obtain the output of the Transformer block:
where ⊗ represents the channel attention weights multiplied by the corresponding feature map,
and
represent the two shared fully connected layers that perform dimensionality operations, and
and
represent global average pooling and global max pooling.
The Transformer block can adaptively assign feature weights on the channel and spatial domains according to the degree of correlation of features in the smoke image. It also allows for essential features to be enhanced and invalid information to be suppressed.
The segmentation task for the enhanced smoke images is challenging due to the blurred appearances. We modify the Pyramid Pooling Module (PPM) [
22] and extend it into a dense style using DenseNet [
23]. After each module of our backbone network, we implement a fusion module to upsample the low-resolution feature maps. By concatenating the feature maps of different scales and repeating the upsampling process, our network can increase the receptive field of the feature maps and extract more context information effectively. The structure of Dense PPM is shown in
Figure 10.
In the proposed network, we implement depth-wise separable convolution [
24] instead of original convolutional units to reduce the computation amount during the training process, which results in a notable improvement in the network’s training speed.
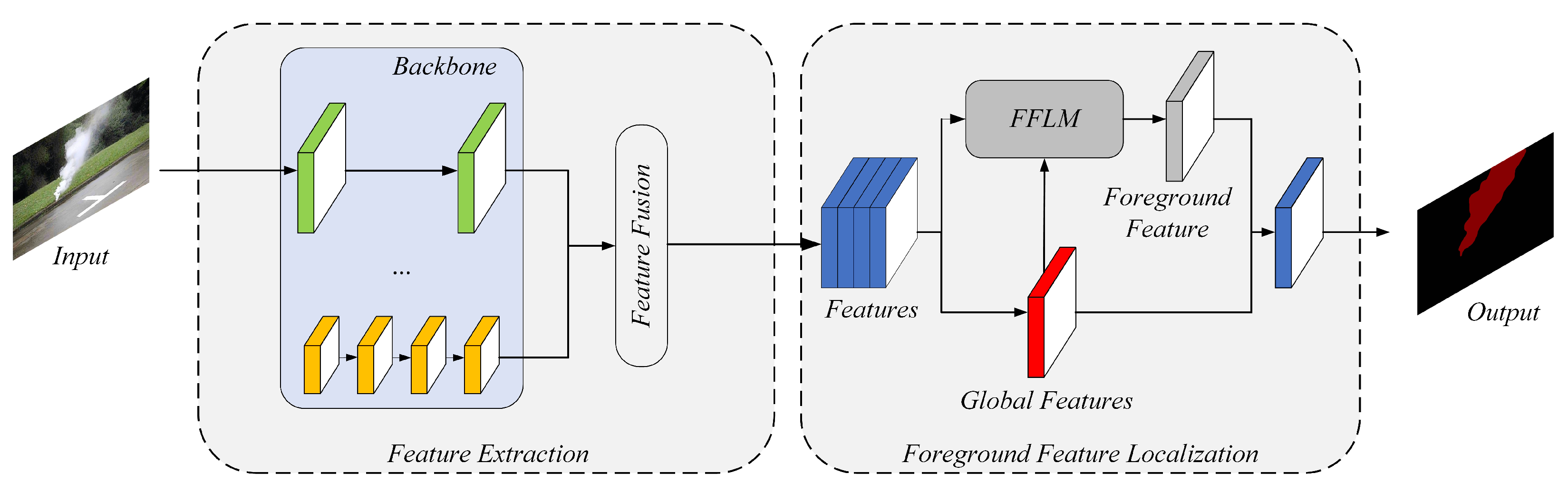
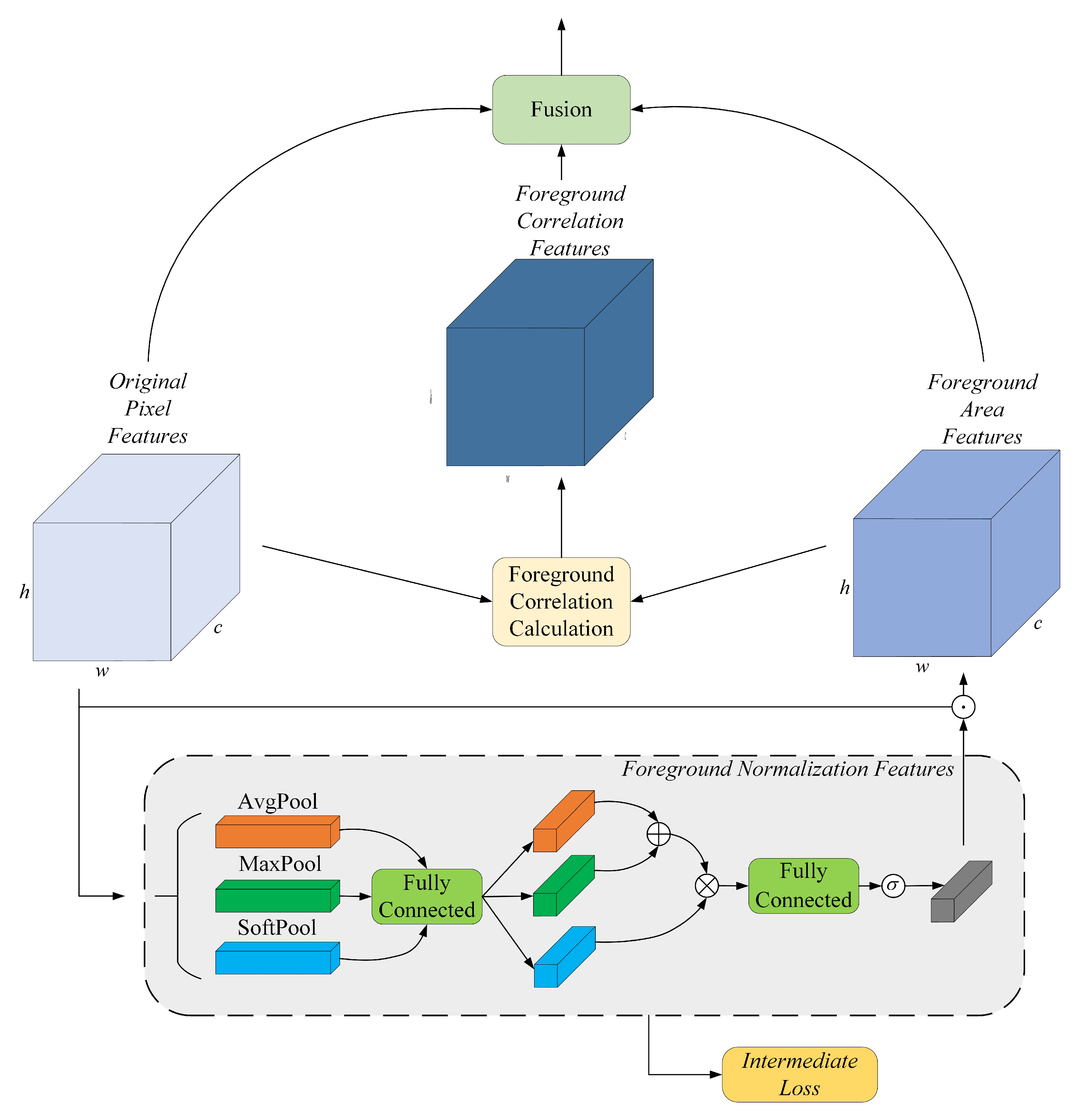
To accurately distinguish smoke from the background areas and ensure that the segmentation effect is not disturbed by external factors, we propose a foreground feature localization module called FFLM, which can precisely segment the thin smoke areas in the images through the calculation of correlation between each pixel and the smoke foreground. FFLM also helps to increase the differentiation between smoke areas and background information and prevent confusion. The specific structure of FFLM is shown in
Figure 11.
The output feature maps
, which contain rich and detailed features and semantic information, are processed with average pooling, max pooling, and soft pooling [
25] techniques in the channel dimension. The statistics obtained from these techniques are combined through a shared fully connected layer. The sum of average and max pooling is then multiplied by the index weights of soft pooling. With the obtained global weight description passing through a fully connected layer and a sigmoid function, the foreground normalized features of each channel of the output feature maps are presented.
Finally, the foreground normalized features are multiplied with the original pixel features
to obtain the foreground area features:
where
represents the foreground area features,
represents the statistical feature description after the sum of average pooling and max pooling,
represents the description of the statistical features obtained by soft pooling.
,
, and
correspond to the operations of average pooling, max pooling, and soft pooling in the channel dimension.
and
are fully connected layers. ⊙ is the point-by-point product operation.
The degree of association between each pixel and the foreground areas can be calculated with the foreground area features and the original pixel features:
where
is the foreground correlation representation.
is the foreground correlation calculation function implemented by convolution, BN, and Rectified Linear Units (ReLUs).
The output features enhanced by FFLM can be obtained by fusing foreground correlation features, foreground area features, and original pixel features:
where
and
are the fusion functions implemented by convolution, BN, and ReLUs.
is the enhanced output features. FFLM can help improve the overall quality of images by enhancing the features in the foreground area while reducing the impact of the background on smoke feature extraction. Additionally, FFLM can improve the ability of segmentation in thin smoke areas.
The smoke segmentation task is a pixel-level dense binary classification, and each pixel needs to be classified between the foreground and background areas. Therefore, we use a binary cross-entropy loss to design the loss function of our segmentation network:
where
N is the number of pixels in the feature map.
is the probability that the pixel is predicted as smoke foreground.
is the ground truth of the pixel.
When analyzing images with smoke areas, it is important to consider the proportion of the smoke areas in relation to the background regions. If the loss function treats these areas with a consistent weight, the party with a larger proportion will play a more dominant role in the backward propagation process, resulting in a higher weight during the prediction. Therefore, we introduce weighted coefficients to the two parts of the loss function based on the relative sizes of the smoke areas and background regions. The coefficients allow our model to balance the feature learning process between the two regions and adapt to the unique characteristics of each image. The modified loss function includes a foreground weight coefficient
:
We add an intermediate layer loss to the foreground feature localization process and weigh it against the loss on the segmentation results to balance the supervision throughout the network training process. Both the intermediate layer loss and the final loss use a foreground-weighted binary cross-entropy loss function:
where
and
are the intermediate layer loss and final loss.
and
are the probability value that the intermediate layer pixel and output feature pixel are classified to the foreground.
is the balance weight parameter of the union loss. After conducting numerous experiments, it has been determined that our segmentation model achieves optimal performance with a value of 0.25 for
when applied to our smoke dataset.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}