
UAVs-Based Visual Localization via Attention-Driven Image Registration Across Varying Texture Levels


Abstract
1. Introduction
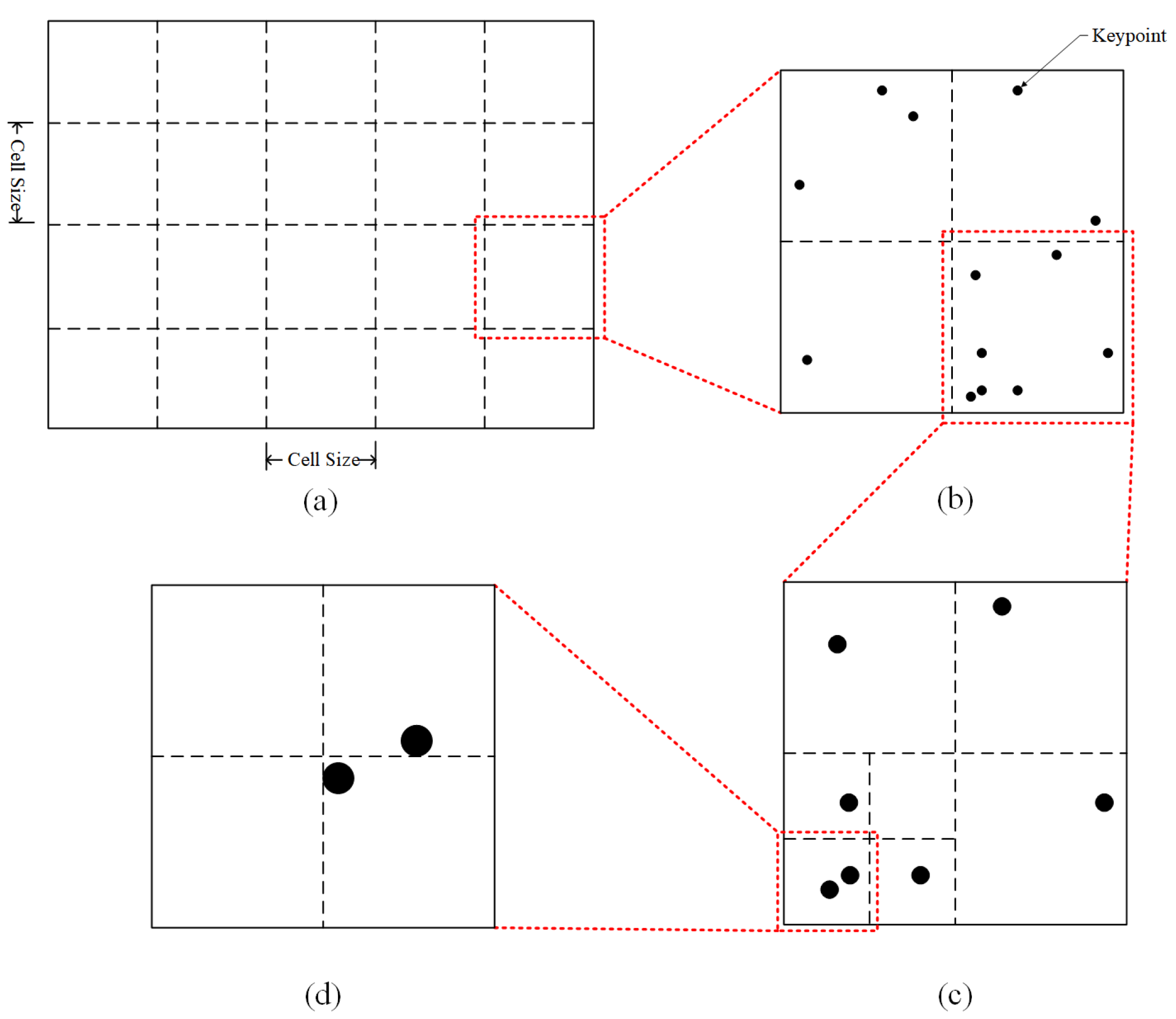
- This study introduces a quadtree feature point uniformization algorithm applied to Oriented FAST and Rotated BRIEF (ORB) feature points. The aim is to reduce the negative impact of densely concentrated feature points in areas with significant texture variation on motion estimation. This enhancement improves the accuracy of motion estimation for UAVs during high-speed flight in low-texture environments;
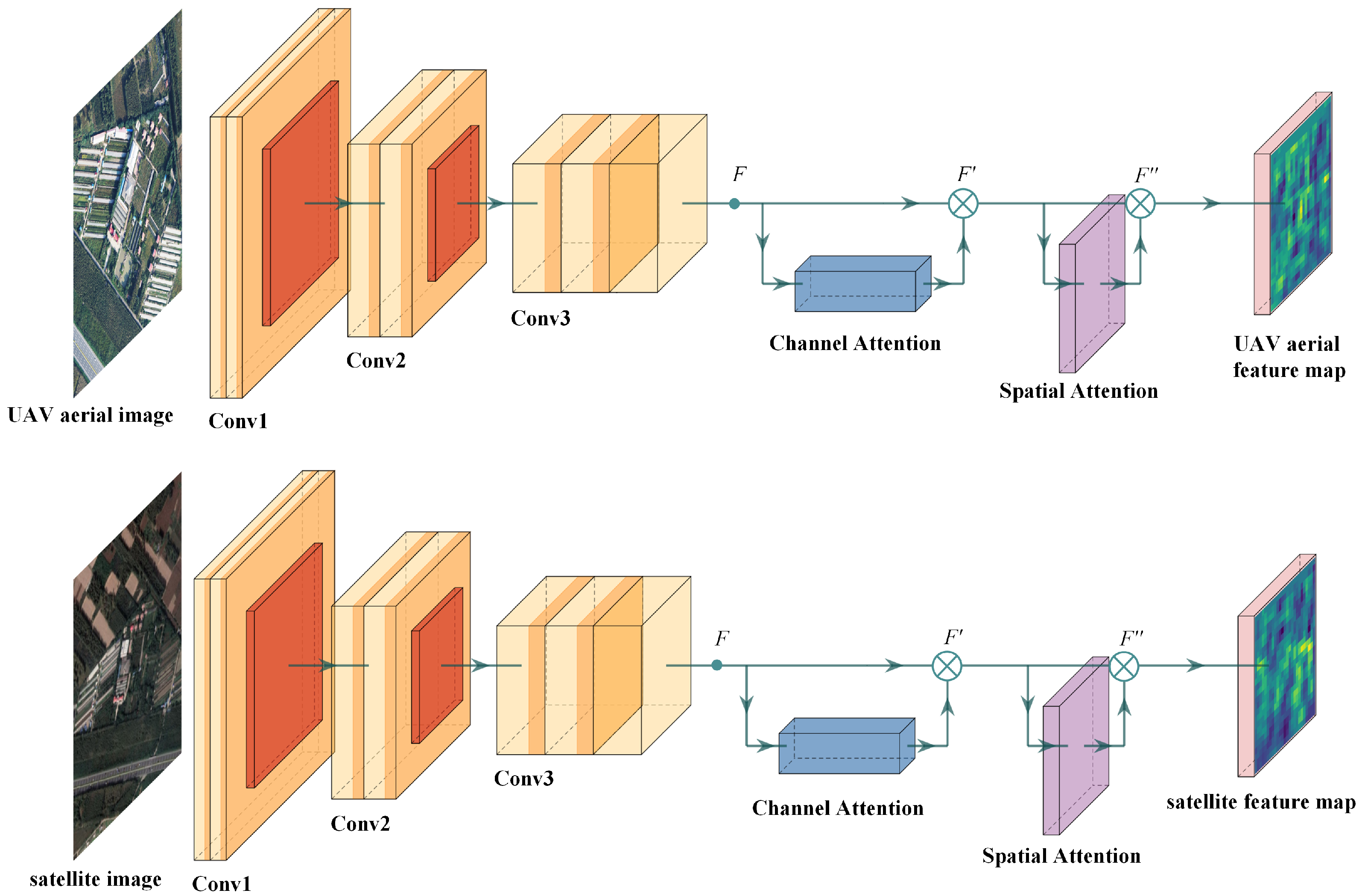
- This study present a twin neural network registration algorithm that leverages an attention mechanism by integrating the Convolutional Block Attention Module (CBAM) into the feature extraction layer of neural network. The Lucas-Kanade algorithm is then employed to align the feature maps processed by the convolutional network. This enhanced algorithm shows a marked improvement in matching performance for low-texture images;
- This study propose a novel vision positioning method that combines relative and absolute visual positioning through image registration. This method effectively mitigates the cumulative error associated with relative visual positioning during long-distance flights, enabling rapid and accurate positioning in low-texture environments, such as agricultural fields and river landscapes.
2. Related Works
3. Proposed Methodology
3.1. Estimation of Initial Motion for UAVs
3.2. Siamese Neural Network Based on Attention Mechanism
3.3. Image Registration Based on the Lucas-Kanade Algorithm
3.4. Train
4. Experiments
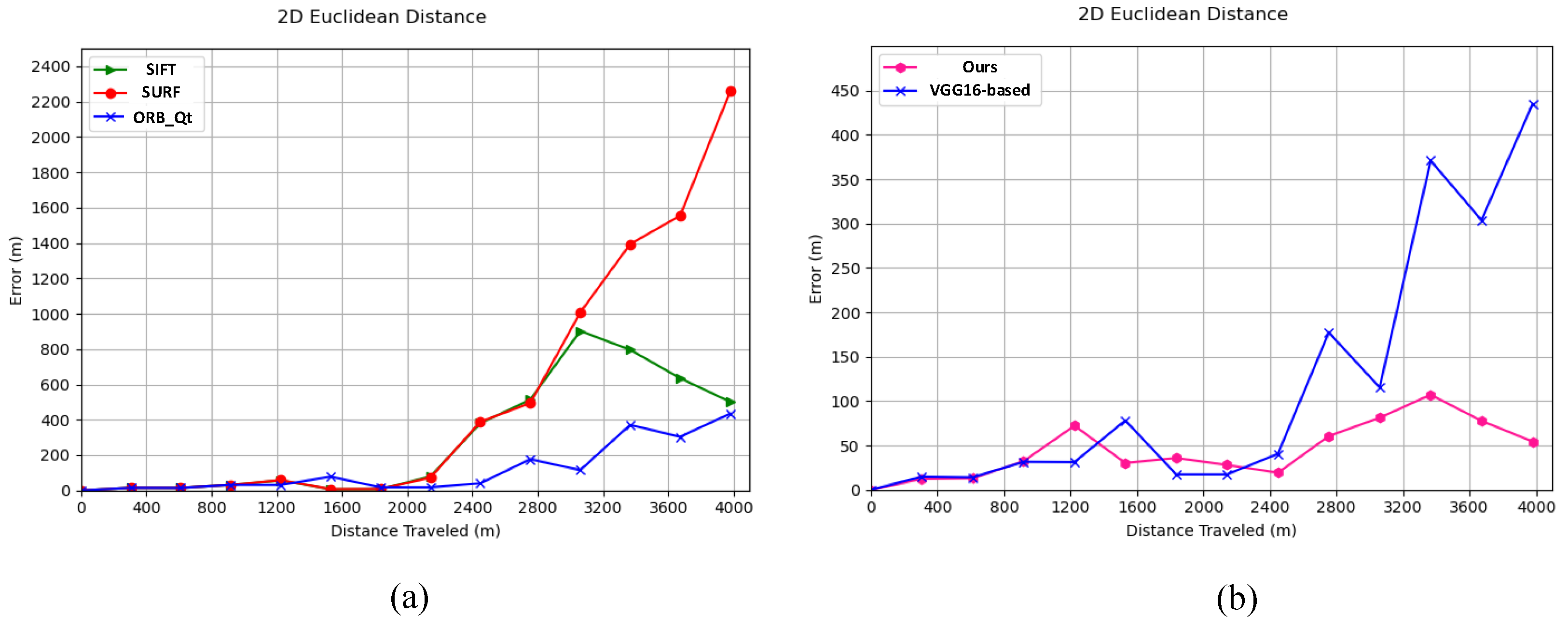
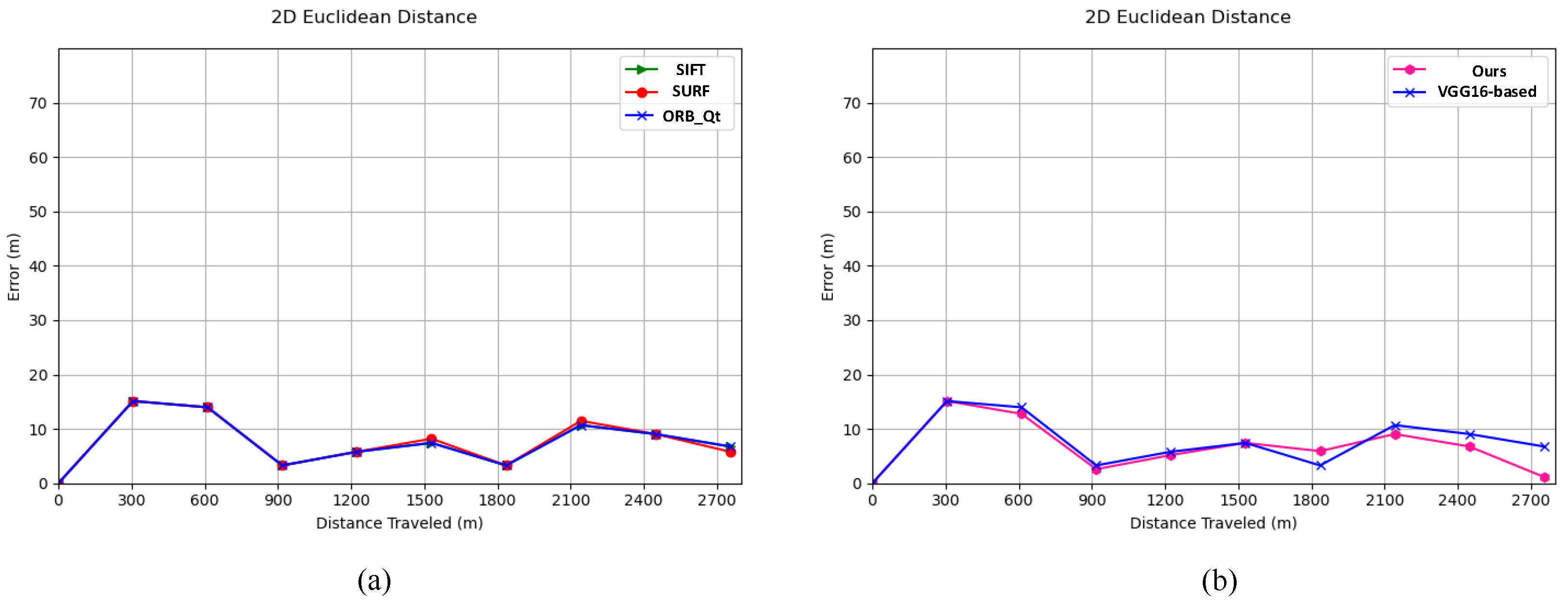
4.1. Feature Point Extraction and Matching
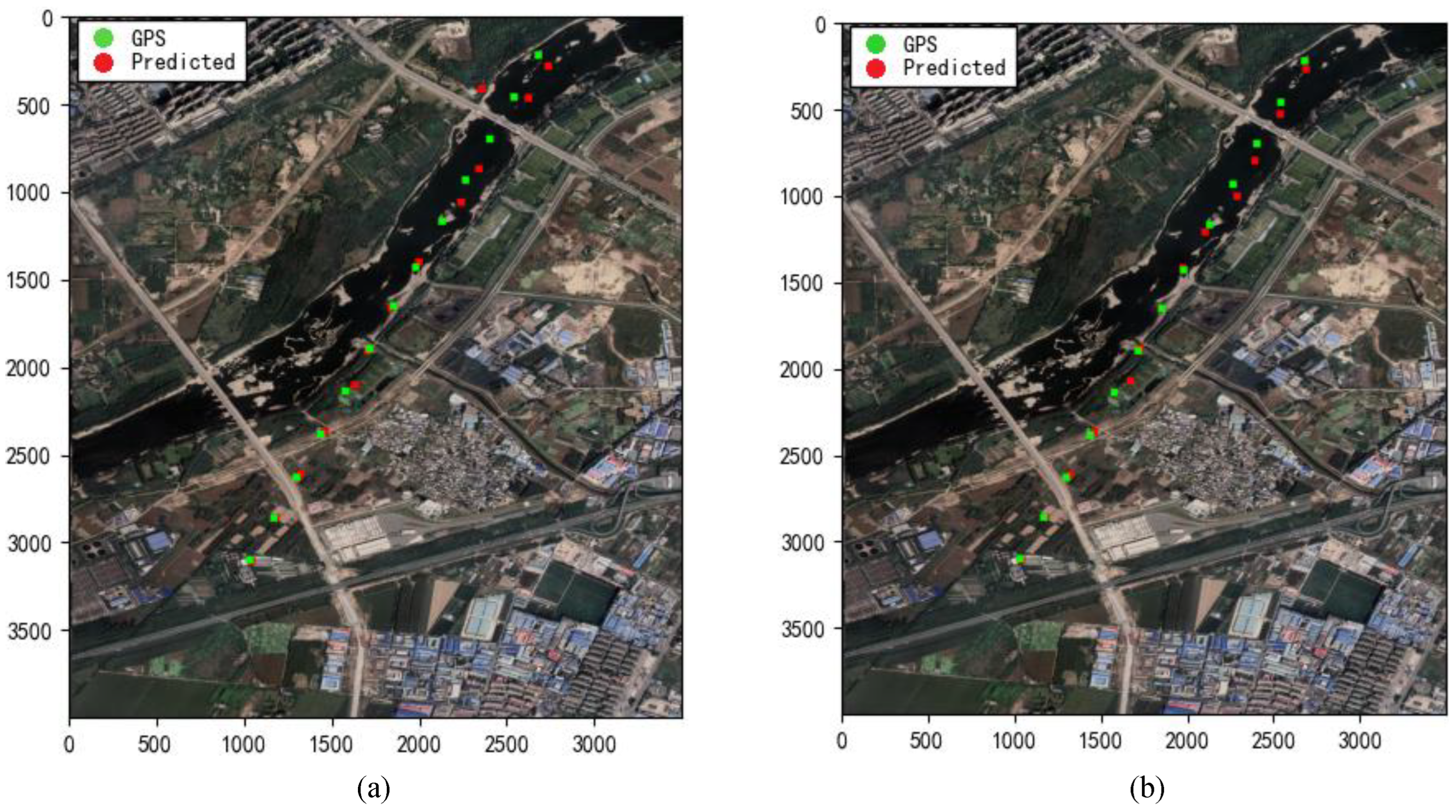
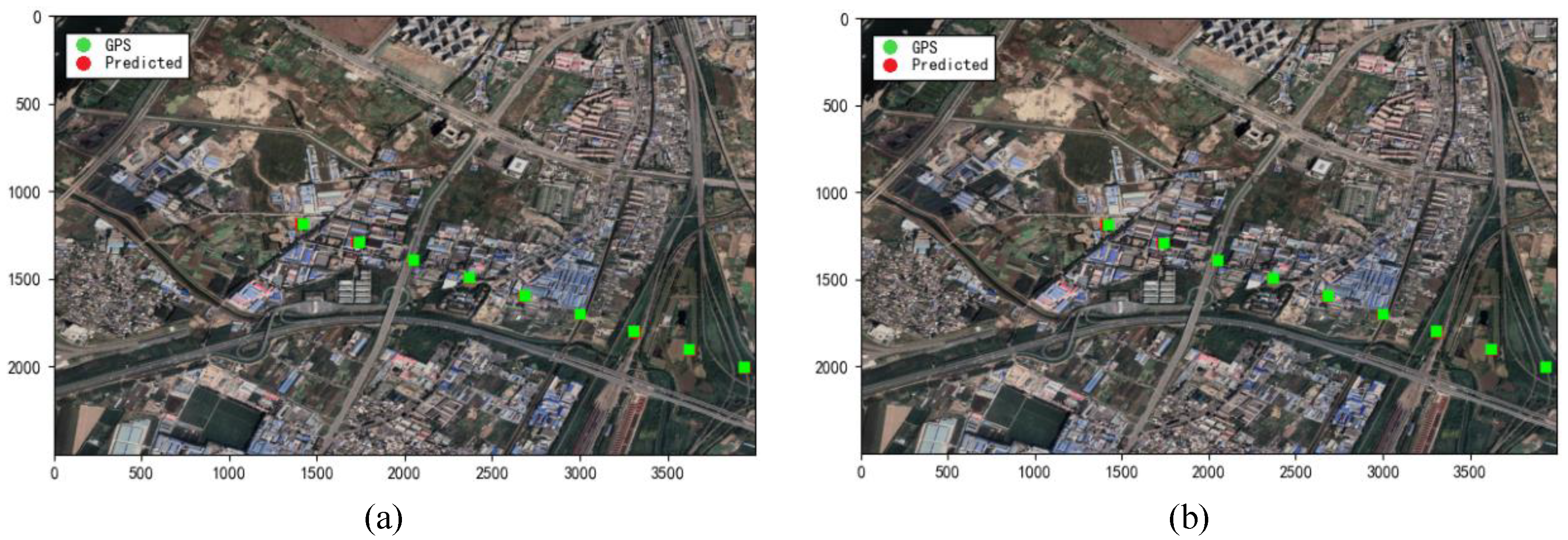
4.2. Image Registration and Localization for Low-Texture Areas
4.3. Image Registration and Localization for High-Texture Areas
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Scherer, J.; Yahyanejad, S.; Hayat, S.; Yanmaz, E.; Andre, T.; Khan, A.; Rinner, B. An autonomous multi-UAV system for search and rescue. In Proceedings of the First Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Florence, Italy, 18 May 2015; pp. 33–38. [Google Scholar]
- Siebert, S.; Teizer, J. Mobile 3D Mapping for Surveying Earthwork Using an Unmanned Aerial Vehicle (UAV). In Proceedings of the International Symposium on Automation and Robotics in Construction, Montreal, QC, Canada, 11 August 2013. [Google Scholar]
- Tokekar, P.; Hook, J.V.; Mulla, D.; Isler, V. Sensor Planning for a Symbiotic UAV and UGV System for Precision Agriculture. IEEE Trans. Robot. 2016, 32, 1498–1511. [Google Scholar] [CrossRef]
- Lu, Y.; Macias, D.; Dean, Z.S.; Kreger, N.R.; Wong, P.K. A UAV-Mounted Whole Cell Biosensor System for Environmental Monitoring Applications. IEEE Trans. Nanobiosci. 2015, 14, 811–817. [Google Scholar] [CrossRef] [PubMed]
- Tomaštík, J.; Mokroš, M.; Surový, P.; Grznárová, A.; Merganič, J. UAV RTK/PPK method—An optimal solution for mapping inaccessible forested areas? Remote Sens. 2019, 11, 721. [Google Scholar] [CrossRef]
- Choi, J.; Myung, H. BRM localization: UAV localization in GNSS-denied environments based on matching of numerical map and UAV images. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4537–4544. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lu, Z.; Liu, F.; Lin, X. Vision-based localization methods under GPS-denied conditions. arXiv 2022, arXiv:2211.11988. [Google Scholar]
- Couturier, A.; Akhloufi, M.A. A review on absolute visual localization for UAV. Robot. Auton. Syst. 2021, 135, 103666. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Trajković, M.; Hedley, M. Fast corner detection. Image Vis. Comput. 1998, 16, 75–87. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the 11th European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Patel, B.; Barfoot, T.D.; Schoellig, A.P. Visual localization with Google Earth images for robust global pose estimation of UAVs. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6491–6497. [Google Scholar]
- Majidizadeh, A.; Hasani, H.; Jafari, M. Semantic segmentation of UAV images based on U-NET in urban area. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 10, 451–457. [Google Scholar] [CrossRef]
- Zhong, L.; Meng, L.; Hou, W.; Huang, L. An improved visual odometer based on Lucas-Kanade optical flow and ORB feature. IEEE Access 2023, 11, 47179–47186. [Google Scholar] [CrossRef]
- Zhang, G.; Yuan, Q.; Liu, Y. Research on Optimization Method of Visual Odometer Based on Point Line Feature Fusion. In Proceedings of the 2023 7th International Conference on High Performance Compilation, Computing and Communications, Jinan, China, 17–19 June 2023; pp. 274–280. [Google Scholar]
- Mu, Q.; Guo, S. Improved algorithm of indoor visual odometer based on point and line feature. In Proceedings of the 2022 2nd International Conference on Control and Intelligent Robotics, Nanjing, China, 24–26 June 2022; pp. 794–799. [Google Scholar]
- Goforth, H.; Lucey, S. GPS-denied UAV localization using pre-existing satellite imagery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2974–2980. [Google Scholar]
- He, M.; Zhu, C.; Huang, Q.; Ren, B.; Liu, J. A review of monocular visual odometry. Vis. Comput. 2020, 36, 1053–1065. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Alvey Vision Conference; Alvey Vision Club: Manchester, UK, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Smith, S.M.; Brady, J.M. SUSAN—A new approach to low level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Morel, J.M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, Z.; Fan, H.; Fu, S.; Tang, Y. Unsupervised person re-identification based on adaptive information supplementation and foreground enhancement. IET Image Process. 2024. [Google Scholar] [CrossRef]
- Ren, W.; Luo, J.; Jiang, W.; Qu, L.; Han, Z.; Tian, J.; Liu, H. Learning Self-and Cross-Triplet Context Clues for Human-Object Interaction Detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 9760–9773. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhao, P.; Zhang, D.; Wang, H. MR-DCAE: Manifold regularization-based deep convolutional autoencoder for unauthorized broadcasting identification. Int. J. Intell. Syst. 2021, 36, 7204–7238. [Google Scholar] [CrossRef]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in Euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Ebel, P.; Mishchuk, A.; Yi, K.M.; Fua, P.; Trulls, E. Beyond Cartesian representations for local descriptors. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 253–262. [Google Scholar]
- Verdie, Y.; Yi, K.; Fua, P.; Lepetit, V. Tilde: A temporally invariant learned detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5279–5288. [Google Scholar]
- Barroso-Laguna, A.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Key.net: Keypoint detection by handcrafted and learned CNN filters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5836–5844. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VI 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 467–483. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A trainable CNN for joint description and detection of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8092–8101. [Google Scholar]
- Hou, H.; Xu, Q.; Lan, C.; Lu, W.; Zhang, Y.; Cui, Z.; Qin, J. UAV pose estimation in GNSS-denied environment assisted by satellite imagery deep learning features. IEEE Access 2020, 9, 6358–6367. [Google Scholar] [CrossRef]
- Xu, Y.; Zhong, D.; Zhou, J.; Jiang, Z.; Zhai, Y.; Ying, Z. A novel UAV visual positioning algorithm based on A-YOLOX. Drones 2022, 6, 362. [Google Scholar] [CrossRef]
- Gurgu, M.M.; Queralta, J.P.; Westerlund, T. Vision-based GNSS-free localization for UAVs in the wild. In Proceedings of the 2022 7th International Conference on Mechanical Engineering and Robotics Research (ICMERR), Krakow, Poland, 9–11 December 2022; pp. 7–12. [Google Scholar]
- Ren, Y.; Liu, Y.; Huang, Z.; Liu, W.; Wang, W. 2ChADCNN: A template matching network for season-changing UAV aerial images and satellite imagery. Drones 2023, 7, 558. [Google Scholar] [CrossRef]
- Abdelaziz, S.I.K.; Elghamrawy, H.Y.; Noureldin, A.M.; Fotopoulos, G. Body-centered dynamically-tuned error-state extended Kalman filter for visual inertial odometry in GNSS-denied environments. IEEE Access 2024, 12, 15997–16008. [Google Scholar] [CrossRef]
- Pang, W.; Zhu, D.; Chu, Z.; Chen, Q. Distributed adaptive formation reconfiguration control for multiple AUVs based on affine transformation in three-dimensional ocean environments. IEEE Trans. Veh. Technol. 2023, 72, 7338–7350. [Google Scholar] [CrossRef]
- Hajder, L.; Barath, D. Relative planar motion for vehicle-mounted cameras from a single affine correspondence. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8651–8657. [Google Scholar]
- Wang, S.; Guo, Z.; Liu, Y. An image matching method based on SIFT feature extraction and FLANN search algorithm improvement. J. Phys. Conf. Ser. 2021, 2037, 012122. [Google Scholar] [CrossRef]
- Martínez-Otzeta, J.M.; Rodríguez-Moreno, I.; Mendialdua, I.; Sierra, B. RANSAC for robotic applications: A survey. Sensors 2022, 23, 327. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Route | SIFT [23] | SURF [24] | Method [18] | Ours | ||||
|---|---|---|---|---|---|---|---|---|
| Time (s) | Error (m) | Time (s) | Error (m) | Time (s) | Error (m) | Time (s) | Error (m) | |
| Low-texture route I | 198.429 | 281.332 | 346.932 | 543.122 | 53.288 | 33.06 | 33.176 | 38.670 |
| Low-texture route II | 140.862 | 6.919 | 260.785 | 6.925 | 47.517 | 17.82 | 26.538 | 6.502 |
| High-texture route I | 92.120 | 4.515 | 174.056 | 4.481 | 20.159 | 5.061 | 17.276 | 3.914 |
| High-texture route II | 118.591 | 7.539 | 168.616 | 7.599 | 28.367 | 6.324 | 18.186 | 7.512 |
| BASE | CAM | PAM | Low-Texture Route I | Low-Texture Route II | High-Texture Route I | High-Texture Route II |
|---|---|---|---|---|---|---|
| ✓ | 58.11 | 16.56 | 9.523 | 10.66 | ||
| ✓ | ✓ | 46.31 | 10.23 | 5.061 | 90.34 | |
| ✓ | ✓ | 44.57 | 8.223 | 5.166 | 7.135 | |
| ✓ | ✓ | ✓ | 38.67 | 6.502 | 3.914 | 7.512 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Dong, G.; Zhang, T.; Zhang, M.; Chen, X.; Xue, M. UAVs-Based Visual Localization via Attention-Driven Image Registration Across Varying Texture Levels. Drones 2024, 8, 739. https://doi.org/10.3390/drones8120739
Ren Y, Dong G, Zhang T, Zhang M, Chen X, Xue M. UAVs-Based Visual Localization via Attention-Driven Image Registration Across Varying Texture Levels. Drones. 2024; 8(12):739. https://doi.org/10.3390/drones8120739
Chicago/Turabian StyleRen, Yan, Guohai Dong, Tianbo Zhang, Meng Zhang, Xinyu Chen, and Mingliang Xue. 2024. "UAVs-Based Visual Localization via Attention-Driven Image Registration Across Varying Texture Levels" Drones 8, no. 12: 739. https://doi.org/10.3390/drones8120739
APA StyleRen, Y., Dong, G., Zhang, T., Zhang, M., Chen, X., & Xue, M. (2024). UAVs-Based Visual Localization via Attention-Driven Image Registration Across Varying Texture Levels. Drones, 8(12), 739. https://doi.org/10.3390/drones8120739