
Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector


Abstract
1. Introduction
- We construct two datasets of vehicle targets captured from the perspective of drone aerial photography, effectively overcoming the issue of data scarcity in this research area.
- We design a backbone network tailored for detecting small targets within complex backgrounds. Additionally, we adjust the anchors of the region proposal network (RPN) to enhance detection accuracy and speed.
- We introduce a postprocessing classification method based on out-of-distribution detection, enabling the identification of vehicle classes that were not encountered during the training phase.
2. Related Work
2.1. Object Detection Algorithm
2.2. Object Detection Algorithm for UAV
2.3. Out-of-Distribution Detection Algorithm
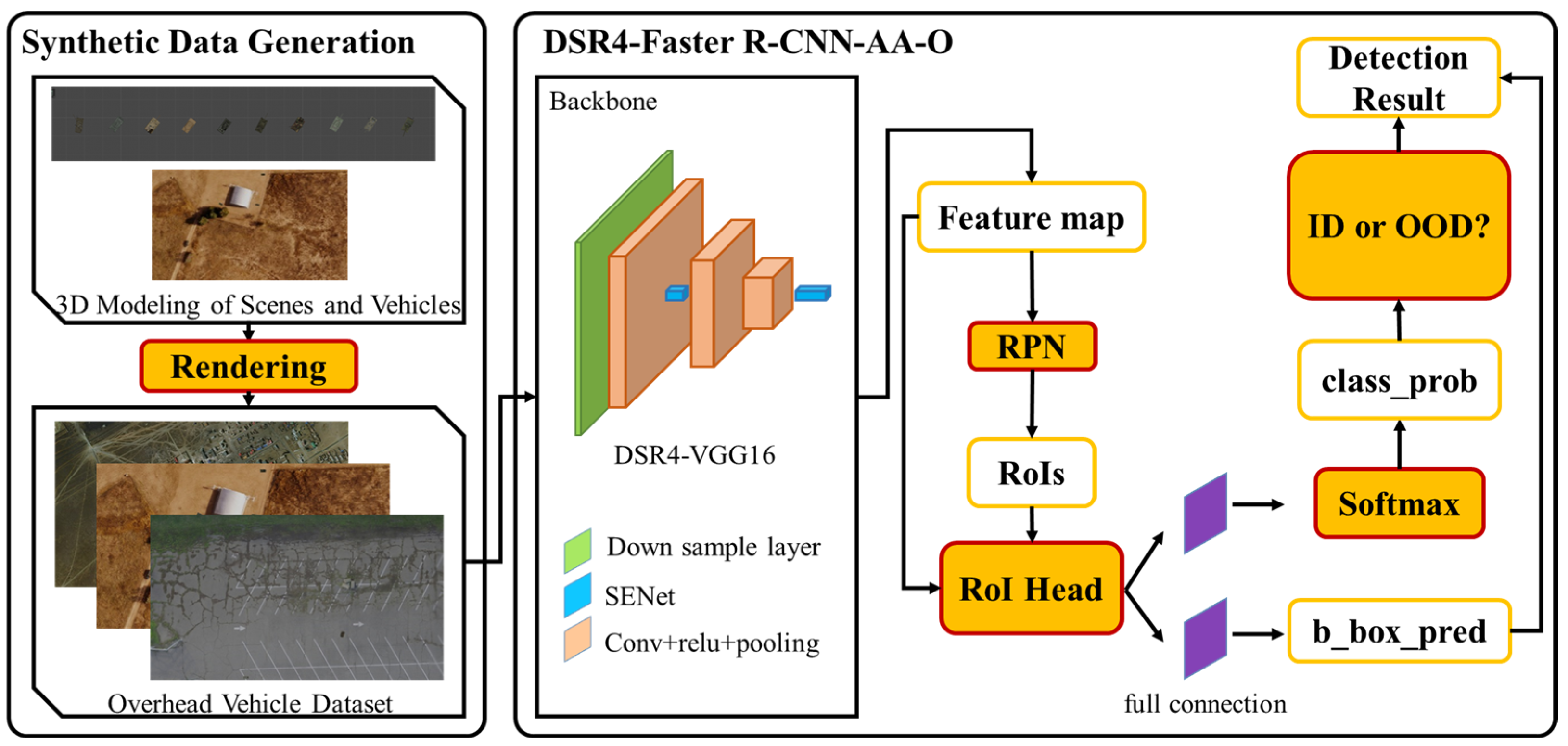
3. Proposed Method
3.1. Synthetic Data Generation
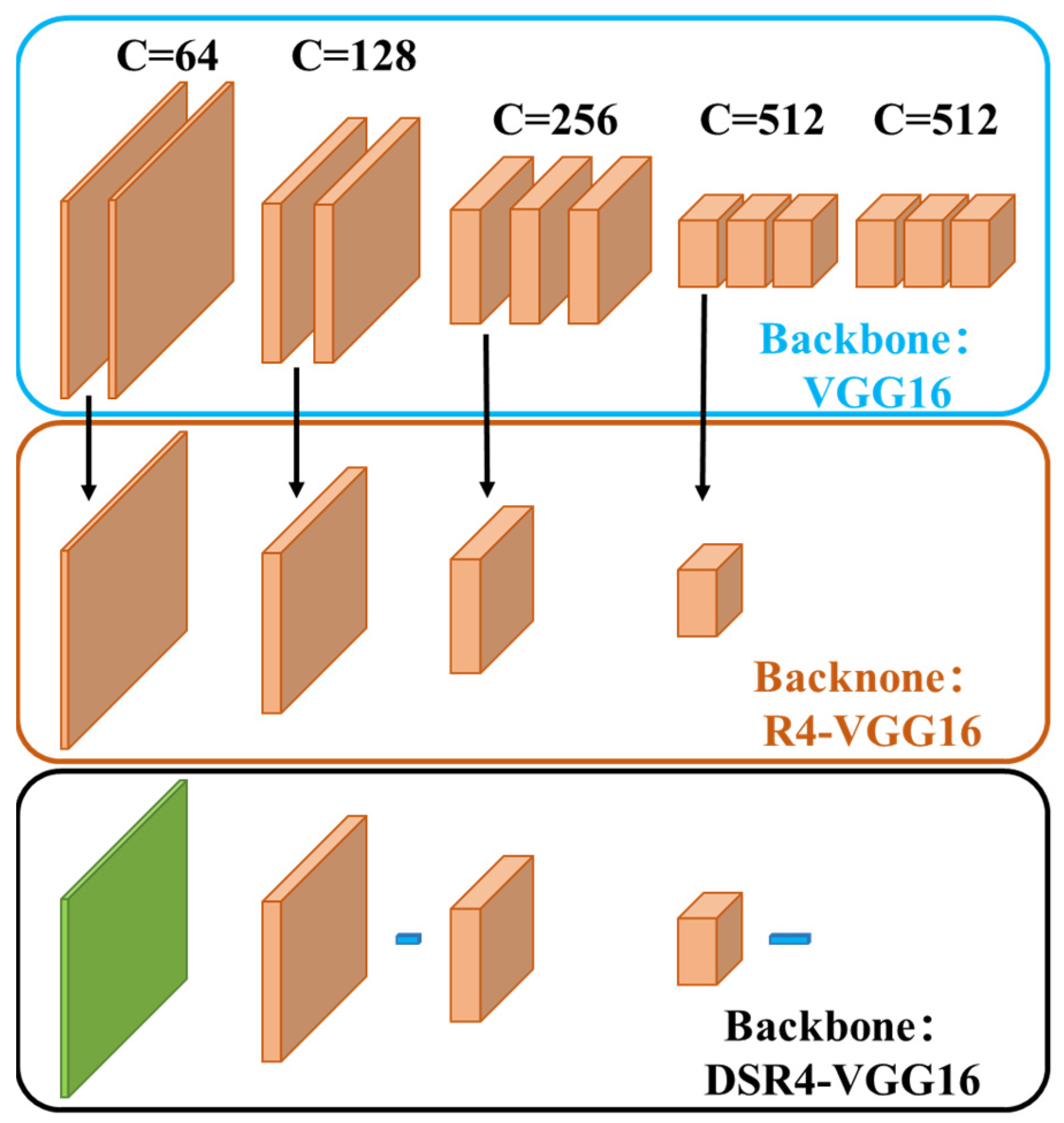
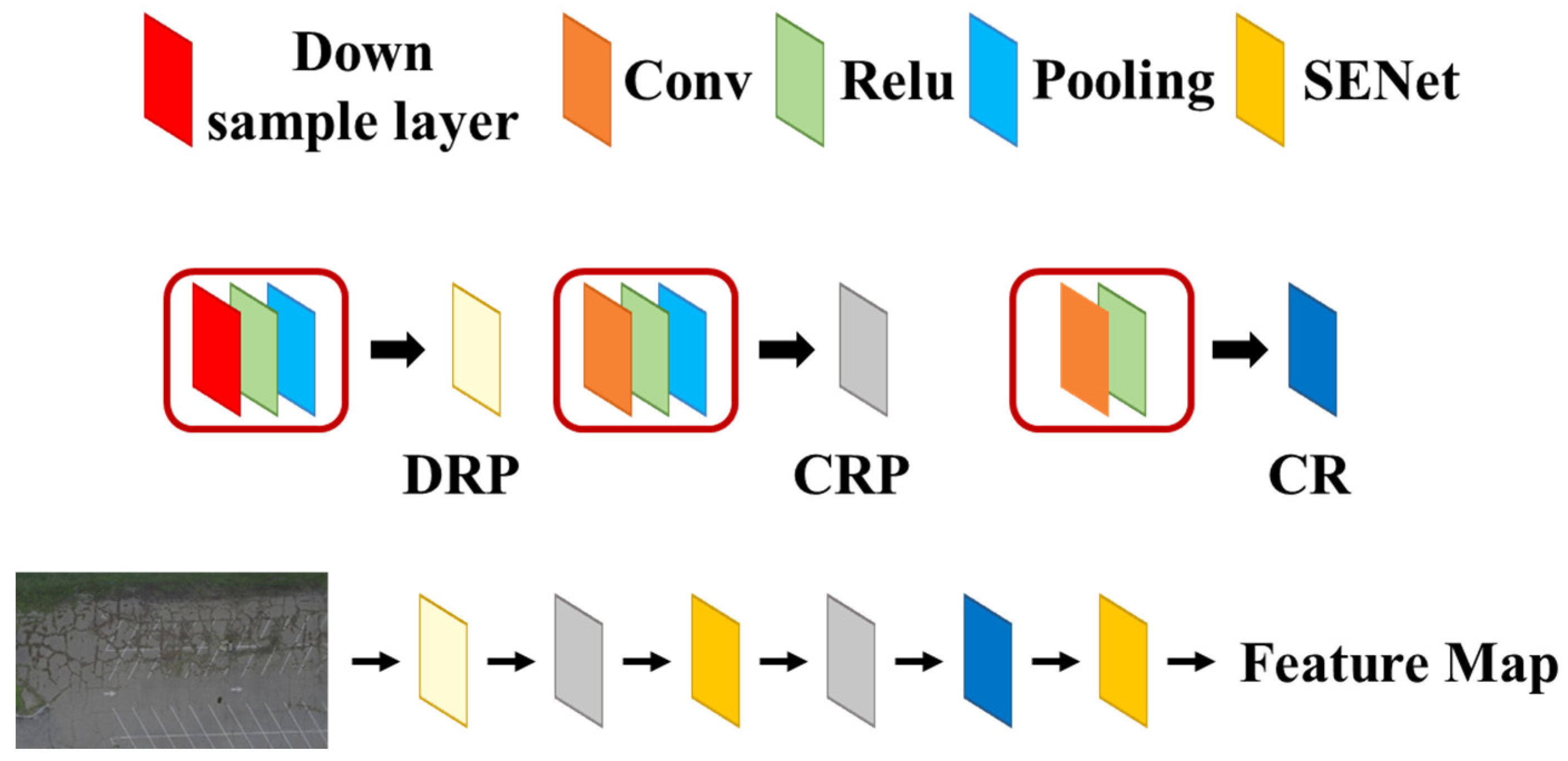
3.2. Backbone Design
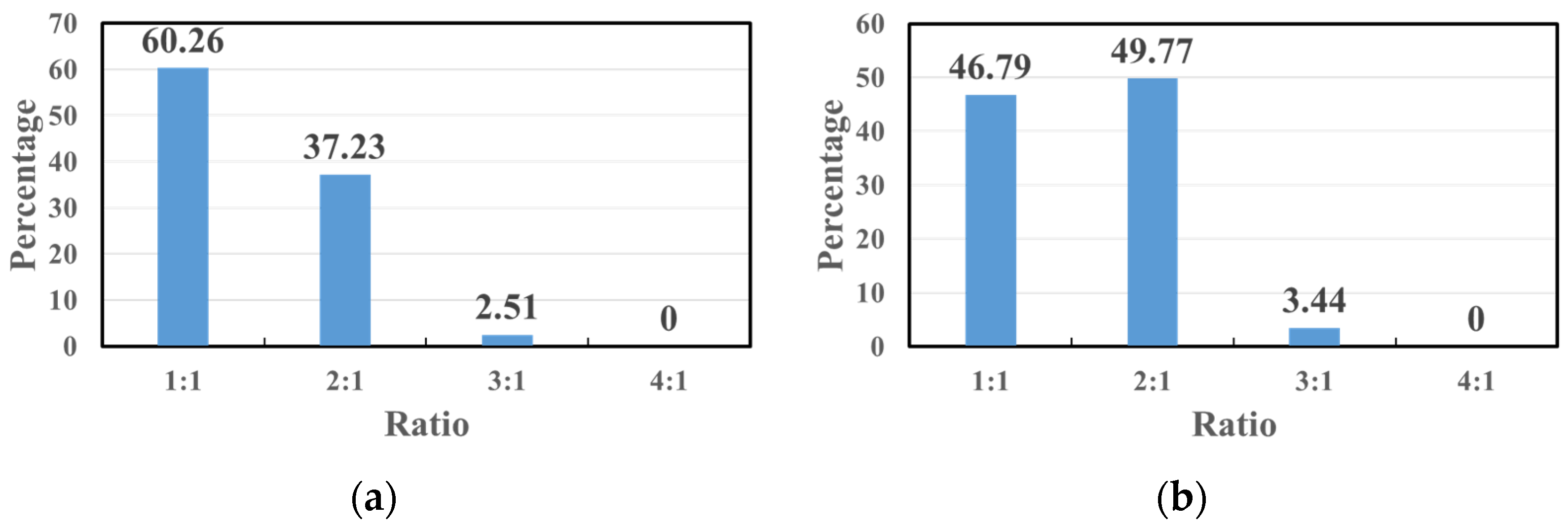
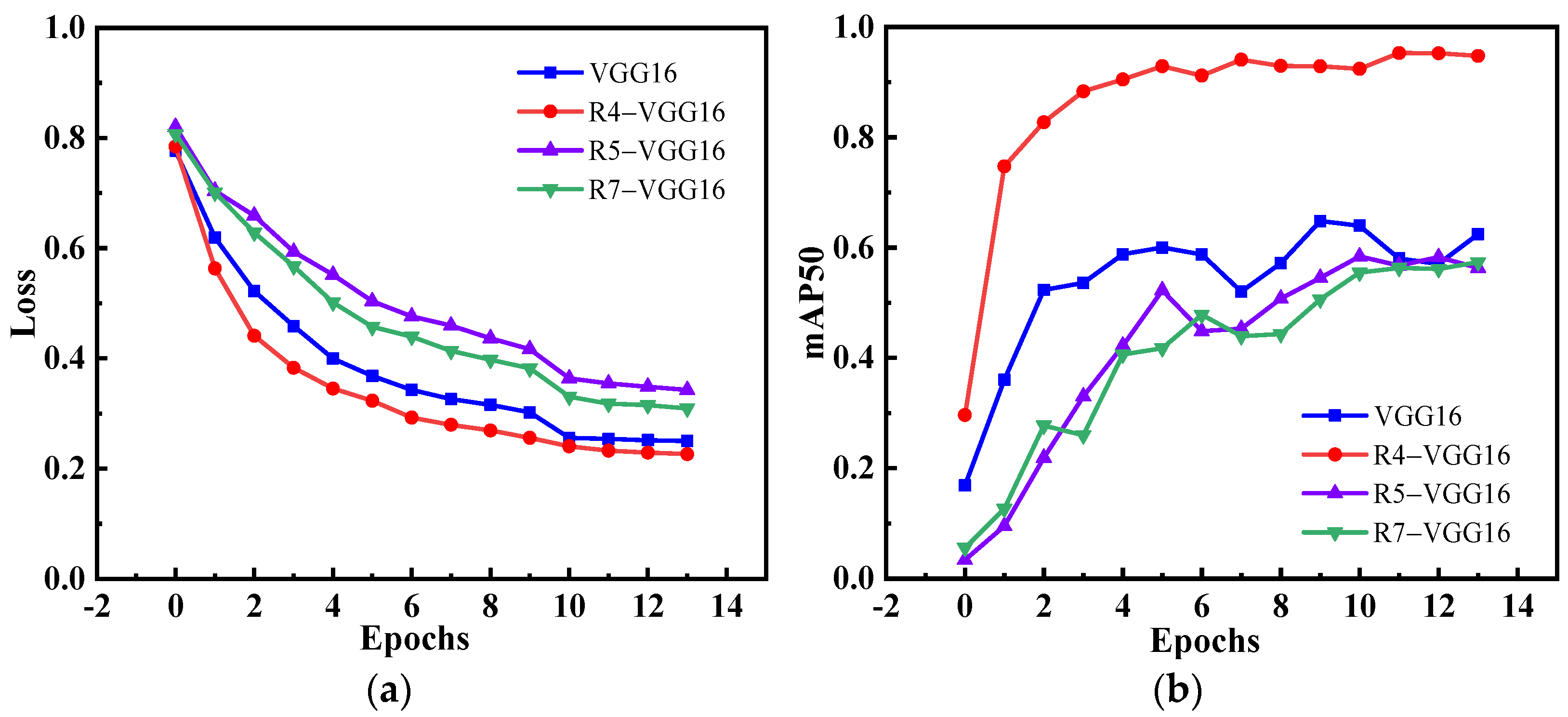
3.3. RPN’s Anchor Adjustment
3.4. Open Set Vehicle Recognition
4. Experiments
4.1. Datasets and Evaluation Criteria
4.2. Implementation Details and Settings
4.3. Experiment Results
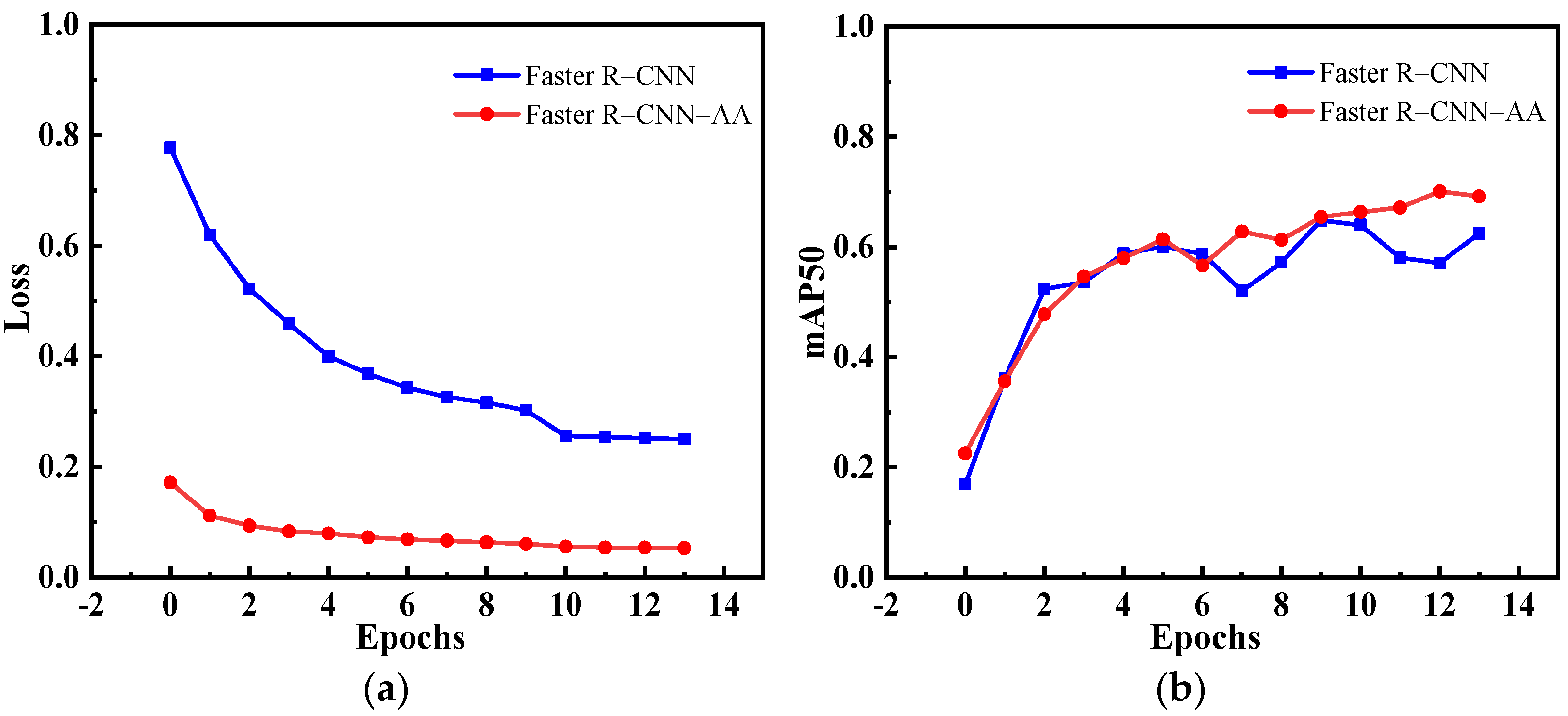
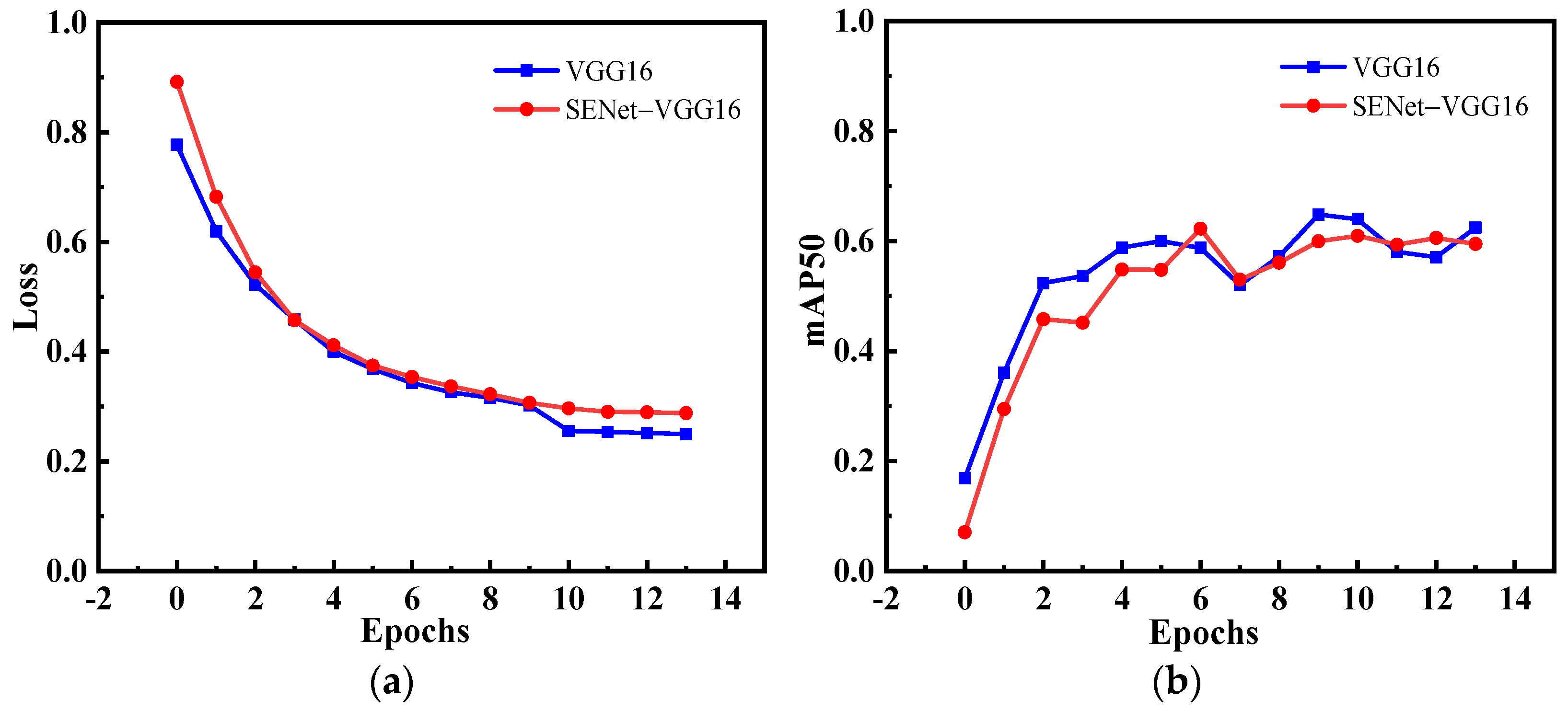
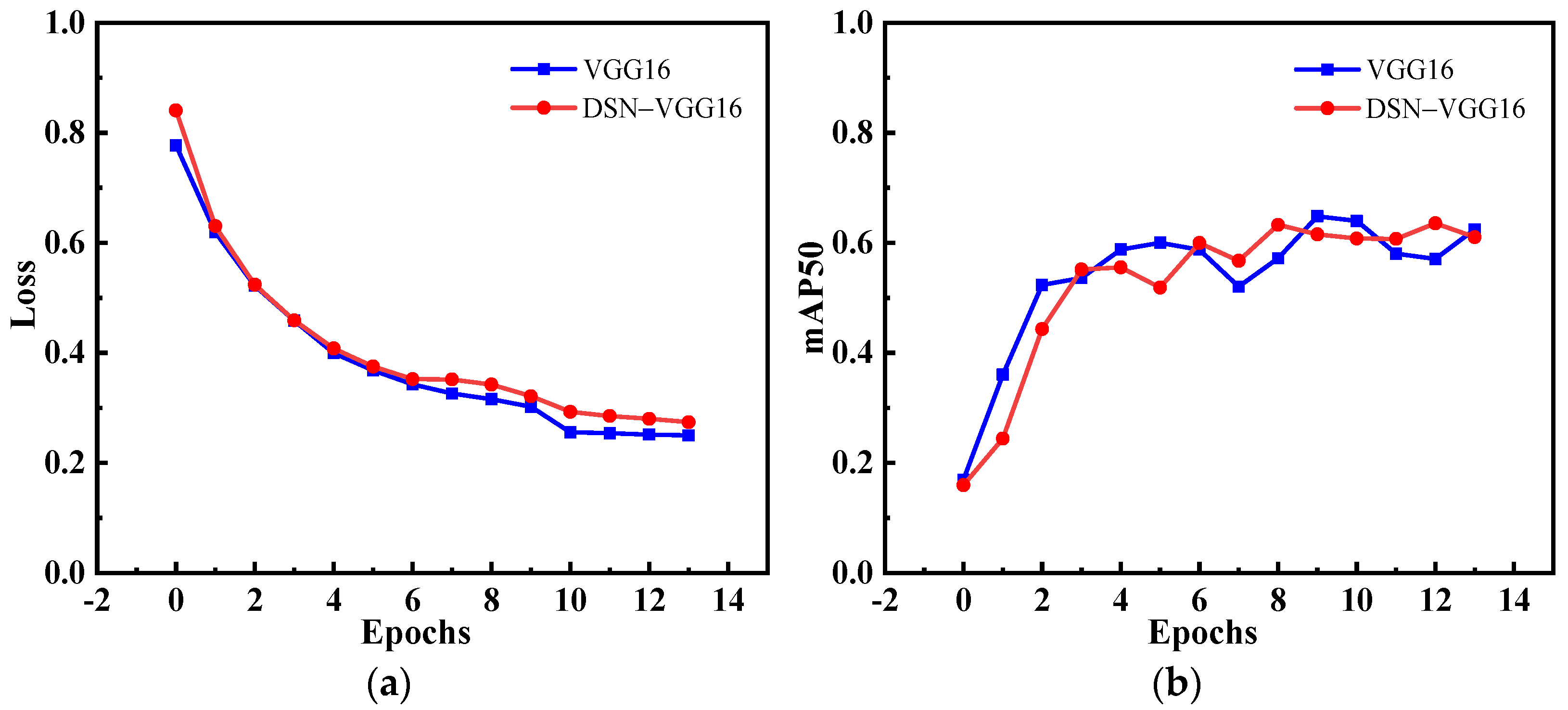
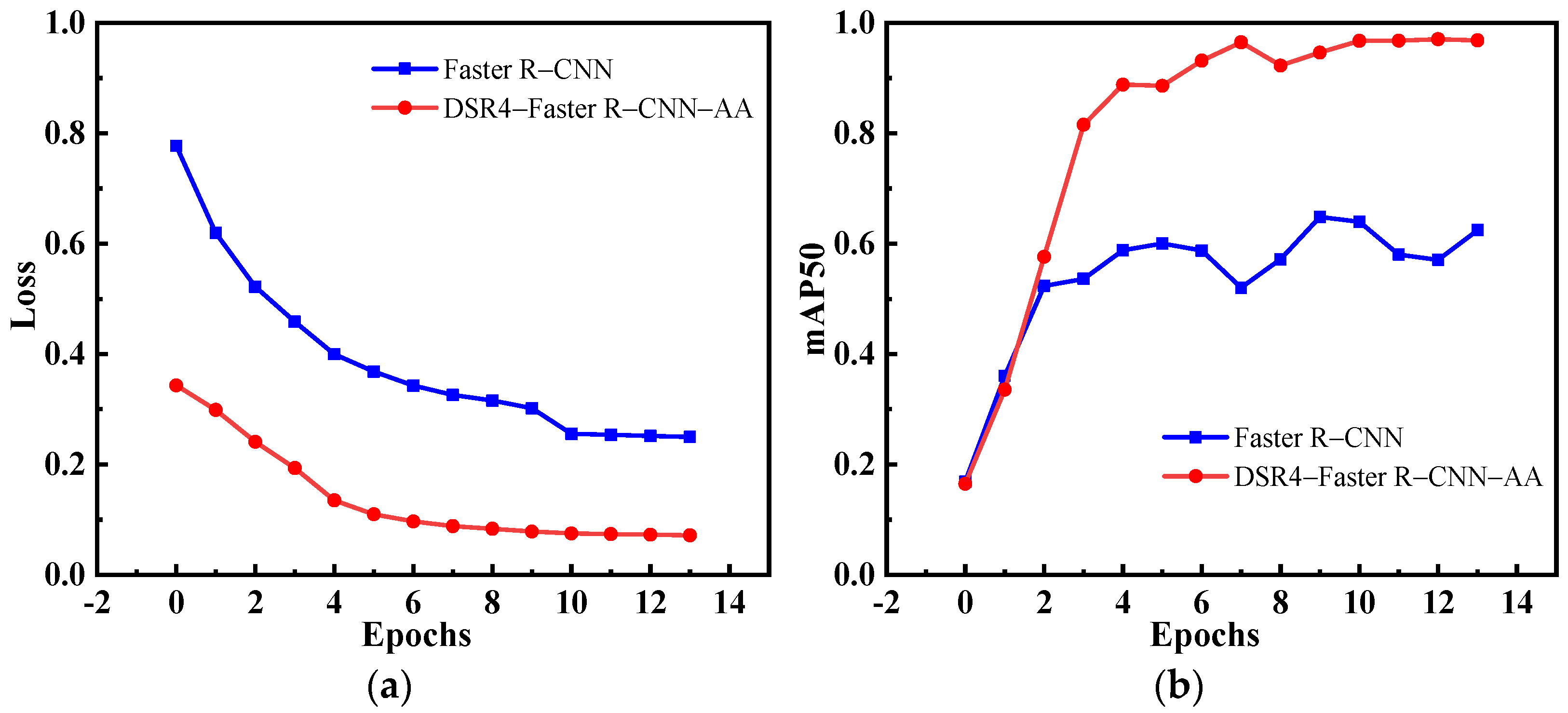
4.3.1. Ablation Experiment
4.3.2. Results of BIT-VEHICLE10-300 Datasets
4.3.3. Results of BIT-VEHICLE10-150 Datasets
4.4. Flight Experiments
4.4.1. Experiment Settings
4.4.2. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Christiansen, M.P.; Laursen, M.S.; Jørgensen, R.N.; Skovsen, S.; Gislum, R. Designing and Testing a UAV Mapping System for Agricultural Field Surveying. Sensors 2017, 17, 2703. [Google Scholar] [CrossRef] [PubMed]
- Preethi Latha, T.; Naga Sundari, K.; Cherukuri, S.; Prasad, M.V. Remote Sensing UAV/Drone technology as a tool for urban development measures in APCRDA. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 525–529. [Google Scholar] [CrossRef]
- Jayaweera, H.M.P.C.; Hanoun, S. UAV Path Planning for Reconnaissance and Look-Ahead Coverage Support for Mobile Ground Vehicles. Sensors 2021, 21, 4595. [Google Scholar] [CrossRef]
- Yousefi, D.B.M.; Rafie, A.S.M.; Al-Haddad, S.A.R.; Azrad, S. A Systematic Literature Review on the Use of Deep Learning in Precision Livestock Detection and Localization Using Unmanned Aerial Vehicles. IEEE Access 2022, 10, 80071–80091. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y. Deep learning-based detection from the perspective of small or tiny objects: A survey. Image Vis. Comput. 2022, 123, 104471. [Google Scholar] [CrossRef]
- Kiyak, E.; Unal, G. Small aircraft detection using deep learning. Aircr. Eng. Aerosp. Technol. 2021, 93, 671–681. [Google Scholar] [CrossRef]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet: Exploiting high resolution feature maps for small object detection. Eng. Appl. Artif. Intell. 2020, 91, 103615. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An improved faster R-CNN for small object detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Zhou, H.; Ma, A.; Niu, Y.; Ma, Z. Small-Object Detection for UAV-Based Images Using a Distance Metric Method. Drones 2022, 6, 308. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 6568–6577. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Liu, Y.; Yang, F.; Hu, P. Small-object detection in UAV-captured images via multi-branch parallel feature pyramid networks. IEEE Access 2020, 8, 145740–145750. [Google Scholar] [CrossRef]
- Yundong, L.; Han, D.; Hongguang, L.; Zhang, X.; Zhang, B.; Zhifeng, X. Multi-block SSD based on small object detection for UAV railway scene surveillance. Chin. J. Aeronaut. 2020, 33, 1747–1755. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Liang, S.; Li, Y.; Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv 2017, arXiv:1706.02690. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Fei, Z.; Wenzhong, L.; Yi, S.; Zihao, Z.; Wenlong, M.; Chenglong, L. Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector. Available online: https://github.com/zhaoXF04/BIT-VEHICLE10-150-300 (accessed on 11 May 2023).
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Alexey, B.; Wang, C.; Mark Liao, H. Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object detection in aerial images: A large-scale benchmark and challenges. arXiv 2021, arXiv:2102.12219. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 8232–8241. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y.; et al. PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Width/Pixel | Height/Pixel | Mean/Pixel |
|---|---|---|---|
| BIT-VEHICLE10-150 | 46–123 | 41–120 | 84 |
| BIT-VEHICLE10-300 | 18–48 | 18–48 | 38 |
| Method | Anchor Adjustment | mAP50 | mAP70 | FPS |
|---|---|---|---|---|
| Faster R-CNN | - | 63.64 | 10.69 | 15.1 |
| Faster R-CNN | √ | 72.35 | 36.30 | 15.1 |
| Backbone | mAP50 | mAP70 | FPS |
|---|---|---|---|
| VGG16 | 63.64 | 10.69 | 15.1 |
| SENet-VGG16 | 65.50 | 12.99 | 14.0 |
| Backbone | mAP50 | mAP70 | FPS |
|---|---|---|---|
| VGG16 | 63.64 | 10.69 | 15.1 |
| R7-VGG16 | 65.79 | 18.32 | 19.4 |
| R5-VGG16 | 66.90 | 20.58 | 24.3 |
| R4-VGG16 | 93.80 | 47.64 | 20.4 |
| Backbone | mAP50 | mAP70 | FPS |
|---|---|---|---|
| VGG16 | 63.64 | 10.69 | 15.1 |
| DSN-VGG16 | 64.53 | 16.43 | 12.4 |
| Menthod | Image Input Size | mAP50 | mAP70 | FPS |
|---|---|---|---|---|
| Faster R-CNN | 960 × 540 | 63.64 | 10.69 | 15.1 |
| DSR4-Faster R-CNN-AA | 96.17 | 67.13 | 23.3 | |
| Faster R-CNN | 640 × 360 | 7.01 | 0.13 | 15.4 |
| DSR4-Faster R-CNN-AA | 81.02 | 44.95 | 32.4 | |
| Faster R-CNN | 480 × 270 | - | - | - |
| DSR4-Faster R-CNN-AA | 68.44 | 31.57 | 36.9 |
| Method | mAP50 | mAP70 | FPS |
|---|---|---|---|
| SSD | 8.30 | 2.44 | 43.6 |
| YOLOv4 | 9.44 | 5.08 | 60.7 |
| PPYOLO | 15.19 | 6.21 | 46.2 |
| PPYOLOv2 | 14.78 | 5.96 | 30.8 |
| PPYOLOE_s | 7.97 | 2.87 | 47.9 |
| PPYOLOE_l | 12.52 | 5.06 | 29.1 |
| FCOS | 5.06 | 1.99 | 22.2 |
| PicoDet_s | 5.18 | 1.69 | 58.2 |
| Faster R-CNN | 7.01 | 0.13 | 15.4 |
| FR-H | 19.76 | 9.57 | 18.2 |
| SCRDet | 20.94 | 11.26 | 21.4 |
| DSR4-Faster R-CNN-AA(ours) | 81.02 | 44.95 | 32.4 |
| Method | mAP50 | mAP70 | FPS |
|---|---|---|---|
| DSR4-Faster R-CNN-AA-O | 71.34 | 36.58 | 19.4 |
| Image Input Size | Average Pre-Processing Time (ms) | Average Inference Time (ms) | Average Post-Processing Time (ms) | Average Total Process Time (ms) | FPS |
|---|---|---|---|---|---|
| 960 × 540 | 3.2 | 82.4 | 2.7 | 88.3 | 11.32 |
| 640 × 360 | 4.5 | 53.2 | 3.9 | 61.6 | 16.24 |
| 480 × 270 | 5.3 | 44.2 | 4.4 | 53.9 | 18.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Lou, W.; Sun, Y.; Zhang, Z.; Ma, W.; Li, C. Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector. Drones 2023, 7, 434. https://doi.org/10.3390/drones7070434
Zhao F, Lou W, Sun Y, Zhang Z, Ma W, Li C. Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector. Drones. 2023; 7(7):434. https://doi.org/10.3390/drones7070434
Chicago/Turabian StyleZhao, Fei, Wenzhong Lou, Yi Sun, Zihao Zhang, Wenlong Ma, and Chenglong Li. 2023. "Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector" Drones 7, no. 7: 434. https://doi.org/10.3390/drones7070434
APA StyleZhao, F., Lou, W., Sun, Y., Zhang, Z., Ma, W., & Li, C. (2023). Open Set Vehicle Detection for UAV-Based Images Using an Out-of-Distribution Detector. Drones, 7(7), 434. https://doi.org/10.3390/drones7070434