
Text Mining Approach for Trend Tracking in Scientific Research: A Case Study on Forest Fire


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Gathering
2.2. Text Mining
- Foremost, the database containing the texts related to the researched subject is selected (in this study, the Web of Science database was selected);
- Documents with specific characteristics are filtered by keywords (“forest” or “wild” and “fire”, grouped by country);
- Relevant documents from the filtered database are saved in a different format for analysis (documents downloaded as .txt files are saved in MS Excel format and tabulated with many features (title, summary, country, year, number of citations, etc.) to facilitate further analysis);
- Text contents are analyzed with a suitable text mining software (Statistica’s text mining tool was used in this study. The use of Statistica’s text mining tool along with the user interfaces is given in step-by-step reference [10]);
- The abstracts of the publications were selected as input texts to be mined.
- Then, words are indexed using the abovementioned stop lists, synonym lists, and phrase lists limited with maximum number of selected words with a minimum occurrence frequency.
- Raw Frequency:If it is only important how often the words are repeated, the raw statists method, which gives the total number of times the indexed word is repeated in all documents, is used;
- Binary Frequency:Binary statistics (1 or 0) are used if the use of any word contains valuable information for research;
- Logarithmic Frequency:Sometimes the repetition of a word in one document more than the other may not mean that the document attaches more importance to that subject at the same rate. In this case, the logarithmic frequency method can be preferred to weight the words:where Fi is the logarithmic frequency of indexed word i, and wrfi stands for row frequency of word i;Fi = 1 + log(wrfi) for wrfi > 0
- Inverse Document Frequency (idf):
3. Results
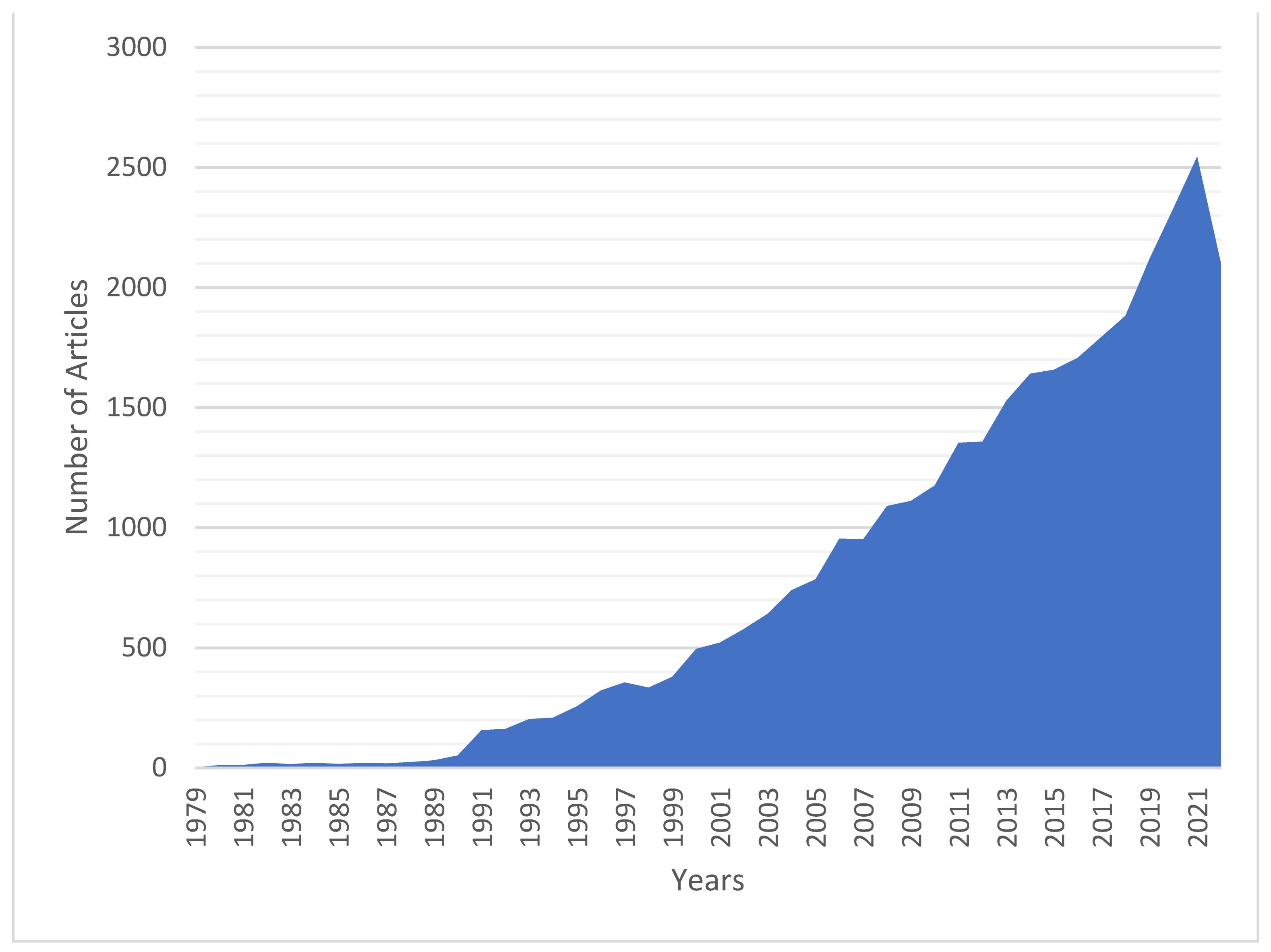
3.1. Basic Text Mining Results
3.2. Country and Year Based Results
4. Discussion and Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global Forest Watch. Available online: https://www.globalforestwatch.org/dashboards (accessed on 22 November 2022).
- Web of Science. Available online: https://www.webofscience.com (accessed on 22 November 2022).
- Ananiadou, S.; Rea, B.; Okazaki, N.; Procter, R.; Thomas, J. Supporting systematic reviews using text mining. Soc. Sci. Comput. Rev. 2009, 27, 509–523. [Google Scholar] [CrossRef]
- Babić, D.; Kalić, M. Modeling the Selection of Airline Network Structure in a Competitive Environment. J. Air Transp. Manag. 2018, 66, 42–52. [Google Scholar] [CrossRef]
- Jun, S.; Park, S.S.; Jang, D.S. Document Clustering Method Using Dimension Reduction and Support Vector Clustering to Overcome Sparseness. Expert Syst. Appl. 2014, 41, 3204–3212. [Google Scholar] [CrossRef]
- Monali, P.; Sandip, K. A Concise Survey on Text Data Mining. Int. J. Adv. Res. Comput. Commun. Eng. 2014, 3, 8040–8043. [Google Scholar] [CrossRef]
- Him, J.-G.; Ryu, K.-H.; Lee, S.H.; Cho, E.-A.; Lee, Y.J.; Ahn, J.H. Text Mining Approaches to Analyze Public Sentiment Changes Regarding COVID-19 Vaccines on social media in Korea. Int. J. Environ. Res. Public Health 2021, 18, 6549. [Google Scholar] [CrossRef] [PubMed]
- Kitsios, F.; Kamariotou, M.; Karanikolas, P.; Grigoroudis, E. Digital Marketing Platforms and Customer Satisfaction: Identifying eWOM Using Big Data and Text Mining. Appl. Sci. 2021, 11, 8032. [Google Scholar] [CrossRef]
- Atay, M.; Eroğlu, Y.; Ulusam Seçkiner, S. Investigation of breaking points in the airline industry with airline optimization studies through text mining before the covid-19 pandemic. Transp. Res. Rec. 2021, 2675, 301–313. [Google Scholar] [CrossRef]
- Eroglu, Y.; Seçkiner, S.U. Trend Topic Analysis for Wind Energy Researches: A Data Mining Approach Using Text Mining. J. Technol. Innov. Renew. Energy 2016, 5, 44–58. [Google Scholar] [CrossRef]
- Ertek, G.; Kailas, L. Analyzing a Decade of Wind Turbine Accident News with Topic Modeling. Sustainability 2021, 13, 12757. [Google Scholar] [CrossRef]
- Mustaqim, T.; Umam, K.; Muslim, M.A. Twitter text mining for sentiment analysis on government’s response to forest fires with vader lexicon polarity detection and k-nearest neighbor algorithm. J. Phys. Conf. Ser. 2020, 1567, 032024. [Google Scholar] [CrossRef]
- Miner, G.; Elder, J.; Hill, T.; Nisbet, R.; Delen, D.; Fast, A. Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications, 1st ed.; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Delen, D.; Crossland, M.D. Seeding the survey and analysis of research literature with text mining. Expert Syst. Appl. 2008, 34, 1707–1720. [Google Scholar] [CrossRef]
- Miller, T.W. Data and Text Mining: A Business Applications Approach; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Baker, K. Singular Value Decomposition Tutorial; The Ohio State University: Columbus, OH, USA, 2005; Volume 24. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Stable Forests (Mha) | Burned Forest Area 2021 (kha) | Burned Forest Area 2001–2021 (Mha) | Burned Forest Area 2001–2021 (%) |
|---|---|---|---|---|
| Australia | 80.3 | 132 | 6.26 | 7.796 |
| Brazil | 414 | 596 | 9.51 | 2.297 |
| Canada | 257 | 1610 | 2.68 | 1.043 |
| England | 1.2 | 0.021 | 0.007 | 0.583 |
| France | 15.8 | 3.51 | 0.048 | 0.304 |
| Germany | 11.7 | 0.476 | 0.006 | 0.051 |
| Italy | 9.26 | 6.3 | 0.045 | 0.486 |
| China | 202 | 22.7 | 0.893 | 0.442 |
| Russia | 686 | 5360 | 52.8 | 7.697 |
| Spain | 11.4 | 16.1 | 0.300 | 2.632 |
| USA | 238 | 846 | 11.1 | 4.664 |
| Funding Agencies | Record Count | % |
|---|---|---|
| National Science Foundation NSF | 2067 | 5.05 |
| European Commission EC | 1461 | 3.57 |
| United States Department of Agriculture USDA | 1406 | 3.43 |
| United States Forest Service USFS | 1120 | 2.73 |
| National Natural Science Foundation of China NSFC | 1001 | 2.44 |
| Natural Sciences and Engineering Research Council of Canada NSERC | 941 | 2.30 |
| Spanish Government | 784 | 1.91 |
| Conselho Nacional de Desenvolvimento Cientifico e Tecnologico CNPQ | 649 | 1.58 |
| UK Research Innovation UKRI | 640 | 1.56 |
| National Aeronautics Space Administration NASA | 608 | 1.48 |
| Natural Environment Research Council NERC | 506 | 1.23 |
| Australian Research Council | 505 | 1.23 |
| United States Department of Health Human Services | 476 | 1.16 |
| National Institutes of Health NIH USA | 461 | 1.12 |
| Portuguese Foundation for Science and Technology | 436 | 1.06 |
| Coordenacao de Aperfeicoamento de Pessoal de Nivel Superior Capes | 434 | 1.06 |
| Joint Fire Science Program | 406 | 0.99 |
| CGIAR | 372 | 0.90 |
| United States Department of Energy DOE | 354 | 0.86 |
| Russian Foundation for Basic Research RFBR | 333 | 0.81 |
| Australian Government | 332 | 0.81 |
| German Research Foundation DFG | 332 | 0.81 |
| Ministry of Science and Innovation Spain MICINN | 255 | 0.62 |
| Fundacao de Amparo a Pesquisa do Estado de Sao Paulo FAPESP | 251 | 0.61 |
| NSF Directorate for Biological Sciences BIO | 249 | 0.60 |
| Country | Number of Publications |
|---|---|
| USA | 14,181 |
| Canada | 3732 |
| Australia | 3214 |
| Spain | 2567 |
| Germany | 1828 |
| Peoples R. China | 1802 |
| England | 1703 |
| Brazil | 1521 |
| France | 1436 |
| Italy | 1155 |
| Russia | 1011 |
| Country | Number of Publications |
|---|---|
| Portugal | 998 |
| Sweden | 823 |
| India | 727 |
| Netherlands | 724 |
| Japan | 688 |
| Switzerland | 655 |
| Finland | 553 |
| Greece | 536 |
| South Africa | 508 |
| Country | Number of Publications | Country | Number of Publications |
|---|---|---|---|
| Indonesia | 464 | Poland | 248 |
| Argentina | 406 | Israel | 229 |
| Mexico | 394 | Iran | 197 |
| Chile | 329 | Czech Republic | 190 |
| South Korea | 324 | Wales | 185 |
| Scotland | 323 | Denmark | 157 |
| Norway | 304 | Malaysia | 151 |
| New Zeland | 297 | Singapore | 151 |
| Australia | 288 | Thailand | 147 |
| Belgium | 271 | Taiwan | 100 |
| Turkey | 267 |
| Clusters | Indexed Words (Descending Ordered by Importance Weights) |
|---|---|
| Cluster 1 | Soil, fuel, treatment, emission, aerosol, stand, seed, pine, species, tree, oak, seed settlement, habitat, carbon, burn, model, savanna, climate |
| Cluster 2 | Disturb, plant, prescribe, biomass, communicate, post-fire, manage, harvestvegetation, regeneration, simulate, plot, temperature, charcoal, sediment, concentrate, cover, season, landscape, water, organ, spatial, site, smoke, growth, rich, wood, air, map, pollen, boreal, sever, ha, year, land, heat, change, composite, population, estimation, area, divers, mortal, risk, ecosystem, thin, Holocene, log, restore, image, density, structure, predict, moisturecanopy, erosion, spruce, lake, data, abundance, increase, product, regime, particle, record, detect, region, CO2, pollution, cm, class, effect, scenario, surface, climate change, drive, content, atmosphere, tropic, sample, rate, patternconserve, dry, degree, unburn, period, response, age, active, nutrient, survive, differ, size, height |
| Cluster 3 | Measure, pinus, human, global, native, reduce, method, impact, source, condition, signific, layer, accuracy, observe, dynamic, large, total, distribute, control, future, satellite, index, analysis, dominate, low, combust, factor, load, across, time, high, flux, burnt, system, nature, scale, type, recovery, understory, event, diameter, develop, value, spread, transport, weather, black, algorithm, propose, matter, depth, property, Quercus, ecology, influence, stem, relate, loss, annual, litter, precipitate, range, decrease, higher, recruit, frequency, patch, shrub, indicate, base, grass, study, quality, compare, show, import, ignite, process, resolution, rainfall, miner, summer, invasion, suggest, assess, affect, approach, deforest, occurrence, establish, environment, potential, grassland, variate, project, function, net, follow, state, history, provide, Mediterranean, inform, warm, understand, number, occur, reconstruct, unit, result, monitor, biodiverse, level, basal, crown, average, relationship, mass, reduction, correlation, associate, similar, interact, south, mean, ratio, nitrogen, perform, network, open, available, small, intense, radiation, local, month, protect, include, flow, present, decline, early, cause, however, found, century, agriculture, interval, last, late, temporary, timber, current, improv, drought, resource, aim, plan, success, evaluate, research, main, cycle, posit, day, western, locate, degrade, past, policy, behavior, km, nation, determine, deposit, resilience, identify, disperse, mountain, probably, chemic, slope, shift, health, trend, select, reserve, wind, contribute, test, dead, energy, conifer, northern, strategi, ca, need, recent, characteristic, individual, practice, role, anthropogeny, like, respect, regress, strong, suppress, since, experience, long-term, north, first, limit, elevation, field, mechanism, frequent, apply, group, root, negative, examine |
| Cluster 4 | Fragment, extreme, application, remove, new, Canada, right, evidence, variable, live, gradient, well, collect, obtain, cost, combine, eastern, wet, parameter, hazard, service, investigate, fraction, major, spring, Australia, economy, remote sensing, sustain, consider, support, require, succession, winter, damage, distance, maintain, derive, accrue, additive, adapt, date, zone, complex, produce, competition, accumulate, grow, core, material, old, mitigate, mix, fine, experiment, normal, environ, decade, operation, remain, primary, mature, inventory, ground, heterogeny, quantify, explain, initial, amount, case, general, moderate, survey, implement, find, release, integral, part, overall, represent, particular, public, extent, valid, statist, calculation, expanse, enhance, conduct, park, direct, long, character, central, dependent, generate, daily, common, random, benefit, consistent, problem, persist, highest, extract, design, set, stage, previous, tool, uncertainty, maximum, USA, work, decision, prevent, America, continue, account, sensitivity, technique, vulnerable, component, demonstrate, California, key, serial, efficient, transit, dataset, focus, better, form, yield, feature, multiple, reveal, order, basin, emerge, near, element, framework, expect, presence, create, threat, rapid, proport, challenge, knowledge, reflect, specify, critic, suitable, conclude, input, peak, country, lead, terrestrial, contrast, little, action, clear, whereas, report, describe, origin, possible, appear, effort, light, term, even, point, especial, promote, balance, phase, substantial, threaten, return, play, recovery, physic, take, consequent, five, power, close, attribute, format, whether, known, geography, therefor, help, approximate, extensa, address, make, context, contain, capacity, immediate, highlight, achieve, program, experiment, reach, European, vary, second, linear, altern, concern, wide, goal, ability, exhibit, subsequent, aspect, rare, magnitude, link, document, single, carry, shape, despite, discuss, upper, widespread, background, typic, prior, final, issue, least, involve, explore, toward, biology, implicit, distinct, lack, correspond, poor, standard, fire-prone, utility, either, publish, incorporate, couple, great, consider, world, interpret, surround, define, facility, short, hypothesis, space, adjacent, place, percentage, detail, advance, numerical, independent, good, way, example, absence, led, relevance, regard, purpose, question, greatest, science, except, subject, complete, interest, separate, basic, necessary, minimum, essential, modify, confirm |
| Class | Concept |
|---|---|
| 1 | Concept 1 |
| 2 | Concept 2 |
| 3 | Concepts 3–4 |
| 4 | Concepts 5–12 |
| 5 | Concepts 13–29 |
| Concept ID | Top Ten Indexed Words (Ordered by Importance Weight) | Concept ID | Top Ten Indexed Words (Ordered by Importance Weights) |
|---|---|---|---|
| Concept 1 | Species, burn, soil, tree, model, vegetation, area, site, year, change | Concept 16 | Seed, fuel, spruce, stand, boreal, regeneration, emission, temperature, moisture, rich |
| Concept 2 | Species, tree, stand, seed settlement, regeneration, pine, treatment, seed, plant, plot | Concept 17 | Erosion, cover, sediment, log, canopy, water, aerosol, surface, flow, rainfall |
| Concept 3 | Manage, map, landscape, risk, model, spatial, approach, habitat, inform, plan | Concept 18 | Habitat, simulate, harvest, water, landscape, seed, restore, soil, temperature, treatment |
| Concept 4 | Pollen, Holocene, charcoal, climate, record, lake, year, sediment, reconstruct, human | Concept 19 | Heat, detect, image, fuel, smoke, log, boreal, temperature, surface, degree |
| Concept 5 | Soil, communicate, ecosystem, organ, carbon, conserve, plant, nutrient, biodiverse, manage | Concept 20 | Pine, habitat, oak, unburn, species, mortal, population, climate change, pinus, emission |
| Concept 6 | Emission, carbon, fuel, climate change, CO2, treatment, climate, future, stand, scenario | Concept 21 | Treatment, heat, degree, aerosol, simulate, scenario, size, thin, particle, ha |
| Concept 7 | Aerosol, emission, species, smoke, habitat, air, pollution, rich, source, atmosphere | Concept 22 | Treatment, thin, map, mortal, lake, climate, charcoal, class, tree, density |
| Concept 8 | Carbon, boreal, soil, disturb, map, CO2, spatial, net, ecosystem, global | Concept 23 | Pine, flux, heat, temperature, CO2, scale, water, flow, spatial, pinus |
| Concept 9 | Stand, charcoal, year, harvest, carbon, ha, pollen, sediment, lake, age | Concept 24 | Seed, restore, drive, ha, dry, resilience, sample, range, tree, ecology |
| Concept 10 | Fuel, burn, prescribe, rich, habitat, divers, load, cover, treatment, communicate | Concept 25 | Oak, post-fire, burn, aerosol, charcoal, Quercus, heat, unburn, manage, height |
| Concept 11 | Seed settlement, burn, season, image, treatment, cover, land, satellite, year, annual | Concept 26 | Oak, harvest, wood, heat, product, plant, combust, concentrate, Quercus, class |
| Concept 12 | Stand, post-fire, sever, log, concentrate, event, boreal, spruce, harvest, erosion | Concept 27 | Plot, cm, depth, communicate, ha, soil, layer, air, nation, surface |
| Concept 13 | Ha, population, tree, cm, diameter, protect, conserve, savanna, risk, habitat | Concept 28 | Savanna, emission, drive, air, pollution, treatment, tropic, propose, CO2, spruce |
| Concept 14 | Seed, post-fire, sediment, erosion, patch, fuel, landscape, disperse, simulate, burnt | Concept 29 | Spruce, risk, boreal, black, zone, slope, cost, energy, cover, communicate |
| Concept 15 | Harvest, habitat, rich, abundance, treatment, log, rate, response, species, number |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eroglu, Y. Text Mining Approach for Trend Tracking in Scientific Research: A Case Study on Forest Fire. Fire 2023, 6, 33. https://doi.org/10.3390/fire6010033
Eroglu Y. Text Mining Approach for Trend Tracking in Scientific Research: A Case Study on Forest Fire. Fire. 2023; 6(1):33. https://doi.org/10.3390/fire6010033
Chicago/Turabian StyleEroglu, Yunus. 2023. "Text Mining Approach for Trend Tracking in Scientific Research: A Case Study on Forest Fire" Fire 6, no. 1: 33. https://doi.org/10.3390/fire6010033
APA StyleEroglu, Y. (2023). Text Mining Approach for Trend Tracking in Scientific Research: A Case Study on Forest Fire. Fire, 6(1), 33. https://doi.org/10.3390/fire6010033