
Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment


Abstract
1. Introduction
- Design a cost-effective social robot that is robust and friendly.
- Design a lesson for teaching day-to-day tasks to the intellectually impaired student.
- Implement efficient deep learning models on the development boards for better perception of the robot.
- Utilize the power of a single board controller for the use of deep learning models.
2. Related Works
3. Hardware
3.1. Design
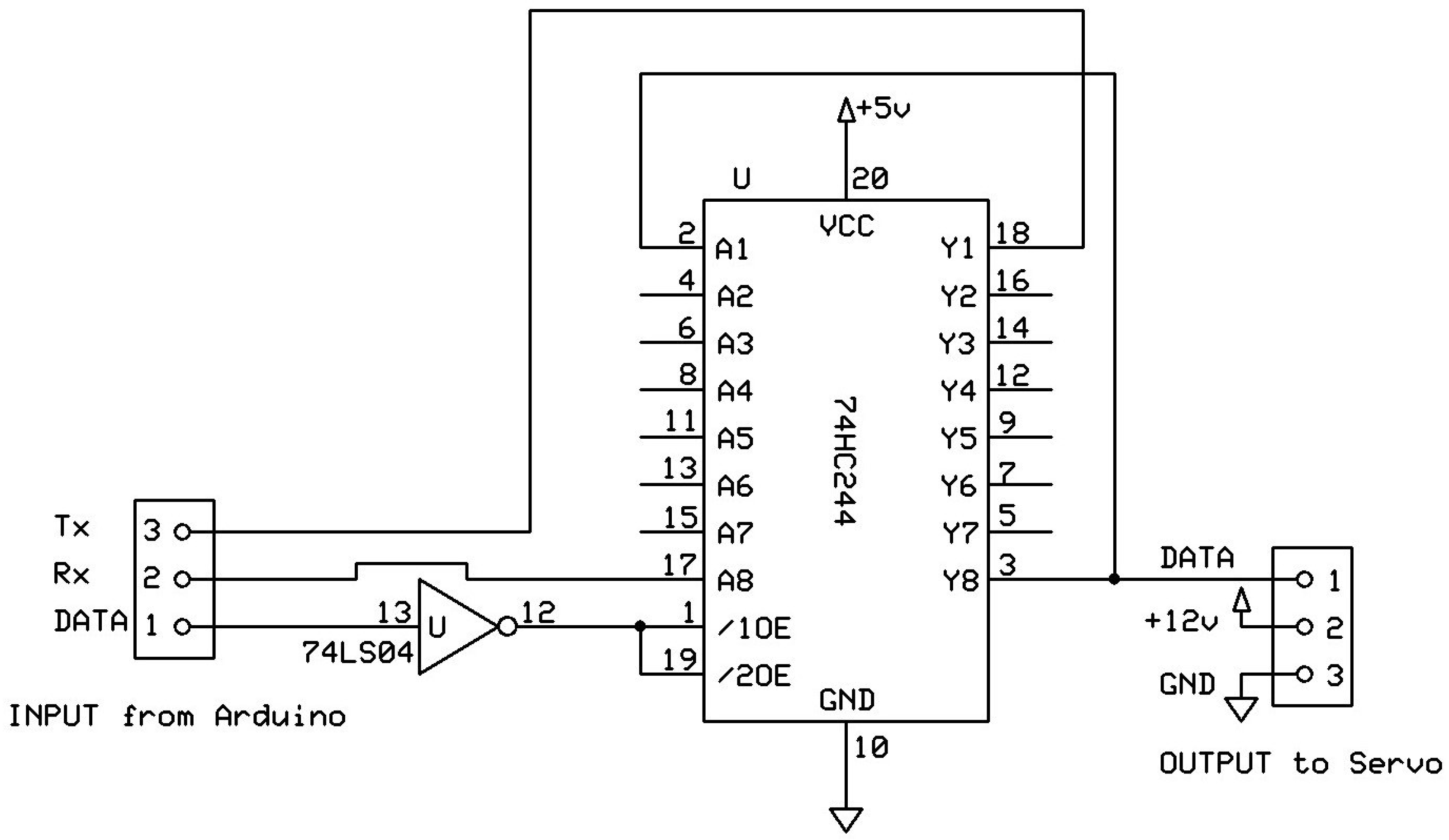
3.2. Electronics
4. Software
4.1. Speech Processing
4.2. Computer Vision
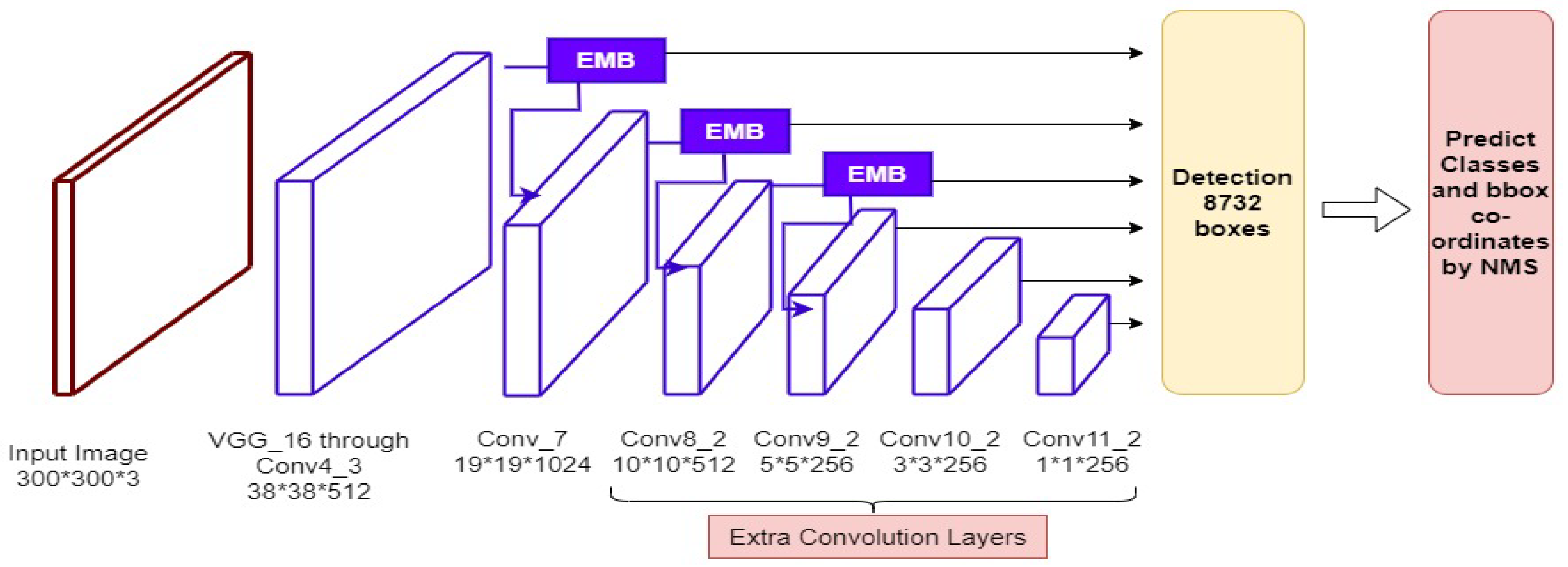
4.2.1. Single-Shot Detector (SSD)
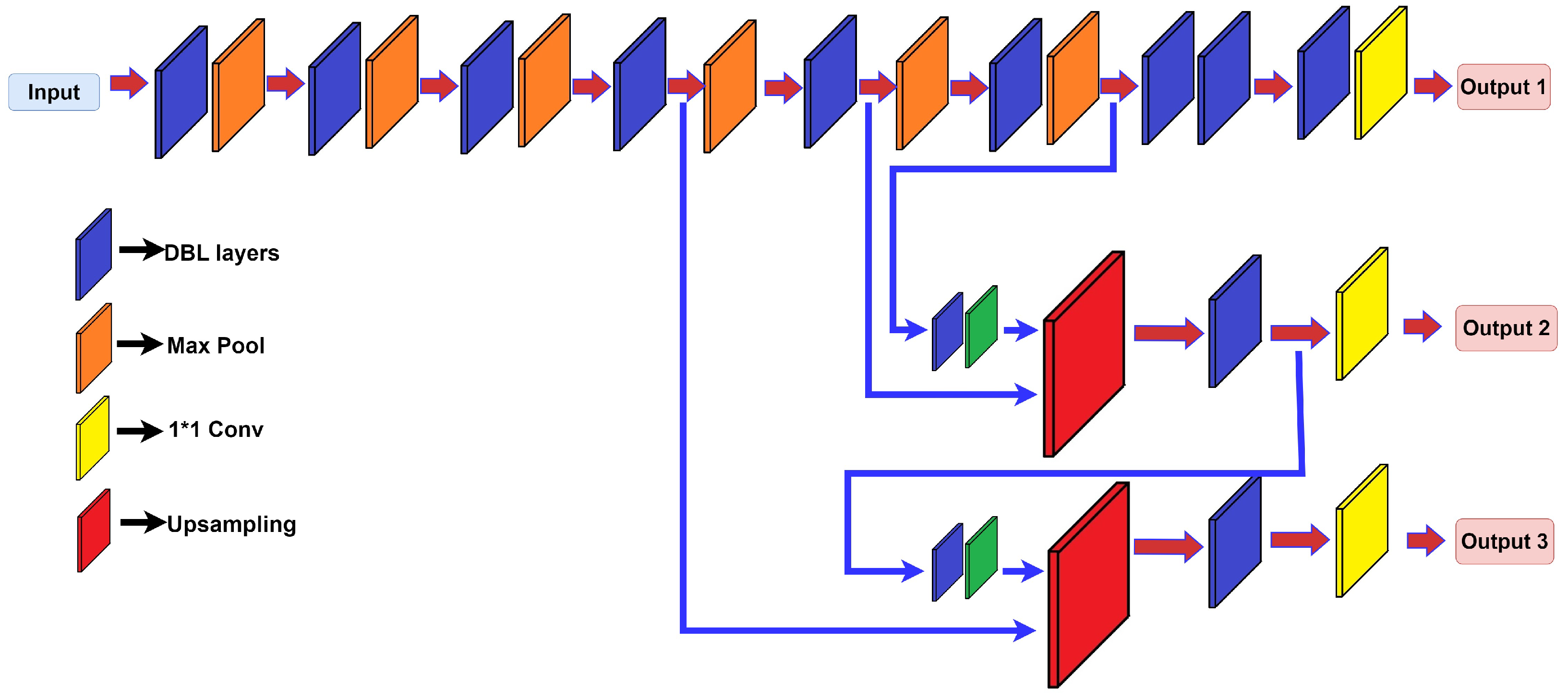
4.2.2. Yolo V3-Tiny
4.3. Non-Verbal Communication
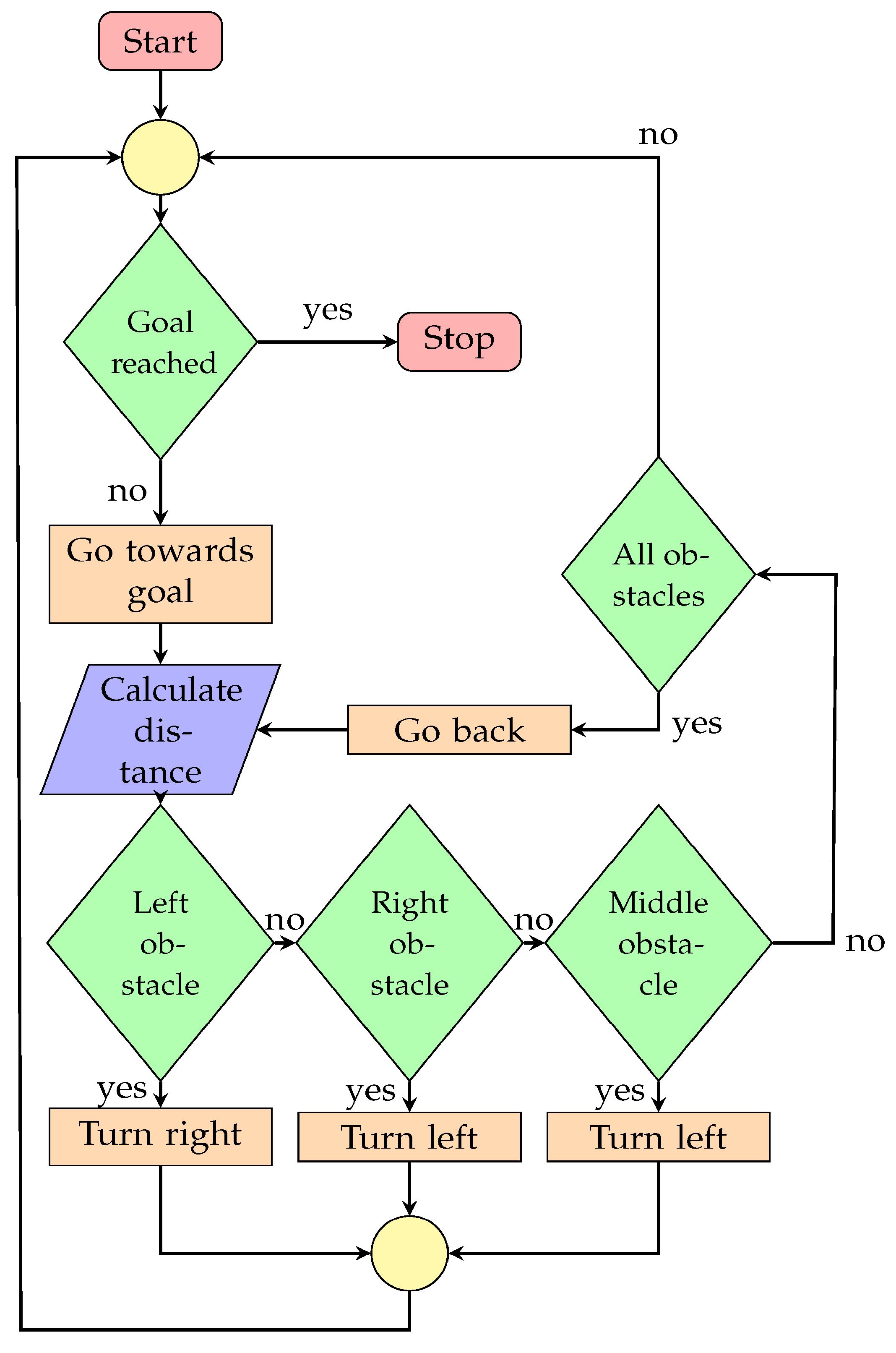
4.4. Obstacle Avoidance
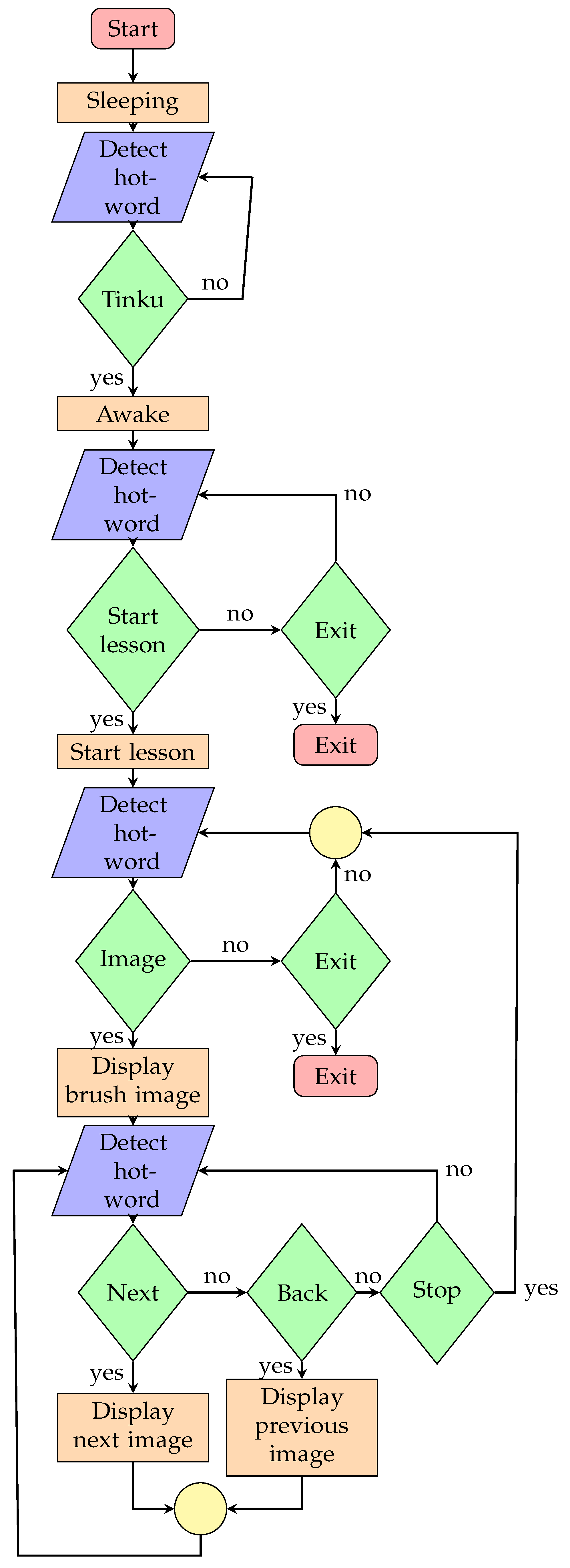
4.5. Teaching
- Identify the toothbrush.
- Pick up the toothbrush.
- Hold it properly in the left/right hand.
- Rinse the toothbrush.
- Apply toothpaste on the toothbrush bristle.
- Put the bristle in your mouth.
- Move the brush gently in all directions to clean your teeth.
- Brush for at least 3 minutes.
- Do not intake the foam and spit it out.
- Rinse your mouth properly.
- Rinse your brush properly.
- Put the brush in its place.
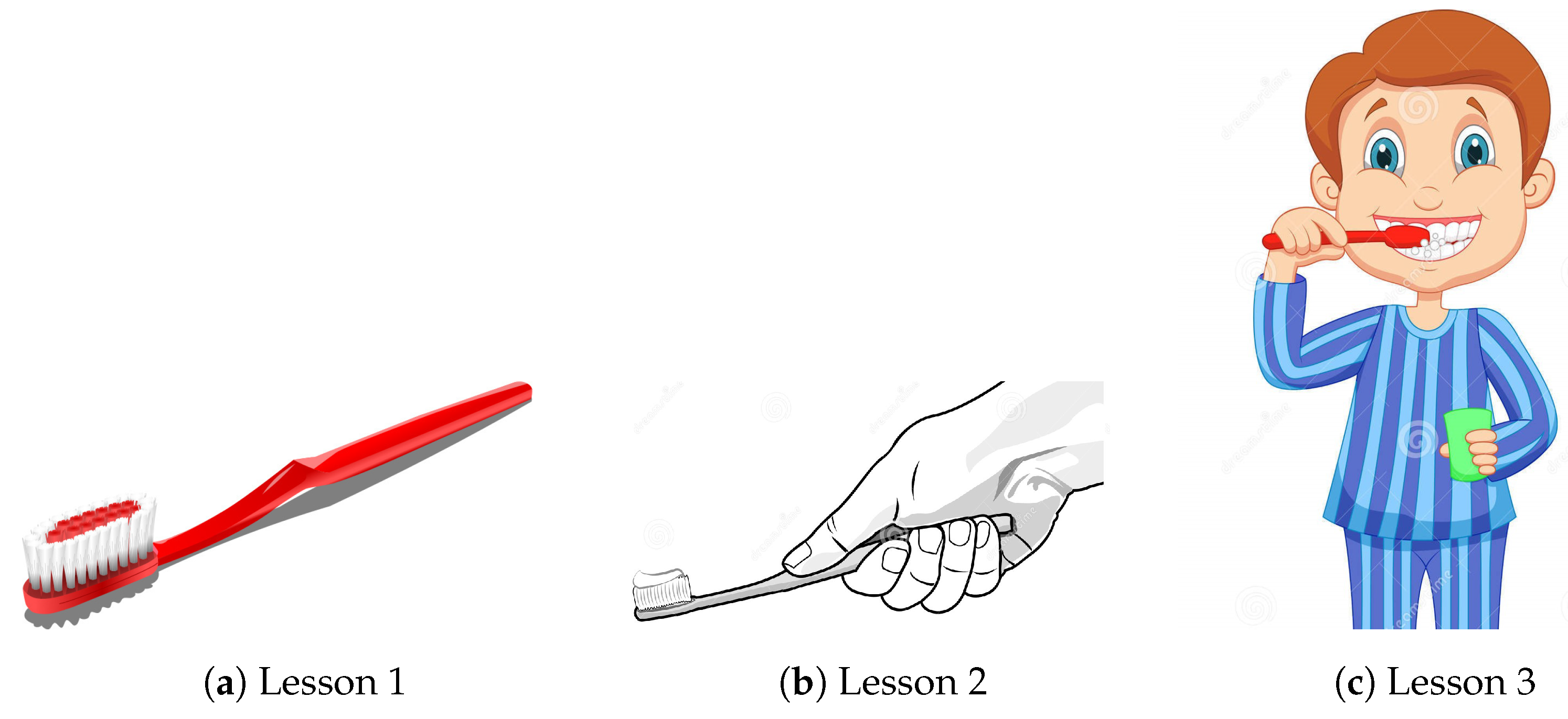
- Lesson 1: Identify the brush.
- Lesson 2: Hold the brush properly.
- Lesson 3: Brushing.
5. Configuration and Training
6. Results and Discussion
- Design a cost-effective and social robot which is robust as well as friendly looking.
- Design a lesson for teaching day to day task to the intellectually impaired student.
6.1. Challenge 1: Hardware
- Design a social robot.
- It should be cost effective.
- It should be friendly looking.
- It should be robust.
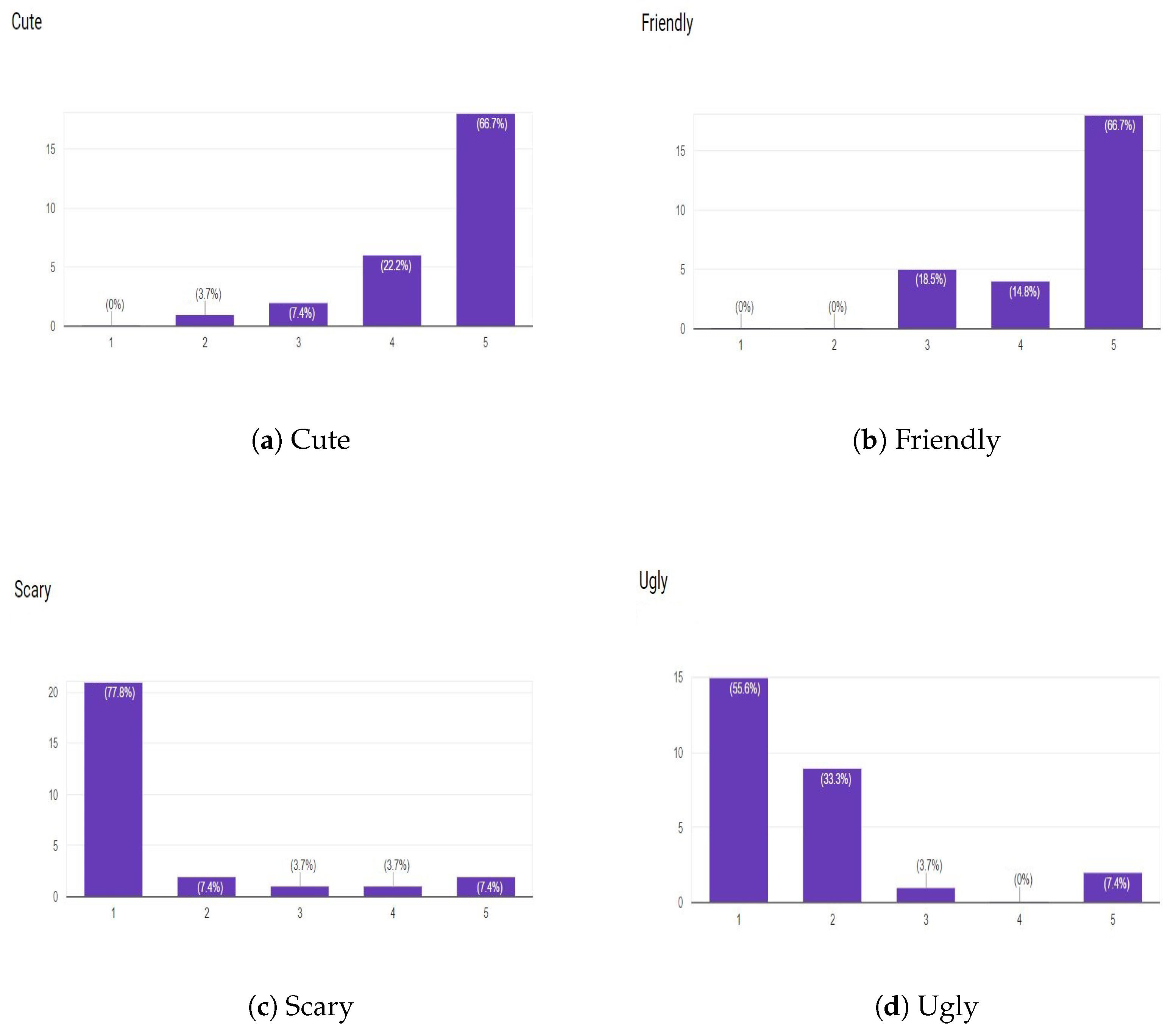
6.1.1. Social and Friendly Design
6.1.2. Cost
6.1.3. Robustness
6.2. Challenge 2: Software
- Make robot social.
- Design lesson for daily tasks.
6.2.1. Make Robot Social
- Visual communication.
- Body language.
- Sound effect.
- Happy.
- Sad.
- Anger.
- Excitement.
- Sleepy.
6.2.2. Design Lesson for Day to Day Tasks
6.2.3. Implementation of a Deep Learning Algorithm on Development Board
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolution neural network |
| DNN | Deep neural network |
| CV | Computer vision |
| ML | Machine learning |
| NLP | Natural language processing |
| STEM | Science, technology, engineering, and mathematics |
| AI | Artificial intelligence |
References
- Aleem, S.; Kumar, T.; Little, S.; Bendechache, M.; Brennan, R.; McGuinness, K. Random data augmentation based enhancement: A generalized enhancement approach for medical datasets. arXiv 2022, arXiv:2210.00824. [Google Scholar]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Bae, S. Class Specific Autoencoders Enhance Sample Diversity. J. Broadcast Eng. 2021, 26, 844–854. [Google Scholar]
- Khan, W.; Raj, K.; Kumar, T.; Roy, A.; Luo, B. Introducing urdu digits dataset with demonstration of an efficient and robust noisy decoder-based pseudo example generator. Symmetry 2022, 14, 1976. [Google Scholar] [CrossRef]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.; Hussain, A.; Shen, Y. Precise Single-stage Detector. arXiv 2022, arXiv:2210.04252.2022. [Google Scholar]
- Roy, A.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Naude, J.; Joubert, D. The Aerial Elephant Dataset: A New Public Benchmark for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 48–55. [Google Scholar]
- Kim, Y.; Park, J.; Jang, Y.; Ali, M.; Oh, T.; Bae, S. Distilling Global and Local Logits with Densely Connected Relations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6290–6300. [Google Scholar]
- Tran, L.; Ali, M.; Bae, S. A Feature Fusion Based Indicator for Training-Free Neural Architecture Search. IEEE Access 2021, 9, 133914–133923. [Google Scholar] [CrossRef]
- Ali, M.; Iqbal, T.; Lee, K.; Muqeet, A.; Lee, S.; Kim, L.; Bae, S. ERDNN: Error-resilient deep neural networks with a new error correction layer and piece-wise rectified linear unit. IEEE Access 2020, 8, 158702–158711. [Google Scholar] [CrossRef]
- Khan, W.; Turab, M.; Ahmad, W.; Ahmad, S.; Kumar, K.; Luo, B. Data Dimension Reduction makes ML Algorithms efficient. arXiv 2022, arXiv:2211.09392. [Google Scholar]
- Kumar, T.; Park, J.; Bae, S. Intra-Class Random Erasing (ICRE) augmentation for audio classification. In Proceedings of the Korean Society of Broadcast Engineers Conference, Las Vegas, NV, USA, 23–27 April 2022; pp. 244–247. [Google Scholar]
- Park, J.; Kumar, T.; Bae, S. Search for optimal data augmentation policy for environmental sound classification with deep neural networks. J. Broadcast Eng. 2020, 25, 854–860. [Google Scholar]
- Turab, M.; Kumar, T.; Bendechache, M.; Saber, T. Investigating multi-feature selection and ensembling for audio classification. arXiv 2022, arXiv:2206.07511. [Google Scholar] [CrossRef]
- Park, J.; Kumar, T.; Bae, S. Search of an Optimal Sound Augmentation Policy for Environmental Sound Classification with Deep Neural Networks. 2020, pp. 18–21. Available online: https://koreascience.kr/article/JAKO202001955917251.do (accessed on 16 November 2022).
- Sarwar, S.; Turab, M.; Channa, D.; Chandio, A.; Sohu, M.; Kumar, V. Advanced Audio Aid for Blind People. arXiv 2022, arXiv:2212.00004. [Google Scholar]
- Singh, A.; Ranjbarzadeh, R.; Raj, K.; Kumar, T.; Roy, A. Understanding EEG signals for subject-wise Definition of Armoni Activities. arXiv 2023, arXiv:2301.00948. [Google Scholar]
- Ullah, I.; Khan, S.; Imran, M.; Lee, Y. RweetMiner: Automatic identification and categorization of help requests on twitter during disasters. Expert Syst. Appl. 2021, 176, 114787. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Jamil, S.; Abbas, M.S.; Roy, A.M. Distinguishing Malicious Drones Using Vision Transformer. AI 2022, 3, 260–273. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. A deep learning enabled multi-class plant disease detection model based on computer vision. AI 2021, 2, 413–428. [Google Scholar] [CrossRef]
- Roy, A.M. An efficient multi-scale CNN model with intrinsic feature integration for motor imagery EEG subject classification in brain-machine interfaces. Biomed. Signal Process. Control 2022, 74, 103496. [Google Scholar] [CrossRef]
- Roy, A.M. A multi-scale fusion CNN model based on adaptive transfer learning for multi-class MI classification in BCI system. bioRxiv 2022. [Google Scholar] [CrossRef]
- Roy, A.M. Adaptive transfer learning-based multiscale feature fused deep convolutional neural network for EEG MI multiclassification in brain–computer interface. Eng. Appl. Artif. Intell. 2022, 116, 105347. [Google Scholar] [CrossRef]
- Bose, R.; Roy, A. Accurate Deep Learning Sub-Grid Scale Models for Large Eddy Simulations; Bulletin of the American Physical Society: New York, NY, USA, 2022. [Google Scholar]
- Khan, W.; Kumar, T.; Cheng, Z.; Raj, K.; Roy, A.; Luo, B. SQL and NoSQL Databases Software architectures performance analysis and assessments—A Systematic Literature review. arXiv 2022, arXiv:2209.06977. [Google Scholar]
- Dillmann, R. Teaching and learning of robot tasks via observation of human performance. Robot. Auton. Syst. 2004, 47, 109–116. [Google Scholar] [CrossRef]
- Sahin, A.; Ayar, M.; Adiguzel, T. STEM Related After-School Program Activities and Associated Outcomes on Student Learning. Educ. Sci. Theory Pract. 2014, 14, 309–322. [Google Scholar] [CrossRef]
- Mubin, O.; Stevens, C.; Shahid, S.; Al Mahmud, A.; Dong, J. A review of the applicability of robots in education. J. Technol. Educ. Learn. 2013, 1, 13. [Google Scholar] [CrossRef]
- Singh, A.; Narula, R.; Rashwan, H.; Abdel-Nasser, M.; Puig, D.; Nandi, G. Efficient deep learning-based semantic mapping approach using monocular vision for resource-limited mobile robots. Neural Comput. Appl. 2022, 34, 15617–15631. [Google Scholar] [CrossRef]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Ko, J.; Bae, S. Binary-classifiers-enabled filters for semi-supervised learning. IEEE Access 2021, 9, 167663–167673. [Google Scholar] [CrossRef]
- Chio, A.; Shen, Y.; Bendechache, M.; Inayat, I.; Kumar, T. AUDD: Audio Urdu digits dataset for automatic audio Urdu digit recognition. Appl. Sci. 2021, 11, 8842. [Google Scholar]
- Singh, A.; Pandey, P.; Nandi, G. Influence of human mindset and societal structure in the spread of technology for Service Robots. In Proceedings of the 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Dehradun, India, 11–13 November 2021; pp. 1–6. [Google Scholar]
- Belpaeme, T.; Kennedy, J.; Ramachandrran, A.; Scassellati, B.; Tanaka, F. Social robots for education: A review. Sci. Robot. 2018, 3, eaa5954. [Google Scholar]
- Billard, A. Robota: Clever Toy and Educational Tool. Robot. Auton. Syst. 2003, 42, 259–269. Available online: http://robota.epfl.ch (accessed on 16 November 2022). [CrossRef]
- Ricks, D.; Colton, M. Trends and considerations in robot-assisted autism therapy. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 4354–4359. [Google Scholar]
- Breazeal, C.; Kidd, C.; Thomaz, A.; Hoffman, G.; Berlin, M. Effects of nonverbal communication on efficiency and robustness in human-robot teamwork. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, (IROS 2005), Edmonton, AB, Canada, 2–6 August 2005. [Google Scholar]
- Fong, T.; Nourbakhsh, I.; Dautenhahn, K. A survey of socially interactive robots. Robot. Auton. Syst. 2003, 42, 143–166. [Google Scholar] [CrossRef]
- Bar-Cohen, Y.; Breazeal, C. Biologically inspired intelligent robots. In Proceedings of the Smart Structures and Materials 2003: Electroactive Polymer Actuators and Devices (EAPAD), San Diego, CA, USA, 3–6 March 2003; Volume 5051, pp. 14–20. [Google Scholar]
- Kidd, C.; Breazeal, C. Effect of a robot on user perceptions. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 4, pp. 3559–3564. [Google Scholar]
- Breazeal, C. Toward sociable robots. Robot. Auton. Syst. 2003, 42, 167–175. [Google Scholar] [CrossRef]
- Maleki, F.; Farhoudi, Z. Making Humanoid Robots More Acceptable Based on the Study of Robot Characters in Animation. IAES Int. J. Robot. Autom. 2015, 4, 63. [Google Scholar] [CrossRef]
- School, T. Topcliffe Primary School. 2021. Available online: http://www.topcliffe.academy/nao-robots (accessed on 16 November 2022).
- Lite, T. TensorFlow Lite. 2021. Available online: https://tensorflow.org/lite (accessed on 16 November 2022).
- Phadtare, M.; Choudhari, V.; Pedram, R.; Vartak, S. Comparison between YOLO and SSD Mobile Net for Object Detection in a Surveillance Drone. Int. J. Sci. Res. Eng. Man 2021, 5, 1–5. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2969239–2969250. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ning, C.; Zhou, H.; Song, Y.; Tang, J. Inception single shot multibox detector for object detection. In Proceedings of the 2017 IEEE International Conference on Multimedia & ExpoWorkshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 549–554. [Google Scholar]
- Roy, A.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2022, 101919. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ding, S.; Long, F.; Fan, H.; Liu, L.; Wang, Y. A novel YOLOv3-tiny network for unmanned airship obstacle detection. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 277–281. [Google Scholar]
- RobotLAB Group. NAO Version Six Price. 1981. Available online: https://www.robotlab.com/store/nao-power-v6-standard-edition (accessed on 16 November 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processor | NXP® i.MX 6 ARM Cortex-A9 CPU quad core 1 GHz |
| RAM | DDR3, 1 GB |
| ROM | 8 GB micro SD card |
| Connectivity | Ethernet RJ45 and Wifi module |
| OS | UDOObuntu 2.0 |
| Microcontroller | ATmega 1280 |
| Camera and Mic | Logitech c-270 |
| Screen | Waveshare 7, 800 × 480 touch screen |
| DC Motor | Side shaft, high torque motor |
| Motor Driver | L298n IC |
| Servo Motor | Dynamixel AX-12+ |
| Sensors | Ultrasonic sensor, Motor encoder |
| Power | 11.1v, Lipo battery, 3000 mAh |
| S. No. | Item |
|---|---|
| 1 | Arduino Mega 1280 |
| 2 | Udoo quad |
| 3 | DC motor driver (L298) |
| 4 | Logitech webcam c-270 |
| 5 | 6 Ultrasonic distance sensor |
| 6 | 11.1v Lipo battery |
| 7 | Voltage regulators |
| 8 | Touch screen (7) |
| 9 | T plug male connector |
| 10 | Servo motor driver |
| 11 | Sensor connector PCB |
| 12 | 3 servo motors |
| 13 | 2 DC motors |
| 14 | Robot’s body |
| 15 | Miscellaneous |
| Techniques | Detection Speed (fps) | Reported mAP |
|---|---|---|
| TF-Lite (SSD Mobilenet) | 2.5 | 82% |
| Tiny- YOLO | 0.7 | 23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, A.; Raj, K.; Kumar, T.; Verma, S.; Roy, A.M. Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment. Drones 2023, 7, 81. https://doi.org/10.3390/drones7020081
Singh A, Raj K, Kumar T, Verma S, Roy AM. Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment. Drones. 2023; 7(2):81. https://doi.org/10.3390/drones7020081
Chicago/Turabian StyleSingh, Aditya, Kislay Raj, Teerath Kumar, Swapnil Verma, and Arunabha M. Roy. 2023. "Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment" Drones 7, no. 2: 81. https://doi.org/10.3390/drones7020081
APA StyleSingh, A., Raj, K., Kumar, T., Verma, S., & Roy, A. M. (2023). Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment. Drones, 7(2), 81. https://doi.org/10.3390/drones7020081