1. Introduction
Thanks to the rapid development of control algorithms and computing platforms, research on unmanned aerial vehicles has made a series of progress [
1,
2,
3]. Due to their high efficiency, portability, and economy, Unmanned Aerial Vehicles (UAVs) are widely used in many fields, such as remote rescue [
4,
5], logistics delivery [
6,
7], environmental monitoring [
8,
9], and smart agriculture [
10,
11]. In most tasks performed by UAVs, their core role can be defined as the mission of flying between two points, and during this process the UAV can achieve automatic navigation and obstacle avoidance [
12]. However, in real-life scenarios, high-density and highly dynamic working environments such as woods and pedestrians pose great challenges to the autonomous planning and navigation of UAVs, which requires the UAV to be able to effectively identify obstacles and respond in a timely manner [
13,
14]. Therefore, how to improve the autonomous flight performance of UAVs in complex environments has become a core issue for scholars and industry.
UAVs usually need to choose a reasonable path to the target point by evaluating perceived environmental information. In recent years, the development of deep reinforcement learning (DRL) has provided new solutions and ideas for autonomous UAV navigation, which learns and optimizes strategies through continuous trial and error [
15,
16,
17,
18]. Many classic DRL algorithms have been applied in the field of autonomous navigation of unmanned systems and deployed on real machines [
19,
20,
21,
22]. In actual research, Guo et al. [
23] divided the autonomous navigation of a UAV into two subtasks, navigation and obstacle avoidance, and proposed a targeted distributed DRL framework. This method can achieve the navigation task of a UAV in a highly dynamic environment without prior knowledge. Liu et al. [
24] proposed a hierarchical network architecture to improve the algorithm performance by introducing a temporal attention mechanism and verified it in real and simulated scenarios, but the test environment of the algorithm is relatively simple. In order to improve the interpretability of the model, Shao et al. [
25] proposed a UAV collision avoidance scheme based on DRL, which improved the training speed of the model by introducing the idea of curriculum learning to achieve autonomous flight in a restricted closed environment. In response to the distribution differences between the simulated training environment and actual application environment of the DRL algorithm, reference [
26] built a random environment generation platform to train the DRL model, and improved the stability of the model deployed on the real machine through dynamic training. Reference [
27] uses light detection and ranging (LiDAR) measurement data as input and proposes an end-to-end autonomous navigation algorithm, which uses a fast stochastic gradient algorithm to solve the constraint model and realize autonomous navigation in complex 3D unknown environments. To improve the perception and tracking accuracy of UAVs, reference [
28] combines the improved differential amplification method with the DRL algorithm. Compared with the traditional motion control method, the proposed DRL algorithm has stronger flexibility and better performance.
Although the effectiveness of DRL-based UAV autonomous navigation solutions has been proven by many studies, most algorithms are only tested in simulation environments with few obstacles and simple scenes, making it difficult to evaluate their application effects in complex environments with high-density and highly dynamic obstacles. In addition, there are several issues in current research that need further study: (1) Sparse rewards: The agent will only be rewarded when it reaches the goal point during model training. This typically makes it more difficult for the agent to effectively learn the correct behavior strategy during the exploration process, which causes the trained model to converge slowly or not at all [
29,
30]; (2) Exploration and utilization: The exploration of an agent means trying new behaviors to discover possible high-reward states, while utilization means selecting the current optimal behavior based on known information, which corresponds to the conservative and radical behavior of the UAV [
31,
32]; (3) State space: The choice of state space is crucial to the DRL model. Most agents only make decisions based on the information at the current moment, ignoring the dynamic changing trends of the agent (such as the translation and rotation of the UAV) [
12,
33].
Researchers have conducted targeted research on the above problems. Wang et al. [
34] generated actions for the agent to interact with the environment by combining current strategies and prior strategies, and gradually improved the agent performance under sparse rewards by setting dynamic learning goals. However, higher complexity and constraints limit the further promotion of this algorithm. Wang et al. [
33] built a two-stream Q network to process the temporal information and spatial information extracted from the UAV’s current moment state and the previous moment state, respectively. This algorithm provides a new idea for the selection of state space, but when using observation changes, it only considers the position changes caused by the translation of the UAV and ignores the angle changes caused by its rotation. Based on this, Zhang et al. [
35] developed a two-stream Actor-Critic architecture by combining a two-stream network and TD3, and constructed a non-sparse reward function that can balance the exploration behavior and radical behavior of UAVs. This algorithm also ignores the angle information of the UAV, and essentially its reward function remains fixed during the entire training process.
Based on the above analysis, this paper proposes an improved UAV autonomous navigation algorithm based on SAC in view of the current status of UAV autonomous navigation based on DRL in complex environments. By analyzing the continuous maneuvering mechanism of UAVs in complex environments, a more reasonable state space is constructed; the comprehensive performance of the intelligent agent is improved by designing a dynamic reward function. Based on the proposed method, this paper realizes autonomous path planning of UAVs in high-density and highly dynamic environments. The main contributions are as follows:
- (1)
The impact of UAV position changes and angle changes on navigation performance in complex scenarios was analyzed, and angle change information was introduced as input to the DRL model to expand ideas for research on LiDAR-based navigation algorithms;
- (2)
A dynamic reward function is constructed based on a non-sparse reward function to balance the conservative behavior and exploratory behavior of the agent during the model training process, and improve the flight efficiency while improving the success rate of UAV navigation;
- (3)
Flight simulation scenarios with high-density and highly dynamic obstacles were constructed, respectively, to verify the effectiveness and reliability of the proposed navigation algorithm.
The structure of subsequent chapters of this article is as follows:
Section 2 introduces the theoretical background related to DRL.
Section 3 formulates the DRL-based UAV navigation problem.
Section 4 describes the algorithm proposed in this paper.
Section 5 presents the experimental details and discusses the results. The last section summarizes this article and gives future work plans.
4. Proposed Approach
4.1. State Space Representation Method
As mentioned in
Section 3, the state space is crucial to the performance of DRL models. In autonomous UAV navigation tasks based on LiDAR, most studies directly use the LiDAR-measured data shown in Equation (10) as observation information. Reference [
33] proves that the flight performance of the UAV is further improved after adding dynamic information as observation information, but the impact of changes in the angle of the UAV is not considered.
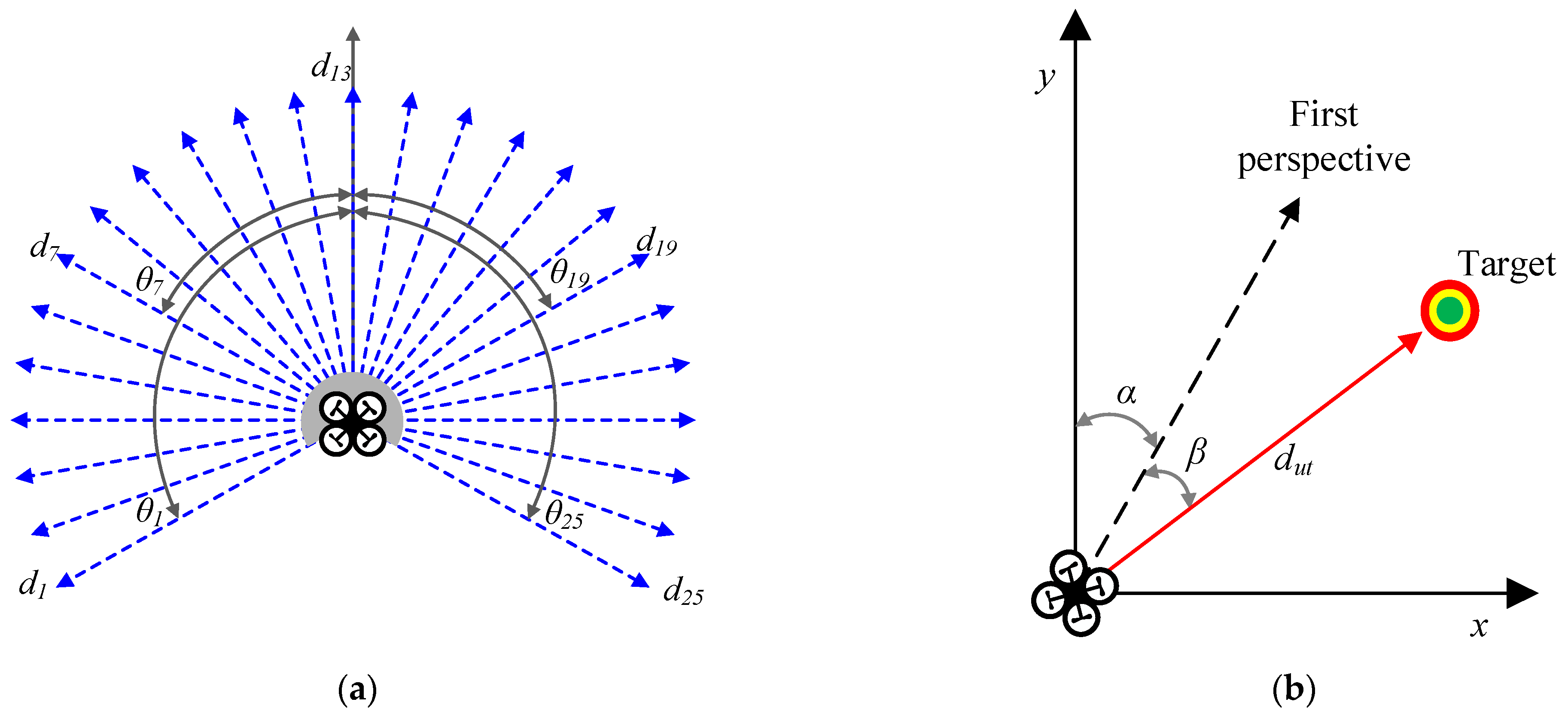
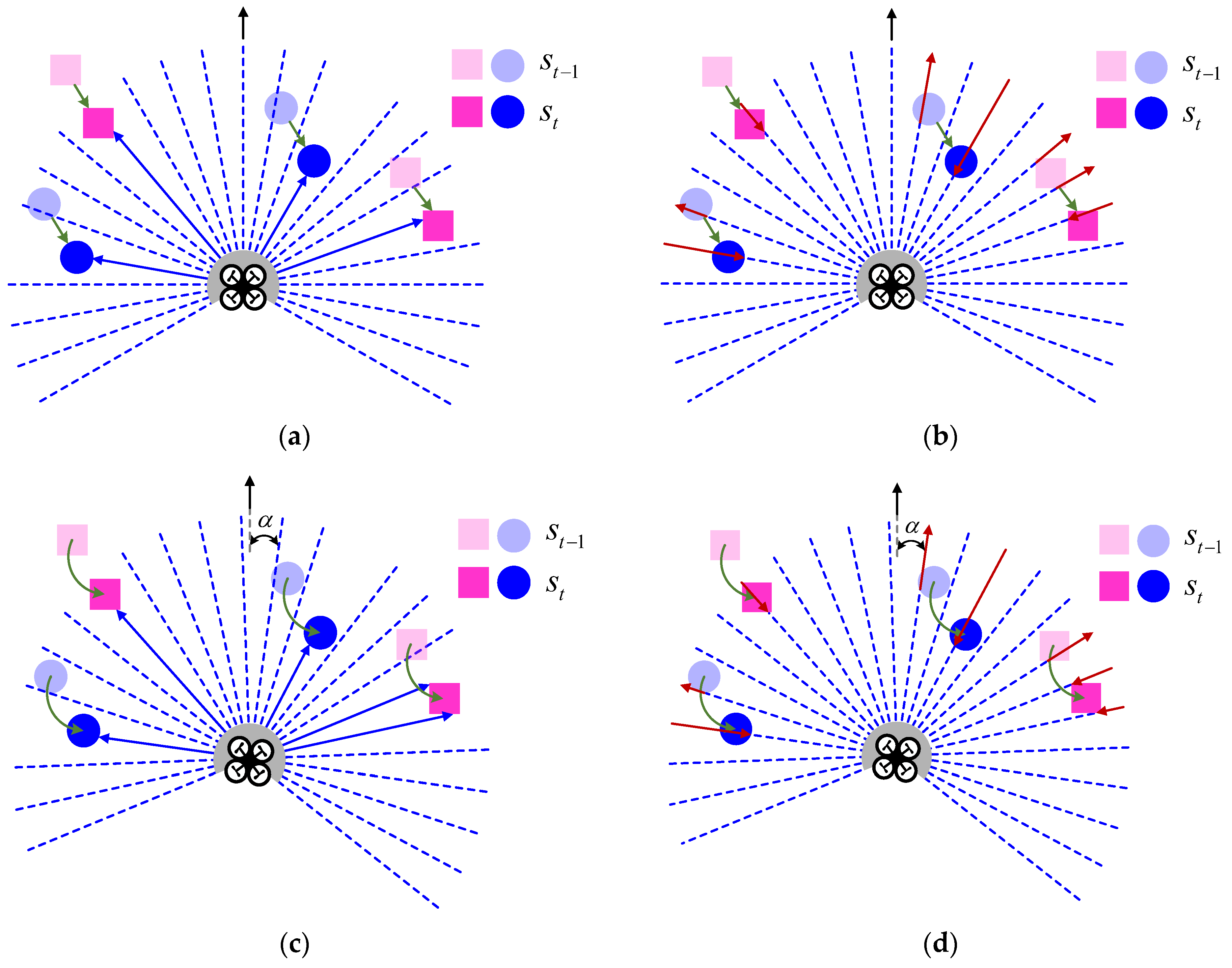
As shown in
Figure 3a,b, LiDAR can obtain a set of measurement data at time
t, and the UAV can estimate the distance and distribution of surrounding obstacles based on
. Compared with time
t-1, the position of the UAV relative to the obstacle has changed, and the change value
of the measurement data at adjacent moments can provide the movement trend of the UAV relative to the obstacle. As shown in
Figure 3c,d, the attitude changes of the UAV during actual flight include not only changes in position but also changes in flight angle.
Based on the above analysis, this paper proposes a state space representation method that considers angle change information. First, add the angle information corresponding to the laser beam when obtaining the LiDAR measurement data
, as shown below:
Furthermore, according to Equation (12), the dynamic information
at adjacent moments after adding angle information can be expressed as:
Since the corresponding angle
of the laser beam is fixed, Equation (24) can be further simplified as follows:
where
represents the change value of yaw angle. As shown in
Figure 4, when the obstacles in the flight environment are stationary or the density is relatively sparse, the impact of changes in flight angle is not obvious. However, when the UAV flies in a highly dynamic or high-density complex environment, the angle change of the UAV can be expressed as:
The above formula shows that when the time interval is , the yaw angle of the UAV changes, and the impact of this change on the UAV’s flight decision-making in a complex environment cannot be ignored.
Based on the above analysis, the DRL model state space determined in this article is as follows:
According to the Equations (14) and (27), the dimension of the state space in this paper is 83, the action space dimension is 2, and the network architecture adopted by the algorithm is shown in
Figure 5.
4.2. Dynamic Reward Function
During the training process of the agent, how to balance the conservative and radical behavior of the agent is the focus that needs to be paid attention to. For UAVs, conservative means that the UAV is as safe as possible to avoid suffering larger penalties, while radical means that the UAV is more inclined to receive larger rewards and perform risky behaviors. If the agent obtains a larger reward after executing action a, it means that the action is more conducive to achieving the goal. Therefore, when the strategy is updated, the agent is more likely to subsequently choose to perform this action.
The non-sparse reward function designed in the current study usually remains unchanged during the training process of the agent. In fact, we hope that in the early stages of model training, the agent can be more radical to explore more possibilities. With the training of the model, the agent gradually tends to be conservative after it has the basic ability to complete tasks, thereby encouraging the agent to improve its own performance on the basis of ensuring its own safety.
Based on the above analysis, this paper proposes a dynamically changing reward function. By adjusting the distance reward
, step reward
, and collision reward
, the agent is given gradually changing guidance at different stages of training to improve its overall performance. They can be expressed as:
where
represents the current number of training rounds;
represents the set maximum number of rounds;
and
are constants set according to the task.
By changing the parameters , , and , the reward function is dynamically adjusted in different training stages. In the initial stage of training, the agent is encouraged to explore the environment by giving smaller distance rewards and collision penalties. As training proceeds, the distance reward and collision penalty are increased while the step penalty is decreased to encourage the agent to stay away from obstacles.
5. Experiment and Discussion
5.1. Experimental Settings
In order to verify the algorithm proposed in this article, simulation scenarios of high-density and highly dynamic obstacles were built based on gazebo. The training scene for algorithms is shown in
Figure 6, where there are 75 cylindrical obstacles with a radius of 0.15 and 75 cuboid obstacles with a side length of 0.2 in a 20 × 20 rectangular field. In each episode training, the coordinates of all obstacles are randomly generated and the target point is randomly selected among [0, 7], [0, −7], [7, 0], and [−7, 0]. The flight mission of the UAV is defined as flying from the origin to the destination within a specified number of steps, and the criteria for the end of each episode include: (1) the UAV successfully reaches the destination; (2) the UAV collides with an obstacle; (3) the UAV neither reaches the target nor collides within the maximum number of steps.
In order to verify the advantages of the method proposed in this article, DDPG, TD3, and SAC are used for comparison. All three algorithms use fixed reward functions and traditional state space expressions. In addition, in order to objectively evaluate the performance of the algorithm, we choose the following five quantitative indicators to measure the completion of the task.
- (1)
Success rate : the proportion of the number of times the UAV completes the navigation task to the total number of trials;
- (2)
Collision rate : the proportion of the number of times the UAV encountered obstacles to the total number of trials;
- (3)
Loss rate : the proportion of the number of times the UAV neither reaches the target point nor collides within the specified number of steps to the total number of trials;
- (4)
Average flight distance : the average distance flown by the UAV when it successfully completes its mission;
- (5)
Average number of flight steps : the average number of steps required for the UAV to successfully complete the mission.
Among the above indicators, the larger is, the better the autonomous navigation performance of the UAV is. The smaller and are, the higher the flight efficiency of the UAV is.
5.2. Training Results
The proposed method and the three comparison algorithms are deployed on the hardware platform of Intel Core i5-11400F CPU @2.6 GHz × 12 and NVIDIA GTX 1650. For objective comparison, the training settings of the four algorithms are consistent, with the replay buffer size of 10,000, the network discount rate of 0.99, the batch size of 512, and the same network structure. In addition, the parameters of the reward function in
Section 4.2 are set to
,
, and
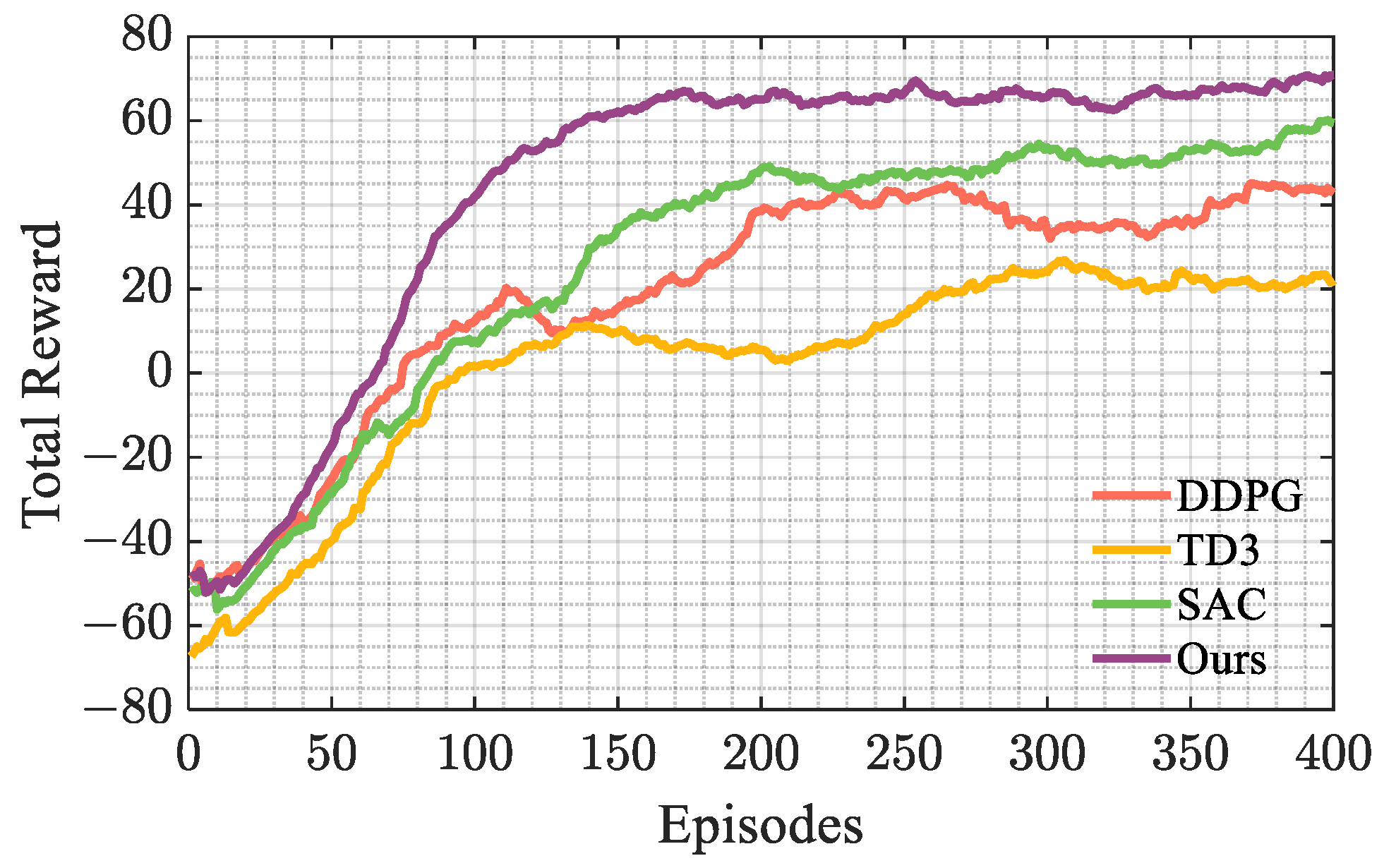
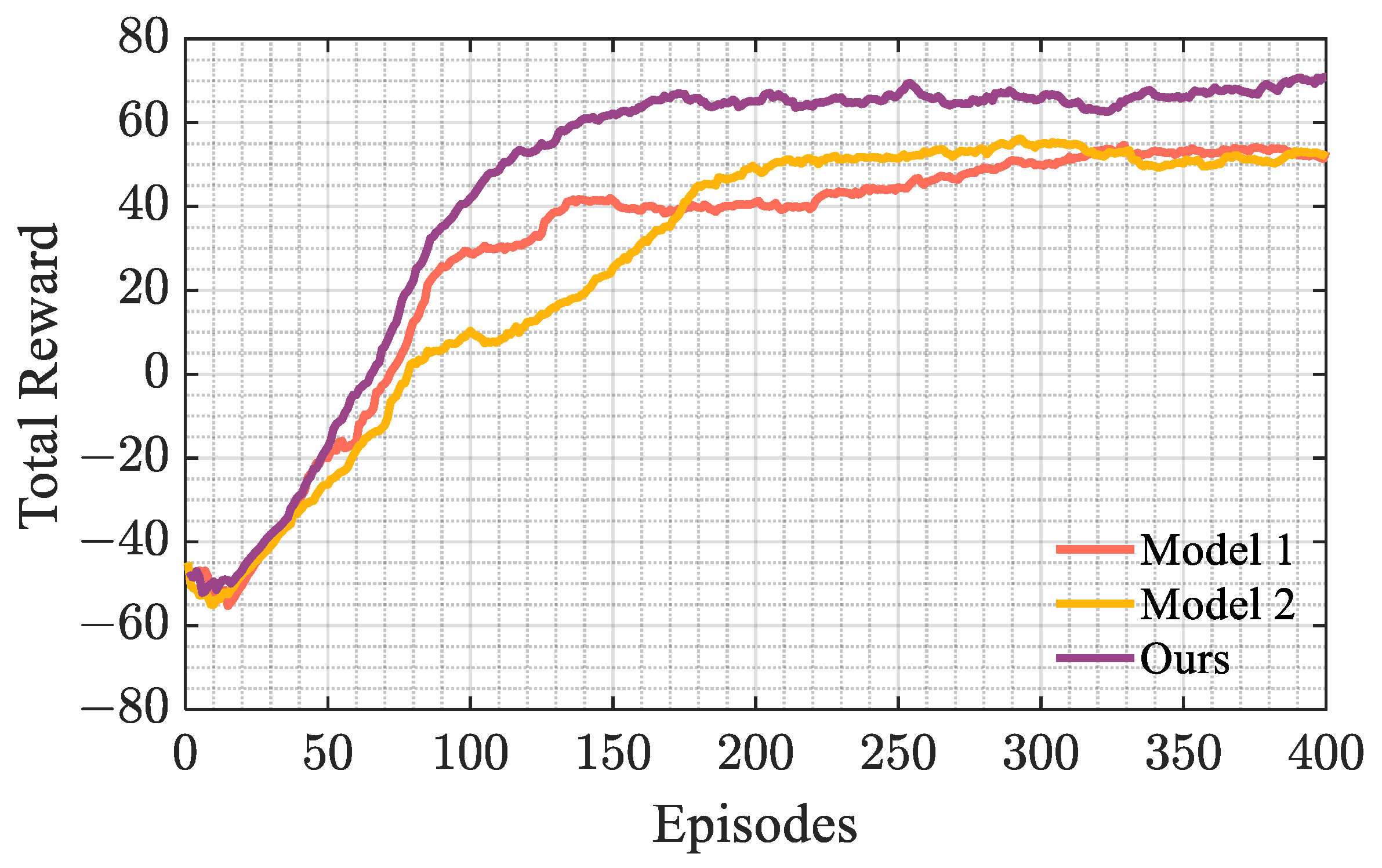
, respectively. The results of the cumulative rewards of different algorithms changing with the number of training episodes are shown in
Figure 7. All data in the figure have been smoothed.
According to
Figure 7, the proposed algorithm has faster convergence speed and higher reward than the other three algorithms, among which our algorithm starts to converge around the 150th episode, SAC and DDPG start to converge around the 200th episode, while TD3 starts to converge around the 300th episode and has the lowest reward. Therefore, the training results show that the proposed algorithm has better convergence.
5.3. Experiment I: High-Density Scene Verification
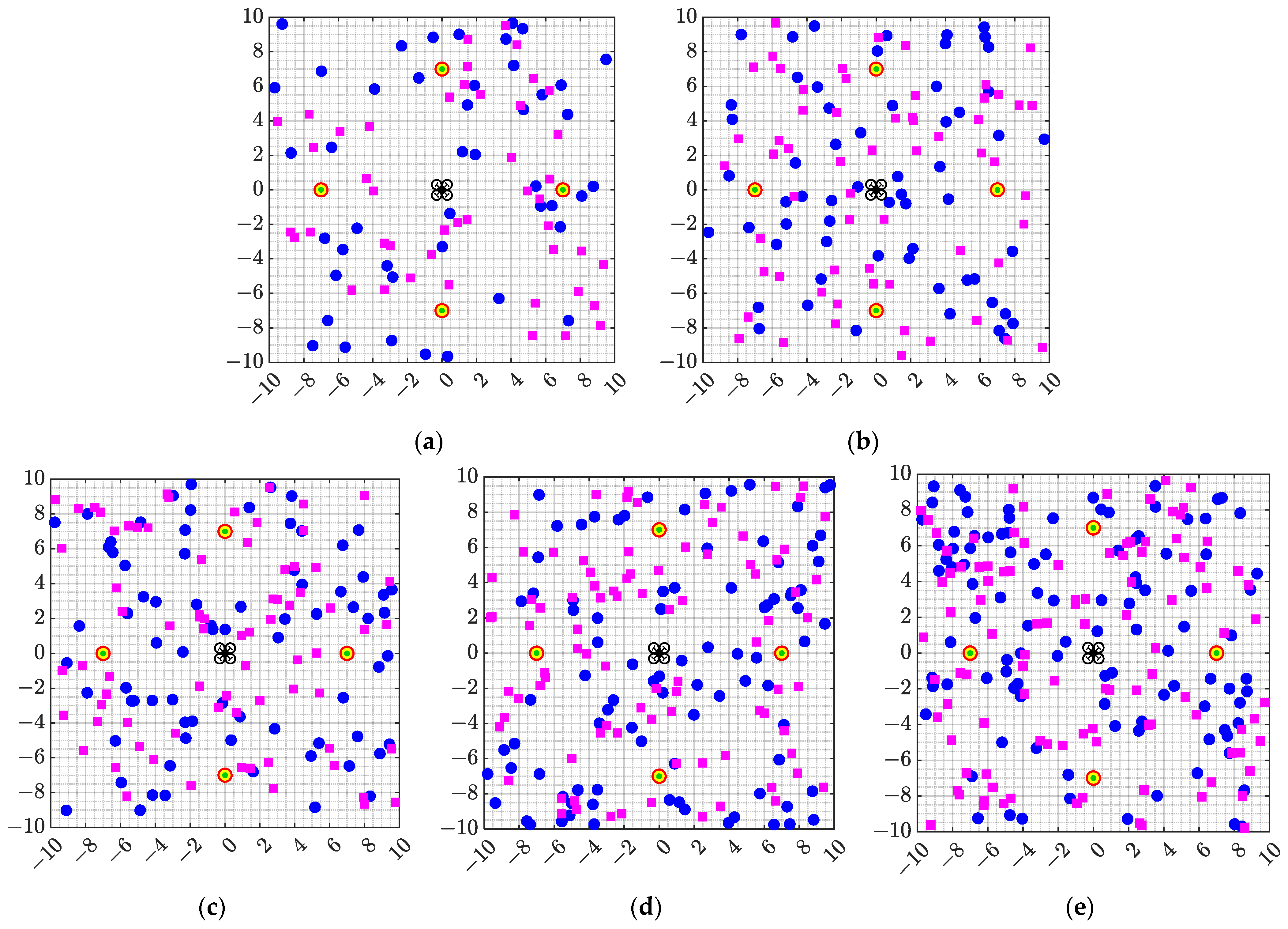
In order to verify the effect of the proposed algorithm, the DRL model trained in
Section 5.2 was tested in simulation scenarios with different numbers of obstacles. The test scene is shown in
Figure 8, where
represents the number of obstacles, and ρ represents the obstacle density, which is used to measure the density of obstacles present per unit area.
The UAV based on the four algorithms performed 100 navigation missions in five scenarios with different obstacle densities. Similar to the training process, the location of the obstacles was re-randomly generated and the target point was re-selected after each flight mission.
The navigation success rate
, collision rate
, and loss rate
of the four algorithms under different obstacle densities are shown in
Table 1. As can be seen from the table, the proposed algorithm achieved the highest navigation success rate and the lowest collision rate in all five scenarios, and the navigation performance of the SAC algorithm is better than DDPG and TD3. Due to the high density of obstacles in the experimental scene, only DDPG experienced flight loss. Comparing the experimental results of scene 1 and scene 5, it can be seen that with the substantial increase in obstacle density, the success rate of our algorithm is only reduced by 18%, while the success rates of the other three algorithms are reduced by 28%, 48%, and 29%, which further demonstrates the stability of our algorithm.
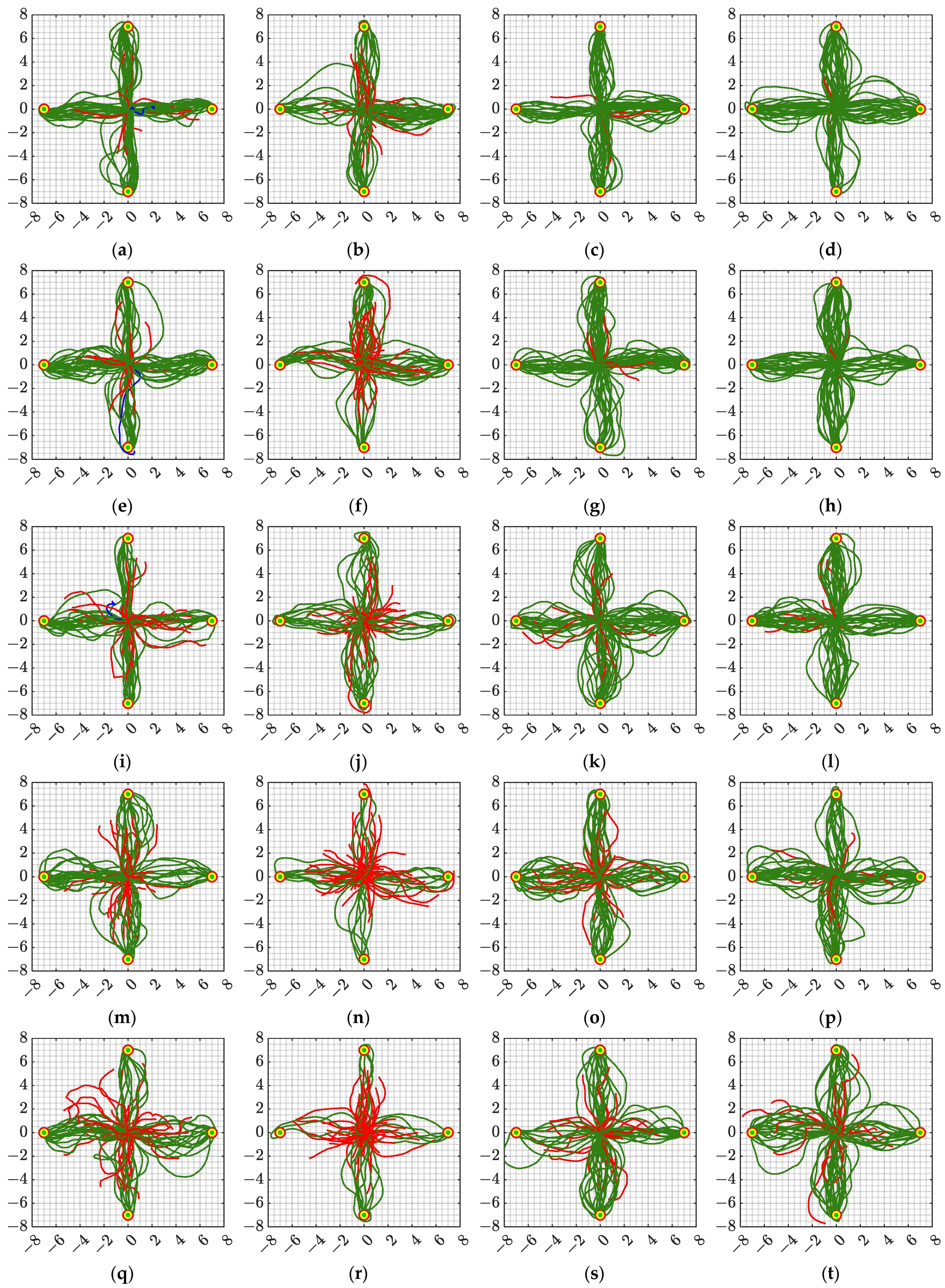
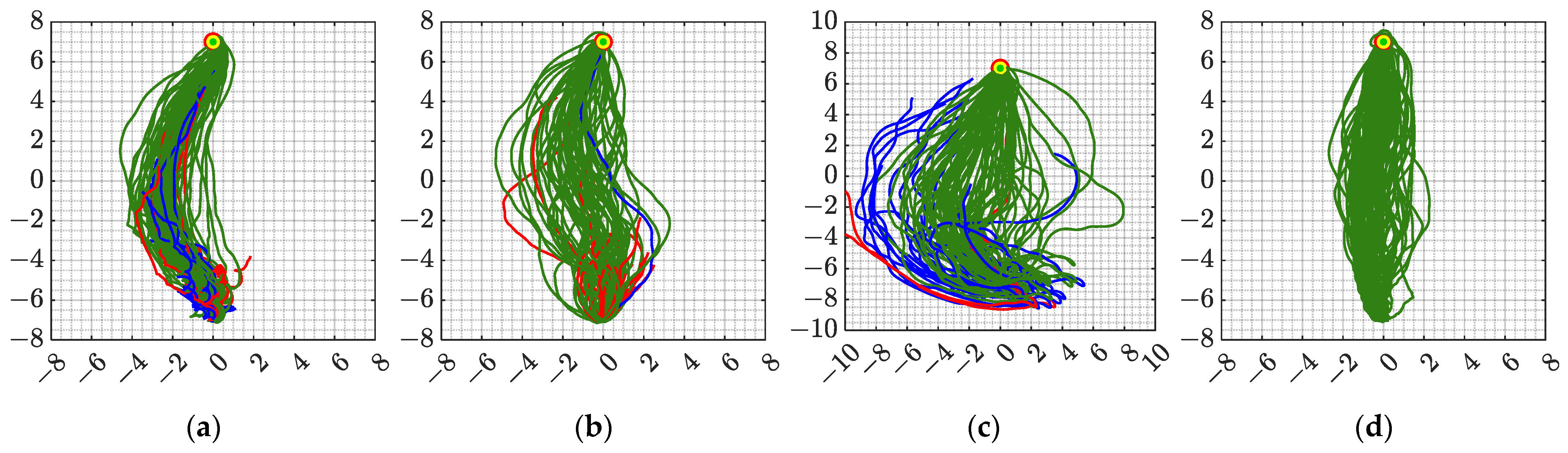
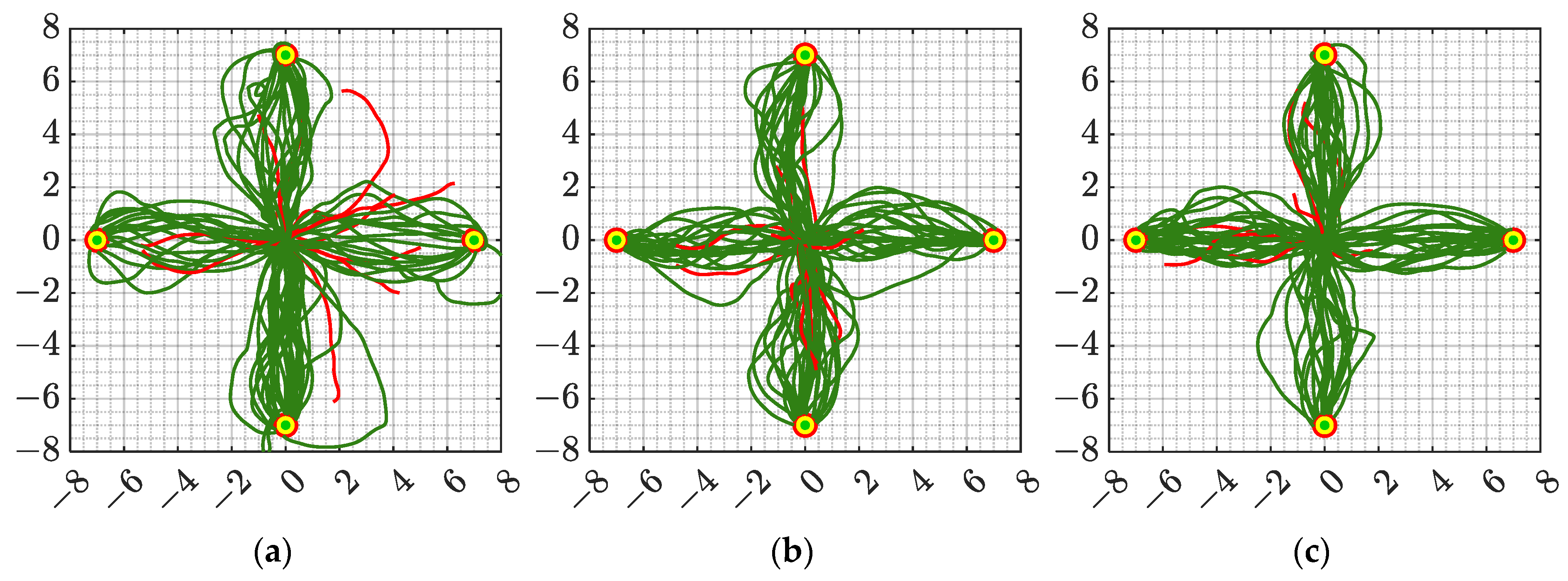
The flight trajectories of the UAV in all tests are shown in
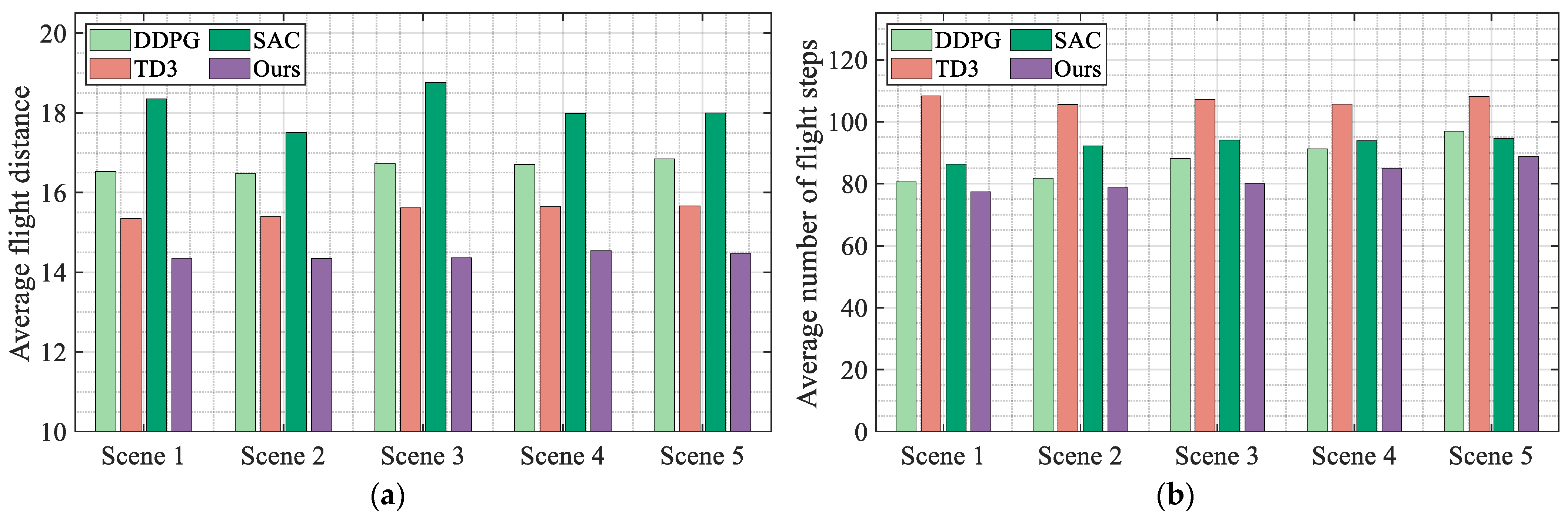
Figure 9. As can be seen from the figure, the algorithm proposed in this article has the most successful flight trajectories in all scenarios. In addition, as the density of obstacles increases, the flight path of the UAV becomes more complex. Based on the flight trajectory data, the average flight distance and average number of flight steps for all experiments were calculated, as shown in
Figure 10.
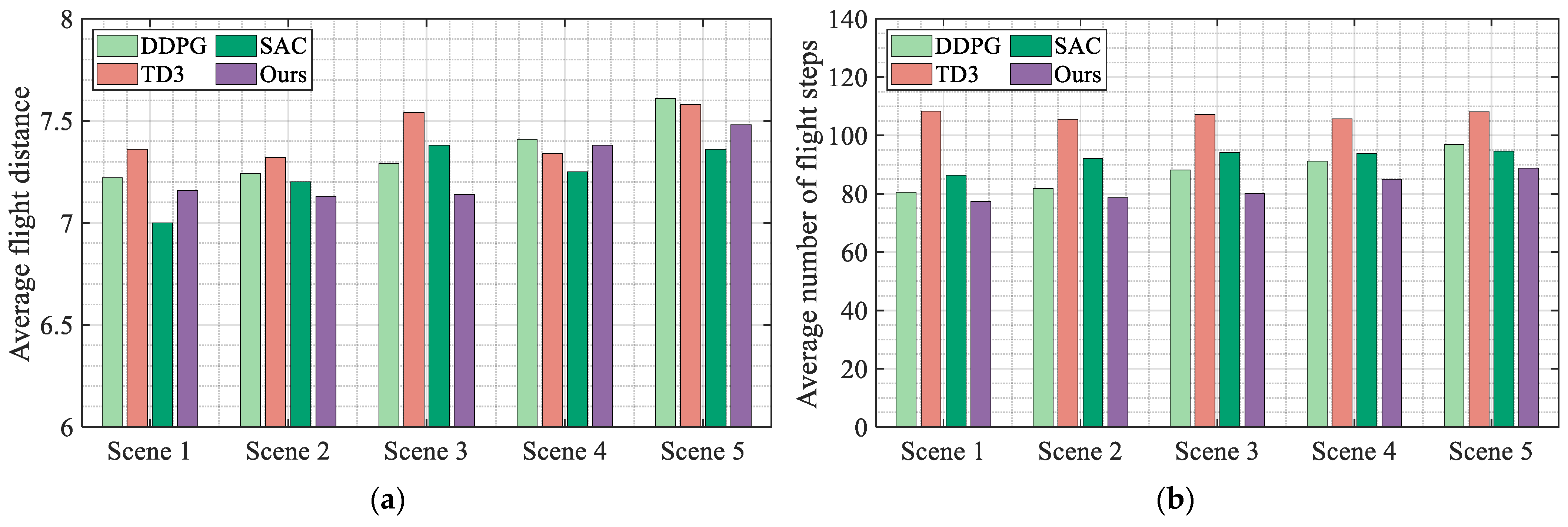
According to
Figure 10a, the proposed algorithm has the shortest average flight distance in scenarios 2 and 3, and has an average flight distance only larger than SAC in scenarios 1 and 5. According to
Figure 10b, the proposed algorithm requires the minimum average number of flight steps in all five scenarios. Therefore, based on the above analysis, it can be seen that compared with the other three classic algorithms, the algorithm proposed in this article not only has the highest navigation success rate and stability but also has the optimal flight efficiency in high-density flight environments.
5.4. Experiment II: Highly Dynamic Scene Verification
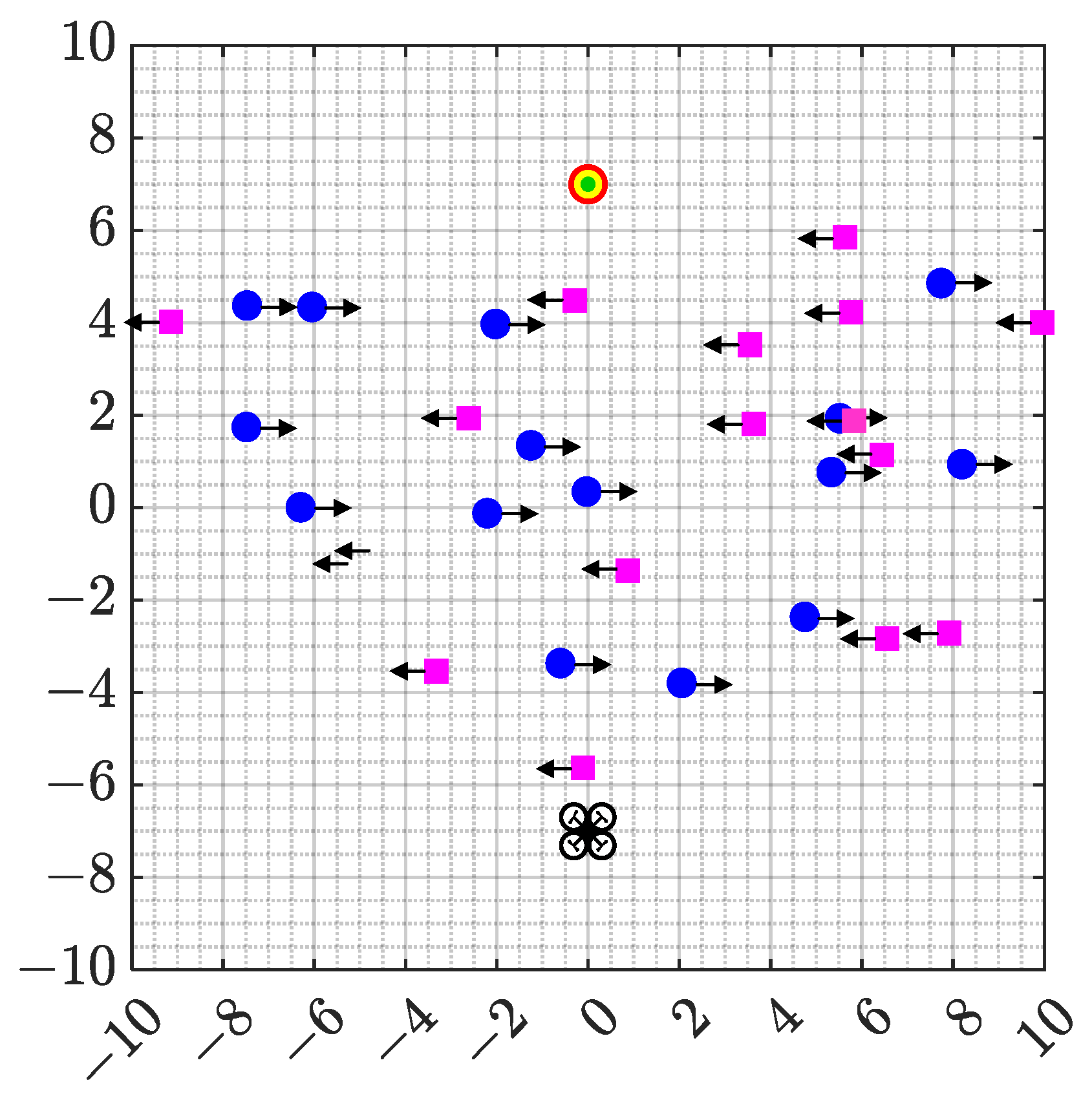
To further verify the performance of the trained algorithm, a dynamic test scenario is constructed as shown in
Figure 11. The starting and target points are represented in the figure as [0, −7] and [0, 7], respectively. The UAV’s flight mission is defined as autonomous flight from the starting point to the target point. During each test, 30 obstacles are randomly generated in the test area. The movement direction of the obstacles is marked by the arrow in the figure. After reaching the edge of the field, the obstacles will continue to move in the opposite direction until the end of this test. The moving speeds of the obstacles are set at 0.01 m/s, 0.05 m/s, 0.1 m/s, 0.15 m/s, and 0.2 m/s, respectively. Each set of experiments is performed 100 times, and the position of the obstacle will be regenerated after each test.
The experimental results of all algorithms in five dynamic scenes are presented in
Table 2. It can be seen from the table that the proposed algorithm achieved the highest navigation success rate and the lowest collision rate in the experiments under different moving speeds of obstacles, and no flight loss occurred, which shows the effectiveness of the proposed algorithm in highly dynamic scenarios. For comparison, the other three algorithms all experienced flight loss, among which SAC and DDPG had higher loss rates. It should be noted that as the speed of obstacle movement increases, the difficulty for the UAV to avoid obstacles increases sharply, resulting in a significant reduction in the success rate of all algorithms.
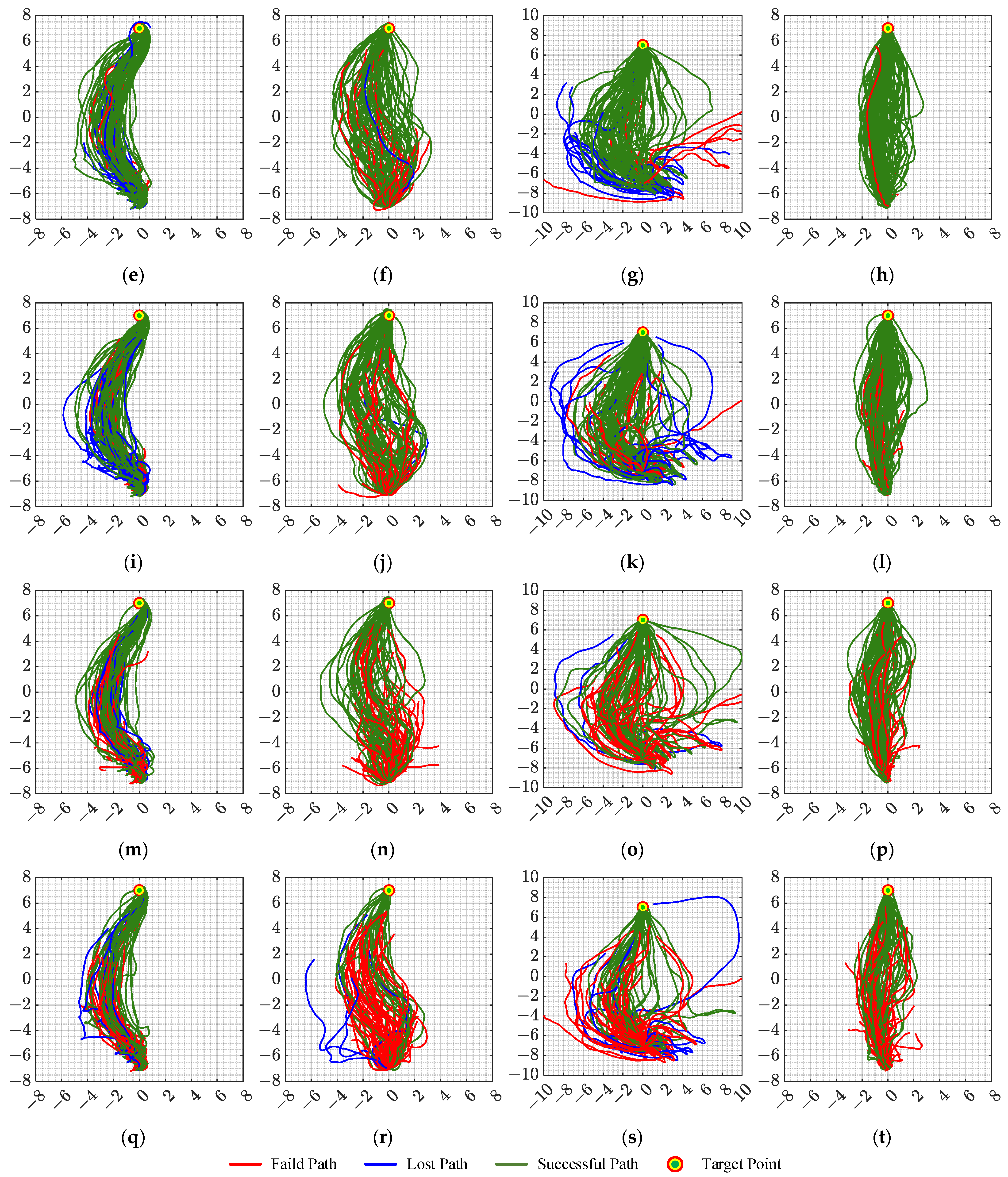
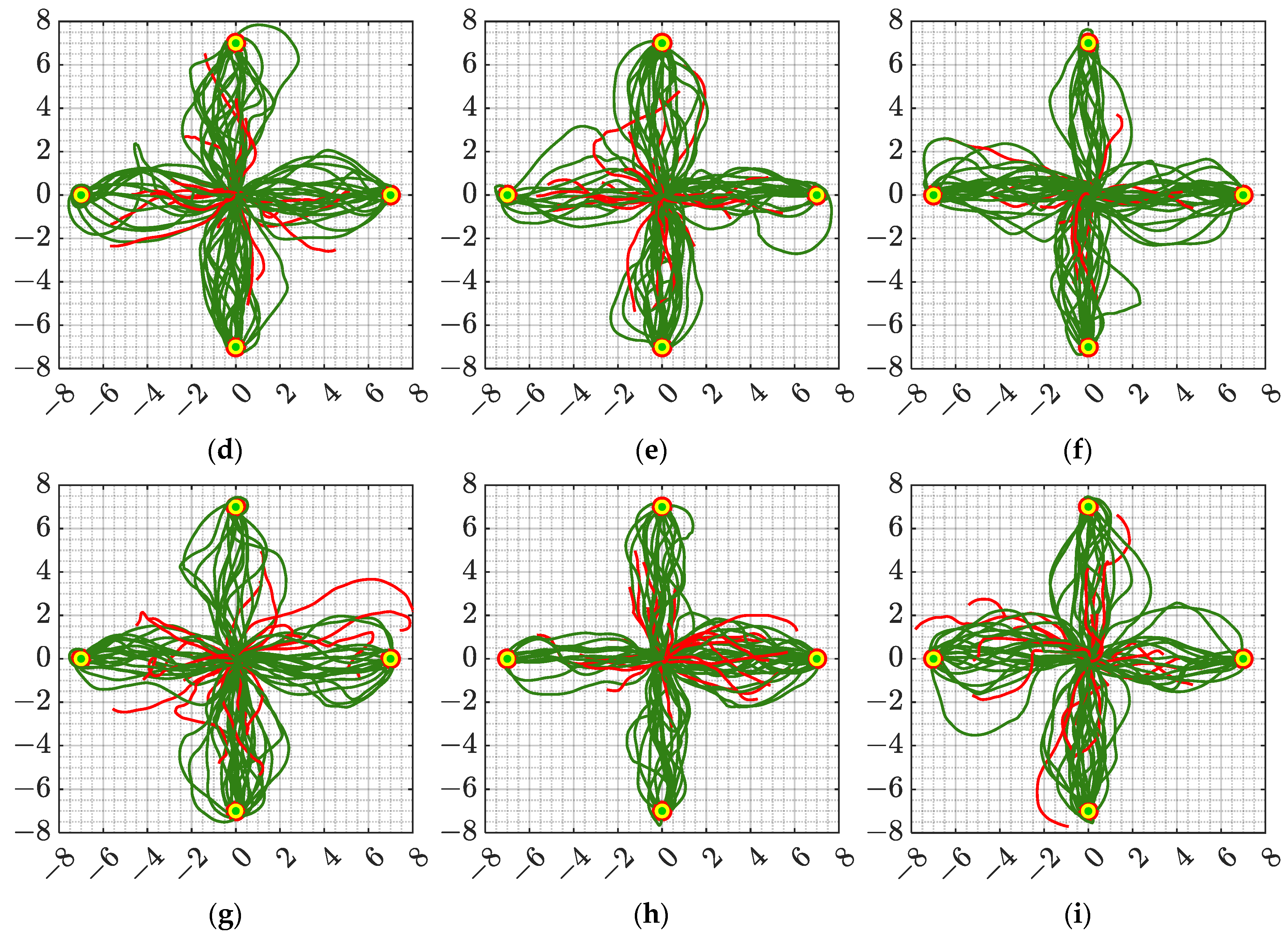
The flight trajectory of the UAV in the highly dynamic test is shown in
Figure 12. It can be seen from the flight trajectory in the figure that the algorithm proposed in this article can fly from the starting point to the target point more directly, while several other algorithms have more messy flight trajectories, which shows that the proposed algorithm can not only adapt to high-density flight environments, but also apply to highly dynamic scenarios that have not appeared in the training phase. Based on the flight trajectory of the UAV, the average flight distance
, and the average number of flight steps
of the UAV in the dynamic scenario are calculated, as shown in
Figure 13.
As can be seen from
Figure 13, the proposed algorithm has the shortest average flight distance and the least average number of flight steps in all five dynamic flight scenarios. Corresponding to the flight trajectory in
Figure 12, although SAC has a higher navigation success rate than TD3 and DDPG, its required flight distance is much higher than other algorithms. The TD3 algorithm has a lower average flight distance but the largest number of flight steps, which shows that the algorithm is more “cautious” in dynamic scenes.
Figure 13 shows that the proposed algorithm not only has a high navigation success rate but also has the highest navigation efficiency when facing a highly dynamic flight environment, enabling the UAV to achieve autonomous navigation quickly and accurately.
5.5. Experiment III: Verify the Validity of the Reward
Experiments on UAVs in high-density and highly dynamic scenarios verified the effectiveness and reliability of the proposed algorithm. Based on the analysis in
Section 4.2, we constructed “radical” and “conservative” reward function models by setting different step rewards, collision rewards, and distance rewards in order to further compare and illustrate the effect of the dynamic reward function designed in this article. The specific description is as follows:
Model 1: Based on Formulas (28)–(30), set , , , respectively. By giving the agent a smaller step penalty and a larger collision penalty, the agent tends to choose a conservative behavior away from obstacles.
Model 2: Based on Formulas (28)–(30), set , , , respectively. By giving the agent a larger step penalty and a smaller collision penalty, the agent is inclined to choose radical behavior to explore the environment.
Models with different reward functions were trained in the simulation scenario shown in
Figure 6, and the reward convergence curve obtained is shown in
Figure 14.
It can be seen from the figure that compared with the other two models, the model proposed in this article has the fastest convergence speed and optimal reward. In addition, since model 1 has a more “conservative” reward function, it converges faster than model 2 in the early stage of training, and model 2 explores a better strategy after a period of training, so it converges faster than model 1.
In order to verify the performance of the two trained models, the high-density simulation environment shown in
Figure 8c–e is used for testing. The test results are shown in
Table 3. As can be seen from the table, comparing the two algorithms with fixed reward functions, the proposed algorithm has the highest navigation success rate in all scenarios, and the navigation success rate of model 1 is slightly higher than that of model 2.
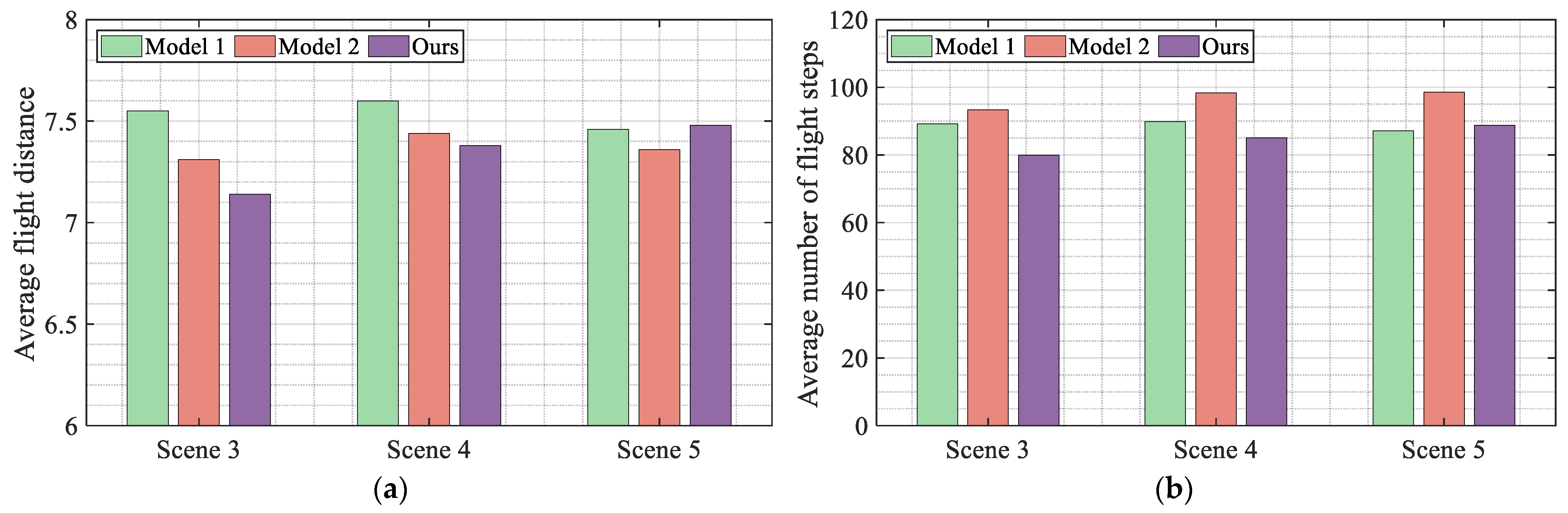
The flight trajectory of the UAV in the test is drawn as shown in
Figure 15, and the average flight distance and average number of flight steps calculated based on the flight trajectory are shown in
Figure 16. Combining all the experimental results in the figure, it can be seen that the proposed algorithm has the optimal flight efficiency.
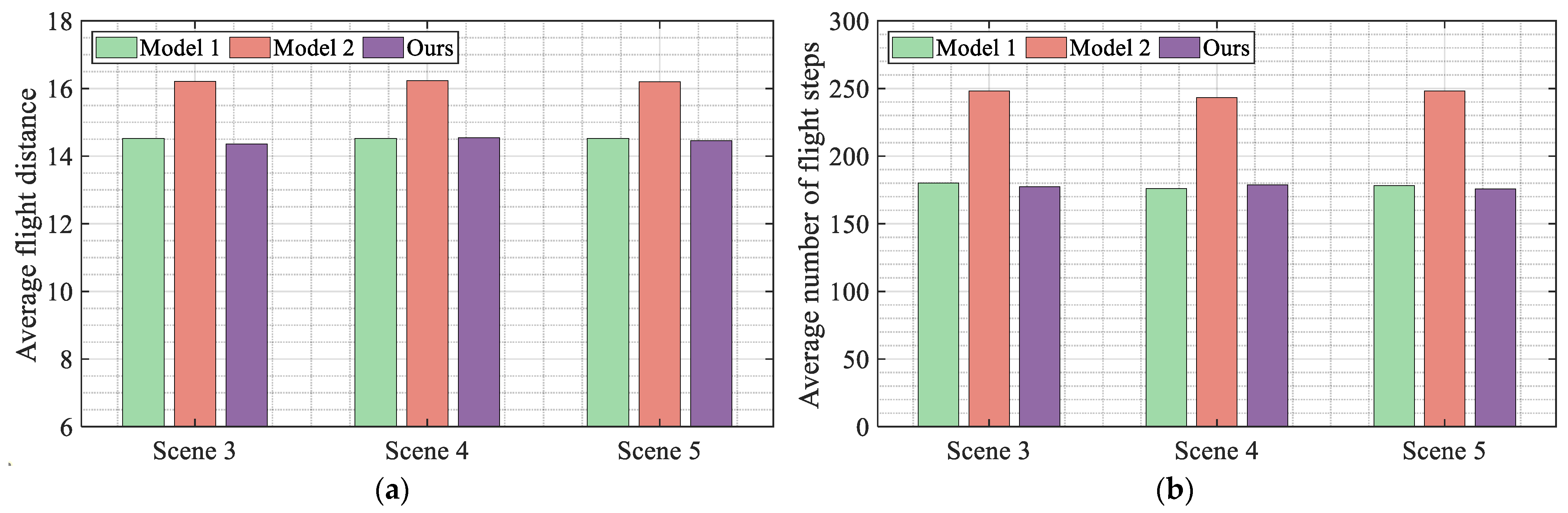
Model 1 and model 2 were verified in highly dynamic scenarios with obstacle movement speeds of 0.1 m/s, 0.15 m/s, and 0.2 m/s, respectively. The obtained test results and UAV flight trajectories are shown in
Table 4 and
Figure 17 and
Figure 18.
As can be seen from
Table 4, the proposed algorithm still has the optimal navigation success rate in a highly dynamic flight environment. In addition, the navigation success rate of model 1 in dynamic scenes is higher than that of model 2, which demonstrates the advantages of models with conservative reward functions compared to models with radical reward functions. Comparing the flight trajectories shown in
Figure 15 and
Figure 17, it can be seen that the flight trajectory of model 2 in the dynamic scene has significant bends, which indicates that the model has poor generalization, resulting in model 2 having the highest average flight distance and average flight steps. As can be seen from
Figure 18, the dynamic reward function constructed in this article can effectively improve the navigation performance of the UAV and further optimize its flight efficiency.
6. Conclusions
This paper proposes a DRL-based autonomous navigation and obstacle avoidance algorithm for UAV to achieve autonomous path planning in high-density and highly dynamic environments. First, by analyzing the impact of UAV position changes and angle changes on flight performance in complex environments, a state space representation method containing angle change information is proposed. Then, a dynamic reward function is constructed to balance the exploratory and conservative behaviors of the agent. Finally, a highly dynamic and high-density simulation environment is built to verify the proposed algorithm. The results show that the proposed algorithm can have the highest navigation success rate, and can improve the efficiency of autonomous flight while improving the navigation performance of the UAV.
Although the effectiveness of the proposed algorithm has been verified in a simulation environment, there are still some issues that deserve further study, for example, comparison with some more advanced algorithms and verification of the performance of the proposed method in a real environment. Therefore, we will test the flight effect of the proposed algorithm in a real environment on a physical UAV platform in the future to promote the practical application of the algorithm.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}