As one of the most harmful natural disasters today, fire causes tens of billions of economic and property losses to our world every year, and seriously threatens the lives and properties of people [
1]. After entering the 21st century, with the advancement of urbanization and industrialization in the world, buildings such as factories, residential areas, and schools have become increasingly denser, and the risk of fires has also increased. Once a fire breaks out, it will cause unrecoverable economic and environmental losses. As an early phenomenon of fire, smoke can be more observable than flame [
2]. Therefore, exploiting this feature of fire to detect early smoke can give timely warnings of fire. Nowadays, with the advancement of science and technology, the fire alarm system is also rapidly changing every day. From the initial smoke alarm to the smoke detection based on ordinary cameras, technological innovation has brought new directions and ideas to fire smoke detection. The means of applying new technologies to smoke detection are innovative and play a vital role for the prevention and control of fires [
3].
Existing smoke detection algorithms are mainly classified into two categories: traditional smoke detection algorithms and deep learning-based smoke detection algorithms [
4]. The current traditional smoke detection algorithms are based on extracting various features of smoke, such as color, texture, motion and shape irregularities. The traditional feature-based smoke detection is mainly based on framing the candidate region of smoke, then extracting the features of smoke and finally classifying and detecting smoke [
5]. Smoke detection consists of two tasks: smoke identification and localization. The core step of smoke identification is to extract and classify smoke features in images, and the core step of smoke localization is to locate the smoke regions that appear in images and provide marks [
6]. Based on this, many researchers have proposed smoke detection methods; Zhou et al. [
7] proposed a smoke detection algorithm combining dynamic and static features, which can have a fast detection of the presence of smoke, but it has a high false alarm rate and cannot distinguish between real smoke and fake smoke. Gomez-Rodriguez et al. [
8] used a wavelet decomposition and optical flow method for smoke detection in wildfire, which is suitable for the extraction of multiple smoke features, but its drawback is the large computational cost. Filonenko et al. [
9] proposed a smoke detection method based on smoke edge roughness and edge density. Liu et al. [
10] proposed a video smoke detection algorithm based on contrast, wavelet analysis and color segmentation, and in order to use shape information, they proposed an RGB contrast image and shape which is constrained to improve the smoke detection algorithm. In the initial research of deep learning algorithms, some researchers and scholars started from deep learning networks and kept digging deeper into the layers of the network structure, and were devoted to extracting more expressive smoke features, from CNN at the beginning to the one-stage algorithm and two-stage algorithm. Nowadays, the network model is getting bigger and bigger; both the feature extraction ability and the generalization of the algorithm are getting stronger. Frizzi et al. [
11] also proposed a CNN-based algorithm for the amount of smoke detection, which is based on the technical support of early target detection, by using LeNet5 [
12] to extract the smoke features in the image, and using the sliding window method to detect the smoke image after chunking. Although this method adds deeper deep convolution to the original CNN framework, the extra deep convolution leads to problems such as high computational load and slow detection speed. After applying the target detection algorithm, based on the CNN framework, directly to the smoke detection task, the smoke detection algorithm began an epoch-making development, and researchers began to make improvements to the existing target detection algorithms, in which the main research objectives are the one-stage algorithms and two-stage algorithms. One-stage algorithms are characterized by high speed, simple models and easy deployment, and their representative algorithms are the YOLO series and SSD series [
13,
14]. For example, Saponara et al. [
15] designed a real-time fire and smoke detection algorithm based on YOLOv2 and met the requirements of embedded platforms. Chen et al. [
16] proposed a smoke recognition algorithm based on YOLOv5 combined with a Gaussian mixed background modeling algorithm, which effectively reduced the interference of objects in the background for smoke detection. Wang et al. [
17] proposed an improved YOLOv5-based smoke detection model by adding the dynamic anchor frame mechanism, channel attention and spatial attention to improve the detection performance of the algorithm. Yazan Al-Smadi et al. [
18] proposed a new framework that can reduce the sensitivity of various YOLO detection models and also compared this with the performance of different YOLO detection models. The fast speed of the single-stage algorithm has led to a significant increase in the detection speed of the smoke detection algorithm, but the detection accuracy is not high. The two-stage algorithm, on the other hand, has an incremental improvement in algorithm accuracy, but it requires a greater computational cost. Yuan et al. [
19] designed a new multi-scale convolutional structure, DMCNN, which can fully extract multi-scale smoke features and improve the accuracy of smoke detection. Zhang et al. [
20] used the Faster R-CNN target detection network to obtain specific coordinate information of smoke in smoke images and used rectangular boxes to frame the smoke, to achieve the recognition of fire smoke in forests. Gagliardi et al. [
21] proposed a method based on Kalman filtering and CNN for real-time video smoke detection, which automatically selects smoke regions in images by moving the generated object bounding box. Lin et al. [
22] developed a joint detection framework based on Faster-RCNN and 3D-CNN, which achieves smoke target localization with static spatial information by Faster R-CNN, and then uses 3D-CNN combined with dynamic spatio-temporal information to achieve smoke identification.
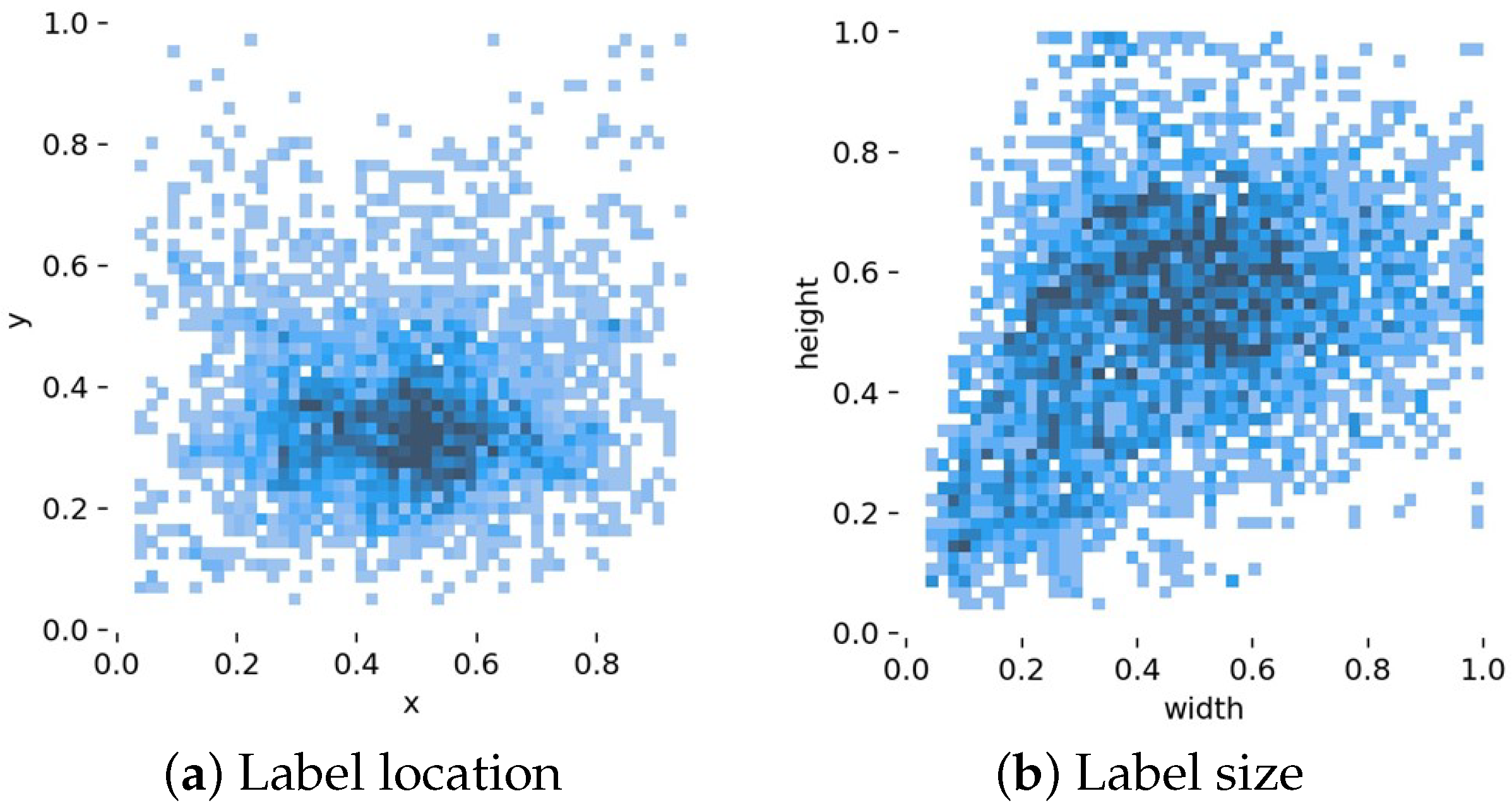
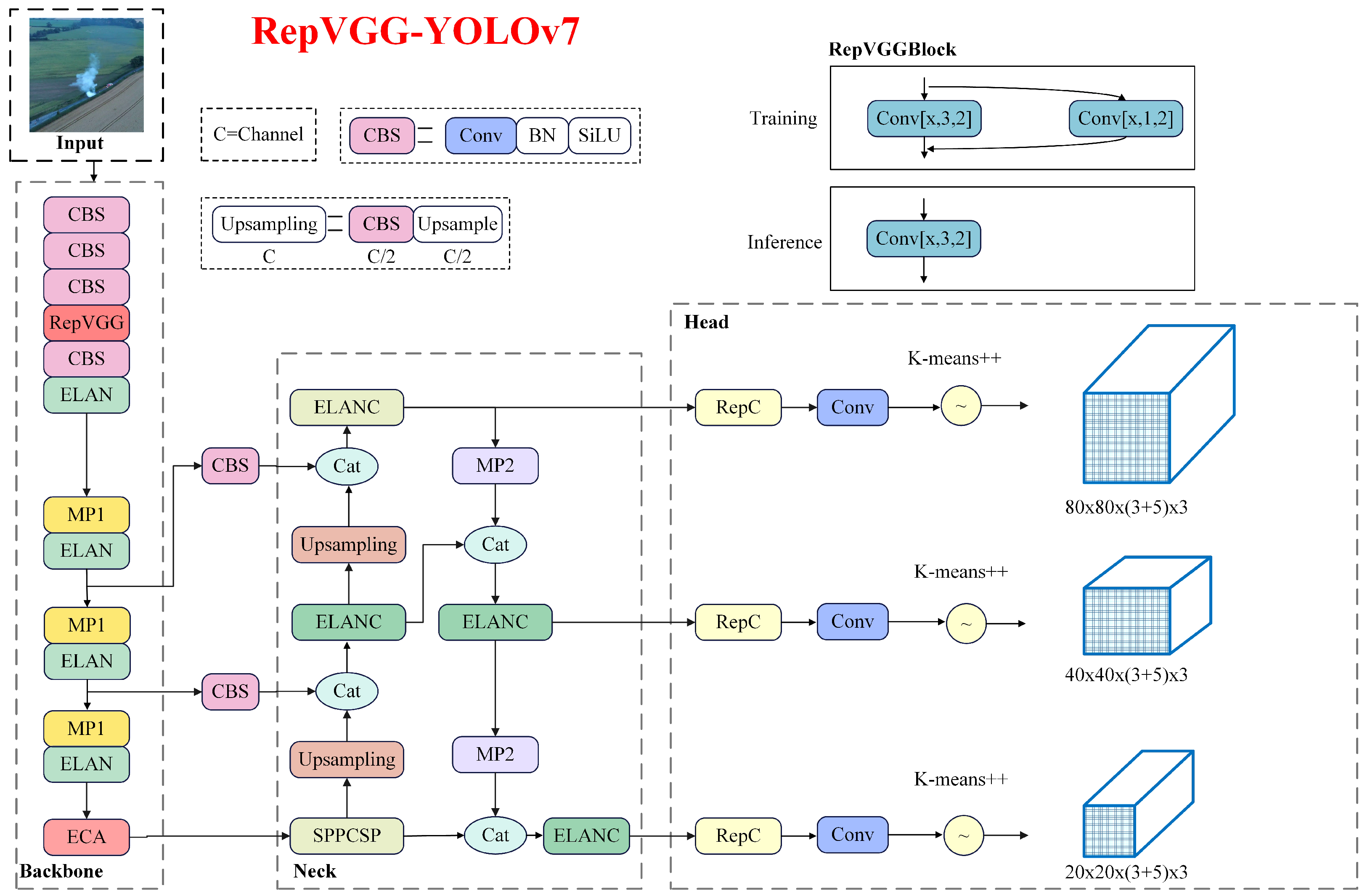
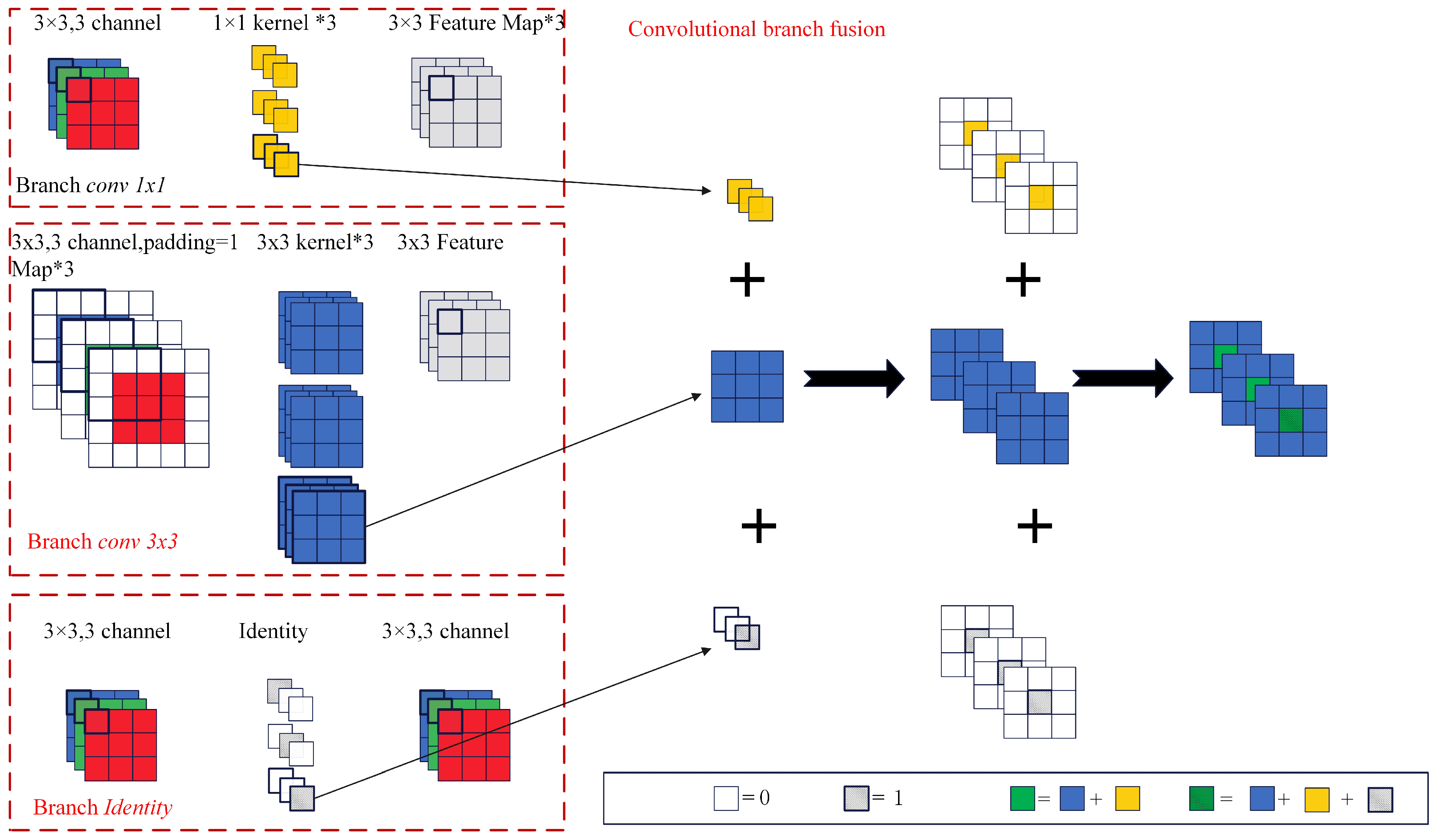
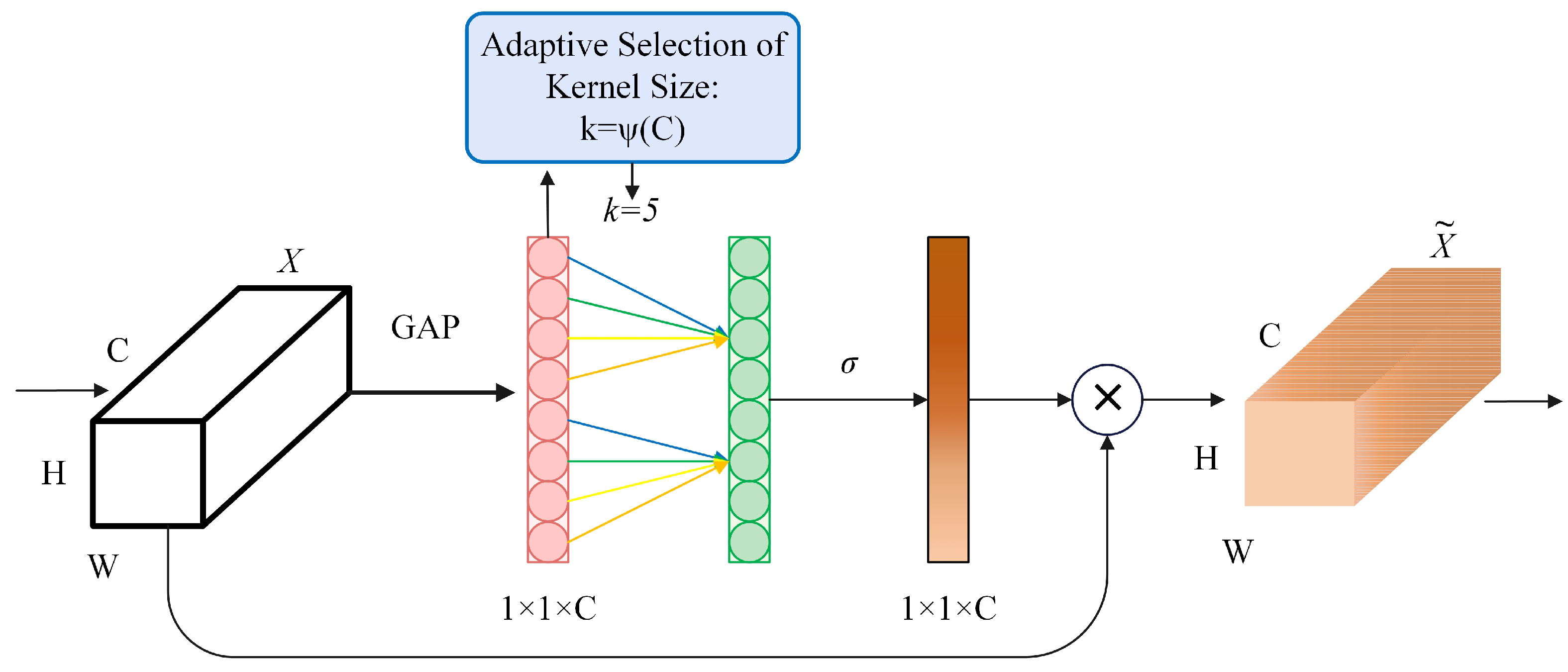
In summary, with the development of deep learning technology, significant progress has been made in using deep learning technology for smoke detection, but there are still severe open challenges. On the one hand, there is no complete dataset for the current deep learning-based video smoke detection, and the existing fire smoke dataset types and scenes are simple, leading to low generalization of the trained algorithms. On the other hand, increasing the detection speed of fire smoke will reduce the accuracy of smoke recognition. When the recognition accuracy is improved, it will result in high model complexity, high computational cost and low portability. What is more, it is difficult to detect fire smoke quickly and accurately in the face of complex scenes and environments with many interference factors. In particular, the detection rate for small target smoke or obscured smoke needs to be improved. Therefore, the main contributions and novelties of this paper are reflected in the following aspects:









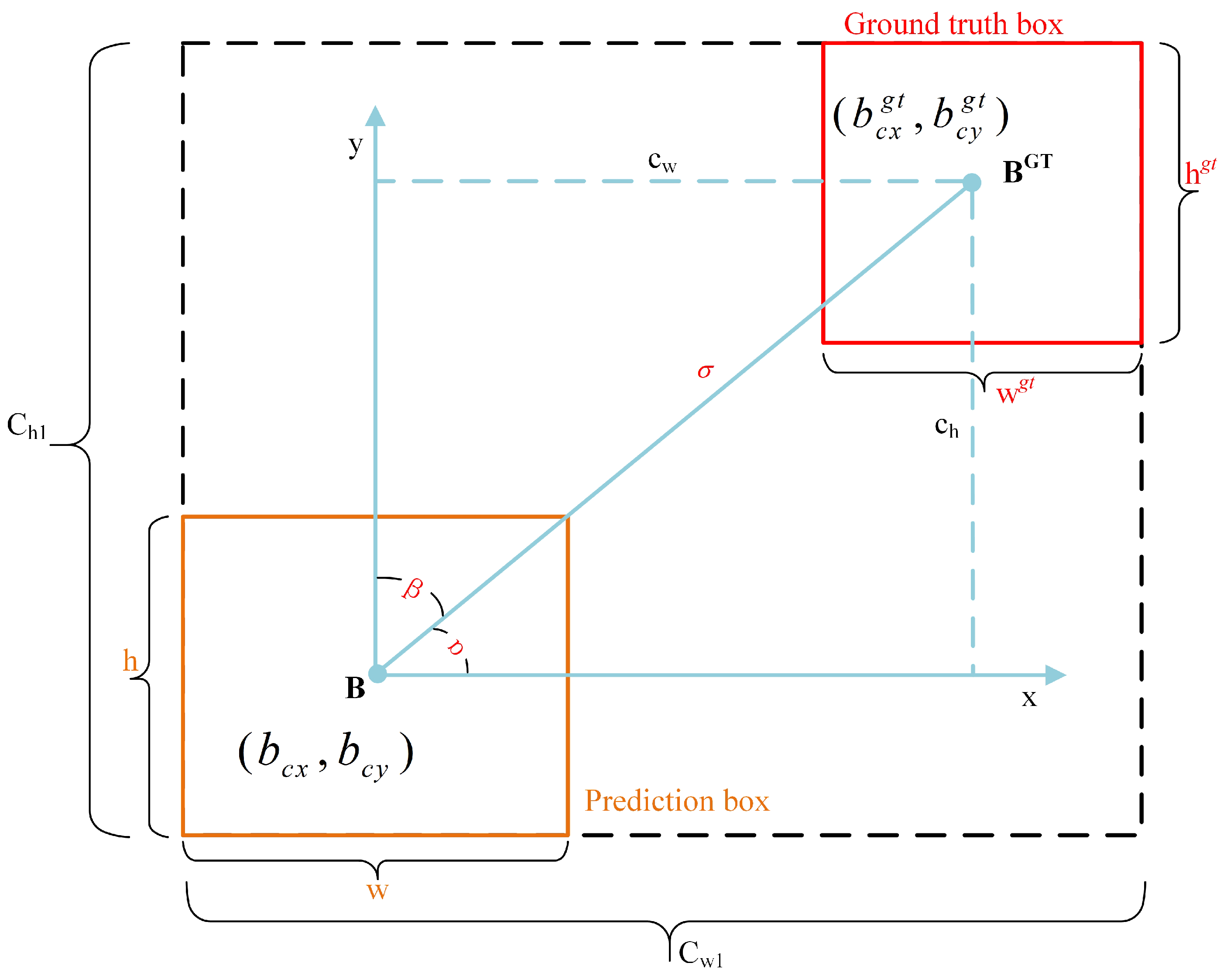
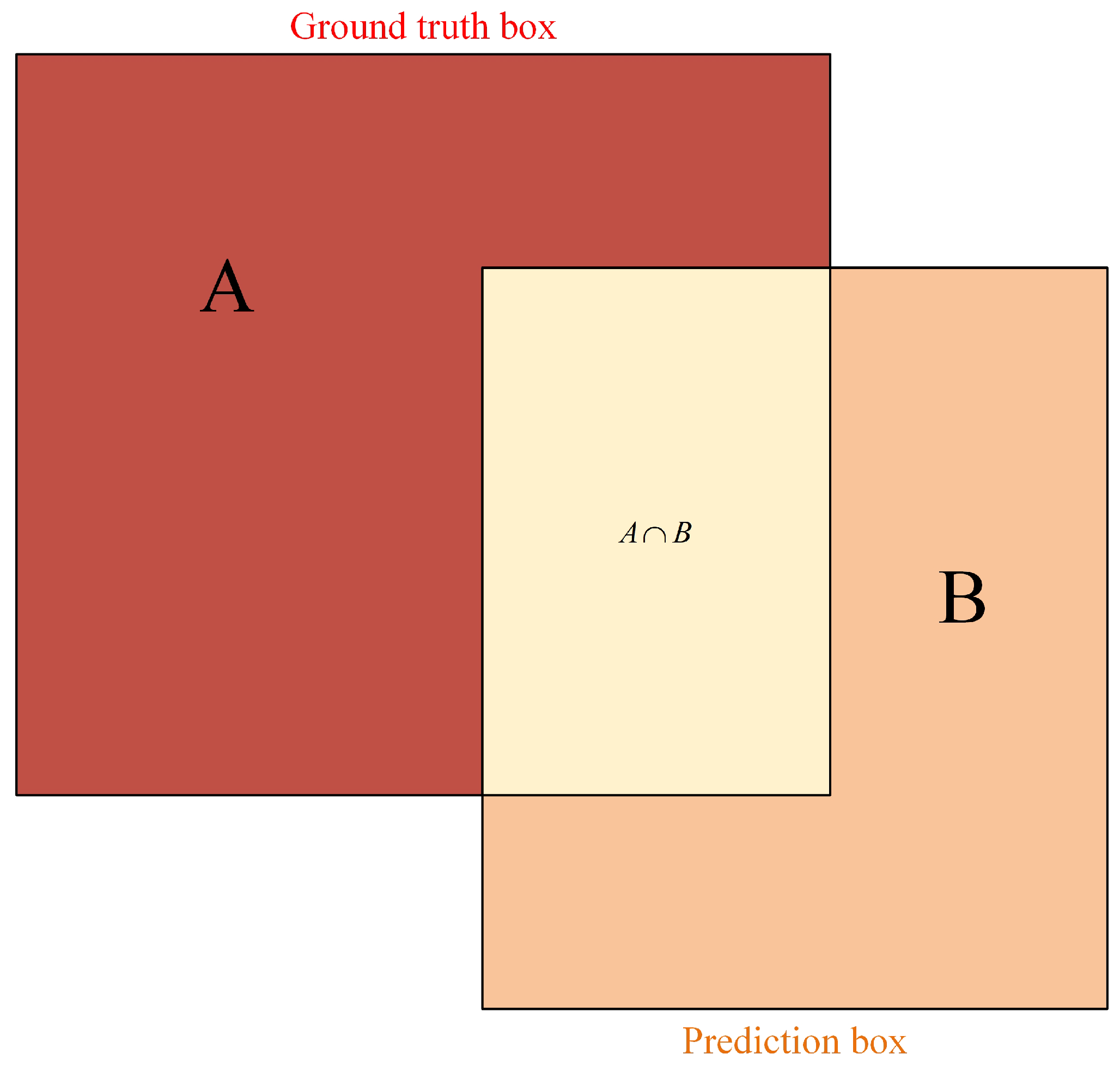
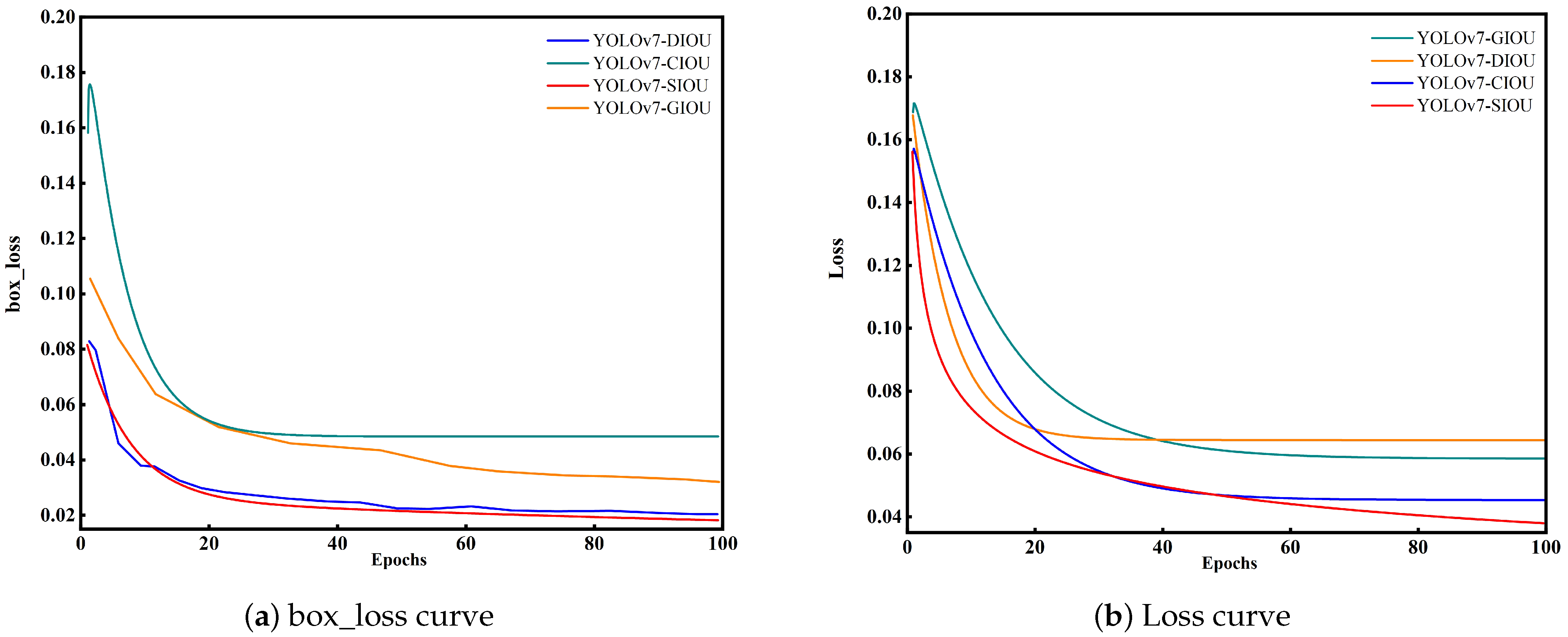
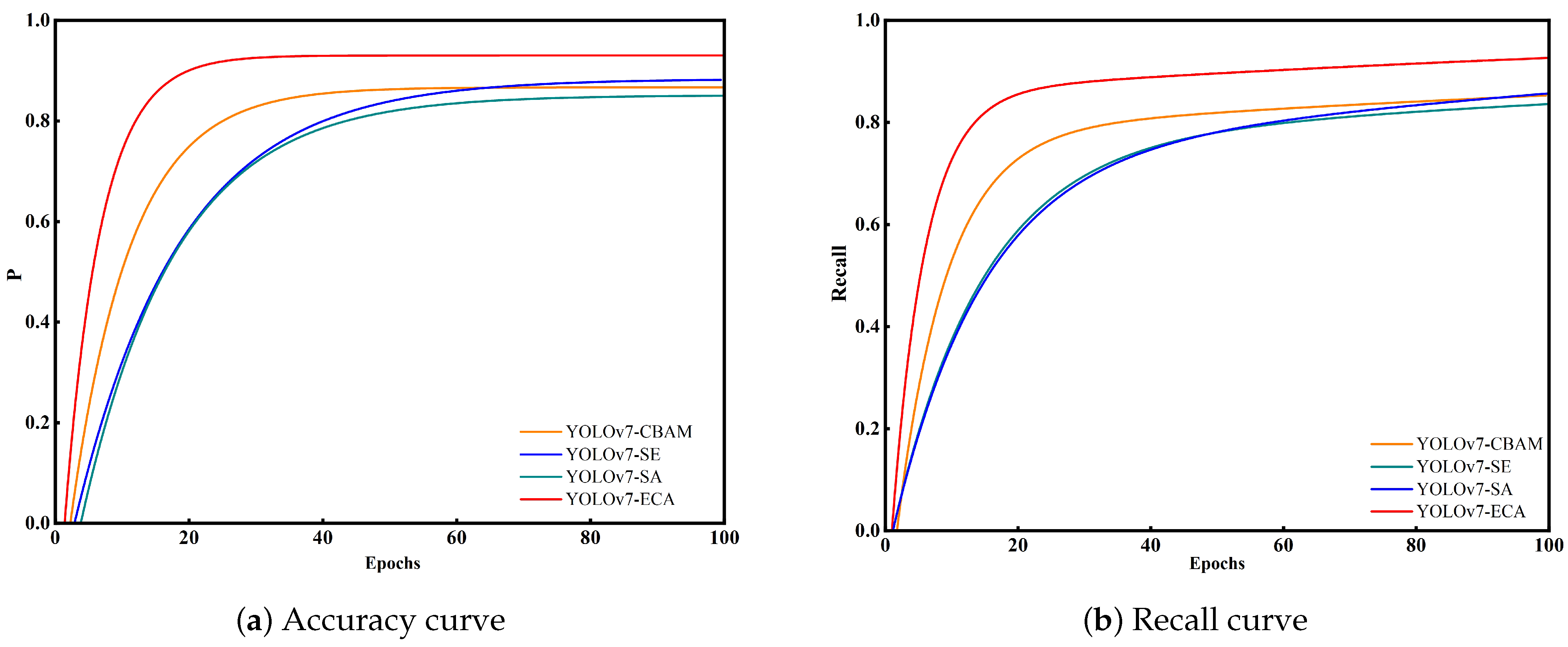

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







