1. Introduction
In recent years, driven by advancements in the low-altitude economy, drones have increasingly taken on important roles in production and daily life. Drone technology encompasses three key domains: perception, decision-making, and control. A significant aspect of the perception domain is multi-view, multi-target tracking, which involves UAVs autonomously detecting and tracking multiple targets from diverse perspectives while sharing crucial target information. This ensures consistent target identity recognition across different views, leading to a substantial improvement in tracking performance by shifting the focus from traditional cross-camera methods to utilizing UAV perspectives. In low-altitude scenes, UAVs can leverage their lower flight altitudes to capture many target appearance features. However, challenges such as the dynamic movement of UAVs and frequent occlusions can complicate the use of motion, background, and distribution information for effective identity association. Therefore, the primary challenge lies in extracting robust appearance features from UAV perspectives and employing them for similarity computation to effectively tackle the inherent complexities in multi-view, multi-target tracking in low-altitude environments. Existing methods addressing this challenge can be broadly categorized into three main groups:
- (1)
Target re-identification mechanisms: In low-altitude environments, the apparent distinctions between targets are often pronounced. Once a target is detected, its appearance features can be extracted to construct an appearance similarity matrix from multiple viewpoints, enabling optimal matching through bipartite matching algorithms [
1]. This approach leverages the bipartite graph’s structure to achieve optimal matching results while ensuring computational efficiency, even for large-scale problems. For instance, Zhang et al. [
2] introduced the first pedestrian re-identification dataset, PRAI-1581, from an aerial perspective and developed an end-to-end re-identification model that employed convolutional feature map subspace pooling to learn highly discriminative target features in middle- and low-altitude scenarios. Teng et al. [
3] proposed a vehicle re-identification dataset, UAV-VeID, created from a drone perspective and constructed a benchmark re-identification model for this dataset by extracting multi-scale features of target vehicles and enhancing feature robustness by utilizing a discriminator. Nguyen et al. [
4] developed the AG-ReID.v2 dataset to improve pedestrian re-identification in mixed aerial and ground perspectives. They employed the powerful spatiotemporal feature capture capabilities of Transformers to extract target human attribute information, achieving identity association matching across substantially different perspectives.
- (2)
Leveraging positional information for identity association: When drones operate in close proximity to targets, they can maximize state estimation capabilities, particularly by acquiring depth information that enables the computation of absolute target positions within a unified world coordinate system. This positional information can be effectively utilized to facilitate identity association from multiple perspectives. For example, Pan et al. [
5] introduced a dataset constructed within a simulated environment using AirSim [
6]. Their approach converted target positions resolved from various perspectives into a unified world coordinate system, achieving identity association based on proximity. Similarly, Shen et al. [
7] conducted experiments on MUMO [
8], a simulated cross-view vehicle tracking dataset created with an indoor motion capture system. Their method integrated targets’ appearance and positional features, incorporating temporal weighting to account for natural gradual changes over time.
- (3)
End-to-end detection and tracking: Deep learning models have proven effective at integrating target detection, tracking, and re-identification tasks within a unified network architecture, ensuring consistent optimization objectives throughout the training process. These models process perceptual data from multiple viewpoints as their input and directly output globally unique target identities. For instance, Han et al. [
9] introduced the DMHA simulation dataset to unify high- and low-altitude perspectives. Their approach achieved precise identity association by estimating viewpoint orientations and constructing polar coordinates to align target distributions from varying perspectives. Similarly, Hao et al. [
10] presented the DIVOTrack dataset, designed specifically for low-altitude scenarios, and at the same time, they proposed CrossMOT, a method that integrates detection, tracking, and re-identification into a single model. By optimizing task-specific loss functions, overall model consistency was ensured, enabling accurate tracking based on appearance features.
The approach proposed in this study aligns with the third category, focusing on the appearance characteristics of targets in low-altitude environments. Through incorporating loss reinforcement and coupled constraints, the method enhances the model’s capability to effectively distinguish small targets. Additionally, during the inference phase, target appearance similarities across multiple viewpoints are leveraged to refine the temperature coefficient, improving the effectiveness of the constructed target identity-matching cost matrix. Our proposed strategy adjusts the end-to-end model loss during the training phase and accounts for target characteristics observed from multiple low-altitude perspectives during inference. Compared to the state-of-the-art CrossMOT algorithm used on the DIVOTrack dataset, our method achieves improvements of 2.19% and 1.95% in the CVMA and CVIDF1, respectively. Notably, the contributions of this study lie in directly improving the model’s performance without increasing resource consumption or compromising computational efficiency, while optimizing multi-view, multi-target tracking in low-altitude UAV scenarios, thereby partially enhancing its practical utility in real-world applications.
The main contributions of this paper can be summarized as follows:
Building upon existing end-to-end detection and tracking frameworks, we introduce three loss optimization strategies tailored to address the characteristics of targets observed from multiple low-altitude perspectives. These include (1) positive and negative reinforcement for detection loss, (2) self-attention reinforcement for re-identification loss, and (3) coupled constraints for detection and tracking loss. These strategies enhance tracking accuracy and efficiency.
During the inference phase, we analyze the unique characteristics of multi-view, multi-target tracking tasks and introduce a temperature coefficient that accounts for both target quantity and similarity from varying perspectives. This approach modestly improves tracking performance while maintaining inference efficiency.
Comprehensive experiments conducted on the open-source DIVOTrack dataset validate the effectiveness of the optimization strategies proposed for multi-target detection and tracking. Our method stands as a state-of-the-art multi-view, multi-target tracking approach tailored for low-altitude scenarios involving UAVs, exhibiting meaningful practical value in this particular context.
The remainder of this paper is organized as follows:
Section 2 provides an overview of the related work and identifies gaps in existing research.
Section 3 describes the proposed multi-view, multi-target tracking method involving UAVs, outlining its theoretical foundations and implementation details.
Section 4 presents the experimental setup and results, demonstrating the effectiveness of the proposed approach.
Section 5 discusses the implications of the findings, acknowledging potential limitations and proposing directions for future research. Finally,
Section 6 concludes the paper by summarizing its key contributions and outcomes.
2. Related Studies
We begin by discussing the principles of multi-view, multi-target tracking involving UAVs, followed by an examination of target tracking specifically from the UAV’s perspective. Finally, we explore advancements in end-to-end multi-target tracking.
2.1. Multi-View, Multi-Target Tracking Involving UAVs
Multi-view, multi-target tracking involving UAVs is a novel area of research. Unlike traditional surveillance camera systems, UAVs operate at lower altitudes with dynamic fields of view, meaning that conventional strategies for re-identification, trajectory matching, and topology solving are insufficient in this context. To tackle these challenges, existing methodologies emphasize three specific task scenarios, each utilizing unique target features that align with the characteristics of the scenario. This approach aims to enhance the performance of multi-view, multi-target tracking, leveraging the UAV’s perspective to effectively address the complexities inherent in tracking multiple targets from diverse viewpoints.
- (1)
Overhead tracking scenario: Liu et al. [
11] introduced the MDMT dataset alongside its benchmark model, MIA-Net, designed for tracking ground vehicle targets overhead using multiple drones. In this context, overlapping fields of view between drones enable the projection of multiple images onto a single plane by computing homography matrices, thereby facilitating cross-view identity matching based on target proximity. Zhu et al. [
12] proposed the MDOT dataset and its corresponding benchmark model, ASNet, for the coordinated tracking of a single target using multiple drones. Their approach successfully achieved continuous tracking from different perspectives by leveraging template sharing and matching techniques implemented through a Siamese neural network framework. Building on these methods, Chen et al. [
13] and Xue et al. [
14] utilized Transformers’ advanced spatiotemporal modeling capabilities to enhance and fuse extracted target features. These approaches relied on consistent information across perspectives, enabling accurate multi-view identity association and significantly improving tracking performance.
- (2)
Oblique tracking scenario: In addition to Hao et al. [
10], Fan et al. [
15] introduced the VisionTrack dataset along with its benchmark model, GMT. This model unifies the encoding of the appearances and spatiotemporal features of targets, leveraging Transformers to generate a target identity association similarity matrix. Furthermore, GMT recovers the trajectories of unmatched targets by utilizing historical tracking results, enhancing overall tracking robustness and accuracy.
- (3)
Collaborative tracking scenario: Han et al. [
16] introduced the CVMHT dataset and its benchmark model, CVMHAT, which employs iterative processes to estimate the positions and observation angles of side views overhead. By constructing spatial relationship vectors for targets within the images, the model computes similarity metrics to effectively confirm target identities. In a subsequent study, Han et al. [
17] proposed the CvMHAT dataset along with its benchmark model, MHATB. This approach defines the identity-matching problem as a constrained generalized maximum graph model, utilizing a multi-view target similarity matrix. The alternating direction method of multipliers (ADMM) then achieves an optimal solution, significantly enhancing the accuracy and efficiency of cross-view identity matching.
A comprehensive review of the existing literature identifies six primary categories of target information that are crucial for multi-view, multi-target tracking tasks involving UAVs: appearance, motion, distribution, background, projection, and position. Each category offers distinct insights that enhance overall tracking performance. By assessing the trade-offs between tracking effectiveness and efficiency across different task scenarios, researchers can strategically select the most suitable type of target information to optimize performance. This approach ensures that the tracking system achieves high accuracy and computational efficiency, as it is tailored to the specific requirements of each scenario.
2.2. Target Tracking from a Drone’s Perspective
Observing targets from a drone perspective presents unique challenges due to factors such as their small scale and dual-source movement, which impede the direct application of traditional multi-target tracking methods. The emergence of competitors such as VisDrone-MOT [
18] has spurred the development of specialized methodologies tailored to these drone-specific tracking characteristics. These advancements have significantly improved public evaluation benchmarks, underscoring the progress achieved in this field.
For example, the HMTT model developed by Pan et al. [
19] employs a hierarchical approach combining the strengths of single-target tracking and target re-identification to enhance detection results. By leveraging a homography matrix computed from adjacent frames, the model evaluates drone motion states, effectively filtering unreliable tracking outputs. This strategic fusion of methodologies enables the robust handling of the unique challenges associated with aerial perspectives in multi-target tracking. The PASTracker, proposed by Stadler et al. [
20], integrates target position, appearance, and scale information to connect detection and tracking outputs. A notable feature of this model is its camera motion compensation module, which identifies misdetections caused by camera movement, indirectly improving overall tracking performance. The GIAOTracker, introduced by Du et al. [
21], adopts a global optimization perspective. It first generates trajectory fragments using motion information from both the camera and the targets, as well as target appearance features. These fragments are then globally connected to form complete trajectories, followed by post-processing, to deliver final tracking results. The UAVMOT model, developed by Liu et al. [
22], enhances multi-target tracking from the drone’s perspective through three key strategies: updating target identity features, extracting local spatial relationships, and balancing category and scale losses. These optimization techniques have demonstrated effectiveness across multiple datasets, significantly improving tracking performance in aerial scenarios. The DroneMOT model, proposed by Wang et al. [
23], enhances target appearance and motion features in both temporal and spatial dimensions. By employing an adaptive weighting strategy inspired by attention mechanisms, the model synchronously extracts the temporal trajectory and spatial state information of its targets. This approach effectively addresses challenges such as small target sizes and dynamic viewpoint changes, providing a robust solution for drone-based multi-target tracking. The HomView-MOT model, introduced by Ji et al. [
24], focuses on the efficient computation of homography matrices between adjacent frames, projecting sequential targets onto a unified plane for spatial distance-based matching. This spatial alignment improves tracking accuracy across frames. Additionally, HomView-MOT employs attention mechanisms to encode and decode temporal features, capturing appearance attributes minimally affected by viewpoint changes. By effectively managing variations across consecutive observations, this method significantly enhances multi-drone tracking systems’ robustness and accuracy.
2.3. End-to-End Multi-Target Tracking
The success of multi-target tracking tasks relies heavily on accurate state prediction and identity matching, both strongly influenced by detection results’ precision. End-to-end models have emerged as a robust solution, integrating detection, tracking, and re-identification tasks into a unified framework with a single optimization objective. These models automatically extract temporal features from image data during training, creating a more efficient target identity-matching cost matrix. Consequently, they enhance multi-target tracking’s accuracy and efficiency across both same-view and cross-view scenarios.
A notable example of an end-to-end tracking method is the MOTR framework, introduced by Zeng et al. [
25], which represents the first fully Transformer-based tracking framework. MOTR excels at capturing long-term state changes in targets through its innovative tracking query module, which efficiently records complete trajectories for individual targets. By unifying detection and tracking tasks within a singular processing flow, MOTR has significant potential for improving multi-target tracking methodologies’ effectiveness and accuracy. Building on the foundation of MOTR, Zhang et al. [
26] proposed MOTRv2, which integrates the YOLOX [
27] target detector. This addition enables the implicit decoupling of detection and tracking tasks within the end-to-end framework, mitigating conflicts between optimization objectives during the operation of the model’s encoding and decoding processes. MOTRv2 demonstrates excellent scalability and has achieved remarkable results across a range of multi-target tracking datasets. The MeMOTR framework, introduced by Gao et al. [
28], further advances end-to-end tracking using a long-sequence memory interaction module. Recognizing that individual frame data may suffer from occlusion or blurring, MeMOTR employs attention mechanisms to enhance target features from adjacent frames. It then applies adaptive multi-frame data fusion through an exponential moving average, allowing the model to leverage historical target information for identity confirmation. This innovative approach significantly enhances tracking robustness and accuracy, particularly in complex occlusion scenarios. IANet, proposed by Li et al. [
29], adopts a two-stage approach to multi-target tracking. In the first stage, a geometric refinement network extracts spatiotemporal information, including direction and speed, to generate initial trajectory fragments. In the second stage, an identity confirmation module integrates these fragments into complete target trajectories. This method effectively addresses challenges such as interactions and occlusions, ensuring the coherent and accurate reconstruction of target paths. On the other hand, CTGMOT, introduced by Cao et al. [
30], integrates convolutional neural networks (CNNs), Transformers, and graph neural networks (GNNs) into a unified framework. CNNs extract local image features, while Transformers capture global contextual information. GNNs then model the spatial relationships among targets within frames and temporal trajectories across frames. This comprehensive approach facilitates the construction of a target identity-matching similarity matrix, modestly improving the model’s ability to track and identify targets across continuous video streams by leveraging spatial and temporal insights.
3. Methods
During low-altitude close reconnaissance missions, UAV involvement enables the comprehensive capture of target appearance details from multiple views. In this scenario, targets exhibit substantial variations in background, motion, and distribution from different perspectives. Consequently, we must maximize the utilization of appearance features for cross-view target identity association. This section is organized into four main components: positive and negative reinforcement for detection loss, self-attention reinforcement for re-identification loss, coupled constraints for detection and tracking loss, and the refinement of the temperature coefficient during the inference phase.
Regarding detection loss positive and negative reinforcement, target size is incorporated into the weighted optimization of offset and size loss, improving the model’s ability to detect small targets. The re-identification loss with self-attention reinforcement employs self-attention mechanisms to focus on appearance features’ critical regions, increasing feature distinctiveness and enhancing reliability in cross-view association matching. The coupled constraints of detection and tracking loss impose a proportional limit between the two factors, ensuring the consistency of the model’s optimization direction. Finally, the refinement of the temperature coefficient during the inference phase not only accounts for the number of cross-view target matches but also incorporates average and median target matching similarity. This adjustment ensures effective tracking in scenarios involving numerous targets with high similarity.
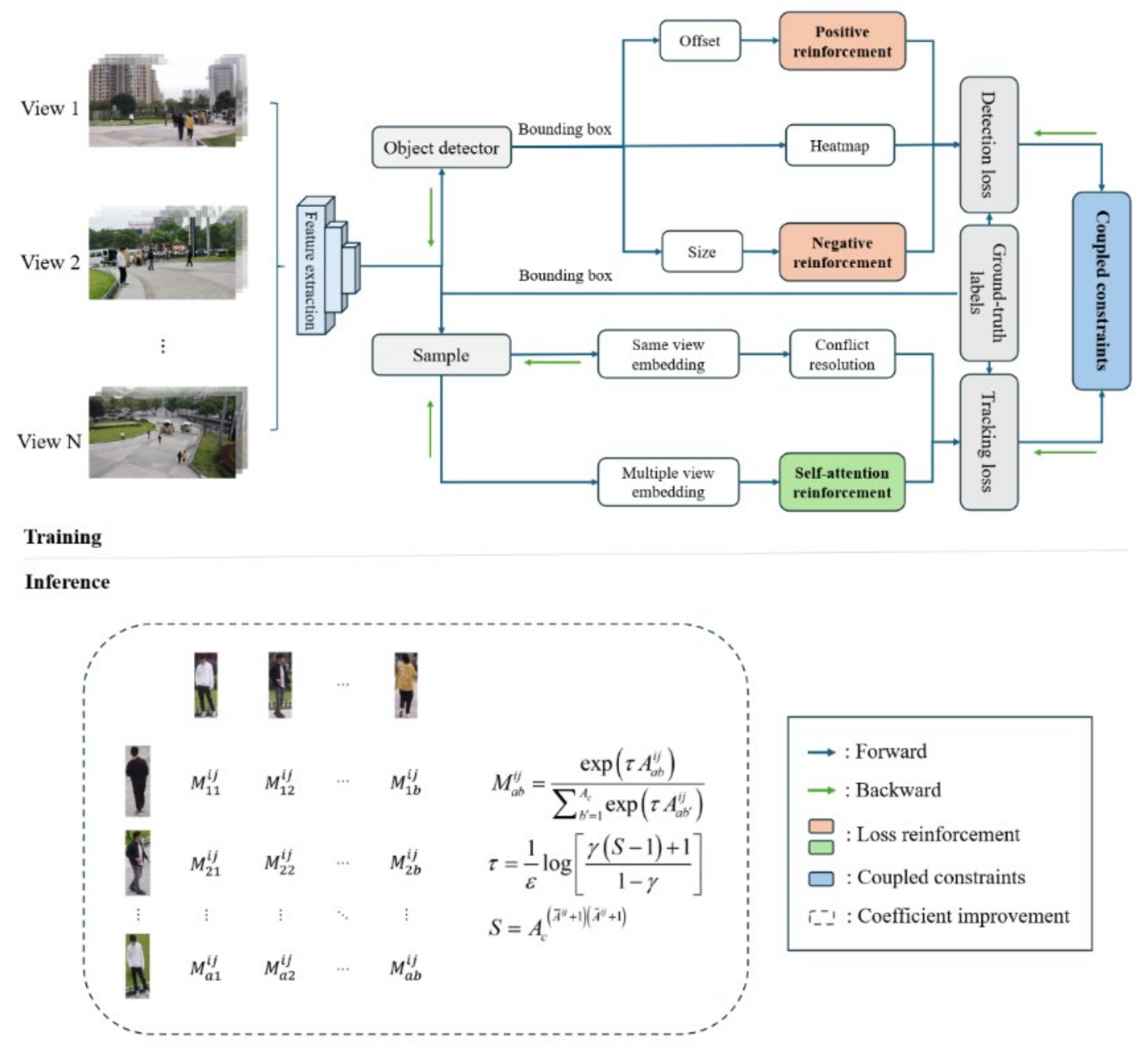
The relationships between these modules are illustrated in
Figure 1. The input multi-view image data are first processed through the deep layer aggregation (DLA) [
31] backbone network for feature extraction and subsequently passed into the detection module to obtain the bounding box corresponding to each target. First, the detection loss is calculated using the bounding boxes output by the detector, and then the tracking loss is computed using the bounding boxes from the ground-truth labels for both same-view and multi-view scenarios, thereby completing the model’s backpropagation training. The main contribution of this study is emphasized in
Figure 1, comprising three key modules: loss reinforcement, coupled constraints, and coefficient improvement. For details regarding the meanings of related variables in
Figure 1, please refer to
Section 3.4.
3.1. Detection Loss Positive and Negative Reinforcement
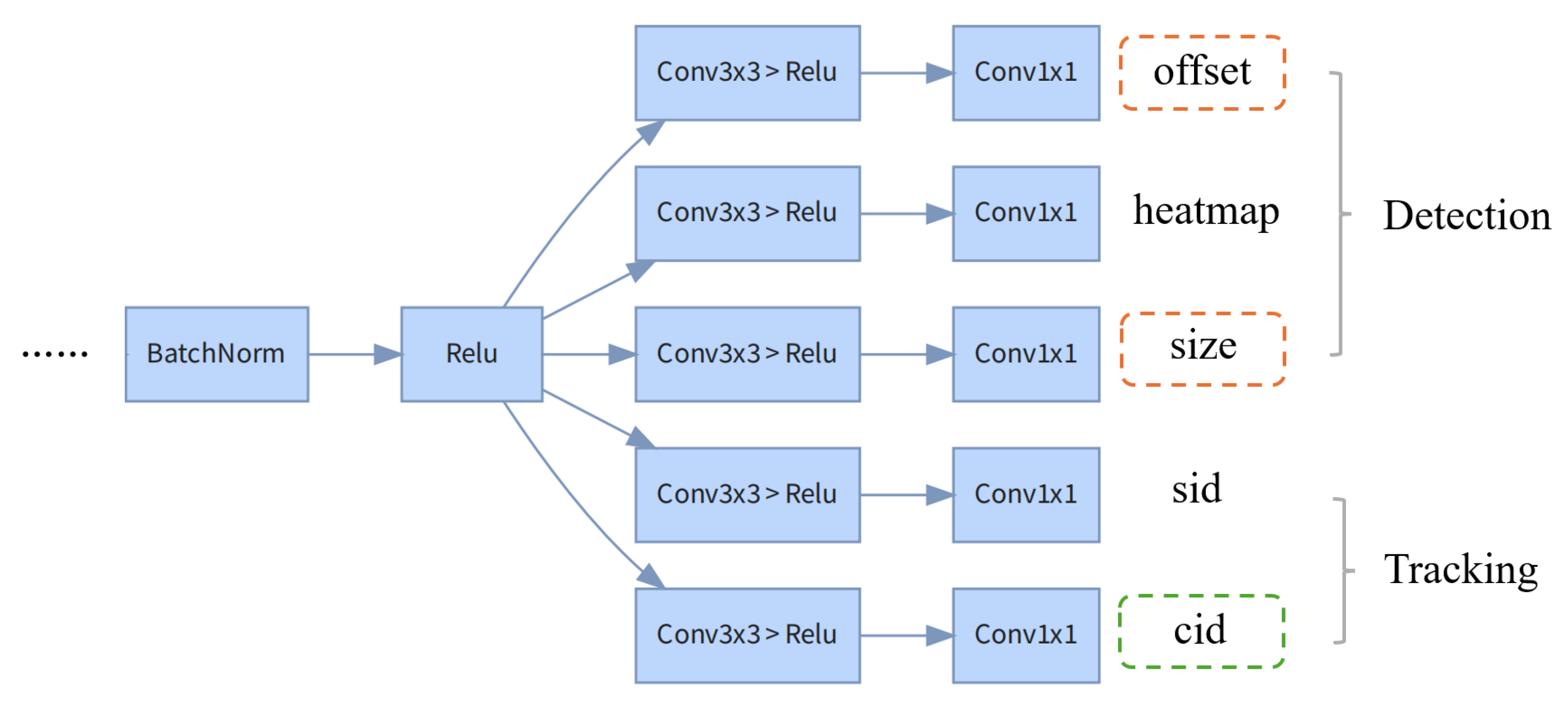
Targets observed from low-altitude perspectives have distinctive features, which can be effectively extracted post-detection for identity association through cross-view re-identification. This study employed the three-head prediction architecture from CenterNet [
32], which predicts object positions using offsets, sizes, and heatmaps. Based on this, the tracking architecture for both the same view and multiple views constructed in CrossMOT is further adopted, ultimately resulting in the five output branches shown in
Figure 2. The detection loss reinforcement in this section mainly focuses on the offset and size output branches.
As CenterNet downsamples the input image by a factor of
, projecting the feature maps back onto the original image may introduce errors. Therefore, we must predict an offset
for each key point
. The calculation of the
loss is illustrated as follows:
The specific offset loss is defined as follows:
where
denotes the predicted offset of the key point coordinates,
denotes the ground truth key point coordinates, and
denotes the predicted key point coordinates. Additionally, the width and height scales for each target must be predicted as
. The specific size loss is defined as follows:
where
represents the ground truth target size and
represents the predicted target size.
refers to the number of true targets in the image. The calculation processes for
and
are described as follows:
Each ground truth detection box corresponds to the position of a key point and its corresponding size information.
For larger targets, the prediction error of the offset has a more significant impact on the detection bounding box, while for smaller targets, the size prediction error is more influential. In the domain of object detection, larger detection boxes demonstrate a significant decrease in the intersection area when their center points are perturbed. In contrast, smaller detection boxes typically do not experience substantial offsets; otherwise, their corresponding intersection over union (IoU) will approach the minimal value, resulting in a disproportionately high loss. Therefore, during the training process, it is essential to place a greater focus on the offset loss associated with larger detection boxes. Therefore, it is essential to apply a positive reinforcement mechanism for the offset loss that is proportional to the target’s scale; specifically, as the scale of the target increases, the significance of the offset loss correspondingly intensifies. Regarding target size prediction, applying the same error leads to a more substantial reduction in the IoU ratio for smaller detection boxes. This phenomenon arises because the error associated with smaller areas significantly affects their intersection areas, thus increasing the overall burden on the IoU metric. Consequently, a negative reinforcement approach is warranted for the size loss, indicating that as the target scale diminishes, the criticality of the size loss becomes increasingly pronounced. Therefore, incorporating a loss coefficient based on the target scale can enhance the detection model’s adaptability to targets of different sizes. The specific form of the
function is presented as follows:
The detailed processes for positive and negative reinforcement are described as follows:
where
and
represent the ground truth widths and heights of targets during training. The parameter
defines the scale of small objects in object detection, with 32 × 32 corresponding to a value of 1024 [
33]. These calculations evaluate the relative size of a traditionally small target, computing the offset coefficient in a positively correlated manner and the size coefficient in a negatively correlated manner, before integrating these factors into the
loss calculation process. This approach enhances detection loss with positive and negative correlations regarding target size. The final detection loss is presented as follows:
which integrates offset, heatmap, and size losses.
adopts the original calculation method from CenterNet [
32].
3.2. Re-Identification Loss with Self-Attention Reinforcement
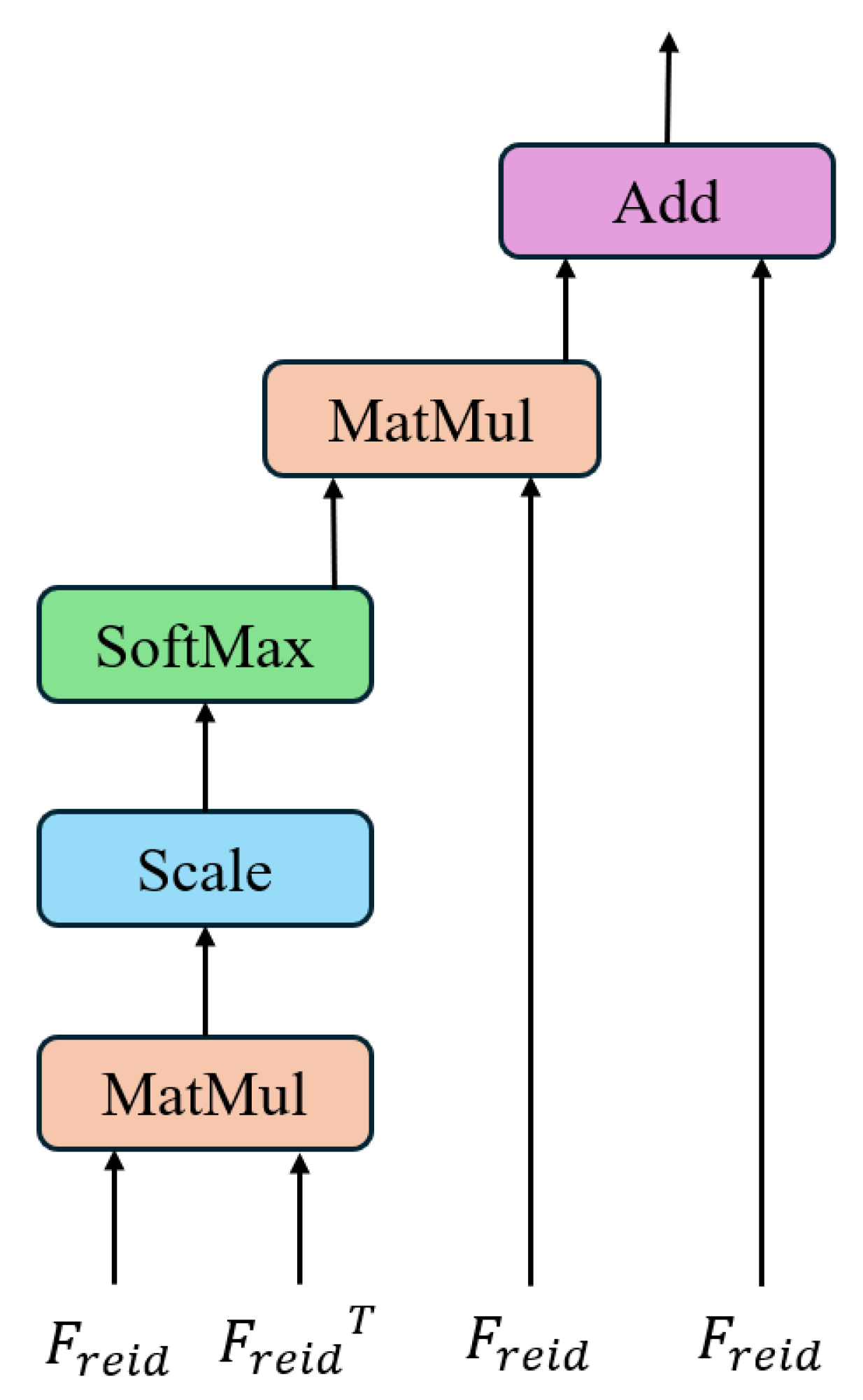
Re-identification between views based on appearance features relies heavily on these features’ distinctiveness. By applying self-attention reinforcement, the unique characteristics of the target’s features are accentuated, modestly improving their discriminability. The cid output branch in
Figure 2 is primarily considered in the re-identification loss reinforcement detailed in this section. The principle of self-attention reinforcement for re-identification features is illustrated in
Figure 3. After extracting target appearance features, matrix multiplication and scaling are performed to calculate weighting coefficients, which are subsequently applied to enhance the original features. The specific form of the
function is presented as
with the detailed procedure described as follows:
First, a self-attention weight matrix is generated using the appearance features
extracted from the target detection box. The weighted matrix is subsequently fused with the original features to generate
. Here,
represents the dimensionality of the features. Thus, the final features are refined to capture more salient information about the target. The same-view and cross-view re-identification losses can be computed using the cross-entropy function. The mathematical representation is defined as follows:
where
denotes the ground truth target identity in a single view, whereas
denotes the ground truth target identity across multiple views. The detailed expanded forms of the two functions used in Equations (15) and (16) are presented as follows:
where Equation (
17) presents a widely adopted linear classifier model, whereas Equation (
18) presents the cross-entropy loss function used in object re-identification. In these equations,
and
denote the weight vector and bias term, respectively.
N refers to the total number of samples, while
C refers to the number of categories.
3.3. Coupled Detection and Tracking Loss Constraints
From
Figure 1, it can be seen that when training end-to-end models, the losses associated with detection and tracking tasks exhibit some independence while collectively influencing the model’s cross-view tracking performance. As depicted in
Figure 4, the target appearances remain relatively stable over time within the same view, yet they exhibit significant variations across different views at the same time point. This finding emphasizes the importance of integrating the constraints’ relationships between these two tasks into the overall loss function to ensure consistency during training. The specific coupling mechanism is represented as follows:
Based on Equation (
19), to minimize the overall loss
, the three loss types (
,
,
) must decrease simultaneously, and the absolute values of their corresponding coefficients (
,
,
) should also decrease appropriately. However, the relative magnitudes of the coefficients
and
are constrained by
. For
to decrease,
needs to decrease and
needs to increase. This ensures that during the training process, the model prioritizes reliable features under the same view for backpropagation, while the influence of unreliable features across different views is relatively weakened, thereby enhancing the model’s ability to recognize targets to some extent under both same-view and cross-view conditions. The target identity labels used for these losses differ: the same-view re-identification loss utilizes local labels, whereas the cross-view loss employs global labels. The value of
is set to 0.5. Considering the characteristics of target appearance changes in
Figure 4, it is necessary to balance both accuracy and generalization when designing the model’s total loss function. To mitigate optimization direction conflicts caused by inconsistencies between same-view and cross-view re-identification losses during training, the conflict resolution approach proposed in [
10] is adopted. The principle underlying this method is detailed as follows:
which involves constructing same-view target re-identification loss by only considering data from the same view, automatically preventing interference from cross-view data. If the targets represented by
and
appear in the same view,
is set to 1; otherwise, it is set to 0.
are the learnable parameters of the fully connected layer in the ReID network.
represents the number of detected targets.
3.4. Improvement of the Temperature Coefficient in the Inference Phase
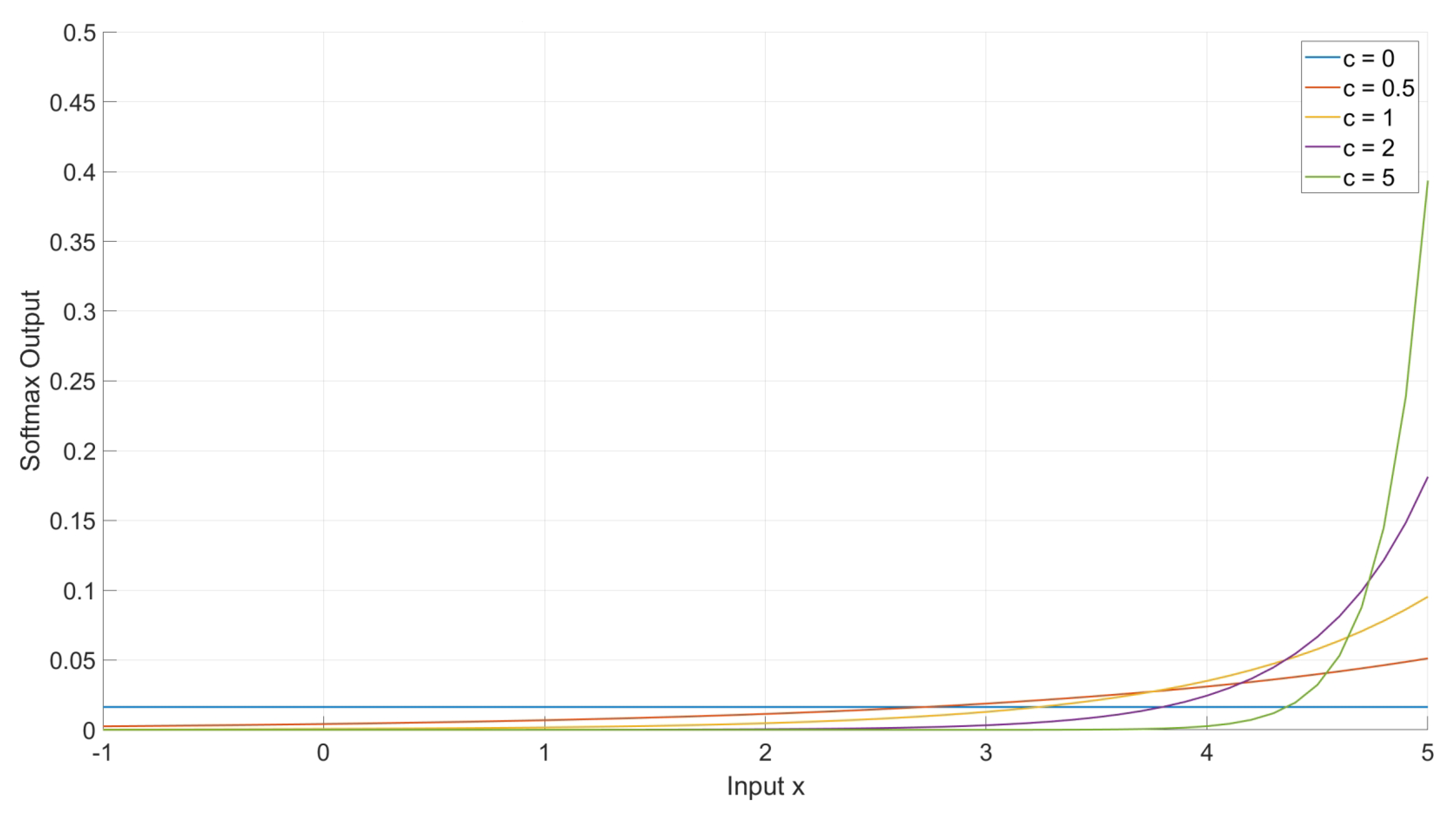
In practical cross-view multi-target tracking scenarios, the spatial distribution of individuals often fluctuates between dense and sparse, while the average appearance similarity may vary from low to high. As illustrated in
Figure 5, analyzing the softmax function properties indicates that a larger temperature coefficient amplifies the probability disparity, making the probability of finding the correct class significantly higher for other class outputs. Building on the methodology proposed in [
34,
35], which dynamically adjusts the temperature coefficient based on the number of targets, this study introduced an additional factor—average target similarity. By incorporating this factor, the temperature coefficient could be adaptively modified to enable effective identity differentiation, particularly in densely distributed scenarios where targets exhibit high appearance similarity under cross-view conditions. The
function with a constant term
c and
K classes is mathematically expressed as follows:
From
Figure 5, it is evident that an increase in the constant
c results in a steeper slope of the corresponding function curve, providing valuable insights for optimizing the calculation of the temperature coefficient. After completing model training, the similarity matrix
is computed based on the feature sets
and
, which are extracted following the target detection in frame
t of videos
and
. The computation process of
is shown in the following Equation (
22):
As illustrated in
Figure 1, the cross-view target feature similarity matrix is further processed to result in the final target identity-matching cost matrix
for all targets in the i-th and j-th views. This cost matrix is resolved using the Hungarian algorithm [
1] to establish associations between target identities. The improved processing step is outlined as follows:
which carefully considers both the scale of the targets being matched and their respective similarities when calculating the elements of the cost matrix. This method incorporates critical factors that enhance differentiation, particularly in scenarios with high volumes of targets and pronounced similarities. In Equation (
23),
a and
b represent the row and column indices in
, respectively. In Equation (
25),
represents the number of columns in
, while
and
represent the mean and median values of the target feature similarities between the two views, respectively. The constants
and
, both set to 0.5 in the experiments, regulate the weights in the cost matrix calculations. By incorporating the apparent similarity between targets from different viewpoints into the calculation of the temperature coefficient, the reliability of the target identity-matching cost matrix can be improved. Even in scenarios with a large number of highly similar targets, the cost matrix constructed using this method can effectively distinguish subtle differences between the targets. As a result, the model’s cross-view tracking capability can be modestly enhanced.
4. Results
In this section, we first introduce the dataset, evaluation metrics, and experimental details utilized in our study. Subsequently, we validate the advantages of using the proposed method in key metrics for multi-view target detection and tracking through ablation studies and performance comparison experiments. Furthermore, we present visualized experimental results to more intuitively demonstrate the method’s superiority.
4.1. Datasets and Evaluation Metric
The DIVOTrack dataset [
10] was utilized for experimental evaluation, which primarily consists of image data captured from three distinct viewpoints. Aerial viewpoint data were collected using a UAV, while horizontal viewpoint data were captured by two individuals using handheld cameras. The dataset includes 10 scenes, divided into training and testing subsets. Notably, ground truth annotations are available for five testing scenes only. For algorithm validation, the evaluation metrics used were CVMA and CVIDF1, as introduced in [
36], to assess the model’s performance in cross-view multi-target tracking. The specific calculation processes used for the two aforementioned metrics are presented below:
where the definitions of the relevant variables at time
t are as follows:
: Represents the number of correctly associated target ID pairs identified by the multi-view, multi-target tracking algorithm;
: Denotes the ground-truth associated target ID pairs, representing the total number of correctly associated multi-target ID pairs established in the ground truth;
: Indicates the number of ID pairs incorrectly associated by the tracking algorithm, where the associations do not correspond to true target ID pairs;
: Represents the number of ID pairs missed or incorrectly associated by the multi-view, multi-target tracking algorithm but present in the ground truth;
: Refers to the number of false positives found in the detection process, representing incorrectly identified targets that do not correspond to any actual target;
: Symbolizes the total number of objects present across two views, encompassing all possible targets requiring tracking.
These terms are critical for defining performance metrics and evaluating the effectiveness of tracking algorithms for accurately associating target IDs within scenarios involving UAVs.
4.2. Implementation Details
To validate the effectiveness of the proposed method, the MVTL-UAV algorithm was trained and evaluated on the DIVOTrack dataset. The training was conducted on a platform equipped with two RTX 3090 graphics processing units (GPUs), each with 24 GB of memory. An initial learning rate of 0.0004 was used, with a batch size of eight, and the model was trained over 30 epochs. The model employs DLA-34 [
32] as its backbone network.
4.3. Ablation Experiment
The results presented in
Table 1 are sourced from an ablation study conducted on our proposed method. By progressively incorporating individual improvement modules into the baseline model, each proposed module helps to improve the model’s tracking performance. Although the inclusion of the third module slightly decreases the CVMA metric compared to the baseline model, it effectively enhances the CVIDF1 metric. Moreover, this module has a synergistic effect on optimization when integrated with other modules. The data further reveal that adjusting the temperature coefficient during the inference phase modestly improves cross-view multi-target tracking performance, resulting in optimal CVMA values with neither additional training nor substantial computational overhead. Overall, the experimental results in
Table 1 show that the proposed modules do not adversely affect one another. Instead, the integration of multiple modules yields performance improvements that exceed those of individual modules, resulting in consistent and robust improvements in multi-view target tracking performance.
The Recall metric in the multi-target tracking model quantifies the detector’s performance, highlighting variations in detection capabilities before and after the application of positive and negative reinforcements to the detection loss. As shown in
Figure 6, the model’s overall detection capability improves modestly after implementing offset and regression reinforcement strategies adapted to varying target scales. The calculation process for the Recall metric is outlined as follows:
where true positives (
TP) are instances where the model correctly detects an object, and false negatives (
FN) are instances where the model fails to detect a present object. Prior to using positive–negative reinforcement, the model achieved a Recall of 0.8774, with a
TP of 118,142 and an
FN of 16,502. After implementing positive and negative reinforcement, the model’s recall increased to 0.8809, with a
TP of 118,609 and an
FN of 16,035.
The rationale for employing self-attention reinforcement is to improve feature distinctiveness, enhancing target matching accuracy during multi-view target re-identification. As shown in
Figure 7, the left panel depicts the target identity features before reinforcement in a spectrogram-like format, whereas the right panel showcases the enhanced target identity features in a similar style. Notably, the post-reinforcement features exhibit improved separation and distinctiveness, thereby enabling more effective identity matching among a wide array of visually similar targets.
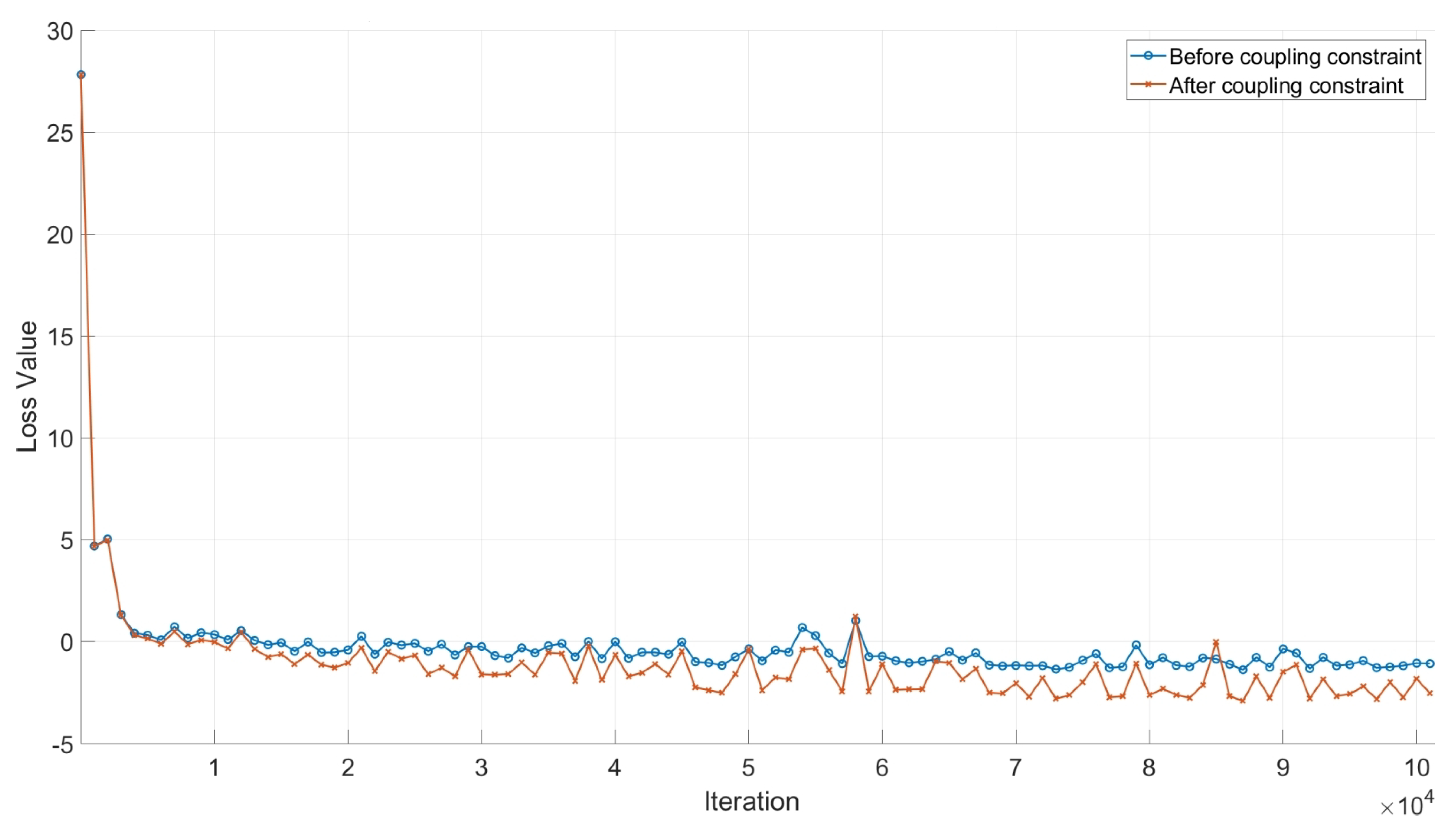
Figure 8 demonstrates that prior to applying the detection and tracking loss coupled constraints, the model’s loss stabilizes in the later stages of training. However, upon introducing the constraints, noticeable fluctuations appear in the loss. These fluctuations suggest the increased sensitivity of the model to data features, implying that the model acquires more complex representations and decision boundaries. This behavior mitigates the risk of the model becoming trapped in local minima and, consequently, improves its generalization capabilities. By addressing the differing emphases of single-view and multi-view re-identification features, coupling the two ensures that the total loss effectively accounts for both scenarios, culminating in enhanced detection, tracking, and re-identification performance.
Figure 9 and
Figure 10 demonstrate that a modest improvement in similarity values for highly similar targets across different views occurred after adjusting the temperature coefficient during the inference phase. Conversely, similarity values for targets with low similarity across various views are systematically reduced. For example, in the fifth rows and third columns of
Figure 9 and
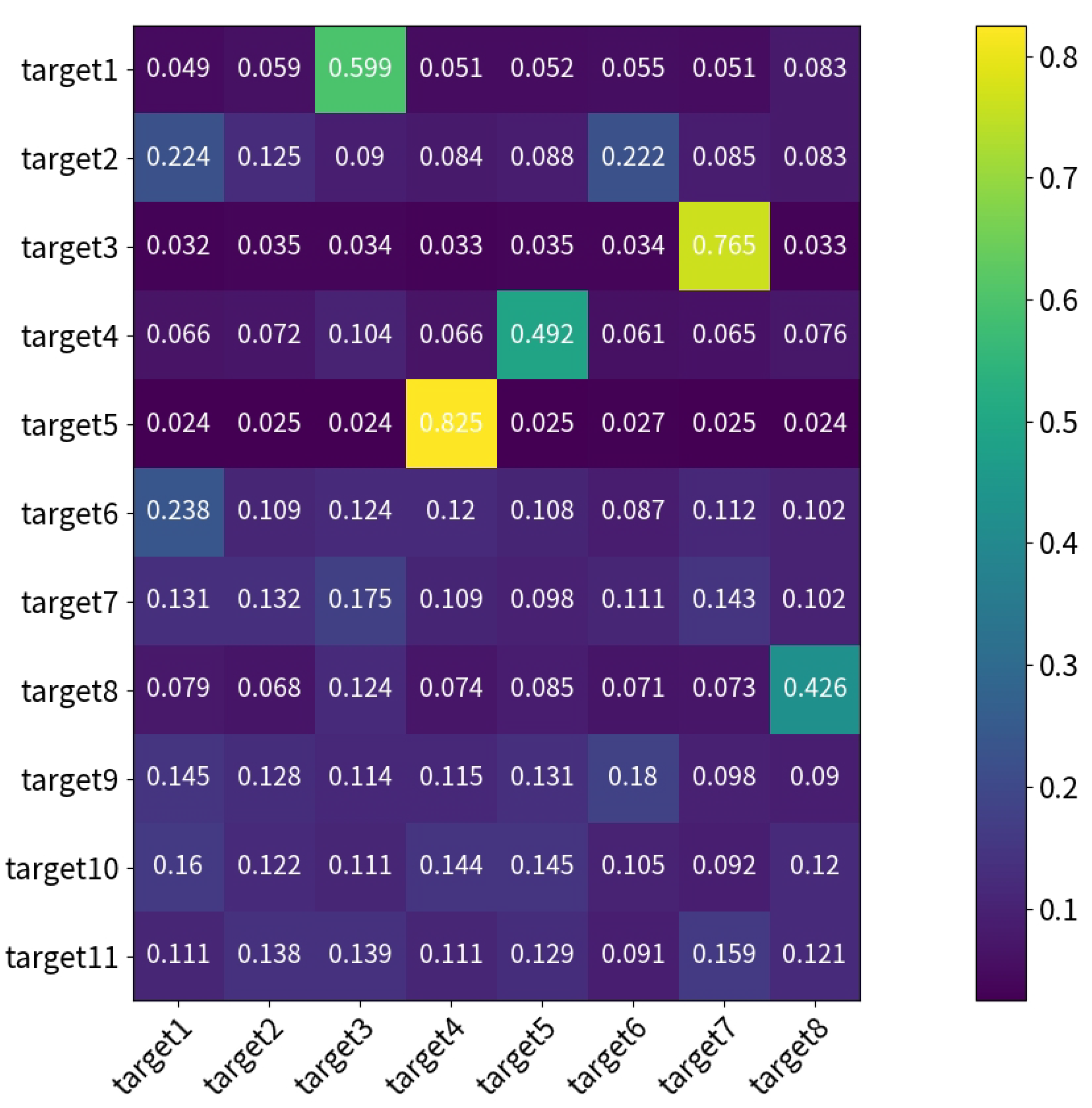
Figure 10, the similarity value of the blue block decreases from 0.024 to 0.022, while the similarity value for the yellow block in the fifth row and fourth columns increases from 0.825 to 0.839. By effectively balancing the amplification of similarities and differences among targets across views, this approach modestly enhances the accuracy of multi-view identity matching.
4.4. Performance Comparison
We trained the improved MVTL-UAV algorithm using the DIVOTrack training set [
10] and evaluated its performance on the DIVOTrack test set; the results are presented in
Table 2 and
Table 3. A detailed analysis of the data in
Table 2 reveals that our proposed MVTL-UAV method achieved the highest CVMA scores in four out of five scenarios and the best CVIDF1 scores in all evaluated scenarios, underscoring the proposed approach’s effectiveness. The performance metrics for the other algorithms listed in
Table 3 are obtained from their respective publications or reproduced using publicly available code. Moreover, as shown in
Table 3, MVTL-UAV outperformed the original CrossMOT algorithm [
10], with a 2.19% improvement in the CVMA metric and a 1.95% improvement in the CVIDF1 metric, establishing a new state-of-the-art benchmark for this dataset.
Furthermore, while the proposed method demonstrates an improvement in tracking performance, the spatiotemporal resources utilized during operation remain largely unchanged compared to the baseline model.
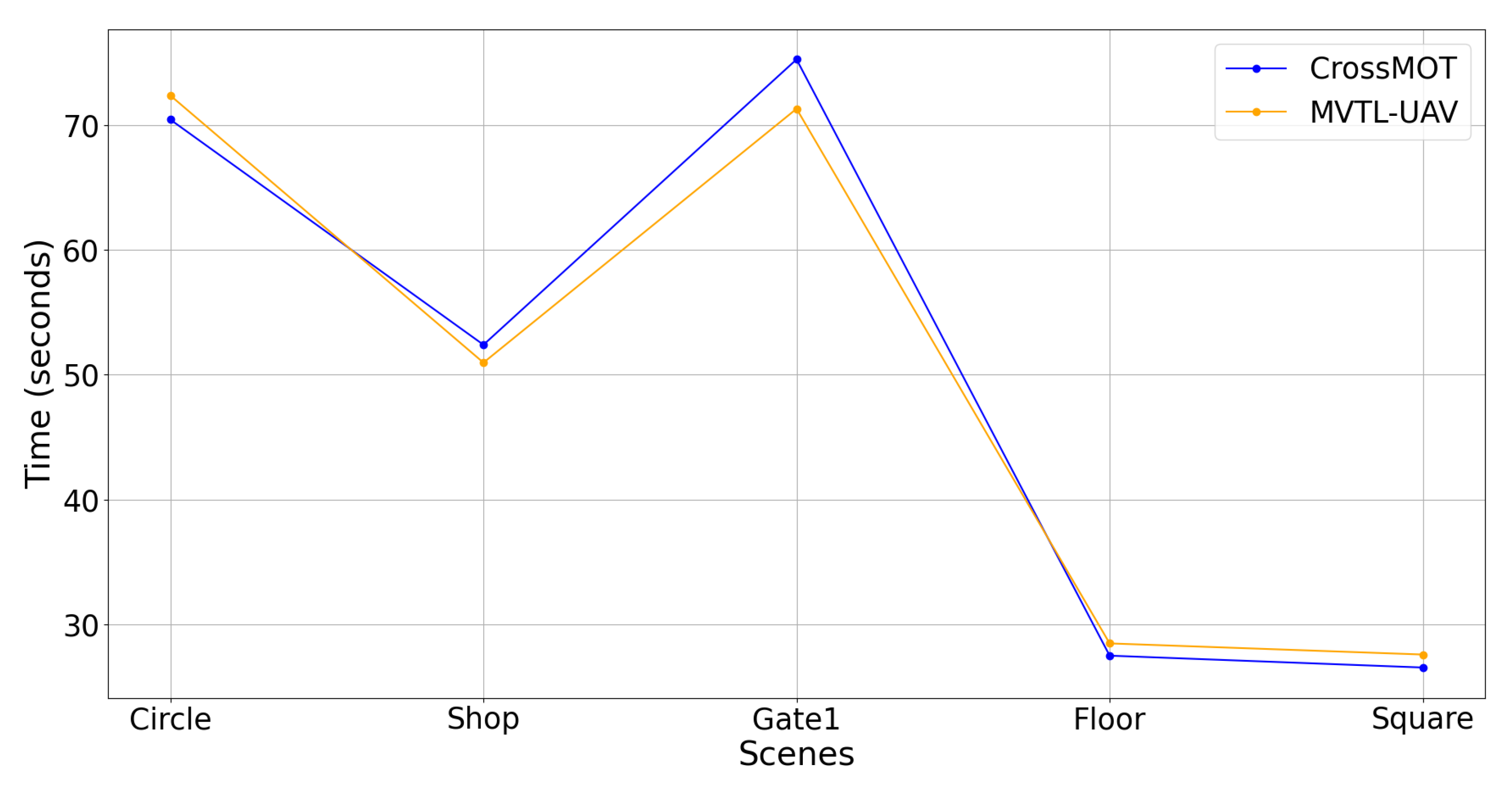
Figure 11 illustrates the tracking time of the two methods across five different scenes, demonstrating that our proposed MVTL-UAV requires slightly less total computation time than CrossMOT. Specifically, the total time taken by our proposed MVTL-UAV to complete the target tracking task in the five scenes is 250.67 s, while CrossMOT requires 252.10 s.
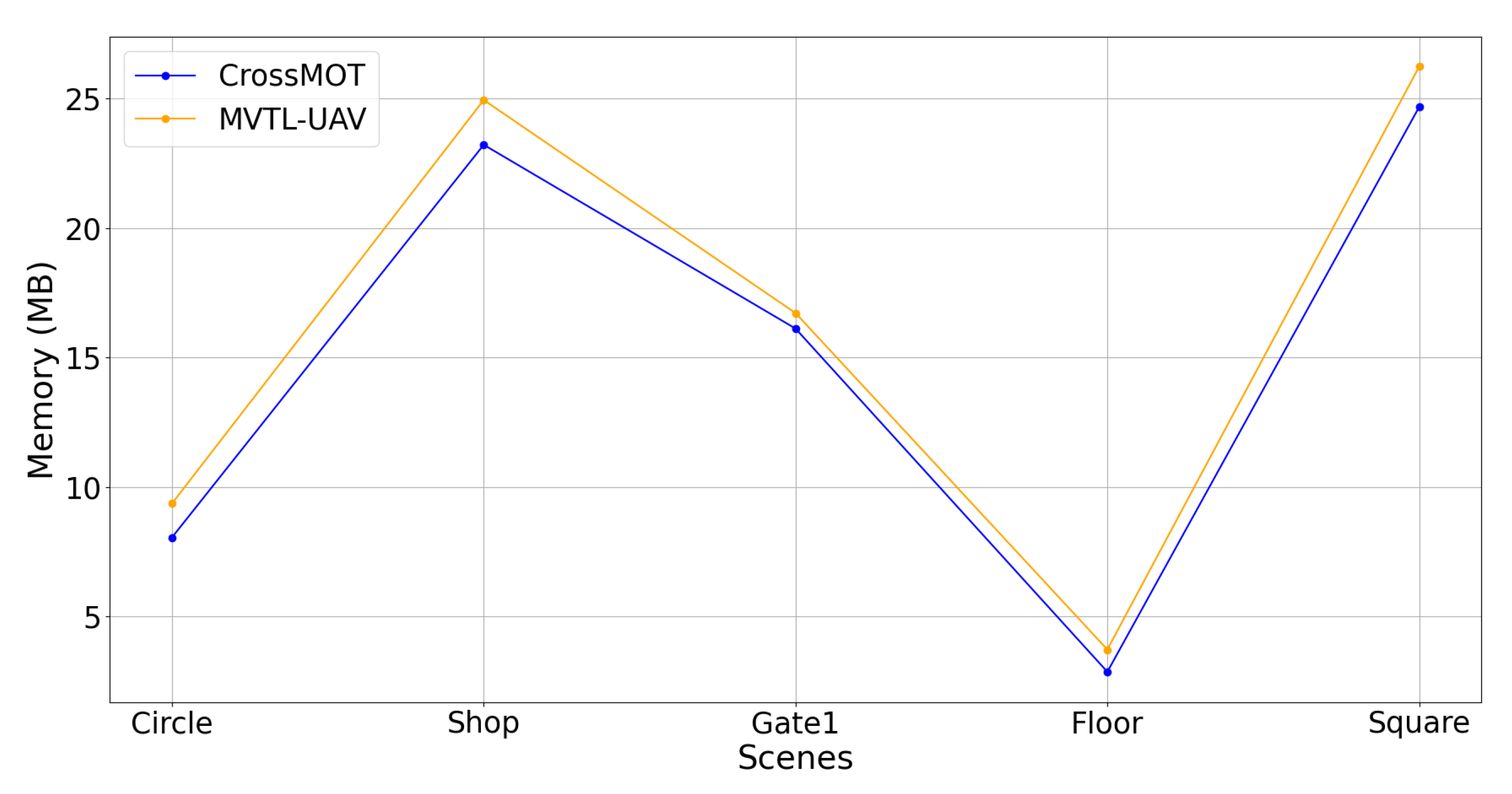
Figure 12 illustrates the random access memory (RAM) usage of the two methods across the five scenes, revealing that our proposed MVTL-UAV requires slightly more RAM compared to CrossMOT in most scenarios while maintaining overall relative stability. Specifically, the total RAM consumption of our proposed MVTL-UAV for completing the target tracking task across the five scenes is 81.00 MB, whereas CrossMOT consumes 74.93 MB. From a comprehensive perspective, the proposed MVTL-UAV framework demonstrates a 1.43-s reduction in total inference time compared to CrossMOT under identical experimental configurations, while showing only a marginal increase in memory footprint of 6.07 MB. Although this improvement may appear marginal at first glance, its cumulative effect could significantly enhance the system’s responsiveness and processing efficiency in high-load processing scenarios. This performance profile underscores its enhanced suitability for deployment on resource-constrained embedded platforms, such as UAV systems, where real-time processing capabilities and computational efficiency are critical operational requirements. From
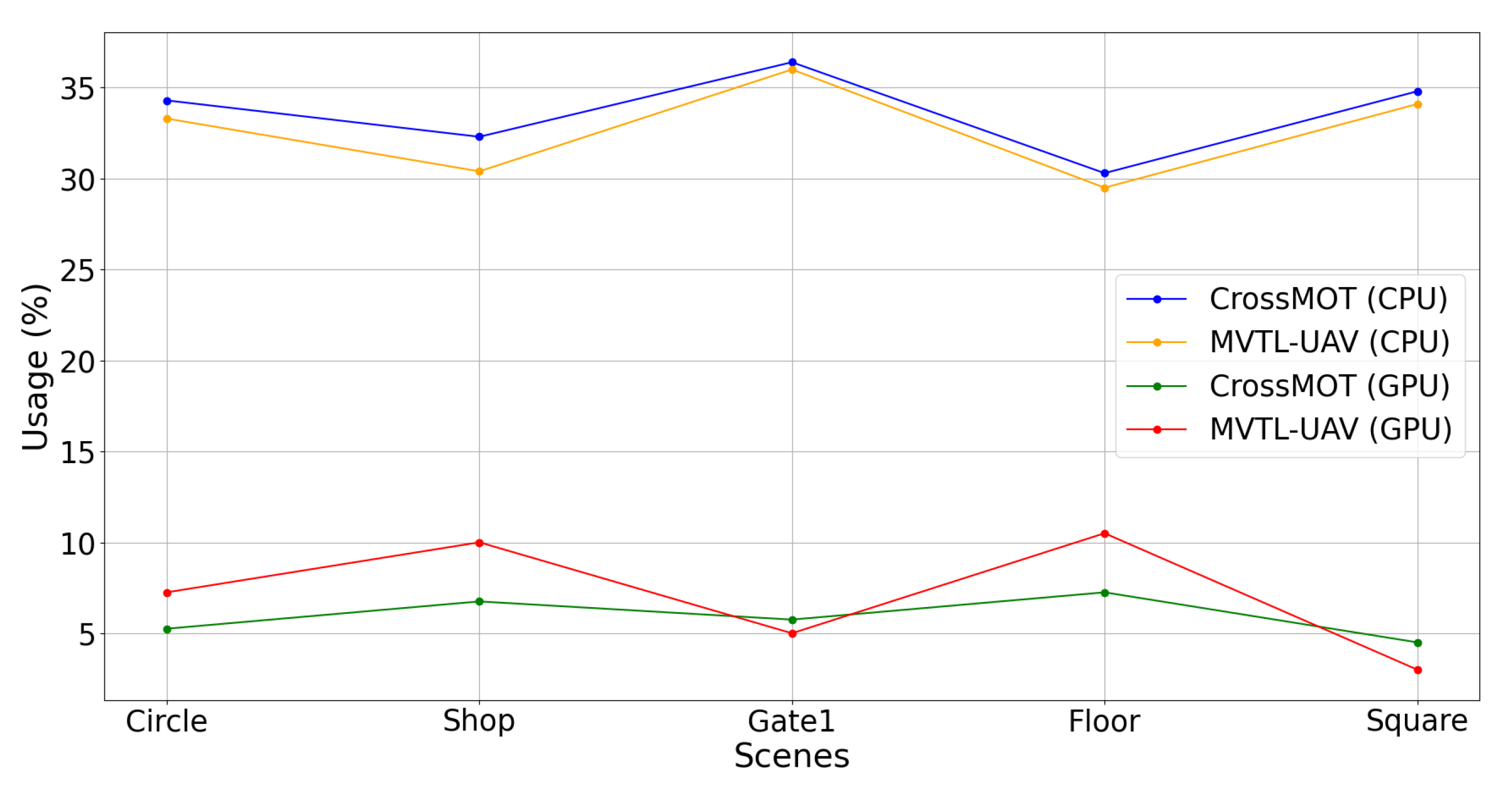
Figure 13, it can be observed that our proposed MVTL-UAV demonstrates lower central processing unit (CPU) utilization compared to the baseline model CrossMOT. Specifically, the average CPU utilization of our proposed MVTL-UAV across five scenarios is 32.66%, whereas CrossMOT shows a CPU utilization of 33.62%. In terms of GPU utilization, our proposed MVTL-UAV performs better in the “Gate1” and “Square” scenarios, while CrossMOT outperforms in the remaining three scenarios. Specifically, the average GPU utilization of our proposed MVTL-UAV across five scenarios is 7.15% compared to CrossMOT’s average GPU utilization of 5.90%. The proposed MVTL-UAV framework demonstrates a strategic computational advantage over CrossMOT by effectively redistributing inference-phase workloads from CPU to GPU architectures. This hardware-aware optimization enhances the utilization of specialized parallel computing units (GPUs), thereby reducing aggregate system power consumption and achieving a higher energy efficiency ratio (EER). This approach ensures real-time performance for critical tasks such as UAV flight control and communication links, effectively preventing system lag or loss of control due to CPU overload. In summary, the analysis indicates that the method proposed in this study achieves a modest improvement in target tracking performance compared to the baseline model while incurring virtually no additional resource costs, and more importantly, demonstrates enhanced applicability in scenarios requiring strict real-time constraints for target tracking algorithms.
4.5. Visualization
As illustrated in
Figure 14, we visually demonstrate the tracking results achieved by the MVTL-UAV model proposed in this study, offering an intuitive depiction of its advancements. This evaluation utilizes a widely recognized multi-view, multi-target tracking dataset specifically designed for low-altitude scenarios. The sections highlighted by yellow arrows in the figure clearly illustrate that our MVTL-UAV model successfully maintains identity associations for the same target across multiple views, mitigating tracking errors caused by occlusions. In
Figure 14, CrossMOT fails to detect the occluded target indicated by the yellow arrow in image (b) and does not correctly associate the same target in images (a) and (c). Conversely, MVTL-UAV not only accurately detects the occluded target but also establishes precise identity associations across all three viewpoints in images (d), (e), and (f). In summary, the proposed method effectively addresses challenges related to occlusion-induced detection failures and errors in cross-view identity association, modestly improving performance in low-altitude multi-target tracking scenarios. Given that the model can accurately detect and track small targets or partially occluded objects from various perspectives, the requirements for input image resolution and frame rate can be moderately relaxed, thereby effectively reducing the consumption of sensor resources.
5. Discussion
The obtained experimental results demonstrate that our method achieves moderately improved performance in detecting and tracking occluded targets compared to existing models. This improvement is attributed to our emphasis on the loss function’s contribution for small targets during model training, which enhances the model’s capability to perform multi-view tracking of partially occluded targets. Furthermore, during the inference phase, the refinement of temperature coefficient calculation improves discrimination among visually similar targets, increasing the effectiveness of the target identity-matching cost matrix. This ultimately guarantees the precise association of target identities across views. Meanwhile, the innovative strategies introduced in this study primarily focused on the optimization of training loss and the enhancement of inference coefficients. Consequently, these strategies can be readily adapted to other frameworks without incurring additional computational and storage resource demands, thereby demonstrating meaningful practical value.
Given the computational power limitations and energy consumption constraints of drone-based computing platforms, as well as to address the inherent complexity of multi-view and multi-target tracking tasks, our future studies will focus on accelerating the inference process of the trained deep model. This optimization aims to ensure its seamless integration on cloud servers or ground control stations. Subsequently, we will implement single-view visual algorithms on each drone platform to enable the transmission of detection and tracking results along with multiple video data streams to the algorithm introduced in this study. To build on this, and consider the application of visual algorithms in real tracking tasks involving UAVs, we can integrate the collaborative decision-making and control methods from [
41,
42]. By doing this, we aim to develop a comprehensive perception–decision–control system for multi-target tracking in low-altitude environments.
6. Conclusions
This study presents an end-to-end model for multi-view visual tracking of multiple targets in low-altitude environments involving UAVs. The proposed approach focuses on loss optimization and inference coefficient refinement to enhance model performance. Initially, the components of the detection loss—namely, offset and size—are optimized by integrating positive and negative correlations that are tailored to the target’s scale. This reinforcement improves the model’s capability to effectively handle a variety of object sizes. Subsequently, the cross-view re-identification features of targets are enhanced through self-attention mechanisms, which effectively highlight unique target features. To ensure alignment between the detection and re-identification tasks, coupled constraints are imposed on their respective loss components, ensuring a coherent optimization trajectory throughout the model. Moreover, during the inference phase, target similarity is incorporated into the temperature coefficient, enhancing the model’s ability to distinguish between highly similar targets. Extensive experiments conducted on the DIVOTrack dataset have substantiated the superiority of the proposed method, emphasizing its potential to enhance joint visual tracking in UAV systems characterized by stringent real-time requirements, all while avoiding additional resource overhead. Consequently, this advancement modestly improves the feasibility of deploying robust visual algorithms on resource-constrained UAV platforms. In future research, we will continue to expand and enhance our methods by exploring a more diverse range of observation perspectives and more complex application scenarios.
Author Contributions
Conceptualization, P.W.; methodology, P.W.; software, P.W.; validation, Y.L. and Z.L.; formal analysis, P.W. and Y.L.; investigation, X.Y. and D.X.; resources, D.X.; data curation, Y.L.; writing—original draft preparation, P.W.; writing—review and editing, P.W.; visualization, Y.L.; supervision, D.X.; project administration, P.W. and D.X.; funding acquisition, D.X. All authors have read and agreed to the published version of this manuscript.
Funding
This study is supported by the National Natural Science Foundation of China under Grant 11902103.
Data Availability Statement
The original contributions presented in this study are included in this article; further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Q.; Yang, Y.; Wei, X.; Wang, P.; Jiao, B.; Zhang, Y. Person re-identification in aerial imagery. IEEE Trans. Multimed. 2020, 23, 281–291. [Google Scholar] [CrossRef]
- Teng, S.; Zhang, S.; Huang, Q.; Sebe, N. Viewpoint and scale consistency reinforcement for UAV vehicle re-identification. Int. J. Comput. Vis. 2021, 129, 719–735. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, K.; Sridharan, S.; Fookes, C. AG-ReID.v2: Bridging Aerial and Ground Views for Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2024, 19, 2896–2908. [Google Scholar] [CrossRef]
- Pan, T.; Dong, H.; Deng, B.; Gui, J.; Zhao, B. Robust Cross-Drone Multi-Target Association Using 3D Spatial Consistency. IEEE Signal Process. Lett. 2024, 31, 71–75. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics; Springer International Publishing: Cham, Switzerland, 2018; pp. 621–635. [Google Scholar] [CrossRef]
- Shen, H.; Lin, D.; Yang, X.; He, S. Vision-Based Multiobject Tracking Through UAV Swarm. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Shen, H.; Yang, X.; Lin, D.; Chai, J.; Huo, J.; Xing, X.; He, S. A benchmark for vision-based multi-UAV multi-object tracking. In Proceedings of the 2022 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Bedford, UK, 20–22 September 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Han, R.; Gan, Y.; Li, J.; Wang, F.; Feng, W.; Wang, S. Connecting the complementary-view videos: Joint camera identification and subject association. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2416–2425. [Google Scholar] [CrossRef]
- Hao, S.; Liu, P.; Zhan, Y.; Jin, K.; Liu, Z.; Song, M.; Hwang, J.N.; Wang, G. DIVOTrack: A novel dataset and baseline method for cross-view multi-object tracking in diverse open scenes. Int. J. Comput. Vis. 2024, 132, 1075–1090. [Google Scholar] [CrossRef]
- Liu, Z.; Shang, Y.; Li, T.; Chen, G.; Wang, Y.; Hu, Q.; Zhu, P. Robust multi-drone multi-target tracking to resolve target occlusion: A benchmark. IEEE Trans. Multimed. 2023, 25, 1462–1476. [Google Scholar] [CrossRef]
- Zhu, P.; Zheng, J.; Du, D.; Wen, L.; Sun, Y.; Hu, Q. Multi-drone-based single object tracking with agent sharing network. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 4058–4070. [Google Scholar] [CrossRef]
- Chen, G.; Zhu, P.; Cao, B.; Wang, X.; Hu, Q. Cross-drone transformer network for robust single object tracking. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4552–4563. [Google Scholar] [CrossRef]
- Xue, Y.; Jin, G.; Shen, T.; Tan, L.; Wang, N.; Gao, J.; Wang, L. Consistent Representation Mining for Multi-Drone Single Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10845–10859. [Google Scholar] [CrossRef]
- Fan, H.; Zhao, T.; Wang, Q.; Fan, B.; Tang, Y.; Liu, L. GMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking. arXiv 2024, arXiv:2407.01007. [Google Scholar] [CrossRef]
- Han, R.; Feng, W.; Zhang, Y.; Zhao, J.; Wang, S. Multiple human association and tracking from egocentric and complementary top views. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5225–5242. [Google Scholar] [CrossRef]
- Han, R.; Feng, W.; Wang, F.; Qian, Z.; Yan, H.; Wang, S. Benchmarking the complementary-view multi-human association and tracking. Int. J. Comput. Vis. 2024, 132, 118–136. [Google Scholar] [CrossRef]
- Chen, G.; Wang, W.; He, Z.; Wang, L.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-MOT2021: The vision meets drone multiple object tracking challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2839–2846. [Google Scholar] [CrossRef]
- Pan, S.; Tong, Z.; Zhao, Y.; Zhao, Z.; Su, F.; Zhuang, B. Multi-object tracking hierarchically in visual data taken from drones. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Stadler, D.; Sommer, L.W.; Beyerer, J. PAS Tracker: Position-, appearance-and size-aware multi-object tracking in drone videos. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 604–620. [Google Scholar] [CrossRef]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, J. GIAOTracker: A comprehensive framework for mcmot with global information and optimizing strategies in visdrone 2021. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2809–2819. [Google Scholar] [CrossRef]
- Liu, S.; Li, X.; Lu, H.; He, Y. Multi-object tracking meets moving UAV. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8876–8885. [Google Scholar] [CrossRef]
- Wang, P.; Wang, Y.; Li, D. DroneMOT: Drone-based Multi-Object Tracking Considering Detection Difficulties and Simultaneous Moving of Drones and Objects. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 7397–7404. [Google Scholar] [CrossRef]
- Ji, D.; Gao, S.; Zhu, L.; Zhu, Q.; Zhao, Y.; Xu, P.; Lu, H.; Zhao, F.; Ye, J. View-centric multi-object tracking with homographic matching in moving uav. arXiv 2024, arXiv:2403.10830. [Google Scholar] [CrossRef]
- Zeng, F.; Dong, B.; Zhang, Y.; Wang, T.; Zhang, X.; Wei, Y. MOTR: End-to-end multiple-object tracking with transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 659–675. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, T.; Zhang, X. MOTRv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22056–22065. [Google Scholar] [CrossRef]
- Zheng, G.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Gao, R.; Wang, L. MeMOTR: Long-term memory-augmented transformer for multi-object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 9901–9910. [Google Scholar] [CrossRef]
- Li, R.; Zhang, B.; Teng, Z.; Fan, J. An end-to-end identity association network based on geometry refinement for multi-object tracking. Pattern Recognit. 2022, 129, 108738. [Google Scholar] [CrossRef]
- Cao, W.; Wang, X.; Liu, X.; Xu, Y. A deep learning framework for multi-object tracking in team sports videos. IET Comput. Vis. 2024, 18, 574–590. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Gan, Y.; Han, R.; Yin, L.; Feng, W.; Wang, S. Self-supervised multi-view multi-human association and tracking. In Proceedings of the 29th ACM International Conference on Multimedia (MM ’21), Virtual Event, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 282–290. [Google Scholar] [CrossRef]
- Han, R.; Feng, W.; Zhao, J.; Niu, Z.; Zhang, Y.; Wan, L.; Wang, S. Complementary-view multiple human tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10917–10924. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar] [CrossRef]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Wieczorek, M.; Rychalska, B.; Dąbrowski, J. On the unreasonable effectiveness of centroids in image retrieval. In Proceedings of the Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Proceedings, Part IV 28. Springer: Berlin/Heidelberg, Germany, 2021; pp. 212–223. [Google Scholar] [CrossRef]
- Memon, S.A.; Son, H.; Kim, W.G.; Khan, A.M.; Shahzad, M.; Khan, U. Tracking Multiple Unmanned Aerial Vehicles through Occlusion in Low-Altitude Airspace. Drones 2023, 7, 241. [Google Scholar] [CrossRef]
- Memon, S.A.; Kim, W.G.; Khan, S.U.; Memon, T.D.; Alsaleem, F.N.; Alhassoon, K.; Alsunaydih, F.N. Tracking Multiple Autonomous Ground Vehicles Using Motion Capture System Operating in a Wireless Network. IEEE Access 2024, 12, 61780–61794. [Google Scholar] [CrossRef]
Figure 1.
The key innovative modules of the proposed MVTL-UAV.
Figure 1.
The key innovative modules of the proposed MVTL-UAV.
Figure 2.
The output branch of the multi-view, multi-target tracking network model.
Figure 2.
The output branch of the multi-view, multi-target tracking network model.
Figure 3.
An illustration of self-attention reinforcement in re-identification features.
Figure 3.
An illustration of self-attention reinforcement in re-identification features.
Figure 4.
Appearance transformation of targets across and within views.
Figure 4.
Appearance transformation of targets across and within views.
Figure 5.
The variation in the softmax function curve with different temperature coefficients.
Figure 5.
The variation in the softmax function curve with different temperature coefficients.
Figure 6.
Comparison of recall metrics before and after applying positive and negative reinforcement.
Figure 6.
Comparison of recall metrics before and after applying positive and negative reinforcement.
Figure 7.
The amplitude spectra of the target appearance features before and after applying self-attention reinforcement.
Figure 7.
The amplitude spectra of the target appearance features before and after applying self-attention reinforcement.
Figure 8.
Loss variation curves showing how coupling detection and tracking losses influence model optimization.
Figure 8.
Loss variation curves showing how coupling detection and tracking losses influence model optimization.
Figure 9.
The cross-view multi-target correlation heatmap before improving the temperature coefficient.
Figure 9.
The cross-view multi-target correlation heatmap before improving the temperature coefficient.
Figure 10.
The cross-view multi-target correlation heatmap after improving the temperature coefficient.
Figure 10.
The cross-view multi-target correlation heatmap after improving the temperature coefficient.
Figure 11.
Comparison of tracking time for CrossMOT and MVTL-UAV in different scenes.
Figure 11.
Comparison of tracking time for CrossMOT and MVTL-UAV in different scenes.
Figure 12.
Comparison of required memory space for CrossMOT and MVTL-UAV in different scenes.
Figure 12.
Comparison of required memory space for CrossMOT and MVTL-UAV in different scenes.
Figure 13.
Comparison of CPU and GPU resource utilization rates between CrossMOT and MVTL-UAV under different scenarios.
Figure 13.
Comparison of CPU and GPU resource utilization rates between CrossMOT and MVTL-UAV under different scenarios.
Figure 14.
The proposed method’s tracking performance evaluated against the baseline algorithms on frame 58 of the DIVOTrack test set. The red check mark indicates that the corresponding target has been successfully detected and correctly matched, while the red cross signifies that the corresponding target was not successfully detected or was mismatched.
Figure 14.
The proposed method’s tracking performance evaluated against the baseline algorithms on frame 58 of the DIVOTrack test set. The red check mark indicates that the corresponding target has been successfully detected and correctly matched, while the red cross signifies that the corresponding target was not successfully detected or was mismatched.
Table 1.
An ablation study on the DIVOTrack benchmark. Bold entries indicate the best metric values. The numbers 1, 2, 3, and 4 correspond to the four innovative modules described in
Section 3.
Table 1.
An ablation study on the DIVOTrack benchmark. Bold entries indicate the best metric values. The numbers 1, 2, 3, and 4 correspond to the four innovative modules described in
Section 3.
| Method | CVMA↑(%) | CVIDF1↑(%) |
|---|
| Baseline [10] | 70.22 | 71.36 |
| +1 | 70.56 | 72.99 |
| +2 | 71.27 | 72.05 |
| +3 | 70.53 | 72.09 |
| +4 | 71.55 | 72.15 |
| +23 | 71.60 | 72.14 |
| +123 | 71.35 | 72.73 |
| +1234 | 72.41 | 73.31 |
Table 2.
A comparison of tracking performances for various scenarios on the DIVOTrack test benchmark. CA denotes CVMA, and C1 denotes CVIDF1.
Table 2.
A comparison of tracking performances for various scenarios on the DIVOTrack test benchmark. CA denotes CVMA, and C1 denotes CVIDF1.
| Scenario | CrossMOT(CA) | MVTL-UAV(CA) | CrossMOT(C1) | MVTL-UAV(C1) |
|---|
| Circle | 71.39 | 75.24 | 72.95 | 74.19 |
| Gate1 | 76.60 | 79.58 | 84.39 | 85.00 |
| Shop | 66.02 | 67.56 | 56.74 | 58.67 |
| Square | 64.86 | 63.97 | 70.97 | 76.48 |
| Floor | 72.23 | 75.70 | 71.75 | 72.21 |
Table 3.
The results of different trackers on the DIVOTrack test benchmark. Bold entries indicate the best metric values.
Table 3.
The results of different trackers on the DIVOTrack test benchmark. Bold entries indicate the best metric values.
| Method | Year | Journal (Conference) | CVMA↑(%) | CVIDF1↑(%) |
|---|
| OSNet [37] | 2019 | ICCV | 34.30 | 46.00 |
| Strong [38] | 2019 | CVPRW | 40.90 | 45.80 |
| AGW [39] | 2021 | TPAMI | 57.00 | 56.80 |
| MvMHAT [35] | 2021 | TPAMI | 61.10 | 62.60 |
| CT [40] | 2021 | JGRP | 64.90 | 65.00 |
| CrossMOT [10] | 2023 | IJCV | 70.22 | 71.36 |
| MVTL-UAV (Ours) | 2024 | - | 72.41 | 73.31 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}