
Research on Swarm Control Based on Complementary Collaboration of Unmanned Aerial Vehicle Swarms Under Complex Conditions


Abstract
1. Introduction
- A self-adaptive behavior matching based on dual-layer imitation learning was proposed to enhance the formation collaboration capability of UAV swarm. Unlike traditional multi-objective optimization, this method combines implicit and explicit alignment processes to make full use of expert knowledge by dynamically balancing policy search so that policy generation can better balance multiple objectives, which in turn improves the understanding and imitation of formation behavior by student networks. In the process of behavior allocation, it adopts an adaptive feature embedding mechanism to ensure that the agents are flexibly divided according to their respective capabilities in the swarm formation, giving full play to the collaborative advantages of each UAV in the swarm formation. This method can effectively mitigate the nonlinear coupling effect induced by heterogeneity and enhance the mission execution capability in complex environments.
- A behavior learning based on cognitive dissonance optimization was designed, aiming to improve the behavior learning efficiency of multi-agent under complex conditions by balancing individual cognitive dissonance loss and team cognitive dissonance loss. This method, combined with the individual behaviors assigned to each agent in the behavior allocation phase, is conducive to give full play to the overall advantages of UAV swarm formation, strengthen the complementary capabilities between platforms, effectively mitigate the decision-making miscalculation caused by the inconsistency of adjustment and feedback of the differentiated formation model, meet the collaborative decision-making needs of UAV swarm in complex environments, and ultimately realize the highly efficient collaborative control of the swarm.
2. Related Work
3. UAV Swarm Control Methods Under Complex Conditions
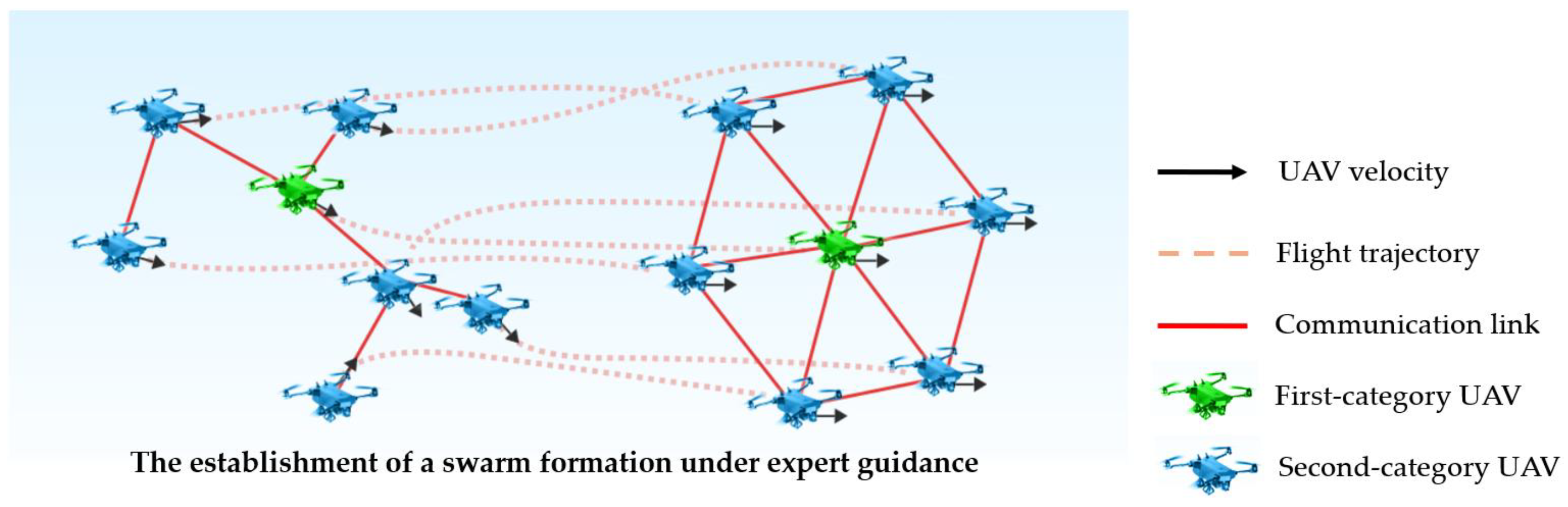
3.1. Problem Statement
3.2. Problem Modeling and Analysis
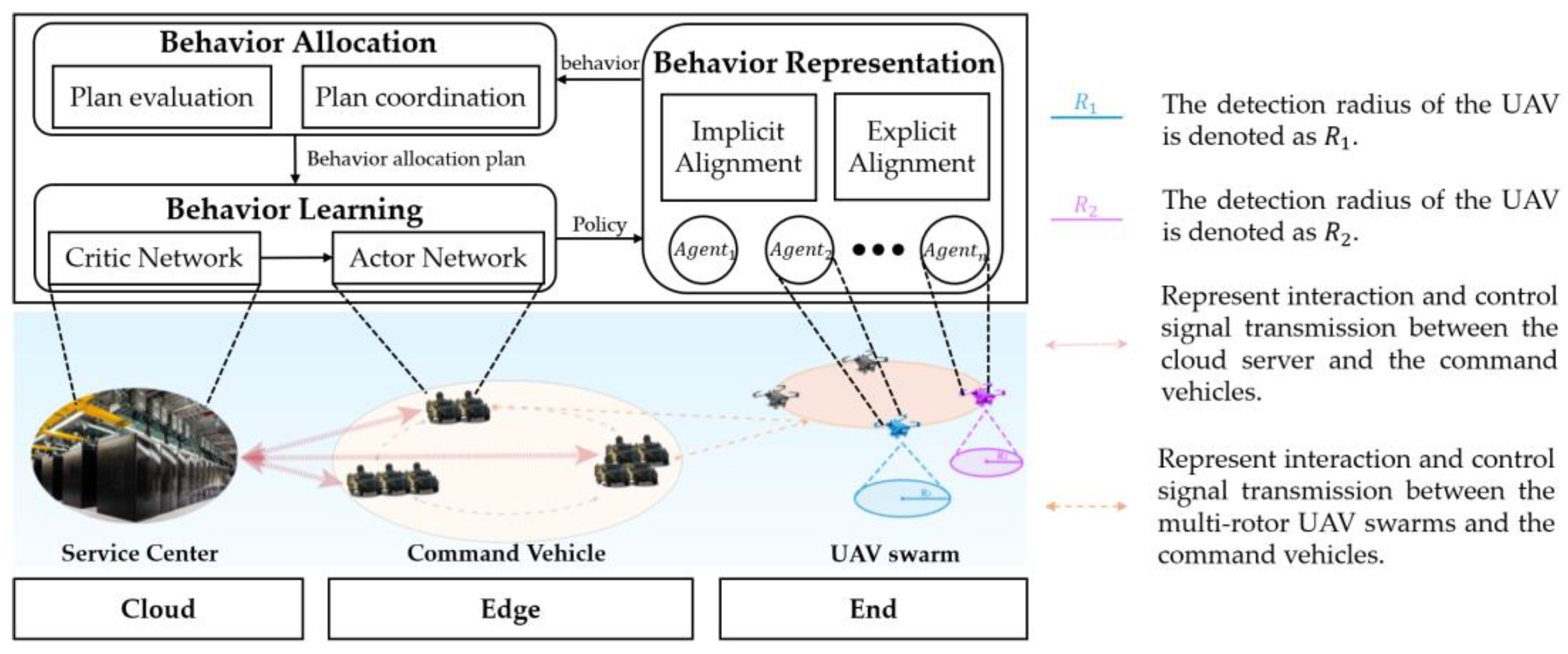
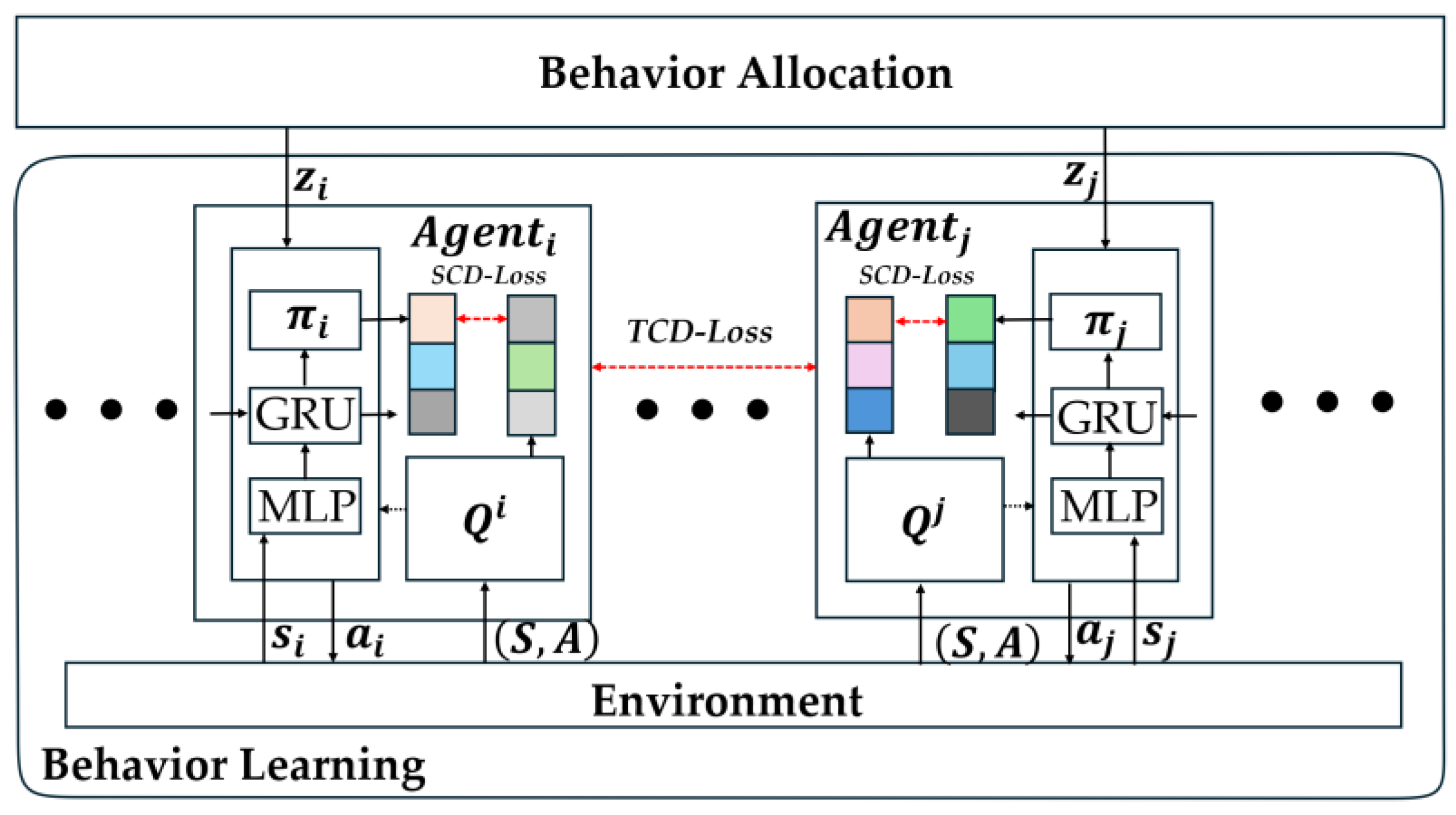
3.3. System Structure
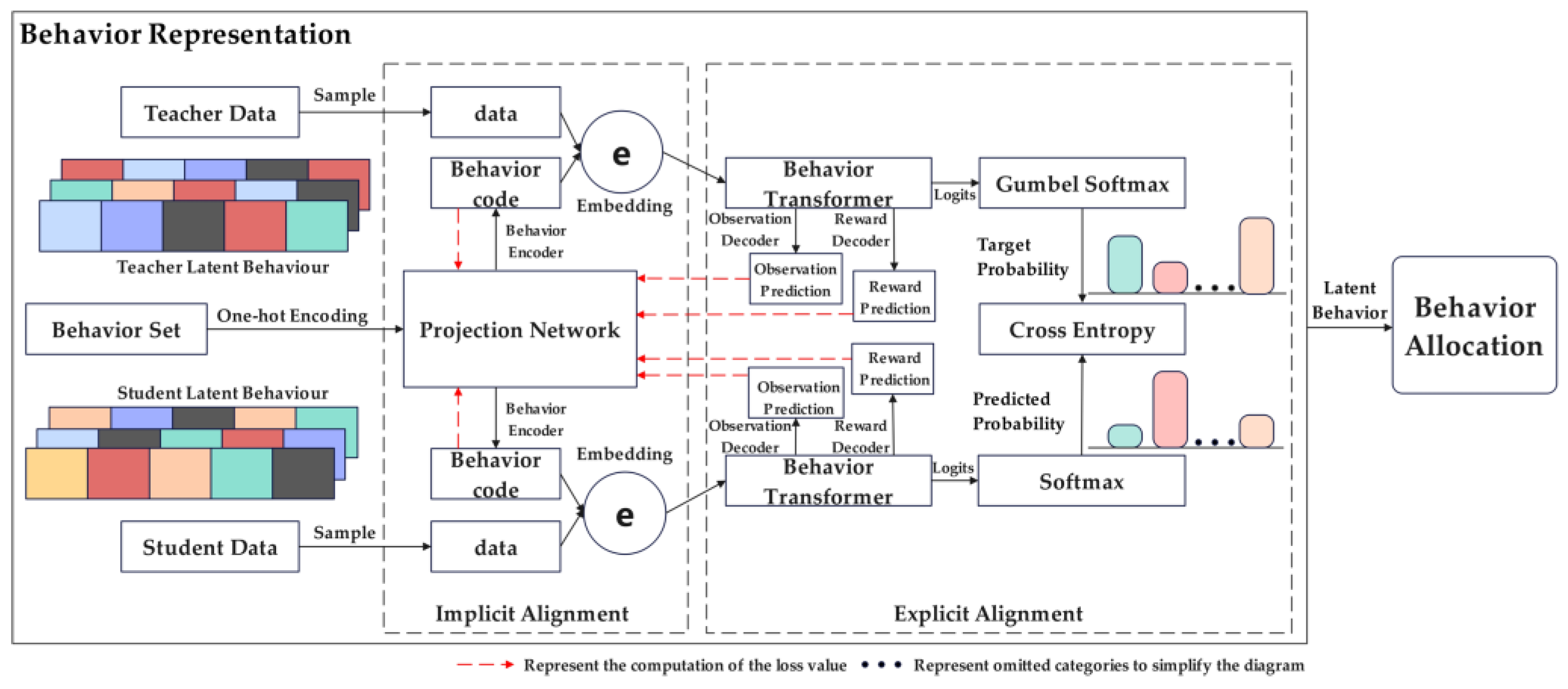
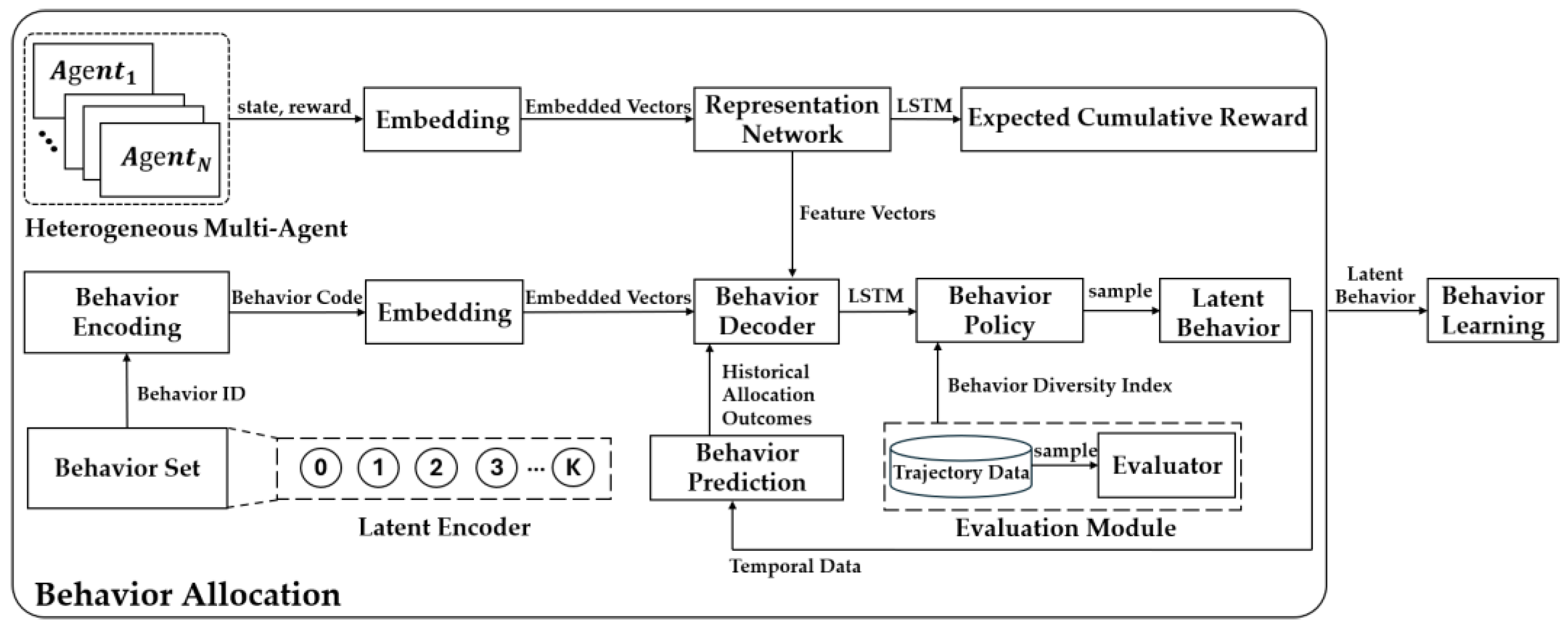
3.4. Adaptive Behavior Matching Based on Dual-Layer Imitation Learning
3.5. Behavior Learning Based on Cognitive Dissonance Optimization
3.6. Algorithm Pseudo-Code
| Algorithm 1. Formation control decision-making method for Hybrid UAV swarm. |
| function EdgeServer (): Compute swarm latent behavioral variables by the teacher and student datasets. with respect to Equation (5) for to max_episode do env.reset() for to train_steps_limits do Collect global state and agents’ partial observations from environments if − mod Sample skills . with respect to Equation (6) For each agent , choose action , then extract the global action feature in environments Concatenate into Take into UAV swarm graph and get , and save state-action history Compute reward value for each drone Store in replay buffer = CloudServer () return based on policy ray.init(address=CloudServer_config[‘cloud_node_ip_address’] @ray.remote function CloudServer (D): if || > batch_size then for to do Sample minibatch from ; Generate flight state information Update by minimizing . with respect to Equation (7) Update by minimizing . with respect to Equation (8) Update policy network return |
4. Experimental Analysis
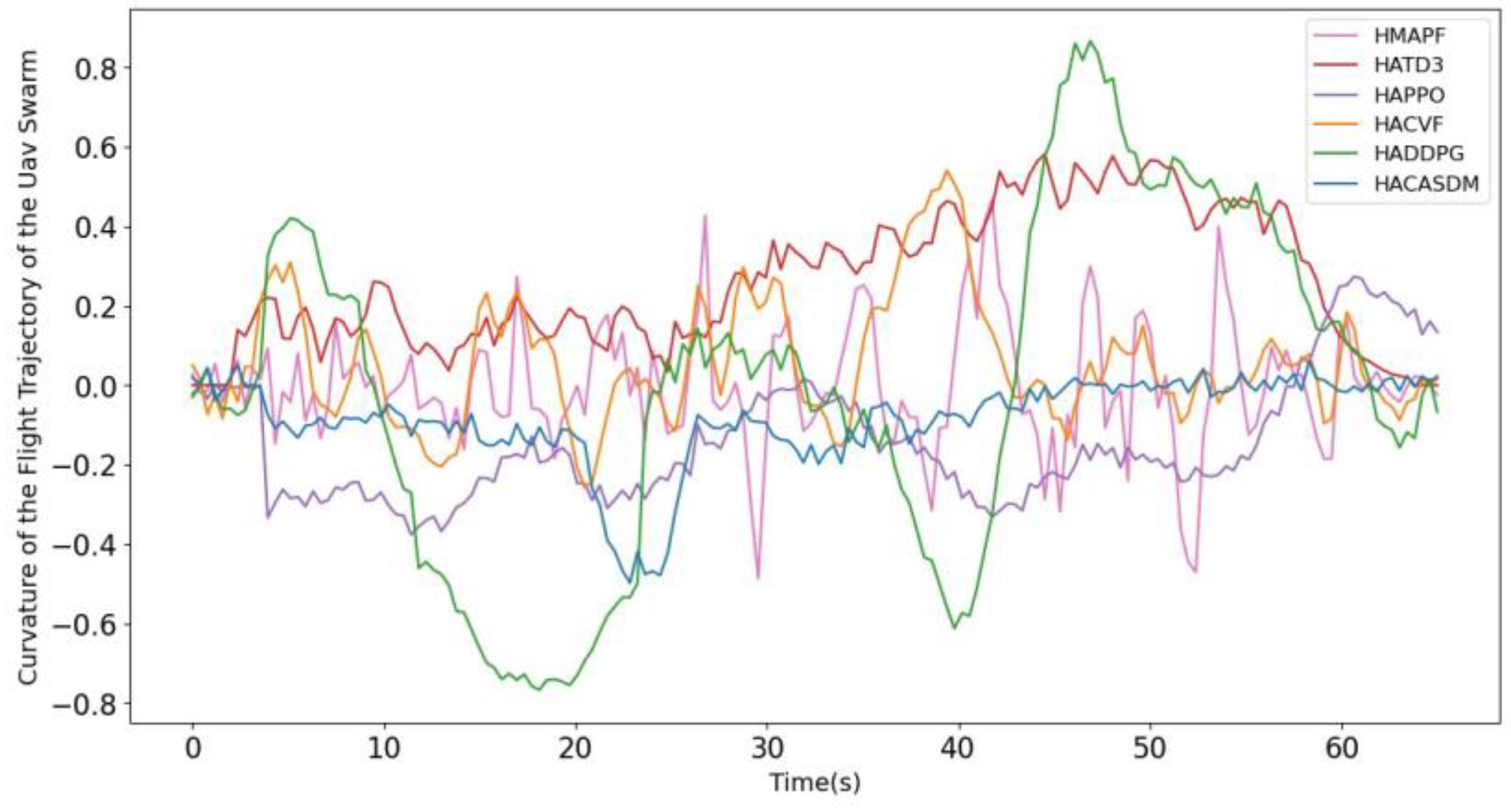
- Formation stability: To evaluate the relative position and attitude stability of various types of UAVs in a UAV swarm, it needs to take into account the differences in the flight characteristics and other aspects of different types of UAVs, which are measured by the position deviation and attitude deviation to ensure that the swarm remains smooth and steady during flight.
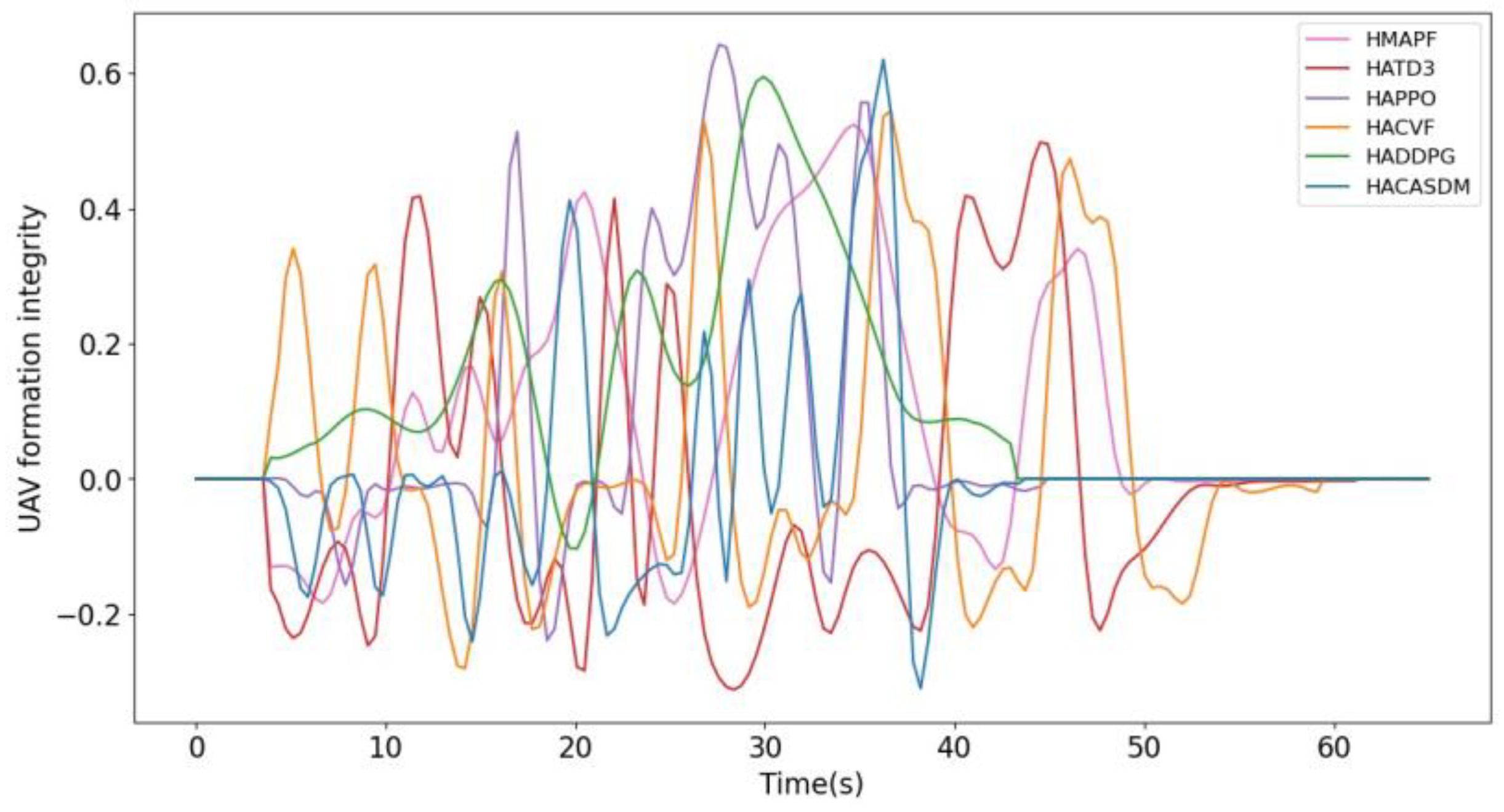
- Formation integrity: It is used to evaluate the formation integrity of the UAV swarm during flight, aiming to ensure that when it encounters interference from the external environment, the various types of UAVs in the swarm can still maintain the overall formation, so as to collaborate in accomplishing the mission and improve the execution efficiency.
4.1. Experimental Setup
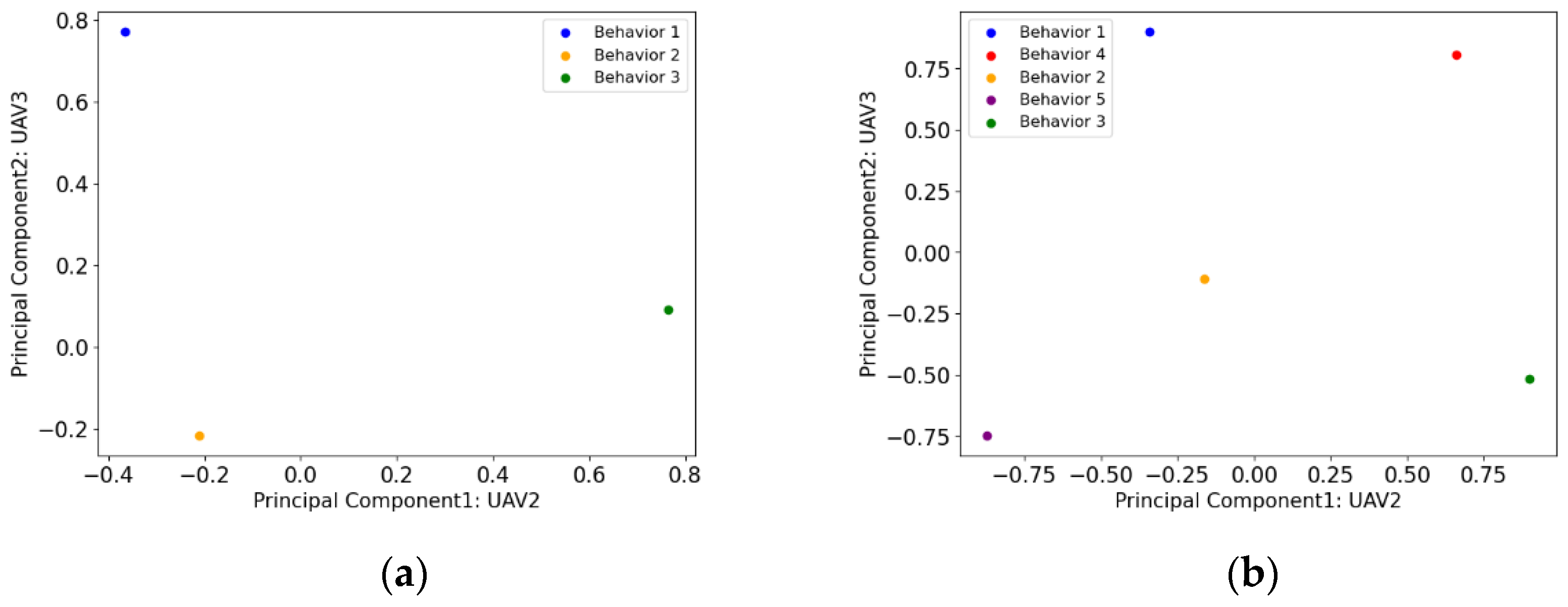
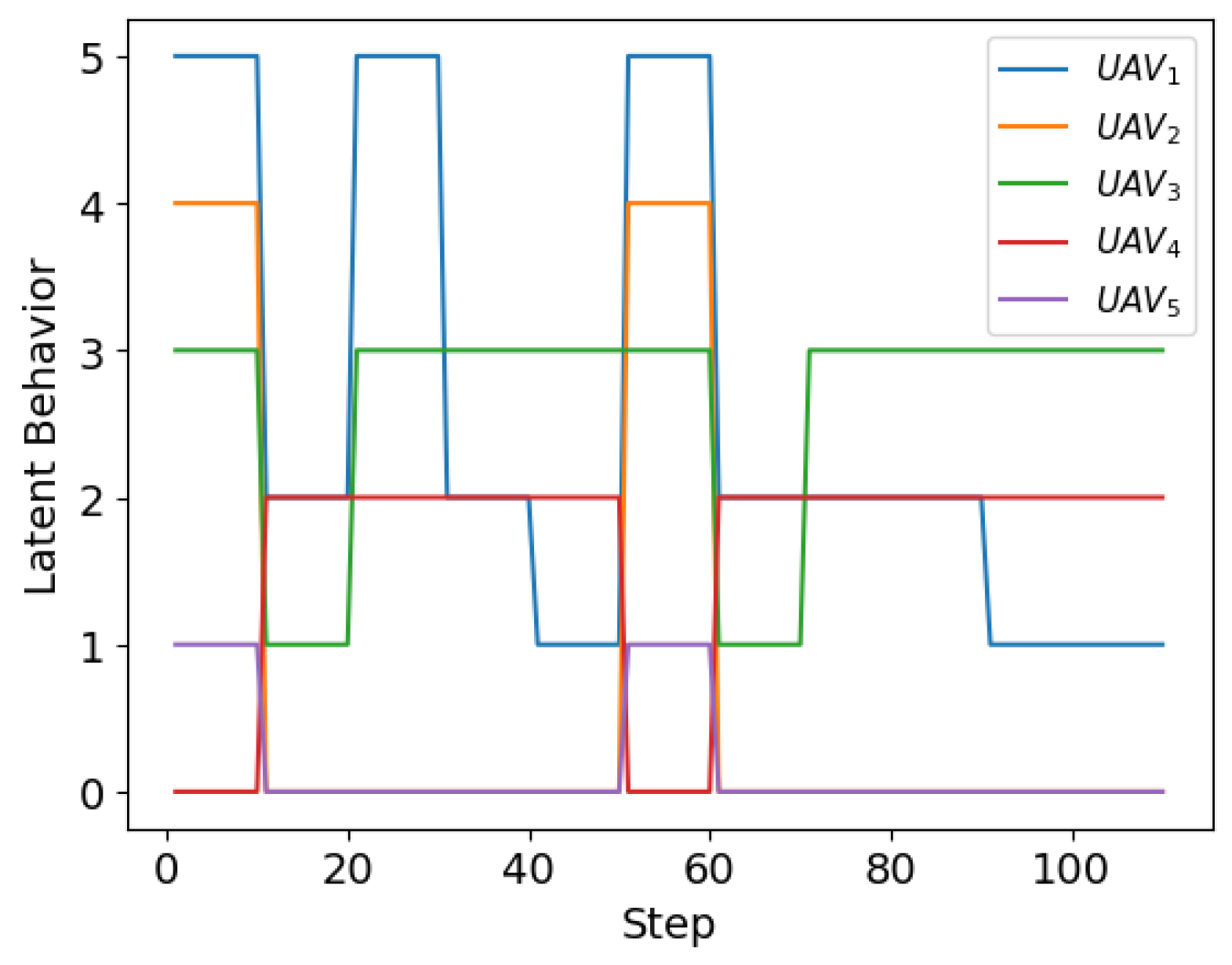
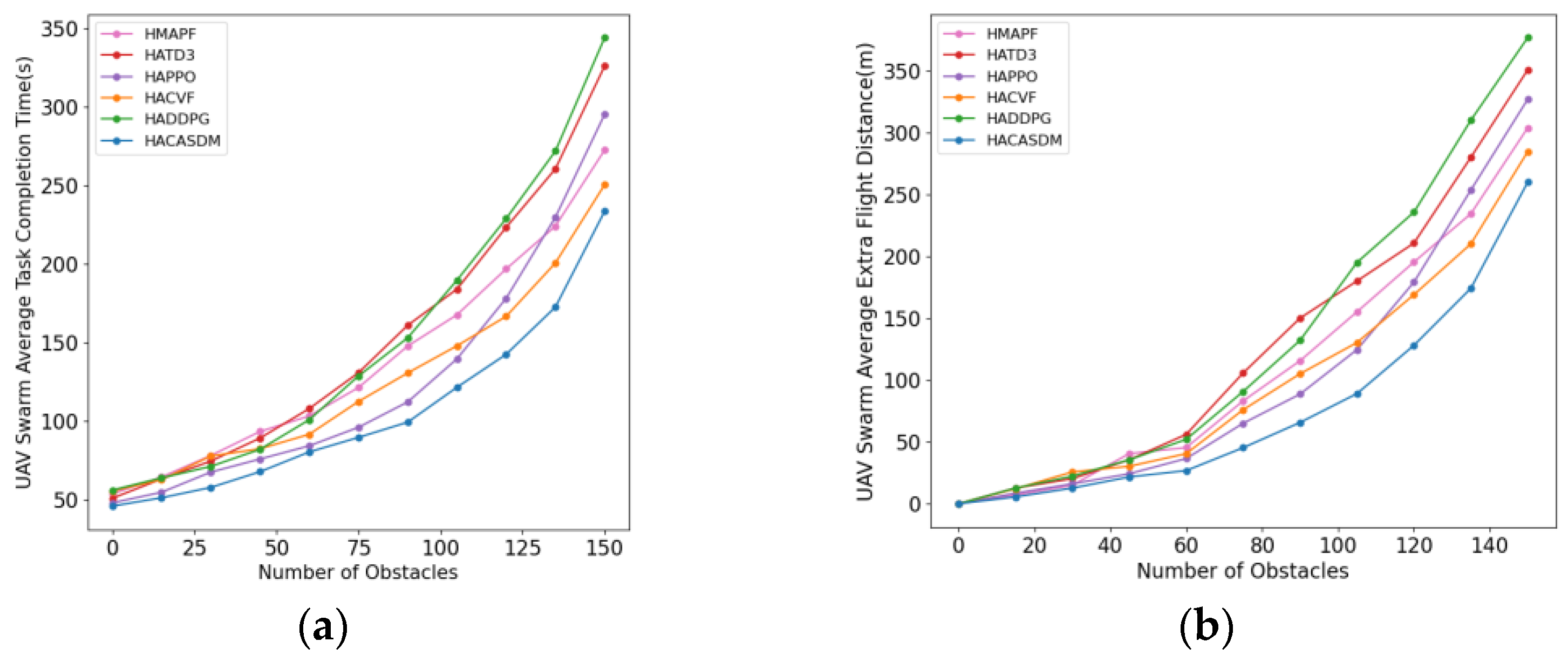
4.2. Experimental Results
- Research indicator 1: swarm stability
- Research indicator 2: swarm integrity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Şahin, E. Swarm robotics: From sources of inspiration to domains of application. In International Workshop on Swarm Robotics; Şahin, E., Spears, W.M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 10–20. [Google Scholar]
- Şahin, E.; Girgin, S.; Bayindir, L.; Turgut, A.E. Swarm Intell; Blum, C., Merkle, D., Eds.; Natural Computing Series; Springer: Berlin/Heidelberg, Germany, 2008; pp. 87–100. [Google Scholar]
- Brambilla, M.; Ferrante, E.; Birattari, M.; Dorigo, M. Swarm robotics: A review from the swarm engineering perspective. Swarm Intell. 2013, 7, 1–41. [Google Scholar] [CrossRef]
- Adnan, M.H.; Zukarnain, Z.A.; Amodu, O.A. Fundamental design aspects of UAV-enabled MEC systems: A review on models, challenges, and future opportunities. Comput. Sci. Rev. 2024, 51, 100615. [Google Scholar] [CrossRef]
- Javaid, S.; Saeed, N.; Qadir, Z.; Fahim, H.; He, B.; Song, H.; Bilal, M. Communication and control in collaborative UAVs: Recent advances and future trends. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5719–5739. [Google Scholar] [CrossRef]
- Peng, X.J.; He, Y. Aperiodic sampled-data consensus control for homogeneous and heterogeneous multi-agent systems: A looped-functional method. Int. J. Robust Nonlinear Control. 2023, 33, 8067–8086. [Google Scholar] [CrossRef]
- Lu, Y.; Xu, Z.; Li, L.; Zhang, J.; Chen, W. Formation preview tracking for heterogeneous multi-agent systems: A dynamical feedforward output regulation approach. ISA Trans. 2023, 133, 102–115. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Chen, B.; Hu, F. Research on cooperative obstacle avoidance decision making of unmanned aerial vehicle swarms in complex environments under end-edge-cloud collaboration model. Drones 2024, 8, 461. [Google Scholar] [CrossRef]
- Khoei, T.T.; Al Shamaileh, K.; Devabhaktuni, V.K.; Kaabouch, N. A comparative assessment of unsupervised deep learning models for detecting GPS spoofing attacks on unmanned aerial systems. In Proceedings of the 2024 Integrated Communications, Navigation and Surveillance Conference (ICNS), Herndon, VA, USA, 23–25 April 2024; pp. 1–10. [Google Scholar]
- Zhuang, Y.; Sun, X.; Li, Y.; Huai, J.; Hua, L.; Yang, X.; Cao, X.; Zhang, P.; Cao, Y.; Qi, L.; et al. Multi-sensor integrated navigation/positioning systems using data fusion: From analytics-based to learning-based approaches. Inf. Fusion 2023, 95, 62–90. [Google Scholar] [CrossRef]
- Sery, T.; Shlezinger, N.; Cohen, K.; Eldar, Y. Over-the-air federated learning from heterogeneous data. IEEE Trans. Signal Process. 2021, 69, 3796–3811. [Google Scholar] [CrossRef]
- Li, Y.; Wu, Y.; Xue, X.; Liu, X.; Xu, Y.; Liu, X. Efficiency-first spraying mission arrangement optimization with multiple UAVs in heterogeneous farmland with varying pesticide requirements. Inf. Process. Agric. 2024, 11, 237–248. [Google Scholar] [CrossRef]
- Sun, L.; Wang, J.; Wan, L.; Li, K.; Wang, X.; Lin, Y. Human-UAV interaction assisted heterogeneous UAV swarm scheduling for target searching in communication denial environment. IEEE Trans. Autom. Sci. Eng. 2024. early access. [Google Scholar] [CrossRef]
- Adderson, R.; Pan, Y.-J. Continuously varying formation for heterogeneous multi-agent systems with novel potential field avoidance. IEEE Trans. Ind. Electron. 2024, 72, 1774–1783. [Google Scholar] [CrossRef]
- Wu, Y.; Liang, T.; Gou, J.; Tao, C.; Wang, H. Heterogeneous mission planning for multiple UAV formations via metaheuristic algorithms. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3924–3940. [Google Scholar] [CrossRef]
- Meng, X.; Zhu, X.; Zhao, J. Obstacle avoidance path planning using the elite ant colony algorithm for parameter optimization of unmanned aerial vehicles. Arab. J. Sci. Eng. 2023, 48, 2261–2275. [Google Scholar] [CrossRef]
- Kumar, H.; Datta, D.; Pushpangathan, J.V.; Kandath, H.; Dhabale, A. AGVO: Adaptive geometry-based velocity obstacle for heterogenous UAVs collision avoidance in UTM. In Proceedings of the IECON 2023—49th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 16–19 October 2023; pp. 1–7. [Google Scholar]
- Sellers, T.; Lei, T.; Luo, C.; Liu, L.; Carruth, D.W. Enhancing human-robot cohesion through hat methods: A crowd-avoidance model for safety aware navigation. In Proceedings of the 2024 IEEE 4th International Conference on Human-Machine Systems (ICHMS), Toronto, ON, Canada, 15–17 May 2024; pp. 1–6. [Google Scholar]
- Ghaderi, F.; Toloei, A.; Ghasemi, R. Heterogeneous formation sliding mode control of the flying robot and obstacles avoidance. Int. J. ITS Res. 2024, 22, 339–351. [Google Scholar] [CrossRef]
- Geng, M.; Pateria, S.; Subagdja, B.; Tan, A.-H. HiSOMA: A hierarchical multi-agent model integrating self-organizing neural networks with multi-agent deep reinforcement learning. Expert Syst. Appl. 2024, 252, 124117. [Google Scholar] [CrossRef]
- Wang, C.; Wei, Z.; Jiang, W.; Jiang, H.; Feng, Z. Cooperative sensing enhanced UAV path-following and obstacle avoidance with variable formation. IEEE Trans. Veh. Technol. 2024, 73, 7501–7516. [Google Scholar] [CrossRef]
- Hou, P.; Jiang, X.; Wang, Z.; Liu, S.; Lu, Z. Federated deep reinforcement learning-based intelligent dynamic services in UAV-assisted MEC. IEEE Internet Things J. 2023, 10, 20415–20428. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, H.; Hua, M.; Wang, F.; Yi, J. P-DRL: A framework for multi-UAVs dynamic formation control under operational uncertainty and unknown environment. Drones 2024, 8, 475. [Google Scholar] [CrossRef]
- Xia, X.; Chen, F.; He, Q.; Cui, G.; Grundy, J.; Abdelrazek, M.; Bouguettaya, A.; Jin, H. OL-MEDC: An online approach for cost-effective data caching in mobile edge computing systems. IEEE Trans. Mob. Comput. 2023, 22, 1646–1658. [Google Scholar] [CrossRef]
- Chen, Q.; Meng, W.; Quek, T.Q.S.; Chen, S. Multi-tier hybrid offloading for computation-aware IoT applications in civil aircraft-augmented SAGIN. IEEE J. Sel. Areas Commun. 2023, 41, 399–417. [Google Scholar] [CrossRef]
- Tao, M.; Li, X.; Feng, J.; Lan, D.; Du, J.; Wu, C. Multi-agent cooperation for computing power scheduling in UAVs empowered aerial computing systems. IEEE J. Sel. Areas Commun. 2024, 42, 3521–3535. [Google Scholar] [CrossRef]
- Wu, R.-Y.; Xie, X.-C.; Zheng, Y.-J. Firefighting drone configuration and scheduling for wildfire based on loss estimation and minimization. Drones 2024, 8, 17. [Google Scholar] [CrossRef]
- Poursiami, H.; Jabbari, B. On multi-task learning for energy efficient task offloading in multi-UAV assisted edge computing. In Proceedings of the 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar]
- Tang, J.; Wu, G.; Jalalzai, M.M.; Wang, L.; Zhang, B.; Zhou, Y. Energy-optimal DNN model placement in UAV-enabled edge computing networks. Digit. Commun. Netw. 2024, 10, 827–836. [Google Scholar] [CrossRef]
- Ma, M.; Wang, Z.; Guo, S.; Lu, H. Cloud–edge framework for AoI-efficient data processing in multi-UAV-assisted sensor networks. IEEE Internet Things J. 2024, 11, 25251–25267. [Google Scholar] [CrossRef]
- Raja, G.; Essaky, S.; Ganapathisubramaniyan, A.; Baskar, Y. Nexus of deep reinforcement learning and leader–follower approach for AIoT enabled aerial networks. IEEE Trans. Ind. Inform. 2023, 19, 9165–9172. [Google Scholar] [CrossRef]
- Mao, S.; Jin, J.; Xu, Y. Routing and charging scheduling for EV battery swapping systems: Hypergraph-based heterogeneous multiagent deep reinforcement learning. IEEE Trans. Smart Grid 2024, 15, 4903–4916. [Google Scholar] [CrossRef]
- Schegg, P.; Ménager, E.; Khairallah, E.; Marchal, D.; Dequidt, J.; Preux, P.; Duriez, C. SofaGym: An open platform for reinforcement learning based on soft robot simulations. Soft Robot. 2023, 10, 410–430. [Google Scholar] [CrossRef]
- Chaysri, P.; Spatharis, C.; Blekas, K.; Vlachos, K. Unmanned surface vehicle navigation through generative adversarial imitation learning. Ocean Eng. 2023, 282, 114989. [Google Scholar] [CrossRef]
- Spatharis, C.; Blekas, K.; Vouros, G.A. Modelling flight trajectories with multi-modal generative adversarial imitation learning. Appl. Intell. 2024, 54, 7118–7134. [Google Scholar] [CrossRef]
- Grecov, P.; Prasanna, A.N.; Ackermann, K.; Campbell, S.; Scott, D.; Lubman, D.I.; Bergmeir, C. Probabilistic causal effect estimation with global neural network forecasting models. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 4999–5013. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Song, Z.; Zhou, Y.; Ao, T.; Chen, B.; Liu, L. MoConVQ: Unified physics-based motion control via scalable discrete representations. ACM Trans. Graph. 2024, 43, 1–21. [Google Scholar] [CrossRef]
- Chen, X.; Liu, X.; Zhang, S.; Ding, B.; Li, K. Goal consistency: An effective multi-agent cooperative method for multistage tasks. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 172–178. [Google Scholar]
- Zhang, C.; Meng, Y.; Prasanna, V. A framework for mapping DRL algorithms with prioritized replay buffer onto heterogeneous platforms. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 1816–1829. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Loscos, D.; Martí-Oliet, N.; Rodríguez, I. Generalization and completeness of stochastic local search algorithms. Swarm Evol. Comput. 2022, 68, 100982. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Q.; Shen, Y.; Dai, N.; He, B. Multi-AUV cooperative control and autonomous obstacle avoidance study. Ocean Eng. 2024, 304, 117634. [Google Scholar] [CrossRef]
- Bahaidarah, M.; Marjanovic, O.; Rekabi-Bana, F.; Arvin, F. Improving formation in swarm robotics with a leader-follower approach. In Proceedings of the 2024 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2024; pp. 1447–1452. [Google Scholar]
- Zhong, Y.; Kuba, J.G.; Feng, X.; Hu, S.; Ji, J.; Yang, Y. Heterogeneous-agent reinforcement learning. J. Mach. Learn. Res. 2024, 25, 1–67. [Google Scholar]
- Mesías-Ruiz, G.A.; Peña, J.M.; de Castro, A.I.; Borra-Serrano, I.; Dorado, J. Cognitive computing advancements: Improving precision crop protection through UAV imagery for targeted weed monitoring. Remote Sens. 2024, 16, 3026. [Google Scholar] [CrossRef]
- Swathi, P.; Pothuganti, K. Overview on principal component analysis algorithm in machine learning. Int. Res. J. Mod. Eng. Technol. 2020, 2, 241–246. [Google Scholar]
- Wang, Y.; Zhang, H.; Shi, Z.; Zhou, J.; Liu, W. Nonlinear time series analysis and prediction of general aviation accidents based on multi-timescales. Aerospace 2023, 10, 714. [Google Scholar] [CrossRef]
- Zhu, Y.; Liang, Y.; Jiao, Y.; Ren, H.; Li, K. Multi-type task assignment algorithm for heterogeneous UAV cluster based on improved NSGA-II. Drones 2024, 8, 384. [Google Scholar] [CrossRef]
- Sun, T.; Sun, W.; Sun, C.; He, R. Multi-UAV formation path planning based on compensation look-ahead algorithm. Drones 2024, 8, 251. [Google Scholar] [CrossRef]
- Celestini, D.; Primatesta, S.; Capello, E. Trajectory planning for UAVs based on interfered fluid dynamical system and Bézier curves. IEEE Robot. Autom. Lett. 2022, 7, 9620–9626. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, Y.; Zhang, X.; Feng, Z.; Wan, L.; Zhuang, Z. Relation-Aware heterogeneous graph network for learning intermodal semantics in textbook question answering. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 11872–11883. [Google Scholar] [CrossRef]
- Yin, Y.; Xie, K.; He, S.; Li, Y.; Wen, J.; Diao, Z.; Zhang, D.; Xie, G. GraphIoT: Lightweight IoT device detection based on graph classifiers and incremental learning. IEEE Trans. Serv. Comput. 2024, 17, 3758–3772. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Parameter | Value |
|---|---|---|
| Cloud Server | Operating system | Ubuntu 22.04 |
| Processor | Intel Core i7-1260P | |
| Memory | 372 GB | |
| Hard disk | 10 TB | |
| Network card | I350-US | |
| Graphics card | NVIDIA T4 | |
| Edge Server | Operating system | Ubuntu 20.04 |
| Processor | Intel Core i7-10700 | |
| Memory | 64 GB | |
| Hard disk | 100 GB | |
| Network card | I219-V | |
| Graphics card | NVIDIA Tesla K80 | |
| UAV Simulation Platform | Operating system | Ubuntu 18.04 |
| Processor | Intel Core i7-1260P | |
| Memory | 16 GB | |
| Hard disk | 50 GB | |
| Network card | I219-V | |
| Graphics card | NVIDIA GeForce RTX 3060 |
| Type | ID | Resolution | FOV | ||||
|---|---|---|---|---|---|---|---|
| Multi-rotor | 0.8 kg | 0.72 MP | |||||
| 0.8 kg | 0.72 MP | ||||||
| 0.4 kg | 0.3 MP | ||||||
| 0.4 kg | 0.3 MP | ||||||
| 0.4 kg | 0.3 MP |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Chen, B.; Hu, F. Research on Swarm Control Based on Complementary Collaboration of Unmanned Aerial Vehicle Swarms Under Complex Conditions. Drones 2025, 9, 119. https://doi.org/10.3390/drones9020119
Zhao L, Chen B, Hu F. Research on Swarm Control Based on Complementary Collaboration of Unmanned Aerial Vehicle Swarms Under Complex Conditions. Drones. 2025; 9(2):119. https://doi.org/10.3390/drones9020119
Chicago/Turabian StyleZhao, Longqian, Bing Chen, and Feng Hu. 2025. "Research on Swarm Control Based on Complementary Collaboration of Unmanned Aerial Vehicle Swarms Under Complex Conditions" Drones 9, no. 2: 119. https://doi.org/10.3390/drones9020119
APA StyleZhao, L., Chen, B., & Hu, F. (2025). Research on Swarm Control Based on Complementary Collaboration of Unmanned Aerial Vehicle Swarms Under Complex Conditions. Drones, 9(2), 119. https://doi.org/10.3390/drones9020119