
Edge-Deployed Band-Split Rotary Position Encoding Transformer for Ultra-Low-Signal-to-Noise-Ratio Unmanned Aerial Vehicle Speech Enhancement



Abstract
1. Introduction
- The proposal of Edge-BS-RoFormer, a novel lightweight Transformer architecture specifically designed for UAV ultra-low-SNR speech enhancement and optimized for edge deployment which demonstrates robust performance even under dynamic noise conditions.
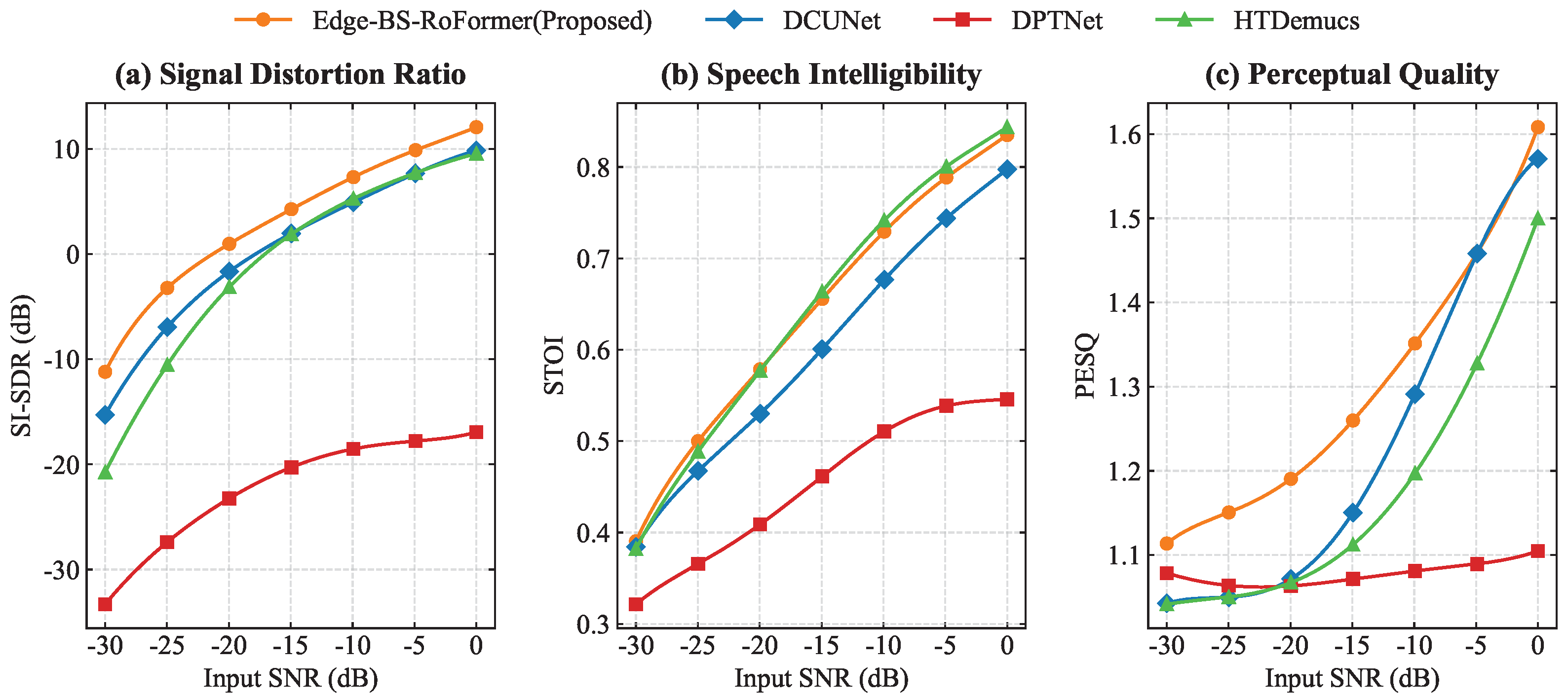
- Extensive experimental validation on our self-constructed DroneNoise-LibriMix (DN-LM) dataset. Under a −15 dB SNR, Edge-BS-RoFormer achieves Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) improvements of 2.2 dB, 25.0 dB, and 2.3 dB, and Perceptual Evaluation of Speech Quality (PESQ) enhancements of 0.11, 0.18, and 0.15 compared to Deep Complex U-Net (DCUNet), the Dual-Path Transformer Network (DPTNet), and HTDemucs, respectively. Qualitative analysis also confirms its superior handling of dynamic noise.
- Comprehensive edge deployment validation on an NVIDIA Jetson AGX Xavier, showcasing its practical viability with only 11.617 GFLOPs, 8.534 MB model storage, a sub-500 MB runtime memory footprint, a Real-Time Factor (RTF) of 0.325 (latency: 330.830 ms), and a power consumption of 6.536W, fulfilling real-time processing demands.
- The construction and open-sourcing of the DroneNoise-LibriMix (DN-LM) dataset and the Edge-BS-RoFormer model, providing valuable resources for advancing research and standardized evaluation in UAV speech enhancement.
2. Related Work
3. Proposed Method
3.1. Speech Signal Processing Fundamentals
3.2. Band-Split Strategy
3.3. Transformer Architecture
3.3.1. Rotary Position Encoding Mechanism
3.3.2. Time-Domain Transformer Module
3.3.3. Feedforward Module Design
3.4. Multi-Band Mask Estimation
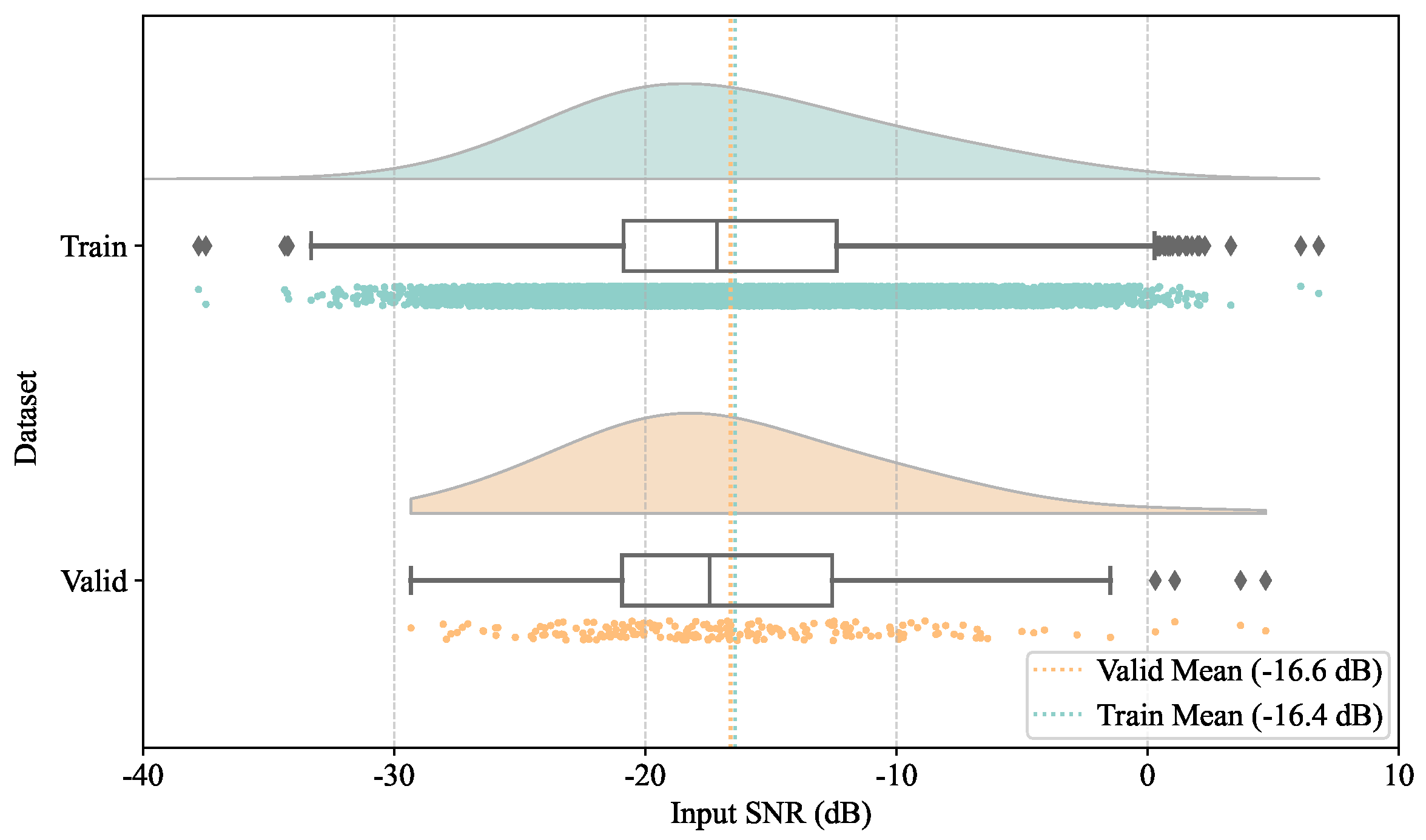
3.5. Datasets
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Baseline Models
4.1.2. Training Protocol
4.1.3. Evaluation Metrics
- Floating Point Operations (FLOPs) [54] quantified the total computational volume per inference.
- Model Storage (MB) indicated the disk space required for the model parameters.
- Peak Runtime Memory (MB) was measured during inference to assess on-device RAM requirements.
- Latency (ms) denoted the actual processing time for a standard input audio segment.
- Real-Time Factor (RTF) [55] quantified processing speed relative to the audio duration:
- Power Consumption (W) was measured on the edge device during model inference to evaluate energy efficiency.
4.2. Main Results
4.2.1. Model Performance Comparison
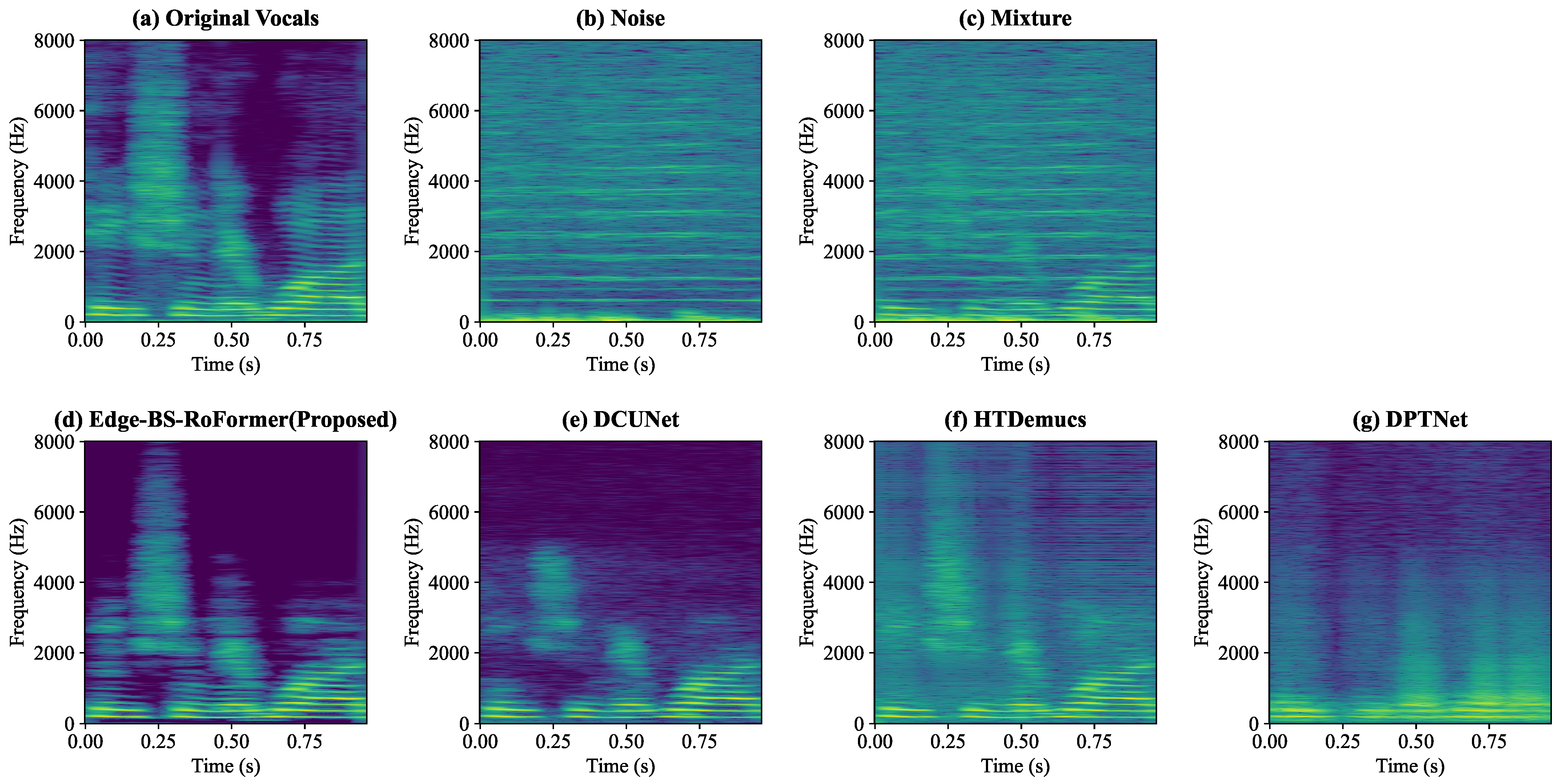
4.2.2. Time–Frequency Characteristics Analysis
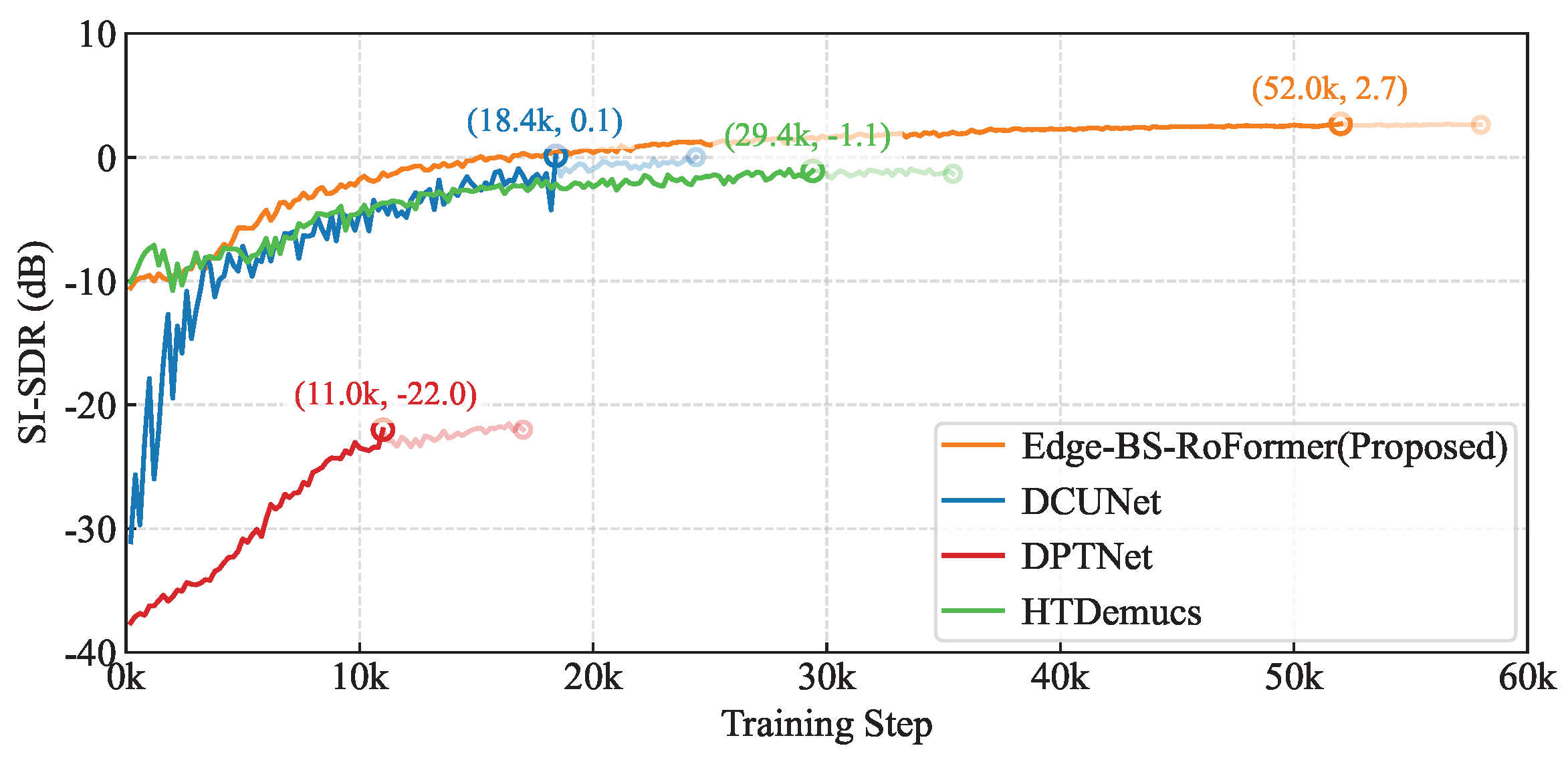
4.2.3. Training Dynamics Analysis
4.3. Edge Deployment Experiments
4.4. Ablation Study
- Edge-BS-RoFormer (FlashAttention, RoPE): The proposed model, employing the FlashAttention mechanism and RoPE.
- Edge-BS-RoFormer (FlashAttention, SPE): RoPE is replaced with standard Sine Positional Encoding (SPE) in this variant.
- Edge-BS-RoFormer (LinearAttention, SPE): Based on the SPE configuration, FlashAttention is replaced with standard Linear Attention.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jahani, H.; Khosravi, Y.; Kargar, B.; Ong, K.L.; Arisian, S. Exploring the role of drones and UAVs in logistics and supply chain management: A novel text-based literature review. Int. J. Prod. Res. 2025, 63, 1873–1897. [Google Scholar] [CrossRef]
- Wu, Q.; Su, Y.; Tan, W.; Zhan, R.; Liu, J.; Jiang, L. UAV Path Planning Trends from 2000 to 2024: A Bibliometric Analysis and Visualization. Drones 2025, 9, 128. [Google Scholar] [CrossRef]
- Shuaibu, A.S.; Mahmoud, A.S.; Sheltami, T.R. A Review of Last-Mile Delivery Optimization: Strategies, Technologies, Drone Integration, and Future Trends. Drones 2025, 9, 158. [Google Scholar] [CrossRef]
- Bine, L.M.; Boukerche, A.; Ruiz, L.B.; Loureiro, A.A. Connecting internet of drones and urban computing: Methods, protocols and applications. Comput. Netw. 2024, 239, 110136. [Google Scholar] [CrossRef]
- Molina, A.A.; Huang, Y.; Jiang, Y. A review of unmanned aerial vehicle applications in construction management: 2016–2021. Standards 2023, 3, 95–109. [Google Scholar] [CrossRef]
- Gu, X.; Zhang, G. A survey on UAV-assisted wireless communications: Recent advances and future trends. Comput. Commun. 2023, 208, 44–78. [Google Scholar] [CrossRef]
- Bevins, A.; Kunde, S.; Duncan, B.A. User-designed human-UAV interaction in a social indoor environment. In Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, Boulder, CO, USA, 11–15 March 2024; pp. 23–31. [Google Scholar]
- Marciniak, J.B.; Wiktorzak, B. Automatic Generation of Guidance for Indoor Navigation at Metro Stations. Appl. Sci. 2024, 14, 10252. [Google Scholar] [CrossRef]
- Lyu, M.; Zhao, Y.; Huang, C.; Huang, H. Unmanned aerial vehicles for search and rescue: A survey. Remote Sens. 2023, 15, 3266. [Google Scholar] [CrossRef]
- Choi, S.H.; Kim, Z.C.; Buu, S.J. Speech-Guided Drone Control System Based on Large Language Model. In Proceedings of the 2025 International Conference on Electronics, Information, and Communication (ICEIC), Osaka, Japan, 19–22 January 2025; pp. 1–4. [Google Scholar]
- Izquierdo, A.; Del Val, L.; Villacorta, J.J.; Zhen, W.; Scherer, S.; Fang, Z. Feasibility of discriminating UAV propellers noise from distress signals to locate people in enclosed environments using MEMS microphone arrays. Sensors 2020, 20, 597. [Google Scholar] [CrossRef]
- Wang, L.; Cavallaro, A. Ear in the sky: Ego-noise reduction for auditory micro aerial vehicles. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 152–158. [Google Scholar]
- Wang, L.; Cavallaro, A. Microphone-array ego-noise reduction algorithms for auditory micro aerial vehicles. IEEE Sens. J. 2017, 17, 2447–2455. [Google Scholar] [CrossRef]
- Wang, L.; Cavallaro, A. Acoustic sensing from a multi-rotor drone. IEEE Sens. J. 2018, 18, 4570–4582. [Google Scholar] [CrossRef]
- Manamperi, W.N.; Abhayapala, T.D.; Samarasinghe, P.N.; Zhang, J.A. Drone audition: Audio signal enhancement from drone embedded microphones using multichannel wiener filtering and gaussian-mixture based post-filtering. Appl. Acoust. 2024, 216, 109818. [Google Scholar] [CrossRef]
- Sinibaldi, G.; Marino, L. Experimental analysis on the noise of propellers for small UAV. Appl. Acoust. 2013, 74, 79–88. [Google Scholar] [CrossRef]
- Mukhutdinov, D.; Alex, A.; Cavallaro, A.; Wang, L. Deep learning models for single-channel speech enhancement on drones. IEEE Access 2023, 11, 22993–23007. [Google Scholar] [CrossRef]
- Tengan, E.; Dietzen, T.; Ruiz, S.; Alkmim, M.; Cardenuto, J.; van Waterschoot, T. Speech enhancement using ego-noise references with a microphone array embedded in an unmanned aerial vehicle. arXiv 2022, arXiv:2211.02690. [Google Scholar]
- Karam, M.; Khazaal, H.F.; Aglan, H.; Cole, C. Noise removal in speech processing using spectral subtraction. J. Signal Inf. Process. 2014, 5, 32–41. [Google Scholar] [CrossRef]
- Chen, C. Research on Single Channel Speech Noise Reduction Algorithm Based on Signal Processing. In Proceedings of the 2020 5th International Conference on Technologies in Manufacturing, Information and Computing (ICTMIC 2020), San Jose, CA, USA, 9–12 March 2020. [Google Scholar]
- Lei, Y.; Liqin, T.; Junyi, W. A Study on a Two-Stage UAV Noise Removal Method Based on Deep Residual Neural Networks. Curr. Sci. 2025, 5, 1422–1431. [Google Scholar] [CrossRef]
- Watanabe, S.; Mandel, M.; Barker, J.; Vincent, E.; Arora, A.; Chang, X.; Khudanpur, S.; Manohar, V.; Povey, D.; Raj, D.; et al. CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings. arXiv 2020, arXiv:2004.09249. [Google Scholar]
- Lu, W.T.; Wang, J.C.; Kong, Q.; Hung, Y.N. Music Source Separation With Band-Split Rope Transformer. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 481–485. [Google Scholar] [CrossRef]
- Défossez, A.; Usunier, N.; Bottou, L.; Bach, F. Music source separation in the waveform domain. arXiv 2019, arXiv:1911.13254. [Google Scholar]
- Rouard, S.; Massa, F.; Défossez, A. Hybrid transformers for music source separation. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing 2024, 568, 127063. [Google Scholar] [CrossRef]
- Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; Ré, C. Flashattention: Fast and memory-efficient exact attention with io-awareness. Adv. Neural Inf. Process. Syst. 2022, 35, 16344–16359. [Google Scholar]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Chen, J.; Mao, Q.; Liu, D. Dual-path transformer network: Direct context-aware modeling for end-to-end monaural speech separation. arXiv 2020, arXiv:2007.13975. [Google Scholar]
- Luo, Y.; Chen, Z.; Yoshioka, T. Dual-path rnn: Efficient long sequence modeling for time-domain single-channel speech separation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 46–50. [Google Scholar]
- Song, Y.; Kindt, S.; Madhu, N. Drone ego-noise cancellation for improved speech capture using deep convolutional autoencoder assisted multistage beamforming. In Proceedings of the 2022 25th International Conference on Information Fusion (FUSION), Linköping, Sweden, 4–7 July 2022; pp. 1–8. [Google Scholar]
- Wang, L.; Cavallaro, A. A blind source separation framework for ego-noise reduction on multi-rotor drones. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2523–2537. [Google Scholar] [CrossRef]
- Tan, Z.W.; Nguyen, A.H.; Khong, A.W. An efficient dilated convolutional neural network for UAV noise reduction at low input SNR. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1885–1892. [Google Scholar]
- Wang, L.; Cavallaro, A. Deep learning assisted time-frequency processing for speech enhancement on drones. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 5, 871–881. [Google Scholar] [CrossRef]
- Choi, H.S.; Kim, J.H.; Huh, J.; Kim, A.; Ha, J.W.; Lee, K. Phase-aware speech enhancement with deep complex u-net. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Pandey, A.; Wang, D. Self-attending RNN for speech enhancement to improve cross-corpus generalization. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1374–1385. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; He, B.; Zhu, W.P. TSTNN: Two-stage transformer based neural network for speech enhancement in the time domain. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7098–7102. [Google Scholar]
- Sun, T.; Bohté, S. DPSNN: Spiking neural network for low-latency streaming speech enhancement. Neuromorphic Comput. Eng. 2024, 4, 044008. [Google Scholar] [CrossRef]
- Chen, X.; Bi, H.; Lai, W.T.; Ma, F. Monaural speech enhancement on drone via Adapter based transfer learning. In Proceedings of the 2024 18th International Workshop on Acoustic Signal Enhancement (IWAENC), Aalborg, Denmark, 9–12 September 2024; pp. 85–89. [Google Scholar]
- Lu, W.T.; Wang, J.C.; Won, M.; Choi, K.; Song, X. SpecTNT: A time-frequency transformer for music audio. arXiv 2021, arXiv:2110.09127. [Google Scholar]
- Luo, Y.; Yu, J. Music source separation with band-split RNN. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 1893–1901. [Google Scholar] [CrossRef]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 24, 483–492. [Google Scholar] [CrossRef]
- Zhang, B.; Sennrich, R. Root mean square layer normalization. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Al-Emadi, S.; Al-Ali, A.; Mohammad, A.; Al-Ali, A. Audio based drone detection and identification using deep learning. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 459–464. [Google Scholar]
- Beranek, L.L.; Mellow, T. Acoustics: Sound Fields and Transducers; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Solovyev, R.; Stempkovskiy, A.; Habruseva, T. Benchmarks and leaderboards for sound demixing tasks. arXiv 2023, arXiv:2305.07489. [Google Scholar]
- Le Roux, J.; Wisdom, S.; Erdogan, H.; Hershey, J.R. SDR–half-baked or well done? In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 626–630. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Hunger, R. Floating Point Operations in Matrix-Vector Calculus; Technical report; Associate Institute for Signal Processing: Munich, Germany, 2005. [Google Scholar]
- Defossez, A.; Synnaeve, G.; Adi, Y. Real time speech enhancement in the waveform domain. arXiv 2020, arXiv:2006.12847. [Google Scholar]
- Schäffer, B.; Pieren, R.; Heutschi, K.; Wunderli, J.M.; Becker, S. Drone noise emission characteristics and noise effects on humans—A systematic review. Int. J. Environ. Res. Public Health 2021, 18, 5940. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FLOPs (G) | Mem (MB) | Storage (MB) | Latency (ms) | RTF | Power (W) |
|---|---|---|---|---|---|---|
| Edge-BS-RoFormer (Proposed) | 11.617 | 491.544 | 8.534 | 330.830 | 0.325 | 6.536 |
| DCUNet | 112.136 | 162.830 | 10.772 | 192.642 | 0.214 | 5.065 |
| DPTNet | 41.797 | 341.883 | 187.316 | 304.740 | 0.319 | 6.578 |
| HTDemucs | 48.391 | 223.139 | 160.331 | 296.554 | 0.145 | 4.861 |
| Model | SI-SDR (dB) | STOI | PESQ | FLOPs (G) | Mem (MB) | RTF | Storage (MB) | Latency (ms) | Power (W) |
|---|---|---|---|---|---|---|---|---|---|
| Edge-BS-RoFormer (FlashAttention, RoPE) | 2.558 | 0.623 | 1.229 | 7.480 | 337.021 | 0.220 | 7.547 | 231.668 | 5.288 |
| Edge-BS-RoFormer (FlashAttention, SPE) | −1.715 | 0.519 | 1.194 | 7.480 | 303.437 | 0.159 | 8.646 | 176.328 | 4.444 |
| Edge-BS-RoFormer (LinearAttention, SPE) | −1.818 | 0.519 | 1.197 | 7.480 | 321.864 | 0.166 | 8.646 | 177.789 | 4.696 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Li, M.; Guo, L.; Guo, H.; Cao, J.; Zhao, W.; Wang, J. Edge-Deployed Band-Split Rotary Position Encoding Transformer for Ultra-Low-Signal-to-Noise-Ratio Unmanned Aerial Vehicle Speech Enhancement. Drones 2025, 9, 386. https://doi.org/10.3390/drones9060386
Liu F, Li M, Guo L, Guo H, Cao J, Zhao W, Wang J. Edge-Deployed Band-Split Rotary Position Encoding Transformer for Ultra-Low-Signal-to-Noise-Ratio Unmanned Aerial Vehicle Speech Enhancement. Drones. 2025; 9(6):386. https://doi.org/10.3390/drones9060386
Chicago/Turabian StyleLiu, Feifan, Muying Li, Luming Guo, Hao Guo, Jie Cao, Wei Zhao, and Jun Wang. 2025. "Edge-Deployed Band-Split Rotary Position Encoding Transformer for Ultra-Low-Signal-to-Noise-Ratio Unmanned Aerial Vehicle Speech Enhancement" Drones 9, no. 6: 386. https://doi.org/10.3390/drones9060386
APA StyleLiu, F., Li, M., Guo, L., Guo, H., Cao, J., Zhao, W., & Wang, J. (2025). Edge-Deployed Band-Split Rotary Position Encoding Transformer for Ultra-Low-Signal-to-Noise-Ratio Unmanned Aerial Vehicle Speech Enhancement. Drones, 9(6), 386. https://doi.org/10.3390/drones9060386